
Abstract
We consider the swelling of hydrogels as an example of a chemo-mechanical problem with strong coupling between the mechanical balance relations and the mass diffusion. The problem is cast into a minimization formulation using a time-explicit approach for the dependency of the dissipation potential on the deformation and the swelling volume fraction to obtain symmetric matrices, which are typically better suited for iterative solvers. The MPI-parallel implementation uses the software libraries deal.II, p4est and FROSch (Fast of Robust Overlapping Schwarz). FROSch is part of the Trilinos library and is used in fully algebraic mode, i.e., the preconditioner is constructed from the monolithic system matrix without making explicit use of the problem structure. Strong and weak parallel scalability is studied using up to 512 cores, considering the standard GDSW (Generalized Dryja-Smith-Widlund) coarse space and the newer coarse space with reduced dimension. The FROSch solver is applicable to the coupled problems within in the range of processor cores considered here, although numerical scalablity cannot be expected (and is not observed) for the fully algebraic mode. In our strong scalability study, the average number of Krylov iterations per Newton iteration is higher by a factor of up to six compared to a linear elasticity problem. However, making mild use of the problem structure in the preconditioner, this number can be reduced to a factor of two and, importantly, also numerical scalability can then be achieved experimentally. Nevertheless, the fully algebraic mode is still preferable since a faster time to solution is achieved.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Chemo-mechanics problems have gained increasing attention in the past decades, as a more refined understanding of processes in man-made and natural materials as well as living tissue can only be obtained by incorporation of mechanical and chemical loading conditions and their mutual interactions. Research in various fields of chemo-mechanics have emerged and are concerned for example with the coupling of deformation and diffusion in gels [18, 19, 28, 42, 58], the prediction of the transition from pitting corrosion to crack formation in metals [17, 20], hydrogen diffusion [22, 55] and embrittlement [1, 4, 45], functional degradation in Li-ion batteries [53, 54], chemical reaction-induced degradation of concrete [52, 64], diffusion mediated tumor growth [29, 65], or modeling of lithium-ion batteries [51].
As all of these examples involve a strong coupling of mechanical balance relations and mass diffusion, either of Fickian or gradient extended Cahn-Hilliard type, we adopt an established benchmark problem of swelling of hydrogels [14, 43, 57] that at the one hand accounts for this coupling and on the other hand is simple enough to develop efficient, problem specific numerical solution schemes.
In this paper, we are interested in the model presented in [13], which is derived from an incremental variational formulation and can therefore easily be recast into a minimization formulation as well as into a saddle point problem. The different variational formulations also have consequences for the solver algorithms to be applied.
In this contribution, as a first step, we consider the minimization formulation. The discretization of our three-dimensional model problem by finite elements is carried out using the deal.II finite element software library [2]. We solve the arising nonlinear system by means of a monolithic Newton–Raphson scheme; the linearized systems of equations are solved using the Fast and Robust Overlapping Schwarz (FROSch) solver [30, 37] which is part of the Trilinos software [63]. The FROSch framework provides a parallel implementation of the GDSW [26, 27] and RGDSW-type Overlapping Schwarz preconditioners [25]. These preconditioners have shown a good performance for problems ranging from the fluid–structure interaction of arterial walls and blood flow [7] to land ice simulation [39]. Monolithic preconditioners of GDSW type for fluid flow problems, where the coarse problem is, again, a saddle point problem were presented in [34, 36]. These preconditioners make use of the block structure. Within this project, FROSch has first been applied in [44]. The preconditioner also provides a recent extension using more than two levels, which has been tested up to 220,000 cores [41].
Let us note that, in this paper, our focus is on obtaining robustness for a challenging nonlinear coupled problem rather than on achieving a high range of parallel scalability for linear benchmark problems. We will therefore apply only two-level methods. The FROSch preconditioners considered in this paper are constructed algebraically, i.e., from the assembled finite element matrix, without the use of geometric information and without explicit knowledge of the block structure. The construction of the preconditioners therefore needs to make use of certain approximations as in [33]. Also note that, in this work, a node-wise numbering is used in the case of the \(Q_{1} Q_{1}\) discretization and a block-wise numbering is used for the \(Q_{1} RT_{0}\); see Sect. 4.2. In this paper, we will always apply the preconditioners from FROSch in fully algebraic mode; this implies that no explicit information on the block structure is provided in the construction of the preconditioner. Note that recent RGDSW methods with adaptive coarse spaces are not fully algebraic; e.g., [40] and cannot be used here.
For our benchmark problem of the swelling of hydrogels, we consider two sets of boundary conditions. We also compare the consequences of two different types of finite element discretizations for the flux flow: Raviart-Thomas finite elements and standard Lagrangian finite elements. We then evaluate the numerical and parallel performance of the iterative solver applied to the monolithic system, discussing strong and weak parallel scalability.
2 Variational framework of fully coupled chemo-mechanics
In order to evaluate the performance of the FROSch framework in the context of multi-physics problems, the variational framework of chemo-mechanics is adopted without further modifications as outlined in [11, 13]. This framework is suitable to model hydrogels.
This setting is employed here to solve some representative model problems involving full coupling between mechanics and mass diffusion in a finite deformation setting.
The rate-type potential
serves as a starting point for our description of the coupled problem, where the deformation is denoted \({\varvec{\varphi }}\), the swelling volume fraction v, and the fluid flux \(\varvec{J}_{v}\), consistent with the notation introduced in [11]. The stored energy functional E of the body \(\mathcal{B}\) is computed from the free-energy \(\psi \) as
Furthermore, the global dissipation potential functional is defined as
involving the local dissipation potential \(\widehat{\phi }\).
Note that the dissipation potential possesses an additional dependency on the deformation via its material gradient and the swelling volume fraction. However, this dependency is not taken into account in the variation of the potential \(\Pi \) when determining the corresponding Euler-Lagrange equations, as indicated by the semicolon in the list of arguments. Lastly, the external load functional is split into a solely mechanical and solely chemical contribution of the form
where the former includes the vector of body forces per unit reference volume \(\varvec{R}_{{\varvec{\varphi }}}\) and the prescribed traction vector \(\bar{\varvec{T}}\) at the surface of the body \(\partial \mathcal{B}^{\varvec{T}}\) such that
The latter contribution in (4) incorporates the prescribed chemical potential \(\bar{\mu }\) and the normal component of the fluid flux \(H_{v}\) at the surface \(\partial \mathcal{B}^{\mu }\) as
Along the disjoint counterparts of the mentioned surface, namely \(\partial \mathcal{B}^{{\varvec{\varphi }}}\) and \(\partial \mathcal{B}^{H_{v}}\), the deformation and the normal component of the fluid flux are prescribed, respectively.Taking into account the balance of solute volume
in (1) allows one to derive the two-field minimization principle
which solely depends on the deformation and the fluid flux. Herein, (7) is accounted for locally to capture the evolution of v and update the corresponding material state. To summarize, the deformation map and the flux field are determined from
using the following admissible function spaces.
2.1 Specific free-energy function and dissipation potential
Following [11, 13], the choice of the free-energy function employed in this study is motivated by the fact that it accurately captures the characteristic nonlinear elastic response of a certain class of hydrogels [48] with moderate water content as well as the swelling induced volume changes. In principle, it also incorporates softening due to pre-swelling, despite its rather simple functional form. The isotropic, Neo-Hookean type free-energy reads as
in which the first invariant of the right Cauchy-Green tensor is defined as \(I_{1}^{{{{\textbf{C}}}}}={\text {tr}}\left( {{{\textbf{C}}}}\right) ={\text {tr}}\left( {{{\textbf{F}}}}^{\textrm{T}}\!\cdot {{{\textbf{F}}}}\right) \), while the determinant of the deformation gradient \({{{\textbf{F}}}}=\nabla {\varvec{\varphi }}\) is given as \(J={\text {det}}\left( {{{\textbf{F}}}}\right) \). The underlying assumption of the particular form of this energy function is the multiplicative decomposition of the deformation gradient
which splits the map from the reference configuration (dry-hydrogel) to the current configuration into a purely volumetric deformation gradient associated with the pre-swelling of the hydrogel \({{{\textbf{F}}}}_{\textrm{0}}\) and the deformation gradient \({{{\textbf{F}}}}\), accounting for elastic and diffusion-induced deformations. Clearly, (12) describes the energy relative to the pre-swollen state of the gel. In its derivation it is assumed, additionally, that the pre-swelling is stress-free and the energetic state of the dry-state and the pre-swollen state are equivalent, which gives rise to the scaling \(J_{\textrm{0}}^{-1}\) of the individual terms of the energy. Although the incompressibility of both the polymer, forming the dry hydrogel, and the fluid is widely accepted, its exact enforcement is beyond the scope of the current study and a penalty formulation is employed here, utilizing a quadratic function that approximately enforces the coupling constraint
for a sufficiently high value of the first Lamé constant \(\uplambda \). Thus, in the limit \(\uplambda \rightarrow \infty \), the volume change in the hydrogel is solely due to diffusion and determined by the volume fraction v, which characterizes the amount of fluid present in the gel. On the other hand, relaxing the constraint by choosing a small value of \(\uplambda \) allows for additional elastic volume changes.
Energetic contributions due to the change in fluid concentration in the hydrogel are accounted for by the Flory-Rehner type energy, in which the affinity between the fluid and the polymer network is controlled by the parameter \(\upchi \). Finally, demanding that the pre-swollen state is stress-free requires the determination of the initial swelling volume fraction from
A convenient choice of the local dissipation potential, in line with [13], is given as
which is formulated with respect to the pre-swollen configuration. It is equivalent to an isotropic, linear constitutive relation between the spatial gradient of the chemical potential and the spatial fluid flux, in the current configuration. Again, the state dependence of the dissipation potential through the right Cauchy–Green tensor and the swelling volume fraction is not taken into account in the course of the variation of the total potential. The material parameters employed in the strong and weak scaling studies in Sects. 7.2 and 7.3 are summarized in Table 1. Note that the chosen value of the pre-swollen Jacobian is problem dependent and indicated in the corresponding section.
2.2 Incremental two-field potential
Although the rate-type potential (1) allows for valuable insight into the variational structure of the coupled problem, e.g., a minimization formulation for the model at hand, an incremental framework is typically required for the implementation into a finite element code. This necessitates the integration of the total potential over a finite time step \(\Delta t = t_{n+1}-t_{n}\). Thus, the incremental potential takes the form
in which an Euler implicit time integration scheme is applied to approximate the global dissipation potential (3) as well as the external load functional (4). Furthermore, the balance of solute volume is also integrated numerically by means of the implicit backward Euler scheme yielding an update formula for the swelling volume fraction
which is employed to evaluate the stored energy functional (2) at \(t_{n+1}\). Note that, quantities given at the time step \(t_{n}\) are indicated by subscript \({}_{n}\), while the subscript is dropped for all quantities at \(t_{n+1}\) to improve readability. Additionally, it is remarked that the stored energy functional at \(t_{n}\) is excluded from (17) as it only changes its absolute value, while it does not appear in the first variation of \(\Pi ^{\Delta t}\), because it is exclusively dependent on quantities at \(t_{n}\). Finally, the state dependence of the local dissipation potential is only accounted for in an explicit manner, as recommended in [11, 13, 58, 61], in order to ensure consistency with the rate-type potential (1) and thus guarantee the symmetry of the tangent operators in the finite element implementation. An alternative approach based on a predictor-corrector scheme that also ensures the symmetry of the tangent operators and employs a fully implicit time integration scheme has recently been proposed in [59], which is however not pursued in this contribution as the corrector step generates additonal computational overhead.
For symmetric systems, we can hope for a better convergence of the Krylov methods applied to the preconditioned system. On the other hand, we are restricted by small time steps.
3 Fast and Robust Overlapping Schwarz (FROSch) Preconditioner
Domain decomposition solvers [62] are based on the idea to construct an approximate solution to a problem, defined on a computational domain, from the solutions of parallel problems on small subdomains and, typically, of an additional coarse problem, which introduces the global coupling. Originally, the coarse problem of classic overlapping Schwarz methods was defined on a coarse mesh. In the FROSch software, however, we only consider methods where no explicit coarse mesh needs to be provided.
Domain decomposition methods are typically used as a preconditioner in combination with Krylov subspace methods such as conjugate gradients or GMRES.
In overlapping Schwarz domain decomposition methods [62], the subdomains have some overlap. A large overlap increases the size of the subdomains but typically improves the speed of convergence.
The C++ library FROSch [30, 37], which is part of the Trilinos software library [63], implements versions of the Generalized Dryja-Smith-Widlund (GDSW) preconditioner, which is a two-level overlapping Schwarz domain decomposition preconditioner [62] using an energy-minimizing coarse space introduced in [26, 27]. This coarse space is inspired by iterative substructuring methods such as FETI-DP and BDDC methods [46, 47, 62]. An advantage of GDSW-type preconditioners, compared to iterative substructuring methods and classical two-level Schwarz domain decomposition preconditioners, is that they can be constructed in an algebraic fashion from the fully assembled stiffness matrix.

Decomposition of a cube into non-overlapping (top) and overlapping subdomains (bottom) on a structured grid with \(\delta =1h\). The GDSW preconditioner uses the overlapping subdomains to define the local solvers and the non-overlapping subdomains to construct the second level, which ensures global transport of information
Therefore, they do not require a coarse triangulation (as in classical two-level Schwarz methods) nor access to local Neumann matrices for the subproblems (as in FETI-DP and BDDC domain decomposition methods).
For simplicity, we will describe the construction of the preconditioner in terms of the computational domain, although the construction is fully algebraic in FROSch, i.e., subdomains arise only implicitly from the algebraic construction: the computational domain \(\Omega \) is decomposed into non-overlapping subdomains \(\lbrace \Omega _i\rbrace _{i = 1 \ldots N}\); see Fig. 1. Extending each subdomain by k-layers of elements, we obtain the overlapping subdomains \(\lbrace \Omega _i' \rbrace _{i = 1 \ldots N}\) with an overlap \(\delta = k h\), where h is the size of the finite elements. We denote the size of a non-overlapping subdomain by H. The GDSW preconditioner can be written in the form
where \(K_i = R_i K R_i^T, i = 1, \ldots N\) represent the local overlapping subdomain problems. The coarse problem is given by the Galerkin product \(K_0 = \Phi ^T K \Phi \). The matrix \(\Phi \) contains the coarse basis functions spanning the coarse space \(V^0\). For the classical two-level overlapping Schwarz method these functions would be nodal finite elements functions on a coarse triangulation.
The GDSW coarse basis functions are chosen as energy-minimizing extensions of the interface functions \(\Phi _{\Gamma }\) to the interior of the non-overlapping subdomains. These extensions can be computed from the assembled finite element matrix. The interface functions are typically chosen as restrictions of the nullspace of the global Neumann matrix to the vertices \(\vartheta \), edges \(\xi \), and faces \(\sigma \) of the non-overlapping decomposition, forming a partition of unity. Figure 2 illustrates the interface components for a small 3D decomposition of a cube into eight subdomains. In terms of the interior degrees of freedom (I) and the interface degrees of freedom (\(\Gamma \)) the coarse basis functions can be written as
where \(K_{II}\) and \(K_{I\Gamma }\) are submatrices of K. Here \(\Gamma \) corresponds to degrees of freedom on the interface of the non-overlapping subdomains \(\lbrace \Omega _i\rbrace _{i = 1 \ldots N}\) and I corresponds to degrees of freedom in the interior. The algebraic construction of the extensions is based on the partitioning of the system matrix K according to the \(\Gamma \) and I degrees of freedom, i.e.,
Here, \(K_{II} = \hbox {diag}(K_{II}^{(i)})\) is a block-diagonal matrix, where \(K_{II}^{(i)}\) defines the i-th non-overlapping subdomain. The computation of its inverse \(K_{II}^{-1}\) can thus be performed independently and in parallel for all subdomains.

Illustration of the interface components of the non-overlapping decomposition into eight subdomains
By construction, the number of interface components determines the size of the coarse problem. This number is smaller for the more recent RGDSW methods, which use a reduced coarse space [25, 31, 41].
For scalar elliptic problems and under certain regularity conditions the GDSW preconditioner allows for a condition number bound
where C is a constant independent of the other problem parameters; cf. [26, 27]; also cf. [24] for three-dimensional compressible elasticity. Here, H is the diameter of a subdomain, h the diameter of a finite element, and \(\delta \) the overlap.
For three-dimensional almost incompressible elasticity, using adapted coarse spaces, and a bound of the form
was established for the GDSW coarse space [23] and also for a reduced dimensional coarse space [24].
The more recent reduced dimensional GDSW (RGDSW) coarse spaces [25] are constructed from nodal interface function, forming a different partition of unity on the interface. The parallel implementation of the RGDSW coarse spaces is also part of the FROSch framework; cf. [32]. The RGDSW basis function can be computed in different ways. Here, we use the fully algebraic approach (Option 1 in [25]), where the interface values are determined by the multiplicity [25]; see [32] for a visualization. Alternatives can lead to a slightly lower number of iterations and a faster time to solution [32], but these use geometric information [25, 32].
For problems up to 1000 cores the GDSW preconditioner with an exact coarse solver is a suitable choice. The RGDSW method is able the scale up to 10,000 cores. For even larger numbers of cores and subdomains, a multi-level extension [35, 38] is available in the FROSch framework. Although it is not covered by theory, the FROSch preconditioner is sometimes able to scale even if certain dimension of the coarse space are neglected [30, 33], i.e., for linear elasticity the linearized rotations can sometimes be neglected.
4 Parallel software environment
4.1 Finite element implementation
The implementation of the coupled problem by means of the finite element method is based on the incremental two-field potential (17), in which the arguments of the local incremental potential \(\pi ^{\Delta t}\) and the external load functional are expressed by the corresponding finite element approximations. Introducing the generalized B- and N-matrix in the following manner
and denoting the degrees of freedom of the finite elements by \(\widetilde{()}\), gives rise to the rather compact notation of (17)
Upon the subdivision of the domain \(\mathcal{B}\) into finite elements and the inclusion of the assembly operator A, the necessary condition to find a stationary value of the incremental potential is expressed as
which represents a system of nonlinear equations
with

and

Equation (26) is solved efficiently by means of a monolithic Newton–Raphson scheme. The corresponding linearization is inherently symmetric and is computed as
in which the individual contributions take the form




where \(\widehat{\psi }\) is the hyperelastic energy associated with the mechanical problem and \(\widehat{\phi }\) the dissipation potential corresponding to the diffusion problem; see Sect. 2.1. The implementation of the model is carried out using the finite element library deal.II [2] and some already implemented functions for standard tensor operations available from [50]. The finite elements employ tri-linear Lagrange ansatz functions for the deformation, while two different approaches have been chosen to approximate the fluid flux: First, also a tri-linear Lagrange ansatz function is used for the flux variable, which is not the standard conforming discretization but was nevertheless successfully applied in the context of diffusion-induced fracture of hydrogels [12]. Second, the lowest order, conforming Raviart-Thomas ansatz is selected, ensuring the continuity of the normal trace of the flux field across element boundaries.
In the following, we denote the tri-linear Lagrange ansatz functions by \(Q_1\) and the Raviart-Thomas ansatz functions of lowest order by \(RT_0\). We then denote the combination for the deformation and flux elements by \(Q_1 Q_1\) and \(Q_1 RT_0\). Both element combinations are fully integrated numerically by means of a Gauss quadrature. They are depicted in Fig. 3.

Two different finite element combinations employed in the current study. i Lagrange/Lagrange ansatz functions \(Q_{1} Q_{1}\) and ii Lagrange/Raviart–Thomas ansatz functions \(Q_{1} RT_{0}\). Note that, vectorial degree of freedom associated with the deformation are indicated by \(\bullet \), while vectorial fluid flux degree of freedom are illustrated as \(\bigcirc \) and scalar normal traces of the flux field are shown as thick solid lines ((-))
4.2 Linearized monolithic system
For completeness we state the linearized monolithic system of equations that has to be solved at each iteration k of the Newton-Raphson scheme as
where \(\underline{{{{\textbf{K}}}}}_{\varvec{J}_{v}\,{\varvec{\varphi }}}\!=\underline{{{{\textbf{K}}}}}^{\textrm{T}}_{{\varvec{\varphi }}\,\varvec{J}_{v}}\), to update the degrees of freedom associated with the deformation as well as the flux field according to
The convergence criteria employed in this study are outlined in Table 3.
Since our preconditioner is constructed algebraically, it is important to note that in deal.II the ordering of the degrees of freedom for the two-field problem is different for different discretizations.
In the case of a \(Q_{1} Q_{1}\) discretization, a node-wise numbering is used, and the global vector thus has the form
On the contrary, in the \(Q_{1} RT_{0}\) discretization, all degrees of freedom associated with the deformation are arranged first, followed by the flux degrees of freedom. Thus the global vector thus takes the form
4.2.1 Free-swelling boundary value problem
The boundary value problem of a free-swelling cube is studied in the literature, cf. [13] for 2D and [49] for 3D results, and adopted here as a benchmark problem for the different finite element combinations. Considering a cube with edge length \(2\textrm{L}\), the actual simulation of the coupled problem is carried out employing only one eighth of the domain, as shown in Fig. 4, due to the intrinsic symmetry of the problem. Therefore, symmetry conditions are prescribed along the three symmetry planes, i.e. \(X_{1}=0, X_{2}=0, X_{3}=0\), which correspond to a vanishing normal component of the displacement vector and the fluid flux. At the outer surface the mechanical boundary conditions are assumed as homogeneous Neumann conditions, i.e. \(\bar{\varvec{T}}=\varvec{0}\), while two different boundary conditions are used for the diffusion problem, namely
-
(i)
Dirichlet conditions, i.e. the normal component of the fluid flux \(H_{v}\), are prescribed or
-
(ii)
Neumann conditions, i.e. the chemical potential \(\bar{\mu }\), are specified as shown in Fig. 5 and Table 2.
Note that, due to the coupling of mechanical and diffusion fields, the boundary conditions (i) and (ii) result in different temporal evolution of the two fields. However, in both cases a homogeneous, stress-free state is reached under steady state conditions.

One eighth of the cube domain, highlighted in dark gray, with edge length \(\textrm{L}=1\,\hbox {mm}\) employed in the parallel scalability study
Type (i) boundary conditions are used for strong scalability study outlined in Sect. 7.2.2, while type (ii) boundary conditions are employed in the weak parallel scalability study described in Sect. 7.3.

Time-dependent boundary conditions for the free-swelling problem: (i) flux control and (ii) control through chemical potential
4.2.2 Mechanically induced diffusion boundary value problem
Similar to the free-swelling problem, the mechanically induced diffusion problem is also solved on a unit cube domain with appropriate symmetry conditions applied along the planes \(X_{1}=0, X_{2}=0, X_{3}=0\), as shown in Fig. 6. Along the subset \(\left( X_{1},X_{3}\right) \in \left[ -\frac{\textrm{L}}{3},\frac{\textrm{L}}{3}\right] \times \left[ -\frac{\textrm{L}}{3},\frac{\textrm{L}}{3}\right] \) at the plane \(X_{2}=\textrm{L}\) the coefficients of the displacement vector are prescribed as \(u_{i}=[0,-\hat{u},0]\), mimicking the indentation of the body with a rigid flat punch under very high friction condition. The non-vanishing displacement coefficient is increased incrementally and subsequently held constant, similar to the function for the chemical potential illustrated in Fig. 5. The corresponding parameters read as \(t_{1}=1\,\hbox {s}\), \(t_{4}=6\,\hbox {s}\) and \(\hat{u}=0.4\,\hbox {mm}\). Additionally, the normal component of the fluid flux is set to zero at the complete outer surface of the cube together with traction free conditions at the remaining part of the outer boundary.

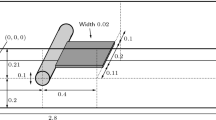
One eighth of the cube domain, highlighted in dark gray, with edge length \(\textrm{L}=1\,\hbox {mm}\) employed in the parallel scalability study. The shaded dark gray surface indicates the area with prescribed vertical displacement, mimicking the indentation of the body with a rigid flat punch
4.3 Distributed memory parallelization using deal.ii, p4est, and Trilinos
In early versions of our software, the assembly of the system matrix and the Newton steps were performed on a single core, and after distribution of the system matrix to all cores, it was solved by FROSch in fully algebraic mode [44].
In this work, the simulation is fully MPI-parallel. We assemble the system matrix in parallel using the deal.II classes from the parallel::distributed namespace. In deal.II, parallel meshes for distributed memory machines are handled by a parallel::distributed::Triangulation object, which calls the external library p4est [16] to determine the parallel layout of the mesh data.
As a result, each process owns a portion of cells (called locally owned cells in deal.II) of the global mesh. Each process stores one additional layer of cells surrounding the locally owned cells, which are denoted as ghost cells. Using the ghost cells two MPI ranks corresponding to neighboring nonoverlapping subdomains can, both, access (global) degrees of freedom on the interface.
Each local stiffness matrix is assembled by the process which owns the associated cell (i.e., the finite element), thus the processes work independently and concurrently. The handling of the parallel data (cells and degrees of freedom) distribution is performed by a DofHandler object. A more detailed describtion of the MPI parallelization in deal.II can be found in [8].
For the parallel linear algebra, deal.II interfaces to either PETSc [6] or Trilinos [63]. In this work, we make use of the classes in the dealii::LinearAlgebraTrilinos::MPI namespace, such that we obtain Trilinos Epetra vectors and matrices, which can be processed by FROSch. Similarly to the DofHandler the Trilinos Map object handles the data distribition of the parallel linear algebra objects.
To construct the coarse level, FROSch needs information on the interface between the subdomains. The FROSch framework uses a repeatedly decomposed Map to identify the interface components. In this Map the degrees of freedom on the interface are shared among the relevant processes. This Map can be provided as an input by the user. However, FROSch also provides a fully algebraic construction of the repeated Map [37], which is what we use here.
4.4 Solver settings
We use the deal.II software library (version 9.2.0) [2, 3] to implement the model in variational form, and to perform the finite element assembly in parallel. The parallel decomposition of the computational domain is performed in deal.II by using the p4est software library [16]. We remark that using p4est small changes in the number of finite elements and the number of subdomains may result in decompositions with very different subdomain shapes; see Fig. 7. A bad subdomain shape will typically degrade the convergence of the domain decomposition solver. We always choose an overlap of two elements. However, since the overlap is constructed algebraically in some positions there can be deviations from a geometric overlap of \(\delta =2h\).

Decomposition of the computational domain with 4096 finite elements into 8 (top), 27 (middle) and 64 (bottom) non-overlapping subdomains
In the Newton–Raphson scheme, we use absolute and relative tolerances for the deformation \({\varvec{\varphi }}\) and the fluid flux \(\varvec{J}_{v}\) according to Table 3, where \(\Vert r_k \Vert \) is the residual at the k-th Newton step and \(\Vert r_0 \Vert \) the initial residual.
FROSch is part of Trilinos [63] and makes heavy use of the parallel Trilinos infrastructure. The Trilinos software library is applied using the master branch of October 2021 [63].
On the first level of overlapping subdomains we always apply the restrictive additive Schwarz method. A one-to-one correspondence for the subdomains and cores is employed.
The linearized systems are solved using the parallel GMRES implementation provided by the Trilinos package Belos using the relative stopping criterion of \(\Vert r_k \Vert /\Vert r_0 \Vert \le 10^{-8}\). We use a vector of all zeros as the initial vector for the iterations.
The arising subproblems in the FROSch framework are solved by Trilinos’ built-in KLU sparse direct linear solver.
All parallel experiments are performed on the Compute Cluster of the Fakultät für Mathematik und Informatik at Technische Universität Freiberg. A cluster node has two Intel Xeon Gold 6248 processors (20 cores, 2.50 GHz).
5 Limitations
This study has some limitations which are described in more detail in Appendix A:
-
The coupling constraint may, potentially, depending on the discretization, lead to stability problems. However, in our parallel experiments the penalty parameter for the coupling constraint is rather low and no stability problems are observed experimentally.
-
A penalty formulation can lead to ill-conditioning of the stiffness matrix and slow convergence of the iterative solver. As the penalty parameter is mild, the convergence of solver is acceptable in our parallel experiments.
-
In some of our experiments standard \(H^1\)-conforming finite elements are used for the fluid. This may give bad results if the solution cannot be approximated well in \(H^1\).
-
We make use of the sparse direct solver KLU, which belongs to the Trilinos library, for the solution of the local problems and the coarse problem of the preconditioner. Other sparse direct solvers should also be tested in the future.
6 Stability of the finite element formulations
We briefly discuss the stability of the finite element discretization, namely the \(Q_{1} Q_{1}\) and \(Q_{1} RT_{0}\) ansatz; see also Appendix A.3 Here, the mechanically induced diffusion problem, described in Sect. 4.2.2, is solved for the complete loading history, employing a discretization with \(24^{3}\) finite elements, resulting in 93,750 degrees of freedom for the \(Q_{1} Q_{1}\) and 90,075 degrees of freedom for the \(Q_{1} RT_{0}\) ansatz function. Note that this discretization corresponds to only one uniform refinement step less than the discretizations considered in Sects. 7.2 and 7.3. The material parameters in this study are taken as \(\uplambda =10\,\hbox {N}/\hbox {mm}^{2}\) and \(J_{0}=4.5\), while all the remaining parameter are chosen according to Table 1. The penalty parameter \(\uplambda \) is thus larger by a factor of 50 compared to Table 1.

Evolution of the spatial distribution of i the chemical potential \(\mu \), ii the swelling volume fraction v and iii Jacobian J obtained with the \(Q_{1} RT_{0}\) discretization at \(t=1\,\hbox {s}\), \(t=2\,\hbox {s}\) and \(t=6\,\hbox {s}\) (from left to right)
Inspecting the spatial distributions of the chemical potential, the swelling volume fraction and the Jacobian in Fig. 8 obtained with the \(Q_{1} RT_{0}\) ansatz function, it becomes apparent that the mechanical deformation leads to a significant redistribution of the fluid inside the body. In particular, it can be seen that after the initial stage of the loading history (\(0\le t \le 1\,\hbox {s}\)), the chemical potential just below the flat punch has increased considerably due to the rather strict enforcement of the penalty constraint by the choice of material parameters \(\frac{\uplambda }{\upgamma }=100\). Given the definition of the chemical potential, which specializes to
for the free-energy function given in (12), the contribution associated with the constraint can readily be identified as the first term on the right hand side of (38).
During the subsequent holding stage of the loading history, i.e., the displacement coefficient \(\hat{u}\) is constant, a relaxation of the body can be observed, which results in a balanced chemical potential field alongside with a strong reduction of the swelling volume fraction below the flat punch. The spatial distribution of the Jacobian depicted in Fig. 8 (iii) is closely tied to the distribution of the swelling volume fraction.
In principle, similar observations are made in the simulation of the deformation induced diffusion problem, which employs the \(Q_{1} Q_{1}\) ansatz functions. However, significant differences occur during the holding stage of the loading history, in which deformations are due to the diffusion of the fluid. In particular, a checker board pattern develops below the flat punch, which is clearly visible in all three fields depicted in Fig. 9 at the end of the simulation at \(t=6\,\hbox {s}\). This is a result of the \(Q_{1}\) discretization; see the brief discussion in Appendix A.3.
For the \(Q_{1}\) ansatz for the fluid flux \(\varvec{J}_{v}\) the swelling volume fraction is not constant within a finite element. Due to the rather strict enforcement of the incompressibility constraint this heterogeneity is further amplified. Of course, a selective reduced integration technique is able to cure this problem, as shown in [13] for the two-dimensional case. Herein, (18) is solved at a single integration point per element and the current value v are subsequently transferred to the remaining Gauss points. Other choices, such as a three-field formulation, are also possible. The use of the \(RT_{0}\) ansatz function, however, may be more appropriate as it yields, both, a conforming discretization and a lower number of degree of freedom per element compared to the standard Lagrange approximation.
Note, however, that in the subsequent parallel simulations, the penalty parameter is smaller by more than an order of magnitude such that the problems described in this section were not observed.

Evolution of the spatial distribution of i the chemical potential \(\mu \), ii the swelling volume fraction v and iii Jacobian J obtained with the \(Q_{1} Q_{1}\) discretization at \(t=1\,\hbox {s}\), \(t=2\,\hbox {s}\) and \(t=6\,\hbox {s}\) (from left to right)
7 Numerical results
7.1 Performance of the iterative solver
To evaluate the numerical and parallel performance of the FROSch framework applied to the monolithic system in fully algebraic mode we consider the boundary value problems described in Sects. 4.2.1 and 4.2.2. We refer to the one in Sect. 4.2.1 as the free-swelling problem and denote the problem specified in Sect. 4.2.2 as the mechanically induced problem.
We compare the use of \(Q_1 RT_0\) and \(Q_1 Q_1\) ansatz functions regarding the consequences for the numerical and parallel performance of the simulation.
The different ansatz functions result in different numbers of degrees of freedom per node. For the \(Q_1 Q_1\) ansatz each node has six degrees of freedom. The usage of \(Q_{1} RT_0\) elements leads to three degree of freedoms per node and one per element face. If not noted otherwise, the construction of the coarse spaces uses the nullspace of the Laplace operator. The computing times are always sums over all time steps and Newton steps. We denote the time to assemble the tangent matrix in each Newton step by Assemble Matrix Time.
By Solver Time we denote the time to build the preconditioner (Setup Time) and to perform the Krylov iterations (Krylov Time).
For the triangulation, we executed four refinement cycles on an initial mesh with 27 finite elements resulting in a structured mesh of 110,592 finite elements.
7.2 Strong parallel scalability
For the strong scalability, we consider our problem on the structured mesh of 110,592 cells, which results in 691,635 degrees of freedom for the \(Q_1 RT_0\) elements and 705,894 degrees of freedom for the \(Q_1 Q_1\) discretization. We then increase the number of subdomains and cores and expect the computing time to decrease.
7.2.1 Linear elasticity benchmark problem
To provide a baseline to compare with, we first briefly present strong scaling results for a linear elastic benchmark problem on the unit cube \((0,1)^3\), using homogeneous Dirichlet boundary conditions on the complete boundary and discretized using \(Q_1\) elements; see Table 4. Here, the 110,592 finite elements result in only 352,947 degrees of freedom since the diffusion problem is missing. We use a generic right-hand-side vector of ones \((1,\ldots ,1)^T\).
We will use this simple problem as a baseline to evaluate the performance of our solver for our nonlinear coupled problems. Note that due to the homogeneous boundary conditions on the complete boundary, this problem is quite well conditioned, and a low number of Krylov iterations should be expected.
In Table 4, we see that, using the GDSW coarse space for elasticity (with three displacements but without rotations), we observe numerical scalability, i.e., the number of Krylov iterations does not increase and stays below 30. Note that this coarse space is algebraic, however, it exploits the knowledge on the numbering of the degrees of freedom. Other than for FETI-DP and BDDC methods, the GDSW theory does not guarantee numerical scalability for this coarse space missing the three rotations, however, experimentally, numerical scalability has been observed previously for certain, simple linear elasticity problems [30, 33].
In Table 4, the strong scalability is good when scaling from 64 (28.23 s) to 216 cores (7.43 s). The Solver Time increases when scaling from 216 to 512 cores (41.66 s), indicating that the coarse problem of size 26,109 is too large to be solved efficiently by Amesos2 KLU. The sequential coarse problem starts to dominate the solver time.
Note that, as we increase the number of cores and subdomains, the subdomain sizes decrease. In our strong parallel scalability experiments, we thus profit from the superlinear complexity of the sparse direct subdomain solvers.
We also provide results for the fully algebraic mode. Here, the number of Krylov iterations is slightly higher and increases slowly as the number of cores increase. This is not surprising since in fully algebraic mode, we make use of the space spanned by the constant vector \((1,1,\ldots ,1)\) in the construction of the second level of the preconditioner, which is only suitable for Laplace problems.
However, the Solver Time is comparable for both coarse spaces for 64 (28.23 s vs. 27.35 s), 125 (16.25 s vs. 13.35 s), and 216 (7.43 s vs. 5.69 s) cores. Notably, the Solver Time is better for the fully algebraic mode for 512 cores (41.66 s vs 6.59 s) as a result of the smaller coarse space in the fully algebraic mode (8594 vs. 26,109).
In Table 5, more details of the computational cost are presented. These timings show that for 64, 125, and 216 cores the cost is dominated by the factorizations of the subdomain matrices \(K_i\). Only for 512 cores this is not the case any more.
Interestingly, the fully algebraic mode is thus preferable within the range of processor cores discussed here, although numerical scalability is not achieved.
7.2.2 Free swelling problem
We now discuss the strong scalabilty results for the free-swelling problem; see Sect. 4.2.1. Here, the pre-swollen Jacobian \(J_0\) is chose as \(J_0=1.01\). The other material paramater are chosen according to Table 1 and Table 2.
For the parallel performance study, we perform two time steps for each test run. In each time step, again, 5 Newton iterations are needed for convergence.
For a numerically scalable preconditioner, we would expect the number of Krylov iterations to be bounded. In Table 6, we observe that we do not obtain good numerical scalability, i.e., the number of iteration increases by 50 percent when scaling from 64 to 512 cores. This can be attributed to the fully algebraic mode, whose coarse space is not quite suitable to obtain numerical scalability; see also Sect. 7.2.1. Interestingly, the results are very similar for GDSW and RGDSW with the exception of 512 cores, where the smaller coarse space of the RGDSW method results in slightly better Solver Time. This is interesting, since the RGDSW coarse space is typically significantly smaller. This indicates that the RGDSW coarse space should be preferred in our future works.
The number of iterations is smaller for the \(Q_1RT_0\) discretization compared to the \(Q_1Q_1\) discretization. Since, in addition, the local subdomain problems are significantly larger when using \(Q_1Q_1\) (see Table 7) the Solver Times are better by (approximately) a factor of two when using \(Q_1RT_0\) discretizations.
Strong parallel scalability is good when scaling from 64 to 216 cores. Only incremental improvements are obtained for 512 cores indicating that the problem is too small.
If we relate these results to our linear elasticity benchmark problem in Sect. 7.2.1, we see that with respect to the number of iterations, the (average) number of Krylov iterations is higher by a factor 1.5 to 2 for the coupled problem compared to the linear elastic benchmark. We believe that this is an acceptable result.
If we compare the Solver Time, we need to multiply the Solver Time in Table 4 by a factor of 10, since 10 linearized systems are solved in the nonlinear coupled problem. Here, we see that the Solver Time is higher by a factor slightly more than 3 when using \(Q_1RT_0\) compared to solving 10 times the linear elastic benchmark problem of Sect. 7.2.1. For \(Q_1Q_1\), this factor is closer to 6 or 7. Interestingly, in both cases, this is mostly a result of larger factorization times for the local subdomain matrices (see Table 7) and only to a small extent a result of the larger number of Krylov iterations.
7.2.3 Mechanically induced diffusion problem
For the mechanically induced problem, we chose a value of \(J_0=4.5\) for the pre-swollen Jacobian \(J_0\). The other problem parameters are chosen according to Tables 1 and 2.
Effect of the time step size Let us note that in our simulations the time step size \(\Delta t\) has only a small influence on the convergence of the preconditioned GMRES method. Using different choices of the time step \(\Delta t\), in Table 8 we show the number of Newton and GMRES iterations. The model problem is always solved on 216 cores until the time \(t=0.1\,\hbox {s}\) is reached. The number of Newton iterations for each time step slighty differs; see Table 8. The small effect of the choice of the time step size on the Krylov iterations is explained by the lack of a mass matrix in the structure part of our model. However, the diffusion part of the model does contain a mass matrix. Moreover, time stepping is needed as a globalization technique of the Newton method, i.e., large time steps will result in a failure of Newton convergence. A different formulation including a mass matrix for the mechanical part of the model should be considered in the future as a possibility to improve solver convergence.
Strong scalability for the mechanically induced diffusion We, again, perform two time steps for each test run. In each time step 5 Newton iterations are needed for convergence. In Table 9, we present results using 64 up to 512 processor cores.
First, we observe that the average number of Krylov iterations is significantly higher compared to Sect. 7.2.2, indicating this problem is significantly harder as a result of the boundary conditions.
Next, we observe that the average number of Krylov iterations is similar for the \(Q_1 RT_0\) and the \(Q_1 Q_1\) case, which is different than in Sect. 7.2.2.
In both discretizations, the number average of Krylov iterations increases by about 50 percent for a larger number of cores. This is valid for the GDSW as well as for the RGDSW coase space.
We also see that the Solver Time for \(Q_1 RT_0\) is significantly better in all cases. Indeed, the time for the Krylov iteration (Krylov Time) as well as the time for the setup of the preconditioner (Setup Time) is larger for \(Q_1Q_1\). The Setup Times are often drastically higher for \(Q_1Q_1\). As illustrated in Table 10, this is a result of larger factorization times for the sparse matrices arising from \(Q_1Q_1\) discretizations.
To explain this effect, in Fig. 12 the sparsity patterns for \(Q_1 RT_0\) and \(Q_1Q_1\) are displayed. Although the difference is visually not pronounced, the number of nonzeros almost doubles using \(Q_1Q_1\). Precisely, we have for our example with 27 finite elements a tangent matrix size of 300 with 8688 nonzero entries for \(Q_1RT_0\), which compares to a a size of 384 with 16,480 nonzero entries for \(Q_1 Q_1\). Therefore, it is not surprising if the factorizations are more computationally expensive using \(Q_1Q_1\).
In Table 9, good strong parallel scalability is generally observed when scaling from 64 to 216 cores. Again, only incremental improvements are visible, when using 512 cores. This is, again, an indication that the problem is too small for 512 cores. A three-level approach could also help, here.
If we relate the results to the linear elastic benchmark problem in Sect. 7.2.1, we see that the number of Krylov iterations is now larger by a factor of 4 to 6, which is significant. This is not reflected in the Solver Time, since it is, again, dominated by the local factorization. However, for a local solver significantly faster than KLU, the large number of Krylov iterations could be very relevant for the time-to-solution.
Next, we therefore investigate if we can reduce the number of iterations by improving the preconditioner.

Strong scalability of the Solver Time (Setup Time + Krylov Time) for the free-swelling problem; see Table 6 for the data

Detailed timers for the free-swelling problem; see Table 6 for the data
Making more use of the problem structure in the preconditioner We have observed in Table 9 that the number of Krylov iterations increased by roughly 50 percent when scaling from 64 to 512 processor cores. We explain this by the use of the fully algebraic mode of FROSch which applies the null space of the Laplace operator to construct the second level.
To improve the preconditioner, the we use, for the \(Q_1Q_1\) discretization, the three translations (in x, y, and z direction) for the construction of the coarse problem for, both, the structure and the diffusion problem: we use six basis vectors \((1,0,0,0,0,0),\,(0,1,0,0,0,0),\ldots ,(0,0,0,0,0,1)\) for construction of the coarse space. Here, the first three components refer to the structure problem and the last three components to the diffusion problem. Note that the rotations are missing from the coarse space since they would need access to the point coordinates.
In Table 11, we see that, by using this enhanced coarse space, we can reduce the number of Krylov iterations, and, more importantly, we can avoid the increase in the number of iterations. This means that, experimentally, in Table 11, we observe numerical scalability within the range of processor cores considered here.

Sparsity pattern for the tangent matrix of the mechanically induced problem using the \(Q_1 RT_0\) ansatz functions (top) and and the \(Q_1 Q_1\) ansatz functions (bottom). Here, 27 finite elements are employed resulting in 300 degrees of freedom for \(Q_1 RT_0\) and respectively 384 degrees of freedom for \(Q_1 Q_1\)
Note that the larger coarse space resulting from this approach is not amortized in terms of computing times for the two-level preconditioner. Therefore, within the range of processor cores considered here, the fully algebraic approach is preferable. Again, a three-level method may help, especially, for the GDSW preconditioner, which has a larger coarse space compared to RGDSW.
A similar approach could be taken for \(Q_1RT_0\), i.e., the three translations could be used for the deformation, and the Laplace nullspace could be used for the diffusion. However, this was not tested here.
Effect of Unstructured Grids Finally, we also consider the effect of unstructured grids; see Fig. 15 and Table 12. The mesh is regular where the boundary condition is applied. Let us note that even for structured meshes, the domain decomposition is often unstructured; see, e.g., Fig. 7 (middle).
Compared to the results for \(Q_1Q_1\) in Table 9 the problem is substantially larger (1,128,294 d.o.f. in Table 12 compared to 705,894 d.o.f. in Table 9).
For the unstructured grid the number of Krylov iterations is slightly higher and, as for the structured grid, the average number of Krylov iterations increases from 125 cores to 512 cores. As a result of the larger problem, the solver time is substantially larger than for the problem in Table 9. We only have parallel runs for 125 cores, 216 cores and 512 cores, however, the parallel scalability is acceptable.

Strong scalability of the Solver Time (Setup Time + Krylov Time) for the mechanically induced problem; see Table 9 for the data
7.3 Weak parallel scalability
For the weak parallel scalability, we only consider the free-swelling problem with type (ii) Neumann boundary condition as described in Sect. 4.2.1. The material parameters are chosen as in Sect. 7.2.2. On the initial mesh we perform different numbers of refinement cycles such that we obtain 512 finite elements per core.

Detailed timers for the mechanically induced problem; see Table 9 for the data
For the smallest problem of 8 cores, we have a problem size of 27,795 which compares to largest problem size of 1,622,595 using 512 cores.
Hence, we increase the problem size as well as the number of processor cores. For this setup, in the best case, the average number of Krylov iterations Avg. Krylov and the Solver Time should remain constant.
We observe that, within the range of 8 to 512 processor cores considered, the number of Krylov iterations grows from 16.1 to 71.4 for GDSW and from 14.6 to 76.6 for RGDSW. This increase is also reflected in the Krylov Time, which increases from \(2.51\,\hbox {s}\) to \(33.52\,\hbox {s}\) for GDSW and from \(2.06\,\hbox {s}\) to \(31.03\,\hbox {s}\) for RGDSW.
However, a significant part of the increase in the Solver Time comes from a load imbalance in the problems with more than 64 cores: the maximum local subdomain size is 7919 for 8 cores and 14,028 for 512 cores; see also Table 14. However, Table 14 also shows that the load imbalance does not increase when scaling from 64 to 512 cores, which indicates that the partitioning scheme works well enough.
Again, we see that the coarse level is not fully sufficient to obtain numerical scalability, and more structure should be used, as in Table 11, if numerical scalability is the goal.
Note that even for three-dimensional linear elasticity, we typically see an increase of the number of Krylov iterations when scaling from 8 to 512 cores, even for GDSW using with the full coarse space for elasticity (including rotations) [30, Fig. 15], which is covered by the theory. In [30, Fig. 15] the number of Krylov iterations only stays almost constant beyond about 2000 cores. However, the increase in the number of iterations is mild for the full GDSW coarse space in [30, Fig. 15] when scaling from 64 to 512 cores.

Domain decomposition into eight subdomains of an unstructured grid of a cube. Here, two uniform refinement cycles were are visualized; for the computations four refinement steps were used
Concluding, we see that using the fully algebraic mode, for the range of processor cores considered here, leads to an acceptable method although numerical scalability and optimal parallel scalability is not achieved.
Interestingly, the results for RGDSW are very similar in terms of Krylov iterations as well as the Solver Time although RGDSW has a significantly smaller coarse space. This advantage is not yet visible here, however, for a larger number of cores RGDSW can be expected to outperform GDSW by a large margin.

Increasing the the number of finite elements assigned to one core, we expect the weak parallel scalability to improve.
7.4 Conclusion and outlook
The FROSch framework has shown a good parallel performance applied algebraically to the fully coupled chemo-mechanic problems. We have compared two benchmark problems with different boundary conditions. The time step size was of minor influence for our specific benchmark problems.
Our GDSW-type preconditioners implemented in FROSch are a suitable choice when used as a monolithic solver for the linear systems arising from the Newton linearization. They perform well when applied in fully algebraic mode even when numerical scalability is not achieved.
Our experiments of strong scalability have shown that, with respect to average time to solve a monolithic system of equations obtained from linearization of the nonlinear monolithic coupled problem discretized by \(Q_1 RT_0\), we have to invest a factor of slightly more than three in computing time compared to a solving a standard linear elasticity benchmark problem discretized using the same number of \(Q_1\) finite elements. This is a good result, considering that the monolithic system is larger by a factor of almost 2.
Using a \(Q_1 Q_1\) discretization, the computing times are much slower. This is mainly a result of a lower sparsity of the finite element matrices.
We have also discussed that, using more structure, we can achieve numerical scalability in our experiments. However, this approach will only be efficient when used with a future three-level extension of our preconditioner.
References
Anand L, Mao Y, Talamini B (2019) On modeling fracture of ferritic steels due to hydrogen embrittlement. J Mech Phys Solids 122:280–314. https://doi.org/10.1016/j.jmps.2018.09.012
Arndt D, Bangerth W, Davydov D et al (2021) The deal.II finite element library: Design, features, and insights. Comput Math with Appl 81:407–422. https://doi.org/10.1016/j.camwa.2020.02.022
Arndt D et al (2020) The deal.II library, version 9.2. J Numer Math 28(3):131–146. https://doi.org/10.1515/jnma-2020-0043
Auth KL, Brouzoulis J, Ekh M (2022) A fully coupled chemo-mechanical cohesive zone model for oxygen embrittlement of nickel-based superalloys. J Mech Phys Solids 164:104880. https://doi.org/10.1016/j.jmps.2022.104880
Averweg S, Schwarz A, Schwarz C et al (2022) 3d modeling of generalized Newtonian fluid flow with data assimilation using the least-squares finite element method. Comput Methods Appl Mech Eng 392:114668. https://doi.org/10.1016/j.cma.2022.114668
Balay S, Abhyankar S, Adams MF et al (2022) PETSc Web page. https://petsc.org/
Balzani D, Deparis S, Fausten S et al (2016) Numerical modeling of fluid-structure interaction in arteries with anisotropic polyconvex hyperelastic and anisotropic viscoelastic material models at finite strains. Int J Numer Method Biomed Eng 32(10):e02,756. https://doi.org/10.1002/cnm.2756
Bangerth W, Burstedde C, Heister T et al (2011) Algorithms and data structures for massively parallel generic adaptive finite element codes. ACM Trans Math Softw 38:14/1-28
Bavier E, Hoemmen M, Rajamanickam S et al (2021) Amesos2 and belos: direct and iterative solvers for large sparse linear systems. Sci Program. https://doi.org/10.3233/SPR-2012-0352
Benzi M, Deparis S, Grandperrin G et al (2016) Parameter estimates for the relaxed dimensional factorization preconditioner and application to hemodynamics. Comput Methods Appl Mech Eng 300:129–145. https://doi.org/10.1016/j.cma.2015.11.016
Böger L (2020) Saddle-point and minimization principles for diffusion in solids: phase separation, swelling and fracture. Institute of Applied Mechanics, Stuttgart. https://doi.org/10.18419/opus-10838
Böger L, Keip MA, Miehe C (2017) Minimization and saddle-point principles for the phase-field modeling of fracture in hydrogels. Comput Mater Sci 138:474–485. https://doi.org/10.1016/j.commatsci.2017.06.010
Böger L, Nateghi A, Miehe C (2017) A minimization principle for deformation–diffusion processes in polymeric hydrogels: constitutive modeling and FE implementation. Int J Solids Struct 121:257–274. https://doi.org/10.1016/j.ijsolstr.2017.05.034
Bouklas N, Landis CM, Huang R (2015) A nonlinear, transient finite element method for coupled solvent diffusion and large deformation of hydrogels. J Mech Phys Solids 79:21–43. https://doi.org/10.1016/j.jmps.2015.03.004
Brinkhues S, Klawonn A, Rheinbach O et al (2013) Augmented Lagrange methods for quasi-incompressible materials-applications to soft biological tissue. Int J Numer Method Biomed Eng 29(3):332–350. https://doi.org/10.1002/cnm.2504
Burstedde C, Wilcox LC, Ghattas O (2011) p4est: Scalable algorithms for parallel adaptive mesh refinement on forests of octrees. SIAM J Sci Comput 33(3):1103–1133. https://doi.org/10.1137/100791634
Chen Z, Jafarzadeh S, Zhao J et al (2021) A coupled mechano-chemical peridynamic model for pit-to-crack transition in stress-corrosion cracking. J Mech Phys Solids 146:104203. https://doi.org/10.1016/j.jmps.2020.104203
Chester SA, Anand L (2010) A coupled theory of fluid permeation and large deformations for elastomeric materials. J Mech Phys Solids 58(11):1879–1906. https://doi.org/10.1016/j.jmps.2010.07.020
Chester SA, Di Leo CV, Anand L (2015) A finite element implementation of a coupled diffusion–deformation theory for elastomeric gels. Int J Solids Struct 52:1–18. https://doi.org/10.1016/j.ijsolstr.2014.08.015
Cui C, Ma R, Martínez-Pañeda E (2021) A phase field formulation for dissolution-driven stress corrosion cracking. J Mech Phys Solids 147:104254. https://doi.org/10.1016/j.jmps.2020.104254
Davis TA, Natarajan EP (2010) Algorithm 907. ACM Trans Math Softw 37:1–17
Di Leo CV, Anand L (2013) Hydrogen in metals: a coupled theory for species diffusion and large elastic–plastic deformations. Int J Plast 43:42–69. https://doi.org/10.1016/j.ijplas.2012.11.005
Dohrmann CR, Widlund OB (2009) An overlapping Schwarz algorithm for almost incompressible elasticity. SIAM J Numer Anal 47(4):2897–2923. https://doi.org/10.1137/080724320
Dohrmann CR, Widlund OB (2010) Hybrid domain decomposition algorithms for compressible and almost incompressible elasticity. Int J Numer Methods Eng 82(2):157–183. https://doi.org/10.1002/nme.2761
Dohrmann CR, Widlund OB (2017) On the design of small coarse spaces for domain decomposition algorithms. SIAM J Sci Comput 39(4):A1466–A1488. https://doi.org/10.1137/17M1114272
Dohrmann CR, Klawonn A, Widlund OB (2008) Domain decomposition for less regular subdomains: overlapping Schwarz in two dimensions. SIAM J Numer Anal 46(4):2153–2168
Dohrmann CR, Klawonn A, Widlund OB (2008) A family of energy minimizing coarse spaces for overlapping Schwarz preconditioners. In: Domain decomposition methods in science and engineering XVII, LNCSE, vol 60. Springer
Duda FP, Souza AC, Fried E (2010) A theory for species migration in a finitely strained solid with application to polymer network swelling. J Mech Phys Solids 58(4):515–529. https://doi.org/10.1016/j.jmps.2010.01.009
Faghihi D, Feng X, Lima EABF et al (2020) A coupled mass transport and deformation theory of multi-constituent tumor growth. J Mech Phys Solids 139:103936. https://doi.org/10.1016/j.jmps.2020.103936
Heinlein A, Klawonn A, Rheinbach O (2016) A parallel implementation of a two-level overlapping Schwarz method with energy-minimizing coarse space based on Trilinos. SIAM J Sci Comput 38(6):C713–C747. https://doi.org/10.1137/16M1062843
Heinlein A, Klawonn A, Rheinbach O et al (2018) Improving the parallel performance of overlapping schwarz methods by using a smaller energy minimizing coarse space. Lect Notes Comput Sci Eng 125:383–392
Heinlein A, Klawonn A, Rheinbach O et al (2018) Improving the parallel performance of overlapping Schwarz methods by using a smaller energy minimizing coarse space. Domain decomposition methods in science and engineering XXIV. Springer, Cham, pp 383–392. https://doi.org/10.1007/978-3-319-93873-8_36
Heinlein A, Hochmuth C, Klawonn A (2019) Fully algebraic two-level overlapping Schwarz preconditioners for elasticity problems. In: Vermolen FJ, Vuik C (eds) Numerical mathematics and advanced applications ENUMATH 2019. Springer, Cham, pp 531–539. https://doi.org/10.1007/978-3-030-55874-1_52
Heinlein A, Hochmuth C, Klawonn A (2019) Monolithic overlapping Schwarz domain decomposition methods with gdsw coarse spaces for incompressible fluid flow problems. SIAM J Sci Comput 41(4):C291–C316. https://doi.org/10.1137/18M1184047
Heinlein A, Klawonn A, Rheinbach O et al (2019) A three-level extension of the GDSW overlapping Schwarz preconditioner in two dimensions. In: Advanced finite element methods with applications: selected papers from the 30th Chemnitz finite element symposium 2017. Springer, Cham, pp 187–204. https://doi.org/10.1007/978-3-030-14244-5_10
Heinlein A, Hochmuth C, Klawonn A (2020) Reduced dimension gdsw coarse spaces for monolithic schwarz domain decomposition methods for incompressible fluid flow problems. Int J Numer Methods Eng 121(6):1101–1119. https://doi.org/10.1002/nme.6258
Heinlein A, Klawonn A, Rajamanickam S et al (2020) FROSch: A fast and robust overlapping Schwarz domain decomposition preconditioner based on Xpetra in Trilinos. In: Haynes R, MacLachlan S, Cai XC et al (eds) Domain decomposition methods in science and engineering XXV. Springer, Cham, pp 176–184. https://doi.org/10.1007/978-3-030-56750-7_19
Heinlein A, Klawonn A, Rheinbach O et al (2020) A three-level extension of the GDSW overlapping Schwarz preconditioner in three dimensions. In: Domain decomposition methods in science and engineering XXV. Springer, Cham, pp 185–192, https://doi.org/10.1007/978-3-030-56750-7_20
Heinlein A, Perego M, Rajamanickam S (2021) FROSch Preconditioners for land ice simulations of greenland and Antarctica. SIAM J Sci Comput 44(2):B339–B367. https://doi.org/10.1137/21M1395260
Heinlein A, Klawonn A, Knepper J et al (2022) Adaptive gdsw coarse spaces of reduced dimension for overlapping schwarz methods. SIAM J Sci Comput 44(3):A1176–A1204. https://doi.org/10.1137/20M1364540
Heinlein A, Rheinbach O, Röver F (2022) Parallel scalability of three-level FROSch preconditioners to 220,000 cores using the theta supercomputer. SIAM J Sci Comput. https://doi.org/10.1137/21M1431205
Hong W, Zhao X, Zhou J et al (2008) A theory of coupled diffusion and large deformation in polymeric gels. J Mech Phys Solids 56(5):1779–1793. https://doi.org/10.1016/j.jmps.2007.11.010
Hong W, Liu Z, Suo Z (2009) Inhomogeneous swelling of a gel in equilibrium with a solvent and mechanical load. Int J Solids Struct 46(17):3282–3289. https://doi.org/10.1016/j.ijsolstr.2009.04.022
Kiefer B, Prüger S, Rheinbach O et al (2021) Variational settings and domain decomposition based solution schemes for a coupled deformation-diffusion problem. Proc Appl Math Mech 21(1):e202100,163. https://doi.org/10.1002/pamm.202100163
Kristensen PK, Niordson CF, Martínez-Pañeda E (2020) A phase field model for elastic-gradient-plastic solids undergoing hydrogen embrittlement. J Mech Phys Solids 143:104093. https://doi.org/10.1016/j.jmps.2020.104093
Li J, Widlund OB (2006) Feti-dp, bddc, and block Cholesky methods. Int J Numer Methods Eng 66(2):250–271. https://doi.org/10.1002/nme.1553
Mandel J, Dohrmann CR (2003) Convergence of a balancing domain decomposition by constraints and energy minimization. Numer Linear Algebra Appl 10(7):639–659. https://doi.org/10.1002/nla.341
Manish V, Arockiarajan A, Tamadapu G (2021) Influence of water content on the mechanical behavior of gelatin based hydrogels: Synthesis, characterization, and modeling. Int J Solids Struct 233:111219. https://doi.org/10.1016/j.ijsolstr.2021.111219
Mauthe SA (2017) Variational multiphysics modeling of diffusion in elastic solids and hydraulic fracturing in porous media. Institut für Mechanik (Bauwesen), Lehrstuhl für Kontinuumsmechanik, Universität Stuttgart, Stuttgart. https://doi.org/10.18419/opus-9321
McBride A, Javili A, Steinmann P et al (2015) A finite element implementation of surface elasticity at finite strains using the deal.II library. arXiv:1506.01361 [physics] https://arxiv.org/abs/arXiv:1506.01361 [physics]
Nateghi A, Keip MA (2021) A thermo-chemo-mechanically coupled model for cathode particles in lithium-ion batteries. Acta Mech. https://doi.org/10.1007/s00707-021-02970-1
Nguyen TT, Waldmann D, Bui TQ (2019) Computational chemo-thermo-mechanical coupling phase-field model for complex fracture induced by early-age shrinkage and hydration heat in cement-based materials. Comput Methods Appl Mech Eng 348:1–28. https://doi.org/10.1016/j.cma.2019.01.012
Rejovitzky E, Di Leo CV, Anand L (2015) A theory and a simulation capability for the growth of a solid electrolyte interphase layer at an anode particle in a Li-ion battery. J Mech Phys Solids 78:210–230. https://doi.org/10.1016/j.jmps.2015.02.013
Rezaei S, Asheri A, Xu BX (2021) A consistent framework for chemo-mechanical cohesive fracture and its application in solid-state batteries. J Mech Phys Solids 157:104612. https://doi.org/10.1016/j.jmps.2021.104612
Salvadori A, McMeeking R, Grazioli D et al (2018) A coupled model of transport-reaction-mechanics with trapping. Part I—Small strain analysis. J Mech Phys Solids 114:1–30. https://doi.org/10.1016/j.jmps.2018.02.006
Schwarz A, Steeger K, Schröder J (2014) Weighted overconstrained least-squares mixed finite elements for static and dynamic problems in quasi-incompressible elasticity. Comput Mech 54:603–612. https://doi.org/10.1007/s00466-014-1009-1
Sprave L, Kiefer B, Menzel A (2016) Computational aspects of transient diffusion-driven swelling. In: 29th Nordic seminar on computational mechanics (NSCM-29). Chalmers, Gothenburg, pp 1–4
Sriram S, Polukhov E, Keip MA (2021) Transient stability analysis of composite hydrogel structures based on a minimization-type variational formulation. Int J Solids Struct 230–231:111080. https://doi.org/10.1016/j.ijsolstr.2021.111080
Stark S (2021) On a certain class of one step temporal integration methods for standard dissipative continua. Comput Mech 67(1):265–287. https://doi.org/10.1007/s00466-020-01931-0
Steeger K (2017) Least-squares mixed finite elements for geometrically nonlinear solid mechanics. PhD thesis, Universität Duisburg-Essen, Germany
Teichtmeister S, Mauthe S, Miehe C (2019) Aspects of finite element formulations for the coupled problem of poroelasticity based on a canonical minimization principle. Comput Mech 64(3):685–716. https://doi.org/10.1007/s00466-019-01677-4
Toselli A, Widlund O (2005) Domain decomposition methods—algorithms and theory. Springer Series in Computational Mathematics, vol 34. Springer, Berlin
Trilinos public git repository (2021). https://github.com/trilinos/trilinos
Wu T, Temizer İ, Wriggers P (2014) Multiscale hydro-thermo-chemo-mechanical coupling: application to alkali–silica reaction. Comput Mater Sci 84:381–395. https://doi.org/10.1016/j.commatsci.2013.12.029
Xue SL, Yin SF, Li B et al (2018) Biochemomechanical modeling of vascular collapse in growing tumors. J Mech Phys Solids 121:463–479. https://doi.org/10.1016/j.jmps.2018.08.009
Yu C, Malakpoor K, Huyghe JM (2020) Comparing mixed hybrid finite element method with standard FEM in swelling simulations involving extremely large deformations. Comput Mech 66(2):287–309. https://doi.org/10.1007/s00466-020-01851-z
Acknowledgements
The authors acknowledge the DFG Project 441509557 (https://gepris.dfg.de/gepris/projekt/441509557) within the Priority Program SPP2256 “Variational Methods for Predicting Complex Phenomena in Engineering Structures and Materials” of the Deutsche Forschungsgemeinschaft (DFG). The authors also acknowledge the compute cluster (DFG Project No. 397252409, https://gepris.dfg.de/gepris/projekt/397252409) of the Faculty of Mathematics and Computer Science of Technische Universität Bergakademie Freiberg, operated by the Universitätsrechenzentrum URZ.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A.1 Appendix: Limitations of this study
This work is a first step towards a co-design of variational formulation, finite element discretization, and parallel iterative solver environment. However, this work has some limitations, which we now briefly discuss.
1.1 Coupling constraint
Our model incorporates a coupling constraint \( J J_0 -1 - v = 0 \) which couples the volumetric deformation of the structure to the swelling volume fraction v; see Sect. 2.1; this constraint is implemented using a quadratic penalty \( \frac{\uplambda }{2J_{0}}\left[ JJ_{0}-1- v\right] ^{2}, \) where \(\uplambda \) is the penalty parameter. For \(v=0\) this constraint corresponds to an (almost) incompressibility constraint. It is well known that, for almost incompressible elasticity, low-order standard Lagrange finite elements can result in locking, and stable discretizations should be used if the penalty parameter \(\uplambda \) is high. A standard technique is the use of a three-field formulation known also as the \(\bar{\textbf{F}}\)-method, which is also successfully applied in fully coupled chemo-mechanic problems, cf. [19]. In the \(\bar{\textbf{F}}\)-method, the point-wise constraint is relaxed, and the penalty enforces the constraint only in a mean sense. In Sect. 6, where the penalty parameter \(\uplambda \) is chosen as \(\uplambda =10\,\hbox {N}/\hbox {mm}^{2}\), we observe oscillations which indicate the instability of the standard Q1-Lagrange discretization for the structure. However, for our numerical results in Sect. 7.1, a much lower penalty parameter \(\uplambda =0.2\,\hbox {N}/\hbox {mm}^{2}\) is used. For this value, no stability problems were observed experimentally.
A.2 Penalty formulation for the coupling constraint
A penalty formulation affects the conditioning of the stiffness matrix which can degrade the performance of iterative solvers. When direct solvers are used the quality of the solution will degrade if the penalty parameter is high. The penalty parameter used in our numerical experiments in Sect. 7 is mild. For a larger penalty parameter ill-conditioning of the stiffness matrix could be avoided, e.g., by using an Augmented Lagrange approach as in [15], at the cost of an additional outer iteration.
1.1 A.3 Discretization of the fluid flux
In some of our experiments a \(Q_1Q_1\) finite element discretization is used, where the fluid flow is approximated by standard Q1 elements. Due to the stronger patching condition compared to the \(H({\text {div}})\)-conforming Raviart-Thomas discretizations certain solutions cannot be approximated well using \(Q_1\) elements; see, e.g., [60] for a detailled discussion. However, such discretizations have been considered also elsewhere, e.g., in the context of least-squares formulations [5], where no LBB condition has to be fulfilled; see also [56], where different combinations of Raviart-Thomas elements with Lagrange elements have been considered for least-squares formulations of the Navier-Stokes problem in the almost incompressible case. Considering coupled problems involving mechanics and diffusion, the hybridization technique introduced in [66] is promising, where the incompressibility constraint of the fluid is exactly enforced by altering the balance of solute volume (7) as a consequence of the constant volume of the solid, i.e. the fluid flux is directly coupled to the overall volume change. Furthermore, incorporating refined material models based on the theory of porous media, c.f. [61], in principle allows one to enforce the incompressibility of the solid and the fluid independently. However, these types of models and the corresponding finite element formulations are beyond the scope of the current contribution, and we leave it for future work.
1.2 A.4 Sparse direct solver
We apply the KLU sparse direct solver [21] which is the default solver of the Trilinos Amesos2 package [9]. It is used as a subdomain local sparse solver and as solver for the coarse problem. KLU was originally developed for problems from circuit simulation and is therefore often not the fastest choice available for the factorization of finite element matrices, especially if they are large. However, it was found that it can sometimes outperform other established sparse direct solvers also for matrices from finite element problems; see [10]. In the future, other well-known fast sparse direct solvers should, however, also be tested in our context.
1.3 A.5 Fully algebraic construction of the preconditioner
In this work, it is our approach to use the two-level version of the preconditioners in FROSch in fully algebraic mode, i.e., without making use of the structure of the problem when constructing the preconditioner from the monolithic finite element matrix. Therefore, the second level is constructed in the same way as for a scalar elliptic problem. It is known that this coarse level is not the correct choice for elasticity.
As a result, numerical scalability in the strict sense should not be expected, i.e., the number of iterations can be expected to grow with the number of cores. We will investigate how fast the number of iterations grow, and we will show experiments which indicate that we may be able to achieve numerical scalability by using some additional information on the problem in the construction of the preconditioner.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kiefer, B., Prüger, S., Rheinbach, O. et al. Monolithic parallel overlapping Schwarz methods in fully-coupled nonlinear chemo-mechanics problems. Comput Mech 71, 765–788 (2023). https://doi.org/10.1007/s00466-022-02254-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00466-022-02254-y