
Abstract
Background
Anastomotic leakage (AL), a severe complication following colorectal surgery, arises from defects at the anastomosis site. This study evaluates the feasibility of predicting AL using machine learning (ML) algorithms based on preoperative data.
Methods
We retrospectively analyzed data including 21 predictors from patients undergoing colorectal surgery with bowel anastomosis at four Swiss hospitals. Several ML algorithms were applied for binary classification into AL or non-AL groups, utilizing a five-fold cross-validation strategy with a 90% training and 10% validation split. Additionally, a holdout test set from an external hospital was employed to assess the models' robustness in external validation.
Results
Among 1244 patients, 112 (9.0%) suffered from AL. The Random Forest model showed an AUC-ROC of 0.78 (SD: ± 0.01) on the internal test set, which significantly decreased to 0.60 (SD: ± 0.05) on the external holdout test set comprising 198 patients, including 7 (3.5%) with AL. Conversely, the Logistic Regression model demonstrated more consistent AUC-ROC values of 0.69 (SD: ± 0.01) on the internal set and 0.61 (SD: ± 0.05) on the external set. Accuracy measures for Random Forest were 0.82 (SD: ± 0.04) internally and 0.87 (SD: ± 0.08) externally, while Logistic Regression achieved accuracies of 0.81 (SD: ± 0.10) and 0.88 (SD: ± 0.15). F1 Scores for Random Forest moved from 0.58 (SD: ± 0.03) internally to 0.51 (SD: ± 0.03) externally, with Logistic Regression maintaining more stable scores of 0.53 (SD: ± 0.04) and 0.51 (SD: ± 0.02).
Conclusion
In this pilot study, we evaluated ML-based prediction models for AL post-colorectal surgery and identified ten patient-related risk factors associated with AL. Highlighting the need for multicenter data, external validation, and larger sample sizes, our findings emphasize the potential of ML in enhancing surgical outcomes and inform future development of a web-based application for broader clinical use.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Anastomotic Leakage (AL) is a severe and potentially deadly complication of significant clinical importance following gastrointestinal surgery [1]. According to Rahbari et al. [2], AL is defined as a defect at the anastomotic site that results in a connection between intra—and extraluminal compartments. AL is considered an independent risk factor for adverse clinical and oncological outcomes like decreased survival of cancer patients and increased readmission rates after surgery [3,4,5]. The approximated incidence of AL is 3.3% after colon anastomosis and 8.6% after colorectal anastomosis in specialized centers [4]. However, these rates are likely considerably higher in centers lacking dedicated colorectal surgery teams and after emergency surgery. In fact, depending on diagnostic criteria, AL rates of over 10% have been reported in the literature [6,7,8,9,10]. Hospital stay is extended by twelve days on average, and healthcare-related expenses are increased by up to 30.000 USD in patients who experience AL [1, 2].
In previous publications, a multitude of risk factors for AL have been identified more or less consistently, e.g., age, body mass index (BMI), comorbidity indexes, emergency surgery, steroids, or active smoking [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25]. Integrating all of these risk factors into one holistic clinical prediction of AL is a very challenging task, even for experienced physicians. Indeed, even experienced surgeons were reported to systematically underestimate the risk of AL by clinical assessment [26]. Undoubtedly, the ability to preoperatively predict AL precisely would allow for better resource allocation, enhanced patient preparation, and improved patient–physician relationships due to the improved quality of informed consent. Specifically, by identifying preoperative risk factors on the one hand, the modifiable risk factors could be addressed to reduce the individual patient risk of AL. On the other hand, for such patients, modification of the surgical approach could be considered; for example, the creation of a deviating stoma to mitigate the consequences of AL.
Machine learning (ML) algorithms can be exceptionally competent at integrating diverse patient variables into a unified risk model that can generate predictions specific to each patient. However, the development and rigorous validation of clinical prediction models require large amounts of multicentre data as well as external validation. Before embarking on said multicenter data collection, piloting a modeling strategy to assess the feasibility and identify the most valuable inputs is crucial. Consequently, the aim of this pilot study is to assess whether AL can be predicted from preoperative data from four Swiss surgical centers using machine learning (ML) algorithms.
Methods
Overview and data collection
Data were extracted retrospectively from the patient registry of the University Hospital of Basel, the GZO Hospital Wetzikon, Emmental Teaching Hospital, and the Cantonal Hospital Liestal and entered into a shared REDCap database. The data collection was performed by consultants, surgical residents, or master students of the medical field under supervision. Patients who underwent colon anastomosis for various reasons, including neoplasia, diverticulitis, ischemia, iatrogenic or traumatic perforation, or inflammatory bowel disease between 1st of January 2012 and 31st of December 2020 and had a follow-up of at least 6 months were eligible where general consent was available. This study was completed based on the transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD) statement checklist for the development of clinical prediction models [27]. Utilizing the aforementioned data, we developed ML models with the aim of predicting AL.
Patient and public involvement
Patients and the public have not been involved in planning, managing, designing or carrying out the research.
Predictors and outcome measures
AL was defined according to Gessler et al. [28] and Rahbari et al. [2] as any clinical sign of leakage, confirmed by radiological examination, endoscopy, clinical examination of the anastomosis, or upon reoperation. Recorded variables included 21 risk factors that already have been reported in the literature such as age, sex, body mass index (BMI), active smoking (up to 6 weeks before surgery), alcohol abuse (> 2 alcoholic beverages per day), prior abdominal surgery, preoperative leucocytosis (≥ 10.000 per mm3), preoperative steroid use, Charlson Comorbidity index (CCI), American Society of Anesthesiologists (ASA) score, renal function (chronic kidney disease (CKD) stages G1 to G5), albumin (g/dl), and hemoglobin level (g/dl), liver metastasis (at the time of surgery proven by radiological imaging or biopsy preoperatively), indication (e.g., tumor, diverticular disease, ileus, ischemia, inflammatory bowel disease), type of surgery (right or left sided hemicolectomy, ileocecal resection, transverse colectomy, sigmoidectomy, rectosigmoidectomy, colostomy, or Hartmann’s reversal), emergency surgery, bowel perforation, surgical approach (laparoscopic, robotic or open), anastomotic technique (hand-sewn or stapler), and defunctioning ileostomy.
Model development
Python 3.10 was used to perform all analyses. The Sklearn and xgb packages were used for implementing all machine learning models, including Logistic Regression (generalize linear model; GLM), Lasso Regression (lasso), Artificial Neural Network, Random Forest, Extreme Gradient Boosting (XGBoost), and Support Vector Machine (SVM) models [29]. For data preprocessing, missing values were replaced by − 1 for both numeric and categorical features. For data normalization, one-hot encoding was used for categorical features and minmax scaling for numeric features [30]. To avoiding overfitting, data augmentation was used by applying Gaussian noise to the dataset to increase the number of samples synthetically [31].
To evaluate model performance, data were split into random test set (10%) and a train set (90%). In this study, we employed a five-fold cross-validation methodology for model training. A gridsearch algorithm based on the F1 Score was used to tune the hyperparameters. In addition, for testing the model’s robustness, an additional test set from another hospital has been used separately.
Results
Cohort
In the training process, a total of 1244 patients were included in the training set, of which 112 (9.0%) suffered from AL. Figure 1 shows the flowchart of the patients included into the study. Only patients were entered into the database where general consent was available. Other reasons why patients did not qualify for data entry were mostly missing follow-up, colonic resection without anastomosis, death after surgery, or a deviating stoma still in place at last follow-up. A total of 5 patients had missing data > 25% and thus were excluded from the algorithm. In the holdout test set, a total of 198 patients were included, of which 7 (3.5%) suffered from AL.

Flowchart of included patients from all hospitals
The mean age was 65.5 ± 14.8 (holdout test set: 64.7 ± 14.6). Furthermore, 578 (46.5%) patients were male and 666 (53.5%) female (holdout test set: 97 male [49%] and 101 female [51%]). The mean BMI was 25.7 ± 5.3 (holdout test set: 27.9 ± 5.5) and 292 (23.5%) patients were active smokers (holdout test set: 13 [6.6%]). Tables 1 and 2 provide an overview of the cohorts.
Model performance
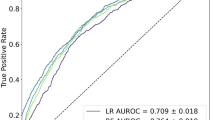
The Random Forest model demonstrated a good performance for binary classification, with an area under the receiver operating characteristic (AUC) of 0.78 (SD: [± 0.01]) and an accuracy of 0.82 (SD: [± 0.04]). Additionally, it achieved an F1 Score of 0.58 (SD: [± 0.03]). The model’s performance on the external holdout test set achieved an AUC score of 0.60 (SD: [± 0.05]), an accuracy of 0.87 (SD: [± 0.08]), and a F1 Score of 0.51 (SD: [± 0.03]). Considering the performance for the out-of-domain generalization, the Logistic Regression model performed with an AUC of 0.69 (SD: [± 0.01]) on the random test set and 0.61 (SD: [± 0.05]) on the holdout test set, and with an F1 Scores of 0.53 (SD: [± 0.04]) and 0.51 (SD: [± 0.02]), respectively. The performance of other models and additional metrics are detailed in Table 3. Specific feature importance within the models is highlighted in Table 4. Comparative ROC-AUC curves for the models, illustrating their performance in the random test set and the holdout test set, are presented in Fig. 2 and Fig. 3, respectively.

Area under the receiver operating characteristics curves (ROC-AUC) of the implemented models on the random test set

Area under the receiver operating characteristics curves (ROC-AUC) of the implemented models on the external holdout test set GLM Logistic regression, lasso lasso regression, NNET artificial neural network, RF random forest classifier, SVM support vector machine, XGBoost extreme gradient boosting
Discussion
In a pilot study using data from four centers in Switzerland for colorectal surgery, we assess the feasibility of predicting AL accurately from tabular data using ML techniques. Our findings demonstrate that predicting AL to a certain extent is feasible and identifies the most important input variables, laying the basis for a more extensive international multicenter study.
Even though a plethora of studies have analyzed risk factors for AL, up to this day, no reliable clinical prediction model for AL has been established [11,12,13,14,15,16,17,18,19,20,21,22,23,24,25]. This study aims to prove whether using a machine learning algorithm is proficient to solve the classification problem into AL and non-AL (‘will my patient suffer from AL after colorectal surgery?’).
Our results are promising, showing the potential of methodologies associated with machine learning for a prospective study for predicting AL. Souwer et al. [32] published 2020 a systematic review of existing models predicting mortality and complications after colorectal and colorectal cancer surgery. Seven models with the endpoint of AL prediction build a score based on standard statistical methods and ML techniques with a wide range of included patients between 159 and 10392 [33,34,35,36,37,38,39]. The range of the performance of the AUC values was between 0.63 and 0.95 for the development cohort and 0.58 to 1.0 for the validation cohort. Our model’s performance lies within these findings with an AUC of 0.78, respectively. Most of the studies used a combination of preoperative, intraoperative, and postoperative features, like duration of surgery [34,35,36], blood loss [36, 38], or wound infection [35] and, moreover, non-patient or procedural-related features, like hospital size [33]. We favored using predictors of the preoperative setting to aid in patient information prior to surgery.
A comparison to existing risk-calculating morbidity models, like the POSSUM score [40] or the ACS-NSQIP [41], should be done cautiously since the definition of complications and their severity differs. Moreover, the choice of different risk factors included and the lack of external validation makes a comparison challenging. Still, these findings will help develop a more precise future model. In general, predictive models and their performance are subject to their individual training and validation cohort and developing conditions, like regional and technical differences, risk profile of a population, and surgical indication. Therefore, validation or re-calibration with patient cohorts from different countries or hospital sizes would make them more sustainable and generalizable. Additionally, a re-calibration could be sensible after several years due to possible minor adaptions in current surgical practice.
The Random Forest model excels at providing probability-based predictions that are invaluable for informed clinical decision-making, particularly in an in-domain context. Similarly, the Logistic Regression model is adept at offering robust probability estimates that can be critical for decision-making in out-of-domain settings. While the model’s performance on the external holdout test set was notably lower in the Random Forest model, we attribute this discrepancy to a domain shift. If the robustness for out-of-domain generalization were prioritized, the Logistic Regression model would be the model of choice due to its more consistent performance. Given the pilot nature of this study, our focus is on assessing the model’s efficacy within a specific domain with the Random Forest model, understanding its capabilities and limitations, before considering external domain applications with the Logistic Regression model. It is crucial to emphasize that both models, due to their probabilistic nature, do not provide direct class label predictions but instead offer the probability associated with each instance, facilitating nuanced clinical judgment. Well-calibrated predicted probabilities are arguably more important in clinical practice (“How likely is it that I am going to experience AL?’—‘Your probability is 17%’) instead of binary predictions (‘Am I going to suffer from AL?’—‘The model predicts yes/no’). Physicians are experts at dealing with uncertainty and risks, and probabilities are thus more appreciated by patients and physicians than a mere yes or no answer—apart from the fact that patients are never binary but instead represent a spectrum of risk [42]. A rule-in model could prove to be of great value for clinicians by simply identifying the high-risk group, and, if possible, modifiable risk factors can be adjusted. Still, a model that is proficient to detect gray-zone patients at low risk for AL is of great value to identify those patients who conversely could be waived of protective stoma, thus, if an AL occurs might suffer from more severe complications. Nevertheless, our model is valuable for shared decision-making.
Clinical prediction models can facilitate assessing individual risks and making more informed decisions based on predictive analytics that are tailored to each patient. However, especially in colorectal surgery, the indication for surgery is rarely truly elective. Therefore, a prediction model can only help decide whether an intervention should be postponed to improve the risk profile or, especially for emergency interventions, whether a patient would benefit from a diverting stoma to minimize and modify risk factors before re-joining the colon. On the other hand, a comprehensive predictive model may also increase a patient’s acceptance of the primary placement of a protective stoma. Thus, such a model could potentially also help to improve the physician-patient relationship through enhanced patient education.
There is a widespread misunderstanding that variable importance measures gleaned from clinical prediction models can discover correlations and causalities like explanatory modeling does (prediction versus explanation) [43]. Indeed, this common misconceptualization exists because predictive and explanatory modeling are often not as explicitly distinguished as attempted here in this study. Indeed, the interchangeable use of the concepts of in-sample correlation and out-of-sample generalization can lead to false clinical decision-making [44]. While those variables identified as having high feature importance in this study may indeed be the most crucial ones for precise and generalizable prediction of AL, it cannot safely be concluded that these variables are necessarily also important independent risk factors for AL in their own right.
Another separate question is the initial choice of input variables for clinical prediction modeling, which can be achieved in various ways [45]. In any case, a balance between performance through the inclusion of many variables and between the goal of arriving at parsimonious models that truly generalize needs to be struck. The choice of variables for this study was focused on common risk factors described in literature and preoperatively available patient-related risk factors to minimize the statistical noise from differing standard procedures in distinct clinical centers.
Another difficulty in clinical prediction modeling is choosing the appropriate sample size. According to a common rule of thumb, there should be at least ten minority class observations in a dataset per feature [46]. This study relies on 21 patient-related risk factors, thus making a total number of 1000 patients with AL who would be necessary for training the final model. Other architectures, such as random forests, and SVMs seem to require much more data per feature [47]. Therefore, it is conceivable that including more patients will further refine the current model. Additionally, with more data, more complex methods can be implemented that would avoid the use of techniques such as data augmentation to generate synthetic information and further improve the model performance.
Yet, the results of a predictive model cannot be seen as a clear recommendation pro or contra an intervention as the risk profile is tailored only to a specific endpoint and thus does not entirely reflect the patient’s global situation. Indeed, components of decision-making such as the psychological distress of a patient with chronic diverticulitis are not included in the model and have a decisive influence on the indication. Consequently, prediction models should be seen only as adjunctive information to be used in a complementary way for informed shared decision-making. Nevertheless, the necessity for evidence-based clinical prediction models becomes clear when considering the relative inability of even experienced clinicians in predicting clinical outcomes [26], while the ethical implications of an ‘artificial intelligence doctor’ technology independent from human control have to be taken into account, too [48]. Consequently, ML-based clinical prediction models could be deemed a contemporary optimal trade-off between the clinical experience of human experts and the exploitation of big data by learning algorithms.
Limitations
Besides the caveat of the retrospective data collection, our cohort’s relatively high AL rate of 9.0% can be seen as a limitation. Similarly, the difference in AL incidence among the dataset represents an additional hurdle that is realistic, as AL rate is described inconsistently in the literature [4, 6,7,8,9,10]. The patient population at the included hospitals with 23.8% emergency cases and a cohort that includes transplanted and immunosuppressed patients is expected to have higher complication rates [22]. Nevertheless, such a difference to other hospitals should be reflected in the ASA score, the CCI, and blood values and thus also in our results. By including patient data from other institutions in future analyses, this number will be balanced out, and a differentiated breakdown according to emergency interventions, immunosuppressant use, previous radio/chemotherapy, and cancer diagnosis, which additionally reflect a patient’s health status, is conceivable and could be implemented in our ML algorithm.
Furthermore, despite choosing common preoperative risk factors for AL from previous works, there are certainly several more unknown features influencing anastomotic healing we did not consider in our analysis. For instance, intraoperative factors like the surgeon’s experience are reported to influence postoperative morbidity [49, 50]. Zarnescu et al. [50] recently presented their summary of risk factors of AL, distributing them into pre-, intra-, and postoperative risk factors for AL, of which there are some modifiable and others are not. Other than that there might be further influencing circumstances leading to an AL, which are less convenient to measure and hence to include in a future ML algorithm, like blood flow or tension on the anastomosis. Aligning with this, we have included a broad variance of indications in our algorithm rather than performing a subgroup analysis, reflecting the daily situation of colon surgery also in smaller hospitals. As expected, the type of surgical procedure was one of the main features for the model performance.There is the potential that the future ML model, using multicenter data, will perform differently, and some other features will be more relevant in the algorithm. Recruiting more patient data from other hospitals is crucial and will further allow for more detailed statistical models and subgroup analyses, especially for less common surgical indications. The current algorithm will require updating and re-calibration, and the performance will be re-evaluated [51].
One further caveat of any model is the danger of overfitting. In clinical prediction modeling, overfitting means that an algorithm adheres too strictly to the training data, especially its inherent variance and possible noise factors (e.g., noise generated by a hospital’s standardized procedures). With enough training, the algorithm will perform extremely well on the training data while losing its generalization capability toward new data from other centers. Indeed, it is not unlikely that this study might suffer from slight overfitting due to standardized hospital procedures. However, this weakness could be addressed by recruiting more patient data from other hospitals. Furthermore, it is important to highlight that the ROC-AUC metric is influenced by class distribution imbalance. Here, the F1 score to demonstrate the model’s robustness in both categories.
Lastly, as of the nature of a pilot study, assessing the feasibility of a method in a limited patient cohort is a caveat, not allowing to draw clinical implications from the results so far. The performance of the external validation cohort, using a fairly small sample size with a rare event to be predicted, will be considerably impaired by each error in the prediction. According to the central limit theorem, we expect an enhanced performance of the internal and external validation sets using more patient data, again emphasizing the cruciality of more patient data after conducting this pilot study. Therefore, we have purposefully not yet deployed the model for clinical application in, e.g., a web-app, as any small sample sized and not extended externally validated clinical prediction model is not yet recommended for clinical use [52].
Conclusion
In this pilot study, we developed an ML-based prediction model for AL after colorectal surgery using ten patient-related risk factors associated with AL. However, it is crucial to include and externally validate the results on international multicenter data with larger sample sizes to develop a robust and generalizable model.
References
Lee SW, Gregory D, Cool CL (2020) Clinical and economic burden of colorectal and bariatric anastomotic leaks. Surg Endosc 34(10):4374–4381. https://doi.org/10.1007/s00464-019-07210-1
Rahbari NN, Weitz J, Hohenberger W, Heald RJ, Moran B, Ulrich A, Holm T, Wong WD, Tiret E, Moriya Y, Laurberg S, den Dulk M, van de Velde C, Büchler MW (2010) Definition and grading of anastomotic leakage following anterior resection of the rectum: a proposal by the international study group of rectal cancer. Surgery 147(3):339–351. https://doi.org/10.1016/j.surg.2009.10.012
Mirnezami A, Mirnezami R, Chandrakumaran K, Sasapu K, Sagar P, Finan P (2011) Increased local recurrence and reduced survival from colorectal cancer following anastomotic leak: systematic review and meta-analysis. Ann Surg 253(5):890–899. https://doi.org/10.1097/SLA.0b013e3182128929
Krell RW, Girotti ME, Fritze D, Campbell DA, Hendren S (2013) Hospital readmissions after colectomy: a population-based study. J Am Coll Surg 217(6):1070–1079. https://doi.org/10.1016/j.jamcollsurg.2013.07.403
Hammond J, Lim S, Wan Y, Gao X, Patkar A (2014) The burden of gastrointestinal anastomotic leaks: an evaluation of clinical and economic outcomes. J Gastrointest Surg: Off J Soc Surg Aliment Tract 18(6):1176–1185. https://doi.org/10.1007/s11605-014-2506-4
Sørensen LT, Jørgensen T, Kirkeby LT, Skovdal J, Vennits B, Wille-Jørgensen P (1999) Smoking and alcohol abuse are major risk factors for anastomotic leakage in colorectal surgery. Br J Surg 86(7):927–931. https://doi.org/10.1046/j.1365-2168.1999.01165.x
Law WI, Chu KW, Ho JW, Chan CW (2000) Risk factors for anastomotic leakage after low anterior resection with total mesorectal excision. Am J Surg 179(2):92–96. https://doi.org/10.1016/s0002-9610(00)00252-x
Kang CY, Halabi WJ, Chaudhry OO, Nguyen V, Pigazzi A, Carmichael JC, Mills S, Stamos MJ (2013) Risk factors for anastomotic leakage after anterior resection for rectal cancer. JAMA Surg 148(1):65–71. https://doi.org/10.1001/2013.jamasurg.2
Eberl T, Jagoditsch M, Klingler A, Tschmelitsch J (2008) Risk factors for anastomotic leakage after resection for rectal cancer. Am J Surg 196(4):592–598. https://doi.org/10.1016/j.amjsurg.2007.10.023
Kruschewski M, Rieger H, Pohlen U, Hotz HG, Buhr HJ (2007) Risk factors for clinical anastomotic leakage and postoperative mortality in elective surgery for rectal cancer. Int J Colorectal Dis 22(8):919–927. https://doi.org/10.1007/s00384-006-0260-0
Komen N, Dijk JW, Lalmahomed Z, Klop K, Hop W, Kleinrensink GJ, Jeekel H, Ruud Schouten W, Lange JF (2009) After-hours colorectal surgery: a risk factor for anastomotic leakage. Int J Colorectal Dis 24(7):789–795. https://doi.org/10.1007/s00384-009-0692-4
Bakker IS, Grossmann I, Henneman D, Havenga K, Wiggers T (2014) Risk factors for anastomotic leakage and leak-related mortality after colonic cancer surgery in a nationwide audit. Br J Surg 101(4):424–432. https://doi.org/10.1002/bjs.9395
Trencheva K, Morrissey KP, Wells M, Mancuso CA, Lee SW, Sonoda T, Michelassi F, Charlson ME, Milsom JW (2013) Identifying important predictors for anastomotic leak after colon and rectal resection: prospective study on 616 patients. Ann Surg 257(1):108–113. https://doi.org/10.1097/SLA.0b013e318262a6cd
Park JS, Choi GS, Kim SH, Kim HR, Kim NK, Lee KY, Kang SB, Kim JY, Lee KY, Kim BC, Bae BN, Son GM, Lee SI, Kang H (2013) Multicenter analysis of risk factors for anastomotic leakage after laparoscopic rectal cancer excision: the Korean laparoscopic colorectal surgery study group. Ann Surg 257(4):665–671. https://doi.org/10.1097/SLA.0b013e31827b8ed9
Silva-Velazco J, Stocchi L, Costedio M, Gorgun E, Kessler H, Remzi FH (2016) Is there anything we can modify among factors associated with morbidity following elective laparoscopic sigmoidectomy for diverticulitis? Surg Endosc 30(8):3541–3551. https://doi.org/10.1007/s00464-015-4651-6
Buchs NC, Gervaz P, Secic M, Bucher P, Mugnier-Konrad B, Morel P (2008) Incidence, consequences, and risk factors for anastomotic dehiscence after colorectal surgery: a prospective monocentric study. Int J Colorectal Dis 23(3):265–270. https://doi.org/10.1007/s00384-007-0399-3
Alves A, Panis Y, Trancart D, Regimbeau JM, Pocard M, Valleur P (2002) Factors associated with clinically significant anastomotic leakage after large bowel resection: multivariate analysis of 707 patients. World J Surg 26(4):499–502. https://doi.org/10.1007/s00268-001-0256-4
Slieker JC, Komen N, Mannaerts GH, Karsten TM, Willemsen P, Murawska M, Jeekel J, Lange JF (2012) Long-term and perioperative corticosteroids in anastomotic leakage: a prospective study of 259 left-sided colorectal anastomoses. Arch Surg 147(5):447–452. https://doi.org/10.1001/archsurg.2011.1690
Konishi T, Watanabe T, Kishimoto J, Nagawa H (2006) Risk factors for anastomotic leakage after surgery for colorectal cancer: results of prospective surveillance. J Am Coll Surg 202(3):439–444. https://doi.org/10.1016/j.jamcollsurg.2005.10.019
Kim MJ, Shin R, Oh HK, Park JW, Jeong SY, Park JG (2011) The impact of heavy smoking on anastomotic leakage and stricture after low anterior resection in rectal cancer patients. World J Surg 35(12):2806–2810. https://doi.org/10.1007/s00268-011-1286-1
Peeters KC, Tollenaar RA, Marijnen CA, Klein Kranenbarg E, Steup WH, Wiggers T, Rutten HJ, van de Velde CJ (2005) Risk factors for anastomotic failure after total mesorectal excision of rectal cancer. Br J Surg 92(2):211–216. https://doi.org/10.1002/bjs.4806
McDermott FD, Heeney A, Kelly ME, Steele RJ, Carlson GL, Winter DC (2015) Systematic review of preoperative, intraoperative and postoperative risk factors for colorectal anastomotic leaks. Br J Surg 102(5):462–479. https://doi.org/10.1002/bjs.9697
Zheng H, Wu Z, Wu Y, Mo S, Dai W, Liu F, Xu Y, Cai S (2019) Laparoscopic surgery may decrease the risk of clinical anastomotic leakage and a nomogram to predict anastomotic leakage after anterior resection for rectal cancer. Int J Colorectal Dis 34(2):319–328. https://doi.org/10.1007/s00384-018-3199-z
Naumann DN, Bhangu A, Kelly M, Bowley DM (2015) Stapled versus handsewn intestinal anastomosis in emergency laparotomy: a systemic review and meta-analysis. Surgery 157(4):609–618. https://doi.org/10.1016/j.surg.2014.09.030
Choy PY, Bissett IP, Docherty JG, Parry BR, Merrie A, Fitzgerald A (2011) Stapled versus handsewn methods for ileocolic anastomoses. Cochrane Database Syst Rev. https://doi.org/10.1002/14651858.CD004320.pub3
Karliczek A, Harlaar NJ, Zeebregts CJ, Wiggers T, Baas PC, van Dam GM (2009) Surgeons lack predictive accuracy for anastomotic leakage in gastrointestinal surgery. Int J Colorectal Dis 24(5):569–576. https://doi.org/10.1007/s00384-009-0658-6
Collins GS, Reitsma JB, Altman DG, Moons KG (2015) Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the tripod statement. Br J Surg 102(3):148–158. https://doi.org/10.1002/bjs.9736
Gessler B, Eriksson O, Angenete E (2017) Diagnosis, treatment, and consequences of anastomotic leakage in colorectal surgery. Int J Colorectal Dis 32(4):549–556. https://doi.org/10.1007/s00384-016-2744-x
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O et al (2011) Scikit-learn: machine learning in python. J Mach Learn Res 12:2825–2830
Jain AK, Murty MN, Flynn PJ (1999) Data clustering: a review. ACM Comput Surv 31(3):264–323. https://doi.org/10.1145/331499.331504
Bishop C (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
Souwer ETD, Bastiaannet E, Steyerberg EW, Dekker JT, van den Bos F, Portielje JEA (2020) Risk prediction models for postoperative outcomes of colorectal cancer surgery in the older population—a systematic review. J Geriatric Oncol 11(8):1217–1228. https://doi.org/10.1016/j.jgo.2020.04.006
Frasson M, Flor-Lorente B, Rodríguez JL, Granero-Castro P, Hervás D, Alvarez Rico MA, Brao MJ, Sánchez González JM, Garcia-Granero E, ANACO Study Group (2015) Risk factors for anastomotic leak after colon resection for cancer: multivariate analysis and nomogram from a multicentric, prospective, national study with 3193 patients. Ann surg 262(2):321–330. https://doi.org/10.1097/SLA.0000000000000973
Pasic F, Salkic NN (2013) Predictive score for anastomotic leakage after elective colorectal cancer surgery: a decision making tool for choice of protective measures. Surg Endosc 27(10):3877–3882. https://doi.org/10.1007/s00464-013-2997-1
Rencuzogullari A, Benlice C, Valente M, Abbas MA, Remzi FH, Gorgun E (2017) Predictors of anastomotic leak in elderly patients after colectomy: nomogram-based assessment from the american college of surgeons national surgical quality program procedure-targeted cohort. Dis Colon Rectum 60(5):527–536. https://doi.org/10.1097/DCR.0000000000000789
Dekker JW, Liefers GJ, van Otterloo JCDM, Putter H, Tollenaar RA (2011) Predicting the risk of anastomotic leakage in left-sided colorectal surgery using a colon leakage score. J Surg Res 166(1):e27–e34. https://doi.org/10.1016/j.jss.2010.11.004
Rojas-Machado SA, Romero-Simó M, Arroyo A, Rojas-Machado A, López J, Calpena R (2016) Prediction of anastomotic leak in colorectal cancer surgery based on a new prognostic index PROCOLE (prognostic colorectal leakage) developed from the meta-analysis of observational studies of risk factors. Int J Colorectal Dis 31(2):197–210. https://doi.org/10.1007/s00384-015-2422-4
Hu X, Cheng Y (2015) A clinical parameters-based model predicts anastomotic leakage after a laparoscopic total mesorectal excision: a large study with data from China. Medicine 94(26):e1003. https://doi.org/10.1097/MD.0000000000001003
Hoshino N, Hida K, Sakai Y, Osada S, Idani H, Sato T, Takii Y, Bando H, Shiomi A, Saito N (2018) Nomogram for predicting anastomotic leakage after low anterior resection for rectal cancer. Int J Colorectal Dis 33(4):411–418. https://doi.org/10.1007/s00384-018-2970-5
Copeland GP, Jones D, Walters M (1991) POSSUM: a scoring system for surgical audit. Br J Surg 78(3):355–360. https://doi.org/10.1002/bjs.1800780327
Bilimoria KY, Liu Y, Paruch JL, Zhou L, Kmiecik TE, Ko CY, Cohen ME (2013) Development and evaluation of the universal ACS NSQIP surgical risk calculator: a decision aid and informed consent tool for patients and surgeons. J Am Coll Surg 217(5):833–42.e423. https://doi.org/10.1016/j.jamcollsurg.2013.07.385
Staartjes VE, Kernbach JM (2020) Letter to the editor importance of calibration assessment in machine learning-based predictive analytics. J Neurosurg Spine. https://doi.org/10.3171/2019.12.SPINE191503
Shmueli G (2010) POLITIKA konkurencije evropske unije i usluge od opšteg ekonomskog interesa. Explain or Predict? 25(3):289–310
Yarkoni T, Westfall J (2017) Choosing prediction over explanation in psychology: lessons from machine learning. Perspect Psychol Sci: J Assoc Psychol Sci 12(6):1100–1122. https://doi.org/10.1177/1745691617693393
Chowdhury MZI, Turin TC (2020) Variable selection strategies and its importance in clinical prediction modelling. Fam Med Community Health 8(1):e000262. https://doi.org/10.1136/fmch-2019-000262
Peduzzi P, Concato J, Kemper E, Holford TR, Feinstein AR (1996) A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol 49(12):1373–1379. https://doi.org/10.1016/s0895-4356(96)00236-3
van der Ploeg T, Austin PC, Steyerberg EW (2014) Modern modelling techniques are data hungry: a simulation study for predicting dichotomous endpoints. BMC Med Res Methodol 14:137. https://doi.org/10.1186/1471-2288-14-137
Keskinbora KH (2019) Medical ethics considerations on artificial intelligence. J Clin Neurosci: Off J Neurosurg Soc Australas 64:277–282. https://doi.org/10.1016/j.jocn.2019.03.001
García-Granero E, Navarro F, Cerdán Santacruz C, Frasson M, García-Granero A, Marinello F, Flor-Lorente B, Espí A (2017) Individual surgeon is an independent risk factor for leak after double-stapled colorectal anastomosis: an institutional analysis of 800 patients. Surgery 162(5):1006–1016. https://doi.org/10.1016/j.surg.2017.05.023
Zarnescu EC, Zarnescu NO, Costea R (2021) Updates of risk factors for anastomotic leakage after colorectal surgery. Diagnostics 11(12):2382. https://doi.org/10.3390/diagnostics11122382
Collins GS, de Groot JA, Dutton S, Omar O, Shanyinde M, Tajar A, Voysey M, Wharton R, Yu LM, Moons KG, Altman DG (2014) External validation of multivariable prediction models: a systematic review of methodological conduct and reporting. BMC Med Res Methodol 14:40. https://doi.org/10.1186/1471-2288-14-40
Staartjes VE, Kernbach JM (2020) Significance of external validation in clinical machine learning: let loose too early? Spine J: Off J North Am Spine Soc 20(7):1159–1160. https://doi.org/10.1016/j.spinee.2020.02.016
Funding
Open access funding provided by University of Basel. This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Disclosures
Dr. Taha-Mehlitz, Miss Wentzler, Dr. Angehrn, Mr. Hendie, Mr. Ochs, Dr. Wolleb, Dr. Staartjes, Mr. Baltuonis, Dr. Enodien, Prof. Vorburger, Dr. Frey, Prof. Rosenberg, Prof. von Flüe, Prof. Müller-Stich, Prof. Cattin, Dr. Taha, and Dr. Steinemann have no conflicts of interest to disclose.
Ethical approval
The study was approved by the Northwestern and Central Ethics Committee Switzerland (BASEC-Nr 2020-02265) and Zurich Ethics Committee Switzerland (BASEC-Nr 2021-02105).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Taha-Mehlitz, S., Wentzler, L., Angehrn, F. et al. Machine learning-based preoperative analytics for the prediction of anastomotic leakage in colorectal surgery: a swiss pilot study. Surg Endosc 38, 3672–3683 (2024). https://doi.org/10.1007/s00464-024-10926-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00464-024-10926-4