
Abstract
We study a continuous facility location problem on a graph where all edges have unit length and where the facilities may also be positioned in the interior of the edges. The goal is to position as many facilities as possible subject to the condition that any two facilities have at least distance \(\delta\) from each other. We investigate the complexity of this problem in terms of the rational parameter \(\delta\). The problem is polynomially solvable, if the numerator of \(\delta\) is 1 or 2, while all other cases turn out to be NP-hard.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A large part of the facility location literature deals with desirable facilities that people like to have nearby, such as service centers, police departments, fire stations, and warehouses. However, there also do exist facilities that are undesirable and obnoxious, such as nuclear reactors, garbage dumps, chemical plants, military installations, and high security penal institutions. A standard goal in location theory is to spread out such obnoxious facilities and to avoid their accumulation and concentration in a small region; see for instance Erkut and Neuman [7] and Cappanera [3] for comprehensive surveys on this topic.
In this paper, we investigate the location of obnoxious facilities in a metric space whose topology is determined by a graph. Formally, let \(G=(V,E)\) be an undirected connected graph, where every edge is rectifiable and has unit length. Let P(G) denote the continuum set of points on all the edges in E together with all the vertices in V. For two points \(p,q\in P(G)\), we denote by d(p, q) the length of a shortest path connecting p and q in the graph. A subset \(S\subset P(G)\) is said to be \(\delta\)-dispersed for some positive real number \(\delta\), if any two points \(p,q\in S\) with \(p\ne q\) are at distance \(d(p,q)\ge \delta\) from each other. Our goal is to compute for a given graph \(G=(V,E)\) and a given positive real number \(\delta\) a maximum cardinality subset \(S\subset P(G)\) that is \(\delta\)-dispersed. Such a set S is called an optimal \(\delta\)-dispersed set, and |S| is called the \(\delta\)- dispersion number \(\delta \text{-Disp }(G)\) of the graph G.
1.1 Known and Related Results
Obnoxious facility location goes back to the seminal articles of Goldman and Dearing [11] from 1975 and Church and Garfinkel [4] from 1978. The area actually covers a wide variety of problem variants and models; some models specify a geometric setting, while other models use a graph-theoretic setting.
For example, Abravaya and Segal [1] consider a purely geometric variant of obnoxious facility location, where a maximum cardinality set of obnoxious facilities has to be placed in a rectangular region, such that their pairwise distance as well as the distance to a fixed set of demand sites is above a given threshold. Further geometric variants of obnoxious facility location are analyzed by Ben-Moshe et al. [2] and Katz et al. [14]. As another example we mention the graph-theoretic model of Tamir [19], where every edge \(e\in E\) of the underlying graph \(G=(V,E)\) is rectifiable and has a given edge-dependent length \(\ell (e)\). Tamir discusses the complexity and approximability of various optimization problems with various objective functions. One consequence of [19] is that if the graph G is a tree, then the value \(\delta \text{-Disp }(G)\) can be computed in polynomial time. Segal [18] locates a single obnoxious facility on a network under various objective functions, such as maximizing the smallest distance from the facility to the clients on the network or maximizing the total sum of the distances between facility and clients.
Megiddo and Tamir [16] consider the covering problem that is dual to the \(\delta\)-dispersion packing problem: Given a graph \(G=(V,E)\) with rectifiable unit-length edges, find a minimum cardinality subset \(S\subset P(G)\) such that every point in P(G) is at distance at most \(\delta\) from one of the facilities in S. Among many other results [16] shows that this covering problem is NP-hard for \(\delta =2\).
1.2 Our Results
We provide a complete picture of the complexity of computing the \(\delta\)-dispersion number for connected graphs \(G=(V,E)\) and positive rational numbers \(\delta\).
-
If \(\delta =1/b\) for some integer b, then the \(\delta\)-dispersion number of G can be written down without really looking at the structure of the graph: If G is a tree then \(\delta \text{-Disp }(G)=b|E|+1\), and if G is not a tree then \(\delta \text{-Disp }(G)=b|E|\).
-
If \(\delta =2/b\) for some integer b, then \(\delta \text{-Disp }(G)\) can be computed in polynomial time. The algorithm uses the Edmonds–Gallai decomposition of G and reformulates the problem as a submodular optimization problem.
-
If \(\delta =a/b\) for integers a and b with \(a\ge 3\) and \(\gcd (a,b)=1\), then the computation of \(\delta \text{-Disp }(G)\) is an NP-hard problem.
The rest of the paper is organized as follows. Section 2 summarizes the basic notations and states several technical observations. Section 3 presents the NP-hardness results. The reductions are essentially based on routine methods, but need to resolve certain number-theoretic issues. Our technical main contribution is the polynomial time algorithm for the case \(\delta =2\) as developed in Sect. 4; this result is heavily based on tools from matching theory. Section 5 summarizes the polynomially solvable special cases and provides additional structural insights. Section 6 completes the paper with a short conclusion.
2 Notation and Technical Preliminaries
All graphs in this paper are undirected and connected, and all edges have unit length. Throughout the paper we use the word vertex in the graph-theoretic sense, and we use the word point to denote the elements of the geometric structure P(G). For a graph \(G=(V,E)\) and a subset \(V'\subseteq V\), we denote by \(G[V']\) the subgraph induced by \(V'\). For an integer \(c\ge 1\), the c-subdivision of G is the graph that results from G by subdividing every edge in E by \(c-1\) new vertices into c new edges.
For an edge \(e=\{u,v\}\) and a real number \(\lambda\) with \(0\le \lambda \le 1\), we denote by \(p(u,v,\lambda )\) the point on e that has distance \(\lambda\) from vertex u. Note that \(p(u,v,0)=u\) and \(p(u,v,1)=v\), and note that point \(p(u,v,\lambda )\) coincides with point \(p(v,u,1-\lambda )\); hence we will sometimes assume without loss of generality that \(\lambda \le 1/2\).
Lemma 2.1
Let G be a graph, let \(c\ge 1\) be an integer, and let \(G'\) be the c-subdivision of G. Then for every \(\delta >0\), the \(\delta\)-dispersed sets in G are in one-to-one correspondence with the \((c\cdot \delta )\)-dispersed sets in \(G'\). In particular, \(\delta \text{-Disp }(G)=(c\cdot \delta )\text{-Disp }(G')\).
Proof
Every point \(p(u,v,\lambda )\) in P(G) translates into a corresponding point in \(P(G')\) that lies on the subdivided edge between u and v and is at distance \(c\cdot \lambda\) from vertex u. \(\square\)
Lemma 2.1 has many useful consequences, as for instance the following:
Lemma 2.2
Let \(\delta >0\) and let \(c\ge 1\) be an integer.
-
If the problem of computing the \(\delta\)-dispersion number is NP-hard, then also the problem of computing the \((c\cdot \delta )\)-dispersion number is NP-hard.
-
If the problem of computing the \((c\cdot \delta )\)-dispersion number is polynomially solvable, then also the problem of computing the \(\delta\)-dispersion number is polynomially solvable.
Proof
By Lemma 2.1 the c-subdivision of a graph yields a polynomial time reduction from computing \(\delta\)-dispersions to computing \((c\cdot \delta )\)-dispersions. \(\square\)
For integers \(\ell\) and k, the rational number \(\ell /k\) is called k- simple. A set \(S\subseteq P(G)\) is k-simple, if for every point \(p(u,v,\lambda )\) in S the number \(\lambda\) is k-simple.
Lemma 2.3
Let \(\delta =a/b\) with integers a and b, and let \(G=(V,E)\) be a graph. Then there exists an optimal \(\delta\)-dispersed set \(S^*\) that is 2b-simple.
Proof
We first handle the cases with \(b=1\), so that \(\delta\) is integer. Consider an optimal \(\delta\)-dispersed set S for graph G. Note that for every vertex u, at most one point \(p(u,v,\lambda )\) with \(v\in V\) and \(0\le \lambda <1/2\) is in S. For every point \(p=p(u,v,\lambda )\) with \(0\le \lambda \le 1/2\) in S, we put a corresponding point \(p^*\) into set \(S^*\): If \(0\le \lambda <1/2\) then \(p^*=p(u,v,0)\), and if \(\lambda =1/2\) then \(p^*=p(u,v,1/2)\). As all points in the resulting set \(S^*\) are either vertices or midpoints of edges, we get that \(S^*\) is 2-simple. We claim that \(S^*\) is still \(\delta\)-dispersed: Consider two distinct points \(p^*\) and \(q^*\) in \(S^*\). Note that \(d(p,p^*)<1/2\) and \(d(q,q^*)<1/2\) by construction.
-
If \(p^*\) and \(q^*\) both are vertices in V, then the distance \(d(p^*,q^*)\) is integer. Suppose for the sake of contradiction that \(d(p^*,q^*)<\delta\), which by integrality implies \(d(p^*,q^*)\le \delta -1\) The triangle inequality yields \(d(p,q)\le d(p,p^*)+d(p^*,q^*)+d(q^*,q)\). The left hand side in this inequality is at least \(\delta\), wheras its right hand side is strictly smaller than \((1/2)+(\delta -1)+(1/2)\). This contradiction shows \(d(p^*,q^*)\ge \delta\).
-
If \(p^*\) and \(q^*\) both are midpoints of edges, then \(p=p^*\) and \(q=q^*\) yields \(d(p^*,q^*)\ge \delta\).
-
If \(p^*\) is the midpoint of some edge and \(q^*\) is a vertex, then \(d(p^*,q^*)=D+1/2\) for some integer D. The triangle inequality together with \(p=p^*\) implies \(\delta \le d(p,q)=d(p^*,q)\le d(p^*,q^*)+d(q^*,q)<D+1\). This implies \(D\ge \delta\), so that the desired \(d(p^*,q^*)\ge \delta +1/2\) holds.
Since S and \(S^*\) have the same cardinality, we conclude that \(S^*\) is an optimal \(\delta\)-dispersed set that is 2-simple, exactly as desired.
In the cases where \(\delta =a/b\) for some integer \(b\ge 2\), we consider the b-subdivision \(G'\) of G. By the above discussion, \(G'\) possesses an optimal a-dispersed set \(S'\) that is 2-simple. Then Lemma 2.1 translates \(S'\) into an optimal \(\delta\)-dispersed set S for G that is 2b-simple. \(\square\)
3 NP-Completeness Results
In this section we present our NP-hardness proofs for computing the \(\delta\)-dispersion number. All proofs are done through polynomial time reductions from the following NP-hard variant of the independent set problem; see Garey and Johnson [10].
Problem: Independent Set in Cubic Graphs (Cubic-Ind-Set)
Instance: An undirected, connected graph \(H=(V_H,E_H)\) in which every vertex is adjacent to exactly three other vertices; an integer bound k.
Question: Does H contain an independent set I with \(|I|\ge k\) vertices?
Throughout this section we consider a fixed rational number \(\delta =a/b\), where a and b are positive integers that satisfy \(\gcd (a,b)=1\) and \(a\ge 3\). Section 3.1 discusses the cases with odd numerators \(a\ge 3\), and Sect. 3.2 discusses the cases with even numerators \(a\ge 4\). It is instructive to verify that our arguments do not work for the cases with \(a=1\) and \(a=2\), as our gadgets and our arguments break down at various places.
3.1 NP-Hard Cases with Odd Numerator
Throughout this section we consider a fixed rational number \(\delta =a/b\) where \(\gcd (a,b)=1\) and where \(a\ge 3\) is an odd integer. For the NP-hardness proof, we first determine four positive integers \(x_1,y_1,x_2,y_2\) that satisfy the following equations (1) and (2).
Note that the value \(a-1\) on the right hand side of Eq. (1) is even, and hence is divisible by the greatest common divisor \(\gcd (2b,2a)=2\) of the coefficients in the left hand side. With this, Bézout’s lemma yields the existence of positive integers \(x_1\) and \(y_1\) that satisfy (1). Bézout’s lemma also yields the existence of positive integers \(x_2\) and \(y_2\) in Eq. (2), as the coefficients in the left hand are relatively prime.
Our reduction now starts from an arbitrary instance \(H=(V_H,E_H)\) and k of Cubic-Ind-Set, and constructs a corresponding dispersion instance \(G=(V_G,E_G)\) from it.
-
For every vertex \(v\in V_H\), we create a corresponding vertex \(v^*\) in \(V_G\).
-
For every edge \(e=\{u,v\}\in E_H\), we create a corresponding vertex \(e^*\) in \(V_G\).
-
For every edge \(e=\{u,v\}\in E_H\), we create (i) a path with \(x_1\) edges that connects vertex \(u^*\) to vertex \(e^*\), (ii) another path with \(x_1\) edges that connects \(v^*\) to \(e^*\), and (iii) a cycle C(e) with \(x_2\) edges that runs through vertex \(e^*\).
This completes the description of the graph \(G=(V_G,E_G)\); see Fig. 1 for an illustration. We claim that graph H contains an independent set of size k, if and only if \((a/b)\text{-Disp }(G)\ge k+(2y_1+y_2)|E_H|\).

The edge \(e=\{u,v\}\) in the instance of Cubic-Ind-Set translates into three vertices \(u^*\), \(e^*\), \(v^*\) in the dispersion instance, together with two paths and one cycle
Lemma 3.1
If graph H contains an independent set of size k, then the (a/b)-dispersion number of graph G is at least \(k+(2y_1+y_2)|E_H|\).
Proof
Let I be an independent set of size k in graph \(H=(V_H,E_H)\). We construct from I a \(\delta\)-dispersed set \(S\subset P(G)\) as follows. Let \(u\in V_H\) be a vertex, and let \(e_1,e_2,e_3\) be the three edges in \(E_H\) that are incident to u.
-
If \(u\in I\), then we put point \(u^*\) into S. On each of the three paths that connect vertex \(u^*\) respectively to vertex \(e_i^*\) (\(i=1,2,3\)), we select \(y_1\) further points for S. The first selected point is at distance \(\delta\) from \(u^*\), and every further selected point is at distance \(\delta =a/b\) from the preceding selected point. By Eq. (1), on each of the three paths the distance from the final selected point to point \(e_i^*\) (\(i=1,2,3\)) then equals \((a-1)/(2b)\).
-
If \(u\notin I\), then on each of the three paths between \(u^*\) and \(e_i^*\) (\(i=1,2,3\)) we select \(y_1\) points for S. The first selected point is at distance \(\delta /2=a/(2b)\) from \(u^*\), and every further selected point is at distance \(\delta\) from the preceding selected point. By Eq. (1), the distance from the final selected point to point \(e^*\) then equals \((2a-1)/(2b)\).
Furthermore, for every edge \(e\in E_H\) we select \(y_2\) points from the cycle C(e) for S:
-
We start in point \(e^*\) and traverse C(e) in clockwise direction. The first selected point is at distance \((a+1)/(2b)\) from point \(e^*\), and every further selected point is at distance \(\delta\) from the preceding selected point. By Eq. (2), the distance from the final selected point to point \(e^*\) then equals \((a+1)/(2b)\).
This completes the construction of set S. Now let us count the points in S. First, there are the k points \(u^*\in S\) for which \(u\in I\). Furthermore, for every edge \(e=\{u,v\}\in E_H\) there are \(2y_1\) points in S that lie on the two paths from \(u^*\) to \(e^*\) and from \(e^*\) to \(v^*\). Finally, for every edge \(e\in E_H\) there are \(y_2\) points that lie on the cycle C(e). Altogether, this yields the desired size \(k+(2y_1+y_2)|E_H|\) for S.
It remains to verify that the point set S is \(\delta\)-dispersed. By construction, the points selected from each path are at distance at least \(\delta\) from each other, and the same holds for the points selected from each cycle. If vertex \(u^*\) is in S, then all selected points on the three incident paths are at distance at least \(\delta\) from \(u^*\). If vertex \(u^*\) is not in S, then the first selected point on every path is at distance \(\delta /2\) from \(u^*\), so that these points are pairwise at distance at least \(\delta\) from each other. Hence the only potential trouble could arise in the neighborhood of point \(e^*\), where paths and cycles are glued together. Every selected point on C(e) is at distance at least \((a+1)/(2b)\) from point \(e^*\). Every selected point on some path from \(u^*\) to \(e^*\) is at distance at least \((a-1)/(2b)\) from \(e^*\) if \(u\in I\) and is at distance at least \((2a-1)/(2b)\) if \(u\notin I\). Since for any edge \(e=\{u,v\}\in E_H\) at most one of the end vertices u and v is in I, at most one selected point can be at distance \((a-1)/(2b)\) from \(e^*\), and all other points are at distance at least \((a+1)/(2b)\) from \(e^*\). Hence S is indeed \(\delta\)-dispersed. \(\square\)
Lemma 3.2
If the (a/b)-dispersion number of graph G is at least \(k+(2y_1+y_2)|E_H|\), then graph H contains an independent set of size k.
Proof
Let S be an (a/b)-dispersed set of size \(k+(2y_1+y_2)|E_H|\). By Lemma 2.3 we assume that for every point \(p(u,v,\lambda )\) in S, the denominator of the rational number \(\lambda\) is 2b.
For an edge \(e=\{u,v\}\in E_H\), let us consider its corresponding path \(\pi\) on \(x_1\) edges that connects vertex \(u^*\) to vertex \(e^*\). Suppose that there is some point p in \(S\cap \pi\) with \(d(p,e^*)\le (a-2)/(2b)\). Then by Eq. (2), set S will contain at most \(y_2-1\) points from the cycle C(e). In this case we restructure S as follows: We remove point p together with the at most \(y_2-1\) points on cycle C(e) from S, and instead insert \(y_2\) points into S that are \(\delta\)-dispersed on C(e) and that all are at distance at least \((a+1)/(2b)\) from \(e^*\). As this restructuring does not decrease the size of S, we will from now on assume without loss of generality that \(d(p,e^*)\ge (a-1)/(2b)\) holds for every point \(p\in S\cap \pi\).
Now let us take a closer look at the points in \(S\cap \pi\). Equation (1) can be rewritten into \(x_1=y_1\delta +(a-1)/(2b)\), which yields \(|S\cap \pi |\le y_1+1\).
-
In the equality case \(|S\cap \pi |=y_1+1\), we must have \(u^*\in S\) and also the point on \(\pi\) at distance \((a-1)/(2b)\) from \(e^*\) must be in S.
-
In case \(|S\cap \pi |\le y_1\), there is ample space for picking \(y_1\) points from \(\pi\) that are \(\delta\)-dispersed and that are at distance at least \(\delta /2\) from \(u^*\) and at distance at least \(\delta /2\) from \(e^*\). Hence we will from now on assume \(|S\cap \pi |=y_1\) in these cases.
Now let us count: Set S contains exactly \(y_1\) interior points from every path \(\pi\), and altogether there are \(2|E_H|\) such paths. Set S contains exactly \(y_2\) points from every cycle C(e), and altogether there are \(|E_H|\) such cycles. Since \(|S|\ge k+(2y_1+y_2)|E_H|\), this means that S must contain at least k further points on vertices \(u^*\) with \(u\in V_H\). The corresponding subset of \(V_H\) is called I.
Finally, we claim that this set I with \(|I|\ge k\) forms an independent set in graph H. Suppose for the sake of contradiction that there is an edge \(e=\{u,v\}\in E_H\) with \(u\in I\) and \(v\in I\). Consider the two paths that connect \(e^*\) to \(u^*\) and \(v^*\). By the above discussion, S then contains two points at distance \((a-1)/(2b)\) from \(e^*\). As these two points are then at distance at most \((a-1)/b<\delta\) from each other, we arrive at the desired contradiction. \(\square\)
The statements in Lemma 3.1 and in 3.2 yield the following theorem.
Theorem 3.3
Let a and b be positive integers with \(\gcd (a,b)=1\) and odd \(a\ge 3\). Then it is NP-hard to compute the (a/b)-dispersion number of a graph G.
3.2 NP-Hard Cases with Even Numerator
In this section we consider a fixed rational number \(\delta =a/b\) where \(\gcd (a,b)=1\) and where \(a\ge 4\) is an even integer. The NP-hardness argument is essentially a minor variation of the argument in Sect. 3.1 for the cases with odd numerators. Therefore, we will only explain the modifications, and leave all further details to the reader.
The NP-hardness proof in Sect. 3.1 is centered around the four positive integers \(x_1,y_1,x_2,y_2\) introduced in Eqs. (1) and (2). We perform the same reduction from Cubic-Ind-Set as in Sect. 3.1 but with positive integers \(x_1,y_1,x_2,y_2\) that satisfy the following Eqs. (3) and (4).
In (3), the right hand side \(a-2\) is even and divisible by the greatest common divisor of the coefficients in the left hand side. In (4), the coefficients in the left hand are relatively prime. Therefore Bézout’s lemma can be applied to both equations.
The graph \(G=(V_G,E_G)\) is defined as before, with a vertex \(v^*\) for every \(v\in V_H\) and a vertex \(e^*\) for every \(e\in E_H\), with paths on \(x_1\) edges and cycles C(e) on \(x_2\) edges. The arguments in Lemmas 3.1 and 3.2 can easily be adapted and yield the following theorem.
Theorem 3.4
Let a and b be positive integers with \(\gcd (a,b)=1\) and even \(a\ge 4\). Then it is NP-hard to compute the (a/b)-dispersion number of a graph G.
3.3 Containment in NP
In this section we consider the decision version of \(\delta\)-dispersion: “ For a given graph \(G=(V,E)\), a positive real \(\delta\), and a bound k, decide whether \(\delta \text{-Disp }(G)\le k\).” Our NP-certificate specifies the following partial information on a \(\delta\)-dispersed set S in a graph \(G=(V,E)\):
-
The certificate specifies the set \(W:=V\cap S\) of vertices in S.
-
For every edge \(e\in E\), the certificate specifies the number \(n_e\) of facilities that are located in the interior of e.
As every edge accommodates at most \(1/\delta\) points from S, the encoding length of our certificate is polynomially bounded in the instance size. For verifying the certificate, we introduce for every vertex u and for every incident edge \(e=\{u,v\}\in E\) with \(n_e>0\) a corresponding real variable x(u, e), which models the distance between vertex u and the closest point from S in the interior of edge e. Finally, we introduce the following linear constraints:
-
The non-negativity constraints \(x(u,e)\ge 0\).
-
For every edge \(e=\{u,v\}\in E\), the inequality \(x(u,e)+(n_e-1)\delta +x(v,e)\le 1\).
-
For all \(u,v\in W\) with \(u\ne v\), the inequality \(d(u,v)\ge \delta\).
-
For all \(w\in W\) and \(e=\{u,v\}\in E\), the inequality \(x(u,e)+d(u,w)\ge \delta\).
-
For all \(e=\{u,v\}\in E\) and \(e'=\{u',v'\}\in E\), the inequality \(x(u,e)+d(u,u')+x(u',e')\ge \delta\).
These inequalities enforce that on every edge the variables properly work together, and that the underlying point set indeed is \(\delta\)-dispersed. For verifying the certificate, we simply check in polynomial time whether the resulting linear program has a feasible solution, and whether \(|W|+\sum _{e\in E}n_e\ge k\) holds.
Theorem 3.5
The decision version of \(\delta\)-dispersion lies in NP, even if the value \(\delta\) is given as part of the input. \(\square\)
4 The Polynomial Time Result for \(\delta =2\)
This section derives a polynomial time algorithm for computing the 2-dispersion number of a graph. This algorithm is heavily based on tools from matching theory, as for instance developed in the book by Lovász and Plummer [15]. As usual, the size of a maximum cardinality matching in graph G is denoted by \(\nu (G)\).
Lemma 4.1
Every graph \(G=(V,E)\) satisfies \(2\text{-Disp }(G)\ge \nu (G)\).
Proof
The midpoints of the edges in every matching form a 2-dispersed set. \(\square\)
A 2-dispersed set is in canonical form, if it entirely consists of vertices and of midpoints of edges. Recall that by Lemma 2.3 every graph \(G=(V,E)\) possesses an optimal 2-dispersed set in canonical form. Throughout this section, we will consider 2-dispersed (but not necessarily optimal) sets \(S^*\) in canonical form; we always let \(V^*\) denote the set of vertices in \(S^*\), and we let \(E^*\) denote the set of edges whose midpoints are in \(S^*\). Finally, \(N^*\subseteq V\) denotes the set of vertices in \(V-V^*\) that have a neighbor in \(V^*\). As \(S^*\) is 2-dispersed, the vertex set \(V^*\) forms an independent set in G, and the edge set \(E^*\) forms a matching in G. Furthermore, the vertex set \(N^*\) separates the vertices in \(V^*\) from the edges in \(E^*\); in particular, no edge in \(E^*\) covers any vertex in \(N^*\). We start with two technical lemmas that will be useful in later arguments.
Lemma 4.2
Let \(G=(V,E)\) be a graph with a perfect matching, and let \(S^*\) be some 2-dispersed set in canonical form in G. Then \(|S^*|\le \nu (G)\).
Proof
Let \(M\subseteq E\) denote a perfect matching in G, and for every vertex \(v\in V\) let e(v) denote its incident edge in matching M. Consider the vertex set \(V^*\) and the edge set \(E^*\) that correspond to set \(S^*\). Then \(E^*\) together with the edges e(v) with \(v\in V^*\) forms another matching \(M'\) of cardinality \(|E^*|+|V^*|=|S^*|\) in G. Now \(|S^*|=|M'|\le \nu (G)\) yields the desired inequality. \(\square\)
A graph G is factor-critical [15], if for every vertex \(x\in V\) there exists a matching that covers all vertices except x. A near-perfect matching in a graph covers all vertices in V except one. Note that the statement in the following lemma cannot be extended to graphs that consist of a single vertex.
Lemma 4.3
Every 2-dispersed set \(S^*\) in a factor-critical graph \(G=(V,E)\) with \(|V|\ge 3\) satisfies \(|S^*|\le \nu (G)\).
Proof
Without loss of generality we assume that \(S^*\) is in canonical form, and we let \(V^*\) and \(E^*\) denote the underlying vertex set and edge set, respectively. If \(V^*\) is empty, we have \(|S^*|=|E^*|\le \nu (G)\) since \(E^*\) is a matching. If \(V^*\) is non-empty, we consider a near-perfect matching M, and we let e(v) denote the edge incident to \(v\in V\) in matching M (here we use the condition \(|V|\ge 3\)). Then \(E^*\) together with the edges e(v) with \(v\in V^*\) forms another matching \(M'\) of cardinality \(|E^*|+|V^*|=|S^*|\) in G. The claim follows from \(|S^*|=|M'|\le \nu (G)\). \(\square\)

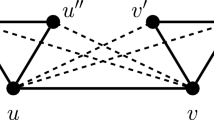
An illustration for the Edmonds–Gallai structure theorem. A maximum matching is shown with fat edges, and the non-matching edges are dashed
The following theorem goes back to Edmonds [6] and Gallai [8, 9]; see also Lovász and Plummer [15]. Figure 2 gives an illustration.
Theorem 4.4
(Edmonds–Gallai structure theorem) Let \(G=(V,E)\) be a graph. The following decomposition of V into three sets X, Y, Z can be computed in polynomial time.
The Edmonds–Gallai decomposition has the following properties:
-
G[X] is the union of the odd-sized components of \(G-Y\); every such odd-sized component is factor-critical. G[Z] is the union of the even-sized components of \(G-Y\).
-
Every maximum matching in G induces a perfect matching on every (even-sized) component of G[Z] and a near-perfect matching on every (odd-sized) component of G[X]. Furthermore, the matching matches the vertices in Y to vertices that belong to |Y| different components of G[X]. \(\square\)
We further subdivide the set X in the Edmonds–Gallai decomposition into two parts: Set \(X_1\) contains the vertices of X that belong to components of size 1, and set \(X_{\ge 3}\) contains the vertices that belong to (odd-sized) components of size at least 3. The vicinity \(\text {vic}(v)\) of a vertex \(v\in V\) consists of vertex v itself and of the midpoints of all edges incident to v.
Lemma 4.5
There exists an optimal 2-dispersed set \(S^*\) in canonical form (with underlying edge set \(E^*\)) that additionally satisfies the following three properties.
- P1.
In every component of \(G[X_{\ge 3}]\), the set \(E^*\) induces a near-perfect matching.
- P2.
For every vertex \(y\in Y\), the set \(\text {vic}(y)\cap S^*\) is either empty or consists of the midpoint of some edge between X and Y.
- P3.
In every component of G[Z], the set \(E^*\) induces a perfect matching.
Proof
We start from an arbitrary optimal 2-dispersed set \(S^*\) (in canonical form, with corresponding sets \(V^*\) and \(E^*\)) and transform it in two steps into an optimal 2-dispersed set of the desired form.
In the first transformation step, we exploit a matching M between sets Y and X that matches every vertex \(y\in Y\) to some vertex M(y), so that for \(y_1\ne y_2\) the vertices \(M(y_1)\) and \(M(y_2)\) belong to different components of G[X]; see Theorem 4.4. A vertex \(y\in Y\) is called blocked, if it is adjacent to some \(x\in X_1\cap S^*\). As for a blocked vertex the set \(\text {vic}(y)\cap S^*\) is already empty (and hence already satisfies property P2), we will not touch it at the moment. We transform \(S^*\) in the following way.
-
For every non-blocked vertex \(y\in Y\), the set \(\text {vic}(y)\cap S^*\) contains at most one point. We remove this point from \(S^*\), and we insert instead the midpoint of the edge between y and M(y) into \(S^*\). These operations cannot decrease the size of \(S^*\).
-
Every (odd-sized) component C of \(G[X_{\ge 3}]\) contains at most one point M(y) with \(y\in Y\). We compute a near-perfect matching \(M_C\) for C that misses this vertex M(y) (and if no such vertex is in C, matching \(M_C\) misses an arbitrary vertex of C). We remove all points in C from \(S^*\), and we insert instead the midpoints of the edges in \(M_C\). As by Lemma 4.3 we remove at most \(\nu (C)\) points and as we insert exactly \(\nu (C)\) points, these operations will not decrease the size of \(S^*\).
The resulting set \(S^*\) is of course again in canonical form, and it is also easy to see that \(S^*\) is still 2-dispersed. Furthermore, \(S^*\) now satisfies properties P1 and P2.
In the second transformation step, we note that the current \(S^*\) does neither contain vertices from Y nor midpoints of edges between Y and Z. For every (even-sized) component C of G[Z], we compute a perfect matching \(M_C\). We remove all points in C from \(S^*\), and we insert instead the midpoints of the edges in \(M_C\). As by Lemma 4.3 we remove at most \(\nu (C)\) points and as we insert exactly \(\nu (C)\) points, these operations will not decrease the size of \(S^*\). The resulting set \(S^*\) is 2-dispersed and satisfies properties P1, P2, and P3. \(\square\)
The optimal 2-dispersed sets in Lemma 4.5 are strongly structured and fairly easy to understand: The perfect matchings in set Z contribute exactly |Z|/2 points to \(S^*\). Every (odd-sized) component C in \(G[X_{\ge 3}]\) contributes exactly \((|C|-1)/2\) points to \(S^*\). The only remaining open decisions concern the points in \(X_1\) and the midpoints of the edges \(\{y,M(y)\}\) for \(y\in Y\). So let us consider the set \(T:=S^*\cap X_1\), and let \(\Gamma (T)\subset Y\) denote the vertices in Y that are adjacent to some vertex in T. Then every vertex \(y\in Y-\Gamma (T)\) contributes the midpoint of \(\{y,M(y)\}\) to \(S^*\), and every vertex \(x\in T\) contributes itself to \(S^*\).
Hence the remaining optimization problem boils down to finding a subset \(T\subseteq X_1\) that maximizes the function value \(f(T):=|Y-\Gamma (T)|+|T|\), which is equivalent to minimizing the function value
The set function g(T) in (5) is a submodular function, as it satisfies \(g(A)+g(B)\ge g(A\cup B)+g(A\cap B)\) for all \(A,B\subseteq X_1\); see for instance Grötschel, Lovász and Schrijver [12]. Therefore, the minimum value of g(T) can be determined in polynomial time by the ellipsoid method [12], or by Cunningham’s combinatorial algorithm [5].
We also describe another way of minimizing the function g(T) in polynomial time, that avoids the heavy machinery of submodular optimization and that formulates the problem as a minimum s-t-cut computation in a weighted directed auxiliary graph. The auxiliary graph is defined as follows.
-
Its vertex set contains a source s and a sink t, together with all the vertices in \(X_1\) and all the vertices in Y.
-
For every \(x\in X_1\), there is an arc (s, x) of weight \(w(s,x)=1\) from the source to x. For every \(y\in Y\), there is an arc (y, t) of weight \(w(y,t)=1\) from y to the sink. Whenever the vertices \(x\in X_1\) and \(y\in Y\) are adjacent in the original graph G, the auxiliary graph contains the arc (x, y) of weight \(w(x,y)=+\infty\).
Now let us consider some s-t-cut of finite weight, which is induced by some vertex set U in the auxiliary graph with \(s\in U\) and \(t\notin U\). As all arcs from set \(X_1\) to set Y have infinite weights, whenever U contains some vertex \(x\in X_1\) then U must also contain all the neighbors of x in Y. By setting \(T:=X_1\cap U\), we get that the value of the cut equals \(|X_1-T|+|\Gamma (T)|\); hence the minimizer for (5) can be read off the minimizing cut in the auxiliary graph.
We finally summarize all our insights and formulate the main result of this section.
Theorem 4.6
The 2-dispersion number of a graph \(G=(V,E)\) can be computed in polynomial time O(|V||E|).
Proof
It only remains to justify the time complexity. The Edmonds–Gallai decomposition of G can be computed in O(|V||E|) time by using the blossom algorithm; see for instance Schrijver [17]. The weighted directed auxiliary graph is easily computed in \(O(|V|+|E|)\) time, and the final minimum s-t-cut computation costs O(|V||E|) time [17]. \(\square\)
5 The Polynomially Solvable Cases
Theorem 4.6 and Lemma 2.2 together imply that for every rational number \(\delta =a/b\) with numerator \(a\le 2\), the \(\delta\)-dispersion number of a graph can be computed in polynomial time. We now present some results that provide additional structural insights into these cases. The cases where the numerator is \(a=1\) are structurally trivial, and the value of the corresponding \(\delta\)-dispersion number can be written down with the sole knowledge of |V| and |E|.
Lemma 5.1
Let \(\delta =1/b\) for some integer b, and let \(G=(V,E)\) be a connected graph.
-
If G is a tree then \(\delta \text{-Disp }(G)=b|E|+1\).
-
If G is not a tree then \(\delta \text{-Disp }(G)=b|E|\).
Proof
If G is a tree, we use a \(\delta\)-dispersed set S that contains all vertices in V and that for every edge \(e=\{u,v\}\) contains all points p(u, v, i/b) with \(i=1,\ldots ,b-1\). Clearly \(|S|=b|E|+1\). If G is not a tree, set S contains for every edge \(e=\{u,v\}\) all the points \(p(u,v,(2i-1)/(2b))\) with \(i=1,\ldots ,b\). Clearly \(|S|=b|E|\).
It remains to show that there are no \(\delta\)-dispersed sets of larger cardinality. If G is a tree, we root it at an arbitrary vertex so that it becomes an out-tree. We partition P(G) into \(|E|+1\) regions: one region consists of the root, and all other regions consist of the interior points on some edge together with the sink vertex of that edge. A \(\delta\)-dispersed set contains at most b points from every edge-region and at most one point from the root region. If G is not a tree, we similarly partition P(G) into |E| regions: Every region either consists of the interior points of some edge, or of the interior points of an edge together with one of its incident vertices. A \(\delta\)-dispersed set contains at most b points from every such region. \(\square\)
The following lemma derives an explicit (and very simple) connection between the 2-dispersion number and the (2/b)-dispersion number (with odd denominator b) of a graph. The lemma also implies directly that for every odd b, the computation of (2/b)-dispersion numbers is polynomial time equivalent to the computation of 2-dispersion numbers.
Lemma 5.2
Let \(G=(V,E)\) be a graph, let \(z\ge 1\) be an integer, and let \(\delta =2/(2z+1)\). Then the dispersion numbers satisfy \(\delta \text{-Disp }(G)=2\text{-Disp }(G)+z|E|\).
Proof
We first show that \(\delta \text{-Disp }(G)\ge 2\text{-Disp }(G)+z|E|\). Indeed, let \(S_2\) denote an optimal 2-dispersed set for G. By Lemma 2.3 we assume that \(S_2\) is in canonical form and hence entirely consists of vertices and of midpoints of edges. We partition the edge set E into three parts: Part \(E_1\) contains the edges, for which one end vertex is in \(S_2\). Part \(E_{1/2}\) contains the edges whose midpoint lies in \(S_2\). Part \(E_0\) contains the remaining edges (which hence are disjoint from \(S_2\)). We construct a point set \(S_{\delta }\subset P(G)\) as follows:
-
For every edge \(\{u,v\}\in E_1\) with \(u\in S_2\), we put point u together with the z points \(p(u,v,i\delta )\) with \(i=1,\ldots ,z\) into \(S_{\delta }\).
-
For every edge \(\{u,v\}\in E_{1/2}\), we put the \(z+1\) points \(p(u,v,(4i-3)\delta /4)\) with \(i=1,\ldots ,z+1\) into \(S_{\delta }\).
-
For every \(\{u,v\}\in E_0\), we put the z points \(p(u,v,(4i-1)\delta /4)\) with \(i=1,\ldots ,z\) into \(S_{\delta }\).
It is easily verified that the resulting set \(S_{\delta }\) is \(\delta\)-dispersed and contains \(|S_2|+z|E|\) points.
Next, we show that \(\delta \text{-Disp }(G)\le 2\text{-Disp }(G)+z|E|\). Let \(S_{\delta }\) denote an optimal \(\delta\)-dispersed set for G. By Lemma 2.3 we assume that for every point \(p(u,v,\lambda )\) in \(S_{\delta }\), the denominator of the rational number \(\lambda\) is \(2(2z+1)\). Our first goal is to bring the points in \(S_{\delta }\) into a particularly simple constellation.
-
As long as there exist edges \(e=\{u,v\}\in E\) with \(u,v\in S_{\delta }\), we remove all points on e from \(S_{\delta }\) and replace them by the \(z+1\) points \(p(u,v,(4i-3)\delta /4)\) with \(i=1,\ldots ,z+1\).
-
Next, for every edge \(e=\{u,v\}\in E\) with \(u\in S_{\delta }\) and \(v\notin S_{\delta }\), we remove all points on e from \(S_{\delta }\) and replace them by the \(z+1\) points \(p(u,v,i\delta )\) with \(i=1,\ldots ,z\).
-
Finally, for every edge \(e=\{u,v\}\in E\) with \(u,v\notin S_{\delta }\) we remove all points on e from \(S_{\delta }\) and replace them by the z points \(p(u,v,(4i-1)\delta /4)\) with \(i=1,\ldots ,z\).
It can be seen that these transformations do not decrease the cardinality of \(S_{\delta }\), and that the resulting set is still \(\delta\)-dispersed. Finally, we construct the following set \(S_2\) from \(S_{\delta }\): First, \(S_2\) contains all points in \(V\cap S_{\delta }\), Secondly, whenever \(S_{\delta }\) contains \(z+1\) points from the interior of some edge \(e\in E\), then we put the midpoint of e into \(S_2\). It can be shown that the resulting set \(S_2\) is 2-dispersed and has the desired cardinality. \(\square\)
6 Conclusions
We have investigated the \(\delta\)-dispersion number of an input graph G, and we have fully classified the computational complexity of \(\delta\)-dispersion for all rational values of \(\delta\): The problem is easy if the numerator of \(\delta\) is 1 or 2, and all other cases have turned out to be NP-complete. The cases with irrational values of \(\delta\) remain open. By modifying the techniques from Sect. 3.3, one can show that for every irrational algebraic \(\delta >0\) the \(\delta\)-dispersion problem is contained in the complexity class NP. Furthermore, by modifying the hardness arguments from Sect. 3, one can show that the \(\delta\)-dispersion problem is NP-hard for \(\delta =\sqrt{2}\) (and for certain other algebraic numbers that allow nice Diophantine approximations). We conjecture that the \(\delta\)-dispersion problem actually is NP-complete for every irrational algebraic \(\delta >0\), and as an open problem we pose to prove or to disprove this conjecture.
Finally we mention a closely related line of research on \(\delta\)-covering of graphs, where the objective is kind of dual to the dispersion objective: Place as few facilities as possible on the graph, subject to the condition that every point in P(G) is at distance at most \(\delta\) from one of the facilities. In other words, the objective in \(\delta\)-covering is not to pack the facilities, but to cover the set P(G) with them. Hartmann, Lendl and Woeginger [13] have shown that \(\delta\)-covering is easy if the numerator of the rational number \(\delta\) is 1, wheras all other cases with rational \(\delta\) turn out to be NP-complete.
References
Abravaya, S., Segal, M.: Maximizing the number of obnoxious facilities to locate within a bounded region. Comput. Oper. Res. 37, 163–171 (2010)
Ben-Moshe, Boaz, Katz, Matthew J., Segal, Michael: Obnoxious facility location: complete service with minimal harm. Int. J. Comput. Geom. Appl. 10(6), 581–592 (2000)
Cappanera, P.: A survey on obnoxious facility location problems. Technical report, Dipartimento di Informatica, Universitá di Pisa, Italy (2010)
Church, R.L., Garfinkel, R.S.: Locating an obnoxious facility on a network. Transp. Sci. 12, 107–118 (1978)
Cunningham, W.R.: On submodular function minimization. Combinatorica 5, 185–192 (1985)
Edmonds, J.: Paths, trees, and flowers. Can. J. Math. 17, 449–467 (1965)
Erkut, E., Neuman, S.: Analytical models for locating undesirable facilities. Eur. J. Oper. Res. 40, 275–291 (1989)
Gallai, T.: Kritische Graphen II. A Magyar Tudományos Akadémia Matematikai Kutató Intézetének KÖzleményei 8, 373–395 (1963)
Gallai, T.: Maximale Systeme unabhängiger Kanten. A Magyar Tudományos Akadémia Matematikai Kutató Intézetének Közleményei 9, 401–413 (1964)
Garey, M.R., Johnson, D.S.: Computers and Intractability: A Guide to the Theory of NP-Completeness. W. H. Freeman, New York (1979)
Goldman, A.J., Dearing, P.M.: Concepts of optimal location for partially noxious facilities. ORSA Bull. 23, B-31 (1975)
GrÖtschel, M., Lovász, L., Schrijver, A.: Geometric Algorithms and Combinatorial Optimization. Springer, New York (1988)
Hartmann, T.A., Lendl, S., Woeginger, G.J.: Continuous facility location on graphs. In: Proceedings of the 21st International Conference on Integer Programming and Combinatorial Optimization (IPCO 2020), volume 12125 of Lecture Notes in Computer Science, pp. 171–181. Springer (2020)
Katz, M.J., Kedem, K., Segal, M.: Improved algorithms for placing undesirable facilities. Comput. Oper. Res. 29(13), 1859–1872 (2002)
Lovász, L., Plummer, M.D.: Matching Theory. Annals of Discrete Mathematics 29. North-Holland, Amsterdam (1986)
Megiddo, N., Tamir, A.: New results on the complexity of p-center problems. SIAM J. Comput. 12, 751–758 (1983)
Schrijver, A.: Combinatorial Optimization: Polyhedra and Efficiency. Springer, New York (2003)
Segal, M.: Placing an obnoxious facility in geometric networks. Nordic J. Comput. 10, 224–237 (2003)
Tamir, A.: Obnoxious facility location on graphs. SIAM J. Discrete Math. 4, 550–567 (1991)
Acknowledgements
The research in this paper has been started during the Lorentz Center Workshop on Fixed-Parameter Computational Geometry, which was organized in May 2018 in Leiden. We thank the Lorentz Center for its hospitality. Alexander Grigoriev and Gerhard Woeginger acknowledge helpful discussions with Fedor Fomin, Petr Golovach and Jesper Nederlof.
Funding
Open Access funding enabled and organized by Projekt DEAL.. Stefan Lendl: Supported by the Austrian Science Fund (FWF): W1230, Doctoral Program “Discrete Mathematics”. Gerhard J. Woeginger Supported by the DFG RTG 2236 “UnRAVeL”
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Grigoriev, A., Hartmann, T.A., Lendl, S. et al. Dispersing Obnoxious Facilities on a Graph. Algorithmica 83, 1734–1749 (2021). https://doi.org/10.1007/s00453-021-00800-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00453-021-00800-3