
Abstract
We study a general class of percolation models in Euclidean space including long-range percolation, scale-free percolation, the weight-dependent random connection model and several other previously investigated models. Our focus is on the weak decay regime, in which inter-cluster long-range connection probabilities fall off polynomially with small exponent, and for which we establish several structural properties. Chief among them are the continuity of the bond percolation function and the transience of infinite clusters.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction and overview
We study (edge-)inhomogeneous percolation models of the following type: let \(\eta \subset \mathbb {R}^d, d\ge 1\), denote a stationary ergodic point set of unit intensity. Canonical choices of \(\eta \) are a homogeneous Poisson point process or the integer lattice \(\mathbb {Z}^d\). A more detailed discussion of the class of underlying point sets for which our results hold is given in Sect. 2 together with an alternative and more rigorous construction of the model. Let \(\eta '\) denote an independent marking of \(\eta \) by i.i.d. \({\text {Uniform}}(0,1)\) random variables. We call \(\textbf{x}=(x,s)\in \eta '\) a vertex in location \(x\in \eta \) with (vertex) mark \(s\in (0,1)\). We denote by \(\mathscr {G}=\mathscr {G}_{\phi ,\eta }=({V}(\mathscr {G}),{E}(\mathscr {G}))\) the random geometric graph obtained by first choosing \(V(\mathscr {G})=\eta '\) and then, conditionally on \(\eta '\), generating the edge set \(E(\mathscr {G})\) by adding unoriented edges between \(\textbf{x},\textbf{y}\in \eta '\) independently with probability
where \(A^{[2]}=\{ B\subset A: |B|=2 \}\) for any set A and \(\phi (\textbf{x}\textbf{y})\) is the connection function of the model. Note that, we always write \(\textbf{x}\textbf{y}\) for the set \(\{\textbf{x},\textbf{y}\}\), when we refer to edges.
We focus on the spatially homogeneous case in which
where \(\varphi :(0,1)\times (0,1)\times (0,\infty )\) is a function of marks and mutual vertex distance only (since we consider unoriented edges, this requires \(\varphi \) to be symmetric in the first two arguments). Here, \(|\cdot |\) denotes Euclidean distance, but all our results remain true for any other norm on \(\mathbb {R}^d\). We only consider \(\varphi \) which are non-increasing in each argument. Together with a corresponding assumption on \(\eta \), this ensures that the model has non-negative correlations, see Sect. 2 below. We further assume that
which ensures local finiteness of \(\mathscr {G}_{\eta ,\phi }\). A large variety of previously studied percolation models can be obtained as instances of \(\mathscr {G}_{\eta ,\phi }\) by a suitable choice of \(\eta \) and \(\phi \). Some of the most important ones are
-
classical i.i.d. Bernoulli(p) bond percolation: \(\eta =\mathbb {Z}^d\),
$$\begin{aligned} \varphi (s,t,r)=-\log (1-p)\mathbbm {1}\{r=1\}; \end{aligned}$$ -
long-range percolation [19]: \(\eta =\mathbb {Z}^d\), \(\varphi (s,t,r)=\beta r^{-\delta d}\), for \(\beta >0\);
-
scale-free percolation [6]: \(\eta =\mathbb {Z}^d\), \(\varphi (s,t,r)=\beta s^{-\gamma }t^{-\gamma } r^{-\delta d}\), for \(\beta >0\) and suitably chosen exponents \(\gamma ,\delta \);
-
the weight-dependent random connection model [11]: take a symmetric function \(g:(0,1)^2\rightarrow (0,\infty )\) and a non-increasing, integrable function \(\rho :(0,\infty )\rightarrow [0,\infty )\), let
$$\begin{aligned} \varphi (s,t,r)=\rho (g(s,t)r^{d})\quad s,t\in (0,1), r\in (0,\infty ), \end{aligned}$$(1)and let \(\eta \) be a Poisson point process.
Note, however, that the results in this article pertain solely to genuine long-range models in which no upper bound on the length of potential edges exists. More precisely, our goal in the present article is to analyse the weak decay regime of inhomogeneous long-range percolation, i.e. the regime in which \(\delta _{\textsf{eff}}<2\), where \(\delta _{\textsf{eff}}\) is the (dimension free) exponent of decay of the probability of a long-range connection between large clusters
We discuss this quantity (or rather a closely related one) formally in Sect. 2, and assume for the moment that it is well-defined. Its role is akin to that of the decay exponent \(\delta \) in classical long-range percolation (see the examples above). The significance of \(\delta _{\textsf{eff}}\) had been conjectured in [11] and its importance for the existence of an infinite cluster for one-dimensional models was established in [10]. In [16] it was shown that \(\delta _{\textsf{eff}}>2\) implies the existence of a subcritical phase in any dimension, even for models in which connection probabilities between vertices are allowed to depend on other vertices in their spatial vicinity.
To give an intuition of how \(\delta _{\textsf{eff}}\) influences the structure of \(\mathscr {G}\), assume that \(\varphi \) is given via (1), for some kernel g and \(\rho (x)\asymp x^{-\delta }\). If the kernel g is bounded away from 0, then our model is merely an inhomogeneous perturbation of classical long-range percolation, for which it is well-known, see e.g. [3, 19], that if \(\rho \) decays weakly, namely if \(\delta =\delta _{\textsf{eff}}<2\), then the model feels little of the geometry of the embedding space \(\mathbb {R}^d\) and behaves very unlike nearest neighbour percolation on \(\mathbb {Z}^d\) and more like a short-range model in high dimensions in some aspects. As was already observed upon the invention of the model [19], this can be derived from the behaviour under rescaling: if one checks whether two large local clusters, each of size N, say, are connected directly by a long edge, then the ‘gain’ obtained from independent trials associated with the \(N^2-N\) pairs of vertices asymptotically beats the spatial decay of connection probabilities and one finds a connection with high probability if the distance of the clusters is \(O(N^{1/d})\). This observation is at the heart of the classical renormalisation group arguments for long-range percolation with \(\delta <2\). In particular, \(\delta \) moderates both the inter-point connection probabilities and the inter-cluster connection probabilities at large scales, cf. [3, Lemma 2.4]. However, as was first observed in [11], this is not true in the general weight-dependent random connection model: if the kernel g decays sharply at 0, then the inter-cluster connection probabilities also depend on g. Thus, the regime in which the model easily overcomes the geometric restrictions of the embedding space cannot be found by looking at \(\delta \) alone. Instead, one needs to consider the derived exponent \(\delta _{\textsf{eff}}\le \delta \) depending both on \(\delta \) and g and which naturally appears in renormalisation arguments, see [10].
Below, we establish that \(\delta _{\textsf{eff}}<2\) is sufficient to imply a number of important results which where established for homogeneous long range percolation with \(\delta <2\) in [3]. Namely, under varying assumptions on the underlying vertex locations \(\eta \), we prove
-
an asymptotic density result for local clusters of sublinear size (Theorem 2.3),
-
continuity of the bond percolation function for \(\mathscr {G}\) in dimensions 2 and above (Theorem 2.4),
-
a robustness result for the infinite cluster under removal of long edges in dimensions 2 and above (Theorem 2.6),
-
transience of the infinite cluster (Theorem 2.7).
There are several technical challenges that we have to overcome which complicate the analysis of the inhomogeneous model compared to long-range percolation. The most crucial one is the presence of additional strong dependencies induced by the vertex marks, which prevents the use of a number of well-established tools for i.i.d (long-range) percolation. Another severe drawback is, as discussed above, that the inhomogeneity influences the scaling behaviour of the models: Coarse-graining a homogeneous long-range percolation model yields another homogeneous long-range percolation model, whereas coarse-graining \(\mathscr {G}_{\eta ,\phi }\) does not lead to a model that can be readily related to some suitable \(\mathscr {G}_{\eta ',\phi '}\). The solution of the first problem can be considered as the main contribution of this work on a technical level: We establish renormalisation techniques akin to those in [3] that rely solely on non-negative correlations instead of independence. Our renormalisation relies on a careful use of the FKG-inequality for certain events that are increasing with respect to a sub-\(\sigma \)-field but not with respect to the full configuration. To the author’s knowledge, this is the first use of an argument of this type in the context of percolation; in the field of stochastic processes a technique that is somewhat similar in spirit was used in [1]. In particular, our proofs are novel even for homogeneous long-range percolation and some of our results are also new for this special case, namely whenever \(\eta \) is not Poisson, deterministic or an i.i.d. percolated lattice.
Unfortunately, we were not able to overcome the second challenge mentioned above in a similarly comprehensive manner and this is partly reflected in our main results – most notably we were not able to show that the bond percolation function is continuous throughout the whole weak decay regime if \(d=1\), cf. Remark 2.5.
Notation Throughout the article, we use the Landau symbols \(f(x)= O(g(x)), f(x)= o(g(x))\) and write \(f(x)\asymp g(x)\) if both \(f(x)=O(g(x))\) and \(g(x)=O(f(x))\). We use \(f(x)\sim g(x)\) to denote the stronger statement that f(x)/g(x) converges to 1.
Overview of the paper In the next section, we provide a formal construction of our model, present our main results and discuss them in more detail. Section 3 contain the proof of Theorem 2.3, which forms the basis of all other main results. Transience of the infinite cluster is obtained in Sect. 4 and the remaining results are proved in Sect. 5.
2 Model definition and main results
Before formulating our main results, we provide a rigorous construction of the model and definitions of the key quantities and notions involved.
Construction from a doubly marked point process Among our fundamental assumptions are that \(\mathscr {G}\) has a unique (if any) infinite component, and that its distribution is the same everywhere in space. We begin by discussing which vertex location sets \(\eta \) fall within our framework. Let \(\Lambda \subset \mathbb {R}^d\) be either \(\mathbb {Z}^d\) or \(\mathbb {R}^d\) and let \(\eta \) denote a simple point processFootnote 1 of finite intensity on \(\Lambda \), which is stationary and ergodic under \(\mathbb {P}\) with respect to the natural group of shifts \((T_x)_{x\in \lambda }, T_x(y)=x+y\) for all \(y\in \Lambda \), associated with \(\Lambda \).
Remark 2.1
The choice \(\Lambda =\mathbb {Z}^d\) is the most natural one for the discrete set up. However, we do not use any symmetry properties specific to \(\mathbb {Z}^d\). Our results are based on renormalisation arguments which use half-open cubes of the form \((-a,a]^d\) and their translates. All our results remain valid, if one chooses \(\Lambda =\{Bz,z\in \mathbb {Z}^d\}\), where B is some non-singular \(d\times d\)-matrix and replaces the cubes by the the corresponding parallelepiped. This changes a few constants appearing below which relate volumes and distances but does not alter the content of the theorems. The same applies of course to adapting the norm \(|\cdot |\) to \(\Lambda \) – it usually is more natural to work with the corresponding lattice distance on \(\Lambda \) instead of Euclidean distance.
The canonical examples for \(\eta \) are a homogeneous Poisson process and i.i.d. \({\text {Bernoulli}}(p)\) percolation on \(\mathbb {Z}^d\) with \(p\in (0,1]\). For simplicity, we assume that \(\mathbb {E}\eta ((-1/2,1/2]^d)=1\), this can always be achieved by a straightforward rescaling of the ambient space. Although some parts of our considerations are valid under the sole assumptions of ergodicity and positive correlations on \(\eta \) (see the paragraph below), most of our main results require a stronger control on dependencies. We say that \(\eta \) has finite range, if there exists some number K such that \(\eta (A)\) and \(\eta (B)\) are independent, if \(A,B\subset \mathbb {R}^d\) are at distance further than K of each other. Often, it is convenient to view \(\eta \) from a typical point, hence we frequently work with the Palm version \(\eta _0\) of \(\eta \) that has a point at the origin \(0\in \mathbb {R}^d\). Note that \(\eta \) is translation invariant under shifts of \(\Lambda \) if and only if, under \(\mathbb {P}_0\), \(\eta \) is invariant under shifting the origin into another typical point of \(\eta \), see [20]. Our model is now constructed as a deterministic functional of the points of \(\eta \), and two independent i.i.d. sequences of edge and vertex marks. Let \(X_1,X_2,\dots \) denote an enumeration of \(\eta \) and let \(\mathcal {T}=\{T_j: j\in \mathbb {Z}\}\) be a family of i.i.d. random variables distributed uniformly on (0, 1) independent of \(\eta \). Set
hence, \(\eta '\) is a point process on \(\Lambda \times (0,1)\) with unit intensity. Let further \(\mathcal {V}=\{V_{i,j}: i<j\in \mathbb {Z}\}\) be a second family of i.i.d. Uniform(0, 1) random variables, independent of \(\eta '\), that we call edge marks, which we assign to the elements of \((\eta ')^{[2]}\). We denote the point and edge marked process by \(\xi \). For given \(\varphi \), the graph \(\mathscr {G}\) is now deterministically constructed from \(\xi \) as the graph with vertex set \(\eta \) and edge set
Palm versions \(\eta '_0, \xi _0\) and \(\mathscr {G}_0\) of \(\eta ',\xi \), and \(\mathscr {G}\), respectively, are obtained by replacing \(\eta \) in the above construction by \(\eta _0\). In the remainder of the paper, the enumeration of the locations plays no role and we usually denote vertices \(\textbf{x}=(x,s)\in \eta '\) as in the introduction and occasionally write \(s_{x}\) for the mark of vertex \(\textbf{x}\) in location x, and \(V_{\textbf{x}\textbf{y}}\) for the edge mark associated with the pair \(\textbf{x}\textbf{y}\in (\eta ')^{[2]}\).
Finally, to assure that there is at most 1 infinite component in \(\mathscr {G}\), \(\eta \) and \(\phi \) should satisfy a suitable ‘finite energy property’, c.f. [5, 9, 18] and we shall always assume tacitly that this is the case.
Monotonicity and positive correlation The inverse vertex mark \(s_{x}^{-1}\) can be viewed as weight or fitness of the vertex in location \(x\in \eta \), (giving the weight-dependent random connection model its name), the likelihood of connections should be increasing with weight and proximity. Our arguments heavily use the weak FKG-property and to obtain non-negative correlations, we require \(\varphi \) to be decreasing in all three arguments. Formally, an increasing map of a doubly marked point configuration \(\xi \) does not decrease if either
-
vertices are added to \(\eta '\),
-
vertex marks are decreased,
-
edge marks are decreased.
In particular, if we interpret \(\mathscr {G}\) as a map on marked point configurations, it is increasing in the above sense for the canonical partial order on random geometric graphs. An increasing event \(E\in \sigma (\xi )\) is such that \(\mathbbm {1}_E\) is an increasing functional of \(\xi \). We require \(\mathscr {G}\) to satisfy the weak FKG-property, i.e. we have that
for any increasing functionals f, g on configurations \(\xi \). A sufficient condition for this is that \(\varphi (\cdot ,\cdot ,\cdot )\) is non-increasing in all 3 arguments and that \(\eta \) has the weak FKG-property, i.e.
where \(f',g'\) are non-decreasing functionals of point configurations under addition of points, c.f. [11, 12] for related constructions.
Remark 2.2
Note that the stated conditions on \(\varphi \) and \(\eta \) suffice, because the edge and vertex marks are added in an i.i.d. fashion. However, the monotonicity assumption on \(\varphi \) can be relaxed, e.g. if \(\eta \) is a Poisson process. Then increasing the intensity of \(\eta \) can always be realised by adding another independent Poisson process and thus always increases the resulting graph \(\mathscr {G}\), even if \(\rho \) is not monotone. On the other hand increasing intensity and contracting space, i.e. reducing all inter-location distances, are equivalent. A different direction in which our setup can be generalised is to weaken the requirement of positive correlation on \(\eta \), as long as the marks remain independent of \(\eta \), since most calculations only require that the model has positive correlations conditionally on \(\eta \). Similarly, we believe that our techniques can be adapted without much effort to certain situations in which edge and vertex marks are weakly dependent upon each other or even upon \(\eta \), as long as vertex marks and edge marks remain positively correlated. We have not attempted to strive for the most general results in this respect, since the main motivation for our model was to cover all Poisson and lattice based models with i.i.d. marks that have so far been treated in the literature in a unified setting. A model with strong positive correlations that is not covered by our approach but might be amenable to certain techniques from the present paper is the spatial preferential attachment model [14, 15].
Weak decay regime We now give a precise definition of the exponent \(\delta _{\textsf{eff}}\) discussed in the introduction. For any \(\mu \in [0,1)\) we may set
By monotonicity, the limit \(\bar{\delta }_{\textsf{eff}}(0+)=\lim _{\mu \downarrow 0}\bar{\delta }_{\textsf{eff}}(\mu )\) exists and we say that \(\varphi \) is weakly decaying, if
The standard situation is that both \(\bar{\delta }_{\textsf{eff}}(0+)=\bar{\delta }_{\textsf{eff}}(0)\) and that the \(\liminf \) in the definition of \(\bar{\delta }_{\textsf{eff}}(0)\) can be replaced by an actual limit. In this case, \(\bar{\delta }_{\textsf{eff}}(0)\) coincides with the exponent \(\delta _{\textsf{eff}}\) discussed in the Sect. 1. In particular, this is the case in the homogeneous case in which \(\varphi \) can be represented as a function \(\rho (\cdot )\) of inter-location distance only that satisfies \(\rho (z)\asymp z^{-\delta }\). There, we see immediately that \(\bar{\delta }_{\textsf{eff}}(0)=\bar{\delta }_{\textsf{eff}}(0+)=\delta \), cf. [10].
Percolation For \(\textbf{x}\in \eta '\), we write \(\mathscr {C}_x\) for the connected component of \(\textbf{x}=(x,s)\) in \(\mathscr {G}\). More generally, if \(\mathcal {G}\) is any stationary ergodic geometric random graph, we write \(\mathscr {C}_x(\mathcal {G})\) for the (possibly empty if x is no point of \(\eta \)) connected component \(\mathcal {G}\) of the vertex located in x. The maximal component of \(\mathcal {G}\) is denoted by \(\mathscr {C}_{\textsf{max}}(\mathcal {G})\) or \(\mathscr {C}_{\infty }(\mathcal {G})\) if it happens to be of infinite size (recall that we exclusively consider situations in which \(\mathscr {C}_{\infty }(\mathcal {G})\) is unique). Set now
where \(\mathcal {G}_0\) is the Palm version of \(\mathcal {G}\) (the latter always exists, since \(V(\mathcal {G})\) must be distributionally invariant under shifts along \(\Lambda \) by stationarity). By ergodicity, we have that \(\theta _{\mathcal {G}}\in [0,1]\) is constant and corresponds to the density of the infinite component.
Our first and most general result localises the existence of an infinite cluster. We use the notation \(\mathscr {G}[\Gamma ^n]\) to denote the subgraph induced in \(\mathscr {G}\) by the vertices located in \(\Gamma ^n=(-n/2,n/2]^d\).
Theorem 2.3
(Local clusters of sublinear size are asymptotically dense) Let \(\mathscr {G}\) denote an instance of inhomogeneous long-range percolation on a stationary, ergodic and positively correlated point set \(\eta \) such that \(\bar{\delta }_{\textsf{eff}}(0+)<2\). If \(\theta _\mathscr {G}>0\), then for every \(\lambda \in (0,1)\), we have
It stands to reason, that the assertion of Theorem 2.3 can be improved to a stretched exponential bound on the probability of existence of a local cluster of linear size, at least if we assume independence for \(\eta \). We plan to address this in future work. The corresponding result for classical long-range percolation was established in [4, Theorem 3.2].
Set now
where \(\mathscr {G}^p\) is obtained from \(\mathscr {G}\) by independent Bernoulli bond percolation with retention probability p. When no additional percolation is involved we also write \(\theta =\theta (1)\) for the density of the infinite cluster in \(\mathscr {G}\). The following result states that \(\theta (p)\) is a continuous function of p in two or more dimensions as long as we remain in the weak decay regime.
Theorem 2.4
(Continuity of bond percolation function) If \(d\ge 2\), \(\mathscr {G}\) is locally finite, \(\eta \) has finite range and \(\bar{\delta }_{\textsf{eff}}(0+)<2\), then
is a continuous function on [0, 1].
Theorem 2.4 extends [3, Theorem 1.5], [8, Corollary 4] and [7, Theorem 3.3] for \(d\ge 2\). However, note that all three previous results correspond to the case in which \(\bar{\delta }_{\textsf{eff}}(0+)\) trivially coincides with the a priori spatial decay exponent \(\delta \) (in the notation of Sec.1). In particular, in the special case of scale-free percolation [6,7,8], \(\bar{\delta }_{\textsf{eff}}(0+)<2\le \delta \) precisely if the critical threshold is 0, in which case Theorem 2.4 is standard.
Remark 2.5
The conclusion of Theorem 2.4 does not include \(d=1\), unless one has that \(\bar{\delta }_{\textsf{eff}}(0+)\) coincides with the spatial decay exponent of the connection probabilities. In that case, our models is only a weak perturbation of homogeneous long-range percolation and the corresponding result is a minor extension of Berger [3, Theorem 1.5] that can be obtained with the help of our Theorem 2.3 and the block-renormalisation techniques of Berger [3]. The difficulty in one dimension is rooted in the scaling behaviour for truly inhomogeneous model instances: in general, block-renormalised versions of the model behave quite differently to the original model. For homogeneous long-range percolation the opposite is true, as discussed in the introduction, cf. [3, Lemma 2.4]. In our renormalisation arguments, the tool used to connect large clusters is Lemma 3.2 below, which is only effective for clusters close enough to each other. Therefore our proof of Theorem 2.4 relies on comparison with supercritical nearest-neighbour models, whereas the \(d=1\) case would require a comparison with a suitable supercritical long-range model. To establish such a comparison in dimension 1 when \(\delta _{\textsf{eff}}<2\) is outside the scope of this article but the subject of ongoing research. The related fact that percolation may occur in \(d=1\) only inside the weak decay regime (or possibly at its boundary) was established in [10] for the weight-dependent random connection model. However, the techniques used there are not strong enough to make assertions about the behaviour of \(\theta (p)\) near the critical value.
It follows from the proof of Theorem 2.4, that percolation in \(\mathscr {G}\) is also robust under edge truncation, which we formulate as our next theorem. Denote by \(\mathscr {G}^{\{\ell \}}\) the graph obtained from \(\mathscr {G}\) by removing all edges longer than \(\ell >0.\)
Theorem 2.6
(Truncation property) If \(d\ge 2\), \(\eta \) has finite range, \(\bar{\delta }_{\textsf{eff}}<2\) and \(\mathscr {G}\) percolates, then
In the strong decay regime, the truncation property was recently established for classical long range percolation in [2]. Note that both Theorems 2.3 and 2.6 provide ‘locality’-type statements for percolation, i.e. if \(\mathscr {G}\) percolates and \(\mathscr {G}_n\rightarrow \mathscr {G}\) locally, then the \(\mathscr {G}_n\) will percolate eventually. In Theorem 2.6, the approximating sequence is obtained by graphs of bounded edge length and in Theorem 2.3 by the model restricted to large cubes. Note that in the latter case, ‘percolation’ on the approximating graph corresponds to the existence of a cluster that grows with the size of the box.
Transience. A connected loop-free multigraph \(\mathcal {G}=(V(\mathcal {G}),E(\mathcal {G}))\) together with a conductance function \(C:E(\mathcal {G})\rightarrow (0,\infty )\) is called a network. Note that we may always view C as a function defined on \(V(\mathcal {G})^{[2]}\) setting \(C(xy)=0\) for potential edges \(xy\notin E(G)\). The random walk \(Y=(Y_i)_{i\ge 0}\) on \((\mathcal {G},C)\) is obtained by reweighing the transition probabilities of simple random walk on \(\mathcal {G}\) according to C, i.e. the walker chooses their way with probabilities proportional to the sum of the conductances on the edges incident to their current position. In particular, we obtain simple random walk on G as a special case, if C is constant. We only consider locally finite networks, i.e.
Note that \(\pi \) is an invariant measure for Y. Let further \(\textsf{P}^\mathcal {G}(v\rightarrow Z)\) denote the probability that Y visits \(Z\subset V(\mathcal {G})\) before returning to \(v\in V(\mathcal {G})\) when started in \(Y_0=v\in V(\mathcal {G}).\) Now define the effective conductance between \(v\in V(\mathcal {G})\) and \(Z\subset V(\mathcal {G})\) as
for finite \(\mathcal {G}\) and then extend the notion to infinite graphs via a limiting procedure. In particular, by identifying all vertices at graph distance further than n from \(v\in V(\mathcal {G})\) with one vertex \(z_n\) (whilst removing any loops and keeping multiple edges with their conductances) we obtain a sequence of finite networks \((\mathcal {G}_n,C_n)\). Moreover, the limit
is well-defined. We say that Y (or \(\mathcal {G}\) if Y is simple random walk on \(\mathcal {G}\)) is transient if
Moreover, if \(\mho (v,\infty )>0\) for some \(v\in V(\mathcal {G})\), then \(\mho (v,\infty )>0\) for all \(v\in V(\mathcal {G})\).
Theorem 2.7
(Transience of infinite cluster) Let \(\varphi \) be such that \(\bar{\delta }_{\textsf{eff}}<2\) and let \(\eta \) be either a Poisson process or an i.i.d. percolated version of \(\mathbb {Z}^d\) with retention probability PE [0, 1], Then, if an infinite component in \(\mathscr {G}\) exits, it is almost surely transient.
The proof of Theorem 2.7 is given in Sect. 4. Theorem 2.7 is strictly stronger than the previous transience results in [3, 11, 13] and in particular establishes the recurrence-transience transition conjectured for the two-dimensional soft Boolean model in [11]. In \(d\ge 3\) transience should of course also hold outside the weak decay regime, but this is difficult to establish for the same reason as the corresponding truncation result.
3 Percolation in finite boxes
Throughout the following sections, we work repeatedly with the collections of half-open cubes
We write \(\Gamma ^m(x)=x+[-m/2,m/2)^d\), \(x\in m\mathbb {Z}^d\) for the cube of side length m centred at \(x\in m \mathbb {Z}^d\) and write \(\Gamma ^m\) for \(\Gamma ^m(0).\) For any bounded domain \(\Lambda \subset \mathbb {R}^d\), we define the k-neighbourhood of \(\Lambda \) as
If \(\mathcal {G}=\big (V(\mathcal {G}),E(\mathcal {G})\big )\) is any random geometric graph and \(D\subset \mathbb {R}^d\) is some bounded domain, we write \(\mathcal {G}[D]\) for the subgraph of \(\mathcal {G}\) induced by vertices located in D.
To prove Theorem 2.3, we first establish some auxiliary results and develop an improved version of the renormalisation approach used in [3] to study homogeneous long-range percolation. Let us begin by setting up some notation. We say that a finite collection M of numbers in (0, 1) is \(\mu \)-regular, for \(\mu \in (0,1/2)\), if for all \(i\in I(\mu ,M):= \{1,\dots ,\lfloor |M|^{1-\mu } \rfloor \}\) it holds that
A vertex set \(V\subset \eta '\) is called \((\mu ,k)\)-regular, if there exist \((x_1,s_1),\dots ,(x_k,s_k)\in V\), such that \(\{s_1,\dots ,s_k\}\) is \(\mu \)-regular.
Lemma 3.1
Fix \(\mu \in (0,1/2)\). Any finite collection M of i.i.d. Uniform(0, 1) random variables is \(\mu \)-regular with probability exceeding
Proof
Let \(n=|M|\). We have
and, by Bernstein’s inequality,
By definition of \(I(\mu ,M)\), we have \(|I(\mu ,M)|\le n^{1-\mu }\) and the claimed bound follows. \(\square \)
The purpose of \(\mu \)-regularity is to obtain lower bounds on connection probabilities for large vertex sets that depend solely on their size and distance of each other. We say that two disjoint vertex sets \(V_1,V_2\subset \eta '\) are adjacent (in \(\mathscr {G}\)), denoted by \(V_1 {\leftrightarrow } V_2\), if there exist \(\textbf{x}\in V_1,\textbf{y}\in V_2\) with \(\textbf{x}\textbf{y}\in E(\mathscr {G}).\)
Lemma 3.2
There exist a constant \(C=C(\varphi )>0\) and for any \(\mu \in (0,1/2)\) some \(v^*(\mu )< \infty \) such that for all \(v\ge v^*(\mu )\) and any disjoint pair \(V_1,V_2\subset \eta '\) of \((\mu ,v)\)-regular vertex sets that satisfy \(diam (\{x:(x,s)\in V_1\cup V_2\})\le D\), we have the uniform deterministic bound
Remark 3.3
\(\mu \)-regularity of a vertex set is solely a property of the i.i.d. vertex marks and, conditionally on \(\eta '\), the event \(V_1 {\leftrightarrow } V_2\) is measurable with respect to the edge marks of edges joining \(V_1\) and \(V_2\) only. Hence, Lemma 3.1 yields a large deviation bound for untypical behaviour of vertex marks and Lemma 3.2 is essentially a large deviation bound for the i.i.d. sequence of edge marks, given that the vertex marks involved show typical behaviour.
Proof of Lemma 3.2
Let \(V_i, i=1,2\) denote vertex sets of size v such that all locations of vertices in \(V_1\cup V_2\) are within distance D of each other and such that \(V_1\) and \(V_2\) have \(\mu \)-regular marks. Let further \(F_i\) be the empirical distribution function of the vertex marks corresponding to \(V_i\), \(i=1,2\), set \(n=|V_1|\), \(r=|I(\mu ,V_1)|\) and denote by \(M_1=\{s_1,\dots ,s_n\}\) the vertex marks corresponding to \(V_1\). We have, for \(t\in [0,1]\),
Since \(M_1\) is \(\mu \)-regular, this implies that
A similar argument holds for \(F_2\) and it follows that, for \(|V_1|, |V_2|\) sufficiently large,
Now note that \(\textbf{x}_i=(x_i,t_i)\in V_1\) and \(\textbf{x}_j=(x_j,t_j)\in V_2\) are always connected if their corresponding edge mark satisfies
which can be evaluated independently of the exact spatial positions. Since the edge mark collection \(\{V_{\textbf{x}_i\textbf{x}_j}; \textbf{x}_i,\textbf{x}_j\}\) is i.i.d. and independent of \(\eta '\), we have for the number \(\Sigma \) of edges between \(V_1,V_2\)
It now follows from (2) and the non-negativity of distribution functions that for \(h(s,t)=\varphi (s,t,D), (s,t)\in (0,1)^2\),
and the assertion of the lemma follows, because the estimate is uniform in the configuration \(\eta '\) on the event that \(V_1,V_2\) are \(\mu \)-regular. \(\square \)
The renormalisation scheme we use to prove Theorem 2.3 requires a number of interdependent parameters, which we now introduce. We first choose a sequence of density parameters \((\varrho _n)\) such that \(\varrho _n<1/4\) for all \(n\in \mathbb {N}\) and
In fact, the precise polynomial decay of \(\varrho _n\) is not important as long as
Now fix \(\mu ^*=\mu ^*(\varphi )\in (0,1/2)\) such that
which is possible due to our assumption on \(\bar{\delta }_{\textsf{eff}}(0+)\). Now choose \(\nu =\nu (\varphi )\) satisfying
and let
Finally, we choose \((\sigma _n)\) such that \(\sigma _n\in 2\mathbb {N}+1\) for all n and such that for all but finitely many n,
where \(\omega =\omega (\varphi )\) satisfies
For the remainder of the section, one should think of the sequences \((\varrho _n),(\sigma _n)\) and the numbers \(\nu ,\mu \) and \(\omega \) as having been fixed. Assume further, that two large integers \(k\in \mathbb {N},\ell \in 2\mathbb {N}\) are given – we are going to specify these parameters below dependening on the density \(\theta \) of the infinite cluster and the auxiliary variable \(\lambda \) appearing in the formulation of Theorem 2.3. Define a sequence \((m_n)=(m_n(\ell ))\) of lengths via
To lighten notation, we write \(\Gamma _n(x)=\Gamma ^{m_n}(x),x\in m_n\mathbb {Z}^d,\) for the stage-n cube at x, i.e. the cube in \(\mathfrak {C}(m_n)\) with midpoint x. Note that for any \(n\in \mathbb {N}\), each stage-n cube can be decomposed into precisely \(\sigma _n^d\) stage-\(n-1\) cubes, which we call its subcubes. The preclusters of a cube \(\Gamma _n(x)\) are maximal subsets (with respect to inclusion) of \(\eta '\cap \Gamma _n(x)\times (0,1)\) which are contained in the same connected component of \(\mathscr {G}[\Delta _k\Gamma _n(x)]\) (note that their definition depends on k).
A stage-0 cube is a cube \(\Gamma _0(x)\in \mathfrak {C}(\ell )\) and said to be alive if it contains a precluster with at least \(\lceil \ell ^d\theta /2\rceil \) vertices. Similarly, the cardinality thresholds
act as lower bounds for the number of vertices in the preclusters at further stages, but the condition for aliveness becomes a little more complex. For \(n\ge 1\), a stage-n cube \(\Gamma _n(x)\) is alive, if
- A(n):
-
at least \(r_n:=\lceil \varrho _n\sigma _n^d\rceil \) of its subcubes are alive;
- B(n):
-
at least \(r_n\) of its living subcubes contain a \((\mu ,v_{n-1})\)-regular precluster;
- C(n):
-
there are \((\mu ,v_{n-1})\)-regular preclusters \(\mathcal {C}_1,\dots ,\mathcal {C}_{r_n}\), each associated with a different subcube, which are are all mutually adjacent in \(\mathscr {G}\).
There is some redundancy in defining aliveness via the properties \(\textsf {A}(n),\textsf {B}(n)\) and \(\textsf {C}(n)\), but this formulation makes it straightforward to relate the definition to probabilities. Note, that the construction ensures that a living stage-n subcube always contains a precluster of size at least \(v_n\). Furthermore, the events
are increasing. The main tool needed to prove Theorem 2.3 is the following lemma.
Lemma 3.4
There exists some constant \(0<C<\infty \) depending only on \(\varphi \) and \(\ell \) such that
To establish Lemma 3.4, we proceed in several steps. For \(n\in \mathbb {N}\cup \{0\}\), we denote by \(\Gamma _n\in \mathfrak {C}(m_n)\) the stage-n cube centred at the origin. We now define the events
-
\(A_n=\{\Gamma _n \text { is alive}\}, n\in \mathbb {N}_0\),
-
\(A'_n=\{\Gamma _n \text { has at least }r_n \text { living subcubes} \}, n\ge 1,\)
-
\(B_n=\{\Gamma _n \text { satisfies condition }\textsf {B}(\)n\()\}, n\ge 1,\)
-
\(C_n=\{\Gamma _n \text { satisfies condition }\textsf {C}(\)n\()\}, n\ge 1,\)
and aim to give lower bounds for their probabilities. Our first result is a straightforward recursive bound for \(\mathbb {P}(A'_n)\) in terms of \(\mathbb {P}(A_n)\).
Lemma 3.5
Set
Then
Proof
By translation invariance and Markov’s inequality,
\(\square \)
To obtain further bounds involving the events \(B_n\) and \(C_n\), we define the maximal precluster \(\mathcal {C}^{n,k}(x)\subset \Gamma _n(x)\times (0,1)\) of a stage-n cube \(\Gamma _n(x)\) to be its precluster of largest cardinality (note that \(\mathcal {C}^{n,k}(x)\) may be empty if \(\eta \cap \Gamma _n(x)\) is empty), unless there is a tie between several preclusters, in which case the maximal precluster is the (almost surely unique) one amongst them containing the vertex with the smallest mark. This definition only works for almost every configuration \(\xi \), we thus set \(\mathcal {C}^{n,k}(x)=\emptyset \) on the set of configurations \(\xi \) on which there are at least two preclusters of maximal size with the same minimal mark to obtain a well-defined precluster in any case. Analogously, we define \(\mathcal {R}^{n,k}(x)\subset \Gamma _n(x)\times (0,1)\) to be the maximal \((\mu ,v_n)\)-regular precluster associated with a stage-n cube \(\Gamma _n(x)\).
Remark 3.6
Note that once \(\mathcal {C}^{n,k}(x)\) is non-empty for some configuration \(\xi \), it remains non-empty if any vertex mark of a vertex in \(\mathcal {C}^{n,k}(x)\) is decreased or if any edge mark of an edge adjacent to \(\mathcal {C}^{n,k}(x)\) is decreased. The same is true for \(\mathcal {R}^{n,k}(x)\), respectively. This fact is needed to obtain a monotonicity property of the events \(E(\cdot ),F(\cdot ,\cdot )\) defined in Lemma 3.7.
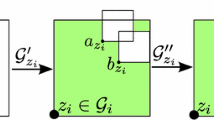
Let now \(\Gamma _n[1],\dots ,\Gamma _n[\sigma _n^d]\) denote the subcubes of \(\Gamma _n, n\in \mathbb {N}\) with corresponding centers \(x_n(i)\) and maximal preclusters \(\mathcal {C}^{n-1,k}(x_n(i)),\mathcal {R}^{n-1,k}(x_n(i)), 1\le i\le \sigma _n^d\).
Lemma 3.7
For any \(n\in \mathbb {N}\), we have
where
-
\(A_{n-1}(i)=\{\Gamma _n[i]\text { is alive}\}, 1\le i\le \sigma _n^d\);
-
\(B(i)=\{\Gamma _n[i]\text { contains a }(\mu ,v_{n-1})\text {-regular precluster} \}, 1\le i\le \sigma _n^d\);
-
\(E(i)=\{ \mathcal {C}^{n-1,k}(x_n(i)) \text { is not }(\mu ,v_{n-1})\text {-regular}\}, 1\le i\le \sigma _n^d\);
-
\(F(i,j)= \{\mathcal {R}^{n-1,k}(x_n(i)) \not \leftrightarrow \mathcal {R}^{n-1,k}(x_n(j))\}, 1\le i,j\le \sigma _n^d\).
Proof
We have the disjoint decomposition
and on the first event \(B_n^{\textsf{c}}\cap A'_n\), there has to be a living subcube that has no \((\mu ,v_{n-1})\)-regular precluster, which implies that its largest precluster cannot be \((\mu ,v_{n-1})\)-regular. The second event satisfies
where \(\mathcal {I}\) is the set of indices i, such that \(\mathcal {R}^{n-1,k}(x_i)\ne \emptyset .\) If \(r_n=1\) (which we have not explicitly excluded), then \(C_n\) always holds on \(B_n\cap A'_n.\) Otherwise, on \(B_n\cap A'_n\), we have that \(\mathcal {I}\) contains at least \(r_n\ge 2\) indices. Hence on
there has to be a pair of boxes containing a \((\mu ,v_{n-1})\)-regular precluster each, but such that the maximal such preclusters in either box are not adjacent. Thus, (10) is established. \(\square \)
The next two lemmas complete the estimates that we need to prove Lemma 3.4. For their proofs we use the following auxiliary subsampling of vertices: Let \(\eta \) be given. To each stage-n cube \(\Gamma _n(x)\in \mathfrak {C}(m_n)\), we assign a sample \(X(x,n)=\{X_1(x,n),\dots ,X_{v_n}(x,n)\}\) of tagged vertex locations in \(\eta \cap \Gamma _n(x)\), chosen uniformly without replacement and such that the collection of point sets
is mutually independent over all distinct choices of indices (x, n) and also the whole collection is independent of all vertex and edge marks. If \(\eta \cap \Gamma _n(x)\) contains fewer than \(v_n\) vertices, then we set \(X(x,n)=\emptyset \). We write
for the collection of tagged vertex sets corresponding to the tagged sites in each cube. The configuration \(\xi \) augmented by the independent tagging is denoted \(\bar{\xi }\) and the induced probability distribution on tagged configurations by \(\bar{\mathbb {P}}\).
Lemma 3.8
Let
then
Proof
A simple union bound and translation invariance yield
Hence it remains to estimate the probability on the right. Fix \(n\ge 1\). We define an alternative tagging of vertex locations in \(\Gamma _n[1]\) depending on \(\eta \) as well as edge and vertex marks. Namely, we set \(Y=\emptyset \) on \(A_{n-1}(1)^{\textsf{c}}\) and on \(A_{n-1}(1)\), we set \(Y=\{Y_1,\dots ,Y_{v_{n-1}}\}\), where \(Y_1,\dots ,Y_{v_{n-1}}\) are chosen uniformly without replacement amongst the vertex locations belonging to the maximal precluster \(\mathcal {C}^{n-1,k}(x_n(1))\) of \(\Gamma _n(1)\). Let \(\bar{\textbf{P}}_\eta (\cdot ):=\bar{\mathbb {P}}(\cdot |\eta )\) and denote the joint distribution of \(\xi \) and Y by \(\tilde{\mathbb {P}}\) and its conditional version given a fixed point configuration \(\eta \) by \(\tilde{\textbf{P}}_\eta \). Note that on \(A_{n-1}(1)\), \(\eta \) must have at least \(v_{n-1}\) points in \(\Gamma _n[1]\). It follows from the uniformity of the sample \(X(x_n(1),n-1)\) and its independence of edge end vertex marks, that
since a uniform sample drawn from a finite set S conditioned to be contained in an independently generated random subset \(S'\subset S\) has the same distribution as a uniform sample drawn from \(S'\). We have
where we define the conditional probabilities to equal 0 if \(|\eta \cap \Gamma _n[1]|<v_{n-1}\) and the equalities are due to the fact that the events \(E(1),A_{n-1}(1)\) do not involve the tagging at all. However, denoting by \(S=\{S_1,\dots ,S_{v_{n-1}}\}\) the vertex marks belonging to the tagged vertex locations in \(X(x_n(1),n-1)\) and by \(T=\{T_1,\dots ,T_{v_{n-1}}\}\) the vertex marks belonging to the tagged vertex locations in Y, we also have
by (12). Yet S is an i.i.d. sample of \(v_{n-1}\) \({\text {Uniform}}(0,1)\) random variables under \(\bar{\mathbb {P}}(\cdot |\eta )\), whenever \(|\eta \cap \Gamma _n(1)|\ge v_{n-1}\). Moreover, we claim that the events \(A_{n-1}(1)\) and \(D:=\{ \textbf{X}(x_n(1),n-1)\subset \mathcal {C}^{n-1,k}(x_n(1))\}\) are increasing in S and that the event \(\{S \text { is not }\mu \text { -regular}\}\) is decreasing in S. This is easily seen to be true for \(A_{n-1}(1)\) and E(1). The statement for D holds because if \((\xi ,X(x_n(1),n-1))\) is such that \(\{ \textbf{X}(x_n(1),n-1)\subset \mathcal {C}^{n-1,k}(x_n(1))\}\), then decreasing any one of the marks \(S_i, 1\le i\le v_n\), can only increase the maximal precluster \(\mathcal {C}^{n-1,k}(x_n(1))\) in size (or decrease the lowest mark, if there is a tie in sizes), in particular this means that none of the tagged vertices can leave \(\mathcal {C}^{n-1,k}(x_n(1))\) if their marks are decreased. Combining (13) with (14), the FKG-inequality and Lemma 3.1, we obtain
Integration over the point configurations \(\eta \) and inserting the result into (11) yields
which concludes the proof. \(\square \)
Lemma 3.9
Let
then
Proof
We use a similar approach as in the proof of Lemma 3.8, albeit we need to take a little more care, since the events involved are more complicated. Let \(n\in \mathbb {N}\), \(1\le i<j\le \sigma _n^d\), and the corresponding subcubes \(\Gamma _n(i),\Gamma _n(j)\subset \Gamma _n\) be fixed. Our goal is to bound the probability \(\mathbb {P}(B(i)\cap B(j) \cap F(i,j))\). As in the previous proof, we define additional randomly tagged locations that depend on edge and vertex marks. More precisely, set \(Y(i)=Y(j)=\emptyset \) on \((B(i)\cap B(j))^{\textsf{c}}\) and on \(B(i)\cap B(j)\), we sample two sets of locations \(Y(i)=\{Y_1(i),\dots ,Y_{v_{n-1}}(i)\}\) from \(\mathcal {R}^{n-1,k}(x_n(i))\) and \(Y(j)=\{Y_1(j),\dots ,Y_{v_{n-1}}(j)\}\) from \(\mathcal {R}^{n-1,k}(x_n(j))\), respectively, uniformly and without replacement. The joint distribution of \(\xi \) and the tagged sets Y(i), Y(j) is denoted by \(\tilde{\mathbb {P}}\). The vertex mark collections corresponding to Y(i) and Y(j) are denoted by T(i) and T(j), the corresponding vertex sets by \(\textbf{Y}(i),\textbf{Y}(j)\subset \eta '\), and the vertex mark sets associated with the independently tagged locations \(X(x_n(i),n-1)\) and \(X(x_n(j),n-1)\) are denoted by S(i) and S(j), respectively. The edge marks on potential edges between \(X(x_n(i),n-1)\) and \(X(x_n(j),n-1)\) are denoted by
Arguing precisely as in the proof of Lemma 3.8, we find that
where
and \(\textbf{P}_\eta ,\tilde{\textbf{P}}_\eta \) and \(\bar{\textbf{P}}_\eta \) denote the conditional versions of \(\mathbb {P},\tilde{\mathbb {P}}\) and \(\bar{\mathbb {P}}\), respectively, given a fixed point configuration \(\eta \). We may thus rewrite
Let us say, that two vertices \(\textbf{x}=(x,s),\textbf{y}=(y,t)\) with \(x,y\in \eta \cap \Gamma _n\) are strongly connected, if
If \(V,W\subset \eta '\cap \Gamma _n\times (0,1)\) are disjoint vertex sets, then we set
We further have, that
since \(\sqrt{d}m_n\) is an upper bound for the distance of any two vertices in \(\Gamma _n\) and the event \(\{S(i),S(j)\text { are }\mu \text {-regular}\}\) almost surely occurs conditionally on G. In fact, denoting by \(S^\lnot =S^\lnot (X)\) the collection of vertex marks not belonging to \(S(i)\cup S(j)\) and by \(V^\lnot =V^\lnot (X)\) the collection of edge marks belonging to edges with at least one endpoint mark not in \(S(i)\cup S(j)\), we may disintegrate the measure \(\bar{\textbf{P}}_\eta \) as follows
Almost every one of the measures \(\bar{\textbf{P}}_{\eta ,(X,S^\lnot ,V^\lnot )}\) coincides with
and acts on the \(\sigma \)-field \(\sigma (S(i),S(j),V(i,j))\). Fix any configuration of coordinates
Let \(\mathcal {X}_\eta \) denote the state space of tagged sub-configurations of \(\eta \). For any function
of tags, vertex and edge marks, we denote by
its restriction to the coordinates not prescribed by \(\omega \), i.e. its restriction to the coordinates corresponding to \(S(i)\cup S(j)\cup V(i,j)\). We argue now that the following \(\sigma (S(i),S(j),V(i,j))\)-measurable functions are increasing
-
(i)
\(\mathbbm {1}\{\textbf{X}(x_n(i),n-1)\leftrightharpoons \textbf{X}(x_n(j),n-1) \text { and } S(i),S(j)\text { are }\mu \text {-regular}\}\),
-
(ii)
\( \mathbbm {1}^\omega _{B(i)\cap B(j)}\), and
-
(iii)
\( \mathbbm {1}_G^\omega .\)
Firstly, the event in (i) is itself measurable with respect to \(\sigma (S(i),S(j),V(i,j))\) and increasing. Secondly, \(B(i)\cap B(j)\) is clearly an increasing event with respect to the full configuration \(\xi \) and thus increasing in the coordinates defined by (S(i), S(j) and V(i, j)) for almost every realisation of tags X. Finally, for (iii) we note that the event G is increasing in S(i), S(j) and V(i, j) for a fixed complementary configuration \(\omega \), since if a tagged full configuration \(\bar{\xi }\) satisfies G, then any configuration obtained by decreasing the mark of a tagged vertex in \(S(i)\cup S(j)\) or a corresponding edge mark in V(i, j) must also be in G. For vertex marks, this is checked as in the proof of Lemma 3.8 under the additional provision that \((\mu ,v_n)\)-regularity be not violated for either maximal precluster, which follows from the monotonicity of that property in S(i) and S(j), respectively. For the edge marks V(i, j), this follows from the fact that the graph \(\mathscr {G}\) (and therefore the composition of the maximal preclusters) can only be affected if the edge corresponding to the mark is added. But since \(\bar{\xi }\) satisfies G, this means adding an edge incident to both maximal \((\mu ,v_{n-1})\)-regular preclusters, which can only make those clusters larger and preserve maximality. We remark that the event G is not monotone with respect to the full configuration \(\xi \) but only with respect to the sub-\(\sigma \)-field \(\sigma (S(i),S(j),V(i,j))\).
We conclude that we may apply the FKG-inequality for the product measure (18) to obtain
Lemmas 3.1 and 3.2 together with the independence of edge and vertex marks imply that
uniformly over all realisations of \(\eta \) (and any complementary realisation \((X,S^\lnot ,V^\lnot )=\omega \)) that put sufficiently many points into the cubes \(\Gamma _n(i),\Gamma _n(j)\). Substituting (20) into (19), eliminating the integral, and then applying the bound (17) yields the lower bound
Combining the estimate (21) with (16) and integrating over point configurations \(\eta \), we get
and this estimate is uniform in the choice of subcubes \(\Gamma _n(i),\Gamma _n(j)\). It follows that
and the proof is concluded. \(\square \)
We are now ready to prove Lemma 3.4.
Proof of Lemma 3.4
By Lemma 3.7, we have
thus combining Lemmas 3.5, 3.8 and 3.9 yields, for any \(n\in \mathbb {N}\),
To bound the right hand side further, we first observe that, by definition of \(\sigma _n\),
for all but finitely many \(n\in \mathbb {N}\). Since \(v_n\rightarrow \infty \) as \(n\rightarrow \infty \), we also have
for all sufficiently large n, and finally, we claim that
for all sufficiently large n, which we show at the end of the proof. Inserting (23)–(25) into (22), we obtain
Setting \(\tilde{v}_{n-1}=v_{n-1}^{\nu }\) and using the definition of \(\bar{\delta }_{\textsf{eff}}(\mu ^*)<2\) as well as \(\mu <\mu ^*\), we see that there exists some small \(\zeta _0>0\) with \(\bar{\delta }_{\textsf{eff}}(\mu ^*)+\zeta _0<2\), such that for every \(\zeta \in (0,\zeta _0)\) there exists some \(N(\zeta )\) such that for all \(n>N(\zeta )\)
Using that \(\bar{\delta }_{\textsf{eff}}(\mu ^*)<2\) and the choice (6) of \(\nu \), it is easy to see that if we chose \(\zeta \) small enough, we can find some small value \(\mu _0\) (depending on \(\mu ,\nu \)), such that for all sufficiently large n
From the choice of \(\omega \) in (8) and the definition of \(v_{n-1}\), it follows that \(v_n\) grows at least like a small power of n!. Since \(\rho _n\) decays only polynomially, we can find some large \(L\in \mathbb {N}\), such that
and since \(\varrho _n<1/4\) for all \(n\in \mathbb {N}\), we conclude that
which by induction yields
Since \((\varrho _n)\) is summable, the product on the right hand side converges and we obtain the uniform bound (9) asserted in the lemma.
We conclude by verifying (25). Note that
and, writing \(\nu =1+\varepsilon _\nu \) with \(\varepsilon _\nu >0\), it is sufficient to show for all sufficiently large \(n\in \mathbb {N}\), that
which follows from the following calculation based on the choices of \(\varrho _n\) and \(\sigma _n\): We can find numbers \(K,R\in \mathbb {N}\), such that for all \(n>K+1\),
Using the the bound (8), we see that \(\varepsilon _\nu (d\omega -2)>2\) and hence we can find \(\varepsilon '\) such that
for all sufficiently large n, which concludes the proof. \(\square \)
The remainder of this section is devoted to the completion of the proof of Theorem 2.3.
Proof of Theorem 2.3
Let \(\varepsilon \in (0,1/2)\) and \(0<\lambda <1\) be given. Fix \(\omega \) such that
and note that this condition implies (8) and let the other parameters \(\mu ,\nu ,(\sigma _n)\) and \((\rho _n)\) be defined as before. We have not yet specified the initial cube length \(\ell =m_0\) and the parameter k used in the definition of preclusters, which we do now. By ergodicity, we may choose \(\ell \) so large, that with probability exceeding \(1-\varepsilon /2\), there is a set A of at least \(\theta \ell ^d /2\) vertices inside \(\Gamma _0\) that belong to the infinite cluster. Since the infinite cluster is unique, there is some \(k^*(\ell )<\infty \) such that all the vertices in A are contained within the same cluster of \(\mathscr {G}[\Delta _k\Gamma _0]\) with probability exceeding \(1-\varepsilon /2\) if \(k>k^*(\ell )\). We thus have shown that, with probability exceeding \(1-\varepsilon \) we can find a \((v_0,\mu )\)-precluster in \(\Gamma _0\) and conclude that \(a_0=\mathbb {P}(\Gamma _0\text { is not alive})\le \varepsilon .\) Invoking Lemma 3.4, we now obtain that
where C depends only on \(\varphi \) and \(\ell \). If the stage-L cube \(\Gamma _L\) is alive, then it follows from the definitions of aliveness and preclusters, that \(\Delta _k\Gamma _L\) contains a cluster of size
Let \(\tilde{\Gamma }_L\) denote the union of \(\Gamma _L\) with the \(3^d-1\) stage-L cubes neighbouring it. Since k depends only on the initial cube size \(\ell \), we can find \(L_0\in \mathbb {N}\) such that
From the choice of \((\varrho _n),(\sigma _n)\) and (26) we can also deduce the existence of constants \(0<q_1,q_2,q_3,q_4<\infty \), such that
for L sufficiently large. Since we can choose \(\varepsilon \) arbitrarily close to 0 and \(\lambda \) arbitrarily close to 1, the conclusion of Theorem 2.3 now follows easily for the subsequence \((\mathbb {P}(|\mathscr {C}_{\textsf{max}}(\mathscr {G}[\Gamma ^{m_n}])|> m_n^{\lambda d}), n\in \mathbb {N})\). To obtain the result for the original sequence, fix \(\varepsilon >0\) and \(1>\lambda '>\lambda \) arbitrarily. Now choose N so large that for all \(k\ge N\) both
are satisfied. Then, if \(n\ge M_n\), we can always find k with \(m_k\le n<m_{k+1}\) and such that
and the proof is complete. \(\square \)
4 Transience
We show that \(\mathscr {C}_\infty \) is transient by explicitly constructing a transient subgraph. To this end, we use the notion of renormalised graphs [3, Definition 2.8].
Definition 4.1
An \(\ell \)-merger of an infinite graph \(\mathcal {H}\) is any graph \(\mathcal {H}'\) obtainable by partitioning \(V(\mathcal {H})\) into subsets \(v_1,v_2,\dots \) of size \(\ell \), setting \(V(\mathcal {H}')=\{v_i,i\in \mathbb {N}\}\) and \(v_iv_j\in E(\mathcal {H}')\) if and only if there are \(u_i\in v_i,u_j\in v_j\) with \(u_iu_j\in E(\mathcal {H})\). The graph \(G_0=(V_0,E_0)\) is renormalised for the sequence \((\ell _n)_{n\in \mathbb {N}}\) if we can construct a sequence of \(G_1,G_2,\dots \) of graphs with \(G_i=(V_i,E_i)\) such that
-
\(G_i\) is an \(\ell _i\)-merger of \(G_{i-1}\) for all \(i\in \mathbb {N}\);
-
for every \(i\ge 2\), there is a partition of \(V_i\) into subsets \(v_1,v_2,\dots \) of size \(\ell _{i+1}\) such that for every k and every pair \((u_1,u_2)\in v_k\times v_k\) (interpreted as subsets of \(V_{i-1}\)) and every distinct \(w_1\in u_1,w_2\in u_2\) (interpreted as a pair of subsets of \(V_{i-2}\)), we have that \(w_1\leftrightarrow w_2\) in \(G_0\) (interpreted as subsets of \(V_0\)).
Remark 4.2
The wording of our definition of renormalised graphs differs from Berger [3, Definition 2.8], but it is straightforward to check that the two formulations are in fact equivalent.
Proposition 4.3
If \(\eta \) is either a Poisson process or an independently percolated lattice, \(\varphi \) is such that \(\bar{\delta }_{\textsf{eff}}(0+)<2\) and \(\theta >0\), then \(\mathscr {G}\) contains a transient subgraph almost surely.
Let us prepare the proof of Proposition 4.3 with some notation. Define for \(n\in \mathbb {N}\) the values
where \(\lambda \in (1/2,1)\). Our goal is to show that \(\mathscr {C}_\infty \) contains a subgraph that is renormalised for \((\alpha _n)_{n\in \mathbb {N}}\), by Berger [3, Lemma 2.7], this implies transience.
Fix furthermore a parameter \(\mu \in (0,1/2)\) which governs the regularity of vertex weights just as in the previous section. Once again, the scaling sequence \((\sigma _n)\) tells us how fast the scales of the renormalisation scheme grow, but the construction of connections between clusters at different scales will be significantly different to make it compatible with Definition 4.1. Recall that \(\mathfrak {C}(m)\) denotes the collection of disjoint cubes of side-length m centred at the points of \(m\mathbb {Z}^d\). A cube
for \(n\ge 1\), is called a stage-n cube. We now define the procedure that will allow us to conclude the renormalisability of \(\mathscr {C}_\infty \) for \((\alpha _n)\). The scheme requires us to start at some sufficiently large scale, so let \(n_1\in \mathbb {N}\) be the smallest stage of cubes we will consider. We do not fix \(n_1\) yet and assume only that it is large. We now define what it means for a cube to be good or bad. We begin at the bottom levels, namely \(\Gamma \in \mathfrak {C}^{n_1}\) is good if
- \(\textsf{E}(n_1)\):
-
The subgraph \(\mathscr {G}[\Gamma ]\) contains a \(\left( \prod _{i=1}^{n_1}\alpha _i, \mu \right) \)-regular connected component.
We call a connected component of \(\mathscr {G}[\Gamma ]\) which realises condition \(\textsf{E}(n_1)\) an \(n_1\)-renormalised cluster. Moving to level \(n_1+1\), we declare an \((n_1+1)\)-level cube \(\Gamma \) good, if
-
\(\textsf{E}_1(n_1+1)\) it has at least \(\alpha _{n_1+1}\) good subcubes at level \(n_1\);
-
\(\textsf{E}_2(n_1+1)\) at least \(\alpha _{n_1+1}\) good subcubes of \(\Gamma \) at level \(n_1\) contain \(n_1\)-renormalised clusters which are all mutually adjacent in \(\mathscr {G}[\Gamma ];\)
-
\(\textsf{E}_3(n_1+1)\) the adjacency requirement \(\textsf{E}_2(n_1+1)\) produces at least one cluster in \(\mathscr {G}{G}[\Gamma ]\) that is \((\prod _{i=1}^{n_1+1}\alpha _i, \mu )\)-regular.
A cluster qualifying for the condition imposed in \(\textsf{E}_3(n_1+1)\) is called an \((n_1+1)\)-renormalised cluster.
Having declared what happens at the bottom levels, we are now prepared to initiate the recursive part of the scheme. For a given level-n cube \(\Gamma \) with \(n>n_1+1\), we say that a pair \((\Gamma _1,\Gamma _2)\) of good subcubes is \(well-connected \), if
-
there exist \((n-2)\)-renormalised clusters \(\mathcal {C}^{i}_1,\dots ,\mathcal {C}^{i}_{\alpha _{n-2}}\) inside \(\Gamma _i\), for \(i=1,2\);
-
each of the pairs of sets \(\{ \mathcal {C}^{1}_k,\mathcal {C}^{2}_l: 1\le k,l\le \alpha _{n-2} \}\) is adjacent in \(\mathscr {G}{G}[\Gamma ]\).
Based on the goodness at levels \(n_1,n_1+1\) and the notion of well-connectedness, we now declare an stage-\(n\) cube \(\Gamma \) with \(n>n_1+1\) to be good, if there exists a subset \(\mathfrak {F}\) of the good subcubes of \(\Gamma \) satisfying
- \(\textsf{F}_1(n)\):
-
\(|\mathfrak {F}|\ge \alpha _n\);
- \(\textsf{F}_2(n)\):
-
any pair \((\Gamma _1,\Gamma _2)\in \mathfrak {F}\times \mathfrak {F}\) is well-connected;
- \(\textsf{F}_3(n)\):
-
at least one cluster formed by mutual well-connectedness of \(\{(\Gamma _1,\Gamma _2):\Gamma _{1},\Gamma _{2}\in \mathfrak {F}\}\) from the \((n-2)\)-renormalised clusters inside subcubes of \(\Gamma _1,\Gamma _2\) is \((\prod _{i=1}^{n}\alpha _i,\mu )\)-regular.
Any cluster formed from \((n-2)\)-renormalised clusters in the way specified by \(\textsf{F}_1(n)\)–\(\textsf{F}_3(n)\) is called an n-renormalised cluster of \(\Gamma \). Observe that the event \(\{\Gamma \in \mathfrak {C}^n\}\) is good is increasing.
Remark 4.4
The recursive architecture induced by a hierarchy of good cubes is more complex than the one used in the proof of Theorem 2.3, due to the intertwining of levels n and \(n+2\). However, note that the goodness of \(\Gamma \) only depends on \(\mathscr {G}[\Gamma ]\) and therefore is independent of the status of cubes on the same level, if \(\eta \) is the (percolated) lattice or a Poisson process.
A careful inspection of the above construction yields that it produces indeed a renormalised graph sequence.
Lemma 4.5
If \(\Gamma _n, n\ge n_1\) are all good, then \(\mathscr {C}_\infty \) contains a subgraph that is renormalised for \((\alpha _n)\).
Having defined our renormalisation scheme subject to the precise choice of the parameters \(\lambda ,\mu \) and \(n_1\), we are now ready to complete the proof.
Proof of Lemma 4.3
The calculation is very similar to the proof of Theorem 2.3, which allows us to recycle some of the parameters chosen there. Let, in particular, \(\mu ^*>0\) be given as in (5) and define \(\nu >1\) and \(\mu <\mu ^*\) as in (6) and (7). Finally, choose
Let \(E_n,E^i_n,F^i_n, i\in \{1,2,3\},\) denote the events that the conditions \(\textsf{E}(n),\textsf{E}_i(n),\textsf{F}_i(n)\) are satisfied respectively for the stage-n cube \(\Gamma ^n\) centred at the origin. Similarly, we write \(L_n, n\ge n_1\) for the event that \(\Gamma ^n\) is good. Note that transience of \(\mathscr {C}_\infty \) has either probability 0 or 1 by ergodicity. Due to translation invariance and Lemma 4.5 it is thus enough to show that
and since the events \(L_n\) are increasing, this can be further simplified, using the FKG inequality, to
Note that by construction, \(L_{n_1}\) and \(L_{n_1+1}\) are defined differently than the other scales, so we will bound their probabilities separately. We first upper bound the probability of the converse event \(L_n^{\textsf{c}}\) for \(n>n_1+1\) and begin by writing
To bound \(\mathbb {P}((F^3_n)^{\textsf{c}}\cap (F^1_n\cap F^2_n))\), one may argue as in the proof of Lemma 3.8 to obtain
It follows that, for n sufficiently large,
for some constants \(c,C>0\) which only depend on \(\mu .\) Moving on to bound \(\mathbb {P}((F^2_n)^{\textsf{c}}\cap F^1_n)\), note that any two vertices in \(\Gamma ^n\) are at most at distance
away from each other. Let \(q_n\) be the probability that two renormalised clusters of \((n-2)\)-level subcubes in the same \(n\)-level cube are not connected. We note that by construction, any \((n-2)\)-renormalised cluster in any good \((n-2)\)-level cube contains at least \(\prod _{i=1}^{n-2}\alpha _i\) vertices. Therefore, by Lemma 3.2, and noting that \(\lambda >1/\nu \) implies
we may argue precisely as in the proof of Lemma 3.9 to obtain that
for some positive constants \(c,C\). There are
possible pairs of \(n-2\)-level cubes in \(\Gamma ^n\). Taking a union bound, we obtain, for some \(\tilde{c}>0\),
where the second inequality holds for all sufficiently large \(n\). We now proceed to bound \(\mathbb {P}(F^1_n)\). Note that by independence, the number of good subcubes of \(\Gamma \) dominates a \({\text {Bin}}(m,q)\) random variable X, where \(q=\mathbb {P}(L_{n-1})\), \(m=\sigma _n^d\). Fixing \(\Theta \in (0,1)\), Chernoff’s bound states
i.e. for \(\Theta =1-\frac{\alpha _n}{\sigma _n^d}\frac{1}{\mathbb {P}(L_{n-1})}\) this leads to
where we used the definitions of \(\alpha _n\), \(\sigma _n\) and the definition of \(F^1_n\) itself. Combining (29), (31) and (30) into (28) and relabelling constants, we obtain the recursive inequality
The same bound applies to \(\mathbb {P}(L_{n_1+1}^c)\), since the calculation for the complements of the defining events \(E^1_{n_1+1},E^2_{n_1+1}\) and \(E^3_{n_1+1}\) can be done along the same lines as for the \(F^i_n\). Finally, we have by Theorem 2.3 that for any \(\lambda \in (0,1)\) and any \(\varepsilon >0\), \(\mathbb {P}(L_{n_1})>1-\varepsilon \) if \(n_1\) is chosen sufficiently large.
Define now the sequence \(\ell _n:=1-(n+1)^{-3/2}\) and observe that \(\prod _{i=1}^{\infty }\ell _i>0\). We will now show that if \(\mathbb {P}(L_n)>\ell _n\), then it follows inductively that \(\mathbb {P}(L_{n+1})>\ell _{n+1}\). We calculate
where the second inequality holds if \(n\) is sufficiently large. Let \(n_1\) now be large enough so that all \(n>n_1\) satisfy the previous assumptions about \(n\) being large and furthermore let \(n_1\) be large enough that \(\mathbb {P}(L_{n_1})>1-2^{-3/2}\). Then, using the same calculation yields that \(\mathbb {P}(L_{n_1+1})>\ell _{n_1+1}\) and the claim follows for all larger \(n\).
We can now write
Together with Lemma 4.5, this gives the existence of the renormalized graph sequence with positive probability and concludes the proof. \(\square \)
5 Continuity properties of percolation
For a given graph \(\mathcal {G}\), we denote by \(p\mathcal {G}\) the graph obtained from \(\mathcal {G}\) by independent Bernoulli vertex percolation and that \(\eta \) is finite range, if \(\eta (A)\) and \(\eta (B)\) are independent, whenever A and B are sufficiently far separated.
Proposition 5.1
(Continuity of percolation from the left, \(d\ge 2\)) Let \(d\ge 2\) and let \(\mathscr {G}\) be an instance of inhomogeneous long range percolation on a finite range point set \(\eta \) with \(\bar{\delta }_{\textsf{eff}}(0+)<2\). Assume that an infinite cluster exists. Then there exists \(p<1\) such that \(p\mathscr {G}\) contains an infinite cluster almost surely.
Proof
We renormalise the model using the cubes \(\mathfrak {C}(m)\). By the finite range assumption on \(\eta \), we my fix \(m_0\) so large, that \(\eta (\Gamma ^{m}(x))\) and \(\eta (\Gamma ^{m}(y))\) are independent for all \(m\ge m_0\) and all \(x,y\in m\mathbb {Z}^d\) with \(|x-y|\ge 3\,m\). Using the classical domination result of Liggett et al. [17], it is straightforward to show that there are retention probabilities \(p^*_{3,d},q^*_{3,d}<1\), such that any ergodic 3-independent (p, q)-site-bond percolation measure on \(\mathbb {Z}^d\) with \(p>p^*_{3,d}\) and \(q>q*_{3,d}\) almost surely produces an infinite cluster.
A \(\lambda \)-good cube \(\Gamma \in \mathfrak {C}(m)\) is such that \(\mathscr {G}[\Gamma ]\) contains a \(\mu (\lambda )\)-regular cluster of size at least \(m^{\lambda d}\), where \(\mu (\lambda )\) is chosen such that
Note that by assumption such a choice is always possible, if \(\lambda \) is sufficiently close to 1. By Theorem 2.3 and the fact that \(\mu \)-regularity is a monotone event for a given cube, we can choose m so large, that the density \(p_\lambda \) of \(\lambda \)-good cubes is arbitrarily close to 1. In particular, we can achieve \(p_\lambda \in (p^*_{3,d},1)\). By Lemma 3.2 the maximal local clusters in two good cubes associated with neighbouring vertices in \(m\mathbb {Z}^d\) are connected with probability at least
and we obtain, by choice of \(\lambda \) and \(\mu (\lambda )\)
for large enough m and this estimate holds independently for disjoint pairs of \(\lambda \)-good cubes. Now given a large value m such that the above estimates hold, we observe that
-
the induced site-bond percolation model on cubes in \(\mathfrak {C}(m)\) percolates, since it dominates a 3-independent percolating bond-site model on \(\mathbb {Z}^d\),
-
if \(p_\lambda (r)\) denotes the probability that a \(\lambda \)-good cluster exists in an m-cube for the percolated graph \(r\mathscr {G}\), then we have
$$\begin{aligned} \lim _{r\uparrow 1} p_\lambda (r)=p_{\lambda }, \end{aligned}$$since the involved events only depend on a finite domain,
-
the lower bound on \(q_\lambda \) remains valid for any \(\lambda \)-good pair of neighbouring m-cubes in \(r\mathscr {G}\).
Hence, choosing r sufficiently close to 1, we obtain that the induced site-bond percolation model on cubes in \(\mathfrak {C}(m)\) still percolates for \(r\mathscr {G}\) and thus there exists an infinite cluster in \(r\mathscr {G}\). \(\square \)
The following corollary establishes Theorem 2.6.
Corollary 5.2
(Continuity under truncation) Let \(d\ge 2\) and \(\bar{\delta }_{\textsf{eff}}(0+)<2\). If \(\mathscr {G}\) is has an infinite cluster, then there exists some \(\ell <\infty \) such that \(\mathscr {G}\) retains an infinite cluster after removing all edges of length at least \(\ell \) from \(\mathscr {G}\).
Proof
The auxiliary infinite cluster constructed from the coarse-grained bond-site model on m-cubes in the proof of Proposition 5.1 uses no edge longer than \(2\sqrt{d}m\). \(\square \)
Finally, we establish continuity of the percolation function in all points.
Proof of Theorem 2.4
Recall that \(\mathscr {G}_p\) denotes the graph obtained from \(\mathscr {G}\) by independent Bernoulli bond percolation with retention parameter \(p\in [0,1]\). Since \(\mathscr {G}\) is locally finite, it is elementary, to see that
is a right-continuous function of p, since \(\theta (p)\) can be written as a decreasing limit of polynomials in p. Furthermore, a classical result of van den Berg and Keane [21] states that \(\theta (\cdot )\) is continuous above the critical threshold. By monotonicity, it follows that \(\theta (p)\) is continuous, if it is left-continuous at the critical value. This follows from Proposition 5.1 for site-percolation and an elementary coupling argument between explorations in bond percolation clusters and explorations in site percolation clusters shows that the conclusion of Proposition 5.1 remains true for bond percolation. \(\square \)
Notes
If \(\Lambda \) is discrete, then a ‘point process’ on \(\Lambda \) is just a random subset.
References
Aurzada, F., Guillotin-Plantard, N., Pène, F.: Persistence probabilities for stationary increment processes. Stoch. Process. Appl. 128(5), 1750–1771 (2018)
Bäumler, J.: Continuity of the critical value for long-range percolation. (2023). arXiv:2312.04099 [math.PR]
Berger, N.: Transience, recurrence and critical behavior for long-range percolation. Commun. Math. Phys. 226(3), 531–558 (2002). Corrected version arXiv:math/0110296v3
Biskup, M.: On the scaling of the chemical distance in long-range percolation models. Ann. Probab. 32(4), 2938–2977 (2004)
Burton, R.M., Meester, R.W.J.: Long range percolation in stationary point processes. Rand. Struct. Algorithms 4(2), 177–190 (1993)
Deijfen, M., van der Hofstad, R., Hooghiemstra, G.: Scale-free percolation. Ann. Inst. Henri Poincaré Probab. Stat. 49(3), 817–838 (2013)
Deprez, P., Wüthrich, M.V.: Scale-free percolation in continuum space. Commun. Math. Stat. 7(3), 269–308 (2019)
Deprez, P., Hazra, R., Wüthrich, M.: Inhomogeneous long-range percolation for real-life network modeling. Risks 3(1), 1–23 (2015)
Gandolfi, A., Keane, M.S., Newman, C.M.: Uniqueness of the infinite component in a random graph with applications to percolation and spin glasses. Probab. Theory Relat. Fields 92(4), 511–527 (1992)
Gracar, P., Lüchtrath, L., Mönch, C.: Finiteness of the percolation threshold for inhomogeneous long-range models in one dimension (2022). arXiv:2203.11966
Gracar, P., Heydenreich, M., Mönch, C., Mörters, P.: Recurrence versus transience for weight-dependent random connection models. Electron. J. Probab. 27, 1–31 (2022)
Heydenreich, M., van der Hofstad, R., Last, G., Matzke, K.: Lace expansion and mean-field behavior for the random connection model (2019). arXiv:1908.11356
Heydenreich, M., Hulshof, T., Jorritsma, J.: Structures in supercritical scale-free percolation. Ann. Appl. Probab. 27(4), 2569–2604 (2017)
Jacob, E., Mörters, P.: Spatial preferential attachment networks: power laws and clustering coefficients. Ann. Appl. Probab. 25(2), 632–662 (2015)
Jacob, E., Mörters, P.: Robustness of scale-free spatial networks. Ann. Probab. 45(3), 1680–1722 (2017)
Jahnel, B., Lüchtrath, L.: Existence of subcritical percolation phases for generalised weight-dependent random connection models (2023). arXiv:2302.05396
Liggett, T.M., Schonmann, R.H., Stacey, A.M.: Domination by product measures. Ann. Probab. 25(1), 71–95 (1997)
Meester, R., Roy, R.: Uniqueness of unbounded occupied and vacant components in Boolean models. Ann. Appl. Probab. 4(3), 933–951 (1994)
Newman, C.M., Schulman, L.S.: One dimensional \(1/|j-i|^s\) percolation models: The existence of a transition for \(s\le 2\). Commun. Math. Phys. 104(4), 547–571 (1986)
Thorisson, H.: Point-stationarity in \(d\) dimensions and Palm theory. Bernoulli 5(5), 797–831 (1999)
van den Berg, J., Keane, M.: On the continuity of the percolation probability function. In: Conference in Modern Analysis and Probability (New Haven, Conn., 1982), vol. 26, pp. 61–65. Contemp. Math. Amer. Math. Soc., Providence (1984)
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
The work was entirely conducted by the single author.
Corresponding author
Ethics declarations
Conflict of interest
The author declares no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supported by Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—Grant No. 443916008/SPP2265.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mönch, C. Inhomogeneous long-range percolation in the weak decay regime. Probab. Theory Relat. Fields 189, 1129–1160 (2024). https://doi.org/10.1007/s00440-024-01281-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-024-01281-5