
Abstract
Several studies predicting Functional Connectivity (FC) from Structural Connectivity (SC) at individual level have been published in recent years, each promising increased performance and utility. We investigated three of these studies, analyzing whether the results truly represent a meaningful individual-level mapping from SC to FC. Using data from the Human Connectome Project shared accross the three studies, we constructed a predictor by averaging FC of training data and analyzed its performance in the same way. In each case, we found that group average FC is an equivalent or better predictor of individual FC than the predictive models in terms of raw prediction performance. Furthermore, we showed that additional analyses performed by the authors of the three studies, in which they attempt to show that their predicted FC has value beyond raw prediction performance, could also be reproduced using the group average FC predictor. This makes it unclear whether any of the three methods represent a meaningful individual-level predictive model. We conclude that either the methods are not appropriate for the data, that the sample size is too small, or that the data does not contain sufficient information to learn a mapping from SC to FC. We advise future individual-level studies to explicitly report results in comparison to the performance of the group average, and carefully demonstrate that their predictions contain meaningful individual-level information. Finally, we believe that investigating alternatives for the construction of SC and FC may improve the chances of developing a meaningful individual-level mapping from SC to FC.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
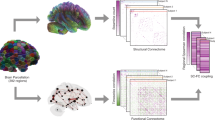
Understanding how anatomical connections in the brain give rise to functional interactions, which in turn support the cognitive functioning of individuals, is one of the major goals in neuroscience. In recent years, these ideas have been conceptualized in terms of networks consisting of connections between regions of interest (Bullmore and Sporns 2009; Honey et al. 2009; Sporns et al. 2005). Structural connections are represented by structural connectivity (SC), which quantifies the strength of white matter tracts connecting each pair of brain regions (Hagmann et al. 2008; Sporns et al. 2005; van den Heuvel and Hulshoff Pol 2010). Functional interactions are represented by functional connectivity (FC), which expresses the degree of co-activation between pairs of regions (Beckmann et al. 2005; Damoiseaux et al. 2006). There exists a substantial body of work that studies the relation between SC and FC (see e.g. Suárez et al. 2020 for a recent overview). One of the main goals is to predict FC from SC, using approaches such as biophysical models and network communication models. However, the performance achieved by these models is modest, and usually only reported at a group level (e.g., Avena-Koenigsberger et al. 2018; Goñi et al. 2014; Mišić et al. 2016; Seguin et al. 2018; Wang et al. 2019). For clinical applications, such as neurosurgical planning, we must take into account that the organization of each patient’s brain network can vary strongly, especially when considering brain tumor patients (Almairac et al. 2021; Harris et al. 2014; Jütten et al. 2020; Maesawa et al. 2015; Park et al. 2016). It is therefore essential that predictions of function from structure are accurate at an individual level if we wish to implement these methods in clinical practice.
In the past years, several studies have attempted to predict function from structure at an individual level (Becker et al. 2018; Benkarim et al. 2022; Cummings et al. 2022; Deslauriers-Gauthier et al. 2020; Neudorf et al. 2022; Sarwar et al. 2021), generally based on machine learning techniques. We closely examined three of these studies, which demonstrated the most promising results on large and diverse data sets, to determine whether their methods are suitable for further development in a clinical setting. Each of the three studies followed the existing literature, calculating FC as the Pearson correlation between the activity levels over time in each brain region, while calculating SC from the number of white matter fibers as found by tractography connecting each pair of brain regions. The studies then attempted to predict FC from SC in a number (n between 250 and 1000) of healthy subjects from the Human Connectome Project (HCP), which allows us to compare their results. Two of the studies also considered supplementary data sets.
In the following, we briefly summarize the three studies we examined. After this, we show that we can reproduce their results using the group average FC with added random noise, which does not contain individual information, directly as a predictor (i.e. without using any machine learning models). From this we conclude that the authors of the three studies have not demonstrated that the learned individual-level mappings preserve individual information. This might indicate that either individual-level methods as they are currently applied in the task of predicting function from structure are not yet suitable, or that the data they are applied to does not contain sufficient information to learn a mapping from.
Predicting individual FC from SC: a summary
In Structure-function coupling in the human connectome: A machine learning approach, Sarwar and colleagues (2021) trained a 10-layer fully connected neural network with a loss function designed to preserve inter-individual variation in FC, ensuring that predictions did not converge to a group average. This loss function was parametrized by two parameters, γ and λ, which induced a trade-off between prediction accuracy and inter-individual variation in predictions. The final tuned model achieved a correlation between predicted FC (pFC) and empirical FC (eFC) of 0.9 ± 0.1 on a group level and 0.55 ± 0.1 on an individual level, improving upon the performance of earlier work using biophysical and network communication models. On the data used in the supplementary materials, the performance was even higher, reaching a correlation of 0.7 ± 0.1 at an individual level. The differing performance is probably due to the use of different pre-processing and connectivity mapping methods. The authors simultaneously demonstrated that the model did not predict a group average by explicitly showing that the inter-subject variance in pFC is similar to that in eFC. Furthermore, the authors showcased the usefulness of individual-level pFC, in which they predicted variation in cognitive performance from pFC. The results suggest that predicting cognition from pFC works almost as well as predicting cognition from eFC, achieving a correlation between predicted and actual cognitive performance of 0.33 using eFC and 0.29 using pFC. This further supports the conclusion that the machine learning model preserved relevant individual information contained in SC, and did not simply output some averaged FC that correlates well with the whole data set.
In Structure can predict function in the human brain: a graph neural network deep learning model of functional connectivity and centrality based on structural connectivity, Neudorf et al. (2022) used a deep learning model more directly suited to the task. Leveraging the network structure present in SC and FC, they applied a Graph Neural Network (GNN) model, trained on the same data used by Sarwar et al. Furthermore, they explicitly trained another model to predict the degree centrality, eigenvector centrality and PageRank centrality of nodes in FC, which are known to be related to age and sex differences (Zuo et al. 2012) and to various pathologies (Chen et al. 2015; Deng et al. 2019). The results were presented in terms of variance explained, where the authors show that pFC explains 56% of the variance in eFC i.e. R2 = 0.56. Since this is a univariate regression, we can convert to correlation by taking the square root, which yields a correlation of R = \(\sqrt{0.56}\) = 0.75. While the authors suggested that this means that their method outperforms the methods by Sarwar et al. in terms of raw performance, Sarwar et al. reported their correlation as an average of correlations per individual, rather than the single correlation of all individuals’ eFC and pFC concatenated. Therefore, these numbers are not comparable. Besides raw prediction performance, network centrality measures calculated from pFC also correlated with centrality measures calculated from eFC at individual level, explaining 81% of the variance in degree centrality. The authors thus demonstrated that the model learned a mapping from SC to FC that also preserved the network structure of FC.
Finally, in A Riemannian approach to predicting brain function from the structural connectome, Benkarim and colleagues (2022) developed a more complex framework for FC prediction, using a generalized diffusion model on the SC network to simulate communication dynamics. This model allows the authors to explicitly model the “walk length” that is used, which represents the number of connections that are used by information propagating along the structural network. The hyperparameters were fitted on a small subset of data (n = 26) and validated on 250 subjects from the HCP data set. The presented results improved upon the results of Sarwar et al. in terms of raw performance (individual correlation = 0.775 ± 0.049 on the 200-parcel Schaefer atlas), and the authors provided some additional analyses investigating in which parts of the brain FC is harder to predict. In particular, they found that their method performed better at predicting FC in the visual, somatomotor and attention regions of the brain than in the default mode, frontoparietal and limbic regions. Furthermore, predictions in the default mode and frontoparietal regions benefitted the most from using longer walks on the structural connectome. This suggests that these regions require more polysynaptic connections to function, in agreement with earlier results in the literature indicating the same dependencies (Suárez et al. 2020; Vázquez-Rodríguez et al. 2019).
As a measure of accuracy, one must be careful when considering correlation. Specifically, given some subject’s eFC, there exist an infinite number of FC profiles that have the same correlation with this eFC. This means that, by itself, an average individual-level correlation of 0.55 or 0.77 gives no guarantee that a model preserves useful information contained in an individual’s eFC. Furthermore, in the setting of predicting FC, we must consider that the group average FC is a very good predictor by itself in terms of raw performance, as identified earlier by Deslauriers-Gauthier and colleagues (2022). In the following, we show that pFC in each of the three studies does not outperform a predictor that outputs the average eFC of the training data with added random noise, without using any machine learning models. Critically, this means that a predictor based on no individual information (i.e. not requiring any input) can match the performance of complex machine learning methods.
Considering this, it is important to judge the quality of results from prediction methods not only by raw performance (in terms of correlation), but also by other metrics. Each of the three considered studies analyzed some other aspect of pFC besides raw prediction performance. We show that each of these analyses can also be reproduced using the group average eFC. This means that, in addition to not exceeding the raw prediction performance of the group average eFC, none of the three studies sufficiently demonstrated that pFC as generated by their methods contains more individual information than group average eFC.
Methods
Data set
We used data from 1000 healthy participants of the Human Connectome Project (HCP) (Van Essen et al. 2013), a data set shared across the three studies. For each subject, we obtained minimally preprocessed diffusion-weighted and resting-state functional MRI images. Preprocessing pipelines are described in (Van Essen et al. 2013).
Construction of eFC
Since the three studies used different cortical parcellations (atlases), we also used multiple atlases to control for differences in performance. Sarwar et al. presented most of their results on the Desikan-Killiany (DK) cortical parcellation (Desikan et al. 2006). Neudorf et al. presented their results for both the DK and Automated Anatomical Labeling (AAL) atlas (Tzourio-Mazoyer et al. 2002), achieving the highest performance on the DK atlas. Finally, Benkarim et al. used a functional parcellation by Schaefer et al. (Schaefer et al. 2018) and a structural parcellation based on a refinement of the DK atlas (Vos de Wael et al., 2020), attaining the best results with the Schaefer atlas. Given that the best results and most additional analyses across the three studies are based on the DK and Schaefer atlases, we decided to use the DK and 200-parcel Schaefer atlases in our analyses.
We calculated eFC matrices in the same way as described by Sarwar et al. We used two minimally preprocessed resting-state functional MRI images, one with right-to-left and one with left-to-right phase encoding, for each HCP subject. fMRI images were acquired using a multiband gradient-echo planar imaging period of 14.4 min, with a repetition time of 720ms and a multiband factor of 8. Subjects were instructed to keep their eyes open and fixate on a projected cross-hair on a dark background. Preprocessing is again described in (Van Essen et al. 2013). In short, the images were denoised and motion-scrubbed with ICA-FIX (Salimi-Khorshidi et al. 2014), then normalized to standard MNI space. The two images were temporally demeaned and concatenated, resulting in a single, longer, image. Activity time series were calculated for each region in the considered atlases (DK and Schaefer) by averaging the comprising voxel activity time series. eFC was then calculated as the pair-wise Pearson correlation coefficient between each region’s time series. The methods used by Neudorf et al. and Benkarim et al. to construct eFC slightly differ, but the main processing steps are identical: activity time series are averaged over ROIs and FC is calculated as the Pearson correlation between these time series. Therefore, we expect the differences in the resulting eFC matrices to be minor and to not affect our analyses.
Assessing prediction performance
Following Sarwar et al., we adopted a 10-fold cross-validation framework for predicting eFC. We split the data set in 10 folds of equal size, using 9 folds as training data and the remaining fold to assess performance i.e. training on 900 subjects and assessing performance on 100 subjects. Repeating this 10 times, using each fold for validation exactly once, we assessed the performance of predictors described below on the full data set. Firstly, we calculated the individual-level performance of predictors by correlating each subject’s eFC with the predictor and reporting the resulting distribution over all subjects. Secondly, we concatenated the eFC and predictors for each subject, and calculated the variance explained on the full data set. We then compared the performance of our predictors to those of Sarwar et al., Benkarim et al., and Neudorf et al. side by side.
Noisy average eFC
Given the fact that the group average eFC is a good predictor for individual eFC (Deslauriers-Gauthier et al. 2022), we can artificially obtain the performance of any predictor with a lower or equal performance by independently adding randomly generated noise to the group average for each subject. In this procedure, we first calculated the group average eFC of the training data. Then, for each subject in the validation set, we generated random noise from a normal distribution and assigned the training group average eFC plus noise to this subject. This way, we also simulated inter-individual variability, since the added noise between any two subjects was not related. This predictor was named noisy average FC (navgFC). Note that navgFC does not contain subject-specific information, since the only data we used to construct navgFC was the training eFC, which did not contain the eFC or SC matrices of the subject under consideration.
Reproducing deep learning model by Sarwar et al
In order to reproduce the analyses conducted by Sarwar et al. described below, we required the pFC as generated by their deep learning model, which means we needed to reconstruct the SC matrices of all subjects as well. To construct SC matrices, we obtained minimally preprocessed diffusion-weighted MRI scans for each HCP subject. Details of preprocessing are described in (Van Essen et al. 2013). In short, spin-echo planar imaging was used to acquire 90 gradient directions at b-values of 1000, 2000 and 3000 s/mm2. The images were corrected for head motion, gradient-nonlinearity distortions and eddy currents, and subsequently normalized to standard MNI space. We performed whole-brain tractography on this data using a deterministic algorithm (as suggested in (Sarwar et al. 2019), estimating fiber orientations with constrained spherical deconvolution (Tournier et al. 2007) using a spherical harmonic order of 8. Using a white matter mask generated from the diffusion data, dilated one voxel to account for the white and grey matter boundary, we uniformly seeded two million streamlines, propagated using the tckgen function in MRtrix (Tournier et al. 2019) with the sd_stream algorithm. Default tractography parameters were used (step size 0.1 x voxel size, angle threshold 9˚ x step size / voxel size, FOD threshold 0.1) and maximum streamline length was set to 400 mm. This whole-brain tractogram was mapped into an SC matrix by counting the number of streamlines connecting each pair of regions in the considered atlases (DK and Schaefer). To account for order of magnitude differences in matrix entries that result from this procedure, a Gaussian resampling method was applied (Honey et al. 2009). Briefly, a value is sampled from a standard normal distribution for each matrix entry. These values are then assigned to the SC matrix in order, i.e. the smallest sampled value is assigned to the smallest SC value, the second-smallest sampled value to the second-smallest SC value, and so on until the SC matrix is fully replaced by sampled values. Finally, the SC matrix was rescaled to a mean of 0.5 and standard deviation of 0.1.
we reconstructed the deep learning model described in their paper (i.e. ten fully connected feed-forward layers of 1024 hidden neurons, for details see (Sarwar et al. 2021), training it to predict eFC from SC using the same loss function with γ = 0.4 and λ = 0.01 in 20,000 epochs. Training was performed using a 10-fold cross validation framework, where we generated pFC by having the model predict the FC of subjects in the validation folds.
Prediction of cognitive performance
Sarwar et al. presented additional analyses in which they attempted to predict cognitive performance of individuals from their pFC and their eFC. Using pFC as generated by the deep learning model as well as pFC generated by a biophysical model, the authors first regressed out SC in order to remove the strong linear dependence that is retained by the biophysical model. The residuals were then used to predict cognition, resulting in a correlation of 0.33 when using eFC, 0.29 when using pFC from deep learning, and 0.21 when using pFC from the biophysical model. Based on this, the authors argued that pFC retained information about individuals that could be used to predict cognition.
We conducted additional analyses regarding the predictive power of pFC. In particular, we focused on the step in which SC is regressed out of pFC, and examined whether this step unintentionally obfuscates the predictive power of pFC. We performed the analyses as described by Sarwar and colleagues, predicting the same cognition outcome from FC using lasso regression in a 10-fold cross validation. We repeated this process in 10 outer cross validation loops using different randomized folds, in order to prevent the results from depending on a specific subdivision of subjects. We differentiated between predictors with SC regressed out and predictors without SC regressed out by using the suffix “\SC”. To examine the reliance of predictive performance of pFC\SC on SC, we constructed an alternative predictor by randomly shuffling pFC between subjects (rpFC) and then regressing out the SC of the “correct” individual (i.e. when predicting cognition of subject A, we take a random other individual’s pFC and then regress out the SC of subject A). This predictor was named rpFC\SC. Furthermore, we analyzed the predictive properties of noisy average FC (navgFC), with noise tuned to capture performance and inter-individual correlations as presented in Fig. 1b. Finally, we used average training eFC without noise (avgFC) as predictor. Correlation coefficients and p-values were calculated by correlating the predicted cognition values with the actual cognition values of each inner cross-validation fold concatenated.

(adapted from(Sarwar et al. 2021) Figure S1e-f under CC-BY 4.0 license, no changes made). The left-hand plot shows inter-subject variance for eFC (blue) and pFC as generated by the deep learning model (red). In the right-hand plot, the first boxplot shows the prediction performance of the deep learning model. b) Distribution of correlations between subjects’ eFC, between 1000 generated navgFC instances, and between eFC and navgFC per subject using the DK atlas
Comparison of performances reported by Sarwar et al. with navgFC performance. a) Distributions of inter-individual variation and prediction performance as reported by Sarwar et al. in supplementary materials.
Analyzing differences in performance across the cortex
Benkarim et al. showed how each of Yeo’s 7 brain networks (Yeo et al. 2011) contributed to the prediction errors in their pFC and how these errors depended on the walk length considered by their model. We replicated these analyses using our group average predictor by calculating the same error measure as Benkarim and colleagues (log(1 – correlation)) separately on each parcel of the Schaefer 200-parcel atlas. We then averaged the errors over each of Yeo’s 7 networks using the network identities provided with the atlas and finally averaged the resulting network-level errors over all subjects.
Prediction of centrality measures
Neudorf et al. presented additional analyses in which they show that their model can also explain variance in centrality measures of eFC. The authors calculated degree centrality, eigenvector centrality and PageRank centrality of each node in both the eFC and pFC matrices. The measures were calculated on a thresholded version of the FC matrices, where a significance threshold of p = 0.0001 on the correlation coefficients was used (Zuo et al. 2012). The centrality measures were then z-score standardized and rescaled such that their values ranged from − 1 to 1. Then, all values were concatenated for all subjects and the total variance in eFC centrality explained by pFC centrality was presented. Again adopting the 10-fold cross-validation framework, we computed the centrality measures on all eFC matrices using the DK atlas with the described procedure and averaged the cenrality values over all training subjects. These average centralies per node were then used as predictors for eFC centrality measures. The authors also trained a separate model to specifically predict centrality measures, which performed better at explaining variance in centrality measures than pFC. However, since we are only interested in the information contained in pFC, we did not consider this model in our analyses.
Results
Performance of group average eFC
We observed that the group average eFC matrix scores an average correlation with individual-level eFC of 0.84 using the DK atlas (see Fig. 2a). Taking the group average of the training set as predictor for the validation set in each fold, we achieve a nearly identical performance distribution (Fig. 2b). Similarly, we find an average correlation of 0.76 using the Schaefer atlas (Fig. 2c-d).

Distribution of correlations between individual eFC for each HCP subject and (a) whole group average eFC (DK atlas); (b) training set group-average eFC (DK atlas); (c) whole group average eFC (Schaefer atlas); and (d) training set group-average eFC (Schaefer atlas)
We clearly see that the performance benchmark is different for each atlas, which we should take into account when comparing performances in terms of correlations between studies.
Performance of noisy group average eFC
Using a standard deviation of 0.1 for the noise in navgFC (chosen via manual tuning) yields correlational distributions with the same averages as the distributions presented by Sarwar et al. (Fig. 1). Note that we have used plots from the supplementary material of Sarwar et al. here (Sarwar et al. 2021 Figure S1e-f), since these correlation distributions matched our own experiments on the same data, in which we found inter-individual variation in eFC (inter-eFC) to center around 0.7. The prediction performance of Sarwar et al. (Fig. 1a, right-hand plot, left-most boxplot) is matched by navgFC (Fig. 1b, right-most boxplot). Importantly, the average of the distribution of inter-individual variation in pFC (inter-pFC) of Sarwar et al. (Fig. 1a, left-hand plot, red distribution) is also matched by the average variation in navgFC (Fig. 1b, middle boxplot).
Since the performance reported by Benkarim et al. is nearly equal to the performance of the group average (0.775 using the 200-parcel Schaefer atlas), adding no noise (or equivalently, noise with 0 standard deviation) yields a distribution with nearly the same average (Fig. 3). The results reported by Benkarim et al. are slightly better than that of the group average here (0.775 versus 0.76 respectively), but this small difference might well be attributed to minor differences in preprocessing.

Comparison of performances reported by Benkarim et al. with navgFC performance. (a) Performance as reported by Benkarim et al. (copied from (Benkarim et al. 2022) Fig. 2a under CC-BY-NC-ND 4.0 license) for varying walk lengths used by their model. Each boxplot represents the distribution of individual-level prediction performance when using the number of corresponding walks, with the color indicating the number of parcels used in the construction of connectivity matrices. In the bottom-left plot, the blue boxplots represent the performance achieved on the 200-parcel Schaefer atlas used in our analyses. In this plot, the right-most blue boxplot corresponds to the best obtained performance. (b) Performance of navgFC with zero standard deviation using the 200-parcel Schaefer atlas
Neudorf et al. did not explicitly report distributions of performance, but rather reported performance in terms of variance explained (R2 = 0.56) in the whole data set using the DK atlas. If we insert the training group average (i.e. navgFC with 0 standard deviation) using the DK atlas as predictor for each subject, then the R2 is also almost equal to 0.56 (Fig. 4).

(adapted from (Neudorf et al. 2022) Figure S1 under CC-BY 4.0 license, no changes made)
Relation between predictors and individual-level eFC for (a) average training eFC (i.e. navgFC with zero standard deviation) using the DK atlas and (b) pFC by Neudorf et al.
Clearly, navgFC has the same average inter-subject correlation as reported by Sarwar et al., as well as the same average performance predicting eFC in terms of correlation as all three studies when the noise is appropriately tuned.
Preservation of individual differences
It is important to note that navgFC does not preserve inter-individual correlations (i.e. pairs of subjects with high inter-eFC may have low inter-navgFC and vice versa). In particular, since the noise is normally distributed and added independently for each subject, this correlation is exactly 0 on average. However, although Sarwar et al. showed that in their study average inter-pFC is equal to average inter-eFC, these inter-individual correlations are not preserved at an individual level in pFC either.
We generated pFC matrices for each subject using the deep learning network proposed by Sarwar et al., as described in our methods. For each pair of subjects, we calculated the correlation between their eFC matrices and their pFC matrices. Plotting each of these as data points, with inter-pFC as function of inter-eFC, yields Fig. 5, where we find that the correlation between individual-level inter-eFC and inter-pFC is almost 0. Even though the distribution of inter-individual variation is conserved in the study by Sarwar and colleagues, the individual differences are not preserved at an individual level. In the studies of Benkarim et al. and Neudorf et al., the variability in predicted pFC is not quantified, which means there is no evidence that the prediction models preserve individual differences.

Relation between inter-eFC and inter-pFC at individual level, resulting from eFC and pFC generated by following the methods of Sarwar et al.
Predicting cognitive performance
Again using pFC as generated by the deep learning model proposed by Sarwar et al., we found that eFC, SC, pFC\SC, rpFC\SC, navgFC\SC and avgFC\SC could significantly predict cognition, while pFC, rpFC, navgFC and avgFC could not (Fig. 6). The fact that rpFC\SC can significantly predict cognition implies that it does not matter whose pFC matrix we use when predicting cognition, as long as we regress out the correct subject’s SC. Furthermore, we see that pFC by itself cannot significantly predict cognition. Finally we observe that average FC with and without added random noise can predict cognition when SC is regressed out. This means that even starting with a predictor which contains no personalized information can produce a significant predictor if SC (with personalized information) is regressed out. Therefore, we conclude that the predictive power of pFC\SC relies on the step in which SC is regressed out, rather than information retained in pFC itself.

Performance of several predictors in predicting cognition using Lasso regression. Error bars indicate variance of performance between outer cross validation loops
Differences in performance across the cortex
Benkarim et al. found that their model performed worse in predicting eFC in the default mode, frontoparietal and limbic networks than in the visual, somatomotor and attention networks of the brain. Furthermore, predictions in the default mode and frontoparietal regions benefitted the most from using longer walks on the structural connectome (Fig. 7). Inserting the group average eFC into this analysis revealed a similar pattern of errors (Table 1), where lower values of the error metric correspond to better predictions. While the training average scores slightly worse than pFC in these metrics on average, the overall order between networks is preserved, and the performance difference may be attributed to differences in preprocessing. The dependency on walk length observed by Benkarim and colleagues can likely be attributed to a general lower performance when using shorter paths. We conclude that also for this study, we cannot determine whether the model predicts something more informative than the group average.

Prediction errors (log(1 – R), with R the correlation between eFC and the predictor) per each of Yeo’s 7 functional networks for varying walk lengths used as reported by Benkarim et al. (copied from (Benkarim et al. 2022), Fig. 4b under CC-BY-NC-ND 4.0 license). Lower values of the error metric correspond to better performance
Explaining network centrality measures in eFC
Using average centrality of each node as predictor for the centrality of each validation subject’s nodes yielded the same or better performance as reported by Neudorf et al. (Fig. 8). The variance in degree centrality explained by the training group average was slightly smaller than that of pFC as reported by Neudorf et al., but this small difference can again be attributed to minor differences in preprocessing. In eigenvector and PageRank centrality, the training group average even performs much better than pfC (Fig. 8b-c). From this we conclude that there is no evidence that the graph neural network presented by Neudorf et al. has learned anything other than the group average with some minor deviations.

Variance in centrality measures explained by group average (left column) and pFC due to Neudorf et al. (right column) respectively for (a) degree centrality (b) eigenvector centrality and (c) PageRank centrality. Right column figures adapted from (Neudorf et al. 2022), Figures S3, 5, 7 under CC-BY 4.0 license
Discussion
Since group average FC correlates so highly with individual FC in human connectome studies, we feel that the results from individual-level structure-function prediction methods should explicitly be compared to the group average or the inherent variation in the data. Prediction methods are usually a black box from which we seek to obtain the highest possible performance, and we should compare their performance to the highest reference performance, which in this case is not a biophysical model such as considered by Sarwar et al., but rather from the group average eFC. Biophysical models enjoy the advantage of being partly explanatory, i.e. we may learn something about brain dynamics by inspecting the fitted models. Machine learning models do not typically have this property, and can thus only be judged on the usefulness of their outputs, or employ additional methods to analyze their decision-making. By extension, the comparison by Neudorf et al. to the performance of Sarwar et al. and the comparison by Benkarim et al. to other machine learning methods suffer from the same issues, since the group average is still a better predictor than all of these other methods. Deslauriers-Gauthier and colleagues also found that the group average acts as a sort of “glass ceiling” for prediction performance, considering several methods (Deslauriers-Gauthier et al. 2022). This may indicate that the current methods run into some fundamental barrier that we do not understand yet. One could argue that the performances of the prediction models provide a lower bound for the optimal performance of structure-function models, indicating that other methods such as biophysical models and network communication models could theoretically be improved to produce an individual-level eFC-pFC of at least 0.7 using the DK atlas and at least 0.77 using the Schaefer atlas. However, the group average eFC shows that we should be able to achieve at least 0.84 on the DK atlas and confirms the 0.77 lower bound for the Schaefer atlas, since any model can be “trained” to output the average training eFC when presented with any form of input data and eFC as output training data.
From these results we argue that one should consider more than just the performance of models in terms of raw correlations, since these may give an optimistic impression of prediction performance, especially when the performance of the group average is not explicitly reported in comparison. Sarwar et al. attempted this by predicting cognition, but given the results of our analyses above, it is not clear whether pFC as generated by the deep learning model is able to do so. Neudorf et al. showed that their model can explain variance in centrality measures and thus is informative of FC network structure, but the group average can do this equally well or better. Finally, Benkarim et al. infer from cortical patterns in prediction accuracy that the model captures the need for indirect connections in higher-order association areas such as the default mode and frontoparietal networks. However, we were able to show that this is simply due to FC deviating more from the group average in these regions, which might make them inherently harder to predict and does not indicate that the model has learned a meaningful aspect of SC-FC coupling.
We conclude that we cannot ascertain that the models as presented in these three studies have learned a meaningful mapping from SC to FC for the following reasons. Firstly, the group average eFC performs better in terms of correlation with individual eFC. Secondly, the individual information contained in pFC may be limited, since we could not use pFC by Sarwar et al. by itself to significantly predict cognition, and the group average performed identically on the additional analyses presented by both Neudorf et al. and Benkarim et al. Finally, the properties of noisy average FC, both in terms of inter-subject variance and prediction performance, appear almost identical to that of pFC when noise is tuned appropriately, which means that a prediction model not taking any individual information into account can mimic the results presented by each of the three studies.
Current limitations and alternatives
It is difficult to ascertain why SC-FC predictions at an individual level in healthy subjects do not appear to be possible at this stage. While group-level studies have been successful in revealing aspects of the relation between SC and FC using a variety of models (e.g. Avena-Koenigsberger et al. 2018; Baum et al. 2020; Vázquez-Rodríguez et al. 2019; Wang et al. 2019), it is possible that we have not yet found an appropriate model for the mapping between SC and FC at an individual level, or that the machine learning models used in the three studies are not powerful enough to express such a mapping. Alternatively, it is possible that the current ways of constructing SC and FC do not capture enough relevant information to allow such a mapping at an individual level. From fingerprinting studies (examining individual identifiability) we know that sufficient information is present to distinguish between individuals in both SC (Yeh et al. 2016) and FC (Finn et al. 2015). Then, if the data is indeed to blame, either the individual variations in SC are not informative for individual differences in functional activation patterns, or the individual differences in FC are not pronounced enough to trace them back to differences in anatomical organization.
For example, the spatial resolution of diffusion or functional MRI scans may be too coarse to capture individual differences between subjects that are informative for structure-function mapping. For resting-state functional MRI, the time resolution may also be a limiting factor, since we cannot capture individual activation pathways (which occur in the order of miliseconds), but rather only the time-delayed result of activations at 1–2 s time intervals.
Alternatively, the processing pipelines may fail to recover such differences between individuals. For instance, we may not be able to capture variation in anatomy sufficiently well using standardized atlases. There is a large variability in the sizes and anatomy of predefined regions between subjects (Caspers et al. 2006; Eichert et al. 2021; Fornito et al. 2008; Meesters et al. 2023; Ono et al. 1990). This means that normalization procedures used to register atlases onto individual scans may mislabel parts of the brain, e.g. under- or over-estimating the size of ROIs. Personalizing parcellations of the cortex by employing methods such as Bayesian networks (Kong et al. 2019, 2021) or deep learning atlases (Henschel et al. 2020; Huo et al. 2019; Wachinger et al. 2018) may alleviate these issues by ensuring that the natural variation in anatomy between individuals is accounted for. While the Desikan-Killiany atlas does some individual mapping, it may fail to capture information relevant to structure-function mapping due to being based on anatomical subdivisions, rather than connectivity.
On the structural side, the counting of streamlines to compute SC matrices, as done by Sarwar et al. and Neudorf et al., may not reflect meaningful differences in connection strength, as this count will strongly depend on confounding factors such as differences in region sizes, differences in bundle diameter, and specific choices for tractography parameters (Jones 2010; Jones et al. 2013; Smith et al. 2013; Yeh et al. 2021). Integrity measures such as Fractional Anisotropy or Mean Diffusivity may be more meaningful to quantify connection strength, although these are accompanied by some problems e.g. in and around crossing fibers (Jones 2010; Jones et al. 2013; Vos et al. 2012). Developing metrics to measure the integrity and strength of white matter connections, e.g. building upon methods such as SIFT (Smith et al. 2015a, b), as used by Benkarim et al., or investigating alternative microstructure measures (Chamberland et al. 2019; Raffelt et al. 2012), may strongly improve the individual-level information in SC.
Regarding functional connectivity, a controversial processing step in the context of functional connectivity mapping is the definition of edges in FC. The dominant choice to calculate the Pearson correlation coefficient between the activation time series of each pair of ROIs has been extensively criticized. Criticisms regard the failure to capture time dependencies in associations between brain regions (Chang and Glover 2010; Hutchison et al. 2013; Preti et al. 2017), the fact that Pearson correlation does not consider the causal processes that underlie activity patterns (Reid et al. 2019), or the dubious interpretability of negative correlations (Buckner et al. 2013; Murphy et al. 2009). Several alternatives have been proposed, such as explicitly modeling functional connectivity in a dynamic way (Preti et al. 2017) or investigating the causality in activations (effective connectivity) using Granger causality (Barnett and Seth 2014; Roebroeck et al. 2005). Although none of the alternatives has definitively proven to improve upon Pearson correlation in e.g. test-retest reliability (Noble et al. 2019), there has been little study into the structure-function relation using alternative definitions of FC. It is possible that the variation in the structure of the brain that we are able to measure with SC does not inform variation in Pearson correlation, but does inform variation in e.g. effective connectivity. Other steps in the functional preprocessing pipeline, such as the controversial Global Signal Regression (Liu et al. 2017; Mayhew et al. 2016; Murphy and Fox 2017) or bandpass filtering (Shirer et al. 2015) could also significantly affect results. We think it is important to systematically investigate the assumptions underlying the different methods of constructing both SC and FC, and achieve some consensus on a processing pipeline that reliably captures the most informative inter-individual variation.
Finally, as in all modeling problems, an increased sample size may allow for a better fit of the proposed models and increase their generalizability.
Future work
We believe it is important to continue this line of work, and to expand upon the methodology of the three studies in order to achieve higher prediction performance or otherwise meaningful predictions. We especially think it is important to explicitly ensure that predictive models do not simply converge to predicting some group average, such as the proposed method by Sarwar et al. did, and this practice should become the standard in structure-function prediction publications. Finally, we believe that taking a step back and re-assessing the construction of SC and FC may yield more informative versions of both, and thus improve the chances of finding a meaningful mapping from structure to function at an individual level. Specifically, for the construction of SC, more meaningful metrics of connection strength should be considered. For FC, alternatives for the Pearson correlation coefficient that take into account time dependence or causality may be more informative. Finally, we wish to emphasize that our results do not suggest that studying the mapping between SC and FC is flawed in general, since much has been learned from group-level studies in the past. Rather, we argue that additional care should be taken to properly design and interpret the results of studies conducted at an individual level.
Data availability
The data used in this work is openly available at http://www.humanconnectome.org/.
References
Almairac F, Deverdun J, Cochereau J, Coget A, Lemaitre A-L, Moritz-Gasser S, Duffau H, Herbet G (2021) Homotopic redistribution of functional connectivity in insula-centered diffuse low-grade glioma. NeuroImage: Clin 29:102571. https://doi.org/10.1016/j.nicl.2021.102571
Avena-Koenigsberger A, Misic B, Sporns O (2018) Communication dynamics in complex brain networks. Nat Rev Neurosci 19(1):17–33. https://doi.org/10.1038/nrn.2017.149
Barnett L, Seth AK (2014) The MVGC multivariate Granger causality toolbox: a new approach to Granger-causal inference. J Neurosci Methods 223:50–68. https://doi.org/10.1016/j.jneumeth.2013.10.018
Baum GL, Cui Z, Roalf DR, Ciric R, Betzel RF, Larsen B, Cieslak M, Cook PA, Xia CH, Moore TM, Ruparel K, Oathes DJ, Alexander-Bloch AF, Shinohara RT, Raznahan A, Gur RE, Gur RC, Bassett DS, Satterthwaite TD (2020) Development of structure-function coupling in human brain networks during youth. Proc Natl Acad Sci USA 117(1):771–778. https://doi.org/10.1073/pnas.1912034117
Becker CO, Pequito S, Pappas GJ, Miller MB, Grafton ST, Bassett DS, Preciado VM (2018) Spectral mapping of brain functional connectivity from diffusion imaging. Sci Rep 8(1):1411. https://doi.org/10.1038/s41598-017-18769-x
Beckmann CF, DeLuca M, Devlin JT, Smith SM (2005) Investigations into resting-state connectivity using independent component analysis. Philosophical Trans Royal Soc B: Biol Sci 360(1457):1001–1013. https://doi.org/10.1098/rstb.2005.1634
Benkarim O, Paquola C, Park B, Royer J, Rodríguez-Cruces R, de Wael V, Misic R, Piella B, G., Bernhardt BC (2022) A riemannian approach to predicting brain function from the structural connectome. NeuroImage 257:119299. https://doi.org/10.1016/j.neuroimage.2022.119299
Buckner RL, Krienen FM, Yeo BTT (2013) Opportunities and limitations of intrinsic functional connectivity MRI. Nat Neurosci 16(7):832–837. https://doi.org/10.1038/nn.3423
Bullmore E, Sporns O (2009) Complex brain networks: graph theoretical analysis of structural and functional systems. Nat Rev Neurosci 10(3):186–198. https://doi.org/10.1038/nrn2575
Caspers S, Geyer S, Schleicher A, Mohlberg H, Amunts K, Zilles K (2006) The human inferior parietal cortex: Cytoarchitectonic parcellation and interindividual variability. NeuroImage 33(2):430–448. https://doi.org/10.1016/j.neuroimage.2006.06.054
Chamberland M, Raven EP, Genc S, Duffy K, Descoteaux M, Parker GD, Tax CMW, Jones DK (2019) Dimensionality reduction of diffusion MRI measures for improved tractometry of the human brain. NeuroImage 200:89–100. https://doi.org/10.1016/j.neuroimage.2019.06.020
Chang C, Glover GH (2010) Time–frequency dynamics of resting-state brain connectivity measured with fMRI. NeuroImage 50(1):81–98. https://doi.org/10.1016/j.neuroimage.2009.12.011
Chen C, Wang H-L, Wu S-H, Huang H, Zou J-L, Chen J, Jiang T-Z, Zhou Y, Wang G-H (2015) Abnormal degree centrality of bilateral Putamen and Left Superior Frontal Gyrus in Schizophrenia with Auditory Hallucinations. Chin Med J 128(23):3178–3184. https://doi.org/10.4103/0366-6999.170269
Cummings JA, Sipes B, Mathalon DH, Raj A (2022) Predicting Functional Connectivity from observed and latent structural connectivity via Eigenvalue Mapping. Front NeuroSci 16. https://doi.org/10.3389/fnins.2022.810111
Damoiseaux JS, Rombouts SARB, Barkhof F, Scheltens P, Stam CJ, Smith SM, Beckmann CF (2006) Consistent resting-state networks across healthy subjects. Proc Natl Acad Sci 103(37):13848–13853. https://doi.org/10.1073/pnas.0601417103
de Vos R, Benkarim O, Paquola C, Lariviere S, Royer J, Tavakol S, Xu T, Hong S-J, Langs G, Valk S, Misic B, Milham M, Margulies D, Smallwood J, Bernhardt BC (2020) BrainSpace: a toolbox for the analysis of macroscale gradients in neuroimaging and connectomics datasets. Commun Biology 3(1):103. https://doi.org/10.1038/s42003-020-0794-7
Deng W, Zhang B, Zou W, Zhang X, Cheng X, Guan L, Lin Y, Lao G, Ye B, Li X, Yang C, Ning Y, Cao L (2019) Abnormal degree centrality associated with cognitive dysfunctions in early bipolar disorder. Front Psychiatry 10. https://doi.org/10.3389/fpsyt.2019.00140
Desikan RS, Ségonne F, Fischl B, Quinn BT, Dickerson BC, Blacker D, Buckner RL, Dale AM, Maguire RP, Hyman BT, Albert MS, Killiany RJ (2006) An automated labeling system for subdividing the human cerebral cortex on MRI scans into gyral based regions of interest. NeuroImage 31(3):968–980. https://doi.org/10.1016/j.neuroimage.2006.01.021
Deslauriers-Gauthier S, Zucchelli M, Frigo M, Deriche R (2020) A unified framework for multimodal structure–function mapping based on eigenmodes. Med Image Anal 66:101799. https://doi.org/10.1016/j.media.2020.101799
Deslauriers-Gauthier S, Zucchelli M, Laghrissi H, Deriche R (2022) A riemannian revisiting of structure–function mapping based on eigenmodes. Front Neuroimaging 1. https://doi.org/10.3389/fnimg.2022.850266
Eichert N, Watkins KE, Mars RB, Petrides M (2021) Morphological and functional variability in central and subcentral motor cortex of the human brain. Brain Struct Function 226(1):263–279. https://doi.org/10.1007/s00429-020-02180-w
Finn ES, Shen X, Scheinost D, Rosenberg MD, Huang J, Chun MM, Papademetris X, Constable RT (2015) Functional connectome fingerprinting: identifying individuals using patterns of brain connectivity. Nat Neurosci 18(11):1664–1671. https://doi.org/10.1038/nn.4135
Fornito A, Wood SJ, Whittle S, Fuller J, Adamson C, Saling MM, Velakoulis D, Pantelis C, Yücel M (2008) Variability of the paracingulate sulcus and morphometry of the medial frontal cortex: associations with cortical thickness, surface area, volume, and sulcal depth. Hum Brain Mapp 29(2):222–236. https://doi.org/10.1002/hbm.20381
Goñi J, van den Heuvel MP, Avena-Koenigsberger A, Velez de Mendizabal N, Betzel RF, Griffa A, Hagmann P, Corominas-Murtra B, Thiran J-P, Sporns O (2014) Resting-brain functional connectivity predicted by analytic measures of network communication. Proceedings of the National Academy of Sciences, 111(2), 833–838. https://doi.org/10.1073/pnas.1315529111
Hagmann P, Cammoun L, Gigandet X, Meuli R, Honey CJ, Wedeen VJ, Sporns O (2008) Mapping the structural core of human cerebral cortex. PLoS Biol 6(7):e159. https://doi.org/10.1371/journal.pbio.0060159
Harris RJ, Bookheimer SY, Cloughesy TF, Kim HJ, Pope WB, Lai A, Nghiemphu PL, Liau LM, Ellingson BM (2014) Altered functional connectivity of the default mode network in diffuse gliomas measured with pseudo-resting state fMRI. J Neurooncol 116(2):373–379. https://doi.org/10.1007/s11060-013-1304-2
Henschel L, Conjeti S, Estrada S, Diers K, Fischl B, Reuter M (2020) FastSurfer - A fast and accurate deep learning based neuroimaging pipeline. NeuroImage 219:117012. https://doi.org/10.1016/j.neuroimage.2020.117012
Honey CJ, Sporns O, Cammoun L, Gigandet X, Thiran JP, Meuli R, Hagmann P (2009) Predicting human resting-state functional connectivity from structural connectivity. Proceedings of the National Academy of Sciences, 106(6), 2035–2040. https://doi.org/10.1073/pnas.0811168106
Huo Y, Xu Z, Xiong Y, Aboud K, Parvathaneni P, Bao S, Bermudez C, Resnick SM, Cutting LE, Landman BA (2019) 3D whole brain segmentation using spatially localized atlas network tiles. NeuroImage 194:105–119. https://doi.org/10.1016/j.neuroimage.2019.03.041
Hutchison RM, Womelsdorf T, Allen EA, Bandettini PA, Calhoun VD, Corbetta M, Della Penna S, Duyn JH, Glover GH, Gonzalez-Castillo J, Handwerker DA, Keilholz S, Kiviniemi V, Leopold DA, de Pasquale F, Sporns O, Walter M, Chang C (2013) Dynamic functional connectivity: Promise, issues, and interpretations. NeuroImage 80:360–378. https://doi.org/10.1016/j.neuroimage.2013.05.079
Jones DK (2010) Challenges and limitations of quantifying brain connectivity in vivo with diffusion MRI. Imaging Med 2(3):341–355. https://doi.org/10.2217/iim.10.21
Jones DK, Knösche TR, Turner R (2013) White matter integrity, fiber count, and other fallacies: the do’s and don’ts of diffusion MRI. NeuroImage 73:239–254. https://doi.org/10.1016/j.neuroimage.2012.06.081
Jütten K, Mainz V, Delev D, Gauggel S, Binkofski F, Wiesmann M, Clusmann H, Na C (2020) Asymmetric tumor-related alterations of network‐specific intrinsic functional connectivity in glioma patients. Hum Brain Mapp 41(16):4549–4561. https://doi.org/10.1002/hbm.25140
Kong R, Li J, Orban C, Sabuncu MR, Liu H, Schaefer A, Sun N, Zuo X-N, Holmes AJ, Eickhoff SB, Yeo BTT (2019) Spatial topography of individual-specific cortical networks predicts human cognition, personality, and emotion. Cereb Cortex 29(6):2533–2551. https://doi.org/10.1093/cercor/bhy123
Kong R, Yang Q, Gordon E, Xue A, Yan X, Orban C, Zuo X-N, Spreng N, Ge T, Holmes A, Eickhoff S, Yeo BTT (2021) Individual-specific areal-level parcellations improve functional connectivity prediction of behavior. Cereb Cortex 31(10):4477–4500. https://doi.org/10.1093/cercor/bhab101
Liu TT, Nalci A, Falahpour M (2017) The global signal in fMRI: nuisance or information? NeuroImage. 150:213–229. https://doi.org/10.1016/j.neuroimage.2017.02.036
Maesawa S, Bagarinao E, Fujii M, Futamura M, Motomura K, Watanabe H, Mori D, Sobue G, Wakabayashi T (2015) Evaluation of resting state networks in patients with gliomas: connectivity changes in the unaffected side and its relation to cognitive function. PLoS ONE 10(2):e0118072. https://doi.org/10.1371/journal.pone.0118072
Mayhew SD, Mullinger KJ, Ostwald D, Porcaro C, Bowtell R, Bagshaw AP, Francis ST (2016) Global signal modulation of single-trial fMRI response variability: Effect on positive vs negative BOLD response relationship. NeuroImage 133:62–74. https://doi.org/10.1016/j.neuroimage.2016.02.077
Meesters S, Landers M, Rutten G-J, Florack L (2023) Subject-specific automatic reconstruction of white matter tracts. J Digit Imaging. https://doi.org/10.1007/s10278-023-00883-0
Mišić B, Betzel RF, de Reus MA, van den Heuvel MP, Berman MG, McIntosh AR, Sporns O (2016) Network-level structure-function relationships in human neocortex. Cereb Cortex 26(7):3285–3296. https://doi.org/10.1093/cercor/bhw089
Murphy K, Fox MD (2017) Towards a consensus regarding global signal regression for resting state functional connectivity MRI. NeuroImage 154:169–173. https://doi.org/10.1016/j.neuroimage.2016.11.052
Murphy K, Birn RM, Handwerker DA, Jones TB, Bandettini PA (2009) The impact of global signal regression on resting state correlations: are anti-correlated networks introduced? NeuroImage 44(3):893–905. https://doi.org/10.1016/j.neuroimage.2008.09.036
Neudorf J, Kress S, Borowsky R (2022) Structure can predict function in the human brain: a graph neural network deep learning model of functional connectivity and centrality based on structural connectivity. Brain Struct Function 227(1):331–343. https://doi.org/10.1007/s00429-021-02403-8
Noble S, Scheinost D, Constable RT (2019) A decade of test-retest reliability of functional connectivity: a systematic review and meta-analysis. NeuroImage 203:116157. https://doi.org/10.1016/j.neuroimage.2019.116157
Ono M, Kubik S, Abernathey CD (1990) Atlas of the cerebral sulci. G. Thieme Verlag ; Thieme Medical, Stuttgart New York
Park JE, Kim HS, Kim SJ, Kim JH, Shim WH (2016) Alteration of long-distance functional connectivity and network topology in patients with supratentorial gliomas. Neuroradiology 58(3):311–320. https://doi.org/10.1007/s00234-015-1621-6
Preti MG, Bolton TA, Van De Ville D (2017) The dynamic functional connectome: state-of-the-art and perspectives. NeuroImage 160:41–54. https://doi.org/10.1016/j.neuroimage.2016.12.061
Raffelt D, Tournier J-D, Rose S, Ridgway GR, Henderson R, Crozier S, Salvado O, Connelly A (2012) Apparent Fibre density: a novel measure for the analysis of diffusion-weighted magnetic resonance images. NeuroImage 59(4):3976–3994. https://doi.org/10.1016/j.neuroimage.2011.10.045
Reid AT, Headley DB, Mill RD, Sanchez-Romero R, Uddin LQ, Marinazzo D, Lurie DJ, Valdés-Sosa PA, Hanson SJ, Biswal BB, Calhoun V, Poldrack RA, Cole MW (2019) Advancing functional connectivity research from association to causation. Nat Neurosci 22(11):1751–1760. https://doi.org/10.1038/s41593-019-0510-4
Roebroeck A, Formisano E, Goebel R (2005) Mapping directed influence over the brain using Granger causality and fMRI. NeuroImage 25(1):230–242. https://doi.org/10.1016/j.neuroimage.2004.11.017
Salimi-Khorshidi G, Douaud G, Beckmann CF, Glasser MF, Griffanti L, Smith SM (2014) Automatic denoising of functional MRI data: combining independent component analysis and hierarchical fusion of classifiers. NeuroImage 90:449–468. https://doi.org/10.1016/j.neuroimage.2013.11.046
Sarwar T, Ramamohanarao K, Zalesky A (2019) Mapping connectomes with diffusion MRI: deterministic or probabilistic tractography? Magn Reson Med 81(2):1368–1384. https://doi.org/10.1002/mrm.27471
Sarwar T, Tian Y, Yeo BTT, Ramamohanarao K, Zalesky A (2021) Structure-function coupling in the human connectome: a machine learning approach. NeuroImage 226:117609. https://doi.org/10.1016/j.neuroimage.2020.117609
Schaefer A, Kong R, Gordon EM, Laumann TO, Zuo X-N, Holmes AJ, Eickhoff SB, Yeo BTT (2018) Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity MRI. Cereb Cortex 28(9):3095–3114. https://doi.org/10.1093/cercor/bhx179
Seguin C, van den Heuvel MP, Zalesky A (2018) Navigation of brain networks. Proc Natl Acad Sci 115(24):6297–6302. https://doi.org/10.1073/pnas.1801351115
Shirer WR, Jiang H, Price CM, Ng B, Greicius MD (2015) Optimization of rs-fMRI pre-processing for enhanced signal-noise separation, test-retest reliability, and group discrimination. NeuroImage 117:67–79. https://doi.org/10.1016/j.neuroimage.2015.05.015
Smith RE, Tournier J-D, Calamante F, Connelly A (2013) SIFT: spherical-deconvolution informed filtering of tractograms. NeuroImage 67:298–312. https://doi.org/10.1016/j.neuroimage.2012.11.049
Smith RE, Tournier J-D, Calamante F, Connelly A (2015a) SIFT2: enabling dense quantitative assessment of brain white matter connectivity using streamlines tractography. NeuroImage 119:338–351. https://doi.org/10.1016/j.neuroimage.2015.06.092
Smith RE, Tournier J-D, Calamante F, Connelly A (2015b) The effects of SIFT on the reproducibility and biological accuracy of the structural connectome. NeuroImage 104:253–265. https://doi.org/10.1016/j.neuroimage.2014.10.004
Sporns O, Tononi G, Kötter R (2005) The human connectome: a structural description of the human brain. PLoS Comput Biol 1(4):e42. https://doi.org/10.1371/journal.pcbi.0010042
Suárez LE, Markello RD, Betzel RF, Misic B (2020) Linking structure and function in macroscale brain networks. Trends Cogn Sci 24(4):302–315. https://doi.org/10.1016/j.tics.2020.01.008
Tournier J-D, Calamante F, Connelly A (2007) Robust determination of the fibre orientation distribution in diffusion MRI: non-negativity constrained super-resolved spherical deconvolution. NeuroImage 35(4):1459–1472. https://doi.org/10.1016/j.neuroimage.2007.02.016
Tournier J-D, Smith R, Raffelt D, Tabbara R, Dhollander T, Pietsch M, Christiaens D, Jeurissen B, Yeh C-H, Connelly A (2019) MRtrix3: a fast, flexible and open software framework for medical image processing and visualisation. NeuroImage 202:116137. https://doi.org/10.1016/j.neuroimage.2019.116137
Tzourio-Mazoyer N, Landeau B, Papathanassiou D, Crivello F, Etard O, Delcroix N, Mazoyer B, Joliot M (2002) Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. NeuroImage 15(1):273–289. https://doi.org/10.1006/nimg.2001.0978
van den Heuvel MP, Hulshoff Pol HE (2010) Exploring the brain network: a review on resting-state fMRI functional connectivity. Eur Neuropsychopharmacol 20(8):519–534. https://doi.org/10.1016/j.euroneuro.2010.03.008
Van Essen DC, Smith SM, Barch DM, Behrens TEJ, Yacoub E, Ugurbil K (2013) The WU-Minn Human Connectome Project: an overview. NeuroImage 80:62–79. https://doi.org/10.1016/j.neuroimage.2013.05.041
Vázquez-Rodríguez B, Suárez LE, Markello RD, Shafiei G, Paquola C, Hagmann P, van den Heuvel MP, Bernhardt BC, Spreng RN, Misic B (2019) Gradients of structure–function tethering across neocortex. Proc Natl Acad Sci 116(42):21219–21227. https://doi.org/10.1073/pnas.1903403116
Vos SB, Jones DK, Jeurissen B, Viergever MA, Leemans A (2012) The influence of complex white matter architecture on the mean diffusivity in diffusion tensor MRI of the human brain. NeuroImage 59(3):2208–2216. https://doi.org/10.1016/j.neuroimage.2011.09.086
Wachinger C, Reuter M, Klein T (2018) DeepNAT: deep convolutional neural network for segmenting neuroanatomy. NeuroImage 170:434–445. https://doi.org/10.1016/j.neuroimage.2017.02.035
Wang P, Kong R, Kong X, Liégeois R, Orban C, Deco G, van den Heuvel MP, Yeo T, B. T (2019) Inversion of a large-scale circuit model reveals a cortical hierarchy in the dynamic resting human brain. Sci Adv 5(1). https://doi.org/10.1126/sciadv.aat7854
Yeh F-C, Vettel JM, Singh A, Poczos B, Grafton ST, Erickson KI, Tseng W-YI, Verstynen TD (2016) Quantifying differences and similarities in Whole-Brain White Matter Architecture using local Connectome fingerprints. PLoS Comput Biol 12(11):e1005203. https://doi.org/10.1371/journal.pcbi.1005203
Yeh C, Jones DK, Liang X, Descoteaux M, Connelly A (2021) Mapping structural connectivity using diffusion MRI: challenges and opportunities. J Magn Reson Imaging 53(6):1666–1682. https://doi.org/10.1002/jmri.27188
Yeo BTT, Krienen FM, Sepulcre J, Sabuncu MR, Lashkari D, Hollinshead M, Roffman JL, Smoller JW, Zöllei L, Polimeni JR, Fischl B, Liu H, Buckner RL (2011) The organization of the human cerebral cortex estimated by intrinsic functional connectivity. J Neurophysiol 106(3):1125–1165. https://doi.org/10.1152/jn.00338.2011
Zuo X-N, Ehmke R, Mennes M, Imperati D, Castellanos FX, Sporns O, Milham MP (2012) Network centrality in the human functional connectome. Cereb Cortex 22(8):1862–1875. https://doi.org/10.1093/cercor/bhr269
Acknowledgements
We would like to thank prof. Andrew Zalesky and dr. Tabinda Sarwar for their valuable input and helping us to reproduce their results.
Funding
This publication is part of the project “A personalized care path for brain tumor patients”, which is (partly) funded by The Netherlands Organisation for Health Research and Development (ZonMw), project number 10070012010006, and part of the project “Bringing Tractography into Daily Neurosurgical Practice ”, which is (partly) financed by the Dutch Research Council (NWO), project number KICH1.ST03.21.004. The work of Remco van der Hofstad is supported in part by the Netherlands Organisation for Scientific Research (NWO) through the Gravitation NETWORKS grant no.\ 024.002.003.
Author information
Authors and Affiliations
Contributions
All authors contributed to the conceptualization of the study. Data analysis was performed by L.S. A first draft of the manuscript was written by L.S. All authors commented and critically revised each version of the manuscript. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
The authors declare no conflict of interest. All HCP participants gave full informed consent prior to the data collection, following Washington University–University of Minnesota (WU-Minn HCP) Consortium ethical guidelines.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Smolders, L., De Baene, W., Rutten, GJ. et al. Can structure predict function at individual level in the human connectome?. Brain Struct Funct 229, 1209–1223 (2024). https://doi.org/10.1007/s00429-024-02796-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00429-024-02796-2