
Abstract
Reward benefits to memory formation have been robustly linked to dopaminergic activity. Despite the established characterization of dopaminergic mechanisms as operating at multiple timescales, potentially supporting distinct functional outcomes, the temporal dynamics by which reward might modulate memory encoding are just beginning to be investigated. In the present study, we leveraged a mixed block/event experimental design to disentangle transient and sustained reward influences on task engagement and subsequent recognition memory in an adapted monetary-incentive-encoding (MIE) paradigm. Across three behavioral experiments, transient and sustained reward modulation of item and context memory was probed, at both 24-h and ~ 15-min retention intervals, to investigate the importance of overnight consolidation. In general, we observed that transient reward was associated with enhanced item memory encoding, while sustained reward modulated response speed but did not appear to benefit subsequent recognition accuracy. Notably, reward effects on item memory performance and response speed were somewhat inconsistent across the three experiments, with suggestions that RT speeding might also be related to time on task, and we did not observe reward modulation of context memory performance or amplification of reward benefits to memory by overnight consolidation. Taken together, the observed pattern of behavior is consistent with potentially distinct roles for transient and sustained reward in memory encoding and cognitive performance and suggests that further investigation of the temporal dynamics of dopaminergic contributions to memory formation will advance the understanding of motivated memory.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
With the abundance of environmental stimuli surrounding us in our daily lives, it is advantageous for humans to prioritize attending to and remembering motivationally salient information, over that which does not have motivational value. Despite recognition of this general tendency, the mechanisms by which motivation modulates cognition and information processing are only beginning to be elucidated. A growing body of evidence suggests that experimental manipulations of motivational incentives, such as rewards, typically enhance cognitive performance: this has been observed in terms of both attention and controlled performance (Botvinick & Braver, 2015; Chiew & Braver, 2013; Engelmann & Pessoa, 2014; Williams et al., 2017; Yee & Braver, 2018) as well as in terms of enhanced memory encoding (Adcock et al., 2006; Miendlarzewska et al., 2016; Murty et al., 2016; Spaniol et al., 2014; Wittmann et al., 2005). Such modulation has generally been interpreted as reflecting the role of rewards in promoting goal-directed, adaptive cognition in the service of survival (Chiew & Adcock, 2019; Clewett & Murty, 2019).
Neurobiologically, reward modulation of cognitive performance has been linked to activity in the mesolimbic dopamine (DA) system. Decades of evidence, much of it relying on animal models, indicate that DA activity is integral to incentive salience, reward processing, and motivated behavior (Berridge & Robinson, 1998; Wise & Rompre, 1989). In this system, dopamine pathways project from midbrain regions (notably, the ventral tegmental area [VTA]) to both cortical and subcortical regions supporting higher cognitive processes, including the prefrontal cortex and hippocampus: this anatomical circuit is thought to underlie the effects that reward motivation can have on cognitive performance (Chiew & Braver, 2013; Braver et al., 2014; Lisman & Grace, 2005; Sawaguchi & Goldman-Rakic, 1991). Consistent with this, evidence from human fMRI, using the now-classic monetary incentive encoding (MIE) paradigm (Adcock et al., 2006), has demonstrated enhanced memory for reward-incentivized targets preceded by an anticipatory cue, in association with increased anticipatory activity in the VTA and hippocampus as well as increased functional connectivity between these regions. These observations support a model whereby reward-enhanced dopaminergic input to the hippocampus promotes greater memory encoding and subsequent memory benefit for motivationally-salient stimuli.
While subsequent research studies have yielded evidence consistent with this neuroanatomical model (e.g., Chowdhury et al., 2012; Gruber et al., 2014; Murty et al., 2016), effects of mesolimbic DA in the brain are complex and multifaceted, and the extent to which differential aspects of DA function might support distinct cognitive outcomes is not well-understood. In particular, DA activity has been identified to operate via separable dynamics at different timescales that might have distinct mechanistic contributions to cognition and behavior. These dynamics include phasic DA bursts, or rapid synaptic firing in response to unexpected reward (i.e., reward prediction errors; (Schultz et al., 1997)): these signals have been linked to updating of mental representations (Braver & Cohen, 2000; O’Reilly & Frank, 2006) and reward-based learning (Floel et al., 2008; Schultz, 1998). In contrast, tonic DA activity refers to sustained, extrasynaptic “background” activity (Goto et al., 2007; Grace, 1991), thought to index the long-term average reward rate of the current environment and modulating response vigor and rate of reward pursuit (Beierholm et al., 2013; Niv et al., 2007). Most direct characterizations of dopamine activity at these different timescales have come from neuronal recordings in animal models. However, functional homology in DA systems across humans and other mammals (Berridge & Kringelbach, 2008) suggests that analogous phasic and tonic DA responses can also be solicited in humans by behavioral manipulations of reward. Consistent with this, a growing number of studies have used behavioral manipulations to disentangle transient and sustained reward dynamics, potentially reflecting phasic and tonic dopamine, respectively, and their separate contributions to human cognitive performance (Engelmann et al., 2009; Jimura et al., 2010; Kostandyan et al., 2019; Williams et al., 2018).
In our prior work, we used a mixed block/event experimental design to examine sustained versus transient effects of motivational incentive on cognitive control performance (Chiew & Braver, 2013). In this design, participants complete separate baseline (no-incentive) and reward task blocks; within the reward block, non-incentive and incentive trials (50% each) are randomly intermixed. This design allows for the examination of transient, trial-based effects of incentives by contrasting performance on non-incentive and incentive trials (whereby incentive status is randomly manipulated on a trial-by-trial basis) within the reward task block. This design also allows for the examination of more sustained, block-based effects of reward motivation by contrasting performance on baseline block trials (where performance is thought to be relatively lower in a motivational context) with non-incentive trials in the reward block (where such trials, while not directly incentivized, are occurring in the broader motivational context of a task block with reward incentive prospect). This experimental approach is similar to the more general mixed block/event-related fMRI design approach that has been used to examine transient and sustained brain activity separately (Visscher et al., 2003). It is important to note that the contrast thought to characterize transient reward (i.e., non-incentive versus incentive trials within a reward block) compares two conditions differing in terms of direct reward incentive, while the contrast thought to characterize sustained reward (i.e., baseline block trials versus non-incentive trials within a reward block) compares two conditions differing in terms of reward prospect. Given neurobiological accounts of tonic dopamine as a slower, extrasynaptic index of average reward rate in a given environment, as opposed to phasic dopamine as a measure of transient synaptic firing in response to eliciting events, baseline block trials versus non-incentive trials within a reward block should potentially differ in terms of tonic dopamine and sustained reward while comparing non-incentive and incentive trials within a reward block should potentially characterize differences phasic dopamine and transient reward (with comparable levels of tonic dopamine activity in both non-incentive and incentive trials when randomly intermixed, slowly updating over the course of the reward task block). Prior observations from our and others’ research using mixed block/event task designs with reward manipulations suggest that it can elicit distinct physiological (both pupil and fMRI) indices of both transient and sustained reward as well as their separate effects on behavioral performance (Chiew & Braver, 2013, 2014; Jimura et al., 2010).
Many studies seeking to disentangle transient and sustained reward influences on cognition using a mixed block/event trial design have observed them to have temporally distinct, but directionally similar, effects on performance: for example, in our own work, we have observed that transient and sustained reward were both associated with shifts towards enhanced proactive control and cue-based processing (Chiew & Braver, 2013, 2014). Intriguingly, however, one recent study (Kostandyan et al., 2019) instead observed differential effects of sustained and transient reward on cognitive performance using an adapted Flanker attention paradigm. Specifically, Kostandyan and colleagues observed that when reward incentive was manipulated solely in a block-based (i.e., sustained) fashion, it was not associated with changes in task performance; in contrast, when reward incentive was manipulated in a mixed block/event fashion (enabling investigation of both sustained and transient reward, similar to the mixed block/event design described above), transient, but not sustained, reward was associated with improved task performance. While these behavioral findings were not explicitly interpreted in terms of phasic versus tonic dopaminergic mechanisms, Kostandyan and colleagues noted that observed associations between reward dynamics and performance benefit might be task-specific. Such specificity would be consistent with accounts of differential dopamine dynamics serving distinct functions at varying temporal profiles.
In line with this idea, a recent study demonstrated that behaviorally manipulating the timing and certainty of reward cues, putatively engaging rapid phasic versus slower, multi-second ramping dopamine dynamics, resulted in varying memory outcomes for incidental stimuli shown during reward anticipation (Stanek et al., 2019). While this study provides evidence that temporally-distinct reward dynamics may support separable outcomes in terms of memory encoding performance, Stanek et al. did not compare the effects of transient and sustained reward manipulation (and associated contributions of putative phasic and tonic dopamine). Meanwhile, studies demonstrating separable but similar effects of transient and sustained reward on cognition (i.e., Chiew & Braver, 2013, 2014; Engelmann et al., 2009; Jimura et al., 2010) have generally used cognitive control tasks, where effects of reward on cognition are examined in terms of the accuracy and speed of overt responses during the immediate, online performance. In contrast to such outcomes, in a memory encoding paradigm, performance is not typically indexed in terms of immediate overt response, but instead subsequent memory at retrieval. These diverging task demands might potentially lead to different effects of transient and sustained reward when examining cognitive performance in the memory domain, as opposed to cognitive control.
In particular, recent work in the motivated memory literature has suggested that reward might enhance memory through multiple mechanisms, occurring both at and after encoding. The extent to which such mechanisms might be associated with dopaminergic activity at distinct temporal dynamics is not currently well-characterized. Some studies have obtained evidence for reward-based memory selectivity that might relate to attentional and cognitive control processes engaged in encoding. For example, value-based modulation of memory encoding has been suggested to involve strategic engagement of brain regions involved in semantic processing (Cohen et al., 2014), adjust in response to feedback regarding ongoing performance (Ariel & Castel, 2014; Castel, 2007), and decline selectively with divided attention (Elliott et al., 2019). However, other studies have identified mechanisms of reward-facilitated memory occurring after encoding or independently of cognitive processes at encoding. For example, recent fMRI evidence demonstrated that VTA-hippocampal connectivity during a post-encoding period predicted memory benefits for rewarded stimuli (Gruber et al., 2016); meanwhile, Studte et al. (2017) observed that nap sleep after encoding benefited subsequent memory retrieval for high- but not low-reward information. Finally, Bowen et al. (2020) observed that reward anticipation enhanced memory but did not improve directed forgetting, suggesting that reward can bolster memory independently of attentional control processes that can be directed towards either remembering or forgetting.
To investigate this further, we conducted three behavioral experiments examining incentivized memory encoding of target items (photographic images of scenes, following Adcock et al., 2006) under transient versus sustained reward (engaging putative phasic versus tonic DA, respectively) using a mixed block/event design. Along with the presentation of target stimuli, each trial included a simple response task to index online performance at encoding. On the basis of prior research evidence, we anticipated that transient and sustained rewards would have diverging effects on memory encoding. Given observations from both the memory encoding and the cognitive control literature that transient reward, potentially engaging phasic DA, might enhance subsequent memory and cognitive performance (e.g., Kostandyan et al., 2019; Stanek et al., 2019), we hypothesized that transient reward might specifically be associated with memory benefit in our paradigm. Two potential outcomes regarding the effects of sustained reward on memory were identified on the basis of inconsistent prior findings in the literature. Given accounts that tonic DA might support increased response vigor (Niv et al., 2007), we hypothesized that sustained reward might be associated with enhanced online performance at encoding (i.e., faster response speed) but not necessarily enhanced subsequent memory; on the other hand, given observations that sustained reward might not significantly modulate cognitive performance (Kostandyan et al., 2019), we also considered it possible that sustained reward might be associated with null effects altogether. Given the fixed order of our mixed block/event design, where a baseline block is collected prior to a reward block with intermixed non-incentive and incentive trials, we also tested whether time on task across the two task blocks modulated either online performance at encoding or subsequent memory for presented stimuli.
In addition to examining the effects of differing reward dynamics on memory for target items, in Experiments 2 and 3 we also examined whether sustained and transient reward benefited memory context information (colored borders around presented target images) as well as for target items themselves. Prior evidence has suggested reward benefits to hippocampally-based binding of item and context information, as well as an associative memory (Murty et al., 2011; Shigemune et al., 2014; Wolosin et al., 2012), and recollective memory for contextual details has been shown to be enhanced for high- versus low-value items on a study list when tested in both an interspersed manner as well as with one final test (Cohen et al., 2017). However, other observations have suggested a reward benefit to the item but not context memory (Villaseñor et al., 2021). Given these mixed results, we were interested in investigating whether reward would benefit context memory in a similar fashion to item memory or not in the present study, and if this effect would vary with reward timing. Finally, while Experiments 1 and 2 examined memory with a 24-h interval between encoding and retrieval, in Experiment 3 we used a 15-min encoding-retrieval interval to examine the relative importance of overnight consolidation to potential transient and sustained reward-based modulation of memory. As described above, evidence suggests that reward benefits to memory can occur post-encoding (Gruber et al., 2016; Studte et al., 2017); further, reward benefits to memory performance have been shown to increase with an overnight encoding-retrieval interval relative to the use of a same-day interval (Murayama & Kitagami, 2014; Spaniol et al., 2014).
Taken together, the present study aimed to disentangle contributions of transient versus sustained reward (reflecting potential modulation by phasic versus tonic DA, respectively) to episodic memory encoding. On the basis of prior evidence suggesting distinct functional roles for phasic and tonic DA, as differing observed effects of sustained and transient reward on cognition, we hypothesized that transient reward should benefit memory performance while sustained reward might not. Across experiments, the effects of reward on both item and context memory were investigated, as were time-on-task effects and the importance of an overnight consolidation period. Identifying potentially dissociable functional roles for transient and sustained reward in contributing to memory formation would advance a more nuanced understanding of how motivational influences modulate memory: specifically, by elucidating the multiple mechanisms by which such modulation takes place and the timescales by which they operate.
Experiment 1
In this experiment, we used a mixed block/event design to examine the effects of transient reward (comparing between incentivized and non-incentivized trials, manipulated on a trial-by-trial basis) and sustained reward (comparing between baseline block trials and non-incentivized trials presented under reward prospect) on memory encoding in terms of subsequent recognition memory performance. Reward incentive was contingent on the memory success of presented target images at 24-h retrieval. Additionally, on each trial, target images to be encoded were followed by a simple response task, allowing us to examine sustained and transient reward effects on online performance and relate this metric to subsequent memory.
Experiment 1: methods
Sample size determination
To determine the sample size needed to test the effect of sustained and transient reward on recognition memory, we estimated effect size using the effect of transient reward on recognition memory performance in Adcock et al. (2006), calculated as d = 0.614. A sample size analysis in G*Power 3 (Faul et al., 2007) indicated that 24 participants would provide sufficient power to detect a similar effect of reward on recognition memory (alpha = 0.05, 1 − β = 0.80). This estimate was used to determine the sample size for Experiment 1 and all subsequent experiments.
Participants
Thirty-six young adult participants were enrolled in the study (26 females, 10 males; mean age 20.5 years, SD = 0.50 years; mean years of education 14.1 years, SD = 0.38 years). Participants were recruited from the Denver area using flyers and the University of Denver’s online SONA psychology participant pool. All participants had a normal or corrected-to-normal vision, were fluent English speakers, had no known history of neurological disorder or injury, no current diagnosis of psychiatric or psychological disorder, and no current use of psychotropic medication. The experiment protocol was approved by the Institutional Review Board of the University of Denver and written informed consent was obtained from all subjects prior to study participation. Participants took part in the experiment for either course credit or $10/h compensation, with the possibility of an additional bonus payment of up to $5 based on task performance.
Nine participants were eliminated from our final sample for the following reasons: not showing up for Day 2 of the two-day study (N = 1); for having a global accuracy score lower than 60% on the arrow task at encoding (described below), indicating poor task engagement during the encoding period (N = 5), and communicating to the researcher that they ignored or did not understand the incentive cues (N = 3). This yielded a sample of twenty-seven usable participants (20 female, 7 male; mean age: 20.7 years, SD = 0.63 years; mean years of education: 14.33 years, SD = 2.40 years) who were included in the analyses reported below.
Experimental procedure
The experiment was presented on a Dell PC computer using E-prime software (Psychology Software Tools, Pittsburgh, PA, USA). Subject responses, accuracy, and reaction time (RT) data were collected using an E-prime button box connected to the stimulus presentation computer.
On Day 1 of the study, subjects completed a monetary incentive encoding (MIE) task (adapted from Adcock et al., 2006) with a block design in which a baseline block (with no reward prospect) always preceded the reward block. Stimuli were presented on a gray background. On each task trial, participants were first presented with a cue (either a peach circle or a blue triangle) for 1 s; in the baseline block, participants were told that both cues indicated the upcoming target stimulus and otherwise did not differ, while in the subsequent reward block, participants were instructed that one cue indicated incentive trials (where successful subsequent recognition of the stimulus would be rewarded with a monetary bonus) and one cue indicated non-incentive trials. Cue status was counterbalanced between participants. Cue presentation was followed by a 2.5-s inter-stimulus interval (ISI; a fixation cross), which was then followed by the presentation of a target stimulus (an image of an indoor or outdoor scene; images were color photographs previously used as stimuli in Adcock et al., 2006), which was passively viewed for 1 s. Following the presentation of the target stimulus on each trial, participants were immediately presented with three arrow stimuli (presented one at a time in sequence for 0.67 s each, or 2 s in total) and required to indicate with a button press whether each arrow was pointing to the left or to the right. While, as in Adcock et al. (2006), this “arrow task” served to standardize the duration of memory elaboration for each target image, performance on this task (accuracy and reaction time) was also examined as a measure of online performance during encoding. Trials were separated by a 2-s inter-trial interval (ITI).
In the baseline block, participants were shown 80 target image stimuli (40 indoor scenes and 40 outdoor scenes). In the reward block, participants were shown 160 target image stimuli (80 indoor scenes and 80 outdoor scenes), of which half were on incentive trials and half were on non-incentive trials (equal numbers of indoor/outdoor scenes per incentive condition). Trial order was randomized in all blocks. Prior to beginning the reward block, participants were instructed that scenes preceded by an incentive cue may be included on a memory recognition test in 24 h and that they could earn up to $5 in bonus money for successful recognition performance.
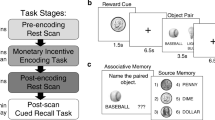
~ 24 h after the Day 1 session, participants returned to the lab for a self-paced recognition memory test. In the recognition test, participants were shown 120 old images (previously viewed in the Day 1 session; 40 from the baseline block, 40 from non-incentive trials in the reward block, 40 from incentive trials in the reward block) as well as 120 novel images (thus, 240 recognition trials in total). As in the encoding paradigm, half of the images depicted indoor scenes and half of the images depicted outdoor scenes; image presentation order was randomized. We did not show all stimuli presented at encoding and a corresponding number of novel images (which would require 480 trials in total) to limit the length of the recognition task. Upon being presented with each image in the recognition task, participants indicated whether the image was old or new, then rated their memory confidence on a 3-point Likert scale (1 = very confident to 3 = just guessing). Trial structure for the MIE paradigm (both encoding and recognition sessions, across all three experiments) is depicted in Fig. 1.

Encoding and retrieval task trial structure for the three experiments used in the study. A All three experiments used an adapted monetary incentive encoding (MIE) paradigm where cues preceded an intentionally-encoded target stimulus. At encoding, in the baseline block, participants were instructed that the two cues had no meaning beyond alerting the participant to the upcoming target stimulus. In the reward block, participants were instructed that one cue that successful recognition of the upcoming target would be associated with a monetary reward (incentive trials), while one cue did not (non-incentive trials). Following the target stimulus, participants performed a simple response task (the “arrow task”), a performance which was examined as a metric of online performance during encoding, and an inter-trial interval prior to the next trial. B At recognition, participants identified a target stimulus as old or new as well as their memory confidence on each trial (item memory); in Experiments 2 and 3, for target stimuli identified as “Old”, participants also made a context memory judgment (identifying the colored border presented with the target item at encoding) and rated memory confidence for this context judgment
Data analysis
Performance outcomes
Arrow task performance was characterized in terms of error rates and average correct reaction times (RTs) across the three arrows presented on each trial. Memory performance was examined on a trial-by-trial basis (subsequent hit versus miss) as a function of incentive condition and arrow task performance. Finally, we examined memory confidence as a function of memory status (hit versus miss) and incentive condition.
Arrow task performance
Linear mixed effects models, implemented in R (version 4.0.5) using the nlme package (Pinheiro et al., 2013), were used to examine arrow performance at the individual trial level within each subject. Incentive (baseline, non-incentive, incentive), Memory Status (hit versus miss), and the Incentive × Memory Status interaction term were examined as fixed effects in linear mixed effects models with arrow performance (error rate and RT) as continuous outcome measures, using maximum likelihood estimate and subject modeled as a random effect. Each analysis was conducted on the full amount of data available: thus, Incentive was examined as a predictor of arrow performance on all trials at encoding, while Memory Status and the Incentive × Memory Status interaction were examined as predictors of arrow performance only for trials with stimuli presented subsequently at recognition (i.e., half of the trials presented overall at encoding). Analyses examining Incentive as a predictor of arrow performance only on trials with stimuli presented subsequently at recognition were also conducted and are presented in the supplementary material. For each outcome, model comparison and selection were conducted by comparing a model containing each fixed main effect (Incentive, Memory Status) against a baseline model including only the intercept. Where one or more fixed effects significantly predicted model outcome, a follow-up analysis including the interaction term (Incentive × Memory Status) was conducted and compared against a baseline model including the fixed main effects alone. Finally, to examine whether Incentive had a significant effect on arrow performance over and above time on task effects, we conducted follow-up analyses where time on task (trial order across the two task blocks) was examined as a fixed effect. When time on task was observed to be a significant predictor, we added Incentive as a fixed effect to the model, to examine whether Incentive had a significant effect on arrow performance over and above the effect of time on the task alone.
Recognition memory performance
We used logistic mixed effects models (using the lme4 package in R; Bates et al., 2018) to examine whether memory performance as a binary outcome (hit versus miss) was predicted by fixed effects of Incentive condition and arrow task performance. Once again, we used maximum likelihood estimation and subject modeled as a random effect. For this model, Incentive was entered first as a fixed effect and the model was compared against a baseline model including only the intercept; subsequently, arrow error rates were added into the model, which was then tested against the Incentive model as a baseline. (note that the model did not converge with the addition of arrow RT as a predictor, so examination of arrow RT was omitted.) This approach enabled testing, on a trial-by-trial level, of whether the Incentive condition predicted memory outcome as well as whether arrow performance (as a metric of online task performance during encoding), itself potentially modulated by Incentive, accounted for significant variance in memory outcome over and above that predicted by Incentive alone. As when examining arrow task performance, follow-up analyses were conducted examining time on task (TOT) as a fixed effect; if TOT was significant, Incentive was added to the model to examine whether it predicted subsequent memory performance over and above the effect of TOT alone. Finally, memory confidence was examined using a linear mixed effects model (using the nlme package in R) with Incentive and Memory Status as fixed effects and with an observed significant fixed effect, follow-up analysis including the Incentive × Memory Status interaction term. As previously, we also conducted analyses examining TOT as a fixed effect on memory confidence, and where significant, comparing the TOT model to a model containing both TOT and Incentive as predictors. Model comparison and selection procedure were parallel to that used for examining arrow performance measures (accuracy and RT) as a function of these fixed effects.
While the main results are described below, the full mixed effects model building and comparison process for each outcome variable, for both arrow task and memory performance outcomes, is presented in the supplementary material.
Experiment 1: results
Arrow task performance
Arrow performance, both errors and RTs, are visualized as a function of incentive condition in Fig. 2A. When examining arrow error rates as an outcome, adding Incentive as a fixed effect significantly improved model fit over baseline (Likelihood Ratio (LR) = 24.54; p < 0.001); adding Memory Status as a fixed effect marginally improved model fit over baseline (LR = 3.25, p = 0.072). The Incentive effect was driven by decreased errors in the Incentive condition vs. both Baseline (estimate = − 0.01, 95% CI = − 0.02 to 0.00, p = 0.041) and Non-Incentive (estimate = − 0.03, 95% CI = − 0.04 to − 0.02, p < 0.001) conditions, as well as elevated errors in Non-Incentive relative to Baseline (estimate = 0.02, 95% CI = 0.01–0.03, p < 0.001). The trend-level effect of Memory Status was due to lower errors for subsequent memory hits vs. misses (estimate = − 0.01, 95% CI = − 0.02–0.00, p = 0.072). Also, adding the Incentive × Memory Status interaction term significantly improved model fit over Incentive and Memory Status fixed effects alone (LR = 6.32, p = 0.042): the interaction was driven by significant differences in arrow error rates between hits and misses in the Baseline vs. Non-Incentive conditions, with elevated errors in Non-Incentive subsequent misses vs. hits, but comparable errors across Baseline hits and misses (estimate = − 0.04, 95% CI = − 0.07 to − 0.01, p = 0.013). Follow-up analyses did not reveal a significant TOT effect on arrow error rates over baseline (LR = 0.23, p = 0.629).

Performance on the “arrow task” (i.e., a simple response task used to index online performance at encoding) as a function of Incentive Condition and Memory Status (“misses” versus “hits”—i.e., subsequently forgotten versus remembered item targets) across (A) Experiment 1; (B) Experiment 2A and 2B; (C) Experiment 3. Arrow task performance was measured in terms of error rates as well as average correct reaction times (RTs)
When examining arrow RTs as an outcome, adding Incentive as a fixed effect significantly improved model fit over baseline (LR = 74.70, p < 0.001), due to faster RTs in Non-Incentive vs. Baseline conditions (estimate = − 15.28, 95% CI = − 18.76 to − 11.81, p < 0.001) and Incentive vs. Baseline conditions (estimate = − 9.07, 95% CI = − 12.54 to − 5.60, p < 0.001), as well as significantly faster RTs in Non-Incentive vs. Incentive trials (estimate = 6.21, 95% CI = 2.74–9.68, p < 0.001). Adding Memory Status as a fixed effect did not significantly improve model fit over baseline (LR = 1.52, p = 0.22) and the addition of the Incentive × Memory Status interaction term did not improve model fit over the fixed main effects (LR = 1.03, p = 0.596) and were not explored further. Follow-up analyses did reveal a significant TOT effect on arrow RTs over baseline (LR = 47.52, p < 0.001) due to decreasing RTs (i.e., speeding) over the course of the two task blocks (estimate = -0.07, 95% CI = − 0.09 to − 0.05, p < 0.001). However, the effect of Incentive was significant over and above TOT alone (LR = 27.78, p < 0.001), and all contrasts between Incentive conditions as described above remained significant.
Recognition memory performance
Memory hit rates as a function of Incentive are visualized in Fig. 3A. When examining memory outcome (hit versus miss) using a logistic mixed effects model, adding Incentive as a fixed effect significantly improved model fit over baseline (i.e., random effects only; χ2 = 11.49, p < 0.001). This was due to increased recognition memory (greater proportion of hits versus misses) in the Baseline condition versus Non-Incentive (estimate = -0.21, 95% CI = − 0.40 to − 0.03, p = 0.021) as well as in the Incentive condition versus Non-Incentive (estimate = 0.31, 95% CI = 0.12–0.49, p < 0.001). Addition of arrow error rates as a fixed effect did not significantly improve the model over Incentive alone (χ2 = 2.61, p = 0.11). Follow-up analyses revealed a significant TOT effect on subsequent recognition memory relative to baseline (χ2 = 5.36, p = 0.021), which was due to poorer subsequent memory with increasing time on task (estimate = − 0.001, 95% CI = − 0.002 to − 0.000, p = 0.021). However, the effect of the Incentive remained significant over and above TOT (χ2 = 14.96, p < 0.001) due to enhanced subsequent memory for items presented in the Incentive condition versus Baseline (estimate = − 0.43, 95% CI = − 0.72 to − 0.14, p = 0.003) and Non-Incentive (estimate = − 0.31, 95% CI = − 0.49 to − 0.13, p < 0.001) conditions in this updated model.

Item memory performance (in terms of proportion correct judgments, or “hits”) as a function of Incentive on (A) Experiment 1; (B) Experiment 2A and 2B; (C) Experiment 3. Statistically significant differences in memory performance are indicated
When examining memory confidence using a linear mixed effects model, adding Incentive as a fixed effect did not significantly improve model fit (LR = 3.68, p = 0.16) while adding Memory Status as a fixed effect robustly improved the model over baseline (LR = 176.12, p < 0.001), due to higher memory confidence for hits versus misses, as expected. Further, adding the Incentive × Memory Status interaction term significantly improved model fit over Incentive and Memory Status fixed effects alone (LR = 12.67, p = 0.002): this interaction was driven by a greater confidence gap between memory hits and misses for Incentive targets versus Baseline (estimate = − 0.118, 95% CI = − 0.223 to − 0.013, p = 0.028) and Non-Incentive (estimate = − 0.191, 95% CI = − 0.297 to − 0.085, p < 0.001) targets. Follow-up analyses did not reveal a significant effect of TOT on memory confidence over the baseline model (LR = 0.48, p = 0.489).
Experiment 1: discussion
Reward incentive has previously been shown to enhance recognition memory of associated target stimuli, but in prior experimental designs it has generally been manipulated on a transient, trial-by-trial basis (e.g., Adcock et al., 2006; Wolosin et al., 2012). Given the evidence that phasic and tonic DA might serve distinct functional roles, in the present experiment we used a mixed block/event design to disentangle transient and sustained reward (putatively engaging phasic versus tonic DA, respectively) and examined their effects on task engagement and memory encoding. We observed the effects of incentive on both arrow performance, as a metric of online performance during the encoding stage, and subsequent recognition memory 24 h later. Given the fixed order of baseline and reward task blocks, we also tested whether time on task could account for observed Incentive effects. While we did observe some TOT effects, including RT speeding over time (potentially reflecting a practice effect; Mowbray & Rhoades, 1959) as well as decreased recognition memory over time (potentially reflecting decreased vigilance with fatigue; Bowyer et al., 1983), Incentive effects remained significant over and above effects of TOT.
When contrasting Incentive versus Non-Incentive trials (i.e., examining effects of transient reward), we observed higher arrow accuracy but slower arrow RTs: this may be interpreted as improved online task performance during the encoding period as a function of transient reward. Additionally, subsequent recognition memory for stimuli presented in Incentive vs. Non-Incentive trials was enhanced both in terms of higher hit rates as well as in terms of a larger memory confidence “gap” between subsequent accurate and inaccurate responses (i.e., hits and misses; with higher memory confidence argued to potentially reflect detail-rich recollective memory, which might preferentially rely on the hippocampus, to a greater extent; Yonelinas, 1994). Taken together, the arrow performance data at encoding and subsequent memory data suggest that transient reward was associated with enhanced task performance during the encoding period and subsequent memory for target stimuli (although note that arrow task performance was incidental to the to-be-remembered target stimuli, and arrow error rates did not significantly improve the model predicting memory outcomes over and above the effect of Incentive as a predictor). Such differences in memory performance were not observed when contrasting Non-Incentive and Baseline trials (i.e., examining the effects of sustained reward). Arrow performance was faster in Non-Incentive versus Baseline trials, but also less accurate; subsequent memory performance, in terms of either corrected hit rates or memory confidence, did not significantly differ between Non-Incentive and Baseline trials.
When considering all three incentive conditions together, a pattern of RT speeding emerged whereby Non-Incentive trials were faster than both Incentive and Baseline trials, but this was accompanied by a decrease in accuracy; Incentive trials were also faster than Baseline trials, but this speeding was accompanied by an increase in accuracy. (Note that correlations between error rates and average RTs in all three conditions were non-significant, suggesting that these findings do not reflect a systematic speed-accuracy tradeoff.Footnote 1) The observed pattern, whereby both Non-Incentive and Incentive trials were significantly faster than Baseline trials, is consistent with accounts that sustained reward prospect, associated with tonic DA, can promote response vigor and decrease response times even when incentives are not contingent on response speed (Manohar et al., 2017). In contrast, reward benefits to memory observed here were limited to the transient reward manipulation (contrasting Incentive versus Non-Incentive trials), thought to tap phasic DA activity. Thus, distinct effects of sustained and transient reward were observed on task performance, with sustained reward appearing to specifically enhance response vigor in terms of RT speeding, while the transient reward was associated with more accurate arrow task performance at encoding and improved subsequent recognition memory.
Given the suggestion of a memory benefit associated with transient (but not sustained) reward in Experiment 1 data, as well as prior evidence suggesting that reward might specifically benefit associative or contextual memory owing to preferential reward-related recruitment of the hippocampus at encoding (Shigemune et al., 2014; Wolosin et al., 2012), we conducted a second experiment that largely replicated Experiment 1 but also included context information (a colored border around presented target item stimuli) that was also tested for at recognition, upon endorsement of an item as remembered, as a function of incentive condition.
Experiment 2
In Experiment 1, we observed distinct effects of sustained and transient reward on task performance: specifically, transient but not sustained reward was associated with improved accuracy in the arrow task at encoding and enhanced subsequent memory. In Experiment 2, we aimed to replicate this observation as well as extending our investigation to compare the effects of sustained and transient reward on context memory as well as item memory.
Task design for Experiment 2 mirrored Experiment 1, with the addition of contextual information (a colored border around each presented target stimulus). At subsequent recognition test, target items that were endorsed as remembered were also subject to a contextual memory judgment, with memory for context information on correctly-remembered items examined as a function of incentive condition. Note that unlike memory for item stimuli, which was associated with incentive payout, memory for contextual information was incidental, with no directed encoding instruction or associated incentive for context memory success. We did not have explicit hypotheses regarding potential differences in reward effects on memory as a function of intentional versus incidental encoding, given prior evidence that reward can benefit memory for information encountered in both kinds of encoding contexts (e.g., Adcock et al., 2006; Gruber et al., 2016; Spaniol et al., 2014; Stanek et al., 2019). While we recently speculated that reward benefit to memory in intentional versus incidental encoding might be supported by different mechanisms (Chiew & Bowen, in press), such differences and their implications for memory performance outcomes are not yet well-understood.
To foreshadow our Experiment 2 findings, in our initial Experiment 2 sample (hereon referred to as Experiment 2A) we did not observe an expected effect of reward incentive on item or context memory recognition, or, once accounting for time on task, on arrow task performance. Given these unexpected findings, we replicated Experiment 2B in a second sample (hereon referred to as Experiment 2B) and combined the two samples together, including Experiment (2A versus 2B) as a variable, to examine for potential effects of reward on memory and task performance with improved statistical power. With this larger sample, we did observe the expected effects of reward incentive on arrow task performance as well as memory confidence but continued to observe a null effect of reward incentive on recognition memory. We also observed significant differences in arrow error rates and item memory confidence between Experiment 2A and 2B, but no differences in incentive effects. These results are reported below and full implications are discussed in the General Discussion. Separate results for Experiment 2A and Experiment 2B are also fully reported in the Supplement.
Experiment 2: methods
Participants
Sample size was determined using the same estimation procedure as in Experiment 1.
Experiment 2A
Thirty-five young adult participants were enrolled in the study (20 females, 14 males, 1 non-binary; mean age 20.14 years, SD = 0.62 years; mean years of education 13.34 years, SD = 2.26 years). Participants were recruited from the University of Denver’s SONA participant pool and participant eligibility criteria and compensation were the same as in Experiment 1. Four participants were eliminated from our final sample for the following reasons: not showing up for Day 2 of the two-day study (N = 1), for technical issues in the experiment program whereby responses were not logged correctly (N = 1), and for having a global accuracy score lower than 60% on the arrow task at encoding, indicating that they were not attending during the encoding period (N = 2). This yielded a sample of thirty-one usable participants (18 females, 13 males, 1 non-binary; mean age: 19.18 years, SD = 0.47 years; mean years of education: 13.32 years, SD = 1.77 years) who were included in the analyses reported below.
Experiment 2B
Thirty young adult participants were enrolled in the study (19 females, 7 males, 4 non-binary or declined to specify); mean age 19.07 years, SD = 1.08 years; mean years of education 12.93 years, SD = 0.94 years). Participants were recruited from the University of Denver’s SONA participant pool and participant eligibility criteria and compensation were the same as in Experiment 1 and Experiment 2A. Five participants were eliminated from our final sample for not showing up for Day 2 of the two-day study (N = 2); and for having a global accuracy lower than 60% on the arrow task at encoding (described below), indicating poor task engagement during the encoding period (N = 4). This yielded a sample of twenty-four Experiment 2B participants (13 females, 7 males, 4 non-binary or declined to specify; mean age: 19.12 years, SD = 1.12 years; mean years of education: 12.92 years, SD = 0.97 years).
With these participants, the combined Experiment 2A and 2B sample were fifty-five participants in total (20 males, 30 females, and 5 non-binary or declined to specify gender; mean age: 19.53 years, SD = 2.17 years; mean years of education: 13.15 years, SD = 1.48 years).
Experimental procedure
The Day 2 experimental procedure was very similar to the Day 1 procedure described previously for Experiment 1 (same stimuli, block design, numbers of trials, and trial timing structure). The only differing aspect of the Day 1 procedure in Experiment 2 was that the target image on each trial was presented surrounded by either a red or a blue border (equal numbers of target images with red and blue borders in all three incentive conditions; border colors were counterbalanced between participants). Participants were informed that reward receipt would be contingent on successfully remembering the presented images of scenes (i.e., successful item memory) on incentivized trials in a subsequent memory test. As in Experiment 1, participants returned for a self-paced recognition memory test ~ 24 h after completing the Day 1 procedure; this recognition memory test followed Experiment 1 in its numbers of previously-viewed and novel image stimuli, and of the previously-viewed images, the numbers of stimuli from each of the three incentive conditions. However, in Experiment 2’s recognition memory test, after participants made an old/new item memory judgment for image stimuli items and rated their item memory confidence (using a 3-point Likert scale as in Experiment 1), image items that were rated as “old” were also subject to a context memory judgment, whereby the image was presented on the screen again, now with both a red border and a blue border as in the Day 1 procedure. Participants had to choose which of the two versions of the image was presented the day before and rated their memory confidence for this context information on a 3-point Likert scale.
Data analysis
Performance outcomes
As in Experiment 1, arrow task performance was characterized in terms of error rates and average correct reaction times (RTs) across the three arrows presented on each trial. Memory performance was now calculated in terms of item memory (as corrected hit rates as well as trial-level hits vs. misses, as in Experiment 1) as well as context memory performance (correct vs. incorrect context information judgments on item hits) for each incentive condition. Memory confidence levels were also examined for correct and incorrect item and context memory judgments as a function of incentive condition.
Arrow task performance
As in Experiment 1, linear mixed-effects models were employed to examine arrow error rates and RTs, with the use of the same fixed effects (Incentive, Memory Status, and the Incentive × Memory interaction term) and model comparison and selection procedure. Following Experiment 1, each analysis was conducted on the full amount of data available: thus, analyses examining Incentive as a predictor of arrow performance were conducted on all trials, while analyses examining Memory Status and Incentive × Memory Status were conducted only on trials with stimuli subsequently presented at recognition. Again, analyses examining Incentive as a predictor of arrow performance only on trials with stimuli presented subsequently at recognition were conducted and are presented in the supplementary material. Follow-up analyses were conducted where time on task (TOT) was examined as a fixed effect; when this was significant, Incentive was added as a fixed effect to the model to examine whether it had a significant effect on performance over and above TOT alone.
Recognition memory performance
Again, as in Experiment 1, logistic mixed effects models were used to examine item memory performance as a binary outcome (hit versus miss), again with the addition of fixed effects (Incentive condition and arrow error rates). Item and context memory confidence were examined using linear mixed-effects models with fixed effects (Incentive, Memory Status, and their interaction), model comparison, and selection procedures paralleling those conducted in Experiment 1. Follow-up analyses were again conducted to examine TOT as a predictor, and where significant, adding Incentive as an additional predictor to examine its effect over and above TOT alone. As in Experiment 1, results are described below, with full model output and model comparison procedures for our mixed effects models examining both arrow task and memory outcomes included in the supplementary material.
Experiment 2 (combined 2A and 2B): results
Arrow task performance
Experiment 2A and 2B arrow performance, both errors and RTs, are visualized as a function of incentive condition in Fig. 2B. When examining arrow error rates as an outcome measure in the combined Experiment 2 dataset, adding Experiment (2A vs. 2B) as a fixed effect improved the model (LR = 7.44, p = 0.01); this was due to higher overall error rates in Experiment 2B compared to Experiment 2A (estimate = 0.06, 95% CI = 0.02–0.10, p = 0.01). In terms of task factors, adding Memory Status as a fixed effect did not significantly improve model fit over baseline (LR = 1.24, p = 0.27), while adding Incentive as a fixed effect did significantly improve the model (LR = 8.01, p = 0.02). The effect of Incentive was due to increased errors in the Non-Incentive condition relative to the Incentive condition (estimate = − 0.01, 95% CI = − 0.02 to 0.00, p = 0.005). The addition of the Incentive × Memory Status interaction term did not improve model fit over fixed main effects of Incentive and Memory Status (LR = 4.06, p = 0.13). We also did not observe a significant effect of TOT on arrow error rates over the baseline model (LR = 0.41, p = 0.52).
When examining arrow RT as an outcome in the combined Experiment 2 dataset, adding Experiment (2A vs. 2B) as a fixed effect did not improve the model (LR = 0.05, p = 0.82), indicating that arrow RTs did not significantly differ between Experiment 2A and 2B. However, adding Incentive as a fixed effect significantly improved model fit over baseline (LR = 70.06, p < 0.001), an effect driven by speeding in Non-Incentive and Incentive trials relative to Baseline (Non-Incentive vs. Baseline: estimate = − 10.85, 95% CI = − 13.46 to − 8.24, p < 0.001; Incentive vs. Baseline: estimate = − 7.69, 95% CI = − 10.29 to − 5.08, p < 0.001) as well as speeding in Non-Incentive trials relative to Incentive (Non-Incentive vs. Incentive: estimate = 3.16, 95% CI = 0.57–5.76, p = 0.02). The fixed main effect of Memory Status did not improve model fit over baseline (LR = 0.08, p = 0.78). However, addition of the Incentive × Memory Status interaction term did improve model fit over fixed main effects of Incentive and Memory Status to a trend level (LR = 5.62, p = 0.06): this was due to differences in arrow RTs for subsequent hits versus misses in Baseline vs. Non-Incentive trials (whereby RTs to subsequent memory misses were slower than hits in Baseline, but RTs to subsequent memory hits versus misses were comparable in Non-Incentive; estimate = 7.72, 95% CI = 0.26–15.18, p = 0.04) as well as in Baseline vs. Incentive trials (whereby RTs to subsequent memory misses were slower than hits in Baseline, but RTs to subsequent memory hits versus misses were slower in Incentive; estimate = 7.76, 95% CI = 0.35–15.18, p = 0.04). Notably, with the addition of the Incentive × Memory Status interaction term, the main effect of Memory Status in the model also reached trend-level (estimate = − 4.56, 95% CI = − 9.82 to 0.71, p = 0.09), due to faster RTs in subsequent memory misses versus hits. Finally, follow-up analyses revealed a significant TOT effect on arrow RTs over baseline (LR = 56.98, p < 0.001) due to RT speeding with increasing time on task (estimate = − 0.06, 95% CI = − 0.07 to − 0.04, p < 0.001), but the effect of Incentive on arrow RTs remained significant over and above TOT (LR = 16.09, p < 0.001).
Item recognition memory performance
Experiment 2A and 2B item memory hit rates as a function of Incentive are visualized in Fig. 3B. We examined item memory outcome (hit versus miss) in the combined Experiment 2 dataset using logistic mixed effects models. Adding Experiment (2A vs. 2B) did not improve model fit over baseline (χ2 = 0.04, p = 0.83), indicating that item memory did not significantly differ between Experiment 2A and 2B. In terms of task factors, adding Incentive as a fixed effect did not significantly improve model fit over baseline (χ2 = 3.75, p = 0.15). Additionally, adding arrow error rates as a fixed effect did not significantly improve the model over Incentive alone (χ2 = 1.29, p = 0.26). Follow-up analyses did not reveal a significant TOT effect on item memory recognition over baseline (χ2 = 0.54, p = 0.46).
When examining item memory confidence in the combined Experiment 2 dataset, adding Experiment (2A vs. 2B) as a fixed effect significantly improved the model (LR = 5.16, p = 0.02); this was due to lower overall memory confidence in Experiment 2B relative to 2A (estimate = 0.22, 95% CI = 0.03–0.42, p = 0.02). In terms of task factors, adding Memory Status as a fixed effect significantly improved the model over baseline (LR = 244.97, p < 0.001), due to higher item memory confidence for hits versus misses (estimate = − 0.25, 95% CI = − 0.28 to − 0.22, p < 0.001). The addition of Incentive as a fixed effect did not significantly improve the model over baseline (LR = 0.67, p = 0.72). However, adding the Incentive × Memory Status interaction term revealed a significant improvement over the main effects of Incentive and Memory Status (LR = 6.58, p = 0.04): this interaction was driven by a greater confidence gap between memory hits and misses for Non-Incentive targets versus Baseline targets (estimate = − 0.08, 95% CI = − 0.16 to − 0.01, p = 0.02) and for Incentive targets versus Baseline targets (estimate = − 0.08, 95% CI = − 0.15 to − 0.01, p = 0.03). Finally, follow-up analyses did not reveal a significant TOT effect on item memory confidence over the baseline model (LR = 0.01, p = 0.93).
Context recognition memory performance
Experiment 2A and 2B context memory hit rates are visualized as a function of Incentive in Fig. 4A. We examined context memory outcome (correct versus incorrect) in the combined Experiment 2 dataset using logistic mixed effects models. Adding Experiment (2A vs. 2B) did not improve model fit over baseline (χ2 = 0.04, p = 0.85), indicating that context memory did not significantly differ between Experiment 2A and 2B. Adding Incentive also did not significantly improve model fit over baseline (χ2 = 0.06, p = 0.82), and adding arrow error rates as a fixed effect did not significantly improve the model over Incentive alone (χ2 = 0.06, p = 0.81). Follow-up analyses did not reveal a significant effect of TOT on context memory over the baseline model (χ2 = 0.01, p = 0.91).

Context memory performance (in terms of proportion correct judgments) as a function of Incentive on (A) Experiment 2A and 2B; (B) Experiment 3
When examining context memory confidence in the combined Experiment 2 dataset, adding Experiment (2A vs. 2B) as a fixed effect did not improve the model (LR = 0.40, p = 0.53), indicating that context memory confidence did not significantly differ between the two experiments. Likewise, adding fixed effects of Incentive and Memory Status did not significantly improve the model (Incentive: LR = 0.22, p = 0.90; Memory Status: LR = 0.06, p = 0.81), and adding the Incentive × Memory Status interaction did not significantly improve the model over fixed main effects alone (LR = 1.25, p = 0.54). Follow-up analyses did not reveal a significant TOT effect on context memory confidence over the baseline model (LR = 0.47, p = 0.49).
Experiment 2: discussion
Given findings from Experiment 1 indicating that transient reward was associated with enhanced task performance during the encoding period and improved subsequent memory for target stimuli, we sought to replicate these observations as well as examining the effects of transient and sustained reward on context memory in Experiment 2. In our initial Experiment 2A sample, the effects of Incentive on performance were limited to observations of RT speeding, which no longer reached significance when controlling for time on task. We conducted a replication of this experiment in a second sample (Experiment 2B). When we examined effects in the combined sample, but included Experiment (2A vs. 2B) as a predictor, we did note that arrow error rates were higher and item memory confidence was lower in Experiment 2B than in Experiment 2A. A difference that could have potentially driven this effect was that Experiment 2B was conducted in Fall 2022, after the onset of COVID-19, while Experiment 2A was conducted prior to COVID-19; the potential implications of this and variation across experiment samples are discussed further in our General Discussion below.
In the larger, combined Experiment 2 sample, as in Experiment 1, we observed higher errors and faster RTs on Non-Incentive versus Incentive trials, as well as faster RTs on both Non-Incentive and Incentive trials relative to Baseline trials. We also observed an interaction of Incentive × Memory Status on item memory confidence—specifically, increasing memory confidence “gap” between subsequent accurate and inaccurate responses (hits and misses) with an incentive in Experiment 2. However, notably, this difference in memory confidence was observed as a function of sustained reward (in comparing Non-Incentive and Incentive conditions relative to Baseline) instead of as a function of transient reward (comparing Incentive versus Non-Incentive conditions), as observed in Experiment 1. Additionally, we did not observe any significant effects of Incentive or Memory Status on context memory or context memory confidence.
Experiment 2’s results diverged from Experiment 1 in that transient reward (i.e., the comparison between Incentive and Non-Incentive trials) was not associated with benefit to subsequent memory accuracy. The null effect of reward on recognition memory was observed for both target items, the successful retrieval of which was associated with incentive payment, as well as for incidental context information. As in Experiment 1, mixed effects models indicated that arrow error rates were not a significant predictor of memory performance, suggesting that reward effects on a simple response task during the encoding phase might be independent of memory outcomes. These observations suggest that the benefits of transient reward to memory encoding previously observed in Experiment 1, while consistent with a body of behavioral and neural evidence suggesting reward benefits to memory encoding, might be less robust than originally anticipated. Additionally, differences in memory confidence for hits and misses were observed as a function of sustained reward, potentially reflecting differences in the ability to remember detail-rich, recollective memories (Yonelinas, 2001) across incentive conditions despite insignificant differences in memory accuracy itself as a function of incentive. Importantly, these differences in memory confidence were observed as a sustained reward (i.e., increased between Baseline and both Non-Incentive and Incentive conditions), not transient reward (between Non-Incentive and Incentive conditions), suggesting that potential benefits of reward on memory might not be limited to transient timescales. One final observation in the combined Experiment 2 sample, that diverged from Experiment 1 results, was a trend-level interaction of Incentive × Memory Status on arrow RTs: on Baseline trials, response times were slower on trials with subsequently-forgotten versus subsequently-remembered stimuli, while on Incentive trials, the reverse was observed: response times were faster on trials with subsequently-forgotten versus subsequently-remembered stimuli. However, the extent to which faster RTs at encoding might be associated with better or worse subsequent memory, and why that might vary by incentive condition, are currently unclear.
To probe these findings further, we conducted a third experiment. Experiment 3 was a replication of Experiment 2 but with a ~ 15-min interval between encoding and retrieval instead of a 24-h interval as in Experiments 1 and 2. Manipulating the retention interval in this fashion allowed us to investigate the relative importance of overnight consolidation to memory modulation via transient and sustained reward.
Experiment 3
In Experiment 3, we largely replicated Experiment 2’s protocol, but instead of a 24-h interval between encoding and retrieval, the retention interval was approximately 15 min. The goal of Experiment 3 was to clarify the relative contribution of transient versus sustained reward-related processes occurring during overnight consolidation, versus processes occurring during encoding, supporting memory modulation.
Extensive evidence suggests that sleep is vital to successful memory consolidation (Klinzing et al., 2019; Marshall & Born, 2007; Stickgold, 2005; Walker & Stickgold, 2004). In particular, it has been suggested that consolidation processes during sleep might selectively strengthen memories that are adaptive or of relevance to the future, such as memories of emotionally or motivationally-salient information (Payne et al., 2012). Consistent with this idea, sleep-based consolidation has been demonstrated to amplify memory benefits for reward-related information (Murayama & Kitagami, 2014; Spaniol et al., 2014; Studte et al., 2017). Given these findings, we anticipated that in Experiment 3, which had no overnight consolidation period, memory would be enhanced by transient reward, but that the benefit of reward to memory would be attenuated relative to that observed in Experiment 1.
Experiment 3: methods
Participants
Sample size was determined using the same estimation procedure as in the previous experiments. Thirty-one young adult participants were enrolled in the study (24 females, 7 males; mean age 19.35 years, SD = 0.28 years; mean years of education 13.03 years, SD = 0.25 years). Participants were recruited from the University of Denver’s SONA participant pool and participant eligibility criteria and compensation were the same as in Experiment 1 and 2.
One participant was eliminated from our final sample for having an accuracy score lower than 60% on the arrow task at encoding, indicating poor task engagement during the encoding period. This yielded a sample of thirty usable participants (23 females, 7 males; mean age: 19.44 years, SD = 0.30 years; mean years of education: 13.00 years, SD = 1.38 years) who were included in the analyses reported below.
Experimental procedure and data analysis
Experimental procedure was identical to that implemented in Experiment 2, except that the interval between encoding and retrieval was ~ 15 min instead of ~ 24 h. Data analysis followed procedures previously outlined for Experiment 2. As in the prior two experiments, results are described below, with full model output and model comparison procedures for our mixed effects models included in the supplementary material.
Experiment 3: results
Arrow task performance
Arrow performance, both errors and RTs, are visualized as a function of incentive conditions in Fig. 2C. When examining arrow error rates as an outcome, adding Incentive as a fixed effect significantly improved model fit over baseline (LR = 13.89, p = 0.001); this effect was driven by increased errors in the Non-Incentive condition vs. both Baseline (estimate = 0.02, 95% CI = 0.00–0.03, p = 0.01) and Incentive (estimate = − 0.02, 95% CI = − 0.03 to − 0.01, p < 0.001) conditions. Adding Memory Status as a fixed effect did not improve model fit over baseline (LR = 1.14, p = 0.285). Additionally, adding the Incentive × Memory Status interaction term did not significantly improve model fit over Incentive and Memory Status fixed effects alone (LR = 1.40, p = 0.497). Follow-up analyses did not reveal a significant effect of TOT on arrow error rates (LR = 0.72, p = 0.393).
When examining arrow RTs as an outcome, adding Incentive as a fixed effect significantly improved model fit over baseline (LR = 15.11, p = 0.001), due to slower RTs in the Baseline condition vs. both the Non-Incentive condition (estimate = -6.49, 95% CI = − 9.80 to − 3.19, p < 0.001) and the Incentive condition (estimate = -4.05, 95% CI = − 7.35 to − 0.74, p = 0.02). Adding Memory Status as a fixed effect did not significantly improve model fit over baseline (LR = 1.52, p = 0.217) and addition of the Incentive × Memory Status interaction term did not significantly improve model fit over the fixed main effects (LR = 4.64, p = 0.10) and were not explored further. Follow-up analyses revealed a significant effect of TOT on arrow RTs (LR = 33.01, p < 0.001) due to RT speeding over the course of the two task blocks (estimate = -0.06, 95% CI = − 0.08 to − 0.04, p < 0.001). The effect of Incentive on arrow RTs was trend-level over and above TOT alone (LR = 5.61, p = 0.061), due to RT differences between Incentive and Baseline conditions as described above (note that in the model including both TOT and Incentive as predictors, the previously significant contrast between Baseline and Non-Incentive trials no longer reached significance (estimate = 3.43, 95% CI = − 1.75 to 8.63, p = 0.195)).
Item recognition memory performance
Item memory hit rates as a function of Incentive are visualized in Fig. 3C. When examining item memory outcome (hit versus miss) using a logistic mixed effects model, adding Incentive as a fixed effect significantly improved model fit over baseline (i.e., random effects only; χ2 = 38.20, p < 0.001). This was due to increased recognition memory (greater proportion of hits versus misses) in the Incentive condition versus Baseline (estimate = 0.50, 95% CI = 0.33–0.67, p < 0.001) and Non-Incentive (estimate = 0.42, 95% CI = 0.25–0.59, p < 0.001) conditions. Additionally, adding arrow error rates as a fixed effect did not significantly improve the model over Incentive alone (χ2 = 1.07, p = 0.30). Follow-up analyses did reveal a significant effect of TOT on item memory relative to the baseline model (χ2 = 9.21, p = 0.002); this was due to improving subsequent memory with increasing time on task (estimate = 0.0015, 95% CI = 0.0005–0.0025, p = 0.002). However, the effect of Incentive remained significant over and above TOT (χ2 = 29.00, p < 0.001); all contrasts between Incentive conditions as described above remained significant.
When examining item memory confidence, adding Incentive as a fixed effect significantly improved model fit (LR = 35.26, p < 0.001), due to significantly higher memory confidence levels in the Incentive condition relative to both Baseline (estimate = − 0.14, 95% CI = − 0.19 to − 0.09, p < 0.001) and Non-Incentive (estimate = − 0.13, 95% CI = − 0.18 to − 0.08, p < 0.001) conditions. Adding Memory Status as a fixed effect also improved the model over baseline (LR = 107.95, p < 0.001), due to higher item memory confidence for hits versus misses (estimate = − 0.23, 95% CI = − 0.28 to − 0.19, p < 0.001). Adding the Incentive × Memory interaction further improved the model over fixed main effects (LR = 27.46, p < 0.001): this interaction was driven by a greater confidence gap between memory hits and misses for Incentive targets versus Baseline (estimate = − 0.26, 95% CI = − 0.36 to − 0.16, p < 0.001) or Non-Incentive (estimate = − 0.20, 95% CI = − 0.30 to − 0.10, p < 0.001) targets. Follow-up analyses revealed a significant TOT effect on item memory confidence over the baseline model (LR = 5.68, p = 0.017) due to decreasing item memory confidence with increasing time on task (estimate = − 0.0004, 95% CI = − 0.0007 to − 0.0001, p = 0.017). However, the effect of Incentive was significant over and above TOT (LR = 29.90, p < 0.001), with all contrasts between Incentive conditions as described above remaining significant.
Context memory performance
Experiment 3 context memory hit rates are visualized in Fig. 4B. When examining context memory outcome (correct versus incorrect) using a logistic mixed effects model, adding Incentive did not significantly improve model fit over baseline (χ2 = 2.83, p = 0.24). Additionally, adding arrow error rates as a fixed effect did not significantly improve the model over Incentive alone (χ2 = 0.25, p = 0.62). Follow-up analyses did not reveal a significant effect of TOT on context memory recognition over the baseline model (χ2 = 0.09, p = 0.77).
When examining context memory confidence, adding Incentive as a fixed effect significantly improved model fit (LR = 17.67, p < 0.001), due to lower context memory confidence for Baseline targets relative to Non-Incentive targets (estimate = − 0.13, 95% CI = − 0.20 to − 0.06, p < 0.001) or Incentive targets (estimate = − 0.13, 95% CI = − 0.20 to − 0.06, p < 0.001). The addition of Memory Status as a fixed effect did not improve the model over baseline (LR = 0.75, p = 0.386) and the addition of the Incentive × Memory Status interaction term did not improve the model over fixed main effects alone (LR = 0.63, p = 0.729); thus, these effects were not explored further. Follow-up analyses revealed a significant effect of TOT over the baseline model on context memory confidence (LR = 4.93, p = 0.026) due to decreasing memory confidence with increasing time on task. However, the effect of Incentive on context memory confidence remained significant over and above TOT (LR = 13.33, p = 0.001), again due to higher context memory confidence in Incentive trials than in Baseline (here dropping to a trend effect; estimate = − 0.09, 95% CI = − 0.21 to 0.01, p = 0.088) or Non-Incentive trials (estimate = − 0.13, 95% CI = − 0.20 to − 0.06, p < 0.001).
Experiment 3: discussion
The procedure for Experiment 3 replicated Experiment 2 except for the retention interval between encoding and retrieval, which was ~ 15 min instead of ~ 24 h (as in both Experiment 1 and 2). In Experiment 2, the sustained reward was associated with RT speeding and changes in item memory confidence, while reward effects on either item or context memory accuracy were not observed. In contrast, in Experiment 3, we observed significant reward effects both on arrow performance and subsequent memory performance that largely paralleled observations from Experiment 1, despite design differences between Experiment 1 and 3 that included both manipulation of context information (present at Experiment 3 and absent at Experiment 1) and retention interval (~ 15 min in Experiment 3 and ~ 24 h in Experiment 1).
Notably, in Experiment 3, we observed elevated arrow error rates in Non-Incentive trials, relative to both Baseline and Incentive trials, as well as RT speeding in Incentive trials relative to Baseline trials. This pattern of arrow performance is somewhat consistent with observations from Experiment 1, where increased arrow accuracy was observed on Incentive vs. Non-Incentive trials, and interpreted as potentially reflecting enhanced online task performance under transient reward (although note that in Experiment 1, Incentive trials were both slower and more accurate relative to Non-Incentive trials, whereas in Experiment 3, Non-Incentive and Incentive RTs did not significantly differ).
Along with increased arrow accuracy, the transient reward was also associated with enhanced subsequent recognition, as characterized by both higher item memory accuracy as well as a larger memory confidence “gap” between subsequent item memory hits and misses, for stimuli shown in the Incentive versus Baseline and Non-Incentive conditions. Both of these observations of transient reward effects on item memory accuracy and memory confidence are consistent with Experiment 1 results. Interestingly, while we did not observe Incentive effects on context memory accuracy, we observed that context memory confidence was elevated in Incentive trials, relative to Non-Incentive and Baseline trials. Surprisingly, this effect occurred in the absence of a significant effect of Memory Status (i.e., accuracy) on context memory confidence. Recent evidence suggests that reward is associated with a more liberal response bias (Bowen, Marchesi, & Kensinger, 2019); such a bias may have potentially contributed to elevated confidence levels for Incentive targets, even in the absence of accuracy effects on memory confidence.
Taken together, these results are consistent with Experiment 1 in suggesting that transient reward (Incentive vs. Non-Incentive trials) was associated with both improved arrow task accuracy at encoding as well as enhanced subsequent item memory. In contrast, RT speeding appeared to be sensitive to sustained reward (differentiating Non-Incentive and Incentive trials vs. Baseline trials), potentially reflecting enhanced vigor, but note that this effect dropped to a trend level, driven by differences between Incentive and Baseline trials when accounting for time on task. Context memory accuracy was not significantly modulated by either transient or sustained reward, although we observed that context memory confidence was significantly higher as a function of sustained reward (i.e., in Non-Incentive and Incentive trials relative to Baseline trials). Intriguingly, the results of Experiment 3 also suggest that the observed benefits of transient reward to item memory were not dependent on overnight consolidation. If anything, the significant effect of Incentive on memory hit rates was larger in Experiment 3 (χ2 = 38.20) than in Experiment 1 (χ2 = 11.49); suggesting that, contrary to hypotheses, reward benefit to memory was actually more robust with a ~ 15 min versus ~ 24-h retention interval. Implications of this observation are discussed further in the General Discussion below.
General discussion
Widespread evidence indicates that motivationally-salient information is prioritized in attention and memory and that such prioritization might be supported by dopaminergic modulation of cortical and subcortical activity critical to cognition (Braver et al., 2014). Given the characterization of DA system activity at multiple temporal dynamics, reflecting distinct neurobiological mechanisms and potentially supporting distinct functional outcomes (Grace, 1991; Niv, 2007), we compared the potential effects of transient and sustained reward, putatively associated with phasic versus tonic DA, respectively, on memory encoding in the present study. Across three experiments, we leveraged a mixed block/event task paradigm similar to those we have previously used to disentangle transient reward (by comparing performance on incentivized versus non-incentivized trials, manipulated on a trial-by-trial basis) and sustained reward (by comparing performance on trials in a baseline block, versus non-incentivized trials in a task block with reward prospect) on cognitive control (Chiew & Braver, 2013). In two of the three experiments conducted in the present study (Experiment 1 and 3), we observed a benefit of transient reward on subsequent item memory accuracy. In contrast, sustained reward did not appear to have a significant effect on subsequent memory accuracy. Instead, the sustained reward was associated with altered performance (specifically, decreased RTs) in a simple response task performed during the encoding stage. Notably, RT speeding also increased with time on task in all three experiments, and when accounting for time on task as a factor, RT differences as a function of incentive dropped to a trend level in Experiment 3. However, RT differences as a function of sustained reward (faster RTs in both Non-Incentive and Incentive trials relative to baseline) remained significant after accounting for time on task in both Experiment 1 and 2. Taken together across the three experiments, these observations suggest potentially separate functional roles for transient and sustained reward, and in particular, a benefit of transient reward (putatively engaging phasic dopamine) to memory formation.
Importantly, not all of our observations were consistent with predictions. In particular, in Experiment 2, we did not observe any reward benefit (on either a transient or sustained timescale) to subsequent item memory, even after conducting a replication-enabling investigation with a larger sample. These results were inconsistent in both Experiments 1 and 3 but are difficult to pinpoint why, given similar paradigms in all three experiments, consistent retention intervals across both Experiments 1 and 2, and similar young adult samples recruited from an undergraduate subject pool at the University of Denver for all three experiments. When examining for demographic differences across participant samples, we did observe some variation in gender, age, and years of education,Footnote 2 but these differences do not clearly distinguish Experiment 2 participant samples from samples for Experiments 1 and 3. While many prior studies have suggested a reward benefit to memory in MIE-type paradigms, where a reward cue precedes the presentation of a to-be-remembered target, one recent study (Poh et al., 2019) did not observe a significant benefit of reward to incidental memory. While this observation was interpreted as potentially stemming from the lack of an overnight consolidation period, this suggests that reward benefits to memory should not be considered globally robust.
Along with these inconsistent effects of reward incentive on item memory accuracy, we also observed effects of reward incentive on item memory confidence: specifically, larger differences in confidence levels in correct versus incorrect responses to previously-shown stimuli (i.e., “hits” versus “misses”). Interestingly these effects were observed across all three experiments, but in Experiments 1 and 3, reward effects on memory confidence differences were observed as a function of transient reward (i.e., larger differences in confidence levels for memory hits versus misses in Incentive trials compared to Non-Incentive and Baseline trials), while in Experiments 2A and 2B, reward effects on memory confidence differences were observed as a function of sustained reward (i.e., larger differences in confidence levels were observed in Incentive and Non-Incentive trials, compared to Baseline trials). High-confidence memory recognition has been suggested to reflect recollective processes preferentially depending on the hippocampus (Kim & Cabeza, 2009), which is parsimonious with an account whereby reward-related dopamine modulation might improve memory via input to hippocampal structures. However, why these memory confidence differences might be occurring with transient reward in Experiments 1 and 3, where item memory accuracy also increased with reward, and sustained reward with Experiment 2, where item memory accuracy did not change with reward, is not currently clear. Memory confidence is often, but not always, related to memory accuracy (Busey, Tunnicliff, Loftus, & Loftus, 2000) and some evidence suggests that dopamine can have differential effects on memory performance versus metacognitive confidence but has not examined such influences at different timescales (Clos et al., 2019). Further research examining the effects of reward motivation on memory accuracy versus confidence, and potential differences as a function of temporal dynamics could help clarify this issue further.
In considering differences across experiments in the present study and variation across experimental samples more broadly, we noted that when comparing performance in Experiment 2A to its replication, Experiment 2B, error rates were higher and item memory confidence was lower in Experiment 2B. In considering these performance differences between Experiment 2A and 2B, we note that Experiment 2A (as well as Experiment 1 and 3) were conducted prior to the onset of COVID-19 in the United States in the Spring of 2020, while Experiment 2B was conducted later, in Fall 2022. While all participant samples used consistent eligibility criteria, including no known history of neurological disorder or injury, no current diagnosis of psychiatric or psychological disorder, and no current use of psychotropic medication, the COVID-19 pandemic and related disruption have been a major and ongoing source of chronic stress worldwide, characterized in samples including U.S.-based university students similar to the population recruited for the present study (Copeland et al., 2021; Kecojevic et al., 2020) and associated with decrements in cognitive task performance (da Silva Castanheira et al., 2021). Separate work has observed reduced memory confidence under stress (Corbett et al., 2017), suggesting that lower memory confidence in Experiment 2B could potentially be related to increased stress as a result of COVID-19 as well. While we did not obtain measures of stress or affective state from our participants, such influences could act as potential sources of variation in task performance. Indeed, our own recent work (Chiew et al., 2018) suggests that the effect of motivational influences on memory might vary with individual differences. Future research leveraging larger sample sizes could further explore individual variation in stress, affect, and trait differences as potential contributions to variability in motivated memory effects.
Additionally, across Experiments 2 and 3, memory accuracy for context information was not significantly modulated by reward. We had anticipated that context memory should be enhanced by reward motivation, potentially to an equal or greater extent than item memory, on the basis of prior findings suggesting that reward motivation facilitates hippocampal associative binding processes, integrating event elements such as item and context information together into coherent memory representations (Shigemune et al., 2014; Shohamy & Adcock, 2010; Wolosin et al., 2012). The null effects of reward on context memory in the present study, in contrast to such prior studies, may have resulted from a number of possible factors. First, given that context memory judgments were only performed for target items reported as “old” at recognition, the number of trials where context memory judgments could be evaluated as correct or incorrect (i.e., trials where a previously-shown target item was correctly remembered) were relatively limited relative to the number of trials where item memory was evaluated,Footnote 3 making it more difficult to detect incentive-related differences. Recent work from the psychological methods literature has suggested that, in addition to considering sample size when ensuring adequate statistic power, the number of task trials be also considered (Boudewyn et al., 2018). While to our knowledge, guidelines have yet to be established regarding statistical power and appropriate numbers of trials in a recognition memory task, the limited number of context memory trials completed likely limited our ability to detect differences between incentive conditions. In addition to this limitation, context memory performance, in terms of proportion of trials correct, was at ~ 0.5 (chance levels) in both Experiment 2 and 3.Footnote 4 Performance at this level may reflect a floor effect, with context memory performance too low to reveal susceptibility to reward manipulations. It is possible that context memory was at this level because the context information being judged (discerning whether the target item was paired with a red or blue colored border) was relatively devoid of semantic content, as opposed to stimuli such as object pairs that have been used to examine reward benefits to associative encoding (e.g., Wolosin et al., 2012) and that might be more amenable to memory elaboration and encoding. However, note that other researchers such as Shigemune et al. (2014) have successfully demonstrated reward benefits to context memory information such as item location (i.e., whether the remembered item was presented on the left versus right side of the screen at encoding), which also lacks semantic information, similarly to our manipulation. Follow-up studies with a larger number of context memory task trials will be helpful in further clarifying these results and the potential nature of transient and sustained reward on context memory.
Another unexpected finding that emerged from our data is that the largest benefit of transient reward to memory performance was observed in Experiment 3, where the encoding-retrieval interval was ~ 15 min (instead of ~ 24 h as in Experiments 1 and 2). Given research suggesting that reward-related benefits to memory encoding might be amplified by overnight consolidation (Murayama & Kitagami, 2014; Spaniol et al., 2014), we anticipated that shortening the retention interval should attenuate the benefit of reward on memory performance (although note that other studies have observed reward-enhanced memory with immediate retrieval following encoding; (Gruber et al., 2013; Murty & Adcock, 2014). Additionally, in Experiment 3, the reward was not associated with significantly higher arrow accuracy and the reward-related benefit to memory did not appear to relate to arrow task performance at encoding (as indicated by lack of model improvement when adding arrow error rates as a predictor of item memory outcome). Similar to these null findings in Experiment 3, we observed an inconsistent relationship between arrow task performance and subsequent memory in Experiment 2, with faster RTs predicting hits versus misses in the Baseline condition, but faster RTs predicting misses versus hits in the Incentive condition. Given these findings, it is uncertain to what extent reward effects on subsequent memory are associated with reward-related changes in performance or attention at encoding, as previously been suggested in the value-directed remembering literature (Cohen et al., 2014; Elliott et al., 2019). Additionally, while performance on our arrow task was characterized during the encoding period, performance on this task was incidental to the to-be-remembered target stimuli and cannot be considered a direct proxy for attention to the target stimuli themselves. In future work, measures beyond overt task performance, such as eye-tracking or neuroimaging, might be able to better characterize the nature of task performance and attention at encoding and their relationships to subsequent memory under transient and sustained reward, clarifying these observed results further.
It is also important to note that the mixed block/event reward manipulation we used in the present study, enabling characterizations of sustained versus transient reward, has been previously used to examine cognitive control but not, to our knowledge, memory encoding. Our observations suggest that transient reward (comparing between non-incentive and incentive trials, with reward incentive manipulated trial-by-trial) benefited memory accuracy while sustained reward (comparing between baseline and non-incentive trials, with reward prospect manipulated on a blocked basis) did not. Given that baseline and reward blocks were presented in a set order, our results also suggest that time on task was a significant contributor to both arrow task performance as well as subsequent memory, and may have accounted for some observed effects of sustained reward on RT speeding in Experiments 2 and 3. Future studies that counterbalance the order of baseline and reward blocks should help mitigate such time-on-task effects. The null effect of sustained reward on subsequent memory performance is consistent with prior pharmacological evidence that increased tonic dopamine does not benefit associative memory (Breitenstein et al., 2006), although opposing evidence suggests that hippocampally-reliant spatial memory in rodents remained intact when phasic dopamine activity was selectively disabled (Zweifel et al., 2009) and those reward manipulations can retroactively benefit memory for previously-presented neutral stimuli in humans (Murayama & Kitagami, 2014). These observations continue to suggest a potential role for sustained reward and tonic dopamine in supporting memory formation that has yet to be fully characterized.
An additional consideration for future work is how sustained versus transient reward dynamics are distinguished. Neuroimaging studies in humans have suggested that memory encoding might be enhanced in motivational contexts where reward prospect and associated neural regions (e.g., the VTA) are active over temporally extended periods that have been described as sustained (MacInnes et al., 2016; Shohamy & Adcock, 2010; Stanek et al., 2019). However, it is important to note that the temporal windows identified in these prior studies are multi-second but < 1 min in length: MacInnes et al. (2016) observed sustained VTA activation related to motivation in ~ 20-s time windows, while in Stanek et al. (2019), reward benefits to memory were behaviorally characterized for stimuli presented ~ 3–3.6 s following reward cue onset in association with putative slow, ramping dopamine responses. In contrast, our study examined task performance was a function of sustained reward in terms of blockwise effects (e.g., comparing between baseline and reward-prospect blocks), with task blocks of ~ 20 min in length. Thus, our characterization of sustained reward in the present study was over a considerably longer time period than those previously characterized as “sustained” and linked to memory benefit. As we have previously noted (Chiew et al., 2016), reward-related dopaminergic responses have been characterized as rapid, phasic responses; tonic responses over a sustained period; or multi-second ramping responses, thought to operate on a temporal window intermediate to phasic and tonic activity. Given these findings, additional clarification of what might constitute transient versus sustained reward, characterization of associated dopaminergic responses and the timescales on which they operate, as well as their contributions to memory formation, continues to be important for a comprehensive understanding of reward and dopaminergic modulation of memory.
In conclusion, in two out of three experiments, we obtained evidence suggesting that transient reward was generally associated with enhanced item memory accuracy, while the sustained reward was associated with RT speeding but with no benefit to memory accuracy. This pattern of results was interpreted as potentially consistent with accounts positing distinct roles for phasic and tonic dopamine in cognition, and in particular, the idea that phasic dopamine might support updating of mental representations and reward learning (Braver & Cohen, 2000; Floel et al., 2008; Schultz, 1998), while tonic dopamine might promote response vigor and speeding, even when reward receipt is not contingent on speed (Manohar et al., 2017; Niv et al., 2007). However, we also observed results contrary to our predictions, including a null effect of reward on overall memory benefit in Experiment 2, null effects of reward on context memory accuracy in both Experiment 2 and 3, and the largest reward-related memory benefit in Experiment 3, where overnight consolidation was eliminated. We also observed effects of reward incentive on differences in item memory confidence for correct versus incorrect responses (“hits” versus “misses”) across all three experiments, but in Experiments 1 and 3 this reward effect was observed at a transient timescale, along with transient reward benefit to item memory accuracy, while in Experiment 2, the reward effect on memory confidence was observed at a sustained timescale, in the absence of reward effects on item memory accuracy. Future research should incorporate designs including larger samples, greater numbers of context memory trials, measures of trait individual differences, and biological measures such as eye-tracking and neuroimaging to clarify the nature of these effects. Such efforts would advance further our understanding of transient and sustained reward contributions to memory encoding and cognitive performance.
Data availability
Data and code for this study are available at: https://osf.io/eayxg/
Notes
In addition to Experiment 1, we tested for significant correlations between errors and RTs in each incentive condition of the subsequently-described Experiment 2 and 3. The only significant correlation observed was between errors and RTs in the baseline condition of Experiment 2B. This suggests that differences in error rates and RTs specifically as a function of changes in incentive are not likely to be the product of systematic speed-accuracy tradeoff.
Testing for demographic differences across experiments: Race: χ2(12, N = 116) = 15.64, p = 0.21; Gender: χ2(6, N = 88) = 15.57, p = 0.02; Age: F(3,108) = 2.37, p = 0.07; Years of Education: F(3,108) = 3.81, p = 0.01. By pairwise comparisons, the effect on Gender was driven by differences between Experiment 2B (13 females, 7 males, 4 non-binary or declined to specify) and Experiment 3 (23 females, 7 males). By pairwise comparisons, the trend effect on Age was driven by differences between Experiment 1 (M = 20.7 years, SD = 3.26) and Experiment 2B (M = 19.1 years, SD = 1.12). By pairwise comparisons, the effect on Years of Education was driven by differences between Experiment 1 (M = 14.3 years, SD = 2.40) and 2B (M = 12.9 years, SD = 0.97) as well as Experiment 1 and Experiment 3 (M = 13.00, SD = 1.39). While these differences suggest some demographic variability across our experiments, they do not neatly account for a null effect of transient reward on memory accuracy in Experiment 2 versus Experiments 1 and 3.
In Experiment 2A and 2B combined, an average of 18.1 (SD = 7.4) context memory judgments (i.e., for correctly identified item hits) were conducted per incentive condition, and in Experiment 3 an average of 18.2 (SD = 7.3) context memory judgments were conducted per incentive condition (versus 40 item memory judgments per incentive condition in all three experiments).
In item memory recognition, previously-shown target stimuli were correctly endorsed as old (i.e., “hits”) at a proportion of ~ 0.5 as well. However, across all experiments, the proportion of hits was significantly greater than “false alarms” (novel stimuli at recognition that were incorrectly endorsed as old), indicating that item memory accuracy was greater than chance. No such opportunity for false alarms was available for context memory judgments.
References
Adcock, R. A., Thangavel, A., Whitfield-Gabrieli, S., Knutson, B., & Gabrieli, J. D. E. (2006). Reward-motivated learning: Mesolimbic activation precedes memory formation. Neuron, 50(3), 507–517. https://doi.org/10.1016/j.neuron.2006.03.036
Ariel, R., & Castel, A. D. (2014). Eyes wide open: Enhanced pupil dilation when selectively studying important information. Experimental Brain Research, 232(1), 337–344.
Bates, D., Maechler, M., Bolker, B., Walker, S., Christensen, R. H. B., Singmann, H., … Green, P. (2018). Package ‘lme4’. Version, 1(17), 437.
Beierholm, U., Guitart-Masip, M., Economides, M., Chowdhury, R., Düzel, E., Dolan, R., & Dayan, P. (2013). Dopamine modulates reward-related vigor. Neuropsychopharmacology, 38(8), 1495–1503.
Berridge, K. C., & Kringelbach, M. L. (2008). Affective neuroscience of pleasure: reward in humans and animals. Psychopharmacology (berl), 199(3), 457–480.
Berridge, K. C., & Robinson, T. E. (1998). What is the role of dopamine in reward: Hedonic impact, reward learning, or incentive salience? Brain Research Reviews, 28(3), 309–369. https://doi.org/10.1016/S0165-0173(98)00019-8
Botvinick, M., & Braver, T. (2015). Motivation and cognitive control: From behavior to neural mechanism. Annual Review of Psychology, 66, 83–113. https://doi.org/10.1146/annurev-psych-010814-015044
Boudewyn, M. A., Luck, S. J., Farrens, J. L., & Kappenman, E. S. (2018). How many trials does it take to get a significant ERP effect? It depends. Psychophysiology, 55(6), e13049.
Bowen, H.J., Marchesi, M., & Kensinger, E. (2019). Reward motivation influences response bias on a recognition memory task.
Bowen, Holly J, Gallant, S. N., & Moon, D. H. (2020). Influence of reward motivation on directed forgetting in younger and older adults. Frontiers in Psychology, 11.
Bowyer, P. A., Humphreys, M. S., & Revelle, W. (1983). Arousal and recognition memory: The effects of impulsivity, caffeine and time on task. Personality and Individual Differences, 4(1), 41–49.
Braver, T. S., & Cohen, J. D. (2000). On the control of control: The role of dopamine in regulating prefrontal function and working memory. In S. Monsell & J. Driver (Eds.), Attention and performance XVIII (pp. 713–737). MIT Press.
Braver, T. S., Krug, M. K., Chiew, K. S., Kool, W., Westbrook, J. A., Clement, N. J., & Somerville, L. H. (2014). Mechanisms of motivation-cognition interaction: challenges and opportunities. Cognitive, Affective and Behavioral Neuroscience, 14(2), 443–472.
Breitenstein, C., Korsukewitz, C., Flöel, A., Kretzschmar, T., Diederich, K., & Knecht, S. (2006). Tonic dopaminergic stimulation impairs associative learning in healthy subjects. Neuropsychopharmacology, 31(11), 2552–2564.
Busey, T. A., Tunnicliff, J., Loftus, G. R., & Loftus, E. F. (2000). Accounts of the confidence-accuracy relation in recognition memory. Psychonomic Bulletin and Review, 7(1), 26–48.
Castel, A. D. (2007). The adaptive and strategic use of memory by older adults: Evaluative processing and value-directed remembering. Psychology of Learning and Motivation, 48, 225–270.
Chiew, K. S., & Adcock, R. A. (2019). Motivated memory: integrating cognitive and affective neuroscience. Cambridge Handbook of Motivation and Learning.
Chiew, K. S., & Bowen, H. J. (2022). Neurobiological mechanisms of selectivity in motivated memory. In A. Elliot (Ed.), Advances in motivation science. USA: Elsevier.
Chiew, K. S., & Braver, T. S. (2013). Temporal dynamics of motivation-cognitive control interactions revealed by high-resolution pupillometry. Frontioers Psychology, 4, 15.
Chiew, K. S., & Braver, T. S. (2014). Dissociable influences of reward motivation and positive emotion on cognitive control. Cognitive, Affective and Behavioral Neuroscience, 14(2), 509–529.
Chiew, K. S., & Braver, T. S. (2016). Reward favors the prepared: Incentive and task-informative cues interact to enhance attentional control. Journal of Experimental Psychology: Human Perception and Performance, 42(1), 52–66. https://doi.org/10.1037/xhp0000129
Chiew, K. S., Hashemi, J., Gans, L. K., Lerebours, L., Clement, N. J., Vu, M.-A.T., & Adcock, R. A. (2018). Motivational valence alters memory formation without altering exploration of a real-life spatial environment. PLoS ONE, 13, e0193506.
Chiew, K. S., Stanek, J. K., & Adcock, R. A. (2016). Reward anticipation dynamics during cognitive control and episodic encoding: implications for dopamine. Frontiers in Human Neuroscience, 10, 555. https://doi.org/10.3389/fnhum.2016.00555
Chowdhury, R., Guitart-Masip, M., Bunzeck, N., Dolan, R. J., & Düzel, E. (2012). Dopamine modulates episodic memory persistence in old age. Journal of Neuroscience, 32(41), 14193–14204.
Clewett, D., & Murty, V. P. (2019). Echoes of emotions past: How neuromodulators determine what we recollect. Eneuro, 6(2).
Clos, M., Bunzeck, N., & Sommer, T. (2019). Dopamine is a double-edged sword: Dopaminergic modulation enhances memory retrieval performance but impairs metacognition. Neuropsychopharmacology, 44(3), 555–563.
Cohen, M. S., Rissman, J., Hovhannisyan, M., Castel, A. D., & Knowlton, B. J. (2017). Free recall test experience potentiates strategy-driven effects of value on memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(10), 1581.
Cohen, M. S., Rissman, J., Suthana, N. A., Castel, A. D., & Knowlton, B. J. (2014). Value-based modulation of memory encoding involves strategic engagement of fronto-temporal semantic processing regions. Cognitive, Affective and Behavioral Neuroscience, 14(2), 578–592. https://doi.org/10.3758/s13415-014-0275-x
Copeland, W. E., McGinnis, E., Bai, Y., Adams, Z., Nardone, H., Devadanam, V., & Hudziak, J. J. (2021). Impact of COVID-19 pandemic on college student mental health and wellness. Journal of the American Academy of Child and Adolescent Psychiatry, 60(1), 134–141.
Corbett, B., Weinberg, L., & Duarte, A. (2017). The effect of mild acute stress during memory consolidation on emotional recognition memory. Neurobiology of Learning and Memory, 145, 34–44.
da Silva Castanheira, K., Sharp, M., & Otto, A. R. (2021). The impact of pandemic-related worry on cognitive functioning and risk-taking. PLoS ONE, 16(11), e0260061.
Elliott, B. L., Brewer, G. A., Zwaan, R., & Madan, C. (2019). Divided attention selectively impairs value-directed encoding. Collabra: Psychology, 5(1).
Engelmann, J. B., Damaraju, E., Padmala, S., & Pessoa, L. (2009). Combined effects of attention and motivation on visual task performance: Transient and sustained motivational effects. Frontiers in Human Neuroscience, 3, 4.
Engelmann, J. B., & Pessoa, L. (2014). Motivation sharpens exogenous spatial attention. Motivation Science., 1, 64.
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G*Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191.
Floel, A., Garraux, G., Xu, B., Breitenstein, C., Knecht, S., Herscovitch, P., & Cohen, L. G. (2008). Levodopa increases memory encoding and dopamine release in the striatum in the elderly. Neurobiology of Aging, 29(2), 267–279.
Goto, Y., Otani, S., & Grace, A. A. (2007). The Yin and Yang of dopamine release: A new perspective. Neuropharmacology, 53(5), 583–587.
Grace, A. A. (1991). Phasic versus tonic dopamine release and the modulation of dopamine system responsivity: a hypothesis for the etiology of schizophrenia. Neuroscience, 41(1), 1–24.
Gruber, M. J., Gelman, B. D., & Ranganath, C. (2014). States of curiosity modulate hippocampus-dependent learning via the dopaminergic circuit. Neuron, 84(2), 486–496. https://doi.org/10.1016/j.neuron.2014.08.060
Gruber, M. J., Ritchey, M., Wang, S. F., Doss, M. K., & Ranganath, C. (2016). Post-learning hippocampal dynamics promote preferential retention of rewarding events. Neuron, 89(5), 1110–1120. https://doi.org/10.1016/j.neuron.2016.01.017
Gruber, M. J., Watrous, A. J., Ekstrom, A. D., Ranganath, C., & Otten, L. J. (2013). Expected reward modulates encoding-related theta activity before an event. NeuroImage, 64, 68–74.
Jimura, K., Locke, H. S., & Braver, T. S. (2010). Prefrontal cortex mediation of cognitive enhancement in rewarding motivational contexts. Proceedings of the National Academy of Sciences of the United States of America, 107(19), 8871–8876.
Kecojevic, A., Basch, C. H., Sullivan, M., & Davi, N. K. (2020). The impact of the COVID-19 epidemic on mental health of undergraduate students in New Jersey, cross-sectional study. PLoS ONE, 15(9), e0239696.
Kim, H., & Cabeza, R. (2009). Common and specific brain regions in high-versus low-confidence recognition memory. Brain Research, 1282, 103–113.
Klinzing, J. G., Niethard, N., & Born, J. (2019). Mechanisms of systems memory consolidation during sleep. Nature Neuroscience, 22(10), 1598–1610.
Kostandyan, M., Bombeke, K., Carsten, T., Krebs, R. M., Notebaert, W., & Boehler, C. N. (2019). Differential effects of sustained and transient effort triggered by reward—a combined EEG and pupillometry study. Neuropsychologia, 123, 116–130.
Lisman, J. E., & Grace, A. A. (2005). The hippocampal-VTA loop: Controlling the entry of information into long-term memory. Neuron, 46(5), 703–713. https://doi.org/10.1016/j.neuron.2005.05.002
MacInnes, J. J., Dickerson, K. C., Chen, N., & Adcock, R. A. (2016). Cognitive neurostimulation: Learning to volitionally sustain ventral tegmental area activation. Neuron, 89(6), 1331–1342. https://doi.org/10.1016/j.neuron.2016.02.002
Manohar, S. G., Finzi, R. D., Drew, D., & Husain, M. (2017). Distinct motivational effects of contingent and noncontingent rewards. Psychological Science, 28(7), 1016–1026.
Marshall, L., & Born, J. (2007). The contribution of sleep to hippocampus-dependent memory consolidation. Trends in Cognitive Sciences, 11(10), 442–450.
Miendlarzewska, E. A., Bavelier, D., & Schwartz, S. (2016). Influence of reward motivation on human declarative memory. Neuroscience and Biobehavioral Reviews, 61, 156–176.
Mowbray, G. H., & Rhoades, M. V. (1959). On the reduction of choice reaction times with practice. Quarterly Journal of Experimental Psychology, 11(1), 16–23.
Murayama, K., & Kitagami, S. (2014). Consolidation power of extrinsic rewards: Reward cues enhance long-term memory for irrelevant past events. Journal of Experimental Psychology: General, 143(1), 15–20. https://doi.org/10.1037/a0031992
Murty, V. P., & Adcock, R. A. (2014). Enriched encoding: Reward motivation organizes cortical networks for hippocampal detection of unexpected events. Cerebral Cortex, 24(8), 2160–2168. https://doi.org/10.1093/cercor/bht063
Murty, V. P., LaBar, K. S., & Adcock, R. A. (2016). Distinct medial temporal networks encode surprise during motivation by reward versus punishment. Neurobiology of Learning and Memory. https://doi.org/10.1016/j.nlm.2016.01.018
Murty, V. P., LaBar, K. S., Hamilton, D. A., & Adcock, R. A. (2011). Is all motivation good for learning? Dissociable influences of approach and avoidance motivation in declarative memory. Learning & Memory (cold Spring Harbor N.y.), 18(11), 712–717. https://doi.org/10.1101/lm.023549.111
Niv, Y. (2007). Cost, benefit, tonic, phasic: What do response rates tell us about dopamine and motivation? Annals of the New York Academy of Sciences, 1104, 357–376.
Niv, Y., Daw, N. D., Joel, D., & Dayan, P. (2007). Tonic dopamine: Opportunity costs and the control of response vigor. Psychopharmacology (berl), 191(3), 507–520.
O’Reilly, R. C., & Frank, M. J. (2006). Making working memory work: A computational model of learning in the prefrontal cortex and basal ganglia. Neural Computation, 18, 283–328.
Payne, J., Chambers, A. M., & Kensinger, E. A. (2012). Sleep promotes lasting changes in selective memory for emotional scenes. Frontiers in Integrative Neuroscience, 6, 108.
Pinheiro, J., Bates, D., DebRoy, S., & Sarkar, D. (2013). nlme: Linear and nonlinear mixed effects models. R Package Version., 3, 1–89.
Poh, J. H., Massar, S. A., Jamaluddin, S. A., & Chee, M. W. (2019). Reward supports flexible orienting of attention to category information and influences subsequent memory. Psychonomic Bulletin & Review, 26, 559–568.
Sawaguchi, T., & Goldman-Rakic, P. S. (1991). D1 dopamine receptors in prefrontal cortex: involvement in working memory. Science, 251(4996), 947–950.
Schultz, W. (1998). Predictive reward signal of dopamine neurons. Journal of Neurophysiology, 80(1), 1–27.
Schultz, W., Dayan, P., & Montague, P. R. (1997). A neural substrate of prediction and reward. Science, 275(5306), 1593–1599.
Shigemune, Y., Tsukiura, T., Kambara, T., & Kawashima, R. (2014). Remembering with gains and losses: Effects of monetary reward and punishment on successful encoding activation of source memories. Cerebral Cortex (new York, NY), 24(5), 1319–1331. https://doi.org/10.1093/cercor/bhs415
Shohamy, D., & Adcock, R. A. (2010). Dopamine and adaptive memory. Trends in Cognitive Sciences, 14(10), 464–472. https://doi.org/10.1016/j.tics.2010.08.002
Spaniol, J., Schain, C., & Bowen, H. J. (2014). Reward-enhanced memory in younger and older adults. Journals of Gerontology Series b: Psychological Sciences and Social Sciences, 69(5), 730–740.
Stanek, J. K., Dickerson, K. C., Chiew, K. S., Clement, N. J., & Adcock, R. A. (2019). Expected reward value and reward uncertainty have temporally dissociable effects on memory formation. Journal of Cognitive Neuroscience, 31(10), 1443–1454.
Stickgold, R. (2005). Sleep-dependent memory consolidation. Nature, 437(7063), 1272–1278.
Studte, S., Bridger, E., & Mecklinger, A. (2017). Sleep spindles during a nap correlate with post sleep memory performance for highly rewarded word-pairs. Brain and Language, 167, 28–35.
Villaseñor, J. J., Sklenar, A. M., Frankenstein, A. N., Levy, P. U., McCurdy, M. P., & Leshikar, E. D. (2021). Value-directed memory effects on item and context memory. Memory & Cognition, 49(6), 1082–1100.
Visscher, K. M., Miezin, F. M., Kelly, J. E., Buckner, R. L., Donaldson, D. I., McAvoy, M. P., & Petersen, S. E. (2003). Mixed blocked/event-related designs separate transient and sustained activity in fMRI. NeuroImage, 19(4), 1694–1708.
Walker, M. P., & Stickgold, R. (2004). Sleep-dependent learning and memory consolidation. Neuron, 44(1), 121–133.
Williams, R. S., Biel, A. L., Dyson, B. J., & Spaniol, J. (2017). Age differences in gain-and loss-motivated attention. Brain and Cognition, 111, 171–181.
Williams, R. S., Kudus, F., Dyson, B. J., & Spaniol, J. (2018). Transient and sustained incentive effects on electrophysiological indices of cognitive control in younger and older adults. Cognitive, Affective, and Behavioral Neuroscience, 18(2), 313–330.
Wise, R. A., & Rompre, P. P. (1989). Brain dopamine and reward. Annual Review Psychology, 40, 191–225.
Wittmann, B. C., Schott, B. H., Guderian, S., Frey, J. U., Heinze, H.-J., & Düzel, E. (2005). Reward-related fMRI activation of dopaminergic midbrain is associated with enhanced hippocampus- dependent long-term memory formation. Neuron, 45(3), 459–467. https://doi.org/10.1016/j.neuron.2005.01.010
Wolosin, S. M., Zeithamova, D., & Preston, A. R. (2012). Reward modulation of hippocampal subfield activation during successful associative encoding and retrieval. Journal of Cognitive Neuroscience, 24(7), 1532–1547. https://doi.org/10.1162/jocn_a_00237
Yee, D. M., & Braver, T. S. (2018). Interactions of motivation and cognitive control. Current Opinion in Behavioral Sciences, 19, 83–90.
Yonelinas, A. P. (1994). Receiver-operating characteristics in recognition memory: Evidence for a dual-process model. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20(6), 1341.
Yonelinas, A. P. (2001). Components of episodic memory: the contribution of recollection and familiarity. Philosophical Transactions of the Royal Society of London. Series b: Biological Sciences, 356(1413), 1363–1374.
Zweifel, L. S., Parker, J. G., Lobb, C. J., Rainwater, A., Wall, V. Z., Fadok, J. P., & Paladini, C. A. (2009). Disruption of NMDAR-dependent burst firing by dopamine neurons provides selective assessment of phasic dopamine-dependent behavior. Proceeding National Academy of Sciences, 106(18), 7281–7288.
Acknowledgements
We thank Haley Paez for their assistance with data collection.
Funding
This work was funded by the National Institute of Mental Health (1R15MH117690) and the University of Denver.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
Author Gholston declares that she has no conflict of interest. Author Thurmann declares that he has no conflict of interest. Author Chiew declares that she has no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gholston, A.S., Thurmann, K.E. & Chiew, K.S. Contributions of transient and sustained reward to memory formation. Psychological Research 87, 2477–2498 (2023). https://doi.org/10.1007/s00426-023-01829-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-023-01829-5