
Abstract
Working memory (WM) training has gained interest due to its potential to enhance cognitive functioning and reduce symptoms of mental disorders. Nevertheless, inconsistent results suggest that individual differences may have an impact on training efficacy. This study examined whether individual differences in training performance can predict therapeutic outcomes of WM training, measured as changes in anxiety and depression symptoms in sub-clinical and healthy populations. The study also investigated the association between cognitive abilities at baseline and different training improvement trajectories. Ninety-six participants (50 females, mean age = 27.67, SD = 8.84) were trained using the same WM training task (duration ranged between 7 to 15 sessions). An algorithm was then used to cluster them based on their learning trajectories. We found three main WM training trajectories, which in turn were related to changes in anxiety symptoms following the training. Additionally, executive function abilities at baseline predicted training trajectories. These findings highlight the potential for using clustering algorithms to reveal the benefits of cognitive training to alleviate maladaptive psychological symptoms.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Cognitive training programs have yielded improvements in mental health symptoms. In two recent meta-analyses, computerized cognitive training was found to reduce symptoms among people with depression while also improving their overall cognition (Launder et al., 2021; Woolf et al., 2021). In other meta-analyses, participants with mild cognitive impairment or dementia showed improved cognitive abilities and alleviation of anxiety symptoms (García-Casal et al., 2017; Li et al., 2011). While these promising results have been the basis for many cognitive training studies, the findings have been questioned for their inconsistency across studies (for discussion, see Shani et al., 2019; Okon-Singer, 2018). Diverging outcomes of the training are common, even in studies that have used an identical training program and similar sample characteristics. These diverging outcomes have motivated the suggestion to examine the inherent potential of training dynamics in understanding and explaining the differential outcomes in cognitive training (Könen & Karbach, 2015). The aim of the current investigation was to identify how specific training trajectories are related to training efficacy. To this end, we chose a training program that targets working memory (WM), a system that has limited capacity in storing and processing relevant information (Baddeley & Hitch, 1974) and that influences and is influenced by vulnerability to psychological symptoms, including anxiety and depression (Moran, 2016; Semkovska, 2019; see Derakshan, 2020, for a review).
According to cognitive theories, deficient attentional control plays a key role in maintaining the vicious cycles of depression and anxiety (Berggren & Derakshan, 2013; Eysenck et al., 2007; Joormann & D’Avanzato, 2010; Koster et al., 2017). Attentional control is a dominant feature of WM and is defined as the ability to select only relevant information while ignoring irrelevant material (Duncan & Humphreys, 1989; Unsworth et al., 2012). Studies have suggested that poor ability to filter irrelevant information from WM may lead to psychological symptoms such as worry, anxiety and depression (Derakshan, 2020; Stout et al., 2015; Daches & Mor, 2014; Owens et al., 2013). The Attentional Control Theory (ACT, Eysenck et al., 2007) predicts a compensatory relation between emotion and cognition. Enhanced bottom-up processing undermines top-down regulation, which in turn leads to increased emotional processing. Conversely, when cognitive resources are required to identify a threat, emotional resources dwindle (for a review, see Berggren & Derakshan, 2013).
In recent years, WM training has been shown to play a role in alleviating symptoms of anxiety and depression (Sari et al., 2016; Beloe & Derakshan, 2019; see Derakshan, 2020, for a review). Such training studies usually include one task that serves as the training task and other tasks that are used to examine transfer to other cognitive domains (hereinafter: transfer tasks). Training-related changes as a function of WM training have been found in structurally similar tasks (near transfer). Such changes are also generalized to other untrained, dissimilar cognitive abilities (far transfer), which in turn may reduce anxiety and depression-related symptomatology (Owens et al., 2013; Sari et al., 2016). Nevertheless, inconsistent findings have generated controversy over the efficacy of WM training (for reviews, see Melby-Lervåg et al., 2016; Schwaighofer et al., 2015; Melby-Lervåg & Hulme, 2016; Wanmaker, Geraert & Franken, 2015). These diverging results can be attributed to different designs and methodological preferences (Karbach & Verhaeghen, 2014). Yet even participants who went through the same training task with similar training features demonstrated a high degree of variance in training outcomes (Könen & Karbach, 2015). It is possible that individual differences in training performance may help in understanding the mixed results regarding training effectiveness with respect to psychological symptoms (Könen & Karbach, 2015; Von Bastian & Oberauer, 2014). For example, Hotton et al. (2017) suggested that the absence of training-related improvements may explain the ineffectiveness of symptom reduction among high worriers. More recently, Ciobotaru et al. (2021) showed that training-related effects on improvements in emotional vulnerability were moderated by baseline levels of psychopathology.
Studies that have examined the effect of training progression focused on the training task itself or on other near-transfer cognitive tasks to evaluate training gains (Bürki et al., 2014; Guye et al., 2017). Nevertheless, very few studies have investigated the potential association between training trajectories and improvement in psychological symptoms. Moreover, training studies have adopted different analytical approaches in analyzing training efficacy (e.g., Bürki et al., 2014; Guye et al., 2017), possibly due to different training factors such as training tasks, number of sessions and duration of each session. These differences in analytical approach also highlight the importance of applying a more flexible and adaptive method in analyzing training trajectories.
Individual differences in cognitive abilities at baseline constitute another primary factor that may explain differences across cognitive training performance outcomes. A recent meta-analysis of 16 studies using adaptive WM training contends that near and far transfer cognitive abilities at baseline are consistent negative predictors of WM training outcomes (Ophey et al., 2020). In contrast, findings about training task baseline scores as predictors for training outcomes are more heterogenous (Ophey et al., 2020; Roheger et al., 2021), such that some studies report greater gains for low baseline cognitive ability (e.g., Borella et al., 2017; Zinke et al., 2014) while others report opposite effects (e.g., Brehmer et al., 2011; Heinzel et al., 2014).
In summary, despite the evidence that WM training may alleviate symptoms of anxiety and depression, findings are mixed. Most of the research so far has focused on the impact of training on behavioral outcomes and not on individual differences in learning patterns during training and on how these differences may be related to training efficacy and effects on well-being. To fill this gap, the current investigation sought to improve the understanding of WM training efficacy by examining inter-individual differences in learning patterns during training.
We collected data from six studies conducted in our laboratory and by collaborators, all using the same dual n-back training task. The dual n-back is an online computerized task that has been widely used in recent years to improve WM and other aspects of cognitive abilities (see Au et al. 2015, for a review). The studies we included used different pre-selection criteria and training durations, enabling us to examine the association between potential factors and training outcomes. Each study included at least one emotional questionnaire and transfer task in the pre- and post-training assessments. To define different learning curve trajectories, we used k-means, an innovative algorithm in this field, to cluster participants with homogenous learning characteristics. Finally, we examined the differences in psychological symptoms between these learning clusters as well as the potential predictors of the learning trajectories. Implementing a large-scale, diverse dataset enabled us to optimize the definition of varied training trajectories.
Given the sparsity of research and controversial disagreements in the field of inter-individual differences in cognitive training, we adopted an exploratory approach in our analyses. Based on diverging results in training outcomes, even for the same training regimes, we expected to find several trajectories for the dual n-back training that are associated with different psychological symptoms. Moreover, we predicted that learning trajectories are related to differences in cognitive abilities at baseline.
Methods
Participants
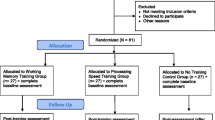
Six datasets were collected, comprising a total of 96 participants. The data included five datasets from the lab of Nazanin Derakshan (Course-Choi et al., 2017; Ducrocq et al., 2017; Hotton et al., 2017; Owens et al., 2013; Sari et al., 2016) and one from a study conducted by Wiener and Okon-Singer (unpublished results). The dropout rates ranged between 8 and 20%. All these studies included the following information: demographic details, pre-post emotional questionnaires, and pre-post cognitive tasks (Table 1). Three of the studies also included a 4-week follow-up measurement that entailed questionnaires and tasks. The data encompass participants who exhibit a large variety of mental disorders, among them anxiety, sub-clinical depression and worry, as well as healthy participants. Training sessions ranged from 7 to 15 days. Table 1 depicts the characteristics of all datasets.
Instruments and measurements
Cognitive tasks
Participants completed a daily practice session that entailed a computerized dual n-back task (Jaeggi et al., 2008) installed on their personal PCs. In this training task, the participant is simultaneously confronted with both an auditory and a visual stimulus and must decide whether both, one or none of the stimuli match the stimuli that were presented n items back, where n is changed adaptively from 1 to 4 according to the participant’s performance. In addition to the training task, each participant’s cognitive abilities were tested before and after the training. To examine the near-transfer effect, we implemented the change detection task (CDT; Owens et al., 2013). This task, adapted from Vogel et al. (2005), measures visuospatial working memory. To measure the far-transfer effect, we assessed inhibition using a modified version (Berggren & Derakshan, 2013) of the original flanker task (Eriksen & Eriksen, 1974). More details about the training and transfer tasks are provided in the supplementary material.
Psychological symptoms indices
All participants completed at least one questionnaire before and after the training to assess training-related improvement in emotional symptoms. The included studies employed different questionnaires to measure symptoms of anxiety and depression. In order to collapse these measures across studies, we created index scores based on several questionnaires. The rationale for creating main indices is the desire to use as much of the available data as possible. These indices allow for the use of large-scale and diverse data to examine relations between training performance and changes in psychological symptoms. The three main indices were created while taking into account statistical and theoretical issues (for a similar approach, see Rohr et al., 2015). The anxiety index consisted of the State-Trait Anxiety Inventory (STAI; Spielberger et al., 1970), the Penn State Worry Questionnaire (PSWQ; Meyer et al., 1990), and the Sports Anxiety Scale-2 (SAS-2; Smith et al., 2006) questionnaires, while the depression index included the Beck Depression Inventory-II (BDI-II; Beck et al., 1996) and the Ruminative Responses Scale (RRS; Nolen-Hoeksema & Morrow, 1991) questionnaires.
The final index—the general psychological symptoms index—was computed as the average of the scores on both the anxiety and the depression indices. For details about the questionnaires, see the supplementary material.
Data analysis
Defining learning trajectories
The k-means clustering algorithm was used to facilitate data-driven identification of training trajectories classes. For this purpose, we used the “kml” package for R (version 3.5.3; R Core Team, 2018), which is designed for working with longitudinal data (version 2.4.1; Genolini et al., 2015). The k-means algorithm belongs to the EM class (expectation–maximization; Celeux & Govaert, 1992). Depending on the initial configuration chosen, after k cluster centers have been set, the algorithm clusters all the training trajectories to k-number of clusters based on the minimal distance between the trajectory and each cluster center. In the expectation phase, the central position of each cluster, also called the seed, is computed. During the maximization phase, all training trajectories are reassigned to their nearest cluster based on the distance to its seed. Regarding studies with shorter training durations, the algorithm calculates the main learning clusters based on all training trajectories and available data, even from shorter trajectories. These two phases are repeated until none of the observations in each cluster change on the next partition. It is important to note that the main training trajectories are not limited to any specific model type such as linear, non-linear or quadratic models. The trajectories are computed as the average score of all trajectories in the cluster. This fluid algorithm enables us to define different types of trajectories that provide better discrimination between trajectories clusters and show smaller differences within each cluster.
We ran the algorithm with its default settings: The initial configuration to k-cluster centers was k means + + (Arthur & Vassilvitskii, 2007) and the EM phases were run 20 times for each number of clusters. After the algorithm was run, the first step was to choose the fittest number of clusters for this specific study, ranging from 2 to 6. We strove to achieve the highest number of clusters possible to capture as much of the variance in the data as possible. Clusters with exceptionally unequal groups (six clusters) were eliminated to avoid groups that were too small. Finally, several quality indices were examined for each number of clusters to decide the right number of clusters.
After defining the number of the main trajectories, we selected the iteration with the highest score (out of 20) according to the Calinski and Harabasz criterion (Calinski & Harabasz, 1974): \({\text{C}}\left( {\text{k}} \right)\, = \,\frac{{{\text{Trace}} \left( B \right)}}{{{\text{Trace }}\left( W \right)}} \cdot \frac{n - k}{{k - 1}}\) where B is the between-cluster covariance matrix and W is the within-cluster covariance matrix. Higher values of Trace (B) and lower values of Trace (W) are a strong indication of correct clustering.
To better understand each trajectory and its unique nature, the study examined the differences between the training score trajectories on the first day (i.e., baseline), the score on each training day and the level of daily improvement on the trained task (i.e., slope). Training task improvement was based on each participant’s score on each training cluster on the last training session day minus the score on the first day. These effects were analyzed using ANOVA and by a post-hoc Tukey test in case of significance. Due to the exploratory nature of these analyses, we did not correct for multiple comparisons.
Cross-validation of the main trajectories
To validate our results, we ran a cross-validation test on the entire dataset (Farrell & Lewandowsky, 2018). Data were split based on odd or even participant numbers to create two mixed, equally numbered sub-groups of 48 participants each. We used each group as a training group and applied the k-means algorithm for clustering into three main training patterns. The participants in each test group—the odd-numbered group and the even-numbered group—were clustered according to their training trajectories.
Learning performance and psychological symptoms
After the main trajectories clusters were defined, we examined differences in psychological index improvement between all clusters. To this end, we used ANOVA to examine the relationship between training trajectory classes and improvement in the anxiety index, depression index, and general psychological symptoms index (pre-post). Improvement was defined as the separate change scores on each of these three indices. When the original study included follow-up measurements, we ran the same tests on the follow-up measurements to examine the long-term effects of the training on psychological symptoms. Tests and diagrams were conducted using the “ggpubr” package (Kassambra, 2018) in R. Significant results were analyzed using a post-hoc Tukey test, taking into account Bonferroni correction. In case of a between-group difference on one of the measures, an additional T test was conducted to examine whether this measure improved significantly in each of the groups.
Predicting clustering by demographic details, cognitive abilities and psychological symptoms
An ANOVA was run to examine the association between training clusters and pre-training cognitive abilities, namely WM (assessed by the CDT task) and inhibition (assessed by the flanker task). Similarly, we tested whether training trajectories can be predicted by any of the psychological symptom indices, namely, anxiety, depression, and general psychological symptoms indices. A post-hoc Tukey test was used to analyze significant results. Finally, to check whether demographics are a factor in the prediction of learning clusters, the same analyses were conducted on gender and age.
Mediation analysis
Based on our results, we fitted a structural equation model (SEM) to estimate the association between training performance and inter-individual differences in cognitive abilities and well-being. SEM analyses were conducted using the "lavaan" package (version 0.6-4; Rosseel, 2012) in R. To investigate all the relationships, we built a mediation model using SEM. In our model, maximum likelihood (ML) was used to overcome missing data. We compared our model to a baseline model that included the mean and variance of all observed variables plus the covariances of all observed exogenous variables.
Please note that the methodological process in this study was exploratory. Consequently, no pre-registration protocol was applied for this study.
Results
Defining learning trajectories
Three trajectories were defined (Fig. 1A) based on the following rationale: First, the three-cluster allocation achieved an intermediate score on each criterion of the algorithm, better than any of the other allocations. Second, the three-cluster allocation yielded groups almost of equal size, suggesting that this allocation was not caused by a very small group. Criteria scores for the three clusters were: “(1) Calinski Harabatz-1: 137.12; (2) Calinski Harabatz-2: 3.01; (3) Calinski Harabatz-3: 193.92; (4) Ray Turi: − 0.03; (5) Davies Bouldin: − 1.20. For standardized criteria, see Fig. 1B. The three clusters were characterized as follows: The first cluster (cluster 1) included 30 participants (31.2%) of the 96. As can be seen in Fig. 1A (red line), most of these participants did not show any improvement during the training sessions. This main trajectory begins with a mean score of n = 1.39, followed by a slight improvement until session 8 (n = 1.76). This improvement is not maintained, as the trajectory finishes with a mean score of n = 1.28. The second trajectory cluster (cluster 2; blue line) included 36 participants (37.5%). This trajectory begins with a higher score than the first cluster, with a mean score of n = 1.86. In addition, throughout all the training days, this trajectory cluster was significantly higher than the trajectory in cluster 1. The trajectory improved consistently over the sessions until reaching an n-score of 3.34. The third cluster (cluster 3) also included 30 participants (31.2%) who showed the highest mean score in each session of the training. This cluster starts with the highest training score, with a mean of n = 2.46. The progression of this trajectory is slightly curved and ends with a score of n = 3.70, which was statistically different from the score on the last day in cluster 1 but not in cluster 2. For a comprehensive comparison between training trajectories please see the supplementary material.

Defining Training Trajectories. a All trajectories were grouped into three main clusters (trajectories) as suggested by the algorithm. Cluster 1 (red) did not show any improvement, cluster 2 (blue) demonstrated consistent improvement, and cluster 3 (green) demonstrated non-linear improvement. b Quality criteria for score/time trajectories. Each line represents a criterion score for each cluster number (possible range 2–6). Standardized criteria all agreed on an intermediate score for three clusters. c Participants in each of the three clusters (red, blue, and green) were present in (almost) all datasets
To verify that this clustering did not result from the specific studies included in our sample, we checked how the clustering was applied to each of our base studies. The studies included participants from all three clusters, except for one study that had participants from only two training clusters (Fig. 1C). Please note that the inclusion criterion for this study was similar to that of another study (i.e., participants with high scores on a worry questionnaire).
The amount of improvement on the training task differed between the training trajectories \(\left[ {F_{{\left( {2,93} \right)}} = 36.1, \,p < 0.0001, \,\eta^{2} = 0.437} \right]\). In a post-hoc Tukey-HSD, the improvements in training cluster 3 \(\left[ {M = 1.32, \,SD = 0.577} \right]\) and cluster 2 \(\left[ {M = 1.28, \,SD = 0.692} \right]\) were higher than those in training cluster 1 \(\left[ {M = 0.171, \,SD = 0.508} \right]\). The training trajectories also differed from each other on the first-day score of the training task \(\left[ {F_{{\left( {3,93} \right)}} = 43.73, \,p < 0.0001,\, \eta^{2} = 0.485} \right]\), such that participants in training cluster 3 had a higher average first-day score \(\left[ {M = 2.46, \,SD = 0.506} \right]\) than participants in cluster 2 \(\left[ {M = 1.86,\, SD = 0.468} \right]\). Moreover, participants in training cluster 2 scored higher on the training task than participants in cluster 1 \(\left[ {M = 1.39, \,SD = 0.338} \right]\).
Cross-validation of the main trajectories
In a cross-validation test of the main trajectories, both training groups (i.e., datasets from the odd and the even participants) exhibited trajectory lines similar to those found based on all the data. Specifically, 91 out of the 96 participants were clustered to the same learning trajectory to which they had been clustered based on the full data. Percentages of participant allocation to each cluster were also similar, with only small variations. In the odd training group, allocation percentages to clusters 1–3 were 29.2, 33.3, and 37.5%, respectively, while in the even training group allocation percentages to clusters 1–3 were 27.1, 39.6, and 33.3%, respectively.
Learning performance and psychological symptoms
To examine the effect of training performance on psychological symptoms, we used repeated-measures ANOVAs. In each ANOVA, the independent variable was the learning clusters, and the dependent variable was the change in each psychological symptom index (pre-post).
Improvement in anxiety symptoms from pre- to post-training differed between learning clusters (Fig. 2) \(\left[ {F_{{\left( {2,81} \right)}} = 4.854, \,p < 0.05, \,\eta^{2} = 0.107} \right]\). Yet no difference between clusters emerged for change in depression symptoms \(\left[ {F_{{\left( {2,47} \right)}} = 0.103, \,p = 0.902, \,\eta^{2} = 0.004} \right]\) or for general psychological symptoms \(\left[ {F_{{\left( {2,92} \right)}} = 1.433, \,p = 0.244, \,\eta^{2} = 0.03} \right]\). Furthermore, Tukey-HSD testing was used for post-hoc comparisons, taking into consideration alpha inflation by using Bonferroni correction. Our analysis indicated that the improvement in anxiety symptoms among participants in cluster 3 \(\left[ {M = 0.193, \,SD = 0.478} \right]\) was greater than among those in cluster 1 \(\left[ {M = - 0.208, \,SD = 0.513} \right]\).

Improvement in anxiety index pre-post training (T1-T2). Participants in cluster 3 showed more improvement than participants in cluster 1. Error bars show standard errors
T-tests that examined the change in anxiety symptoms in each cluster showed that anxiety symptoms decreased only in cluster 3 \(\left[ {T_{{\left( {28} \right)}} = 2.179, \,p < 0.05, \,Cohen^{\prime}s d = 0.405} \right]\) (Fig. 3).

Intra-group improvement in anxiety symptoms pre-post training (T1-T2). Only participants in cluster 3 demonstrated a reduction in anxiety symptoms. Error bars show standard errors
We conducted ANOVAs on follow-up measurements to identify differences between learning clusters on long-term improvements in psychological symptoms. The analyses indicated a difference in anxiety symptom improvements even over the long term \(\left[ {F_{{\left( {2,54} \right)}} = 6.062, \,p < 0.01, \,\eta^{2} = 0.183} \right]\). In contrast, long-term improvements in depression \(\left[ {F_{{\left( {2,45} \right)}} = 0.575, \,p = 0.567, \,\eta^{2} = 0.025} \right]\) and in general psychological symptoms \(\left[ {F_{{\left( {2,65} \right)}} = 1.398,\, p = 0.254, \,\eta^{2} = 0.041} \right]\) were not related to cluster allocation. In a post-hoc analysis for anxiety symptoms, the Tukey-HSD analysis demonstrated a significant difference between learning cluster 3 \(\left[ {M = 0.380,\, SD = 0.431} \right]\) and cluster 1 \(\left[ {M = - \,0.270, \,SD = 0.825} \right]\).
Predicting clustering by demographic details, cognitive abilities and psychological symptoms
An examination to determine whether demographic details, cognitive abilities or pre-training psychological symptoms predicted clusters found that clusters were not related to gender, age or psychological symptoms (Table 2). Nevertheless, the pre-training score on the CDT task differed between clusters \(\left[ {{\varvec{F}}_{{\left( {{\mathbf{2,79}}} \right)}} = {\mathbf{5}}{\mathbf{.164}},\,{ }{\varvec{p}} < {\mathbf{0}}{\mathbf{.01}},\,{ }{\varvec{\eta}}^{{\mathbf{2}}} = {\mathbf{0}}{\mathbf{.116}}} \right]\). Post-hoc multiple comparisons revealed a higher score for participants in cluster 3 \(\left[ {{\varvec{M}} = {\mathbf{1}}{\mathbf{.73}},{ }{\mathbf{SD}} = {\mathbf{0}}{\mathbf{.447}}} \right]\) than for those in cluster 1 \(\left[ {{\varvec{M}} = {\mathbf{1}}{\mathbf{.03}}\,,{ }{\mathbf{SD}} = {\mathbf{1}}{\mathbf{.09}}} \right]\). In addition, the pre-training flanker scores differed between clusters \(\left[ {{\varvec{F}}_{{\left( {{\mathbf{2,50}}} \right)}} = {\mathbf{9}}{\mathbf{.274}},\,{ }{\varvec{p}} < {\mathbf{0}}{\mathbf{.001}},\,{ }{\varvec{\eta}}^{{\mathbf{2}}} = {\mathbf{0}}{\mathbf{.271}}} \right]\), such that participants in cluster 3 had a better flanker score \(\left[ {{\varvec{M}} = {\mathbf{41}}{\mathbf{.2}},\,{ }{\mathbf{SD}} = {\mathbf{28}}{\mathbf{.1}}} \right]\) than participants in cluster 2 \(\left[ {{\varvec{M}} = {\mathbf{78}}{\mathbf{.4}},\,{ }{\mathbf{SD}} = {\mathbf{35}}{\mathbf{.7}}} \right]\) and in cluster 1 \(\left[ {{\varvec{M}} = {\mathbf{79}},\,{ }{\mathbf{SD}} = {\mathbf{32}}{\mathbf{.7}}} \right]\).
Mediation analysis
Based on the findings of an effect of learning clusters on anxiety symptoms and of a relation between pre-training cognitive abilities and training trajectories, a mediation model (Fig. 4) was used to examine whether training improvement mediated between cognitive abilities and anxiety improvement. Due to an insufficient number of participants who performed a flanker task, we used only the CDT task scores (82 observations).

The relations among cognitive abilities, learning clusters and improvement in anxiety symptoms. CDT baseline score exhibited a positive relation to learning performance. Moreover, learning performance exhibited a marginally significant positive relation to improvement in anxiety symptoms
The model was found to fit better than the baseline model \([\chi_{\left( 3 \right)}^{2} = 13.289, \,p < 0.01]\). Pre-training CDT scores predicted training clusters \([\beta = 0.283,\, SD = 0.096,\, Z = 2.940,\, p < 0.01]\) and a marginally significant relation emerged between training performance (cluster) and anxiety improvement \(\left[ {\beta = 0.157,\, SD = 0.083,\, Z = 1.893,\, p = 0.058} \right]\). CDT scores pre-training did not directly predict anxiety improvement \(\left[ {\beta = 0.036,\, SD = 0.075,\, Z = 0.482,\, p = 0.630} \right]\).
Discussion
The current study aimed to explain WM training efficacy by means of learning trajectories. We examined training performance patterns and their relation to improvement in well-being. The main finding of this study was that patterns of training performance were highly related to anxiety improvement following the training. Specifically, a sharp learning curve at the early stages of WM training combined with a higher baseline training score explained improvement in anxiety symptoms. Consistent with previous research (Guye et al., 2017), we also found that learning trajectory mediated the relation between cognitive abilities at baseline and the impact of training on anxiety symptoms.
Understanding training trajectories can contribute to building tailored training programs based on patient characteristics (Shani et al., 2019). In the last decade, the research domain of personalized treatment based on individual characteristics has grown substantially (Zilcha-Mano, 2019). To build an optimal training trajectory for a sample of patients with similar characteristics, training settings should be continually adapted during the sessions to maximize training effectiveness. Likewise, constant deviations from an optimal training trajectory during the first sessions can indicate that the cognitive task is ineffective for the individual and suggest the need for modification or replacement of the training program.
In this exploratory study, we used a k-means algorithm for longitudinal data to define different trajectories in the dual n-back training. To the best of our knowledge, the use of this semi-automatic algorithm is unprecedented in this field and provides a new perspective for examining WM training. Moreover, based on our data, we generated three psychological symptom indices to investigate the relation between training trajectories and improvement in the symptoms of anxiety, depression and general psychological symptoms. We believe that using this algorithm can enhance our understanding of who benefits more from cognitive trainings and can thus enable us to utilize training gains.
Our results show that training trajectories can be clustered to a small number of main training trajectories that differ on baseline training task score, learning curve and degree of improvement. Moreover, these training trajectories were robust in a strict cross-validation test. These results can help us understand the high variance of individual differences during training and how this variance is related to training outcomes (Hotton et al., 2017; Könen & Karbach, 2015). It is important to note that we defined the trajectories based only on the training scores while ignoring the original study from which they were collected. This method is designed to find more general clusters that can be implemented on other cognitive training tasks for different cognitive skills, for example, cognitive bias modification (CBM) training, which has demonstrated questionable efficacy (Cristea et al., 2015).
Our findings show that executive inhibitory abilities at baseline are positively related to training outcomes. Indeed, recent empirical studies indicated a strong relationship between individuals with high cognitive abilities and WM training gains (Guye et al., 2017; Wiemers et al., 2019). Nevertheless, a mediation test model built on our data revealed that learning trajectories may mediate the relation between WM abilities at baseline and post-training improvement in anxiety symptoms. Furthermore, expansion of this analysis demonstrated that training trajectories explain training outcomes above baseline and last training day scores in terms of effect size (see supplementary materials). This finding underscores that learning trajectories may serve as a potential factor in understanding who benefits more from the clinical implications of this type of training.
One interesting finding of this study is that a considerable proportion of individuals do not show training improvements throughout the course of training. Stout, Snackman & Larson, (2013) proposed that anxiety symptoms are related to impaired WM ability due to ineffective filtering of threat-related cues. Therefore, it is likely that poor performance on the WM training task may explain the mixed findings regarding the effectiveness of training on psychological symptoms (e.g., Hotton et al., 2017). More cognitive training studies are needed to explore training trajectories to shed more light on training efficacy.
Our study points to some hypothetical explanations as to why participants in the non-linear training trajectory (Fig. 1, green trajectory) exhibited better training gains. As both the non-linear and the linear (Fig. 1, blue trajectory) trajectories exhibited an identical level of improvement on the n-back task, and no statistical difference was found between these two training trajectories on their last training day score, it is possible that training outcomes are achieved only by a combination of higher pre-training cognitive abilities and a certain level of training gain. Alternatively, a thorough examination of the non-linear improvement trajectory reveals a ceiling effect, as many of the participants who were clustered around this trajectory achieved the maximum score possible on the task. Before each training session, participants in all experiments were told what n-back level they should act upon. This way, participants knew inherently whether they had progressed or deteriorated during the training. Thus, progression during the training was intrinsically rewarding for the participants who improved during the training and especially for those who reached the highest possible level in the task. Consequently, participants in this learning pattern received more rewarding feedback compared to the other trajectories. Participants in the non-linear trajectory may have experienced an increased sense of self-efficacy during the sessions. It has long been established that self-efficacy plays a central role in the self-regulation of mental disorders (Bandura, 1997; Muris, 2002). Self-efficacy is also critical for training motivation, which is known to be an antecedent for training outcomes (Colquitt et al., 2000). Furthermore, we tested the relation between the clusters and the improvements in the flanker task and the CDT scores. These analyses demonstrated a main effect for the training that improved the CDT scores only. In contrast, the improvement in CDT scores was unrelated to the clusters, suggesting that all clusters showed similar improvement in WM. This finding may provide indirect support for the possibility that self-efficacy plays a role in reducing anxiety symptoms (see supplementary materials). Since we did not examine self-efficacy, this suggestion should be considered with caution. Future studies can manipulate self-efficacy directly, for example by using different types of feedback or manipulating the difficulty of the training to examine the effect on anxiety improvement.
Despite the uniqueness of our study, a few limitations should be noted. First, all included studies used an adaptive dual n-back task limited to 4-back, even though most participants are prone to reach level four around session 7 (Jaeggi et al., 2008). Consequently, it is likely that there is an artificial ceiling effect that does not allow participants to reach their maximum potential. It is possible that without any artificial ceiling effect, some changes within the trajectories might occur, especially on the third trajectory. Second, in our mediation model test, training trajectories exhibited a marginally significant relation to improvement in anxiety symptoms. Yet it is reasonable to assume that this relation stems from an insufficient number of observations, as our model used only 82 participants. Another explanation can be derived from the inability of the lavaan package to deal with nominal scales (Rosseel, 2012). Finally, in this study the learning clusters showed no significant difference between depression improvement and general psychological symptom improvement. It is likely that the small number of participants with depression symptoms (only 12 had mild depression according to their BDI-II score) made it difficult to detect such improvement. Hence, caution should be taken with respect to this analysis.
Although this study does not strive to reach a final and conclusive decision regarding training effectiveness, as a proof of concept it lays the groundwork for future studies to investigate the relations between training trajectories and training outcomes. To determine a causal relation, future studies can manipulate training trajectories for each participant by controlling individual training levels to facilitate comparisons with the current results.
To the best of our knowledge, this is the first study to examine the effect of learning trajectories and their association with mental health improvements. Our findings point to a medium to strong relationship between different learning patterns and anxiety symptoms. This proof-of-concept study highlights that learning patterns play a fundamental role in the clinical cognitive training field and provides insight into individual differences in benefiting from cognitive training. Therefore, we believe that learning patterns should be a key factor in developing an adaptive tailored cognitive training program. Future studies can advance our work by examining learning trajectories using other cognitive training paradigms and larger sample sizes to determine their importance in attaining effective training outcomes.
References
Arthur, D., & Vassilvitskii, S. (2007). k-means++ the advantages of careful seeding In SODA’07: proceedings of the eighteenth annual ACM-SIAM symposium on discrete algorithms (pp. 1027–1035). Philadelphia, PA: Society for Industrial and Applied Mathematics.
Au, J., Sheehan, E., Tsai, N., Duncan, G. J., Buschkuehl, M., & Jaeggi, S. M. (2015). Improving fluid intelligence with training on working memory: a meta-analysis. Psychonomic bulletin & review, 22(2), 366–377.
Baddeley, A. D., & Hitch, G. (1974). Working memory in psychology of learning and motivation (Vol. 8, pp. 47–89). Academic Press.
Bandura, A. (1997). Self-efficacy of control. Macmillan.
Beck, A. T., Steer, R. A., & Brown, G. K. (1996). Beck depression inventory-II. San Antonio, 78(2), 490–498.
Beloe, P., & Derakshan, N. (2019). Adaptive working memory training can reduce anxiety and depression vulnerability in adolescents. Developmental Science, 23(4), e12831.
Berggren, N., & Derakshan, N. (2013). Attentional control deficits in trait anxiety: Why you see them and why you don’t. Biological Psychology, 92(3), 440–446.
Borella, E., Carretti, B., Sciore, R., Capotosto, E., Taconnat, L., Cornoldi, C., & De Beni, R. (2017). Training working memory in older adults: Is there an advantage of using strategies? Psychology & Aging, 32(2), 178.
Brehmer, Y., Rieckmann, A., Bellander, M., Westerberg, H., Fischer, H., & Bäckman, L. (2011). Neural correlates of training-related working-memory gains in old age. NeuroImage, 58(4), 1110–1120.
Bürki, C. N., Ludwig, C., Chicherio, C., & de Ribaupierre, A. (2014). Individual differences in cognitive plasticity: An investigation of training curves in younger and older adults. Psychological Research Psychologische Forschung, 78(6), 821–835.
Caliński, T., & Harabasz, J. (1974). A dendrite method for cluster analysis. Communications in Statistics-Theory & Methods, 3(1), 1–27.
Celeux, G., & Govaert, G. (1992). A classification EM algorithm for clustering and two stochastic versions. Computational Statistics & Data Analysis, 14(3), 315–332.
Ciobotaru, D., Jefferies, R., Lispi, L., & Derakshan, N. (2021). Rethinking cognitive training: the moderating roles of emotional vulnerability and perceived cognitive impact of training in high worriers. Behaviour Research & Therapy, 144, 103926.
Colquitt, J. A., LePine, J. A., & Noe, R. A. (2000). Toward an integrative theory of training motivation: A meta-analytic path analysis of 20 years of research. Journal of Applied Psychology, 85(5), 678.
Course-Choi, J., Saville, H., & Derakshan, N. (2017). The effects of adaptive working memory training and mindfulness meditation training on processing efficiency and worry in high worriers. Behaviour Research & Therapy, 89, 1–13.
Cristea, I. A., Kok, R. N., & Cuijpers, P. (2015). Efficacy of cognitive bias modification interventions in anxiety and depression: Meta-analysis. The British Journal of Psychiatry, 206(1), 7–16.
Daches, S., & Mor, N. (2014). Training ruminators to inhibit negative information: A preliminary report. Cognitive Therapy & Research, 38(2), 160–171.
Derakhshan, N. (2020). Attentional control and cognitive biases as determinants of vulnerability and resilience in anxiety and depression. Cognitive biases in health and psychiatric disorders (pp. 261–274). Academic Press.
Ducrocq, E., Wilson, M., Smith, T. J., & Derakshan, N. (2017). Adaptive working memory training reduces the negative impact of anxiety on competitive motor performance. Journal of Sport & Exercise Psychology, 39(6), 412–422.
Duncan, J., & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96(3), 433.
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise letters upon the identification of a target letter in a nonsearch task. Perception & Psychophysics, 16(1), 143–149.
Eysenck, M. W., Derakshan, N., Santos, R., & Calvo, M. G. (2007). Anxiety and cognitive performance: Attentional control theory. Emotion, 7(2), 336.
Farrell, S., & Lewandowsky, S. (2018). Computational modeling of cognition and behavior. Cambridge University Press.
García-Casal, J. A., Loizeau, A., Csipke, E., Franco-Martín, M., Perea-Bartolomé, M. V., & Orrell, M. (2017). Computer-based cognitive interventions for people living with dementia: A systematic literature review and meta-analysis. Aging & Mental Health, 21(5), 454–467.
Genolini, C., Alacoque, X., Sentenac, M., & Arnaud, C. (2015). kml and kml3d: R packages to cluster longitudinal data. Journal of Statistical Software, 65(4), 1–34.
Guye, S., De Simoni, C., & von Bastian, C. C. (2017). Do individual differences predict change in cognitive training performance? A latent growth curve modeling approach. Journal of Cognitive Enhancement, 1(4), 374–393.
Heinzel, S., Lorenz, R. C., Brockhaus, W.-R., Wüstenberg, T., Kathmann, N., Heinz, A., et al. (2014). Working memory load-dependent brain response predicts behavioral training gains in older adults. Journal of Neuroscience, 34, 1224–1233. https://doi.org/10.1523/JNEUROSCI.2463-13.2014
Hotton, M., Derakshan, N., & Fox, E. (2017). A randomised controlled trial investigating the benefits of adaptive working memory training for working memory capacity and attentional control in high worriers. Behaviour Research & Therapy, 100, 67–77.
Jaeggi, S. M., Buschkuehl, M., Jonides, J., & Perrig, W. J. (2008). Improving fluid intelligence with training on working memory. Proceedings of the National Academy of Sciences, 105(19), 6829–6833.
Joormann, J., & D’Avanzato, C. (2010). Emotion regulation in depression: Examining the role of cognitive processes: Cognition & Emotion Lecture at the 2009 ISRE Meeting. Cognition & Emotion, 24(6), 913–939.
Karbach, J., & Verhaeghen, P. (2014). Making working memory work: A meta-analysis of executive-control and working memory training in older adults. Psychological Science, 25(11), 2027–2037.
Kassambara, A. (2018). ggpubr:“ggplot2” based publication ready plots. R package version 0.2. 999
Könen, T., & Karbach, J. (2015). The benefits of looking at intraindividual dynamics in cognitive training data. Frontiers in Psychology, 6, 615.
Koster, E. H., Hoorelbeke, K., Onraedt, T., Owens, M., & Derakshan, N. (2017). Cognitive control interventions for depression: a systematic review of findings from training studies. Clinical Psychology Review, 53, 79–92.
Launder, N. H., Minkov, R., Davey, C. G., Gavelin, H. M., Finke, C., & Lampit, A. (2021). Computerized cognitive training in people with depression: A systematic review and meta-analysis of randomized clinical trials. medRxiv.
Li, H., Li, J., Li, N., Li, B., Wang, P., & Zhou, T. (2011). Cognitive intervention for persons with mild cognitive impairment: A meta-analysis. Ageing Research Reviews, 10(2), 285–296.
Melby-Lervåg, M., & Hulme, C. (2016). There is no convincing evidence that working memory training is effective: A reply to Au et al. (2014) and Karbach and Verhaeghen (2014). Psychonomic Bulletin & Review, 23(1), 324–330.
Melby-Lervåg, M., Redick, T. S., & Hulme, C. (2016). Working memory training does not improve performance on measures of intelligence or other measures of “far transfer” evidence from a meta-analytic review. Perspectives on Psychological Science, 11(4), 512–534.
Meyer, T. J., Miller, M. L., Metzger, R. L., & Borkovec, T. D. (1990). Development and validation of the penn state worry questionnaire. Behaviour Research & Therapy, 28(6), 487–495.
Moran, T. P. (2016). Anxiety and working memory capacity: A meta-analysis and narrative review. Psychological Bulletin, 142(8), 831.
Muris, P. (2002). Relationships between self-efficacy and symptoms of anxiety disorders and depression in a normal adolescent sample. Personality & Individual Differences, 32(2), 337–348.
Nolen-Hoeksema, S., & Morrow, J. (1991). A prospective study of depression and posttraumatic stress symptoms after a natural disaster: The 1989 Loma Prieta Earthquake. Journal of Personality & Social Psychology, 61(1), 115.
Okon-Singer, H. (2018). The role of attention bias to threat in anxiety: Mechanisms, modulators and open questions. Current Opinion in Behavioral Sciences, 19, 26–30.
Ophey, A., Roheger, M., Folkerts, A. K., Skoetz, N., & Kalbe, E. (2020). A systematic review on predictors of working memory training responsiveness in healthy older adults: methodological challenges and future directions. Frontiers in Aging Neuroscience, 12, 575804.
Owens, M., Koster, E. H., & Derakshan, N. (2013). Improving attention control in dysphoria through cognitive training: Transfer effects on working memory capacity and filtering efficiency. Psychophysiology, 50(3), 297–307.
R Core Team. (2018) R: a language and environment for statistical computing. Vienna: R Foundation for Statistical Computing Retrieved from https://www.r-project.org. Accessed 21 May 2018.
Roheger, M., Liebermann-Jordanidis, H., Krohm, F., Adams, A., & Kalbe, E. (2021). Prognostic factors and models for changes in cognitive performance after multi-domain cognitive training in healthy older adults: A systematic review. Frontiers in Human Neuroscience, 15, 199.
Rohr, C. S., Dreyer, F. R., Aderka, I. M., Margulies, D. S., Frisch, S., Villringer, A., & Okon-Singer, H. (2015). Individual differences in common factors of emotional traits and executive functions predict functional connectivity of the amygdala. NeuroImage, 120, 154–163.
Rosseel, Y. (2012). Lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. URL http://www.jstatsoft.org/v48/i02
Sari, B. A., Koster, E. H., Pourtois, G., & Derakshan, N. (2016). Training working memory to improve attentional control in anxiety: A proof-of-principle study using behavioral and electrophysiological measures. Biological Psychology, 121, 203–212.
Schwaighofer, M., Fischer, F., & Bühner, M. (2015). Does working memory training transfer? A meta-analysis including training conditions as moderators. Educational Psychologist, 50(2), 138–166.
Semkovska, M., Quinlivan, L., O’Grady, T., Johnson, R., Collins, A., O’Connor, J., & Gload, T. (2019). Cognitive function following a major depressive episode: A systematic review and meta-analysis. The Lancet Psychiatry, 6(10), 851–861.
Shani, R., Tal, S., Zilcha-Mano, S., & Okon-Singer, H. (2019). Can machine learning approaches lead toward personalized cognitive training? Frontiers in Behavioral Neuroscience, 13, 64.
Smith, R. E., Smoll, F. L., Cumming, S. P., & Grossbard, J. R. (2006). Measurement of multidimensional sport performance anxiety in children and adults: The sport anxiety scale-2. Journal of Sport & Exercise Psychology, 28(4), 479–501.
Spielberger, C. D., Gorsuch, R. L., & Lushene, R. E. (1970). Stai manual for the state-trait anxiety inventory (self evaluation questionnaire). Palo Alto California: Consulting Psychologist, 22, 1–24.
Stout, D. M., Shackman, A. J., & Larson, C. L. (2013). Failure to filter: Anxious individuals show inefficient gating of threat from working memory. Frontiers in Human Neuroscience, 7, 58.
Stout, D. M., Shackman, A. J., Johnson, J. S., & Larson, C. L. (2015). Worry is associated with impaired gating of threat from working memory. Emotion, 15(1), 6.
Unsworth, N., Redick, T. S., Spillers, G. J., & Brewer, G. A. (2012). Variation in working memory capacity and cognitive control: Goal maintenance and microadjustments of control. Quarterly Journal of Experimental Psychology, 65(2), 326–355.
Vogel, E. K., McCollough, A. W., & Machizawa, M. G. (2005). Neural measures reveal individual differences in controlling access to working memory. Nature, 438(7067), 500.
Von Bastian, C. C., & Oberauer, K. (2014). Effects and mechanisms of working memory training: A review. Psychological Research Psychologische Forschung, 78(6), 803–820.
Wanmaker, S., Geraerts, E., & Franken, I. H. (2015). A working memory training to decrease rumination in depressed and anxious individuals: A double-blind randomized controlled trial. Journal of Affective Disorders, 175, 310–319.
Wiemers, E. A., Redick, T. S., & Morrison, A. B. (2019). The influence of individual differences in cognitive ability on working memory training gains. Journal of Cognitive Enhancement, 3(2), 174–185.
Woolf, C., Lampit, A., Shahnawaz, Z., Sabates, J., Norrie, L. M., Burke, D., & Mowszowski, L. (2021). A systematic review and meta-analysis of cognitive training in adults with major depressive disorder. Neuropsychology Review, 32, 419–437.
Zilcha-Mano, S. (2019). Major developments in methods addressing for whom psychotherapy may work and why. Psychotherapy Research, 29(6), 693–708.
Zinke, K., Zeintl, M., Rose, N. S., Putzmann, J., Pydde, A., & Kliegel, M. (2014). Working memory training and transfer in older adults: Effects of age, baseline performance, and training gains. Developmental Psychology, 50(1), 304.
Acknowledgements
This study was supported by the JOY ventures grant for neurowellness research #100006159 awarded to HOS. In addition, part of this work was made possible by resources made available by the Data Science Research Center at the University of Haifa (from the Council for Higher Education), grant #100008976 awarded to HOS.
Funding
This research was supported by the JOY ventures grant for neuro-wellness research awarded to H.O.S.
Author information
Authors and Affiliations
Contributions
ODA developed the study concept and drafted the manuscript under the supervision of HOS, ODA took part in data preparation and conducted all data analyses. UH and HOS took part in brainstorming, guided the statistical analysis and provided critical revisions. ND and AW and RS collected the data and took part in the data processing. All authors participated in writing the manuscript and approved the final version for submission.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
The methodology for this study was approved by the local ethics review committee of the University of Haifa (Ethics approval number: 21/042).
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Consent to publish
The methodology for this study was approved by the local ethics review committee of the University of Haifa (Ethics approval number: 21/042).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Agassi, O.D., Hertz, U., Shani, R. et al. Using clustering algorithms to examine the association between working memory training trajectories and therapeutic outcomes among psychiatric and healthy populations. Psychological Research 87, 1389–1400 (2023). https://doi.org/10.1007/s00426-022-01728-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-022-01728-1