
Abstract
Sex and chronological age estimation are crucial in forensic investigations and research on individual identification. Although manual methods for sex and age estimation have been proposed, these processes are labor-intensive, time-consuming, and error-prone. The purpose of this study was to estimate sex and chronological age from panoramic radiographs automatically and robustly using a multi-task deep learning network (ForensicNet). ForensicNet consists of a backbone and both sex and age attention branches to learn anatomical context features of sex and chronological age from panoramic radiographs and enables the multi-task estimation of sex and chronological age in an end-to-end manner. To mitigate bias in the data distribution, our dataset was built using 13,200 images with 100 images for each sex and age range of 15–80 years. The ForensicNet with EfficientNet-B3 exhibited superior estimation performance with mean absolute errors of 2.93 ± 2.61 years and a coefficient of determination of 0.957 for chronological age, and achieved accuracy, specificity, and sensitivity values of 0.992, 0.993, and 0.990, respectively, for sex prediction. The network demonstrated that the proposed sex and age attention branches with a convolutional block attention module significantly improved the estimation performance for both sex and chronological age from panoramic radiographs of elderly patients. Consequently, we expect that ForensicNet will contribute to the automatic and accurate estimation of both sex and chronological age from panoramic radiographs.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
Sex and chronological age estimation are essential in forensic investigations and research for individual identification, which can help narrow down potential suspects. Given the well-preserved skull, panoramic radiographs can serve as a tool for identifying unidentified individuals in mass disasters and accidents [1, 2]. Various conventional methods have been employed for sex and chronological age estimation, including forensic deoxyribonucleic acid (DNA) analysis and morphological measurements of hard tissues such as teeth and bones. Forensic DNA analysis is a common method for sex and chronological age estimation that yields high accuracy and reliability [3]. However, forensic DNA analysis is time-consuming and labor-intensive; these problems can lead to challenges in terms of timeliness, particularly when there is a large caseload or when limited resources are available [4]. The hard tissues of the human body, such as teeth and bones, can preserve their shape and structure in hostile environments, making them suitable for sex and chronological age estimation in forensic applications [5, 6]. Recently, various dental-related parameters obtained from morphological measurements of anatomical structures, such as the maxillofacial bones, teeth, and frontal and paranasal sinuses, have been used in forensic dentistry for sex and age estimation [7,8,9,10]. These parameters can also be calculated from panoramic radiographs commonly used in the dental field to provide a broad view of the maxillofacial region as two-dimensional radiographic images [11].
Most dental age estimation methods involve radiographic assessment of teeth, which can provide information on skeletal maturity and is less affected by environmental factors [12]. Several methods are used to estimate dental age in children and adolescents using radiographic images. The Demirjian method was used to estimate chronological age by estimating the seven teeth on the left side of the mandible [13]. The Nolla method was used to evaluate the mineralization of permanent dentition in 10 stages. After assigning a value to each tooth, the sum of the values of maxillary and mandibular teeth was calculated and compared with the reference value [14]. The Cameriere method measures the ratio between the length of the projection of open apices and the length of the tooth axis major [15]. For dental age estimation in adults, the Kvaal method calculates the pulp-to-tooth ratio of six mandibular and maxillary teeth, including the maxillary central and lateral incisors, maxillary second premolars, mandibular lateral incisors, mandibular canines, first premolars. The coronal pulp cavity index was calculated as the correlation between the reduction in the coronal pulp cavity and chronological age, considering only the mandibular premolars and molars [6]. Recently, An et al. assessed age-related changes in dental development and the maturation of teeth and mandibular structures on panoramic radiographs. The results demonstrated changes in various radiographic parameters with increasing age [16].
Several studies have reported differences in tooth and bone size between males and females [8, 17]. These differences in the skeletal structure may serve as a preliminary reference for estimating sex. Recently, anatomical information on the maxillofacial and dental structures, such as mandibular angle; area of the mandibular foramen; the height of the symphysis in the mandible [18]; a volume of the maxillary, frontal, and paranasal sinuses [9]; crown dimension [19]; and pulp chamber volume [20], has been widely used for sex prediction. Although the aforementioned manual methods have been applied successfully to diverse populations, low reproducibility, and measurement bias remain limitations for clinical applications [21]. These manual methods include several steps, such as image preprocessing, manual segmentation, feature extraction, classification, and regression, and each step is labor-intensive, time-consuming, and error-prone [22]. Therefore, an automatic and accurate method for simultaneously estimating sex and chronological age using radiographs is required.
Recently, deep learning has been widely used for medical image analysis tasks, such as image segmentation, classification, detection, denoising, and synthesis [23,24,25]. Several studies have reported the use of deep learning-based methods for sex or age estimation from panoramic radiographs. Guo et al. [21] proposed a deep learning-based method to directly classify dental ages and compared it with a manual method on 10,257 panoramic radiographs of 4,579 males and 5,678 females aged between 5 and 24 years old. The results demonstrated that the deep learning-based method outperformed the manual method. Milošević et al. [26] investigated the potential use of deep learning in estimating chronological age based on panoramic radiographs. They built a dataset with 4,035 images from 2,368 males and 1,667 females aged 18–90 years. The performance of the age estimation model resulted in a mean absolute error (MAE) value of 3.96 ± 2.95. Bu et al. [27] investigated the potential use of a deep network in predicting sex based on panoramic radiographs of 10,703 patients (4,789 males and 5,914 females) aged 5–25 years. The accuracy of sex estimation using a convolutional neural network was higher for adults (90.97%) than for minors (82.64%). The deep learning-based methods simultaneously estimated sex and age from panoramic radiographs. Vila–Blanco et al. [28] proposed the use of DASNet to estimate sex and age based on 2,289 panoramic radiographs of subjects aged 4.5–89.2 years. The MAE value for age estimation was 2.84 ± 3.75 years, and the sex estimation accuracy was 85.4%. Fan et al. [29] estimated sex and age using DASE-Net for 15,195 panoramic radiographs aged 16–50; the MAE for age estimation was 2.61 years and the accuracy of sex estimation was 95.54%. These studies used datasets with insufficient or non-uniform sex and age distributions. In their datasets, over half of the total data were samples from individuals in their 20 and 30 s, with twice as many female samples as male samples. Zhang et al. [30] proposed a sex-prior guided Transformer-based model for chronological age estimation on 10,703 panoramic radiographs acquired from patients aged 5–25 and achieved an MAE of 0.80 for chronological age estimation. As far as we know, no previous study is based on a dataset with uniform sex and age distributions across the age range of 15–80 years.
The purpose of this study was to estimate sex and chronological age from panoramic radiographs automatically and robustly using a multi-task deep learning network (ForensicNet). To mitigate bias in the data distribution, our dataset was built using 13,200 images with 100 images for each sex and the age range from 15 to 80. Our main contributions are as follows: (1) A multi-task deep learning network was designed to automatically estimate the sex and chronological age simultaneously from panoramic radiographs in an end-to-end manner. (2) Using a convolutional block attention module (CBAM), a deep learning network was trained to learn the long-range relationships between anatomical structures for robust estimation of sex and chronological age from panoramic radiographs of elderly patients. In addition, the effectiveness of the CBAM was demonstrated by an experimental ablation study. (3) A weighted multi-task loss function was proposed to handle the imbalance of binary cross-entropy and MAE losses for estimating sex and chronological age.
Materials and methods
Data acquisition and preparation
Our dataset was built using 13,200 panoramic radiographs acquired from patients who underwent dental imaging at the Seoul National University Dental Hospital between 2017 and 2021 in South Korea. This study was approved by the Institutional Review Board of Seoul National University Dental Hospital (ERI23025). The ethics committee approved the waiver of informed consent because this was a retrospective study. The study was performed following the Declaration of Helsinki. Panoramic radiographs were acquired using OP-100 (Instrumentarium Dental, Tuusula, Finland), Rayscan alpha-P (Ray, Seoul, South Korea), and Rayscan alpha-OCL (Ray, Seoul, South Korea) under conditions of tube energy of 73 kVp and tube current of 10 mA.
The collected panoramic radiographs were unfiltered real-world data. We excluded only low-quality images caused by artifacts (the patient’s earrings, removable prosthesis, etc.), inadequate anatomical coverage, patient positioning errors, and pre-and post-processing errors (noise, enhancement errors, abnormal density, and contrast) [31]. Representative samples of patients aged 15–80 years from our dataset are shown in Fig. 1. Our dataset included panoramic radiographs acquired from patients with alterations, dental implants, caries, bridges, fillings, retainers, missing teeth, or crowns. However, the exclusion criteria were as follows: edentulous patients, patients undergoing orthodontic treatment, patients undergoing orthognathic surgery, maxillofacial reconstruction patients, and patients with large intraosseous lesions.

Examples of panoramic radiographs of males or females aged 15–80 years
Each panoramic radiograph was labeled with the specific sex and chronological age of the patient. Our dataset has the same distribution of sex and chronological age, with approximately equal numbers of images for each sex and age group. The datasets were randomly separated into training, validation, and test sets, where each set consisted of the same distribution of sex (male and female) and chronological age (15–80 years old). The splitting ratio was 3:1:1, and each set contained 7920, 2640, and 2640 images [32]. The dataset consists of high-resolution 8-bit panoramic radiographs. The heights of the panoramic radiographs ranged from 976 to 1468 pixels, while the widths ranged from 1976 to 2988 pixels. For the network training, the images were resized to 480 \(\times\) 960 pixels.
The minimum sample size was estimated to detect significant differences in accuracy between ForensicNet and the other networks when both assessed the same subjects (panoramic radiographs). Sample size calculation was designed to capture a mean accuracy difference of 0.05 and a standard deviation of 0.10 between the ForensicNet and other networks. Based on an effect size of 0.25, a significance level of 0.05, and a statistical power of 0.95, a sample size of 305 was obtained by G* Power (Windows 10, version 3.1.9.7; Universität Düsseldorf, Germany). The dataset of panoramic radiographs was split into 7920, 2640, and 2640 images for the training, validation, and test sets, respectively.
Proposed multi-task deep learning network (ForensicNet)
The architecture of the proposed network, ForensicNet, consisted of a backbone, sex, and age attention branches (Fig. 2). Popular feature extraction networks such as VGG16 [33], MobileNet v2 [34], ResNet101 [35], DenseNet121 [36], Vision Transformer [37], Swin Transformer [38], Encoder of TransUNet (TransNet) [39], and EfficientNet-B3 [40] were used as backbones in ForensicNet.

Overview of the proposed multi-task deep learning network (ForensicNet). ForensicNet consists of a backbone with age and sex attention branches. Each attention branch has a convolutional block attention module (CBAM) composed of channel and spatial attention modules. ForensicNet takes panoramic radiographs as inputs and simultaneously estimates sex and chronological age by each attention branch
VGG16 consists of 16 layers, including 13 convolutional layers with ReLU activation, 5 max-pooling layers, and 3 fully connected layers. VGG16 contains approximately 15.1 million trainable parameters [33]. MobileNet v2 is designed to implement the inference of deep networks with low computing power, such as mobile devices [34]. To design a lightweight model, MobileNet v2 uses depth-wise separable convolutions instead of standard convolutions. MobileNet v2 has approximately 4.7 million trainable parameters. A residual neural network, also called ResNet, adopts a residual learning method that employs the addition of a skip connection between layers [35]. This skip connection is an element-wise addition between the input and output of the residual block, without additional parameters or computational complexity. ResNet101 contained 48.8 million trainable parameters. The densely connected network DenseNet121 uses a cross-layer connection approach in each layer to solve the problem of the vanishing gradient. In the DenseNet121 architecture, the feature maps of each previous layer are used as inputs for all subsequent layers. DenseNet121 contains approximately 8.6 million trainable parameters [36]. Vision Transformer adapts the original Transformer architecture for use in computer vision [37]. It takes an input image by dividing it into non-overlapping patches and generating the linear embedding from these patches based on the linear projection. To include the location information of each patch, positional encodings are appended to this linear embedding. Subsequently, these embedding vectors are fed into a Transformer encoder. Vision Transformer contains approximately 87.0 million trainable parameters [37]. Swin Transformer is a type of Transformer architecture that has been specifically designed for computer vision tasks [38]. Swin Transformer applies shifted local windows in an image across different levels of detail, allowing the model to capture both local details and global context. Swin Transformer contains approximately 89.8 million trainable parameters [38]. TransNet is the encoder of TransUNet which combines the advantages of Transformer and convolutional neural networks (CNN) to improve segmentation performance by capturing both global and local features [39]. In TransNet, ResNet50 is used as a CNN-based encoder to extract high-level features. Then, high-level features are fed to the Transformer with self-attention layers to capture global contextual relationships. TransNet contains approximately 31.5 million trainable parameters [39]. EfficientNet is a state-of-the-art network that significantly outperforms other popular networks in classification tasks with fewer parameters and high model efficiency. EfficientNet employs a compound scaling method to efficiently adjust the width, depth, and resolution of a deep network. EfficientNet-B3 contains approximately 14.3 million trainable parameters [40].
On panoramic radiographs, anatomical structures are typically observed in different sizes and shape variations according to the sex and chronological age of the patients. To learn these features, a deep network must cover different scales of receptive fields to capture long-range relationships between anatomical structures. In this study, a CBAM [41] was embedded before each output layer in the sex and age attention branches of the proposed ForensicNet. The CBAM contained two submodules for channel and spatial attention (Fig. 2). An input feature map \({F}_{i}\in {\mathbb{R}}^{C\times H\times W}\) are fed to the channel attention module (CAM) to obtain a 1D channel attention map \({A}_{c}\in {\mathbb{R}}^{C\times 1\times 1}\) as follows:
,
where \(C\), \(H\), and \(W\) indicate channels, height, and width of a feature map, respectively. \(\sigma\), MLP, MaxPool, and AvgPool denote the Sigmoid activation function, shared multi-layer perceptron layers, a global max-pooling layer, and a global average-pooling layer, respectively. Then, a channel-attentive feature map \({F}_{i}^{{\prime }}\in {\mathbb{R}}^{C\times H\times W}\) is acquired by:
,
where \(\otimes\) denotes element-wise multiplication. To obtain a spatial attention feature map \({A}_{s}\in {\mathbb{R}}^{1\times H\times W}\), a channel-attentive feature map \({F}_{i}^{{\prime }}\) is fed to the spatial attention module (SAM) as follows:
,
where \(\sigma\), \({s}^{7\times 7}\), MaxPool, and AvgPool denote the Sigmoid activation function, a \(7\times 7\) convolution layer, a 2D max-pooling layer, and a 2D average-pooling layer, respectively. \(\left[\bullet \right]\) indicates channel-wise concatenation operation. Then, a spatial-attentive feature map \({F}_{i}^{{\prime }{\prime }}\in {\mathbb{R}}^{C\times H\times W}\) is obtained by:
,
where \(\otimes\) denotes element-wise multiplication. Finally, a spatial-attentive feature map \({F}_{i}^{{\prime }{\prime }}\)of CBAM combined with spatial and channel attention were fed to a global average pooling layer. CBAM can promote deep networks to focus on semantic information and effectively refine intermediate features.
To output multi-task classes for both sex and chronological age estimation in an end-to-end manner, sex and age attention branches were designed, where each branch comprised a CBAM, a global average pooling layer, and an output layer (Fig. 2). In the age attention branch, high-level feature maps from the backbone were fed to the CBAM to extract channel and spatial attentive feature maps. The channel and spatial attentive feature maps were then reduced to a one-dimensional vector using a global average pooling layer, and the vector was fed to an output layer with a linear activation function to estimate a continuous age value. The sex attention branch had the same structure as the attention branch, except for the activation function of the output layer, where sigmoid activation was used to classify a categorical sex value, such as male or female.
Weighted multi-task loss function
For network training, a weighted multi-task loss (WML) function combined with MAE and binary cross-entropy (BCE) was proposed. The MAE measures the mean of the absolute difference between the ground truth and the estimated chronological age. The MAE is defined as
,
where \(y\) and \(\widehat{y}\) are the ground truth and estimated chronological ages, respectively. The \(N\) is the number of panoramic radiographs. The BCE measures the average probability error between the ground truth and the estimated sex. The BCE is defined as follows:
,
where \(p\) and \(\widehat{p}\) are the ground truth and estimated sex, respectively. \(N\) is the number of panoramic radiographs. The MAE was more difficult to minimize than the BCE for multi-task learning. Therefore, asymmetric weights \(\alpha\) and \(\beta\) for MAE and BCE were set in WML, respectively. Finally, the WML is defined as
where \(\alpha\) and \(\beta\) are weight constants for MSE and BCE, respectively, and the \(\beta\)is calculated as \(\left(1-\alpha \right)\). Empirically, \(\alpha\) and \(\beta\) were set to 0.7 and 0.3 (Table 1), respectively.
Training environment
The deep networks were trained for 200 epochs with a mini-batch size of 16. Data augmentation was performed with rotation (ranging from − 10° to 10°) and width and height shifts (ranging from − 10 to 10% of the image size) in the horizontal and vertical axes. Adam optimizer was used with \({\beta }_{0}=0.9\) and \({\beta }_{1}=0.999\), and a learning rate was initially set to 10−3, which was reduced by half up to 10−6 when the validation loss saturated for 25 epochs. The deep networks were implemented using Python3 based on Keras with a TensorFlow backend, using an NVIDIA TITAN RTX GPU of 24GB.
Evaluation metrics
To evaluate the estimation performance for sex and chronological age, the MAE, coefficient of determination (R2), maximum deviation (MD), successful estimation rate (SER), sensitivity (SEN), specificity (SPE), and accuracy (ACC) were used. The MAE is the mean of the absolute difference between the estimated and actual ages of a sample. R2 is a statistical measure of the fit of a regression model (measures the variations in the data explained by the model). Maximum Deviation (MD) is the highest deviation of the absolute difference between the estimated and actual ages, compared to their mean. SER is the percentage of successfully estimated ages in the ranges of 1-, 3-, 5-, 8-, and 10-year errors, and SEN is a metric that evaluates the ability of a model to estimate the true positives of each available category of sex. SPE is a metric that evaluates the ability of a model to estimate the true negatives of each available category of sex. ACC is the ratio of the number of correct sex estimations to the total number of input samples.
The impact of dataset size on the estimation of sex and chronological age was also evaluated. The training sets were expanded to include 2640, 5260, and 7920 images, respectively, while the validation and test sets were fixed. An analysis of variance test was performed to compare the estimation performances between the backbones in ForensicNet (PSS Statistics for Windows 10, Version 26.0; IBM, Armonk, New York, USA), and the statistical significance level (p-value) was set to 0.05.
To interpret the decision-making processes of a deep network, gradient-weighted class activation mapping (Grad-CAM) was used [42]. Grad-CAM is used to visualize the heatmap of the regions that the deep network focuses on when making an estimation. This method calculates the gradients of the target (here, an output layer to estimate sex and chronological age) and plugs them into a previous convolutional layer to provide a heatmap of the regions that contribute the most to the output decision.
Results
The performances of backbones such as VGG16, MobileNet v2, ResNet101, DenseNet121, Vision Transformer, Swin Transformer, TransNet, and EfficientNet-B3 used in ForensicNet were compared. To ensure a fair comparison, all the deep networks were run in the same computing environment and with the same data augmentations used in our comparative experiments. As shown in Table 2, all deep networks achieved high estimation performance for sex and chronological age from the panoramic radiographs. In estimating sex and chronological age, EfficientNet-B3 outperformed the other backbones for most evaluation metrics, particularly in the estimation performance of chronological age. From the quantitative results of the sex estimation, EfficientNet-B3 achieved ACC, SPE, and SEN values of 0.992, 0.993, and 0.990, respectively (Table 2). Compared with the second-highest results from DenseNet121, the ACC and SPE of EfficientNet-B3 improved by 0.004 and 0.012, respectively. Significant differences were observed in the MAE between EfficientNet-B3 and the other backbones including VGG16, Vision Transformer, Swin Transformer, and TransNet (p-value < 0.05), whereas no significant differences were observed in the sex estimation performance except for those of TransNet (Table 2). Figure 3 illustrates the confusion matrices for the sex estimation performance of all backbones.

Confusion matrices for sex estimation from different backbones. (a)–(h) Results of VGG16, MobileNet v2, ResNet101, DenseNet121, Vision Transformer, Swin Transformer, TransNet, and EfficientNet-B3, respectively
In chronological age estimation, EfficientNet-B3 achieved better results with MAE of 2.93 ± 2.61, MD of 16.13, R2 of 0.957, and SERs of 26.78, 61.74, 81.55, 94.09, and 97.99% than those of the other backbones (Tables 2 and 3). When comparing the estimation performances for each chronological age group, all deep networks exhibited a gradual increase in age estimation errors (Table 4). In addition, the median errors in age estimation gradually increased, as shown in Fig. 4. EfficientNet-B3 obtained an estimation performance comparable to that of the other backbones from panoramic radiographs acquired from patients younger than 50 years, whereas it achieved superior performance improvements in those obtained from patients older than 50 years. Figure 5 shows the representative results with the ground truth and the estimated results for both sex and chronological age from EfficientNet-B3. Figures 6 and 7 show the linear regression and Bland–Altman plots for chronological age estimation, respectively.

Box plots for estimation performance of chronological age from different backbones on each age group. Each blue box contains the first and third quartiles of accuracy. Medians are located inside the blue boxes as black lines, with the minimum and maximum values visualized as vertical lines. Black circles are outliers. (a)–(h) Results of VGG16, MobileNet v2, ResNet101, DenseNet121, Vision Transformer, Swin Transformer, TransNet, and EfficientNet-B3, respectively

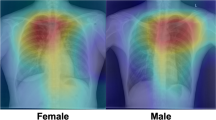
Representative estimation results and corresponding Grad-CAM generated by EfficientNet-B3. GT and PR are the ground truth and estimation results, respectively

Linear regression plots for estimation performance of chronological age from different backbones. Blue dots are observations between ground truth and estimated ages, and the red line denotes a linear regression line. R2 is a measure of the goodness of fit of a backbone. (a)–(h) Results of VGG16, MobileNet v2, ResNet101, DenseNet121, Vision Transformer, Swin Transformer, TransNet, and EfficientNet-B3, respectively

Bland–Altman plots for estimation performance of chronological age by backbones. Blue dots denote the differences between ground truth and estimated ages, the red line presents a mean difference, and black dash lines are 95% limits of agreement. (a)–(h) Results of VGG16, MobileNet v2, ResNet101, DenseNet121, Vision Transformer, Swin Transformer, TransNet, and EfficientNet-B3, respectively
Ablation studies were performed to demonstrate the effectiveness of CBAM in ForensicNet (Table 5). For sex estimation, ForensicNet without CBAM obtained lower ACC and SEN of 0.908 and 0.882, respectively, than with CBAM of 0.992 and 0.990. Furthermore, the estimation performance of chronological age was improved from the MAE of 3.07 ± 2.67 to 2.93 ± 2.61 by embedding CBAM in ForensicNet. As shown in Table 5, significant differences were observed in both MAE and sex estimation performance between the models with and without CBAM (p-value < 0.05). In addition, the models with CBAM achieved performance improvements in panoramic radiographs obtained from patients older than 50 years (Table 6).
To find the optimal weights of WML in ForensicNet, we conducted ablation studies to compare the performance of different weight values between \(\alpha\) and \(\beta\). Table 1 shows the quantitative results from ForensicNet according to the different weight values of \(\alpha\) and \(\beta\) in WML. When \(\alpha\) and \(\beta\) were set as 0.7 and 0.3 respectively, ForensicNet achieved the superior estimation performance for sex and chronological age. In addition, the ForensicNet with the optimal weights of \(\alpha\) and \(\beta\) achieved performance improvements in panoramic radiographs obtained from patients older than 40 years (Table 7).
In Table 8, the impact of dataset size in ForensicNet with EfficientNet-B3 was validated. The results exhibited better estimation performance for sex and chronological age by further increasing the training dataset. Even when only approximately a quarter of the total dataset was used for network training, the estimation performance for sex and chronological age achieved an ACC of 0.963 and an MAE of 3.63 ± 2.98, respectively. By increasing the size of the training dataset, the estimation performance for sex and chronological age gradually improved, achieving an ACC of 0.992 and an MAE of 2.93 ± 2.61, respectively. Significant differences were observed in both MAE and sex estimation performance between the data sizes of 7920 and 2640 images (p-value < 0.05), whereas no significant differences were observed for sex estimation performance between the data sizes of 7920 and 5280 images (Table 8).
To interpret the decision-making processes of ForensicNet, Grad-CAM was used to visualize regions that contributed the most to the output decision (5). The heatmap regions generated by Grad-CAM from ForensicNet varied significantly, depending on the chronological age group. For patients younger than 30 years, ForensicNet focused on the near nasal bone, coronoid process, molar teeth, and their surrounding alveolar bone. In the panoramic radiographs of patients older than 40 years, regions near the upper and lower teeth, including dental implants, amalgam fillings, and dental crowns contributed more to estimating sex and chronological age.
Discussion
Forensic dentistry uses dental evidence and parameters to identify individuals, reconstruct events, and assess the trauma. One of the most important applications of forensic dentistry is sex and chronological age estimation for human identification during mass disasters, homicides, and accidents [43]. Various dental-related parameters obtained from morphological measurements of anatomical structures, such as the maxillofacial bones, teeth, and frontal and paranasal sinuses, have been used in forensic dentistry to estimate sex and chronological age [8, 44, 45]. These anatomical structures were assessed using panoramic radiographs commonly used in the dental field, which provide a broad view of the maxillofacial region [11]. Recently, deep learning has been widely used in forensic dentistry to estimate sex and chronological age from panoramic radiographs [28, 29]. However, previous studies have used datasets with insufficient or non-uniform sex and age distributions, which could lead to inaccurate estimation for a particular sex or age owing to data bias. In this study, ForensicNet was proposed to simultaneously estimate sex and chronological age from panoramic radiographs. To mitigate bias in the data distribution, our dataset was built using 13,200 images with 100 images for each sex and age range from 15 to 80 years.
The estimation performance of backbones such as VGG16, MobileNet v2, ResNet10, DenseNet121, Vision Transformer, Swin Transformer, TransNet, and EfficientNet-B3 used in ForensicNet was compared. In our experiments, EfficientNet-B3 outperformed the other backbones in estimating both sex and chronological age from panoramic radiographs (Table 2). ForensicNet with EfficientNet-B3 achieved a superior performance owing to three key factors. EfficientNet-B3 utilizes a compound scaling method that simultaneously optimizes the depth, width, and resolution of the deep network [40]. This approach allows for better model representation and feature extraction across different scales and complexities of anatomical structures in panoramic radiographs. Second, sex and age attention branches were designed, including CBAM, which promoted a deep network to focus on anatomical features related to estimating sex and chronological age from panoramic radiographs. The proposed sex and age attention branches improved the estimation performance for both sex and chronological age, and their effectiveness was demonstrated by an ablation study, as shown in Table 5. In addition, ForensicNet demonstrated accurate and robust estimation of sex and chronological age in panoramic radiographs obtained from patients older than 50 years by learning anatomical context features using CBAM (Table 6). Finally, ForensicNet achieved superior performance by adopting a multi-task learning approach to simultaneously estimate sex and chronological age from panoramic radiographs. The primary reason for this improvement is that chronological age and sex are often correlated [46], and ForensicNet can learn complementary contextual information between sex and age using a multi-task learning approach.
We observed that ForensicNet with EfficientNet-B3 outperformed the other Transformer-based backbones for most evaluation metrics, particularly in the estimation performance of chronological age (Table 2). There are two factors that we believe contribute to the superior performance of EfficientNet-B3 over Transformer-based backbones: (1) In our task for chronological age and sex estimation, local patterns of anatomical structures are more important than global long-range relationships between anatomical structures. Because most previous works based on manual analysis focused on shapes and volumes of each local anatomical structure such as teeth [47], mandibular angle [18], maxillary sinuses [9], and pulp chamber [20, 48] to estimate chronological age and sex from panoramic radiographs. (2) Transformers, lacking inductive biases such as locality and translation invariance of CNNs, sometimes require substantially more datasets to learn the same local features and textures [49]. Although we collected 13,200 images with 100 images for each sex and age range of 15–80 years, the size of the dataset is not guaranteed to be sufficient to train the Transformer-based backbones.
ForensicNet exhibited a relatively higher estimation performance for chronological age in younger age groups than in older age groups (Table 4). The different developmental signs in the teeth during the growth and adolescent phases allow for more accurate age estimation for these individuals [50], where the tooth eruption sequence, tooth calcification, and root development are common tooth development indicators [13, 14]. The results from ForensicNet showed that the estimation performance of chronological age gradually decreased in the panoramic radiographs of patients aged over 50 years. Older patients typically undergo mechanical and chemical dental wear and dental treatments [51]. In addition, cumulative periodontal destruction of the alveolar bone owing to tooth decay is typically observed in older patients [52]. Furthermore, the teeth condition is highly diverse among older patients owing to socio-environmental factors such as education level, access to healthcare, and socioeconomic status [53, 54]. These factors further complicate chronological age estimation in panoramic radiographs of older patients [51]. The activation of the heatmap regions generated by Grad-CAM became more diverse and complex with increasing age, as shown in Fig. 5. ForensicNet achieved superior sex estimation performance (Table 2). As the influence of hormones, morphological shape and size differences are present between males and females in the maxillofacial bone and teeth [55], which allows for a relatively higher performance of sex estimation.
In Fig. 5, Grad-CAM was used to visualize the regions that contributed significantly to the decision regarding the output of ForensicNet. For sex and chronological age estimation, heatmap regions with high activation generated by Grad-CAM appeared on the nasal bone, mandible, second and third molars with their surrounding alveolar bone, and coronoid process area across all ages in panoramic radiographs (see Supplementary Materials for Figures S1-S6). In previous studies, the nasal bone was used as an indicator for assessing dental parameters such as nasal height, nasal width, and pyriform aperture for sex estimation [56]. The third molars and their surrounding alveolar bone show sexual dimorphism between males and females, and the third molars of males have more enamel deposition than those of females [57]. The shape of the coronoid process exhibits sexual dimorphism between males and females [58]. Molar teeth and their surrounding alveolar bone contain informative indicators for estimating chronological age from panoramic radiographs [47]. The pulp dimensions of the mandibular first molar are significant indicators of chronological age [48]. Pulp dimensions decrease with age owing to secondary dentin deposition, tooth mineralization, and dental attrition [6]. The accumulated changes in the alveolar bone resulting from periodontitis can be utilized as indicators for chronological age estimation [59]. On panoramic radiographs of older patients, complex activation of heatmap regions related to dental treatment, including dental prosthetics and implants. As depicted in Fig. 5, the activation regions generated by Grad-CAM from ForensicNet were similar to the anatomical regions used as indicators in previous studies on sex and chronological age estimation from panoramic radiographs.
ForensicNet was compared with previous studies based on deep learning for sex and chronological age estimation from panoramic radiographs (Table 9) [26,27,28,29,30]. In age estimation, Milošević et al. [26] reported an MAE of 3.96 on the dataset with a non-uniform age distribution between the younger and older age groups, while the proposed ForensicNet achieved an MAE of 2.93 ± 2.61 on the dataset with uniform age distribution ranging from 15 to 80 years. Bu et al. [27] obtained ACC and SEN values for sex estimation using 10,703 panoramic radiographs from samples aged 5–25 years. In contrast, our ForensicNet achieved values of 0.992 for ACC, 0.990 for SEN, and 0.993 for SPE, respectively. Two deep learning-based methods simultaneously estimated sex and age from panoramic radiographs. Vila–Blanco et al. [28] proposed DASNet for sex and age estimation on 2,289 panoramic radiographs acquired from patients aged 4.5 to 89.2 years. They reported an ACC of 0.854 for sex estimation and an MAE of 2.84 ± 3.75 for chronological age estimation. Similarly, Fan et al. [29] proposed a Transformer-based model for sex and chronological age estimation on 15,195 panoramic radiographs acquired from patients aged 16–50 and achieved an ACC of 0.955 for sex estimation and an MAE of 2.61 for chronological age estimation. Zhang et al. [30] proposed a sex-prior guided Transformer-based model for chronological age estimation on 10,703 panoramic radiographs acquired from patients aged 5–25 and achieved an MAE of 0.80 for chronological age estimation. However, previous studies evaluated their deep learning models on small test sets that had a relatively higher proportion of young females compared to older subjects. ForensicNet was evaluated on a test set with uniform sex and chronological age distribution from 15 to 80 years to minimize the impact of data bias and obtained a comparable estimation performance for sex and chronological age.
Estimation errors occurred in certain patients whose dental conditions differed from the typical dental conditions in that age group (Fig. 8). The chronological age estimated by ForensicNet was overestimated compared with the actual age of patients with tooth loss, dental treatment, or periodontitis for their age, with their regions activated by Grad-CAM on panoramic radiographs. Conversely, the estimated chronological age was underestimated compared to the actual age, particularly in patients who maintained excellent dental conditions and received minimal dental treatment for their age. Therefore, a lower chronological age estimation performance was observed in the panoramic radiographs of patients with significantly different dental conditions compared to those in the same age group.

Representative estimation errors and corresponding Grad-CAM generated by EfficientNet-B3. GT and PR are the ground truth and estimation results, respectively
Automatically estimating sex and chronological age using panoramic radiographs is difficult because of three major challenges. The first challenge is related to skeletal development and oral health conditions among patients, influenced by various factors such as age, sex, genetics, and environmental and oral health conditions. As adults undergo skeletal changes more slowly and are influenced by various factors, including genetics, lifestyle, and environmental conditions. Furthermore, accurate sex and chronological age estimation of elderly patients is generally more difficult than those of children owing to variations in dental conditions including dental implants, crowns, fillings, tooth caries, and missing teeth observed in elderly patients [6]. Therefore, estimating the sex and chronological age of adults may become more difficult than that of children [53]. Second, panoramic radiographs have overlapping anatomical structures and various imaging positions, contrasts, and resolutions [60], making it difficult to estimate sex and chronological age. Clinical practice requires an automated method that is accurate and robust against variations in image quality and the presence of overlapping anatomical structures. The latter is related to data collection bias, such as unbalanced data distribution across different sex and age groups. When the data are unbalanced, a deep learning network may learn to focus on the majority class and overlook the minority class [61]. This may lead to inaccurate estimations for the minority class.
The following issues will be addressed in future studies to improve the estimation performance of ForensicNet. First, our dataset was built using panoramic radiographs from patients aged 15 to 80 years, all of whom had nearly finished developing their permanent dentition and maxillofacial bone growth. Additional datasets from children and adolescents with mixed dentition or incomplete mandibular growth are required to improve the capability of our method for sex and chronological age estimation. Second, our method may have limited generalizability. It relies solely on internal data including only living individuals from a single organization in South Korea, which might not be representative of deceased individuals, broader populations, or different organizational contexts. Therefore, further research is required to train and evaluate ForensicNet using panoramic radiograph datasets collected by multiple organizations and devices from deceased individuals, diverse ethnicities, and populations. Finally, several exclusion criteria were set for collecting panoramic radiographs. In future studies, we will improve the generalizability and clinical efficacy of ForensicNet using large-scale panoramic radiographs of all ages, including the excluded samples. In addition, we plan to study an optimal hybrid model of Transformer, CNN, and Diffusion models to improve estimation performance for the chronological age and sex of ForensicNet [30, 49, 62].
Conclusion
In this study, an automatic and robust network (ForensicNet) was proposed for both sex and chronological age estimation from panoramic radiographs. The network was trained and evaluated using a large dataset with a uniform distribution of sex and age ranging from 15 to 80 years. ForensicNet with EfficientNet-B3 outperformed the other backbones in estimating sex and chronological age and demonstrated accurate and robust estimation of sex and chronological age from panoramic radiographs for patients older than 50 years by learning anatomical context features using the proposed sex and age attention branches with CBAM. This method is expected to enable the automatic and robust estimation of sex and chronological age and improve the workflow of forensic investigation and research for individual identification. In future studies, we will improve the generalizability and clinical efficacy of ForensicNet using large-scale panoramic radiographs collected by multiple organizations and devices from diverse ethnicities and populations.
Change history
08 April 2024
In Table 6 and 7, the character corresponding to '?' was displayed in the PDF are not aligned properly, this is now updated here.
References
Kumar R, Athota A, Rastogi T, Karumuri SK (2015) Forensic radiology: an emerging tool in identification. J Indian Acad Oral Med Radiol 27:416–422. https://doi.org/10.4103/0972-1363.170478
Mincer HH, Chaudhry J, Blankenship JA, Turner EW (2008) Postmortem dental radiography. J Forensic Sci 53:405–457. https://doi.org/10.1111/j.1556-4029.2007.00645.x
Zubakov D, Liu F, Kokmeijer I et al (2016) Human age estimation from blood using mRNA, DNA methylation, DNA rearrangement, and telomere length. Forensic Sci Int : Genet 24:33–43. https://doi.org/10.1016/j.fsigen.2016.05.014
Ruitberg CM, Reeder DJ, Butler JM (2001) STRBase: a short tandem repeat DNA database for the human identity testing community. Nucleic Acids Res 29:320–322. https://doi.org/10.1093/nar/29.1.320
Gustafson G (1950) Age determinations on teeth. J Am Dent Assoc 41:45–54. https://doi.org/10.14219/jada.archive.1950.0132
Kvaal SI, Kolltveit KM, Thomsen IO, Solheim T (1995) Age estimation of adults from dental radiographs. Forensic Sci Int 74:175–185. https://doi.org/10.1016/0379-0738(95)01760-g
Khazaei M, Mollabashi V, Khotanlou H, Farhadian M (2022) Sex determination from lateral cephalometric radiographs using an automated deep learning convolutional neural network. Imaging Sci Dent 52:239. https://doi.org/10.5624/isd.20220016
Franklin D, O’Higgins P, Oxnard C (2008) Sexual dimorphism in the mandible of indigenous South africans: a geometric morphometric approach. S Afr J Sci 104:101–106. https://doi.org/10.10520/EJC96786
Demiralp K, Cakmak SK, Aksoy S, Bayrak S, Orhan K, Demir P (2019) Assessment of paranasal sinus parameters according to ancient skulls’ gender and age by using cone-beam computed tomography. Folia Morphol 78:344–350. https://doi.org/10.5603/FM.a2018.0089
Magat G, Ozcan S (2022) Assessment of maturation stages and the accuracy of age estimation methods in a Turkish population: a comparative study. Imaging Sci Dent 52:83. https://doi.org/10.5624/isd.20210231
Choi J-W (2011) Assessment of panoramic radiography as a national oral examination tool: review of the literature. Imaging Sci Dent 41:1–6. https://doi.org/10.5624/isd.2011.41.1.1
Demirjian A, Goldstein H (1976) New systems for dental maturity based on seven and four teeth. Ann Hum Biol 3:411–421. https://doi.org/10.1080/03014467600001671
Demirjian A, Goldstein H, Tanner JM (1973) A new system of dental age assessment. Hum Biol :211–227
Nolla CM (1952) The development of permanent teeth. University of Michigan Ann Arbor
Cameriere R, Ferrante L, Cingolani M (2006) Age estimation in children by measurement of open apices in teeth. Int J Legal Med 120:49–52. https://doi.org/10.1007/s00414-005-0047-9
Lee Y-H, An J-S (2021) Age estimation with panoramic radiomorphometric parameters using generalized linear models. J Oral Med Pain 46:21–32. https://doi.org/10.14476/jomp.2021.46.2.21
Lukacs JR (2022) Sexual dimorphism in deciduous tooth crown size: variability within and between groups. Am J Hum Biology 34:e23793. https://doi.org/10.1002/ajhb.23793
Coquerelle M, Bookstein FL, Braga J, Halazonetis DJ, Weber GW, Mitteroecker P (2011) Sexual dimorphism of the human mandible and its association with dental development. Am J Phys Anthropol 145:192–202. https://doi.org/10.1002/ajpa.21485
Richardson ER, Malhotra SK (1975) Mesiodistal crown dimension of the permanent dentition of American Negroes. Am J Orthod 68:157–164. https://doi.org/10.1016/0002-9416(75)90204-3
Fardim KAC, Junior EO, Rodrigues R et al (2021) Volume measurement of mandibular teeth pulp chamber as a prediction tool of gender and ethnicity in a Brazilian population. Brazilian Dent Sci 24:6. https://doi.org/10.14295/bds.2021.v24i1.2230
Guo Y-C, Han M, Chi Y et al (2021) Accurate age classification using manual method and deep convolutional neural network based on orthopantomogram images. Int J Legal Med 135:1589–1597. https://doi.org/10.1007/s00414-021-02542-x
Marroquin T, Karkhanis S, Kvaal S, Vasudavan S, Kruger E, Tennant M (2017) Age estimation in adults by dental imaging assessment systematic review. Forensic Sci Int 275:203–211. https://doi.org/10.1016/j.forsciint.2017.03.007
Hwang J-J, Jung Y-H, Cho B-H, Heo M-S (2019) An overview of deep learning in the field of dentistry. Imaging Sci Dent 49:1–7. https://doi.org/10.5624/isd.2019.49.1.1
Ortiz AG, Soares GH, da Rosa GC, Biazevic MGH, Michel-Crosato E (2021) A pilot study of an automated personal identification process: applying machine learning to panoramic radiographs. Imaging Sci Dent 51:187. https://doi.org/10.5624/isd.20200324
Shin N-Y, Lee B-D, Kang J-H et al (2020) Evaluation of the clinical efficacy of a TW3-based fully automated bone age assessment system using deep neural networks. Imaging Sci Dent 50:237. https://doi.org/10.5624/isd.2020.50.3.237
Milošević D, Vodanović M, Galić I, Subašić M (2022) Automated estimation of chronological age from panoramic dental X-ray images using deep learning. Expert Syst Appl 189:116038. https://doi.org/10.1016/j.eswa.2021.116038
Bu W-q, Guo Y-x, Zhang D et al (2023) Automatic sex estimation using deep convolutional neural network based on orthopantomogram images. Forensic Sci Int 348:111704. https://doi.org/10.1016/j.forsciint.2023.111704
Vila-Blanco N, Carreira MJ, Varas-Quintana P, Balsa-Castro C, Tomas I (2020) Deep neural networks for chronological age estimation from OPG images. IEEE Trans Med Imaging 39:2374–2384. https://doi.org/10.1109/TMI.2020.2968765
Fan F, Ke W, Dai X et al (2023) Semi-supervised automatic dental age and sex estimation using a hybrid transformer model. Int J Legal Med 137:721–731. https://doi.org/10.1007/s00414-023-02956-9
Zhang D, Yang J, Du S, Bu W, Guo Y-c (2023) An uncertainty-aware and sex-prior guided biological age estimation from orthopantomogram images. IEEE J Biomedical Health Inf. https://doi.org/10.1109/JBHI.2023.3297610
Choi B-R, Choi D-H, Huh K-H et al (2012) Clinical image quality evaluation for panoramic radiography in Korean dental clinics. Imaging Sci Dent 42:183–190. https://doi.org/10.5624/isd.2012.42.3.183
Gholamy A, Kreinovich V, Kosheleva O (2018) Why 70/30 or 80/20 relation between training and testing sets. A pedagogical explanation
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv Preprint arXiv 14091556. https://doi.org/10.48550/arXiv.1409.1556
Howard AG, Zhu M, Chen B et al (2017) Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:170404861
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. Proc. IEEE Int. Conf. Comput. Vis. 770–778. https://doi.org/10.1109/CVPR.2016.90
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks. Proc IEEE Int Conf Comput Vis 4700–4708. https://doi.org/10.1109/CVPR.2017.243
Dosovitskiy A, Beyer L, Kolesnikov A et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv Preprint arXiv 201011929. https://doi.org/10.48550/arXiv.2010.11929
Liu Z, Lin Y, Cao Y et al (2021) Swin transformer: Hierarchical vision transformer using shifted windows. Proc. IEEE Int. Conf. Comput. Vis. 10012–10022
Chen J, Lu Y, Yu Q et al (2021) Transunet: transformers make strong encoders for medical image segmentation. arXiv Preprint arXiv 210204306. https://doi.org/10.48550/arXiv.2102.04306
Tan M, Le Q (2019) Efficientnet: rethinking model scaling for convolutional neural networks. Int J Mach Learn Comput PMLR. 6105–6114
Woo S, Park J, Lee J-Y, Kweon IS (2018) Cbam: Convolutional block attention module. Proceedings of the European conference on computer vision (ECCV). 3–19. https://doi.org/10.1007/978-3-030-01234-2_1
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2017) Grad-cam: visual explanations from deep networks via gradient-based localization. Proc IEEE Int Conf Comput Vis 618–626. https://doi.org/10.1109/ICCV.2017.74
Pretty I, Sweet D (2001) A look at forensic dentistry–part 1: the role of teeth in the determination of human identity. Br Dent J 190:359–366. https://doi.org/10.1038/sj.bdj.4800972
Prabhat M, Rai S, Kaur M, Prabhat K, Bhatnagar P, Panjwani S (2016) Computed tomography based forensic gender determination by measuring the size and volume of the maxillary sinuses. J Forensic Dent Sci 8:40. https://doi.org/10.4103/0975-1475.176950
Willems G (2001) A review of the most commonly used dental age estimation techniques. J Forensic Odontostomatol 19:9–17
Abdolrashidi A, Minaei M, Azimi E, Minaee S (2020) Age and gender prediction from face images using attentional convolutional network. arXiv preprint arXiv:201003791
Lewis JM, Senn DR (2010) Dental age estimation utilizing third molar development: a review of principles, methods, and population studies used in the United States. Forensic Sci Int 201:79–83. https://doi.org/10.1016/j.forsciint.2010.04.042
Ge Z-p, Ma R-h, Li G, Zhang J-z, Ma X-c (2015) Age estimation based on pulp chamber volume of first molars from cone-beam computed tomography images. Forensic Sci Int 253:133. https://doi.org/10.1016/j.forsciint.2015.05.004
Han K, Wang Y, Chen H et al (2022) A survey on vision transformer. IEEE Trans Pattern Anal Mach Intell 45:87–110. https://doi.org/10.1109/TPAMI.2022.3152247
Franklin D (2010) Forensic age estimation in human skeletal remains: current concepts and future directions. Leg Med 12:1–7. https://doi.org/10.1016/j.legalmed.2009.09.001
Tiwari T, Scarbro S, Bryant LL, Puma J (2016) Factors associated with tooth loss in older adults in rural Colorado. J Community Health 41:476–481. https://doi.org/10.1007/s10900-015-0117-y
López R, Smith PC, Göstemeyer G, Schwendicke F (2017) Ageing, dental caries and periodontal diseases. J Clin Periodontol 44:S145–S52. https://doi.org/10.1111/jcpe.12683
Petersen PE (2003) The world oral health report 2003: continuous improvement of oral health in the 21st century–the approach of the WHO Global Oral Health Programme. Community Dent Oral Epidemiol 31:3–24
Townsend G, Richards L, Hughes T, Pinkerton S, Schwerdt W (2005) Epigenetic influences may explain dental differences in monozygotic twin pairs. Aust Dent J 50:95–100. https://doi.org/10.1111/j.1834-7819.2005.tb00347.x
Dutra V, Yang J, Devlin H, Susin C (2004) Mandibular bone remodelling in adults: evaluation of panoramic radiographs. Dentomaxillofac Radiol 33:323–328. https://doi.org/10.1259/dmfr/17685970
Dudhbade S, Tivaskar S, Barai J, Luharia A (2022) Age and sex determination using CT scan nasal bone imaging. J Pharm Negat 13:1085–1089. https://doi.org/10.47750/pnr.2022.13.03.176
Schwartz GT, Dean MC (2005) Sexual dimorphism in modern human permanent teeth. Am J Phys Anthropology: Official Publication Am Association Phys Anthropologists 128:312–317. https://doi.org/10.1002/ajpa.20211
Subbaramaiah M, Bajpe R, Jagannatha S, Jayanthi K (2015) A study of various forms of mandibular coronoid process in determination of sex. Indian J Clin Anat Physiol 2:199–203. https://doi.org/10.5958/2394-2126.2015.00020.1
Koh K, Tan J, Nambiar P, Ibrahim N, Mutalik S, Asif MK (2017) Age estimation from structural changes of teeth and buccal alveolar bone level. J Forensic Leg Med 48:15–21. https://doi.org/10.1016/j.jflm.2017.03.004
Suomalainen A, Pakbaznejad Esmaeili E, Robinson S (2015) Dentomaxillofacial imaging with panoramic views and cone beam CT. Insights into Imaging 6:1–16. https://doi.org/10.1007/s13244-014-0379-4
He H, Garcia EA (2009) Learning from imbalanced data. IEEE Trans Knowl Data Eng 21:1263–1284. https://doi.org/10.1109/TKDE.2008.239
Croitoru FA, Hondru V, Ionescu RT, Shah M (2023) Diffusion models in vision: a survey. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2023.3261988
Acknowledgements
This study was supported by Grant No. 02-2022-0220 from the SNUDH Research Fund and the National Research Foundation of Korea (NRF) Grant funded by the Korean Government (MSIT) (No. 2023R1A2C200532611). This study was also supported by a Korea Medical Device Development Fund Grant by the Korean government (Ministry of Science and ICT; Ministry of Trade, Industry, and Energy; Ministry of Health and Welfare; Ministry of Food and Drug Safety) (Project Number: 1711194231, KMDF_PR_20200901_0011, 1711174552, KMDF_PR_20200901_0147).
Funding
Open Access funding enabled and organized by Seoul National University.
Author information
Authors and Affiliations
Contributions
S-JP: Conceptualization; Data curation; Formal analysis; Investigation; Methodology; Validation; Original draft; Review & editing.
SY: Conceptualization; Formal analysis; Investigation; Methodology; Software; Validation; Visualization; Original draft; Review & editing.
J-MK: Formal analysis; Methodology; Review & editing.
J-HK: Conceptualization; Data curation; Validation; Review & editing.
J-EK: Conceptualization; Data curation; Validation; Review & editing.
K-HH: Conceptualization; Data curation; Validation; Review & editing.
S-SL: Conceptualization; Data curation; Validation; Review & editing.
W-JY: Conceptualization; Formal analysis; Funding acquisition; Methodology; Resources; Supervision; Validation; Original draft; Review & editing.
M-SH: Conceptualization; Formal analysis; Funding acquisition; Methodology; Resources; Supervision; Validation; Original draft; Review & editing.
Corresponding authors
Ethics declarations
Ethical approval
This study was approved by the Institutional Review Board of Seoul National University Dental Hospital (ERI23025). The ethics committee approved the waiver of informed consent because this was a retrospective study. The study was performed following the Declaration of Helsinki.
Informed consent
Informed consent was obtained from all participants included in the study.
Research involving human participants and/or animals
Not applicable.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.






Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cite this article
Park, SJ., Yang, S., Kim, JM. et al. Automatic and robust estimation of sex and chronological age from panoramic radiographs using a multi-task deep learning network: a study on a South Korean population. Int J Legal Med 138, 1741–1757 (2024). https://doi.org/10.1007/s00414-024-03204-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00414-024-03204-4