
Abstract
Purpose
To develop a convolutional neural network (CNN)-based model for classifying videostroboscopic images of patients with sulcus, benign vocal fold (VF) lesions, and healthy VFs to improve clinicians’ accuracy in diagnosis during videostroboscopies when evaluating sulcus.
Materials and methods
Videostroboscopies of 433 individuals who were diagnosed with sulcus (91), who were diagnosed with benign VF diseases (i.e., polyp, nodule, papilloma, cyst, or pseudocyst [311]), or who were healthy (33) were analyzed. After extracting 91,159 frames from videostroboscopies, a CNN-based model was created and tested. The healthy and sulcus groups underwent binary classification. In the second phase of the study, benign VF lesions were added to the training set, and multiclassification was executed across all groups. The proposed CNN-based model results were compared with five laryngology experts’ assessments.
Results
In the binary classification phase, the CNN-based model achieved 98% accuracy, 98% recall, 97% precision, and a 97% F1 score for classifying sulcus and healthy VFs. During the multiclassification phase, when evaluated on a subset of frames encompassing all included groups, the CNN-based model demonstrated greater accuracy when compared with that of the five laryngologists (%76 versus 72%, 68%, 72%, 63%, and 72%).
Conclusion
The utilization of a CNN-based model serves as a significant aid in the diagnosis of sulcus, a VF disease that presents notable challenges in the diagnostic process. Further research could be undertaken to assess the practicality of implementing this approach in real-time application in clinical practice.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Sulcus is a pathological condition affecting the vocal folds (VF) that is characterized by the presence of a sulcus, which refers to an indentation, groove, or furrow located at the edge of the VF [1]. The formation of the sulcus correlates with a rise in collagen fiber density. This process may occur solely in the superficial layer of the lamina propria along the VF edge; in more severe cases, it extends through the vocal ligament and reaches the thyroarytenoid muscle [2]. The sulcus is distinguished by the presence of spindle-shaped glottal insufficiency during phonation, resulting in heightened air leakage. This condition is further defined by augmented VF stiffness, which manifests as a high-pitched, rough, breathy, and asthenic voice. Patients with sulcus also exhibit compensatory supraglottal hyperactivity. The observed clinical manifestations encompass hoarseness, vocal fatigue, and exertion during vocalization [1].
Though sulcus is categorized as a condition affecting the VFs, diagnosing and distinguishing it from other conditions is difficult due to its subtle manifestations. Unlike anatomical abnormalities (e.g., cysts and polyps), sulcus presents with a less pronounced appearance. Videostroboscopy is the current gold-standard examination for this purpose [3]. It is established by reduced amplitude of the mucosal wave, a bowed or curved aspect to the free edge of the involved VF, glottic incompetence, and compensatory hyperfunction of the ventricular folds in certain cases [1, 2]. Nevertheless, VFs may appear normal during in office laryngoscopy [4]. Difficulties in diagnosing sulcus with the use of videostroboscopy have also been documented by Dailey et al. [5] and Sunter et al. [6]. According to Dailey et al. [5], sulcus is a mucosal condition that is commonly misdiagnosed. In addition, videostroboscopy yields qualitative data, leading to significant interindividual variability, with which untrained clinicians may struggle when attempting to accurately diagnose sulcus [7]. The infrequent incidence of the disease and subsequent lack of familiarity among clinicians, along with the challenges associated with videostroboscopic diagnosis, have led clinicians to explore auxiliary computer-based diagnostic approaches.
Due to the progress in computational capabilities, extensive utilization of deep learning techniques (e.g., convolutional neural networks [CNN]) has contributed to significant advancements in artificial intelligence (AI) models, particularly in the field of image recognition [8]. Videostroboscopy, a popular laryngoscopic procedure executed by otolaryngologists, provides a wealth of images for AI models in machine learning and computer vision. Furthermore, the availability of such a substantial dataset has facilitated the application of AI in the field of otolaryngology, leading to an increase in publications on this subject [9,10,11]. These studies encompass a wide range of applications, including lesion recognition, vibration analysis, determination of vocal cord movement, identification and characterization of laryngeal structures, image enhancement, and informative frame selection [10].
Despite the presence of various existing studies related to the diagnosis and classification of both benign and malignant VF lesions, no studies have specifically addressed the inclusion of sulcus. In this study, our main objective is to construct a CNN-based model for distinguishing videostroboscopic images to differentiate sulcus from those corresponding to healthy groups and benign VF lesions such as polyps, nodules, papillomas, cysts, and pseudocysts. This aims to improve the clinician-based accuracy of diagnostic assessments of laryngoscopy findings.
Materials and methods
A retrospective study was conducted in accordance with the regulations of the Declaration of Helsinki after the approval of the tertiary medical faculty Ethics Committee for Clinical Research on October 27, 2023, with number 09.2022.1449. All patient data was anonymized and utilized in a blind manner. Because the study was designed retrospectively, informed consent was not obtained from the patients.
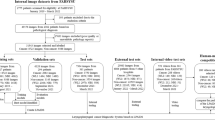
The requisite frames for training the CNN-based model were obtained from the videostroboscopy database maintained by the Ear, Nose, and Throat Department of a tertiary medical center. Data was collected for the period from 2019 to 2023. Videostroboscopy procedures were performed using a rigid 8 × 180 mm or flexible 3.9 mm laryngoscope from XION Medical Systems. No exclusion criteria were imposed based on age, gender, or race. Videostroboscopies of 433 cohorts belonging to seven categories were retrospectively evaluated: healthy, polyps, nodules, papilloma, cysts, pseudocysts, and sulcus. Videos were recorded at a frame rate of 25 frames per second (fps). The size of each frame is \(768\times 576\) pixels. Fellowship-trained laryngologists with at least five years of experience who were involved in the conducted study ensured accurate diagnoses and the incorporation of confirmed pathological diagnosis (N.E). Frames from the relevant records were selected to create a dataset. Specifically, the focus was on VF lesions, excluding frames with underexposure, blurriness, saliva, or specular reflections. The process of dataset preparation yielded a total of 91,159 informative frames. Each individual frame was resized to \(451\times 468\) pixels to eliminate peripheral areas and saved in red-green-blue (RGB) color format. Authors in the field of otorhinolaryngology (Ö.T.K, N.E) meticulously examined each frame in the videos and categorized it based on the disease indicators. Table 1 shares the details of the number of participants and frames selected from each study group. Figure 1 provides examples of annotated images.

Representative frames from each subset (Healthy, Nodule, Polyp, Cyst, Pseudocyst, Papilloma, Sulcus) in the dataset employed for convolutional neural network (CNN) model development
The study developed two classifiers. Based on the existing literature, it is evident that the sulcus represents the most commonly undiagnosed benign VF lesion, and it may appear normal during indirect laryngoscopy [1, 5]. A binary classifier was then developed with the goal of distinguishing an image corresponding to a patient diagnosed with sulcus from one corresponding to a healthy subject. In the second phase of the study, a multi-class classifier was developed to classify a given image into one of seven distinct categories. The “Supporting Information” section describes the overall architecture of the CNN-based model.
Selected frames from the original dataset were divided into appropriate sets to train, validate, and test the CNN-based classifiers. Furthermore, survey data collected from the original dataset was used to assess the classification performance of the proposed CNN-based model in comparison to five laryngologists who were not involved in the study. Table 2 provides a summary of the number of frames utilized during the training, validation, and testing stages in both binary and multi-class classification and presents the number of frames collected specifically for survey data.
A preprocessing stage was performed to improve overall efficiency, which involved converting the frames from the RGB color format to grayscale, resulting in a reduction of color channels from three to one. Additionally, the frames were resized to 25% of their original dimensions, and original pixel values ranging from 0 to 255, were normalized to the [0,1] range. As a consequence, the size of the frames was reduced to \(112\times 117\) pixels in grayscale format for multi-class classification and to \(45\times 46\) pixels in RGB format for binary classification.
The adaptive momentum (ADAM) algorithm was employed to iteratively optimize the model parameters (see Supporting Information, Methods). Supporting Table 1 lists the optimal values of the hyperparameters for binary and multi-class classifiers. Various evaluation metrics (e.g., accuracy, recall, precision, F1-score, macro average F1-score [average of F1 scores calculated in multiclassification], Cohen-Kappa score [CKS], and Matthews correlation coefficient [MCC]) values were employed to assess classifier performance.
Results
Figure 2 illustrates the accuracy and loss curves of the classifiers with respect to epoch number during training and validation processes. These curves were achieved by using the optimal hyperparameters in the CNN-based models. The CNN-based model achieved a performance of over 95% in all metrics in the binary classification phase for detecting frames indicating sulcus. Table 3 provides the model’s predictions regarding the classification of frames into respective subsets as a confusion matrix and metrics derived from the confusion matrix.

Accuracy and loss curves of the proposed convolutional neural network (CNN) models across epochs in training and validation processes: (a) binary classifier, (b) multi-class classifier
The subsequent phase of the study aimed to evaluate the model’s multi-class classification performance in testing data that included 6,319 frames from all included groups. The CNN-based model achieved 85% accuracy in the multi-class case. Table 4; Fig. 3 present the detailed results for other metrics and the confusion matrix. To compare classification performance in survey data that included 544 frames, the confusion matrices and performance metrics of the CNN-based model and laryngologists were reviewed.

Confusion matrix for the convolutional neural network (CNN)-Based multi-class classifier
The CNN-based model showed comparable recall (80% versus 62–89% [average 79.6%]) and notably high precision metrics (85% versus 66–76% [average 69.8%]) in the healthy group in comparison to the performance of laryngologists. In the nodule group, the CNN-based model achieved comparable recall (76% versus 67–77% [average 71.2%]) and precision metrics (69% versus 63–84% [average 74.8%]) to those achieved by laryngologists. In the papilloma group, the CNN-based model had higher recall (91% versus 80–84% [average 81.2%]) performance but lower precision performance (80% versus 91–98% [average 94.2%]) compared to laryngologists. In the polyp group, the CNN-based model demonstrated lower recall (73% versus 87–96% [average 92%]) but higher precision (74% versus 52–72% [average 59.4%]) when compared to laryngologists. In the sulcus group, the CNN-based model showed higher recall (78% versus 55–64% [average 60.8%]) and comparable precision metrics (72% versus 72–83% [average 78.2%]) to those achieved by laryngologists. In the cyst group, the CNN-based model was shown to achieve higher levels of recall (73% versus 37–44% [average 41.4%]) and comparable precision performance (74% versus 70–87% [average 80.4%]) to those achieved by laryngologists. Lastly, for the pseudocyst category, the CNN-based model showed higher levels of recall (82% versus 5–50% [average 25.6%]) and precision metrics (79% versus 22–62% [average 45.4%]) in comparison to the performance of laryngologists. Furthermore, the CNN-based model outperformed laryngologists, as it achieved higher scores across various metrics such as accuracy, CKS, macro average F1-score, and MCC. These results highlight the robust performance of the CNN-based model in comparison to expert laryngologists in the multi-class classification task. Table 4 displays accuracy, recall, precision, CKS, macro average F1-score, and average MCC values, and Fig. 4 depicts the relevant confusion matrices. As a final remark, the CNN-based model not only demonstrated superior accuracy in classification but also achieved much faster classification times compared to the laryngologists (CNN: milliseconds versus C1: 32 min, C2: 42 min, C3: 30 min, C4: 36 min, and C5: 35 min).

The confusion matrices for all participants, including the proposed model, based on survey data
Discussion
Sulcus refers to a groove located at the free edge of the VF, which is typically linked to a reduced vibration pattern [1]. In conjunction with clinical symptoms, videostroboscopy serves as a diagnostic modality for sulcus. Nevertheless, the process of diagnosis can present challenges, as evidenced by the existing literature [5, 6]. It is subjective and highly dependent on the examiner’s expertise. Additionally, not all physicians have sufficient training, experience, or equipment to fully visualize the larynx for a diagnosis of VF disease. These difficulties have necessitated the development of supplementary computer-based systems that incorporate AI to aid clinicians in the diagnostic process.
In our study, two CNN-based classifiers were developed for the purpose of distinguishing images of patients diagnosed with sulcus from those with other VF diseases and from healthy individuals. The proposed models demonstrated promising performance metrics. Specifically, the binary classifier reached an accuracy of 98% and an F1 value of 97%. The multi-class classifier achieved 85% accuracy, which is comparable to clinicians in distinguishing between sulcus, healthy individuals, and benign VF diseases. Our study’s findings indicate that the utilization of CNN-based models holds promise for enhancing clinical laryngoscopy assessments and has the potential to contribute to the development of a contemporary automated system for diagnosing challenging conditions such as sulcus.
Previous studies have investigated AI models in various applications within the field of laryngology (i.e., glottal area segmentation, VF vibration analysis, movement determination, and lesion recognition) [10]. In the context of VF lesion recognition and classification, most studies used traditional machine learning methods such as support vector machines (SVM) and k-nearest neighbors [12,13,14,15,16,17,18,19,20]. However, a limited number of studies employed deep learning algorithms (specifically CNN), which exhibit significant computational capabilities when using larger datasets, particularly in the field of lesion recognition and classification [21,22,23,24,25,26]. In addition, assessment and classification of the sulcus with CNN-based models were not conducted in any studies. To our knowledge, only a single study by Turkmen et al. classified sulcus along with a set of VF diseases in the present literature [19]. Turkmen et al. used a region-growing and vessel-linking-based segmentation algorithm to segment blood vessels. They used features extracted from the blood vessels as input into SVM, random forest, and k-nearest neighbors classification algorithms to classify images into healthy, polyp, nodule, sulcus, and laryngitis groups. Then, they assessed the performance of their method using laryngeal pictures from 70 patients, and found that the sensitivities for the healthy, polyp, nodule, laryngitis, and sulcus classes were 86%, 94%, 80%, 73%, and 76%, respectively. Nevertheless, Turkmen et al. employed a binary decision tree model that integrates human expertise and machine learning techniques to effectively classify VF. To the best of our knowledge, our study is the first to assess sulcus using a CNN-based model. In contrast to Turkmen et al., our classification process did not involve human intervention. On the contrary, we solely utilized an AI-based model. Human intervention was limited to the preparation of the whole dataset for the purpose of training and testing the proposed classifiers and the formation of the survey data.
Conducting comparative research between AI models and clinicians is of the utmost importance to validate and promote widespread utilization of AI applications as diagnostic tools [27]. Ren et al. [24] and Xiong et al. [26] conducted research for the purpose of AI-based classification of normal, precancerous, and cancerous laryngeal lesions, and the studies involved a comparison of their respective findings with those of clinicians. The researchers demonstrated in their studies [24, 26] that their CNN-based model exhibited higher accuracy rates in classifying lesions compared to human experts. In our study, we compared the performance metrics of the CNN-based model and those of clinicians. Despite imposing no constraint in the frame inclusion process to form the datasets, the F1 score of the CNN-based classifier surpassed the average F1 scores achieved by five laryngologists across various groups, including healthy, polyp, sulcus, cyst, and pseudocyst. However, in the case of the nodule and papilloma groups, the F1 score of the CNN-based classifier was observed to be inferior. The clinicians included in this study were laryngologists with at least five years of experience in the field of laryngology. In this context, we obtained noteworthy results by comparing the laryngologist model to the AI model. Nevertheless, it is imperative to acknowledge that the diagnostic data presented to clinicians consisted of videotroboscopy frames and that the accuracy of clinicians in classifying lesions would have been enhanced by the demonstration of videostroboscopy.
In our study, the dataset was created by extracting frames from videostroboscopies recorded at 25 fps. Considering the fast inference ability of the proposed models, developing advanced AI models to make real-time assessments during laryngoscopies should be a subject of future research. To our knowledge, a single report in the laryngology field by Azam et al. [25] investigates the application of a CNN model for the purpose of real-time assessment of laryngeal squamous cell cancer during both white light and narrow-band imaging video laryngoscopies. Given this gap in the existing literature, the next phase of our research will focus on developing advanced AI models in real-time videostroboscopy settings. Through the implementation of this method, the potential for improving clinicians’ accuracy in diagnosis during laryngoscopies may be boosted, particularly when evaluating challenging lesions such as sulcus.
This study has certain limitations. The inclusion of images obtained from videostroboscopy as data for the AI algorithm, as opposed to the assessment of videostroboscopy itself, results in the elimination of many videostroboscopy findings that are routinely assessed in the diagnostic process of sulcus by clinicians. In our study, evaluating individual frames rather than entire videos may restrict clinicians’ capacity to accurately assess sulcus. Another limitation of our study pertains to the inclusion of patients who did not undergo routine biopsy or surgery. The criteria for inclusion in the dataset relied primarily on the evaluation of videostroboscopies by a fellowship-trained laryngologist (N.E.) with at least five years of experience rather than on pathologically confirmed disease or during suspension microlaryngoscopy examination (10 pseudocyst, 90 nodule cases that were not pathologically confirmed, and 20 sulcus patients did not undergo suspension microlaryngoscopy). Nonetheless, due to its unique visual characteristics and unanimous validation by all specialists, the precision of the dataset per se is ensured.
Conclusion
This study proposes a CNN-based approach that facilitates the diagnosis of sulcus using videotroboscopy frames. The CNN-based algorithm our research describes has the potential to be trained using diverse datasets pertaining to various VF diseases. Improved deep learning models trained on larger datasets are likely to increase the accuracy and applicability of classifiers in diagnosing VF lesions. Additionally, our dataset can be utilized in multicenter collaboration for training upcoming deep learning models in the field of interest.
References
Giovanni A, Chanteret C, Lagier A (2007) Sulcus Vocalis: a review. Eur Arch Otorhinolaryngol 264:337–344. https://doi.org/10.1007/s00405-006-0230-8
Hirano M et al (1990) Sulcus vocalis: functional aspects Annals of otology, rhinology & laryngology, 99(9): pp. 679–683. https://doi.org/10.1177/000348949009900901
Lim J-Y et al (2009) Sulcus configurations of vocal folds during phonation. Acta Otolaryngol 129(10):1127–1135. https://doi.org/10.1080/00016480802579058
Saraniti C, Patti G, Verro B (2023) Sulcus Vocalis and Benign Vocal Cord lesions: is there any relationship? Int J Environ Res Public Health 20(9):5654. https://doi.org/10.3390/ijerph20095654
Dailey SH, Spanou K, Zeitels SM (2007) The evaluation of benign glottic lesions: rigid telescopic stroboscopy versus suspension microlaryngoscopy. J Voice 21(1):112–118. https://doi.org/10.1016/j.jvoice.2005.09.006
Sunter AV et al (2011) Histopathological characteristics of sulcus vocalis. Otolaryngology–Head Neck Surg 145(2):264–269. https://doi.org/10.1177/0194599811404639
Yildiz MG et al (2021) Assessment of Subjective and Objective Voice Analysis According to types of Sulcus Vocalis. J Voice. https://doi.org/10.1016/j.jvoice.2021.04.018
Sampieri C et al (2023) Artificial Intelligence for Upper Aerodigestive Tract Endoscopy and Laryngoscopy: A Guide for Physicians and State-of‐the‐Art Review. Otolaryngology–Head Neck Surg 169(4):811–829. https://doi.org/10.1002/ohn.343
Crowson MG et al (2020) A contemporary review of machine learning in otolaryngology–head and neck surgery. Laryngoscope 130(1):45–51. https://doi.org/10.1002/lary.27850
Yao P et al (2022) Applications of artificial intelligence to office laryngoscopy: a scoping review. Laryngoscope 132(10):1993–2016. https://doi.org/10.1002/lary.29886
Alter IL et al (2024) An introduction to machine learning and generative artificial intelligence for otolaryngologists—head and neck surgeons: a narrative review. Eur Arch Otorhinolaryngol 1–9. https://doi.org/10.1007/s00405-024-08512-4
Araújo T et al (2019) Learned and handcrafted features for early-stage laryngeal SCC diagnosis. Med Biol Eng Comput 57:2683–2692. https://doi.org/10.1007/s11517-019
Gelzinis A et al (2009) Categorizing sequences of laryngeal data for decision support. In Electrical and Control Technologies: proceedings of the 4th international conference, ECT 2009, May 7–8, Kaunas, Lithuania. IFAC Committee of National Lithuanian Organisation
Bethanigtyas H, Anggraini CD (2019) Classification system vocal cords disease using digital image processing. In 2019 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT). IEEE. https://doi.org/10.1109/ICIAICT.2019.8784832
Turkmen HI, Karsligil ME, Kocak I (2013) Classification of vocal fold nodules and cysts based on vascular defects of vocal folds. In 2013 IEEE International Workshop on Machine Learning for Signal Processing (MLSP). IEEE. https://doi.org/10.1109/MLSP.2013.6661959
Huang C-C et al (2014) Automatic recognizing of vocal fold disorders from glottis images. Proceedings of the Institution of Mechanical Engineers, Part H: Journal of Engineering in Medicine, 228(9):952–961. https://doi.org/10.1177/0954411914551851
Ilgner JF et al (2003) Colour texture analysis for quantitative laryngoscopy. Acta Otolaryngol 123(6):730–734. https://doi.org/10.1080/00016480310000412
Unger J et al (2013) A multiscale product approach for an automatic classification of voice disorders from endoscopic high-speed videos. In. 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE. https://doi.org/10.1109/EMBC.2013.6611258
Turkmen HI, Karsligil ME, Kocak I (2015) Classification of laryngeal disorders based on shape and vascular defects of vocal folds. Comput Biol Med 62:76–85. https://doi.org/10.1016/j.compbiomed.2015.02.001
Unger J et al (2015) A noninvasive procedure for early-stage discrimination of malignant and precancerous vocal Fold lesions based on laryngeal dynamics analysis. Cancer Res 75(1):31–39. https://doi.org/10.1158/0008-5472.CAN-14-1458
Wang P, Fan E, Wang P (2021) Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit Lett 141:61–67. https://doi.org/10.1016/j.patrec.2020.07.042
Luan B et al (2019) R-fcn based laryngeal lesion detection. In 2019 12th International Symposium on Computational Intelligence and Design (ISCID). IEEE. https://doi.org/10.1109/ISCID.2019.10112
Dunham ME et al (2022) Optical biopsy: automated classification of airway endoscopic findings using a convolutional neural network. Laryngoscope 132. https://doi.org/10.1002/lary.28708. p. S1-S8
Ren J et al (2020) Automatic recognition of laryngoscopic images using a deep-learning technique. Laryngoscope 130(11). https://doi.org/10.1002/lary.28539. p. E686-E693
Azam MA et al (2022) Deep learning applied to white light and narrow band imaging videolaryngoscopy: toward real-time laryngeal cancer detection. Laryngoscope 132(9):1798–1806. https://doi.org/10.1002/lary.29960
Xiong H et al (2019) Computer-aided diagnosis of laryngeal cancer via deep learning based on laryngoscopic images. EBioMedicine 48:92–99. https://doi.org/10.1016/j.ebiom.2019.08.075
Dallari V et al (2024) Is artificial intelligence ready to replace specialist doctors entirely? ENT specialists vs ChatGPT: 1 – 0, ball at the center. Eur Arch Otorhinolaryngol 281(2):995–1023. https://doi.org/10.1007/s00405-023-08321-1
Acknowledgements
Bengü Çobanoğlu M.D., Mehmet Akif Kılıç M.D, Elad Azizli M.D., Nurullah Türe M.D, Müge Özçelik Korkmaz M.D.
Funding
Not applicable.
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical approval
This study was approved by the Marmara University Medical Faculty Ethics Committee for Clinical Research on 03/02/2023 with number 09.2023.272.
Informed consent
Because the study was designed retrospectively, informed consent was not obtained from the patients.
Conflict of interest
The authors have no conflicts of interest relevant to the content of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kavak, Ö.T., Gündüz, Ş., Vural, C. et al. Artificial intelligence based diagnosis of sulcus: assesment of videostroboscopy via deep learning. Eur Arch Otorhinolaryngol (2024). https://doi.org/10.1007/s00405-024-08801-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00405-024-08801-y