
Abstract
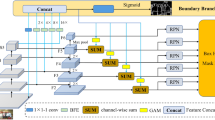
State-of-the-art instance segmentation approaches, such as Mask R-CNN, have exhibited remarkable performance under clear weather conditions. However, their effectiveness is significantly compromised in foggy environments, primarily due to reduced visibility and obscured object details. To address this challenge, we introduce a joint defogging learning with boundary refinement (JDLMask) framework. Unlike conventional strategies that treat image dehazing as a preprocessing step, JDLMask employs a shared structure that enables the joint learning of defogging and instance segmentation. This integrated approach greatly bolsters the model’s adaptability to foggy scenarios. Recognizing challenges in feature extraction due to fog interference, we propose a multi-scale feature fusion mask head, based on the encoder–decoder architecture. This component is designed to acquire both local and global information, thereby enhancing the model’s feature representation capacity. Furthermore, we integrate a boundary refinement module, which sharpens the model’s localization accuracy by focusing on critical boundary details. Addressing the scarcity of datasets tailored, for instance, segmentation in real-world foggy scenes, we have enriched the Foggy Driving dataset with meticulously crafted instance mask annotations and named it the Foggy Driving InstanceSeg. Comprehensive experiments demonstrate JDLMask’s superiority. Compared to the baseline Mask R-CNN, JDLMask achieves improvements of 4.4% and 3.8% in mask AP on the Foggy Cityscapes and Cityscapes validation sets, respectively, and a 2.5% gain on the Foggy Driving InstanceSeg dataset.













Similar content being viewed by others

Availability of data and materials
The datasets utilized and/or analyzed during this study can be accessed from the following repositories: Cityscapes: https://www.cityscapes-dataset.com/. Foggy Cityscapes: https://www.cityscapes-dataset.com/. Foggy Driving InstanceSeg: https://github.com/XJWang628/Foggy-Driving-InstanceSeg.
References
Minaee, S., Boykov, Y., Porikli, F., Plaza, A., Kehtarnavaz, N., Terzopoulos, D.: Image segmentation using deep learning: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 44(7), 3523–3542 (2022). https://doi.org/10.1109/TPAMI.2021.3059968
Huang, Z., Huang, L., Gong, Y., Huang, C., Wang, X.: Mask scoring R-CNN. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6402–6411 (2019). https://doi.org/10.1109/CVPR.2019.00657
Cai, Z., Vasconcelos, N.: Cascade R-CNN: high quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 43(5), 1483–1498 (2021). https://doi.org/10.1109/TPAMI.2019.2956516
Wang, X., Zhang, R., Kong, T., Li, L., Shen, C.: SOLOv2: dynamic and fast instance segmentation. In: Proceedings Advances in Neural Information Processing Systems (NeurIPS) (2020)
Tian, Z., Shen, C., Chen, H.: Conditional convolutions for instance segmentation. In: Computer Vision–ECCV 2020, pp. 282–298 (2020). https://doi.org/10.1007/978-3-030-58452-8_17. Springer
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 42(2), 386–397 (2020). https://doi.org/10.1109/TPAMI.2018.2844175
Chunle, G., Yan, Q., Anwar, S., Cong, R., Ren, W., Li, C.: Image dehazing transformer with transmission-aware 3D position embedding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5802–5810 (2022). https://doi.org/10.1109/CVPR52688.2022.00572
Sakaridis, C., Dai, D., Van Gool, L.: Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. (2018). https://doi.org/10.1007/s11263-018-1072-8
He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 33(12), 2341–2353 (2011). https://doi.org/10.1109/TPAMI.2010.168
Qin, X., Wang, Z., Bai, Y., Xie, X., Jia, H.: FFA-Net: Feature fusion attention network for single image dehazing. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 11908–11915 (2020). https://doi.org/10.1609/aaai.v34i07.6865
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3213–3223 (2016). https://doi.org/10.1109/CVPR.2016.350
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2017). https://doi.org/10.1109/TPAMI.2016.2577031
Bi, X., Hu, J., Xiao, B., Li, W., Gao, X.: IEMask R-CNN: information-enhanced mask R-CNN. IEEE Trans. Big Data (2022). https://doi.org/10.1109/TBDATA.2022.3187413
Liu, S., Qi, L., Qin, H., Shi, J., Jia, J.: Path aggregation network for instance segmentation. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8759–8768 (2018). https://doi.org/10.1109/CVPR.2018.00913
Chen, K., Pang, J., Wang, J., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Shi, J., Ouyang, W., et al.: Hybrid task cascade for instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4974–4983 (2019). https://doi.org/10.1109/CVPR.2019.00511
Shen, X., Yang, J., Wei, C., Deng, B., Huang, J., Hua, X., Cheng, X., Liang, K.: DCT-Mask: discrete Cosine transform mask representation for instance segmentation. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8716–8725 (2021). https://doi.org/10.1109/CVPR46437.2021.00861
Wang, X., Kong, T., Shen, C., Jiang, Y., Li, L.: SOLO: segmenting objects by locations. In: Computer Vision—ECCV 2020. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58523-5_38
Yang, Z., Wang, Y., Yang, F., Yin, Z., Zhang, T.: Real-time instance segmentation with assembly parallel task. Vis. Comput. (2022). https://doi.org/10.1007/s00371-022-02537-8
Zhang, G., Lu, X., Tan, J., Li, J., Zhang, Z., Li, Q., Hu, X.: RefineMask: Towards high-quality instance segmentation with fine-grained features. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6857–6865 (2021). https://doi.org/10.1109/CVPR46437.2021.00679
Kirillov, A., Wu, Y., He, K., Girshick, R.: PointRend: image segmentation as rendering. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9796–9805 (2020). https://doi.org/10.1109/CVPR42600.2020.00982
Gao, Y., Qi, Z., Zhao, D.: Edge-enhanced instance segmentation by grid regions of interest. Vis. Comput. (2022). https://doi.org/10.1007/s00371-021-02393-y
Hu, Q., Zhang, Y., Zhu, Y., Jiang, Y., Song, M.: Single image dehazing algorithm based on sky segmentation and optimal transmission maps. Vis. Comput. 39, 1–17 (2022). https://doi.org/10.1007/s00371-021-02380-3
Li, Z.-X., Wang, Y.-L., Han, Q.-L., Peng, C.: Zrdnet: zero-reference image defogging by physics-based decomposition–reconstruction mechanism and perception fusion. Vis. Comput. (2023). https://doi.org/10.1007/s00371-023-03109-0
Sun, Y., Su, L., Luo, Y., Meng, H., Zhang, Z., Zhang, W., Yuan, S.: Irdclnet: instance segmentation of ship images based on interference reduction and dynamic contour learning in foggy scenes. IEEE Trans. Circuits Syst. Video Technol. 32, 6029–6043 (2022). https://doi.org/10.1109/TCSVT.2022.3155182
Li, B., Peng, X., Wang, Z., Xu, J., Feng, D.: AOD-Net: all-in-one dehazing network. In: 2017 IEEE international conference on computer vision (ICCV), pp. 4780–4788 (2017). https://doi.org/10.1109/ICCV.2017.511
Huang, S.-C., Le, T.-H., Jaw, D.-W.: DSNet: joint semantic learning for object detection in inclement weather conditions. IEEE Trans. Pattern Anal. Mach. Intell. 43(8), 2623–2633 (2021). https://doi.org/10.1109/TPAMI.2020.2977911
Liu, W., Ren, G., Yu, R., Guo, S., Zhu, J., Zhang, L.: Image-adaptive YOLO for object detection in adverse weather conditions. In: Proc. AAAI Conference on Artificial Intelligence, vol. 36, pp. 1792–1800 (2022). https://doi.org/10.1609/aaai.v36i2.20072
Zhang, S., Tuo, H., Hu, J., Jing, Z.: Domain adaptive yolo for one-stage cross-domain detection. In: Asian conference on machine learning, pp. 785–797 (2021). PMLR
Li, J., Xu, R., Ma, J., Zou, Q., Ma, J., Yu, H.: Domain adaptive object detection for autonomous driving under foggy weather. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 612–622 (2023)
Jiqing, C., Depeng, W., Teng, L., Tian, L., Huabin, W.: All-weather road drivable area segmentation method based on CycleGAN. Vis. Comput. (2022). https://doi.org/10.1007/s00371-022-02650-8
Zhu, J.-Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2242–2251 (2017). https://doi.org/10.1109/ICCV.2017.244
Lee, S., Son, T., Kwak, S.: FIFO: learning fog-invariant features for foggy scene segmentation. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 18889–18899 (2022). https://doi.org/10.1109/CVPR52688.2022.01834
Li, Y., Chang, y., Yu, C., Yan, L.: Close the loop: a unified bottom-up and top-down paradigm for joint image deraining and segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 1438–1446 (2022). https://doi.org/10.1609/aaai.v36i2.20033
Lin, T., Dollar, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 936–944 (2017). https://doi.org/10.1109/CVPR.2017.106
Nayar, S.K., Narasimhan, S.G.: Vision in bad weather. In: Proceedings of the Seventh IEEE International Conference on Computer Vision (ICCV), vol. 2, pp. 820–8272 (1999). https://doi.org/10.1109/ICCV.1999.790306
Narasimhan, S., Nayar, S.: Contrast restoration of weather degraded images, pp. 1–12 (2008). https://doi.org/10.1145/1508044.1508114
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–9 (2015). https://doi.org/10.1109/CVPR.2015.7298594
Zhang, J., Cao, Y., Wang, Y., Wen, C., Chen, C.W.: Fully point-wise convolutional neural network for modeling statistical regularities in natural images. In: Proceedings of the 26th ACM International Conference on Multimedia. MM ’18, pp. 984–992. Association for Computing Machinery, New York, NY, USA (2018). https://doi.org/10.1145/3240508.3240653
Sobel, I., Feldman, G.: A 3\(\times \)3 isotropic gradient operator for image processing. In: Pattern Classification and Scene Analysis, pp. 271–272 (1973)
Milletari, F., Navab, N., Ahmadi, S.-A.: V-net: Fully convolutional neural networks for volumetric medical image segmentation. In: 2016 Fourth International Conference on 3D Vision (3DV), pp. 565–571 (2016). https://doi.org/10.1109/3DV.2016.79
Cheng, T., Wang, X., Huang, L., Liu, W.: Boundary-preserving mask R-CNN. In: Computer Vision—ECCV 2020, pp. 660–676. Springer, Berlin, Heidelberg (2020). https://doi.org/10.1007/978-3-030-58568-6_39
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: common objects in context. In: Computer Vision—ECCV 2014, pp. 740–755. Springer, Berlin, Heidelberg (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng, D., Zhu, C., Cheng, T., Zhao, Q., Li, B., Lu, X., Zhu, R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy, C.C., Lin, D.: MMDetection: Open MMLab Detection Toolbox and Benchmark (2019) arXiv:1906.07155
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A., Fei-Fei, L.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. (2014). https://doi.org/10.1007/s11263-015-0816-y
Bolya, D., Foley, S., Hays, J., Hoffman, J.: TIDE: A general toolbox for identifying object detection errors. In: Computer Vision—ECCV 2020, pp. 558–573. Springer, Berlin, Heidelberg (2020). https://doi.org/10.1007/978-3-030-58580-8_33
Funding
This work was supported in part by the National Natural Science Foundation of China (No.62171315), in part by the National Key Research and Development Program of China (No. 2022ZD0160400), and in part by Tianjin Research Innovation Project for Postgraduate Students (No.2021YJSB153).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection, and analysis were performed by XW, JG, YW, and WH. The first draft of the manuscript was written by XW and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors certify that there are no competing interests, as defined by Springer, or any other interests that could potentially influence the results and/or discussion reported in this paper.
Ethical approval
This declaration is not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, X., Guo, J., Wang, Y. et al. Jdlmask: joint defogging learning with boundary refinement for foggy scene instance segmentation. Vis Comput (2024). https://doi.org/10.1007/s00371-023-03230-0
Accepted:
Published:
DOI: https://doi.org/10.1007/s00371-023-03230-0