
Abstract
The development of robust prediction tools based on machine learning (ML) techniques requires the availability of complete, consistent, accurate, and numerous datasets. The application of ML in structural engineering has been limited since, although real size experiments provide complete and accurate data, they are time-consuming and expensive. On the other hand, validated finite element (FE) models provide consistent and numerous synthetic data. Depending on the complexity of the problem, they might require large computational time and cost, and could be subjected to uncertainties and limitation in prediction capability given they are approximations of real-world problems. Hybrid approaches to combine experimental and synthetic datasets have emerged as an alternative to improve the reliability of ML model predictions. In this paper, we explore two hybrid methods to propose a robust approach for the prediction of the extended hollo-bolt (EHB) connection strength, stiffness, and column face displacement: (1) supervised ML methods with data fusion (DF) where learning is optimized with particle swarm optimization (PSO), and (2) artificial neural networks (ANN) based method with model fusion (MF). Based on the analysis of a dataset that combines 22 tensile experimental results with 2000 synthetic datapoints based on FE models, we concluded that using the first method (ML with DF and PSO) is the most suitable method for the prediction of the connection behavior. The ANN-based method with MF shows to be a promising method for the characterization of the EHB connection, however, more extensive experimental data is required for its implementation. Finally, a graphical user interface application was developed and shared in a public repository for the implementation of the proposed hybrid model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Literature review
In recent years, the development of cutting-edge soft-computing technologies and their application to engineering problems demonstrated promising potential to simulate complex non-linear problems. However, the development of robust prediction tools based on machine learning (ML) techniques requires the availability of complete, consistent, accurate, and numerous datasets.
Real size experiments are time-consuming and expensive, limiting the range of parameters that can be studied and the development of reliable analytical models. Alternatively, validated finite element (FE) models are used to capture the behaviour of complex systems, partially replacing more costly experiments, and giving access to inspect aspects that are not attainable during experiments [1]. Nevertheless, such models come with their own challenges, such as the associated large computational time and cost, convergence issues, uncertainties over replicating the correct phenomena outside of the fitted/validated ranges, etc., which prevent a systematic exploration of all the possible design parameters of the investigated problem.
In turn, ML techniques offer an attractive and practical approach to characterise the behavior of complex systems along different engineering disciplines, such as underground construction [2], wind turbine monitoring [3], earthquake engineering [4], structural engineering [5], among others. In general, the accuracy of ML models, among others, depends on the availability of a significant body of accurate and consistent data to span a large design parameter domain. The use of ML methods in bolted connections has been limited since extensive experimental datasets are not always available, and synthetic data does not always have the same level of accuracy as the experimental results. To overcome this, hybrid methods which fuse synthetic and experimental results, offer a promising alternative for handling complex problems when datasets are scarce [6].
1.2 Application background
The use of concrete-filled steel tube (CFST) columns in modern structures has increased over the last years in high-rise construction due to their enhanced structural performance in comparison with conventional hollow steel tube columns. For instance, CFST offer better axial load carrying capacity, higher strength-to-weight ratio, and increased strength and torsional resistance. Thus, CFST columns have been used in several projects, such as electric transmission towers [7], high-rise buildings, and bridges including arch, suspension, truss, among other types of bridges [8].
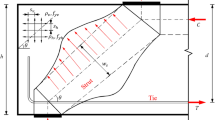
Blind-bolted connections, such as the extended hollo-bolt, have been developed to connect tubular steel members to other steel sections in construction. Blind bolts are installed from one side of the tubular section (Fig. 1), overcoming the installation challenges given by the lack of space to install a standard nut in the inner part of the steel tube. These connections are under investigation for the development of moment-resisting connections [9,10,11]. In the field of bolted connections in structural engineering, the use of traditional methods such as the component method [12] for the characterization of new bolting techniques continues to be highly researched [13,14,15]. However, these connections are complex to characterise due to the multiple interactions between different components and materials and therefore traditional approaches have not been successful for the full characterization of complex connections.
In the last decade, a number of researchers [16,17,18] have conducted experimental testing, or developed empirical, analytical or numerical models for prediction of the blind-bolted connections behavior, however all these models are limited, either in comprehension of complex behavior or range of applicably. Hence, this paper proposes a ML-based method to combine different prediction models and extend the scope of applicability.
In this paper, we explore two hybrid approaches to develop a robust model which predicts the EHB connection behavior in terms of strength, stiffness and column face displacement (which is used to characterise the connection failure mode). These methods are: (1) supervised ML methods with data fusion where learning is optimized with Particle Swarm optimisation (PSO), and (2) artificial neural network (ANN)-based method with model fusion. These models explore the combination of different data sources at different stages of training and assembly. The main benefit of the proposed model is that it allows the combination of the limited experimental dataset based on 11 pairs of experiments reported by Tizani et. al [19], with a synthetic dataset based on 2000 FE simulations using a hybrid ML approach. The performance of the proposed hybrid algorithm enhanced when compared with approaches that only use synthetic data for the predictions.
The remainder of the paper is organized as follows: Sect. 2 presents the description of the problem and nature of the datasets; Sect. 3 presents a description of the hybrid ML methodologies used in this paper; the results are discussed in Sect. 4, and recommendations are given in Sect. 5 as well as the development of a GUI prediction tool; finally, the conclusions of the work, limitations and future work are presented in Sect. 6.
2 Problem description
2.1 Dataset
The design variables used in this study include six geometry and material properties of the EHB connection: bolt diameter \(d_{\rm b}\), bolt grade \(b_{\rm g}\), bolt gauge distance g, concrete grade \(c_{\rm g}\), bolt shank length \(l_{\rm s}\), and tube slenderness ratio \(\mu\) (column width over thickness ratio), see Fig. 1. These variables are either constrained (discrete parameter which can only take certain commercial values), or unconstrained (continuous parameter which can take any value). The connection tensile behavior is quantified in terms of strength F, stiffness k, and column face displacement \(\delta\), which in turn determines the connection failure mode.
The dataset comprises the results of 22 pure tensile experiments and a synthetic dataset based on 2000 simulations carried out in Abaqus/CAE software [20]. The range of experimental and synthetic input design parameters are summarized in Table 1. The experimental results are summarized in Table 2 and the numerical results in Table 3 along with the respective numerical error values.

EHB connection illustration and bolt parts
The synthetic dataset was generated by means of sampling techniques comprising: 11 validated FE models which match the experimental results (benchmark models); 32 models generated by CROSS combination: each value sampled for an individual parameter is combined with a reference value of all the other parameters, which allows for the exploration of changing one design parameter at a time and their direct impact on the connection behavior; and 1956 additional models generated by random sampling, using the benchmark values as reference and changing two or more variables at a time.
ML models are usually sensitive to the ranges and distribution of the training data used for their development. Figure 2 shows the histograms of the data utilized in this study, the most frequent parameters correspond to the benchmark values: diameter 16, grade 8.8, gauge 140 mm, shank length 170 mm, tube slenderness ratio 30, and concrete grade 40 MPa.

Histograms of independent input variables a bolt diameter, b bolt grade, c bolt gauge distance, d concrete strength, e shank length, f slenderness ratio
2.2 Sensitivity analysis
Sensitivity analysis (SA) were performed to study how the input variation affects the output of a model and its uncertainty. Two correlation coefficients (Pearson correlation coefficient r, and Spearman rank correlation coefficient \(\rho\)) [21], and Sobol sensitivity analysis from SALib Python library were used for this purpose.
The coefficients r, and \(\rho\) can take values between \(+\) 1 and − 1. There is a positive correlation between the compared values if the correlation coefficient is positive, a perfect positive correlation is given by \(+\) 1; a negative correlation is given by negative values of the correlation coefficient, a perfect negative correlation is given by − 1. Coefficients equal to 0 indicate no correlation, between 0 and 0.3 (or \(-\) 0.3) represent a weak relationship, between 0.3 and 0.7 (or \(-\) 0.3 and \(-\) 0.7) indicate a moderate relationship, and between 0.7 and 1.0 (or \(-\) 0.7 and \(-\) 1.0) indicate strong relationship [22]. Figure 3 shows the calculated values of the two coefficients in a heatmap graph. The general trend of the graphs indicate that there is no correlation or weak relationship between the design parameters.

Variable correlation heatmap
SALib is an open source Python library written in Python which provides a decoupled workflow for performing SA. SALib samples the model inputs and computes the sensitivity indices from the model outputs. Multiple sampling and analyze functions are available in SALib, one of them is Sobol sensitivity analysis, which is one of the most powerful techniques and therefore was adopted in this study.
S1 are first-order indices which measure the contribution of a single model input to the output variance. S2 in turn are second-order indices which quantify the contribution to the output variance caused by the interaction of two model inputs.
Table 4 presents the calculated first-order indices for the connection strength, stiffness, and column displacement. The results show that only bolt diameter and grade exhibit first-order sensitivities for the connection strength, slenderness ratio for the connection stiffness, and gauge distance for the column displacement, respectively. The second-order indices for all outputs presented in Table 5 show that there is low to no correlation between the design variables which is in agreement with the statistical results.
According to both the statistical and Sobol sensitivity analyses, the most influential design parameter in terms of connection strength is the bolt grade; for the connection stiffness is the slenderness ratio; and for the column face displacement are the concrete grade and gauge distance. The sensitivity analysis has also shown that there is low to no correlation between the studied design variables, and therefore, they are all relevant to the connection design.
2.3 Data normalization and split
Data normalization for a parameter x was carried out using Eq. 1, which maps all input–output pairs to the interval [0.1, 0.9] in order to delete the differential effect of multiple design parameter ranges over a cost function. After the complete dataset has been processed, data was back-normalized to its original ranges.
where \(x_\textrm{max}\) and \(x_\textrm{min}\) are the maximal and minimal values of the variable x, and \(\tilde{x}_\textrm{min}\) and \(\tilde{x}_\textrm{max}\) are the maximal and minimal values of the variable x after normalization, defined as 0.1 and 0.9.
Data split was performed by dividing the dataset into three sets: training, testing, and validation. Common splits in the literature vary from 60–20–20 to 80–10–10. After testing multiple data splits, 70–20–10 ratio was found suitable for the model requirements. The model was established on the basis of the training and testing datasets to avoid overfitting, while the validation set was used to measure the performance of the model with data that had never been used throughout the training and testing phases.
2.4 Accuracy evaluation
The accuracy of each algorithm was calculated using the relative Root Mean Square Error (\(r_\textrm{RMSE}\)) between predicted and measured connection behavior values, which reflects the quality of the prediction results. This is also referred as the cost function and it is calculated as:
R-squared (\(R^2\)) value was also used as an indicator of the models performance and it is calculated as:
where \(o_{k}\) is the predicted output, \(\bar{o}_k\) is the mean of \(o_{k}\), \(t_{k}\) is the true value of the output features, and p is the total number of input patterns.
3 Machine learning methodologies
The combination of available data and ML algorithms adequacy are explored in this section for the development of a reliable prediction model for the connection behavior. Five different supervised learning regression algorithms from the scikit-learn Python library [23] were chosen for the evaluation of the hybrid models: Linear Regression with Stochastic Gradient Descent (LR-SGD), Grid Search Support Vector Regression (GS-SVR), Support Vector Regression with Radial Basis Function kernel (SVR-RBF), Support Vector Regression with Polynomial kernel function (SVR-Poly), and artificial neural networks (ANNs). Supervised regression models were chosen based on the data fusion requirements to fit input–output values.

Gradient descent methods a batch gradient descent and b stochastic gradient descent
3.1 Machine learning algorithms and hyperparameter optimization
3.1.1 Linear regression with stochastic gradient descent (LR-SGD)
This model makes predictions by computing a weighted sum of the input features plus a bias term:
where \(\hat{y}\) is the predicted value, n in the number of features, \(x_i\) is the ith feature value, \(\theta _0\) is the bias term, and \(\theta _1, \theta _2,\ldots ,\theta _n\) are the feature weights.
Gradient descent (GD) is a generic optimization algorithm capable of finding optimal solutions to a wide range of problems by measuring the local gradient of the error function with regards to the parameter vector \(\theta\), and moving in the direction of descending gradient. Once the gradient is zero, a minimum is reached. A random initialization is carried out by filling \(\theta\) with random values and then the output is improved gradually, taking one step at a time attempting to decrease the cost function, until the algorithm converges to a minimum [24].
To implement the GD, the gradient of the cost function with regards to each model parameter \(\theta _j\) needs to be computed. For instance, batch gradient descent (BGD) uses the whole training set to compute the gradients at every step (see Fig. 4a). On the other hand, stochastic gradient descent (SGD) picks a random instance in the training set at every step and computes the gradients based only on that single instance. SGD is faster than BGD facilitating for the training on big training sets, since only one instance needs to be in memory at each iteration. Due to its stochastic (i.e., random) nature, this algorithm is less regular than other algorithms, meaning that the cost function will bounce up and down, decreasing only on average. Over time it will end up very close to the minimum, but once it gets there it will continue to bounce around, never settling down (see Fig. 4b).

SVM regression using a a linear kernel and b a 2nd-degree polynomial kernel
3.1.2 Support vector machine-regression (SVR)
Support vector machines (SVMs) are powerful and versatile ML models, capable of performing linear or nonlinear classification, regression, and outlier detection. They are particularly well suited for classification of complex but small- or medium-sized datasets. Support Vector Regression (SVR) uses the same principle as the SVMs for the prediction of discrete values [24]. Radial Basis Function and Polynomial functions were used as Kernel hyperparameters.
The SVR hyperparameters are:
-
(a)
Hyperplane: The objective of a SVM algorithm is to find a hyperplane in an n-dimensional space that distinctly classifies the data points. The data points on either side of the hyperplane that are closest to the hyperplane are called Support Vectors which influence the position and orientation of the hyperplane.
-
(b)
Kernel: they are a set functions which transform the data into a higher dimensional feature which allow to perform the linear separation. The function K(a, b) is capable of computing the dot product \(\phi (a)^T \cdot \phi (b)\) based only on the original vectors a and b, without having to compute the transformation \(\phi\). The most widely used kernels include: Linear: \(K(a,b) = a^T \cdot b\) Polynomial: \(K(a,b) = ( \gamma a^T \cdot b+r)^d\) Radial Basis Function (RBF): \(K(a,b) = exp( -\gamma ||a - b||^2)\)
-
(c)
Boundary Lines: these are the two lines that are drawn around the hyperplane at threshold value epsilon \(\varepsilon\). It is used to create a margin between the data points.
Figure 5 shows two examples of SVM regression using linear and polynomial kernel for illustration purposes.

Simplified models of a biological neural network and b artificial neural network
3.1.3 Artificial neural networks (ANNs)
These are simplified mathematical models inspired by the biological neural system in the human brain. The human nervous system is comprised of neurons which are connected to each other to form networks. Each neuron has a body, an axon and multiple dentrites, the regions where axons and dentrites connect are called synapses as illustrated in Fig. 6a. An artificial neuron mimics the biological structure, it has a body where computations are performed, a number of input and output channels connected to the body through synaptic weights as displayed in Fig. 6b. The ANN is composed of multiple neurons which process the input signal to compute the output [25].
The ANN is composed of multiple neurons which process the input signal to compute the output.
The network components are:
-
(a)
The input layer is represented by an input vector \(X=[x_{1},x_{2},\ldots ,x_{n}]^{T}\).
-
(b)
The synaptic weights are associated to the connection between the neuron j and neuron i, labeled as \(w_{ji}\) and represent the influence of input \(x_{i}\). Negative weights inhibit the output node, and positive weights excite the output node. Values of weights are optimized during the training process.
-
(c)
The summing function is the relation between the input and the weights and it is represented as \(X^{T}W\) so that each input node \(x_{i}\) is multiplied by its corresponding weight \(w_{ji}\).
-
(d)
The bias determines the activation of the neuron, hence, the output is affected by the threshold \(b_{j}\) as follows: \(v_{j}=\sum _{i=1}^{n} x_{i}w_{ji}-b_{i}\)
-
(e)
The activation function introduces non-linearities in the relationship between the input and output data. The most common functions are sigmoid, tangent hyperbolic, and rectified linear unit.
-
(f)
The learning process is the systematic change of the input–output behavior when presenting a series of training data resulting from adjustment of the synaptic weights.
Feedforward neural networks or multilayer perceptrons, are the most widely used type of neural network for engineering applications. In these models, information flows through the function from the input to the output nodes with no feedback connections as displayed in Fig. 7a. These networks are divided into multiple layers: input, hidden and output layers. Each layer has a defined number of neurons which execute simple processing and pass the information to the next layer. For learning purposes, these networks are combined with back propagation algorithm to update the weights and reduce the cost function [26].

Basic structure of a feedforward neural network and b backpropagation neural network
The back propagation algorithm consists of two steps: Feedforward step, Fig. 7a, and Backpropagation step, Fig. 7b. The synaptic weights are updated using the SGD method in the back propagation step. The gradient of the error for each training example is calculated and the weights are updated immediately [27]. This model is used in this project to preform function approximation.

Flowchart for training ML models with data fusion and PSO
3.1.4 Particle swarm optimization (PSO)
Particle swarm optimization (PSO) is an evolutionary computational algorithm introduced by Kennedy [28]. In PSO, the system is initialized with a population of random solutions (the particles) placed in the search space, and each evaluates the objective function at its current location. Each particle is described by two properties: velocity (\(v_{ij}\)) and position (\(x_{ij}\)). Each particle keeps track of its coordinates in the problem space, which are associated with the best solution (fitness), and achieves the particle-best value \(p_\textrm{best}\) (\(x^{p_\textrm{best}}_{ij}\)). If a particle takes the complete population as its topological neighbors, the best value is a global best \(g_\textrm{best}\) (\(x^{g_\textrm{best}}_{ij}\)). Eventually the swarm as a whole, like a flock of birds collectively foraging for food, is likely to move close to an optimum of the fitness function. An inertia weight (w) is also used in the basic update rule to reduce the particle speed when particle swarms are searching a large area. The new velocity and position of the particles is updated in each iteration using the following equations:
where \(r_1\) and \(r_2\) are random numbers uniformly distributed over [0, 1] and \(\phi _1\) and \(\phi _2\) are “cognition and social learning factors”.

Connection strength machine learning model with data fusion and particle swarm optimization development a \(r_\textrm{RMSE}\) for 5 ML algorithms and b combined dataset vs predicted values

Connection stiffness machine learning model with data fusion and particle swarm optimisation development a \(r_\textrm{RMSE}\) for 5 ML algorithms and b combined dataset vs predicted values

Column displacement machine learning model with data fusion and particle swarm optimisation development a \(r_\textrm{RMSE}\) for 5 ML algorithms and b combined dataset vs predicted values, where failure zones are denoted as: I Bolt failure, II Combined failure, and III Column face failure
PSO was used to perform meta-optimisation, which means using an optimisation method to update the hyper parameters of another optimisation method, in this case the chosen ML methods.
3.2 Hybrid machine learning methodologies
Two hybrid ML methodologies were explored in this paper for finding the best ML algorithm and the best combination of available datasets: supervised ML methods with data fusion where learning is optimized with PSO, and ANN-based method with model fusion. The main difference between these two methods is that the first combines the experimental and synthetic datasets before feeding it into the ML algorithms, while the second one, feeds the experimental and synthetic datasets to independent models, and a fusion of two models is performed rather than of datasets. A detailed description of each methodology is presented next.

Flowchart for ANN-based method with model fusion
3.2.1 Machine learning methods with data fusion (DF) and PSO
In this method, the experimental and synthetic datasets were combined into one single dataset which then was used as input for the five ML algorithms from the scikit-learn Python library [23]: Linear Regression with Stochastic Gradient Descent (LR-SGD), Grid Search Support Vector Regression (GS-SVR), Support Vector Regression with Radial Basis Function kernel (SVR-RBF), Support Vector Regression with Polynomial kernel function (SVR-Poly), and artificial neural networks (ANNs). PSO was used to optimize free parameters of the training algorithms, such as learning rate, number of nodes, degree, kernel coefficient, etc. After this, the best algorithm was selected based on the accuracy evaluation for the test set as proposed by Ninic et al. [29]. Figure 8 displays the flowchart for the model development process based on the ML method with data fusion and PSO.
Figures 9, 10 and 11 show the steps the taken for the development of the optimized models used for the prediction of the connection strength, stiffness, and column displacement, respectively. In each figure, part (a) corresponds to the comparison between error values from the five ML algorithms, and (b) is the measured versus predicted values using the best model.
Figures 9a, 10a and 11a show the comparison between the \(r_\textrm{RMSE}\) values for training, testing, and validation sets for each ML model. The figures show that, as expected, the \(r_\textrm{RMSE}\) value for the validation set is the largest value compared to training and testing sets, this is caused by the fact that the validation set is not used during the learning process and therefore these values have not been seen by the algorithm. The figures also show that for the three studied variables (strength, stiffness and column face displacement) ANN exhibits that best performance among the five tested ML algorithms.
The ANN offers the lowest values of \(r_\textrm{RMSE}\) for the test set, this is 8%, 6%, and 8% for the connection strength, stiffness, and column face displacement respectively. The second best model is GS-SVR with \(r_\textrm{RMSE}\) values of 17%, 14%, and 26%. This shows that the ANN models exhibit appropriately half error values than the second best model and therefore it was chosen for the prediction of the connection strength, stiffness and column displacement. This model is denoted as DF.
Figures 9b, 10b and 11b show the error values for training, testing, and column displacement sets, for each connection parameter respectively. some discrepancies are observed with respect to the perfect fit line. This is attributed to numerical errors from the synthetic dataset as well as training problems caused by the direct fusion of the datasets. As datasets are fused at the beginning of the algorithm, samples with both synthetic and experimental data points exhibit different output values for the same configuration of input parameters. This could cause inaccuracies in the training process, and therefore it was reflected in the models predictions.

Strength ANN with model fusion development, a experimental, b synthetic, and c differential models

Stiffness ANN with model fusion development, a experimental, b synthetic, and c differential models

Column displacement ANN with model fusion development, a experimental, b synthetic, and c differential models. Where failure zones are denoted as: I Bolt failure, II Combined failure, and III Column face failure
3.2.2 Artificial neural network-based method with model fusion (MF)
The objective of model fusion is to account for numerical and training errors, and enhance the accuracy compared to a model trained based on the experimental dataset. This method assumes the experimental results to be accurate enough to be considered as the model development benchmark. Given that ANN was the most adequate algorithm for the EHB connection prediction in the previous section, it was chosen for the second hybrid method development. The development of a ANN-based method with Model Fusion (MF) is based on the training of three models using:
-
(a)
the validated synthetic data ANN\((x^\textrm{syn},y^\textrm{syn}) \rightarrow o^\textrm{syn}\)
-
(b)
the experimental dataset ANN\((x^\textrm{exp},y^\textrm{exp}) \rightarrow o^\textrm{exp}\)
-
(c)
the residual \(\Delta\) between experimental values and a the trained synthetic dataset model in (a) ANN\((x^\textrm{exp},\Delta ) \rightarrow o^\textrm{diff}\), where \(\Delta =y^\textrm{exp} - o^\textrm{syn}\)
where ANN\((x^i,y^i)\) is a ANN model trained based on \({x^i,y^i}\) data pairs, \(o^i\) is the output of the trained ANN\((x^i,y^i)\) model, and i is the data type. Data types i are: syn for synthetic, exp for experimental, and diff for residual.
The fused model was then assembled as the predicted synthetic output plus the predicted difference output using Eq. 7:
Figure 12 shows the flowchart for the model development process based on the ANN-based method with model fusion approach.
Figures 13, 14 and 15 show the ANN models required for the assembly of the fused model, used for the prediction of the connection strength, stiffness, and column displacement, respectively. In each figure, part (a) and (b) correspond to the ANN model trained based on the experimental and synthetic datasets respectively, and (c) is the differential model which predicts the residual between the experimental and predictions from the model trained based on the synthetic dataset.
Figures 13a, 14a and 15a show the experimental values versus the values predicted using an ANN trained based only on the experimental dataset for the connection strength, stiffness, and column displacement respectively. These models present \(r_\textrm{RMSE}\) values for the test set of 11%, 18%, and 17% for the connection strength, stiffness, and column face displacement respectively, suggesting medium to low accuracy for the parameter predictions due to the small experimental dataset used for training.
Figures 13b, 14b and 15b show the predicted values obtained based on models trained on 2000 synthetic data points. The accuracy of these models was increased, reporting \(r_\textrm{RMSE}\) values of 10%, 6%, and 11%, given the use of a larger training dataset. Even though the general accuracy in the predictions for the synthetic models is better than the experimental models, typical numerical errors in FE simulations make it difficult to predict accurate values with respect to the experimental observations.
Figures 13c, 14c and 15c show the training, testing, and validation set prediction for the differential model. The accuracy of these models appears to be low, with \(r_\textrm{RMSE}\) values of 34%, 14%, and 8% for the testing set of column strength, stiffness, and column face displacement respectively. This is caused by the small number of data points used for the model development. This means the prediction of the differential values for datapoints that have not been tested is expected to be low.

Experimental versus predicted strength based on a DF model and b MF model

Experimental versus predicted stiffness based on a DF model and b MF model

Experimental versus predicted column displacement based on a DF model and b MF model. Where failure zones are denoted as: I Bolt failure, II Combined failure, and III Column face failure
4 Results and discussion
4.1 Measuring the models performance for the experimental dataset
Figures 16, 17 and 18 show the experimental versus predicted values for the connection strength, stiffness, and column displacement respectively. In each figure, the predictions correspond to values from (a) DF model, and (b) MF model. The results display a close agreement between actual and estimated connection parameters for both models with the lowest value of \(R^{2}\) being 0.979 (Fig. 18a).
The MF models, show an improvement in the \(R^{2}\) values compared to the ANN trained based only on the experimental dataset. This is in agreement with Bauchy’s [6] results, as the fused model is stated to perform better than an experimental model showing the benefits of using a hybrid method over traditional methods. These values were enhanced from 0.993 to 0.995 for the connection strength model, from 0.992 to 0.998 for the connection stiffness, and from 0.945 to 0.999 for the column face displacement (see Figs. 13a, 14a, 15a). This is attributed to the larger number of data points used during the training process. These results illustrate the benefits the use of hybrid techniques for combination of available data sources over traditional methods.
Regarding the performance of DF and MF, both models exhibit the same accuracy for predicting the connection strength (\(R^{2} = 0.995\)). In turn, MF models display slight higher accuracy for the prediction of the connection stiffness, \(R^{2} = 0.998\) for MF compared to \(R^{2} = 0.983\) for DF, and column face displacement \(R^{2} = 0.999\) for MF compared to \(R^{2} = 0.979\) for DF.
4.2 Measuring models performance depending on size of the synthetic dataset
Given that both models showed good accuracy for the prediction of the connection behavior when experimental values were evaluated, the models performance was also tested for synthetic values to evaluate the applicability of the predictions for values that have not been tested. In this section, the FE column face displacement results are assumed as the reference values for evaluating the models performance for illustration purposes.
Three sizes of synthetic datasets were explored: 1, 2, and 3% of the total available synthetic dataset equivalent to 20, 40, and 60 datapoints. The numerical versus predicted values are presented in Figs. 19, 20 and 21.
Figure 19a, b show that for the smallest number of synthetic datapoints (1% of the synthetic dataset), the performance of DF and MF models is similar, with values of \(R^{2} = 0.989\) and 0.977 respectively. As the data points are increased to 2% of the synthetic dataset, Fig. 20a shows that the performance of DF model is improved with a value of \(R^{2} = 0.993\). On the other hand, Fig. 20b shows the \(R^{2}\) of the MF model to prod to a value of 0.858. As the number of data points is further increased to 3% of the synthetic dataset, the DF \(R^{2}\) continues improving to 0.995, while MF value decreases to 0.524 (see Figs. 21a, b respectively).

Numerical versus predicted column face displacement based on a DF model and b MF model for 1% sample of synthetic dataset

Numerical versus predicted column face displacement based on a DF model and b MF model for 2% sample of synthetic dataset

Numerical versus predicted column face displacement based on a DF model and b MF model for 3% sample of synthetic dataset
These results suggest that the accuracy of the MF approach is uncertain over values that have not been tested. This is attributed to the fact that the development of the residual model ANN\((x^\textrm{exp}, \Delta )\) was based on a small dataset given the scarce availability of experimental points, and the uncertainty of this model could be extended to values that are not part of the experimental dataset. Hence, MF model is not recommended for the current available dataset of the EHB connection. At this stage of the EHB connection research, the proposed DF model is recommended for the prediction of the EHB connection strength, stiffness, and failure mode.
5 Proposed metamodel architecture and graphical user interface application
The parameters for the model estimators are presented in Table 6. Figure 22 shows the architecture of developed DF models designated for predicting the connection behaviour.

The architecture of developed ANN with DF models for predicting the connection a strength F, b stiffness k and c column displacement \(\delta\)
Given that the networks have already been trained, Algorithm 1 shows how to use the optimized models for new predictions.


a EHB connection tool main tab. b Validation tab. c Further details tab. EHB connection–prediction tool GUI snapshots. (1) Toggle switch input parameters, (2) slider input parameters, (3) fixed design parameters, (4) predicted connection values, (5) output Notebook 5.1 predicted values, 5.2 strength, stiffness, and failure validation graphs, 5.3 further details about failure mode, (6) graphic representation of the connection
To allow a wider use of the proposed metamodel, a Graphical User Interface (GUI) application was developed in Python [30]. The EHB connection behaviour application is a tab-page-based standalone GUI program. There are three main sections in the main application:
-
1.
Design parameters (user input): the user can select the design parameter values in this section. Input data which has been restricted the entries to commercial and feasible values for the EHB connection. The proposed framework enables the user to explore multiple scenarios under the combination of all design parameters.
-
2.
Drawing (graphic representation of the connection): this section allows the user to visualize the geometry of the connection in real time.
-
3.
Calculation (output): the calculated EHB connection strength, stiffness, and failure mode are presented in a notebook, along with the validation graphs, and further failure information. The user is given a detailed description of the failure mode and alternatives to change it based on the sensitivity analyses.
Figure 23 shows are series of software snapshots indicating the tool sections and their use. The complete code can be found at [31] along with an executable application file.
6 Conclusions
This study evaluated two hybrid machine learning methodologies in order to develop a robust model for the prediction of the extended hollo-bolt connection tensile behaviour. The first method uses machine learning methods with data fusion (DF) and particle swarm optimization. The second method uses artificial neural network-based methods with Model Fusion (MF). The studied connection properties are strength, stiffness, and column face displacement (which determines the connection failure mode). The main conclusions are:
-
In the first method, five supervised machine learning regression algorithms with synthetic and experimental data fusion, and particle swarm optimization were evaluated. Artificial neural network models, exhibited the lowest values of relative root mean square error with values of 8%, 6%, and 8% for the connection strength, stiffness, and column face displacement, respectively. These values are half the values obtained for the second best method (support vector machines), proving the artificial neural networks to be the most suitable algorithm for the EHB connection behaviour prediction.
-
The second method, artificial neural network-based methods with Model Fusion was developed based on the training of three independent artificial neural network models for each evaluated connection parameter (strength, stiffness and column face displacement). In agreement with the literature, the finalized fused model exhibited improved \(R^{2}\) values with respect to a model trained based only on the experimental dataset. These values were enhanced from 0.993 to 0.995 for the connection strength model, from 0.992 to 0.998 for the connection stiffness, and from 0.945 to 0.999 for the column face displacement.
-
Both hybrid methods showed high accuracy for the prediction of the connection behaviour, when experimental values were used, with the lowest value of \(R^{2}\) being 0.979, and therefore the recommendation for the use of one of them was based on the model development process.
-
Three portions of the total synthetic dataset were used to illustrate the performance of the DF and MF models when values that have not been tested are used. The DF model showed higher accuracy than the MF model. This is attributed to the low accuracy of the residual model ANN\((x^\textrm{exp}, \Delta )\). The development of this model was based on a small dataset given the scarce availability of experimental points, and the uncertainty of this model could be extended to predictions that are not part of the experimental dataset. This suggests that for the available number of EHB connection experimental datapoints, the MF model is not recommended at this stage of the research. Therefore, the DF method is proposed for predicting the EHB connection strength, stiffness, and column face displacement (failure mode).
-
The recommended hybrid DF model was integrated within a Graphical User Interface (GUI) to create a software application for the prediction of the EHB connection behaviour. The GUI code is shared in a public repository [31].
These results illustrate the benefits of combining machine learning methods with finite element analysis, rather than directly relying on available experimental data, as well as the use of hybrid techniques for combination of available data sources. Even though the MF method was not recommended for the prediction of the EHB connection behaviour, this method offers a promising approach for combining datasets from multiple sources.
The present study only considered the case of one row of two EHBs in tension. Additional experimental data is required to expand these methodologies for the EHB group behaviour when multiple rows of bolts are used in the connection, as well as other loading conditions.
References
Cabrera M, Tizani W, Mahmood M, Shamsudin MF (2020) Analysis of extended hollo-bolt connections: combined failure in tension. J Constr Steel Res 165:105766. https://doi.org/10.1016/j.jcsr.2019.105766
Huang MQ, Ninic J, Zhang QB (2021) Bim, machine learning and computer vision techniques in underground construction: current status and future perspectives. Tunn Undergr Space Technol 108:103677. https://doi.org/10.1016/j.tust.2020.103677
Azimi M, Eslamlou AD, Pekcan G (2020) Data-driven structural health monitoring and damage detection through deep learning: state-of-the-art review. Sensors. https://doi.org/10.3390/s20102778
Kong Y (2019) Design of artificial neural network using particle swarm optimisation for automotive spring durability. J Mech Sci Technol 38:1–9. https://doi.org/10.1007/s12206-019-1003-9
Hanoon AN, Al Zand AW, Yaseen ZM (2022) Designing new hybrid artificial intelligence model for CFST beam flexural performance prediction. Eng Comput 38(4):3109–3135. https://doi.org/10.1007/s00366-021-01325-7
Yang K, Bauchy M. Combining synthetic and experimental data inmachine learning models. In: Proceedings of the 2021 ASCE Engineering Mechanics Institute International Conference, Durham and Newcastle, UK
Wang J, Zhang N (2017) Performance of circular CFST column to steel beam joints with blind bolts. J Constr Steel Res 130:36–52. https://doi.org/10.1016/j.jcsr.2016.11.026
Han L-H, Li W, Bjorhovde R (2014) Developments and advanced applications of concrete-filled steel tubular (CFST) structures: members. J Constr Steel Res 100:211–228. https://doi.org/10.1016/j.jcsr.2014.04.016
Pokharel T, Goldsworthy HM, Gad EF (2019) Tensile behaviour of double headed anchored blind bolt in concrete filled square hollow section under cyclic loading. Constr Build Mater 200:146–158. https://doi.org/10.1016/j.conbuildmat.2018.12.089
Sun L, Liang Z, Cai M, Liu X, Wang P (2022) Experimental investigation on monotonic bending behaviour of TSOBs bolted beam to hollow square section column connection with inner stiffener. J Build Eng 46:103765. https://doi.org/10.1016/j.jobe.2021.103765
Cabrera M, Tizani W, Ninic J (2021) A review and analysis of testing and modeling practice of extended hollo-bolt blind bolt connections. J Constr Steel Res 183:106763. https://doi.org/10.1016/j.jcsr.2021.106763
European Committee for Standardisation (CEN) (2005) Design of steel structures, part 1-8: design of joints. Eurocode 3, UK. EN 1993-1-8
Pitrakkos T, Tizani W, Wang Z (2010) Pull-out behaviour of anchored blind-bolt: a component based approach. In: Proceedings of the international conference on computing in civil and building engineering (ICCCBE)
Oktavianus Y, Chang H, Goldsworthy H, Gad E (2017) Component model for pull-out behaviour of headed anchored blind bolt within concrete filled circular hollow section. Eng Struct 148:210–224. https://doi.org/10.1016/j.engstruct.2017.06.056
Debnath PP, Chan T-M (2022) Experimental evaluation and component model for single anchored blind-bolted concrete filled tube connections under direct tension. J Constr Steel Res 196:107391. https://doi.org/10.1016/j.jcsr.2022.107391
Mahmood M, Tizani W, Elamin A (2014) Experimental investigation of anchorage length on face bending behaviour of blind bolted connections. In: Proceedings of the international conference on civil engineering, energy and environment
Pitrakkos T, Tizani W (2015) A component method model for blind-bolts with headed anchors in tension. J Steel Compos Struct 18:1305–1330. https://doi.org/10.12989/scs.2015.18.5.1305
Tizani W, Mahmood M, Bournas D (2020) Effect of concrete infill and slenderness on column-face component in anchored blind-bolt connections. J Struct Eng 146(4):04020041. https://doi.org/10.1061/(ASCE)ST.1943-541X.0002557
Tizani W, Cabrera M, Mahmood M, Ninic J, Wang F (2022) The behaviour of anchored extended blind bolts in concrete-filled tubes. Steel Constr 15(S1):51–58. https://doi.org/10.1002/stco.202100037
Dassault Systemes (2014) Abaqus analysis user’s guide, version 6.14. Dassault Systemes Simulia Corp
Dodge Y (2008) The concise encyclopedia of statistics. Springer, New York
Schober P, Boer C, Schwarte L (2018) Correlation coefficients: appropriate use and interpretation. Anesth Analg 126(5):1763–1768. https://doi.org/10.1213/ANE.0000000000002864
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit-learn: machine learning in Python. J Mach Learn Res 12:2825–2830
Géron A (2017) Hands-on machine learning with Scikit-Learn and TensorFlow: concepts, tools, and techniques to build intelligent systems. O'Reilly Media, Sebastopol, CA
Zhelavskaya I, Shprits Y, Spasojevic M (2018) Reconstruction of plasma electron density from satellite measurements via artificial neural networks. In: Elsevier eBooks, pp 301–327. https://doi.org/10.1016/b978-0-12-811788-0.00012-3
Gordan B, Armaghani DJ, Hajihassani M, Monjezi M (2016) Prediction of seismic slope stability through combination of particle swarm optimization and neural network. Eng Comput 32:85–97. https://doi.org/10.1007/s00366-015-0400-7
Gou P, Yu J (2018) A nonlinear ANN equalizer with mini-batch gradient descent in 40gbaud pam-8 im/dd system. Opt Fiber Technol 46:113–117. https://doi.org/10.1016/j.yofte.2018.09.015
Kennedy J, Eberhart RC (1995) Particle swarm optimization. In: Proceedings of the 1995 IEEE international conference on neural networks, Perth, Australia, pp 1942–1948
Ninic J, Koch C, Tizani W (2018) Meta models for real-time design assessment within an integrated information and numerical modelling framework. Springer, Cham. https://doi.org/10.1007/978-3-319-91635-4_11
The Python Software Foundation (2022) GUI Programming in Python. https://wiki.python.org/moin/GuiProgramming. Accessed 20 June 2022
Cabrera M (2022) EHB connection behaviour prediction tool. GitHub Repository. https://github.com/UoNMCabreraRepository/EHBTool.git
Acknowledgements
The authors wish to acknowledge Lindapter International, Tata Steel, and the University of Nottingham HPC for making this research possible.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cabrera, M., Ninic, J. & Tizani, W. Fusion of experimental and synthetic data for reliable prediction of steel connection behaviour using machine learning. Engineering with Computers 39, 3993–4011 (2023). https://doi.org/10.1007/s00366-023-01864-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-023-01864-1