
Abstract
A new multi-fidelity modelling-based probabilistic optimisation framework for composite structures is presented in this paper. The multi-fidelity formulation developed herein significantly reduces the required computational time, allowing for more design variables to be considered early in the design stage. Multi-fidelity models are created by the use of finite element models, surrogate models and response correction surfaces. The accuracy and computational efficiency of the proposed optimisation methodology are demonstrated in two engineering examples of composite structures: a reliability analysis, and a reliability-based design optimisation. In these two benchmark examples, each random design variable is assigned an expected level of uncertainty. Monte Carlo Simulation (MCS), the First-Order Reliability Method (FORM) and the Second-Order Reliability Method (SORM) are used within the multi-fidelity framework to calculate the probability of failure. The reliability optimisation is a multi-objective problem that finds the optimal front, which provides both the maximum linear buckling load and minimum mass. The results show that multi-fidelity models provide high levels of accuracy while reducing computation time drastically.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The conventional design approach for composite structures may cause the structures to be overdesigned because this approach involves the use of conservative safety factors to prevent structural failure. However, every design parameter in engineering has an associated uncertainty. The consideration of this uncertainty is significant during the design process of composite structures because it allows engineers to design more reliable and economic composite structures [1]. The reliability analysis, which considers the uncertainty of each design variable, calculates the probability of failure of structures. Reliability-based design optimisation (RBDO), a probabilistic optimisation method involving reliability analysis, has been applied in the field of engineering because it provides the best possible design through considering each design uncertainty in random design variables during the optimisation process.
Hassanien et al. [2] proposed a new methodology to analyse dented steel pipes which are used in the aerospace, oil and gas industries. The finite element method (FEM) and reliability analysis were used to conduct structural analyses and consider design uncertainties, respectively. This methodology provided reasonable solutions and also proved to have a more economical computational cost. Morse et al. [3] performed the reliability analysis of a 2D rectangular plate with a hole under uniaxial tension using the boundary element method. The reliability indices, which represent the probability of success, were compared using different reliability methods, such as Monte Carlo Simulation (MCS), the First-Order Reliability Method (FORM) and the Second-Order Reliability Method (SORM). Sbaraglia [4] optimised a composite C-beam by RBDO which accounts for design uncertainties. Kriging was used to reduce the computation time during the optimisation process. MCS and FORM were used to calculate the probability of failure. Lopez et al. [5] applied RBDO and deterministic optimisation to a composite stiffened panel design. In particular, these optimisation methods found the stacking sequence of the composite panel to maximise the ultimate load in the post-buckling regime. The hybrid mean value algorithm to find the most probable failure point (MPP) was used and this algorithm has different approaches depending on the type of limit-state function. Based on the initial configuration from DO, RBDO was performed to obtain the orientation of layers that satisfy some target reliability. In Lee et al. [6], a cantilever beam and a composite fuselage were presented to validate a new reliability analysis approach, RBDO by moving probability density function. This analysis method was suggested to decrease computational cost and provide higher accuracy than the advanced first-order second moment. In both case studies, the optimisation results between MCS and this RBDO approach were compared over the thickness of each layer. The computation time of this RBDO approach was much shorter than that of general RBDO.
In general, the probabilistic optimisation method considering design uncertainties is a computationally expensive way to find optimal solutions. To overcome this high computational cost, surrogate models or metamodels have been investigated and applied to the area of structural optimisation. Wang et al. [7] introduced a surrogate model as an essential tool to conduct the optimisation. In particular, surrogate models have a significant role in Multi-Objective Optimisation (MOO) and Multidisciplinary Design Optimisation (MDO) because surrogate models improve the computational performance and it is useful for understanding the effects of design variables. The use of surrogate modelling has been expanded to large-scale problems and more flexible modelling approaches. Hassanien et al. [2] applied a surrogate model that is created by the Response Surface Method (RSM) to conduct the reliability analysis of dented pipes. RSM was used to reduce the computational cost of reliability analysis. FORM was performed to calculate the reliability index and the probability of failure. The results showed a good agreement with the results of MCS. Scarth et al. [8] generated a surrogate model using support vector machines to conduct RBDO. A support vector machine was combined with Gaussian process emulators to consider the discontinuities of aero-elastic flutter speed. The surrogate model generated by the support vector machine was determined to be highly accurate. Bacarreza et al. [9] used Radial Basis Functions (RBF), a type of artificial neural network (ANN), to create a surrogate model of a composite stiffened panel. The surrogate model was generated by a combination of input and output pairs from a FEM model so that the combination of a simple function can approximate a multivariable function. Sampling methods contribute significantly to the performance of the final surrogate model. An increase in computational cost might be caused by an inappropriate sampling process. In Jin et al. [10], the sequential sampling method was introduced and adopted to RBF and the Kriging method to evaluate the benefit in comparison to the Optimal Latin Hypercube Sampling (OLHS) method. It was observed that the sequential sampling method had better performance than other sampling methods. Eason and Cremaschi [11] demonstrated new sampling methods for surrogate modelling using ANNs. These sampling methods are based on the sequential sampling method and developed to provide a more appropriate sampling point. Two proposed adaptive sequential sample generation methods generated the new sampling points far away from previous points and added new points to a more important region. Through numerical experiments, a smaller sampling size was required and the computational efficiency of the surrogate model was improved.
Although the use of surrogate models reduces computation time, composite structures have a number of design variables and require a high computational cost to simulate even one high-fidelity model. To address this problem, the concept of multi-fidelity models has been introduced in the area of structural optimisation. Multi-fidelity models, which are created by the use of High-Fidelity Models (HFMs) and Low-Fidelity Models (LFMs), provide results of similar accuracy to surrogate models only based on HFMs while also providing a noticeable reduction in computational cost. There have been research papers with respect to the use of multi-fidelity models. This concept has been improved and applied to structural optimisation. Vitali et al. [12] introduced the concept of multi-fidelity models through crack propagation in a composite structure. The concept is to use the ratio and the difference between the LFMs and the HFMs, which are called correction response surfaces. The combination of the correction response surfaces and the surrogate models creates the multi-fidelity models that provide an accurate solution as well as low computational cost. Alexandrov et al. [13] demonstrated the first-order approximation and model management optimisation to solve a computationally expensive optimisation problem. To address high computational cost caused by the repeated simulations of the HFMs, the HFMs and the LFMs are combined using the multiplicative correction function. This multiplicative correction function is constructed by Taylor-series approximation and it makes the LFMs follow the response of the HFMs. This shows dramatic computation time savings compared to the HFMs. In Zadeh et al. [14], a surrogate model was used to overcome the high computational cost and slow convergence rate of collaborative optimisation. When the multi-fidelity models are based on the HFMs, the calculation time rises dramatically with respect to the number of design variables whereas the multi-fidelity models based on the LFMs is less accurate. They presented the concept of a tuned low-fidelity simulation model where the tuned LFMs show similar accuracy to the HFMs. In Goldfeld et al. [15], the optimisation of buckling analysis for a laminated shell was conducted using multi-fidelity models using LFMs. Correction response surfaces which are a ratio between the HFMs and the LFMs, are built by various polynomial functions to create the multi-fidelity models. Through this approximation, the LFMs were changed to a high-order polynomial response surface which shows better accuracy and computation time savings. The multi-fidelity models showed very similar results compared to the results of the HFMs. The multi-fidelity models have applied to the area of deterministic optimisation. However, its application in probabilistic optimisation of composite design has not been actively performed so far.
In addition, the idea of MOO has drawn attention as the optimisation problem becomes more complex and the number of objectives and design variables increases. The final optimal solution in MOO is decided by engineers through the concept of Pareto optimality. Marler and Arora [16] summarised MOO in the engineering industry with respect to concept, definition, theorem, articulation of preferences and genetic algorithm (GA). As a priori articulation of preferences, the weighted global criterion method and the weighted sum method were introduced, whereas the normal boundary intersection method and the normal constraint method were explained as a posteriori articulation of preferences. The Design and Analysis of Computer Experiments (DACE) has also been introduced to apply surrogate modelling to MDO. It is stated in a review by Simpson et al. [17] that response surfaces, kriging and ANN are used to generate surrogate models using a number of input–output datasets through DACE. Even though the research of DACE to generate surrogate models has increased, the application of surrogate models in MDO or structural optimisation has not been actively conducted so far. The challenges of DACE application in MDO are the computational complexity and the validation of the surrogate models. As stated by DeBlois et al. [18], the application of MDO is a challenge due to its computational cost. To overcome this challenge, the concept of multi-fidelity models and the simplification of optimisation strategies were considered. In particular, the multidisciplinary design feasibility and the collaborative optimisation were investigated and a hybrid formulation of two methods was proposed. The optimisation framework was operated by Insight, which provides a software to integrate design and simulations [19].
In this paper, a novel multi-fidelity formulation is developed for reliability analysis and optimisation of composite structures considering design uncertainties. This new framework provides not only similar accuracy to the conventional high-fidelity modelling, but also offers considerable computational time savings. The proposed multi-fidelity framework is used to conduct the reliability analysis and RBDO of a mono-stringer stiffened composite panel for the first time. The accuracy and computational cost are evaluated and compared to the results of the conventional surrogate models using only HFMs. This comparison demonstrates the significant benefits of utilising a multi-fidelity framework in reliability analysis and optimisation of composite structures.
2 Multi-fidelity model
Multi-fidelity models are created by the combination of different fidelity models depending on the characteristics of the problem, and the aim of these models is to reduce the high computational cost whilst providing accurate solutions. In engineering design fields, there are two model types: HFMs and LFMs. The HFMs provide acceptable accuracy but these models are computationally expensive because they consist of all the information that an original model has. The LFMs are less expensive and less accurate compared to the HFMs. The primary aim of the multi-fidelity models is to provide solutions as accurate as those of the HFMs but with a lower computational cost. The main idea of multi-fidelity models is to create the surrogate models using correction methods that make the LFMs replace the HFMs [20]. In this study, the multiplicative and additive correction functions were used [12]. The estimated response of the HFMs using the multiplicative correction function can be expressed by
where \(\hat{y}_{\text{HF}}\) is the estimated response of the HFMs, \(\beta (x)\) is the ratio between the HFMs and the LFMs, \(x\) is independent design variables, \(y_{\text{LF}} (x)\) is the response of the LFMs.
The estimated response of the HFMs using the additive correction function can be written by
where \(\delta (x)\) is the difference between the HFMs and the LFMs.
If even the LFMs are computationally expensive, \(y_{\text{LF}} (x)\) can be also replaced by a form of surrogate model to reduce computational time further.
The multi-fidelity models depend on the quality of surrogate models that are created by sampling points using the Design of Experiments (DOE). The sampling points estimate the variability of performance led by design parameters having uncertainties [4, 11]. In OLHS considered in this work, the design space is divided by the uniform interval of probability and the sampling points in each interval are combined randomly. Then, an optimisation process creates a new design matrix that evenly distributes the sampling points. In general, reliability analysis and optimisation considering design uncertainties require a large number of simulations that cause the computational cost to be very high. The surrogate model, which has an explicit form between design variables and responses, has been suggested to reduce this high computational cost. In this work, RBF which is a function type of ANN was used to produce the surrogate model [7, 17]. In particular, RBF network consists of the radial basis function as the activation function [21]. The basic concept of RBF is that functions which depend on the distance from a centre vector are radially symmetric [22]. Mathematically, the basic RBF model is expressed as
where \(N\) is the number of neurons in the hidden layer. \(h(x)\) and \(w_{n}\) are hypothesis and the weight of neuron \(i\), respectively. \(x - x_{n}\) is the radial distance between the input and centre point of neuron \(i\), the norm is typically calculated by the Euclidean distance.
This ANN creates multi-fidelity surrogate models using each training dataset such as HFMs, LFMs and response correction functions. Each test dataset is also used to assess the multi-fidelity surrogate models to see whether the output data of these models show an acceptable level of confidence. These following multi-fidelity surrogate models are used for structural reliability analysis and optimisation process in this study
where \(\hat{y}_{\text{MF}}\) is the response of the generated multi-fidelity surrogate models, \(\beta^{\text{ANN}} (x)\) and \(\delta^{\text{ANN}} (x)\) are the surrogate models of the response correction function, \(x\) is independent design variables, \(y_{\text{LF}}^{\text{ANN}} (x)\) is the surrogate model of the LFMs.
3 Multi-fidelity structural reliability analysis
A reliability analysis evaluates whether a limit-state function exceeds the required constraints and calculates the probability of failure. The limit-state means a structure is not able to conduct its purpose in a relevant design criteria. If the probability of failure is larger than the specific value, the structure is not considered reliable [23]. In general, the limit-state function shows the safety margin between resistance and structure loading. The limit-state function using the multi-fidelity modelling can be written as
where \(g_{\text{MF}} (X)\) is the limit-state function using the multi-fidelity models, \(P_{f}\) is the probability of failure, \(X\) is a vector of all design variables under consideration, \(R_{\text{MF}}\) and \(S_{\text{MF}}\) are the resistance and the loading of structure, respectively, which come from the multi-fidelity models.
If the value of \(g_{\text{MF}} (X)\) is less than zero, the structure is in the failure region. Conversely, if the value of \(g_{\text{MF}} (X)\) equals zero or is larger than zero, the structure is in the failure surface or the safe region, respectively. Three numerical methods including MCS, FORM and SORM that calculate the probability of failure are considered using the multi-fidelity models in this work.
3.1 Monte Carlo simulation
MCS is a simple random sampling method that is based on randomly created sampling points for design variables [24]. MCS consists of the generation of random variables and the statistical analysis of the outcomes. The basic process of MCS is extended to the reliability analysis. When \(N\) simulations are carried out, the probability of failure using the multi-fidelity models is calculated by
where \(N_{{f,{\text{MF}}}}\) and \(N_{{{\text{total}},{\text{MF}}}}\) are the number of failed simulations and the total number of simulations conducted using the multi-fidelity models.
In this work, MCS using Sobol sampling was applied to conduct the reliability analysis. Sobol sampling, which is a sort of quasi-random sequence, provides more uniformly distributed sampling points than the simple random sampling. This sampling method aims to reduce the variance of statistical predictions for MCS. In particular, Sobol sampling provides more robust results than Latin Hypercube Sampling (LHS) [25].
3.2 First-order reliability method
The reliability analysis is used to calculate reliability indices that present the shortest distance from the origin point to the failure surface in the standard normal distribution. Hasofer and Lind improved the mean value first-order second-moment by suggesting the Hasofer and Lind (HL) transformation [23]. Through this transformation, the mean value point of the original space (\(X\)-space) is moved to the origin of normal space (\(U\)-space). The improvement of this HL iteration method is to change the expansion point from the mean value point to MPP. The first-order Taylor series expansion of \(g_{\text{MF}} \left( U \right)\) at MPP \(U^{*}\) using the multi-fidelity models is defined as
The shortest distance from the origin to the failure surface is defined as
This HL iteration is repeated until the estimate of reliability index \(\beta_{\text{MF}}\) using the multi-fidelity models converges to a certain tolerance criteria. When the limit-state function is normally distributed, the probability of failure using the multi-fidelity models is defined as
where \(\phi ( \cdot )\) is the standard normal cumulative distribution function.
3.3 Second-order reliability method
Generally, FORM provides acceptable results when the limit-state surface has only one shortest point and it is almost linear near the design point. If the failure surface shows high nonlinearity, the reliability index calculated by FORM may represent inaccurate outcomes. To overcome this problem, SORM uses the second order approximation to replace the failure surface of the original function. The second-order approximation of limit-state function \(g_{\text{MF}} \left( U \right) = 0\) is derived by the second-order Taylor series expansion at MPP using the multi-fidelity models:
where \(\nabla^{2} g_{\text{MF}} \left( {U^{ *} } \right)\) is the Hessian matrix, which is the symmetric matrix of the second derivative of the limit-state function.
The Hessian matrix creates additional computational cost during the reliability analysis, however, it ensures that SORM provides more accurate reliability index in a nonlinear limit-state function:
The \(\beta_{\text{MF}}\) is the calculated reliability index from FORM using the multi-fidelity models and the \(k_{i}\) indicates the curvature of response surface at MPP. In particular, if the finite difference method (FDM) for evaluating the gradient of the limit-state function is considered [26], the computational cost of FDM might affect the efficiency of reliability analysis. In this work, the Breitung formulation was used to calculate the probability of failure using the multi-fidelity models [23].
4 Methodology description
The conventional form of RBDO can be defined as
where, \(F\) is the objective function, \(g_{j}\) is the deterministic constraint, \(G_{i}\) is the \(i\) probabilistic constraint, \(d\) and \(x\) are design variables and random variables, respectively. \(P\left[ \right]\) is the probability operator and \(P_{f}\) is the probability of failure.
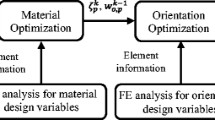
A novel multi-fidelity modelling-based RBDO framework which is developed in this work is shown in Fig. 1. The conventional RBDO methodology uses computationally intensive models or high-fidelity based surrogate models [4, 5, 8, 27]. In this framework, multi-fidelity models are constructed using both HFM and LFM before RBDO process is carried out. The type of fidelity that defines the HFM and the LFM is an element size of the FEM model. DOE provides appropriate design sampling points to build the training and test datasets in given design space. ANN creates three surrogate models of LFMs and two response correction functions. These models should be evaluated by a proper error analysis to see if they provide an acceptable level of accuracy in this framework. Finally, the multi-fidelity models are created by the combination of these surrogate models. Two types of multi-fidelity models are considered: direct type and indirect type [3]. The direct type calls the first buckling load directly from the low-fidelity FEM models when the multi-fidelity modelling is carried out. The indirect type uses the first buckling load from the surrogate models based on LFMs. The details of these multi-fidelity types are introduced in the next section. Once the multi-fidelity models are constructed, RBDO is conducted to find the optimal design variables that meet the required constraints and objectives. Results of this optimisation framework are evaluated in terms of accuracy and computation time savings compared to the results from the conventional RBDO process, which is made up of surrogate models using a number of HFMs. This methodology is demonstrated by two numerical examples in the following section.

Multi-fidelity modelling-based reliability-based design optimisation framework
5 Numerical examples
Two numerical examples were conducted with respect to the reliability analysis and RBDO for a mono-stringer stiffened composite panel. MCS, FORM and SORM using the multi-fidelity models were used to conduct reliability analyses for both numerical examples. The multi-fidelity models were also generated to carry out reliability analysis and optimisation. In these two numerical examples, it is demonstrated that multi-fidelity models for the probabilistic design of composite structures provide an acceptable level of accuracy and computation time savings.
5.1 Numerical model description
The composite panel considered in this work is shown in Fig. 2 [27]. The geometry of this composite panel is parametrised by X1, X2, X3 and X4 which are stringer foot length, stringer height, horizontal distance between top and foot, and stringer top length, respectively. The material properties and dimension of this composite panel are described in Table 1. This panel is clamped at both the right-hand and left-hand ends, but the left-hand end is free to move in the loading direction (z-direction). The interaction between the stiffener and the skin is not considered, so they are constrained by the tie condition. The composite panel was analysed in the linear buckling regime in order to obtain the maximum first buckling load [1]. In the example of the reliability analysis, linear buckling under eccentric load was considered, while linear buckling under centric load was considered in RBDO. In order to create the multi-fidelity models, a HFM and a LFM are defined. The level of discretisation of FEM models was considered as a type of fidelity in this work. The FEM models consist of a 8-node quadrilateral continuum shell (SC8R) and these models are built using Abaqus/CAE (2019) [28]. The mesh convergence study was performed to define both the HFM and the LFM having different accuracy and computation time. As can be seen in Fig. 3, the mesh size was determined that the HFM and the LFM are 4.0 mm and 30.0 mm, respectively. The accuracy difference between the two models was 10% and the computation time using the LFM was 80% less than the HFM.

Mono-stringer stiffened composite panel

The HFM with 4 mm mesh size (left) and the LFM with 30 mm mesh size (right)
5.2 Multi-fidelity modelling-based reliability analysis
The multi-fidelity reliability analysis using MCS, FORM and SORM was performed on the mono-stringer stiffened composite panel. The composite panel was loaded by an eccentric compressive axial load. Five random variables, four parameters defining the geometry and one load eccentricity, were considered. The limit-state function, which is made up of five random variables and one constraint, can be written as
where \(P_{{{\text{cr}}, c}}\) is the minimum buckling load as a constraint, \(P_{{{\text{cr}},e,{\text{MF}}}}\) is the first buckling load from the use of multi-fidelity model.
The structure fails when \(g_{\text{MF}} \left( X \right) < 0\). Each random variable has a probability distribution having mean and standard deviation as seen in Table 2.
5.2.1 Multi-fidelity modelling
In this example, ANN is used to generate surrogate models based on the HFMs and the LFMs. To produce the multi-fidelity models, the correction response surfaces of \(\beta \left( x \right)\) and \(\delta (x)\) were used that are the ratio and difference, respectively, between the HFMs and the LFMs. The design points to create the surrogate models using ANN are obtained using OLHS. The sampling range was determined by the value of each random variable’s cumulative distribution function from 0.5 to 99.5%. The reason is that the sampling points are highly concentrated in the high probability region of each random variable and less concentrated in the low probability region. Once the sampling process is completed, the HFMs and the LFMs calculate the corresponding output values with respect to the input values. Then the training datasets to create the surrogate models are obtained. Using OLHS, the training dataset having 11 design points was sampled because it is the minimum number of sampling points for ANN to generate two surrogate models of the HFMs and the LFMs, respectively. In order to evaluate the quality of the surrogate models, the test datasets of 30 design points were also sampled from each variable’s cumulative distribution function from the same sampling range. ANN created four surrogate models, which are the HFM, the LFM, the ratio and the difference between the HFMs and the LFMs. These models were validated by the separation method using the test dataset. The multi-fidelity models were created using these surrogate models and the low-fidelity FEM model as shown in Table 3.
The direct multi-fidelity models, MF1 and MF2 in Table 3, require expensive computation time to conduct the reliability analysis because they call the first buckling load from the low-fidelity FEM models. It should be noted that the computation time of the low-fidelity FEM models is not insignificant. To provide more computation time savings, the surrogate models of MF1 and MF2 were also generated using the training dataset having forty points and the test dataset having twenty points from the same range of cumulative distribution function. The indirect multi-fidelity models, MF3 and MF4, were created without calling the low-fidelity FEM models.
5.2.2 Results and discussion
In this section, the multi-fidelity models were applied to the reliability analysis of the composite panel with respect to the linear buckling under eccentric load. The reliability analysis was carried out using MCS, FORM and SORM. A minimum buckling load constraint of 20 kN was applied and it is drawn in the figures as a dashed line. If the buckling load of each simulation is lower than this constraint, the composite panel is supposed to fail. Surrogate models using different number of the HFMs were also generated to see how accurate the multi-fidelity models are and to find the equivalent number of the HFMs that shows the similar level of accuracy to the multi-fidelity models.
The accuracy of the multi-fidelity models is evaluated by the comparison of mean and standard deviation at the mean value point. As can be seen from Tables 4, 5 and 6, the results of reliability analysis using the multi-fidelity models are very close to the result of a HF100. The HF100, which is a surrogate model using 100 design points of the HFMs, showed the most accurate value. In addition, a HF11 is also a surrogate model that uses the minimum number of the HFMs for ANN. As the number of the HFMs to generate the surrogate model decreases, the surrogate models do not produce accurate solutions compared to the HF100. These mean and standard deviation values are calculated by the outcomes of design points of MCS using Sobol sampling whereas FORM and SORM calculate these two values using output and gradient at the mean value point. In Table 4 and Fig. 4, the mean and standard deviation of the HF100 are 27.88 kN and 7.13, respectively. These values are used as the most accurate value to evaluate the accuracy of the multi-fidelity models. The difference of mean between the HF100 and the HF11 is 6.1% while the differences with respect to the direct multi-fidelity models, MF1 and MF2, are smaller at 2.5%. However, the indirect multi-fidelity models, MF3 and MF4, show similar differences to the HF11, which are 5.5% and 6.0%, respectively. The standard deviation of the HF100 using MCS is 7.13. The standard deviation of MF1 and MF2 at the mean value point are 6.72 and 6.05, respectively, whereas the MF3 and MF4 show the values of 6.40 and 6.51, respectively. In Figs. 5 and 6, it should be noted that the MF1 and MF2 show similar levels of accuracy to the HF100, although the standard deviation of MF2 is smaller. Tables 5 and 6 clearly show that the mean and standard deviation are identical between FORM and SORM since they use the same output and gradient at the mean value point. The means of FORM and SORM at the mean value point are slightly smaller than the mean of MCS but the standard deviation is nearly the same with MCS. It is interesting to note that the difference error of the mean of the HF11 using FORM and SORM is over 11% compared to the mean of the HF100. When the number of the HFMs used to generate the surrogate model is more than 40, the differences with regard to the HF100 are less than 1%. The MF1 and MF2 provided better accuracy than the MF3 and MF4. In particular, the standard deviation of MF1 was more accurate than the HF50. It can be seen from Tables 4, 5 and 6 that the reliability indexes from SORM are closer to the MCS results than the FORM results. It suggests that SORM can provide a more accurate solution in the domain of failure than FORM because SORM takes into account the curvature of the limit-state function using second-order derivatives. It is found that the reliability index of MF1 is much more accurate to the HF100 compared to even the HF50. Although the MF2 provided the accurate mean, its reliability index is not correct because the standard deviation is smaller than other multi-fidelity models. The MF3 and MF4 show similar levels of reliability indexes to the HF11 and HF20.

Reliability analysis results using MCS

Reliability analysis results using FORM

Reliability analysis results using SORM
In order to evaluate computational time savings, the computation time of each model was normalised by the computation time of the HF100 using MCS. The average FEM simulation time periods for the HFMs and the LFMs were 47 s and 10 s, respectively. The average computation time for one surrogate model was 0.0057 s and this computation time was calculated over 1,000,000 runs. The computation time of each reliability analysis using different models was calculated by the multiplication of the simulation number and the average computation time. The computation time savings are compared in Fig. 7. The MF1 and MF2 were constructed by both 11 design points of the HFMs and 51 design points of the LFMs while the MF3 and the MF4 were constructed by both 11 design points of the HFMs and 11 design points of the LFMs. It is interesting to note that there were notable computation time savings in the use of multi-fidelity models. In particular, the computation time of both the MF1 and the MF2, that presented highly accurate solutions, are about 45% of the HF100 using MCS. The computational cost of these two models is also lower than the HF40 having the equivalent accuracy. It is seen that FORM and SORM do not show the large difference in computation time compared to MCS because this problem converges to a small number of MCS. If the problem is more complex or the reliability analysis is conducted using the only high-fidelity FEM models, the computation time savings through the use of multi-fidelity models will increase a lot more. This comparison clearly highlights that the multi-fidelity model provides not only accurate solutions that are similar to the HFMs having a number of design points but also computation time that is a lot more economic than the HFMs.

Computation time with respect to different multi-fidelity models
5.3 Multi-fidelity modelling based reliability design optimisation
In this section, multi-objective probabilistic optimisation is carried out. It is demonstrated that the multi-fidelity models provide accurate solutions and high computation time savings compared to the surrogate model of the HFMs. Multi-fidelity RBDO is conducted to validate the concept of multi-fidelity models in a probabilistic optimisation process which considers a number of simulation and design uncertainties. The four geometric design variables of the same composite panel have their own uncertainty as shown in Table 2. NSGA-II which is a multi-objective evolutionary optimisation method is used.
5.3.1 Problem definition
In general, RBDO includes reliability analysis in its optimisation process and involves considering the uncertainties of four geometrical parameters of the composite panel. RBDO process ensures that the optimal design meets the requirement of a specific probabilistic constraint defined by a prescribed reliability index \(\beta\). In this example, random design variables are characterised by a normal distribution, a probability failure \(P_{{f,{\text{MF}}}}\) is related to the prescribed reliability index \(\beta_{\text{MF}}\) as \(P_{{f,{\text{MF}}}} = \varPhi \left( { - \beta_{\text{MF}} } \right)\). As mentioned before, there are three methods to calculate the reliability of structure such as MCS, FORM and SORM. In particular, MCS was conducted by the Sobol sampling method because the simple random sampling requires a number of simulations during the optimisation process. In Table 7, the number of MCS using the Sobol sampling is less than 20% of the simple random sampling, although the mean and standard deviation of the result are nearly identical to each other. To ensure the accuracy of FORM and SORM, the step size of FDM was set as 0.001 and the convergence tolerance was determined by 0.0001. The constraints of this optimisation process are the maximum mass and the target probability of failure that are 1.0 kg and 0.00135, respectively. The objectives are to maximise the first buckling load and to minimise the structural mass. Parameter studies using NSGA-II were carried out to set the population size and generation number and they were determined by 12 and 60, respectively. The details of the multi-fidelity models are described in the next section.
5.3.2 Multi-fidelity modelling
The minimum number of design points for ANN to generate the surrogate models was 10 because there are four geometric design variables. The multi-fidelity models were generated using 10 design points of the HFMs and 10 design points of the LFMs. The surrogate models using 100 design points of the HFMs were also generated to evaluate the quality of the multi-fidelity models. OLHS is employed to build the training and test datasets. In particular, total 300 design points, 100 for the training dataset and 200 for the test dataset, were sampled to generate the surrogate models made by the HFMs. A total of 30 design points, 10 for the training dataset and 20 for the test dataset, were also sampled to generate two surrogate models of the HFMs and the LFMs, respectively. These training and test datasets also were used to generate the two correction factors, \(\beta \left( x \right)\) and \(\delta \left( x \right)\), for the LFMs to provide a similar response to the HFMs. The design points for the training dataset were determined by the range from − 20 to + 20% with respect to the mean of each design variable. The design points for the test dataset were selected by the wider range from − 25 to + 25% in order to evaluate the quality of the surrogate model. Through the training dataset from the sampling range, two direct multi-fidelity models and two indirect multi-fidelity models are generated as can be seen in Table 3.
Table 8 highlights that the two direct multi-fidelity models, MF1 and MF2, showed better quality than the two indirect multi-fidelity models, MF3 and MF4. A HF100 which are made up of 100 design points of HFMs presented nearly the same response with the high-fidelity FEM models whereas a HF10 which consists of 10 design points of the HFMs showed large differences compared to the four multi-fidelity models. All models provided the correct mass because the response surface regarding the variation of mass is not challenging for the multi-fidelity models to capture its whole design space. It is interesting to note that the MF1 and the MF2 provided better results of buckling load and mass than the HF10 even though the computation time of these two models was slightly more expensive, because the extra LFMs were required to improve the quality of the multi-fidelity models. The use of this extra computation time caused by the LFMs is justified since the multi-fidelity models provide more accurate results than the HF10. If the number of the HFMs increases until the accuracy is similar to the multi-fidelity models, the computation time caused by this increase should be much higher than that of the multi-fidelity models. It is seen that the errors of the indirect multi-fidelity models were higher than the direct multi-fidelity models because these indirect multi-fidelity models use the surrogate models based on the design points from the LFMs. These four multi-fidelity models were validated to conduct the RBDO process as an alternative model to the HFMs.
5.3.3 Results and discussion
In Figs. 8 and 9, the optimisation results of the multi-fidelity models using FORM are compared to the results of the HFMs. The results using MCS and SORM are not presented in this paper because they are nearly the same as the FORM results. As can be seen in these figures, the Pareto Fronts show the optimal design results that are satisfied with the desired objectives and constraints. It should be noted that the slope of the Pareto Front line is changed when the structural mass is at around 0.94 kg. It means that the first buckling load increases gradually until the mass reaches 0.94 kg. However, when the mass is more than 0.94 kg, the buckling load does not raise as much as the increase in the structure mass. It is determined that the design geometries around the mass of 0.94 kg are the reasonable design values in the given design space.

Comparison to RBDO results using FORM (HFMs vs direct MFMs)

Comparison to RBDO results using FORM (HFMs vs indirect MFMs)
Table 9 and Fig. 10 show the comparison of chosen geometries when the mass of the composite panel is 0.94 kg that the linear buckling load is the economically maximum value. The result of the HF100 is the most accurate value because this model consists of a number of the HFMs that provide the correct first buckling load. It is worth noting that the geometry values from the multi-fidelity models are nearly the same as HF100 results. The mean and standard deviation of the multi-fidelity models are also similar to those of the HFMs in the same mass. Figure 10 shows the probabilistic distribution of each multi-fidelity model. In Fig. 11, the chosen optimal geometric design from RBDO is highlighted to see that the final geometric design is changed to be more reliable than the initial design in terms of the probability of failure. The direct multi-fidelity models, MF1 and MF2, have almost the same mean and standard deviation. The probabilistic distributions of indirect multi-fidelity models, MF3 and MF4, have a slightly different mean of first buckling loads, although they have nearly the same standard deviation. Therefore, the accuracy of all multi-fidelity models was validated.

Reliability-based design optimisation results

Mono-stringer stiffened panel geometry optimised for maximum linear buckling load based on 0.94 kg: a initial model [mm] and b RBDO model using MF1 [mm]
Computational time savings as well as accuracy are the main goals of this study. It is important to show how large a computational time saving can be achieved through the use of the multi-fidelity models. In order to be able to compare the computation time of each model reasonably, the simulation number of each model during this optimisation process is compared. The average computation time of a HFM and a LFM using Abaqus/CAE [28] was calculated over 100 runs. This computation time was 47 s and 10 s, respectively. The computation time of a single surrogate model was measured by the total simulation time divided by the total simulation number that was used in the whole optimisation process. The total simulation time and the number of simulations using all surrogate models were 7036 s and 1,229,085, respectively. Then, the computation time of a single surrogate model was 0.0057 s. The computation time of each optimisation was measured by the sum of the total simulation number that consists of the number of surrogate models and FEM models for the optimisation process and the multi-fidelity modelling, respectively. As can be seen in Fig. 12, all computation times are normalised by the computation time of the HF100 using MCS which is the most computationally expensive. This figure clearly shows that the multi-fidelity models require a lot less computation time than the HFMs. MCS is much more expensive compared with FORM and SORM. FORM is little cheaper than SORM because SORM requires more simulation for a second-order Taylor expansion at the failure domain. The direct multi-fidelity models, MF1 and MF2, are slightly more expensive than the indirect multi-fidelity models, MF3 and MF4, because the direct models call the low-fidelity FEM models when they generate the surrogate models. In particular, all multi-fidelity models show a similar level of the computation time to the LF100, which consists of 100 low-fidelity FEM models. It should be noted that the computation time of the multi-fidelity models is reduced by at least 70% compared to the HF100. If the optimisation is conducted using the high-fidelity FEM models without the surrogate models, the multi-fidelity models will reduce the computation time by a lot more than 70%.

Computation time with respect to different multi-fidelity models
6 Conclusion
In this work, a multi-fidelity formulation for reliability analysis and optimisation of composite structures is presented for the first time. The accuracy and computational efficiency of this new framework are demonstrated by its application to reliability analysis and RBDO of a mono-stringer stiffened composite panel involving design uncertainties. The multi-fidelity models were generated by ANN that uses evenly distributed design points in the desired design space. The multi-fidelity reliability analyses considering design uncertainties were conducted using MCS, FORM and SORM that calculate the reliability of the structure under the given limit-state function. Two numerical examples demonstrated the performance of the multi-fidelity models: reliability analysis and RBDO. In the example of multi-fidelity reliability analysis, the direct multi-fidelity models provided a highly accurate solution, which is equivalent to the use of 40 high-fidelity FEM models. These multi-fidelity models provided computation time savings of over 50% compared to the conventional computationally expensive method using only HFMs. The concept of multi-fidelity modelling was also applied to the probabilistic multi-objective optimisation problem. The direct and indirect multi-fidelity models provided very close optimisation solutions to the results of the conventional method. The computation time using MCS was decreased by at least 70%, and time savings were a lot larger when FORM and SORM were used in the optimisation process. These results suggest that the new multi-fidelity framework can be applied to reliability analysis and optimisation having design uncertainties. This framework provides an acceptable level of accuracy and large computation time savings compared to the conventional method using only HFMs.
References
Jones RM (1997) Mechanics of composite materials. Taylor & Francis, New York. https://doi.org/10.1177/004051755002000101
Hassanien S, Kainat M, Adeeb S, Langer D (2016) On the use of surrogate models in reliability-based analysis of dented pipes. In: Proceedings of 2016 11th international pipeline conference, Calgary, Alberta, Canada: ASME; 2016, pp 1–9. https://doi.org/10.1115/IPC2016-64470
Morse L, Khodaei ZS, Aliabadi MH (2017) Multi-fidelity modeling-based structural reliability analysis with the boundary element method. J Multiscale Model 8:1740001. https://doi.org/10.1142/S1756973717400017
Sbaraglia F, Farokhi H, Aliabadi MHF (2018) Robust and reliability-based design optimization of a composite floor beam. Key Eng Mater 774:486–491
López C, Bacarreza O, Baldomir A, Hernández S, Ferri H, Aliabadi M (2017) Reliability-based design optimization of composite stiffened panels in post-buckling regime. Struct Multidiscip Optim 55:1121–1141. https://doi.org/10.1007/s00158-016-1568-1
Lee S, Kim I-G, Cho W, Shul C (2014) Advanced probabilistic design and reliability-based design optimization for composite sandwich structure. Adv Compos Mater 23:3–16. https://doi.org/10.1080/09243046.2013.862381
Wang GG, Shan S (2007) Review of metamodeling techniques in support of engineering design optimization. J Mech Des 129:370–380. https://doi.org/10.1115/1.2429697
Scarth C, Sartor PN, Cooper JE, Weaver PM, Silva GHC (2017) Robust and reliability-based aeroelastic design of composite plate wings. AIAA J 55:3539–3552. https://doi.org/10.2514/1.J055829
Bacarreza O, Aliabadi MH, Apicella A (2015) Robust design and optimization of composite stiffened panels in post-buckling. Struct Multidiscip Optim 51:409–422. https://doi.org/10.1007/s00158-014-1136-5
Jin R, Chen W, Sudjianto A (2002) On sequential sampling for global metamodeling in engineering design. In: Proceedings of DETC’02 ASME 2002 international design engineering technical conferences and computers and information in engineering, Montreal, Canada: ASME; 2002, p DETC2002/DAC-34092. https://doi.org/10.1115/DETC2002/DAC-34092
Eason J, Cremaschi S (2014) Adaptive sequential sampling for surrogate model generation with artificial neural networks. Comput Chem Eng 68:220–232. https://doi.org/10.1016/j.compchemeng.2014.05.021
Vitali R, Haftka RT, Sankar BV (2002) Multi-fidelity design of stiffened composite panel with a crack. Struct Multidiscip Optim 23:347–356. https://doi.org/10.1007/s00158-002-0195-1
Alexandrov NM, Lewis RM, Gumbert CR, Green LL, Newman PA (2001) Approximation and model management in aerodynamic optimization with variable-fidelity models. J Aircr 38:1093–1101. https://doi.org/10.2514/2.2877
Zadeh PM, Toropov VV, Wood AS (2009) Metamodel-based collaborative optimization framework. Struct Multidiscip Optim 38:103–115. https://doi.org/10.1007/s00158-008-0286-8
Goldfeld Y, Vervenne K, Arbocz J, van Keulen F (2005) Multi-fidelity optimization of laminated conical shells for buckling. Struct Multidiscip Optim 30:128–141. https://doi.org/10.1016/j.tws.2004.07.003
Marler RT, Arora JS (2004) Survey of multi-objective optimization methods for engineering. Struct Multidiscip Optim 26:369–395. https://doi.org/10.1007/s00158-003-0368-6
Simpson T, Toropov V, Balabanov V, Viana F (2008) Design and analysis of computer experiments in multidisciplinary design optimization: a review of how far we have come—or not. In: 12th AIAA/ISSMO multidisciplinary analysis optimization conference Victoria, British Columbia, Canada: AIAA; 2008, p 1–22. https://doi.org/10.2514/6.2008-5802
DeBlois A, Abdo M (2010) Multi-fidelity multidisciplinary design optimization of metallic and composite regional and business jets. In: 13th AIAA/ISSMO multidisciplinary analysis optimization conference Fort Worth, Texas: AIAA; 2010, p 2011. https://doi.org/10.2514/6.2010-9191
Isight Documentation 2017. Simulia; 2017
Fernández-Godino MG, Park C, Kim N-H, Haftka RT (2016) Review of multi-fidelity models. ArXiv Prepr 2016:arXiv:1609.07196v3. https://doi.org/10.1016/j.jcp.2015.01.034
Hassoun MH (1995) Fundamentals of artificial neural networks. MIT Press, Cambridge. https://doi.org/10.1109/tnn.1996.501738
Yaser SA, Malik Magdon-Ismail H-TL (2012) Learning from data. AMLBook, Chicago
Choi S-K, Grandhi R, Canfield RA (2006) Reliability-based structural design. Springer Science & Business Media, New York
Robert E, Melchers ATB (2018) Structural reliability analysis and prediction. Wiley, New York
Burhenne S, Jacob D, Henze GP (2011) Sampling based on sobol sequence for monte carlo techniques applied to building simulation. In: Proceedings of the international building simulations 2011 12th conference, Sydney, 2011, pp 1816–23
Causon D, Mingham C (2010) Introductory finite difference methods for PDEs. Bookboon, London
Farokhi H, Bacarreza O, Aliabadi MHF (2020) Probabilistic optimisation of mono-stringer composite stiffened panels in post-buckling regime. Struct Multidiscip Optim. https://doi.org/10.1007/s00158-020-02565-9
Simulia. Abaqus Documentation 2019. 2019
Acknowledgements
The authors would like to acknowledge L. Morse at Imperial College London for his insightful and helpful comments and supports.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yoo, K., Bacarreza, O. & Aliabadi, M.H.F. A novel multi-fidelity modelling-based framework for reliability-based design optimisation of composite structures. Engineering with Computers 38, 595–608 (2022). https://doi.org/10.1007/s00366-020-01084-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-020-01084-x