
Abstract
In Optimal Recovery, the task of learning a function from observational data is tackled deterministically by adopting a worst-case perspective tied to an explicit model assumption made on the functions to be learned. Working in the framework of Hilbert spaces, this article considers a model assumption based on approximability. It also incorporates observational inaccuracies modeled via additive errors bounded in \(\ell _2\). Earlier works have demonstrated that regularization provides algorithms that are optimal in this situation, but did not fully identify the desired hyperparameter. This article fills the gap in both a local scenario and a global scenario. In the local scenario, which amounts to the determination of Chebyshev centers, the semidefinite recipe of Beck and Eldar (legitimately valid in the complex setting only) is complemented by a more direct approach, with the proviso that the observational functionals have orthonormal representers. In the said approach, the desired parameter is the solution to an equation that can be resolved via standard methods. In the global scenario, where linear algorithms rule, the parameter elusive in the works of Micchelli et al. is found as the byproduct of a semidefinite program. Additionally and quite surprisingly, in case of observational functionals with orthonormal representers, it is established that any regularization parameter is optimal.
Similar content being viewed by others

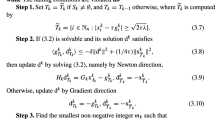
Notes
matlab and Python files illustrating the findings of this article are located at https://github.com/foucart/COR.
Intuitively, the solution to the program (10) written as the minimization of \(\Vert Rf-r\Vert ^2 + (\tau /(1-\tau ))\Vert Sf-s\Vert ^2\) becomes, as \(\tau \rightarrow 1\), the minimizer of \(\Vert Rf-r\Vert ^2\) subject to \(\Vert Sf-s\Vert ^2=0\). This explains the interpretation of \(f_1\). A similar argument explains the interpretation of \(f_0\).
References
Beck, A., Eldar, Y.C.: Regularization in regression with bounded noise: a Chebyshev center approach. SIAM J. Matrix Anal. Appl. 29(2), 606–625 (2007)
Binev, P., Cohen, A., Dahmen, W., DeVore, R., Petrova, G., Wojtaszczyk, P.: Data assimilation in reduced modeling. SIAM/ASA J. Uncertain. Quantif. 5(1), 1–29 (2017)
Boyd, S.P., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Chen, Z., Haykin, S.: On different facets of regularization theory. Neural Comput. 14(12), 2791–2846 (2002)
Cohen, A., Dahmen, W., Mula, O., Nichols, J.: Nonlinear reduced models for state and parameter estimation (2020). SIAM/ASA J. Uncertain. Quantif. 10(1), 227–267 (2022)
DeVore, R., Petrova, G., Wojtaszczyk, P.: Data assimilation and sampling in Banach spaces. Calcolo 54(3), 963–1007 (2017)
Diamond, S., Boyd, S.: CVXPY: a Python-embedded modeling language for convex optimization. J. Mach. Learn. Res. 17(83), 1–5 (2016)
Ettehad, M., Foucart, S.: Instances of computational optimal recovery: dealing with observation errors. SIAM/ASA J. Uncertain. Quantif. 9(4), 1438–1456 (2021)
Foucart, S.: Mathematical Pictures at a Data Science Exhibition. Cambridge University Press, Cambridge (2022)
Foucart, S., Liao, C., Shahrampour, S., Wang, Y.: Learning from non-random data in Hilbert spaces: an optimal recovery perspective. Sampl. Theory Signal Process. Data Anal. 20, 1–19 (2022)
Garkavi, A.L.: On the optimal net and best cross-section of a set in a normed space. Izvest. Rossiiskoi Akad. Nauk. Seriya Matemat. 26(1), 87–106 (1962)
Grant, M., Boyd, S.: CVX: Matlab software for disciplined convex programming, version 2.1 (2014).http://cvxr.com/cvx
Hastie, T., Tibshirani, R., Friedman, J.: The Elements of Statistical Learning, 2nd edn. Springer, Berlin (2009)
Maday, Y., Patera, A.T., Penn, J.D., Yano, M.: A parameterized-background data-weak approach to variational data assimilation: formulation, analysis, and application to acoustics. Int. J. Numer. Methods Eng. 102(5), 933–965 (2015)
Melkman, A.A., Micchelli, C.A.: Optimal estimation of linear operators in Hilbert spaces from inaccurate data. SIAM J. Numer. Anal. 16(1), 87–105 (1979)
Micchelli, C.A.: Optimal estimation of linear operators from inaccurate data: a second look. Numer. Algorithms 5(8), 375–390 (1993)
Micchelli, C.A., Rivlin, T.J.:. A survey of optimal recovery. In: Optimal Estimation in Approximation Theory, pp. 1–54. Springer, Berlin (1977)
Novak, E., Woźniakowski, H.: Tractability of Multivariate Problems: Linear Information. European Mathematical Society, Zürich (2008)
Plaskota, L.: Noisy Information and Computational Complexity. Cambridge University Press, Cambridge (1996)
Pólik, I., Terlaky, T.: A survey of the S-lemma. SIAM Rev. 49(3), 371–418 (2007)
Polyak, B.T.: Convexity of quadratic transformations and its use in control and optimization. J. Optim. Theory Appl. 99(3), 553–583 (1998)
Schölkopf, B., Smola, A.J.: Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. MIT Press, Cambridge (2002)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Albert Cohen.
Dedicated to Ron DeVore, a constant source of enlightenment and inspiration, to celebrate his 80th birthday.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
S. F. is supported by grants from the NSF (CCF-1934904, DMS-2053172) and from the ONR (N00014-20-1-2787)
Appendix
Appendix
This additional section collects justifications for a few facts that were mentioned but not explained in the main text. These facts are: the uniqueness of a Chebyshev center for the model- and data-consistent set (see p. 1.3), the efficient computation of the solution to (7) when \(\Lambda \Lambda ^* = \mathrm {Id}_{\mathbb {R}^m}\) (see p. 2.2), the form of Newton method when solving Eq. (29) (see p. 8), and the reason why the constraint in (41) always implies the constraint in (40) (see pp. 4.1 and 4.2).
1.1 Uniqueness of the Chebyshev Center
Let \(\widehat{f_1},\widehat{f_2}\) be two Chebyshev centers, i.e., minimizers of \(\max \{ \Vert f-g\Vert : \Vert P_{\mathcal {V}^\perp } g \Vert \le \varepsilon , \Vert \Lambda g - y\Vert \le \eta \}\) and let \(\mu \) be the value of the minimum. Consider \(\overline{g} \in H\) such that \(\Vert (\widehat{f_1}+\widehat{f_2})/2 - \overline{g}\Vert = \max \{ \Vert (\widehat{f_1}+\widehat{f_2})/2 - g\Vert : \Vert P_{\mathcal {V}^\perp } g \Vert \le \varepsilon , \Vert \Lambda g - y\Vert \le \eta \}\). Then
Thus, equality must hold all the way through. This implies that \(\widehat{f_1} - \overline{g} = \widehat{f_2} - \overline{g}\), i.e., that \(\widehat{f_1} = \widehat{f_2}\), as expected.
1.2 Computation of the Regularized Solution
Let \((v_1,\ldots ,v_n)\) be a basis for \(\mathcal {V}\) and let \(u_1,\ldots ,u_m\) denote the Riesz representers of the observation functionals \(\lambda _1,\ldots ,\lambda _m\), which form an orthonormal basis for \(\mathrm{{im}}(\Lambda ^*)\) under the assumption that \(\Lambda \Lambda ^* = \mathrm {Id}_{\mathbb {R}^m}\). With \(C \in \mathbb {R}^{m \times n}\) representing the cross-Gramian with entries \(\langle u_i,v_j \rangle = \lambda _i(v_j)\), the solution to the regularization program (7) is given, even when H is infinite dimensional, by
where the coefficient vectors \(a \in \mathbb {R}^m\) and \(b \in \mathbb {R}^n\) are computed according to
This is fairly easy to see for \(\tau =0\) and it has been established in Foucart, Liao, Shahrampour, and Wang [10, Theorem 2] for \(\tau =1\), so the general result follows from Proposition 3. Alternatively, it can be obtained by replicating the steps from the proof of the case \(\tau = 1\) with minor changes.
1.3 Newton Method
Equation (29) takes the form \(F(\tau ) = 0\), where
Newton method produces a sequence \((\tau _k)_{k \ge 0}\) converging to a solution using the recursion
In order to apply this method, we need the ability to compute the derivative of F with respect to \(\tau \). Setting \(\lambda _{\min } = \lambda _{\min }((1-\tau )R+\tau S)\), this essentially reduces to the computation of \(d \lambda _{\min }/d\tau \), which is performed via the argument below. Note that the argument is not rigorous, as we take for granted the differentiability of the eigenvalue \(\lambda _{\min }\) and of a normalized eigenvector h associated with it. However, nothing prevents us from applying the scheme (50) using the expression for \(d \lambda _{\min }/d\tau \) given in (51) below and agree that a solution has been found if the output \(\tau _K\) satisfies \(F(\tau _K) < \iota \) for some prescribed tolerance \(\iota >0\). Now, the argument starts from the identities
which we differentiate to obtain
By taking the inner product with h in the first identity and using the second identity, we derive
According to Lemma 9, this expression can be transformed, after some work, into
1.4 Relation Between Semidefinite Constraints
Suppose that the constraint in (41) holds for a regularization map \(\Delta _\tau \). In view of the expressions
this constraint also reads
Multiplying on the left by \(\begin{bmatrix} P_{\mathcal {V}^\perp } \; | \; \Lambda ^* \end{bmatrix}\) and on the right by \(\begin{bmatrix} P_{\mathcal {V}^\perp } \\ \hline \Lambda \end{bmatrix}\) yields
This is the constraint in (40).
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Foucart, S., Liao, C. Optimal Recovery from Inaccurate Data in Hilbert Spaces: Regularize, But What of the Parameter?. Constr Approx 57, 489–520 (2023). https://doi.org/10.1007/s00365-022-09590-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00365-022-09590-5