
Abstract
It is known that composite quantile regression (CQR) could be much more efficient and sometimes arbitrarily more efficient than the least squares estimator. Based on CQR method, we propose a weighted CQR (WCQR) method for single-index models with heteroscedasticity and general error distributions. Because of the use of weights, the estimation bias is eliminated asymptotically. By comparing asymptotic relative efficiency, WCQR estimation outperforms the CQR estimation and least squares estimation. The simulation studies and a real data application are conducted to illustrate the finite sample performance of the proposed methods.
Similar content being viewed by others

References
Fan J, Gijbels I (1996) Local polynomial modelling and its applications. Chapman and Hall, London
Fan Y, Zhu L (2013) Estimation of general semi-parametric quantile regression. J Stat Plan Inference 143:896–910
Jiang R, Qian WM, Zhou ZG (2012a) Variable selection and coefficient estimation via composite quantile regression with randomly censored data. Stat Probab Lett 2:308–317
Jiang R, Zhou ZG, Qian WM, Shao WQ (2012b) Single-index composite quantile regression. J Korean Stat Soc 3:323–332
Jiang R, Zhou ZG, Qian WM, Chen Y (2013) Two step composite quantile regression for single-index models. Comput Stat Data Anal 64:180–191
Jiang R, Qian WM, Li JR (2014a) Testing in linear composite quantile regression models. Comput Stat 29:1381–1402
Jiang R, Qian WM, Zhou ZG (2014b). Test for single-index composite quantile regression. Hacettepe J Math Stat, Accepted.
Jiang R, Qian WM, Zhou ZG (2014c). Composite quantile regression for linear errors-in-variables models. Hacettepe J Math Stat, Accepted.
Kai B, Li R, Zou H (2011) New efficient estimation and variable selection methods for semiparametric varying-coefficient partially linear models. Ann Stat 39:305–332
Kai B, Li R, Zou H (2010) Local composite quantile regression smoothing: an efficient and safe alternative to local polynomial regression. J R Stat Soc, Ser B 72:49–69
Knight K (1998) Limiting distributions for \(L_{1}\) regression estimators under general conditions. Ann Stat 26:755–770
Liang H, Liu X, Li R, Tsai C (2010) Estimation and testing for partially linear single-index models. Ann Stat 38:3811–3836
Lin W, Kulasekera KB (2007) Identifiability of single-index models and additive-index models. Biometrika 94:496–501
Liu WR, Lu XW (2011) Empirical likelihood for density-weighted average derivatives. Stat Pap 52:391–412
Mack Y, Silverman B (1982) Weak and strong uniform consistency of kernel regression estimates. Z. Wahrscheinlichkeitstheorie Verw. Geb. 61:405–415
Pollard D (1991) Asymptotics for least absolute deviation regression estimators. Econom Theory 7:186–199
Ruppert D, Sheather SJ, Wand MP (1995) An effective bandwidth selector for local least squares regression. J Am Stat Assoc 90:1257–1270
Ruppert D, Wand MP, Holst U, Hossjer O (1997) Local polynomial variance-function estimation. J Am Stat Assoc 39:262–273
Silverman BW (1986) Density estimation. Chapman and Hall, London
Sun J, Gai Y, Lin L (2013) Weighted local linear composite quantile estimation for the case of general error distributions. J Stat Plan Inference 143:1049–1063
Wang JL, Xue LG, Zhu LX, Chong YS (2010) Estimation for a partial-linear single-index model. Ann Stat 38:246–274
Wu TZ, Yu K, Yu Y (2010) Single-index quantile regression. J Multivar Anal 101:1607–1621
Xu P, Zhu L (2012) Estimation for a marginal generalized single-index longitudinal model. J Multivar Anal 105:285–299
Xia Y, Härdle W (2006) Semi-parametric estimation of partially linear single-index models. J Multivar Anal 97:1162–1184
Xia Y, Tong H, Li WK, Zhu L (2002) An adaptive estimation of dimension reduction space. J R Stat Soc Ser B 64:363–410
Yu H, Liu HL (2014) Penalized weighted composite quantile estimators with missing covariates. Stat Pap. Published online
Yu Y, Ruppert D (2002) Penalized spline estimation for partially linear single-index models. J Am Stat Assoc 97:1042–1054
Zhu L, Huang M, Li R (2012) Semiparametric quantile regression with high-dimensional covariates. Stat Sin 22:1379–1401
Zhu LP, Zhu LX (2009) Nonconcave penalized inverse regression in single-index models with high dimensional predictors. J Multivar Anal 100:862–875
Zou H, Yuan M (2008) Composite quantile regression and the oracle model selection theory. Ann Stat 36:1108–1126
Acknowledgments
The authors would like to thank Dr. Yong Chen for sharing the walking behavior survey data and thank the Editor and Referees for their helpful suggestions that improved the paper. The research is supported by Fundamental Research funds for the Central Universities 14D210906 and NSFC grant 11301391.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
To prove main results in this paper, the following technical conditions are imposed.
- C1. :
-
The kernel \(K(\cdot )\) is a symmetric density function with finite support.
- C2. :
-
The density function of \(X^{T}\upgamma \) is positive and uniformly continuous for \(\upgamma \) in a neighborhood of
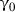 . Further the density of
. Further the density of  is continuous and bounded away from 0 and \(\infty \) on its support.
is continuous and bounded away from 0 and \(\infty \) on its support. - C3. :
-
The function \(g_{0}(\cdot )\) has a continuous and bounded second derivative.
- C4. :
-
Assume that the model error \(\varepsilon \) has a positive density \(f(\cdot )\).
- C5. :
-
The conditional variance \(\sigma (\cdot )\) is positive and continuous.
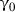 . Further the density of
. Further the density of  is continuous and bounded away from 0 and
is continuous and bounded away from 0 and Remark 4
Conditions C1-C4 are standard conditions, which are commonly used in single-index regression model, see Wu et al. (2010). And condition C5 is also assumed in Sun et al. (2013).
Lemma 1
Let \((X_{1},Y_{1}),\cdots ,(X_{n},Y_{n})\) be independent and identically distributed random vectors, where the \(Y_{i}\) are scalar random variables. Further assume that \(E|y|^{s}<\infty \), and \(\sup _{x}\int |y|^{s}f(x,y)dy<\infty \), where \(f(\cdot ,\cdot )\) denotes the joint density of \((X,Y)\). Let \(K\) be a bounded positive function with a bounded support, satisfying a Lipschitz condition. Given that \(n^{2\varepsilon -1}h\rightarrow \infty \) for some \(\varepsilon <1-s^{-1}\), then
Proof
This follows immediately from the result obtained by Mack and Silverman (1982). \(\square \)
Proof of Theorem 1
Note that

where  is a local linear estimator of \(g_{0}(\cdot )\) when the index coefficient
is a local linear estimator of \(g_{0}(\cdot )\) when the index coefficient  is known. By Theorem 3.1 in Sun et al. (2013), we have
is known. By Theorem 3.1 in Sun et al. (2013), we have

and  can be shown \(o_{p}(1)\). The details are given below.
can be shown \(o_{p}(1)\). The details are given below.
For given \(u\), for notational simplicity, we write \(\sum _{k=1}^{q}w_k\hat{a}_{\hat{\upgamma }k}\triangleq \hat{g}(u;h,\hat{\upgamma })\); \(\hat{b}_{\hat{\upgamma }}\triangleq \hat{g}'(u;h,\hat{\upgamma })\);  and
and  which are the solutions of the following minimization problems, respectively,
which are the solutions of the following minimization problems, respectively,

Denote

where \(e_{k}\) is a q-vector with 1 on the kth position and 0 elsewhere. Further, write \(K_{i}^{*}=K\left( \frac{X_{i}^{T}\hat{\upgamma }-u}{h}\right) \),  , \(\eta _{i,k}=I(\varepsilon _{i}\le c_{k})-\tau _{k}\),
, \(\eta _{i,k}=I(\varepsilon _{i}\le c_{k})-\tau _{k}\),  ,
,  , where
, where  and
and  .
.
Let  , where \(\Delta _{i,k}=\{Z_{i,k}^{*}\}^{T}\theta ^{*}/\sqrt{nh}\). Then, \(\bar{\theta }^{*}\) is also the minimizer of
, where \(\Delta _{i,k}=\{Z_{i,k}^{*}\}^{T}\theta ^{*}/\sqrt{nh}\). Then, \(\bar{\theta }^{*}\) is also the minimizer of

By applying the identity (Knight 1998)
we have

where \(W_{n}^{*}=\frac{1}{\sqrt{nh}}\sum _{k=1}^{q}\sum _{i=1}^{n}\eta _{i,k}^{*}(u)Z_{i,k}^{*}K_{i}^{*}\) and

Since \(B_{n,k}^{*}(\theta ^{*})\) is a summation of i.i.d. random variables of the kernel form, it follows by Lemma 1 that
The conditional expectation of \(\sum _{k=1}^{q}B_{n,k}^{*}(\theta ^{*})\) can be calculated as

Then,
It can be shown that \(E[S_{n}^{*}]=\frac{f_{U_{0}}(u)}{\sigma (u)}S^{*}+O(h^{2})\), where
where \(C\) is a \(q\times q\) diagonal matrix with \(C_{jj}=f(c_{j})\). Therefore, we can write \(L_{n}^{*}(\theta ^{*})\) as
By applying the convexity lemma (Pollard 1991) and the quadratic approximation lemma (Fan and Gijbels 1996), the minimizer of \(L_{n}^{*}(\theta ^{*})\) can be expressed as
\(\bar{\theta }^{**}\) can be shown similarly as
where \(S^{**}=S^{*}\) and \(W_{n}^{**}=\frac{1}{\sqrt{nh}}\sum _{k=1}^{q}\sum _{i=1}^{n}\eta _{i,k}^{**}(u)Z_{i,k}^{**}K_{i}^{**}\). Thus, we can obtain
The last equality is due to the fact that  ,
,
which also implies \(E(\bar{\theta }^{*}-\bar{\theta }^{**})=o(1)\). Thus, \(\bar{\theta }^{*}-\bar{\theta }^{**}=E(\bar{\theta }^{*}-\bar{\theta }^{**})+o_{p}(1)=o_{p}(1)\) according to its first and second term. Therefore \(\bar{\theta }^{*}-\bar{\theta }^{**}=o_{p}(1)\). Then, we can obtain  . This completes the proof. \(\square \)
. This completes the proof. \(\square \)
Proof of Theorem 2
For given X,

by the Taylor theorem,  . Thus, Theorem 2 is the result of Theorem 1.
. Thus, Theorem 2 is the result of Theorem 1.
Proof of Theorem 3
The proof is similar to that of Theorem 3.1 of Sun et al. (2013). \(\square \)
Proof of Theorem 4
Write  and given \((\hat{a}_{1j},\ldots ,\hat{a}_{qj},\hat{b}_{j})\), note that \(\hat{\upgamma }^{*}\) minimizes the following
and given \((\hat{a}_{1j},\ldots ,\hat{a}_{qj},\hat{b}_{j})\), note that \(\hat{\upgamma }^{*}\) minimizes the following
Then, \(\hat{\upgamma }^{*}\) is also the minimizer of

where  .
.
By applying the identity (Knight 1998), we can rewrite \(L_{n}^{*}(\upgamma ^{*})\) as follows:

where

Firstly, we consider the conditional expectation of \(L_{2n}(\upgamma ^{*})\),

In the following, we consider \(L_{2n1}(\upgamma ^{*})\) and \(L_{2n2}(\upgamma ^{*})\),
Next consider \(L_{2n2}(\upgamma ^{*})\), note that

and by the result \(\bar{\theta }^{**}=-\frac{\sigma (u)}{f_{U_{0}}(u)}\{S^{*}\}^{-1}W_{n}^{**}+o_{p}(1)\), we can obtain

It is easy to obtain that  , thus
, thus

Then,

where  . It follows by the convexity lemma (Pollard 1991) that the quadratic approximation to \(L_{n}(\upgamma ^{*})\) holds uniformly for \(\upgamma ^{*}\) in any compact set \(\Theta \). Thus, it follows that
. It follows by the convexity lemma (Pollard 1991) that the quadratic approximation to \(L_{n}(\upgamma ^{*})\) holds uniformly for \(\upgamma ^{*}\) in any compact set \(\Theta \). Thus, it follows that
By the Cramér-Wald theorem and the Central Limit Theorem for \(W_{n}\) holds and \(Var(W_{n})\rightarrow \sum _{k=1}^{q}\sum _{k'=1}^{q}\tau _{kk'}S\). This completes the proof. \(\square \)
Rights and permissions
About this article

Cite this article
Jiang, R., Qian, WM. & Zhou, ZG. Single-index composite quantile regression with heteroscedasticity and general error distributions. Stat Papers 57, 185–203 (2016). https://doi.org/10.1007/s00362-014-0646-y
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-014-0646-y