
Abstract
We study a contest design problem in which a designer chooses how many Tullock contests to have, how much to award to each contest, and which contestants (of high or low type) should be assigned to which contest. Our main result is that a single grand contest maximizes total effort. We consider three extensions. First, when the designers’ objective changes to maximizing the effort submitted by the winning contestant, we find that the optimal design involves the high-type contestants being assigned to a set of pairwise contests. Second, under multiple participations (a player’s effort is valid in multiple contests, as in several applications), running a contest open to all, along with a parallel contest open only to low types, increases total effort over a single grand contest. Third, tilting the playing field (a player’s effort is multiplied by a tilting factor) in favor of low types increases total effort in a single grand contest, even more than what is possible with multiple participations; thus, in applications, a quota reserved for traditionally disadvantaged categories results in lower total effort than a grand contest that optimally handicaps advantaged categories.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In a contest, contestants exert costly and irreversible efforts to win prizes.Footnote 1 In designing a contest, a designer could, for instance, group all contestants into the same grand contest for a single prize, or group them by ability into several sub-contests with smaller prizes, or only the two top contestants could be selected to compete for a single grand prize with everyone else being excluded.
In applications, it is common for contestants to be assigned to contests that have different prizes. For instance, school admission contests could be open to everybody, or a quota could be reserved for a selected population subgroup. In practice, we often observe quotas reserved for traditionally disadvantaged categories. For instance, Kumar et al. (2022) report that, in India, schools are required to reserve 25% of their enrollment slots for economically underprivileged students. A grant-giving entity can organize a single, generous grant or several small grants could be opened to scholars according to their seniority level; examples are the Society for Neuroscience Jacob P. Waletzky Award and the Young Investigator Award, both given to an early career neuroscientist.Footnote 2
In this paper, we study the effort-maximizing type-based centralized assignment of contestants and prizes into Tullock contests: a contest designer chooses how many winner-take-all contests to induce, how much of her prize budget to award to the winner of each contest, and who participates in each such contest.Footnote 3
In our main setup in Sect. 4, each contestant participates in at most one contest, and each contest treats contestants identically.Footnote 4 We model the contests à la Tullock under complete information and with contestants’ types equal to the constant marginal cost of effort, which can be high or low. Our main finding is that the total-effort-maximizing centralized assignment allocates all contestants (of both types) and all the prize budget into a single grand contest. Establishing the optimality of a single grand contest is non-trivial and, to our knowledge, is not a direct consequence of existing results. Intuitively, if in a grand contest high types sufficiently outnumber low types so that the latter would be discouraged—or even inactive—the designer could spur efforts of low types by, for instance, shifting part of the prize budget away from the grand contest to a parallel low-type-only contest. However, the consequent increase in low-type efforts would be dominated by the decrease in high-type efforts resulting from the lower prize left in the high-type-only contest.
We then analyze three extensions. First, in Sect. 5, we analyze the optimal centralized assignment when the designer maximizes the expected equilibrium winners’ efforts (WE), instead of the expected equilibrium total effort (TE). WE is relevant in all applications where the designer benefits only from the amount of effort exerted by the winner, but not that of the losers; for instance, in a grant competition, the winner’s project is particularly valuable—as it receives more attention, funding, and visibility—and thus only the winner’s effort is valuable to the designer. Similarly, students compete for admission to a school, and the school may care more about the effort exerted (as a proxy for a student’s training) by the admitted—hence, winning—students, rather than the effort exerted by the non-admitted ones. A key remark is in order. We interpret the noise in the contest outcome as an exogenous probability of making a “mistake” and not selecting the best project/student as the winner: for instance, a designer may have limited resources (time or money) to screen projects/students and pick the “best.” In other words, the noise could be due to a “performance measurement error” (see, e.g., Fu and Lu 2012b).Footnote 5 Hence, a designer aware of such an exogenous probability of a mistake should consider it and thus weigh in her objective each effort (as a proxy for actual quality) by its “noisy” probability of winning. We find that a WE-maximizing designer organizes (multiple) pairwise contests, each between two high types, and fully excludes all low types. Hence, the optimality of a grand contest fails when maximizing WE rather than TE. The intuition is as follows. As large efforts are more likely to win—and hence to enter into WE—than small efforts, the designer tends to benefit more from high-type efforts than low-type efforts, in contrast to TE. Our results show that this novel WE-specific force dominates all others, yielding the optimality of allocating the budget entirely to pairwise high-high contests.Footnote 6
In our second extension in Sect. 6, we build on the contribution by Dahm and Esteve-González (2018) and assume that some contestants, with the same effort, compete in more than one contest, so that they may win more than one prize: i.e., a setup with multiple participations. As reported by Dahm and Esteve-González (2018): “Consider scholarships for students from under-represented groups that aim at enhancing the diversity of the university community. These scholarships are open to students from minority groups and coexist with scholarships based on merit.” As Dahm and Esteve-González (2018) show, having a parallel contest only for low types can yield a larger TE than in the grand contest under single participation. Note that the effort exerted by low types (e.g., the training of disadvantaged students) is now valid also for the contest with all types, which is the reason for the difference with our main result under single participation. We also derive an upper bound on the prize to be allocated to the low-type-only contest, which shows that the contest with all types should be allocated the vast majority of the prize budget.
In our third extension in Sect. 7, we move back to a setup of single participation in a single grand contest, but allow the designer to treat contestants differently by tilting the playing field in favor of some types. We then compare TE under optimal tilting with TE under multiple participation and show that the former outperforms even the maximum TE with a parallel low-type-only contest (described in Sect. 6). This ranking of TE is novel and reaffirms the optimality of a grand contest as in the main model; if a designer can choose between a parallel low-type-only contest or tilting the playing field in favor of low types in a single grand contest as two alternative tools to stimulate efforts, the latter dominates. Note that, in fact, it is not uncommon to observe policies favoring low types in practice. According to the so-called Environmental Context Dashboard, student SAT scores are disclosed to colleges together with an index of the students’ rigor of their high schools and socio-economic background (e.g., crime rates and poverty levels in students’ neighborhoods). In the words of the College Board, this dashboard levels the playing field as it “shines a light on students who have demonstrated resourcefulness to overcome challenges and achieve more with less” (College Board 2020), hence helping students who grew up in challenging conditions in their competition with more fortunate students. From the normative viewpoint, our novel result (the maximum TE when tilting the playing field outperforms that with multiple participation) suggests that, rather than reserving an admission quota to students who come from a disadvantaged socio-economic background, a unified admission in which the scores of disadvantaged students are given a “boost” may better stimulate overall efforts.
2 Literature review
When contestants are (ex-ante) identical, the optimality of a single grand contest has been shown by several authors. An example is Moldovanu and Sela (2006), which focuses on private information all-pay auctions where sub-contests are restricted to have an equal number of contestants and identical prizes.Footnote 7 Another example is Fu and Lu (2009), which allows for multiple prizes within the same (sub)contest; e.g., including also a prize for the second-ranked contestants.Footnote 8 The optimality of a single grand contest when contestants are identical is intuitive; “simply merging smaller contests always creates more competition and induces contestants to exert more effort, no matter how these smaller contests are constructed” (Fu and Lu 2009). However, the case of heterogeneous contestants is relevant; in the words of Rosen (1988), “How are contestants stratified and sorted among contests according to their talents and motivation? [...] The question is important because known heterogeneity among contestants reduces performance incentives. Therefore ‘tracking’ or sorting contestants by known abilities across different games has positive value.” Hence, in contrast to the above-mentioned papers, we study the centralized assignment of heterogeneous contestants by types to a set of contests, which is a field of applied interest.
The analysis of selecting heterogeneous contestants into a single contest has been studied widely. The exclusion principle by Baye et al. (1993) states that excluding the strongest contestants from an all-pay auction increases total effort when the excluded contestants are outliers in skills and the remaining bidders are sufficiently homogenous.Footnote 9 Also, Fullerton and McAfee (1999), in a complete information Tullock contest with heterogeneous contestants, show that the selection of only the two best contestants is optimal under a mild condition. The intuition why a WE -maximizing designer organizes contests between pairs of high types resembles the intuition behind the selection of the two strongest finalists in Fullerton and McAfee (1999), even if their model is different.Footnote 10 Nevertheless, in these papers, the designer selects contestants into a single contest, while in our setting the designer assigns contestants to multiple contests and finetunes the allocation of the prize budget across those contests. Similarly, a parallel branch of the literature studies the allocation of multiple prizes in a single contest with heterogeneous players (e.g., González-Díaz and Siegel 2013; Xiao 2016, 2018). While we do not allow for more than one prize per contest, we allow for more than one contest rather than a single one.
The main focus of Fu and Lu (2009) is on identical players, but they also numerically investigate the case of two high types and two low types. “When contestants are endowed with differing talents, an additional line of freedom is added to the contest design problem. [...] Although a complete characterization of a general model is hard to obtain, one may imagine that the optimal contest design would depend on the distribution of talents.” They conclude their numerical example by saying “designing effort-maximizing contests with substantially heterogeneous contestants requires greater sophistication in the matching of contestants and prizes. A more general theory is required that can adequately illuminate the subtlety of this dimension despite the technical difficulty”. In the stylized setup of the present paper, we provide a tool—namely, segregations—that allows us to characterize the optimal assignment with binary heterogeneity. Hence, while Fu and Lu (2009) show that the optimality of a single grand contest extends to multiple-winner setups, our main result shows that it extends to a setup with heterogeneous contestants. Allowing for heterogeneous types creates an extra layer of difficulty; namely, the choice of assignment affects the contestants’ endogenous participation. For instance, a low type competing in a contest with many high types would rather not participate (exert 0 effort). This extra layer of difficulty that heterogeneity adds is the reason behind the simplicity of our other assumptions, such as that of a linear impact function in the Tullock contest success function and of binary types.
Like the present paper, Mathews and Namoro (2008), Leuven et al. (2011), and Xiao (2023) analyze situations where a designer has a fixed budget and a fixed set of contestants of heterogeneous types to be allocated among contests. Mathews and Namoro (2008) and Leuven et al. (2011) mainly focus on players’ voluntary decision to enter into contests. Mathews and Namoro (2008) consider two strategic and heterogeneous contestants choosing which contest to enter, out of two possibilities. Leuven et al. (2011) also derive a result about the optimality of a grand contest. Unlike the present paper, Leuven et al. (2011) consider dividing a grand contest into two sub-contests, rather than any number. Furthermore, they consider neither WE -maximization nor the comparison between TE under multiple participations and TE under tilting the playing field. Xiao (2023)’s analysis is more general than ours in that contestants can be of more than two types and each contest may have more than one prize, but he does not allow for multiple participations, tilting of the playing field, or a design that induces partial participation. However, the most important difference is structural: unlike the present paper, Xiao (2023) models the contests as all-pay auctions. This has two important consequences. First, because of the intense competition of all-pay auctions, heterogeneity is particularly detrimental to efforts: two identical contestants exert an equilibrium aggregate effort equal to the prize (full rent dissipation) and hence Xiao’s main result is that “separating – assigning participants with the same ability together – is superior to mixing – assigning participants with different abilities together”: “by separating the students according to their abilities, we can introduce intense competition among asymmetric players”, (Xiao 2023, p. 1–2). In our setup, the noise of the Tullock contest stimulates low types’ efforts when up against high types: hence, the optimal assignment in our noisy setup is a single grand contest with both high and low types. Second, as Xiao works with all-pay auctions, his results build on the elegant and tractable characterizations of Siegel (2009) and Siegel (2010) and cleverly provide the optimal centralized assignment of contestants circumventing the need for a full characterization of equilibria. On the contrary, we work with Tullock contests, which are not covered by Siegel’s results, and consequently we develop a novel technique: the analysis of segregations.
Our WE-maximization builds on the recently blossoming field that studies objectives other than TE in contest design. Maximizing the winner’s entry is crucial in innovation contests (see, e.g., Taylor 1995; Ales et al. 2017; Mihm and Schlapp, 2018). Serena (2017) compares WE-maximization to TE-maximization in Tullock contests in terms of exclusion and leveling of the playing field. The WE-optimal biases are considered by Drugov and Ryvkin (2017) in a two-player symmetric contest (with general contest success function) and by Barbieri and Serena (2022) in a dynamic best-of-three setup. WE-maximizing sequential-elimination contests are considered by Fu and Wu (2018a), Fu and Wu (2018b).Footnote 11 None of these papers analyze the WE -maximizing assignment of an exogenous pool of contestants into contests.
Our results in the multiple-participation setup share common features with the intuition behind (Szymanski and Valletti 2005) and directly draw from Dahm and Esteve-González (2018). Szymanski and Valletti (2005) show that, “in a three-person contest where one contestant is very strong, a second prize can be optimal from the point of view of eliciting maximum effort from every contestant”. The intuition behind their result is that the second prize gives the two weak contestants something to fight for, which is particularly valuable to boost their efforts when the strong contestant is highly talented. Similarly, we find that the extra prize for low types only encourages low types and hence mitigates their discouragement due to being up against high types. Szymanski and Valletti (2005) do not consider the possibility of multiple contests or endogenous centralized assignments. In Dahm and Esteve-González (2018), contestants all compete for the main prize, while only disadvantaged contestants (the set of weakest, not necessarily identical, contestants) compete for an extra prize, with the same effort they exert for the main prize. While Dahm and Esteve-González (2018)’s setup is more general than ours as it does not restrict attention to binary types, our binary setup (with only high and low types) allows us to derive two novel analytical results. The first novel result is that TE achievable by creating a parallel low-type-only contest is lower than that achieved in a single contest by tilting the playing field in favor of low types, thus restoring, to some extent, the optimality of a single grand contest found in our main setup. The second novel result shows that the contest open to all should be allocated the vast majority of the prize budget and the low-type-only contest significantly less. This finding helps us understand real-life contests where the prize (in monetary terms, fame, visibility, prestige, etc.) for the low-type-only contests is typically significantly lower than that of the grand contest.
The tilting-the-playing-field policy has a solid tradition in the contest literature (for a survey see, e.g., Mealem and Nitzan 2016. Some classic results are, for instance, in Nti (1999) and Franke (2012). A key insight therein is that giving player-idiosyncratic multiplicative advantages to underdogs and/or disadvantages to favorites levels the playing field, thus stimulating competition and efforts.
3 The main model
There are \(m\ge 2\) high-type contestants, each with marginal cost of effort equal to \(h\in \left( 0,1\right) \), and \(n\ge 2\) low-type contestants, each with marginal cost of effort equal to 1. For simplicity, we assume that m and n are even. In the first period, the designer assigns contestants to any number of contests and splits her use-it-or-lose-it budget \(V>0\) into a winning prize for each contest.Footnote 12 In the second period, contestants are fully informed of the designer’s first-period choices, and each of them simultaneously exerts a nonnegative level of effort. Each contest is assumed to be à la Tullock; that is, a player’s probability of victory if her effort is x and total effort in the contest is X is x/X.Footnote 13
We now describe the designer’s first-period decision more formally, borrowing from Xiao (2023). The contest designer is given an exogenous (use-it-or-lose-it) prize budget of \(V>0\) and an exogenous set of heterogenous contestants \({\mathcal {C}}\). The overall number of contestants is \(\left| {\mathcal {C}}\right| =m+n\) (m high-type contestants and n low-type contestants). The contest designer chooses a set partition \( {\mathcal {P}}\) of the set of contestants \({\mathcal {C}}\). The set partition \( {\mathcal {P}}\) specifies the contest designer’s choice of both the number \( \left| {\mathcal {P}}\right| \) of contests, each modeled as a winner-take-all Tullock contest, and, for each contest \(j\in \{1,...,| {\mathcal {P}}|\}\), which set of contestants are assigned to contest j. The contest designer also chooses the prize structure. In particular, the prize structure \({\mathcal {V}}\) is a \(|{\mathcal {P}}|-\)tuple \({\mathcal {V}} =\{v^{1},...,v^{|{\mathcal {P}}|}\}\) that satisfies the feasibility constraint that \(\sum _{j=1}^{|{\mathcal {P}}|}v^{j}=V\), where for each \(j\in \{1,...,| {\mathcal {P}}|\}\), the prize in contest j is denoted as \(v^{j}\in [0,V]\). The prize structure \({\mathcal {V}}\) provides the contest designer’s choice of the values of the winner-take-all prizes for each of the \(| {\mathcal {P}}|\) Tullock contests.Footnote 14
In the second period, contestants observe the pair \(({\mathcal {P}},{\mathcal {V}} ) \) chosen by the designer and simultaneously exert efforts. Letting \(\Phi \) denote the set of all feasible pairs of a set partition \({\mathcal {P}}\) of \( {\mathcal {C}}\) and prize structure \({\mathcal {V}}\) for the \(|{\mathcal {P}}|\) contests specified by \({\mathcal {P}}\), the designer’s first-period problem is to choose a feasible pair \(({\mathcal {P}},{\mathcal {V}})\in \Phi \) to maximize TE.Footnote 15
In our equilibrium analysis, we focus on type-symmetric subgame-perfect equilibria, which we will simply call “equilibria.” Type-symmetry means that all low-(high-)type contestants in the same contest exert the same equilibrium effort \(e_{l}\) (\( e_{h}\)). These equilibrium efforts, in principle, differ across contests according to the specific centralized assignment (of players and prizes), but we omit such dependence in the notation for simplicity. We work by backward induction: throughout the paper, we first analyze how contestants behave in the second period for a given centralized assignment (how many players of each type they are up against, and for what prize they compete), and then we analyze the optimal assignment for the designer in the first period.
4 TE-maximizing centralized assignment
In this section, we derive the TE-maximizing centralized assignment in the model in Sect. 3. We first derive preliminary results that will be used repeatedly throughout our analysis.
4.1 Preliminary results
This section’s results are valid for a single contest and have immediate (and omitted) proof.
Lemma 1
Consider a single Tullock contest with prize \({\tilde{V}}\), \( {\tilde{m}}\) high types, and \({\tilde{n}}\) low types. Equilibrium efforts are
and total equilibrium effort in the contest is
The conditions that appear in equations (1) and (2) determine whether low types are active: in fact, note that low types are inactive if \( \frac{{\tilde{m}}-1}{h{\tilde{m}}}\ge 1\iff {\tilde{m}}\ge \frac{1}{1-h}\), which holds when high types are particularly strong (h is small) or numerous (\( {\tilde{m}}\) large). The bottom part of (3) is the well-known expression for total effort in an \({\tilde{m}}\)-player homogeneous contest with prize \({\tilde{V}}\) and marginal effort cost h. (When no confusion arises, we omit the qualifier “equilibrium” for equilibrium efforts.) The top expression of (3) is the total effort when both high and low types are active. The following lemma analyzes how the top expression of (3 ) depends on \({\tilde{m}}\) and \({\tilde{n}}\).
Lemma 2
For any \({\tilde{m}}\ge 0\), \(n\ge 0\), and \(h\in \left( 0,1\right) \),
From the above lemma and (3), we immediately see that, if the designer can organize only one contest, she would never exclude contestants as total effort in (3) strictly increases in \({\tilde{m}}\) and increases in \({\tilde{n}}\) (strictly if low types are active, as in the top expression of (3), and weakly if low types are inactive, as in the bottom expression of (3))—see also Fang (2002). However, our designer can organize any number of contests with any number of high or low types in each contest. This difference makes our results in Sect. 4.2 below non-trivial and not a direct consequence of existing results. In fact, our designer can implement any exclusion or inclusion of players by ability. Such broad policy space allows the designer to finetune the heterogeneity across players within each contest. Thus, the standard intuition for the optimality of a grand contest under full homogeneity does not trivially carry over to our setup with heterogeneous contestants.
4.2 Segregations and TE-maximizing centralized assignment
The main result of this section is that, for single-participation contests, the designer organizes a grand contest and allocates the entire prize budget V to it. We prove this result by showing that, starting from any contest, “segregations” reduce TE. In particular, we call the starting contest the unified contest with prize \(V_{1}\le V\), \(m_{1}\le m\) high types, and \(n_{1}\le n\) low types. Alternatively, the designer may decide to assign the prize \(V_{1}\) and the \( m_{1}\) and \(n_{1}\) contestants into two sub-contests: a new contest with prize \(d\in \left[ 0,V_{1}\right] \) in which \(m_{2}\in \left\{ 0,...,m_{1}\right\} \) high types and \(n_{2}\in \left\{ 0,...,n_{1}\right\} \) low types compete, and the original contest with the remaining players and prize (i.e., \(m_{1}-m_{2}\) high types and \(n_{1}-n_{2}\) low types competing for a prize \(V_{1}-d\)). We call such an assignment a segregation of \(\left( m_{2},n_{2}\right) \) contestants with prize d. Informally, one can think of a segregation as splitting the unified contest. We use index “u” for the unified contest, “\(s-o\)” for the original contest after segregation, and “\(s-n\)” for the new contest after segregation. We visualize an example of a segregation in Fig. 1 with \(m_{1}=4\), \(n_{1}=6\), and \( n_{2}=m_{2}=2\).
In what follows, we show that any segregation reduces TE, regardless of \( V_{1}\), d, \(m_{1}\), \(m_{2}\), \(n_{1},\) and \(n_{2}\). As any contest organization can be reached with appropriate segregations starting from the single grand contest with all contestants and prize V, the optimality of a grand contest follows.

Segregation: unified, original and new contests (\(m_{1}=4\), \( n_{1}=6 \), \(n_{2}=m_{2}=2\))
Without segregation, the total effort in the unified contest, \( TE^{u}\), is as in (3):
With the segregation of \(\left( m_{2},n_{2}\right) \) contestants with prize d, total effort in the original contest, \(TE^{s-o}\left( V_{1}-d\right) ,\) is
and total effort in the new contest between \(\left( m_{2},n_{2}\right) \) contestants, \(TE^{s-n}\left( d\right) ,\) is
using (3) specialized to the original and new contests. Finally, we define the maximum total effort that could result from the segregation of \(\left( m_{2},n_{2}\right) \) contestants as
i.e., the sum of (7) and (8). The main result of this section is that \(TE^{s}\le TE^{u}\) for any \(\left( m_{2},n_{2}\right) \).
We begin with two cases of special interest: (1) a segregation of low types only, and (2) a segregation of high types only. The first segregation is especially interesting from a technical point of view as it reduces the discouragement of low types in the unified contest, and may even turn them from being inactive to active. From an applied point of view, the first segregation may correspond to creating a new contest reserved only for relatively young or inexperienced contestants while excluding them from the original contest. The second segregation is especially interesting from a technical point of view when enough high types are segregated away from the original contest so that low types in the original contest move from being inactive to active. From an applied point of view, the second segregation may correspond to creating a new contest reserved only for particularly distinguished contestants. For those two cases of special interest, we obtain the following results.
Lemma 3
(Segregations of low types reduce TE) Consider the segregation of \(\left( 0,n_{2}\right) \) players with \(n_{2}\ge 0\). Then \(TE^{s}\le TE^{u}.\)
Proof
See Appendix A. \(\square \)
Lemma 4
(Segregations of high types reduce TE) Consider the segregation of \(\left( m_{2},0\right) \) players with \(m_{2}\ge 0\). Then \(TE^{s}\le TE^{u}.\)
Proof
See Appendix A. \(\square \)
Lemmas 3 and 4 show that, when the objective is TE, neither creating a new contest reserved for (some) low types nor one reserved for (some) high types is beneficial. We next show the same conclusion applies to segregations of any combinations of some high and some low types jointly.
Proposition 1
(Segregations reduce TE) Consider the segregation of \(\left( m_{2},n_{2}\right) \) players, with \(m_{2},n_{2}\ge 0\). Then \(TE^{s}\le TE^{u}.\)
Proof
See Appendix A. \(\square \)
As any structure of contests can be reached with the appropriate segregations starting from the single grand contest with all contestants and prize V, Proposition 1 immediately implies the optimality of a single grand contest.
Corollary 1
(Optimal assignment) TE is maximized by a grand contest with all contestants and the entire prize budget.
While the suboptimality of segregations of high types (Lemma 4 ) is perhaps not surprising, the intuition behind the suboptimality of segregations of low types (Lemma 3) is crucial to understanding the optimality of a single grand contest (Corollary 1). First, consider the case of (relatively) many low types and (relatively) few high types. Then, segregating low types does not pay simply because the discouragement of low types in the grand contest is not too severe. Second, consider the more delicate case of (relatively) many high types and (relatively) few low types, so that the latter would be greatly discouraged, or even inactive, in a grand contest. Then, the designer could still spur efforts of low types by moving some prize budget away from the grand contest into a parallel low-type-only contest with non-negative prize d; however, the consequent increase in efforts of low types due to d would be dominated by the reduction of high-type efforts resulting from lowering the prize they fight for from V to \(V-d\). The reason why the latter effect dominates the former is exactly that we are considering the case of high types sufficiently outnumbering low types, and hence the high types in the grand contest are very productive as the competition among them is fierce. A reduction in the prize high types fight for is not worth the extra effort obtained from low types by relocating d to a low-type-only parallel contest. The result of Corollary 1 follows; there is neither room for exclusion nor segregation by the designer.
In the main setup analyzed so far, we considered the TE-maximizing centralized assignment under single-participation and with equal treatment of contestants within contests. In the remainder of the paper, we consider three extensions: WE-maximizing centralized assignments, multiple participations, and tilting of the playing field.
5 WE-maximizing centralized assignments
In this section, we derive the WE-maximizing centralized assignments in the model of Sect. 3. Importantly, note that WE is a structurally different objective than the highest effort. In fact, consider, for instance, a one-shot Tullock contest with one high and one low type exerting efforts \(e_{h}\) and \(e_{l}<e_{h}\), respectively; then, while the highest effort is \(e_{h}\), we have that \(WE=e_{h}\cdot \left( e_{h}/TE\right) +e_{l}\cdot \left( e_{l}/TE\right) \), which is different than \(e_{h}\). In words, even the player exerting the lowest effort could win in a Tullock contest, and, if so, the contest organizer cares about the effort of the low type. Recall that maximizing WE is relevant for all applications where the designer only benefits from the effort exerted by the winner. Using (1) and (2), we obtain the following.
Lemma 5
Consider a single Tullock contest with prize \({\tilde{V}}\), \({\tilde{m}}\) high types, and \({\tilde{n}}\) low types. The expected winner’s effort in the contest is
where \({\hat{p}}_{h}\) and \({\hat{p}}_{l}\) are the equilibrium probabilities of victory of a high and low type, respectively.
Proof
See Appendix A. \(\square \)
Proposition 1 finds that it never pays to exclude agents under TE-maximization. Under WE-maximization, instead, we find that exclusions may pay.
Proposition 2
(WE in a single contest) In a single Tullock contest with prize \({\tilde{V}}\), \({\tilde{m}}\) high types, and \({\tilde{n}}\) low types, WE decreases in \({\tilde{n}}\), and it can strictly decrease or increase in \({\tilde{m}}\).
Proof
See Appendix A. \(\square \)
In Sect. 5.1, we use Proposition 2 as a building block to derive the number, composition, and prize distribution of the WE-maximizing contests. In particular, we mirror the structure of the analysis of TE in Sect. 4.2 by analyzing how segregations affect WE; we find that segregation may increase WE, in contrast to the result for TE.
5.1 Segregations may increase WE
We use the same terminology and notation of Sect. 4.2, except that we analyze WE rather than TE. Without segregation, WE in the unified contest, \(WE^{u}\), is as in (9) with \({\tilde{m}}=m_{1}\) and \({\tilde{n}}=n_{1}\):
With the segregation of \(\left( m_{2},n_{2}\right) \) contestants, WE in the original contest, \(WE^{s-o}\left( V_{1}-d\right) ,\) reads as
where
and WE in the new contest between \(\left( m_{2},n_{2}\right) \) contestants, \(WE^{s-n}\left( d\right) ,\) reads as
using (9) specialized to the original and new contests. Finally, we define WE after segregation and with optimally chosen prizes as
The main result of this section is that some segregations increase WE, and in particular we find that a WE-maximizing assignment has any number of contests between pairs of high types with any prize allocation. In order to understand the intuition, we first explain why “small” contests (with a few contestants) yield greater WE than big ones (those with many contestants) and second why, within the class of small contests, having only high types yields the highest WE.
To intuitively understand the first point, consider a homogeneous contest. In this case, WE is the individual effort of the (only) winner. As individual efforts decrease in the number of contestants, the intuition follows.
To intuitively understand the second point, consider a two-player contest and let \(e_{ij}\) be the equilibrium effort of a type i up against a type j. In a high-high contest, \(WE=e_{hh}\), in a low-low contest, \(WE=e_{ll}\), and intuitively \(e_{hh}>e_{ll}\). In a high-low contest, WE is a convex combination between \(e_{hl}\) and \(e_{lh}\), which are both lower than \(e_{hh}\), as commonly known in the literature; asymmetries dampen competition. For these reasons, a high-high contest is WE-maximizing within the class of two-player contests.
The two above pieces of intuition suggest the optimality of small homogeneous contests. In fact, we formally obtain the following result.
Proposition 3
(Optimal assignment to maximize WE) The WE-maximizing structure is one with any arbitrary allocation of the prize budget V to any number of pairwise contests, each between two high types.
Proof
See Appendix A. \(\square \)
Note that any number of high-high contests with arbitrary prize allocation is WE-equivalent because, in any such contest, \(WE=e_{hh}\) and \(e_{hh}\) is linear in the prize allocated to that contest.Footnote 16
The result of Proposition 3, together with the corresponding result for TE we derived in Corollary 1, highlights the importance of a careful specification of the designer’s objective function, as it has the potential of drastically changing the optimum. This result parallels one of the findings of Moldovanu and Sela (2006). They analyze whether it is better to organize one unified contest or some sub-contests whose winners compete against each other. Their derived optimum crucially depends on the objective of the designer (maximization of expected total effort or highest effort); likewise, in our setup, the optimal contest structure crucially depends on whether the designer maximizes TE or WE.
Despite Proposition 3 showing that segregations of high types are beneficial to WE, one may still wonder about the optimal structure if the designer does not have so much leeway and rather has only control over low types, as we did in Lemma 3 for TE-maximization. In particular, we allow the designer to segregate away from the original contest any number of low types in any number of contests, but to neither exclude nor segregate high types from the original contest.Footnote 17 Hence, the only things the designer can finetune in the original contest are the prize and the number of low types. This setting is realistic, for instance, in case of contests with minimum entry requirements, which matter only when applicants’ qualifications do not meet a minimum requirement. We find the following.
Proposition 4
(Segregating only low-types might increase WE) Consider a designer who can segregate low types only. If \( m_{1}>2\left( 1+\sqrt{1-h}\right) /h\), then a WE-maximizing designer allocates all the prize budget to a segregated contest with two low types only. If \(m_{1}<2\left( 1+\sqrt{1-h}\right) /h\), then a WE-maximizing designer allocates all the prize budget to the original contest with high types only (that is, segregate, or exclude, the low types).
Proof
See Appendix A. \(\square \)
The intuition behind the optimal structure of Proposition 4 is simple and builds on the intuition behind the optimality of high-high contests (Proposition 3). If the number of high types \( m_{1}\) is high, then the original contest is far from the ideal high-high-only contest, and thus a low-low-only contest with full prize budget becomes optimal. If \(m_{1}\) is small, on the contrary, then the original contest is close to the ideal high-high-only contest, especially if the designer excludes all low types from the competition (formally, segregates them into a separate contest with 0 prize). It is necessary to exclude low types from the original contest when they would otherwise exert strictly positive effort, and this would decrease WE; in fact, we know from (1) that low types exert strictly positive effort if \(m_{1}<1/\left( 1-h\right) \), which is the case under \(m_{1}<2\left( 1+ \sqrt{1-h}\right) /h\) if \(h>3/4\). This is intuitive; when \(h>3/4\), high and low types are similarly talented, and thus low types are not discouraged in the contest with high types and exert strictly positive effort. This is exactly when the designer is better off excluding the low types.
6 Multiple participations
We now consider the possibility of multiple participations. With respect to the model in Sect. 3, now some contestants, with the same effort, compete in more than one contest. We begin by showing that, starting from a grand contest (which was optimal under single participation), TE increases under multiple participation after the following segregation; high and low types compete for \(V-d>0\) and low types compete for \(d\in \left( 0,V\right) \) in a parallel low-type-only contest. This multiple-participation setup is directly inspired by the work of Dahm and Esteve-González (2018).
Proposition 5
(Dahm and Esteve-González 2018) If \(\frac{m-1}{m}<h<1-\frac{1}{1+n\left( n+m-2\right) }\), then there exist \(d\in (0,V)\) such that, if
-
(1)
high and low types compete for \(V-d,\) and
-
(2)
low types compete among themselves in a parallel new contest with prize d,
then TE is strictly larger than the TE of the grand contest in which all types compete for V.
Proof
See Appendix A. \(\square \)
The intuition behind Proposition 5 is as follows. As low types have the chance of winning two prizes with the same effort, while high types can win only one, this segregation effectively biases the competition in favor of weaker contestants. As known in the literature, this tends to increase efforts (e.g., Nti 1999; Franke 2012). Note also that the value of h can neither be too large nor too small; it has to be intermediate.Footnote 18 In fact, if h was too small, high types would be so much stronger than low types that the prize d that would boost efforts of low types and make them competitive enough in the contest with all types would be too costly for the designer. If h was too large, high and low types would be very similar in skills. Think about the extreme case of \(h\rightarrow 1\); then, the contest with all types would be highly competitive, being among almost equally skilled contestants, and thus giving an extra reason to fight to low types only—namely, the extra prize d—would unlevel the playing field of the contest with all types (competition for \(V-d\)) and discourage high types.
The derivation of the TE-maximizing d in the multiple-participation contest (described in Proposition 5) is challenging. Nevertheless, as numerical simulations show that the optimal d is often small relative to the prize in the original contest (\(V-d\)), we provide analytically two upper bounds, collected in the following proposition.
Proposition 6
Suppose \(\left( m-1\right) /m\le h\le 1-1/\left( 1+n\left( n+m-2\right) \right) \) and consider the multiple-participation contest described in Proposition 5. Let \(\delta \) be the level of d that maximizes TE. Then
Proof
See Appendix A. \(\square \)
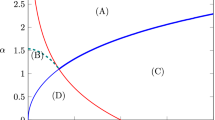
We now discuss the upper bounds on the right-hand side of (13). Note that it depends on h. Fixing \(\left( m,n\right) \) and considering \(h\in \left[ \left( m-1\right) /m,1-1/\left( 1+n\left( n+m-2\right) \right) \right] \) (see Proposition 5), there exists a “most permissive” value of h such that the right-hand side of (13) is the largest. Even for such a value of h, we still obtain quite low values of the right-hand side of (13), which implies that the extra prize \(\delta \) for low types is significantly lower than the prize \(V-\delta \) for the contest with all types. We plot in Fig. 2 the right-hand side of (13) under such a most permissive value of h for the tightness of the bound in (13). When \(m=2\), the upper bound in (13) is not tight and mostly not informative. For any other value of m, Fig. 2 shows that \( \delta /\left( V-\delta \right) <1/3\) regardless of the number of low types n and h; that is, the extra prize for low types is always at most half the prize for the contest with all types. The upper bound becomes particularly tight for high values of m and n. For instance, when \( m=n=10 \) [20], the right-hand side of (13) with most permissive value of h equals 1/9 [1/19].

Right-hand side of (13) with most permissive h, as a function of m and n, each between 2 and 30
One could consider other assignments with multiple participation. For instance, one could show that the diametrically opposed assignment, where high and low types compete for \(V-d>0\) and high types compete for \( d\in \left( 0,V\right) \) in a parallel high-type-only contest, would yield a lower TE. This is intuitive; not only low types are discouraged because they are weaker, but also because the high types they face have a further incentive to exert high efforts as they compete simultaneously for the extra prize d. In fact, in the words of (Dahm and Esteve-González 2018, p. 126), this assignment “does not seem interesting from an affirmative action point of view.”
Finally, one could wonder how the result of Proposition 5 derived in our binary setup with only high and low types extends to more than three types. Despite the proof becoming more tedious and algebraically complex, in Appendix B we show that the main structure of the optimal assignment under multiple participations carries over. In particular, we provide sufficient conditions on the primitives (number and marginal costs of high, medium, and low types), such that TE increases with respect to the grand contest when the designer organizes three prizes, one for a contest with all types, one for a contest with low and medium types, and one for a contest with low types only.
7 Tilting the playing field
With respect to the model in Sect. 3, we now abandon the assumption that the designer treats contestants identically. Instead, we now assume that the effort of each high type is multiplied by a factor \(\beta >0\) in affecting the probability of victory.
In the grand contest with multiplicative bias \(\beta \) for high types, the maximization problem of a high type reads as
and that of a low type as
In a type-symmetric (\(x=e_{l}\) and \(y=e_{h}\)) and interior equilibrium, we obtain similar equilibrium expressions to (1) and (2). However, now we have to take into account corner equilibria for both high and low types. In fact, if \(\beta \) is sufficiently high (i.e., \(\beta \ge hm/\left( m-1\right) \)), the effect of \(\beta \) does not suffice to encourage low types to participate, and hence low types exert 0 effort. If \(\beta \) is sufficiently low (i.e., \(\beta \le h\left( n-1\right) /n\)), the disadvantage given to high types is too big and hence high types exert 0 effort. As the former threshold of \(\beta \) is always greater than the latter, we obtain three regions for the equilibrium efforts in the grand contest;
Therefore, total effort equals
In what follows, we can ignore both \(\beta \le h\left( n-1\right) /n\) and \( \beta \ge hm/\left( m-1\right) \), as the resulting contest would be outcome-equivalent to one with only high or low types and no tilting of playing field which, as we know from Sect. 4.2, is not optimal. Hence, we focus on the values of \(\beta \) such that the equilibrium efforts are strictly positive for both types; namely, when \( \beta \in \left( h\left( n-1\right) /n,hm/\left( m-1\right) \right) \). In this region, one can see that the derivative of (14) with respect to \(\beta \) equals 0 if and only if \(\beta =\beta ^{*}\), where
i.e., \(\beta ^{*}\) is the unique critical point for TE. At the two boundaries of the interval \(\beta \in \left[ h\left( n-1\right) /n,hm/\left( m-1\right) \right] \), TE equals, respectively, \(\frac{n-1}{n}V\) and \(\frac{ m-1}{hm}V\). One can show that TE at \(\beta =\beta ^{*}\) is greater than TE at either of these boundaries. Hence, since \(\beta ^{*}\) is the only critical point of TE, \(\beta ^{*}\) is the TE-maximizing value of \(\beta \).
Notice that \(\beta ^{*}\in \left( 0,1\right) \), as intuition would suggest: it is optimal to give a disadvantage to high types so as to level the playing field. If we plug \(\beta ^{*}\) into the expression for TE in (14), again focusing on \( \beta \)’s such that low and high types are active, we obtain the following level of total effort under optimal tilting \(\beta ^{*}\), which we denote by \(TE^{\beta }\):
One can immediately see that \(TE^{\beta }\) is greater than under no tilting (as in (3)), because the second addend of \( TE^{\beta }\) is positive. We conclude by showing that \(TE^{\beta }\) is also greater than the maximum of TE obtained under multiple participation.
Proposition 7
The total effort obtained with optimal tilting of the playing field (giving a disadvantage to efforts of high types through \( \beta ^{*}\) in (15)) is greater than that obtained with optimal multiple participations (creating a low-type-only contest with optimal prize \(d^{*}\)).
Proof
See Appendix A. \(\square \)
Proposition 7 reaffirms the optimality of a single grand contest when the two alternative tools of creating a parallel low-type-only contest or tilting the playing field in the original grand contest are compared.
8 Conclusions
In a simple setup with binary types, we investigate the effort-maximizing centralized assignment of contestants and prizes across Tullock contests. Our main result is that a single grand contest maximizes total effort; contestant exclusions do not pay. We consider three extensions; the first one changes the objective function of the designer, and the second and third change the tools in her hands. As for the first, when considering the centralized assignment that maximizes the expected winners’ efforts instead of total effort, the optimal assignment involves pairwise high-type-only contests; particular types of exclusions do pay. As for the second and third, we allow the designer to let some contestants participate in more than one contest with the same effort, or treat contestants differently by tilting the playing field, respectively. The literature suggests both tools increase total effort. We show that tilting the playing field increases total effort more than multiple participations, thus reaffirming the optimality of a grand contest when the two alternative tools of creating a parallel low-type-only contest or tilting the playing field in the original grand contest are compared. Furthermore, we characterize an upper bound on the optimal prize allocated to the low-type-only parallel contest and show that such a prize is significantly smaller than that of the contest to which all contestants have access.
Several avenues of future research open up. First, our setup is purposefully stylized to prioritize simplicity and tractability; in fact, we assume linear impact and cost functions, and binary types. However, it is known that, for instance, the canonical results on tilting the playing field and equalizing win probabilities across contestants do not extend to more general setups (see, e.g., Franke et al. 2013; Drugov and Ryvkin 2017; Deng et al. 2020a, b; Fu and Wu 2020). Generalizations of our simple setup are also likely to uncover further insights into the issue of optimal centralized assignment and the long-standing question of when a single grand contest is optimal.
Data availability
We do not analyse or generate any datasets, because our work proceeds within a theoretical and mathematical approach.
Notes
We suppose for simplicity that the designer awards a single prize to the winner of each contest, rather than allowing for multiple prizes. Modeling the probability of being ranked in a specific spot below the winner in a Tullock contest is not trivial: for examples of multi-prize lottery contest models, see for instance (Clark and Riis 1996, 1998; Amegashie 2000; Yates and Heckelman 2001; Szymanski and Valletti 2005; Fu and Lu 2009, 2012a, b; Azmat and Möller 2009; Schweinzer and Segev 2012; Vesperoni 2016). In practice, the designer can assign different types of contestants to different contests, for instance, by deploying entry credential requirements or by direct observation of types after repeated interaction with the same pool of contestants.
An alternative interpretation of the noise is also mentioned by Fu and Lu (2012b): “perturbation in production.” We thank a referee for raising the important issue of the nature of the noise.
It bears keeping in mind that, in real-life, designers may have a variety of objectives other than TE or WE maximization —e.g., equity, inclusion, or steering talented young researchers into a long-term career in a specific field.
When the contest is in more than one round and the winners of each group in the first round goes up to the next round, then the optimality of a grand contest does not necessarily hold; see Gradstein and Konrad (1999) and Moldovanu and Sela (2006). However, the present paper exclusively focuses on static setups.
At the same time, creating a parallel contest with the excluded strong contestants may then further increase total effort. For instance, Parreiras and Rubinchik (2015), in an all-pay auction where a contestant of ability \( \alpha _{i}\) privately knows her valuation \(V_{i}\sim U\left[ 0,\alpha _{i} \right] \), find that homogeneity of abilities increases efforts and that separating contestants according to their ability into two groups of exogenously assumed equal size may be beneficial.
For instance, Fullerton and McAfee’s model includes entry fees collected by and valuable for the designer.
We rule out the possibility that prizes depend on actual exerted efforts (see, e.g., Cohen et al. 2008; Chowdhury and Sheremeta 2011). Furthermore, the prize in a specific contest does not depend on the identity of the winner. That is, any two players assigned to the same contest obtain an identical prize in case of victory, in contrast to Riis (2010).
Any one of the usual tie-breaking rules suffices to rule out that total effort equals 0 as an equilibrium outcome in any contest with a strictly positive prize, so we omit this aspect from our formal analysis. Note also that the analysis is not, in general, tractable under a generalized Tullock success function with discriminatory parameter \(r>0\). As soon as, in a contest, there is more than 1 player per type, there is no general closed-form solution for equilibrium efforts. Furthermore, even for “simple” values of r, one may run into tractability issues: for instance, for \(m=4\), \(n=2\), \(h=1/4\), and \(r=1/3\), algebraic solutions for equilibrium efforts must be expressed through complex numbers (i.e., a “casus irreducibilis” ). A proof is available upon request.
Note that the designer can essentially exclude from all the contests the contestant assigned to contest j by setting \(v^{j}=0\).
In Sect. 5, we consider WE as an alternative objective.
We assume that, in case of multiple contests, the overall WE is the sum of the WE of each contest. First, this definition prevents nearly meaningless results; if only one contest would impact WE, then there would trivially never be room for allocating a strictly positive amount of budget to more than one contest. Second, and more importantly, this definition is in line with the applications spelled out in the Introduction; in case of multiple grants for scholars, the winning effort in each such contest is valuable.
Note that segregation of all high types remains possible by segregating all low types.
One can show that \(\left( m-1\right) /m<1-1/\left( 1+n\left( n+m-2\right) \right) <1,\) so some \(h<1\) that satisifes the hypothesis of Proposition 5 exists for any m and n.
References
Ales L, Cho SH, Körpeoğlu E (2017) Optimal award scheme in innovation tournaments. Oper Res 65(3):693–702
Amegashie JA (2000) Some results on rent-seeking contests with shortlisting. Public Choice 105:245–253
Azmat G, Möller M (2009) Competition among contests. Rand J Econ 40:743–768
Barbieri S, Serena M (2022) Biasing dynamic contests between ex-ante symmetric players. Games Econom Behav 136:1–30
Baye MR, Kovenock D, De Vries CG (1993) Rigging the lobbying process: an application of the all-pay auction. Am Econ Rev 83(1):289–294
Chowdhury SM, Sheremeta RM (2011) A generalized Tullock contest. Public Choice 147(3):413–420
Clark DJ, Riis C (1996) A multi-winner nested rent-seeking contest. Public Choice 87:177–184
Clark DJ, Riis C (1998) Influence and the discretionary allocation of several prizes. Eur J Polit Econ 14(4):605–625
Cohen C, Kaplan TR, Sela A (2008) Optimal rewards in contests. Rand J Econ 39(2):434–451
College Board (2020) Frequently asked questions: environmental context dashboard. Available at: https://secure-media.collegeboard.org/pdf/environmental-context-dashboard-faqs.pdf
Corchón L, Serena M (2018) Contests theory: a survey. Edward Elgar, Handbook of game theory and industrial organization
Dahm M, Esteve-González P (2018) Affirmative action through extra prizes. J Econ Behav Organ 153:123–142
Deng S, Fang H, Fu Q, Wu Z (2020a) Confidence management in tournaments (No. w27186). National Bureau of Economic Research
Deng S, Fu Q, Wu Z (2020b) Optimally biased tullock contests. Working Paper
Drugov M, Ryvkin D (2017) Biased contests for symmetric players. Games Econom Behav 103:116–144
Fang H (2002) Lottery versus all-pay auction models of lobbying. Public Choice 112(3–4):351–371
Franke J (2012) Affirmative action in contest games. Eur J Polit Econ 28(1):105–118
Franke J, Kanzow C, Leininger W, Schwartz A (2013) Effort maximization in asymmetric contest games with heterogeneous contestants. Econ Theor 52(2):589–630
Fu Q, Lu J (2009) The beauty of “bigness’’: on optimal design of multi-winner contests. Games Econom Behav 66(1):146–161
Fu Q, Lu J (2012) The optimal multiple-stage contest. Econ Theor 51(2):351–382
Fu Q, Lu J (2012) Microfoundations for generalized multi-prize contest: a noisy ranking perspective. Soc Choice Welf 38(3):497–517
Fu Q, Wu Z (2018a) Contests: theory and topics. Working Paper
Fu Q, Wu Z (2018b) Feedback and favoritism in sequential elimination contests. Mimeo
Fu Q, Wu Z (2020) On the optimal design of biased contests. Theor Econ 15:1435–1470
Fullerton RL, McAfee RP (1999) Auctioning entry into tournaments. J Polit Econ 107(3):573–605
González-Díaz J, Siegel R (2013) Matching and price competition: beyond symmetric linear costs. Int J Game Theory 42(4):835–844
Gradstein M, Konrad KA (1999) Orchestrating rent seeking contests. Econ J 109(458):536–545
Hui KX (2017) Tailor, 71, sews up prize for best new retail entrant. Available at: https://www.straitstimes.com/singapore/tailor-71-sews-up-prize-for-best-new-retail-entrant
Konrad K (2009) Strategy and dynamics in contests. Oxford University Press Inc, New York
Kumar A, Brar V, Chaudhari C, Raibagkar SS (2022) Discrimination against private-school students under a special quota for the underprivileged: a case in India. Asia Pac Educ Rev 2:1–10
Leuven E, Oosterbeek H, van der Klaauw B (2011) Splitting contests. Working paper
Mathews T, Namoro SD (2008) Participation incentives in rank order tournaments with endogenous entry. J Econ 95(1):1–23
Mealem Y, Nitzan S (2016) Discrimination in contests: a survey. Rev Econ Des 20(2):145–172
Mihm J, Schlapp J (2019) Sourcing innovation: on feedback in contests. Manag Sci 65(2):559–576
Moldovanu B, Sela A (2006) Contest architecture. J Econ Theory 126(1):70–96
Nti KO (1999) Rent-seeking with asymmetric valuations. Public Choice 98(3–4):415–430
Parreiras SO, Rubinchik A (2015) Group composition in contests. Working paper
Riis C (2010) Efficient contests. J Econ Manag Strat 19(3):643–665
Rosen S (1988) Promotions, elections and other contests. J Inst Theor Econ 144(1):73–90
Schweinzer P, Segev E (2012) The optimal prize structure of symmetric Tullock contests. Public Choice 153:69–82
Secher NH (1983) The physiology of rowing. J Sports Sci 1(1):23–53
Serena M (2017) Quality contests. Eur J Polit Econ 46:15–25
Serena M (2021) Harnessing beliefs to optimally disclose contestants’ types. Econ Theory 2:1–30
Siegel R (2009) All-pay contests. Econometrica 77(1):71–92
Siegel R (2010) Asymmetric contests with conditional investments. Am Econ Rev 100(5):2230–60
Szymanski S, Valletti TM (2005) Incentive effects of second prizes. Eur J Polit Econ 21(2):467–481
Taylor CR (1995) Digging for golden carrots: an analysis of research tournaments. Am Econ Rev 2:872–890
Vesperoni A (2016) A contest success function for rankings. Soc Choice Welf 47(4):905–937
Xiao J (2016) Asymmetric all-pay contests with heterogeneous prizes. J Econ Theory 163:178–221
Xiao J (2018) Equilibrium analysis of the all-pay contest with two nonidentical prizes: complete results. J Math Econ 74:21–34
Xiao J (2023) Ability grouping in contests. J Math Econ 104:102792
Yates AJ, Heckelman JC (2001) Rent-setting in multiple winner rent-seeking contests. Eur J Polit Econ 17:835–852
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We are pleased to acknowledge useful comments by Mikhail Drugov, Kai Konrad, Dan Kovenock, and three anonymous referees. A previous version circulated as “Sorting Contests and Contestants.” All errors are our own.
Appendices
Appendix A: Proofs
Proof of Lemma 3
Plugging \(m_{2}=0\) into (8), \(TE^{s-n}\left( d\right) = \frac{n_{2}-1}{n_{2}}d\), and thus, using also (7), we obtain
Let \(d^{*}\equiv \arg \max _{d\in \left[ 0,V_{1}\right] }\left\{ TE^{s-o}\left( V_{1}-d\right) +TE^{s-n}\left( d\right) \right\} .\) Consider two cases.
Case 1. If \(\frac{m_{1}-1}{hm_{1}}\ge 1\), then \(\frac{m_{1}-1}{hm_{1}}\ge 1>\frac{n_{2}-1}{n_{2}}\), so \(d^{*}=0\) and \(TE^{s}=\frac{m_{1}-1}{hm_{1}} V=TE^{u}\). In words, if in the unified contests low types exert no effort, then segregating \(n_{2}\) low types and allocating part of the prize to the new contest does not pay off as the loss in competition in the original contest is greater than the benefit of having a new contest in which low types exert effort.
Case 2. If \(\frac{m_{1}-1}{hm_{1}}<1\), note that, using \(h<1\), (4), and \(m_{1}+n_{1}>n_{2}\), we obtain
while (5) implies
Therefore, these last two displayed equations imply
and this concludes the proof. \(\square \)
Proof of Lemma 4
By (7) and (8), the total effort resulting from the segregation is
As in the Proof of Lemma 3, let \(d^{*}\) maximize the above expression. We consider three cases.
Case 1. If \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }\ge 1\), then \( \frac{m_{1}-1}{hm_{1}}\ge 1\) by (4), and thus, we can use (6) and the above-displayed expression to rewrite \(TE^{u}>TE^{s}\) as
As \(m_{1}>m_{1}-m_{2}\) and \(m_{1}>m_{2}\), by (4) we have \(\frac{ m_{1}-1}{hm_{1}}>\frac{\left( m_{1}-m_{2}\right) -1}{h\left( m_{1}-m_{2}\right) }\) and \(\frac{m_{1}-1}{hm_{1}}>\frac{m_{2}-1}{hm_{2}}\), hence the same logic leading to (17) yields \(TE^{u}>TE^{s}.\)
Case 2. If \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }<1\) and \(\frac{ m_{1}-1}{hm_{1}}\ge 1\), \(TE^{u}>TE^{s}\) can be rewritten as
As \(\frac{m_{1}-1}{hm_{1}}\ge 1=\frac{m_{1}+n_{1}-m_{2}-1}{ m_{1}-m_{2}-1+n_{1}}>\frac{m_{1}+n_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) +n_{1}}\) by \(h<1\) and \(\frac{m_{1}-1}{hm_{1}}>\frac{m_{2}-1}{hm_{2}}\) by ( 4), the same logic leading to (17) yields \(TE^{u}>TE^{s}\).
Case 3. If \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }<1\) and \(\frac{ m_{1}-1}{hm_{1}}<1\), \(TE^{u}>TE^{s}\) can be rewritten as
As \(\frac{m_{1}+n_{1}-1}{hm_{1}+n_{1}}>\frac{\left( m_{1}-m_{2}\right) +n_{1}-1}{h\left( m_{1}-m_{2}\right) +n_{1}}\) by (4), and \(\frac{ m_{1}+n_{1}-1}{hm_{1}+n_{1}}>\frac{m_{1}-1}{hm_{1}}>\frac{m_{2}-1}{hm_{2}}\), first by (5) and \(\frac{m_{1}-1}{hm_{1}}<1\), and then by (4) and \(m_{1}>m_{2}\), the same logic leading to (17) yields \( TE^{u}>TE^{s} \). \(\square \)
Proof of Proposition 1
Using (6), (7), and (8), the expressions to be compared depend on whether the thresholds \(\frac{m_{1}-1}{ hm_{1}},\) \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }\), and \(\frac{ m_{2}-1}{hm_{2}}\) are larger or smaller than 1. As by (4) we have \( \frac{m_{1}-1}{hm_{1}}\ge \max \left\{ \frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) },\frac{m_{2}-1}{hm_{2}}\right\} \), letting \(d^{*}\) maximize TE after the segregation, there are two possibilities to consider.
-
1.
If \(\frac{m_{1}-1}{hm_{1}}<1\), then \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }<1\) and \(\frac{m_{2}-1}{hm_{2}}<1\) as well. In words, if the number of high types in the unified contest is too low to generate a corner equilibrium in which low types exert zero effort, then segregations can neither lead to corners in the original contest nor in the new contest. From (6), (7), and (8), \( TE^{u}>TE^{s}\) is equivalent to
$$\begin{aligned} \frac{m_{1}+n_{1}-1}{hm_{1}+n_{1}}V_{1}>\frac{m_{1}-m_{2}+n_{1}-n_{2}-1}{ h\left( m_{1}-m_{2}\right) +n_{1}-n_{2}}\left( V_{1}-d^{*}\right) +\frac{ m_{2}+n_{2}-1}{hm_{2}+n_{2}}d^{*}, \end{aligned}$$and as \(\frac{m_{1}+n_{1}-1}{hm_{1}+n_{1}}>\frac{\left( m_{1}-m_{2}\right) +n_{1}-1}{h\left( m_{1}-m_{2}\right) +n_{1}}>\frac{\left( m_{1}-m_{2}\right) +\left( n_{1}-n_{2}\right) -1}{h\left( m_{1}-m_{2}\right) +\left( n_{1}-n_{2}\right) }\), first by (4) and then by (5) and \( \frac{m_{1}-1}{hm_{1}}<1\), the same logic leading to (17) yields \( TE^{u}>TE^{s}\).
-
2.
If \(\frac{m_{1}-1}{hm_{1}}\ge 1,\) then we further distinguish four subcases
-
(a)
If \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }\ge 1\) and \( \frac{m_{2}-1}{hm_{2}}\ge 1\), then \(TE^{u}>TE^{s}\) is equivalent to
$$\begin{aligned} \frac{m_{1}-1}{hm_{1}}V_{1}>\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) } \left( V_{1}-d^{*}\right) +\frac{m_{2}-1}{hm_{2}}d^{*}. \end{aligned}$$As \(\frac{m_{1}-1}{hm_{1}}>\frac{\left( m_{1}-m_{2}\right) -1}{h\left( m_{1}-m_{2}\right) }\) and \(\frac{m_{1}-1}{hm_{1}}>\frac{m_{2}-1}{hm_{2}}\) by (4), the same logic leading to (17) yields \(TE^{u}>TE^{s}\).
-
(b)
If \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }\ge 1\) and \( \frac{m_{2}-1}{hm_{2}}<1\), then \(TE^{u}>TE^{s}\) is equivalent to
$$\begin{aligned} \frac{m_{1}-1}{hm_{1}}V_{1}>\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) } \left( V_{1}-d^{*}\right) +\frac{m_{2}+n_{2}-1}{hm_{2}+n_{2}}d^{*}. \end{aligned}$$As \(\frac{m_{1}-1}{hm_{1}}>\frac{\left( m_{1}-m_{2}\right) -1}{h\left( m_{1}-m_{2}\right) }\) by (4), and \(\frac{m_{1}-1}{hm_{1}}>\frac{ m_{2}-1}{hm_{2}}>\frac{m_{2}+n_{2}-1}{hm_{2}+n_{2}}\) (first by (4), and then by (5) and \(\frac{m_{2}-1}{hm_{2}}<1\)), the same logic leading to (17) yields \(TE^{u}>TE^{s}\).
-
(c)
If \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }<1\) and \(\frac{ m_{2}-1}{hm_{2}}\ge 1\), then \(TE^{u}>TE^{s}\) is equivalent to
$$\begin{aligned} \frac{m_{1}-1}{hm_{1}}V_{1}>\frac{m_{1}-m_{2}+n_{1}-n_{2}-1}{h\left( m_{1}-m_{2}\right) +n_{1}-n_{2}}\left( V_{1}-d^{*}\right) +\frac{m_{2}-1 }{hm_{2}}d^{*}. \end{aligned}$$As \(\frac{m_{1}-1}{hm_{1}}>\frac{\left( m_{1}-m_{2}\right) -1}{h\left( m_{1}-m_{2}\right) }>\frac{m_{1}-m_{2}+\left( n_{1}-n_{2}\right) -1}{h\left( m_{1}-m_{2}\right) +\left( n_{1}-n_{2}\right) }\) (first by (4), and then by (5) and \(\frac{\left( m_{1}-m_{2}\right) -1}{h\left( m_{1}-m_{2}\right) }<1\)), and \(\frac{m_{1}-1}{hm_{1}}>\frac{m_{2}-1}{hm_{2}}\) by (4), the same logic leading to (17) yields \(TE^{u}>TE^{s}\).
-
(d)
If \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }<1\) and \(\frac{ m_{2}-1}{hm_{2}}<1\), then \(TE^{u}>TE^{s}\) is equivalent to
$$\begin{aligned} \frac{m_{1}-1}{hm_{1}}V_{1}>\frac{m_{1}-m_{2}+n_{1}-n_{2}-1}{h\left( m_{1}-m_{2}\right) +n_{1}-n_{2}}\left( V_{1}-d^{*}\right) +\frac{ m_{2}+n_{2}-1}{hm_{2}+n_{2}}d^{*}. \end{aligned}$$As
$$\begin{aligned} \frac{m_{1}-1}{hm_{1}}\ge 1=\frac{m_{1}-m_{2}+n_{1}-n_{2}-1}{\left( m_{1}-m_{2}-1\right) +n_{1}-n_{2}}>\frac{m_{1}-m_{2}+n_{1}-n_{2}-1}{h\left( m_{1}-m_{2}\right) +n_{1}-n_{2}}, \end{aligned}$$where the last step follows by \(\frac{m_{1}-m_{2}-1}{h\left( m_{1}-m_{2}\right) }<1\), and
$$\begin{aligned} \frac{m_{1}-1}{hm_{1}}\ge 1=\frac{m_{2}+n_{2}-1}{m_{2}-1+n_{2}}>\frac{ m_{2}+n_{2}-1}{hm_{2}+n_{2}}, \end{aligned}$$where the last step follows by \(\frac{m_{2}-1}{hm_{2}}<1\), the same logic leading to (17) yields \(TE^{u}>TE^{s}\).
-
(a)
\(\square \)
Proof of Lemma 5
When \(\frac{{\tilde{m}}-1}{h{\tilde{m}}}\ge 1\), expected winner’s effort coincides with \(e_{h}\) by \(e_{l}=0\); otherwise expected winner’s effort is the sum of efforts of high and low types, each weighted by corresponding probabilities of victory, which are
for a high type and
for a low type. Expression (9) follows simplifying the expression \({\hat{p}}_{h}e_{h}+{\hat{p}}_{l}e_{l}\). \(\square \)
Proof of Proposition 2
Consider the expected winner’s effort in (9). When \(\frac{{\tilde{m}}-1}{h{\tilde{m}}}\ge 1\), WE is constant in n and decreases in \({\tilde{m}}\). When \(\frac{{\tilde{m}}-1}{h{\tilde{m}}}<1\), simple algebra shows that WE decreases in \({\tilde{n}}\) if and only if \(\omega \left( h\right) \equiv {\tilde{m}}ah^{2}-{\tilde{m}}bh+{\tilde{n}}c<0\), where
Note that \(\omega \left( h\right) \) is convex in h as \(a\ge 0\). Hence, it suffices to show that \(\omega \left( h\right) <0\) at the two boundaries of the domain of h; namely, \(\left( {\tilde{m}}-1\right) /{\tilde{m}}\) and 1. When \(h=\left( {\tilde{m}}-1\right) /{\tilde{m}}\), \(\omega \left( h\right) \) takes value \(\left( 3-2{\tilde{m}}\right) \left( {\tilde{m}}+{\tilde{n}}-1\right) ^{2}/{\tilde{m}}<0\). When \(h=1\), \(\omega \left( h\right) \) takes value \((2- {\tilde{m}}-{\tilde{n}})({\tilde{m}}+{\tilde{n}})<0\). Therefore, \(\omega \left( h\right) <0\).
We are left to consider the derivative of WE with respect to \({\tilde{m}}\) when \(\frac{{\tilde{m}}-1}{h{\tilde{m}}}<1\). The claim holds also at \({\tilde{m}}= {\tilde{n}}=2\), hence we focus on this case, where we obtain
Now, at \({\tilde{m}}={\tilde{n}}=2\), \(\frac{{\tilde{m}}-1}{h{\tilde{m}}}<1\) reads \( h>1/2\). Let \({\tilde{h}}\equiv \left( 29-3\sqrt{33}\right) /16\approx 0.735\,\). Then, (18) implies that when \(h\in \left( 1/2, {\tilde{h}}\right) \) WE strictly increases in \({\tilde{m}}\), while when \(h\in \left( {\tilde{h}},1\right) \) WE strictly decreases in \({\tilde{m}}\). \(\square \)
Proof of Proposition 3
Imagine any possible assignment of contestants into contests. Any sub-contest necessarily belongs to one of the following two categories; either it has high types, or it does not. Note that a contest with high types must exist by \(m\ge 2\).
Consider a contest with high types and prize \({\tilde{V}}\). By Proposition 2, WE decreases in the number of low types. Hence, WE increases by excluding all low types. Finally, note that in the remaining contest, which has only high types, \(WE=e_{h}\), which is maximized excluding all high types but two (see (2)); in particular, in such a contest with two high types only, then \(WE=e_{h}=\frac{{\tilde{V}}}{4h}\).
Consider now a contest without high types and prize \({\tilde{V}}\). Here, \( WE=e_{l}<\frac{{\tilde{V}}}{4}\) by (1). It is profitable to switch the prize \({\tilde{V}}\) to the contest with two high types only, where in fact \(WE=\frac{{\tilde{V}}}{4h}\), as \(h<1\).
By the above reasoning, the structure maximizing WE, must be composed of two-player high-type-only contests. Finally, \(e_{h}\) is linear in the prize, and thus WE is maximized for any number of two-player high-type-only contests with any prize allocation; namely, \(WE= \frac{V}{4h}\) regardless of how many two-high-type contests are organized and of their prize allocation. \(\square \)
Proof of Proposition 4
We proceed with similar initial steps to those of the proof of Lemma 3.
Plugging \(m_{2}=0\) into (12), \(WE^{s-n}\left( d\right) = \frac{\left( n_{2}-1\right) n_{2}}{n_{2}^{3}}d=\frac{n_{2}-1}{n_{2}^{2}}d\), and thus, using also (10), we obtain
where \(\Psi \) is defined in (11). Let \(d^{*}\equiv \arg \max _{d\in \left[ 0,V_{1}\right] }\left\{ WE^{s-o}\left( V_{1}-d\right) +WE^{s-n}\left( d\right) \right\} .\)
-
1.
If \(\frac{m_{1}-1}{hm_{1}}\ge 1\), then, the above-displayed expression is maximized by \(n_{2}^{*}=2\) (the least possible competition level), as can be immediately seen in the term \(\frac{n_{2}-1}{n_{2}^{2}}\). For \(n_{2}^{*}=2\), we obtain
$$\begin{aligned} WE^{s-o}\left( V_{1}-d\right) +WE^{s-n}\left( d\right) =\frac{m_{1}-1}{ hm_{1}^{2}}\left( V_{1}-d\right) +\frac{d}{4}. \end{aligned}$$Hence, \(d^{*}=0\) if \(\frac{m_{1}-1}{hm_{1}^{2}}<\frac{1}{4}\iff m_{1}>2 \frac{1+\sqrt{1-h}}{h}\), and \(d^{*}=V\) if \(\frac{m_{1}-1}{hm_{1}^{2}}> \frac{1}{4}\iff m_{1}<2\frac{1+\sqrt{1-h}}{h}\). Notice that the condition \( m_{1}<2\frac{1+\sqrt{1-h}}{h}\) may hold (for instance, it does hold when \( m_{1}=2\)).
-
2.
If \(\frac{m_{1}-1}{hm_{1}}<1\), then segregating two low types might induce a reduction of the low types in the original contest, and thus such segregation might decrease \(WE^{s-o}\). However, tedious, but routine algebra shows that the \(\partial WE^{s-o}/\partial n_{2}>0\), and thus it is never optimal to leave any low types competing in the original contest; namely, \(n_{2}^{*}=n_{1}\). And, as discussed above, in a low-type-only contest, \(WE=e_{l}\), which is in turn maximized by leaving only two low types, which is achieved by excluding all but two low types. Therefore, we obtain the same expression for \(WE^{s-o}\left( V_{1}-d\right) +WE^{s-n}\left( d\right) \) of the case \(\frac{m_{1}-1}{hm_{1}}\ge 1\) above; namely, \(\frac{m_{1}-1}{hm_{1}^{2}}\left( V_{1}-d\right) +\frac{1}{4}d\). The optimal \(d^{*}\) is then identical too.
\(\square \)
Proof of Proposition 5
Despite the result closely mirroring Proposition 6 in Dahm and Esteve-González (2018), we provide here for completeness a proof specific to our notation and high-low setup. The payoff of a low type who exerts effort x is
so at an interior type-symmetric solution the following first-order condition (FOC) must hold:
The payoff of a high type who exerts effort y is
leading to the following FOC:
Now multiply (19) by n and (20) by m, and then add them up to get
Implicitly differentiating (21) with respect to d, we obtain
where \(\left( me_{H}+ne_{L}\right) ^{\prime }\) is the derivative of equilibrium total effort with respect to d. (An analogous interpretation holds for quantities such as \(e_{L}^{\prime }.\)) Letting \(d\downarrow 0\) and continuing to assume that the equilibrium is interior so that the efforts of all agents are positive, (22) becomes
The last step of the proof uses the fact that at \(d=0,\) we have \(\left( n-1\right) e_{H}>ne_{L}\). To see this, evaluating (19) and (20) at \(d=0\) and dividing one by the other, we obtain
Note that our hypothesis \(h>\frac{m-1}{m}\) guarantees that \(e_{H}\) and \( e_{L} \) are both positive, thus validating our assumption that in equilibrium all types of agents exert positive effort. Note as well that \( h<1-1/\left( 1+n\left( n+m-2\right) \right) \) guarantees \(\left( n-1\right) e_{H}>ne_{L}.\) Substituting this inequality into (23) we see that, at \(d=0\), \(\left( me_{H}+ne_{L}\right) ^{\prime }>0\), so a marginal increase to \(d>0\) increases total effort. \(\square \)
Proof of Proposition 6
We proceed in three steps. In Step 1, we prove a preliminary result needed to characterize the two upper bounds on \(\delta \); namely, \(ne_{L}<\left( n-1\right) e_{H}\). In Step 2 and Step 3, we prove respectively the first and second upped bounds in the proposition.
Step 1. To simplify notation, in this proof we denote \( TE=me_{H}+ne_{L}\). First note that at the optimal solution \(d=\delta ,\) both types exert strictly positive effort. To see this, note that, by Proposition 5, \(\delta >0.\) The condition \(\delta >0\) implies \( e_{L}>0\) by any of the standard tie-breaking rule arguments applied to the separate new contest reserved for low types. Furthermore, if \(e_{H}=0\) at \( d=\delta ,\) then \(TE=ne_{L}=\frac{n-1}{n}V,\) where the last equality follows by (19). But then a better strategy would be to set \( d=0\), which by (3) yields a total effort of \( \frac{m+n-1}{n+hm}V\), and \(\frac{m+n-1}{n+hm}V>\frac{n-1}{n}V\) by (4). Therefore, at \(d=\delta \) both (19) and (20) hold.
Implicitly differentiating (20) with respect to d, we obtain
Imposing optimality of d, i.e., \(e_{H}^{\prime }=-\frac{n}{m}e_{L}^{\prime }\), (24) gives
Furthermore, imposing optimality of d , i.e., \(\left( me_{H}+ne_{L}\right) ^{\prime }=0,\) (22) gives
As \(e_{L}^{\prime }>0\) at the optimal solution by (25), the above implies that we must have
or
Step 2. We now show that if \(V-\delta<\) \(V\left( h\frac{m+n-1}{n+hm }\right) \), then \(TE\le \frac{m+n-1}{n+hm}V,\) so \(d=\delta \) would yield lower total effort than \(d=0\), which is a contradiction. This is immediate, as we can rearrange (20) to obtain
and the extremes of the above yield \(TE\le \frac{V-\delta }{h}<\frac{m+n-1}{ n+hm}V\).
Note now that \(V-\delta \ge \) \(V\left( h\frac{m+n-1}{n+hm}\right) \iff \delta \le V\left( 1-h\frac{m+n-1}{n+hm}\right) \), so
Step 3. We now show that, in addition to (27), the following upper bound also holds:
To see this, note that multiplying (20) by 1/h and subtracting (19) from the result, we obtain
Isolating \(\frac{\delta }{V-\delta }>0\) and using \(e_{H}>\frac{n}{n-1}e_{L}\) from (26) in Step 1, we obtain
From (20) we obtain \(\frac{e_{H}}{TE}=\left( 1-\frac{h }{V-\delta }TE\right) \), which we plug in the above expression to obtain
Note that \(\left( 1-Ax\right) \left( Bx-1\right) \) is maximized for x at \( x=\frac{A+B}{2AB}\); that is \(\frac{TE}{V-\delta }=\frac{n+2\,h-hn}{2\,h\left( n+h-hn\right) }\). We then obtain the upper bound reached at
Conditions (27) and (28) prove the statement of the proposition. \(\square \)
Proof of Proposition 7
Consider the equilibrium described in Proposition 5 and denote by \(TE^{d}\) the resulting total effort. Solving (19) and (20) gives that total effort equals
Comparing the above displayed value with (16), we see that \(TE^{\beta }\ge TE^{d}\) is equivalent to
Squaring both sides and simplifying \(\left( 1-\left( 1-h\right) m\right) ^{2}n^{2}\left( V-d\right) ^{2}\), the above reduces to
Moving all terms in \(d\left( V-d\right) \) to the left-hand side and dividing both sides by \(\left( mV\right) ^{2}\) we obtain
We now define \(\phi \left( h,m,n,z\right) \) the difference between the left-hand side of the above-displayed expression and its right-hand side, where we replace \(\left( 1-\frac{d}{V}\right) \) with \(z:\)
The rest of the proof shows that \(\phi \left( h,m,n,z\right) <0\) for any \( z\in \left[ 0,1\right] \), if \(\frac{m-1}{m}<h<\frac{n\left( n+m-2\right) }{ 1+n\left( n+m-2\right) }\).
We begin by showing that
This follows because if \(h=\frac{n\left( n+m-2\right) }{1+n\left( n+m-2\right) }\), then \(\left( n\left( 1-h\right) \left( m+n-2\right) -h\right) =0\), and this is the only addendum that can be positive in \(\phi \).
We now show that even at the level of z that maximizes \(\phi \), \(\phi \) remains negative. First, note that \(\phi \left( h,m,n,0\right) <0\) and \(\phi \left( h,m,n,1\right) <0.\) Second, focusing on an interior solution, standard calculations imply that
where
Thus, the proposition is proven if we can show that \(f\left( h,m,n\right) <0\). To see this, consider the value of \(f\left( h,m,n\right) \) in the two boundaries of the domain of \(h\in \left( \frac{m-1}{m},\frac{n\left( n+m-2\right) }{1+n\left( n+m-2\right) }\right) \). First, \(f\left( \frac{ n\left( n+m-2\right) }{1+n\left( n+m-2\right) },m,n\right) <0\), because \( \phi \left( \frac{n\left( n+m-2\right) }{1+n\left( n+m-2\right) },m,n,z\right) <0\) for any \(z\in \left[ 0,1\right] .\) Second, note that
We will next show that \(f\left( h,m,n\right) \) is convex in h, thus concluding that \(f\left( h,m,n\right) <0\). We have that
with
and hence \(g\left( h,m,n\right) \ge g\left( \frac{m-1}{m},m,n\right) =8-6n^{2}+8mn(-2+m+n)>0\), thus concluding the proof that f is strictly convex in h. \(\square \)
9 Appendix B: Multiple-participation with 3 types
In this extension, we assume there are \(n_{h}\ge 2\) high types, \(n_{m}\ge 2 \) medium types, and \(n_{l}\ge 2\) low types, with marginal cost of effort equal, respectively, to \(c_{h},c_{m}\), and \(c_{l}\), with \( 0<c_{h}<c_{m}<c_{l} \). We investigate robustness of our result in Proposition 5 showing conditions such that total effort is not maximized in the grand contest, but instead by separating contestants with relatively low type to balance out the contest, if multiple participations are possible.
Proposition 8
(Split contests with three types) Consider the following three conditions:
If (29) holds and at least one between (30) and (31) holds, then there exists a split contest in which
-
(1)
all types compete for a prize \(V_{LMH}<V,\)
-
(2)
low and medium types compete for a prize \(V_{LM}\ge 0,\)
-
(3)
low types compete for a prize \(V_{L}\ge 0,\) with \(V_{L}+V_{LM}+V_{LMH}=V\), and such that total effort in the split contest is strictly larger than that of the unified grand contest in which all types compete for V.
Proof
In our equilibrium characterization, we denote equilibrium efforts in the type symmetric equilibrium as \(\left( e_{h},e_{m},e_{l}\right) \) and we proceed under the assumption that efforts are all positive. Following the same logic as for the proof of Proposition 5, equilibrium efforts are characterized by the following first-order conditions:
We now multiply the first FOC by \(n_{l}\), the second by \(n_{m}\), and the third by \(n_{h}\), and add them to obtain
Then, using implicit differentiation we get
Recall that \(V=V_{LMH}+V_{LM}+V_{LM},\) so \(dV_{LMH}=-dV_{L}-dV_{LM}.\) Therefore, as \(V_{L},V_{LM}\downarrow 0\), the above becomes
The strategy of proof is to show that, at \(V_{L}=V_{LM}=0\), the left-hand side of (33) is positive if at least one between (30) and (31) holds. Therefore, we can conclude that total effort is not maximized by the joint contest, but instead total effort would increase after increasing \(V_{L}\) or \(V_{M}\).
We now turn to the determination of the equilibrium effort levels at \( V_{L}=V_{LM}=0\). Now, (32) when \(V_{L}=V_{LM}=0\) read
which solve as
Using \(0<c_{h}<c_{m}<c_{l},\) we obtain \(e_{H}>e_{M}>e_{L}\), so the solution is interior if (29) holds. Recalling (33), total effort increases when
which, given (34), boils down to (30). Total also increases if \(e_{H}\left( n_{l}+n_{m}-1\right) >e_{L}n_{l}+e_{M}n_{m}\), which, given (34), boils down to (31). \(\square \)
The next example illustrates Proposition 8. Consider \( n_{h}=n_{m}=n_{l}=2\), and \(c_{l}=1.\) Under these conditions (29) becomes \(c_{h}>\frac{3}{2}-c_{m}\), (30) becomes \(c_{h}<\frac{16}{9}-c_{m}\), and (31) becomes \(c_{h}<\frac{8+8c_{m}}{17}\). Recalling as well that \(c_{h}<c_{m}\), we see that if \(c_{h}=0.8\), \(c_{m}=0.9\), then (29), (30), and (31) are all satisfied. Furthermore, numerical simulations show that the optimal distribution of prizes is \(V_{L}\cong 0.014,V_{LM}\cong 0.021,V_{LMH}\cong 0.964\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Barbieri, S., Serena, M. Centralized assignment of prizes and contestants. Soc Choice Welf 62, 117–152 (2024). https://doi.org/10.1007/s00355-023-01483-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00355-023-01483-1