
Abstract
Equality of opportunity is an important normative ideal of distributive justice. In spite of its wide acceptance and economic relevance, standard estimation approaches suffer from data limitations that can lead to both downward and upward biased estimates of inequality of opportunity. These shortcomings may be particularly pronounced for emerging economies in which comprehensive household survey data of sufficient sample size is often unavailable. In this paper, we assess the extent of upward and downward bias in inequality of opportunity estimates for a set of twelve emerging economies. Our findings suggest strongly downward biased estimates of inequality of opportunity in these countries. To the contrary, there is little scope for upward bias. By bounding inequality of opportunity from above, we address recent critiques that worry about the prevalence of downward biased estimates and the ensuing possibility to downplay the normative significance of inequality.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Equality of opportunity (EOp) is an ideal of distributive justice that garners wide-spread public support and is plausibly related to macro-economic indicators of development (Marrero and Rodríguez 2013; Ferreira et al. 2018; Aiyar and Ebeke 2019; Cappelen et al. 2007; Alesina et al. 2018). However, limitations in the underlying data sources lead to both upward and downward biased estimates of inequality of opportunity (IOp). Both biases are potentially large in emerging countries where the data quality is arguably worse than in industrialized economies. However, it is not clear ex ante which of the two biases prevails and whether IOp estimates rather tend to be downward or upward biased. In this paper, we address this uncertainty by constructing lower bound (LB) and upper bound (UB) estimates of IOp for twelve emerging economies and compare them to estimates from the conventional approach.
EOp distinguishes ethically justifiable (fair) inequalities from unjustifiable (unfair) inequalities using the concepts of circumstances and effort.Footnote 1 Circumstances are defined as all factors that are not under the control of the individual—for instance, the biological sex, the parental background and the birthplace. To the contrary, working hours and educational decisions are under the (partial) control of individuals and are therefore characterized as efforts. Opportunity egalitarians consider inequalities based on exogenous circumstances as unfair, while inequalities resulting from effort exertion are deemed fair sources of inequality (among others Cohen 1989; Arneson 1989).
This distinction is not only relevant from a normative perspective but provides important insights for the patterns and drivers of economic development (Marrero and Rodríguez 2013; Peragine et al. 2014; Ferreira et al. 2018; Neidhöfer et al. 2018). For instance, a leveled playing field fosters human capital accumulation by providing incentives for skill acquisition (Mejía and St-Pierre 2008). Furthermore, circumstance-based variation in life outcomes reflects horizontal inequality and segregation, both of which are important drivers of social tensions and conflict (Rohner 2011).
What we call the “standard approach” (S) towards IOp estimation in this paper, constructs a counterfactual distribution of life outcomes from a linear prediction using all circumstance information observable by the econometrician. In line with the opportunity-egalitarian doctrine, inequality in this counterfactual distribution is considered “unfair” since it only varies with immutable circumstance characteristics. Due to limitations in the underlying data sources, this conventional method can lead to both upward and downward biased empirical measurements of IOp. First, due to the partial observability of circumstances, standard IOp estimates tend to be downward biased (Balcázar 2015; Hufe et al. 2017). The downward bias may be particularly pronounced in countries that lack household surveys combining information on the outcome of interest with rich information on individual characteristics. Most emerging economies fall into this category. Second, if the ratio between the number of parameters to be estimated and the available degrees of freedom is large, the ensuing noise in the parameter estimates will artificially inflate the measured impact of observed circumstances on individual life outcomes (Brunori et al. 2019b). Emerging economies may again be particularly susceptible to such upward bias in standard IOp estimates since the sample sizes of available household surveys tend to be comparatively small. Ex ante it is unclear which of the two biases prevails for the group of emerging economies. As a consequence, policy makers that rely on standard estimates may over- or underestimate the true degree of IOp and enact policy measures without considering the uncertainty around such estimates (Kanbur and Wagstaff 2016).
In this paper, we address the uncertainty around empirical IOp estimates by drawing on longitudinal household surveys from twelve emerging economies which enable us to estimate both LB and UB measures of IOp. First, we calculate LB measures of IOp by estimating the impact of observable circumstances on incomes with a cross-validated lasso procedure. Assessing statistical models by out-of-sample cross-validation disciplines the process of model selection and therefore prevents overfitting the circumstance parameters to the estimation sample. As a consequence, the relevant circumstance parameters are estimated with less noise which in turn cushions upward biases in IOp measures.
Second, we leverage the panel dimension of the data to calculate UB estimates based on the individual fixed effect (FE) estimator proposed in Niehues and Peichl (2014). By their most common definition, circumstance characteristics are time-constant but partly unobservable by the econometrician. Individual FEs capture the full set of unobservable circumstances and therefore yield the maximum amount of outcome variation that can be explained by circumstances. However, individual FEs also capture time-constant effort variables and therefore may overstate the extent of unequal opportunities. Hence, they yield an upper bound of the true IOp estimate.
Our results can be summarized as follows. In emerging economies the standard approach of estimating inequality of opportunity produces results that closely align with the lower bound. In theory, the restricted data infrastructures of many emerging economies could lead to either upward biased (small sample sizes) or downward biased (little circumstance information) estimates. In practice, the latter concern clearly dominates the former in our sample. With respect to individual (equivalized household) incomes, the average difference between the standard estimate and the lower bound estimate is 5.7 (5.0) percentage points (pp). To the contrary, the average distance between the standard estimate and the upper bound estimate is 22.8 pp (28.5 pp).
These results from emerging economies contrast recent evidence for European countries. For example, Brunori et al. (2018) show for a set of European countries that standard estimates may be upward biased by up to 300%. This contrast emphasizes that the particularities of data environments are crucial for an assessment of the relative importance of upward and downward biases. Second, the large distance between the standard estimate and the upper bound estimate in emerging economies emphasizes the concern of providing misleading reference points to policymakers who could use downward-biased estimates of IOp to downplay the moral significance of inequality (Kanbur and Wagstaff 2016). In the absence of data innovations, providing reasonable bounds on inequality of opportunity may be the only way to address such concerns. Our paper is the first to conduct such a bounding exercise for a set of emerging economies with broad geographical coverage and thereby contributes to the growing literature on EOp in these countries.Footnote 2
The remainder of this paper is organized as follows. In Sect. 2 we formalize the EOp concept and outline the corresponding estimation strategies for its LB and UB measures. After introducing the data sources in Sect. 3, we present results and robustness analyses for both LB and UB estimates in Sect. 4. Section 5 concludes the paper.
2 Conceptual framework
Important life outcomes such as income and consumption are determined by an extensive vector of personal characteristics that can be subsumed by a binary classification into circumstances and efforts. Those characteristics that are completely beyond the realm of individual control are called circumstances. To the contrary, those characteristics that are at least partially controlled by individuals are called efforts. The more the distribution of outcomes depends on circumstances, the stronger the violation of the opportunity-egalitarian ideal and the higher the measure of inequality of opportunity.
Consider a finite population indexed by \(i\in \{1,\ldots ,N\}\).Footnote 3 Each individual is characterized by the tuple \(\{y_{it}, \mathbf {C_i}, \mathbf {E_{it}}\}\). \(y_{it}\) constitutes the period-specific outcome of interest, \( \mathbf {C_i} \) the vector of time-invariant circumstances, and \(\mathbf {E_{it}}\) period-specific effort. Life outcomes are a function of circumstances and effortsFootnote 4:
Note that we allow circumstances to have a direct and an indirect impact on the outcome of interest. For example, certain groups may be excluded from offices and positions based on outright discrimination (direct impact). However, such discrimination may also lead to adjustments in individual effort exertion since the imposed circumstance constraints alter the individual optimization calculus (indirect impact). Whether the correlation between circumstances and efforts contributes to the fair or the unfair part of inequality is widely debated (Jusot et al. 2013). In this paper we follow Roemer (1998) who proposes that outcome differences due to a correlation between circumstances and effort constitute a violation of EOp.Footnote 5
The literature on EOp further distinguishes the ex-ante from the ex-post approach (Ramos and Van De Gaer 2016). While the ex-ante approach requires that there are no differences in life outcomes across circumstance types, the ex-post approach demands that individuals exerting the same effort enjoy the same level of advantage. In this paper we focus on the ex-ante approach. That is, we use \(\mathbf {C_i}\) to construct a partition of disjunct types \(\Pi =\{T_1,\ldots ,T_P\}\) such that all members of a type are homogeneous in circumstances. The average outcome of type k is denoted by \(\mu ^k_t\). EOp is achieved if type-means in period t are equalized across types, i.e. if \(\mu ^k_{t}=\mu ^l_{t}~\forall ~l,k~|~T_k,T_l\in \Pi \).
Computing inequality in a counterfactual distribution \(M_{t}=\left( \mu ^1_{1t},\ldots ,\mu ^k_{it},\ldots ,\mu ^P_{Nt}\right) \), in which each individual i of type k is assigned its corresponding type outcome \(\mu ^k_{t}\) yields a scalar measure of IOp. It decreases with Pigou-Dalton transfers between circumstance types but is invariant to such transfers within circumstance types. Inequality in the counterfactual distribution of type-means can thus be considered unfair as it only depends on disparities due to immutable circumstance characteristics.
Standard Estimation (S) The standard approach towards IOp measurement (Bourguignon et al. 2007; Ferreira and Gignoux 2011) constructs an estimate for the counterfactual distribution of type means in a two-step procedure. First, for the year of interest t we estimate:
Note that this specification accounts for both the direct and the indirect effect of circumstances since the correlation between \(\mathbf {C_i}\) and \(\mathbf {E_{it}}\) is implicitly captured by \(\varvec{\beta }\). Second, we use the vector of estimated parameters \(\varvec{\hat{\beta }}\) to parametrically construct an estimate for the distribution of type means \({\tilde{M}}^S_{t}=\left( {\tilde{\mu }}^S_{1t},\ldots ,{\tilde{\mu }}^S_{it},\ldots ,{\tilde{\mu }}^S_{Nt}\right) \)Footnote 6:
Lower bound estimation (LB) Conceptually, Ferreira and Gignoux (2011) show that the outlined standard estimate of IOp is a LB of its true value if the circumstance vector \(\mathbf {C_i}\) contains only a subset of all relevant circumstances. Empirically, however, this lower bound measure may be upward biased due to sampling variance in the distribution of type means (Brunori et al. 2019b). With decreasing sample size and increasing size of the circumstance set, the available degrees of freedom to estimate \(\varvec{\beta }\) shrink. The ensuing noise in \(\varvec{\hat{\beta }}\) artificially inflates the variance in the distribution of estimated type means \({\tilde{M}}_{t}^{S}\), which in turn leads to upward biased lower bound measures of IOp.
The literature has proposed different methods to address the upward bias in IOp estimates. Using the European Union Survey on Income and Living Conditions (EU-SILC), Brunori et al. (2019b) select models by 5-fold cross validation. Thereby, the authors pre-specify a large variety of potential models which differ in circumstance characteristics and their interactions. After estimating these models on random folds of the data, the algorithm chooses the model which minimizes the average out of sample mean squared error.Footnote 7 An alternative approach to model selection are conditional inference trees and forests (Brunori et al. 2018). The regression tree method recursively splits the data according to the circumstance variables which have the strongest association with the outcome of interest while regression forest provide average estimates over multiple regression trees applied to random subsets of the data.
In this work we calculate lower bound estimates based on two different cross-validated lasso estimations that select the relevant circumstances to maximize the out-of-sample prediction accuracy of the model. Lasso estimations have two advantages in comparison to previous methods. First, one does not have to pre-specify the models to be evaluated by cross-validation—the preferred method in Brunori et al. (2019b). Second, they are less computationally expensive than random forests—the preferred method in Brunori et al. (2018). In Fig. 4, we use EU-SILC data to validate the lasso methodology against the findings of Brunori et al. (2018, 2019b). Both lasso estimates align very closely with the alternative estimation procedures. The implied Pearson correlation coefficients are 0.90/0.87 in comparison to the findings of Brunori et al. (2019b), and 0.91/0.89 in comparison to the findings of Brunori et al. (2018). All correlation coefficients are not statistically different from one at the 5% significance level.
In both estimation approaches, we first estimate
Part (1) of Eq. 4 is a perfect mirror of the OLS algorithm used to estimate Eq. 2. Part (2) however introduces a penalization term that varies with the absolute value of the estimated coefficient \(\hat{\beta _j}^{lasso}\). The larger (smaller) the penalization term \(\lambda \), the more (less) parsimonious the model and the lower the variance (bias) in the predictions based on the parameter vector \(\hat{\varvec{\beta }}^{lasso}\). We choose the optimal parameterization of \(\lambda \) by means of 5-fold cross validation.Footnote 8
The first lower bound estimate (LB1) uses the resulting vector \(\hat{\varvec{\beta }}^{lasso}\) to construct the counterfactual distribution \({\tilde{M}}_{t}^{LB1}=({\tilde{\mu }}^{LB 1}_{1t},\ldots ,{\tilde{\mu }}^{LB 1}_{it},\ldots ,{\tilde{\mu }}^{LB 1}_{Nt})\):
The second lower bound estimate (LB2) implements a post-OLS lasso estimation (Hastie et al. 2013). We only retain the subset \(\mathbf {C^r}\subseteq {\mathbf {C}}\), i.e. those circumstances whose coefficients were not shrunk to zero in Eq. 4. Then, we estimate \(\hat{\varvec{\beta }}^{Post-lasso}\) by running an OLS regression on the restricted set of circumstances:
We use \(\hat{\varvec{\beta }}^{Post-lasso}\) to construct the counterfactual distribution \({\tilde{M}}_{t}^{LB2}=\left( {\tilde{\mu }}^{LB 2}_{1t},\ldots ,{\tilde{\mu }}^{LB 2}_{it},\ldots ,{\tilde{\mu }}^{LB 2}_{Nt}\right) \):
Note that LB1 and LB2 are just different estimates of the same parameter vector. The choice between these two estimation methods is not straightforward. On the one hand, Belloni and Chernozhukov (2013) argue that the post-lasso may have a superior prediction accuracy than the standard lasso approach. On the other hand, the methodological validation based on EU-SILC reveals that the standard lasso approach tends to align more closely with the results in Brunori et al. (2018, 2019b) (Fig. 4). In our empirical application, we refer to standard lasso as our baseline LB estimate. However, we show that our main conclusions are insensitive to this choice.Footnote 9
Upper bound estimation (UB) Since S and LB are based on the subset of observable circumstances only, the resulting IOp estimates may be downward biased. Following Niehues and Peichl (2014) we therefore construct UBs of IOp using an individual fixed effects (FE) estimator. Assuming circumstances to be time-invariant, individual FEs capture the full set of \(\mathbf {C_i}\) even though not all circumstances are observable by the econometrician. A counterfactual distribution of type means constructed from individual FEs thus captures the upper ceiling of outcome variation that can be attributed to the impact of circumstances. In particular, the smoothed distribution of the UB is constructed as follows.
First, using observations from all periods \(v\ne t\), we estimate the individual FE \(c_i\) while accounting for common year-specific shocks \(u_v\):Footnote 10
Second, we regress the individual outcome in period t on the estimated individual FE:
Third, we use the vector of parameters \(\hat{\Psi }\) to construct the counterfactual distribution \({\tilde{M}}_{t}^{UB}=\left( {\tilde{\mu }}^{UB}_{1t},\ldots ,{\tilde{\mu }}^{UB}_{it}, \ldots ,{\tilde{\mu }}^{UB}_{Nt}\right) \):
Note that this estimator would yield the true estimate of IOp if \(c_i\) captured time-invariant circumstances only. However, the individual FE may also absorb time-invariant effort exertion (e.g. long-term motivation, ambition) leading to an UB interpretation of this IOp estimate.
Inequality measurement We follow existing IOp literature and summarize the information in counterfactual distributions \({\tilde{M}}_{t}^{S}\), \({\tilde{M}}_{t}^{LB1}\), \({\tilde{M}}_{t}^{LB2}\), and \({\tilde{M}}_{t}^{UB}\) by the mean log deviation (MLD) and the Gini coefficient. The MLD is part of the generalized entropy class of inequality measures satisfying symmetry, the Pigou–Dalton transfer principle, scale invariance, population replication, as well as additive and path-independent subgroup decomposability (Shorrocks 1980; Foster and Shneyerov 2000). However, the MLD is very sensitive to low incomes many of which are smoothed out when constructing counterfactual distributions. Therefore, Brunori et al. (2019a) argue in favor of using the Gini index in spite of its imperfect subgroup decomposability.Footnote 11 For both inequality measures, we provide relative measures of IOp that relate the MLD (Gini) of the counterfactual distributions \({\tilde{M}}_{t}^{S}\), \({\tilde{M}}_{t}^{LB1}\), \({\tilde{M}}_{t}^{LB2}\) and \({\tilde{M}}_{t}^{UB}\) to the actual outcome distribution \(Y_t\). The latter measures can be interpreted as the share of total inequality that is explained by circumstances and thus violates the opportunity-egalitarian ideal.
3 Data
We estimate IOp in income and consumption expenditure for twelve emerging economies in different geographical areas of the world ranging from Africa (Ethiopia, Malawi, South Africa, Tanzania), Central and South America (Argentina, Chile, Mexico, Peru), Europe and Central Asia (Russia), to East and South-East Asia (China, Indonesia, Thailand). The country selection is guided by the availability of household panel data with (1) information on relevant circumstance variables, and (2) a sufficient number of observations in the longitudinal dimension.Footnote 12 Table 2 provides an overview of the underlying data sources.
We consider three outcomes of interest. First, we calculate IOp in individual income—before or after taxes and transfers depending on data availability. Second, we account for resource sharing at the household level and calculate IOp in equivalized household income. Accounting for resource sharing at the household level is particularly relevant in emerging economies since female participation in formal labor markets tends to be low (Cubas 2016). Third, to derive a more direct measure of IOp in material well-being, we also consider equivalized household consumption expenditures. Household income and consumption expenditure are deflated by the modified OECD equivalence scale.
Throughout the paper, we restrict ourselves to within-country comparisons. Table 2 documents many differences across the underlying data sources. These include differences in the reference period, the income and consumption expenditure aggregates, the detail of available circumstance characteristics, as well as the sampled populations. For example, while the data for Mexico avails net income information until 2004, the data for Thailand provides gross income figures until 2016. The Ethiopian panel provides a rather parsimonious set of circumstances for a rural fraction of the population, whereas the Russian panel provides a rich set of circumstances for a nationally representative sample of households. We therefore refrain from cross-country comparisons but focus our discussion on intra-country comparisons between the different estimation approaches.
To ensure the consistency of these intra-country comparisons, we only retain those units of observation for which we observe (1) all circumstance variables, and (2) positive outcomes in all available outcome dimensions for at least three periods of observation. We further restrict our samples to individuals aged 25–55.Footnote 13
Table 1 displays relevant summary statistics for the estimation of S, LB, and UB by country.
4 Results
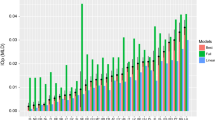
Figure 1 displays bounds of relative IOp, i.e. the percentage of total inequality that can be explained by exogenous circumstances.Footnote 14 Standard estimates (S) indicate IOp based on all observable circumstances available in the particular country data set. Lower bound estimates (LB) also use the full set of observable circumstances but account for potential upward biases through lasso estimation in which irrelevant circumstance parameters are shrunk to zero.Footnote 15 Upper bound estimates (UB) account for unobservable circumstances through the FE estimation procedure outlined in Sect. 2.
Individual income Panel (a) shows the results for individual income. The standard IOp estimate (S) for individual income ranges from 9.3% (Argentina) to 30.6% (Peru, South Africa). Accounting for sampling variation and the ensuing potential for upward biases in S provides only minor reductions in IOp. According to LB, between 6% (China) and 25.9% (Peru) of outcome inequality must be considered unfair. The average difference between S and LB estimates amounts to 5.7pp.Footnote 16 When using the post-lasso OLS procedure, the average difference is even smaller and equals 0.5pp. These results suggest that the standard estimation approach (S) is largely uncompromised by overfitting circumstance parameters to the available data. Instead—and in line with the theoretical reasoning of Ferreira and Gignoux (2011)—the standard approach indeed recovers estimates close to the lower bound (LB) estimate in all countries under consideration. Note that this result stands in contrast to recent evidence for European countries suggesting that the standard approach overestimates lower bound IOp by up to 300% (Brunori et al. 2018, 2019b). This difference is reconciled by the quality of the underlying data sources. While the richness of the European data confers the opportunity to overfit the circumstance information to the data, the sparsity of circumstance information in the household surveys under consideration prevents upward biases in the standard estimate (S).
The lower bound estimator selects the circumstance parameters with the highest out-of-sample prediction accuracy. In Table 5, we show for each outcome of interest, which of the circumstance variables and categories are chosen by the lasso estimator in a particular country. Across all countries, gender plays a prominent role reflecting concerns about gender inequality in the context of emerging and developing economies (Jayachandran 2015). However, it is important to note that the selection of particular variables by lasso only indicate a predictive correlation and does not necessarily imply a causal relationship. For instance, even though both maternal and paternal education could causally affect the income of individuals, a high correlation between fathers’ and mothers’ education might lead the lasso to choose only one of the two circumstance characteristics.

Source: Own calculations based on data described in Table 2
Bounds of Inequality of Opportunity. The figure shows estimates of relative IOp for individual incomes (a), equivalized household incomes (b) and equivalized household expenditures (c) based on the MLD. Standard estimates (S) use the full set of country-specific circumstances disclosed in Table 1. Lower bound (LB) estimates use the full set of country-specific circumstances disclosed in Table 1 but estimate the relevant parameters by means of a lasso estimation to account for sampling variance. Upper bound (UB) estimates are based on predictions from individual fixed effects.
While sparse circumstance information limits the scope for upward biases, it may lead to downward biases due to the neglection of circumstances that are unobserved by the econometrician. Therefore, we take account of unobservable circumstances by means of the fixed effect estimation outlined in Sect. 2. The UB estimates of IOp vary between 17.2% (Mexico) and 72.5% (South Africa). On average, UB exceeds S by 22.8pp. It therefore yields a significant upward correction of IOp in comparison to S and LB, respectively. The difference between UB and S is broadly comparable to the respective gap in developed economies (Niehues and Peichl 2014). As such, our results reflect recent concerns that downward biased IOp estimates based on observable circumstance characteristics provide misleading reference points as regards the normative significance of inequality (Kanbur and Wagstaff 2016).Footnote 17
Household income Panel (b) of Fig. 1 displays analogous IOp estimates for equivalized household income. In contrast to the results on individual income, we thereby account for resource sharing at the household level and heterogeneity in household compositions. Estimates for S (LB) decrease for the vast majority of countries and now lie between 1.2% in Argentina (0%, China) and 35.9% in South Africa (24.7%, South Africa). This decrease follows from the assumption of resource sharing at the household level that largely nullifies gender-based differences in incomes. Hence, the average difference between S and LB remains at a very low level of 5.0pp. Again, using the alternative post-lasso OLS estimation strategy decreases this difference to 1.3 pp. To the contrary, the UB estimates are largely comparable to their individual income analogues. According to UB, IOp ranges between 8.6% (Mexico) and 73.9% (South Africa). As a consequence, the average difference between S and UB increases from 22.8 pp to a level of 28.5 pp when considering household instead of individual incomes. Our general conclusion, however, remains intact: In the context of the developing economies under consideration, the standard estimation approach recovers an estimate close to LB. However, its large distance to UB suggests severe underestimations due to the influence of unobservable circumstances.
Household expenditure In Panel (c), we show IOp estimates for equivalized household expenditure. There are different explanations for potential deviations of IOp in household expenditure and household income. First, if households smooth consumption its distribution is less unequal than the distribution of income. Additionally, assuming transitory fluctuations to be more strongly reflected in the outcome distribution \(Y_t\) than the smoothed distribution \({\tilde{M}}_t\), we would expect relative IOp in consumption expenditures to be higher than in income.Footnote 18 In fact, this is the pattern observed by Ferreira and Gignoux (2011) when comparing IOp in income and consumption for five Latin-American countries. Second, even if households smooth consumption, expenditures for consumption items, especially durables, can be lumpy (Meyer and Sullivan 2017). This tendency is amplified by the fact that reference periods for expenditure reporting are oftentimes shorter (e.g. weekly, monthly, quarterly) in order to allow survey respondents to recall their expenditures in different categories. Again, assuming transitory fluctuations to be more strongly reflected in the outcome distribution \(Y_t\) than the smoothed distribution \({\tilde{M}}_t\), we would expect relative IOp in consumption expenditures to be lower than in income. Which of the two tendencies dominates is an empirical question and varies with the mode of data collection in the different countries. In our country sample the second channel tends to dominate. Compared to relative IOp in household income, IOp in household expenditure is on average 2.5 pp (S), 1.6 pp (LB), and 4.5 pp (UB) lower. However, there is heterogeneity across countries. According to the standard estimate, relative IOp for household expenditure is higher than IOp for income in Peru, South Africa, and Thailand. The reverse is true for China, Ethiopia, Indonesia, and Russia.
Estimates for S (LB) with respect to consumption expenditure lie between 6.3% in Tanzania (0%, China) and 40.3% in South Africa (29.5%, South Africa). According to UB, IOp ranges between 12.2% (Tanzania) and 67.6% (South Africa). As a consequence, the average difference between S and LB (UB) amounts to 5.9pp (20.2 pp). These findings support our conclusion that the standard estimation approach recovers an estimate close to LB.
Sensitivity analysis We conduct four sensitivity checks in which we probe the robustness of our conclusions to alternative specification choices.
MLD vs. Gini coefficient The majority of empirical IOp estimations draw on the MLD due to its path-independent decomposability property. In the context of IOp measurment, this property allows for a perfect decomposition into circumstance-based unfair inequality and effort-based fair inequality. However, as noted by Brunori et al. (2019a) the MLD’s senstivity to low income values leads to low relative measures of IOp.
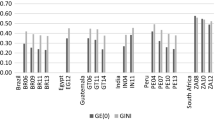
Hence, we replicate our analysis based on the Gini coefficient and show the results in Fig. 2. Indeed, relative IOp based on the Gini is larger than suggested by the MLD. For individual incomes, the standard estimate on average increases by 30 pp and now lies between 34.1% (Argentina) and 68.1% (Peru). The corresponding UB on average increases by 26pp and ranges from 43.5% (Mexico) to 89.8% (South Africa). The LB on average increases by 27.8 pp and lies between 28.7% (China) and 62.3% (Peru). The pattern is very similar for equivalized household income and expenditure (see Table 3).
These results indicate that the attenuating effect implied by the tail sensitivity of the MLD largely outweighs the attenuating effect implied by the imperfect decomposability of the Gini coefficient. Furthermore, although using the Gini coefficient widens the gap between S and LB, the difference between UB and S is still larger for the majority of outcomes and countries in our sample. This observation confirms that independent of the inequality measure, the potential for downward biased IOp estimates is much larger than the potential to overestimate IOp in emerging economies.

Source: Own calculations based on data described in Table 2
Bounds of Inequality of Opportunity, Gini coefficient. The figure shows estimates of relative IOp for individual incomes (a), equivalized household incomes (b) and equivalized household expenditures (c) based on the Gini coefficient. Standard estimates (S) use the full set of country-specific circumstances disclosed in Table 1. Lower bound (LB) estimates use the full set of country-specific circumstances disclosed in Table 1 but estimate the relevant parameters by means of a lasso estimation to account for sampling variance. Upper bound (UB) estimates are based on predictions from individual fixed effects.

Source: Own calculations based on data described in Table 2
Sensitivity Checks. The figure shows the robustness of our results according to three variations. In Panel (a) we harmonize the set of circumstances. In Panel (b) we harmonize the number of periods used to calculate UB. In Panel (c) we harmonize the year of interest for the calculation of IOp according to the scheme outlined in Table 6. In all figures, the x-axis shows the percentage point (pp) difference between the standard estimate (S) and the lower bound (LB) (upper bound (UB)) according to our baseline specification. The y-axis provides analogous statistics after the respective harmonization.
Circumstance availability The differences between S and LB (UB) may vary with the size of the invoked circumstance set. To test the relevance of this concern in our sample, we re-estimate S and LB while restricting ourselves to a harmonized set of circumstances that is available in all countries under consideration. The internationally comparable circumstance set includes gender and year of birth. In Panel (a) of Fig. 3 we plot the difference between S and UB (LB) according to the harmonized circumstance specification (y-axis) against the analogous differences in our baseline estimates (x-axis). The closer data points align with the 45 degree line, the more similar the results between the baseline and the alternative specification.
Restricting the circumstance set mechanically attenuates S but leaves UB unaltered. It is therefore unsurprising that the difference between S and UB increases for all countries under consideration. The reverse holds true for the difference between S and LB. In fact, the restriction of the circumstance set leads to a zero difference between S and LB for the majority of the country cases. These results therefore confirm our main conclusion: The more parsimonious the circumstance set, the stronger the correspondence between S and LB and the higher the downward bias. Unfortunately, we cannot run the reverse test by increasing the number of circumstances. Therefore, we cannot provide a direct assessment of the precise conditions under which S and LB come adrift.
Number of periods The difference between S and UB may differ with the number of periods used to construct the individual FEs. In the baseline we set a minimum threshold for the number of periods used to calculate the fixed effect. However, in spite of implementing this minimum threshold the de facto number of observations used for the construction of the individual FEs is not bounded from above and therefore varies across countries (Table 1). To test the relevance of this concern, we construct UB estimates in which we restrict the sample to the three most recent observations for each individual in each country. In Panel (b) of Fig. 3 we plot the differences between S and UB according to this harmonized specification (y-axis) against the analogous differences according to our baseline estimates (x-axis). The closer data points align with the 45 degree line, the more similar the results between the baseline and the alternative specification.
We find that all data points with respect to the difference between S and UB closely align to the 45 degree line. This pattern suggest that even short panels deliver reliable indicators for UB inequality of opportunity. Note that the panel length impinges upon the UB estimate only. Therefore, all differences between S and LB remain unaffected by this harmonization.
Year of interest Our results may be sensitive to alternations in the time period of interest. In our baseline analysis we focus on the most recent available data years covering a range from 2009 to 2017. Therefore, we replicate our analysis for the country-specific wave in closest proximity to 2009.Footnote 19 In Panel (c) of Fig. 3 we plot the differences between S and UB (LB) according to this harmonized specification (y-axis) against the analogous differences according to our baseline estimates (x-axis). The closer the data points align with the 45 degree line, the more similar the results between the baseline and the alternative specification.
Given that a society’s opportunity structure is shaped by long-run institutional features, one would expect these differences to be small. Indeed, we find that the data points for the difference between S and UB closely group around the 45 degree line. A similar conclusion holds for the difference between S and LB although the dispersion around the 45 degree line is somewhat larger.
5 Conclusion
Measures of IOp are of considerable policy relevance since they reflect widely-held principles of distributive justice and plausibly correlate with measures of economic development. In spite of their interest, point estimates of IOp are surrounded by severe uncertainty since they can be both upward and downward biased. Due to poorer data infrastructures with smaller sample sizes and less information on circumstance characteristics, IOp estimates in emerging economies may be particularly susceptible to both biases and it is unclear which of the two biases prevails.
We show that downward bias clearly dominates in the context of emerging economies. On the one hand, sparsely populated circumstance sets restrict the scope for overfitting circumstance information to the data. As a consequence, standard estimates of IOp strongly correspond to their lower bound analogues. This result stands in contrast to recent evidence from countries with richer data environments. On the other hand, the sparsity of observable circumstance information leads to large differences between standard estimates of IOp and their upper bound analogues. The extent of these differences is largely comparable to more developed countries and ranges between 20 pp and 30 pp.
While we provide reasonable bounds for IOp in these countries, substantial differences between lower and upper bound IOp remain. Our results therefore tie in with recent concerns that downward biased IOp estimates could misguide judgments on the normative significance of inequality. In the future, such gaps may be closed as better data sets become available. However, until such innovations materialize, bounding the range of potential estimates remains a viable way to limit the scope for downplaying the normative significance of inequality in the countries of interest.
Notes
We follow the notational conventions established in Ferreira and Gignoux (2011).
Note that the current literature largely abstracts from time-variant circumstance characteristics. This abstraction can be rationalized by the blurry distinction between time-variant factors beyond individual control and individual efforts. For example, consider local economic shocks or local outburst of conflict as potential embodiments of time-variant circumstances. Their effect could be confounded by individual migration decisions which are at least partially under individual control. However, as we outline below, our normative framework accounts for the effect of such factors to the extent that they are correlated with time-constant factors such as the region of birth.
This normative assumption is adopted by much of the empirical literature on IOp but can be easily relaxed, see Niehues and Peichl (2014) and Jusot et al. (2013). We refrain from doing so in our empirical application since restricting samples on availability of effort information would further reduce the number of observations.
\(\frac{\sigma ^2}{2}\) represents the residual variance that corrects for differences in the marginal impact of circumstances due to the log-transformation (Blackburn 2007).
Intuitively, k-fold cross-validation works as follows. The sample is divided into k-folds. Under each specification, the model parameters are estimated on \(k-1\) folds and the ensuing predictions are benchmarked against the data points in the \(k{th}\) fold. Repeating this procedure k times, one chooses the model that delivers the lowest average mean-squared prediction error across the k iterations.
The general idea of cross-validation is explained in footnote 7. In the case of lasso estimations, its implementation is as follows: We re-estimate Eq. 4 for different values of \(\lambda \) on each of the five folds. Ultimately, we choose \(\lambda \) that on average minimizes the mean-squared prediction error across the five folds. The mean-squared prediction error is a standard measure of prediction accuracy (Hastie et al. 2013) and the appropriate target statistic to trade-off upward and downward bias in inequality of opportunity estimates (Brunori et al. 2019b). In Table 3 we show the chosen values of \(\lambda \) for each country in our sample.
The post-lasso approach will yield results that are more in line with standard estimations based on OLS. This is the case since standard lasso retains parameter estimates that are shrunk by penalization. To the contrary—and analogous to OLS—post-lasso re-estimates these parameters without penalization.
Accounting for year-specific shocks is necessary since the panel data used to estimate the fixed effect are unbalanced. In case of a balanced panel, the individual fixed effect would be completely orthogonal to the year-specific shock, i.e. one could abstract from \(u_v\).
Technically, the Gini coefficient nevertheless yields conservative IOp estimates as the residual in the Gini decomposition does contain elements of between-group inequality (Brunori et al. 2019a).
For countries, in which multiple panel data sets are available, we use the data set with the highest number of waves.
In Table 4 we show how samples change as we sequentially impose these data restrictions.
Point estimates for absolute IOp, relative IOp, as well as total inequality are disclosed in Table 3.
As highlighted above: Unless otherwise indicated the LB estimate refers to the standard lasso estimation.
This cross-country average conceals heterogeneity. In particular, the lower the sample size relative to the number of estimated circumstance parameters, the larger the difference between S and LB. See Table 3 where we list the ratio of sample size and estimated parameters by country.
Due to differences in the underlying data, we refrain from comparing our results to other IOp estimates in the relevant countries: See for example, Brock et al. (2016), Brunori et al. (2019a) Ferreira and Gignoux (2011), Ferreira et al. (2018), Golley et al. (2019), Piraino (2015), Song and Zhou (2019), Juárez Wendelspiess Chávez (2015), Zhang and Eriksson (2010). These differences pertain to reference periods, the considered outcomes of interest, the detail of available circumstance characteristics, sample selection criteria, estimation methods, as well as inequality indices. However, we provide detailed information on these studies in Table 7.
A similar line of thought can be found in Bourguignon et al. (2007) who argue that the presence of transitory fluctuations in the residual tends to bias IOp estimates downward.
Table 6 shows the country-specific year chosen for this sensitivity check.
References
Aiyar S, Ebeke C (2019) Inequality of opportunity, inequality of income and economic growth. Imf Working Paper Ser 19:34
Alesina A, Hohmann S, Michalopoulos S, Papaioannou E (2019) Intergenerational mobility in Africa. Econometrica 89(1):1–35
Alesina A, Stantcheva S, Teso E (2018) Intergenerational mobility and preferences for redistribution. Am Econ Rev 108(2):521–554
Andreoli F, Fusco A (2019) Robust cross-country analysis of inequality of opportunity. Econ Lett 182:86–89
Arneson R (1989) Equality and equal opportunity for welfare. Philos Stud 56(1):77–93
Balcázar C (2015) Lower bounds on inequality of opportunity and measurement error. Econ Lett 137:102–105
Belloni A, Chernozhukov V (2013) Least squares after model selection in high-dimensional sparse models. Bernoulli 19(2):521–547
Blackburn M (2007) Estimating wage differentials without logarithms. Labour Econ 14(1):73–98
Bourguignon F, Ferreira FHG, Menéndez M (2007) Inequality of opportunity in Brazil. Rev Income Wealth 53(4):585–618
Brock J, Peragine V, Tonini S (2016) Inequality of opportunity. transition for all: equal opportunities in an unequal world. Ebrd Chap 3:81–98
Brunori P, Hufe P, Mahler D (2018) The roots of inequality: estimating inequality of opportunity from regression trees. Ifo Work Pap 2018:252
Brunori P, Palmisano F, Peragine V (2019a) Inequality of opportunity in sub-saharan Africa. Appl Econ 51(60):6428–6458
Brunori P, Peragine V, Serlenga L (2019b) Upward and downward bias when measuring inequality of opportunity. Soc Choice Welf 52(4):635–661
Cappelen AW, Hole AD, Sørensen EØ, Tungodden B (2007) The pluralism of fairness ideals: an experimental approach. Am Econ Rev 97(3):818–827
Cohen G (1989) On the currency of Egalitarian justice. Ethics 99(4):906–944
Cubas G (2016) Distortions, infrastructure, and female labor supply in developing countries. Eur Econ Rev 87:194–215
Ferreira F, Gignoux J (2011) The measurement of inequality of opportunity: theory and an application to Latin America. Rev Income Wealth 57(4):622–657
Ferreira F, Lakner C, Lugo M, Özler B (2018) Inequality of opportunity and economic growth: how much can cross-country regressions really tell us? Rev Income Wealth 64(4):800–827
Fleurbaey M (1995) Three solutions for the compensation problem. J Econ Theory 65(2):505–521
Foster J, Aa S (2000) Path independent inequality measures. J Econ Theory 91(2):199–222
Golley J, Zhou Y, Wang M (2019) Inequality of opportunity in China’s labor earnings: the gender dimension. China World Econ 27(1):28–50
Hastie T, Tibshirani R, Friedman J (2013) The elements of statistical learning: data mining, inference, and prediction. Springer, Heidelberg
Hufe P, Peichl A, Je R, Ungerer M (2017) Inequality of income acquisition: the role of childhood circumstances. Soc Choice Welf 143(3–4):499–544
Jayachandran S (2015) The roots of gender inequality in developing countries. Annu Rev Econ 7(1):63–88
Jusot F, Tubeuf S, Trannoy A (2013) Circumstances and efforts: how important is their correlation for the measurement of inequality of opportunity in health? Health Econ 22(12):1470–1495
Kanbur R, Wagstaff A (2016) How useful is inequality of opportunity as a policy construct? inequality and growth: patterns and policy. In: Basu K, Stiglitz JE (eds), vol 1. Palgrave Macmillan, London, pp 131–150
Marrero G, Rodríguez J (2013) Inequality of opportunity and growth. J Dev Econ 104:107–122
MejíA D, St-Pierre M (2008) Unequal opportunities and human capital formation. J Dev Econ 86(2):395–413
Meyer BD, Sullivan JX (2017) Consumption and income inequality in the U.S. since the 1960S. In: National Bureau Of Economic Research Working Paper Series 23655
Neidhöfer G, Serrano J, Gasparini L (2018) Educational inequality and intergenerational mobility in latin America: a new database. J Dev Econ 134:329–349
Niehues J, Peichl A (2014) Upper bounds of inequality of opportunity: theory and evidence for Germany and the us. Soc Choice Welf 43(1):73–99
Peragine V, Palmisano F, Brunori P (2014) Economic growth and equality of opportunity. World Bank Econ Rev 28(2):247–281
Piraino P (2015) Intergenerational earnings mobility and equality of opportunity in South Africa. World Dev 67(1):396–405
Ramos X, Van De Gaer D (2016) Empirical approaches to inequality of opportunity: principles, measures, and evidence. J Econ Surv 30(5):855–883
Roemer J (1998) Equality of opportunity. Harvard University Press, Cambridge
Rohner D (2011) Reputation, group structure and social tensions. J Dev Econ 96(2):188–199
Shorrocks A (1980) The class of additively decomposable inequality measures. Econometrica 48(3):613–625
Song Y, Zhou G (2019) Inequality of opportunity and household education expenditures: evidence from panel data in China. China Econ Rev 55(1):85–98
Juárez Wendelspiess Chávez F (2015) Measuring inequality of opportunity with latent variables. J Hum Dev Capab 16(1):106–121
Zhang Y, Eriksson T (2010) Inequality of opportunity and income inequality in nine Chinese provinces, 1989–2006. China Econ Rev 21(4):607–616
Funding
Open Access funding enabled and organized by Projekt DEAL. This was supported by NORFACE via Deutsche Forschungsgemeinschaft (Grant no. PE 1675/5-1).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank John E. Roemer (editor) and two anonymous referees for many insightful comments on earlier drafts. This paper benefited from discussions with Paolo Brunori, Daniel Mahler, and Valentin Lang. Furthermore, we are grateful to seminar and conference audiences in Canazei, Luxembourg and Munich. We gratefully acknowledge funding from Deutsche Forschungsgemeinschaft (DFG) through NORFACE project “IMCHILD: The impact of childhood circumstances on individual outcomes over the life-course” (PE 1675/5-1).
Appendices
Additional tables
Additional figures
See Fig. 4.

Methodological Validation. The figure shows how lower bound methodologies from the literature compare to the lasso estimation in this paper. The left panel compares the lasso procedure with the regression forest estimates from Brunori et al. (2018) while the right panel compares the lasso procedure with the cross-validated model selection approach in Brunori et al. (2019b). Filled diamonds refer to the standard lasso. White diamonds refer to post-OLS lasso.
Existing studies
See Table 7.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hufe, P., Peichl, A. & Weishaar, D. Lower and upper bound estimates of inequality of opportunity for emerging economies. Soc Choice Welf 58, 395–427 (2022). https://doi.org/10.1007/s00355-021-01362-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00355-021-01362-7