
Abstract
Objectives
To validate an AI system for standalone breast cancer detection on an entire screening population in comparison to first-reading breast radiologists.
Materials and methods
All mammography screenings performed between August 4, 2014, and August 15, 2018, in the Region of Southern Denmark with follow-up within 24 months were eligible. Screenings were assessed as normal or abnormal by breast radiologists through double reading with arbitration. For an AI decision of normal or abnormal, two AI-score cut-off points were applied by matching at mean sensitivity (AIsens) and specificity (AIspec) of first readers. Accuracy measures were sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and recall rate (RR).
Results
The sample included 249,402 screenings (149,495 women) and 2033 breast cancers (72.6% screen-detected cancers, 27.4% interval cancers). AIsens had lower specificity (97.5% vs 97.7%; p < 0.0001) and PPV (17.5% vs 18.7%; p = 0.01) and a higher RR (3.0% vs 2.8%; p < 0.0001) than first readers. AIspec was comparable to first readers in terms of all accuracy measures. Both AIsens and AIspec detected significantly fewer screen-detected cancers (1166 (AIsens), 1156 (AIspec) vs 1252; p < 0.0001) but found more interval cancers compared to first readers (126 (AIsens), 117 (AIspec) vs 39; p < 0.0001) with varying types of cancers detected across multiple subgroups.
Conclusion
Standalone AI can detect breast cancer at an accuracy level equivalent to the standard of first readers when the AI threshold point was matched at first reader specificity. However, AI and first readers detected a different composition of cancers.
Clinical relevance statement
Replacing first readers with AI with an appropriate cut-off score could be feasible. AI-detected cancers not detected by radiologists suggest a potential increase in the number of cancers detected if AI is implemented to support double reading within screening, although the clinicopathological characteristics of detected cancers would not change significantly.
Key Points
• Standalone AI cancer detection was compared to first readers in a double-read mammography screening population.
• Standalone AI matched at first reader specificity showed no statistically significant difference in overall accuracy but detected different cancers.
• With an appropriate threshold, AI-integrated screening can increase the number of detected cancers with similar clinicopathological characteristics.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Breast cancer is the leading cause of cancer-related deaths amongst women [1]. Systematic screening has been proven efficient in detecting breast cancer at early, less advanced stages and reducing overall breast cancer-specific mortality [2, 3]. The quality of screening varies with the quantity of resources, mammographic image characteristics, and the accuracy and experience level of readers [4,5,6]. For organized screening of women aged 50–69 years, the European Commission Initiative on Breast Cancer recommends double reading of mammograms with consensus or arbitration for discordant readings [7]. Such screening programs require a large capacity of specialized radiologists in a field highly affected by staff shortages [8, 9].
Integration of artificial intelligence (AI) solutions in breast cancer screening has shown potential to help overcome capacity issues, standardize accuracy, and improve efficiency [10,11,12]. Possible implementation sites range from the application as a reader-aid to functioning as a standalone reader for triage or replacement of radiologists [11, 13]. One study investigated different scenarios with AI as a standalone reader and found it theoretically possible to reduce screen reading volume without reducing cancer detection rates [14]. While a recent systematic review on standalone AI breast cancer detection found that the time has come to investigate implementation strategies [12], other reviews have considered the existing evidence insufficient to recommend implementation in real-world settings [10, 11, 15]. The European Commission Initiative on Breast Cancer currently recommends the implementation of AI only as a reader aid for support in double reading with arbitration or consensus reading [16]. Limitations in current literature include cancer-enriched or small datasets, low generalizability, and non-representative reference standards. Hence, there is a lack of consecutive cohorts representative of a screening population with a reliable reference standard [10, 15].
This study aimed to validate a deep learning-based AI system for standalone breast cancer detection on a consecutive cohort of mammograms representative of an entire screening population with a setting of double reading and arbitration. Specifically, the objectives were to (i) determine the standalone detection accuracy of the AI system, and (ii) compare the accuracy of the AI system to that of first reading breast radiologists.
Materials and methods
Study design
Ethics approval was granted by the Danish National Committee on Health Research Ethics (identifier D1763009). The study followed the Standard for Reporting of Diagnostic Accuracy Studies (STARD) reporting guideline (Supplementary eMethod 1) [17]. This was a multicenter accuracy study performed on a retrospective cohort of digital mammograms from an entire regional screening population.
Study population
The Region of Southern Denmark offers biennial mammography screening to asymptomatic women aged 50–69 years. Women with a history of breast cancer can participate until the age of 79, while women with genetic predisposition are offered lifelong screening. All mammograms performed in the screening program in the Region of Southern Denmark between August 4, 2014, and August 15, 2018, were eligible for inclusion. The study period was selected to ensure the inclusion of two consecutive national screening rounds and a sufficient follow-up period. Regional breast cancer centers were in the cities of Odense, Vejle, Esbjerg, and Aabenraa that cover 1.22 million inhabitants of which approximately 75,000 women constitute an entire target population for screening within the region. The examinations were excluded in case of missing images, lack of follow-up, insufficient image quality, or image data types not supported by the AI system.
Data collection
A consecutive image dataset was extracted in raw DICOM format from local radiology archives by using the women’s unique Danish identification number. Mammograms were performed on a single mammography vendor (Siemens Mammomat Inspiration, Siemens Healthcare A/S). Images included a minimum of one craniocaudal and/or mediolateral oblique projection of at least one breast per screening. Screening data including assessment results and information on the reviewing radiologists were extracted from the joint regional Radiological Information System. All mammograms were originally assessed through blinded double reading with a binary decision outcome as either normal or abnormal. Arbitration, i.e., a third reading, was performed in case of discordant readings. The arbitrator had access to the decisions of both the first and second readers. Abnormal outcomes resulted in a recall for a diagnostic work-up at a dedicated breast imaging unit. Clearly defined criteria for the designation of radiologists into first and second reader positions in Denmark do not exist. However, in practice, second readers tend to have more experience than first readers. The position of the arbitrator is routinely allotted to the most experienced radiologists, which, though, could have screen-read the same mammogram. Data on the experience level of radiologists were self-reported, with “Years engaged in reading screening mammograms” as the variable of interest. Follow-up information on breast cancer diagnosis and tumor characteristics was obtained by matching with the database of the Danish Breast Cancer Cooperative Group (DBCG) and the Danish Quality Database on Mammography Screening (DKMS) [18, 19], obtained via the Danish Clinical Quality Program – National Clinical Registries (RKKP).
Artificial intelligence system
All mammograms were analyzed by the commercially available AI system Lunit INSIGTH MMG (v.1.1.7.1, Lunit Inc.), CE-marked and FDA-approved for concurrent reading aid. The AI system is based on a deep learning model that provides a per-view abnormality score of 0–100%, for which a score of 100% signifies the highest suspicion of malignancy. The maximum of the per-view scores was used to define an exam-level Lunit score for the study, which was further dichotomized into an AI score to enable comparability with the binary reader outcomes. Two different thresholds were explored, AIsens and AIspec, which were matched at mean sensitivity and specificity of first reader outcome, respectively, with outcomes above the threshold considered as recalls. These thresholds were chosen to enable testing and comparison of the AI system at a level equivalent to a well-defined group of radiologists in terms of breast cancer detection. The choice of these two thresholds would also ensure approximately equivalent numbers of false positive recalls or missed cancers, respectively, should AI replace the first reader in a real-life AI-integrated screening. The AI system did not include clinical data, previous mammograms, or screening results in the assessment. The mammograms in this study have never been used for training, validation, or testing of the AI system.
Reference standard
Positive cancer outcomes were determined by a documented breast cancer diagnosis, including non-invasive breast cancer, i.e., ductal carcinoma in situ, following recall from screening (screen-detected cancer) or before the next consecutive screening within 24 months (interval cancer). Negative cancer outcomes were defined by cancer-free follow-up up until next screening or within 24 months. Follow-up data on cancer outcomes was extracted from the DKMS and DBCG registries.
Statistical analysis
Binomial proportions for the accuracy of AI and radiologists were calculated and supplemented by 95% Clopper-Pearson (“exact”) confidence intervals (CI). McNemar’s test or exact binomial test, when discordant cells were too small, was used to compare the accuracy of AI and radiologists, while t-test was used to evaluate associations for continuous variables. Measures of accuracy were sensitivity and specificity as co-primary outcomes, and positive predictive value (PPV), negative predictive value (NPV), and recall rate (RR) as secondary outcomes. The analysis was supplemented with empirical receiver operating characteristic (ROC) curves with corresponding area under the curve (AUC) values, for which asymptotic normal CIs were applied. The co-primary and secondary outcomes were determined for all radiologists by reading position (first reader, second reader, arbitrator, and combined reading) and for the standalone AI system for each of the two thresholds (AIsens and AIspec). The outcome of the arbitrator was calculated as that of the other readers but was based on a selected group of screen-read disagreements between the first reader and second reader, making it a smaller number of screenings.
Specific subgroup analyses compared the detection rates across age and cancer subgroups, including histological subtype, tumor size, malignancy grade, TNM stage, lymph node positivity, estrogen receptor status, and HER2 status. To explore and compare the ability of AI and first readers in early breast cancer detection, an exploratory analysis of cancer detection accuracy was carried out while including next-round screen-detected cancers (diagnosed at next consecutive screening) and long-term cancers (diagnosed > 2–7 years after screening) in the positive cancer outcomes. For this purpose, linear regression with the measure of performance as outcome was used to take the correlation between women and possible multiple cancers into account. p < 0.05 was considered statistically significant. All statistical analyses were carried out using Stata/SE (Release 17, www.stata.com).
Results
Study sample
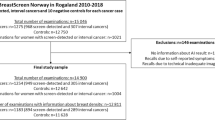
A total of 272,008 screenings were performed within the inclusion period. Of these, 22,606 mammograms (8.3%) were excluded from the analyses (Fig. 1). Thus, 249,402 mammograms from 149,495 women were included in the study sample (Table 1). The sensitivity analysis showed a statistically significant difference across variables for excluded screenings with sufficient data and follow-up (n = 15,892), although absolute differences were found small (Supplementary eTable 1).

Study flowchart. The study included screening examinations from an entire mammography screening population across two screening rounds in the Region of Southern Denmark. Due to the biennial screening interval, multiple consecutive screening examinations from a single woman could be included. Abbreviation: AI, artificial intelligence. MG, mammography
The included number of breast cancers was 2033 (0.8%), which included 1475 (72.6%) screen-detected cancers and 558 (27.4%) interval cancers. A total of 23 radiologists were involved in the screen reading. All 23 figured as first readers, 14 as second readers, and 10 were arbitrators. Screenings read by first readers were, in most cases (56.5%), by radiologists with 0–4 years of experience, while 68.0% of second readings and 90.9% of arbitrations were by radiologists with 10 + years of experience. The first and second readers agreed upon the screening outcome in 97.2% of cases.
Radiologist detection accuracy
Accuracy outcomes for the AI system and all readers are presented in Table 2, with ROC curves and AUC values reported in Supplementary eFigure 1. The first reader had a sensitivity of 63.5% (95% CI 61.4–65.6%) and a specificity of 97.7% (97.7–97.8%). The second reader and combined reading achieved higher sensitivity and specificity than the first reader (p < 0.0001 for all). The arbitrator had a higher sensitivity with a markedly lower specificity (p < 0.0001 for both), although this was anticipated considering that only flagged examinations reached arbitration. A comparison between the screening outcome and the results of the reference standard is further detailed in Supplementary eTable 2.
AI score benchmarking
When matching by mean first reader sensitivity and specificity, the cut-off points for AIsens and AIspec were Lunit Score 79.75% and 80.99%, respectively. The distribution of Lunit scores across screenings is depicted in Fig. 2.

Distribution of abnormality scores across the study sample and all cancers. a The distribution of Lunit abnormality scores across all screening examinations in the study sample. A score of 100% signifies the highest suspicion of malignancy. b Enlargement of the score distribution across screening examinations given a score ≥ 10%. c The distribution of Lunit abnormality scores across screening examinations with a screen-detected cancer. d The score distribution across screening examinations from women diagnosed with an interval cancer
Cancer detection accuracy of Standalone AI
Standalone AIspec did not differ statistically significantly from the first reader across any accuracy measures (Table 2). Standalone AIsens showed statistically significantly lower specificity (− 0.2%) and higher RR (+ 0.2%) than first reader (p < 0.0001 for both). The breakdown of accuracy by cancer subgroups, as presented in Table 3, showed fewer screen-detected cancers by Standalone AIsens (− 5.8%) and Standalone AIspec (− 6.5%) compared to the first reader (p < 0.0001 for both). However, Standalone AIsens and Standalone AIspec detected more interval cancers by + 15.6% and + 14.0%, respectively (p < 0.0001 for both). In terms of tumor characteristics, Standalone AI at both thresholds found more 21–50 mm cancers and more lymph node-positive cancers. Yet, when detection rates were stratified across screen-detected cancers and interval cancers, these findings only applied to the latter, while the opposite was the case for screen-detected cancers (Supplementary eTable 3). This pattern of lower and higher accuracy across screen-detected cancers and interval cancers, respectively, was observed for more than half of cancer subgroups, for which Standalone AI at both thresholds had statistically significantly different detection rates compared to the first reader. Moreover, subgroup analyses of detection agreements and discrepancies between the AI and first reader showed that Standalone AI at both thresholds disagreed with the first reader in 23% of all cancer cases, which were either detected by AI and missed by the first reader or vice versa (Supplementary eTable 4).
Exploratory analysis of cancer detection when including next-round screen-detected and long-term cancers showed statistically significantly higher sensitivity of the AI system at both thresholds than first readers (p < 0.0001 for both), as presented in Table 4.
Discussion
Main findings
We obtained a large representative study sample with a cancer detection rate and recall rate, which were in agreement with previously reported screening outcomes from Danish screening rounds [19, 20]. This study observed two main findings. Firsty, the cancer detection accuracy of Standalone AIspec was not statistically significantly different from the first reader across any accuracy measure. Standalone AIsens, however, had a lower specificity and higher recall rate than first readers. Secondly, the AI system exhibited a statistically significantly lower detection rate of screen-detected cancers but a higher detection of interval cancers compared to the first reader at both AI thresholds and a higher accuracy when taking next-round screen-detected cancers and long-term cancers into account. This was expected in the context of a retrospective study design where the AI detection of screen-detected cancers was compared directly to the readers who detected the cancers. However, the AI system detected different cancers than the first reader, even for Standalone AIspec, which exhibited equivalent reading accuracy to the first reader. The observations of a generally lower and higher AI accuracy across screen-detected cancers and interval cancers, respectively, for more than half of the cancer subgroups (Supplementary eTable 3), along with detection discrepancies of a notable number of cancers in the agreement analysis (Supplementary eTable 4), suggest that AI in combination with human readers in double reading could result in an increase in the number of cancers detected. The differences in cancer detection accuracy should also be considered in relation to the clinical relevance of the cancers detected and their malignancy potential. Standalone AI at both thresholds was not equal to or better than first readers at detecting small cancers sized 0–10 mm or grade 3 tumors (Table 3), which both are indicators of high malignancy [21]. These findings suggest that the AI system is not necessarily more capable than first readers at detecting cancers reflecting tumor aggressive potential, which is an important consideration in proportion to the implementation of AI. Notwithstanding, the findings indicate that the clinicopathological characteristics of detected cancers would overall remain unaltered in an AI-supported screening setup.
Comparison with current literature
Other studies investigating standalone AI have reported varying accuracy estimates [10]. The accuracy of standalone AI found in this study was consistent with results from Salim et al [22]. They assessed three independent AI systems on a selected, double-reader screening cohort and found the best-performing AI to exceed the sensitivity of first readers when tested at an AI score threshold matched at first reader specificity [22]. Both Rodriguez-Ruiz et al and McKinney et al found similar results with the accuracy of their standalone AI systems being non-inferior to and superior to single readers, respectively [23, 24]. Although similar findings are observed, these and other previously published validation studies [25, 26] show discrepancies in their methodological approaches regarding choice of AI score threshold and comparator, among others. For instance, Rodriguez-Ruiz et al matched the AI threshold at the average specificity of single readers across several international datasets, including both general and breast radiologists from the US and Europe, with varying quality assurance standards [24]. McKinney et al chose different thresholds in their UK training set, depending on which group of readers figured as comparator and then applied the algorithm with those thresholds to a separate US test set for comparison [23]. Their intent was to find a threshold where the accuracy of the AI exceeded or was non-inferior to the average reader. Moreover, most studies on standalone AI cancer detection have, in several systematic reviews, been assessed to suffer from a high risk of bias or low level of generalizability mostly due to cancer enrichment, selection biases, and/or varying reference standard [10, 11, 15]. More recently, a few studies with large population-based cohorts have been published that methodologically minimize some limitations. Lauritzen et al included an unselected Danish screening sample and found significantly lower specificity for standalone AI when the AI score threshold was matched at sensitivity, although this was in comparison to the consensus of both radiologists in double reading [27]. A large study by Leibig et al reported significantly lower sensitivity and specificity of standalone AI compared to a single radiologist when the threshold was set to maintain the radiologist’s sensitivity [28]. This study, however, excluded > 35% of participants and used adjusted sample weighting in the external test set to compensate for oversampling with cancer enrichment, introducing a high risk of selection bias.
Strengths and limitations
In contrast, the major strength of our study was the large representative sample of unselected, consecutive mammograms from an entire screening population. High-quality data from multiple national registries were used to ensure a comprehensive sample and reliable reference standard. Although our findings might transfer to similar populations, accuracy estimates could differ in populations with a different breast cancer prevalence or significantly different population characteristics.
Among the limitations in our work is the lack of a gold standard for all screening mammograms, i.e., verification bias, as examinations with a positive AI outcome, not recalled by the radiologists, were not offered diagnostic work-up due to the retrospective nature of this study [29]. This potentially skews the estimation of the AI accuracy. The exploratory analysis, including next-round screen-detected and long-term cancers (Table 4) partially solves this issue and could potentially be a more accurate approximation of the actual accuracy outcome. Additional bias is introduced as the reference standard is correlated to the manual reads by radiologists. Women who were recalled after screening had a higher chance of being diagnosed with breast cancer than those marked as normal at screening, potentially skewing the detection accuracy in favor of the human readers. Another limitation is that around 5% of screening examinations were excluded due to technical issues or mammograms not fitting the DICOM conformance statement. It should be noted that some of the limitations of the AI system, such as the inability to process screening exams with more than 4 views, are, according to the developers, mainly related to the experimental usage of retrospective data and not necessarily present in an AI-integrated screening on site. This and similar technical limitations are important for decision-makers to consider when planning the implementation of an AI solution in clinical practice. However, for this study, these exclusions are estimated not to have had any significant impact on the findings, seeing as the study sample was found to be representative of the study population. A final limitation is that the thresholds for the AI system were derived from the study dataset. Using a prespecified threshold would have been a more objective and generalizable approach than setting the sensitivity or specificity of the readers from the same dataset as benchmark. Although this was not possible due to the lack of a binary outcome intrinsic to the AI system, our approach is still valid from a clinical applicability point of view as the minimal anticipated cancer detection accuracy of the AI is no lower than the current standard. To the best of our knowledge, no specific methodological approach has been recommended in this matter. Most previous studies have chosen the same approach as this study or solely matched on either sensitivity or specificity [22, 24,25,26,27,28, 30]. As exemplified by Larsen et al, researchers should consider testing AI systems at several thresholds depending on the intended site of integration, to ensure reliable and realistic estimates of the accuracy of the AI before actual implementation [14].
Perspectives and implications
Our paper, along with other studies, contribute to accurate estimates of breast cancer detection on screening mammograms by different AI systems, which can serve as a breeding ground for the design of future research and recommendations on sites for AI integration [31]. A survey study on attitudes towards the implementation of AI in breast cancer screening showed that UK readers are mostly supportive of partial replacement with AI replacing one reader [32]. The Danish Health Authorities recently recommended implementing AI as a replacement for first readers if investigations show supportive findings [33]. In view of the findings and considerations made in this study, AI accuracy estimates should ideally match the accuracy of the given group of readers that the AI is intended to replace. In addition, one issue that needs to be considered prior to clinical deployment is how the removal of radiologists, for instance, from the first reader position, might affect the detection accuracy of the other reader groups or the screening workflow in general. The accuracy of radiologists is, among other things, associated with the individual annual reading volume [5]. While there is no official standard in terms of designating radiologists into first and second reader positions in Denmark, the most experienced radiologists are ordinarily allotted to the second reader position. This tendency was confirmed in this study, as the majority of first readings were by radiologists with 0–4 years of experience, and most second readers had 10 + years of experience. Replacing first reader with an AI system could present the dilemma of how radiologists without the experience gained through first reading will achieve high levels of accuracy to sustain the high standard achieved through double reading. Implementing AI for triaging mammograms of low suspicion to single reading might lead to similar issues, as high-volume exposure to normal images is important to improve the discriminatory ability of radiologists [5]. These and other issues relating to potential implications in screening practice could be further elucidated in rigorously designed studies on AI-integrated screening, most optimally in the form of prospective randomized controlled trials, which should focus on how integration affects workload and final screening outcome and finding an optimal site of application in a long-term perspective. The first of such studies have most recently emerged, showing promising results from real-world clinical practice of AI-integrated population-based screening [34, 35].
Conclusions
The accuracy of the AI system was comparable to that of first readers in a double-read mammography screening population, mainly when the AI score cut-off was matched at first reader specificity, highlighting the importance of choosing an appropriate threshold. The AI system and first readers detected different cancers, suggesting that integration of AI in a double reading setting could increase the number of cancers detected at screening without markedly changing the clinicopathological characteristics.
Abbreviations
- AI:
-
Artificial intelligence
- AIsens :
-
Artificial intelligence score cut-off point matched at mean sensitivity of the first reader outcome
- AIspec :
-
Artificial intelligence score cut-off point matched at mean specificity of the first reader outcome
- AUC:
-
Area under the curve
- CE:
-
Conformité Européenne (European Conformity)
- CI:
-
Confidence interval
- DBCG:
-
Danish Breast Cancer Cooperative Group
- DCIS:
-
Ductal carcinoma in situ
- DICOM:
-
Digital Imaging and Communications in Medicine
- DKMS:
-
Danish Quality Database on Mammography Screening
- ER:
-
Estrogen receptor
- FDA:
-
Food and Drug Administration
- HER2:
-
Human epidermal growth factor receptor 2
- MG:
-
Mammography
- NVP:
-
Negative predictive value
- PPV:
-
Positive predictive value
- RKKP:
-
Danish Clinical Quality Program – National Clinical Registries
- ROC:
-
Receiver operating characteristic
- RR:
-
Recall rate
- STARD:
-
Standard for Reporting of Diagnostic Accuracy Studies
- TNM:
-
Tumor, nodes, and metastases
References
Fitzmaurice C, Allen C, Barber RM et al (2017) Global, regional, and national cancer incidence, mortality, years of life lost, years lived with disability, and disability-adjusted life-years for 32 cancer groups, 1990 to 2015: a systematic analysis for the global burden of disease study. JAMA Oncol. https://doi.org/10.1001/jamaoncol.2016.5688
Canelo-Aybar C, Ferreira DS, Ballesteros M et al (2021) Benefits and harms of breast cancer mammography screening for women at average risk of breast cancer: a systematic review for the European Commission Initiative on Breast Cancer. J Med Screen. https://doi.org/10.1177/0969141321993866
Youlden DR, Cramb SM, Dunn NA, Muller JM, Pyke CM, Baade PD (2012) The descriptive epidemiology of female breast cancer: an international comparison of screening, incidence, survival and mortality. Cancer Epidemiol. https://doi.org/10.1016/j.canep.2012.02.007
Salim M, Dembrower K, Eklund M, Lindholm P, Strand F (2020) Range of radiologist performance in a population-based screening cohort of 1 million digital mammography examinations. Radiology. https://doi.org/10.1148/radiol.2020192212
Rawashdeh MA, Lee WB, Bourne RM et al (2013) Markers of good performance in mammography depend on number of annual readings. Radiology. https://doi.org/10.1148/radiol.13122581
Giess CS, Wang A, Ip IK, Lacson R, Pourjabbar S, Khorasani R (2019) Patient, radiologist, and examination characteristics affecting screening mammography recall rates in a large academic practice. J Am Coll Radiol. https://doi.org/10.1016/j.jacr.2018.06.016
European Commission Initiative on Breast Cancer (ECIBC). European guidelines on breast cancer screening and diagnosis (2019) Available via https://healthcare-quality.jrc.ec.europa.eu/ecibc/european-breast-cancer-guidelines/organisation-of-screening-programme/double-reading-in-mammography-screening. Accessed 3 July 2023
Wing P, Langelier MH (2009) Workforce shortages in breast imaging: impact on mammography utilization. AJR Am J Roentgenol. https://doi.org/10.2214/ajr.08.1665
Rimmer A (2017) Radiologist shortage leaves patient care at risk, warns royal college. BMJ. https://doi.org/10.1136/bmj.j4683
Freeman K, Geppert J, Stinton C et al (2021) Use of artificial intelligence for image analysis in breast cancer screening programmes: systematic review of test accuracy. BMJ. https://doi.org/10.1136/bmj.n1872
Hickman SE, Woitek R, Le EPV et al (2022) Machine learning for workflow applications in screening mammography: systematic review and meta-analysis. Radiology. https://doi.org/10.1148/radiol.2021210391
Yoon JH, Strand F, Baltzer PAT et al (2023) Standalone AI for breast cancer detection at screening digital mammography and digital breast tomosynthesis: a systematic review and meta-analysis. Radiology. https://doi.org/10.1148/radiol.222639
Le EPV, Wang Y, Huang Y, Hickman S, Gilbert FJ (2019) Artificial intelligence in breast imaging. Clin Radiol. https://doi.org/10.1016/j.crad.2019.02.006
Larsen M, Aglen CF, Hoff SR, Lund-Hanssen H, Hofvind S (2022) Possible strategies for use of artificial intelligence in screen-reading of mammograms, based on retrospective data from 122,969 screening examinations. Eur Radiol. https://doi.org/10.1007/s00330-022-08909-x
Anderson AW, Marinovich ML, Houssami N et al (2022) Independent external validation of artificial intelligence algorithms for automated interpretation of screening mammography: a systematic review. J Am Coll Radiol. https://doi.org/10.1016/j.jacr.2021.11.008
European Commission Initiative on Breast Cancer. Use of artificial intelligence. European guidelines on breast cancer screening and diagnosis (2022) Available via https://healthcare-quality.jrc.ec.europa.eu/ecibc/european-breast-cancer-guidelines/artificial-intelligence. Accessed 3 July 2023
Bossuyt PM, Reitsma JB, Bruns DE et al (2015) STARD 2015: an updated list of essential items for reporting diagnostic accuracy studies. Radiology. https://doi.org/10.1148/radiol.2015151516
Christiansen P, Ejlertsen B, Jensen MB, Mouridsen H (2016) Danish Breast Cancer Cooperative Group. Clin Epidemiol. https://doi.org/10.2147/clep.S99457
Mikkelsen EM, Njor SH, Vejborg I (2016) Danish quality database for mammography screening. Clin Epidemiol. https://doi.org/10.2147/clep.S99467
Lynge E, Beau AB, Christiansen P et al (2017) Overdiagnosis in breast cancer screening: the impact of study design and calculations. Eur J Cancer. https://doi.org/10.1016/j.ejca.2017.04.018
Blanks RG, Wallis MG, Alison RJ, Given-Wilson RM (2020) An analysis of screen-detected invasive cancers by grade in the English breast cancer screening programme: are we failing to detect sufficient small grade 3 cancers? Eur Radiol. https://doi.org/10.1007/s00330-020-07276-9
Salim M, Wåhlin E, Dembrower K et al (2020) External evaluation of 3 commercial artificial intelligence algorithms for independent assessment of screening mammograms. JAMA Oncol. https://doi.org/10.1001/jamaoncol.2020.3321
McKinney SM, Sieniek M, Godbole V et al (2020) International evaluation of an AI system for breast cancer screening. Nature. https://doi.org/10.1038/s41586-019-1799-6
Rodriguez-Ruiz A, Lång K, Gubern-Merida A et al (2019) Stand-alone artificial intelligence for breast cancer detection in mammography: comparison with 101 radiologists. J Natl Cancer Inst. https://doi.org/10.1093/jnci/djy222
Lotter W, Diab AR, Haslam B et al (2021) Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach. Nat Med. https://doi.org/10.1038/s41591-020-01174-9
Schaffter T, Buist DSM, Lee CI et al (2020) Evaluation of combined artificial intelligence and radiologist assessment to interpret screening mammograms. JAMA Netw Open. https://doi.org/10.1001/jamanetworkopen.2020.0265
Lauritzen AD, Rodríguez-Ruiz A, von Euler-Chelpin MC et al (2022) An artificial intelligence-based mammography screening protocol for breast cancer: outcome and radiologist workload. Radiology. https://doi.org/10.1148/radiol.210948
Leibig C, Brehmer M, Bunk S, Byng D, Pinker K, Umutlu L (2022) Combining the strengths of radiologists and AI for breast cancer screening: a retrospective analysis. Lancet Digit Health. https://doi.org/10.1016/s2589-7500(22)00070-x
Taylor-Phillips S, Seedat F, Kijauskaite G et al (2022) UK National Screening Committee’s approach to reviewing evidence on artificial intelligence in breast cancer screening. Lancet Digit Health. https://doi.org/10.1016/s2589-7500(22)00088-7
Marinovich ML, Wylie E, Lotter W et al (2023) Artificial intelligence (AI) for breast cancer screening: BreastScreen population-based cohort study of cancer detection. EBioMedicine. https://doi.org/10.1016/j.ebiom.2023.104498
Batchu S, Liu F, Amireh A, Waller J, Umair M (2021) A review of applications of machine learning in mammography and future challenges. Oncology. https://doi.org/10.1159/000515698
de Vries CF, Colosimo SJ, Boyle M, Lip G, Anderson LA, Staff RT (2022) AI in breast screening mammography: breast screening readers’ perspectives. Insights Imaging. https://doi.org/10.1186/s13244-022-01322-4
Kapacitetsudfordringer på brystkræftområdet. Sundhedsstyrelsen (2022) Available via https://www.sundhedsstyrelsen.dk/-/media/Udgivelser/2022/Kraeft/Brystkraeft/Faglig-gennemgang-og-anbefalinger-til-kapacitetsudfordringer-paa-brystkraeftomraadet.ashx. Accessed 3 July 2023
Lång K, Josefsson V, Larsson AM et al (2023) Artificial intelligence-supported screen reading versus standard double reading in the Mammography Screening with Artificial Intelligence trial (MASAI): a clinical safety analysis of a randomised, controlled, non-inferiority, single-blinded, screening accuracy study. Lancet Oncol. https://doi.org/10.1016/S1470-2045(23)00298-X
Dembrower K, Crippa A, Colón E, Eklund M, Strand F, ScreenTrustCAD Trial Consortium (2023) Artificial intelligence for breast cancer detection in screening mammography in Sweden: a prospective, population-based, paired-reader, non-inferiority study. Lancet Digit Health. https://doi.org/10.1016/S2589-7500(23)00153-X
Acknowledgements
We thank everyone who provided assistance in the conduct of this study. We are thankful to Lunit Inc. for providing their AI software for this research. We would like to thank the Danish Clinical Quality Program – National Clinical Registries (RKKP), the Danish Breast Cancer Cooperative Group (DBCG) and the Danish Quality Database on Mammography Screening (DKMS) for the provision of data. We thank Henrik Johansen (Regional IT, Region of Southern Denmark) for technical assistance and data management support. We are grateful to all collaborating breast radiologists in the Region of Southern Denmark for contributing with expertise and professional back-and-forth. We thank the women and patients for their participation. None of the contributors received financial compensation for their contribution. No exchange of financial funds or other benefits were involved in the agreement with the providers of the AI software. The viewpoints expressed in this paper do not represent the funding part or any other collaborator.
Funding
Open access funding provided by University Library of Southern Denmark This study has received funding from the Innovation Fund of the Region of Southern Denmark (grant number 10240300).
The funder had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Guarantor
The scientific guarantor of this publication is Benjamin Schnack Brandt Rasmussen.
Conflict of interest
Mads Nielsen is a board member of and holds shares in Biomediq A/S.
The remaining authors of this manuscript declare no relationships with any companies whose products or services may be related to the subject matter of the article.
Lunit Inc. provided the AI solution Lunit INSIGHT MMG for the study as well as technical support but had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Statistics and biometry
One of the authors has significant statistical expertise: Oke Gerke.
No complex statistical methods were necessary for this paper.
Informed consent
Written informed consent was waived by the Danish National Committee on Health Research Ethics.
Ethical approval
Ethics approval was granted by the Danish National Committee on Health Research Ethics (identifier D1763009).
Study subjects or cohorts overlap
Some study subjects or cohorts have been previously reported in another related study by our group and are currently under consideration for publication elsewhere.
That study validates a different AI solution based on the same image and registry data. Hence, the index test, study sample, and subsequently, all results differ from the current study. Furthermore, the methodology in terms of the testing of the index test also differs.
Methodology
• retrospective
• diagnostic or prognostic study
• multicenter study
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Johanne Kühl and Mohammad Talal Elhakim are co-first authors.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kühl, J., Elhakim, M.T., Stougaard, S.W. et al. Population-wide evaluation of artificial intelligence and radiologist assessment of screening mammograms. Eur Radiol 34, 3935–3946 (2024). https://doi.org/10.1007/s00330-023-10423-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00330-023-10423-7