
Abstract
We consider the discrete-time migration–recombination equation, a deterministic, nonlinear dynamical system that describes the evolution of the genetic type distribution of a population evolving under migration and recombination in a law of large numbers setting. We relate this dynamics (forward in time) to a Markov chain, namely a labelled partitioning process, backward in time. This way, we obtain a stochastic representation of the solution of the migration–recombination equation. As a consequence, one obtains an explicit solution of the nonlinear dynamics, simply in terms of powers of the transition matrix of the Markov chain. The limiting and quasi-limiting behaviour of the Markov chain are investigated, which gives immediate access to the asymptotic behaviour of the dynamical system. We finally sketch the analogous situation in continuous time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Recombination is a genetic mechanism that ‘mixes’ or ‘reshuffles’ the genetic material of different individuals from generation to generation; it takes place during the reproductive cycle of sexually reproducing organisms. The analysis of models that describe the evolution of populations under recombination together with other processes are among the major challenges in population genetics.
In this contribution, we consider the evolution under the joint action of recombination and migration of individuals between discrete locations (or demes); we mainly focus on discrete time, where generations do not overlap. We will be concerned with a deterministic approach here, which assumes that the population is so large that a law of large numbers applies and random fluctuations (‘genetic drift’) may be neglected. The resulting migration–recombination equation is a large, nonlinear dynamical system that describes the evolution of the genetic composition of each local population over time, where the genetic composition is identified with a probability distribution (or measure) on a space of sequences of finite length. This model is a variant of the migration-selection-recombination equation formulated by Bürger (2009), who analysed its asymptotic behaviour in the classical dynamical systems setting, forward in time. It is our goal to complement this picture by relating this nonlinear dynamical system to a linear one by embedding the solution into a higher dimensional space, a technique known as Haldane linearisation (Hale and Ringwood 1983; Lyubich 1992) in the context of genetic algebras. This extends the approach taken by Baake and Baake (2016) to the case with migration. The resulting linear system has a natural interpretation as a Markov chain on the set of labelled partitions of the set of sequence sites. Intuitively, this Markov chain describes how the genetic material of an individual from the current population is partitioned across an increasing number of ancestors, along with their locations, as the lines of descent are traced back into the past. This backward (or dual) process combines a variant of the ancestral recombination graph (Hudson 1983; Griffiths and Marjoram 1996, 1997; Bhaskar and Song 2012; see also Durrett 2008, Ch. 3.4) with a variant of the ancestral migration graph (Notohara 1990; Matsen and Wakeley 2006). It is tractable in the law of large numbers regime considered here, due to the absence of coalescence; this was previously exploited for the recombination equation (without migration) by Baake et al. (2016), Baake and Baake (2016) and Martínez (2017); see Baake and Baake (2020) for a review. For an application of a similar idea in the context of the ancestral selection graph, see Slade and Wakeley (2005).
All this leads to a stochastic representation of the solution of the (nonlinear, deterministic) migration–recombination equation in terms of the labelled partitioning process. As a consequence, one obtains an explicit solution of the nonlinear dynamics, simply in terms of powers of the transition matrix of the Markov chain. In particular, the asymptotic behaviour of the migration–recombination equation emerges without any additional effort, via the (unique) absorbing state of the Markov chain. We also investigate the quasi-limiting behaviour of the Markov chain, based on ideas by Martínez (2017).
The paper is organised as follows. In Sect. 2, we set the scene and introduce the forward-time model. In Sect. 3, we use the notion of (labelled) recombinators to reformulate the forward model in a compact way. A crucial property of the dynamics, namely its consistency under marginalisation, is established in Sect. 4. The core of the paper is Sect. 5, where we solve the forward iteration, together with Sect. 6, which establishes the connection to the labelled partitioning process in terms of a duality, together with a genealogical interpretation. Section 7 is devoted to its limiting and quasi-limiting behaviour, and Sect. 8 sketches how the approach carries over to continuous time.
2 The migration–recombination model
Let us recapitulate the discrete-time migration–recombination equation by Bürger (2009). The genetic information of an individual is encoded in terms of a finite sequence of letters, indexed by the set \([n] \mathrel {\mathop :}=\{1,\ldots ,n\}\) of sequence sites, where \(n>1\) is the fixed length of the sequences. The sites may either be interpreted as nucleotide positions in a DNA sequence, or as gene loci on a chromosome. For each site \(i \in [n]\), there is a set (or alphabet) \(\mathcal {A}_i\) of letters (to be interpreted as nucleotides or alleles) that may possibly occur at that site. For the sake of simplicity, we restrict ourselves to finite sets \(\mathcal {A}_i\) here, but this generalises easily. A type is thus identified with a sequence
where \(\mathcal {A}\) is called the type space. We denote by \(\mathcal {P}(\mathcal {A})\) the set of all probability measures on \(\mathcal {A}\). We will also refer to such a probability measure as a type distribution or population. This implies that we consider haploid individuals or gametes; it will be sufficient to work at this level, since, in contrast to Bürger (2009), we do not consider selection. Indeed, in the absence of selection, diploid genotypes are independent combinations of haploid gametes at all stages of the life cycle, that is, one has Hardy-Weinberg equilibrium throughout.
It will be crucial for the later analysis to not only consider complete sequences (defined over the full set [n]), but also (sub)sequences (‘marginal’ types) that are defined over subsets of [n]. Given \(U \subseteq [n]\), we set

Note that \(\mathcal {A}_{[n]}=\mathcal {A}\). Furthermore, \(\mathcal {A}_\varnothing \) is the empty Cartesian product, which is a set with a single element, namely the empty sequence e. For \(V \subseteq U \subseteq [n]\) and \(a^{} \in \mathcal {A}_U\), we define the corresponding marginal type with respect to V by
In line with this, for \(\nu ^{} \in \mathcal {P}(\mathcal {A}_U)\), we define its marginal distribution (with respect to V) as the probability distribution on \(\mathcal {A}_V\) given by
for all \(E \subseteq \mathcal {A}_V\). In words, \(\nu ^V(E)\) is the probability that the marginal with respect to V of a randomly sampled type from \(\nu ^{}\) agrees with some element of E. In somewhat more technical terms, \(\nu ^V\) is the push-forward of \(\nu ^{}\) under the canonical projection from \(\mathcal {A}_U\) to \(\mathcal {A}_V\). Clearly, the map \(\nu ^{} \mapsto \nu ^V\) is linear.
In order to discuss migration, we introduce a finite set L of locations (or demes). The population at location \(\alpha \in L\) in generation \(t \in \mathbb {N}_0\) is denoted by \(\mu _t(\alpha ) \in \mathcal {P}(\mathcal {A})\). The collection of all local populations is summarised into the (column) vector \(\mu _t = \big (\mu _t(\alpha ) \big )_{\alpha \in L} \in \mathcal {P}(\mathcal {A})^L\); we call \(\mu \) a spatially structured population, or a metapopulation. Moreover, for \(U \subseteq [n]\), we write \(\mu ^U_t = \big (\mu ^U_t(\alpha ) \big )_{\alpha \in L}\) for the vector of marginal populations. Throughout, indices of vectors and matrices that refer to locations are written as arguments. Unless stated otherwise, vectors are understood as column vectors.
The migration–recombination equation is a discrete-time dynamical system that describes the deterministic evolution of a metapopulation with non-overlapping generations. We assume that, in each generation, this evolution proceeds in two stages. First, individuals migrate between locations; then, random mating takes place among individuals at the same location, followed by reproduction involving recombination.Footnote 1 Discrete generations will be indexed by \(t \in \mathbb {N}_0\), where a population at time t is understood as the population after the tth round of recombination, but before migration; we will use the corresponding half integers \(t+\frac{1}{2}\) to indicate the population after migration, but before recombination.
2.1 Describing migration
We first consider migration, following the presentation by Nagylaki (1992, Chap. 6.2). The most straightforward way to describe migration is via the so-called forward migration matrix \(\tilde{M}\). It is a stochastic matrix indexed by L, where the entry \(\tilde{M}(\alpha ,\beta )\) is the probability that a randomly chosen individual at location \(\alpha \) migrates to location \(\beta \) in the next generation. However, it is more convenient to work instead with the backward migration matrix M. It is also a stochastic matrix, and \(M(\alpha ,\beta )\) is the probability that a randomly chosen individual that currently lives at location \(\alpha \) has migrated from location \(\beta \). We assume that the local population sizes \(c(\alpha ) \in \mathbb {R}_{>0}\) remain constant over time. This is the case if either
for all \(\alpha \in L\), or if population regulation takes place after the migration step. In any case, denoting the location of a randomly sampled individual at time \(t+ \frac{1}{2}\) by \(\ell _{t+\frac{1}{2}}\) and its location in generation t by \(\ell _{t}\), we have
Note that M is stochastic by definition, i.e. \(\sum _{\beta \in L} M(\alpha , \beta )=1\) and \(M(\alpha ,\beta ) \geqslant 0\) for all \(\alpha ,\beta \in L\).
For additional background, see Nagylaki (1992, Chapter 6.2). In what follows, we will work exclusively with the backward migration matrix. Since we are only interested in relative type frequencies, the population sizes \(c(\alpha )\) are irrelevant. After migration (but before recombination), the local population at \(\alpha \) is therefore given by
and the metapopulation may be written compactly as
2.2 Describing recombination
To describe recombination, we slightly modify the model by Bürger (2009) and follow the notation of Martínez (2017). Here, the partitions of [n] and its subsets will play a central role, see also Baake and Baake (2016) or Baake et al. (2016). For \(U \subseteq [n]\), a partition of U is a set \(\delta \) of mutually disjoint, non-empty subsets of U whose union is U. We will also refer to the elements of a partition as blocks. The set of all partitions of U is denoted by \(\mathbb {S}(U)\). We say that \(\varepsilon \) is finer than (is a refinement of) \(\delta \) ( ) if every block of \(\varepsilon \) is contained in some block of \(\delta \). The relation
) if every block of \(\varepsilon \) is contained in some block of \(\delta \). The relation  defines a partial order on \(\mathbb {S}(U)\). We denote the unique minimal and maximal elements in \(\mathbb {S}(U)\) by \( \underline{0}_U^{} \mathrel {\mathop :}=\big \{\{i\} : i \in U \big \} \) and \( \underline{1}_U^{} \mathrel {\mathop :}=\{U\}; \) when \(U = [n]\), we drop the subscript and write \(\underline{0}\) and \(\underline{1}\), rather than \(\underline{0}_{[n]}\) and \(\underline{1}_{[n]}\). By \(\delta \wedge \varepsilon \) we denote the coarsest common refinement of \(\delta \) and \(\varepsilon \), that is,
defines a partial order on \(\mathbb {S}(U)\). We denote the unique minimal and maximal elements in \(\mathbb {S}(U)\) by \( \underline{0}_U^{} \mathrel {\mathop :}=\big \{\{i\} : i \in U \big \} \) and \( \underline{1}_U^{} \mathrel {\mathop :}=\{U\}; \) when \(U = [n]\), we drop the subscript and write \(\underline{0}\) and \(\underline{1}\), rather than \(\underline{0}_{[n]}\) and \(\underline{1}_{[n]}\). By \(\delta \wedge \varepsilon \) we denote the coarsest common refinement of \(\delta \) and \(\varepsilon \), that is,
it is the coarsest partition finer than both \(\delta \) and \(\varepsilon \).
We say that an offspring of a local population \(\nu \) is recombined according to \(\delta = \{d_1,\ldots ,d_m\} \in \mathbb {S}([n])\) if it has m parents of types \(a^{(1)}, \ldots , a^{(m)} \in \mathcal {A}^{[n]}\), all sampled independently from \(\nu \), and inherits the letters at the sites in \(d_i\) from the parent of type \(a^{(i)}\). That is, the type of the offspring is \(b = (b_1,\ldots ,b_n)\), where \( b_i \mathrel {\mathop :}=a^{(j)}_i \) if \(i \in d_j\). The biologically reasonable cases are \(m=1\) (then \(\delta = \underline{1}\) and the full offspring sequence is inherited from a single parent) and \(m=2\) (the offspring sequence is pieced together from two parents). The choice \(m>2\) implies more than two parents, which is not biologically realistic, but we include this case (and, in this way, generalise Bürger (2009)) since it is mathematically interesting and does not require additional effort. It is then clear that the type of an offspring of \(\nu \) that is recombined according to \(\delta \) has the distribution
That is, recombination according to \(\delta \) turns \(\nu \) into the product measure of the marginals with respect to the blocks of \(\delta \); this reflects the random mating, that is, the independence of the parents. Again, we understand this product to respect the ordering of the sites.
We assume that, in each time step, the entire local population is replaced; the proportion of individuals that are replaced by offspring recombined according to \(\delta \in \mathbb {S}([n])\) is denoted by \(r_\delta ^{} \geqslant 0\), where
The collection \((r_\delta ^{})^{}_{\delta \in \mathbb {S}({[n]})}\) is known as the recombination distribution. Thus, the components of \(\mu _{t+1}\) are given by
where we have used (2) and the linearity of marginalisation in the last step. Equation (4) is called the migration–recombination equation, or MRE for short.
3 Reformulation of the model
Extending concepts established by Baake et al. (2016), Baake and Baake (2016) and Martínez (2017), we now formulate the MRE (4) in a more compact way. This involves labelling the blocks of a partition by elements of L to keep track of where the letters in the blocks come from.
Definition 3.1
A labelled partition of \(U \subseteq {[n]}\) is a collection \({\varvec{\delta }}:= \{{\varvec{d}}_1, \ldots , {\varvec{d}}_m\}\) for some \(m \leqslant |U |\), where \({\varvec{d}}_i = (d_i,\lambda _i)\), \(\delta = \{d_1, \ldots , d_m\}\) is a partition of U, and \(\lambda _i \in L\) for \(1 \leqslant i \leqslant m\). We call \(\delta \) the base of \({\varvec{\delta }}\), refer to its elements as the blocks of \({\varvec{\delta }}\), and interpret \(\lambda _i\) as the label of block \(d_i\). We write \(\mathbb {L}\mathbb {S}(U)\) for the set of all labelled partitions of U. \(\diamondsuit \)
In order to rewrite Eq. (4), we now introduce the labelled recombinator. It is the labelled analogue of the recombinator used by Baake and Baake (2016) for unlabelled partitions. Since we will later also be interested in the evolution of the distribution of subsequences (compare Sect. 4), we introduce the concept in the required generality right away.
Definition 3.2
Let \(U \subseteq {[n]}\) and \({\varvec{\delta }}\in \mathbb {L}\mathbb {S}(U)\). Then, the labelled recombinator (with respect to \({\varvec{\delta }}\)), namely \(\mathcal {R}^{U}_{{\varvec{\delta }}} : \mathcal {P}(\mathcal {A}_U^{})^L \rightarrow \mathcal {P}(\mathcal {A}_U^{})\), is defined by
if \(U = {[n]}\), we will drop the superscript and write \(\mathcal {R}^{}_{{\varvec{\delta }}}\) instead of \(\mathcal {R}^{{[n]}}_{{\varvec{\delta }}}\). \(\diamondsuit \)
In words, \(\mathcal {R}_{{\varvec{\delta }}}^{}(\nu )\) is the distribution of the type of an offspring individual that is recombined according to \(\delta \), where the parent of the labelled block \((d,\lambda )\) is sampled from the local population \(\nu ( \lambda )\). A similar interpretation holds for the marginal recombinators; see Theorem 4.3 and Remark 4.5. With this, Eq. (4) can be restated as follows.
Lemma 3.3
The MRE (4) can be written as
with
where the migration–recombination probabilities are given by
and are normalised, i.e. satisfy
Proof
This follows immediately from Definition 3.2 by expanding the measure product in Eq. (4):
where in the third step, we identified the double sum over all partitions of [n] and all possible vectors of labels of their blocks with the sum over all labelled partitions. The normalisation is a consequence of \(\sum _{\delta \in \mathbb {S}({[n]})} r_\delta ^{} = 1 =\sum _{\beta \in L} M(\alpha ,\beta ) \). \(\square \)
We call the probability distribution \(p(\alpha ) = \big ( p_{\varvec{\delta }}(\alpha ) \big )_{{\varvec{\delta }}\in \mathbb {L}\mathbb {S}([n])}\) the migration–recombination distribution at \(\alpha \).
Remark 3.4
Lemma 3.3 has a simple stochastic interpretation. To sample the type of an individual in generation \(t+1\) (say, at location \(\alpha \)), we first pick a random labelled partition \({\varvec{\delta }}\) according to \(p^{}(\alpha )\) and subsequently sample from \(\mathcal {R}^{}_{\varvec{\delta }}(\mu _t)\). The factorisation of \(p_{\varvec{\delta }}^{}(\alpha )\) in Lemma 3.3 implies that the genome is first partitioned across its parents according to \(\delta \), with probability \(r_\delta \). Subsequently, the label is reassigned (conditionally) independently for each block, according to \(M(\alpha ,{\varvec{\cdot }})\), as we trace back the origin of each ancestor. Finally, the offspring type is determined by piecing together (fragments of) independent samples of the ancestral sequences at the appropriate locations, in generation t. This leads to the product measure in Definition 3.2. We will further elaborate on this in Sect. 6. \(\diamondsuit \)
To continue, we need a few additional concepts around labelled partitions. First, the notion of an induced (labelled) partition is required. For \(\varnothing \ne V \subseteq U\) and \({\varvec{\delta }}\in \mathbb {L}\mathbb {S}(U)\), we denote by \({\varvec{\delta }}|_{V}\) the labelled partition induced by \({\varvec{\delta }}\) on V; it is given by
with base
the partition induced by the (unlabelled) partition \(\delta \) on V. Simply put, every block inherits the label of the unique block of the original partition that contains it.
Conversely, given a partition \(\delta \) of U and a family \(({\varvec{\varepsilon }}_d)_{d \in \delta }\) of labelled partitions of its blocks, their union
is a labelled partition of U; its base is the union
of the bases \(\varepsilon _d\).
Finally, given two labelled partitions \({\varvec{\delta }}\) and \({\varvec{\varepsilon }}\), we say that \({\varvec{\varepsilon }}\) is finer than \({\varvec{\delta }}\) ( ) if
) if  . The partial order on \(\mathbb {S}(U)\) thus carries over to a partial order on \(\mathbb {L}\mathbb {S}(U)\). For any \(\alpha \in L\), there is a unique maximal element; namely, the labelled partition \({\varvec{\underline{1}}}_U^\alpha \mathrel {\mathop :}=\{({[n]},\alpha ) \}\) that consists of a single block with label \(\alpha \). If \(U = {[n]}\), we drop the subscript.
. The partial order on \(\mathbb {S}(U)\) thus carries over to a partial order on \(\mathbb {L}\mathbb {S}(U)\). For any \(\alpha \in L\), there is a unique maximal element; namely, the labelled partition \({\varvec{\underline{1}}}_U^\alpha \mathrel {\mathop :}=\{({[n]},\alpha ) \}\) that consists of a single block with label \(\alpha \). If \(U = {[n]}\), we drop the subscript.
Remark 3.5
It is not difficult to see that  if and only if
if and only if
For a fixed \(\delta \in \mathbb {S}({[n]})\), this implies the following bijection between the labelled partitions \({\varvec{\varepsilon }}\) with  and collections \(({\varvec{\varepsilon }}_d)_{d \in \delta }\) of labelled partitions of the individual blocks of \(\delta \). Given \({\varvec{\varepsilon }}\) with
and collections \(({\varvec{\varepsilon }}_d)_{d \in \delta }\) of labelled partitions of the individual blocks of \(\delta \). Given \({\varvec{\varepsilon }}\) with  , we obtain the collection \(( {\varvec{\varepsilon }}|_d)_{d \in \delta }\) of labelled partitions induced by \({\varvec{\varepsilon }}\) on the blocks of \(\delta \). Conversely, given a collection \(({\varvec{\varepsilon }}_d )_{d \in \delta }\) of labelled partitions of the blocks of \(\delta \), we set \({\varvec{\varepsilon }}\mathrel {\mathop :}=\bigcup _{d \in \delta } {\varvec{\varepsilon }}_d\); note that
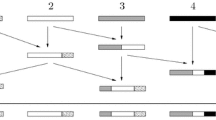
, we obtain the collection \(( {\varvec{\varepsilon }}|_d)_{d \in \delta }\) of labelled partitions induced by \({\varvec{\varepsilon }}\) on the blocks of \(\delta \). Conversely, given a collection \(({\varvec{\varepsilon }}_d )_{d \in \delta }\) of labelled partitions of the blocks of \(\delta \), we set \({\varvec{\varepsilon }}\mathrel {\mathop :}=\bigcup _{d \in \delta } {\varvec{\varepsilon }}_d\); note that  and \({\varvec{\varepsilon }}|_d = {\varvec{\varepsilon }}_d\). See also Fig. 1. \(\diamondsuit \)
and \({\varvec{\varepsilon }}|_d = {\varvec{\varepsilon }}_d\). See also Fig. 1. \(\diamondsuit \)

At the top, an unlabelled partition of [n]. In the middle, a labelled refinement of \(\delta \), which gives rise to labelled partitions of the blocks of \(\delta \) (bottom). Conversely, one can start with the collection of labelled partitions at the bottom and join them to obtain a labelled refinement of \(\delta \)
We will now see that the recombinator for a union of labelled partitions of disjoint subsets is the product of the recombinators for the individual labelled partitions; compare also Baake and Baake (2016, Lemma 2).
Lemma 3.6
Let \(\delta \in \mathbb {S}({[n]})\) and \({\varvec{\varepsilon }}_d \in \mathbb {L}\mathbb {S}(d)\) for all \(d \in \delta \). Then, for all \(\nu \in \mathcal {P}(X)^L\),
In particular, for \({\varvec{\varepsilon }}\in \mathbb {L}\mathbb {S}({[n]})\) with  , we have
, we have
Proof
For the first claim, we write out the labelled recombinators and see that
For the second claim, see Remark 3.5. \(\square \)
We now turn to the marginalisation consistency of the MRE (4), a property that will turn out as the key to its solution.
4 Marginalisation consistency
Just as in the continuous-time case for pure recombination treated by Baake and Baake (2016), the marginalisation consistency of the model is a crucial ingredient. We therefore now turn to the dynamics that the MRE (4) induces on the marginal type distributions. As a warm-up, we prove the following elementary, but useful, result.
Lemma 4.1
Let \(U,V \subseteq {[n]}\), \(U \cap V = \varnothing \), and let \(\nu _U^{}, \nu _V^{}\) be probability measures on \(\mathcal {A}_U\) and \(\mathcal {A}_V\), respectively. Then, we have for any \(W \subseteq U \cup V\)
Proof
Note that \(\mathcal {A}_W = \mathcal {A}_{U \cap W} \times \mathcal {A}_{V \cap W}\). Let us fix \(E_{U \cap W} \subseteq \mathcal {A}_{U \cap W}\) and \(E_{V \cap W} \subseteq \mathcal {A}_{V \cap W}\). Then, for any \(W \subseteq U \cup V\),
\(\square \)
Remark 4.2
It is important to note that Lemma 4.1 remains true if \(U \cap W = \varnothing \) or \(V \cap W = \varnothing \). Assume, for instance, that \(U \cap W = \varnothing \). Recalling that the empty Cartesian product \(\mathcal {A}_\varnothing ^{}\) is the singleton {e} (recall that e is the empty sequence), \(\nu _U^{U \cap W}\) is the unique probability measure on {e} and can be treated as the scalar 1, in the sense that
\(\diamondsuit \)
We now prove the main result of this section, which shows that the MRE is consistent under marginalisation.
Theorem 4.3
Let \((\mu _t)_{t \in \mathbb {N}_0}^{}\) be a solution of the MRE (4) and U a nonempty subset of [n]. Then, \((\mu _t^U)_{t \in \mathbb {N}_0}^{}\) satisfies the marginal MRE
where \(p^U_{\varvec{\delta }}\) is given by
Proof
By Lemma 3.3 and the linearity of marginalisation, we have
Using Lemma 4.1, we obtain for all \({\varvec{\delta }}' \in \mathbb {L}\mathbb {S}({[n]})\)
where in the second step, we ignored the factors corresponding to \(d'\) with \(d' \cap U = \varnothing \) (compare Remark 4.2). Thus,
which is what we wanted to show. \(\square \)
The \(p^U_{\varvec{\delta }}(\alpha )\) are the marginal migration–recombination probabilities (at \(\alpha \)), and, accordingly, \(p^U (\alpha ) = \big (p^U_{\varvec{\delta }}(\alpha ) \big )_{{\varvec{\delta }}\in \mathbb {L}\mathbb {S}([n])}\) is called the marginal migration–recombination distribution (at \(\alpha \)). We will now see that the marginal migration–recombination probabilities have a product structure analogous to that of the migration–recombination probabilities in Lemma 3.3.
Lemma 4.4
The marginal migration–recombination probabilities \(p_{\varvec{\delta }}^{U}(\alpha )\) from Theorem 4.3 can be written as
Proof
We write the (given) labelled partition \({\varvec{\delta }}\) as
Next, we split the conditional sum over the labelled partitions into the sums over the appropriate partitions and their labels. Thus,
where the blocks are indexed so that \(d_j' \cap U = d_j\) for all \(1 \leqslant j \leqslant k\) and \(d_j' \cap U = \varnothing \) for \(k + 1 \leqslant j \leqslant m\). Clearly,
with the usual convention that the empty product is 1. Now, we can use the indicator in the first bracket to eliminate the summation, yielding
The second bracket is equal to one, by the stochasticity of M:
Inserting this back into (6) finishes the proof. \(\square \)
Remark 4.5
The same stochastic interpretation as for Eq. (5) (see Remark 3.4) holds also for the marginalised system. With probability
the subsequence with respect to U of a sampled individual is partitioned across its ancestors according to \(\delta \). Then, the labels are reassigned independently according to M, reflecting their independent migration. \(\diamondsuit \)
5 Solution of the forward iteration
Next, we use the marginalisation consistency established in the previous section to tame the MRE (4). As discussed by Baake and Baake (2016) for pure recombination, the main idea is to consider the time evolution of the (column) vector \(\mathcal {R}^{} (\mu _t) = \big (\mathcal {R}^{}_{\varvec{\delta }}(\mu _t) \big )_{{\varvec{\delta }}\in \mathbb {L}\mathbb {S}([n])}\), rather than \(\mu _{t}\) alone; note that we recover \(\mu _t(\alpha )\) as the \({\varvec{\underline{1}}}^\alpha \)-component of \(\mathcal {R}^{} (\mu _t)\).
Theorem 5.1
Let T be the matrix, indexed by the labelled partitions \(\mathbb {L}\mathbb {S}({[n]})\), with entries

where the \(p_{{\varvec{\varepsilon }}_{|d}}^d (\lambda )\) are as in Lemma 4.4. Then, T is a stochastic matrix. Assume that \((\mu _t)_{t \in \mathbb {N}_0}^{}\) satisfies the MRE (4). Then, \(\mathcal {R}^{}(\mu _t)\) satisfies the linear recursion
In particular,
where \(T^t\) denotes the tth power of T.
Proof
By Definition 3.2 and Theorem 4.3,
By Remark 3.5, the right-hand side is equal to

where we used Lemma 3.6 and the underdot indicates the summation variable. That T is a stochastic matrix is a straightforward consequence of \(p^d(\alpha )\) being a probability distribution on \(\mathbb {L}\mathbb {S}(d)\) for all \(d \subseteq {[n]}\) and all \(\alpha \in L\). \(\square \)
We have just witnessed how the solution of a nonlinear system, embedded in a higher dimensional space, turns into the solution of a linear system and may thus be given explicitly, simply via matrix powers. This is an extension of a technique called Haldane linearisation (Hale and Ringwood 1983; Baake and Baake 2016, 2020) to the case with migration. The underlying mechanism can be found in the genealogical structure, which is discussed next.
6 Stochastic interpretation, genealogical content, and duality
Let us now turn to the probabilistic content of Theorem 5.1. We will see that the appearance of the stochastic matrix T is no coincidence; rather, it has a natural interpretation as the transition matrix of a Markov chain describing the random genealogy of a single individual.
Definition 6.1
The labelled partitioning process (LPP) is a discrete-time Markov chain \({\varvec{\varSigma }}\mathrel {\mathop :}=({\varvec{\varSigma }}_t )_{t \in \mathbb {N}_0}\) with values in \(\mathbb {L}\mathbb {S}({[n]})\) and transition matrix T, that is,
for all \({\varvec{\delta }},{\varvec{\varepsilon }}\in \mathbb {L}\mathbb {S}({[n]})\). \(\diamondsuit \)
In words, \({\varvec{\varSigma }}_{t+1}\) is constructed from \({\varvec{\varSigma }}_t\) by independently replacing each labelled block \((d,\lambda ) \in {\varvec{\varSigma }}_t\), with probability \(p^d_{{\varvec{\varepsilon }}_d} (\lambda )\), by the (labelled) blocks of \({\varvec{\varepsilon }}_d\); see also Fig. 2.
The genealogical interpretation of \({\varvec{\varSigma }}\), started in \({\varvec{\underline{1}}}^{\alpha }\), is as follows. Each labelled block \((d,\lambda )\) of \({\varvec{\varSigma }}_t\) corresponds to a different ancestor of the individual at present, sampled at location \(\alpha \), who lived at location \(\lambda \), at t generations before the present. The elements of d are the sequence sites that are inherited from this ancestor. As we look one generation further into the past, d is replaced by the blocks of a labelled partition \({\varvec{\varepsilon }}_d \in \mathbb {L}\mathbb {S}(d)\), which describes how the type of that ancestor is, in turn, pieced together from its parents, alive \(t+1\) generations before the present. Note that, now, the labelled partitions of d are relevant rather than those of [n]. This is because we already know that this ancestor only contributes sites contained in d, whence we only need to trace back the ancestry of these sites. (This reflects the marginalisation consistency of the model, compare Remark 4.5). Furthermore, the various blocks split independently as the population, in the law of large numbers regime assumed here, is so large that two given individuals never share a common ancestor; thus, their lineages are conditionally independent.
The connection between the solution of the MRE (4) and the genealogical process is formalised in the following theorem, which is a probabilistic restatement of Theorem 5.1 and draws on the notion of duality for Markov processes (Liggett 2010; Jansen and Kurt 2014); in particular, we think about the solution of the forward-time equation as a Markov chain with deterministic transitions.
Theorem 6.2
The LPP and the solution of the MRE (4) are dual with respect to the duality function
That is, for all \({\varvec{\delta }}\in \mathbb {L}\mathbb {S}({[n]})\) and all \(\mu _0 \in \mathcal {P}(\mathcal {A})^L\), we have
In particular, this entails the stochastic representation
for the solution of the MRE (4).
Proof
We prove the theorem by induction over t. For \(t = 0\), there is nothing to show. Assuming now that
for any \(t>0\), we compute, using Theorem 5.1 in the first step, the induction hypothesis in the second, time-homogeneity in the third, and the Markov property in the last:

This proves the statement for \(t + 1\). \(\square \)
Note that the duality function used here is vector valued. This is a slight extension of the standard notion, since the duality function is usually assumed to take values in \(\mathbb {R}\); see the references above for a thorough exposition.
To get a better feel for this probabilistic way of thinking, we take advantage of the stochastic representation from Theorem 6.2 to construct an explicit solution formula in the case of two sites. When evaluating the expectation, we distinguish two cases. Either, the two sites have not been separated until generation t, which happens with probability \(r_{\underline{1}}^{t}\). In this case, both sites have the same ancestor who comes, with probability \((M^t)(\alpha ,\beta )\), from location \(\beta \). Hence, in this case, \(\mu _t^{}(\alpha ) = (M^t \mu _0^{})(\alpha )\). If, on the other hand, the sites have been separated, we denote by \(\sigma \) the smallest t such that \(|{\varvec{\varSigma }}_t| = 2\). In this case, the letters come from two different parents. Their origins are determined by performing independent random walks on L for the remaining time \(t - \sigma + 1\). Summing over all possible values for \(\sigma \) and the label of the block at the time of splitting (which is \(\gamma \) with probability \((M^{\sigma -1})(\alpha , \gamma )\)), we see that

An illustration of the LPP starting from \(\varvec{\underline{1}}^1\), the trivial partition consisting of a single block with label 1; the set of locations is \(L = \{1,2,3,4\}\). Backward time runs from bottom to top. In each generation, the blocks of the partition are first subject to individual splitting and we trace back the ancestral lines that belong to each fragment; compare Remarks 4.5 and 3.4. The fragments provided by each ancestor are labelled with their locations; we write \(\alpha \rightarrow \beta \) to indicate migration from \(\alpha \) to \(\beta \). Recall that in the forward-time model, recombination occurs after migration. Thus, when looking backward in time, splitting due to recombination occurs before the reassignment of the label due to migration. In particular, the first event in this example is a splitting of our sequence located in deme 1
In the case without migration (i.e, when ignoring the labels), this genealogical process is a variant of the ancestral recombination graph (Hudson 1983; Griffiths and Marjoram 1996, 1997; Bhaskar and Song 2012), which was used by Baake and Baake (2016) to solve the recombination equation; see also Baake and Baake (2020). More precisely, the unlabelled partitioning process \(\varSigma \) is simply the base of \({\varvec{\varSigma }}\). Likewise, the transition matrix \(T^{\! \text {ul}}\) of \(\varSigma \) is obtained from T by marginalising over the labels. Thus, \(T^{\! \text {ul}}\) has the entries

and the transition rates for the LPP factorise as
compare Lemma 4.4. Note that \(\varSigma \) is a process of progressive refinement, which never returns to a state the current state. This is due to the absence of coalescence events in the law of large numbers regime, which means that the ancestral recombination graph is actually a tree.
Remark 6.3
The LPP can be interpreted as a multitype branching random walk (BRW) on L, with the types given by the subsets of [n]. The particles move according to the transition kernel M, and, as evident from the product structure of the transitions in Eq. (9), undergo independent branching that is the same at every location; each individual of type d branches with probability \(r_\varepsilon ^d\) into \(|\varepsilon |\) individuals of types \(e_1^{},\ldots ,e^{}_{|\varepsilon |}\), where \(\varepsilon = \{e_1^{},\ldots ,e^{}_{|\varepsilon |}\}\).
7 Limiting and quasi-limiting behaviour of the LPP
We assume now that M is primitive (that is, irreducible and aperiodic), which guarantees the existence of and convergence to a unique stable stationary distribution \(q = \big (q(\alpha ) \big )_{\alpha \in L} \in \mathbb {R}^L\) such that
where \(\mathsf {T}\) denotes transpose.
We also assume that
That is, the coarsest common refinement of all partitions with positive recombination probability is the minimal partition \(\underline{0}\) of [n] into singletons. This is only a matter of technical convenience; otherwise, we could simply consider as a single site any set of sites that are not separated by any partition \(\delta \) with \(r_\delta ^{} > 0\). Note that Eq. (11) implies that \(\underline{0}\) is the unique absorbing state of the unlabelled partitioning process. We can now explicitly state the asymptotic behaviour of the MRE (4).
Theorem 7.1
Under the above assumptions, one has
where
and
for all \(\alpha \in L\). The convergence is geometric, i.e. there is a \(\gamma \in (0,1)\) such that
as \(t \rightarrow \infty \), uniformly in \(\mu _0\).
This is in line with Bürger (2009, Theorem 3.1), which states that the solution of the MRE (4) approaches (at a uniform geometric rate) the submanifold defined by spatial stationarity and linkage equilibrium. Spatial stationarity means that
with q of (10); and, under the assumption (11), linkage equilibrium means that \(\mu (\alpha )\) is the product of its one-dimensional marginals, as in Eq. (12). However, like the explicit time evolution in Theorem 5.1, the explicit expression in Eq. (13) seems to be new.
In view of Theorem 6.2, this result is highly plausible: almost surely (at a uniform geometric rate), the partitioning process will enter its unique absorbing state where all blocks are singletons. In the sequel, independent migration processes will, for each block, converge to the unique stationary distribution q, again at a geometric rate and uniformly in the initial distribution. This behaviour is also clear in terms of the BRW picture. At some point, the type of each particle is a singleton, whence the particles stop branching and just keep performing independent random walks; see Remark 6.3.
For the formal proof, note that the uniform convergence of the migration processes follows directly from the primitivity of M via standard theory (Karlin and Taylor 1975, Appendix, Thm. 2.3). That the partitioning process enters its absorbing state at a uniform geometric rate is the content of the following lemma.
Lemma 7.2
Let
be the maximal sojourn probability of the unlabelled partitioning process and let
be its time to absorption. Then, uniformly in the initial distribution,
for any \(\varepsilon > 0\) as \(t \rightarrow \infty \).
Proof
Since the state space is finite and the partitioning process never returns to a state  the current state, this Markov chain may jump at most a finite number of times, say m times, before it is absorbed in \(\underline{0}\). Thus, for any fixed \(\varepsilon > 0\),
the current state, this Markov chain may jump at most a finite number of times, say m times, before it is absorbed in \(\underline{0}\). Thus, for any fixed \(\varepsilon > 0\),
where \(C' = \sum _{j = 0}^m \Big ( \frac{1 - \eta }{\eta } \Big )^j\) and C is sufficiently large. \(\square \)
Next, we investigate the asymptotic behaviour of the LPP.
Proposition 7.3
There exists a \(\gamma \in (0,1)\) such that
as \(t \rightarrow \infty \), uniformly in \(\alpha ^{}_1,\ldots ,\alpha ^{}_n \in L\) and the initial distribution of the LPP. For \({\varvec{\delta }}\in \mathbb {L}\mathbb {S}({[n]})\) with \(\delta \ne \underline{0}\),
for all \(\varepsilon > 0\), again uniformly in the initial distribution.
Proof
Let \(\tau \) be as in Lemma 7.2. The second statement follows immediately from Lemma 7.2 by noting that
Now, assume that \({\varvec{\delta }}\) is of the form
Then, for all \(\gamma _1 > \eta \),
as \(t \rightarrow \infty \), where the last step follows by an application of Lemma 7.2. Furthermore,
Here, the \( \big ( \Lambda _t^{(i)} \big )_{t \in \mathbb {N}\geqslant \tau _{}}\) for \(i \in L\) are the labels of the (singleton) blocks from time \(\tau \) onwards; they are independent L-valued Markov chains with transition matrix M. By standard theory, we can be sure that, regardless of the initial value, there is a \(\gamma _2 \in (0,1)\) such that
uniformly in \(\alpha _i\). Combining this with Eqs. (14) and (15) proves the theorem. \(\square \)
Proof of Theorem 7.1
By Theorem 6.2, Proposition 7.3, and Definition 3.2, we have for some \(\gamma \in (0,1)\), independent of \(\mu _0\),
\(\square \)
Since the asymptotic behaviour of the LPP is so simple, we now go one step further and inquire about its quasi-limiting behaviour; that is, its asymptotic behaviour, conditioned on non-absorption of its base. Generally speaking, quasi-limiting distributions describe the first-order approximation of the deviation from the stationary behaviour. Recall that the partitioning process (labelled or unlabelled) is a process of progressive refinement, and never returns to a state coarser than the current state. This is very different from the situation considered by Collet et al. (2013), where the focus is on irreducible chains.
Unlike the limiting distribution, the quasi-limiting distribution will generally depend on the initial distribution. For convenience of notation, we let the LPP start from a maximal labelled partition \({\varvec{\underline{1}}}^\alpha \), consisting of a single block with label \(\alpha \). However, the following discussion can easily be adapted to the more general setting. In what follows, we will exclude the pathological case of \(r_{\underline{0}}^{} = 1\), where the probability of non-absorption is zero, and the conditional distribution we are interested in is not well defined.
We start by recalling the quasi-limiting behaviour of \(\varSigma \), which was already investigated by Martínez (2017). We posit throughout that \(\varSigma _0=\underline{1}\). To state the result, we need some additional notation. First, we define the set of states
that are reachable by \(\varSigma \) when starting in \(\underline{1}\). As before, \(\eta \) denotes the maximal sojourn probability of \(\varSigma \) (compare Lemma 7.2). We will also need the set
of reachable states with maximal sojourn probability. Note that our assumption \(r_{\underline{0}}^{} \ne 1\) guarantees that \(\eta > 0\). Finally, we define the first hitting time of any given \(\delta \in \mathbb {S}({[n]})\),
we write \( \tau _\mathcal {F}^{} \mathrel {\mathop :}=\min _{\delta \in \mathcal {F}} \tau _\delta ^{} \) for the first hitting time of \(\mathcal {F}\), and, as before, \( \tau = \tau _{\underline{0}} \) for the time to absorption. The following result is known; see Martínez (2017, Theorem 5.5).
Theorem 7.4
For all \(\delta \in \mathcal {F}\), one has
For all \(\delta \in \mathbb {S}({[n]})\), the limit
exists and is given by
Thus defined, \(\mathbb {P}_{\text {qlim}}^\varSigma \) is a probability measure on \(\mathbb {S}({[n]})\), called the quasi-limiting distribution of \(\varSigma \) (starting from \(\underline{1})\).
Recall that the labels of the different blocks evolve conditionally independently. Thus, we expect the quasi-limiting distribution of the LPP to be similar to the quasi-limiting distribution from Theorem 7.4, garnished with the stationary distribution q of the migration process. To be more explicit, we will prove the following result.
Theorem 7.5
For all \({\varvec{\delta }}\in \mathbb {L}\mathbb {S}({[n]})\),
where q is the unique stationary distribution (10) of the migration process.
Remark 7.6
In Theorem 7.1, we have approximated the solution of the MRE (4) by using Proposition 7.3 to approximate the distribution of the labelled partitioning process by its limiting distribution. We can try to improve on this rather coarse estimate by also taking into account the quasi-limiting distribution; at least in principle, the disintegration
allows us to express the error term in Theorem 7.1 via the quasi-limiting distribution, at least when migration is strong compared to recombination. Acquiring precise asymptotics, however, would require more detailed knowledge about the probability \(\mathbb {P}(\tau > t)\) and the rate of convergence of the conditional distribution \(\mathbb {P}( {\varvec{\varSigma }}_t = {\varvec{\delta }}\mid \tau >t )\) to the quasi-limiting distribution.
At the heart of the proof is the observation that further refinement of any \(\delta \in \mathcal {F}\) immediately leads to absorption; this was also one of the crucial ingredients in the proof of Theorem 7.4, see Martínez (2017, Theorem 5.5) for the original reference.Footnote 2
Lemma 7.7
For all \(\delta \in \mathcal {F}\), we have
Proof
We show that, for all \(\delta \in \mathbb {S}^\downarrow ({[n]})\) with \(T^\mathrm{{ul}}_{\delta \delta } + T^\mathrm{{ul}}_{\delta \underline{0}} \ne 1\), one has \(\delta \notin \mathcal {F}\). Indeed, for any such \(\delta \), there is an \(\varepsilon \notin \{\underline{0}, \delta \}\) with \(T^\mathrm{{ul}}_{\delta \varepsilon } > 0\). For any such \(\varepsilon \), there is at least one block \(e \in \varepsilon \) with \(|e |>1\). For any such e, the partition
is reachable by Assumption (11) (with [n] replaced by individual blocks of \(\delta \)). We then have
where \(\tilde{d}\) is the block in \(\delta \) that contains e. The inequality is true since \(\varepsilon ' \prec \delta \) implies that either \(|e |< |\tilde{d} |\), in which case \(r^e_{\{e\}} > r^{\tilde{d}}_{\{\tilde{d}\}}\); or \(|\{d \in \delta : |d |> 1 \}|> 1\), which entails that the constrained product is not empty (note that \(r^d_{\{d\}}<1\) for d with \(|d |> 1\)). We have thus proved that \(\delta \notin \mathcal {F}\). \(\square \)
Remark 7.8
One might be tempted to assume that the sojourn probability is nondecreasing along every path
from the maximal partition to the absorbing state. To illustrate that this is not true in general, consider the following setup. Let \(n = 4\) and assume the recombination distribution given by \(r^{}_{\underline{0}} = \frac{1}{2}\), \(r^{}_{\{\{1,2\},\{3,4\}\}} = \frac{1}{10}, r^{}_{\underline{1}} = \frac{2}{5}\) and \(r^{}_\delta = 0\) otherwise. Then, the sojourn probability of the state \(\underline{1}\) is \(r^{}_{\underline{1}} = \frac{2}{5}\), while the (finer) state \(\{\{1,2\},\{3,4\}\}\) has the smaller sojourn probability
\(\diamondsuit \)
The idea of the proof of Theorem 7.5 is simple. First, notice that Lemma 7.7 implies that conditional on non-absorption, \(\varSigma \) remains constant after \(\tau _{\mathcal {F}}^{}\). From then on, the labels keep on evolving independently according to M, and their distributions converge to q. To make this rigorous, we just need to make sure that \(t - \tau _\mathcal {F}^{}\) is large enough (conditional on non-absorption). This is the content of the next Lemma.
Lemma 7.9
-
(a)
There exists \(c > 0\) such that \(\mathbb {P}(\tau > t) \geqslant c \eta ^t\) for all \(t \in \mathbb {N}\).
-
(b)
Let \(\eta ' \mathrel {\mathop :}=\max _{\delta \in \mathbb {S}({[n]}) \setminus (\mathcal {F}\cup \{\underline{0}\})} T^\mathrm{{ul}}_{\delta \delta }\). Then, for all \(\eta '' > \eta '\), there exists \(C > 0\) such that \(\mathbb {P}(\tau ^{}_\mathcal {F}\wedge \tau > t) \leqslant C (\eta '')^t\) for all \(t \in \mathbb {N}\).
-
(c)
There is a \(\gamma \in (0,1)\) such that \(\lim _{t \rightarrow \infty } \mathbb {P}(\tau _{\mathcal {F}}^{}> \gamma t \mid \tau > t) = 0\).
Proof
First, we show (a). By definition, \(\mathcal {F}\subseteq \mathbb {S}^\downarrow (I)\). Thus, there exists a \(t_0 \in \mathbb {N}\) such that \(\mathbb {P}(\tau _\mathcal {F}^{} = t_0) > 0\). Then, we have for all \(t \geqslant t_0\) that
with \(c' = \mathbb {P}(\tau _\mathcal {F}^{} = t_0)\). Note that we used Lemma 7.7 in the second-last step. Now, simply choose
For the proof of (b), we couple \((\varSigma _t)_{t \in \mathbb {N}_0}\) to another process \((N_t)_{t \in \mathbb {N}_0}\) with values in \(\mathbb {N}_0 \cup \{\infty \}\) and \(N_0=0\). It evolves as follows. When \(\varSigma _{t+1} = \varSigma _t\), then \(N_{t+1}\mathrel {\mathop :}=N_t\) and when \(\varSigma _{t+1} \in \mathcal {F}\cup \{ \underline{0}\}\), we set \(N_{t+1} \mathrel {\mathop :}=\infty \). In all other cases, we perform a Bernoulli experiment with success probability
Upon success, we set \(N_{t+1} \mathrel {\mathop :}=N_t + 1\); otherwise, \(N_{t+1} \mathrel {\mathop :}=N_t\). Note that the marginal \((N_t)_{t \in \mathbb {N}_0}\) of the coupling \((\varSigma _t,N_t)_{t \in \mathbb {N}_0}\) stochastically dominates a process that has independent Bernoulli increments with parameter \(1 - \eta '\).
As we have argued before, the partitioning process can only jump a finite number of times before hitting either \(\underline{0}\) or \(\mathcal {F}\). Thus, there is a positive integer m such that, for all \(t \in \mathbb {N}\), \(\tau \wedge \tau ^{}_\mathcal {F}> t\) implies \(N_t \leqslant m\). Thus,
where P(t) is a polynomial with degree \(\leqslant m\), and C and \(\eta ''\) are as stated.
Finally, (c) is a straightforward consequence of (a) and (b); first, fix any \(\eta '' \in (\eta ', \eta )\). Then, choose \(\gamma \) such that \((\eta '')^\gamma < \eta \). \(\square \)
After these preparations, the proof of Theorem 7.5 is not difficult.
Proof of Theorem 7.5
Choose \(\gamma \) as in (c) of Lemma 7.9. We split
The first probability tends to zero as \(t \rightarrow \infty \), due to our choice of \(\gamma \). The second can be rewritten as
where we have used that Lemma 7.7 implies
Here, the second factor converges to \(\mathbb {P}_{\text {qlim}}^\varSigma (\delta )\) by the choice of \(\gamma \) and Lemma 7.9(c).
Now consider the first factor. Together with \(\tau > t\) and Lemma 7.7, \(\tau _\delta ^{} \leqslant \gamma t\) implies that \(\varSigma _{s} = \delta \) for all s between \(\gamma t\) and t. During this period, the labels of the blocks of \(\delta \) evolve independently, and by the uniform convergence to the stationary distribution q, we obtain
which completes the argument. For additional details, see also the proof of Proposition 7.3. \(\square \)
8 Recombination and migration in continuous time
Let us close by briefly discussing how our results carry over from the discrete-time to the continuous-time setting. To distinguish the notation from the discrete-time setting, we write \(\omega = (\omega ^{}_t)_{t \geqslant 0}^{}\) instead of \(\mu = (\mu ^{}_t)^{}_{t \in \mathbb {N}_0}\). The recombination distribution r is replaced by a collection \(\varrho = (\varrho ^{}_\delta )^{}_{\delta \in \mathbb {S}([n])}\), respectively. of non-negative recombination rates; for each \(\delta \in \mathbb {S}([n])\), each individual is between time t and \(t + \, \mathrm {d}t\) replaced by a new offspring that is recombined according to \(\delta \), with probability \(\varrho _\delta ^{} \, \mathrm {d}t\).
Instead of the stochastic backward migration matrix, we use a Markov generator N on [n]; between time t and \(t + \, \mathrm {d}t\) and for \(\alpha \ne \beta \), an individual at location \(\alpha \) is, with probability \(N(\alpha ,\beta ) \, \mathrm {d}t\), replaced by an individual from location \(\beta \); we assume that this happens independently of recombination.
Putting this together means for the type distribution that we replace \(\omega _t^{}(\alpha )\) by the convex combination
In other words,
note that we have used that \(N(\alpha ,\alpha ) = -\sum _{\beta \ne \alpha } N(\alpha , \beta )\) since N is a Markov generator. The backward view can be easily adapted as follows. Again, we have an LPP (this time in continuous time) \(\varvec{\varSigma }^{\text {c}}= (\varvec{\varSigma }^{\text {c}}_t)^{}_{t \geqslant 0}\). It evolves as follows. At rate \(\varrho _\varepsilon ^{}\) for all \(\varepsilon \), each labelled block \((d,\lambda )\) of \(\varvec{\varSigma }^{\text {c}}_t\) is split into the blocks of the induced partition \(\varepsilon |^{}_d\); each of these fragments inherits the label \(\lambda \). In addition and independently, for every \(\alpha \in L\), each block with label \(\alpha \) is relabelled \(\beta \) at rate \(N(\alpha ,\beta )\). Somewhat more formally, \(\varvec{\varSigma }^{\text {c}}\) is a Markov chain in continuous time with generator \({\varvec{\mathcal {Q}}}\) defined by its nondiagonal elements
where the marginal recombination rates are defined in analogy with the marginal recombination probabilities (compare Eq. (7)):
Note that, in the case without migration and with recombination restricted to single crossovers, that is, to partitions of the form \(\{[1:i],[i+1,n]\}\) for some \(1 \leqslant i < n\), the continuous-time backward dynamics (and thus, by duality, the forward dynamics; see Eq. (18)) has a simple explicit solution, which is due to the fact that crossover events “rain down” on sequences in an independent Poissonian fashion (Baake and Baake 2020). See also Lambert et al. (2020) for the (much more involved) extension to the case with (a small amount of) coalescence in the infinite-sequence limit.
But let us return to the full Eq. (17). As before (compare Theorem 6.2), one can prove the duality relation
whence we obtain the solution
by solving the associated (linear) Kolmogorov backward equation, in perfect analogy to Theorem 5.1. The duality relation can be proved by a straightforward adaptation of the techniques of Baake and Baake (2016). Indeed, it was shown there that the recombination part of Eq. (17) is dual to the splitting (or branching) part of \(\varvec{\varSigma }^{\text {c}}\). Showing that the migration part is dual to the random walk defined by N is a standard exercise.
Because Eq. (19) is not very concrete, let us derive a more explicit solution formula for the special case \(n = 2\). We give a probabilistic argument, analogous to Eq. (8). First, note that with probability \(\mathrm {e}^{-\varrho ^{}_{\underline{0}} t}\), the sites are not separated until time t, that is, \(\varSigma ^{\text {c}}_t = \underline{1}\); the single block has performed a random walk with transition kernel N for the entire duration t. Hence, in this case, \(\omega _t^{}(\alpha ) = (\mathrm {e}^{t N} \omega _0^{})(\alpha )\). On the other hand, if the blocks have been split at time \(\sigma \in [0,t]\), then both sites have performed independent random walks, starting at time \(\sigma \) at the location \(\gamma \) where the split took place, and the solution is given by \((\mathrm {e}^{(t - \sigma ) N} \omega ^{}_0)^{\{1\}}(\gamma ) \otimes (\mathrm {e}^{(t - \sigma ) N} \omega ^{}_0)^{\{2\}}(\gamma )\). Integrating over all possible values for \(\sigma \) (keeping in mind that \(\sigma \) is exponentially distributed with mean \(1 / \varrho _{\underline{0}}^{}\)) and \(\gamma \) (keeping in mind that, at the moment of splitting, the block has label \(\gamma \) with probability \((\mathrm {e}^{\sigma N})(\alpha , \gamma )\)), we obtain
For more than two loci, one can proceed in a similar fashion, disintegrating the solution conditional on the waiting time(s) between splitting events. However, this becomes cumbersome very quickly as one has to keep track of various different contributions, corresponding to different realisations of the jump chain of the (unlabelled) partitioning process. In particular, the form of these contributions changes, depending on the tree topology; see Fig. 3.

Two realisations of the jump chain of the unlabelled partitioning process. Contributions to the solution corresponding to the left panel consist of two iterated integrals, while the topology on the right gives rise to a single integral as in Eq. (20). Note also that by permutation of the labels in the left panel, there are 2 additional realisations of the jump chain with the same topology
Remark 8.1
It is straightforward to adapt the partitioning process in the diffusion limit to the setting with migration, both for finite, discrete sequences as treated by Baake et al. (2016) as well as continuous sequences; see Lambert et al. (2020). The new feature of this LPP with coalescence is that two blocks can only coalesce if they share the same label. However, an exhaustive treatment would go beyond the scope of this work.
Notes
While recombination, strictly speaking, does not occur during reproduction itself, this is not relevant in the simplified setting of our model; simply put, as we are working at the level of gametes, the word ‘reproduction’ refers, in this context, to the formation of new germ cells prior to mating.
This result is also implicit in Lemma 5.1 of the corresponding corrigendum; for completeness, we present its proof.
References
Baake E, Baake M (2003) An exactly solved model for mutation, recombination and selection. Can J Math 55: 3–41 and Erratum 60: 264–265 (2008)
Baake E, Baake M (2016) Haldane linearisation done right: solving the nonlinear recombination equation the easy way. Discrete Contin Dyn Syst A 36:6645–6656
Baake E, Esser M, Probst S (2016) Partitioning, duality, and linkage disequilibria in the Moran model with recombination. J Math Biol 73:161–197
Baake E, Baake M (2020) Ancestral lines under recombination. In: Baake E, Wakolbinger A (eds) Probabilistic structures in evolution. EMS Press, Berlin (in press). arXiv:2002.08658
Baake E, Baake M, Salamat M (2016) The general recombination equation in continuous time and its solution. Discrete Contin Dyn Syst A 36: 63–95 and Erratum and addendum 36:2365–2366 (2016)
Baake E, von Wangenheim U (2014) Single-crossover recombination and ancestral recombination trees. J Math Biol 68:1371–1402
Bhaskar A, Song YS (2012) Closed-form asymptotic sampling distributions under the coalescent with recombination for an arbitrary number of loci. Adv Appl Probab 44:391–407
Bürger R (2009) Multilocus selection in subdivided populations I. Convergence properties for weak or strong migration. J Math Biol 58:939–978
Christiansen FB (1999) Population genetics of multiple loci. Wiley, Chichester
Collet P, Martínez S, San Martín J (2013) Quasi-stationary distributions. Markov chains, diffusions and dynamical systems. Springer, Berlin
Darroch JN, Seneta E (1965) On quasi-stationary distribution in absorbing discrete-time finite Markov chains. J Appl Probab 2:88–100
Durrett R (2008) Probability models for DNA sequence evolution, 2nd edn. Springer, New York
Griffiths RC, Marjoram P (1996) Ancestral inference from samples of DNA sequences with recombination. J Comput Biol 3:479–502
Griffiths RC, Marjoram P (1997) An ancestral recombination graph. In: Donnelly P, Tavaré S (eds) Progress in population genetics and human evolution. Springer, New York, pp 257–270
McHale D, Ringwood GA (1983) Haldane linearisation of baric algebras. J Lond Math Soc 28:17–26
Hudson RR (1983) Properties of a neutral allele model with intragenic recombination. Theor Popul Biol 23:183–201
Jansen S, Kurt N (2014) On the notion(s) of duality for Markov processes. Probab Surv 11:59–120
Karlin S, Taylor HM (1975) A first course in stochastic processes, 2nd edn. Academic Press, San Diego
Lambert A, Miró Pina V, Schertzer E (2020) Chromosome painting: how recombination mixes ancestral colors. Ann Appl Probab (online first)
Liggett TM (2010) Continuous time Markov processes: an introduction. American Mathematical Society, Providence
Lyubich YI (1992) Mathematical structures in population genetics. Springer, Berlin
Martínez S (2017) A probabilistic analysis of a discrete-time evolution in recombination. Adv Appl Math 91:115–136; and Corrigendum 110:403–411 (2019)
Matsen FA, Wakeley J (2006) Convergence to the island-model coalescent process in populations with restricted migration. Genetics 172:701–708
Nagylaki T (1992) Introduction to theoretical population genetics. Springer, Berlin
Nagylaki T, Hofbauer J, Brunovský P (1999) Convergence of multilocus systems under weak epistasis or weak selection. J Math Biol 38:103–133
Notohara M (1990) The coalescent and the genealogical process in geographically structured populations. J Math Biol 29:59–75
Slade PF, Wakeley J (2005) The structured ancestral selection graph and the many-demes limit. Genetics 169:1117–1131
von Wangenheim U, Baake E, Baake M (2010) Single-crossover recombination in discrete time. J Math Biol 60:727–760
Acknowledgements
It is our pleasure to thank Reinhard Bürger for enlightening discussions and two anonymous referees for insightful comments. This work was supported by the German Research Foundation (DFG), within the SPP 1590 (FA) and the CRC 1283, Project C1 (EB); by Grant CMM Basal CONICYT, Project AFB 170001 (SM); and by ANID/Doctorado en el extranjero doctoral scholarship, Grant No. 2018-72190055 (IL). Thanks for hospitality go from IL to the Bielefeld group and from EB to the Santiago group.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alberti, F., Baake, E., Letter, I. et al. Solving the migration–recombination equation from a genealogical point of view. J. Math. Biol. 82, 41 (2021). https://doi.org/10.1007/s00285-021-01584-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00285-021-01584-4
Keywords
- Migration–recombination equation
- Ancestral recombination graph
- Duality
- Labelled partitioning process
- Quasi-stationarity
- Haldane linearisation