
Abstract
In this work, we approach the minimization of a continuously differentiable convex function under linear equality constraints by a second-order dynamical system with an asymptotically vanishing damping term. The system under consideration is a time rescaled version of another system previously found in the literature. We show fast convergence of the primal-dual gap, the feasibility measure, and the objective function value along the generated trajectories. These convergence rates now depend on the rescaling parameter, and thus can be improved by choosing said parameter appropriately. When the objective function has a Lipschitz continuous gradient, we show that the primal-dual trajectory asymptotically converges weakly to a primal-dual optimal solution to the underlying minimization problem. We also exhibit improved rates of convergence of the gradient along the primal trajectories and of the adjoint of the corresponding linear operator along the dual trajectories. We illustrate the theoretical outcomes and also carry out a comparison with other classes of dynamical systems through numerical experiments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
1.1 Problem Statement and Motivation
In this paper we will consider the optimization problem
where
This model formulation underlies many important applications in various areas, such as image recovery [25], machine learning [20, 31], the energy dispatch of power grids [42, 43], distributed optimization [32, 44] and network optimization [40, 45].
In recent years, there has been a flurry of research on the relationship between continuous time dynamical systems and the numerical algorithms that arise from their discretizations. For the unconstrained optimization problem, it has been known that inertial systems with damped velocities enjoy good convergence properties. For a convex, smooth function \(f: \mathcal {X} \rightarrow \mathbb {R}\), Polyak is the first to consider the heavy ball with friction (HBF) dynamics [37, 38]
Alvarez and Attouch continue the line of this study, focusing on inertial dynamics with a fixed viscous damping coefficient [2,3,4]. Later on, Cabot et al. [21, 22] consider the system that replaces \(\gamma \) with a time dependent damping coefficient \(\gamma \left( t \right) \). In [41], Su, Boyd, and Candès showed that it turns out one can achieve fast convergence rates by introducing a time dependent damping coefficient which vanishes in a controlled manner, neither too fast nor too slowly, as t goes to infinity
For \(\alpha \geqslant 3\), the authors showed that a solution \(x :\left[ t_{0}, +\infty \right) \rightarrow \mathcal {X}\) to (AVD) satisfies \(f(x(t)) - f(x_{*}) = \mathcal {O}\left( \frac{1}{t^{2}}\right) \) as \(t \rightarrow +\infty \). In fact, the choice \(\alpha = 3\) provides a continuous limit counterpart to Nesterov’s celebrated accelerated gradient algorithm [15, 34, 35]. Weak convergence of the trajectories to minimizers of f when \(\alpha > 3\) has been shown by Attouch et al. in [6] and May in [33], together with the improved rates of convergence \(f(x(t)) - f(x_{*}) = o\left( \frac{1}{t^{2}}\right) \) as \(t\rightarrow +\infty \). In the meantime, similar results for the discrete counterpart were also reported by Chambolle and Dossal in [23], and by Attouch and Peypouquet in [13].
In [7], Attouch, Chbani, and Riahi proposed an inertial proximal type algorithm, which results from a discretization of the time rescaled (AVD) system
where \(\delta :\left[ t_{0}, + \infty \right) \rightarrow \mathbb {R}_{+}\) is a time scaling function satisfying a certain growth condition, which enters the convergence statement by way of \(f \left( x \left( t \right) \right) - f \left( x_{*} \right) = \mathcal {O}\left( \frac{1}{t^{2} \delta \left( t \right) } \right) \) as \(t \rightarrow + \infty \). The resulting algorithm obtained by the authors is considerably simpler than the founding proximal point algorithm proposed by Güler in [26], while providing comparable convergence rates for the functional values.
In order to approach constrained optimization problems, Augmented Lagrangian Method (ALM) [39] (for linearly constrained problems) and Alternating Direction Method of Multipliers (ADMM) [20, 24] (for problems with separable objectives and block variables linearly coupled in the constraints) and some of their variants have been shown to enjoy substantial success. Continuous-time approaches for structured convex minimization problems formulated in the spirit of the full splitting paradigm have been recently addressed in [18] and, closely connected to our approach, in [10, 17, 27, 45], to which we will have a closer look in Subsection 2.2. The temporal discretization resulting from these dynamics gives rise to the numerical algorithm with fast convergence rates [28, 29] and with a convergence guarantee for the generated iterate [19], without additional assumptions such as strong convexity.
In this paper, we will investigate a second-order dynamical system with asymptotic vanishing damping and time rescaling term, which is associated with the optimization problem (1.1) and formulated in terms of its augmented Lagrangian. The case when the time rescaling term does not appear has been established in [17]. We show that by introducing this time rescaling function, we are able to derive faster convergence rates for the primal-dual gap, the feasibility measure, and the objective function value along the generated trajectories while still maintaining the asymptotic behaviour of the trajectories towards a primal-dual optimal solution. On the other hand, this work can also be viewed as an extension of the time rescaling technique derived in [7, 9] for the constrained case. To our knowledge, the trajectory convergence for dynamics with time scaling seems to be new in the constrained case.
1.2 Notations and a Preliminary Result
For both Hilbert spaces \(\mathcal {X}\) and \(\mathcal {Y}\), the Euclidean inner product and the associated norm will be denoted by \(\left\langle \cdot , \cdot \right\rangle \) and \(\left\Vert \cdot \right\Vert \), respectively. The Cartesian product \(\mathcal {X}\times \mathcal {Y}\) will be endowed with the inner product and the associated norm defined for \(\left( x, \lambda \right) , \left( z, \mu \right) \in \mathcal {X}\times \mathcal {Y}\) as
respectively.
Let \(f :\mathcal {X}\rightarrow \mathbb {R}\) be a continuously differentiable convex function such that \(\nabla f\) is \(\ell -\)Lipschitz continuous. For every \(x, y \in \mathcal {X}\) it holds (see [35, Theorem 2.1.5])
2 The Primal-Dual Dynamical Approach
2.1 Augmented Lagrangian Formulation
Consider the saddle point problem
associated to problem (1.1), where \(\mathcal {L}:\mathcal {X}\times \mathcal {Y}\rightarrow \mathbb {R}\) denotes the Lagrangian function
Under the assumptions (1.2), \(\mathcal {L}\) is convex with respect to \(x \in \mathcal {X}\) and affine with respect to \(\lambda \in \mathcal {Y}\). A pair \(\left( x_{*}, \lambda _{*} \right) \in \mathcal {X}\times \mathcal {Y}\) is said to be a saddle point of the Lagrangian function \(\mathcal {L}\) if for every \(\left( x, \lambda \right) \in \mathcal {X}\times \mathcal {Y}\)
If \(\left( x_{*}, \lambda _{*} \right) \in \mathcal {X}\times \mathcal {Y}\) is a saddle point of \(\mathcal {L}\) then \(x_{*} \in \mathcal {X}\) is an optimal solution of (1.1), and \(\lambda _{*} \in \mathcal {Y}\) is an optimal solution of its Lagrange dual problem. If \(x_{*} \in \mathcal {X}\) is an optimal solution of (1.1) and a suitable constraint qualification is fulfilled, then there exists an optimal solution \(\lambda _{*} \in \mathcal {Y}\) of the Lagrange dual problem such that \(\left( x_{*}, \lambda _{*} \right) \in \mathcal {X}\times \mathcal {Y}\) is a saddle point of \(\mathcal {L}\). For details and insights into the topic of constraint qualifications for convex duality we refer to [14, 16].
The set of saddle points of \(\mathcal {L}\), called also primal-dual optimal solutions of (1.1), will be denoted by \(\mathbb {S}\) and, as stated in the assumptions, it will be assumed to be nonempty. The set of feasible points of (1.1) will be denoted by \(\mathbb {F}:= \left\{ x \in \mathcal {X}:Ax = b \right\} \) and the optimal objective value of (1.1) by \(f_{*}\).
The system of primal-dual optimality conditions for (1.1) reads
where \(A^{*}: \mathcal {Y}\rightarrow \mathcal {X}\) denotes the adjoint operator of A.
For \(\beta \geqslant 0\), we consider also the augmented Lagrangian \(\mathcal {L}_{\beta }:\mathcal {X}\times \mathcal {Y}\rightarrow \mathbb {R}\) associated with (1.1)
For every \((x, \lambda ) \in \mathbb {F}\times \mathcal {Y}\) it holds
If \(\left( x_{*}, \lambda _{*} \right) \in \mathbb {S}\), then we have for every \(\left( x, \lambda \right) \in \mathcal {X}\times \mathcal {Y}\)
In addition, from (2.3) we have
In other words, for any \(\beta \geqslant 0\) the sets of saddle points of \(\mathcal {L}\) and \(\mathcal {L}_{\beta }\) are identical.
2.2 The Primal-Dual Asymptotic Vanishing Damping Dynamical System with Time Rescaling
In this subsection we present the system under study, and we include a brief discussion regarding the existence and uniqueness of solutions.
The dynamical system which we associate to (1.1) and investigate in this paper reads

where \(t_0 >0\), \(\alpha > 0\), \(\theta > 0\), \(\delta :\left[ t_{0}, +\infty \right) \rightarrow \mathbb {R}\) is a nonnegative continuously differentiable function and \(\left( x_{0}, \lambda _{0} \right) , \bigl ( \dot{x}_{0}, \dot{\lambda }_{0} \bigr ) \in \mathcal {X}\times \mathcal {Y}\) are the initial conditions. Replacing the expressions of the partial gradients of \(\mathcal {L}_{\beta }\) into the system leads to the following formulation for (2.6):

The case (2.6) in which there is no time rescaling, i.e., when \(\delta (t) \equiv 1\), was studied by Zeng et al. in [45], and by Boţ and Nguyen in [17]. The system with more general damping, extrapolation and time rescaling coefficients was addressed by He et al. in [27, 30] and by Attouch et al. in [10]. We mention that extending the results in this paper to the multi-block case is possible. For further details, we refer the readers to [17, Sect. 2.4].
It is well known that the viscous damping term \(\frac{\alpha }{t}\) has a vital role in achieving fast convergence in unconstrained minimization [6, 8, 33]. The role of the extrapolation \(\theta t\) is to induce more flexibility in the dynamical system and in the associated discrete schemes, as it has been recently noticed in [10, 12, 27, 45]. The time scaling function \(\delta \left( \cdot \right) \) has the role to further improve the rates of convergence of the objective function value along the trajectory, as it was noticed in the context of unconstrained minimization problems in [7, 9, 11] and of linearly constrained minimization problems in [10, 30].
It is straightforward to show the existence of local solutions to (2.6), under the additional assumption that \(\nabla f\) is Lipschitz continuous on every bounded subset of \(\mathcal {X}\). First, notice that (2.6) can be rewritten as a first-order dynamical system. Indeed, \(\left( x, \lambda \right) :\left[ t_{0}, + \infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) is a solution to (2.6) if and only if \((x, \lambda , y, \nu ) :\left[ t_{0}, + \infty \right) \rightarrow \mathcal {X} \times \mathcal {Y} \times \mathcal {X} \times \mathcal {Y}\) is a solution to

where \(F :\left[ t_{0}, + \infty \right) \times \mathcal {X} \times \mathcal {Y} \times \mathcal {X} \times \mathcal {Y} \rightarrow \mathcal {X} \times \mathcal {Y} \times \mathcal {X} \times \mathcal {Y}\) is given by
where F is evidently continuous in t, and \(F(t, \cdot )\) is Lipschitz continuous on every bounded subset, provided that the same property holds for \(\nabla f\). We can then employ a theorem such as that by Cauchy-Lipschitz to obtain the existence of a unique solution to the previous system, and thus a unique solution to (2.6), defined on a maximal interval \([t_{0}, T_{\text {max}})\). To go further and show the existence and uniqueness of a global solution (that is, \(T_{\text {max}} = +\infty \)) we will need some energy estimates derived in the next section in a similar way as in [11, 17]. For this reason, the existence and uniqueness of a global solution is postponed to a later stage.
3 Faster Convergence Rates via Time Rescaling
In this section we will derive fast convergence rates for the primal-dual gap, the feasibility measure, and the objective function value along the trajectories generated by the dynamical system (2.6). We will make the following assumptions on the parameters \(\alpha \), \(\theta \), \(\beta \) and the function \(\delta \) throughout this section.

Besides the first three conditions that are known previously in [17], it is worth pointing out that we can deduce from the last one the following inequality for every \(t \geqslant t_{0}\):
This gives a connection to the condition which appears in [7]. A few more comments regarding the function \(\delta \) will come later, after the convergence rates statements.
3.1 The Energy Function
Let \(\left( x, \lambda \right) :\left[ t_{0}, + \infty \right) \rightarrow \mathcal {X}\times \mathcal {Y}\) be a solution of (2.6). Let \((x_{*}, \lambda _{*}) \in \mathbb {S}\) be fixed, we define the energy function \(\mathcal {E}:\left[ t_{0}, + \infty \right) \rightarrow \mathbb {R}\)
where
Notice that, according to (2.4) and (2.5), we have for every \(t \geqslant t_0\)
where \(f_{*}\) denotes the optimal objective value of (1.1). In addition, due to (3.7), we have
The construction of \(\mathcal {E}\) is inspired by [17]. However, one can notice that we only consider \(\mathcal {E}\) defined with respect to a fixed primal-dual solution \(\left( x_{*}, \lambda _{*} \right) \in \mathbb {S}\) rather than a family of energy functions, each defined with respect to a point \(\left( z, \mu \right) \in \mathbb {F} \times \mathcal {Y}\). This gives simpler proofs for some results when compared to those in [17].
Assumption 1 implies the nonnegativity of following quantity, which will appear many times in our analysis:
The following lemma gives us the decreasing property of the energy function. As a consequence of this lemma, we obtain some integrability results which will be needed later. The proofs are postponed to the Appendix.
Lemma 3.1
Let \(\left( x, \lambda \right) :\left[ t_{0}, + \infty \right) \rightarrow \mathcal {X}\times \mathcal {Y}\) be a solution of (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). For every \(t \geqslant t_{0}\) it holds
Proof
See “Proof of Lemma 3.1” in Appendix B. \(\square \)
Theorem 3.2
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution of (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). The following statements are true
-
(i)
it holds
$$\begin{aligned} \int _{t_{0}}^{+\infty } t \sigma (t)\Big [\mathcal {L}\left( x(t), \lambda _{*} \right) - \mathcal {L}(x_{*}, \lambda (t))\Big ]dt&\leqslant \mathcal {E}(t_{0}) \,< +\infty , \end{aligned}$$(3.10)$$\begin{aligned} \beta \int _{t_{0}}^{+\infty } t \delta (t) \left\Vert Ax \left( t \right) - b \right\Vert ^{2}dt&\leqslant \frac{2\mathcal {E}(t_{0})}{\theta } \,< +\infty , \end{aligned}$$(3.11)$$\begin{aligned} \xi \int _{t_{0}}^{+\infty } t \left\Vert \left( \dot{x} \left( t \right) , \dot{\lambda } \left( t \right) \right) \right\Vert ^{2}&\leqslant \frac{\mathcal {E}(t_{0})}{\theta } \, < +\infty ; \end{aligned}$$(3.12) -
(ii)
if, in addition, \(\alpha > 3\) and \(\frac{1}{2} \geqslant \theta > \frac{1}{\alpha - 1}\), then the trajectory \((x(t), \lambda (t))_{t\geqslant t_{0}}\) is bounded and the convergence rate of its velocity is
$$\begin{aligned} \left\Vert \left( \dot{x} \left( t \right) , \dot{\lambda } \left( t \right) \right) \right\Vert = \mathcal {O}\left( \frac{1}{t}\right) \quad \text {as} \quad t\rightarrow +\infty . \end{aligned}$$
Proof
See “Proof of Theorem 3.2” in Appendix B. \(\square \)
3.2 Fast Convergence Rates for the Primal-Dual Gap, the Feasibility Measure and the Objective Function Value
The following are the main convergence rates results of the paper.
Theorem 3.3
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X}\times \mathcal {Y}\) be a solution of (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). The following statements are true
-
(i)
for every \(t\geqslant t_{0}\) it holds
$$\begin{aligned} 0 \leqslant \mathcal {L}\left( x(t), \lambda _{*} \right) - \mathcal {L}(x_{*}, \lambda (t)) \leqslant \frac{\mathcal {E}(t_{0})}{\theta ^{2} t^{2} \delta (t)}; \end{aligned}$$(3.13) -
(ii)
for every \(t\geqslant t_{0}\) it holds
$$\begin{aligned} \left\Vert Ax \left( t \right) - b \right\Vert \leqslant \frac{2 C_{1}}{t^{2} \delta (t)}, \end{aligned}$$(3.14)where
$$\begin{aligned} C_{1}&:= \sup _{t\geqslant t_{0}} t \left\Vert \dot{\lambda } \left( t \right) \right\Vert + (\alpha - 1) \sup _{t\geqslant t_{0}} \left\Vert \lambda \left( t \right) - \lambda _{*} \right\Vert \\&\quad + t_{0}^{2} \delta (t_{0}) \left\Vert Ax(t_{0}) - b \right\Vert + t_{0}\left\Vert \dot{\lambda } \left( t_{0} \right) \right\Vert ; \end{aligned}$$ -
(iii)
for every \(t\geqslant t_{0}\) it holds
$$\begin{aligned} \left|f \left( x \left( t \right) \right) - f_{*} \right|\leqslant \left( \frac{\mathcal {E}(t_{0})}{\theta ^{2}} + 2 C_{1} \left\Vert \lambda _{*} \right\Vert \right) \frac{1}{t^{2} \delta (t)}. \end{aligned}$$(3.15)
Proof
(i) We have already established that \(\mathcal {E}\) is nonincreasing on \(\left[ t_{0}, +\infty \right) \). Therefore, from the expression for \(\mathcal {E}\) and relation (3.6) we deduce
and the first claim follows.
(ii) From the second line of (2.6), for every \(t\geqslant t_{0}\) we have
Fix \(t\geqslant t_{0}\). On the one hand, integration by parts yields
On the other hand, again integrating by parts leads to
Now, integrating (3.17) from \(t_{0}\) to t and using (3.18) and (3.19) gives us
It follows that, for every \(t \geqslant t_{0}\), we have
where
and this quantity is finite in light of (B.7) and (B.5). Now, we set
and we apply Lemma A.1 to deduce that
(iii) For a fixed \(t\geqslant t_{0}\), we have
Therefore, from using (3.22) and (3.16) we obtain, for every \(t\geqslant t_{0}\),
which leads to the last statement. \(\square \)
Some comments regarding the previous proof and results are in order.
Remark 3.4
The proof we provided here is significantly shorter than the one derived in [17] thanks to Lemma A.1. This Lemma is the one used in [28] for showing the fast convergence to zero of the feasibility measure, although the authors study a different dynamical system. On the other hand, when \(\delta \left( t \right) \equiv 1\), the result in [17] is more robust than the one we obtain here, as it gives the \(\mathcal {O}\left( \frac{1}{t^{2}} \right) \) rates for the sum of primal-dual gap and feasibility measure, rather than each one individually. It also allows us to focus only on the energy function defined with respect to a primal-dual optimal solution \(\left( x_{*}, \lambda _{*} \right) \in \mathbb {S}\), rather than on an arbitrary feasible point \(\left( z, \mu \right) \in \mathbb {F} \times \mathcal {Y}\) as in [17].
Remark 3.5
Here are some remarks comparing our rates of convergence to those in [10, 30].
-
Primal-dual gap: According to (3.13), the following rate of convergence for the primal-dual is exhibited:
$$\begin{aligned} \mathcal {L}\bigl (x(t), \lambda _{*}\bigr ) - \mathcal {L}\bigl (x_{*}, \lambda (t)\bigr ) = \mathcal {O}\left( \frac{1}{t^{2} \delta (t)}\right) \quad \text {as} \quad t\rightarrow +\infty , \end{aligned}$$ -
Feasibility measure: According to (3.14), we have
$$\begin{aligned} \left\Vert Ax \left( t \right) - b \right\Vert = \mathcal {O}\left( \frac{1}{t^{2} \delta (t)}\right) \quad \text {as} \quad t\rightarrow +\infty , \end{aligned}$$which improves the rate \(\mathcal {O}\left( \frac{1}{t \sqrt{\delta (t)}}\right) \) reported in [10, 30].
-
Functional values: Relation (3.15) tells us that
$$\begin{aligned} \left|f \left( x \left( t \right) \right) - f_{*} \right|= \mathcal {O}\left( \frac{1}{t^{2} \delta (t)}\right) \quad \text {as} \quad t\rightarrow +\infty . \end{aligned}$$In [10], only the upper bound presents this order of convergence. The lower bound obtained is of order \(\mathcal {O}\left( \frac{1}{t \sqrt{\delta (t)}}\right) \) as \(t \rightarrow +\infty \). In [30], there are no comments on the rate attained by the functional values in the case of a general time rescaling parameter.
-
Further comparisons with [30]: in [30, Theorem 2.16], unlike the preceding result [30, Theorem 2.15], the authors produce a rate of \(\mathcal {O}\left( \frac{1}{t^{1/\theta }}\right) \) as \(t\rightarrow +\infty \) for \(\Vert Ax(t) - b\Vert \) and \(|f(x(t)) - f(x_{*})|\), provided the time rescaling parameter is chosen to be \(\delta (t) = \delta _{0} t^{\frac{1}{\theta } - 2}\), for some \(\delta _{0} > 0\). This choice comes from the solution to the differential equation
$$\begin{aligned} \frac{t \dot{\delta }(t)}{\delta (t)} = \frac{1 - 2\theta }{\theta } \quad \forall t\geqslant t_{0}, \end{aligned}$$and thus is covered by our results when the growth condition (3.1) holds with equality. The rates are consequently
$$\begin{aligned} \mathcal {O}\left( \frac{1}{t^{2} \cdot \delta _{0} t^{\frac{1}{\theta } - 2}}\right) = \mathcal {O}\left( \frac{1}{t^{\frac{1}{\theta }}}\right) \quad \text {as} \quad t\rightarrow +\infty . \end{aligned}$$In this setting, if we wish to obtain fast convergence rates, we need to choose a small \(\theta \). In light of Assumption 1, where we have \(\frac{1}{2}\geqslant \theta \geqslant \frac{1}{\alpha - 1}\), this can be achieved by taking \(\alpha \) large enough. Such behaviour can also be seen in [10] and in the unconstrained case [7, 11].
4 Weak Convergence of the Trajectory to a Primal-Dual Solution
In this section we will show that the solutions to (2.6) weakly converge to an element of \(\mathbb {S}\). The fact that \(\delta \left( t \right) \) enters the convergence rate statement suggests that one can benefit from this time rescaling function when it is at least nondecreasing on \(\left[ t_{0}, +\infty \right) \). We are, in fact, going to need this condition when showing trajectory convergence.

Assumption 2 entails the existence of \(C_{2} > 0\) such that
and therefore it follows further from the nondecreasing property of \(\delta \) that
Moreover, from (4.1), for every \(t\geqslant t_{0}\), we have
which gives
We can now formally state the existence and uniqueness result of the trajectory. The proof follows the same argument as in [17, Theorem 4.1], therefore we omit the details.
Theorem 4.1
In the setting of Assumption 2, for every choice of initial conditions
the system (2.6) has a unique global twice continuously differentiable solution \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\).
The additional Lipschitz continuity condition of \(\nabla f\) and the fact that \(\delta \) is nondecreasing give rise to the following two essential integrability statements.
Proposition 4.2
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution of (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). Then it holds
and
Proof
See “Proof of Proposition 4.2” in Appendix B. \(\square \)
Now, for a given primal-dual solution \((x_{*}, \lambda _{*}) \in \mathbb {S}\), we define the following mappings on \(\left[ t_{0}, +\infty \right) \)
The following are three technical lemmas that we will need in this section. Lemma 4.4 guarantess that the first condition of Opial’s Lemma is met.
Lemma 4.3
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) a solution of (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). The following inequality holds for every \(t\geqslant t_{0}\):
Proof
See “Proof of Lemma 4.3” in Appendix B. \(\square \)
Lemma 4.4
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution to (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). Then the positive part \([\dot{\varphi }]_{+}\) of \(\dot{\varphi }\) belongs to \(\mathbb {L}^{1}\left[ t_{0}, +\infty \right) \) and the limit \(\lim _{t \rightarrow +\infty } \varphi (t)\) exists.
Proof
For any \(t\geqslant t_{0}\), we multiply (4.8) by t and drop the last two norm squared terms to obtain
Recall from (4.6) that for every \(t\geqslant t_{0}\) we have
On the one hand, according to (3.12), the second summand of the previous expression belongs to \(\mathbb {L}^{1}\left[ t_{0}, +\infty \right) \). On the other hand, using (4.3) and (3.10), we assert that
Hence, the first summand of (4.9) also belongs to \( \mathbb {L}^{1}\left[ t_{0}, +\infty \right) \), which implies that the mapping \(t \mapsto tW(t)\) belongs to \(\mathbb {L}^{1}\left[ t_{0}, +\infty \right) \) as well. For achieving the desired conclusion, we make use of Lemma A.4 with \(\phi := \varphi \) and \(w:= \theta W\). \(\square \)
Lemma 4.5
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution to (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). The following inequality holds for every \(t\geqslant t_{0}\)
Proof
See “Proof of Lemma 4.5” in Appendix B. \(\square \)
Lemma 4.6
Let \((x, \lambda ): [t_{0}, +\infty ) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution to (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). Then, for every \(t\geqslant t_{0}\) it holds
where, for \(s\geqslant t_{0}\),
for certain nonnegative constants \(C_{3}, C_{4}\) and \(C_{5}\).
Proof
See “Proof of Lemma 4.6” in Appendix B. \(\square \)
The following proposition provides us with the main integrability result that will be used for verifying the second condition of Opial’s Lemma.
Proposition 4.7
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution to (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). Then it holds
Proof
We divide (4.10) by \(t^{\alpha }\), thus obtaining
Now, we integrate this inequality from \(t_{0}\) to r. We get
We now recall some important facts. First of all, we have
In addition, according to Lemma A.2, it holds
and
respectively.
Finally, integrating by parts leads to
The supremum term is finite due to the boundedness of the trajectory. Now, by using the nonnegativity of \(\varphi \) and the facts (4.13), (4.14), (4.15) and (4.16) on (4.12), we come to
where
According to (3.11) and (3.12) in Theorem 3.2, as well as Lemma 4.4, we know that the mappings \(t \mapsto t V(t)\) and \(t \mapsto t \left( \left\Vert Ax \left( t \right) - b \right\Vert ^{2} + \left\Vert \dot{\lambda } \left( t \right) \right\Vert \right) \) belong to \(\mathbb {L}^{1}\left[ t_{0}, +\infty \right) \). Therefore, by taking the limit as \(r \rightarrow +\infty \) in (4.17) we obtain
Again, from (4.3) we conclude that
which completes the proof. \(\square \)
The following result is the final step towards the second condition of Opial’s Lemma.
Theorem 4.8
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution to (2.6) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\). Then it holds
Consequently,
while, as seen earlier,
Proof
We first show the gradient rate. For \(t\geqslant t_{0}\), it holds
On the one hand, by Assumption 2, we can write
Since \(\delta \) is nondecreasing, for \(t \geqslant t_{0}\) we have \(\sqrt{\delta (t)} \geqslant \sqrt{\delta (t_{0})} > 0\). Set \(t_{1}:= \max \left\{ t_{0}, \frac{1}{\sqrt{t_{0}}}\right\} \). Therefore, for \(t \geqslant t_{1}\) it holds
and thus
On the other hand, for every \(t \geqslant t_{1}\) we deduce
where the last inequality is a consequence of the \(\ell \)-Lipschitz continuity of \(\nabla f\). By combining (4.20), (4.21) and (4.22), from (4.19) we assert that for every \(t\geqslant t_{1}\)
The right hand side of the previous inequality belongs to \(\mathbb {L}^{1} [t_{1}, +\infty )\), according to (3.12) and (4.4). Since \(\delta \) is nondecreasing, for every \(t \geqslant t_{1}\) we have
and thus
This means that the function being differentiated also belongs to \(\mathbb {L}^{1} [t_{1}, +\infty )\). Therefore, Lemma A.3 gives us
Proceeding in the exact same way, for every \(t\geqslant t_{1}\) we have
According to (3.12) and (4.11), the right hand side of the previous inequality belongs to \(\mathbb {L}^{1}[t_{1}, +\infty )\). Arguing as in (4.23), we deduce that the function being differentiated also belongs to \(\mathbb {L}^{1}[t_{1}, +\infty )\). Again applying Lemma A.3, we come to
Finally, recalling that \(A^{*}\lambda _{*} = -\nabla f(x_{*})\), we deduce from the triangle inequality that
and the third claim follows. \(\square \)
Remark 4.9
The previous theorem also has its own interest. It tells us that the time rescaling parameter also plays a role in accelerating the rates of convergence for \(\left\Vert \nabla f \left( x \left( t \right) \right) - \nabla f \left( x_{*} \right) \right\Vert \) and \(\Vert A^{*}(\lambda (t) - \lambda _{*})\Vert \) as \(t\rightarrow +\infty \). Moreover, we deduce from (4.18) that the mapping \((x, \lambda ) \mapsto (\nabla f(x), A^{*}\lambda )\) is constant along \(\mathbb {S}\), as reported in [17, Proposition A.4].
We now come to the final step and show weak convergence of the trajectories of (2.6) to elements of \(\mathbb {S}\).
Theorem 4.10
Let \((x, \lambda ): \left[ t_{0}, +\infty \right) \rightarrow \mathcal {X} \times \mathcal {Y}\) be a solution to (2.6) and \(\left( x_{*}, \lambda _{*} \right) \in \mathbb {S}\). Then \(\bigl (x(t), \lambda (t)\bigr )\) converges weakly to a primal-dual solution of (1.1) as \(t\rightarrow +\infty \).
Proof
For proving this theorem, we make use of Opial’s Lemma (see Lemma A.5). Lemma 4.4 tells us that \(\lim _{t\rightarrow +\infty }\left\| \bigl (x(t), \lambda (t)\bigr ) - (x_{*}, \lambda _{*})\right\| \) exists for every \((x_{*}, \lambda _{*}) \in \mathbb {S}\), which proves condition (i) of Opial’s Lemma. Now let \(\bigl (\tilde{x}, \tilde{\lambda }\bigr )\) be any weak sequential cluster point of \(\bigl ( x(t), \lambda (t)\bigr )\) as \(t\rightarrow +\infty \), which means there exists a strictly increasing sequence \((t_{n})_{n\in \mathbb {N}} \subseteq [t_{0}, +\infty )\) such that
We want to show the remaining condition of Opial’s Lemma, which asks us to check that \(\bigl (\tilde{x}, \tilde{\lambda }\bigr ) \in \mathbb {S}\). In other words, we must show that
Let \((x, \lambda ) \in \mathcal {X} \times \mathcal {Y}\) and \((x_{*}, \lambda _{*}) \in \mathbb {S}\) be fixed. Notice that the functions
are convex and continuous, therefore they are lower semicontinuous. According to a known result (see, for example, [14, Theorem 9.1]), they are also weakly lower semicontinuous. Therefore, we can derive that
where in the second and third equalities we used the fact that, as \(n\rightarrow +\infty \), we have \(f(x(t_{n})) \rightarrow f(x_{*})\) and \(Ax(t_{n}) \rightarrow b\) (Theorem 3.3), and \(A^{*}\lambda _{n} \rightarrow A^{*} \lambda _{*}\) (Theorem 4.8). Similarly, the weak lower semicontinuity of the function \(\bigl \langle \lambda - \tilde{\lambda }, A(\cdot ) - b\bigr \rangle :\mathcal {X} \rightarrow \mathbb {R}\) yields
We have thus showed (4.24) and the proof is concluded. \(\square \)
5 Numerical Experiments
We will illustate the theoretical results by two numerical examples, with \(\mathcal {X} = \mathbb {R}^{4}\) and \(\mathcal {Y} = \mathbb {R}^{2}\). We will address two minimization problems with linear constraints; one with a strongly convex objective function and another with a convex objective function which is not strongly convex. In both cases, the linear constraints are dictated by
Example 5.1
Consider the minimization problem
The optimality conditions can be calculated and lead to the following primal-dual solution pair
Example 5.2
Consider the minimization problem
This problem is similar to the regularized logistic regression frequently used in machine learning. We cannot explicitly calculate the optimality conditions as in the previous case; instead, we use the last solution in the numerical experiment as the approximate solution.
To comply with Assumption 2, we choose \(t_{0} > 0\), \(\alpha = 8\), \(\beta = 10\), \(\theta = \frac{1}{6}\), and we test four different choices for the rescaling parameter: \(\delta (t) = 1\) (i.e., the (PD-AVD) dynamics in [17, 45]), \(\delta (t) = t\), \(\delta (t) = t^{2}\) and \(\delta (t) = t^{3}\). In both examples, the initial conditions are
For each choice of \(\delta \), we plot, using a logarithmic scale, the primal-dual gap \(\mathcal {L}\bigl (x(t), \lambda _{*}\bigr ) - \mathcal {L}\bigl (x_{*}, \lambda (t)\bigr )\), the feasibility measure \(\left\Vert A x \left( t \right) - b \right\Vert \) and the functional values \(\left|f \left( x \left( t \right) \right) - f_{*} \right|\), to highlight the theoretical result in Theorem 3.3. We also illustrate the findings from Theorem 4.8, namely, we plot the quantities \(\left\Vert \nabla f \left( x \left( t \right) \right) - \nabla f \left( x_{*} \right) \right\Vert \) and \(\left\Vert A^{*} \left( \lambda \left( t \right) - \lambda _{*} \right) \right\Vert \), as well as the velocity \(\Vert ( \dot{x} (t), \dot{\lambda } (t) ) \Vert \).
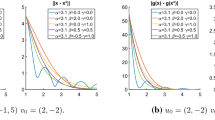
Figures 1 and 2 display these plots for Examples 5.1 and 5.2, respectively. As predicted by the theory, choosing faster-growing time rescaling parameters yields better convergence rates. This is not the case for the velocities.

The function \(\delta \left( t \right) \) influences convergence behaviour in Example 5.1

The function \(\delta \left( t \right) \) influences convergence behaviour in Example 5.2
Next we use Example 5.2 to compare the convergence behaviour of our system (2.6) with the one where the asymptotically vanishing damping term is chosen to be \(\frac{\alpha }{t^{r}}\), for \(r \in [0,1]\). Notice that \(r = 1\) gives our system (2.6). When \(r = 0\), in the setting of [30, Theorem 2.2], we know that the primal-dual gap exhibits a convergence rate of \(\mathcal {O}\left( \frac{1}{t \delta (t)}\right) \) as \(t\rightarrow +\infty \). This is illustrated in Fig. 3, were we plotted the combinations \(\left( \delta (t) = t; r = 0 \right) \), \(\left( \delta (t) = t; r = 1 \right) \), \(\left( \delta (t) = t^{2}; r = 0 \right) \), and \(\left( \delta (t) = t^{2}; r = 1 \right) \). In particular, observe that the rate predicted by [30, Theorem 2.2] for the primal-dual gap for the case \(\left( \delta (t) = t^{2}; r = 0 \right) \) reads \(\mathcal {O}\left( \frac{1}{t\cdot t^{2}}\right) \), while the rate predicted by our Theorem 3.3 for the case \(\left( \delta (t) = t; r = 1 \right) \) reads \(\mathcal {O}\left( \frac{1}{t^{2}\cdot t}\right) \). It is no surprise then to see the combinations \(\left( \delta (t) = t^{2}; r = 0 \right) \) and \(\left( \delta (t) = t; r = 1 \right) \) exhibiting similar convergence behaviour in Fig. 3.

The function \(\delta (t)\), as well as the parameter r, influence convergence behaviour in Example 5.2

The parameter r influences convergence behaviour in Example 5.2
For better understanding, we run Example 5.2 once more to show the plots which result from fixing the time rescaling parameter \(\delta (t) = t\) and varying \(r \in \{0, 0.25, 0.5, 0.75, 1\}\). Notice how the convergence improves as r approaches 1. As \(t\rightarrow +\infty \), [30, Theorem 2.7] predicts convergence rates of \(\mathcal {O}\left( \frac{1}{t^{\tau } \delta (t)}\right) \) for the primal-dual gap and of \(\mathcal {O}\left( \frac{1}{t^{\tau /2}}\right) \) for the velocities, which is reflected in our plots.
References
Abbas, B., Attouch, H., Svaiter, B.F.: Newton-like dynamics and forward-backward methods for structured monotone inclusions in Hilbert spaces. J. Optim. Theory Appl. 161(2), 331–360 (2014). https://doi.org/10.1007/s10957-013-0414-5
Alvarez, F.: On the minimizing property of a second order dissipative system in Hilbert spaces. SIAM J. Control Optim. 38(4), 1102–1119 (2000). https://doi.org/10.1137/S0363012998335802
Attouch, H., Goudou, X., Redont, P.: The heavy ball with friction method, I. The continuous dynamical system: global exploration of the local minima of a real-valued function by asymptotic analysis of a dissipative dynamical system. Commun. Contemp. Math. 02(1), 1–34 (2000). https://doi.org/10.1142/S0219199700000025
Alvarez, F., Attouch, H., Bolte, J., Redont, P.: A second-order gradient-like dissipative dynamical system with Hessian-driven damping: application to optimization and mechanics. J. Math. Pures Appl. 81(8), 747–779 (2002). https://doi.org/10.1016/S0021-7824(01)01253-3
Attouch, H., Chbani, Z., Riahi, H.: Combining fast inertial dynamics for convex optimization with Tikhonov regularization. J. Math. Anal. Appl. 457(2), 1065–1094 (2018). https://doi.org/10.1016/j.jmaa.2016.12.017
Attouch, H., Chbani, Z., Peypouquet, J., Redont, P.: Fast convergence of inertial dynamics and algorithms with asymptotic vanishing viscosity. Math. Program. 168(1), 123–175 (2018). https://doi.org/10.1007/s10107-016-0992-8
Attouch, H., Chbani, Z., Riahi, H.: Fast proximal methods via time scaling of damped inertial dynamics. SIAM J. Optim. 29(3), 2227–2256 (2019). https://doi.org/10.1137/18M1230207
Attouch, H., Chbani, Z., Riahi, H.: Rate of convergence of the Nesterov accelerated gradient method in the subcritical case \(\alpha \le 3\). ESAIM Control Optim. Calc. Var. (2019). https://doi.org/10.1051/cocv/2017083
Attouch, H., Chbani, Z., Riahi, H.: Fast convex optimization via time scaling of damped inertial gradient dynamics. Pure Appl. Funct. Anal. 6(6), 1081–1117 (2021)
Attouch, H., Chbani, Z., Fadili, J., Riahi, H.: Fast convergence of dynamical ADMM via time scaling of damped inertial dynamics. J. Optim. Theory Appl. 193(1), 704–736 (2022). https://doi.org/10.1007/s10957-021-01859-2
Attouch, H., Chbani, Z., Fadili, J., Riahi, H.: First-order optimization algorithms via inertial systems with Hessian driven damping. Math. Program. 193(1), 113–155 (2022). https://doi.org/10.1007/s10107-020-01591-1
Attouch, H., Chbani, Z., Riahi, H.: Fast convex optimization via a third-order in time evolution equation. Optimization 71(5), 1275–1304 (2022). https://doi.org/10.1080/02331934.2020.1764953
Attouch, H., Peypouquet, J.: The rate of convergence of Nesterov’s accelerated forward-backward method is actually faster than \(1/k^{2}\). SIAM J. Optim. 26(3), 1824–1834 (2016). https://doi.org/10.1137/15M1046095
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. CMS Books in Mathematics. Springer, New York (2011). https://doi.org/10.1007/978-1-4419-9467-7
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2(1), 183–202 (2009). https://doi.org/10.1137/080716542
Boţ, R.I.: Conjugate Duality in Convex Optimization, vol. 637. Lecture Notes in Economics and Mathematical Systems. Springer, Berlin (2010). https://doi.org/10.1007/978-3-642-04900-2
Boţ, R.I., Nguyen, D.-K.: Improved convergence rates and trajectory convergence for primal-dual dynamical systems with vanishing damping. J. Differ. Equ. 303, 369–406 (2021). https://doi.org/10.1016/j.jde.2021.09.021
Boţ, R.I., Csetnek, E.R., László, S.C.: A primal-dual dynamical approach to structured convex minimization problems. J. Differ. Equ. 269(12), 10717–10757 (2020). https://doi.org/10.1016/j.jde.2020.07.039
Boţ, R.I., Csetnek, E.R., Nguyen, D.-K.: Fast augmented Lagrangian method in the convex regime with convergence guarantees for the iterates. Math. Program. (2022). https://doi.org/10.1007/s10107-022-01879-4
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1–122 (2010). https://doi.org/10.1561/2200000016
Cabot, A., Engler, H., Gadat, S.: Second-order differential equations with asymptotically small dissipation and piecewise flat potentials. Electron. J. Differ. Equ. 2009(17), 33–38 (2009)
Cabot, A., Engler, H., Gadat, S.: On the long time behavior of second order differential equations with asymptotically small dissipation. Trans. Am. Math. Soc. 361(11), 5983–6017 (2009)
Chambolle, A., Dossal, C.: On the convergence of the iterates of the “Fast iterative shrinkage/thresholding algorithm’’. J. Optim. Theory Appl. 166(3), 968–982 (2015). https://doi.org/10.1007/s10957-015-0746-4
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 2(1), 17–40 (1976). https://doi.org/10.1016/0898-1221(76)90003-1
Goldstein, T., O’Donoghue, B., Setzer, S., Baraniuk, R.: Fast alternating direction optimization methods. SIAM J. Imaging Sci. 7(3), 1588–1623 (2014). https://doi.org/10.1137/120896219
Güler, O.: New proximal point algorithms for convex minimization. SIAM J. Optim. 2(4), 649–664 (1992). https://doi.org/10.1137/0802032
He, X., Hu, R., Fang, Y.P.: Convergence rates of inertial primal-dual dynamical methods for separable convex optimization problems. SIAM J. Control Optim. 59(5), 3278–3301 (2021). https://doi.org/10.1137/20M1355379
He, X., Hu, R., Fang, Y.-P.: Fast primal-dual algorithm via dynamical system for a linearly constrained convex optimization problem. Automatica 146, 110547 (2022). https://doi.org/10.1016/j.automatica.2022.110547
He, X., Hu, R., Fang, Y.-P.: Inertial accelerated primal-dual methods for linear equality constrained convex optimization problems. Numer. Algorithms 90(4), 1669–1690 (2022). https://doi.org/10.1007/s11075-021-01246-y
He, X., Hu, R., Fang, Y.-P.: Inertial primal-dual dynamics with damping and scaling for linearly constrained convex optimization problems. Applicable Anal. (2022). https://doi.org/10.1080/00036811.2022.2104260
Lin, Z., Li, H., Fang, C.: Accelerated Optimization for Machine Learning: First-Order Algorithms. Springer, Singapore (2020). https://doi.org/10.1007/978-981-15-2910-8
Madan, R., Lall, S.: Distributed algorithms for maximum lifetime routing in wireless sensor networks. IEEE Trans. Wirel. Commun. 5(8), 2185–2193 (2006). https://doi.org/10.1109/TWC.2006.1687734
May, R.: Asymptotic for a second-order evolution equation with convex potential and vanishing damping term. Turk. J. Math. 41(3), 681–685 (2017). https://doi.org/10.3906/mat-1512-28
Nesterov, Y.: A method for solving the convex programming problem with convergence rate \(\cal{O}(1/k^{2})\). Proc. USSR Acad. Sci. 269, 543–547 (1983)
Nesterov, Y.: Introductory Lectures on Convex Optimization, vol. 87. Applied Optimization. Springer, Boston (2004). https://doi.org/10.1007/978-1-4419-8853-9
Opial, Z.: Weak convergence of the sequence of successive approximations for nonexpansive mappings. Bull. Am. Math. Soc. 73(4), 591–597 (1967)
Polyak, B.T.: Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 4(5), 1–17 (1964). https://doi.org/10.1016/0041-5553(64)90137-5
Polyak, B.T.: Introduction to Optimization. Translations Series in Mathematics and Engineering. Optimization Software, Publications Division, New York (1987)
Rockafellar, R.T.: Augmented Lagrangians and applications of the proximal point algorithm in convex programming. Math. Oper. Res. 1(2), 97–116 (1976). https://doi.org/10.1287/moor.1.2.97
Shi, G., Johansson, K.H.: Randomized optimal consensus of multi-agent systems. Automatica 48(12), 3018–3030 (2012). https://doi.org/10.1016/j.automatica.2012.08.018
Su, W., Boyd, S., Candès, E.J.: A differential equation for modeling Nesterov’s accelerated gradient method: theory and insights. J. Mach. Learn. Res. 17(1), 5312–5354 (2016)
Yi, P., Hong, Y., Liu, F.: Distributed gradient algorithm for constrained optimization with application to load sharing in power systems. Syst. Control Lett. 83, 45–52 (2015). https://doi.org/10.1016/j.sysconle.2015.06.006
Yi, P., Hong, Y., Liu, F.: Initialization-free distributed algorithms for optimal resource allocation with feasibility constraints and application to economic dispatch of power systems. Automatica 74, 259–269 (2016). https://doi.org/10.1016/j.automatica.2016.08.007
Zeng, X., Yi, P., Hong, Y., Xie, L.: Distributed continuous-time algorithms for nonsmooth extended monotropic optimization problems. SIAM J. Control Optim. 56(6), 3973–3993 (2018). https://doi.org/10.1137/17M1118609
Zeng, X., Lei, J., Chen, J.: Dynamical primal-dual accelerated method with applications to network optimization. IEEE Trans. Autom. Control (2022). https://doi.org/10.1109/TAC.2022.3152720
Acknowledgements
The authors would like to thank the editor and the anonymous referees for their helpful comments and suggestions, which have led to the improvement of this paper.
Funding
Open access funding provided by Austrian Science Fund (FWF). D.-K. Nguyen research supported by FWF (Austrian Science Fund), project P 34922-N.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No potential conflict of interest was reported by the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
Here we collect the auxiliary results that are required to carry out many steps in out analysis.
A proof for the following lemma in the finite-dimensional case can be found in [28, Lemma 6]. The proof for the infinite-dimensional case is short and virtually identical, so we include it here for the sake of completeness.
Lemma A.1
Assume that \(t_{0} > 0\), \(g: \left[ t_{0}, +\infty \right) \rightarrow \mathcal {Y}\) is a continuous differentiable function, \(a: \left[ t_{0}, +\infty \right) \rightarrow [0, +\infty )\) is a continuous function, and \(C \geqslant 0\). If, in the sense of Bochner integrability, we have
then
Proof
Define, for every \(t\geqslant t_{0}\),
Fix \(t\geqslant t_{0}\). The time derivative of G reads
so by using (A.1) and the previous equality we arrive at
Since \(G(t_{0}) = 0\), we have
so by employing (A.2) and the previous equality we obtain, for every \(t\geqslant t_{0}\),
Dividing both sides of the previous inequality by \(e^{\int _{t_{0}}^{t} a(s) ds}\) gives us
Now, by putting (A.1) and (A.3) we finally come to
which leads to the announced statement. \(\square \)
The proofs for the following results can be found in [17, Lemma A.1] and [1, Lemma 5.2], respectively.
Lemma A.2
Let \(0 < t_{0} \leqslant r \leqslant +\infty \) and \(h:\left[ t_{0}, +\infty \right) \rightarrow [0, +\infty )\) be a continuous function. For every \(\alpha > 1\) it holds
If \(r = +\infty \), then equality holds.
Lemma A.3
Let \(t_{0} > 0\), \(1 \leqslant p < +\infty \) and \(1\leqslant q \leqslant +\infty \). Suppose that \(F \in \mathbb {L}^{p}\left[ t_{0}, +\infty \right) \) is a locally absolutely continuous nonnegative function, \(G \in \mathbb {L}^{q}\left[ t_{0}, +\infty \right) \) and
Then, \(\lim _{t\rightarrow +\infty } F(t) = 0\).
The following lemma is a slight variation of results already present in the literature. See, for example, [5, Lemma A.2].
Lemma A.4
Let \(t_{0} > 0\), \(\alpha > 1\), and let \(\phi : [t_{0}, +\infty ) \rightarrow \mathbb {R}\) be a twice continuously differentiable function bounded from below. Furthermore, assume \(w: [t_{0}, +\infty ) \rightarrow [0, +\infty )\) to be a continuously differentiable function such that \(t\mapsto t w(t)\) belongs to \(\mathbb {L}^{1}[t_{0}, +\infty )\) and
Then, the positive part \([\dot{\phi }]_{+}\) of \(\dot{\phi }\) belongs to \(\mathbb {L}^{1}[t_{0}, +\infty )\) and the limit \(\lim _{t\rightarrow +\infty } \phi (t)\) is a real number.
Proof
Fix \(t\geqslant t_{0}\). Adding \((\alpha + 1)t w(t)\) to both sides of the previous inequality and then multiplying it by \(t^{\alpha - 1}\) yields
Since the previous inequality holds for any \(t\geqslant t_{0}\), we can integrate it from \(t_{0}\) to \(t\geqslant t_{0}\) to get
After dropping the nonnegative term \(t^{\alpha + 1}w(t)\) and dividing by \(t^{\alpha }\) we arrive at
where
which further leads to
Now, we integrate this inequality from \(t_{0}\) to \(r\geqslant t_{0}\) and we apply Lemma A.2 with \(h: [t_{0}, +\infty ) \rightarrow [0, +\infty )\) given by \(h(s):= sw(s)\) to obtain
By hypothesis, as \(r\rightarrow +\infty \), the right hand side of the previous inequality is finite. In other words,
The previous statement, together with the fact that we assumed that \(\phi \) was bounded from below, allow us to deduce that the function \(\psi : [t_{0}, +\infty ) \rightarrow \mathbb {R}\) given by
is also bounded from below. An easy computation shows that \(\dot{\psi }\) is nonpositive on \([t_{0}, +\infty )\), thus \(\psi \) is nonincreasing on \([t_{0}, +\infty )\). These facts imply that \(\lim _{t\rightarrow +\infty }\psi (t)\) is a real number. Finally, we conclude that
\(\square \)
The proof for Opial’s Lemma can be found in [36].
Lemma A.5
(Opial’s Lemma) Let \(\mathcal {H}\) be a real Hilbert space, \(S \subseteq \mathcal {H}\) a nonempty set, \(t_{0} > 0\) and \(z: \left[ t_{0}, +\infty \right) \rightarrow \mathcal {H}\) a mapping that satisfies
-
(i)
for every \(z_{*} \in S\), \(\lim _{t\rightarrow +\infty } \Vert z(t) - z_{*}\Vert \) exists;
-
(ii)
every weak sequential cluster point of the trajectory z(t) as \(t \rightarrow +\infty \) belongs to S.
Then, z(t) converges weakly to an element of S as \(t \rightarrow +\infty \).
Appendix B: Missing Proofs
1.1 Proof of Lemma 3.1
Let \(t \geqslant t_{0}\) be fixed. Since \(x_{*} \in \mathbb {F}\), we have
Under these expressions, the system (2.6) can be equivalently written as
which leads to
We get from the distributive property of the inner product
Since \(x_{*} \in \mathbb {F}\), the last four terms in the above identity vanish. Indeed,
Therefore, differentiating \(\mathcal {E}\) with respect to t gives
Furthermore, the convexity of f and the fact that \(x_{*} \in \mathbb {F}\) guarantee
where we recall that the second equality comes from (2.5). By multiplying this inequality by \(\theta t \delta (t)\) and combining it with (B.1), the coefficient attached to the primal-dual gap becomes
which finally gives the desired statement. \(\square \)
1.2 Proof of Theorem 3.2
(i) Recall that Assumption 1 implies \(\sigma (t) \geqslant 0\) for all \(t\geqslant t_{0}\) and \(\xi \geqslant 0\). Moreover, \((x_{*}, \lambda _{*}) \in \mathbb {S}\) yields \(x_{*} \in \mathbb {F}\). Therefore, we can apply (3.7) and Lemma 3.1 to obtain, for every \(t\geqslant t_{0}\),
This means that \(\mathcal {E}\) is nonincreasing on \(\left[ t_{0}, +\infty \right) \). For every \(t\geqslant t_{0}\), by integrating (B.3) from \(t_{0}\) to t, we obtain
where the last inequality follows from (3.8). Since all quantities inside the integrals are nonnegative, we obtain (3.10)–(3.12) by letting \(t \rightarrow +\infty \).
(ii) Let \(t \geqslant t_{0}\) be fixed. Inequality (B.3) tells us that \(\mathcal {E}\) is nonincreasing on \(\left[ t_{0}, +\infty \right) \).
Assuming \(\alpha > 3\) and \(\frac{1}{2} \geqslant \theta > \frac{1}{\alpha - 1}\), we immediately see \(\xi > 0\). From (B.4) we obtain
and
The estimate (B.5) leads to the boundedness of the trajectory. Moreover, applying the triangle inequality and (B.5)–(B.6), we obtain
which gives the desired convergence rate. \(\square \)
1.3 Proof of Proposition 4.2
Thanks to \(\nabla f\) being \(\ell \)-Lipschitz continuous, we can use (1.3) to refine relation (B.2) in the proof of Lemma 3.1
Consequently, combining this inequality with (B.1) yields, for every \(t\geqslant t_{0}\)
Integration of this inequality produces (4.4).
The finiteness of the second integral is only entailed by (3.11) when \(\beta > 0\). For the general case \(\beta \geqslant 0\), we use (3.14) and the fact that \(\delta \) is nondecreasing on \(\left[ t_{0}, +\infty \right) \) to obtain
and the proof is complete. \(\square \)
1.4 Proof of Lemma 4.3
Let \(t\geqslant t_{0}\) be fixed. Differentiating W with respect to time yields
Recall the formulas for the gradients of \(\mathcal {L}\)
since \(x_{*} \in \mathbb {F}\). Plugging this into the expression for \(\dot{W}(t)\) gives us
By regrouping and using (2.6), we arrive at
On the other hand, by the chain rule, we have
By combining these relations, (2.6) and the fact that \(x_{*} \in \mathbb {F}\), we get
The Lipschitz continuity of \(\nabla f\) entails
This, together with (B.9), implies
Multiplying (B.8) by \(\theta t > 0\) and then adding the result to (B.10) yields
where the last inequality follows from Assumption 2
The desired result then follows after some rearranging. \(\square \)
1.5 Proof of Lemma 4.5
Let \(t \geqslant t_{0}\) be fixed. From (2.6) and the fact that \(A^{*}\lambda _{*} = -\nabla f(x_{*})\), we have
Again using (2.6) yields
Adding (B.11) and (B.12) together produces
On the one hand, we have
On the other hand, it holds
Moreover,
Now, using (B.14), (B.15) and (B.16) in (B.13) yields
Finally, since
the conclusion follows after dividing the inequality by \(\delta (t)\). \(\square \)
1.6 Proof of Lemma 4.6
For every \(t \geqslant t_{0}\), by summing up the two inequalities produced by Lemmas 4.3 and 4.5 we deduce that
where
Mutiplying (B.17) by \(t^{\alpha }\) and integrating from \(t_{0}\) to t, we obtain
where
We will furnish five different inequalities from computing each of these integrals separately. Let \(t\geqslant t_{0}\) be fixed.
\(\bullet \) The integral \(I_{1}(t)\). By the chain rule, for \(s \geqslant t_{0}\) it holds
which leads to
\(\bullet \) The integrals \(I_{2}(t)\) and \(I_{4}(t)\). Integration by parts gives
and from here
\(\bullet \) The integral \(I_{3}(t)\). Again by integrating by parts, we get
For \(s\geqslant t_{0}\), according to Assumption 2 we have \(\dot{\delta }(s) \geqslant 0\), hence \(\delta \) is monotonically increasing and therefore
It follows that
\(\bullet \) The integral \(I_{5}(t)\). Integration by parts entails
By the Cauchy–Schwarz inequality, we deduce that
and thus
Now, summing up the inequalities (B.19), (B.20), (B.21), and (B.22), then we proceed to employ (B.18) and obtain
where recall that V was given by
and the constant \(C_{5}\) is given by
We come then to the desired result.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hulett, D.A., Nguyen, DK. Time Rescaling of a Primal-Dual Dynamical System with Asymptotically Vanishing Damping. Appl Math Optim 88, 27 (2023). https://doi.org/10.1007/s00245-023-09999-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s00245-023-09999-9
Keywords
- Augmented Lagrangian method
- Primal-dual dynamical system
- Damped inertial dynamics
- Nesterov’s accelerated gradient method
- Lyapunov analysis
- Time rescaling
- Convergence rate
- Trajectory convergence