
Abstract
The superiorization methodology is intended to work with input data of constrained minimization problems, i.e., a target function and a constraints set. However, it is based on an antipodal way of thinking to the thinking that leads constrained minimization methods. Instead of adapting unconstrained minimization algorithms to handling constraints, it adapts feasibility-seeking algorithms to reduce (not necessarily minimize) target function values. This is done while retaining the feasibility-seeking nature of the algorithm and without paying a high computational price. A guarantee that the local target function reduction steps properly accumulate to a global target function value reduction is still missing in spite of an ever-growing body of publications that supply evidence of the success of the superiorization method in various problems. We propose an analysis based on the principle of concentration of measure that attempts to alleviate this guarantee question of the superiorization method.
Similar content being viewed by others
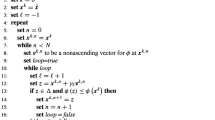

Notes
As common, we use the terms algorithm or algorithmic structure for the iterative processes studied here although no termination criteria are present and only the asymptotic behavior of these processes is studied.
Some support for this reasoning may be borrowed from the American scientist and Noble-laureate Herbert Simon who was in favor of “satisficing” rather than “maximizing”. Satisficing is a decision-making strategy that aims for a satisfactory or adequate result, rather than the optimal solution. This is because aiming for the optimal solution may necessitate needless expenditure of time, energy and resources. The term “satisfice” was coined by Herbert Simon in 1956 [35], see: https://en.wikipedia.org/wiki/Satisficing.
References
Bauschke, H.H., Borwein, J.M.: On projection algorithms for solving convex feasibility problems. SIAM Rev. 38, 367–426 (1996)
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces, 2nd edn. Springer, New York (2017)
Behrends, E.: Introduction to Markov Chains. Springer, New York (2000)
Bell, J.: Trace class operators and Hilbert-Schmidt operators, Technical report, April 18, (2016), 26pp. Available on Semantic Scholar at https://www.semanticscholar.org/
Butnariu, D., Davidi, R., Herman, G.T., Kazantsev, I.G.: Stable convergence behavior under summable perturbations of a class of projection methods for convex feasibility and optimization problems. IEEE J. Sel. Top. Signal Process. 1, 540–547 (2007)
Butnariu, D., Reich,S., Zaslavski, A.J.: Convergence to fixed points of inexact orbits of Bregman-monotone and of nonexpansive operators in Banach spaces, in: H.F. Nathansky, B.G. de Buen, K. Goebel, W.A. Kirk, and B. Sims (Editors), Fixed Point Theory and its Applications, (Conference Proceedings, Guanajuato, Mexico, 2005), Yokahama Publishers, Yokahama, Japan, pp. 11–32, (2006). http://www.ybook.co.jp/pub/ISBN%20978-4-9465525-0.htm
Butnariu, D., Reich, S., Zaslavski, A.J.: Stable convergence theorems for infinite products and powers of nonexpansive mappings. Num. Funct. Anal. Optim. 29, 304–323 (2008)
Carlen, E., Madiman, M., Werner, E.M. (eds.): Convexity and Concentration, The IMA Volumes in Mathematics and its Applications, vol. 161. Springer, New York (2017)
Cegielski, A.: Iterative Methods for Fixed Point Problems in Hilbert Spaces. Springer, Berlin (2012)
Censor, Y.: Superiorization and perturbation resilience of algorithms: A bibliography compiled and continuously updated. (2019) arXiv:1506.04219. http://math.haifa.ac.il/yair/bib-superiorization-censor.html (last updated: September 26)
Censor, Y.: Weak and strong superiorization: Between feasibility-seeking and minimization. Anal. Stiint. Univ. Ovidius Constanta Ser. Mat. 23, 41–54 (2015)
Censor, Y.: Can linear superiorization be useful for linear optimization problems? Inverse Problems33, (2017), 044006 (22 pp.)
Censor, Y., Davidi, R., Herman, G.T.: Perturbation resilience and superiorization of iterative algorithms. Inverse Probl. 26, 065008 (2010)
Censor, Y., Davidi, R., Herman, G.T., Schulte, R.W., Tetruashvili, L.: Projected subgradient minimization versus superiorization. J. Optim. Theory Appl. 160, 730–747 (2014)
Censor, Y., Herman, G.T., Jiang, M. (Editors): Superiorization: Theory and Applications, Inverse Problems33, (2017). Special Issue
Censor, Y., Zaslavski, A.J.: Convergence and perturbation resilience of dynamic string-averaging projection methods. Comput. Optim. Appl. 54, 65–76 (2013)
Censor, Y., Zaslavski, A.J.: Strict Fejér monotonicity by superiorization of feasibility-seeking projection methods. J. Optim. Theory Appl. 165, 172–187 (2015)
Censor, Y., Zur, Y.: Linear superiorization for infeasible linear programming, in: Y. Kochetov, M. Khachay, V. Beresnev, E. Nurminski and P. Pardalos (Editors), Discrete Optimization and Operations Research, Lecture Notes in Computer Science (LNCS), Vol. 9869, Springer, pp. 15–24 (2016)
Davidi, R.: Algorithms for Superiorization and their Applications to Image Reconstruction, Ph.D. dissertation, Department of Computer Science, The City University of New York, NY, USA, (2010). http://gradworks.umi.com/34/26/3426727.html
Davidi, R., Garduño, E., Herman, G.T., Langthaler, O., Rowland, S.W., Sardana, S., Ye, Z.: SNARK14: A programming system for the reconstruction of 2D images from 1D projections. Available at: http://turing.iimas.unam.mx/SNARK14M/. Latest Manuel of October 29, (2017) is at: http://turing.iimas.unam.mx/SNARK14M/SNARK14.pdf
Davidi, R., Herman, G.T., Censor, Y.: Perturbation-resilient block-iterative projection methods with application to image reconstruction from projections. Int. Trans. Oper. Res. 16, 505–524 (2009)
Dubhashi, D.P., Panconesi, A.: Concentration of Measure for the Analysis of Randomised Algorithms. Cambridge University Press, New York (2009)
Edelman, A., Rao, N.R.: Random matrix theory. Acta Numer. 14, 233–297 (2005)
Gromov, M.: Spaces and questions. In: Alon, N., Bourgain, J., Connes, A., Gromov, M., Milman, V. (eds.) Visions in Mathematics, pp. 118–161. Modern Birkhäuser Classics. Birkhäuser Basel, Basel (2010)
Herman, G.T.: Superiorization for image analysis, In: Combinatorial Image Analysis, Lecture Notes in Computer Science Vol. 8466, Springer pp. 1–7 (2014)
Herman, G.T., Garduño, E., Davidi, R., Censor, Y.: Superiorization: an optimization heuristic for medical physics. Med. Phys. 39, 5532–5546 (2012)
Lange, K.: Singular Value Decomposition. In: Numerical Analysis for Statisticians. Springer, New York, pp. 129–142 (2010)
Ledoux, M.: The Concentration of Measure Phenomenon, Mathematical surveys and monographs Vol. 89, The American Mathematical Society (AMS), (2001)
Lee, J.M.: Introduction to Riemannian Manifolds, 2nd Edition. Springer International Publishing, Graduate Texts in Mathematics, Vol. 176, Originally published with title “Riemannian Manifolds: An Introduction to Curvature” (2018)
Samson, P.-M.: Concentration of measure principle and entropy-inequalities. In: Carlen, E., Madiman, M., Werner, E.M. (eds.) Convexity and Concentration, The IMA Volumes in Mathematics and its Applications, vol. 161, pp. 55–105. Springer, New York (2017)
Seneta, E.: A tricentenary history of the law of large numbers. Bernoulli 19, 1088–1121 (2013)
Shapiro, A.: Differentiability properties of metric projections onto convex sets. J. Optim. Theory Appl. 169, 953–964 (2016)
Sidky, E.Y., Pan, X.: Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization. Phys. Med. Biol. 53, 4777–4807 (2008)
S̆ilhavý, M.: Differentiability of the metric projection onto a convex set with singular boundary points. J. Convex Anal. 22, 969–997 (2015)
Simon, H.A.: Rational choice and the structure of the environment. Psychol. Rev. 63, 129–138 (1956)
Song, D., Gupta, A.: \(L_{p}\)-norm uniform distribution. Proc. Am. Math. Soc. 125, 595–601 (1997)
Talagrand, M.: A new look at independence. Ann. Prob. 24, 1–34 (1996)
Zhang, X.: Prior-Knowledge-Based Optimization Approaches for CT Metal Artifact Reduction, Ph.D. dissertation, Dept. of Electrical Engineering, Stanford University, Stanford, CA, USA, (2013). http://purl.stanford.edu/ws303zb5770
Acknowledgements
We thank two anonymous reviewers for their constructive comments. This work was supported by research grant no. 2013003 of the United States-Israel Binational Science Foundation (BSF) and by the ISF-NSFC joint research program grant No. 2874/19.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Some Concentration of Measure Facts in a High-Dimensional \(E^{N}\)
Some Concentration of Measure Facts in a High-Dimensional \(E^{N}\)
1.1 The Probability \(L^{p}\) Norms of Vectors
For a vector \(x\in E^{N}\), and \(1\le p<\infty \), denote by \(\Vert \,\cdot \Vert _{p}^{(\pi )}\) (\(\pi \) stands for “probability space”) its \(L^{p}\) norm when the set of indices \(\{1,2,\ldots ,N\}\) is made into a uniform probability space, giving each index a weight 1 / N, namely,
see, e.g., [36]. As with any probability measure, always \(\Vert \,\cdot \Vert _{p}^{(\pi )}\) increases with p.
For \(x_{1},x_{2},\ldots ,x_{N}\) i.i.d. \(\sim {\mathcal {N}}\), \(\left( \Vert x\Vert _{p}^{(\pi )}\right) ^{p}\) is an average: its expectation \({\mathbb {E}}\) will be the same as the expectation of \(|x|^{p}\) for x a scalar distributed \(\sim {\mathcal {N}}\):
but its standard deviation will be \(1/\sqrt{N}\) that of \(|x|^{p}\) for a scalar \(\sim {\mathcal {N}}\):
Thus, \(\Vert x\Vert _{p}^{(\pi )}\) is highly concentrated around the, not depending on N, \(\left( {\mathbb {E}}\left[ |x|^{p}\right] \right) ^{1/p}\) with degree of concentration \(O(1/\sqrt{N})\).
One may conclude, loosely speaking, that in any case, these \(\Vert \,\cdot \Vert _{p}^{(\pi )}\) norms, having not depending on N means, are expected to be O(1), for all N.
1.2 The Norm of the Sum of Vectors with Given Norms
Suppose we are given M vectors \(y_{1},y_{2},\ldots ,y_{M}\) of known norms \(d_{1},d_{2},\ldots .d_{M}\) in \(E^{N}\). What should we expect the norm of their sum to be?
This can be answered: take the direction of each of them distributed uniformly on \(S^{N-1}\), even conditioned on fixed valued for the others. In other words, take them independent, each with direction distributed uniformly. This can be constructed by taking random M vectors in \(E^{N}\) (that is, a random \(M\times N\) matrix), with entries i.i.d. \(\sim {\mathcal {N}}\), dividing them by \(\sqrt{N}\), then by their norm (now highly concentrated near 1) and multiplying them by \(d_{1},d_{2},\ldots ,d_{M},\) respectively.
The sum \(\sum _{i=1}^{M}y_{i}\), if we ignore the division by the norm, is \(1/\sqrt{N}\) times the random matrix applied to the vector \((d_{1} ,d_{2},\ldots ,d_{M})\). But the distribution of the random matrix is invariant with respect to any transformation which is orthogonal with respect to the Hilbert-Schmidt norm—the square root of the sum of squares of the entries (i.e., \(\Vert T\Vert _{HS}:=\sqrt{{\text {*}}{tr}(T^{\prime }\cdot T)} =\sqrt{{\text {*}}{tr}(T\cdot T^{\prime })}\), \(T^{\prime }\) denoting the transpose and \({\text {*}}{tr}\) standing for the trace, see, e.g., [4]). In particular, the distribution of the sum is the same as that of \(1/\sqrt{N}\) times \(\sqrt{d_{1}^{2}+d_{2}^{2}+\cdots +d_{M} ^{2}}\) times the random matrix applied to \((1,0,\ldots ,0)\), which is, of course, distributed with independent \(\sim {\mathcal {N}}\) entries, thus, with norm concentrated near \(\sqrt{N}\). (With relative deviation \(O(1/\sqrt{N})\).) This leads to the following conclusion.
Conclusion 10
For M vectors \(y_{1},y_{2},\ldots ,y_{M}\) of known norms \(d_{1},d_{2},\ldots .d_{M}\), in \(E^{N}\) we have that \(\Vert \sum _{i=1}^{M} y_{i}\Vert \) is near \(\sqrt{d_{1}^{2}+d_{2}^{2}+\cdots +d_{M}^{2}}\) with almost full probability (With relative deviation \(O(1/\sqrt{N})\).)
1.3 The Accumulation of Given Distances on the Unit Sphere
As in the previous Appendix A.2, we seek to find what should we expect the norm of a sum of M vectors of given norms \(d_{1},d_{2} ,\ldots .d_{M}\) to be. But here the vectors are the differences between consecutive elements in a sequence of points on the unit sphere \(S^{N-1}\subset E^{N}\). Denote by \(\omega _{N-1}\) the normalized to be probability (i.e., of total mass 1) uniform measure on \(S^{N-1}\).
Remark 11
By symmetry, for \(x=(x_{1},x_{2},\ldots ,x_{N})\in S^{N-1}\), \(\int x_{k} ^{2}\,d\omega _{N-1}\) is the same for all k. Of course, their sum is \(\int 1\,d\omega _{N-1}=1\). Therefore,
Hence, for a polynomial of degree \(\le 2\) on \(E^{n}\):
where Q is a symmetric \(N\times N\) matrix, \(a\in E^{N}\) and \(\gamma \in E\), we will have
Note that, for some fixed \(0\le d\le 2\), the set of points in \(S^{N-1}\) of distance d from some fixed vector \(u\in S^{N-1}\) is the \((N-2)\)-sphere \(\subset S^{N-1},\) \(\Sigma (u,d)\) given by
where \({S^{N-2}}_{u^{\bot }}\) stands for the unit sphere in the hyperplane prependicular to u. In our scenario, one performs a Markov chain, see, e.g., [3]. Starting from a point \(u_{0}\) on \(S^{N-1}\), and moving to a point \(u_{1}\in \Sigma (u_{0},d_{1})\) uniformly distributed there. Then, from that \(u_{1}\), to a point \(u_{2}\in \Sigma (u_{1},d_{2})\) uniformly distributed there, and so on, until one ends with \(u_{M}\). We would like to find \({\mathbb {E}}\left[ \Vert u_{M}-u_{0} \Vert \right] \).
If we denote by \({\mathcal {L}}_{d}\) the operator mapping a function p on \(S^{N-1}\) to the function whose value at a vector \(u\in S^{N-1}\) is the average of p on \(\Sigma (u,d)\), then \({\mathcal {L}}_{d_{k}}(p)\) evaluated at u is the expectation of p at the point to which u moved in the k-th step above. Hence, in the above Markov chain, the expectation of \(p(u_{M})\) is
Thus, what we are interested in is
So, let us calculate \({\mathcal {L}}_{d}(p)\) for polynomials of degree \(\le 2\) as in (26). In performing the calculation, assume \(u=(1,0,\ldots ,0)\). For \(x=(x_{1},x_{2},\ldots ,x_{N})\in E^{N}\) write \(y=(x_{2},x_{3} ,\ldots ,x_{N})\in E^{N-1}\). In (26) write \(a=(a_{1},b)\) where \(b=(a_{2},a_{3},\ldots a_{N})\in E^{N-1}\) and
where \(Q^{\prime }\) is a symmetric \((N-1)\times (N-1)\) matrix, \(c\in E^{N-1}\) and \(\eta \in E\). Note that for our \(u=(1,0,\ldots ,0)\), \(a_{1}=\langle a,u\rangle \), \(\eta =\langle Qu,u\rangle \) and \({\text {*}}{tr}\,Q^{\prime }={\text {*}}{tr}\,Q-\eta ={\text {*}}{tr}\,Q-\langle Qu,u\rangle \).
Then, for p as in in (26),
Hence, taking account of (28) for \(u=(1,0,\ldots ,0)\), and using (25),
which, by symmetry, will hold for any \(u\in S^{N-1}\). In particular, we find, as should be expected, that
We are interested, for some fixed \(u\in S^{N-1}\), in
Then there is no Q term, so one has
Consequently,
This is \(O\left( M\cdot \left( \Vert (d_{1},d_{2},\ldots ,d_{M})\Vert _{2} ^{(\pi )}\right) ^{2}\right) \). We also assess the standard deviation, which is
Here \(p(x)=\langle a,x\rangle ^{2}\), so there is only the Q term with \(Q(x):=\langle a,x\rangle ^{2}\). Then \({\text {*}}{tr}\,Q=\Vert a\Vert ^{2}\), and we find
Consequently, for \(a=u_{0}\) (note \(\Vert u_{0}\Vert ^{2}=1\))),
This is \(O\left( (M/N)\cdot \left( \Vert (d_{1},d_{2},\ldots ,d_{M})\Vert _{4}^{(\pi )}\right) ^{4}\right) \), since the constant terms and the terms with \(d_{k}^{2}\) cancel, and the terms which do not cancel are coefficiented by O(1 / N). Therefore, twice its square root, the standard deviation, will be \(O\left( \sqrt{M}/\sqrt{N}\left( \Vert (d_{1},d_{2},\ldots ,d_{M})\Vert _{4}^{(\pi )}\right) ^{2}\right) \), making the relative deviation \(O(1/\sqrt{MN})\). This leads to the following conclusion.
Conclusion 12
The square of the norm of the sum of M vectors of given norms \(d_{1},d_{2},\ldots .d_{M}\), which are differences between consecutive elements in a sequence of points on the unit sphere \(S^{N-1} \subset E^{N}\), modeled by the above Markov chain, is with almost full probability, near
(With relative deviation \(O(1/\sqrt{MN})\).)
1.4 A Reminder: Polar Decomposition and Singular Values of a Matrix
As is well-known, see, e.g., [27], every fixed \(N\times N\) matrix T can be uniquely written as \(T=UA\) with U orthogonal and A symmetric positive semidefinite (take \(A=\sqrt{T^{\prime }\cdot T}\), then for every vector x, \(\Vert Tx\Vert \)=\(\Vert Ax\Vert \), so the map \(Ax\mapsto Tx\) is norm-preserving, i.e., orthogonal), and also uniquely written as \(T=A_{1}U_{1}\) with \(U_{1}\) orthogonal and \(A_{1}\) symmetric positive semidefinite (take \(A_{1}=\sqrt{T\cdot T^{\prime }}\)).
The singular values of T are defined as the eigenvalues of its positive semidefinite part in the above decomposition. (It does not matter from which side: \(T\cdot T^{\prime }\) and \(T^{\prime }\cdot T\) have the same eigenvalues. Note that if T is invertible they are similar: \(T^{\prime -1}(T\cdot T^{\prime })T\).)
Since any positive semidefinite matrix with eigenvalues \(s_{1},s_{2} ,\ldots ,s_{N}\) is of the form
with U orthogonal (\({\text {diag}}\) denotes a diagonal matrix), we find that the general form of a matrix with singular values \(s_{1} ,s_{2},\ldots ,s_{N}\) is
1.5 Square Matrix with Entries Independently \(\sim {\mathcal {N}}\) and the Uniform Distribution on Orthogonals
Take a random \(N\times N\) matrix Y with entries \(Y_{i,j}\) i.i.d. \(\sim {\mathcal {N}}\). If we polarly decompose the random Y as per Appendix A.4, from either side, then the orthogonal part will be distributed uniformly (i.e., by Haar’s measure) on the orthogonal group. This follows from the fact that, by the symmetries of the above distribution of Y, it is invariant under multiplying the random matrix on the right or left by a fixed orthogonal matrix. So, we have here a vehicle to get this uniform distribution. For a general excellent text on random matrices consult [23].
For the positive semidefinite part we have to check, say, \(Y^{\prime }\cdot Y\) for our random matrix Y. But if u is any vector then, by the symmetries of the distribution of the random Y, Yu is distributed like \(\Vert u\Vert \) times \(Y\cdot (1,0,\ldots .0)\)—i.i.d. \(\sim {\mathcal {N}}\) entries, thus, with norm concentrated near \(\Vert u\Vert \cdot \sqrt{N}\), with relative deviation \(O(1/\sqrt{N})\). But, all the entries of \(Y^{\prime }\cdot Y\) being discernible from \(\langle Y^{\prime }\cdot Yu,u\rangle \) if we take as u elements of the standard basis \(e_{i}=(0,\ldots ,0,1,0\ldots ,0)\) and sums of two of these, we obtain the following conclusion.
Conclusion 13
\((1/N)Y^{\prime }\cdot Y\) (and likewise \((1/N)Y\cdot Y^{\prime }\)) is concentrated near \({\mathbf {1}}\) (\({\mathbf {1}}\) denotes the identity matrix), with relative deviation O(1 / N).
In other words, the random Y is, with almost full probability, very near \(\sqrt{N}\) times an orthogonal matrix. Indeed. to check how orthogonal \((1/\sqrt{N})Y\) is, note that the amount it distorts the inner product between unit vectors u and v is
1.6 The Action of a Linear Operator in a High-Dimensional Space
Consider an \(N\times N\) matrix T with given singular values \(s_{1} ,s_{2},\ldots ,s_{N}\) as in (43). Let T act on a unit vector u with direction uniformly distributed over \(S^{N-1}\). By (43) this is distributed, up to an orthogonal “rotation” of the space, the same as \(S={\text {*}}{diag} (s_{1},s_{2},\ldots ,s_{N})\) acting on such a vector.
But by Sect. 4, that would be almost as S applied to \((1/\sqrt{N})x\), x with coordinates i.i.d. \(\sim {\mathcal {N}}\), which is, of course, a vector with independent coordinates but the j-th coordinate distributed as \((1/\sqrt{N})s_{j}\) times \({\mathcal {N}}\).
Now, similarly to what we had in Sect. 4, the square of the norm of \(S\cdot (1/\sqrt{N})x\), which is \((1/N)\sum _{j=1}^{N}s_{j}^{2} x_{j}^{2}\) has mean
around which it is concentrated—its standard deviation being
where \(\sigma \) is the standard deviation for \(x^{2}\) when \(x\sim {\mathcal {N}} \), namely,
By Appendix A.1, the relative deviation is, thus, expected, with almost full probability, to be \(O(1/\sqrt{N})\). Note that since \(T=U_{1} \cdot {\text {*}}{diag}(s_{1},s_{2},\ldots ,s_{N})\cdot U_{2}\), the value around which the norm of T applied to a uniformly distributed unit vector is concentrated is
Dividing T by that value, we get a T with \((1/\sqrt{N})\Vert T\Vert _{HS}=1\) which, with almost full probability, will approximately preserve the norm. How “orthogonal” will it be? Let us see how S distorts the inner product between \((1/\sqrt{N})x\) and \((1/\sqrt{N})y\), all 2N coordinates of x and y i.i.d. \(\sim {\mathcal {N}}\). The mean of the square of the difference
is
Consequently, T is orthogonal, with almost full probability, up to \(O(1/\sqrt{N})\). This leads to the following conclusion.
Conclusion 14
An \(N\times N\) matrix T with given singular values \(s_{1},s_{2},\ldots ,s_{N}\), acting on a high-dimensional \(E^{N}\), would be expected to act, with almost full probability, as
times an orthogonal matrix, up to a relative deviation \(O(1/\sqrt{N})\).
Remark 15
Now we address a seeming mystery raised by Conclusion 14. That conclusion seems to require that \((1/\sqrt{N})\) times the Hilbert-Schmidt norm of the product of two matrices with singular values \((s_{1},s_{2},\ldots ,s_{N})\) and \((s_{1}^{\prime },s_{2}^{\prime }\ldots ,s_{N}^{\prime }),\) respectively, be equal to the product of the same for the factors, i.e., to \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{2}^{(\pi )}\cdot \Vert (s_{1},s_{2} ,\ldots ,s_{N})\Vert _{2}^{(\pi )}\), up to relative deviation \(O(1/\sqrt{N})\). Is that so?
Note that, by (43), the HS-norm of the product is that of \(SUS^{\prime }\) where \(S={\text {*}}{diag}(s_{1},s_{2},\ldots ,s_{N} )\), \(S^{\prime }={\text {*}}{diag}(s_{1}^{\prime },s_{2}^{\prime }\ldots ,s_{N}^{\prime })\) and U is orthogonal. So, if, up to an \(O(1/\sqrt{N})\) relative deviation, we model U as \((1/\sqrt{N})Y\), \(Y=\left( Y_{i,j}\right) _{i,j}\) as in Appendix A.5, then \(SUS^{\prime }=\left( (1/\sqrt{N})s_{i}Y_{i,j}s_{j}^{\prime }\right) _{i,j}\). The square of \((1/\sqrt{N})\) times its HS-norm is \((1/N^{2})\sum _{i,j=1,1}^{N,N} s_{i}^{2}Y_{i,j}^{2}s_{j}^{\prime 2}\), with mean indeed equal to the square of \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{2}^{(\pi )}\cdot \Vert (s_{1}^{\prime },s_{2}^{\prime }\ldots ,s_{N}^{\prime })\Vert _{2}^{(\pi )}\), and with standard deviation \(\sigma \cdot 1/N\) times the square of \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{4}^{(\pi )}\cdot \Vert (s_{1}^{\prime },s_{2}^{\prime }\ldots ,s_{N}^{\prime })\Vert _{4}^{(\pi )}\).
1.7 The Rotation Effected by an Operator and by a Product of Operators in a High-Dimensional Space
Let T be an an \(N\times N\) matrix, and consider the amount of rotation between v and Tv. The square of the distance between these vectors, both normalized to norm 1 will be
where \(T^{(sym)}:=\textstyle {\frac{1}{2}}(T+T^{\prime })\) is the symmetric part of T. Note that \({\text {tr}}\,T^{(sym)} ={\text {*}}{tr}\,T\). So, we are led to investigate the inner product \(\langle Ax,x\rangle \) for A symmetric. Let \((s_{1},s_{2},\ldots ,s_{N})\) be its eigenvalues, then \(A=U^{\prime }SU\) where \(S={\text {*}}{diag} (s_{1},s_{2},\ldots ,s_{N})\) and U orthogonal. As we did above, we take \(v=(1/\sqrt{N})x\), and x with coordinates i.i.d. \(\sim {\mathcal {N}}\). Then
But, Ux being distributed like x, this will have the same distribution as
which has mean \((1/N)\sum _{j=1}^{N}s_{j}=(1/N){\text {*}}{tr}\,A\) and \((1/\sqrt{N})\sigma \Vert (s_{1},\ldots ,s_{N})\Vert _{2}^{(\pi )}\) is its standard deviation. Of course, if A is positive semidefinite then the \(s_{\ell }\ge 0\) and the above mean is \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{1}^{(\pi )}\). This leads to the following conclusion.
Conclusion 16
For T with symmetric part with eigenvalues \((s_{1} ,s_{2},\ldots ,s_{N})\), the square of the distance between v and Tv, both normalized to norm 1, is, with almost full probability, near (with deviation \(O(1/\sqrt{N})\))
which, if the symmetric part of T is positive-semidefinite, is equal to
The next discussion will lead to a conclusion about a product \(A_{M} A_{M-1}\cdots A_{1}\) of a sequence of symmetric operators. Consider a symmetric \(A=U^{\prime }{\text {*}}{diag}(s_{1},s_{2},\ldots ,s_{N})U\) with given \(s_{1},s_{2},\ldots ,s_{N}\). Take U uniformly distributed on the orthogonal group, which we model up to a relative deviation \(O(1/\sqrt{N})\) by \(1/\sqrt{N}\cdot Y\), \(Y=\left( Y_{i,j}\right) _{i,j}\) as in Appendix A.5. Then
Consequently,
But here we cannot say, as we did in previous cases, that, with high probability, A would be near that average—indeed they cannot be “near” since the eigenvalues of the average are all \((1/N){\text {*}}{tr}\,A\) while those of A are with full probability \(s_{1},s_{2},\ldots ,s_{N}\).
To apply the considerations of Appendix A.3, where one relies on a Markov chain employing uniform distribution on spheres, we inquire what is the distribution of \(Av_{0}\), and of the difference vector \(\left( \dfrac{Av_{0}}{\Vert Av_{0}\Vert }-\dfrac{v_{0}}{\Vert v_{0}\Vert }\right) \) for a fixed \(v_{0}\), with A random as in (57) above. To fix matters, assume \(v_{0}=(1,0,\ldots ,0)\). As above, we have \(Av_{0}=U^{\prime }SUv_{0}\). where \(S:={\text {*}}{diag}(s_{1},s_{2},\ldots ,s_{N})\). Or, with U replaced by \(1/\sqrt{N}\cdot Y\), \(Av_{0}\approx (1/N)Y^{\prime }SYv_{0}\). Write Y as (w, Z) where w is the \(N\times 1\) matrix which is the first column of Y, and Z is the \(N\times (N-1)\) matrix of the other columns. Then, with \(v_{0}=(1,0,\ldots ,0)\), \(Yv_{0}=w\), and
Note that the random Z and w are independent. Z is an \(N\times (N-1)\) matrix with entries i.i.d. \(\sim {\mathcal {N}}\), and by the symmetries of this distribution (as in Appendices A.2 and A.5), \((1/N)Z^{\prime }Sw\) is distributed like \((1/N)\Vert Sw\Vert \) times an \((N-1)\) vector with entries i.i.d. \(\sim {\mathcal {N}}\)—near \((1/\sqrt{N})\Vert Sw\Vert \) times a vector uniformly distributed on \(S^{N-2}\). And, as in Appendix A.6, \((1/\sqrt{N})\Vert Sw\Vert \) is concentrated near \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{2}^{(\pi )}\). As for \((1/N)w^{\prime }Sw\)—it is just (54)—its value is concentrated near \((1/N){\text {*}}{tr}\,A\), which if A is positive-semidefinite is equal to \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{1}^{(\pi )}\).
To conclude, the value our random A gives to \((1,0,\ldots ,0)\) is a vector with first coordinate near \((1/N){\text {*}}{tr}\,A\)—which if A is positive-semidefinite is \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{1}^{(\pi )}\), and other coordinates forming a vector near the product of \(\Vert (s_{1} ,s_{2},\ldots ,s_{N})\Vert _{2}^{(\pi )}\) with a vector uniformly distributed on \(S^{N-2}\). Its norm is \(\Vert (s_{1},s_{2},\ldots ,s_{N})\Vert _{2}^{(\pi )}\) up to a deviation O(1 / N), and one obtains values agreeing with the above for \(\langle Ax,x\rangle \) and the square of the distance between v and Av, both normalized.
In particular, for A symmetric, employing uniform distribution on spheres in the Markov chain as in Appendix A.3 and Conclusion 12 is vindicated. Therefore, for a product of a sequence of symmetric operators \(A_{M}A_{M-1}\cdots A_{1}\), we may apply Conclusion 12 to obtain the following conclusion.
Conclusion 17
For a product \(A_{M}A_{M-1}\cdots A_{1}\), of a sequence of symmetric operators \(A_{i}\) with given eigenvalues \((s_{1} ^{(i)},s_{2}^{(i)},\ldots ,s_{N}^{(i)})\), the square of the distance between v and \(A_{M}A_{M-1}\cdots A_{1}v\), both normalized to norm 1, is, with almost full probability, near (with deviation \(O(\sqrt{M}/\sqrt{N})\))
which, if for all i, \(A_{i}\) is positive semidefinite, is equal to
Remark 18
Note that if the \(A_{i}\) are positive semidefinite, the value (61) around which the square of the distance between the points on \(S^{N-1}\) is concentrated, is \(\le 2\), that is, the distance is \(\le \sqrt{2}\) and the angle between the vectors is \(\le 90^{\circ }\).
Rights and permissions
About this article

Cite this article
Censor, Y., Levy, E. An Analysis of the Superiorization Method via the Principle of Concentration of Measure. Appl Math Optim 83, 2273–2301 (2021). https://doi.org/10.1007/s00245-019-09628-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00245-019-09628-4