
Abstract
In this paper, we prove that Hennessy–Milner Logic (HML), despite its structural limitations, is sufficiently expressive to specify an initial property \(\varphi _0\) and a characteristic invariant \(\upchi _{_I}\) for an arbitrary finite-state process P such that \(\varphi _0 \wedge \mathbf{AG }(\upchi _{_I})\) is a characteristic formula for P. This means that a process Q, even if infinite state, is bisimulation equivalent to P iff \(Q \models \varphi _0 \wedge \mathbf{AG }(\upchi _{_I})\). It follows, in particular, that it is sufficient to check an HML formula for each state of a finite-state process to verify that it is bisimulation equivalent to P. In addition, more complex systems such as context-free processes can be checked for bisimulation equivalence with P using corresponding model checking algorithms. Our characteristic invariant is based on so called class-distinguishing formulas that identify bisimulation equivalence classes in P and which are expressed in HML. We extend Kanellakis and Smolka’s partition refinement algorithm for bisimulation checking in order to generate concise class-distinguishing formulas for finite-state processes.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Branching time semantics [34, 35] and, in particular, variants of bisimulation [32, 33, 35, 37, 38, 40] together with their congruence properties [12, 36, 37] are topics that Rob van Glabbeek has at heart. This also comprises probabilistic behavior [8], a topic that we (Rob and Bernhard) cooperated on almost thirty years ago [39]. Hennessy–Milner logic (HML) [17] can be considered the most basic modal logic for capturing branching time semantics. It is therefore not surprising that Rob investigated its congruence properties [10, 11]. The famous theorem of Hennessy and Milner [17] establishes the link between (strong) bisimulation and HML: two finitely branching processes can be separated by means of an HML formula if and only if they are not bisimulation equivalent. This is often stated as HML and bisimulation having the same distinguishing power. Characteristic formulas have a more ambitious role than separating two processes, they are meant to characterize entire bisimulation equivalence classes: \(\upchi \) is a (bisimulation) characteristic formula for a process P if satisfaction of \(\upchi \) coincides with being bisimulation equivalent to P, i.e.:
In [2], Browne et al. showed how characteristic formulas can be constructed for finite-state processes in computational tree logic (CTL).Footnote 1 Moreover, in [28], it was shown how such formulas can be generated within the modal \(\mu \)-calculus (and HML with recursion, respectively).
In this paper, we prove that HML is sufficient to define an initial property \(\varphi _0\) and a characteristic invariant \(\upchi _{_I}\) such that \({\upchi }_{_P} =_{\textit{def}}~\varphi _0 \wedge \mathbf{AG }(\upchi _{_I})\) is a characteristic formula for a given finite-state process P. This means, in particular, that it is sufficient to check an HML formula for each reachable state of a finite-state process to verify that it is bisimulation equivalent to P. In fact, using e.g. the model checking algorithms presented in [5,6,7], context-free processes, pushdown-processes, and sequential processes can be checked for bisimulation equivalence with P.
Key to the construction of \(\upchi _{_{P}}\) is the separation of the specification of the one-step transition potential of states of P from their (loose) characterization. This separation essentially decomposes the global bisimulation property into a number of local-step properties in a way reminiscent of Floyd’s inductive assertion method [9]: the global property is guaranteed via the consistency—here given by the local transition potential—of (loose) invariants. The latter are given by distinguishing formulas for the bisimulation equivalence classes of P.
Whereas the one-step transition potential can be specified in the way proposed in [2], the class-distinguishing formulas that separate non-bisimilar states can be constructed along the classical partition refinement process for minimization up to bisimulation [21]. Key is that the constructed set of distinguishing formulas \(\varPhi \) for P has the following two properties:
Each state of P satisfies some distinguishing formula.
The partition of reachable states in P that is induced by \(\varPhi \) defines a bisimulation relation.
Throughout this paper, we only compare processes from a given universe that is specified by an alphabet \(\varSigma \). This alphabet \(\varSigma \) comprises all considered process actions (transition labels). Based on \(\varSigma \) and the before-mentioned set of distinguishing formulas \(\varPhi \), the desired HML invariant \(\upchi _{_I}\) for specifying the one-step potential of P can be derived as in [2]:
The resulting characteristic formula \(\varphi _0 \wedge \mathbf{AG }(\upchi _{_I})\) conceptually decomposes the verification process in a ‘Floyd-like’ manner using invariants and class-distinguishing formulas. In contrast, the characteristic formulas presented in [28] can rather be considered to be a monolithic, syntactic encoding of P.
After sketching some preliminaries in Sect. 2, Sect. 3 introduces our characteristic HML invariants based on class-distinguishing formulas and proves a corresponding characterization theorem. Subsequently, Sect. 4 presents the concept of a set of class-distinguishing formulas (SCDF) as a means to establish a sufficient condition for guaranteeing that our characteristic formula construction results in a formula that is satisfied by the argument LTS. The effective construction of SCDFs from LTSs is described in Sect. 5. The underlying algorithm is an adaption of Kanellakis and Smolka’s algorithm for checking bisimulation equivalence [21] to generate the required class-distinguishing formulas. Following a discussion of related work in Sect. 6, the paper closes with our conclusions and an outlook in Sect. 7.
2 Preliminaries
In this section, we recall the basic concepts that our approach is based on. Central in this regard are the definition of labeled transition systems and the usual corresponding notion of a process.
Definition 1
(LTS and process) A labeled transition system (LTS) is a triple \(L \,{=}\, (S_{_L}, \varSigma _{_L}, \!\rightarrow _{\!_L})\) with set \(S_{_L}\) of states, alphabet \(\varSigma _{_L}\),Footnote 2 and transition relation \(\rightarrow _{_L} \subseteq S_{_L} \times \varSigma _{_L} \times S_{_L}\).
We use the notation \(p {\mathop {\rightarrow }\limits ^{a}}_{_L} q \) to denote that \((p, a, q) \in \rightarrow _{_L}\) and omit the subscript L in cases where the LTS is unambiguous. Furthermore, given a state \(s' \in S_{_L}\) and a label \(a \in \varSigma _{_L}\), we define the following shorthand notation for the set of a-predecessors of state \(s'\)
This definition extends naturally to sets of states: for each \(S' \subseteq S_{_L}\), we have
Every state \(s \in S_{_L}\) of an LTS L defines a process\(P_{_L}(s)\) that constraints initial transitions to start in s. A state \(s' \in S_{_L}\) is reachable in \(P_{_L}(s)\), denoted by \(s \mathop {{\rightarrow }^*_{_{L}}} s'\), iff there exists a sequence of transitions \(s_i {\mathop {\rightarrow }\limits ^{a_i}}_{_L} s_{i+1}\) in \(\rightarrow _{_L}\) with \(i \in 0\, ..\, (k-1)\) for some \( k\in {\mathbb {N}}\) such that \(s_0 = s\) and \(s_k = s'\). This notion naturally generalizes to a notion of reachability within an LTS L from any state s of L.
We are aiming at characterizing processes up to bisimulation, a semantic equivalence relation that is known to preserve properties expressed in most temporal logics, in particular those that can be expressed in the modal \(\mu \)-calculus [1].
Definition 2
(Bisimulation) Let \(L=(S_{_L}, \varSigma _{_L}, \rightarrow _{_L})\) be an LTS. A symmetric relation R\(\subseteq (S_{_{L}} \times S_{_{L}})\) is called a bisimulation if the following holds for all \((p, q) \in \mathord {R}\):
Two states \(s, s' \in S\) are called bisimilar in L, written as \(s \sim _{_L} s'\), iff there exists a bisimulation R with \((s, s')\in \mathord {R}\).Footnote 3
Given a second LTS \(L' = (S_{_{L'}}, \varSigma _{_{L'}}, \rightarrow _{_{L'}})\), two processes \(P_{_L}(s)\) and \(P_{_{L'}}(s')\) are called bisimilar, written as \(P_{_L}(s) \sim P_{_{L'}}(s')\), iff there exists a bisimulation in  that contains \((s,s')\).Footnote 4
that contains \((s,s')\).Footnote 4
Our characteristic invariants are formulas specified in Hennessy–Milner logic (HML) [17] that extends propositional logic with a modal operator \(\mathord {\mathopen {\langle }{\cdot }\mathclose {\rangle }\,}\) (diamond):
Definition 3
(HML) Given an alphabet \(\varSigma \), Hennessy–Milner logic (HML) is defined by the following grammar in Backus–Naur form
where \(\alpha \) is a meta-variable for an arbitrary element of \(\varSigma \). In addition, the following derived operators are frequently used:
Definition 4
(Semantics of HML) The semantics of HML are defined relative to a given LTS \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) and formalized via the following satisfaction relation \(\mathord {\models _{_L}} \subseteq S \times \mathord {\text {HML}}\):

where \(s \in S\), \(a \in \varSigma \) and \(\varphi , \varphi _1, \varphi _2 \in \mathord {\text {HML}}\). We omit the subscript L of \(\models _{_L}\) if it is unambiguous in a given context, and often abbreviate \(p \models _{_L}\varphi \) and \(q \models _{_L}\varphi \) by \(p,q \models _{_L}\varphi \). In cases were we want to emphasize the process perspective, we write \(P_{_{L}}(s) \models \varphi \) instead of \(s \models _{_{L}} \varphi \).
In the following, we will establish that HML is sufficient to define the invariants required for our characteristic formulas.
3 Generalized characteristic HML invariant
Our definition of a generalized characteristic HML invariant follows the “diamond-box-pattern” originally introduced in [13, 15]:
Definition 5
(Generalized characteristic HML invariant) Let \(\varSigma \) be a global alphabet that contains all considered action labels. With a pair \((\varPhi , \varPsi )\) such that \(\varPhi \) is a finite set of HML formulas and \(\varPsi :\varPhi \times \varSigma \rightarrow 2^{\varPhi }\) a function we associate an HML formula \(\upchi _{_I}(\varPhi , \varPsi )\) called generalized characteristic invariant (GCI) as follows:
Given an LTS \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\), we write \(L \models \mathbf{AG }(\varphi )\) iff \(s \models _{_{L}} \varphi \) holds for all \(s \in S\) and say that \(\upchi _{_I}(\varPhi , \varPsi )\) is a GCI for L iff \(L \models \mathbf{AG }(\upchi _{_I}(\varPhi , \varPsi ))\). We sometimes write \(\upchi _{_I}\) instead of \(\upchi _{_I}(\varPhi , \varPsi )\) iff the arguments are unambiguous in a given context.
In order to capture our notion of a GCI, we extend HML as follows.
Definition 6
(Syntax of HML\(_{\mathrm{AG}}\)) Given an alphabet \(\varSigma \), Hennessy–Milner logic with \(\mathbf{AG }\) (HML\(_{\mathrm{AG}}\)) is defined by the following grammar in Backus–Naur form
where \(\alpha \) is a meta-variable for an arbitrary element of \(\varSigma \). The derived operators of HML are also used for HML\(_{\mathrm{AG}}\) .
\(\mathord {\text {HML}_{\text {AG}}}\) is equivalent to a logic called EF or \(\text {UB}^-\) in the literature [25] and is itself a fragment of CTL. In this paper, we are only interested in two patterns of \(\mathord {\text {HML}_{\text {AG}}}\) formulas, namely \(\mathbf{AG }(\upchi _{_I})\) and \(\varphi _0 \wedge \mathbf{AG }(\upchi _{_I})\) where \(\varphi _0,\upchi _{_I}\in \mathord {\text {HML}}\). Definition 6 therefore specifies \(\mathbf{AG }\) instead of an \(\mathbf{EF }\) operator.
Definition 7
(Semantics of \(HML_{\mathrm{AG}}\)) The semantics of \(\mathord {\text {HML}_{\text {AG}}}\) are defined relative to a given LTS \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\). Given an LTS L, the satisfaction relation \(\mathord {\models _{_L}} \subseteq S \times \mathord {\text {HML}_{\text {AG}}}\) extends Definition 4 with the following clause:
where \(s \in S\) and \(\varphi \in \mathord {\text {HML}_{\text {AG}}}\). Shorthand notations are defined as in Definition 4.
Note the overloading of \(\mathbf{AG }\). In fact, we have:
Please recall that we only consider LTSs and processes from a universe that is specified by an alphabet \(\varSigma \), i.e. the set of possible actions. The following lemma illustrates the power of the “diamond-box-pattern” [13, 15] that underlies our definition of GCIs.
Lemma 1
Let \(\upchi _{_I}(\varPhi , \varPsi )\) be a GCI and \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) an LTS such that \(L \models \mathbf{AG }(\upchi _{_I})\). Then
is a bisimulation.
Proof
Let \(\upchi _{_I}(\varPhi , \varPsi )\) be a GCI that is based on some finite set \(\varPhi \) of HML formulas and some function \(\varPsi :\varPhi \times \varSigma \rightarrow 2^{\varPhi }\). Furthermore, let L be any LTS such that \(L \models \mathbf{AG }(\upchi _{_I}(\varPhi , \varPsi ))\). As the empty relation is clearly a bisimulation, we can assume that R is not empty. Let us now consider an arbitrary pair \((p,q) \in R\). Then there exists a formula \(\varphi \in \varPhi \) with \(p,q \models \varphi \). Therefore, we know due to \(L \models \mathbf{AG }(\upchi _{_I}(\varPhi , \varPsi ))\) that both p and q satisfy
R is obviously symmetric. Therefore, it suffices to prove the defining invariance property of bisimulation (Definition 2). Let \(p {\mathop {\rightarrow }\limits ^{b}} p'\) be an arbitrary transition starting in p. Looking at the subformula
that must be satisfied by p, we know that \(p' \models \bigvee _{\psi \in \varPsi (\varphi ,b)} \psi \). Therefore, there exists a \(\psi ' \in \varPsi (\varphi , b)\) that is satisfied by \(p'\). The fact that q satisfies the subformula
now yields that q satisfies \(\mathord {\mathopen {\langle }{b}\mathclose {\rangle }\,} \psi '\), i.e., the existence of a transition \(q {\mathop {\rightarrow }\limits ^{b}} q'\) such that \(q'\) satisfies \(\psi '\). Thus, both \(p'\) and \(q'\) satisfy \(\psi '\) which guarantees \((p',q') \in R\). \(\square \)
Of course, not every GCI fits each LTS L, e.g., the bisimulation guaranteed by the above characterization lemma may well be empty. GCIs develop their full characterizing power only in combination with an initial condition:
Lemma 2
Let \(\upchi _{_I}(\varPhi , \varPsi )\) be a GCI and \(\varphi _0 \in \varPhi \). Moreover, let \(L = (S_{_L}, \varSigma _{_L}, \rightarrow _{_L})\), \(L' = (S_{_{L'}}, \varSigma _{_{L'}}, \rightarrow _{_{L'}})\) be two LTSs with states \(s \in S_{_L}\) and \(s' \in S_{_{L'}}\) such that \(s \models _{_L} \varphi _0\) and \(s' \models _{_{L'}} \varphi _0\), respectively. Then we have:
- 1.
\(L \models \mathbf{AG }(\upchi _{_I})\) and \(L' \models \mathbf{AG }(\upchi _{_I})\) implies \(P_{_L}(s) \sim P_{_{L'}}(s')\).
- 2.
If all states of \(S_{_L}\) are reachable from s in L and all states of \(S_{_{L'}}\) are reachable from \(s'\) in \(L'\), then \(P_{_{L}}(s) \sim P_{_{L'}}(s')\) implies \(L \models \mathbf{AG }(\upchi _{_I})\) and \(L' \models \mathbf{AG }(\upchi _{_I})\).
Proof
Let \(\upchi _{_I}\) be a GCI and L and \(L'\) two LTS with states \(s \in S_{_{L}}\) and \(s' \in S_{_{L'}}\) such that \(s \models _{_{L}} \varphi _0\) and \(s' \models _{_{L'}}\varphi _0\), respectively.
In order to prove the first part of Lemma 2, we assume that \(L \models \mathbf{AG }(\upchi _{_I})\) and \(L' \models \mathbf{AG }(\upchi _{_I})\) hold, and observe that

is a well-defined LTS which also satisfies \(\mathbf{AG }(\upchi _{_I})\) and in which both s and \(s'\) satisfy \(\varphi _0\), i.e., \(s, s' \models _{_{L''}} \varphi _0\). Thus, Lemma 1 guarantees that

is a bisimulation. As \(s, s' \models _{_{L''}} \varphi _0\) also implies \((s, s') \in R\), we can conclude that \(P_{_{L}}(s)\) and \(P_{_{L'}}(s')\) are bisimilar as desired.
Our semantics of \(\mathbf{AG }\) for an entire LTS coincides with the (standard) semantics for processes in which all states are reachable. Thus, the proof of the second part is a consequence of the well-known fact that bisimulation preserves e.g. all CTL and modal \(\mu \)-calculus formulas. \(\square \)
The following theorem is a straightforward reformulation of Lemma 2 considering processes as models of the GCI instead of LTSs:
Theorem 1
(GCI-based characteristic formulas) Let \(\upchi _{_I}\) be a GCI based on a finite set \(\varPhi \) of HML formulas, \(\varphi _0 \in \varPhi \), and \(L = (S_{_{L}}, \varSigma _{_{L}}, {\rightarrow }_{_{L}}), L' = (S_{_{L'}}, \varSigma _{_{L'}}, {\rightarrow }_{_{L'}})\) be two LTSs with states \(s \in S_{_L}\) and \(s' \in S_{_{L'}}\). Then we have:
Whereas the implication from left to right is just a reformulation of Lemma 2(1), the converse implication exploits the fact that satisfaction of invariance properties of processes only concerns the reachable states.
The following section establishes a sufficient condition for sets of formulas \(\varPhi \) to serve as a basis for the definition of non-trivial GCIs for a finite-state LTS, i.e., GCIs that remain valid when initial conditions \(\varphi \in \varPhi \) are added, resulting in characteristic formulas for processes as shown in Theorem 1.
4 Class-distinguishing formulas
Our notion of class-distinguishing formulas is directly based on the concept of bisimulation:
Definition 8
(Set of class-distinguishing formulas (SCDF)) Given any LTS \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\), a finite set \(\varPhi \subseteq \mathord {\text {HML}}\) with \(\forall s \in S.~ \exists \varphi \in \varPhi . \ s \models \varphi \) is called set of class-distinguishing formulas (SCDF) for L iff
is a bisimulation.

Nondeterministic LTS
Example 1
(Set of class-distinguishing formulas (SCDF)) Consider the LTS L depicted in Fig. 1. The history tree in Fig. 2 identifies the set \(\varPhi = \{ \varphi _1,\varphi _2,\varphi _3 \}\) with
as an SCDF for L. The subscript i in \(\varphi _i\) correlates with the corresponding state identifier \(s_i\) such that \(s_i \models \varphi _i\). Note that state 2 is bisimilar to state 5 and that state 3 is bisimilar to state 4.
Being HML formulas, the elements of an SCDF \(\varPhi \) for L can, in general, not fully characterize the behavior of states in L. They are only sufficient to identify bisimulation equivalence classes in the context of L. In the following, we will see how the “diamond-box-pattern” turns this property into a property that universally characterizes processes up to bisimulation, even in the context of infinite-state systems.
Definition 9
(SCDF-based GCIs) Let \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) be an LTS, \(\varPhi \) an SCDF for L, and \(\varPsi :\varPhi \times \varSigma \rightarrow 2^{\varPhi }\) defined by
Then \(\upchi _{_I}(\varPhi , \varPsi )\) is called a GCI forLbased on\(\varPhi \).
A GCI \(\upchi _{_I}\) based on an SCDF for L is sufficient to guarantee that \(L \models \mathbf{AG }(\upchi _{_I})\).
Lemma 3
Let \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) be any LTS, \(\varPhi \) an SCDF for L, and \(\upchi _{_I}\) a GCI for L based on \(\varPhi \). Then we have \(L \models \mathbf{AG }(\upchi _{_I})\).
Proof
Let \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) be an LTS, \(\varPhi \) an SCDF for L, and \(\upchi _{_I}(\varPhi , \varPsi )\) a GCI for L based on \(\varPhi \). Then we have to prove that L satisfies the following formula:
where
According to the semantics of \(L \models \mathbf{AG }(\varphi )\) for some \(\varphi \in \mathord {\text {HML}}\), it suffices to show that every state \(s \in S\) satisfies the conjunction \(\upchi _{_I}(\varPhi , \varPsi )\) that serves as the argument of the \(\mathbf{AG }\) operator. Let \(s \in S\) and \(\varphi \in \varPhi \) be arbitrary but fixed elements. We can assume that \(s \models \varphi \), because otherwise the implication is trivially satisfied. Thus, it remains to be shown that
holds. Therefore, let \(\varphi _c\) be any of the conjuncts in that HML formula. In order to show its validity, we distinguish between two cases:
- Case 1::
\(\varphi _c = \mathord {\mathopen {\langle }{a}\mathclose {\rangle }\,}\psi \) for some \(a \in \varSigma \) with \(\psi \in \varPsi (\varphi , a)\).
Because of \(\psi \in \varPsi (\varphi , a)\), there exist states \(p,q \in S\) and a transition \(p {\mathop {\rightarrow }\limits ^{a}} q\) with \(p \models \varphi \) and \(q \models \psi \). Thus, we have \(p \models \varphi _c\). In addition, \(s,p \models \varphi \) implies \(s \sim _{_L} p\) according to the definition of an SCDF. As bisimilar states satisfy the same HML formulas [17], this yields \(s \models \varphi _c\), which closes the first case.
- Case 2::
\(\varphi _c = \mathord {\mathopen {[}{a}\mathclose {]}\,}\delta \) with \(\delta = \bigvee _{\psi \in \varPsi (\varphi ,a)} \psi \) for some \(a \in \varSigma \).
In this case, the following has to be shown:
$$\begin{aligned} \forall s' \in S.~ s {\mathop {\rightarrow }\limits ^{a}} s' ~\text {implies}~ s' \models \delta \end{aligned}$$Therefore, let \(s' \in S\) be any state such that \(s {\mathop {\rightarrow }\limits ^{a}} s'\) and \(\psi \in \varPhi \) be a corresponding formula with \(s' \models \psi \). Such a formula exists due to the definition of an SCDF. Now, \(s \models \varphi \) implies \(\psi \in \varPsi (\varphi , a)\) by definition of \(\varPsi \) which guarantees that \(\psi \) is a disjunct in \(\delta \) and therefore that \(s' \models \delta \) as desired. \(\square \)
The following theorem follows straightforwardly from Lemma 3 and the definition of SCDFs.
Theorem 2
(Sufficiency for characterization) Let \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) be any LTS with \(s_0 \in S\), \(\varPhi \) an SCDF for L, and \(\upchi _{_I}\) a GCI for L based on \(\varPhi \). Then there exists a \(\varphi _0 \in \varPhi \) such that \(s_0 \models \varphi _0\) and we have:
The presented construction of a GCI for an LTS L depends on a corresponding SCDF (Definition 8). The next section introduces an approach that allows us to elegantly generate these sets of class-distinguishing formulas for any finite-state LTS.
5 Generation of characteristic invariants for finite-state LTSs
In this section, we present an algorithm that automatically generates a finite set of class-distinguishing formulas (SCDF) for any finite-state LTS L. Given this SCDF, a GCI for L can be generated according to Sect. 4.
After a brief sketch of partition refinement [16, 19] and so called splitters, Sect. 5.2 introduces the class-distinguishing functions that we use to generate an SCDF. Afterwards, Sect. 5.3 presents our algorithm together with an accompanying example.
5.1 Partition refinement
Partition refinement serves as the underlying concept of many analysis and verification techniques [31].
Definition 10
(Partition refinement) Given a set S, \(P \subseteq 2^{S}\) is a partition of S iff its elements, called classes, are non-empty, pairwise disjoint, and cover S when merged (\(\bigcup _{X \in P} X = S\)). Given two partitions P and Q of S, PrefinesQ, denoted by \(P \preceq Q\), iff for each \(X \in P\) there exists a \(Y \in Q\) such that \(X \subseteq Y\). We write \(P \prec Q\) iff \(P \preceq Q\) and \(P \ne Q\).
Our algorithm that is presented in Sect. 5.3 relies on partition refinement: it extends the algorithm by Kanellakis and Smolka [21] for the minimization of non-deterministic systems up to bisimulation. Our extension computes HML formulas that allow to identify the individual classes of the partitions that arise during the refinement algorithm.
Partition refinement within this algorithm is based on witnesses, called splitters, which prove that one or more classes contain states that are not bisimilar.
Definition 11
(Splitter) Let \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) be an LTS and P a partition over S. Let \(B,Y \in P\) and \(a \in \varSigma _L\). Then the pair (B, a) is a splitter of Y iff \(Y \cap a^{-1}B \ne \emptyset \) and \(Y \backslash a^{-1}B \ne \emptyset \) (see Definition 1). We denote this by \((B,a) \mid Y\). Furthermore, we define the abbreviations \(Y_B^a=_{\textit{def}}~Y \cap a^{-1}B\) and \(Y_B^{\not {a}}=_{\textit{def}}~Y \backslash a^{-1}B\).
Note that (B, a) might be a splitter for multiple classes in P. A refinement based on (B, a) splits all those classes:
Definition 12
(Splitter-based refinement) Let P be a partition and (B, a) a splitter of some class \(Y \in P\). Let \(P' = \{ Y \in P \mid (B,a) \text { is a splitter of }Y \}\). Then the partition
is called the refinement ofP based on (B, a).
Kanellakis and Smolka [21] proved that exhaustive splitting while starting with the trivial partition inevitably results in the coarsest partition that defines a bisimulation. The next section shows how we obtain formulas that uniquely identify the classes of this partition by the corresponding satisfaction relation, a property that makes the set of those formulas an SCDF.
5.2 Class-distinguishing functions
The SCDFs that we construct depend on the concrete chain of refinements produced by the (typically non-deterministic) partition refinement algorithm. Thus, let us consider an arbitrary but fixed scenario in this subsection, i.e.:
Let \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\) be a finite-state LTS, \(P_0 = \{ S\}\), \((B_0,a_0)\,, \ldots , \, (B_{m-1},a_{m-1})\) a sequence of m splitters, and \(P_0\,, \ldots , \, P_m\) the corresponding sequence of \(m+1\) (refined) partitions such that for all \(k \in 0\, ..\, m-1\), we have
- 1.
\((B_k, a_k)\) is a splitter of some \(Y \in P_k\),
- 2.
\(P_{k+1}\) is the refinement of \(P_k\) based on \((B_k,a_k)\), and
- 3.
\(P_{m}\) cannot be refined based on splitting.
This allows for the following inductive definition:
Definition 13
(Class-distinguishing functions) The sequence \(\varphi _0\,, \ldots , \, \varphi _m\) with \(\varphi _k :P_k \rightarrow \mathord {\text {HML}}\) for all \(k \in 0\, ..\, m\) inductively defined by \(\varphi _0(S) = \mathord { tt }\) and

is called sequence of class-distinguishing functions.
Note that the three cases in the definition of \(\varphi _{k+1}(X)\) are disjoint and that Y is unique in the first two cases. For this sequence of class-distinguishing functions, which is uniquely determined by the considered scenario, we have:
Theorem 3
(Class-distinguishing functions)
Proof
We prove the validity of the statement
by induction over \(k \in 0\, ..\, m\).
Base case (\(k=0\)): Initially, we have \(P_0 = \{S\}\) and \(\varphi _0(S) = \mathord { tt }\) and therefore \(\forall s \in S.~ s \models \mathord { tt }\) as required.
Induction hypothesis: Let A(k) hold for an arbitrary but fixed \(k \in 0\, ..\, (m-1)\).
Induction step (\( k \rightarrow k+1\)): Let \(X \in P_{k+1}\) and \(s \in S\) be both arbitrary but fixed. We proceed by proving the two required implications depending on the cases within Definition 13 for the construction of \(\varphi _{k+1}(X)\).
- Case 1::
\(\exists Y \in P_{k}.~ (B_k,a_k) \mid Y\) and
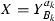
- (i):
\(s \in X ~\text {implies}~ s \models \varphi _{k+1}(X)\):
We assume that \(s \in X\). Because of \((B_k,a_k) \mid Y\), we know that \(X \subset Y\) and therefore \(s \in Y\). Due to the induction hypothesis, we have \(s \models \varphi _k(Y)\). Based on
 , we know that s has an \(a_k\)-successor in \(B_k\) (Definition 11). Let \(s'\) denote such a successor. By induction hypothesis, it follows that \(s' \models \varphi _k(B_k)\). Due to \(s {\mathop {\rightarrow }\limits ^{a_k}} s'\) and HML semantics, we know that \(s \models \mathord {\mathopen {\langle }{a_k}\mathclose {\rangle }\,}\varphi _k(B_k)\). Thus, we have \( s \models \varphi _k(Y) \wedge \mathord {\mathopen {\langle }{a_k}\mathclose {\rangle }\,}\varphi _k(B_k) = \varphi _{k+1}(X)\).
, we know that s has an \(a_k\)-successor in \(B_k\) (Definition 11). Let \(s'\) denote such a successor. By induction hypothesis, it follows that \(s' \models \varphi _k(B_k)\). Due to \(s {\mathop {\rightarrow }\limits ^{a_k}} s'\) and HML semantics, we know that \(s \models \mathord {\mathopen {\langle }{a_k}\mathclose {\rangle }\,}\varphi _k(B_k)\). Thus, we have \( s \models \varphi _k(Y) \wedge \mathord {\mathopen {\langle }{a_k}\mathclose {\rangle }\,}\varphi _k(B_k) = \varphi _{k+1}(X)\).- (ii):
\(s \models \varphi _{k+1}(X) ~\text {implies}~ s \in X\):
We assume \(s \models \varphi _{k+1}(X)\), which means that \(s \models \varphi _k(Y) \wedge \mathord {\mathopen {\langle }{a_k}\mathclose {\rangle }\,}\varphi _k(B_k)\). Because of the induction hypothesis and the first conjunct, we know that \(s \in Y\). Using HML semantics and the induction hypothesis, the second conjunct implies that there exists a transition \(s {\mathop {\rightarrow }\limits ^{a_k}} s'\) such that \(s' \in B_k\). Thus, we have
 .
.
- Case 2::
\(\exists Y \in P_{k}.~ (B_k,a_k) \mid Y\) and

Analogous to case 1.
- Case 3::
X is not split by \((B_k, a_k)\)
Then \(X \in P_k\) and \(\varphi _{k+1}(X) \ = \ \varphi _k(X)\) and therefore by induction as desired:
$$\begin{aligned} s \in X ~\text {iff}~ s \models \ \varphi _k(X) \ ( = \varphi _{k+1}(X)) \end{aligned}$$
 , we know that s has an
, we know that s has an  .
.
\(\square \)
In summary, the class-distinguishing functions are defined such that they reflect information about each splitter in HML. This information can be summarized on the basis of a decision tree with node set
and edges set
where for each \(k \in 0\, ..\, m-1\), all the nodes \(C \in P_{k}\) that are split by \((B_k, a_k)\) are annotated with the predicate \(\mathord {\mathopen {\langle }{a_k}\mathclose {\rangle }\,} \varphi _{k}(B_k)\). If this predicate evaluates to true, then one continues with  , otherwise with
, otherwise with  .
.
Figure 2 illustrates such a decision tree based on the LTS depicted in Fig. 1. As Fig. 2 is intended to also display the partition classes, the predicates were moved to the edges.

Partition refinement history and corresponding class-distinguishing predicates based on the input-LTS from Fig. 1 as generated by a tool that implements Algorithm 1. Dotted arrows denote splitters
In the following, we present our algorithm that incorporates both the partition refinement and the corresponding labeling based on class-distinguishing functions.
5.3 Algorithm for generating an SCDF
We use Algorithm 1 to generate an SCDF (Definition 8). This algorithm is conceptually based on the “naive method” from [21]. As such, the derived partition \(P\) is actually the coarsest partition w.r.t. bisimulation. Additionally, our iteratively defined class-distinguishing function (Definition 13) is incorporated.


The worklist of Algorithm 1 contains potential splitters (Definition 11). Whenever the current partition P is refined and new classes are thereby added to it, these classes are combined with every possible transition label and added to the worklist (Algorithm 2). Every time that such a partition refinement occurs, the class-distinguishing function \(\varphi \) is updated according to Definition 13 in order to incorporate information about the most recent splitter (lines 11–13 of Algorithm 1).
Note that the order in which splitters are applied is not defined by Algorithm 1. In the following, we assume a fixed order of splitters. As stated in Sect. 5.2 and visible in the pseudo code (lines 12 and 13 of Algorithm 1), the definition of the class-distinguishing function throughout the algorithm’s execution is based on that order of splitters. The sequence of splitters is exactly the sequence of those pairs received in line 6 of Algorithm 1 for which the inner for-all loop (line 8) executes at least one iteration.
Example 2
(Algorithm 1) Consider the LTS in Fig. 1 as input for Algorithm 1. Figure 2 illustrates the two refinements during an execution of Algorithm 1 for this input LTS. The actual class-distinguishing formulas generated by Algorithm 1 are as follows. In line with Sect. 5.2, we use a subscript index to refer to different refinements (Definition 12).
The algorithm’s internal variables are initialized to \(P_0 = \{S = \{1,2,3,4,5\}\} \) (line 2) and \(\varphi _0[S] = \mathord { tt }\) (line 4).
The first splitter is \( (S, a) \) (line 6). It splits the class \(S\) into the sets  and
and  (line 10). This split occurs because on the one hand, we have \( 1 {\mathop {\rightarrow }\limits ^{a}} 2, 2 {\mathop {\rightarrow }\limits ^{a}} 3, 5 {\mathop {\rightarrow }\limits ^{a}} 3\), and \(2,3,5 \in S\), and on the other hand, states 3 and 4 do not have outgoing transitions labeled \(a\) (cf. Fig. 1). The new partition is given by \( P_1 = \{\{1,2,5\}, \{3,4\}\} \) (line 10) and the formulas are \(\varphi _1[\{1,2,5\}] = \mathord { tt }\wedge \mathord {\mathopen {\langle }{a}\mathclose {\rangle }\,} \mathord { tt }\) (line 12) and \(\varphi _1[\{3,4\}] = \mathord { tt }\wedge \lnot \mathord {\mathopen {\langle }{a}\mathclose {\rangle }\,} \mathord { tt }\) (line 13).
(line 10). This split occurs because on the one hand, we have \( 1 {\mathop {\rightarrow }\limits ^{a}} 2, 2 {\mathop {\rightarrow }\limits ^{a}} 3, 5 {\mathop {\rightarrow }\limits ^{a}} 3\), and \(2,3,5 \in S\), and on the other hand, states 3 and 4 do not have outgoing transitions labeled \(a\) (cf. Fig. 1). The new partition is given by \( P_1 = \{\{1,2,5\}, \{3,4\}\} \) (line 10) and the formulas are \(\varphi _1[\{1,2,5\}] = \mathord { tt }\wedge \mathord {\mathopen {\langle }{a}\mathclose {\rangle }\,} \mathord { tt }\) (line 12) and \(\varphi _1[\{3,4\}] = \mathord { tt }\wedge \lnot \mathord {\mathopen {\langle }{a}\mathclose {\rangle }\,} \mathord { tt }\) (line 13).
The second splitter is \( (\{1,2,5\}, a) \). Note that in the meantime, several other checks for possible refinements may have been performed that failed. For simplicity, we will only list actual splitters (Definition 11). The splitter \( (\{1,2,5\}, a) \) separates the class \(\{1,2,5\}\) into the sets \(\{1\} \) and \(\{2,5\} \). Again, this happens because on the one hand, we have \( 1 {\mathop {\rightarrow }\limits ^{a}} 2 \) with \(2 \in \{1,2,5\}\), and on the other hand, states from \(\{2,5\}\) do not possess outgoing transitions labeled a that end in \(\{ 1,2,5 \}\). The new and final partition is given by \( P = \{\{1\},\{2,5\},\{3,4\}\} \) and the formulas are:
Note that states 2 and 5 as well as 3 and 4 are bisimilar, respectively. The algorithm terminates (after potentially executing a few more checks for splitters) because the splitter potential is exhausted.
Algorithm 1 resembles the “naive” algorithm by Kanellakis and Smolka [21] which is known to run in cubic time and to terminate with the coarsest partition up to bisimulation. Thus, the following theorem is a consequence of Theorem 3 which guarantees the correct labeling of the partition classes.
Theorem 4
(Correctness of Algorithm 1) Given an LTS L, Algorithm 1 terminates with an SCDF for L.
The following theorem summarizes the main result of this paper. Please recall that by definition of an SCDF, every state \(s \in S\) has a formula \(\varphi \in \varPhi \) with \(s \models _{_L}\varphi \):
Theorem 5
(Main theorem) Let L be an LTS \(L= (S, \varSigma _{_L}, {\mathop {\rightarrow }\limits })\), \(\varPhi \) an SCDF for L generated by Algorithm 1, \(\upchi _{_I}\) the GCI for L based on \(\varPhi \), and \(s \in S\), \(\varphi \in \varPhi \) with \(s \models _{_L}\varphi \). Then for any \(P_{_{L'}}(s')\) based on some LTS \(L' = (S', \varSigma _{_{L'}}', {\rightarrow }')\) with \(s' \in S'\), we have:
Proof
Theorem 4 guarantees that \(\varPhi \) is an SCDF which, by Theorem 2, implies \(P_{_{L}}(s) \models \varphi \wedge \mathbf{AG }(\upchi _{_I})\). Thus, applying Theorem 1 yields the desired statement. \(\square \)
6 Discussion of related work
The coincidence theorem of Hennessy and Milner states that, given a finitely-branching LTS, two states are bisimilar if and only if they enjoy the same set of HML formulas (first stated 1980 in [17] and again in [18]). Thus, HML has distinguishing power: any two non-bisimilar finitely-branching LTSs can be distinguished by a formula in HML.
The idea of characteristic formulas goes beyond distinguishability: It requires that, given a finitely-branching LTS, there exists a (single) formula that distinguishes this LTS from any other non-bisimilar (finitely-branching) LTS. It is clear that this “swap of quantifiers” leads to a requirement that cannot be satisfied by HML as HML formulas are limited in their sensitivity to finite prefixes of computation trees.
In 1984, Graf and Sifakis published a scheme by which characteristic formulas for finite CCS processesFootnote 5 can be derived [13, 15]. Such a scheme is usually referred to as (characteristic) translation. The pattern introduced by Graf and Sifakis, which we refer to as “diamond-box-pattern”, is used in almost all following publications on characteristic formulas, including this paper (see Definition 5). Graf and Sifakis also extended the idea of Hennessy and Milner in the sense that they interpret the coincidence theorem as a strict requirement for sensible temporal logics [14]. Thereby such logics are “sufficiently powerful to distinguish non-congruent terms”. Indeed, as later shown in various publications, many famous temporal logics such as HML, CTL, and \(\mu \)-calculus satisfy this claim.
Browne, Clarke, and Grumberg were the first to take the step from finite to finite-state systems in 1987, again based on the “diamond-box-pattern” by Graf and Sifakis, but this time generalized using implication in order to deal with cycles [2]. The key idea, which is also used in this paper, consists of two steps. First, find a formula for each state that distinguishes it from every other state of the considered finite-state system. Second, show that the generalized “diamond-box-pattern” for connecting these distinguishing formulas is sufficient to define characteristic formulas for finite-state systems. In essence, they observed that non-bisimilar states of finite-state systems can be distinguished by a finite prefix of the corresponding computation treeFootnote 6 which allowed them to infer their distinguishing formulas simply as characteristic formulas up to a certain depth of bisimilarity.
The paper [28] introduced a technique for deriving characteristic formulas in the modal \(\mu \)-calculus for finite-state processes (with divergence potential [26, 27]). Key idea was to associate each state of the LTS with a fixed point variable and to construct a modal equational system on the basis of the “diamond-box-pattern” which can then be translated into the modal \(\mu \)-calculus. As this translation leads to formulas of exponential size, [30] focused on modal equational systems as they provide characterizations that are linear in the size of a property, making bisimulation checking via model checking attractive.
Like [2], the approach presented in this paper is based on the combination of distinguishing formulas using the generalized “diamond-box-pattern”. The main difference is the construction of the distinguishing SCDF based on Algorithm 1 which has a reduced form of linear size in terms of a recursion-free equational system. Key to this construction is an extension of Kanellakis and Smolka’s partition refinement algorithm for bisimulation checking [21] in order to incrementally compute distinguishing formulas for the individual partition classes. By construction, this leads to distinguishing formulas with linearly many distinct subformulas. Therefore, their corresponding representation in terms of a directed acyclic graph or, equivalently, as recursion-free equational system, is guaranteed to be linear in the number of bisimulation equivalence classes. Thus, the characteristic formulas proposed in this paper can be regarded as very concise versions and therefore practical optimizations of the characteristic formulas of [2].
7 Conclusion and outlook
We have shown that HML, despite its structural limitations, is sufficiently expressive to specify an initial property \(\varphi _0\) and a characteristic invariant \(\upchi _{_I}\) for an arbitrary finite-state process P such that \(\varphi _0 \wedge \mathbf{AG }(\upchi _{_I})\) is a characteristic formula for P. This means, in particular, that it is sufficient to check an HML formula for each state of a candidate finite-state process to verify that it is bisimulation equivalent to P. In fact, our proofs do not require the candidate processes to be finite state. In particular, our theorem also holds for context-free [5] and push-down candidate systems [6].
The first model checking algorithm for context-free systems has been presented in 1992 in [5]. It was linear in the size of the context-free process representation and exponential in the size of the, in this case alternation-free, modal \(\mu \)-calculus formula, or better, in the size of a corresponding modal equational system. Extensions covered pushdown-processes [6] and later sequential processes for the full modal \(\mu \)-calculus [7]. Combining these algorithms, whose implementation in the fixed point analysis machine has been presented in CONCUR 1995 [29], with an algorithm that constructs characteristic formulas in terms of modal equational systems (e.g. [30]) immediately implies:
Bisimulation checking of context-free processes with a finite-state process can be performed in exponential time via model checking of characteristic formulas.
Even though not explicitly formulated back then, there existed a corresponding implementation already in 1995 [29]. Related results concerning equivalence checking involving infinite-state systems can be found in [3, 4, 20, 22,23,24].
Currently, we are re-implementing the algorithms for characteristic formula construction and context-free model checking, also with the goal to experimentally evaluate their practical efficiency. Our model checking algorithm uses shared BDDsFootnote 7 to efficiently represent the property transformers that are characteristic of our second-order treatment of context-free systems. It is not clear how the choice of characteristic formula construction interferes with the second-order fixed point computation, whether there are advantageous process patterns, or whether there are certain technological bottlenecks that can be overcome. An example for the latter category is the treatment of the identity function, which is intuitively very simple, but whose representation in terms of shared BDDs is bound to explode.
Notes
Please note that it is not required that Q is finite state.
Note that \(\varSigma _{_{L}} \subseteq \varSigma \) holds for any LTS L, because—as stated in the introduction—we only consider LTSs/processes from a given universe specified by \(\varSigma \).
Note that \(\mathord {\sim }\), which is in fact the union of all bisimulation relations, is itself a bisimulation.
The operator
 stands for the disjoint union of two sets.
stands for the disjoint union of two sets.Such CCS processes can be represented as a labeled tree with finite depth.
This is an immediate consequence of the fact that bisimilarity coincides with the limit of n-bisimilarity for finitely branching systems—a key property originally exploited in [17].
A shared BDD is an aggregation of multiple BDDs into one BDD with multiple start nodes.
 stands for the disjoint union of two sets.
stands for the disjoint union of two sets.References
Bradfield, J.C., Stirling, C.: Modal mu-calculi. In: Blackburn, P., van Benthem, J.F.A.K., Wolter, F. (eds.) Handbook of Modal Logic, Studies in logic and practical reasoning, vol. 3, pp. 721–756. North-Holland (2007). https://doi.org/10.1016/s1570-2464(07)80015-2
Browne, M.C., Clarke, E.M., Grumberg, O.: Characterizing Kripke structures in temporal logic. In: Ehrig, H., Kowalski, R.A., Levi, G., Montanari, U. (eds.) TAPSOFT’87: Proceedings of the International Joint Conference on Theory and Practice of Software Development, Pisa, Italy, March 23–27, 1987, Volume 1: Advanced Seminar on Foundations of Innovative Software Development I and Colloquium on Trees in Algebra and Programming (CAAP’87), Lecture Notes in Computer Science, vol. 249, pp. 256–270. Springer (1987). https://doi.org/10.1007/3-540-17660-8_60
Burkart, O., Caucal, D., Moller, F., Steffen, B.: Verification on infinite structures. In: Bergstra, J., Ponse, A., Smolka, S. (eds.) Handbook of Process Algebra, pp. 545–623. Elsevier Science, Amsterdam (2001). https://doi.org/10.1016/B978-044482830-9/50027-8. http://www.sciencedirect.com/science/article/pii/B9780444828309500278
Burkart, O., Caucal, D., Steffen, B.: Bisimulation collapse and the process taxonomy. In: Montanari, U., Sassone, V. (eds.) CONCUR ’96, Concurrency Theory, 7th International Conference, Pisa, Italy, August 26–29, 1996, Proceedings, Lecture Notes in Computer Science, vol. 1119, pp. 247–262. Springer (1996). https://doi.org/10.1007/3-540-61604-7_59
Burkart, O., Steffen, B.: Model checking for context-free processes. In: Cleaveland, W. (ed.) CONCUR ’92, pp. 123–137. Springer, Berlin Heidelberg, Berlin, Heidelberg (1992)
Burkart, O., Steffen, B.: Pushdown Processes: Parallel Composition and Model Checking, pp. 98–113. Springer Berlin Heidelberg, Berlin, Heidelberg (1994). https://doi.org/10.1007/BFb0015001
Burkart, O., Steffen, B.: Model checking the full modal mu-calculus for infinite sequential processes. In: Degano, P., Gorrieri, R., Marchetti-Spaccamela, A. (eds.) Automata, Languages and Programming, pp. 419–429. Springer, Berlin Heidelberg, Berlin, Heidelberg (1997)
Fischer, N., van Glabbeek, R.: Axiomatising infinitary probabilistic weak bisimilarity of finite-state behaviours. J. Logical Algebraic Methods Program. 102, 64–102 (2019). https://doi.org/10.1016/j.jlamp.2018.09.006. http://www.sciencedirect.com/science/article/pii/S2352220817302201
Floyd, R.W.: Assigning Meanings to Programs, pp. 65–81. Springer Netherlands, Dordrecht (1993). https://doi.org/10.1007/978-94-011-1793-7_4
Fokkink, W., van Glabbeek, R., de Wind, P.: Compositionality of Hennessy–Milner logic through structural operational semantics. In: Lingas, A., Nilsson, B.J. (eds.) Fundamentals of Computation Theory, pp. 412–422. Springer, Berlin Heidelberg, Berlin, Heidelberg (2003)
Fokkink, W., van Glabbeek, R., de Wind, P.: Compositionality of Hennessy–Milner logic by structural operational semantics. Theor. Comput. Sci. 354(3), 421–440 (2006). https://doi.org/10.1016/j.tcs.2005.11.035. http://www.sciencedirect.com/science/article/pii/S0304397505008819
Fokkink, W., van Glabbeek, R., de Wind, P.: Divide and congruence: from decomposition of modalities to preservation of branching bisimulation. In: de Boer, F.S., Bonsangue, M.M., Graf, S., de Roever, W.P. (eds.) Formal Methods for Components and Objects, pp. 195–218. Springer, Berlin Heidelberg, Berlin, Heidelberg (2006)
Graf, S., Sifakis, J.: A modal characterization of observational congruence on finite terms of CCS. In: Paredaens, J. (ed.) Automata, Languages and Programming, 11th Colloquium, Antwerp, Belgium, July 16–20, 1984, Proceedings, Lecture Notes in Computer Science, vol. 172, pp. 222–234. Springer (1984). https://doi.org/10.1007/3-540-13345-3_20
Graf, S., Sifakis, J.: A logic for the description of non-deterministic programs and their properties. Inf. Control 68(1–3), 254–270 (1986). https://doi.org/10.1016/S0019-9958(86)80038-9
Graf, S., Sifakis, J.: A modal characterization of observational congruence on finite terms of CCS. Inf. Control 68(1–3), 125–145 (1986). https://doi.org/10.1016/S0019-9958(86)80031-6
Habib, M., Paul, C., Viennot, L.: Partition refinement techniques: an interesting algorithmic tool kit. Int. J. Found. Comput. Sci. 10(2), 147–170 (1999). https://doi.org/10.1142/S0129054199000125
Hennessy, M., Milner, R.: On observing nondeterminism and concurrency. In: de Bakker, J.W., van Leeuwen, J. (eds.) Automata, Languages and Programming, 7th Colloquium, Noordweijkerhout, The Netherlands, July 14–18, 1980, Proceedings, Lecture Notes in Computer Science, vol. 85, pp. 299–309. Springer (1980). https://doi.org/10.1007/3-540-10003-2_79
Hennessy, M., Milner, R.: Algebraic laws for nondeterminism and concurrency. J. ACM 32(1), 137–161 (1985). https://doi.org/10.1145/2455.2460
Hopcroft, J.: An n log n algorithm for minimizing states in a finite automaton. In: Theory of Machines and Computations, pp. 189–196. Elsevier (1971). https://doi.org/10.1016/B978-0-12-417750-5.50022-1. http://www.sciencedirect.com/science/article/pii/B9780124177505500221
Jancar, P., Kucera, A., Mayr, R.: Deciding bisimulation-like equivalences with finite-state processes. In: Larsen, K.G., Skyum, S., Winskel, G. (eds.) Automata, Languages and Programming, 25th International Colloquium, ICALP’98, Aalborg, Denmark, July 13–17, 1998, Proceedings, Lecture Notes in Computer Science, vol. 1443, pp. 200–211. Springer (1998). https://doi.org/10.1007/BFb0055053
Kanellakis, P.C., Smolka, S.A.: CCS expressions, finite state processes, and three problems of equivalence. In: Probert, R.L., Lynch, N.A., Santoro, N. (eds.) Proceedings of the Second Annual ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing, Montreal, Quebec, Canada, August 17–19, 1983, pp. 228–240. ACM (1983). https://doi.org/10.1145/800221.806724
Kucera, A., Jancar, P.: Equivalence-checking on infinite-state systems: techniques and results. TPLP 6(3), 227–264 (2006). https://doi.org/10.1017/S1471068406002651
Kucera, A., Mayr, R.: On the complexity of semantic equivalences for pushdown automata and BPA. In: Diks, K., Rytter, W. (eds.) Mathematical Foundations of Computer Science 2002, 27th International Symposium, MFCS 2002, Warsaw, Poland, August 26–30, 2002, Proceedings, Lecture Notes in Computer Science, vol. 2420, pp. 433–445. Springer (2002). https://doi.org/10.1007/3-540-45687-2_36
Kucera, A., Schnoebelen, P.: A general approach to comparing infinite-state systems with their finite-state specifications. Theor. Comput. Sci. 358(2–3), 315–333 (2006). https://doi.org/10.1016/j.tcs.2006.01.021
Mayr, R.: Decidability of model checking with the temporal logic EF. Theor. Comput. Sci. 256(1), 31–62 (2001). https://doi.org/10.1016/S0304-3975(00)00101-8. http://www.sciencedirect.com/science/article/pii/S0304397500001018. ISS
Milner, R.: A Calculus of Communicating Systems, Lecture Notes in Computer Science, vol. 92. Springer (1980). https://doi.org/10.1007/3-540-10235-3
Milner, R.: Communication and Concurrency. PHI Series in Computer Science. Prentice Hall, Upper Saddle River (1989)
Steffen, B.: Characteristic formulae. In: Ausiello, G., Dezani-Ciancaglini, M., Rocca, S.R.D. (eds.) Automata, Languages and Programming, 16th International Colloquium, ICALP89, Stresa, Italy, July 11–15, 1989, Proceedings, Lecture Notes in Computer Science, vol. 372, pp. 723–732. Springer (1989). https://doi.org/10.1007/BFb0035794
Steffen, B., Claßen, A., Klein, M., Knoop, J., Margaria, T.: The fixpoint-analysis machine. In: Lee, I., Smolka, S.A. (eds.) CONCUR ’95: Concurrency Theory, pp. 72–87. Springer, Berlin Heidelberg, Berlin, Heidelberg (1995)
Steffen, B., Ingólfsdóttir, A.: Characteristic formulas for processes with divergence. Inf. Comput. 110(1), 149–163 (1994). https://doi.org/10.1006/inco.1994.1028
Steffen, B., Isberner, M., Jasper, M.: Playing with abstraction and representation. In: Probst, C.W., Hankin, C., Hansen, R.R. (eds.) Semantics, Logics, and Calculi, pp. 191–213. Springer International Publishing (2016). https://doi.org/10.1007/978-3-319-27810-0_10
van Glabbeek, R.: A complete axiomatization for branching bisimulation congruence of finite-state behaviours. In: Borzyszkowski, A.M., Sokołowski, S. (eds.) Mathematical Foundations of Computer Science 1993, pp. 473–484. Springer, Berlin Heidelberg, Berlin, Heidelberg (1993)
van Glabbeek, R.: The linear time—branching time spectrum ii. In: Best, E. (ed.) CONCUR’93, pp. 66–81. Springer, Berlin Heidelberg, Berlin, Heidelberg (1993)
van Glabbeek, R.: What is branching time semantics and why to use it? In: Nielsen, M. (ed.) The Concurrency Column, Bulletin of the EATCS 53, pp. 190–198 (1994)
van Glabbeek, R.: The linear time—branching time spectrum i. The semantics of concrete, sequential processes. In: Bergstra, J., Ponse, A., Smolka, S. (eds.) Handbook of Process Algebra, pp. 3–99. Elsevier Science, Amsterdam (2001). https://doi.org/10.1016/B978-044482830-9/50019-9. http://www.sciencedirect.com/science/article/pii/B9780444828309500199
van Glabbeek, R.: A Characterisation of Weak Bisimulation Congruence, pp. 26–39. Springer Berlin Heidelberg, Berlin, Heidelberg (2005). https://doi.org/10.1007/11601548_4
van Glabbeek, R.: On cool congruence formats for weak bisimulations. Theor. Comput. Sci. 412(28), 3283–3302 (2011). https://doi.org/10.1016/j.tcs.2011.02.036. http://www.sciencedirect.com/science/article/pii/S0304397511001605
van Glabbeek, R., Luttik, B., Trčka, N.: Branching bisimilarity with explicit divergence. Fundamenta Informaticae 93(4), 371–392 (2009)
van Glabbeek, R., Smolka, S., Steffen, B.: Reactive, generative, and stratified models of probabilistic processes. Inf Comput 121(1), 59–80 (1995). https://doi.org/10.1006/inco.1995.1123. http://www.sciencedirect.com/science/article/pii/S0890540185711236
van Glabbeek, R., Weijland, W.P.: Branching time and abstraction in bisimulation semantics. J. ACM 43(3), 555–600 (1996). https://doi.org/10.1145/233551.233556
Acknowledgements
Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jasper, M., Schlüter, M. & Steffen, B. Characteristic invariants in Hennessy–Milner logic. Acta Informatica 57, 671–687 (2020). https://doi.org/10.1007/s00236-020-00376-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00236-020-00376-5