
Abstract
Encoding the position of another person in space is vital for everyday life. Nevertheless, little is known about the specific navigational strategies associated with encoding the position of another person in the wider spatial environment. We asked two groups of participants to learn the location of a target (person or object) during active navigation, while optic flow information, a landmark, or both optic flow information and a landmark were available in a virtual environment. Whereas optic flow information is used for body-based encoding, such as the simulation of motor movements, landmarks are used to form an abstract, disembodied representation of the environment. During testing, we passively moved participants through virtual space, and compared their abilities to correctly decide whether the non-visible target was before or behind them. Using psychometric functions and the Bayes Theorem, we show that both groups assigned similar weights to body-based and environment-based cues in the condition, where both cue types were available. However, the group who was provided with a person as target showed generally reduced position errors compared to the group who was provided with an object as target. We replicated this effect in a second study with novel participants. This indicates a social advantage in spatial encoding, with facilitated processing of both body-based and environment-based cues during spatial navigation when the position of a person is encoded. This may underlie our critical ability to make accurate distance judgments during social interactions, for example, during fight or flight responses.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The great majority of studies conducted on spatial navigation has focused on objects as spatial landmarks, or as spatial targets (Burgess 2008). However, we live in a social environment, and encoding the position of another person in space is also vital for everyday life. Subconscious distance judgments to a potential opponent, for example, allow quick decisions about fight or flight responses (Blanchard et al. 2001). Remembering the last position of a person can guide decisions about chasing or letting-go. Both can be critical to the survival of an organism.
Social relationships such as power and affiliation are mapped spatially in the hippocampus (Tavares et al. 2015). There are also complex interactions amongst animals when they navigate as a group towards a common target (Bode et al. 2012). However, almost no work has been conducted on the navigational strategies employed to encode the position of a person in space. This may be because, traditionally, the fields of social cognition and spatial cognition are rather independent (Proulx et al. 2016). One study investigated navigational behavior of children in a real-life environment and observed a rightward bias when children approached adults, compared to objects (Forrester et al. 2014). However, this study did not distinguish between different navigational strategies, and was restricted to children. Studies on spatial body perception, on the other hand, such as studies on peripersonal space and extrapersonal space (Sambo and Forster 2009; Longo et al. 2012; Serino 2016; Grivaz et al. 2017), or on the position of body parts in space (Haggard et al. 2000; Kuehn et al. 2015), usually, do not investigate the position of the body in the wider spatial environment, such as in reference to larger spatial landmarks. Therefore, at present, the navigational strategies that underlie the human ability to encode the position of another person in the wider environment are poorly understood.
Humans use both body-based and environment-based encoding strategies to orient in space (Burgess 2008; Lester et al. 2017). For example, when asked to find a previously visited location, participants use either visual, motor, and proprioceptive self-motion cues to simulate the previously covered path (idiothetic/body-based encoding), or they use environmental landmarks, such as houses or trees, to form an abstract representation of space (allothetic encoding; Burgess 2008). Both processes activate distinct and partly separate neuronal networks: whereas idiothetic encoding involves, in addition to subcortical structures, the posterior parietal cortex, in particular areas 7a and VIP (Britten 2008), allothetic encoding is assumed to be primarily supported by grid and place cells in the entorhinal–hippocampal network (Ono et al. 1991; Hafting et al. 2005). In everyday life, idiothetic- and allothetic-encoding strategies are usually combined, and there are individual differences with respect to which strategy is preferred (Wolbers and Hegarty 2010; Bohbot et al. 2007). There is also evidence that both cue types are combined and weighted in a near to optimal fashion based on Bayesian principles (Cheng et al. 2007; Nardini et al. 2008; Chen et al. 2017).
Here, we asked about the specific navigational strategy employed when the position of a person compared to the position of an object is encoded in a virtual environment. Because observing a person activates embodied simulations also including posterior parietal areas (Brass et al. 2000; Hommel et al. 2001; Schutz-Bosbach and Prinz 2007b; Schutz-Bosbach and Prinz 2007a; Barsalou 2010; Dijkstra and Post 2015), and because it is particularly critical to estimate the correct distance between oneself and a potential opponent rather than the position of a person in an abstract, disembodied space, we hypothesized that encoding the position of a person in space increases the weight of idiothetic cues and decreases the weight of allothetic cues when both cue types are available. This links to the idea that egocentric encoding in social and spatial interactions may have a common basis (Proulx et al. 2016). We also hypothesized that stronger weighting of body-based cues when the position of a person is encoded could be accompanied by facilitated learning as indicated by lower position errors, in particular, when idiothetic cues are available.
To test these hypotheses, we investigated two groups of participants and their ability to learn the position of a target (person or object) within a virtual environment. In different experimental conditions, the environment either provided optic flow information (limited lifetime dots on the floor, idiothetic condition), a spatial landmark (a tree, allothetic condition), or both optic flow information and a spatial landmark (dots on the floor and a tree, combined condition). After an initial (active) learning phase, participants were passively moved to different positions in virtual space, and were asked to judge whether the non-visible target (person or object) was before or behind them. We expected (1) increased weighting of idiothetic cues in the combined condition in the social group compared to the object group and (2) lower position errors of the social group compared to the object group in the idiothetic condition. To preview, the results of this study provide novel insights into the navigational strategies that underlie the human ability to encode the position of a person in space.
Materials and methods
Participants
N = 48 participants were invited to experiment 1 to test the above-outlined hypotheses. Of those, n = 12 participants had to be excluded due to difficulties in solving our task (see first paragraph of “Analyses” section for specific exclusion criteria), which resulted in n = 36 participants used for data analyses [n = 18 females, n = 18 males, mean age = 23.6, ± 3.1 years (SD), all right handed]. Participants were divided into two groups: the social group (n = 9 females, n = 9 males) and the object group (n = 9 females, n = 9 males).
To replicate the findings of experiment 1 (see below), we conducted a second experiment with N = 40 novel, right-handed participants. Of those, n = 8 participants had to be excluded due to difficulties in solving our task (same exclusion criteria as in experiment 1, see first paragraph of “Analyses” section for exclusion criteria). This resulted in n = 32 participants used for data analyses (n = 16 females, n = 16 males, mean age = 23.6 ± 3.6 years). Again, participants were divided into two groups: the social group (n = 8 females, n = 8 males), and the object group (n = 8 females, n = 8 males). Experiment 1 and experiment 2 were conducted by different experimenters (one male and one female) to minimize the possibility that effects were driven by one specific experimenter.
All participants were students of the Otto-von-Guericke University Magdeburg, gave written informed consent, and received monetary compensation for taking part. The local ethics committee of the Otto-von-Guericke University Magdeburg approved both studies, and the studies were conducted according to the guidelines and regulations of the Otto-von-Guericke University Magdeburg, and the DZNE Magdeburg.
Procedure
During both experiments, participants were seated in front of a 17-inch computer screen, where the virtual environment was presented. Participants were first familiarized with the environment by the experimenter, and the target was introduced (an avatar for the social group, an advertisement pole for the object group, avatars were presented gender-matched, i.e., male avatar for male participants, female avatar for female participants, see Fig. 1d). The target was presented on a black screen together with some basic information (e.g., “This is an advertising pole. It is made out of concrete.” for the object group). We only proceeded with the experiment when all information could be correctly recalled shortly after. This ensured similar context associations by all participants towards the targets. Next, participants were provided with written instructions (see Online Appendix A1). The experimenter then conducted three blocks of four trials each to demonstrate the experiment (one block per condition in a randomized order, consisting of two passive learning and two active testing trials). Participants then underwent a training session, where they completed six blocks of eight trials each (two blocks per condition consisting of four active learning and four passive testing trials, no more than two blocks of the same condition were presented consecutively) plus two blocks of no-feedback trials. Participants were given the possibility to ask questions before proceeding to the main experiment.

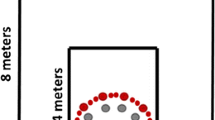
Experimental stimuli and design. a Virtual environment provided either idiothetic, allothetic, or both idiothetic and allothetic spatial cues in different experimental conditions. b A typical trial consisted of a starting screen, where the avatar/object was shown, a screen, where information on the starting position was provided, the virtual passive navigation task, a decision screen, and a feedback screen. c Bird’s eye view of the virtual environment displaying the distance between fixed starting points and target (10 vm), and between target and allothetic cue (25 vm). Idiothetic cues that appeared at random positions are schematically shown as white dots. d Targets: social targets (male and female avatars) and non-social target (advertisement pole)
Stimuli and experimental design
During the task, the virtual environment either provided idiothetic, allothetic, or both idiothetic and allothetic spatial information (see Fig. 1a). The environment consisted of a dark grey floor and a light grey background, with the horizon rendered at infinity (i.e., irrespective of location in the spatial environment, the distance to the horizon was always identical; the horizon could, therefore, not be used as spatial landmark). In the environment that provided idiothetic cues, white dots on the floor were shown. A total of 1000 dots were present at each time point, appearing at randomized positions between the point-of-view and the horizon, disappearing after 1 s. In the environment that provided allothetic cues, a green tree (3.2 virtual meter [vm] high) was presented, and served as spatial landmark. The social group was provided with a gender-matched avatar as target (i.e., female participants were presented with a female avatar, and male participants were presented with a male avatar, see Fig. 1d) wearing neutral clothes. The avatars were three-dimensional but static figures, facing the middle starting point. The object group was provided with an advertising pole as target (see Fig. 1d). Both the gender-matched avatars and the advertising pole were 1.2 vm high and had realistic ratios. Gender-matched avatars were chosen to control for gender-related physical differences between participants and avatars.
At the beginning of each block, participants performed a short learning session (eight active trials), where they were asked to actively navigate to the target position from different starting points (1/6 left, 1/6 right, 2/3 middle, see Fig. 1c for bird’s eye view of the virtual environment). They were asked to press the “Q” button when they thought that they had arrived at the target location. After the response, the target appeared at its correct location and participants corrected their response by moving to the exact position, where the target was displayed. This was done to allow subjects to learn the correct target location. Then, participants proceeded with the passive testing trials. Here, the correct target location was not shown. The target was only presented at the beginning of each block in front of a black screen, where the target location was not visible (see Fig. 1b). Participants had to press the “Space”-button to start the block. Figure 2b provides an overview over the structure of the experiment, i.e., how active and passive trials were arranged in a block structure.

Outcome measures and experimental design. a Dependent variables position error and variance are visualized using a typical psychometric function. Blue lines indicate the 50% threshold (PSE, bias), and green lines indicate the difference between the 25 and 75% thresholds (difference limen, variance). Zero represents the position of the target. Position error reflects the absolute difference between PSE and target location. b Experiment consisted of 9 blocks containing 8 active learning and 16 passive testing trials of the same condition each. Displayed is a possible block distribution. The block sequence (a = allothetic, i = idiothetic, c = combined) was randomized without recurrences each run. Three no-feedback blocks of combined conditions were tested at the end. Active learning trials consisted of start point information (2 s), the active navigation task, feedback, correction phase, and pause (1 s). Passive testing trials consisted of start point information (2 s), the passive navigation task, and feedback (0.5 s). Only during the active learning trials, the correct location of the target was visible
During the passive testing trials, participants were automatically (passively) moved along a straight line to different positions in the virtual environment. The transport stopped in front or behind the (non-visible) target (− 4, − 3, − 2, − 1, + 1, + 2, + 3, and + 4 vm). Participants were asked to decide whether the (non-visible) target was behind them (“down”-button) or before them (“up”-button, two-alternative forced-choice task). Participants were provided with idiothetic cues, allothetic cues, or both idiothetic and allothetic cues for this decision, depending on the condition. There was no time limit for this decision. Feedback was provided via the words “right” or “wrong” appearing on screen for 0.5 s. The correct position of the target was not shown. The feedback was removed during the no-feedback blocks at the end of the experiment. The order of starting points (1/6 of trials started from left starting points, 1/6 of trials started from right starting points, and 2/3 of trials started from middle starting points), and movement speed (2, 2.6, 3.2, 3.8, 4.4, and 5 vm/s) were randomized across trials and counterbalanced across conditions. We only analyzed trials from the middle starting points (2/3 of trials). Similar to the active training trials (see above), also in the passive testing trials, the trials from left and right starting points were only added to increase 3D immersion of the environment, they were not used for data analyses. Note that it was not experimentally checked whether or in which way the trials that started from the left or right starting points indeed increased spatial immersion. Movement speed was randomized across trials to prevent participants from using time (or counting) as metric to solve the task. Within each trial, movement speed was constant. At the beginning of each trial, participants saw a screen for two seconds informing them of their starting point (see Fig. 1b).
We used a blocked-design to arrange our three conditions (allothetic, idiothetic, and combined). We tested 9 blocks (plus three no-feedback blocks at the end of the experiment) of 16 trials each. Three blocks were tested per condition and no blocks of the same condition appeared twice in a row. In total, participants performed 48 trials per condition, adding up to 144 trials in total. Figure 2b provides an overview over the structure of the experiment.
After the experiment, participants filled out a questionnaire, in which they were asked to rate the targets (together with 48 other objects) with respect to their size, salience, permanence (“How often would one expect the position of this item to change in everyday life?”; Auger et al. 2012), and valence using a six-point scale (see Online Appendix A2).
Experiment 2
To minimize the possibility that group differences were due to random individual differences (note that we used a between-subject design), we conducted the same experiment as outlined above a second time, this time with novel participants. The only differences between experiment 1 and experiment 2 were a reduction of the total number of dots on the floor from 1000 to 700, and the introduction of z-axis movements of the dots (dots began to move in line with the participants’ movement direction) in the idiothetic and combined conditions. The introduced z-axis movements decreased the possibility that the moving dots could be used as landmarks, and increased optic flow. Every dot’s movement speed was drawn from a normal distribution around 0 with a standard deviation value of 0.5 vm. We also used a different experimenter in experiment 2.
Analyses
Participants in whom the 25% and/or the 75% threshold was/were not within the tested data range (that is, exceeding + 4 or − 4 vm, respectively) were excluded from the experiment prior to any statistical analyses. This ensured that those participants who were finally included in the analyses could solve the task, and performed within the expected performance range, such that ceiling and floor effects could be reduced.
We calculated bias, position error, and variance as dependent variables (see Fig. 2a). The point of subjective equality (PSE, bias) was calculated by detecting the location of the 50% threshold, that is, the location, where at 50% of the time, participants said that they were located behind the target. This was calculated by fitting logistic functions (Model-free v.1.1 Matlab package, Zychaluk and Foster 2009). Position error was calculated as the absolute difference between PSE and target location. Large position errors indicate large spatial distances between the estimated and actual position of the target, whereas low position errors indicate the reverse. Variance was quantified by the difference limen (Ulrigh and Vorberg 2009), i.e., the difference between the 25 and 75% thresholds of the fitted curves.
Data were entered into an ANOVA using IBM SPSS (Statistical Package for the Social Sciences version 22) with the factors group (social and object) as between-subjects factor and condition (idiothetic, allothetic, and combined) as within-subjects factor, using the values of bias, position error, and variance as dependent measures. We used paired-sample t tests with an uncorrected alpha level of 0.05 to follow up significant ANOVA results.
To test our hypotheses on potential idiothetic/allothetic weighting differences between groups, we calculated participants’ individual predicted weights of allothetic and idiothetic cues, and their predicted variance in the combined condition following the Bayes Theorem (Nardini et al. 2008; Chen et al. 2017). The predicted variance of the combined condition was calculated using the formula:
with σ c = variance of combined estimate, σ A = variance when cue A (allothetic) was provided, and σ B = variance when cue B (idiothetic) was provided. Predicted weights assigned to cue A (allothetic) or B (idiothetic) were calculated using the formulas:
with w A = predicted weight of cue A (allothetic) and w B = predicted weight of cue B (idiothetic). We then calculated participants’ actual weights on the basis of individual biases in the combined condition using the formula:
with W A = actual weight of cue A (allothetic), W B = actual weight of cue B (idiothetic), b A = bias when cue A (allothetic) was provided, b B = bias when cue B (allothetic) was provided and b C = bias when cue A (allothetic) and cue B (idiothetic) were provided.
We also calculated participant’s actual (empirically measured) variance in the combined condition (same analyses as for determining variance in allothetic and idiothetic conditions, see above). Using independent-samples t tests and a Bonferroni-corrected significant threshold of p < 0.017, we compared predicted weights, predicted variances, and actual weights between social and object groups. We also compared predicted variances and predicted weights to actual variances and actual weights. We conducted Wilcoxon-rank tests to compare questionnaire items (answers associated with avatars versus advertising pole).
Results
Experiment 1
We neither obtained a main effect of condition, nor an interaction effect between group and condition in position error. However, we found a main effect of group in position error [F(1,34) = 5.78, p = 0.022]. This effect was driven by a significantly lower position error in the social group compared to the object group across conditions [position error social group = 0.58 ± 0.07 vm (mean ± SE), position error object group = 0.87 ± 0.10 vm, see Fig. 3].

Position error and variance in social and object groups. Line and bar plots show means and standard errors (SE) of position errors and variances of experiments 1 and 2
We obtained a main effect of condition in variance [F(2,34) = 7.88, p = 0.001], but no interaction effect between group and condition, and no main effect of group. The main effect of condition was due to a significantly lower variance in the allothetic condition compared to the idiothetic condition, a significantly lower variance in the combined condition compared to the idiothetic condition, and a trend towards a significantly lower variance in the combined condition compared to the allothetic condition across groups [variance idiothetic = 2.64 ± 0.13 vm, variance allothetic = 2.26 ± 0.15 vm, variance combined = 1.97 ± 0.16 vm, allothetic versus idiothetic: t(35) = − 2.44, p = 0.020, idiothetic versus combined: t(35) = − 3.78, p = 0.001, allothetic versus combined: t(35) = − 1.73, p = 0.092, see Fig. 3].
We also found a main effect of group in bias [F(1,34) = 10.63, p = 0.003]. This effect was driven by a significantly lower bias in the social group compared to the object group across conditions (bias social group = 0.09 ± 0.31 vm, bias object group = 0.58 ± 0.60 vm).
We conducted independent-sample t tests to compare weights in the combined condition between groups. We did not find significant differences between both groups in predicted optimal variance, predicted weights, and real weights (all p > 0.58, see Table 1).
To test whether variance reduced according to the principle of optimal cue integration (Cheng et al. 2007; Chen et al. 2017), we compared the actual (empirically measured) variance in the combined condition to the Bayesian predicted variance. We also compared actual weights with predicted weights to test for the existence of optimal weighting. We found a significant difference between the actual variance in the combined condition and the Bayesian predicted variance [actual variance combined = 1.97 ± 0.16 vm, predicted optimal variance = 1.63 ± 0.09 vm, t(35) = − 2.25, p = 0.031], but no significant difference between actual weights and predicted weights [actual allothetic weight = 0.64 ± 0.04 vm, predicted optimal weight = 0.58 ± 0.03 vm, t(35) = − 1.20, p = 0.24] across groups (see Table 1).
With respect to the questionnaire items, we found significant differences in the estimated permanence [Z(22) = − 4.148, p = 0.01] and size [Z(16) = − 3.344, p = 0.01] of the targets. The avatars were perceived as less permanent and smaller than the advertisement pole even though in fact, both were of equal size. There were no significant differences in estimated salience [Z(16) = − 1.072, p = 0.15] and in estimated valence [Z(13) = − 0.284, p = 0.42].
Experiment 2
Similar to experiment 1, we neither obtained a main effect of condition, nor an interaction effect between group and condition in position error, but we again found a main effect of group in position error [F(1,30) = 6.32, p = 0.029]. This effect was again driven by a significantly lower position error in the social group compared to the object group (position error social group = 0.64 ± 0.09 vm, position error object group = 0.94 ± 0.09 vm, see Fig. 3).
We also performed an ANOVA with the factors group (social, object), and condition (idiothetic, allothetic, and combined) using variance as dependent measure. Again, we obtained a main effect of condition [F(2,30) = 5.10, p = 0.015], and this time also a main effect of group [F(1,30) = 6.32, p = 0.018], but again no interaction between group and condition. The main effect of condition was again due to a significantly lower variance in the allothetic condition compared to the idiothetic condition, and a significantly lower variance in the combined condition compared to the idiothetic condition across groups [variance idiothetic = 2.83 ± 0.24 vm, variance allothetic = 2.09 ± 0.11 vm, variance combined = 2.13 ± 0.23 vm, allothetic versus idiothetic: t(31) = –3.23, p = 0.003, idiothetic versus combined: t(31) = 2.20, p = 0.035, allothetic versus combined: t(31) = − 0.16, p = 0.87, see Fig. 3]. The main effect of group was driven by a significantly lower variance in the social group compared to the object group across conditions (variance social group = 2.04 ± 0.14 vm, variance object group = 2.66 ± 0.21 vm).
We did not find a main effect of condition, a main effect of group, or an interaction between group and condition in bias (all p > 0.35). Whereas the reduced position error in experiment 1 was, therefore, accompanied by a reduction in signed error, the reduced position error in experiment 2 was not accompanied by a reduction in signed error.
We conducted independent-sample t tests to compare weights in the combined condition between social and object groups. Again, we did not find significant differences between both groups neither in the predicted optimal variance, in the predicted weights, nor in the real weights (all p > 0.13, see Table 1).
Effect of gender
In an exploratory approach, we also compared performance between male and female participants using a repeated measures ANOVA with the factor condition (idiothetic, allothetic, and combined) and the between-subject factor gender (male and female). We did not find a significant main effect of gender in position error [experiment 1: F(2,34) = 1.135, p = 0.327, experiment 2: F(2,34) = 0.172, p = 0.842], and we also did not find a significant effect of gender in variance [experiment 1: F(2,34) = 5.90, p = 0.513, experiment 2: F(2,34) = 1.201, p = 0.307].
Discussion
Here, we offer a systematic investigation of the navigational strategies that underlie the human ability to encode the position of another person in the wider spatial environment. To trigger different navigational strategies, we offered either idiothetic (self-motion), allothetic (environmental landmark), or both idiothetic and allothetic (combined condition) navigational cues in a virtual environment. Within this environment, two groups of people either encoded the position of a person in space (social group), or the position of an object in space (object group). Whereas there were no weighting differences of body-based and environment-based cues between groups in the combined condition, where both cue types (idiothetic and allothetic) were available, the social group showed less position errors compared to the object group across conditions. This effect was replicated in a second experiment with novel participants. Our data indicate facilitated encoding of the position of a person using both body-based and environment-based navigational strategies. This may allow an accurate encoding of a person’s position in space.
The first question we targeted in the present study was whether there is a specific preference to use idiothetic encoding strategies when the position of a person is encoded in a virtual environment, compared to when the position of an object is encoded. This hypothesis was developed based on previous insights about idiothetic encoding, which involves body-based cues, such as simulated movements of the encoded path (Burgess 2008). In brief, our data do not confirm this hypothesis, because we did not find significant group differences in the relative weighting of idiothetic cues in a combined condition, where both cue types were available. The social group, therefore, did not show a preference towards the use of idiothetic cues. Our results suggest that individual differences in weighting of idiothetic and allothetic cues are not dependent on the encoded target (that is, object or person), but may rather depend on other factors such as individual age (Nardini et al. 2008), the subjective noise level and reliability of sensory inputs (Cheng et al. 2007; Chen et al. 2017), anatomical variability in key structures of the navigation network (Bohbot et al. 2007), or individual preferences in spatial encoding strategies (Gramann et al. 2005, 2006).
The second question we targeted was whether the social group would show lower position errors in the idiothetic condition compared to the object group. Our data consistently show lower position errors in the social group compared to the object group across experimental conditions. This lower position error in the social group was accompanied by perceiving the target as closer than it actually was in experiment 1, while there was no bias effect in experiment 2. In both experiments, position judgments were more accurate, i.e., they deviated less from the true target position. Whereas the bias reduction in experiment 1 may therefore be explained by the general tendency to perceive a person facing oneself as more close than a person looking away (Jung et al. 2016), and perhaps as more close than the object used here, there was no bias reduction but still a reduction in position error in experiment 2, which in our view cannot be explained by such a systematic shift towards the self. Our results may therefore indicate a social advantage in spatial encoding, similar as has been observed in other contexts, such as attentional capture for faces (Weaver and Lauwereyns 2011), attentional capture for social stimuli (Gluckman and Johnson 2013), enhanced tactile spatial perception when seeing a hand (Kennett et al. 2001), or a social preference when observing complex scenes (Solyst and Buffalo 2014).
Our data indicate a domain-general advantage for social spatial encoding, rather than a domain-specific advantage. How do we define ‘domains’ here? Whereas idiothetic encoding involves, in addition to subcortical structures, the posterior parietal cortex and in particular areas 7a and VIP (Britten 2008), allothetic encoding is assumed to be primarily supported by grid and place cells in the entorhinal–hippocampal network (Ono et al. 1991; Hafting et al. 2005). Spatial navigation therefore relies on distinct anatomical and cognitive networks with different characteristics, and partly different sensory modalities. The cognitive mechanism that facilitated spatial encoding in our study when a social target was used generalized across cue conditions, and may therefore be identified as domain-general (i.e., not specific to those sensory and cognitive networks that mediate idiothetic or allothetic encoding, respectively). The mechanism identified here is likely able to influence both neuronal networks flexibly, rather than being specific for any of the two cue conditions. Alternatively, given that self-motion cues can also update position computations in grid and place cells, the benefit for the social target could also be driven by a general modulation of entorhinal/hippocampal processing.
It has been argued before that visual body perception triggers attentional focus (Weaver and Lauwereyns 2011; Gluckman and Johnson 2013; Solyst and Buffalo 2014), perhaps via attentional prioritization (Truong and Todd 2016). Attentional prioritization also modulates hippocampal networks, and the PPC (Cordova et al. 2016; Levichkina et al. 2017). Here, seeing a person may increase alertness towards any environmental cue that supports the encoding of the person’s spatial position, that is, landmarks and/or optic flow information, respectively. This prioritization does not seem to rely on increased assigned valence or perceived salience of the targets, as indicated by the questionnaires results, but may be mediated by brain mechanism that control the focus on relevant navigational cues. Possible brain areas mediating this computation are the insula and the adjacent anterior cingulate cortex because of their involvement both in empathy and attentional prioritization (Proulx et al. 2016).
Furthermore, due to the influence of reward on event recollection (Loh et al. 2015, 2016; Shigemune et al. 2017), increased reward to correctly identify the position of a person in space compared to the position of an object in space may be relevant. Dopaminergic modulations of hippocampal processing (Wittmann et al. 2005) may be influenced by social reward (Gossen et al. 2014). This hypothesis could be tested by altering reward levels for both social and non-social targets using the present paradigm.
In our experiments, we used static avatars as social targets. Social resonance responses in the sensorimotor system are usually measured during observed or predicted movements (Buccino et al. 2004; Caspers et al. 2010; Gazzola and Keysers 2009), or during observed sensual experiences such as touch (Kuehn et al. 2014, 2015). If sensorimotor ‘mirror’ networks supported the recruitment of idiothetic navigation strategies, presenting a moving avatar, or an avatar receiving tactile stimulation, could induce the choice of more distinct navigation strategies. In our experiments, participants also had to remember the location of the social target when solving the task. Using a perceptual paradigm where distance judgments are conducted while the social cue is still visible may result in stronger differences between encoding the position of an object compared to encoding the position of a person. Whether or not these changes will influence the weighting of encoding strategies during spatial navigation remains to be investigated.
Taken together, we offer a systematic investigation on the navigational strategies that underlie the encoding of a person in space. Whereas our data do not show target-related differences in cue-weighting, they indicate an advantage to localize a person in space compared to localizing an object of equal size when idiothetic, allothetic, and both idiothetic and allothetic cues are present. This advantage may help estimating the correct distance between us and a (potential) social interaction partner.
References
Auger SD, Mullally SL, Maguire EA (2012) Retrosplenial cortex codes for permanent landmarks. PLoS One 7:e43620. https://doi.org/10.1371/journal.pone.0043620
Barsalou LW (2010) Grounded cognition: past, present, and future. Top Cogn Sci 2:716–724. https://doi.org/10.1111/j.1756-8765.2010.01115.x
Blanchard DC, Hynd AL, Minke KA, Minemoto T, Blanchard RJ (2001) Human defensive behaviors to threat scenarios show parallels to fear- and anxiety-related defense patterns of non-human mammals. Neurosci Biobehav Rev 25:761–770. https://doi.org/10.1016/S0149-7634(01)00056-2
Bode NW, Franks DW, Wood AJ, Piercy JJ, Croft DP, Codling EA (2012) Distinguishing social from nonsocial navigation in moving animal groups. Am Nat 179:621–632. https://doi.org/10.1086/665005
Bohbot VD, Lerch J, Thorndycraft B, Iaria G, Zijdenbos AP (2007) Gray matter differences correlate with spontaneous strategies in a human virtual navigation task. J Neurosci 27:10078–10083. https://doi.org/10.1523/JNEUROSCI.1763-07.2007
Brass M, Bekkering H, Wohlschläger A, Prinz W (2000) Compatibility between observed and executed finger movements: comparing symbolic, spatial, and imitative cues. Brain Cogn 44:124–143. https://doi.org/10.1006/brcg.2000.1225
Britten KH (2008) Mechanisms of self-motion perception. Annu Rev Neurosci 31:389–410. https://doi.org/10.1146/annurev.neuro.29.051605.112953
Buccino G, Binkofski F, Riggio L (2004) The mirror neuron system and action recognition. Brain Lang 89:370–376. https://doi.org/10.1016/s0093-934x(03)00356-0
Burgess N (2008) Spatial cognition and the brain. Ann N Y Acad Sci 1124:77–97. https://doi.org/10.1196/annals.1440.002
Caspers S, Zilles K, Laird AR, Eickhoff SB (2010) ALE meta-analysis of action observation and imitation in the human brain. Neuroimage 50:1148–1167. https://doi.org/10.1016/j.neuroimage.2009.12.112
Chen X, McNamara TP, Kelly JW, Wolbers T (2017) Cue combination in human spatial navigation. Cogn Psychol 95:105–144. https://doi.org/10.1016/j.cogpsych.2017.04.003
Cheng K, Shettleworth SJ, Huttenlocher J, Rieser JJ (2007) Bayesian integration of spatial information. Psychol Bull 133:625–637. https://doi.org/10.1037/0033-2909.133.4.625
Córdova NI, Tompary A, Turk-Browne NB (2016) Attentional modulation of background connectivity between ventral visual cortex and the medial temporal lobe. Neurobiol Learn Mem 134 Pt A:115–122. https://doi.org/10.1016/j.nlm.2016.06.011
Dijkstra K, Post L (2015) Mechanisms of embodiment. Front Psychol 6:1525. https://doi.org/10.3389/fpsyg.2015.01525
Forrester GS, Crawley M, Palmer C (2014) Social environment elicits lateralized navigational paths in two populations of typically developing children. Brain Cogn 91:21–27. https://doi.org/10.1016/j.bandc.2014.07.005
Gazzola V, Keysers C (2009) The observation and execution of actions share motor and somatosensory voxels in all tested subjects: single-subject analyses of unsmoothed fMRI data. Cereb Cortex 19:1239–1255. https://doi.org/10.1093/cercor/bhn181
Gluckman M, Johnson SP (2013) Attentional capture by social stimuli in young infants. Front Psychol 4:527. https://doi.org/10.3389/fpsyg.2013.00527
Gossen A, Groppe SE, Winkler L et al (2014) Neural evidence for an association between social proficiency and sensitivity to social reward. Soc Cogn Affect Neurosci 9:661–670. https://doi.org/10.1093/scan/nst033
Gramann K, Müller JH, Eick EM, Schönebeck B (2005) Evidence of separable spatial representations in a virtual navigation task. J Exp Psychol Hum Percept Perform 31:1199–1223. https://doi.org/10.1037/0096-1523.31.6.1199
Gramann K, Müller HJ, Schönebeck B, Debus G (2006) The neural basis of ego- and allocentric reference frames in spatial navigation: evidence from spatio–temporal coupled current density reconstruction. Brain Res 1118:116–129. https://doi.org/10.1016/j.brainres.2006.08.005
Grivaz P, Blanke O, Serino A (2017) Common and distinct brain regions processing multisensory bodily signals for peripersonal space and body ownership. Neuroimage 147:602–618. https://doi.org/10.1016/j.neuroimage.2016.12.052
Hafting T, Fyhn M, Molden S, Moser MB, Moser EI (2005) Microstructure of a spatial map in the entorhinal cortex. Nature 436:801–806. https://doi.org/10.1038/nature03721
Haggard P, Newman C, Blundell J, Andrew H (2000) The perceived position of the hand in space. Percept Psychophys 62:363–377. https://doi.org/10.3758/bf03205556
Hommel B, Müsseler J, Aschersleben G, Prinz W (2001) The Theory of Event Coding (TEC): a framework for perception and action planning. Behav Brain Sci 24:849–878. https://doi.org/10.1017/s0140525x01000103 (discussion 878–937).
Jung E, Takahashi K, Watanabe K, de la Rosa S, Butz MV, Bülthoff HH, Meilinger T (2016) The influence of human body orientation on distance judgments. Front Psychol 7:217. https://doi.org/10.3389/fpsyg.2016.00217
Kennett S, Taylor-Clarke M, Haggard P (2001) Noninformative vision improves the spatial resolution of touch in humans. Curr Biol 11:1188–1191. https://doi.org/10.1016/s0960-9822(01)00327-x
Kuehn E, Trampel R, Mueller K, Turner R, Schütz-Bosbach S (2013) Judging roughness by sight: A 7-T fMRI study on responsivity of the primary somatosensory cortex during observed touch of self and others. Hum Brain Map 34:1882–1895. https://doi.org/10.1002/hbm.22031
Kuehn E, Mueller K, Turner R, Schütz-Bosbach S (2014) The functional architecture of S1 during touch observation described with 7 T fMRI. Brain Struct Funct 219:219–240. https://doi.org/10.1007/s00429-012-0489-z
Kuehn E, De Havas J, Silkoset E, Gomi H, Haggard P (2015) On the bimanual integration of proprioceptive information. Exp Brain Res 233:1273–1288. https://doi.org/10.1007/s00221-015-4205-0
Lester AW, Moffat SD, Wiener JM, Barnes CA, Wolbers T (2017) The aging navigational system. Neuron 95:1019–1035. https://doi.org/10.1016/j.neuron.2017.06.037
Levichkina E, Saalmann YB, Vidyasagar TR (2017) Coding of spatial attention priorities and object features in the macaque lateral intraparietal cortex. Physiol Rep 5:e13136. https://doi.org/10.14814/phy2.13136
Loh E, Deacon M, de Boer L, Dolan RJ, Duzel E (2015) Sharing a Context with Other Rewarding Events Increases the Probability that Neutral Events will be Recollected. Front Hum Neurosci 9:683. https://doi.org/10.3389/fnhum.2015.00683
Loh E, Kumaran D, Koster R, Berron D, Dolan R, Duzel E (2016) Context-specific activation of hippocampus and SN/VTA by reward is related to enhanced long-term memory for embedded objects. Neurobiol Learn Mem 134 Pt A:65–77. https://doi.org/10.1016/j.nlm.2015.11.018
Longo MR, Musil JJ, Haggard P (2012) Visuo-tactile integration in personal space. J Cogn Neurosci 24:543–552. https://doi.org/10.1162/jocn_a_00158
Nardini M, Jones P, Bedford R, Braddick O (2008) Development of cue integration in human navigation. Curr Biol 18:689–693. https://doi.org/10.1016/j.cub.2008.04.021
Ono T, Nakamura K, Fukuda M, Tamura R (1991) Place recognition responses of neurons in monkey hippocampus. Neurosci Lett 121:194–198. https://doi.org/10.1016/0304-3940(91)90683-k
Pasqualotto A, Proulx MJ (2012) The role of visual experience for the neural basis of spatial cognition. Neurosci Biobehav Rev 36:1179–1187. https://doi.org/10.1016/j.neubiorev.2012.01.008
Pasqualotto A, Spiller MJ, Jansari AS, Proulx MJ (2013) Visual experience facilitates allocentric spatial representation. Behav Brain Res 236:175–179. https://doi.org/10.1016/j.bbr.2012.08.042
Proulx MJ, Todorov OS, Taylor Aiken A, de Sousa AA (2016) Where am I? Who am I? The relation between spatial cognition, social cognition and individual differences in the built environment. Front Psychol 7:64. https://doi.org/10.3389/fpsyg.2016.00064
Sambo CF, Forster B (2009) An ERP investigation on visuotactile interactions in peripersonal and extrapersonal space: evidence for the spatial rule. J Cogn Neurosci 21:1550–1559. https://doi.org/10.1162/jocn.2009.21109
Schutz-Bosbach S, Prinz W (2007a) Perceptual resonance: action-induced modulation of perception. Trends Cogn Sci 11:349–355. https://doi.org/10.1016/j.tics.2007.06.005
Schütz-Bosbach S, Prinz W (2007b) Prospective coding in event representation. Cogn Process 8:93–102. https://doi.org/10.1007/s10339-007-0167-x
Serino A (2016) Variability in multisensory responses predicts the self-space. Trends Cogn Sci 20:169–170. https://doi.org/10.1016/j.tics.2016.01.005
Shigemune Y, Tsukiura T, Nouchi R, Kambara T, Kawashima R (2017) Neural mechanisms underlying the reward-related enhancement of motivation when remembering episodic memories with high difficulty. Hum Brain Mapp. https://doi.org/10.1002/hbm.23599 (Epub ahead of print)
Solyst JA, Buffalo EA (2014) Social relevance drives viewing behavior independent of low-level salience in rhesus macaques. Front Neurosci 8:354. https://doi.org/10.3389/fnins.2014.00354
Tavares RM, Mendelsohn A, Grossman Y, Williams CH, Shapiro M, Trope Y, Schiller D (2015) A map for social navigation in the human brain. Neuron 87:231–243. https://doi.org/10.1016/j.neuron.2015.06.011
Truong G, Todd RM (2016) SOAP Opera: Self as Object and Agent in Prioritizing Attention. J Cogn Neurosci:1–16. https://doi.org/10.1162/jocn_a_01083
Ulrigh R, Vorberg D (2009) Estimating the difference limen in 2AFC tasks: pitfalls and improved estimators. Atten Percept Psychophys 71:1219–1227. https://doi.org/10.3758/APP.71.6.1219
Weaver MD, Lauwereyns J (2011) Attentional capture and hold: the oculomotor correlates of the change detection advantage for faces. Psychol Res 75:10–23. https://doi.org/10.1007/s00426-010-0284-5
Wittmann BC, Schott BH, Guderian S, Frey JU, Heinze HJ, Duzel E (2005) Reward-related FMRI activation of dopaminergic midbrain is associated with enhanced hippocampus-dependent long-term memory formation. Neuron 45:459–467. https://doi.org/10.1016/j.neuron.2005.01.010
Wolbers T, Hegarty M (2010) What determines our navigational abilities? Trends Cogn Sci 14:138–146. https://doi.org/10.1016/j.tics.2010.01.001
Zychaluk K, Foster DH (2009) Model-free estimation of the psychometric function. Atten Percept Psychophys 71:12. https://doi.org/10.3758/s13414-013-0574-2
Acknowledgements
Open access funding provided by Max Planck Society. E.K. was funded by the CBBS-ScienceCampus (Aktenzeichen: SAS-2015_LIN_LWC). The project was funded by a Research Grant by the Human Frontiers Science Program (RGP 0062/2014, awarded to T.W.)
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Kuehn, E., Chen, X., Geise, P. et al. Social targets improve body-based and environment-based strategies during spatial navigation. Exp Brain Res 236, 755–764 (2018). https://doi.org/10.1007/s00221-018-5169-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-018-5169-7