
Abstract
A causal structure is a description of the functional dependencies between random variables. A distribution is compatible with a given causal structure if it can be realized by a process respecting these dependencies. Deciding whether a distribution is compatible with a structure is a practically and fundamentally relevant, yet very difficult problem. Only recently has a general class of algorithms been proposed: These so-called inflation techniques associate to any causal structure a hierarchy of increasingly strict compatibility tests, where each test can be formulated as a computationally efficient convex optimization problem. Remarkably, it has been shown that in the classical case, this hierarchy is complete in the sense that each non-compatible distribution will be detected at some level of the hierarchy. An inflation hierarchy has also been formulated for causal structures that allow for the observed classical random variables to arise from measurements on quantum states—however, no proof of completeness of this quantum inflation hierarchy has been supplied. In this paper, we construct a first version of the quantum inflation hierarchy that is provably convergent. It takes an additional parameter, r, which can be interpreted as an upper bound on the Schmidt rank of the observables involved. For each r, it provides a family of increasingly strict and ultimately complete compatibility tests for correlations that are compatible with a given causal structure under this Schmidt rank constraint. From a technical point of view, convergence proofs are built on de Finetti theorems, which show that certain symmetries (which can be imposed in convex optimization problems) imply independence of random variables (which is not directly a convex constraint). A main technical ingredient to our proof is a Quantum de Finetti Theorem that holds for general tensor products of \(C^*\)-algebras, generalizing previous work that was restricted to minimal tensor products.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
1.1 Classical causal models
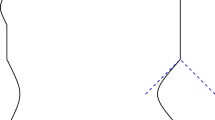
Gaining information about causal relationships between variables from observational data is an important problem in empirical science [1,2,3]. In the formalization laid out in Ref. [4], causal relationships between classical random variables are modeled using directed acyclic graphs (DAGs; also: Bayesian networks or causal structures). Each vertex corresponds to a random variable. Arrows denote causal relationships, in the sense that each variable is taken to be a function of its parents in the graph and independent randomness. Causal structures that we consider here may have two types of vertices: variables that can be directly observed and variables that are not accessible, known as latent or hidden variables. In the graphical notation using DAGs, we will use circles to indicate latent variables and squares for observed ones (see Fig. 1 for an example of a classical and a quantum causal structure).
We are interested in the following causal hypothesis testing problem: Given a joint distribution over the observed random variables and a candidate causal structure, can the distribution be realized in a model that is compatible with the structure? One reason why this question is difficult is that we allow for arbitrary functional relationships between parent and child variables, and also for the unobserved variables to take values in arbitrary sets. (We do, however, restrict attention to the case where the observed variables take values in finite alphabets.)
Because there is an infinite set of possible functional relationships, it is a priori not obvious that the causal hypothesis testing problem is even algorithmically decidable. Two computational solutions have recently been developed, though. The first makes use of the realization that arguments based on Caratheodory’s Theorem can be used to upper-bound the size of the sets in which the unobserved variables take values [5]. For finite-sized alphabets quantifier elimination algorithms can in principle be used to decide compatibility (see, e.g. [6, 7]). The runtime of these solutions, however, renders these approaches impractical even for the smallest non-trivial scenarios.
The second solution is based on linear programming (LP) hierarchies [8, 9]. Given a joint distribution P and a relaxation level n, these approaches construct an LP that runs in time polynomial in n and the number of parameters describing P. If the data fails the LP test at a level k, the distribution is not compatible with the causal structure. If the data passes, no conclusions can be made. As n increases, more and more incompatible distributions will be recognized. Such hierarchies are called complete if every incompatible distribution will be rejected from some level n onward. Geometrically, the set of distributions accepted at relaxation level n is an outer approximation to the set of distributions compatible with a given structure. A complete hierarchy thus corresponds to a sequence of outer approximations that converge to the true set. In a break-through development, a convergent LP hierarchy for the classical causal hypothesis testing problem has been developed under the name of inflation technique [9].
The high-level idea behind the inflation technique is to check for the existence of certain symmetric extensions. Indeed, assume that a distribution is compatible with a candidate causal structure. One can then define an inflated model that involves n independent copies of the hidden variables. This larger model has a number of symmetries: One can exchange a hidden variable from one of the copies with the same hidden variable from another copy, without affecting the distribution (see Fig. 3). The n-th level of the hierarchy tests whether such an n-fold inflated model exhibiting all these symmetries exists.
From a technical point of view, one difficulty of the causal compatibility problem lies in the fact that the distribution of the variables must not show any dependencies other than those that are explicitly modeled by the graph. The set of independent probability distributions is not convex as a subset of all multivariate distributions. Therefore, there is no direct way of enforcing the independence conditions that are part of the definition of a causal model in a convex optimization problem. The inflation hierarchy circumvents this problem by imposing the symmetry constraints that follow from independence. These symmetries are linear relations, which can easily be incorporated into a convex formulation. Fortunately, it has long been realized that in an asymptotic sense, symmetries conversely often do imply independence. Such results are known as de Finetti Theorems [9,10,11,12,13,14]. It is therefore unsurprising that the completeness proof of the classical inflation technique builds on a tailor-made de Finetti Theorem [9], and that a generalized Quantum de Finetti Theorem is at the heart of our own argument.

The triangle scenario—a conceptually simple, but mathematically non-trivial causal structure that serves as the guiding example in this paper. Round vertices denote latent variables that are not directly accessible, while observed variables are written in squares. Arrows represent causal relations. In the classical case depicted in (a), the graph denotes the hypothesis that the observed variables A, B, C arise in a process where (1) the latent variables X, Y, Z are chosen from a product distribution, and (2) each observed variable A, B, C is computed as a function of its graph-theoretical parents and additional independent randomness. Given a joint distribution of the observed variables and a candidate causal structure, we aim to decide whether the distribution is compatible with a process as outlined above. For example, take A, B, C to be binary random variables. It is easy to see that a joint distribution where the outcomes are random but perfectly correlated is not compatible with the triangle scenario. In the quantum case, shown in (b), each of the round nodes represents a bi-partite quantum state. One subsystem is distributed along each outgoing arrow. At each square vertex, a bi-partite measurement is performed on the two incoming quantum systems, and the result is assigned to an observed classical random variable
1.2 Quantum causal structures
It is natural to generalize the causal hypothesis testing problem to quantum causal structures [15,16,17,18,19]. A conceptual difference to classical causal models is that, due to the no-broadcasting theorem, quantum states cannot be both measured and also serve as an input for further processing. A general framework for a graphical notation for quantum causal structures is beyond the scope of this document (a detailed discussion can be found e.g. in Refs. [15, 18, 19]). Here, we mainly focus on the subset of quantum causal structures known as correlation scenarios [20]. These comprise one layer of hidden nodes and one layer of observed nodes, with arrows pointing from hidden to observed ones (more general causal structures are discussed in Sect. 4.3).
The input to the causal hypothesis test for correlation scenarios is a bipartite directed graph and a joint probability distribution with one classical variable corresponding to every observed node (see Figs. 1b and 3b for examples). The problem is then to decide whether the classical distribution could have arisen from the following process:
-
1.
For each hidden node, prepare a quantum state on as many systems as there are outgoing arrows from that node. The quantum state can be entangled among the subsystems, but the states associated with different latent nodes must be independent. Then, distribute the subsystems along the arrows to the observed nodes.
-
2.
At each observed node, perform a global measurement on all incoming quantum systems. Assign the result to the observed random variable.
This is the quantum causal hypothesis testing problem we are concerned with in the present paper.
To give an example, we again take the triangle scenario, which is depicted for the quantum case in Fig. 1b. The latent variables are now quantum systems with quantum states that are labeled according to the observer to which they are sent. For example, \(\rho _{AB}\) is a bipartite quantum state, of which the first part is sent to Alice and the second part to Bob. The arrows indicate independent quantum channels and whenever an arrow ends in a classical observable node, a measurement is performed at that node. Nodes that do not have any incoming edges are called root nodes and are assumed to be prepared in independent initial states. Note the abuse of notation that is commonly used in the graphical representation of quantum causal structures: The hidden nodes are labeled by quantum states, as opposed to the quantum systems on which they live. This is in contrast to the classical case, where the hidden nodes are labeled by the random variables and not by their probability distributions. Here we have opted to adopt this commonly used abuse of notation, as the quantum state is generally considered as the more central object.
Recently, a hierarchy of semidefinite programming tests generalizing the inflation technique to the quantum case has been proposed [16]. However, it is an open problem to decide whether it is complete, i.e. whether every distribution that is incompatible with a given quantum causal structure will be rejected at some level of the hierarchy.
1.2.1 Related problems
In order to get a feeling for the causal hypothesis testing problem, it is instructive to consider a few related examples.
A closely related and particularly well-studied case is the Bell scenario (Fig. 2). In a Bell scenario, observable classical variables come in pairs: A parent variable that is interpreted as a party’s choice of which measurement to perform, and a child variable that is interpreted as the output of the measurement. There is also one hidden variable that connects to every child variable. The celebrated result of Bell says that the set of joint distributions observable in such a scenario differs between the case where the hidden variable is taken to be classical, and the case where it is allowed to be quantum. The causal hypothesis testing problem for Bell scenarios is well-understood, both classically and quantum mechanically. In either case, the set of possible distributions of the measurement results conditioned on the input forms a convex set [21].
If the hidden variable is classical, this convex set is a polytope. As such, it is defined by a finite number of linear inequalities known as Bell inequalities. This immediately gives rise to a finite algorithm for deciding the causal hypothesis test: A distribution is compatible with the causal structure if and only if it satisfies all Bell inequalities for the scenario.
Characterising the set of correlations that can arise from a shared quantum state is considerably harder. In certain low-dimensional situations, complete analytical formulas are known [22, 23]. For the general case, the most explicit known numerical tool is the Navascués–Pironio–Acín (NPA) hierarchy [24,25,26], a convergentFootnote 1 SDP hierarchy.
With the result presented in this paper, the situations for Bell scenarios and correlation scenarios are now analogous: If the hidden variables are classical, then compatibility with both scenarios can be decided using linear programming; if they are quantum, then there exist convergent SDP hierarchies.

The Bell scenario, where the latent variable is a quantum state. The set of correlations that can arise from this quantum version of the Bell scenario is larger than its classical counterpart. This set of quantum correlations can be categorized by the NPA hierarchy, a converging hierarchy of semidefinite programs
Finally, we remark that mathematical methods different from convex optimization hierarchies have been developed for the quantum causal compatibility problem. They are usually computationally cheaper, but fail to be complete and might only be applicable to certain scenarios. These include: polynomial Bell inequalities tailored for quantum networks [27,28,29]; methods using entropy inequalities [15, 30,31,32]; covariance matrices [33,34,35]; methods tailored to bilocality [36] and star network scenarios [37]; correlations obtained in the triangle, when each source produces the same pure entangled state of two qubits [38].
1.3 Results
Our main motivation is the approximate quantum causal compatibility problem.
Problem 1
(Approximate quantum causal compatibility) Given \(\epsilon \ge 0\), a causal structure and a probability distribution over observable variables P, determine whether there exists a distribution \(\tilde{P}\) that can be produced by a quantum model compatible with the causal structure, such that \(\Vert \tilde{P}-P\Vert _2^2 \le \epsilon \).
Following Refs. [9, 16], we will phrase it as a special case of a more general causal polynomial optimization problem. There, the goal is to minimize a polynomial function \(f_0(\rho )\) over states \(\rho \) that are compatible with the causal structure and in addition satisfy a set of polynomial constraints \(f_i(\rho )=0\).
The notion of a “polynomial function in states” needs to be explained. A quantum model associates with each party an algebra of observables. We assume that these algebras possess a finite set of generators \(\mathcal {G}= \{g_i\}_i\) (in the main text, we describe how to derive a suitable set of generators for each causal structure and any given number of outcomes per party). For now, we treat the \(g_i\) as (non-commutative) variables—later we will optimize over all possible assignments of concrete operators to the \(g_i\). Let \(\mathcal {F}^{(k)}(\mathcal {G})\) be the vector space formed by complex linear combinations of words of length k in the symbols \(g_i\) and \(g_i^*\). Each element \(x\in \mathcal {F}^{(k)}\) defines a “linear function f on states” in the following sense: Choose an assignment of operators to the \(g_i\). Let \(\mathcal {D}\) be the resulting algebra of observables. Then x can be understood as an element of \(\mathcal {D}\). Let \(\rho \) be a state on \(\mathcal {D}\). Then the linear function is just \(f: \rho \mapsto \rho (x)\). To define a degree-g polynomial, start with an element x in the g-fold tensor product \(\mathcal {F}^{(k)} \otimes \dots \otimes \mathcal {F}^{(k)}\) and set
We say that x is a polarization of the polynomial f. Note that polarizations x are defined independently of any assignments of concrete operators to the generators—so they can be used to specify polynomial objective functions for problems that optimize over such assignments.Footnote 2
Problem 2
(Quantum causal polynomial optimization). Given a causal structure, the number of possible measurement outcomes for each party, a polynomial function \(f_0\) on quantum states (as defined above), and a countable set of polynomial functions \(f_1, f_2, \dots \) that are non-negative on quantum states compatible with the causal structure. Find
Problem 1 reduces to Problem 2 by choosing \(f_0\) to be the 2-norm distance between the observed data P and the one produced by the state. More general objective functions can be important in applications—see [16, Section VII] for examples.
The rigorous definition of a quantum causal structure depends on a mathematical model of the notion of a “local subsystem”. In this paper, we model local subsystems via commuting observable algebras of bounded operators. One could also consider alternative models: Instead of via commuting algebras, locality could be formalized in terms of tensor products of Hilbert spaces [39,40,41,42]. Even though the causal compatibility problem only involves bounded operators (the algebra generated by the POVM (positive operator-valued measure) elements that give rise to the observed probabilities), one could allow for unbounded operators in the local algebras on which they act. A detailed discussion of these modeling decisions is given in Sect. 2.1. As we argue there, while these distinctions are certainly of mathematical interest, it seems unlikely that they will be relevant for data that arises from physical scenarios.
The SDP hierarchy that we describe differs slightly from the original quantum inflation hierarchy of [16]. Most importantly, we add two new parameters: r, C, which are related to the Schmidt decomposition of the measurement operators. To define them, consider a node of a quantum causal structure, say the one that gives rise to the random variable A in the triangle scenario. Each possible outcome is associated with a POVM element E. As there are two incoming arrows to this vertex, E acts on two quantum systems. Call the observable algebras acting on the respective subsystems \(\mathcal {A}_-, \mathcal {A}_+\). For fixed values of r, C, we assume that E is of the form
for suitable operators \(e_-(\alpha ) \in \mathcal {A}_-, e_+(\alpha ) \in \mathcal {A}_+\) such that
Call models like this rank-constrained with parameters r, C.
Problem 3
(Rank-constrained quantum causal polynomial optimization). With the notation of Problem 2, find

Here, we construct semi-definite programming relaxations for these problems:
Theorem 1
Use the notation of Problems 2 and 3. For every r, C, there exists a hierarchy of semi-definite programs indexed by an inflation parameter n and an NPO parameter k. Denote the optimal values by \(f^\star _{r,C,n,k}\).
The hierarchy is complete in the sense that, as \(n,k\rightarrow \infty \), the \(f^\star _{r,C,n,k}\) converge to \(f^\star _{r,C}\) from below. What is more, as \(r,C\rightarrow \infty \), the \(f^\star _{r,C}\) converge to \(f^\star \) from above.
Increasing the parameter C does not come with significant computational cost (c.f. the discussion of the Archimedean property in [26]). Larger values of r, in contrast, do correspond to a larger number of variables and constraints in the SDP formulation. The decision to add these additional degrees of freedom must therefore be well-justified. While we cannot prove that they are strictly necessary (which would in particular imply that the original quantum inflation hierarchy is not convergent), we identify some challenges that any constructive convergence proof that does not include these extra variables would face (Sect. 2.5).
1.3.1 Auxiliary results
A quantum causal structure imposes independence conditions on the latent nodes. We deduce independence from the symmetry constraints imposed in the SDP hierarchy via a Quantum de Finetti Theorem. A technical challenge arises because SDP hierarchies model local subsystems via commuting observable algebras, rather than via Hilbert space tensor products (also known as minimal tensor products in the \(C^*\)-algebraic literature) [39,40,41,42]. To the best of our knowledge, the existing literature on de Finetti Theorems for infinite systems is phrased only in terms of the minimal tensor product [11, 43], which is not general enough for our purposes. To address this, we show that the arguments in Ref. [11] generalize to the maximal tensor product, and hence to any way of realizing local observables as commuting subalgebras of a global system. This is the content of Theorem 7.
Both the original quantum inflation hierarchy [16] and our work are built on the non-commutative polynomial optimization (NPO) hierarchy introduced in Ref. [26]. Because the generalized Quantum de Finetti Theorem that is central to our convergence proof requires \(C^*\)-algebraic methods, we rephrase the framework of Ref. [26] in this language in Sect. 2.2. Following Ref. [44, Section II.8.3], we give a description of NPO problems as optimizations over the state space of a universal \(C^*\)-algebra. This more abstract formulation might be beneficial in arguments that require algebraic methods.
1.4 Outline
The paper is structured as follows. We start in Sect. 2 by explaining the necessary theory on \(C^*\)-algebras, causal structures and the inflation technique. Here we also outline the main challenges that one faces when trying to tackle the question of causal compatibility. In Sect. 3 we solve one of the challenges by adapting a proof of a de Finetti Theorem for the minimal \(C^*\) tensor product by Raggio and Werner [11] to a similar de Finetti Theorem for the maximal \(C^*\) tensor product. Sect. 4 describes an SDP hierarchy for the causal optimization problem with Schmidt-rank constraints on the measurement operators. We show that this hierarchy is convergent and has the causal compatibility problem as a special case. The proof relies heavily on the de Finetti Theorem of Sect. 3. While formulating the SDP hierarchy and the proof, we focus on the well-known triangle scenario, but in Sect. 4.3 we show that a converging SDP hierarchy can be found for any quantum causal structure. We end the main text of the paper in Sect. 5 by recounting the most important results of the paper and discussing some questions that remain open.
2 Technical Background and Challenges
In this section, we introduce the technical tools used in this paper and explain the challenges one encounters when trying to rigorously formulate and decide the completeness problem for inflation hierarchies.
2.1 Challenge 1: mathematical models of subsystems
The definition of a quantum causal structure depends crucially on the notion of a subsystem. Here, we describe two subtle modeling decisions that have to be made when making this term precise.
2.1.1 Hilbert space tensor products versus commuting observable algebras
In elementary quantum mechanics, the central object that characterizes a quantum system is its Hilbert space. In this framework, one thus associates to each subsystem a Hilbert space \(\mathcal {H}_i\) and takes the joint Hilbert space to be their tensor product \(\mathcal {H}_{12}=\mathcal {H}_1\otimes \mathcal {H}_2\). The set of observables is then derived from the Hilbert space structure. For the individual subsystems, the observables are the linear operators \(\mathcal {A}_i = L(\mathcal {H}_i)\). They can be embedded into \(\mathcal {A}_{12}=L(\mathcal {H}_{12})\) by taking the tensor product with identities on the other subsystem:
In contrast, in algebraic quantum mechanics (c.f. [45, Chapter 8], [46]), the set of observables is seen as being more central. Consequently, one associates an observable algebra \(\mathcal {A}_i\) with each subsystem. A joint system is then any algebra \(\mathcal {A}_{12}\) that contains \(\mathcal {A}_1\) and \(\mathcal {A}_2\) as commuting subalgebras and is generated by them. Clearly, the construction in (2) provides an example of algebras standing in such a relation—but it turns out that there are more general scenarios that cannot be realized using Hilbert space tensor products.
Commutativity has physical consequences, e.g. in terms of joint measurability—so if we accept the quantum-mechanical description of observable phenomena in terms of operators, we are forced to conclude that measurements in space-like separated regions are described in terms of commuting operators. However, the stronger requirement that the underlying Hilbert space forms a tensor product is not obviously physically motivated.
For a long time, it was an open problem to decide whether there are correlations that can be realized by performing measurements on commuting operators, but not on operators acting on distinct factors of a tensor product Hilbert space. In quantum information theory, this question has been known as Tsirelson’s problem and was shown to be equivalent to other long-standing open problems in operator theory, most notably Connes’ embedding problem [39,40,41]. In a recent break-through result, these questions have been decided: The commuting-operator model does capture more general correlations than the tensor-product model [42].
The above raises the question which of the two mathematical models to adopt. Here, we take a pragmatic approach. It has long been realized (and in fact, has historically triggered Tsirelson to speculate) that commutativity is easily encoded as a constraint in SDPs that give outer approximations to the set of quantum correlations [47]. The same is not true for the tensor product property. Since either model is legitimate, but one is a better fit for the SDP hierarchies we want to make a statement about, we opt for the approach in which locality is modeled by commutativity.
Therefore, in our work, we will assume throughout that one can associate an algebra of observables with each party and that these algebras commute.
Terms—like product states or separable states—that are commonly defined in quantum information theory with reference to a Hilbert space tensor product structure will be used in this paper in an analogous way that only relies on commutativity. In particular:
Definition 2
Let \(\mathcal {A}, \mathcal {B}\) be commuting algebras. A state \(\rho \) is said to be a product state across \(\mathcal {A}\mid \mathcal {B}\) if
A state is said to be separable across \(\mathcal {A}\mid \mathcal {B}\) if it can be written as a convex combination of such product states, i.e. if
for some probability measure \(\mu \) over product states.
2.1.2 Bounded versus unbounded local operators
In this paper, we are interested in observable probabilities that describe measurements on quantum systems. Probabilities are associated with POVM elements. POVM elements are bounded: Their operator norm does not exceed 1. It follows that the entire observable algebra generated by POVM elements consists of bounded operators. Many problems—e.g. the problem of characterizing the set of correlations compatible with a Bell scenario sketched above—can be described solely in terms of this algebra. From a technical point of view, this property can provide significant simplifications. For example, the convergence proofs of the NPO hierarchy [26] or the Quantum de Finetti Theorem for infinite-dimensional quantum systems [11] make central use of the fact that operators are bounded.
It thus comes as bad news that this simplifying property is not obviously available for the causal compatibility problem.
Indeed, consider a node of a quantum causal structure, say the one that gives rise to the random variable A in the triangle scenario. Each possible outcome \(A=a\) is associated with a POVM element \(E_a\). As there are two incoming arrows to this vertex, \(E_a\) acts on two quantum systems. We therefore assume that the observable algebra \(\mathcal {A}\) of the joint system is generated by two commuting subalgebras \(\mathcal {A}_-, \mathcal {A}_+\). These local algebras play an important role in the definition of the causal structure: It is with respect to them that the state is required to factorize. But, while \(E_a\) is bounded, the authors are not aware of any result that would imply that one can assume the same is true for elements of \(\mathcal {A}_-, \mathcal {A}_+\).
More concretely, we cannot exclude the possibility that there is a mathematical model of “local quantum systems” in which one can assign a precise meaning to the series
for suitable unbounded operators \(e_-(a,\alpha ) \in \mathcal {A}_-, e_+(a,\alpha ) \in \mathcal {A}_+\), but where no such expression for \(E_a\) exists if the \(e_-, e_+\)’s are required to be bounded.
In our precise definition of a quantum causal model, we will assume that it is not necessary to allow for such singular situations. The convergence proof makes use of this assumption (implicitly, by virtue of being phrased in terms of \(C^*\)-algebras, which model bounded operators). In fact, the main difference between our hierarchy and the original quantum inflation one [16] is that we add explicit generators and norm constraints for these local operators (see Sect. 2.5 for further evidence that some such addition may be necessary).
While it is an interesting question about operator algebras whether the assumption is actually necessary, it seems that under mild physical conditions, observed correlations can be approximated using models for which it is valid. For example, if each subsystem is endowed with a non-degenerate Hamiltonian and the state has finite energy, one can always compress the local observables to finite-dimensional low-energy subspaces on which they are obviously bounded. So as long as not both the observable and the state display rather singular behavior, an approximate bounded model should always be possible in physical situations.
2.2 \(C^*\)-algebras
2.2.1 Definitions and the GNS construction
The mathematical abstraction of an algebra of bounded operators on a Hilbert space is captured by the concept of a \(C^*\)-algebra. In this section, we introduce the notions that are used in this paper. For more details we refer the reader to e.g. Refs. [44, 46, 48].
Consider a complex algebra \(\mathcal {A}\) with an anti-linear involution \(*\). A \(C^*\)-norm on \(\mathcal {A}\) is a norm satisfying
\(\mathcal {A}\) is a \(C^*\)-algebra if it is complete with respect to a \(C^*\)-norm. A \(C^*\)-algebra is unital if it contains the identity \(\mathbb {I}\). In this paper, we only consider unital algebras and will no longer mention this attribute explicitly. For example, the set of bounded operators on a Hilbert space together with the operator norm and the involution given by the adjoint realizes a \(C^*\)-algebra.
Conversely, any abstract \(C^*\)-algebra can be realized as bounded operators on a Hilbert space. To see how, we need to introduce the notion of a state. An element x of a \(C^*\)-algebra \(\mathcal {A}\) is positive if it is of the form \(x = y^* y\) for some \(y\in \mathcal {A}\). A state \(\rho \) on a \(C^*\)-algebra \(\mathcal {A}\) is a linear functional that is positive in the sense that \(\rho (x)\ge 0\) for all positive \(x\in \mathcal {A}\) and which is normalized in that \(\rho (\mathbb {I}) = 1\). We denote the state space of \(\mathcal {A}\) by \(K(\mathcal {A})\).
Any state \(\rho \) induces a sesquilinear form on the algebra \(\mathcal {A}\) via \(\langle x, y\rangle := \rho (x^\dagger y)\). The form turns the quotient \(\mathcal {A}/\{ x \mid \langle x, x\rangle = 0 \}\) into a pre-Hilbert space on which \(\mathcal {A}\) acts in a natural way. The Gelfand–Naimark–Segal (GNS) construction makes this observation precise and associates with every state \(\rho \) a Hilbert space \(\mathcal {H}_\rho \), a representation \(\pi _\rho :\mathcal {A}\rightarrow \mathcal {H}_\rho \), and a vector \(|\Omega \rangle \) such that
Using the GNS construction, one can prove that any \(C^*\)-algebra can be realized as an operator algebra acting on a Hilbert space, providing a converse to the motivating example of a \(C^*\)-algebra above.
2.2.2 \(C^*\)-algebras from generators and relations
To reason numerically about observable algebras, one needs to express them in a format that can be processed by a computer. Both the original quantum inflation hierarchy [16] and our work are built on the non-commutative polynomial optimization (NPO) hierarchy introduced in Ref. [26]. There, algebras are specified by generators and relations. We introduce the theory in this subsection.
Because the generalized Quantum de Finetti Theorem that is central to our convergence proof requires \(C^*\)-algebraic methods, we rephrase the framework of Ref. [26] in this language. To this end, we employ the terminology of universal \(C^*\)-algebras as described in [44, Section II.8.3].
Let \(\mathcal {G}=\{g_i\}_i\) be a countable set of symbols. Denote by \(\mathcal {F}(\mathcal {G})\) the free complex \(*\)-algebra generated by the elements of \(\mathcal {G}\). Put differently, \(\mathcal {F}(\mathcal {G})\) is the set of finite complex linear combinations of words in the symbols \(g_i\) and \(g_i^*\), with multiplication defined by concatenation of words. Choose a countable set \(\mathcal {R} \subset \mathcal {F}(\mathcal {G})\). We aim to define the “largest \(C^*\)-algebra with generators \(\mathcal {G}\), subject to the constraint that each \(q\in \mathcal {R}\) is positive”. We will refer to the elements of \(\mathcal {R}\) as relations.
To make this notion precise, define a representation of \((\mathcal {G}|\mathcal {R})\) to be a homomorphism \(\pi :\mathcal {F}(\mathcal {G})\rightarrow \mathcal {B}(\mathcal {H})\) from the free algebra into the set of bounded operators on some Hilbert space \(\mathcal {H}\), such that \(\pi (q)\) is a positive operator for every \(q \in \mathcal {R}\). On \(\mathcal {F}(\mathcal {G})\), define
Now assume that the relations imply \(\left| \left| x\right| \right| < \infty \) for all \(x\in \mathcal {F}(\mathcal {G})\) (more on how we ensure this in practice below). In this case, \(\left| \left| \cdot \right| \right| \) is a seminorm on \(\mathcal {F}(\mathcal {G})\). The universal \(C^*\)-algebra on \((\mathcal {G}|\mathcal {R})\), abbreviated as \(C^*(\mathcal {G}|\mathcal {R})\), is then the completion of \(\mathcal {F}(\mathcal {G})\) with respect to this \(C^*\)-seminorm.Footnote 3 We will not differentiate notationally between an element \(x\in \mathcal {F}(\mathcal {G})\) and its image in the completion \(C^*(\mathcal {G}|\mathcal {R})\).
In our applications, we will consider two types of relations:
-
a.
Equality constraints. Let \(x,y\in \mathcal {F}(\mathcal {G})\) and assume that \(\mathcal {R}\) contains both \(x-y\) and \(y-x\). It then follows easily that \(x=y\) in the universal \(C^*\)-algebra \(C^*(\mathcal {G}|\mathcal {R})\). We will always assume that \(g_1=:\mathbb {I}\) is constrained to commute with all the others and obeys \(\mathbb {I}x = x \mathbb {I}= x\) for all \(x \in \mathcal {F}(\mathcal {G})\), so that \(C^*(\mathcal {G}|\mathcal {R})\) is unital.
-
b.
Norm constraints. Let \(x\in \mathcal {F}(\mathcal {G}), C\in {\mathbb {R}}_+\) and assume that \(\mathcal {R}\) contains \(C^2\mathbb {I}- x^*x\). Then \(\left| \left| x\right| \right| \le C\) in \(C^*(\mathcal {G}|\mathcal {R})\).
We can now return to the assumption that \(\Vert x\Vert <\infty \) for all \(x\in \mathcal {F}\). First, note that it suffices to ensure that the bound holds for every generator. In quantum applications [16, 24, 25], one is often interested in algebras where the generators represent projections, i.e. satisfy \(g_i=g_i^*=g_i^2\). Non-trivial projections in a \(C^*\)-algebra always have norm equal to 1. The modified quantum inflation hierarchy introduced in this paper makes use of generators that need not be projections. For those, we must include explicit norm constraints \(\Vert g_i\Vert \le C\). (A similar approach is taken in Ref. [26] to achieve what is referred to as the Archimedean property there.)
We will need the following lemma, which justifies our characterization of \(C^*(\mathcal {G}|\mathcal {R})\) as the “largest \(C^*\)-algebra such that each \(q\in \mathcal {R}\) is positive”.
Lemma 3
In \(C^*(\mathcal {G}|\mathcal {R})\), any element \(q\in \mathcal {R}\) is positive.
Proof
We first show that for every representation \(\phi \) of \(C^*(\mathcal {G}|\mathcal {R})\), it holds that \(\phi (q)\) is a positive operator for each \(q\in \mathcal {R}\). (Using the terminology introduced above, this says that a representation of \(C^*(\mathcal {G}|\mathcal {R})\) is also a representation of \((\mathcal {G}|\mathcal {R})\)).
Fix a \(q\in \mathcal {R}\). There is no loss of generality in assuming \(\Vert q\Vert \le 2\).
It holds that \(q=q^*\), because
as \(\pi (q)\) is positive (and hence self-adjoint) by definition of representations of \((\mathcal {G}|\mathcal {R})\).
For every representation \(\pi \) of \((\mathcal {G}|\mathcal {R})\), it holds that \(\Vert \pi (\mathbb {I}-q)\Vert \le 1\) [44, Proposition II.3.1.2(iv)]. From the definition of the seminorm, this implies that \(\Vert \mathbb {I}-q\Vert \le 1\).
Now assume for the sake of reaching a contradiction that for some representation \(\phi \) of \(C^*(\mathcal {G}|\mathcal {R})\), the operator \(\phi (q)\) is not positive. Using again [44, Proposition II.3.1.2(iv)], \(\Vert \phi (\mathbb {I}-q)\Vert >1\ge \Vert \mathbb {I}-q\Vert \), which is a contradiction, as representations are norm-contractions.
Next, let \(\rho \in K(C^*(\mathcal {G}|\mathcal {R}))\). By the above, using the GNS representation,
Hence q is positive by [44, Corollary II.6.3.5]. \(\square \)
2.2.3 The NPO hierarchy
Given generators \(\mathcal {G}\) and relations \(\mathcal {R}\), we are interested in certain linear optimization problems over states on the algebra they generate.
In Ref. [26], the NPO problem is phrased as an optimization over representations \(\pi \) of \(\mathcal {F}(\mathcal {G})\) and normalized vectors \(|\phi \rangle \) in the representation space. Concretely, choose an element \(y_0 \in \mathcal {F}(\mathcal {G})\) and a countable set \(\{y_1, y_2, \ldots \} = \mathcal {Y}\subset \mathcal {F}(\mathcal {G})\) and consider:
We prefer to think of this problem more abstractly, as an optimization over the state space of the universal algebra \(C^*(\mathcal {G}|\mathcal {R})\):
We may write \(\min \) instead of \(\inf \), because the Banach–Alaoglu Theorem implies that the state space is weak\(^*\)-compact and thus that the infimum over states evaluated on any fixed element of the algebra is attained. Following [26, Section 3.6], one can in addition impose constraints of the form \(\rho (\cdot z)=0\) for a countable set of \(z\in \mathcal {F}(\mathcal {G})\). We have omitted this type of constraint from the discussion, as it is not needed for our use cases.
Lemma 4
The solutions of (8) and (9) coincide.
Proof of Lemma 4
Let \(\omega \) be an optimizer of (9). Let \(\pi _\omega \) be the GNS representation and \(\left| \Omega \right\rangle \in \mathcal {H}_\omega \) the vector that implements \(\omega \). By Lemma 3, \((\pi _\omega , \Omega )\) is feasible for (8) and achieves the optimal value of (9).
Conversely, let \((\pi , \phi )\) be an optimizer of (8). For \(x\in \mathcal {F}(\mathcal {G})\), define \(\rho (x):=\left\langle {\phi }\vert \pi (x)\vert {\phi }\right\rangle \). If the seminorm vanishes on x, \(\Vert x\Vert =0\), then, in particular, \(\Vert \pi (x)\Vert =0\) and hence \(\pi (x)=0\). Thus, \(\rho \) is constant on cosets of the ideal of elements on which the seminorm vanishes and therefore well-defined as a functional on \(C^*(\mathcal {G}|\mathcal {R})\). As such, it is feasible for (9) and achieves the optimal value of (8). \(\square \)
We now briefly describe the semidefinite programming hierarchy introduced in Ref. [26] and sketch the completeness proof.
Of course, the difficulty in solving (9) lies in the fact that \(C^*(\mathcal {G}|\mathcal {R})\) is, in general, infinite-dimensional. The broad idea behind the NPO hierarchy is to partition \(\mathcal {F}(\mathcal {G})\) into an increasing family of finite-dimensional subspaces \(\mathcal {F}^{(k)} \subset \mathcal {F}(\mathcal {G})\). At the k-th level of the hierarchy, one imposes the conditions that \(\rho \) be a state and that the relations be fulfilled only to the extent to which they can be expressed using elements from \(\mathcal {F}^{(2k)}\).
To carry out this program, let \(\mathcal {F}^{(k)}\) be the space of all elements \(x\in \mathcal {F}(\mathcal {G})\) that can be expressed as a polynomial in the generators and their adjoints of degree at most k. We fix some basis \(\{b^{(k)}_1, \dots , b^{(k)}_{d_k}\}\) of each \(\mathcal {F}^{(k)}\).
Recall that a linear functional \(\rho \) on \(C^*(\mathcal {G}|\mathcal {R})\) is a state if and only if \(\rho (\mathbb {I})=1\) and \(\rho (x^*x)\ge 0\) for all \(x\in C^*(\mathcal {G}|\mathcal {R})\). We impose a related condition by demanding that the matrix \(\Gamma ^{(k)}\) with elements
be positive semidefinite and that \(\Gamma _{1,1}^{(k)}=\rho (\mathbb {I})=1\).
Next, consider a relation \(q\in \mathcal {R}\). Let l be the smallest integer such that \(q\in \mathcal {F}^{(2l)}\). We relax the requirement that q be positive to demanding that the matrix
be positive semidefinite.
Let \(k_0\) be such that \(x\in \mathcal {F}^{(2k_0)}\). For each \(k\ge k_0\), one thus arrives at a relaxation of Eq. (9) in terms of the semidefinite program
The completeness result of Ref. [26] states that, in the case where \(|\mathcal {Y}|\le \infty \) is finite, the optimal values \(f^k\) of the relaxations (11) converge to \(f^\star _{\textrm{NPO}} = f^\star _{\textrm{uni}}=:f^\star \) from below.
Lemma 5
The completeness result \(\lim _{k\rightarrow \infty } f^k = f^\star \) extends to the case of a countably infinite number of inequality constraints \(\rho (y)\ge 0\).
Proof
Choose some enumeration \(y_1, y_2, \dots \) for the countable set \(\mathcal {Y}\). Let \(\mathcal {Y}_s=\{y_1, \dots , y_s\}\). Assume that (11) with \(\mathcal {Y}\) replaced by \(\mathcal {Y}_s\) is feasible for every k, s, with optimal value \(f^k_s\). Using the convergence proof of Ref. [26] and Lemma 4, there exists a sequence of states \(\rho ^\star _s\in K(C^*(\mathcal {G}|\mathcal {R}))\) that are feasible for (9) with inequality constraints \(\mathcal {Y}_s\) and attain \(f^\star _s:=\lim _{k\rightarrow \infty } f^k_s\). By the Banach-Alaoglu Theorem, there is a convergent subsequence. Let \(\rho ^\star \) be its limit point. Then, for each \(y_i\in \mathcal {Y}\), \(\rho ^\star (y_i) \ge 0\), as this constraint is fulfilled by all but a finite number of the \(\rho ^\star _s\). Thus, \(\rho ^\star \) is feasible for (9) with all inequality constraints \(\mathcal {Y}\) taken into account and attains \(f^\star =\lim _{s\rightarrow \infty }f^\star _s\). \(\square \)
Remark
If a space \(N\subset \mathcal {F}(\mathcal {G})\) of elements with vanishing seminorm is known, then one can replace \(\mathcal {F}(\mathcal {G})\) by the quotient space \(\mathcal {F}(\mathcal {G})/N\) in the constructions above, while retaining convergence. This can result in significantly smaller matrices that need to be treated. In particular, every equality constraint \(x=y\) gives rise to an element \(x-y\in N\).
2.2.4 Tensor products
We return to the problem of precisely modeling the notion of “locality”. If \(\mathcal {A}\) and \(\mathcal {B}\) are the \(C^*\)-algebras of observables on one subsystem each, then the joint system should come with an observable algebra \(\mathcal {C}\) that contains copies of \(\mathcal {A}\) and \(\mathcal {B}\) as commuting subalgebras and is generated by them. Unfortunately, these two requirements are not quite enough to uniquely determine \(\mathcal {C}\). To understand the freedom we have in defining the set of global observables, start with the algebraic tensor product \(\mathcal {C}_0 = \mathcal {A}\otimes _{\text {alg}}\mathcal {B}\). This is the \(*\)-algebra of elements x of the form
with multiplication and involution in \(\mathcal {C}_0\) defined factor-wise as
To promote the \(*\)-algebra \(\mathcal {C}_0\) to a \(C^*\)-algebra \(\mathcal {C}\), we have to endow it with a norm satisfying the \(C^*\)-norm property in Eq. (6) and complete it with respect to this norm. The choice of this norm is not unique [44, 48]. There are two distinguished norms: minimal and maximal, named-so because they constrain the value of any \(C^*\)-norm on the algebraic tensor product by
In the more general case of n tensor factors, they are defined via their respective values on elements of \(\mathcal {A}_1 \otimes _{\text {alg}}\ldots \otimes _{\text {alg}}\mathcal {A}_n\) as
where the suprema are taken over representations of the respective \(C^*\)-algebras as operator algebras on a Hilbert space. We denote the \(C^*\)-algebra generated by the tensor product of \(\mathcal {A}\) and \(\mathcal {B}\) and completed with respect to the norm \(\left| \left| .\right| \right| _\gamma \) by \(\mathcal {A}\otimes _\gamma \mathcal {B}\).
If the \(\mathcal {A}_i\)’s arise as bounded operators on Hilbert spaces \(\mathcal {A}_i = \mathcal {B}(\mathcal {H}_i)\), the approach from elementary quantum mechanics corresponds to their natural embedding into \(\mathcal {B}(\mathcal {H}_1\otimes \dots \otimes \mathcal {H}_n)\). The operator norm in this picture corresponds to the minimal tensor product. In this way, the elementary approach reappears as a special case of the algebraic construction.
Convergence with respect to the maximal norm implies convergence for any operator representation of the global observable algebra, according to the definition in Eq. (16). Thus, in order to obtain the most general results, we will focus on the maximal tensor product e.g. in Sect. 3.
2.3 Description of quantum causal structures in the commuting-operator model
We can now restate the definition of quantum causal structures given informally in Sect. 1.2 in mathematically precise terms. Here, and later for the proof of the main result, we restrict attention to the triangle scenario (Fig. 1b). Section 4.3 discusses how to generalize the result to arbitrary correlation scenarios and causal structures.
Let A, B and C be random variables. We say that a probability distribution P(A, B, C) is compatible with the quantum triangle scenario, if it can be realized in the following mathematical model.
Assume that there is a \(C^*\)-algebra \(\mathcal {D}\) that is generated by commuting subalgebras \(\mathcal {A}, \mathcal {B}, \mathcal {C}\) that are each associated with a vertex of the triangle. Each of the algebras \(\mathcal {A}, \mathcal {B}, \mathcal {C}\) is in turn generated by two commuting subalgebras: \(\mathcal {A}\) by \(\mathcal {A}_-, \mathcal {A}_+\); \(\mathcal {B}\) by \(\mathcal {B}_-, \mathcal {B}_+\); and \(\mathcal {C}\) by \(\mathcal {C}_-, \mathcal {C}_+\). They model the observables measurable on the subsystems that enter the respective node from either side in the diagram (that is, \(\mathcal {A}, \mathcal {B}, \mathcal {C}\) and \(\mathcal {D}\) are \(C^*\)-tensor products in the sense of Sect. 2.2.4—but we take no stance on which particular one). Next, we assume that there is a state \(\rho \) on \(\mathcal {D}\) that factorizes according to the causal structure:
where \(A_-\in \mathcal {A}_-, A_+\in \mathcal {A}_+, B_-\in \mathcal {B}_-\) and so on. Finally, we assume that there are POVMs
such that the joint distribution can be realized as
where P(a, b, c) is short-hand for \(P(A=a,B=b,C=c)\), which is the probability corresponding to the values a, b, and c.
Remark
The GNS construction applied to two commuting algebras acting on a product state gives rise to a tensor product Hilbert space. Thus, by (17), there is no loss of generality in assuming that \(\mathcal {A}= \mathcal {A}_-\otimes _{\min } \mathcal {A}_+\) and likewise for \(\mathcal {B}\) and \(\mathcal {C}\). However, the same is not true for the tensor products between \(\mathcal {A}\), \(\mathcal {B}\), and \(\mathcal {C}\). (Certainly the same argument doesn’t apply—as \(\rho \) does not factorize as a state between the nodes. One can combine the results from Refs. [20, 42] to see that there are correlations P that cannot be modeled using minimal tensor products between nodes at all). This observation does not obviate the need for a generalized Quantum de Finetti Theorem, as we will apply it to the state that is extracted from the SDP hierarchy, and there is no semidefinite constraint that can express that \(\mathcal {A}\) is a minimal, rather than a general, tensor product of its constituents.
2.3.1 Quantum inflation
We give a brief overview of the quantum inflation technique, which was introduced in Ref. [16] and generalizes classical inflation [8, 9] to the case of quantum causal structures. This section serves to motivate the construction of the hierarchy in Sect. 4—but in the rest of the paper, we will not rely on results and notation introduced here. We again focus on the triangle scenario (See Figs. 1b and 3b).

a The \(n=2\) inflation of the classical triangle scenario. In the inflation procedure, the latent variables are copied and the observable variables are indexed according to these copies. For example, the variable \(A_{12}\) is the result of \(Z_1\) and \(X_2\). b The \(n=2\) inflation of the quantum triangle scenario. Again the latent variables are copied, but instead of obtaining copies of the observable variables, Alice, Bob and Charlie now have a choice of measurement operators. The measurements are performed over pairs of copies using the same measurement operators \(\{E_a\}_a, \{F_b\}_b, \{G_c\}_c\), labeled by the copies they act on. For example, \(E_a^{12}\) is acting on the parts of the quantum states \(\rho _{CA}^1\) and \(\rho _{AB}^2\) that are sent to Alice
Given a joint distribution P(A, B, C), assume that there is a quantum model compatible with the triangle scenario. Using the terminology of Sect. 2.3, we thus know there exist a global observable algebra \(\mathcal {D}\) generated by local algebras \(\mathcal {A}_-, \mathcal {A}_+, \mathcal {B}_-, \mathcal {B}_+, \mathcal {C}_-, \mathcal {C}_+\), a state \(\rho \) factorizing as in (17), and POVM elements \(\{E_a\}_a, \{F_b\}_b, \{G_c\}_c\) that reproduce the correlations P as in (19).
Denoting the restrictions of \(\rho \) to the algebra \(\langle \mathcal {C}_+ \cdot \mathcal {A}_-\rangle \) generated by \(\mathcal {C}_+, \mathcal {A}_-\) as \(\rho _{CA}\), to \(\langle \mathcal {A}_+ \cdot \mathcal {B}_-\rangle \) as \(\rho _{AB}\), and to \(\langle \mathcal {B}_+ \cdot \mathcal {C}_-\rangle \) as \(\rho _{BC}\), Eq. (17) is equivalent to demanding that \(\rho \) factorizes as
For any level n, we construct an inflated model as follows. Distribute n independent copies of the original states \(\rho _{AB}\), \(\rho _{BC}\) and \(\rho _{CA}\) among the three nodes A, B, and C. At each node, we consider \(n^2\) POVMs \(\{E_a^{ij}\}_a, \{F_b^{kl}\}_b, \{G_c^{pq}\}_c\). The POVM element \(E_a^{ij}\) replicates the original \(E_a\), but acts on the i-th copy of the state \(\rho _{CA}\) and j-th copy of the state \(\rho _{AB}\). The other two cases are defined analogously. As a result, POVM elements \(E_a^{ij}\), \(F_b^{jl}\), and \(G_c^{li}\) reproduce the original probabilities P(a, b, c).
We now list a number of properties of the inflated model. These properties can be directly imposed as constraints in an NPO program. It follows that if P is compatible with the causal model, then the resulting NPO problem is feasible for any inflation level n [16]. In Sect. 4 we construct a variant of this NPO hierarchy for which we supply a proof of the converse implication.
First, in Ref. [16] it is assumed that the \(\{E_a\}_a\), \(\{F_b\}_b\) and \(\{G_c\}_c\) are orthogonal projective measurements, rather than more general POVMs. This simplifies the SDP and can be done without loss of generality, because we do not restrict dimension and possible dilations would still be compatible with the causal structure.
and similar for \(\{F_b^{kl}\}\) and \(\{G_c^{pq}\}\). In later sections we will drop this restriction, and will only assume that we have POVM elements, i.e. non-negative operators that sum to the identity.
Second, operators that act on different subsystems commute:
Third, there is a permutation symmetry, resulting from the fact that the global state is built out of independent copies of the original one. For any polynomial Q in the measurement operators \(\{E_a^{ij}\}, \{F_b^{kl}\}, \{G_c^{pq}\}\) up to inflation level n and for all permutations \(\pi , \pi ', \pi ''\) of n elements, the following must hold:
For example,
where we have swapped \(\rho _{AB}^1 \leftrightarrow \rho _{AB}^2\) in the first step, \(\rho _{BC}^1 \leftrightarrow \rho _{BC}^2\) in the second and \(\rho _{CA}^1 \leftrightarrow \rho _{CA}^2\) in the third.
Fourth and finally, for the specific problem of causal compatibility the authors of Ref. [16] include constraints of the marginal distribution over \(g\le n\) copies of the triangle scenario. In particular, for the triangle scenario it must hold that
since these variables describe g independent copies of the triangle causal structure. We will not be needing these types of constraints for our quantum inflation hierarchy, since we can already show convergence without them. Instead, for the approximate causal compatibility problem we will choose an objective function that, if the optimal value is \(\epsilon \)-close to 0, ensures that Eq. (27) approximately holds. If \(\epsilon = 0\) Eq. (27) will hold exactly.
2.4 Challenge 2: infinite quantum de finetti theorem for general \(C^*\) tensor products
In addition to the conceptual problems mentioned in Sect. 2.1, switching to a more general notion of locality raises additional technical challenges. Indeed, the basic idea underlying the quantum inflation hierarchy is to relax independence conditions (which define the causal structure, but are non-convex and thus cannot directly be phrased as an SDP constraint) to symmetry conditions (which are linear in elements of the algebra and easily incorporated into an SDP). It is easily seen that independence implies symmetries in the inflated causal structure. Central to convergence arguments is that sometimes, in an asymptotic sense, the converse is also true. This is the case for classical causal structures [9]. Such converse results that obtain independence from symmetries are known as de Finetti Theorems and have been formulated both for classical [49, 50] and for quantum [11,12,13, 43] probability theories.
Now a problem we face is that the literature on de Finetti Theorems for \(C^*\)-algebras to our best knowledge only pertains to minimal tensor products—too narrow for our use case. One of the main technical contributions of this work is the realization that the construction and proof of the Quantum de Finetti Theorem in [11] carries over from the minimal tensor product case for which it was formulated, to general \(C^*\)-tensor products. Implementing this program is the role of Sect. 3.
2.5 Challenge 3: identifying the local observable algebras
We now present what we consider to be the most difficult challenge in deciding completeness of quantum inflation hierarchies.
Assume that a joined probability distribution P(A, B, C) passes all levels of the original quantum inflation hierarchy, as outlined in Sect. 2.3.1. We thus know that there is a \(C^*\)-algebra \(\mathcal {D}\) generated by the observables \(\{E_a^{ij}, F_b^{ij}, G_c^{ij}\}\) and a state \(\rho \) that reproduces the observed correlations (Eq. (27)) and is symmetric (Eq. (25)).
We now need to verify that this quantum model fulfills the causal constraints laid out in Sect. 2.3. This involves, in particular, showing that
-
1.
one can embed the algebra \(\langle \{ E_a^{ii} \}_a \rangle \) containing the measured POVM elements into a potentially larger algebra \(\mathcal {A}^{ii}\) of all observables associated with the vertex A, such that \(\mathcal {A}^{ii}\) is generated by two commuting subalgebras \(\mathcal {A}_-^{i}, \mathcal {A}_+^{i}\), and
-
2.
that the state \(\rho \) can be extended to all of \(\mathcal {A}^{ii}\) and that it factorizes in the sense that for each \(A_-\in \mathcal {A}_-^{i}, A_+\in \mathcal {A}_+^{i}\) we have \(\rho (A_- A_+) = \rho (A_-)\rho (A_+)\).
The second condition can be addressed using the generalized Quantum de Finetti Theorem presented below. The first condition, however, seems much more challenging: There is no obvious ansatz for constructing \(\mathcal {A}^{ii}\) and its commuting generators \(\mathcal {A}^{i}_-, \mathcal {A}^{i}_+\) from the algebra \(\mathcal {D}\) that results from the original quantum inflation hierarchy of Ref. [16]. In fact, in the subsection just below, we will give an argument that suggests that \(\mathcal {D}\) does not in general contain local observable algebras \(\mathcal {A}^i_-, \mathcal {A}^i_+\) that satisfy the two conditions above. It would then follow that if the original hierarchy is complete, any constructive proof of that fact would necessarily have to introduce additional operators that are not generated by the measured POVMs and their copies.
Our modified quantum inflation hierarchy follows such an approach (for details, see Sect. 4). The modified hierarchy contains generators \(e_-^i(a,\alpha ), e_+^j(a,\alpha )\), which are constrained to commute unless both the upper and lower indices coincide. One can then define
The observables at the other two vertices are treated analogously. This modified hierarchy thus fulfills condition 1. listed above by construction. Theorem 11 then shows that the generalized Quantum de Finetti Theorem implies that there exists a state \(\rho \) such that condition 2. holds as well.
2.5.1 Example of measurement operators that do not generate elements from the local algebras
In this subsection, we provide evidence for the claim that the algebra \(\mathcal {D}\) that results from the original quantum inflation hierarchy does not in general contain the local observable algebras satisfying the two conditions laid out above. The purpose of the material presented here is to motivate our ansatz and guide future research—it is not required to understand the rest of the paper.
The strategy is to give a natural example of mutually commuting observable algebras \(\mathcal {A}^i_-, \mathcal {A}^j_+\) and POVMs \(E^{ij}_a \in \mathcal {A}^i_-\cdot \mathcal {A}^j_+\) such that the algebra generated by the \(\{E^{ij}_a\}_{ija}\) does not contain any non-trivial local observable, i.e. no element in any of the \(\mathcal {A}^i_-\) or \(\mathcal {A}^j_+\) other than \(\mathbb {I}\). This does not constitute a proof of the claim made above: We do not know whether there are correlations P(A, B, C) that will cause the original inflation hierarchy to output such a model. But it does show that there are natural choices for the operators \(E^{ij}_a\) that fulfill all the constraints of the hierarchy, while failing to generate the local observables with respect to which the factorization properties of the causal structure are defined.
The model is very simple: For \(i,j=1, \dots , n\), let \(\mathcal {A}^i_-, \mathcal {A}^j_+\) be the observable algebra of one qubit each. Consider the maximally entangled magic basis
and define POVMs
Lemma 6
The algebra \(\mathcal {D}\) generated by \(\{E^{ij}_a\}\) for \(i,j=1, \dots n; a = 1, \dots , 4\) does not contain any non-trivial local operator.
Proof
The magic basis is a stabilizer basis, and we can thus express the projection operator onto each vector by summing over the respective stabilizer group. In terms of the usual Pauli operators, this gives
Let
Because distinct Pauli operators on the same system anti-commute,
and thus \(\mathcal {D}\) is contained in the commutant of \({\bar{X}}, {\bar{Z}}\). But there is no non-trivial local operator that commutes with both \({\bar{X}}\) and \({\bar{Z}}\). \(\square \)
We note that Eqs. (32)–(35) imply that the effects \(E^{ij}_a\) have Schmidt-rank \(\le 4\) and a product decomposition with factors of operator norm \(C\le \frac{1}{4}\).
3 de Finetti Theorem for the Maximal Tensor Product
To the best of our knowledge, the existing literature on de Finetti Theorems for infinite systems is phrased only in terms of the minimal tensor product [11, 43]. These results are not directly applicable to the quantum models that result from the NPO hierarchy. Indeed, the latter naturally guarantees the existence of a representation \(\pi _\rho \) of the algebraic tensor product as operators on a Hilbert space that arise from a state \(\rho \) on \(\mathcal {A}_1 \otimes _{\text {alg}}\ldots \otimes _{\text {alg}}\mathcal {A}_n\) via the GNS construction. While the resulting operator norm \(\Vert \pi _\rho (x)\Vert \) constitutes a \(C^*\)-norm on the tensor product, we have no a priori control over its value beyond the constraints in Eq. (14).
The purpose of this section is therefore to retrace the arguments given by Raggio and Werner in Ref. [11] to verify that the infinite de Finetti Theorem established there generalizes to arbitrary \(C^*\)-norms on algebraic tensor products. We also present a somewhat simpler formulation that is sufficient for our purposes.
In fact, we state the results only in terms of the maximal \(C^*\) tensor product norm. A priori, it is possible that one can derive stronger results for the GNS norm \(\Vert \pi _\rho (\cdot )\Vert \), in particular if the state \(\rho \) is known to have symmetries. We leave this possible improvement open for later investigations.
Let \(\mathcal {D}\) be a unital \(C^*\)-algebra and let
be the completion of the algebraic tensor product of n copies of \(\mathcal {D}\) with respect to the maximal \(C^*\)-norm. The infinite maximal tensor product is defined as the inductive limit
We recall the definition [44, Section II.8.2]: For any \(n,k\in \mathbbm {N}\), there is a natural embedding
It allows us to define addition and multiplication between elements of the union
by embedding the element living in the smaller tensor power into the larger one and performing the operations there. The resulting \(*\)-algebra is the local algebra, called so as each of its elements lives in a finite tensor power. The inductive limit \(\mathcal {D}^\infty \), the quasi-local algebra, is the completion of the local algebra with respect to the \(C^*\)-norm \(\Vert \cdot \Vert _{\mathcal {D}^\infty }\) on (37) which assigns to every \(x\in \mathcal {D}^n\) the value
We will not notationally distinguish between an element \(x\in \mathcal {D}^n\) and its embedding in \(\mathcal {D}^\infty \). Note that any \(x\in \mathcal {D}^n\) and its extensions \(x\otimes \mathbb {I}^k\) are identified in \(\mathcal {D}^\infty \).
For any n and permutation \(\pi \in S_n\), there is an automorphism \(\alpha _\pi \) on \(\mathcal {D}^n\) which acts by permuting tensor factors
It extends to any \(\mathcal {D}^{n+k}\) by letting \(\pi \) act on the first n tensor factors, and by continuity to \(\mathcal {D}^\infty \).
A state \(\rho \) on \(\mathcal {D}^\infty \) is symmetric if \(\rho (x) = \rho (\alpha _\pi (x))\) for every \(x\in \mathcal {D}^\infty \). Denote the set of symmetric states by \(K_s(\mathcal {D}^\infty )\). We aim to show:
Theorem 7
(Max tensor product quantum de Finetti Theorem). Let \(\rho \in K_s(\mathcal {D}^\infty )\) be a symmetric state on an infinite maximal tensor product
Then there exists a unique probability measure \(\mu \) over states on \(\mathcal {D}\) such that for all \(x\in \mathcal {D}^\infty \),
where \(\Pi _\sigma \) is the infinite symmetric product state on \(\mathcal {D}^\infty \) associated with the state \(\sigma \) on \(\mathcal {D}\).
Key to the proof is to show that symmetric states \(\rho \) define a state on the abelian \(C^*\)-algebra of symmetric observables whose multiplication law is derived from the tensor product. It is established in the general theory of \(C^*\)-algebras [46, Chapter 4] that pure states \(\phi \) of abelian algebras are homomorphisms, i.e. that \(\phi (xy) = \phi (x)\phi (y)\), and that general states of abelian algebras are unique convex combinations of pure states. Using the fact that in our case, the product xy is related to the tensor product \(x\otimes y\), we will obtain the claimed decomposition of \(\rho \) as a convex combination of symmetric product states.
To construct the symmetric algebra, define the symmetrization map
and let \({{\,\textrm{Sym}\,}}^n(\mathcal {D})\) be the image of \(\mathcal {D}^n\) under \({{\,\textrm{Sym}\,}}^n\). Define the symmetric local algebra to be the set
with an associative and abelian multiplication law given by the symmetrized tensor product
Our aim is to mimic the construction of \(\mathcal {D}^\infty \) to arrive at a symmetric quasi-local algebra \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\). To this end, define embeddings
As was the case for \(\mathcal {D}^\infty \), addition between two symmetric local elements can now be defined by embedding the lower power into the higher power and performing the addition there. This convention turns the symmetric local algebra into an abelian \(*\)-algebra. One can endow it with a \(C^*\)-seminorm [51, Section 6.1] so that the completion \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\) is an abelian \(C^*\)-algebra:
Lemma 8
The limit
defines a \(C^*\)-seminorm on the symmetric local algebra \(\cup _n {{\,\textrm{Sym}\,}}^n(\mathcal {D})\) fulfilling
The completion \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\) is an abelian \(C^*\)-algebra.
The central ingredient to the proof is the following combinatorial lemma, which shows that the multiplication on \(\cup _n {{\,\textrm{Sym}\,}}^n(\mathcal {D})\) inherited from \(\cup _n \mathcal {D}^n\) and the newly defined \(\star \)-multiplication are asymptotically equivalent.
Lemma 9
Let \(x \in {{\,\textrm{Sym}\,}}^m(\mathcal {D})\) and \(y \in {{\,\textrm{Sym}\,}}^n(\mathcal {D})\). Then
Proof
Choose two sets of respective size m, n uniformly at random from \([k]:=\{1, \ldots , k\}\). The probability that any given element is contained in both sets is \(\frac{m}{k}\frac{n}{k}\). By the union bound, the probability that these two sets intersect at all is not larger than \(\frac{mn}{k}\). Thus
\(\square \)
Proof of Lemma 8
For \(x \in {{\,\textrm{Sym}\,}}^n(\mathcal {D})\), we have the estimate
Using this estimate repeatedly shows that the sequence \(\Vert x\star \mathbb {I}^{\otimes k}\Vert _{\mathcal {D}^\infty }=\Vert (x\star \mathbb {I}^{\otimes (k-1)})\star \mathbb {I}\Vert _{\mathcal {D}^\infty }\) is non-increasing and hence convergent. Subadditivity, absolute homogeneity, and invariance under involution of \(\Vert \cdot \Vert _{{{\,\textrm{Sym}\,}}}\) on \(\cup _n {{\,\textrm{Sym}\,}}^n(\mathcal {D})\) follow directly from the same properties of \(\Vert \cdot \Vert _{\mathcal {D}^\infty }\). For \(x \in {{\,\textrm{Sym}\,}}^m(\mathcal {D})\) and \(y \in {{\,\textrm{Sym}\,}}^n(\mathcal {D})\), Lemma 9 implies the \(C^*\)-norm property
with equality if \(y=x^*\).
We have thus verified the \(C^*\)-seminorm properties, and the second advertised claim follows from the general theory [51, Section 6.1]. \(\square \)
Next, we aim to set up a bijection between the space of symmetric states \(K_s(\mathcal {D}^\infty )\) and the state space \(K({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\) of the abelian algebra. The connection revolves around \(\cup _n{{\,\textrm{Sym}\,}}^n(\mathcal {D})\), as it can be interpreted as a subspace of either algebra. We will thus look for natural ways of extending a state \(\rho \) from \(\cup _n{{\,\textrm{Sym}\,}}^n(\mathcal {D})\) to \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\) and to \(\mathcal {D}^\infty \) respectively.
For the former case, we can use the fact that \(\cup _n{{\,\textrm{Sym}\,}}^n(\mathcal {D})\) is dense in \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\). Thus, if \(\rho \in K_s(\mathcal {D}^\infty )\), it is natural to try to extend it by continuity from \(\cup _n {{\,\textrm{Sym}\,}}^n(\mathcal {D})\) to a state on all of \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\). Lemma 10 shows that this ansatz indeed leads to a well-defined map
Conversely, in order to evaluate a state \(\rho \in K({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\) on an element of \(x\in \mathcal {D}^\infty \), our approach is to map x to a symmetrized version \({{\,\textrm{Sym}\,}}(x)\in {{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\) and then to apply \(\rho \) to \({{\,\textrm{Sym}\,}}(x)\). To define the symmetrization operation, note that any element of \(\mathcal {D}^\infty \) can be represented by a Cauchy sequence \((x_n)_n\) with \(x_n\in \mathcal {D}^n\) and set
Lemma 10 establishes that the result lies in \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\) and that the adjoint
defines a map
Lemma 10
The maps \({{\,\textrm{Sym}\,}}^*\) and E are well-defined and inverses of each other. What is more, \({{\,\textrm{Sym}\,}}^*\) is weakly continuous.
Proof
We will repeatedly make use of the fact [44, Prop. II.6.2.5] that the states on a \(C^*\)-algebra are exactly those functionals \(\rho \) that satisfy
Equation (44) indeed defines a map from \(\mathcal {D}^\infty \rightarrow {{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\): If \((x_n)_n, x_n\in \mathcal {D}^n\) is a Cauchy sequence with respect to \(\Vert \cdot \Vert _{\mathcal {D}^\infty }\), then by Eq. (42), the sequence \(({{\,\textrm{Sym}\,}}^n(x_n))_n\) is Cauchy with respect to \(\Vert \cdot \Vert _{{{\,\textrm{Sym}\,}}}\) and therefore an element of \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\). Next, let \(\rho \in K({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\). Then
thus \({{\,\textrm{Sym}\,}}^*(\rho )\) is a state. Because \({{\,\textrm{Sym}\,}}\circ \alpha _\pi = {{\,\textrm{Sym}\,}}\) for any permutation \(\pi \), \({{\,\textrm{Sym}\,}}^*(\rho )\) is symmetric. The map \({{\,\textrm{Sym}\,}}^*\) is weakly continuous: If a net \(\rho _\lambda \) in \(K({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\) converges weakly to \(\rho \), then in particular \(\rho _\lambda ({{\,\textrm{Sym}\,}}(x)) \rightarrow \rho ({{\,\textrm{Sym}\,}}(x))\) for all \(x\in \mathcal {D}\). Thus \({{\,\textrm{Sym}\,}}^*(\rho _\lambda )\) converges weakly to \({{\,\textrm{Sym}\,}}^*(\rho )\).
To prove that E is well-defined, start with a state \(\rho \in K_s(\mathcal {D}^\infty )\). For \(x\in \cup _n {{\,\textrm{Sym}\,}}^n(\mathcal {D})\), using symmetry and Eq. (47),
In other words, on \(\cup _n{{\,\textrm{Sym}\,}}^n(\mathcal {D})\), \(\rho \) is bounded with respect to the \(\Vert \cdot \Vert _{{{\,\textrm{Sym}\,}}}\)-norm and can thus be uniquely extended by continuity to a functional \(E(\rho )\) on \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\). Using Eq. (47) once more, the preceding estimate also shows that \(E(\rho )\) is a state.
Finally, for each \(\rho \in K_s(\mathcal {D}^\infty ), x\in \mathcal {D}^\infty \) and \(\sigma \in K({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})), y\in \cup _n{{\,\textrm{Sym}\,}}^n(\mathcal {D})\),
which shows that the two maps are inverses of each other. \(\square \)
Proof of Theorem 7
Consider \(E(\rho )\in K({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\). By [46, Example 4.1.30 and Proposition 2.3.27], because \({{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\) is abelian, there exists a unique measure \({\tilde{\mu }}\) over pure states \(K_{\text {pure}}({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\), such that
But then, for \(x_i\in \mathcal {D}\),
Consider one \({\tilde{\sigma }}\in K_{\text {pure}}({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\), let \(R:K({{\,\textrm{Sym}\,}}^\infty (\mathcal {D}))\rightarrow K(\mathcal {D})\) be the map that restricts states
to \(\mathcal {D}\subset {{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\), and let \(\sigma = R({\tilde{\sigma }})\). Because pure states of abelian algebras are homomorphisms,
The restriction R is the adjoint of the embedding \(\mathcal {D}\rightarrow {{\,\textrm{Sym}\,}}^\infty (\mathcal {D})\). As the adjoint of a bounded map, it is weak\(^*\)-continuous by the same argument as the one used in the proof of Lemma 10. Thus the concatenation \(R \circ {{\,\textrm{Sym}\,}}^*: {\tilde{\sigma }}\mapsto \sigma \) is continuous and hence measurable. We can therefore define a measure \(\mu \) on \(K(\mathcal {D})\) by
Then
which proves the claim, as \(\cup _n\mathcal {D}^n\) is dense in \(\mathcal {D}^\infty \). \(\square \)
4 A Convergent Hierarchy
Motivated by the difficulties that were outlined in Sect. 2, we propose a modified hierarchy of semidefinite programs for a Schmidt rank-constrained version of the quantum causal optimization problem that is provably complete. We show that by increasing the Schmidt rank, one can approximate any POVM arbitrarily well.
We use the triangle causal structure without settings as a guiding example to demonstrate the technique and to keep the notation relatively legible. More general scenarios can be accommodated—e.g. it is straight-forward to add additional generators to describe several possible POVMs per party. Extensions of these methods to arbitrary quantum causal structures are discussed in Sect. 4.3.
4.1 Construction of the hierarchy
4.1.1 The universal algebra of the quantum causal structure
First, we define generators and relations for the universal \(C^*\)-algebra \(\mathcal {D}^n\) modeling the most general set of observables for the n-th inflation level of the causal structure. The algebra depends on a number of parameters:
-
1.
The causal structure (taken to be the triangle scenario for now);
-
2.
The number of outcomes M per vertex;
-
3.
The inflation level n;
-
4.
A bound r on the Schmidt rank of the measurement operators;
-
5.
A bound C on the norm of the generators of the local algebra.
The dependency of \(\mathcal {D}^n\) on the parameters will not be made explicit, with the exception of the inflation level.
From this data, define the set \(\mathcal {G}^n\) of \(6(M-1)rn+1\) generators to be
We will use the abbreviations
and
Four types of constraints are imposed. Locality constraints:
Measurement constraints:
Norm constraints:
And finally that
for all generators x. Together, these constraints define the set of relations \(\mathcal {R}^n\). The NPO will run over states on the universal \(C^*\)-algebra \(\mathcal {D}^n=C^*(\mathcal {G}^n|\mathcal {R}^n)\).
4.1.2 Polynomial constraints and objective function
The quantum causal polynomial optimization problem minimizes a polynomial function \(f_0\) over compatible states \(\rho \in K(\mathcal {D}^1)\) that also fulfill a number of polynomial constraints \(f_i(\rho )=0\). Here, we construct these objects precisely.
Choose some \(g, k\in \mathbbm {N}\). Recall the definition of the finite vector space \(\mathcal {F}^{(k)}(\mathcal {G})\) of polynomials of order k in the generators \(\mathcal {G}\) from Sect. 2.2.3. We assume that the functions are such that for every \(f_i\), there exists a \(y_i\) in the g-fold algebraic tensor product \(\mathcal {F}^{(k)}\otimes _\textrm{alg}\dots \otimes _\textrm{alg}\mathcal {F}^{(k)}\) such that \(f_i(\rho )\) equals the evaluation of the product state \(\rho ^{\otimes g}\) on \(y_i\):
For our purposes, it will be enough to take Eq. (52) as the definition of the type of functions we allow for. We remark, though, that passing from a degree-g polynomial function \(f_i\) on \(\mathcal {F}^{(k)}\) to a \(y_i\in (\mathcal {F}^{(k)})^{\otimes _\textrm{alg} g}\) such that Eq. (52) holds is known as a polarization in multi-linear algebra. In this context, it is proven that a unique suitable \(y_i\) always exists.
As an example, consider the 2-norm distance that allows one to reduce Problems 1 to 2 as we will see in Corollary 13. The objective function is then given by
To find the polarization, note that for a compatible state \(\rho \) it holds that
which is indeed of the form \(\rho ^{\otimes g}(y_i)\).
We have now assigned a precise meaning to every object that appeared in the quantum causal polynomial optimization problem (Problem 2), which we restate here with constraints on the Schmidt rank of the POVM elements and the norm of the generators (i.e. as in Problem 3): Given a causal structure, a choice for the parameters M, r, C, and a family of polynomial functions \(f_i\) on \(K(\mathcal {D}^1)\) as defined above and such that the \(f_i, i\ge 1\) are non-negative on states that are compatible with the causal structure. Find
We adopt the common convention that \(f^\star _{r,C}\) is \(\infty \) in case the problem is infeasible.
4.1.3 NPO formulation
We now pass to an NPO problem, which we will show is asymptotically equivalent to the causal optimization problem in Eq. (55). To do so, we will replace the polynomial functions \(f_i\) by their polarizations \(y_i\), and replace the causal constraint on \(\rho \) by symmetry constraints on a degree-n inflation.
Choose some n larger than or equal to the degree of \(y_0\). For permutations \(\pi , \pi ', \pi ''\in S_n\) define an action on generators:
Let \(\alpha _{\pi ,\pi ',\pi ''}\) be the extension of this action to \(\mathcal {F}(\mathcal {G}^n)\).
The NPO problem relaxation of (55) at inflation level n is
where the final symmetry constraint ranges over a basis \(\{b_j^{(n)}\}\) for \(\mathcal {F}^{(n)}(\mathcal {G})\) and a generating set of permutations in \(S_n^{\times 3}\).
We note that (57) is not yet directly a semi-definite program. Instead, every instance gives rise to the infinite (but complete) hierarchy of SDP relaxations discussed in Sect. 2.2.
4.2 Proof of completeness
Now follows the proof that the inflation hierarchy of Eq. (57) is complete, i.e. that in the limit of \(n\rightarrow \infty \), Eqs. (57) and (55) are equivalent. Afterwards, we show that for every \(\epsilon \) in the approximate quantum causal compatibility problem (Problem 1), there exist a Schmidt rank r and a norm bound C such that any compatible distribution can be \(\epsilon \)-approximated by one that can be realized in a model that respects the bounds on r, C.
Theorem 11
The hierarchy (57) is complete for the problem (55) in the sense that
Proof
Since each level of the hierarchy is a relaxation of the original problem, it holds that
The converse inequality is more involved. We start by constructing a state \(\omega _n\) on \(\mathcal {D}^\infty \) for each n by taking the infinite tensor product of some optimizing state of the problem in Eq. (57). By the Banach–Alaoglu Theorem applied to the state space \(K(\mathcal {D}^\infty )\), there exists a weak\(^*\)-convergent subsequence of the \(\omega _n\). Let \(\omega \) be its limit point.
For each \(i\ge 1\), \(y_i\) has a finite degree \(n_i\). The constraint \(\rho (y_i)=0\) in (57) implies that \(\omega _n(y_i)=0\) for every \(n\ge n_i\), and therefore the same is true for the limit:
Because \(\omega _n\) is chosen to be an optimizer, \(\omega _n(y_0)=f^n_{r,C}\) and thus
Likewise, the symmetry constraints in (57) imply that
Restricting to the diagonal case \(\pi =\pi '=\pi ''\), we conclude that the limit \(\omega \) is a symmetric state on \(\mathcal {D}^\infty \), so that Theorem 7 applies.
Next, for each \(1\le n \le \infty \), introduce the algebras
where \((\mathcal {C}_+ \mathcal {A}_-)^n \subset \mathcal {D}^n\) is the subalgebra generated by \(\bigcup _{i\le n}\bigcup _{a,\alpha } \{ g_+^i(a,\alpha ), e_-^i(a,\alpha ) \}\), and similar for \((\mathcal {A}_+ \mathcal {B}_-)^n\) and \((\mathcal {B}_+ \mathcal {C}_-)^n\). As n ranges over all natural numbers, the linear span of elements of the form
with \(u \in (\mathcal {C}_+ \mathcal {A}_-)^{n}\), \(v \in (\mathcal {A}_+ \mathcal {B}_-)^{n}\) and \(w \in (\mathcal {B}_+ \mathcal {C}_-)^{n}\) is dense in \(\mathcal {D}^\infty \). We therefore lose no generality by restricting the analysis of the action of \(\omega \) to elements of this form.

We associate to each quantum system an observable algebra. This means that the POVM elements of Alice generate a subalgebra of a larger algebra \(\mathcal {A}_- \otimes \mathcal {A}_+\), and similar for Bob and Charlie. It is with respect to the splitting \(\mathcal {C}_+ \mathcal {A}_- \mid \mathcal {A}_+ \mathcal {B}_- \mid \mathcal {B}_+ \mathcal {C}_-\) that the global state is supposed to factorize
Fix one \(n\in \mathbbm {N}\) and \(x=uvw\in \mathcal {D}^n\). Using the cycle notation, define the permutations
Then
where Eq. (61) follows from Eqs. (59) and (62) from Theorem 7, and in Eqs. (63) and (64) we have used that \(\Pi _\sigma \) is a symmetric product state for disjoint sets of layers of the inflation.
For each \(\sigma \), the integrand in Eq. (64) factorizes (c.f. Fig. 4). The respective marginals of \(\Pi _\sigma \) will be denoted as
so that the product state appearing in the integrand is
Therefore, \(\omega \) is a convex combination
of states \(\Lambda _\sigma \) that are compatible with the causal structure.
It remains to be shown that we can choose one \(\sigma \), such that \(\Lambda _\sigma (y_0) = f^\infty _{r,C}\) and \(\Lambda _\sigma (y_i) = 0\) for all \(i \ge 1\).
By the definition of Problem 2, the \(y_i\) are non-negative on states compatible with the causal structure, i.e. \(\Lambda _\sigma (y_i)\ge 0\) for all \(i\ge 1\). Because \(\omega (y_i)=0\) as well, the constraints must be fulfilled on a set \(E\subset K(\mathcal {D})\) of measure \(\mu (E)\) equal to one. For every \(\Lambda _\sigma \) with \(\sigma \in E\) it must hold that \(\Lambda _\sigma (y_0) \ge f^\infty _{r,C}\), for else one could have chosen \(\mu \) to be the point measure on a state \(\sigma ' \in E\) with \(\Lambda _{\sigma '}(y_0) < f^\infty _{r,C}\), which contradicts the fact that \(f^\infty _{r,C}\) is a minimum. As before, there must be a subset \(F\subset E\) of measure \(\mu (F)\) equal to one such that \(\Lambda _\sigma (y_0)=f^\infty _{r,C}\) for all \(\sigma \in F\). Therefore, any state \(\Lambda _\sigma \) such that \(\sigma \in F\) is compatible with the constraints of Eq. (55), so that we can conclude
Combining Eqs. (58) and (68) yields \(f^\infty _{r,C} = f^\star _{r,C}\). \(\square \)
Remarks
-
1.
It is not obviously possible to extract a compatible state from the SDP.
-
2.
The proof of Theorem 11 shows that it is in general not possible to add additional constraints of the form \(\rho (x) \ge 0\) to the program for elements x that are not necessarily positive on compatible states: the states \(\Lambda _\sigma \) that are compatible with the causal structure might not obey these constraints, since they only apply to \(\omega \). That is, the set E defined in the proof will in general not have full measure. However, if the optimization problem is a feasibility problem, i.e. if it has a trivial objective function, it is possible to put one such constraint as the objective function and reject the solution if the optimal value does not obey the inequality. We will apply this to the constraints of the causal compatibility problem in Corollary 13 below.
Lemma 12
Consider a probability distribution P that is compatible with a given causal structure. Choose \(\epsilon >0\). There exist constants C, r such that there is a distribution \({\tilde{P}}\) that approximates P in the sense that
which can be realized using only POVM elements of the form
Proof
Consider the original model that gives rise to P. By the definition of a \(C^*\)-tensor product, for each \(a=1, \dots , M-1\), there is a convergent series
Let \(E_a^{(r)}\) be the truncation of the series to the first r terms. Convergence implies that for every \(\delta >0\), there exists an r such that
What remains to be proven is that one can turn these partial sums into an exact POVM. To this end, set
Then the \({\tilde{E}}_a\) are positive. What is more,
so that
is also positive. Therefore \(\{{\tilde{E}}_1, \dots , {\tilde{E}}_M\}\) forms a POVM. Repeating the construction, one arrives at approximations \({\tilde{F}}_b\) to \(F_b\) and \({\tilde{G}}_c\) to \(G_c\).
From Eq. (70), the approximating POVM elements converge to the original ones in operator norm as \(\delta \rightarrow 0\). The same is thus true for all polynomial expressions in the POVM elements. Therefore,
and, because there are only finitely many outcomes,
Thus, choosing r sufficiently high, an arbitrarily good approximation can be achieved. The advertised claim follows by choosing C to be the largest operator norm of any factor of the partial sums involved. \(\square \)
Corollary 13
Given a probability distribution P over observed variables, the SDP hierarchy that corresponds to the optimization problem of Eq. (57) can solve the approximate quantum causal compatibility problem described in Problem 1.
Proof
In order to solve Problem 1, we need to show that there exists a state \(\rho \) that is compatible with the description of the causal structure and that produces statistics that are close in 2-norm to the observed statistics. In particular, for the triangle scenario it must hold that
where \(\rho \) is a compatible state. Once again we can polarize the expression, which yields the objective function
as was shown in Eq. (54).
If the NPO hierarchy attains the optimal value \(f_{r,C}^\infty \) for this objective function, there also exists a product state \(\Pi _\sigma \in K(\mathcal {D}^\infty )\) that is compatible with the infinitely inflated causal structure that attains the same optimal value by Theorem 11. If \(f_{r,C}^n > \epsilon \) for any n, we reject the hypothesis that the given description of the causal structure with measurement operators of rank r and generators with a norm-bound of C can produce the observed statistics. If there does exist a quantum description of P(A, B, C) Lemma 12 ensures that there exist r and C such that the optimal value is not rejected for any n. In that case the restriction of \(\Pi _\sigma \) to \(\mathcal {D}\) is a product state that is compatible with the triangle causal structure and that approximately produces the probability distribution P(A, B, C). \(\square \)
Remark
Though in the limit of \(n\rightarrow \infty \) the objective function (72) is equivalent to Eq. (71), Eq. 72 is likely to be impractical to detect incompatibility. For low values of n the state will not be separable and this objective function can become negative. Therefore, in practice it is more convenient to optimize over the quadratic function (71). The problem is then a convex quadratic program, which can still be solved via semidefinite programming (see e.g. Ref. [52]). Alternatively, one can add the requirement that the measurements evaluate to the correct probabilities as a set of linear constraints on the state. The objective function can then be made trivial, or the problem can be reformulated as an eigenvalue optimization problem (see e.g. Ref. [53, Sec. 5]). However, as mentioned in the remark below Theorem 11, it becomes unclear whether such a hierarchy is still complete.
4.3 Arbitrary quantum causal structures
In this section we will generalize the results presented above to arbitrary causal structures for which all leaf nodes are observed classical variables. (Recall that one can also define quantum causal structures that give rise to quantum states rather than classical variables [15], but such scenarios are beyond the scope of this paper). Ref. [16, Sec. V] discusses a number of transformation rules that bring such general causal structures into a form amenable to the hierarchy introduced above. It is argued there that these rules are sufficient to treat every structure that gives rise to classical random variables. We will not repeat this argument here. However, for each of their transformation rules, we will explain how they can be applied in our modified framework.
We will first argue that the approach described in the previous sections is applicable to all network scenarios, which are two-layered causal structures with observed leaf nodes, i.e. nodes without children. In the second step, we will map any latent exogenous causal structure to such a network scenario. Latent exogenous causal structures are those in which the only unobservable nodes are root nodes, i.e. nodes that have no parents. The final step is to map non-exogenous causal structures to exogenous ones by introducing a new type of node that can also be treated in our model.
4.3.1 Network scenarios
It is not difficult to see that Theorem 11 and Corollary 13 can be extended to arbitrary correlation scenarios, which are the causal structures that only have a bottom layer of independent latent systems with arrows pointing to a top layer of observed variables. The triangle scenario is an example of a correlation scenario. If the causal structure has L latent (quantum) variables, one can employ the proof strategy of Theorem 11 with \(L\cdot g\) levels of inflation. Indeed, for the triangle scenario one has 3 latent quantum systems, and thus 3g levels of inflation were sufficient. The proof that causal polynomial optimization can be solved with an SDP hierarchy as described above remains nearly the same, with the only difference that the algebra \(\mathcal {D}^n\) modeling the level-n inflated causal structure has to be defined in accordance with the proposed causal structure. To show that causal compatibility is also solved, one just needs to write down a similar objective function as in Eq. (72) for the given probability distribution.
By allowing classical root nodes that only have one child in two-layered causal structures, one obtains so called network scenarios. The Bell scenario from Fig. 2 is an example of such a network scenario. Whenever a classical, observed variable is an input to another observed variable, we give the POVM elements of the latter variable an extra index. For example in the Bell scenario, where Alice has the input variable X, the POVM elements of Alice become \(\{E_a^x\}\), with \(\sum _a E^x_a = \mathbb {I}\) for every x, so that x can be interpreted as a measurement setting. POVM elements with different measurement settings, e.g. \(E^x_a\) and \(E^{x'}_a\), need no longer commute. Though this description introduces more variables to the model, nothing major changes in the proofs.
4.3.2 Latent exogenous causal structures
It is also possible to extend our result to quantum causal structures with more than two layers. The reduction of the general case to the proof methods considered here is not immediate. We follow Wolfe et al., who generalize to arbitrary causal structures in two steps. In both cases, they offer a solution for how to alter the description of these causal structures such that they fit in the framework of inflation and NPO. We will adopt the first and alter the second method to adhere to our formalism. One then has to show that these descriptions still obey all the results of the previous sections. Here we briefly outline why this is indeed the case and give the general transformation rules to map those causal structures to equivalent network scenarios.

a The instrumental scenario as an example of a latent exogenous causal structure. The variable A is both a parent and a child and thus the causal structure is not a network scenario. By splitting A into A and \(A_1^\#\), as in (b), and post-selecting \(A_1^\#\) on the outcome of A, the instrumental scenario can be modeled by a network scenario, which happens to be the Bell scenario. This process is an example of maximal interruption
In the first generalization step, the causal structure is also allowed to contain observed nodes that have both one or more parents and one or more children. However, all unobserved nodes remain root nodes. Such causal structures are called latent exogenous. An example is the instrumental scenario in Fig. 5. The probability distribution of the instrumental scenario is denoted by \(P_{IS}(A,B,X)\). However, it is more common to express the statistics in terms of conditional probabilities. For a set of N random variables \(\{A_1, \ldots , A_N\}\) conditioned on K independent variables \(\{X_1, \ldots , X_K\}\), the statistics are fully captured by the combination of the conditional probabilities
and the requirement that the setting-associated variables factorize:
We refer to Ref. [54] for a fuller discussion on why this is necessary and how this works in more general (classical) setups. Hence, checking for compatibility will consist of two separate steps: First one has to confirm that variables that are being conditioned on form a product distribution; Secondly, one checks compatibility with the causal structure via the procedure outlined below.
In particular, for the instrumental scenario this simply reduces to checking compatibility of
The classical random variable A is both a child of \(\rho _{AB}\) and X, as well as a parent of B. This problem is resolved by a process known as maximal interruption [55,56,57,58]: the variable A is split into two random variables A and \(A_1^\#\), where A is only a child and \(A_1^\#\) is only a parent. The causal structure is then effectively mapped to the Bell scenario. By post-selecting \(A_1^\#\) on the outcome \(A=a\), i.e. by setting \(P_{IS}(A=a, B=b\mid X=x) = P_{Bell}(A=a, B=b\mid X=x, A_1^\# = a)\), one can still obtain the allowed distributions of the original graph.

a The triangle scenario with a shared setting X. Via maximal interruption the observed variable X is split into three independent and identically distributed random variables, producing the network scenario (b). The allowed probability distributions of the original causal structure can be obtained from the network scenario by post-selection
In the case that an observable node has multiple children, one applies a similar splitting and post-selection procedure. Consider for example the triangle scenario with a shared setting X depicted in Fig. 6a. Via maximal interruption the observed variable X is split up into three independent and identically distributed random variables \(X_1^{\#}\), \(X_2^{\#}\) and \(X_3^{\#}\) as depicted in Fig. 6b. The resulting causal structure is a network scenario. By post-selecting on \(X_1^{\#} = X_2^{\#} = X_3^{\#} = x\) one can link the (conditional) probability distribution of the network scenario to the (conditional) probability distribution \(P(A,B,C\mid X=x)\) of the triangle with a shared setting and find the allowed distributions in the original causal structure.
In this way, one can map all latent exogenous causal structures to network scenarios. The general rule is then as follows: Whenever an observed node is not a leaf node and is directly connected to multiple other nodes, split the node into as many copies as there are outgoing arrows. Remove every outgoing arrow from the original node and attach it to a copy. If there are no incoming arrows to the original node, remove it. Check whether the setting-associated variables factorize into a product distribution. Finally, analyze this causal structure, which is now a network scenario, and apply post-selection on the copies.
4.3.3 Non-exogenous causal structures
The second step in the generalization is more involved. The causal structures are now also allowed to have latent (quantum) variables with parents. In classical causal structures it is possible to transform these non-exogenous causal structures into exogenous ones, for which it is then possible to apply maximal interruption as described above, if necessary [59]. However, for quantum causal structures this is in general not possible.
Ref. [16] gives a clear example (credited there to Stefano Pironio), which is depicted in Fig. 7. In this example, the quantum system \(\rho _{BC}\) in Fig. 7a is non-exogenous. The structure in Fig. 7b has been exogenized as if it were a classical causal structure, by removing \(\rho _{BC}\) and drawing arrows from the parents of \(\rho _{BC}\) to its children. It can be seen that in the original causal structure it is possible to maximally violate a Bell inequality for either the systems A and B or A and C, based on the setting determined by S. However, after the exogenization depicted on the right, the setting S cannot determine anymore which pair maximally violates a Bell inequality. Since it is impossible that both A and B, as well as A and C maximally violate a Bell inequality due to monogamy of entanglement [60], the causal structure on the right cannot produce the same statistics as the one on the left.
We will split the treatment of non-exogenous causal structures in two parts: First, we will consider unobservable systems with one or more observed parents and at most one unobservable parent. Secondly, we will regard unobservable systems with multiple unobservable parents, but no observed parents. These two solutions can be combined to form a general set of rules for treating non-exogenous causal structures. It will turn out that, even though we cannot directly apply the exogenization procedure for classical causal structures, each observable leaf node will instead get an index associated to each of its parents in the classically exogenized causal structure. These indices then contain the information about commutation relations and independence constraints for the causal structure.
In Ref. [16] unobservable systems are eliminated by instead regarding such a system as a quantum channel applied to its unobservable parents and regarding any observed parents as a classical control for this quantum channel. If there is no observed parent to a non-exogenous system, the quantum channel that replaces it does not have such a control variable.
We opt for a slightly different treatment of non-exogenous systems with a similar interpretation. Instead of acting with a quantum channel on a state, we alter the POVM elements. Consider again the causal structure of Fig. 7a as an example. The intermediate state \(\rho _{BC}\) has the interpretation of redistributing the S subsystem of \(\rho _{AS}\) among Bob and Charlie, based on the observed variable S. Hence, for different outcomes s of S, Bob and Charlie will perform measurements over different parts of the S subsystem of \(\rho _{AS}\). However, for every specific outcome s, the measurements operators will be given by commuting POVMs for Bob and Charlie. We therefore define for every outcome of S the commuting algebras \(\mathcal {B}^{(s)}\) and \(\mathcal {C}^{(s)}\) with elements \(\{F_b^{(s)}\}_b\) and \(\{G_c^{(s)}\}_c\) respectively. Elements from these algebras obey the commutation relations
but whenever two operators have different indices s and \(s'\), they are no longer required to commute. The difference between this description and the measurement settings in network scenarios is that in network scenarios all POVM elements of Bob commute with all POVM elements of Charlie, while that is no longer the case here. We therefore propose a new graphical notation for this exogenization procedure, in which the nodes of Bob and Charlie are initially combined and only become commuting POVMs after the measurement setting s has been processed (see Fig. 7c). We will call such nodes endogenous nodes.

a An example of a non-exogenous causal structure. It is not possible to exogenize such a quantum causal structure as depicted in (b), like one would do for classical causal structures. This can be seen by noting that structure (a) can maximally violate a Bell inequality for A and B or for A and C based on the measurement setting S. Due to monogamy of entanglement this is not possible for structure (b). In structure (c) this is solved by first regarding Bob and Charlie as one observer and only choosing the commuting algebras \(\mathcal {B}\) and \(\mathcal {C}\) after the setting S has been received. This procedure is represented by a new type of node
One can still apply inflation to this causal structure as well. The algebras \(\mathcal {A}\), \(\mathcal {B}^{(s)}\) and \(\mathcal {C}^{(s)}\) will be copied and get the index i corresponding to the i’th copy of \(\rho \). Different inflation levels will be modeled by commuting subalgebras with an exchange symmetry and one can show, using the de Finetti theorem, that in the limit a symmetric global state is separable across copies of \(\rho \). The proofs of Theorem 11 and Corollary 13 then also follow.
In general, one can apply the following rule to remove a non-exogenous system with observed parents and at most one latent parent, starting with non-exogenous systems that are closest to a leaf node: Split up each leaf node according to the structure of its local algebras, similar to the triangle scenario. Combine all leaf nodes that have a directed path from the non-exogenous system to that leaf node into one endogenous node. For every observed variable that is a parent of the non-exogenous node, introduce an index to the elements of the endogenous node. Elements of the algebra of the endogenous node commute if all such setting indices are the same and the elements originated from spatially separated systems (e.g. Bob and Charlie).
The final class of causal structures that has not been discussed yet, is the one where there are multiple unobserved parents to a latent variable. We will again first treat an example and then give the general rule.
Consider the causal structure in Fig. 8a. The intermediate node \(\rho _{BC}\) is non-exogenous and has two latent parents. We start by splitting up the algebras \(\mathcal {C}\) and \(\mathcal {D}\) into their minus and plus sub-algebras, similar to the triangle scenario. Then we remove the non-exogenous node by taking those algebras together into an endogenous node that are its descendants, as was done in Fig. 7c. In this case, that will remove \(\rho _{BC}\) and combine \(\mathcal {B}\) and \(\mathcal {C}_-\) into an endogenous node.

a A more complicated causal structure, where \(\rho _{BC}\) has two latent parents and two observable children. The inflated version of this structure can alternatively be depicted as in (b). The algebras \(\{\mathcal {B}^{ij}\}_{ij}\) and \(\{\mathcal {C}^{ij}_-\}_{ij}\) are taken together and do not commute if there is only one overlapping index
When the causal structure is inflated, the root nodes are copied and given inflation indices i, j, k respectively. The intermediate state \(\rho _{BC}\) would then have gotten the two inflation indices i, j, which in turn are both passed down to \(\mathcal {B}\) and \(\mathcal {C}_-\) (see Fig. 8b). We thus have the following algebras after inflation: \(\mathcal {A}^{i}, \mathcal {B}^{ij}, \mathcal {C}^{ij}_-, \mathcal {C}^k_+, \mathcal {D}^j_-\) and \(\mathcal {D}^k_+\). Operators from these algebras will be denoted in a similar way. Let \(\mathcal {E}^n\) be the algebra describing the level-n inflated causal structure. Though each of these algebras is a subalgebra of \(\mathcal {E}^n\), it is no longer true that \(\mathcal {E}^n\) is the tensor product of all these algebras, because some of them do not commute. This is due to the “mixing” of the root nodes \(\rho _L^i\) and \(\rho _M^j\) by the intermediate nodes \(\rho ^{ij}_{BC}\). In particular, for \(B^{ij} \in \mathcal {B}^{ij}\) and \(C^{i'j'}_- \in \mathcal {C}_-^{i'j'}\)
By requiring that the POVM elements of Bob and Charlie commute when they perform a measurement on the same state \(\rho ^{ij}_{BC}\), or on independent copies of the state, \(\rho ^{ij}_{BC}\) and \(\rho ^{i'j'}_{BC}\) with \(i\ne i',\ j\ne j'\), we ensure that we still model spatially separated measurements in a physical scenario.
The question is now which independence relations hold and how to properly apply the quantum de Finetti theorem to show that these relations hold asymptotically in the inflation formalism.
To answer this question, note that the state \(\rho _{BC}\) masks the independence of the parts of \(\rho _L\) and \(\rho _M\) that are sent to Bob and Charlie: The correlations in this causal structure could have also been produced by a four-partite state, of which the first and fourth subsystems are required to be independent, combined with the independent bi-partite state \(\rho _R\). The independence requirements that still have to hold after the quantum channel that produces \(\rho _{BC}\) are thus
where the first two equalities signify independence within layers of inflation (namely the independence of \(\rho _R\) with respect to \(\rho _L\) and \(\rho _M\), and the independence of A and D), while the last equality corresponds to independence between layers of inflation. Note, however, that the algebras \(\mathcal {B}^{ij}\) and \(\mathcal {C}^{ij}_-\) do not have this independence between inflation layers if the state is evaluated over products of operators of either algebra for which only one of the two indices coincides, e.g. \(\rho (B^{ij} C_-^{i'j}) \ne \rho (B^{ij})\rho (C_-^{i'j})\) and \(\rho (B^{ij} B^{i'j}) \ne \rho (B^{ij})\rho (B^{i'j})\).
Relaxing the independence conditions of Eqs. (78)–(80) to their corresponding symmetry constraints and combining this with the commutation relations and the de Finetti Theorem, we can still asymptotically solve the (rank-constrained) causal compatibility problem even for this causal structure.
The general rule to map each inflation level of a causal structure with non-exogenous systems that have multiple latent parents, but no observed parents to an equivalent latent exogenous causal structure is then as follows: Start with the non-exogenous system that is closest to a leaf node. Split up each leaf node according to the structure of its local algebras. Combine all leaf nodes that have a directed path from the non-exogenous system to that leaf node into one endogenous node. For every root node that is an ancestor of the non-exogenous node, attach the inflation index of that root node to the elements of the endogenous node. Elements of the algebra of the endogenous node commute if either (1) all inflation indices are pair-wise the same, i.e. \(i=i', j=j',\ldots \), and the elements originated from spatially separated systems, e.g. Bob and Charlie, or if (2) all inflation indices are pair-wise different, i.e. \(i\ne i', j\ne j',\ldots \).
More succinctly: to reduce a non-exogenous causal structure to an exogenous one, we attach to every child of a non-exogenous node an index for all of the root nodes of the non-exogenous system, and apply the appropriate commutation relations.
Our approach is thus applicable to all relevant quantum causal structures, by sequentially applying the techniques outlined above, i.e. by first turning a non-exogenous causal structure into an exogenous one with a new type of node that can also be treated in our model, and then applying maximal interruption to turn it into a network scenario. Checking the feasibility of the SDP hierarchy of this network scenario, as well as the required factorization of the setting-associated variables is then a necessary and sufficient procedure for checking causal compatibility.
5 Conclusions and Outlook
Building on the quantum inflation hierarchy of Ref. [16], we have constructed a provably complete semidefinite programming hierarchy for the quantum causal polynomial optimization problem. Along the way, we have generalized the Quantum de Finetti Theorem for infinite systems [11] to arbitrary \(C^*\)-tensor products, and given a description of the NPO hierarchy [26] as an optimization procedure over states of a universal \(C^*\)-algebra.
A number of follow-up questions suggest themselves.
We could not prove completeness of the original quantum inflation hierarchy, due to the difficulty of constructing the local observable algebras (\(\mathcal {A}_-, \mathcal {A}_+\), etc.). To deal with this problem, we had to manually add generators for the algebra to the NPO program, and then manually impose norm constraints. While we have argued that any constructive completeness proof will have to add elements to the algebra that is extracted from the output of the SDP hierarchy, it is not obvious that we have found the most economical way of handling the issue. We also do not know whether there are a priori finite bounds on the norm of the local operators that combine to give the POVM elements. Both questions merit further researcher.
We have focused mostly on the quantum causal compatibility problem, and have not investigated objective functions beyond the 2-norm distance to measured data. While the examples given in [16, Section VII] carry over to our formulation, it would be interesting to look into further applications.
It would be worth investigating what further properties of the universal observable algebra can be enforced with suitable constraints. For example, one could impose that some of the subalgebras are Abelian in order to model partly classical behavior.
Numerical results for the SDP hierarchy described in this paper will be presented elsewhere.
Data sharing
Data sharing is not applicable to this article as no data sets were generated or analysed during the current study.
Notes
Convergence assumes that local subsystems are modeled as commuting observable algebras, see Sect. 2.1 for discussion.
In the context of quantum inflations, there are two distinct sources of “polynomials” that must not be confused. First, general operators arise as (non-commutative) polynomials in the generators. The word “polynomial” in the non-commutative polynomial optimization (NPO) framework refers to this sense. But NPO objective functions are still linear in the state. In contrast, the term “polynomial” in the quantum causal polynomial optimization problem—both as treated here and in Ref. [9, 16]—indicates that we are allowing for objective functions that are polynomials in the state (in the sense explained above). Using the notions introduced in the main text, the degree of polynomial expressions in the generators of the algebra is connected to the level k of the NPO hierarchy, while the degree of polynomial functions of the states corresponds to the level n of the inflation hierarchy.
Recall that, despite the everyday connotations of the word, the process of “completing” a metric space does not necessarily only add elements to it. The completion can be defined as the set of Cauchy sequences, with two considered equivalent if the norm of their differences converges to zero. Every \(x\in \mathcal {F}(\mathcal {G})\) gives rise to an element in \(C^*(\mathcal {G}|\mathcal {R})\), represented by the sequence that is constant and equal to x. Two elements \(x,y\in \mathcal {F}(\mathcal {G})\) induce the same element in \(C^*(\mathcal {G}|\mathcal {R})\) if and only if \(\left| \left| x-y\right| \right| =0\). Put differently, the completion adds elements to the quotient space \(\mathcal {F}(\mathcal {G})/\{ x \mid \Vert x\Vert =0\}\).
References
Balke, A., Pearl, J.: Bounds on treatment effects from studies with imperfect compliance. J. Am. Stat. Assoc. 92(439), 1171–1176 (1997). https://doi.org/10.1080/01621459.1997.10474074
Angrist, J.D., Imbens, G.W., Rubin, D.B.: Identification of causal effects using instrumental variables. J. Am. Stat. Assoc. 91(434), 444–455 (1996). https://doi.org/10.1080/01621459.1996.10476902
Koller, D., Friedman, N.: Probabilistic Graphical Models: Principles and Techniques. MIT Press, Cambridge (2009)
Pearl, J.: Causality. Cambridge University Press, Cambridge (2009)
Rosset, D., Gisin, N., Wolfe, E.: Universal bound on the cardinality of local hidden variables in networks (2017). arXiv:1709.00707
Geiger, D., Meek, C.: Quantifier elimination for statistical problems (2013). arXiv:1301.6698
Lee, C.M., Spekkens, R.W.: Causal inference via algebraic geometry: feasibility tests for functional causal structures with two binary observed variables. J. Causal Inference (2017). https://doi.org/10.1515/jci-2016-0013
Wolfe, E., Spekkens, R.W., Fritz, T.: The inflation technique for causal inference with latent variables. J. Causal Inference (2019). https://doi.org/10.1515/jci-2017-0020
Navascués, M., Wolfe, E.: The inflation technique completely solves the causal compatibility problem. J. Causal Inference 8(1), 70–91 (2020). https://doi.org/10.1515/jci-2018-0008
De Finetti, B.: Theory of Probability: A Critical Introductory Treatment, vol. 6. Wiley, Hoboken (1974)
Raggio, G., Werner, R.: Quantum statistical mechanics of general mean field systems. Helv. Phys. Acta 62(8), 1–19 (1989)
Caves, C.M., Fuchs, C.A., Schack, R.: Unknown quantum states: the quantum de Finetti representation. J. Math. Phys. 43(9), 4537–4559 (2002). https://doi.org/10.1063/1.1494475
Renner, R.: Symmetry of large physical systems implies independence of subsystems. Nat. Phys. 3(9), 645–649 (2007). https://doi.org/10.1038/nphys684
Brandao, F.G., Harrow, A.W.: Quantum de Finetti theorems under local measurements with applications. Commun. Math. Phys. 353(2), 469–506 (2017). https://doi.org/10.1007/s00220-017-2880-3
Chaves, R., Majenz, C., Gross, D.: Information-theoretic implications of quantum causal structures. Nat. Commun. 6(1), 1–8 (2015). https://doi.org/10.1038/ncomms6766
Wolfe, E., Pozas-Kerstjens, A., Grinberg, M., Rosset, D., Acín, A., Navascués, M.: Quantum inflation: a general approach to quantum causal compatibility. Phys. Rev. X 11(2), 021043 (2021). https://doi.org/10.1103/PhysRevX.11.021043
Costa, F., Shrapnel, S.: Quantum causal modelling. New J. Phys. 18(6), 063032 (2016). https://doi.org/10.1088/1367-2630/18/6/063032
Barrett, J., Lorenz, R., Oreshkov, O.: Quantum causal models (2019). arXiv:1906.10726
Allen, J.-M.A., Barrett, J., Horsman, D.C., Lee, C.M., Spekkens, R.W.: Quantum common causes and quantum causal models. Phys. Rev. X 7(3), 031021 (2017). https://doi.org/10.1103/PhysRevX.7.031021
Fritz, T.: Beyond Bell’s theorem: correlation scenarios. New J. Phys. 14(10), 103001 (2012). https://doi.org/10.1088/1367-2630/14/10/103001
Brunner, N., Cavalcanti, D., Pironio, S., Scarani, V., Wehner, S.: Bell nonlocality. Rev. Mod. Phys. 86(2), 419 (2014). https://doi.org/10.1103/RevModPhys.86.419
Cirel’son, B.S.: Quantum generalizations of bell’s inequality. Lett. Math. Phys. 4(2), 93–100 (1980). https://doi.org/10.1007/BF00417500
Masanes, L.: Extremal quantum correlations for n parties with two dichotomic observables per site (2005). arXiv:quant-ph/0512100
Navascués, M., Pironio, S., Acín, A.: Bounding the set of quantum correlations. Phys. Rev. Lett. 98(1), 010401 (2007). https://doi.org/10.1103/PhysRevLett.98.010401
Navascués, M., Feix, A., Araújo, M., Vértesi, T.: Characterizing finite-dimensional quantum behavior. Phys. Rev. A 92(4), 042117 (2015). https://doi.org/10.1103/PhysRevA.92.042117
Pironio, S., Navascués, M., Acin, A.: Convergent relaxations of polynomial optimization problems with non-commuting variables. SIAM J. Optim. 20(5), 2157–2180 (2010). https://doi.org/10.1137/090760155
Rosset, D., Branciard, C., Barnea, T.J., Pütz, G., Brunner, N., Gisin, N.: Nonlinear Bell inequalities tailored for quantum networks. Phys. Rev. Lett. 116(1), 010403 (2016)
Chaves, R.: Polynomial Bell inequalities. Phys. Rev. Lett. 116(1), 010402 (2016)
Tavakoli, A., Pozas-Kerstjens, A., Luo, M.-X., Renou, M.-O.: Bell nonlocality in networks (2021). arXiv:2104.10700
Henson, J., Lal, R., Pusey, M.F.: Theory-independent limits on correlations from generalized Bayesian networks. New J. Phys. 16(11), 113043 (2014)
Weilenmann, M., Colbeck, R.: Analysing causal structures with entropy. Proc. R. Soc. A Math. Phys. Eng. Sci. 473(2207), 20170483 (2017)
Budroni, C., Miklin, N., Chaves, R.: Indistinguishability of causal relations from limited marginals. Phys. Rev. A 94(4), 042127 (2016)
Kela, A., Von Prillwitz, K., Åberg, J., Chaves, R., Gross, D.: Semidefinite tests for latent causal structures. IEEE Trans. Inf. Theory 66(1), 339–349 (2019)
Åberg, J., Nery, R., Duarte, C., Chaves, R.: Semidefinite tests for quantum network topologies. Phys. Rev. Lett. 125(11), 110505 (2020)
Kraft, T., Spee, C., Yu, X.-D., Gühne, O.: Characterizing quantum networks: insights from coherence theory. Phys. Rev. A 103(5), 052405 (2021)
Branciard, C., Rosset, D., Gisin, N., Pironio, S.: Bilocal versus nonbilocal correlations in entanglement-swapping experiments. Phys. Rev. A 85(3), 032119 (2012)
Tavakoli, A., Skrzypczyk, P., Cavalcanti, D., Acín, A.: Nonlocal correlations in the star-network configuration. Phys. Rev. A 90(6), 062109 (2014)
Renou, M.-O., Bäumer, E., Boreiri, S., Brunner, N., Gisin, N., Beigi, S.: Genuine quantum nonlocality in the triangle network. Phys. Rev. Lett. 123(14), 140401 (2019)
Scholz, V.B., Werner, R.F.: Tsirelson’s problem (2008). arXiv:0812.4305
Junge, M., Navascues, M., Palazuelos, C., Perez-Garcia, D., Scholz, V.B., Werner, R.F.: Connes’ embedding problem and Tsirelson’s problem. J. Math. Phys. 52(1), 012102 (2011). https://doi.org/10.1063/1.3514538
Fritz, T.: Tsirelson’s problem and Kirchberg’s conjecture. Rev. Math. Phys. 24(05), 1250012 (2012). https://doi.org/10.1142/S0129055X12500122
Ji, Z., Natarajan, A., Vidick, T., Wright, J., Yuen, H.: \(\rm MIP^*= \rm RE\rm \) (2020). arXiv:2001.04383
Størmer, E.: Symmetric states of infinite tensor products of \(C^*\)-algebras. Pure Math. Preprint series (1967)
Blackadar, B.: Operator Algebras: Theory of \(C^*\)-Algebras and Von Neumann Algebras, vol. 122. Springer, Berlin (2006)
Strocchi, F.: An Introduction to the Mathematical Structure of Quantum Mechanics: A Short Course for Mathematicians, vol. 28. World Scientific, London (2008)
Bratteli, O., Robinson, D.W.: Operator Algebras and Quantum Statistical Mechanics: \(C^*\)-and \(W^*\)-Algebras. Symmetry Groups. Decomposition of States, vol. 1. Springer, Berlin (2012)
Navascués, M., Pironio, S., Acín, A.: A convergent hierarchy of semidefinite programs characterizing the set of quantum correlations. New J. Phys. 10(7), 073013 (2008). https://doi.org/10.1088/1367-2630/10/7/073013
Takesaki, M.: Theory of Operator Algebras I, vol. 124. Springer, Berlin (2001)
De Finetti, B.: Funzione caratteristica di un fenomeno aleatorio. In: Atti del Congresso Internazionale dei Matematici: Bologna del 3 al 10 de Settembre di 1928, pp. 179–190 (1929)
Diaconis, P., Freedman, D.: Finite exchangeable sequences. Ann. Probab. 8, 745–764 (1980)
Murphy, G.J.: \(C^*\)-Algebras and Operator Theory. Academic Press, San Diego (2014)
Wolkowicz, H., Saigal, R., Vandenberghe, L.: Handbook of Semidefinite Programming: Theory, Algorithms, and Applications, vol. 27. Springer, New York (2012)
Pozas Kerstjens, A.: Quantum information outside quantum information (2019)
Richardson, T.S.: A factorization criterion for acyclic directed mixed graphs (2014). arXiv preprint arXiv:1406.6764
Gachechiladze, M., Miklin, N., Chaves, R.: Quantifying causal influences in the presence of a quantum common cause. Phys. Rev. Lett. 125(23), 230401 (2020). https://doi.org/10.1103/PhysRevLett.125.230401
Van Himbeeck, T., Brask, J.B., Pironio, S., Ramanathan, R., Sainz, A.B., Wolfe, E.: Quantum violations in the instrumental scenario and their relations to the Bell scenario. Quantum 3, 186 (2019). https://doi.org/10.22331/q-2019-09-16-186
Agresti, I., Carvacho, G., Poderini, D., Aolita, L., Chaves, R., Sciarrino, F.: Experimental connection between the instrumental and bell inequalities. In: Multidisciplinary Digital Publishing Institute Proceedings, vol. 12, p. 27 (2019). https://doi.org/10.3390/proceedings2019012027
Agresti, I., Poderini, D., Polacchi, B., Miklin, N., Gachechiladze, M., Suprano, A., Polino, E., Milani, G., Carvacho, G., Chaves, R., et al.: Experimental test of quantum causal influences (2021). arXiv:2108.08926
Evans, R.J.: Graphs for margins of Bayesian networks. Scand. J. Stat. 43(3), 625–648 (2016). https://doi.org/10.1111/sjos.12194
Koashi, M., Winter, A.: Monogamy of quantum entanglement and other correlations. Phys. Rev. A 69(2), 022309 (2004). https://doi.org/10.1103/PhysRevA.69.022309
Acknowledgements
We thank Johan Åberg, Nikolai Miklin, Marc-Olivier Renou, Reinhard Werner, and Elie Wolfe for insightful discussions. This work has been supported by Germany’s Excellence Strategy—Cluster of Excellence Matter and Light for Quantum Computing (ML4Q) EXC 2004/1 – 390534769.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by G. Chiribella.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ligthart, L.T., Gachechiladze, M. & Gross, D. A Convergent Inflation Hierarchy for Quantum Causal Structures. Commun. Math. Phys. 401, 2673–2714 (2023). https://doi.org/10.1007/s00220-023-04697-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00220-023-04697-7