
Abstract
Quantum teleportation is one of the fundamental building blocks of quantum Shannon theory. While ordinary teleportation is simple and efficient, port-based teleportation (PBT) enables applications such as universal programmable quantum processors, instantaneous non-local quantum computation and attacks on position-based quantum cryptography. In this work, we determine the fundamental limit on the performance of PBT: for arbitrary fixed input dimension and a large number N of ports, the error of the optimal protocol is proportional to the inverse square of N. We prove this by deriving an achievability bound, obtained by relating the corresponding optimization problem to the lowest Dirichlet eigenvalue of the Laplacian on the ordered simplex. We also give an improved converse bound of matching order in the number of ports. In addition, we determine the leading-order asymptotics of PBT variants defined in terms of maximally entangled resource states. The proofs of these results rely on connecting recently-derived representation-theoretic formulas to random matrix theory. Along the way, we refine a convergence result for the fluctuations of the Schur–Weyl distribution by Johansson, which might be of independent interest.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
1.1 Quantum teleportation protocols
Quantum teleportation [1] is a fundamental quantum information-processing task, and one of the hallmark features of quantum information theory: Two parties Alice and Bob may use a shared entangled quantum state together with classical communication to “teleport” an unknown quantum state from Alice to Bob. The original protocol in [1] consists of Alice measuring the unknown state together with her half of the shared entangled state and letting Bob know about the outcome of her measurement. Based on this information Bob can then manipulate his half of the shared state by applying a suitable correction operation, thus recovering the unknown state in his lab.
From an information-theoretic point of view, quantum teleportation implements a quantum channel between Alice and Bob. If the shared entangled state is a noiseless, maximally entangled state (a so-called EPR state, named after a famous paper by Einstein, Podolski, and Rosen [2]), then this quantum channel is in fact a perfect, noiseless channel. On the other hand, using a noisy entangled state as the shared resource in the teleportation protocol renders the effective quantum channel imperfect or noisy. A common way to measure the noise in a quantum channel is by means of the entanglement fidelity, which quantifies how well the channel preserves generic correlations with an inaccessible environment system (see Sect. 2.1 for a definition).

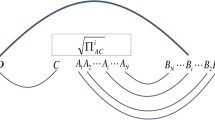
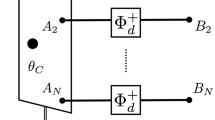
Schematic representation of port-based teleportation (PBT). Like in ordinary teleportation, the sender applies a joint measurement to her input system A and her parts of the entangled resource, \(A_i, i=1,\ldots ,N\), and sends the outcome to the receiver, who applies a correction operation. In PBT, however, this correction operation merely consists of choosing one of the subsystems \(B_i\), the ports, of the entangled resource. A PBT protocol cannot implement a perfect quantum channel with a finite number of ports. There are different variants of PBT. The four commonly studied ones are characterized by whether failures are announced, or heralded (probabilistic PBT) or go unnoticed (deterministic PBT), and whether simplifying constraints on the resource state and the sender’s measurement are enforced
Port-based teleportation (PBT) [3, 4] is a variant of the original quantum teleportation protocol [1], where the receiver’s correction operation consists of merely picking the right subsystem, called port, of their part of the entangled resource state. Figure 1 provides a schematic description of the protocol (see Sect. 3 for a more detailed explanation). While being far less efficient than the ordinary teleportation protocol, the simple correction operation allows the receiver to apply a quantum operation to the output of the protocol before receiving the classical message. This simultaneous unitary covariance property enables all known applications that require PBT instead of just ordinary quantum teleportation, including the construction of universal programmable quantum processors [3], quantum channel discrimination [5] and instantaneous non-local quantum computation (INQC) [6].
In the INQC protocol, which was devised by Beigi and König [6], two spatially separated parties share an input state and wish to perform a joint unitary on it. To do so, they are only allowed a single simultaneous round of communication. INQC provides a generic attack on any quantum position-verification scheme [7], a protocol in the field of position-based cryptography [6, 8,9,10]. It is therefore of great interest for cryptography to characterize the resource requirements of INQC: it is still open whether a computationally secure quantum position-verification scheme exists, as all known generic attacks require an exponential amount of entanglement. Efficient protocols for INQC are only known for special cases [11,12,13,14]. The best lower bounds for the entanglement requirements of INQC are, however, linear in the input size [6, 15, 16], making the hardness of PBT, the corner stone of the best known protocol, the only indication for a possible hardness of INQC.
PBT comes in two variants, deterministic and probabilistic, the latter being distinguished from the former by the fact that the protocol implements a perfect quantum channel whenever it does not fail (errors are “heralded”). In addition, two classes of protocols have been considered in the literature, one using maximally entangled resource states and the other using more complex resources optimized for the protocol. The appeal of the former type of protocol is mostly due to the fact that maximally entangled states are a standard resource in quantum information processing and can be prepared efficiently. Using a protocol based on maximally entangled resources thus removes one parameter from the total complexity of the protocol, the complexity of preparing the resource, leaving the amount of resources as well as the complexity of the involved quantum measurement as the remaining two complexity contributions.
In their seminal work [3, 4], Ishizaka and Hiroshima completely characterize the problem of PBT for qubits. They calculate the performance of the standardFootnote 1 and optimized protocols for deterministic and the EPR and optimized protocols for probabilistic PBT, and prove the optimality of the ‘pretty good’ measurement in the standard deterministic case. They also show a lower bound on the performance of the standard protocol for deterministic PBT, which was later reproven in [6]. Further properties of PBT were explored in [17], in particular with respect to recycling part of the resource state. Converse bounds for the probabilistic and deterministic versions of PBT have been proven in [18] and [19], respectively. In [20], exact formulas for the fidelity of the standard protocol for deterministic PBT with \(N=3\) or 4 in arbitrary dimension are derived using a graphical algebra approach. Recently, exact formulas for arbitrary input dimension in terms of representation-theoretic data have been found for all four protocols, and the asymptotics of the optimized probabilistic case have been derived [21, 22].
Note that, in contrast to ordinary teleportation, a protocol obtained from executing several PBT protocols is not again a PBT protocol. This is due to the fact that the whole input system has to be teleported to the same output port for the protocol to have the mentioned simultaneous unitary covariance property. Therefore, the characterization of protocols for any dimension d is of particular interest. The mentioned representation-theoretic formulas derived in [21, 22] provide such a characterization. It is, however, not known how to evaluate these formulas efficiently for large input dimension.
1.2 Summary of main results
In this paper we provide several characterization results for port-based teleportation. As our main contributions, we characterize the leading-order asymptotic performance of fully optimized deterministic port-based teleportation (PBT), as well as the standard protocol for deterministic PBT and the EPR protocol for probabilistic PBT. In the following, we provide a detailed summary of our results. These results concern asymptotic characterizations of the entanglement fidelity of deterministic PBT, defined in Sect. 3.1, and the success probability of probabilistic PBT, defined in Sect. 3.2.
Our first, and most fundamental, result concerns deterministic PBT and characterizes the leading-order asymptotics of the optimal fidelity for a large number of ports.
Theorem 1.1
For arbitrary but fixed local dimension d, the optimal entanglement fidelity for deterministic port-based teleportation behaves asymptotically as
Theorem 1.1 is a direct consequence of Theorem 1.5 below. Prior to our work, it was only known that \(F_d^*(N) = 1 - \Omega (N^{-2})\) as a consequence of an explicit converse bound [19]. We prove that this asymptotic scaling is in fact achievable, and we also provide a converse with improved dependency on the local dimension, see Corollary 1.6.
For deterministic port-based teleportation using a maximally entangled resource and the pretty good measurement, a closed expression for the entanglement fidelity was derived in [21], but its asymptotics for fixed \(d>2\) and large N remained undetermined. As our second result, we derive the asymptotics of deterministic port-based teleportation using a maximally entangled resource and the pretty good measurement, which we call the standard protocol.
Theorem 1.2
For arbitrary but fixed d and any \(\delta >0\), the entanglement fidelity of the standard protocol of PBT is given by
Previously, the asymptotic behavior given in the above theorem was only known for \(d=2\) in terms of an exact formula for finite N; for \(d>2\), it was merely known that \(F^{\mathrm {std}}_d(N)=1-O\left( N^{-1}\right) \) [4]. In Fig. 2 we compare the asymptotic formula of Theorem 1.2 to a numerical evaluation of the exact formula derived in [21] for \(d\le 5\).

For probabilistic port-based teleportation, Mozrzymas et al. [22] obtained the following expression for the success probability \(p^*_d\) optimized over arbitrary entangled resources:
valid for all values of d and N (see the detailed discussion in Sect. 3). In the case of using N maximally entangled states as the entangled resource, an exact expression for the success probability in terms of representation-theoretic quantities was also derived in [21]. We state this expression in (3.9) in Sect. 3. However, its asymptotics for fixed \(d>2\) and large N have remained undetermined to date. As our third result, we derive the following expression for the asymptotics of the success probability of the optimal protocol among the ones that use a maximally entangled resource, which we call the EPR protocol.
Theorem 1.3
For probabilistic port-based teleportation in arbitrary but fixed dimension d with EPR pairs as resource states,
where \(\mathbf {G}\sim {\text {GUE}}^0_d\).
The famous Wigner semicircle law [24] provides an asymptotic expression for the expected maximal eigenvalue, \( \mathbb E[\lambda _{\max }(\mathbf {G})]\sim 2\sqrt{d}\) for \(d\rightarrow \infty \). Additionally, there exist explicit upper and lower bounds for all d, see the discussion in Sect. 5.

Success probability of the EPR protocol for probabilistic port-based teleporation in local dimension \(d=2,3,4,5\) using N ports [23]. We compare the exact formula (3.9) for \(p_d^{\mathrm {EPR}}\) (blue dots) with the first-order asymptotic formula obtained from Theorem 1.3 (orange curve). The first-order coefficient \(c_d \equiv \mathbb {E}[\lambda _{\max }(\mathbf {G})]\) appearing in the formula in Theorem 1.3 was obtained by numerical integration from the eigenvalue distribution of \({\text {GUE}}_d\)
To establish Theorems 1.2 and 1.3, we analyze the asymptotics of the Schur–Weyl distribution, which also features in other fundamental problems of quantum information theory including spectrum estimation, tomography, and the quantum marginal problem [25,26,27,28,29,30,31,32,33,34,35]. Our main technical contribution is a new convergence result for its fluctuations that strengthens a previous result by Johansson [36]. This result, which may be of independent interest, is stated as Theorem 4.1 in Sect. 4.
Theorem 1.1 is proved by giving an asymptotic lower bound for the optimal fidelity of deterministic PBT, as well as an upper bound that is valid for any number of ports and matches the lower bound asymptotically. For the lower bound, we again use an expression for the entanglement fidelity of the optimal deterministic PBT protocol derived in [22]. The asymptotics of this formula for fixed d and large N have remained undetermined so far. We prove an asymptotic lower bound for this entanglement fidelity in terms of the lowest Dirichlet eigenvalue of the Laplacian on the ordered \((d-1)\)-dimensional simplex.
Theorem 1.4
The optimal fidelity for deterministic port-based teleportation is bounded from below by
where
is the \((d-1)\)-dimensional simplex of ordered probability distributions with d outcomes and \(\lambda _1(\Omega )\) is the first eigenvalue of the Dirichlet Laplacian on a domain \(\Omega \).
Using a bound from [37] for \(\lambda _1(\mathrm {OS}_d)\), we obtain the following explicit lower bound.
Theorem 1.5
For the optimal fidelity of port-based teleportation with arbitrary but fixed input dimension d and N ports, the following bound holds,
As a complementary result, we give a strong upper bound for the entanglement fidelity of any deterministic port-based teleportation protocol. While valid for any finite number N of ports, its asymptotics for large N are given by \(1-O(N^{-2})\), matching Theorem 1.5.
Corollary 1.6
For a general port-based teleportation scheme with input dimension d and N ports, the entanglement fidelity \(F_d^*\) and the diamond norm error \(\varepsilon _d^*\) can be bounded as
Previously, the best known upper bound on the fidelity [19] had the same dependence on N, but was increasing in d, thus failing to reflect the fact that the task becomes harder with increasing d. Interestingly, a lower bound from [38] on the program register size of a universal programmable quantum processor also yields a converse bound for PBT that is incomparable to the one from [19] and weaker than our bound.
Finally we provide a proof of the following ‘folklore’ fact that had been used in previous works on port-based teleportation. The unitary and permutation symmetries of port-based teleportation imply that the entangled resource state and Alice’s measurement can be chosen to have these symmetries as well. Apart from simplifying the optimization over resource states and POVMs, this implies that characterizing the entanglement fidelity is sufficient to give worst-case error guarantees. Importantly, this retrospectively justifies the use of the entanglement fidelity F in the literature about deterministic port-based teleportation in the sense that any bound on F implies a bound on the diamond norm error without losing dimension factors. This is also used to show the diamond norm statement of Corollary 1.6.
Proposition 1.7
(Proposition 3.4 and 3.3 and Corollary 3.5, informal). There is an explicit transformation between port-based teleportation protocols that preserves any unitarily invariant distance measure on quantum channels, and maps an arbitrary port-based teleportation protocol with input dimension d and N ports to a protocol that
-
(i)
has a resource state and a POVM with \(U(d)\times S_N\) symmetry, and
-
(ii)
implements a unitarily covariant channel.
In particular, the transformation maps an arbitrary port-based teleportation protocol to one with the symmetries (i) and (ii) above, and entanglement fidelity no worse than the original protocol. Point (ii) implies that
where \(F_d^*\) and \(\varepsilon _d^*\) denote the optimal entanglement fidelity and optimal diamond norm error for deterministic port-based teleportation.
1.3 Structure of this paper
In Sect. 2 we fix our notation and conventions and recall some basic facts about the representation theory of the symmetric and unitary groups. In Sect. 3 we define the task of port-based teleportation (PBT) in its two main variants, the probabilistic and deterministic setting. Moreover, we identify the inherent symmetries of PBT, and describe a representation-theoretic characterization of the task. In Sect. 4 we discuss the Schur–Weyl distribution and prove a convergence result that will be needed to establish our results for PBT with maximally entangled resources. Our first main result is proved in Sect. 5, where we discuss the probabilistic setting in arbitrary dimension using EPR pairs as ports, and determine the asymptotics of the success probability \(p^{\mathrm {EPR}}_d\) (Theorem 1.3). Our second main result, derived in Sect. 6.1, concerns the deterministic setting in arbitrary dimension using EPR pairs, for which we compute the asymptotics of the optimal entanglement fidelity \(F^{\mathrm {std}}_d\) (Theorem 1.2). Our third result, an asymptotic lower bound on the entanglement fidelity \(F_d^*\) of the optimal protocol in the deterministic setting (Theorem 1.5), is proved in Sect. 6.2. Finally, in Sect. 7 we derive a general non-asymptotic converse bound on deterministic port-based teleportation protocols using a non-signaling argument (Theorem 7.5). We also present a lower bound on the communication requirements for approximate quantum teleportation (Corollary 7.4). We make some concluding remarks in Sect. 8. The appendices contain technical proofs.
2 Preliminaries
2.1 Notation and definitions
We denote by A, B, ...quantum systems with associated Hilbert spaces \(\mathcal {H}_A\), \(\mathcal {H}_B\), ..., which we always take to be finite-dimensional, and we associate to a multipartite quantum system \(A_1\ldots A_n\) the Hilbert space \(\mathcal {H}_{A_1\ldots {}A_n}=\mathcal {H}_{A_1}\otimes \ldots \otimes \mathcal {H}_{A_n}\). When the \(A_i\) are identical, we also write \(A^n=A_1\ldots {}A_n\). The set of linear operators on a Hilbert space \(\mathcal {H}\) is denoted by \(\mathcal {B}(\mathcal {H})\). A quantum state \(\rho _A\) on quantum system A is a positive semidefinite linear operator \(\rho _A\in \mathcal {B}(\mathcal {H}_A)\) with unit trace, i.e., \(\rho _A\ge 0\) and \({{\,\mathrm{tr}\,}}(\rho _A)=1\). We denote by \(I_A\) or \(1_A\) the identity operator on \(\mathcal {H}_A\), and by \(\tau _A=I_A/|A|\) the corresponding maximally mixed quantum state, where \(|A|\,{:}{=}\,\dim \mathcal {H}_A\). A pure quantum state \(\psi _A\) is a quantum state of rank one. We can write \(\psi _A=|\psi \rangle \langle \psi |_A\) for a unit vector \(|\psi \rangle _A\in \mathcal {H}_A\). For quantum systems \(A,A'\) of dimension \(\dim \mathcal {H}_A=\dim \mathcal {H}_{A'}=d\) with bases \(\lbrace |i\rangle _A\rbrace _{i=1}^d\) and \(\lbrace |i\rangle _{A'}\rbrace _{i=1}^d\), the vector \(|\phi ^+\rangle _{A'A} = \frac{1}{\sqrt{d}} \sum _{i=1}^d |i\rangle _{A'}\otimes |i\rangle _A\) defines the maximally entangled state of Schmidt rank d. The fidelity \(F(\rho ,\sigma )\) between two quantum states is defined by \(F(\rho ,\sigma )\,{:}{=}\, \Vert \sqrt{\rho }\sqrt{\sigma }\Vert _1^2\), where \(\Vert X\Vert _1={{\,\mathrm{tr}\,}}(\sqrt{X^\dagger X})\) denotes the trace norm of an operator. For two pure states \(|\psi \rangle \) and \(|\phi \rangle \), the fidelity is equal to \(F(\psi ,\phi )=|\langle \psi |\phi \rangle |^2\). A quantum channel is a completely positive, trace-preserving linear map \(\Lambda :\mathcal {B}(\mathcal {H}_A)\rightarrow \mathcal {B}(\mathcal {H}_B)\). We also use the notation \(\Lambda :A\rightarrow B\) or \(\Lambda _{A\rightarrow B}\), and we denote by \({{\,\mathrm{id}\,}}_A\) the identity channel on A. Given two quantum channels \(\Lambda _1,\Lambda _2:A\rightarrow B\), the entanglement fidelity \(F(\Lambda _1,\Lambda _2)\) is defined as
and we abbreviate \(F(\Lambda )\,{:}{=}\, F(\Lambda ,{{\,\mathrm{id}\,}})\). The diamond norm of a linear map \(\Lambda :\mathcal {B}(\mathcal {H}_A)\rightarrow \mathcal {B}(\mathcal {H}_B)\) is defined by
The induced distance on quantum channels is called the diamond distance. A positive operator-valued measure (POVM) \(E=\lbrace E_x\rbrace \) on a quantum system A is a collection of positive semidefinite operators \(E_x\ge 0\) satisfying \(\sum _x E_x = I_A\).
We denote random variables by bold letters (\(\mathbf {X}\), \(\mathbf {Y}\), \(\mathbf {Z}\), ...) and the valued they take by the non-bold versions (\(X,Y,Z,\ldots \)). We denote by \(\mathbf {X} \sim \mathbb {P}\) that \(\mathbf {X}\) is a random variable with probability distribution \(\mathbb {P}\). We write \(\Pr (\ldots )\) for the probability of an event and \(\mathbb {E}\left[ \ldots \right] \) for expectation values. The notation \(\mathbf {X}_n\overset{P}{\rightarrow }\mathbf {X} \ (n\rightarrow \infty )\) denotes convergence in probability and \(\mathbf {X}_n\overset{D}{\rightarrow }\mathbf {X} \ (n\rightarrow \infty )\) denotes convergence in distribution. The latter can be defined, e.g., by demanding that \(\mathbb {E}\left[ f(\mathbf {X}_n)\right] \rightarrow \mathbb {E}\left[ f(\mathbf {X})\right] \ (n\rightarrow \infty )\) for every continuous, bounded function f. The Gaussian unitary ensemble \({\text {GUE}}_d\) is the probability distribution on the set of Hermitian \(d\times d\)-matrices H with density \(Z_d^{-1} \exp (-\frac{1}{2}{{\,\mathrm{tr}\,}}H^2)\), where \(Z_d\) is the appropriate normalization constant. Alternatively, for \(\mathbf {X}\sim {\text {GUE}}_d\), the entries \(\mathbf {X}_{ii}\) for \(1\le i\le d\) are independently distributed as \(\mathbf {X}_{ii}\sim N(0,1)\), whereas the elements \(\mathbf {X}_{ij}\) for \(1\le i<j\le d\) are independently distributed as \(\mathbf {X}_{ij}\sim N(0,\frac{1}{2})+iN(0,\frac{1}{2})\). Here, \(N(0,\sigma ^2)\) denotes the centered normal distribution with variance \(\sigma ^2\). The traceless Gaussian unitary ensemble \({\text {GUE}}^0_d\) can be defined as the distribution of the random variable \(\mathbf {Y} \,{:}{=}\, \mathbf {X} - \tfrac{{{\,\mathrm{tr}\,}}\mathbf {X}}{d} I\), where \(\mathbf {X}\sim {\text {GUE}}_d\).
For a complex number \(z\in \mathbb {C}\), we denote by \(\mathfrak {R}( z)\) and \(\mathfrak {I}( z)\) its real and imaginary part, respectively. We denote by \(\mu \vdash _d n\) a partition \((\mu _1,\ldots ,\mu _d)\) of n into d parts. That is, \(\mu \in \mathbb {Z}^d\) with \(\mu _1\ge \mu _2\ge \cdots \ge \mu _d\ge 0\) and \(\sum _i\mu _i=n\). We also call \(\mu \) a Young diagram and visualize it as an arrangement of boxes, with \(\mu _i\) boxes in the ith row. For example, \(\mu =(3,1)\) can be visualized as  . We use the notation \((i,j)\in \mu \) to mean that (i, j) is a box in the Young diagram \(\mu \), that is, \(1\le i\le d\) and \(1\le j\le \mu _i\). We denote by \({{\,\mathrm{GL}\,}}(\mathcal {H})\) the general linear group and by \(U(\mathcal {H})\) the unitary group acting on a Hilbert space \(\mathcal {H}\). When \(\mathcal {H}=\mathbb {C}^d\), we write \({{\,\mathrm{GL}\,}}(d)\) and U(d). Furthermore, we denote by \(S_n\) the symmetric group on n symbols. A representation \(\varphi \) of a group G on a vector space \(\mathcal {H}\) is a map \(G\ni g\mapsto \varphi (g)\in {{\,\mathrm{GL}\,}}(\mathcal {H})\) satisfying \(\varphi (gh)=\varphi (g)\varphi (h)\) for all \(g,h\in G\). In this paper all representations are unitary, which means that \(\mathcal {H}\) is a Hilbert space and \(\varphi (g) \in U(\mathcal {H})\) for every \(g\in G\). A representation is irreducible (or an irrep) if \(\mathcal {H}\) contains no nontrivial invariant subspace.
. We use the notation \((i,j)\in \mu \) to mean that (i, j) is a box in the Young diagram \(\mu \), that is, \(1\le i\le d\) and \(1\le j\le \mu _i\). We denote by \({{\,\mathrm{GL}\,}}(\mathcal {H})\) the general linear group and by \(U(\mathcal {H})\) the unitary group acting on a Hilbert space \(\mathcal {H}\). When \(\mathcal {H}=\mathbb {C}^d\), we write \({{\,\mathrm{GL}\,}}(d)\) and U(d). Furthermore, we denote by \(S_n\) the symmetric group on n symbols. A representation \(\varphi \) of a group G on a vector space \(\mathcal {H}\) is a map \(G\ni g\mapsto \varphi (g)\in {{\,\mathrm{GL}\,}}(\mathcal {H})\) satisfying \(\varphi (gh)=\varphi (g)\varphi (h)\) for all \(g,h\in G\). In this paper all representations are unitary, which means that \(\mathcal {H}\) is a Hilbert space and \(\varphi (g) \in U(\mathcal {H})\) for every \(g\in G\). A representation is irreducible (or an irrep) if \(\mathcal {H}\) contains no nontrivial invariant subspace.
2.2 Representation theory of the symmetric and unitary group
Our results rely on the representation theory of the symmetric and unitary groups and Schur–Weyl duality (as well as their semiclassical asymptotics which we discuss in Sect. 4). In this section we introduce the relevant concepts and results (see e.g., [39, 40].
The irreducible representations of \(S_n\) are known as Specht modules and labeled by Young diagrams with n boxes. We denote the Specht module of \(S_n\) corresponding to a Young diagram \(\mu \vdash _d n\) by \([\mu ]\) (d is arbitrary). Its dimension is given by the hook length formula [39, pp. 53–54],
where \(h_\mu (i,j)\) is the hook length of the hook with corner at the box (i, j), i.e., the number of boxes below (i, j) plus the number of boxes to the right of (i, j) plus one (the box itself).
The polynomial irreducible representations of U(d) are known as Weyl modules and labeled by Young diagrams with no more than d rows. We denote the Weyl module of U(d) corresponding to a Young diagram \(\mu \vdash _d n\) by \(V^d_\mu \) (n is arbitrary). Its dimension can be computed using Stanley’s hook length formula [39, p. 55],
where \(c(i,j) = j-i\) is the so-called content of the box (i, j). This is an alternative to the Weyl dimension formula, which states that
We stress that \(m_{d,\mu }\) depends on the dimension d.
Consider the representations of \(S_n\) and U(d) on \({\left( \mathbb {C}^d\right) }^{\otimes n}\) given by permuting the tensor factors, and multiplication by \(U^{\otimes n}\), respectively. Clearly the two actions commute. Schur–Weyl duality asserts that the decomposition of \({\left( \mathbb {C}^d\right) }^{\otimes n}\) into irreps takes the form (see, e.g., [40])
3 Port-Based Teleportation
The original quantum teleportation protocol for qubits (henceforth referred to as ordinary teleportation protocol) is broadly described as follows [1]: Alice (the sender) and Bob (the receiver) share an EPR pair (a maximally entangled state on two qubits), and their goal is to transfer or ‘teleport’ another qubit in Alice’s possession to Bob by sending only classical information. Alice first performs a joint Bell measurement on the quantum system to be teleported and her share of the EPR pair, and communicates the classical measurement outcome to Bob using two bits of classical communication. Conditioned on this classical message, Bob then executes a correction operation consisting of one of the Pauli operators on his share of the EPR pair. After the correction operation, he has successfully received Alice’s state. The ordinary teleportation protocol can readily be generalized to qudits, i.e., d-dimensional quantum systems. Note that while the term ‘EPR pair’ is usually reserved for a maximally entangled state on two qubits (\(d=2\)), we use the term more freely for maximally entangled states of Schmidt rank d on two qudits, as defined in Sect. 2.
Port-based teleportation, introduced by Ishizaka and Hiroshima [3, 4], is a variant of quantum teleportation where Bob’s correction operation solely consists of picking one of a number of quantum subsystems upon receiving the classical message from Alice. In more detail, Alice and Bob initially share an entangled resource quantum state \(\psi _{A^N B^N}\), where \(\mathcal {H}_{A_i}\cong \mathcal {H}_{B_i}\cong \mathbb {C}^d\) for \(i=1,\ldots ,N\). We may always assume that the resource state is pure, for we can give a purification to Alice and she can choose not to use it.Footnote 2 Bob’s quantum systems \(B_i\) are called ports. Just like in ordinary teleportation, the goal is for Alice to teleport a d-dimensional quantum system \(A_0\) to Bob. To achieve this, Alice performs a joint POVM \(\{(E_i)_{A_0A^N}\}_{i=1}^N\) on the input and her part of the resource state and sends the outcome i to Bob. Based on the index i he receives, Bob selects the ith port, i.e. the system \(B_i\), as being the output register (renaming it to \(B_0\)), and discards the rest. That is, in contrast to ordinary teleportation, Bob’s decoding operation solely consists of selecting the correct port \(B_i\). The quality of the teleportation protocol is measured by how well it simulates the identity channel from Alice’s input register \(A_0\) to Bob’s output register \(B_0\).
Port-based teleportation is impossible to achieve perfectly with finite resources [3], a fact first deduced from the application to universal programmable quantum processors [41]. There are two ways to deal with this fact: either one can just accept an imperfect protocol, or one can insist on simulating a perfect identity channel, with the caveat that the protocol will fail from time to time. This leads to two variants of PBT, which are called deterministic and probabilistic PBT in the literature [3].Footnote 3
3.1 Deterministic PBT
A protocol for deterministic PBT proceeds as described above, implementing an imperfect simulation of the identity channel whose merit is quantified by the entanglement fidelity \(F_d\) or the diamond norm error \(\varepsilon _d\). We denote by \(F_d^*(N)\) and \(\varepsilon _d^*(N)\) the maximal entanglement fidelity and the minimal diamond norm error for deterministic PBT, respectively, where both the resource state and the POVM are optimized. We will often refer to this as the fully optimized case.
Let \(\psi _{{A}^N{B}^N}\) be the entangled resource state used for a PBT protocol. When using the entanglement fidelity as a figure of merit, it is shown in [4] that the problem of PBT for the fixed resource state \(\psi _{{A}^N{B}^N}\) is equivalent to the state discrimination problem given by the collection of states
with uniform prior (here we trace over all B systems but \(B_i\), which is relabeled to \(B_0\)). More precisely, the success probability q for state discrimination with some fixed POVM \(\{E_i\}_{i=1}^N\) and the entanglement fidelity \(F_d\) of the PBT protocol with Alice’s POVM equal to \(\{E_i\}_{i=1}^N\), but acting on \(A^NA_0\), are related by the equation \(q=\frac{d^2}{N}F_d\). This link with state discrimination provides us with the machinery developed for state discrimination to optimize the POVM. In particular, it suggests the use of the pretty good measurement [43, 44].
As in ordinary teleportation, it is natural to consider PBT protocols where the resource state is fixed to be N maximally entangled states (or EPR pairs) of local dimension d. This is because EPR pairs are a standard resource in quantum information theory that can easily be produced in a laboratory. We will denote by \(F_d^{\mathrm {EPR}}(N)\) the optimal entanglement fidelity for any protocol for deterministic PBT that uses maximally entangled resource states. A particular protocol is given by combining maximally entangled resource states with the pretty good measurement (PGM) POVM [43, 44]. We call this the standard protocol for deterministic PBT and denote the corresponding entanglement fidelity by \(F^{\mathrm {std}}_d(N)\). For qubits (\(d=2\)), the pretty good measurement was shown to be optimal for maximally entangled resource states [4]:
According to [22], the PGM is optimal in this situation for \(d>2\) as well.
In [3] it is shown that the entanglement fidelity \(F^{\mathrm {std}}_d\) for the standard protocol is at least
Beigi and König [6] rederived the same bound with different techniques. In [19], a converse bound is provided in the fully optimized setting:
Note that the dimension d is part of the denominator instead of the numerator as one might expect in the asymptotic setting. Thus, the bound lacks the right qualitative behavior for large values of d. A different, incomparable, bound can be obtained from a recent lower bound on the program register dimension of a universal programmable quantum processor obtained by Kubicki et al. [38],
where c is a constant. By Proposition 1.7, this bound is equivalent to
Earlier works on programmable quantum processors [45, 46] also yield (weaker) converse bounds for PBT.
Interestingly, and of direct relevance to our work, exact formulas for the entanglement fidelity have been derived both for the standard protocol and in the fully optimized case. In [21], the authors showed that
Here, the inner sum is taken over all Young diagrams \(\mu \) that can be obtained by adding one box to a Young diagram \(\alpha \vdash _d N-1\), i.e., a Young diagram with \(N-1\) boxes and at most d rows. Equation (3.5) generalizes the result of [4] for \(d=2\), whose asymptotic behavior is stated in Eq. (3.2).
In the fully optimized case, Mozrzymas et al. [22] obtained a formula similar to Eq. (3.5) in which the dimension \(d_\mu m_{d,\mu }\) of the \(\mu \)-isotypic component in the Schur–Weyl decomposition is weighted by a coefficient \(c_\mu \) that is optimized over all probability densities with respect to the Schur–Weyl distribution (defined in Sect. 4). More precisely,
where the optimization is over all nonnegative coefficients \(\{c_\mu \}\) such that \(\sum _{\mu \vdash _d N} c_\mu \frac{d_\mu m_{d,\mu }}{d^N}=1\).
3.2 Probabilistic PBT
In the task of probabilistic PBT, Alice’s POVM has an additional outcome that indicates the failure of the protocol and occurs with probability \(1-p_d\). For all other outcomes, the protocol is required to simulate the identity channel perfectly. We call \(p_d\) the probability of success of the protocol. As before, we denote by \(p_d^*(N)\) the maximal probability of success for probabilistic PBT using N ports of local dimension d, where the resource state as well as the POVM are optimized.
Based on the no-signaling principle and a version of the no-cloning theorem, Pitalúa-García [18] showed that the success probability \(p^*_{2^n}(N)\) of teleporting an n-qubit input state using a general probabilistic PBT protocol is at most
Subsequently, Mozrzymas et al. [22] showed for a general d-dimensional input state that the converse bound in (3.7) is also achievable, establishing that
This fully resolves the problem of determining the optimal probability of success for probabilistic PBT in the fully optimized setting.
As discussed above, it is natural to also consider the scenario where the resource state is fixed to be N maximally entangled states of rank d and consider the optimal POVM given that resource state. We denote by \(p^{\mathrm {EPR}}_d\) the corresponding probability of success. We use the superscript \(\mathrm {EPR}\) to keep the analogy with the case of deterministic PBT, as the measurement is optimized for the given resource state and no simplified measurement like the PGM is used. In [4], it was shown for qubits (\(d=2\)) that
For arbitrary input dimension d, Studziński et al. [21] proved the exact formula
where \(\mu ^*\) is the Young diagram obtained from \(\alpha \) by adding one box in such a way that
is maximized (as a function of \(\mu \)).
Finally, we note that any protocol for probabilistic PBT with success probability \(p_d\) can be converted into a protocol for deterministic PBT by sending over a random port index to Bob whenever Alice’s measurement outcome indicates an error. The entanglement fidelity of the resulting protocol can be bounded as \(F_d\ge p_d+\frac{1-p_d}{d^2}\). When applied to the fully optimized protocol corresponding to Eq. (3.8), this yields a protocol for deterministic PBT with better entanglement fidelity than the standard protocol for deterministic PBT. It uses, however, an optimized resource state that might be difficult to produce, while the standard protocol uses N maximally entangled states.
3.3 Symmetries
The problem of port-based teleportation has several natural symmetries that can be exploited. Intuitively, we might expect a U(d)-symmetry and a permutation symmetry, since our figures of merit are unitarily invariant and insensitive to the choice of port that Bob has to select. For the resource state, we might expect an \(S_N\)-symmetry, while the POVM elements have a marked port, leaving a possible \(S_{N-1}\)-symmetry among the non-marked ports. This section is dedicated to making these intuitions precise.
The implications of the symmetries have been known for some time in the community and used in other works on port-based teleportation (e.g. in [22]). We provide a formal treatment here for the convenience of the interested reader as well as to highlight the fact that the unitary symmetry allows us to directly relate the entanglement fidelity (which a priori quantifies an average error) to the diamond norm error (a worst case figure of merit). This relation is proved in Corollary 3.5.
While the sub-structure of the resource state on Alice’s side in terms of N subsystems is natural from a mathematical point of view, it does not correspond to an operational feature of the task of PBT. This is in contrast to the port sub-structure on Bob’s side, in terms of which the port-based condition on the teleportation protocol is defined. In the following, it will be convenient to allow resource states for PBT to have an arbitrary sub-structure on Alice’s side.
We begin with a lemma on purifications of quantum states with a given group symmetry (see [47, 48] and [49, Lemma 5.5]):
Lemma 3.1
Let \(\rho _A\) be a quantum state invariant under a unitary representation \(\varphi \) of a group G, i.e., \([\rho _A,\varphi (g)]=0\) for all \(g\in G\). Then there exists a purification \(|\rho \rangle _{AA'}\) such that \((\varphi (g)\otimes \varphi ^*(g)) |\rho \rangle _{AA'}=|\rho \rangle _{AA'}\) for all \(g\in G\). Here, \(\varphi ^*\) is the dual representation of \(\varphi \), which can be written as \(\varphi ^*(g)=\overline{\varphi (g)}\).
Starting from an arbitrary port-based teleportation protocol, it is easy to construct a modified protocol that uses a resource state such that Bob’s marginal is invariant under the natural action of \(S_N\) as well as the diagonal action of U(d). In slight abuse of notation, we denote by \(\zeta _{B^N}\) the unitary representation of \(\zeta \in S_N\) that permutes the tensor factors of \(\mathcal {H}_B^{\otimes N}\).
Lemma 3.2
Let \(\rho _{A^NB^N}\) be the resource state of a protocol for deterministic PBT with input dimension d. Then there exists another protocol for deterministic PBT with resource state \( \rho '_{{A}^N{B}^NIJ}\), where I and J are additional registers held by Alice, such that \( \rho '_{{B}^N}\) is invariant under the above-mentioned group actions,
and such that the new protocol has diamond norm error and entanglement fidelity no worse than the original one.
In fact, Lemma 3.2 applies not only to the diamond norm distance and the entanglement fidelity, but any convex functions on quantum channels that is invariant under conjugation with a unitary channel.
Proof of Lemma 3.2
Define the resource state
where \(\zeta _{B^N}\) is the action of \(S_N\) on \(\mathcal {H}_B^{\otimes N}\) that permutes the tensor factors, and I is a classical ‘flag’ register with orthonormal basis \(\lbrace |\zeta \rangle \rbrace _{\zeta \in S_N}\). The following protocol achieves the same performance as the preexisting one: Alice and Bob start sharing \(\tilde{\rho }_{A^NB^NI}\) as an entangled resource, with Bob holding \(B^N\) as usual and Alice holding registers \(A^NI\). Alice begins by reading the classical register I. Suppose that its content is a permutation \(\zeta \). She then continues to execute the original protocol, except that she applies \(\zeta \) to the index she is supposed to send to Bob after her measurement, which obviously yields the same result as the original protocol.
A similar argument can be made for the case of U(d). Let \(D\subset U(d)\), \(|D|<\infty \) be an exact unitary N-design, i.e., a subset of the full unitary group such that taking the expectation value of any polynomial P of degree at most N in both U and \(U^\dagger \) over the uniform distribution on D yields the same result as taking the expectation of P over the normalized Haar measure on U(d). Such exact N-designs exist for all N ([50]; see [51] for a bound on the size of exact N-designs). We now define a further modified resource state \(\rho '_{A^NB^NIJ}\) from \(\tilde{\rho }_{A^NB^NI}\) in analogy to (3.12):
where \(\lbrace |U\rangle \rbrace _{U\in D}\) is an orthonormal basis for the flag register J. Again, there exists a modified protocol, in which Bob holds the registers \(B^N\) as usual, but Alice holds registers \(A^NIJ\). Alice starts by reading the register J which records the unitary \(U\in D\) that has been applied to Bob’s side. She then proceeds with the rest of the protocol after applying \(U^\dagger \) to her input state. Note that \(\rho '_{B^N}\) clearly satisfies the symmetries in (3.11), and furthermore the new PBT protocol using \(\rho '_{A^NB^NIJ}\) has the same performance as the original one using \(\rho _{A^NB^N}\), concluding the proof. \(\quad \square \)
Denote by \({{\,\mathrm{Sym}\,}}^N(\mathcal {H})\) the symmetric subspace of a Hilbert space \(\mathcal {H}^{\otimes N}\), defined by
Using the above two lemmas we arrive at the following result.
Proposition 3.3
Let \(\rho _{A^NB^N}\) be the resource state of a PBT protocol with input dimension d. Then there exists another protocol with properties as in Lemma 3.2 except that it has a resource state \(|\psi \rangle \langle \psi |_{{A}^N{B}^N}\) with \(|\psi \rangle _{{A}^N{B}^N}\in {{\,\mathrm{Sym}\,}}^{N}(\mathcal {H}_A\otimes \mathcal {H}_B)\) that is a purification of a symmetric Werner state, i.e., it is invariant under the action of U(d) on \(\mathcal {H}_{A}^{\otimes N}\otimes \mathcal {H}_{B}^{\otimes N}\) given by \(U^{\otimes N}\otimes \overline{U}^{\otimes N}\).
Proof
We begin by transforming the protocol according to Lemma 3.2, resulting in a protocol with resource state \(\rho '_{A^NB^N I J}\) such that Bob’s part is invariant under the \(S_N\) and U(d) actions. By Lemma 3.1, there exists a purification \(|\psi \rangle _{{A}^N{B}^N}\in {{\,\mathrm{Sym}\,}}^n\left( \mathbb {C}^d\otimes \mathbb {C}^d\right) \) of \(\rho '_{B^N}\) that is invariant under \(U^{\otimes N}\otimes \overline{U}^{\otimes N}\) (note that the \(S_n\)-representation is self-dual, so the representation \(\phi \otimes \phi ^*\) referred to in Lemma 3.1 just permutes the pairs of systems \(A_iB_i\)). But Uhlmann’s Theorem ensures that there exists an isometry \(V_{A^N\rightarrow A^N I J E}\) for some Hilbert space \(\mathcal {H}_E\) such that \(V_{A^N\rightarrow A^N I J E}|\psi \rangle _{{A}^N{B}^N}\) is a purification of \(\rho '_{A^NB^N I J}\). The following is a protocol using the resource state \(|\psi \rangle \): Alice applies V and discards E. Then the transformed protocol from Lemma 3.2 is performed. \(\quad \square \)
Using the symmetries of the resource state, we can show that the POVM can be chosen to be symmetric as well. In the proposition below, we omit identity operators.
Proposition 3.4
Let \(\{\left( E_i\right) _{A_0A^N}\}_{i=1}^N\) be Alice’s POVM for a PBT protocol with a resource state \(|\psi \rangle \) with the symmetries from Proposition 3.3. Then there exists another POVM \(\{\left( E'_i\right) _{A_0A^N}\}_{i=1}^N\) such that the following properties hold:
-
(i)
\( \zeta _{A^N}\left( E'_i\right) _{A_0A^N}\zeta _{A^N}^\dagger =\left( E'_{\zeta (i)}\right) _{A_0A^N}\) for all \(\zeta \in S_N\);
-
(ii)
\(\left( U_{A_0}\otimes \overline{U}_{A}^{\otimes N}\right) \left( E'_i\right) _{A_0A^N} \left( U_{A_0}\otimes \overline{U}_{A}^{\otimes N}\right) ^\dagger =\left( E'_i\right) _{A_0A^N}\) for all \(U\in U(d)\);
-
(iii)
the channel \(\Lambda '\) implemented by the PBT protocol is unitarily covariant, i.e.,
$$\begin{aligned} \Lambda '_{A_0\rightarrow B_0}(X)=U_{B_0} \Lambda '_{A_0\rightarrow B_0}(U_{A_0}^\dagger X U_{A_0})U_{B_0}^\dagger \quad \text {for all } U\in U(d); \end{aligned}$$ -
(iv)
the resulting protocol has diamond norm distance (to the identity channel) and entanglement fidelity no worse than the original one.
Proof
Define an averaged POVM with elements
which clearly has the symmetries (i) and (ii). The corresponding channel can be written as
where
where we suppressed \({{\,\mathrm{id}\,}}_{B_i\rightarrow B_0}\). Here we used the cyclicity property
of the partial trace and the symmetries of the resource state, and \(\Lambda _{A_0\rightarrow B_0}\) denotes the channel corresponding to the original protocol. It follows at once that \(\Lambda '_{A_0\rightarrow B_0}\) is covariant in the sense of (iii). Finally, since the identity channel is itself covariant, property (iv) follows from the concavity (convexity) and unitary covariance of the entanglement fidelity and the diamond norm distance, respectively. \(\quad \square \)
Similarly as mentioned below Lemma 3.2, the statement in Proposition 3.4(iv) can be generalized to any convex function on the set of quantum channels that is invariant under conjugation with unitary channels.
The unitary covariance allows us to apply a lemma from [5] (stated as Lemma D.3 in “Appendix D”) to relate the optimal diamond norm error and entanglement fidelity of port-based teleportation. This shows that the achievability results Eqs. (3.5) to (3.4) for the entanglement fidelity of deterministic PBT, as well as the ones mentioned in the introduction, imply similar results for the diamond norm error without losing a dimension factor.
Corollary 3.5
Let \(F_d^*\) and \(\varepsilon _d^*\) be the optimal entanglement fidelity and optimal diamond norm error for deterministic PBT with input dimension d. Then, \(\varepsilon _d^*=2\left( 1-F_d^*\right) \).
Note that the same formula was proven for the standard protocol in [5].
3.4 Representation-theoretic characterization
The symmetries of PBT enable the use of representation-theoretic results, in particular Schur–Weyl duality. This was extensively done in [21, 22] in order to derive the formulas Eqs. (3.5)–(3.9). The main ingredient used in [21] to derive Eqs. (3.5) and (3.9) was the following technical lemma. For the reader’s convenience, we give an elementary proof in “Appendix A” using only Schur–Weyl duality and the classical Pieri rule. In the statement below, \(B_i^c\) denotes the quantum system consisting of all B-systems except the ith one.
Lemma 3.6
[21]. The eigenvalues of the operator
on \((\mathbb {C}^d)^{\otimes (1+N)}\) are given by the numbers
where \(\alpha \vdash _{d}N-1\), the Young diagram \(\mu \vdash _d N\) is obtained from \(\alpha \) by adding a single box, and \(\gamma _\mu (\alpha )\) is defined in Eq. (3.10).
Note that the formula in Lemma 3.6 above gives all eigenvalues of \(T(N)_{AB^N}\), i.e., including multiplicities.
The connection to deterministic PBT is made via the equivalence with state discrimination. In particular, when using a maximally entangled resource, T(N) is a rescaled version of the density operator corresponding to the ensemble of quantum states \(\eta _i\) from Eq. (3.1),
Using the hook length formulas Eqs. (2.1) and (2.2), we readily obtain the following simple expression for the ratio \(\gamma _\mu (\alpha )\) defined in Eq. (3.10):
Lemma 3.7
[52] Let \(\mu =\alpha +e_i\). Then,
i.e.,
Proof
Using Eqs. (2.1) and (2.2), we find
which concludes the proof. \(\quad \square \)
Remark 3.8
It is clear that \(\gamma _\mu (\alpha )\) is maximized for \(\alpha =(N-1,0,\ldots ,0)\) and \(i=1\). Therefore,
This result can be readily used to characterize the extendibility of isotropic states, providing an alternative proof of the result by Johnson and Viola [53].
4 The Schur–Weyl Distribution
Our results rely on the asymptotics of the Schur–Weyl distribution, a probability distribution defined below in (4.1) in terms of the representation-theoretic quantities that appear in the Schur–Weyl duality (2.4). These asymptotics can be related to the random matrix ensemble \({\text {GUE}}^0_d\). In this section we explain this connection and provide a refinement of a convergence result (stated in (4.4)) by Johansson [36] that is tailored to our applications. While representation-theoretic techniques have been extensively used in previous analyses, the connection between the Schur–Weyl distribution and random matrix theory has, to the best of our knowledge, not been previously recognized in the context of PBT (see however [31] for applications in the the context of quantum state tomography).
Recalling the Schur–Weyl duality \({\left( \mathbb {C}^d\right) }^{\otimes n} \cong \bigoplus _{\alpha \vdash _d n} [\alpha ] \otimes V^d_\alpha \), we denote by \(P_\alpha \) the orthogonal projector onto the summand labeled by the Young diagram \(\alpha \vdash _d n\). The collection of these projectors defines a projective measurement, and hence
with \(\tau _d=\frac{1}{d}1_{\mathbb {C}^d}\) defines a probability distribution on Young diagrams \(\alpha \vdash _d n\), known as the Schur–Weyl distribution. Now suppose that \(\varvec{\alpha }^{(n)} \sim p_{d,n}\) for \(n\in \mathbb {N}\). By spectrum estimation [25,26,27, 54, 55], it is known that
This can be understood as a law of large numbers. Johansson [36] proved a corresponding central limit theorem: Let \(\mathbf {A}^{(n)}\) be the centered and renormalized random variable defined by
Then Johansson [36] proved that
for \(n\rightarrow \infty \), where \(\mathbf {G} \sim {\text {GUE}}^0_d\). The result for the first row is by Tracy and Widom [56] (cf. [36, 57]; see [31] for further discussion).
In the following sections, we would like to use this convergence of random variables stated in Eqs. (4.2) and (4.4) to determine the asymptotics of Eqs. (3.9) and (3.5). To this end, we rewrite the latter as expectation values of some functions of Young diagrams drawn according to the Schur–Weyl distribution. However, in order to conclude that these expectation values converge to the corresponding expectation values of functions on the spectrum of \({\text {GUE}}^0_d\)-matrices, we need a stronger sense of convergence than what is provided by the former results. Indeed, we need to establish convergence for functions that diverge polynomially as \(n\rightarrow \infty \) when \(A_{j}=\omega (1)\) or when \(A_{j}=O(n^{-1/2})\).Footnote 4 The former are easily handled using the bounds from spectrum estimation [27], but for the latter a refined bound on \(p_{d,n}\) corresponding to small A is needed. To this end, we prove the following result, which shows convergence of expectation values of a large class of functions that includes all polynomials in the variables \(\mathbf {A}_i\).
In the following, we will need the cone of sum-free non-increasing vectors in \(\mathbb {R}^d\),
and its interior \(\mathrm {int}(C^d)=\lbrace x\in C^d:x_i \ne 0 \text { for }i=1,\ldots ,d\rbrace \).
Theorem 4.1
Let \(g:\mathrm {int}(C^d)\rightarrow \mathbb {R}\) be a continuous function satisfying the following: There exist constants \(\eta _{ij}\) satisfying \(\eta _{ij}> -2-\frac{1}{d-1}\) such that for
there exists a polynomial q with
For every n, let \(\mathbf \alpha ^{(n)} \sim p_{d,n}\) be drawn from the Schur–Weyl distribution, \(\mathbf{A}^{(n)} \,{:}{=}\, \sqrt{d/n}(\mathbf \alpha ^{(n)}-n/d)\) the corresponding centered and renormalized random variable, and \(\tilde{\mathbf{A}}^{(n)}=\mathbf{A}^{(n)}+\frac{d-i}{\sqrt{\frac{n}{d}}}\). Then the family of random variables \(\left\{ g\left( \tilde{\mathbf{A}}^{(n)}\right) \right\} _{n\in \mathbb {N}}\) is uniformly integrable and
where \(\mathbf{A}=\mathrm {spec}(\mathbf {G})\) and \(\mathbf {G} \sim {\text {GUE}}^0_d\).
As a special case we recover the uniform integrability of the moments of \(\mathbf {A}\) (Corollary 4.5), which implies convergence in distribution in the case of an absolutely continuous limiting distribution. Therefore, Theorem 4.1 is a refinement of the result (4.4) by Johansson. The remainder of this section is dedicated to proving Theorem 4.1.
The starting point for what follows is Stirling’s approximation, which states that
It will be convenient to instead use the following variant,
where the upper bound is unchanged and the lower bound follows using \(n!=\frac{(n+1)!}{n+1}\). The dimension \(d_\alpha \) is equal to the multinomial coefficient up to inverse polynomial factors [27]. Defining the normalized Young diagram \(\bar{\alpha }=\frac{\alpha }{n}\) for \(\alpha \vdash n\), the multinomial coefficient \(\left( {\begin{array}{c}n\\ \alpha \end{array}}\right) \) can be bounded from above using Eq. (4.5) as
where \(C_d \,{:}{=}\, \frac{e^{d+1}}{(2\pi )^{d/2}}\). Hence,
Here, \(D(p\Vert q)\,{:}{=}\,\sum _i p_i \log {p_i}/\!{q_i}\) is the Kullback-Leibler divergence defined in terms of the natural logarithm, \(\tau =(1/d,\ldots ,1/d)\) is the uniform distribution, and we used Pinsker’s inequality [58] in the second step.
We go on to derive an upper bound on the probability of Young diagrams that are close to the boundary of the set of Young diagrams under the Schur–Weyl distribution. More precisely, the following lemma can be used to bound the probability of Young diagrams that have two rows that differ by less than the generic \(O(\sqrt{n})\) in length.
Lemma 4.2
Let \(d\in \mathbb {N}\) and \(c_1,\ldots ,c_{d-1}\ge 0\), \(\gamma _1,\ldots ,\gamma _{d-1}\ge 0\). Let \(\alpha \vdash _dn\) be a Young diagram with (a) \(\alpha _i-\alpha _{i+1}\le c_i n^{\gamma _i}\) for all i. Finally, set \(A \,{:}{=}\, \sqrt{d/n}(\alpha -n/d)\). Then,
where \(\gamma _{ij}\,{:}{=}\,\max \{\gamma _i,\gamma _{i+1},\ldots ,\gamma _{j-1}\}\) and \(C=C(c_1,\ldots ,c_{d-1},d)\) is a suitable constant.
Proof
We need to bound \(p_{d,n}(\alpha )=m_{d,\alpha } d_\alpha / d^n\) and begin with \(m_{d,\alpha }\). By assumption (a), there exist constants \(C_{ij}>0\) (depending on \(c_i,\ldots ,c_{j-1}\) as well as on d) such that the inequality \(\alpha _i-\alpha _j+j-i\le C_{ij}n^{\gamma _{ij}}\) holds for all \(i<j\). Using the Weyl dimension formula (2.3) and assumption (a), it follows that
for a suitable constant \(C_1=C_1(c_1,\ldots ,c_{d-1},d)>0\). Next, consider \(d_\alpha \). By comparing the hook-length formulas (2.1) and (2.2), we have
where \(C_2=C_2(d)>0\), and \(\bar{\alpha }_i = \alpha _i/n\). In the inequality, we used that \(\alpha _i + d - i \ge \alpha _i + 1\) for \(1\le i\le d-1\), and for \(i=d\), the exponent of \(\alpha _i + 1\) on the right hand side is zero.
Combining Eqs. (4.7)–(4.6) and setting \(C_3=C_1^2 C_2C_d\), we obtain
Substituting \(\bar{\alpha }_i = \frac{1}{d} + \frac{A_i}{\sqrt{nd}}\) we obtain the desired bound. \(\quad \square \)
In order to derive the asymptotics of entanglement fidelities for port-based teleportation, we need to compute limits of certain expectation values. As a first step, the following lemma ensures that the corresponding sequences of random variables are uniformly integrable. We recall that a family of random variables \(\{\mathbf{X}^{(n)}\}_{n\in \mathbb {N}}\) is called uniformly integrable if, for every \(\varepsilon >0\), there exists \(K<\infty \) such that \(\sup _n \mathbb {E}\left[ |\mathbf{X}^{(n)}|\cdot \mathbb {1}_{|\mathbf{X}^{(n)}|\ge K}\right] \le \varepsilon \).
Lemma 4.3
Under the same conditions as for Theorem 4.1, the family of random variables \(\left\{ g\left( \tilde{\mathbf{A}}^{(n)}\right) \right\} _{n\in \mathbb {N}}\) is uniformly integrable.
Proof
Let \(\mathbf{X}^{(n)} \,{:}{=}\, g\left( \tilde{\mathbf{A}}^{(n)}\right) \). The claimed uniform integrability follows if we can show that
for every choice of the \(\eta _{ij}\). Indeed, to show that \(\{ \mathbf{X}^{(n)} \}\) is uniformly integrable it suffices to show that \(\sup _n \mathbb {E}\left[ |\mathbf{X}^{(n)} |^{1+\delta }\right] <\infty \) for some \(\delta >0\) [59, Ex. 5.5.1]. If we choose \(\delta >0\) such that \(\eta '_{ij} \,{:}{=}\, (1+\delta )\eta _{ij} > -2-\frac{1}{d-1}\) for all \(1\le i < j \le d\), then it is clear that Eq. (4.9) for \(\eta '_{ij}\) implies uniform integrability of the original family.
Moreover, we may also assume that \(h_{\eta }\equiv g/\varphi _{\eta }=1\), since the general case then follows from the fact that \(p_{d,n}(\alpha )\) decays exponentially in \(\Vert A\Vert _1\) (see Lemma 4.2). More precisely, for any polynomial r and any constant \(\theta _1>0\) there exist constants \(\theta _2, \theta _3>0\) such that
In particular, this holds for the polynomial q bounding h from above by assumption. When proving the statement \(\sup _n \mathbb {E}\left[ |\mathbf{X}^{(n)} |\right] <\infty \), the argument above allows us to reduce the general case \(h_{\eta } = g/\varphi _{\eta }\ne 1\) to the case \(h_{\eta }=1\), or equivalently, to
Thus, it remains to be shown that
where
for some constants \(\eta _{ij}\) satisfying the assumption of Theorem 4.1 that we fix for the rest of this proof. Define \(\Gamma _{ij}\,{:}{=}\, A_i-A_j+\frac{j-i}{\sqrt{n/d}}\). Then we have \(f^{(n)}(A) = \prod _{i<j} \Gamma _{ij}^{\eta _{ij}}\), while the Weyl dimension formula (2.3) becomes
Hence, together with Eqs. (4.8) and (4.6) we can bound \(p_{d,n}(\alpha ) = m_{d,\alpha } d_{\alpha } / d^n\) as
where \(C=C(d)\) is some constant, and we used \(\bar{\alpha }_i + \frac{1}{n} = \frac{1}{d}\Big (\sqrt{\frac{d}{n}} A_i + \frac{d}{n} + 1 \Big )\) and \(\tau =(1/d,\ldots ,1/d)\) in the equality. Using \(f^{(n)}(A) = \prod _{i<j} \Gamma _{ij}^{\eta _{ij}}\), this yields the bound
We now want to bound the expectation value in Eq. (4.10) and begin by splitting the sum over Young diagrams according to whether \(\exists i: |A_i|>n^\varepsilon \) for some \(\varepsilon \in (0,\frac{1}{2})\) to be determined later, or \(|A_i|\le n^\varepsilon \) for all i. We denote the former event by \(\mathcal {E}\) and obtain
We treat the two expectation values in (4.13) separately and begin with the first one. If \(|A_i|>n^\varepsilon \) for some i, then \(\Vert A\Vert _1^2 \ge n^{2\varepsilon }\), so it follows by Eq. (4.12) that
Here, \({{\,\mathrm{poly}\,}}(n)\) denotes some polynomial in n and we also used that, for fixed d, the number of Young diagrams is polynomial in n. This shows that the first expectation value in (4.13) vanishes for \(n\rightarrow \infty \).
For the second expectation value, note that \(|A_i|\le n^{\varepsilon }=o(\sqrt{n})\) for all i, and hence there exists a constant \(K>0\) such that we have
Using Eqs. (4.12) and (4.14), we can therefore bound
where we have introduced \(\mathcal {D}_n \,{:}{=}\, \{ A:\alpha \vdash _d n \}\). The summands are nonnegative, even when evaluated on any point in the larger set \(\hat{\mathcal {D}}_n \,{:}{=}\, \left\{ A \in \sqrt{\frac{d}{n}}\left( \mathbb {Z}-\frac{n}{d}\right) ^d : \sum _i A_i = 0, A_i \ge A_{i+1} \forall i \right\} \supset \mathcal {D}_n\), so that we have the upper bound
Let \(x_i=A_i-A_{i+1}, \ i=1,\ldots ,d-1\). Next, we will upper bound the exponential in Eq. (4.15). For this, define \(\tilde{x}_i=\max (\frac{1}{d-1},x_i)\) and let \(S=\{ i\in \{1,\ldots ,d-1\} \;|\; x_i\le \frac{1}{d-1} \}\). Then, assuming \(S^c\ne \emptyset \),
since \(\sum _{i\in S^c} x_i \ge \frac{|S^c|}{d-1}\). This bounds also holds when \(S^c=\emptyset \). Hence,
where \(\gamma \,{:}{=}\, \frac{1}{2d(2d-1)}\) and \(R \,{:}{=}\, e^{\gamma }\). The first inequality follows from \(\sum _{i=1}^{d-1}x_i=A_1-A_d=|A_1|+|A_d| \le \Vert A\Vert _1\). If we use Eq. (4.16) in Eq. (4.15) we obtain the upper bound
where \(C' \,{:}{=}\, CKR\).
Let us first assume that all \(\eta _{ij} \le -2\), so that \(2+\eta _{ij}\in (-\frac{1}{d-1},0]\). Since
and \(\eta _{ij}+2\le 0\), we have that
as power functions with non-positive exponent are non-increasing. We can then upper-bound Eq. (4.17) as follows,
where the first inequality is Eq. (4.17) and in the second inequality we used Eq. (4.18). Since \(\eta _{ij} > -2-\frac{1}{d-1}\) by assumption, it follows that \(\sum _{j=i+1}^d (2+\eta _{ij}) > -\frac{d-i}{d-1} \ge -1\). Thus, each term in the product is a Riemann sum for an improper Riemann integral, as in Lemma D.4, which then shows that the expression converges for \(n\rightarrow \infty \).
The case where some \(\eta _{ij}>-2\) is treated by observing that
for suitable constants \(c_1,c_2>0\). We can use this bound in Eq. (4.17) to replace each \(\eta _{ij}>-2\) by \(\eta _{ij}=-2\), at the expense of modifying the constants \(C'\) and \(\gamma \), and then proceed as we did before. This concludes the proof of Eq. (4.10). \(\quad \square \)
The uniform integrability result of Lemma 4.3 implies that the corresponding expectation values converge. To determine their limit in terms of the expectation value of a function of the spectrum of a \({\text {GUE}}^0_d\)-matrix, however, we need to show that we can take the limit of the dependencies on n of the function and the random variable \(\mathbf {A}^{(n)}\) separately. This is proved in the following lemma, where we denote the interior of a set E by int(E).
Lemma 4.4
Let \(\lbrace \mathbf {A}^{(n)}\rbrace _{n\in \mathbb {N}}\) and \(\mathbf {A}\) be random variables on a Borel measure space E such that \(\mathbf {A}^{(n)}\overset{D}{\rightarrow }\mathbf {A}\) for \(n\rightarrow \infty \) and \(\mathbf {A}\) is absolutely continuous. Let \(f:\mathrm {int}(E)\rightarrow \mathbb {R}\). Let further \(f_n: E\rightarrow \mathbb {R}\), \(n\in \mathbb {N}\), be a sequence of continuous bounded functions such that \(f_n\rightarrow f\) pointwise on \(\mathrm {int}(E)\) and, for any compact \(S\subset \mathrm {int}(E)\), \(\{f_n|_S\}_{n\in \mathbb {N}}\) is uniformly equicontinuous and \(f_n|_S\rightarrow f|_S\) uniformly. Then for any such compact \(S\subset \mathrm {int}(E)\), the expectation value \(\mathbb {E}\left[ f(\mathbf {A})\mathbb {1}_S(\mathbf {A})\right] \) exists and
Proof
For \(n,m\in \mathbb {N}\cup \{\infty \}\), define
with \(f_\infty \,{:}{=}\, f\), \(\mathbf {A}^{(\infty )}\,{:}{=}\, \mathbf {A}\) and \(S\subset \mathrm {int}(E)\) compact. These expectation values readily exist as \(f_n\) is bounded for all n, and the uniform convergence of \(f_n|_S \) implies that \(f|_S\) is continuous and bounded as well. The uniform convergence \(f_n|_S\rightarrow f|_S\) implies that \(f_n|_S\) is uniformly bounded, so by Lebesgue’s theorem of dominated convergence \(b_{\infty m}(S)\) exists for all \(m\in \mathbb {N}\) and
This convergence is even uniform in m which follows directly from the uniform convergence of \(f_n|_S\). The sequence \(\lbrace \mathbf {A}^{(n)}\rbrace _{n\in \mathbb {N}}\) of random variables converges in distribution to the absolutely continuous \(\mathbf {A}\), so the expectation value of any continuous bounded function converges. Therefore,
An inspection of the proof of Theorem 1, Chapter VIII in [60] reveals the following: The fact that the uniform continuity and boundedness of \(f_n|_S\) hold uniformly in n implies the uniformity of the above limit. Moreover, since both limits exist and are uniform, this implies that they are equal to each other, and any limit of the form
for \(m(n)\xrightarrow {n\rightarrow \infty }\infty \) exists and is equal to the limits in Eqs. (4.19) and (4.20). \(\quad \square \)
Finally, we obtain the desired convergence theorem. For our applications, \(\eta _{ij}\equiv -2\) suffices. The range of \(\eta _{ij}\)’s for which the lemma is proven is naturally given by the proof technique.
Proof of Theorem 4.1
The uniform integrability of \(\mathbf {X}^{(n)}\,{:}{=}\, g\left( \tilde{\mathbf {A}}^{(n)}\right) \) is the content of Lemma 4.3. Recall that uniform integrability means that
where \(\mathcal {E}_K\,{:}{=}\, \lbrace x\in \mathbb {R}^d:\Vert x\Vert _\infty \le K\rbrace \). Let now \(\varepsilon >0\) be arbitrary, and \(K<\infty \) be such that the following conditions are true:
where \(\mathbf {A}\) is distributed as the spectrum of a \({\text {GUE}}^0_d\) matrix. For the bound on the second expectation value, recall that the density of the eigenvalues \((\mu ,\ldots ,\mu _d)\) of a \({\text {GUE}}^0_d\) matrix is proportional to \(\exp (-\sum _{i=1}^d \mu _i^2) \prod _{i<j}(\mu _i-\mu _j)^2\), and hence decays exponentially in \(\Vert \mu \Vert _\infty \). By Lemma 4.4, \(\lim _{n\rightarrow \infty }\mathbb {E}\left[ \mathbf {X}^{(n)}\mathbb {1}_{\mathcal {E}_K}\left( \mathbf {A}^{(n)}\right) \right] = \mathbb {E}\left[ g(\mathbf{A})\mathbb {1}_{\mathcal {E}_K}\left( \mathbf {A}\right) \right] \). Thus, we can choose \(n_0\in \mathbb {N}\) such that for all \(n\ge n_0\),
Using the above choices, we then have
for all \(n\ge n_0\), proving the desired convergence of the expectation values. \(\square \)
From Theorem 4.1 we immediately obtain the following corollary about uniform integrability of the moments of \(\mathbf {A}\).
Corollary 4.5
Let \(k\in \mathbb {N}\), let \(j\in \{1,\ldots ,d\}\), and, for every n, let \(\mathbf{A}^{(n)}\) be the random vector defined in (4.3). Then, the sequence of kth moments \(\big \lbrace ( \mathbf{A}^{(n)}_j)^k \big \rbrace _{n\in \mathbb {N}}\) is uniformly integrable and \(\lim _{n\rightarrow \infty } \mathbb {E}\bigl [(\mathbf{A}^{(n)}_j)^k\bigr ] = \mathbb {E}[\mathbf{A}_j^k]\), where \(\mathbf{A} \sim {\text {GUE}}^0_d\).
5 Probabilistic PBT
Our goal in this section is to determine the asymptotics of \(p^{\mathrm {EPR}}_d\) using the formula (3.9) and exploiting our convergence theorem, Theorem 4.1. The main result is the following theorem stated in Sect. 1.2, which we restate here for convenience.
Theorem 1.3
(Restated). For probabilistic port-based teleportation in arbitrary but fixed dimension d with EPR pairs as resource states,
where \(\mathbf {G}\sim {\text {GUE}}^0_d\).
Previously, such a result was only known for \(d=2\) following from an exact formula for \(p^{\mathrm {EPR}}_2(N)\) derived in [4]. We show in Lemma C.1 in “Appendix C” that, for \(d=2\), \(\mathbb E[\lambda _{\max }(\mathbf {G})] = \frac{2}{\sqrt{\pi }}\), hence rederiving the asymptotics from [4].
While Theorem 1.3 characterizes the limiting behavior of \(p^{\mathrm {EPR}}\) for large N, it contains the constant \(\mathbb {E}[\lambda _{\max }(\mathbf {G})]\), which depends on d. As \(\mathbb {E}[\mathbf {M}]=0\) for \(\mathbf {M}\sim {\text {GUE}}_d\), it suffices to analyze the expected largest eigenvalue for \({\text {GUE}}_d\). The famous Wigner semicircle law [24] implies immediately that
but meanwhile the distribution of the maximal eigenvalue has been characterized in a much more fine-grained manner. In particular, according to [61], there exist constants C and \(C'\) such that the expectation value of the maximal eigenvalue satisfies the inequalities
This also manifestly reconciles Theorem 1.3 with the fact that teleportation needs at least \(2 \log d\) bits of classical communication (see Sect. 7), since the amount of classical communication in a port-based teleportation protocol consists of \(\log N\) bits.
Proof of Theorem 1.3
We start with Eq. (3.9), which was derived in [21], and which we restate here for convenience:
where \(\mu ^*\) is the Young diagram obtained from \(\alpha \vdash N-1\) by adding one box such that \(\gamma _\mu (\alpha ) = N\frac{m_{d,\mu } d_\alpha }{m_{d,\alpha },d_\mu }\) is maximal. By Lemma 3.7, we have \(\gamma _\mu (\alpha ) = \alpha _i - i + d + 1\) for \(\mu =\alpha +e_i\). This is maximal if we choose \(i=1\), resulting in \(\gamma _{\mu ^*}(\alpha ) = \alpha _1+d\). We therefore obtain:
Recall that
is a random vector corresponding to Young diagrams with \(N-1\) boxes and at most d rows, where \(p_{d,N-1}\) is the Schur–Weyl distribution defined in (4.1). We continue by abbreviating \(n=N-1\) and changing to the centered and renormalized random variable \(\mathbf {A}^{(n)}\) from Eq. (4.3). Corollary 4.5 implies that
Using the \(\mathbf {A}^{(n)}\) variables from (4.3), linearity of the expectation value and suitable rearranging, one finds that
where we set
Note that, for \(x\ge 0\),
for some constants \(K_i\), where the first inequality follows from the fact that the denominator in the first line is greater than 1 for \(x\ge 0\). Since both \(\mathbf {A}^{(n)}_1\ge 0\) and \(\lambda _{\max }(\mathbf {G})\ge 0\), and using (5.1), it follows that
Thus we have shown that, for fixed d and large N,
which is what we set out to prove. \(\square \)
Remark 5.1
For the probabilistic protocol with optimized resource state, recall from Eq. (3.8) that
For fixed d, this converges to unity as O(1/N), i.e., much faster than the \(O(1/\sqrt{N})\) convergence in the EPR case proved in Theorem 1.3 above.
6 Deterministic PBT
The following section is divided into two parts. First, in Sect. 6.1 we derive the leading order of the standard protocol for deterministic port-based teleportation (see Sect. 3, where this terminology is explained). Second, in Sect. 6.2 we derive a lower bound on the leading order of the optimal deterministic protocol. As in the case of probabilistic PBT, the optimal deterministic protocol converges quadratically faster than the standard deterministic protocol, this time displaying an \(N^{-2}\) versus \(N^{-1}\) behavior (as opposed to \(N^{-1}\) versus \(N^{-1/2}\) in the probabilistic case).
6.1 Asymptotics of the standard protocol
Our goal in this section is to determine the leading order in the asymptotics of \(F^{\mathrm {std}}_d\). We do so by deriving an expression for the quantity \(\lim _{N\rightarrow \infty }N(1 - F^{\mathrm {std}}_d(N))\), that is, we determine the coefficient \(c_1=c_1(d)\) in the expansion
We need the following lemma that states that we can restrict a sequence of expectation values in the Schur–Weyl distribution to a suitably chosen neighborhood of the expectation value and remove degenerate Young diagrams without changing the limit. Let
be the Heaviside step function. Recall the definition of the centered and normalized variables
such that \(\alpha _i = \sqrt{\frac{n}{d}} A_i + \frac{n}{d}\). In the following it will be advantageous to use both variables, so we use the notation \(A(\alpha )\) and \(\alpha (A)\) to move back and forth between them.
Lemma 6.1
Let \(C>0\) be a constant and \(0<\varepsilon <\frac{1}{2}(d-2)^{-1}\) (for \(d=2\), \(\varepsilon >0\) can be chosen arbitrary). Let \(f_N\) be a function on the set of centered and rescaled Young diagrams (see Eq. (4.3)) that that grows at most polynomially in N, and for N large enough and all arguments A such that \(\Vert A\Vert _1\le n^\varepsilon \) fulfills the bound
Then the limit of its expectation values does not change when removing degenerate and large deviation diagrams,
where \(\mathbb {1}_{\mathrm {ND}}\) is the indicator function that is 0 if two or more entries of its argument are equal, and 1 else. Moreover we have the stronger statement
Proof
The number of all Young diagrams is bounded from above by a polynomial in N. But \(p_{d, n}(\alpha (A))=O(\exp (-\gamma \Vert A\Vert _1^2))\) for some \(\gamma >0\) according to Lemma 4.2, which implies that
Let us now look at the case of degenerate diagrams. Define the set of degenerate diagrams that are also in the support of the above expectation value,
Here, \(\mathbf {1}=(1,\ldots ,1)^T\in \mathbb {R}^d\) is the all-one vector. We write
with
It suffices to show that
for all \(k=1,\ldots ,d-1\). We can now apply Lemma 4.2 to \(\Xi _k\) and choose the constants \(\gamma _k=0\) and \(\gamma _i=\frac{1}{2}+\varepsilon \) for \(i\ne k\). Using (4.11), the 1-norm condition on A and bounding the exponential function by a constant we therefore get the bound
for some constant \(C_1>0\). The cardinality of \(\Xi _k\) is not greater than the number of integer vectors whose entries are between \(n/d-n^{1/2+\varepsilon }\) and \(n/d+n^{1/2+\varepsilon }\) and sum to n, and for which the kth and \((k+1)\)st entries are equal. It therefore holds that
By assumption,
Finally, we conclude that
This implies that we have indeed that
In fact, we obtain the stronger statement
The statement follows now using Eq. (6.1). \(\quad \square \)
With Lemma 6.1 in hand, we can now prove the main result of this section, which we stated in Sect. 1.2 and restate here for convenience.
Theorem 1.2
(Restated). For arbitrary but fixed d and any \(\delta >0\), the entanglement fidelity of the standard protocol of PBT is given by
Proof
We first define \(n=N-1\) and recall (3.5), which we can rewrite as follows:
In the third step, we used Lemma 3.7 for the term \(\frac{d_\mu m_{d,\alpha }}{m_{d,\mu } d_\alpha }\) and the Weyl dimension formula (2.3) for the term \(\frac{m_{d,\mu }}{m_{d,\alpha }}\). The expectation value refers to a random choice of \(\alpha \vdash _{d}n\) according to the Schur–Weyl distribution \(p_{d,n}\). The sum over \(\mu =\alpha +e_i\) is restricted to only those \(\mu \) that are valid Young diagrams, i.e., where \(\alpha _{i-1}>\alpha _i\), which we indicate by writing ‘YD’. Hence, we have
In the following, we suppress the superscript indicating \(n=N-1\) for the sake of readability. The random variables \(\varvec{\alpha }\), \(\mathbf {A}\), and \(\varvec{\Gamma }_{ij}\), as well as their particular values \(\alpha \), A, and \(\Gamma _{ij}\), are all understood to be functions of \(n=N-1\).
The function
satisfies the requirements of Lemma 6.1. Indeed we have that
for all \(i\ne j\), and clearly
Therefore we get
for some constant C. If \(\Vert A\Vert _1\le n^\varepsilon \), we have that
and hence
for N large enough. We therefore define, using an \(\varepsilon \) in the range given by Lemma 6.1, the modified expectation value
and note that an application of Lemma 6.1 shows that the limit that we are striving to calculate does not change when replacing the expectation value with the above modified expectation value, and the difference between the members of the two sequences is \(O(n^{-\frac{1}{2}+\varepsilon (d-2)})\).
For a non-degenerate \(\alpha \), adding a box to any row yields a valid Young diagram \(\mu \). Hence, the sum \(\sum _{\mu =\alpha +e_i\text { YD}}\) in (6.2) can be replaced by \(\sum _{i=1}^d\), at the same time replacing \(\mu _i\) with \(\alpha _i+1\). The expression in (6.2) therefore simplifies to
Let us look at the square root term, using the variables \(\mathbf {A}_i\). For sufficiently large n, we write
In the second line we have defined
and in the third line we have written the inverse square root in terms of its power series around 1. This is possible as we have \(\Vert \mathbf {A}\Vert _1\le n^\varepsilon \) on the domain of \(\tilde{\mathbb {E}}\), so \(\gamma _{i,d,n}\sqrt{\frac{d}{n}}\mathbf {A}_i=O(n^{-1/2+\varepsilon })\), i.e., it is in particular in the convergence radius of the power series, which is equal to 1. This implies also that the series converges absolutely in that range. Defining
as in Sect. 4, we can write
Here we have defined \(\tilde{ \mathbf {A}}\) by \(\tilde{ \mathbf {A}}_i=\gamma _{i,d,n}\mathbf {A}_i\) and the polynomials \(P_{i,j}^{(1,s)}\), \(P_{i,j}^{(2,r)}\), for \(s=0,\ldots ,2(d-1)\), \(r\in \mathbb {N}\), \(i,j=1,\ldots ,d\), which are homogeneous of degree r, and s, respectively. In the last equality we have used the absolute convergence of the power series. We have also abbreviated \(\varvec{\Gamma }\,{:}{=}\,(\varvec{\Gamma }_{ij})_{i<j}\), \(\varvec{\Gamma }^{-1}\) is to be understood elementwise, and \(P_{i,j}^{(1,s)}\) has the additional property that for all \(k,l\in \{1,\ldots ,d\}\) it has degree at most 2 in each variable \(\varvec{\Gamma }_{k,l}\).
By the Fubini-Tonelli Theorem, we can now exchange the infinite sum and the expectation value if the expectation value
exists, where the polynomials \(\tilde{P}^{(1,s)}_{i,j}\) and \(\tilde{P}^{(2,r)}_{i,j}\) are obtained from \(P^{(1,s)}_{i,j}\) and \(P^{(2,r)}_{i,j}\), respectively, by replacing the coefficients with their absolute value, and the absolute values \(|\varvec{\Gamma }^{-1}|\) and \(|\tilde{\mathbf {A}}|\) are to be understood element-wise. But the power series of the square root we have used converges absolutely on the range of \(\mathbf {A}\) restricted by \(\tilde{\mathbb {E}}\) (see Eq. (6.3)), yielding a continuous function on an appropriately chosen compact interval. Moreover, if A is in the range of \(\mathbf {A}\) restricted by \(\tilde{\mathbb {E}}\), then so is |A|. The function is therefore bounded, as is \(\tilde{ \mathbf {A}}\) for fixed N, and the expectation value above exists. We therefore get
Now note that the expectation values above have the right form to apply Theorem 4.1, so we can start calculating expectation values provided that we can exchange the limit \(N\rightarrow \infty \) with the infinite sum. We can then split up the quantity \(\lim _{N\rightarrow \infty }R_N\) as follows,
provided that all the limits on the right hand side exist. We continue by determining these limits and begin with Eq. (6.6). First observe that, for fixed r and s such that \(r+s\ge 3\),
This is because the expectation value in Eq. (6.7) converges according to Theorem 4.1 and Lemma 6.1, which in turn implies that the whole expression is \(O(N^{-1/2})\). In particular, there exists a constant \(K>0\) such that, for the finitely many values of r and s such that \(r\le r_0\,{:}{=}\, \lceil (\frac{1}{2}-\varepsilon )^{-1}\rceil \),
Now suppose that \(r>r_0\). On the domain of \(\tilde{\mathbb {E}}\), we have \(\Vert \mathbf {A}\Vert _1\le n^\varepsilon \). Therefore, we can bound
The first step holds because \(\left( \frac{d}{n}\right) ^{\frac{s}{2}} P_{i,j}^{(1,s)}\left( \varvec{\Gamma }^{-1}\right) \) is a polynomial in the variables \(\left( \frac{d}{n}\right) ^{\frac{1}{2}} \varvec{\Gamma }^{-1}_{ij}\le 1 \) with coefficients independent of n, and in the second step we used that \(1+r(\varepsilon -1/2) < 0\). We can therefore apply the dominated convergence theorem using the dominating function
to exchange the limit and the sum in Eq. (6.6). Thus, Eq. (6.7) implies that Eq. (6.6) is zero.
It remains to compute the limits Eqs. (6.4) and (6.5), i.e., the terms
for \(r+s=0,1,2\). The first few terms of the power series for the inverse square root are given by
The relevant polynomials to calculate the remaining limits are, using the above and \(-\varvec{\Gamma }_{ik}=\varvec{\Gamma }_{ki}\),
We now analyze the remaining expectation values using these explicit expressions for the corresponding polynomials.
6.2 Evaluating \(T_{0,0}\)
Using the power series expansions
we simplify
In the second-to-last line we have replaced \(N=n+1\).
6.3 Evaluating \(T_{0,1}\) and \(T_{1,0}\)
We first compute
In the last equation we have used that
as the summation domain is symmetric in i and k, and \( \mathbf \Gamma _{ik}^{-1}=- \mathbf \Gamma _{ki}^{-1}\). But now we can determine the limit,
Here we have used Theorem 4.1 to see that the sequence of expectation values converges, implying that the expression vanishes due to the \(O(n^{-1/2})\) prefactor.
Similarly, to show that \(T_{0,1}\) vanishes as well, we calculate
Here we have used that \(\sqrt{\gamma _{i,d,n}}=1-O(n^{-1})=\gamma _{i,d,n}\), and in the last line we used that \(\sum _{i=1}^d{\mathbf {A}}_i=0\). This implies, using the same argument as in Eq. (6.10), that
6.4 Evaluating \(T_{s,r}\) for \(s+r=2\)
For \(s+r=2\), we first observe that
Therefore we can replace all occurrences of \(\gamma _{i,d,n}\) by 1 using the same argument as in Eq. (6.10). There are three cases to take care of, \((s,r)=\lbrace (2,0),(1,1),(0,2)\rbrace \). For \((s,r)=(2,0)\), we first look at the term
where we have defined \(\pmb {\mathscr {A}}_i=\mathbf {A}_i-i\sqrt{\frac{d}{n}}\). For fixed \(i_0\ne k_0\ne j_0\ne i_0\), all permutations of these indices appear in the sum. For these terms with \(i,j,k\in \{i_0,j_0,k_0\}\),
implying
and therefore
Moving on to the case \((s,r)=(0,2)\), we first note that, as in the previous case \((s,r)=(2,0)\) and again replacing all occurrences of \(\gamma _{i,d,n}\) by 1, we have
Here, \(\mathbf {S}=\mathrm {spec}(\mathbf {G})\sim {\text {GUE}}^0_d\) and we have used Lemma 6.1 to switch back to the unrestricted expectation value and Theorem 4.1 in the second equality. First we observe that \(\mathbf {G}\) is traceless, and hence \(\sum _{i=1}^d{\mathbf {S}}_i=0\) such that the second term in (6.13) vanishes. For the first term in (6.13), let \(\mathbf {X}\sim {\text {GUE}}_d\) such that \(\mathbf {G} = \mathbf {X} - \frac{{{\,\mathrm{tr}\,}}(\mathbf {X})}{d} I\sim {\text {GUE}}^0_d\). We calculate
We have \(\mathbb {E}[\mathbf {X}_{ii}^2] = \mathbb {V}[\mathbf {X}_{ii}] = 1\), where \(\mathbb {V}[\cdot ]\) denotes the variance of a random variable. Similarly, for \(i\ne j\),
and \(\mathbb {E}[\mathbf {X}_{ii}\mathbf {X}_{jj}] = \mathbb {E}[\mathbf {X}_{ii}]\mathbb {E}[\mathbf {X}_{jj}] = 0\), since the entries of a \({\text {GUE}}_d\)-matrix are independent. Hence, taking expectation values in (6.14) gives
and we can calculate
We finally turn to the only missing case, \((s,r)=(1,1)\). The polynomial \(P^{(1,1)}_{ij}\) is symmetric in i and j, therefore we can simplify
where we have used in the second-to-last equation that we can replace any occurrence of \(\gamma _{i,d,n}\) by one, and the last equation follows by the same reasoning as used in the case \((s,r)=(0,1)\) above. Now observe that for each \(i\ne k\), both \(\Gamma _{ik}^{-1}\) and \(\Gamma _{ki}^{-1}=-\Gamma _{ik}^{-1}\) occur in the sum. Therefore we can simplify
where we have used the definition of \(\varvec{\Gamma }_{ij}\) in the last equality. Combining Eqs. (6.16) and (6.17) we arrive at
Collecting all the terms \(T_{r,s}\) for \(r+s\le 2\) that we have calculated in Eqs. (6.9) to (6.12), (6.15) and (6.18), we arrive at
which implies that
To determine the lower order term, note that in all expressions above we have neglected terms of at most \(O(n^{-1/2+\varepsilon (d-2)})\). Eq. (6.8) shows that the terms with \(r+s\ge 3\) are \(O(n^{-1/2+3/2\varepsilon })\), and the difference between \(R_N\) and \(N\left( 1-F^{\mathrm {std}}_d(N)\right) \) is \(O(n^{-1/2+\varepsilon (d-2)})\) as well. As \(\varepsilon \in (0,(d-2)^{-1})\) was arbitrary we conclude that, for all \(\delta >0\),
which concludes the proof. \(\quad \square \)
6.5 Asymptotics of the optimal protocol
In this section, our goal is to obtain an asymptotic lower bound on the optimal entanglement fidelity \(F_d^*\) of a deterministic PBT protocol with both the entangled resource state and the POVM optimized. This is achieved by restricting the optimization in Eq. (3.6) to the class of protocol families that use a density \(c_\mu \) such that the probability distribution \(q(\mu )=c_\mu p_{N,d}(\mu )\) converges for \(N\rightarrow \infty \) in a certain sense. We then continue to show that the optimal asymptotic entanglement fidelity within this restricted class is related to the first eigenvalue of the Dirichlet Laplacian on the simplex of ordered probability distributions.
The main result of this section is the following theorem, which we restate from Sect. 1.2 for convenience.
Theorem 1.4
(Restated). The optimal fidelity for deterministic port-based teleportation is bounded from below by
where
is the \((d-1)\)-dimensional simplex of ordered probability distributions with d outcomes and \(\lambda _1(\Omega )\) is the first eigenvalue of the Dirichlet Laplacian on a domain \(\Omega \).
Before commencing the proof of Theorem 1.4, let us build some intuition for the fact that the fidelity formula Eq. (3.6) is related to a Laplacian. Reparametrizing Equation (3.6), we obtain the expression
where the maximization is taken over all probability distributions p on the set of Young diagrams with N boxes. Rearranging the sums yields
where the sum is taken over all pairs \(\mu ,\mu '\vdash _d N\) such that \(\mu '\) can be obtained from \(\mu \) by removing one box and adding one box, and the “boundary terms” subsume differences that arise when it is possible to remove a box from \(\mu \) and add one back such that the result is not a Young diagram (this will be made more rigorous below). It is now instructive to equip the set of Young diagrams with a graph structure, where we draw an edge between \(\mu \) and \(\mu '\ne \mu \) precisely whenever the pair \(\mu ,\mu '\) is part of the sum in (6.19). This graph is, in fact, the intersection of the root lattice of \(\mathfrak {su}(d)\) with a certain simplex. Observing that \(\sqrt{p}\) is an \(L^2\)-normalized function, we conclude that Eq. (6.19) is equal to the graph Laplacian on the Young diagram lattice we have defined, up to a constant. Normalizing the Young diagrams as done in Sect. 6.1, we see that the graphs for increasing N are finer and finer discretizations of the simplex of ordered probability distributions. We can thus expect that, when p is a sufficiently nice function, these graph Laplacians converge to the continuous Laplacian.
For the proof of Theorem 1.4 it will be convenient to switch back and forth between summation over a lattice and integration, which is the content of Lemma 6.2 below. Before stating the lemma, we make a few definitions. For a set \(\Omega \) we define \(d(x,\Omega )\,{:}{=}\, \inf _{y\in \Omega } \Vert x-y\Vert _2\), and for \(\delta \ge 0\) we define
Let \(V_{0}^{d-1}=\{x\in \mathbb {R}^d|\sum _{i=1}^dx_i=0\}\) and \(\mathbb {Z}^d_0=\mathbb {Z}^d\cap V_0^{d-1}\). For a vector subspace \(V\subset \mathbb {R}^d\) and lattice \(\Lambda \subset \mathbb {R}^d\), we denote by \(v+V\) and \(v+\Lambda \) the affine space and affine lattice with the origin shifted to \(v\in \mathbb {R}^d\), respectively. We denote by \(\lbrace e_i\rbrace _{i=1}^d\) the standard basis in \(\mathbb {R}^d\). For \(y\in e_1+\frac{1}{N} \mathbb {Z}^d_0\), define \(U_N(y)\subset e_1+V_0^{d-1}\) by the condition
In other words, up to sets of measure zero we have tiled \(e_1+V_0^{d-1}\) regularly into neighborhoods of lattice points. This also induces a decomposition \(\mathrm {OS}_{d-1}\subset e_1+ V_0^{d-1}\) via intersection, \(U_N^\mathrm {OS}(y)=U_N(y)\cap \mathrm {OS}_{d-1}\). We define the function \(g_{N}:e_1 + V_0^{d-1} \rightarrow e_1 + \frac{1}{N} \mathbb {Z}_0^d\) via \(g_N(x) = y\) where y is the unique lattice point such that \(x\in U_N(y)\), if such a point exists. On the measure-zero set \(\left( \bigcup _{y\in e_1 + \frac{1}{N} \mathbb {Z}_0^d}U_N(y)\right) ^c\), the function \(g_N\) can be set to an arbitrary value.
Lemma 6.2
Let \(f\in C^1(\mathrm {OS}_{d-1})\cap C(\mathbb {R}^d)\) be such that \(f(x)= O(d(x,\partial \mathrm {OS}_{d-1})^p)\) for some \(p\ge 1\), and \(f\equiv 0\) on \(\mathbb {R}^d{\setminus }\mathrm {OS}_{d-1}\). Then,
If furthermore \(f\in C^2(\mathrm {OS}_{d-1})\), then
Proof
Throughout the proof we set \(\Lambda \,{:}{=}\, \mathrm {OS}_{d-1}\cap \frac{1}{N}\mathbb {Z}^d\). Observe first that the largest radius of the cell \(U_N(y)\) around \(y\in \frac{1}{N}\mathbb {Z}^d\) is equal to half the length \(\frac{\sqrt{d}}{N}\) of a main diagonal in a d-dimensional hypercube of length \(\frac{1}{N}\). Setting \(c\,{:}{=}\, \frac{\sqrt{d}}{2}\), it follows that \(g_N^{-1}(y)\subseteq \mathrm {OS}_{d-1}\) for all \(y\in \Lambda \) with
Hence, we can write
where \(\omega (y)\) assigns the weight \(N^{-d+1}\) to all \(y\in \Lambda \) satisfying (6.20), and \(0\le \omega (y)\le N^{-d+1}\) for all \(y\in \partial _{c/N}\mathrm {OS}_{d-1}\) to compensate for i) the fact that in this region \(g_N\) maps some \(x\in \mathrm {OS}_{d-1}\) to a lattice point outside of \(\mathrm {OS}_{d-1}\), and ii) the fact that for some lattice points in \(y\in \mathrm {OS}_{d-1}\), not all of the neighborhood of y is contained in \(\mathrm {OS}_{d-1}\), i.e., \(U_N(y){\setminus } \mathrm {OS}_{d-1}\ne \emptyset \).
We bound
where in the second inequality we used the assumption \(f\in O(d(x,\partial \mathrm {OS}_{d-1})^p)\), and in the third inequality we used that there are at most \(\frac{c}{N} C_d N^{d-2}\) lattice points in \(\partial _{c/N}\mathrm {OS}_{d-1}\) for some constant \(C_d\) that only depends on d. This proves (i).
In order to prove (ii), we first develop \(f(g_N(x))\) into a Taylor series around a point x:
where we used the bound \(\Vert g_N(x) - x\Vert _2\le \frac{c}{N}\) for some constant c for the remainder term in the Taylor series. Hence, we have
where the second inequality follows from the Cauchy-Schwarz inequality, and in the third inequality we used the fact that by assumption \(\Vert \nabla f(x)\Vert _2\) is a continuous function on the compact domain \(\mathrm {OS}_{d-1}\) and therefore bounded by a constant K, proving (ii).
Finally, we prove assertion (iii). We denote by \(\partial _{ij}f \,{:}{=}\, (e_i-e_j)^T \nabla f\) the partial derivative of f in the direction \(e_{ij}\,{:}{=}\, e_i-e_j\). We approximate \(\partial _{ij} f(x)\) using a central difference \(D_{ij}[f(x)]\,{:}{=}\, f(x+\tfrac{h}{2} e_{ij}) - f(x-\tfrac{h}{2} e_{ij})\), where \(h>0\) is to be chosen later. To this end, consider the Taylor expansions
Subtracting the second expansion from the first and rearranging gives
It is easy to see that
and hence, for the Laplacian \(\Delta = {{\,\mathrm{tr}\,}}(H(\cdot ))\) on \(V_0^{d-1}\) with \(H(\cdot )\) the Hessian matrix, we have
Similarly, denoting by \(\langle \cdot ,\cdot \rangle _{V_0^{d-1}}\) the inner product on \(V_0^{d-1}\), we have
We now calculate, abbreviating \(\sum \nolimits _{y\in \Lambda }' = \sum _{y\in \Lambda } \omega (y)\):
where we used (6.22) in the second equality, and (6.23) and (6.21) in the last equality.
For the first term in (6.24), we have
where the second equality follows from (ii), and the third equality is ordinary integration by parts. For the second term in (6.24), we use the definition of \(D_{ij}\) to obtain
We choose \(h=O(N^{-1})\) such that \(y\pm \tfrac{h}{2} e_{ij}\in \Lambda \) for all \(y\in \Lambda \) sufficiently far away from the boundary of \(\Lambda \). Then all terms in (6.25) cancel except for those terms involving evaluations of f on \(\partial _{h}\mathrm {OS}_{d-1}\) or outside \(\mathrm {OS}_{d-1}\). But these terms in turn are \(O(h)=O(N^{-1})\), which can be seen using the same arguments as those in the proof of (ii). It follows that, with the above choice of \(h=O(N^{-1})\),
In summary, we have shown that
which is what we set out to prove.
We are now ready to prove Theorem 1.4:
Proof of Thm. 1.4
Fix a dimension d, and let \(a\in C^2(\mathrm {OS}_{d-1})\) be twice continuously differentiableFootnote 5 such that \(a|_{\partial \mathrm {OS}_{d-1}}\equiv 0\), \(a(x)\ge 0\) for all \(x\in \mathrm {OS}_{d-1}\), and \(\Vert a\Vert _2=1\), where \(\Vert \cdot \Vert _2\) is the \(L_2\)-norm on \(\mathrm {OS}_{d-1}\). As d is fixed throughout the proof, we omit indicating any dependence on d except when we would like to emphasize the dimension of an object. Note that clearly \(a\in L_2(\mathrm {OS}_{d-1})\) as a is continuous and \(\mathrm {OS}_{d-1}\) is compact.
We use the square of a scaled version of a as a candidate probability distribution q on Young diagrams \(\mu \) with N boxes and at most d rows,
Here \(\eta _{N}\) is a normalization constant which is close to one. Roughly speaking, this is due to the fact that the normalization condition for \(q(\mu )\) is essentially proportional to a Riemann sum for the integral that calculates the \(L_2\)-norm of a, which is equal to unity by assumption. Indeed, since \(a^2\) satisfies the assumptions of Lemma 6.2 with \(p=1\), we have
where the fourth and fifth equality follow from Lemma 6.2(i) and (ii), respectively, and the last equality follows from \(\Vert a\Vert _2=1\). Hence, \(\eta _N = 1 + O(N^{-1})\).
Before we proceed, we restate the fidelity formula in (3.6) for the optimal deterministic protocol for the reader’s convenience:
We bound this expression from below by choosing \(c_\mu =q(\mu )/p(\mu )\), where \(q(\mu )\) is defined as in (6.26) and \(p(\mu )=\frac{d_\mu m_{d,\mu }}{d^N}\) is the Schur–Weyl distribution. The choice of \(c_\mu \) in (6.27) corresponds to a particular PBT protocol whose entanglement fidelity we denote by \(F_a\) in the following. It will be convenient to rewrite the sums over Young diagrams \(\alpha \vdash _d N-1\) and \(\mu =\alpha +\square \) in (6.27) as a sum over Young diagrams \(\mu \vdash _d N\) and \(i,j=1,\ldots , d\), requiring that both \(\mu +e_i-e_j\) and \(\mu - e_j\) be Young diagrams themselves. Using this trick, the quantity \(\frac{d^2}{\eta _N} F_a\) can be expressed as
We first argue that up to order \(N^{-2}\) we only need to consider the first term in the above expression. To this end, we rewrite the sum in the second term as an integral,
where \(f_{i,j}(x)\,{:}{=}\, \mathbb {1}_{\mathrm {YD}}(Ng_N(x)+e_i-e_j) \mathbb {1}_{\mathrm {YD}}(Ng_N(x)-e_j)\). The function \(h_N(x)\in [0,1]\) takes care of normalization around the boundaries of \(\mathrm {OS}_{d-1}\), that is, \(h_N(x)=1\) except in a region \(\partial _{c_1/N}\mathrm {OS}_{d-1}\) for some constant \(c_1\) that only depends on d. Note that the same statement is true for the function \(f_{i,j}(x)\), and therefore, this also holds for the product \(h_N(x)f_{i,j}(x)\). Using Lemma 6.2(i) for the third term in (6.28) gives
Hence, for the difference of the second and third term in (6.28), we obtain
for some constants \(c_2\) and \(c_3\). Here, the first inequality is obtained by a Taylor expansion of the different occurrences of a around the respective closest boundary point and using the fact that a vanishes on the boundary by assumption. The second inequality follows since \(h_N\) is bounded uniformly in N.Footnote 6
We now turn to the first term in (6.28), applying Lemma 6.2(i) once more to obtain
Expanding \(a\left( g_N(x)+\frac{e_i-e_j}{N}\right) \) into a Taylor series gives
where \(\langle \cdot ,\cdot \rangle _{V_0^{d-1}}\) is the standard inner product on \(V_0^{d-1}\) and H(a) denotes the Hessian of a on \(V_0^{d-1}\). Summing over i and j yields
It follows that
where in the first equality the \(N{-1}\) term vanishes due to (6.29), and we defined the Laplace operator \(\Delta (a)={{\,\mathrm{tr}\,}}H(a)\) on \(V_0^{d-1}\). In the second equality we used Lemma 6.2(i) to switch back to discrete summation, in the third equality we used the normalization of a, and in the fourth equality we used Lemma 6.2(iii).
Putting together everything we have derived so far, we obtain
In equation Eq. (3.6), the fidelity is maximized over all densities \(c_\mu \). The above expression shows, that restricting to the set of densities \(c_\mu \) that stem from a function a on \(\mathrm {OS}_{d-1}\) makes the problem equivalent to minimizing the expression
When taking the infimum over \(a\in H^2(\mathrm {OS}_{d-1})\), where \(H^2(\mathrm {OS}_{d-1})\) is the Sobolev space of twice weakly differentiable functions, instead of \(a\in C^2(\mathrm {OS}_{d-1})\), this is exactly one of the variational characterizations of the first Dirichlet eigenvalue of the Laplace operator on \(\mathrm {OS}_{d-1}\). This is because the eigenfunction corresponding to the first eigenvalue of the Dirichlet Laplacian can be chosen positive (see, e.g., [62]). But \(C^2(\mathrm {OS}_{d-1})\) is dense in \(H^2(\mathrm {OS}_{d-1})\), which implies that
where the supremum is taken over all non-negative functions \(a\in C^2(\mathrm {OS}_{d-1})\). \(\square \)
Upper and lower bounds for the first Dirichlet eigenvalue of the Laplacian on a sufficiently well-behaved domain readily exist.
Theorem 6.3
[37, 63] For the first Dirichlet eigenvalue \(\lambda _1(\Omega )\) on a bounded convex domain \(\Omega \subset \mathbb {R}^d\), the following inequalities hold,
where \(B_1\subset \mathbb {R}^d\) is the unit ball and \(r_\Omega \) is the inradius of \(\Omega \).
The inradius of \(\mathrm {OS}_{d-1}\) is equal to \(1/d^2\). This can be seen by guessing the center of the inball \(\hat{x}=((2d-1)/d^2,(2d-3)/d^2,\ldots ,1/d^2)\) and checking that the distance to each facet is \(1/d^2\). Therefore we get the following lower bound on the optimal PBT fidelity. This theorem is stated in Sect. 1.2, and restated here for convenience.
Theorem 1.5
(Restated). For the optimal fidelity of port-based teleportation with arbitrary but fixed input dimension d and N ports, the following bound holds,
Proof
Theorem 1.4 gives us the bound
Using Theorem 6.3 and Lemma D.5 we bound
The first eigenvalue of the Dirichlet Laplacian on the \((d-1)\)-dimensional Ball is given by
where \(j_{\nu ,l}\) is the lth root of the Bessel function of the first kind with parameter \(\nu \). This is, in turn, bounded as [64]
Putting the inequalities together we arrive at
In the appendix, we provide a concrete protocol in Theorem B.1 that achieves the same asymptotic dependence on N and d, with a slightly worse constant.
Intuitively it seems unlikely that a “wrinkly” distribution, i.e. a distribution that does not converge against an \(L_1\) density on \(\mathrm {OS}\), is the optimizer in Eq. (3.6). Supposing that the optimizer comes from a function a as described above, we can also derive a converse bound for the asymptotics of the entanglement fidelity \(F^*_d(N)\) using Theorem 6.3.
Remark 6.4
Let \(P^N_a\) be the PBT protocol with \(c_\mu =N^{d-1}a^2(\mu /N)/P(\mu )\) for some function \(a\in L_2(\mathrm {OS}_{d-1})\). For the asymptotic fidelity of such protocols for large N the following converse bound holds,
This can be seen as follows. From Theorem 1.4 we have that
Theorem 6.3 together with Lemma D.5 yields
where in the second line we have used the volume of the \((d-1)\)-dimensional Ball,
and \(\Gamma (x)\) is the gamma function. Using bound versions of Stirling’s approximation we obtain
Using a lower bound for the first zero of the Bessel function of the first kind [65] we bound
for some constant c, so we finally arrive at
This bound has the nice property that \(N\propto d^2\) if the error of the PBT protocol is fixed, which is what we expect from information theoretic insights (see Sect. 7).
7 Converse Bound
We begin by deriving a lower bound on the communication requirements for approximate quantum teleportation of any kind, i.e., not only for PBT. Such a result could be called folklore, but has, to the best of our knowledge, not appeared elsewhere.Footnote 7
For the proof we need the converse bound for one-shot quantum state splitting that was given in [67] in terms of the smooth max-mutual information \(I_{\max }^{\varepsilon }(E:A)_{\rho }\). To define this quantity, let \(D_{\max }(\rho \Vert \sigma )=\min \left\{ \lambda \in \mathbb {R}\big |2^\lambda \sigma \ge \rho \right\} \) be the max-relative entropy [68], and let \(P(\rho ,\sigma )\,{:}{=}\, \sqrt{1-F(\rho ,\sigma )}\) be the purified distance. Furthermore, let \(B_\varepsilon (\rho )\,{:}{=}\, \lbrace \bar{ \rho }:\bar{ \rho }\ge 0, {{\,\mathrm{tr}\,}}\bar{ \rho }\le 1, P(\rho ,\bar{ \rho })\le \varepsilon \rbrace \) be the \(\varepsilon \)-ball of subnormalized states around \(\rho \) with respect to the purified distance. The smooth max-mutual information is defined as
where \(I_{\max }(E:A)_{\bar{\rho }}\,{:}{=}\,\min _{\sigma _A} D_{\max }(\bar{\rho }_{AE}\Vert \sigma _A\otimes \bar{\rho }_E)\) with the minimization over normalized quantum states \(\sigma _A\).
Lemma 7.1
Let
be the \(d\times d\)-dimensional maximally entangled state. Then
Proof
Let \(\rho \in B(\mathcal {H}_A\otimes \mathcal {H}_{B})\) be a quantum state such that \(I_{\max }^{\varepsilon }(A:B)_{\phi ^+}=I_{\max }(A:B)_{\rho }\), and let \(|\gamma \rangle _{ABE}\) be a purification of \(\rho \). Uhlmann’s Theorem ensures that there exists a pure quantum state \(|\alpha \rangle _E\) such that
This holds without taking the absolute value because any phase can be included in \(|\alpha \rangle \). Let
be the Schmidt decomposition of \(|\gamma \rangle \) with respect to the bipartition A : BE. Let further \(U_A\) be the unitary matrix such that \(U_A|i\rangle _A=|\phi _i\rangle _{A}\). Using the Mirror Lemma D.1 we get
where \(\bar{U}\) is the complex conjugate in the computational basis and \(|\xi _i\rangle _{B}=\bar{U}_B|i\rangle _B\). With this we obtain from (7.1) that
The second inequality is the Cauchy-Schwarz inequality and the third inequality follows from \(\mathfrak {R}\langle \xi _i|_B\langle \alpha |_E|\psi _i\rangle _{BE}\le 1 \).
The next step is to bound the max-mutual information of \(\rho \). Let
By the definition of \(I_{\max }\) there exists a quantum state \(\sigma _B\) such that
Here, \(X^{-1}\) denotes the pseudo-inverse of a matrix X, i.e., \(X^{-1}X=XX^{-1}\) is equal to the projector onto the support of X. Let \(|\phi _\sigma \rangle =\sqrt{d}\sigma _B^{1/2}|\phi ^+\rangle \) be the standard purification of \(\sigma \). We bound
where we used the particular form of \(|\phi _\sigma \rangle \) in the third equality, and (7.2) in the fourth equality, together with the fact that \(\lbrace p_i\rbrace _i\) are the eigenvalues of \(\rho _A\). This proves the claimed up upper bound on \(I_{\max }^{\varepsilon }(A:B)_{\phi ^+}\).
In order to prove the lower bound, let \({r}=\lceil d(1-\varepsilon ^2)\rceil \) and
Then we have
The observation that \(|\phi ^+_{r}\rangle \langle \phi ^+_{r}|\) is a point in the minimization over \(\sigma \) finishes the proof.
\(\square \)
Using the special case of state merging/splitting with trivial side information and the converse bound from [67], we can bound the necessary quantum communication for simulating the identity channel with a given entanglement fidelity.
Corollary 7.2
Let \(\mathcal {E}_{AA'\rightarrow B}\), \(\mathcal {D}_{BB'\rightarrow A}\) be quantum (encoding and decoding) channels with \(\dim \mathcal {H}_A=d\) and \(\dim \mathcal {H}_B= {d'}\) such that there exists a resource state \(\rho _{A'B'}\) achieving
Then the following inequality holds:
Proof
Using Lemma 7.1, this follows from applying the lower bound on the communication cost of one-shot state splitting from [67] to the special case where Alice and the reference system share a maximally entangled state. \(\quad \square \)
Together with superdense coding this implies a lower bound on approximate teleportation.
Corollary 7.3
If in the above corollary \(\mathcal {E}\) is a qc-channel, then
Proof
This follows as any protocol with a lower classical communication in conjunction with superdense coding would violate Corollary 7.2. \(\quad \square \)
For the special case of port-based teleportation, this implies a lower bound on the number of ports.
Corollary 7.4
Any port-based teleportation protocol with input dimension d and N ports has entanglement fidelity at most
Proof
In port-based teleportation, the only information that is useful to the receiver is which port to select. More precisely, given a protocol P for PBT in which Alice sends a message that is not a port number, we can construct a modified protocol P where Alice applies the procedure that Bob uses in P to deduce the port to select and then sends the port number instead. For a given entanglement fidelity F, having fewer than \(\left( {d}{F}\right) ^2\) ports would therefore violate the bound from Corollary 7.3. \(\quad \square \)
The converse bound on the amount of quantum communication in Corollary 7.2 holds for arbitrary protocols implementing a simulation of the identity channels, and Corollary 7.3 puts a lower bound on the classical communication of any (approximate) teleportation scheme. We continue to derive a converse bound specifically for port-based teleportation that is nontrivial for all combinations of d and N. Let us consider a general port-based teleportation scheme, given by POVMs \(\{E_{A^N}^{(i)}\}\) and a resource state \(\rho _{A^NB^N}\), where \(A_0\cong \mathbb {C}^d\) and \(B_1,\ldots ,B_N\cong \mathbb {C}^d\). We would like to upper-bound the entanglement fidelity
where \(B_0\cong \mathbb {C}^d\) and \(F(\rho ,\sigma )=\Vert \sqrt{\rho }\sqrt{\sigma }\Vert _1^2\) is the fidelity. This fidelity corresponds to the special case of Alice using an arbitrary PBT protocol to teleport half of a maximally-entangled state to Bob, who already possesses the other half. An upper bound for this fidelity then directly implies an upper bound for the entanglement fidelity of the PBT protocol. We prove the following
Theorem 7.5
For any port-based teleportation scheme, the entanglement fidelity (7.3) can be bounded from above as
Asymptotically, this bound becomes
Proof
Note first that for a pure state \(|\psi \rangle \) we have \(F(\psi ,\tau ) = \langle \psi |\tau |\psi \rangle \) for any mixed state \(\tau \), and hence \(\tau \mapsto F(\psi ,\tau )\) is linear for any \(\tau \). Since \(\phi ^+_{B_0B_1}\) is pure, the entanglement fidelity (7.3) can hence be rewritten as
for suitable \(\sigma ^{(i)}_{(B_0B_i)^c}\) whose existence is guaranteed by Uhlmann’s Theorem. Here we have introduced \(p(i)={{\,\mathrm{tr}\,}}[(E^{(i)})^{1/2}_A (\rho _{A^NB^N} \otimes \tau _{A_0}) (E^{(i)})^{1/2}_A]\). Abbreviating \(\sqrt{F}(\cdot ,\cdot ) \equiv \sqrt{F(\cdot ,\cdot )}\), we now have for any \(j\in \{1,\ldots ,N\}\) that
where the second step uses joint concavity of the root fidelity, and we trace out all systems but \(B_0B_j\), with \(\sigma _{B_j}\) being some appropriate state. Now, the fact that \(\langle \phi |^+_ {AB} \bigl (X_A \otimes \tau _B\bigr )|\phi \rangle ^+_ {AB} = \frac{1}{d^2}{{\,\mathrm{tr}\,}}(X_A)\) for any operator \(X_A\) and data processing inequality with respect to the binary measurement \(\{\phi ^+_{B_0B_j}, I-\phi ^+_{B_0B_j}\}\) gives
where \(\sqrt{f}(x,y)=\sqrt{xy}+\sqrt{(1-x)(1-y)}\) is the binary root fidelity. Note that \(f(q,p + (1-p)q)\) is monotonically increasing as p decreases from 1 to 0. Now, one of the N probabilities p(j) has to be \(\ge 1/N\). Thus,
To derive the non-asymptotic bound (7.4), Equation (7.6) can be rearranged as
We bound the square roots using \(\sqrt{1+a}\le 1+a/2\) for any \(a\ge -1\) to obtain
which is (7.4). For \(N\rightarrow \infty \) this implies
which is (7.5) and concludes the proof. \(\quad \square \)
Combining Theorem 7.5 with Corollary 7.4 above yields a simplified bound as a corollary, that we stated as Corollary 1.6 in Sect. 1.2 as one of our main results. We restate it below for convenience, and in Fig. 4 we compare the quality of this bound for \(N>d^2/2\) with the converse bound (3.4) derived in [19].
Corollary 1.6
(Restated). For a general port-based teleportation scheme with input dimension d and N ports, the entanglement fidelity \(F_d^*\) and the diamond norm error \(\varepsilon _d^*\) can be bounded as

8 Conclusion
In this paper, we completed the picture of the asymptotic performance of port-based teleportation (PBT) in the important regime when the input dimension is fixed while the number of ports tends to infinity. In particular, we determined the asymptotic performance of deterministic PBT in the fully optimized setting, showing that the optimal infidelity decays as \(\Theta (1/N^2)\) with the number of ports N. We also determined the precise asymptotics of the standard protocol for deterministic PBT (which uses EPR pairs and the ‘pretty good’ measurement) as well as probabilistic PBT using EPR pairs. The asymptotics for probabilistic PBT in the fully optimized setting had been determined previously in [22].
While our work closes a chapter in the study of PBT, it opens several interesting avenues for further investigation, both in the finite and in the asymptotic regime. Note that the limit \(d\rightarrow \infty \) for fixed N is not very interesting, as the error tends to one in this regime. However, it would be natural to consider limits where both N and d tend to infinity. In particular, the fidelity \(F_d^*(N)\) plausibly has a nontrivial limit when the ratio \(N/d^2\) remains fixed. Given the import of PBT to, e.g., instantaneous non-local quantum computation, it would be desirable to determine the limiting value. Finally, we also mention the problem of determining the exact functional dependence on d of the leading order coefficient \(\lim _{N\rightarrow \infty }N^2(1-F_d^*(N))\) in fully optimized deterministic PBT. Furthermore, we hope that our mathematical tools will be helpful for determining the asymptotics of other quantum information-theoretic tasks that can also be characterized in terms of representation-theoretic data, such as quantum state purification.
Notes
The standard protocol uses a maximally entangled resource state and the so-called Pretty Good Measurement.
This can even be done while keeping the structure of the resource state if desired, by adding the purifying system to one of Alice’s systems \(A_i\), or splitting it between all of them.
Alternatively, one could call “deterministic PBT” just “PBT” and for “probabilistic PBT” use the term “heralded PBT”, which is borrowed from quantum optics terminology as used in, e.g., [42]. However, we will stick to the widely used terms.
Here, \(f(n) = \omega (g(n))\) means that |f(n)/g(n)| diverges as \(n\rightarrow \infty \).
The second derivative is continuous and its limit for the argument approaching the boundary exists.
Observe that a constant fraction of \(U_N(y)\) of each lattice point \(y\in \mathrm {OS}_{d-1}\cap \frac{1}{N}\mathbb {Z}^d\) lies inside \(\mathrm {OS}_{d-1}\). This fraction is not uniformly bounded in d, as the solid angle of the vertices of \(\mathrm {OS}_{d-1}\) decreases with d. However, this does not concern us, since we are only interested in the limit \(N\rightarrow \infty \) for fixed d.
Except in the PhD thesis of one of the authors [66].
For a general lattice \(\mathcal {L}_d\subset \mathbb {R}^d\) with basis \(B=\lbrace b_1,\ldots ,b_m\rbrace \) (where \(m\le d\)), the volume of the unit cell of \(\mathcal {L}^d\) is equal to \(\det (\mathcal {L}_d) = \sqrt{\det (B^TB)}\).
This distribution is also known as the Maxwell–Boltzmann distribution.
References
Bennett, C.H., Brassard, G., Crépeau, C., Jozsa, R., Peres, A., Wootters, W.K.: Teleporting an unknown quantum state via dual classical and Einstein–Podolsky–Rosen channels. Phys. Rev. Lett. 70(13), 1895 (1993)
Einstein, A., Podolsky, B., Rosen, N.: Can quantum-mechanical description of physical reality be considered complete? Phys. Rev. 47, 777–780 (1935)
Ishizaka, S., Hiroshima, T.: Asymptotic teleportation scheme as a universal programmable quantum processor. Phys. Rev. Lett. 101(24), 240501 (2008). arXiv:0807.4568 [quant-ph]
Ishizaka, S., Hiroshima, T.: Quantum teleportation scheme by selecting one of multiple output ports. Phys. Rev. A 79(4), 042306 (2009). arXiv:0901.2975 [quant-ph]
Pirandola, S., Laurenza, R., Lupo, C., Pereira, J.L.: Fundamental limits to quantum channel discrimination. npj Quant. Inf. 5(1), 50 (2019). arXiv:1803.02834 [quant-ph]
Beigi, S., König, R.: Simplified instantaneous non-local quantum computation with applications to position-based cryptography. New J. Phys. 13(9), 093036 (2011). arXiv:1101.1065 [quant-ph]
Buhrman, H., Chandran, N., Fehr, S., Gelles, R., Goyal, V., Ostrovsky, R., Schaffner, C.: Position-based quantum cryptography: impossibility and constructions. SIAM J. Comput. 43(1), 150–178 (2014). arXiv:1009.2490 [quant-ph]
Chandran, N., Goyal, V., Moriarty, R., Ostrovsky, R.: Cryptography, position based. In: Halevi, S. (ed.) Advances in Cryptology—CRYPTO, vol. 2009, pp. 391–407. Springer, Berlin (2009)
Malaney, R.: The quantum car. IEEE Wirel. Commun. Lett. 5(6), 624–627 (2016). arXiv:1512.03521 [quant-ph]
Unruh, D.: Verification, quantum position, in the random oracle model. In: Garay, J.A., Gennaro, R. (eds.) Advances in Cryptology—CRYPTO, vol. 2014, pp. 1–18. Springer, Berlin (2014)
Yu, L.: Fast controlled unitary protocols using group or quasigroup structures. arXiv preprint (2011). arXiv:1112.0307 [quant-ph]
Li, Y., Griffths, R.B., Cohen, S.M.: Fast protocols for local implementation of bipartite nonlocal unitaries. Phys. Rev. A 85(1), 012304 (2012). arXiv:1109.5013 [quant-ph]
Broadbent, A.: Popescu–Rohrlich correlations imply eficient instantaneous nonlocal quantum computation. Phys. Rev. A 94(2), 022318 (2016). arXiv:1512.04930 [quant-ph]
Speelman, F.: Instantaneous non-local computation of Low T-depth quantum circuits. In: 11th Conference on the Theory of Quantum Computation, Communication and Cryptography—TQC (2016). arXiv:1511.02839 [quant-ph]
Tomamichel, M., Fehr, S., Kaniewski, J., Wehner, S.: A monogamy-of- entanglement game with applications to device-independent quantum cryptography. New J. Phys. 15(10), 103002 (2013). arXiv:1210.4359 [quant-ph]
Ribeiro, J., Grosshans, F.: A tight lower bound for the BB84-states quantumposition- verification protocol. arXiv preprint (2015). arXiv:1504.07171 [quant-ph]
Strelchuk, S., Horodecki, M., Oppenheim, J.: Generalized teleportation and entanglement recycling. Phys. Rev. Lett. 110(1), 010505 (2013). arXiv:1209.2683 [quant-ph]
Pitalúa-García, D.: Deduction of an upper bound on the success probability of port-based teleportation from the no-cloning theorem and the no-signaling principle. Phys. Rev. A 87(4), 040303 (2013). arXiv:1206.4836 [quant-ph]
Ishizaka, S.: Some remarks on port-based teleportation. arXiv preprint (2015). arXiv:1506.01555 [quant-ph]
Wang, Z.-W., Braunstein, S.L.: Higher-dimensional performance of port-based teleportation. Sci. Rep. 6 (2016)
Studziński, M., Strelchuk, S., Mozrzymas, M., Horodecki, M.: Portbased teleportation in arbitrary dimension. Sci. Rep. 7, 10871 (2017). arXiv:1612.09260 [quant-ph]
Mozrzymas, M., Studziński, M., Strelchuk, S., Horodecki, M.: Optimal port-based teleportation. New J. Phys. 20(5), 053006 (2018). arXiv:1707.08456 [quant-ph]
Supplementary Python code. https://github.com/amsqi/port-based
Wigner, E.P.: Characteristic vectors of bordered matrices with infinite dimensions I. In: Mehra, J. (ed.) The Collected Works of Eugene Paul Wigner, pp. 524–540. Springer, New York (1993)
Keyl, M., Werner, R.F.: Estimating the spectrum of a density operator. Phys. Rev. A 64(5), 052311 (2001). arXiv:quant-ph/0102027
Hayashi, M., Matsumoto, K.: Quantum universal variable-length source coding. Phys. Rev. A 66(2), 022311 (2002). arXiv:quant-ph/0202001
Christandl, M., Mitchison, G.: The spectra of quantum states and the Kronecker coeffcients of the symmetric group. Commun. Math. Phys. 261(3), 789–797 (2006)
O’Donnell, R., Wright, J.: Quantum spectrum testing. In: Proceedings of the 47th Annual ACM Symposium on Theory of Computing. STOC 2015. ACM, pp. 529–538 (2015). arXiv:1501.05028 [quant-ph]
Haah, J., Harrow, A.W., Ji, Z., Xiaodi, W., Nengkun, Yu.: Sampleoptimal tomography of quantum states. IEEE Trans. Inf. Theory 63(9), 5628–5641 (2017). arXiv:1508.01797 [quant-ph]
O’Donnell, R., Wright, J.: Efficient quantum tomography. In: Proceedings of the 48th Annual ACM Symposium on Theory of Computing. STOC 2016. ACM, pp. 899–912 (2016). arXiv:1508.01907 [quant-ph]
O’Donnell, R., Wright, J.: Effcient quantum tomography II. In: Proceedings of the 49th Annual ACM Symposium on Theory of Computing. STOC 2017. ACM, pp. 962–974 (2017). arXiv:1612.00034 [quant-ph]
Christandl, M., Doran, B., Walter, M.: Computing multiplicities of Lie group representations. In: 2012 IEEE 53rd Annual Symposium on Foundations of Computer Science. FOCS 2012. IEEE, pp. 639–648 (2012). arXiv:1204.4379 [cs.CC]
Christandl, M., Doran, B., Kousidis, S., Walter, M.: Eigenvalue distributions of reduced density matrices. Commun. Math. Phys. 332(1), 1–52 (2014). arXiv:1204.0741 [quant-ph]
Christandl, M., Şahinoğlu, M.B., Walter, M.: Recoupling coeffcients and quantum entropies. Ann. Henri Poincaré 19(2), 385–410 (2018). arXiv:1210.0463 [quant-ph]
Christandl, M., Harrow, A.W., Mitchison, G.: Nonzero Kronecker coefficients and what they tell us about spectra. Commun. Math. Phys. 270(3), 575–585 (2007). arXiv:quant-ph/0511029
Johansson, K.: Discrete orthogonal polynomial ensembles and the Plancherel measure. Ann. Math. 153(1), 259–296 (2001). arXiv:math/9906120 [math.CO]
Freitas, P., Krejčiřík, D.: A sharp upper bound for the first Dirichlet eigenvalue and the growth of the isoperimetric constant of convex domains. Proc. Am. Math. Soc. 136(8), 2997–3006 (2008). arXiv:0710.5475 [math.SP]
Kubicki, A.M., Palazuelos, C., Pérez-García, D.: Resource quantification for the no-programing theorem. Phys. Rev. Lett. 122(8), 080505 (2019). arXiv:1805.00756 [quant-ph]
Fulton, W.: Young Tableaux: With Applications to Representation Theory and Geometry, vol. 35. Cambridge University Press, Cambridge (1997)
Simon, B.: Representations of Finite and Compact Groups. Graduate Studies in Mathematics, vol. 10. American Mathematical Society, Providence (1996)
Nielsen, M.A., Chuang, I.L.: Programmable quantum gate arrays. Phys. Rev. Lett. 79(2), 321 (1997). arXiv:quant-ph/9703032
Nielsen, B.M., Neergaard-Nielsen, J.S., Polzik, E.S.: Time gating of heralded single photons for atomic memories. Opt. Lett. 34(24), 3872–3874 (2009). arXiv:0909.0646 [quant-ph]
Belavkin, V.P.: Optimal multiple quantum statistical hypothesis testing. Stoch. Int. J. Probab. Stoch. Process. 1(1–4), 315–345 (1975)
Hausladen, P., Wootters, W.K.: A ‘pretty good’ measurement for distinguishing quantum states. J. Mod. Opt. 41(12), 2385–2390 (1994)
Pérez-García, D.: Optimality of programmable quantum measurements. Phys. Rev. A 73(5), 052315 (2006). arXiv:quant-ph/0602084
Hillery, M., Ziman, M., Bužek, V.: Approximate programmable quantum processors. Phys. Rev. A 73(2), 022345 (2006). arXiv:quant-ph/0510161
Renner, R.: Security of quantum key distribution. Ph.D. thesis. ETH Zürich (2005). arXiv:quant-ph/0512258
Christandl, M., König, R., Renner, R.: Postselection technique for quantum channels with applications to quantum cryptography. Phys. Rev. Lett. 102, 020504 (2009). arXiv:0809.3019 [quant-ph]
Gross, D., Nezami, S., Walter, M.: Schur–Weyl Duality for the Clifford Group with Applications: Property Testing, a Robust Hudson Theorem, and de Finetti Representations. arXiv preprint (2017). arXiv:1712.08628 [quant-ph]
Seymour, P.D., Zaslavsky, T.: Averaging sets: a generalization of mean values and spherical designs. Adv. Math. 52(3), 213–240 (1984)
Kane, D.: Small designs for path-connected spaces and path-connected homogeneous spaces. Trans. Am. Math. Soc. 367(9), 6387–6414 (2015). arXiv:1112.4900 [math.CO]
Mozrzymas, M., Studziński, M., Horodecki, M.: A simplified formalism of the algebra of partially transposed permutation operators with applications. J. Phys. A Math. Theor. 51(12), 125202 (2018). arXiv:1708.02434 [quant-ph]
Johnson, P.D., Viola, L.: Compatible quantum correlations: extension problems for werner and isotropic states. Phys. Rev. A 88(3), 032323 (2013). arXiv:1305.1342 [quant-ph]
Alicki, R., Rudnicki, S., Sadowski, S.: Symmetry properties of product states for the system of N n-level atoms. J. Math. Phys. 29(5), 1158–1162 (1988)
Duffield, N.G.: A large deviation principle for the reduction of product representations. Proc. Am. Math. Soc. 109(2), 503–515 (1990)
Tracy, C.A., Widom, H.: On the distributions of the lengths of the longest monotone subsequences in random words. Probab. Theory Relat. Fields 119(3), 350–380 (2001). arXiv:math/9904042 [math.CO]
Kuperberg, G.: Random words, quantum statistics, central limits, random matrices. arXiv preprint (1999). arXiv: math/9909104 [math.PR]
Pinsker, M.S.: Information and Information Stability of Random Variables and Processes. Holden-Day, San Francisco (1964)
Durrett, R.: Probability: Theory and Examples, 4th edn. Cambridge University Press, Cambridge (2010)
Feller, W.: An Introduction to Probability Theory and Its Applications, vol. 2. Wiley, New York (2008)
Ledoux, M.: Deviation Inequalities on Largest Eigenvalues. Geometric Aspects of Functional Analysis, pp. 167–219. Springer, New York (2007)
Grebenkov, D.S., Nguyen, B.-T.: Geometrical structure of Laplacian eigenfunctions. SIAM Rev. 55(4), 601–667 (2013). arXiv:1206.1278 [math.AP]
Krahn, E.: Über Minimaleigenschaften der Kugel in drei und mehr Dimensionen. Mattiesen (1926)
Chambers, L.G.: An upper bound for the first zero of Bessel functions. Math. Comput. 38(158), 589–591 (1982)
Breen, S.: Uniform upper and lower bounds on the zeros of Bessel functions of the first kind. J. Math. Anal. Appl. 196(1), 1–17 (1995)
Majenz, C.: Entropy in Quantum Information Theory—Communication and Cryptography. Ph.D. thesis. Department of Mathematical Sciences, Faculty of Science, University of Copenhagen (2017)
Berta, M., Christandl, M., Renner, R.: The quantum reverse Shannon theorem based on one-shot information theory. Commun. Math. Phys. 306(3), 579 (2011). arXiv:0912.3805 [quant-ph]
Datta, N.: Min-and max-relative entropies and a new entanglement monotone. IEEE Trans. Inf. Theory 55(6), 2816–2826 (2009). arXiv:0803.2770 [quant-ph]
Leditzky, F., Kaur, E., Datta, N., Wilde, M.M.: Approaches for approximate additivity of the Holevo information of quantum channels. Phys. Rev. A 97(1), 012332 (2018). arXiv:1709.01111 [quant-ph]
Convergence of Riemann sums for improper integrals. https://math.stackexchange.com/questions/1744250/convergence-of-riemann-sums-for-improper-integrals. Accessed 30 Apr 2018
Acknowledgements
We acknowledge interesting discussions with Charles Bordenave, Benoît Collins, Marek Mozrzymas, Māris Ozols, Jan Philip Solovej, Sergii Strelchuk, and Michał Studziński. MC and FS acknowledge financial support from the European Research Council (ERC Grant Agreement No. 337603) and VILLUM FONDEN via the QMATH Centre of Excellence (Grant No. 10059). MC further acknowledges the Quant-ERA project Quantalgo and the hospitality of the Center for Theoretical Physics at MIT, where part of this work was done. FL and GS are supported by National Science Foundation (NSF) Grant No. PHY 1734006. FL appreciates the hospitality of QuSoft, CWI, and the University of Amsterdam, where part of this work was done. CM was supported by a Netherlands Organisation for Scientific Research (NWO) VIDI Grant (639.022.519). GS is supported by the NSF Grant No. CCF 1652560. MW thanks JILA for hospitality, where this work was partly initiated. MW acknowledges financial support by the NWO through Veni Grant No. 680-47-459.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by M. M. Wolf
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Proof of Lemma 3.6
The following lemma was first derived in [21]. In this section we give an alternative proof. Our proof is elementary and only uses the Schur–Weyl duality and the Pieri rule.
Lemma 3.6
(Restated) The eigenvalues of the operator
on \((\mathbb {C}^d)^{\otimes (1+N)}\) are given by the numbers
where \(\alpha \vdash _{d}N-1\), the Young diagram \(\mu \vdash _d N\) is obtained from \(\alpha \) by adding a single box, and \(\gamma _\mu (\alpha )\) is defined in Eq. (3.10).
Proof
We note that the operator T(N) commutes with the action of U(d) by \(\bar{U} \otimes U^{\otimes N}\) as well as with the action of \(S_N\) that permutes the systems \(B_1,\ldots ,B_N\). Let us work out the corresponding decomposition of \((\mathbb {C}^d)^{1+N}\): We first consider the action of \(U(d) \times U(d)\) by \(\bar{U} \otimes V^{\otimes N}\) together with the \(S_N\). By Schur–Weyl duality,
The notation means that \(\mu \) runs over all Young diagrams with N boxes and no more than d rows (i.e., \(\mu _1\ge \ldots \ge \mu _d\ge 0\) and \(\sum _j \mu _j=N\)). We write \(V_\mu ^d\) for the irreducible U(d)-representation with highest weight \(\mu \), and \(W_\mu \) for the irreducible \(S_N\)-representation corresponding to the partition \(\mu \).
The dual representation \((\mathbb {C}^d)^*\) is not polynomial; its highest weight is \((-1,0,\ldots ,0)\). However, \((\mathbb {C}^d)^* \cong V_{(1,\ldots ,1,0)}^d \otimes {\det }^{-1}\). The (dual) Pieri rule tells us that \(V_{(1,\ldots ,1,0)}^d \otimes V_\mu ^d\) contains all irreducible representations whose highest weight can be obtained by adding 1’s to all but one of the rows (with multiplicity one). Tensoring with the determinant amounts to subtracting \((-1,\ldots ,-1)\), so the result of tensoring with \((\mathbb {C}^d)^*\) amounts to subtracting 1 from one of the rows:
where we write \(\epsilon _i\) for the ith standard basis vector. (Note that we set \(\mu _{d+1}=-\infty \), so that \(i=d\) is always a valid choice in the direct sum above; hence, \(\mu -\epsilon _i\) is always a highest weight, but does not need to be a Young diagram.) Thus, we obtain the following multiplicity-free decomposition into \(U(d) \times S_N\)-representations:
The operator T(N) can be decomposed accordingly:
for some \(t_{\mu ,i}\ge 0\). To determine the \(t_{\mu ,i}\), let us denote by \(P_\mu \) the isotypical projectors for the \(S_N\)-action on \((\mathbb {C}^d)^{\otimes N}\) and by \(Q_\alpha \) the isotypical projectors for the U(d) action by \({\bar{U}} \otimes U^{\otimes N}\) (they commute). Then:
On the other hand:
The maximally entangled state \(\phi ^+_{AB_1}\) is invariant under \({\bar{U}} \otimes U\). This means that on the range of the projector \(\phi ^+_{AB_1}\), the actions of \({\bar{U}} \otimes U^{\otimes N}\) and \(I_{AB_1} \otimes U^{\otimes (N-1)}\) agree! Explicitly:
It follows that
where \(Q'_\alpha \) refers to the action of U(d) by \(U^{\otimes (N-1)}\) on \(B_2\ldots {}B_n\), and so
We can now trace over the A-system:
The remaining trace is on \((\mathbb {C}^d)^{\otimes N}\). The operator \(P_\mu \) refers to the \(S_N\)-action, while \(Q'_\alpha \) refers to the U(d)-action by \(U^{\otimes (N-1)}\) on \(B_2\ldots {}B_n\). Equivalently, we can define \(Q'_\alpha \) with respect to the \(S_{N-1}\) action by permuting the last \(N-1\) tensor factors. Using Schur–Weyl duality and the branching rule for restricting \(S_N\) to \(S_1 \times S_{N-1}\):
And hence
in the case of interest. Comparing this with Eq. (A.1), we obtain the following result:
if \(\alpha = \mu - \epsilon _i\) is a partition, and otherwise zero. These are the desired eigenvalues of T(N). \(\quad \square \)
A Family of Explicit Protocols for Deterministic PBT
Guessing a good candidate density \(c_\mu \) with a simple functional form for the optimization in Eq. (3.6) yields a protocol with performance close to the achievability bound Theorem 1.5.
Theorem B.1
For fixed but arbitrary dimension d, there exists a concrete protocol for deterministic PBT with entanglement fidelity
Proof
Assume that \(N/d^2\) is an integer (otherwise use only the first \(d^2\left\lfloor \frac{N}{d^2}\right\rfloor \) ports). Let \(c_\mu \) be defined such that
with
and
is a normalization factor that ensures that q is a probability distribution. \(\hat{\mu }\) has Euclidean distance R from the boundary of the set of Young diagrams, i.e. all vectors \(\mu \in \hat{\mu }+\Lambda _d\) such that \(\Vert \mu -\hat{\mu }\Vert _2\le R\) are Young diagrams. We extend the probability distribution q to be defined on all \(v\in \hat{\mu }+\Lambda _d\) for convenience. Let \(B^{\Lambda _d}_L(v_0)=\{v\in v_0+\Lambda _d|\Vert v-v_0\Vert _2\le L\}\). We now look at the PBT-fidelity for the protocol using the density \(c_\mu \). First note that the formula Eq. (3.6) can be rearranged in the following way,
In the last line, the notation \(\mu '=\mu +\square -\square \) means summing over all possibilities to remove a square from \(\mu \) and adding one, including removing and adding the same square. Noting that all vectors in \(B^{\Lambda _d}_R(\hat{\mu })\) are Young diagrams, we can write
Here we have defined the functions
and
The last equation holds because \(\Vert e_i-e_j\Vert _2=(1-\delta _{ij})\sqrt{2}\), i.e. for all \(\mu \in B^{\Lambda _d}_{R-\sqrt{2}}(\hat{\mu })\) and all \(1\le i,j\le d\) we have \(\mu +e_i-e_j\in B^{\Lambda _d}_{R}(\hat{\mu })\).
We can bound the normalization constant as follows. Denote by \(\mathcal {P}(\Lambda _d)\) the unit cell of \(\Lambda _d\) with smallest diameter, \(\ell \) . The volume of the unit cell is \(\sqrt{d}\), which can be seen as follows.Footnote 8 A basis for the lattice \(\Lambda _d = \lbrace v\in \mathbb {Z}^d:\sum _{i=1}^d v_i = 0\rbrace \) is given by \(B=\lbrace b_i\rbrace _{i=1}^{d-1}\), where \(b_i=e_1-e_{i+1}\). It follows that \(M=B^T B\) is a \((d-1)\times (d-1)\)-matrix with all diagonal elements equal to 2 and all off-diagonal elements equal to 1. The matrix M has one eigenvalue d corresponding to the eigenvector \(\sum _{i=1}^{d-1} e_i\), and \(d-2\) eigenvalues 1 corresponding to the eigenvectors \(e_1-e_{i+1}\), respectively. Hence, \(\det (\Lambda _d) = \sqrt{d}\).
Let further \(g:\mathbb {R}\Lambda _d\rightarrow \Lambda _d\) be the function such that for all \(x\in \mathbb {R}\Lambda ^d\) there exist \(\gamma _i\in (-1/2,1/2]\), \(i=1,\ldots ,d-1\) such that
Heuristically, g is the function that maps every point in the \((d-1)\)-dimensional subspace \(\Lambda ^d\) lives in to the lattice point v in whose surrounding unit cell it lies, where the surrounding unit cell is here the set \(\{v+\sum _{i=1}^{d-1}\gamma _i a_i|\gamma _i\in (-1/2,1/2]\}\), i.e. the point lies in the center of the cell. As f is nonnegative, we have with l as defined above that
The gradient of f is given by
We can bound
so
Here, we changed into spherical coordinates with origin in \(\hat{\mu }\) in the third line, and \({{\,\mathrm{vol}\,}}(\mathbb {S}_{d-2})\) is the volume of the \((d-2)\)-dimensional sphere. Turning to the first term in Eq. (B.2), we calculate
Combining the last two equations, expanding the polynomials of the form \(\left( R+\ell /2\right) ^{k}\) and using the power series expansion of \(1/(1+x)\) we finally arrive at
Returning to equation Eq. (B.1), let us first bound the magnitude of the last term. To this end, observe that for \(r(\mu )\ge R-\sqrt{2}\), we have
Furthermore we have that
and hence
To bound the number of lattice points in the spherical shell \(B^{\Lambda _d}_{R}(\hat{\mu }){\setminus } B^{\Lambda _d}_{R-\sqrt{2}}(\hat{\mu })\), note that i) each lattice point is surrounded by its own unit cell, and ii) these cells have diameter \(\ell \). Therefore all these unit cells are disjoint subsets of a shell of width \(\sqrt{2}+\ell \), and hence we have the bound
Combining the bounds we arrive at
Turning to the first expression on the right hand side of Eq. (B.1), we observe that both the set \(B^{\Lambda _d}_{R-\sqrt{2}}\) and the distribution q are invariant under the map \(\mu \mapsto 2\mu -\hat{\mu }\), i.e. central reflection about \(\hat{\mu }\). Therefore the sum over \(g_{ij}(\mu )\), which is linear in \(\mu -\hat{\mu }\), vanishes, i.e.
Using the same argument as for bounding \(\eta _{N}\), we find
The second term is bounded in the same way as the spherical shell sum above, yielding
Combining all bounds, we arrive at
Using \(R=\frac{N}{d^2}\) we obtain the final bound
\(\square \)
The Maximal Eigenvalue of a \(2\times 2\) GUE\({}_0\) Matrix
The maximal eigenvalue \(\lambda _{\max }(\mathbf {G})\) of a \(2\times 2\) GUE\({}_0\) matrix \(\mathbf {G}\) can be easily analyzed, as \(\lambda _{\max }(\mathbf {G})=\sqrt{\frac{1}{2} {{\,\mathrm{tr}\,}}\mathbf {G}^2}\).
Lemma C.1
For \(\mathbf {X}\sim \mathrm {GUE}_0(2)\), \(\sqrt{2}\lambda _{\max }(\mathbf {G})\sim \chi _3\), where \(\chi _3\) is the chi-distribution with three degrees of freedom.Footnote 9 Consequently, \(\mathbb {E}\left[ \lambda _{\max }(\mathbf {G})\right] =\frac{2}{\sqrt{\pi }}\).
Proof
By definition, the probability density of \(\mathrm {GUE}(d)\) is
and therefore we get
for the density of GUE\({}_0\). Writing \(\mathbf {G}=\sum _{i=1}^3\mathbf {x}_i \sigma _i\) with the Pauli matrices \(\sigma _i, i=1,2,3\), we see that the \(\mathbf {x}_i\) are independent normal random variables with variance 1/2, and
proving the claim. \(\quad \square \)
Technical Lemmas
The following “mirror lemma”, also called “transpose trick”, is well known in the literature, and can be proven in a straightforward way:
Lemma D.1
(Mirror lemma, transpose trick). Let \(\lbrace |i\rangle \rbrace _{i=1}^d\) be a basis and \(|\gamma \rangle =\sum _{i=1}^d |i\rangle |i\rangle \) be the unnormalized maximally entangled state. For any operator X,
where \(X^T\) denotes transposition of X with respect to the basis \(\lbrace |i\rangle \rbrace _{i=1}^d\).
The maximization in the definition of the diamond norm can be carried out explicitly for the distance of two unitarily covariant channels. This is the statement of the following lemma, which is a special case of a more general result about generalized divergences proven in [69].
Lemma D.2
[69]. Let \(\Lambda ^{(i)}_{A\rightarrow A}\) for \(i=1,2\) be unitarily covariant maps. Then the maximally entangled state \(|\phi ^+\rangle _{AA'}\) is a maximizer for their diamond norm distance, i.e.,
The following Lemma from Ref. [5] shows that the entanglement fidelity and the diamond norm distance to the identity channel are even in a 1-1 relation for unitarily covariant channels.
Lemma D.3
[5]. For a unitarily covariant channel \(\Lambda :A\rightarrow A\),
We need an explicit limit of certain Riemann sums. The proof of the following can, e.g., be found in [70].
Lemma D.4
Let \(f:\mathbb {R}_+\rightarrow \mathbb {R}_+\) be nonincreasing such that the (proper or improper) Riemann integral
exists for all \(a,b\in [0,\infty ]\) with \(a<b\). Then
for all \(c\ge 0\) and \(g\in [0,\infty ]\).
The following lemma provides the volume of the simplex of ordered probability distributions as well as the volume of its boundary.
Lemma D.5
Let
be the simplex of ordered probability distributions. The volume of this simplex, and the volume of its boundary, are given by
respectively.
Proof
\(\mathrm {OS}_{d-1}\) is given in its dual description above, let us therefore begin by finding its extremal points. These are clearly given by
i.e. the ith extremal point has i entries \(\frac{1}{i}\) and \(d-i\) entries 0. The supporting (affine) hyperplanes \(H_i\) of the facets \(F_i\), \(i=1,\ldots ,d\) of \(\mathrm {OS}_{d-1}\) in \(V_0^{(d-1)}=\left\{ x\in \mathbb {R}^d|\sum _i x_i=0\right\} \) are given by the normalized normal vectors
Now note that the facet \(F_d=\{x\in \mathrm {OS}_{d-1}|x_d=0\}\) is equal to \(\mathrm {OS}_{d-2}\), and the volume of a \((d-1)\)-dimensional pyramid is given by the product of the volume of its base and its height, divided by \(d-1\). Therefore we get the recursive formula
where we have defied the distance \(h_{i}\) between \(v_i\) and \(H_i\). Let us calculate \(h_d\). This can be done by taking the difference of \(v_d\) and any point in \(H_i\) and calculating the absolute value of its inner product with \(n_d\). We thus get
The recursion therefore becomes
The claimed formula for the volume is now proven by induction. \(\mathrm {OS}_2\) is just the line from (1, 0) to (1/2, 1/2), so its volume is clearly
proving Eq. (D.1) for \(d=2\). For the induction step, assume that the formula Eq. (D.1) holds for \(d=k-1\). Then we have
For the boundary volume, we can use the pyramid volume formula again to obtain
i.e. we obtain the formula
We calculate the heights \(h_i\) for \(i\ne d\). For \(1<i<d\) we get in the same way as above for \(i=d\),
for \(i=1\) we calculate
Therefore we get the boundary volume
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Christandl, M., Leditzky, F., Majenz, C. et al. Asymptotic Performance of Port-Based Teleportation. Commun. Math. Phys. 381, 379–451 (2021). https://doi.org/10.1007/s00220-020-03884-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00220-020-03884-0