
Abstract
A method for the kernel-independent construction of \(\mathcal {H}^2\)-matrix approximations to non-local operators is proposed. Special attention is paid to the adaptive construction of nested bases. As a side result, new error estimates for adaptive cross approximation (ACA) are presented which have implications on the pivoting strategy of ACA.
Similar content being viewed by others

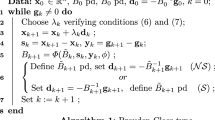

Avoid common mistakes on your manuscript.
1 Introduction
The fast multipole method introduced by Greengard and Rokhlin (see [18, 30]) has become a very popular method for the efficient evaluation of long-range potentials and forces in the n-body problem. In a SIAM News article [17] it has been named to be one of the top 10 algorithms of the 20th century. While in the initial publications two-dimensional electrostatic problems were investigated, later publications [16, 19] have improved the method such that three-dimensional electrostatic problems and also problems with more general physical background can be treated efficiently. All these variants rely on explicit kernel expansions, which on the one hand allows to tailor the expansion tightly to the respective problem, but on the other hand requires its own analytic apparatus including a-priori error estimates for each kernel. In order to overcome this technical difficulty, kernel-independent generalizations [32] were introduced. While the latter keep the analytic point of view, \(\mathcal {H}\)- and \(\mathcal {H}^2\)-matrices (see [20, 21, 23]) generalize the method as much as possible by an algebraic perspective. In addition to the n-body problem, the latter methods can be applied to general elliptic boundary value problems either in its differential or its integral representation; see [9, 22]. Furthermore, approximate replacements of usual matrix operations such as addition, multiplication, and inversion can be carried out with logarithmic-linear complexity, which allows to construct preconditioners in a fairly automatic way.
Nevertheless, \(\mathcal {H}^2\)-matrix approximations cannot be constructed without taking into account the analytic background. For instance, the construction of suitable cluster bases is a crucial task. In order to guarantee as much universality of the method as possible, polynomial spaces are frequently used; see [13]. While this choice is quite convenient due to special properties of polynomials, it is usually not the most efficient approach. To see why, keep in mind that the three-dimensional approach based on spherical harmonics [16] requires \(k=\mathcal {O}(p^2)\) terms in a truncated expansion with precision of order p, while the number of polynomial terms for the same order of precision requires \(k=\mathcal {O}(p^3)\) terms. In the special case of surface problems, an isogeometric approach exploiting surface information and a suitable parameterization can also yield a behavior \(k = \mathcal {O}(p^2)\); see [24]. With the approach presented in the present article also volume problems can be treated.
The number of terms k required to achieve a prescribed accuracy is crucial for the overall efficiency of the method. In addition to its dependence on the kernel, this number also depends on the underlying geometry (local patches of the geometry may have a smaller dimension). Additionally, a-priori error estimates usually lead to an overestimation of k. It is therefore helpful to find k in an automatic way, i.e. by an adaptive procedure. Such a method has been introduced by one of the authors. The adaptive cross approximation (ACA) [8] computes low-rank approximations of suitable sub-blocks using only few of the original matrix entries. From the algorithmic point of view this procedure is similar to a partially pivoted LU factorization. Therefore, it is kernel-independent. In addition to that, it provably achieves asymptotic optimal convergence rates.
The aim of this article is to generalize the adaptive cross approximation method, which was introduced for \(\mathcal {H}\)-matrices, to the kernel-independent construction of \(\mathcal {H}^2\)-matrices for matrices \(A\in \mathbb {R}^{M\times N}\) with entries of the form
Here, \(\varphi _i\) and \(\psi _j\) denote locally supported ansatz and test functions. The kernel function K is of the type
with a singular function \(f(x,y)=|x-y|^{-\alpha }\) and functions \(\xi \) and \(\zeta \) each depending on only one of the variables x and y. Such matrices result, for instance, from a Galerkin discretization of integral operators. In particular, this includes the single layer potential operator \(K(x,y)=|x-y|^{-1}\) and the double layer potential operator of the Laplacian in \(\mathbb {R}^3\) for which \(K(x,y)=\frac{(x-y)\cdot n_y}{|x-y|^3}=\frac{x\cdot n_y}{|x-y|^3}-\frac{y\cdot n_y}{|x-y|^3}\). Note that collocation methods and Nyström methods can also be included by formally choosing \(\varphi _i=\delta _{x_i}\) or \(\psi _j=\delta _{x_j}\), where \(\delta _x\) denotes the Dirac distribution centered at x. In contrast to \(\mathcal {H}\)-matrices for which the method is applied to blocks, in the case of \(\mathcal {H}^2\)-matrices cluster bases have to be constructed. If this is to be done adaptively, special properties of the kernel have to be exploited in order to be able to guarantee that the error is controlled also outside of the cluster. Our approach relies on the harmonicity of the singular part f of the kernel function K. This article also presents a-priori error estimates which are based on interpolation by radial basis functions. The advantage of these new results is that they pave the way to a new pivoting strategy of ACA. While results based on polynomial interpolation error estimates require that the pivots are chosen such that unisolvency of the polynomial interpolation problem is guaranteed, the new estimates show that only the fill distance of pivoting points is crucial for the convergence of ACA.
The article is organized as follows. In the next Sect. 2 we construct interpolants \(s_k\) to kernels f which are harmonic with respect to one variable. The system of functions in which the interpolating function is constructed will be defined from restrictions of f. This construction guarantees that the harmonicity of f is preserved for its interpolation error. Hence, in order to achieve a prescribed accuracy in the exterior of a domain, it is sufficient to check it on its boundary. This allows to construct \(s_k\) in a kernel-independent and adaptive way. The interpolating function \(s_k\) is then used to construct a quadrature rule which will be used in the construction of nested bases. Sect. 2.1 presents error estimates for functions \(\text {e}^{-\gamma |x|}\) based on radial basis functions. These results are used in Sect. 2.2 to derive exponential error estimates (via exponential sum approximation) for \(s_k\) when interpolating \(f(x,y)=|x-y|^{-\alpha }\) for arbitrary \(\alpha >0\). The goal of Sect. 3 is the construction of uniform \(\mathcal {H}\)- and \(\mathcal {H}^2\)-matrix approximations to matrices (1) using the harmonic interpolants \(s_k\). In Sect. 4 we present a new pivoting strategy, which is based on the fill distance, to tackle an old problem that ACA may suffer from on non-smooth domains. Furthermore, we apply the new construction method of \(\mathcal {H}^2\)-matrix approximations to boundary integral formulations of Poisson boundary value problems and to fractional diffusion problems and present numerical results which validate the presented method.
2 Harmonic interpolants and quadrature rules
For the construction of \(\mathcal {H}^2\)-matrix approximations (see Sect. 3), quadrature rules for the computation of integrals
will be required which depend only on the domain of integration \(X\subset \mathbb {R}^d\) and which are valid in the whole far-field of X, i.e. for \(y\in \mathcal {F}_\eta (X)\), where
with given \(\eta >0\). Such quadrature formulas are usually based on polynomial interpolation together with a-priori error estimates. The aim of this section is to introduce new adaptive quadrature formulas which are controlled by a-posteriori error estimates. In the special situation that \(f(x,\cdot )\), \(x\in X\), is harmonic in
and vanishes at infinity it is possible to control the quadrature error for \(y\in \mathcal {F}_\eta (X)\) also computationally. Notice that \(f(x,y)=|x-y|^{-\alpha }\) is harmonic in \(\mathbb {R}^d\), \(d\ge 3\), only for \(\alpha =d-2\). Applying the following arguments in \(\mathbb {R}^{d'+2}\), one can also treat the case \(\alpha =d'\) for arbitrary \(d'\in \mathbb {N}\). Fractional exponents, which appear for instance in the case of the fractional Laplacian, will be treated in a forthcoming article.
Harmonic functions \(u:\varOmega \rightarrow \mathbb {R}\) in an unbounded domain \(\varOmega \subset \mathbb {R}^d\) are known to satisfy the mean value property
for balls \(B_r(x)\subset \varOmega \) and the maximum principle
provided u vanishes at infinity.
Let \(\varSigma \subset \mathbb {R}^d\) be an unbounded domain such that (see Fig. 1)

\(\varSigma \) and the far-fields \(\mathcal {F}_{2\eta }(X)\) and \(\mathcal {F}_\eta (X)\)
A natural choice is \(\varSigma =\mathcal {F}_\eta (X)\). Since our aim is to check the actual accuracy and we cannot afford to inspect it on an infinite set, we introduce the finite set \(M\subset \partial \varSigma \) to be close to \(\partial \varSigma \), i.e., we assume that M satisfies
In [9] we have already used the following recursive definition for the construction of an interpolating function \(s_k\) in the convergence analysis of the adaptive cross approximation [8]. Let \(r_0=f\) and for \(k=0,1,2,\dots \) assume that \(r_k\) has already been defined. Let \(x_{k+1}\in X\) be chosen such that
then set
and \(s_{k+1}:=f-r_{k+1}\), where \(y_{k+1}\in M\) denotes the maximum of \(|r_k(x_{k+1},\cdot )|\) in M.
It can be shown (see [9]) that \(s_k\) interpolates f at the chosen nodes \(x_i\), \(i=1,\dots ,k\), for all \(y\in \mathcal {F}_\eta (X)\), i.e.,
and belongs to \(F_k:=\text {span}\{f(\cdot ,y_1),\dots ,f(\cdot ,y_k)\}\). In addition, the choice of \((x_k,y_k)\in X\times M\) guarantees unisolvency, which can be seen from
where \(C_k\in \mathbb {R}^{k\times k}\) denotes the matrix with the entries \((C_k)_{ij}=f(x_i,y_j)\), \(i,j=1,\dots ,k\). Hence, one can define the Lagrange functions for the system and the nodes \(x_i\), i.e. \(L^{(j)}_k(x_i)=\delta _{ij}\), \(i,j=1,\dots ,k\), as
where \(C^{(i)}_k(x)\in \mathbb {R}^{k\times k}\) results from \(C_k\) by replacing its i-th row with the vector
Another representation of the vector \(L_k\in \mathbb {R}^k\) of Lagrange functions \(L_k^{(i)}\) is
Due to the uniqueness of the interpolation, \(s_k\) has the representation
where \(w_k(y):=[f(x_1,y),\dots ,f(x_k,y)]^T\).
For an adaptive procedure it remains to control the interpolation error \(f-s_k=r_k\) in \(X\times \mathcal {F}_\eta (X)\). The following obvious property follows from (6) via induction.
Lemma 1
If \(f(x,\cdot )\) is harmonic in \(X^c\) and vanishes at infinity for all \(x\in X\), then so do \(s_k(x,\cdot )\) and \(r_k(x,\cdot )\).
The following lemma shows that although \(M\subset \partial \varSigma \) is a finite set, it can be used to find an upper bound on the maximum of \(r_k(x,\cdot )\) in the unbounded domain \(\mathcal {F}_\eta (X)\).
Lemma 2
Let the assumptions of Lemma 1 be valid and let \(2q\eta \,\delta <\text {diam}\,X\), where \(q=(\root d \of {2}-1)^{-1}+2\). Then there is \(c_k>0\) such that for \(x\in X\) it holds
where \(c_k:=\Vert \nabla _y r_k(x,\cdot )\Vert _\infty \).
Proof
Let \(x\in X\) and \(y\in \partial \varSigma \). We define the set
of zeros in \(B_{q\delta }(y)\). If \(N\ne \emptyset \) then with \(z\in N\)
In the other case \(N=\emptyset \), our aim is to find \(y'\in M\) such that \(|r_k(x,y)|\le 2|r_k(x,y')|\). \(r_k\) does not change its sign and is harmonic in \(B_{q\delta }(y)\) due to \(B_{q\delta }(y)\subset X^c\), which follows from (3) as
Due to the assumption (4) we can find \(y'\in B_\delta (y)\cap M\). Then \(B_{(q-2)\delta }(y)\subset B_{(q-1)\delta }(y')\subset B_{q\delta }(y)\). Hence, the mean value property (applied to \(r_k\) if \(r_k\) is positive or to \(-r_k\) if \(r_k\) is negative) shows
Sine \(r_k\) vanishes at infinity, (3) together with the maximum principle shows
\(\square \)
Notice that due to (8) we have
Hence,
with the Lebesgue constant \(\varLambda _k(x):=\sum _{i=1}^k|L_k^{(i)}(x)|\). Although it seems that \(\varLambda _k(x)\sim k\) in practice, there is no proof for this observation up to now. A related topic in interpolation theory are Leja points; see [25].
To see that this special kind of interpolation is more efficient than polynomial interpolation, we present the following example.
Example 1
Let \(X\subset \mathbb {R}^3\) be 1000 points forming a uniform mesh of the unit cube \([0,1]^3\). We choose \(\varSigma =\{x\in \mathbb {R}^3:|x|>10\}\). M is a discretization of \(\partial \varSigma \) with 768 points. We consider \(f(x,y)=|x-y|^{-1}\) and compare the quality of \(s_k\) with the quality of the interpolating tensor Chebyshev polynomial of degree k. Table 1 shows the maximum pointwise error measured at \(X\times M\); see also Fig. 2. Table 2 compares the cross approximation with a sparse grid interpolation obtained from the Sparse Grid Matlab Kit; see [7].

Error versus k of cross approximation (black), Chebyshev interpolation (blue, dotted), and sparse grid interpolation (red, dashed)
2.1 Exponential error estimates for multivariate interpolation
For analyzing the error of the cross approximation, the remainder \(r_k\) has to be estimated. The proof in [9] establishes a connection of \(r_k\) with the best approximation in an arbitrary system \(\varXi = \{ \xi _1, \dots , \xi _k\}\) of functions. There, qualitative estimates are presented for a polynomial system \(\varXi \). For the uniqueness of polynomial interpolation it has to be assumed that the Vandermonde matrix \([\xi _j(x_i)]_{ij} \in \mathbb {R}^{k \times k}\) is non-singular. The goal of the following section is to provide new error estimates for the convergence of cross approximation which avoid the unisolvency assumption by employing radial basis functions (RBF) for the system \(\varXi \) instead of polynomials as the former type of functions are positive definite; see e.g. [15]. Since the interpolation error of RBFs is governed by the fill distance [see (10)], we will be able to state a rule for choosing the next pivotal point \(x_k\) [in addition to (5)] leading to fast convergence.
Let \(\kappa :\mathbb {R}^d\rightarrow \mathbb {R}\) be a continuous function. In the following we assume that \(\kappa \) is positive definite, i.e.
for all \(0\ne \varphi \in C_0^\infty (\mathbb {R}^d)\). The Fourier transform of such functions determines a measure \(\mu \) on \(\mathbb {R}^d\setminus \{0\}\) such that
Following [28] we define \(\mathscr {C}_\kappa \) the set of continuous functions f satisfying
for some constant \(c>0\) and all \(\varphi \in C_0^\infty (\mathbb {R}^d)\). The smallest constant c in (9) defines a norm \(\Vert f\Vert _\kappa \) and \(\mathscr {C}_k\) is a Hilbert space.
Given a set \(X_k := \{x_1,\dots ,x_k\}\subset X\) consisting of \(k \in \mathbb {N}\) nodes \(x_j\), an interpolant \(p \in \text {span}\{\kappa (\cdot -x_j),\,j=1,\dots ,k\}\) has to fulfill the conditions
A solution of this interpolation problem can be written in its Lagrangian form
where \(L^{\kappa }_{i}(x) = \sum _{j = 1}^{k} \alpha _j^{(i)} \kappa (x-x_j)\) denote the Lagrange functions satisfying \(L^{\kappa }_j(x_i) = \delta _{ij}\), i.e., its coefficients \(\alpha ^{(i)}\in \mathbb {R}^k\) are defined as the solution of the linear systems of equations \(A\alpha ^{(i)} = e_i\) with \(A := [\kappa (x_i-x_j)]_{ij}\in \mathbb {R}^{k\times k}\). The error between a function \(f\in \mathscr {C}_\kappa \) and its interpolant p is typically measured in terms of the fill distance
The following result is proved in [28].
Theorem 1
Let X be a cube of side \(b_0\). Suppose that \(\mu \) satisfies
for some \(\rho >0\). Then there is \(0<\lambda <1\) such that for all \(f\in \mathscr {C}_\kappa \) the corresponding interpolant p satisfies
for all \(x\in X\).
Remark 1
The assumption that X is a cube can be generalized. Theorem 1 remains valid as long as X can be expressed as the union of rotations and translations of a fixed cube of side \(b_0\). Actually, any ball in \(\mathbb {R}^d\) or any set X with sufficiently smooth boundary fulfills the requirements.
Elements \(f\in \mathscr {C}_\kappa \) can be characterized (see [26, 27]) by the existence of a function \(g\in L^2_\mu \) such that
For later purposes we prove
Lemma 3
Let \(\kappa (x)=\exp (-\beta |x|^2)\) with \(\beta >0\). Then \(\kappa \) is positive definite and the measure \(\mu \) associated with \(\kappa \) satisfies (11). Furthermore, \(h(x)=\exp (-\gamma |x|)\) with \(\gamma >0\) belongs to \(\mathscr {C}_\kappa \).
Proof
Since the Fourier transform of a Gauss function is again a Gauss function, the measure associated with \(\kappa \) is
\(\mu \) satisfies (11). Let \(H(r)=\exp (-\gamma r)\) with \(r=|x|\). Then \({\hat{h}}(\xi )={\hat{H}}(s)\), where \(s=|\xi |\). Since
with the Bessel function \(J_{d/2-1}\) of order \(d/2-1\), we obtain for the Hankel transform (cf. [6]) that
and
where \(\varGamma \) denotes the Gamma function. Defining the \(L^2_\mu \)-function
we obtain (12), because
\(\square \)
Although RBFs lead to a positive definite Vandermonde matrix A, its numerical stability might be an issue. The eigenvalues of A depend significantly on the distribution of the points and in particular on their distances. A typical measure for this is the separation distance
In our case, i.e. for the Gaussian kernel, the smallest eigenvalue of A can be estimated by
where \(C = C(d) > 0\) is a d-dependent constant; see [31]. One of the main aims of the techniques presented here is a uniform coverage of the considered domain with interpolation points and no generation of local clusters of points, so also from the numerical point of view the Vandermonde matrix A is expected to behave in a stable way.
2.2 Application to \(|x-y|^{-\alpha }\)
We consider functions f of the form
on two domains X, Y satisfying
The validity of the latter condition usually results from a partitioning of the computational domain \(\varOmega \times \varOmega \) induced by a hierarchical partitioning of the matrix (1). In this article, the choice \(Y=M\) is of particular importance, where the set \(M\subset \partial \varSigma \subset \mathcal {F}_{2\eta }(X)\) was introduced at the beginning of this section. Notice that \(\text {diam}\,M\le \text {diam}\,\partial \mathcal {F}_\eta (X)\le \text {diam}\,X+2\,\text {dist}(X,\partial \mathcal {F}_\eta (X))=(1+2/\eta )\,\text {diam}\,X\).
Let \(\kappa (x,y) = \exp (-\beta |x-y|^2)\). For fixed \(y\in Y\) we interpolate f with the radial basis function
on the data set \(X_k = \{x_1, \dots , x_k\}\). Here, \(L_j^{\kappa }\), \(j = 1,\ldots ,k\), are the Lagrange functions for \(\kappa \) and \(X_k\).
Lemma 4
Let \(\sigma :=\text {dist}(X,Y)\). Then for \(x\in X\), \(y\in Y\)
where \(\varLambda ^\kappa _k:=\sup _{x\in X}\sum _{i=1}^k|L_i^\kappa (x)|\) denotes the Lebesgue constant.
Proof
Functions of type f are not covered by Theorem 1. Therefore, we additionally employ exponential sum approximations
of \(g(t):=t^{-\alpha }\) with finite r in order to approximate f on the interval [1, R]. According to [14], there are coefficients \(\omega _j,\gamma _j>0\) such that
Choosing r such that
and \(R=1+\eta (1+c_0)\), (13) implies for \(x\in X\) and \(y\in Y\)
Letting \(h_{j,y}(x)=\sigma ^{-\alpha }\exp (-\gamma _j|x-y|/\sigma )\), we obtain
According to Theorem 1 and Lemma 3, the functions \(h_{j,y}\) can be interpolated using the radial basis function \(\kappa \) on the data set \(X_k = \{x_1, \dots , x_k\}\), i.e.
where
Let \(h^*(x):=\sigma ^{-\alpha }\sup _{y\in Y}\exp (-\beta _*|x-y|)\), where \(\beta _*:=\min _{j=1,\dots ,r}\gamma _j/\sigma \). From
for all \(\varphi \in C_0^\infty (\mathbb {R}^d)\) we obtain that \(\Vert h_{j,y}\Vert _\kappa \le \Vert h^*\Vert _\kappa \). Hence,
Notice that \(\sum _{j=1}^r \omega _j\le \text {e}^{\gamma _*}\sum _{j=1}^r \omega _j\text {e}^{-\gamma _j}=\text {e}^{\gamma _*}g_r(1)\le c\), where \(\gamma _*=\max _{j=1,\dots ,r}\gamma _j\). The last step is to show that
The assertion follows from the triangle inequality. \(\square \)
Since the previous theorem relies on Theorem 1, X is assumed to be smooth. The generalization of Theorem 1 to non-smooth X is not straightforward and needs further investigation. However, the following numerical tests show that the presented theory gives reasonable results also for non-smooth manifolds X.
Example 2
Let \(X = \{ (x,y,z) \in [-1,1]^3 \, : \, x = 1\} \cup \{ (x,y,z) \in [-1,1]^3 \, : \, z = 1\}\) be the union of two faces of the cube \([-1,1]^3\). On several discretizations of X the interpolation of the function \(f(x,y) = |x-y|^{-1}\) is considered using the Gaussian kernel \(\kappa (x) = \exp (-|x|^2)\). The error between f and its approximation p is tested with a discretization of X consisting of 32640 points and two different points \(y_1 = (2, 2, 2)^T\) and \(y_2 = (5, 5, 5)^T\) from the far-field. Then the maximum pointwise error measured at \(X \times \{y_1\}\) and \(X \times \{y_2\}\) can be observed in Table 3.
The convergence can be controlled by choosing the node \(x_{k+1}\) such that the fill distance \(h_{X_{k+1},X}\) is minimized from step k to step \(k+1\). This minimization problem can be solved efficiently, i.e. with logarithmic-linear complexity, with the approximate nearest neighbor search described in [3,4,5].
Remark 2
In practice, we replace possibly uncountable sets X with a sufficiently fine mesh. In our applications, X is a discrete cloud of points.
If we choose the pivots \(x_1,\dots ,x_k\) such that the fill distance behaves like \(h_{X_k,X} \sim k^{-1/d}\), Lemma 4 shows exponential convergence of \(p_y\) with respect to k provided the Lebesgue constant grows sub-exponentially.
Applying the results of the previous lemma to the remainder \(r_k\), we obtain the following result for interpolating f on \(X\times Y\). Notice that this result shows that the convergence is governed only by the fill distance. Hence, the unisolvency assumption on the nodes \(x_1,\dots ,x_k\) in the older convergence proof of ACA (which was based on polynomials; see [9]) can be dropped.
Theorem 2
For \(y \in Y\) let \(p_y\) denote the radial basis function interpolant (14) for \(f_y:= f(\cdot ,y)=|\cdot -y|^{-\alpha }\). Choosing \(y_1,\dots ,y_k\in Y\) such that
where \(c_M>1\) is a constant, it holds that
where \(X_k := \{x_1,\ldots ,x_k\}\).
Proof
Let the vector of the Lagrange functions \(L_{i}^{\kappa }\), \(i = 1,\ldots ,k\), corresponding to the radial basis function \(\kappa \) and the nodes \(x_1,\ldots ,x_k\) be given by
Using (8), we obtain
where the last line follows from Cramer’s rule. The assertion follows from the triangle inequality and Lemma 4. \(\square \)
Remark 3
In practice, Y will be replaced by a discrete set of points. For the choice \(Y=M\) (which is important for this article), it is sufficient to choose the nodes \(y_1,\ldots ,y_k \in Y\) according to the condition
which is much easier to check in practice and which leads to the estimate
for details see [9].
3 Construction of \(\mathcal {H}^2\)-matrix approximations
The aim of this section is to construct hierarchical matrix approximations to the matrix A defined in (1). To this end, we first partition the set of indices \(I\times J\), \(I=\{1,\dots ,M\}\) and \(J=\{1,\dots ,N\}\), into sub-blocks \(t\times s\), \(t\subset I\) and \(s\subset J\), such that the associated supports
satisfy
i.e. \(Y_s\subset \mathcal {F}_\eta (X_t)\) and \(X_t\subset \mathcal {F}_\eta (Y_s)\). Notice that from Sect. 2.2 we know that the singular part f of the kernel function K in (1) can be approximated on the pair \(X_t\times Y_s\).
The usual way of constructing such partitions is based on cluster trees; see [9, 21]. A cluster tree \(T_I\) for the index set I is a binary tree with root I, where each \(t \in T_I\) and its nonempty successors \(S_I(t)=\{t',t''\}\subset T_I\) (if they exist) satisfy \(t = t' \cup t''\) and \(t' \cap t'' = \emptyset \). We refer to \(\mathcal {L}(T_I) = \{t \in T_I:S_I(t)=\emptyset \}\) as the leaves of \(T_I\) and define
where \(\text {dist}(t, s)\) is the minimum distance between t and s in \(T_I\). Furthermore,
denotes the depth of \(T_I\).
Once the cluster trees \(T_I\), \(T_J\) for the index sets I and J have been computed, a partition P of \(I\times J\) can be constructed from it. A block cluster tree \(T_{I\times J}\) is a quad-tree with root \(I\times J\) satisfying conditions analogous to a cluster tree. It can be constructed from the cluster trees \(T_I\) and \(T_J\) in the following way. Starting from the root \(I\times J\in T_{I\times J}\), let the sons of a block \(t\times s\in T_{I\times J}\) be \(S_{I\times J}(t,s):=\emptyset \) if \(t\times s\) satisfies (16) or \(\min \{|t|,|s|\}\le n_{\min }^\mathcal {H}\) with a given constant \(n_{\min }^\mathcal {H}>0\). In the remaining case, we set \(S_{I\times J}(t,s):=S_I(t)\times S_J(s)\). The set of leaves of \(T_{I\times J}\) defines a partition P of \(I\times J\) and its cardinality |P| is of the order \(\min \{|I|,|J|\}\); see [9]. As usual, we partition P into admissible and non-admissible blocks
where each \(t\times s\in P_{\text {adm}}\) satisfies (16) and each \(t\times s\in P_{\text {nonadm}}\) is small, i.e. satisfies \(\min \{|t|,|s|\}\le n_{\min }^\mathcal {H}\).
3.1 Uniform \(\mathcal {H}\)-matrix approximation
Hierarchical matrices are well-suited for treating non-local operators with logarithmic-linear complexity; see [9, 11, 22].
Definition 1
A matrix \(A\in \mathbb {R}^{I\times J}\) satisfying \(\text {rank}\,A|_b\le k\) for all \(b\in P_\text {adm}\) is called hierarchical matrix (\(\mathcal {H}\)-matrix) of blockwise rank at most k.
In order to approximate the matrix (1) more efficiently, we employ uniform \(\mathcal {H}\)-matrices; see [20].
Definition 2
A cluster basis \(\varPhi \) for the rank distribution \((k_t)_{t\in T_I}\) is a family \(\varPhi =(\varPhi (t))_{t\in T_I}\) of matrices \(\varPhi (t) \in \mathbb {R}^{t\times k_t}\).
Definition 3
Let \(\varPhi \) and \(\varPsi \) be cluster bases for \(T_I\) and \(T_J\). A matrix \(A\in \mathbb {R}^{I\times J}\) satisfying
with some \(F(t,s)\in \mathbb {R}^{k_t^\varPhi \times k_s^\varPsi }\) is called uniform hierarchical matrix for \(\varPhi \) and \(\varPsi \).
The storage required for the coupling matrices F(t, s) is of the order \(k\min \{|I|,|J|\}\) if for the sake of simplicity it is assumed that \(k_t\le k\) for all \(t\in T_I\). Additionally, it is not useful to choose \(k_t>|t|\). The cluster bases \(\varPhi \) and \(\varPsi \) require \(k[|I|L(T_I)+|J|L(T_J)]\) units of storage; see [23].
In the following we employ the method from Sect. 2 to construct a uniform \(\mathcal {H}\)-matrix approximation to an arbitrary block \(t\times s\in P_\text {adm}\) of matrix (1). Let \(\varepsilon > 0\) be given and \([x]_t=\{x^t_p,\,p\in \tau _t\}\subset X_t\) and \([v]_t=\{v^t_p,\,p\in \sigma _t\}\subset \mathcal {F}_\eta (X_t)\) be the pivots chosen in (6) such that
for each cluster t. Here, \(L^t(x):=f(x,[v]_t)f^{-1}([x]_t,[v]_t)\) denotes the vector of Lagrange functions defined in (7). \(\tau _t\) and \(\sigma _t\) denote index sets with cardinality k. From Theorem 2 we know that \(k\sim |\log \varepsilon |^d\). Similarly, for \(s\in T_J\) let \([y]_s=\{y^s_q,\,q\in \sigma _s\}\subset Y_s\) and \([w]_s=\{w^s_q,\,q\in \tau _s\}\subset \mathcal {F}_\eta (Y_s)\) be chosen such that
where \(L^s(y):=f^{-1}([w]_s,[y]_s)f([w]_s,y)\). For \(x\in X_t\) and \(y\in Y_s\) this yields the dual interpolation
with corresponding interpolation error
and the Lebesgue constant \(\varLambda _k^t\ge 1\). We define the matrix B of rank at most k
where \(\xi \) and \(\zeta \) are the functions defined in (2). Notice that both matrices
are associated only with t and s, respectively, and can be precomputed independently of each other. Only the matrix \(F(t,s)\in \mathbb {R}^{k\times k}\) with \([F(t,s)]_{pq}:=f(x^t_p,y^s_q)\) depends on both clusters t and s.
Remark 4
Since the vector of Lagrange functions \(L^t(x)\) has the representation \(L^t(x)=C_k^{-1}v_k(x)\), the matrices \(\varPhi (t)\in \mathbb {R}^{t\times \tau _t}\) can be found from solving the linear system
With \(\Vert \varphi _i\Vert _{L^1}=1=\Vert \psi _j\Vert _{L^1}\) the Cauchy-Schwarz inequality implies
and thus
Notice that the computation of the double integral for a single entry of the Galerkin matrix (1) is replaced with two single integrals in (20).
3.2 Nested bases
In order to reduce the amount of storage for storing the bases \(\varPhi \) and \(\varPsi \) one can establish a recursive relation among the basis vectors. The corresponding structure are \(\mathcal {H}^2\)-matrices; see [11, 23]. This sub-structure of \(\mathcal {H}\)-matrices is even mandatory if a logarithmic-linear complexity is to be achieved for high-frequency Helmholtz problems. To this end, directional \(\mathcal {H}^2\)-matrices have been introduced in [10].
Definition 4
A cluster basis \(U=(U(t))_{t\in T_I}\) is called nested if for each \(t\in T_I\setminus {\mathcal {L}(T_I)}\) there are transfer matrices \(T_{t't}\in \mathbb {R}^{k_{t'}\times k_t}\) such that for the restriction of the matrix U(t) to the rows \(t'\) it holds that
For estimating the complexity of storing a nested cluster basis U notice that the set of leaf clusters \({\mathcal {L}(T_I)}\) constitutes a partition of I and for each leaf cluster \(t\in {\mathcal {L}(T_I)}\) at most k|t| entries have to be stored. Hence, \(\sum _{t\in {\mathcal {L}(T_I)}} k|t|=k|I|\) units of storage are required for the leaf matrices U(t), \(t\in {\mathcal {L}(T_I)}\). The storage required for the transfer matrices is of the order k|I|, too; see [23].
Definition 5
A matrix \(A\in \mathbb {R}^{I\times J}\) is called \(\mathcal {H}^2\)-matrix if there are nested cluster bases U and V such that for \(t\times s \in P_\text {adm}\)
with coupling matrices \(F(t,s)\in \mathbb {R}^{k_t^U\times k_s^V}\).
Hence, the total storage required for an \(\mathcal {H}^2\)-matrix is of the order \(k (|I|+|J|)\).
Remark 5
It may be advantageous to consider only nested bases for clusters t having a minimal cardinality \(n_{\min }^{\mathcal {H}^2}\ge n_{\min }^\mathcal {H}\). Blocks consisting of smaller clusters are treated with \(\mathcal {H}\)-matrices.
We define the matrices \(U(t)\in \mathbb {R}^{t\times k_t}\), \(t\in T_I\), by the following recursion. If \(t\in T\setminus \mathcal {L}(T_I)\) then the set of sons \(S_I(t)\) is non-empty and we define
with the transfer matrix
For leaf clusters \(t\in \mathcal {L}(T_I)\) we set \(U(t)=\varPhi (t)\). Similarly, we define matrices \(V(s)\in \mathbb {R}^{s\times k_s}\), \(s\in T_J\), using transfer matrices
Then \(U:=(U(t))_{t\in T_I}\) and \(V:=(V(t))_{t\in T_J}\) are nested bases.
Lemma 5
Assuming that \(\max _{t\in T_I} \{\Vert U(t)\Vert _F,\Vert V(t)\Vert _F,\Vert T_{t't}^U\Vert _F\}\le \gamma \) and \(k_t\le k\) it holds that there exists a constant \(c > 0\) such that
where \(\ell \) denotes the level of \(t\times s\).
Proof
Let \(t\in T_I\setminus \mathcal {L}(T_I)\) and \(s\in T_J\setminus \mathcal {L}(T_J)\). For \(t'\in S_I(t)\) and \(s'\in S_J(s)\) we have
where \(D(t',s'):=F(t',s')-T^U_{t't}F(t,s) (T^V_{s's})^T\). Using
one observes that the previous expression consists of matrices with entries
and
which can be estimated using (17) and (18) due to \(x_i\in X_t\subset \mathcal {F}_\eta (Y_s)\) and \(y_j\in Y_s\subset \mathcal {F}_{\eta }(X_t)\). Thus,
By induction we prove that \(\Vert A|_{ts}-U(t) F(t,s) V(s)^T\Vert _F\le \gamma ^2\sqrt{2(1+\gamma ^2)}(L-\ell )\sqrt{|t||s|}\,\Vert \xi \Vert _\infty \Vert \zeta \Vert _\infty \,\varepsilon \), where \(\ell \) denotes the maximum of the levels of t and s. If both t and s are leaves, then \(\Vert A|_{ts}-\varPhi (t) F(t,s)\varPsi (s)^T\Vert \le 2\varLambda _k^t \sqrt{|t||s|}\,\Vert \xi \Vert _\infty \Vert \zeta \Vert _\infty \,\varepsilon \) due to (21). From (22) we see
This shows
The same kind of estimate holds if t or s is a leaf, because then \(U(t)=\varPhi (t)\) or \(V(s)=\varPsi (s)\). \(\square \)
4 Numerical results
The focus of the following numerical tests lies on three problems. The first problem is academic and shows that the new pivoting strategy for the adaptive cross approximation (ACA) which is based on the fill distance is able to overcome possible difficulties resulting from non-smooth geometries. The second problem is an exterior boundary value problem for the Laplace equation, the third is a fractional diffusion process. The second and third problem compare the method presented in this article (which generates \(\mathcal {H}^2\)-matrices) with an \(\mathcal {H}\)-matrix approximation generated by standard ACA. All computations were performed on a computer consisting of two Intel E5-2630 v4 processors. For the second problem, the construction of the matrix was done with a single core in order to guarantee a better comparability of the computation time. For the third test example, the fractional Poisson problem, this cannot be done in a reasonable time. Therefore, all 20 cores were used there.
4.1 New pivoting strategy for ACA
We apply ACA, i.e. the discrete version of (6) (for details see [9]), together with the pivoting strategy that is based on the fill distance (with respect to x) and (15) (with respect to y) to approximate a single block \(A\in \mathbb {R}^{N\times N}\) having the entries
where the points \(x_i\) are chosen from \(D_1\cup D_2\) and \(y_j\) are chosen from \(D_3\cup D_4\). The vector \(n_{y_j}\) denotes the unit normal vector in \(y_j\) to the boundary of the domain shown in Fig. 3. The two smallest side lengths of this domain were 1; the distance of \(D_1\cup D_2\) and \(D_3\cup D_4\) was chosen to be 9. A similar problem was presented in earlier publications; see [9, 12]. If the points \(x_i\), \(i=1,\dots ,N\), and \(y_j\), \(j=1,\dots ,N\), are ordered such that the first points are in \(D_1\) and \(D_3\), respectively, then A has the structure
As we have already mentioned in [9], standard ACA fails to converge since the pivots stay in one of the blocks \(A_{12}\) or \(A_{21}\) while the other block is not approximated at all. The new pivoting strategy leads to the desired convergence as Fig. 4 indicates.

Sets on the boundary of a box

Error versus rank of the approximation based on the fill distance
4.2 Exterior boundary value problem
We consider the Dirichlet boundary value problem for the Laplace equation in the exterior of the Lipschitz domain \(\varOmega \subset \mathbb {R}^3\), i.e.
where \(\gamma _0^{\text {ext}}\) denotes the exterior trace and g the given Dirichlet data in the trace space \(H^{1/2}(\partial \varOmega )\) of the Sobolev space \(H^1(\varOmega ^c)\). In order to guarantee that the problem is well-defined, we additionally assume suitable conditions at infinity.
Using the single and double layer potential operators
where
denotes the fundamental solution, the solution of (23) is given by the representation formula
The task is to compute the missing Neumann data \(\psi := \gamma ^{\text {ext}}_{1}u \in H^{-1/2}(\partial \varOmega )\) from the boundary integral equation
The unique solvability of the boundary integral equation (24) or (if the \(L^2\)-scalar product is extended to a duality between \(H^{-1/2}(\partial \varOmega )\) and \(H^{1/2}(\partial \varOmega )\)) its variational formulation
is a consequence of the mapping properties of the single layer potential, the coercivity of the bilinear form \((\mathcal {V}\cdot ,\cdot )_{L^2(\partial \varOmega )}\) and the Riesz-Fischer theorem.
A Galerkin approach is used in order to compute \(\psi \) numerically. To this end, let the set \(\{\psi _{1}^0,\dots , \psi _{N}^0\}\) denote the basis of the piecewise constant functions \(\mathcal {P}_{0}(\mathcal {T}) \subset H^{-1/2}(\partial \varOmega )\), where \(\mathcal {T}\) is a regular partition of \(\partial \varOmega \) into N triangles. If g is replaced by some piecewise linear approximation
we obtain the discrete boundary integral equation \(Ax = f\) with \(A\in \mathbb {R}^{N \times N}\) and \(f \in \mathbb {R}^N\) having the entries [see (1)]
We choose various boundary discretizations of the ellipse \(\varOmega := \{ x \in \mathbb {R}^3: x_1^2 + x_2^2 + x_3^2/9 = 1 \}\) as the computational domain and the Dirichlet data \( g = |x - 10 e_1|^2 \). We compare \(\mathcal {H}\)-matrix approximations of A generated via standard ACA with \(\mathcal {H}^2\)-matrix approximations obtained from the method introduced in this article. For both cases the same block cluster tree generated with \(\eta = 0.8\) is used. The minimum sizes of clusters are denoted by \(n_{\min }^\mathcal {H}\) and \(n_{\min }^{\mathcal {H}^2}\), respectively; see the remark after Definition 5. The accuracy \(\varepsilon _{\text {ACA}}^{\mathcal {H}}\) of ACA for the approximation of the \(\mathcal {H}\)-matrix blocks is fixed for both methods at \(\varepsilon _{\text {ACA}}^{\mathcal {H}} = 10^{-6}\) and the corresponding accuracy \(\varepsilon _{\text {ACA}}^{\mathcal {H}^2}\) was adjusted so that both methods produce almost the same relative error
as Table 4 shows. Therefore, we cannot expect any convergence rate of the error \(e_h\). It is interesting to observe that for the coarse grids \(\varepsilon _{\text {ACA}}^{\mathcal {H}^2}\) can be chosen larger than \(\varepsilon _{\text {ACA}}^{\mathcal {H}}\). This is because the number of the \(\mathcal {H}^2\)-blocks is small compared with the number of \(\mathcal {H}\)-blocks and therefore the \(\mathcal {H}\)-blocks dominate the error \(e_h\). For the finer grids this is no longer true. On the one hand, a larger part of the stiffness matrix consists of \(\mathcal {H}^2\)-blocks and on the other hand, the depth of the cluster bases increases, which has to be compensated by a smaller \(\varepsilon _{\text {ACA}}^{\mathcal {H}^2}\); see Lemma 5. Moreover, the approximations differ in the time needed for computing the respective approximation of A and in the required amount of storage, which is presented as the compression rate, i.e. the ratio of the amount of storage required for the approximation and the amount of storage of the original matrix.
The time for the construction of the matrix approximation decreases the more blocks are approximated with the \(\mathcal {H}^2\)-matrix method. While for a small number of degrees of freedom N the \(\mathcal {H}\)-matrix method is faster than the \(\mathcal {H}^2\)-matrix method, the latter requires nearly \(30\%\) less CPU time for the finest discretization. Figs. 5 and 6 give a deeper insight. Figure 5 shows the matrix A for a coarse discretization which was approximated as an \(\mathcal {H}\)-matrix. Green blocks are admissible and were generated by low-rank approximation. The numbers displayed in the blocks show the approximation rank \(k_\mathcal {H}\). Red blocks are not admissible and were generated entry by entry. In Fig. 6, A was approximated as an \(\mathcal {H}^2\)-matrix. The meaning of green and red blocks is the same as in Fig. 5, the blue blocks were generated using the \(\mathcal {H}^2\)-approximation. Obviously, there are several additional blocks that could be approximated with the \(\mathcal {H}^2\)-method. These are, however, omitted due to their size in order to improve the storage requirements. Additionally, we can see that the ranks of the \(\mathcal {H}^2\)-blocks are significantly larger than the ranks of the corresponding \(\mathcal {H}\)-blocks. This is due to the fact that the \(\mathcal {H}^2\)-approach is based on an approximation which is valid for all possible admissible blocks, whereas in the \(\mathcal {H}\)-approach the approximation is tailored to the respective block.

\(A_\mathcal {H}\) for N = 2506

\(A_{\mathcal {H}^2}\) for N = 2506
Table 5 shows the portion of time required for the precalculations and the time for constructing the matrix. For all examples the time required for the precalculation is about \(10\%\) of the time required to compute the stiffness matrix. However, in the smaller examples there are only few blocks which are approximated with the \(\mathcal {H}^2\)-method. Therefore, the precalculations can hardly be exploited and there is only a marginal time difference when setting up the matrices with the two methods. The number of \(\mathcal {H}^2\)-blocks increases as the number of degrees of freedom N increases. In this situation, the precalculations can be used more often. As a result, setting up the matrix with the \(\mathcal {H}^2\)-method becomes faster than with the \(\mathcal {H}\)-method.
Concerning the amount of storage, the new construction of \(\mathcal {H}^2\)-matrix approximations is more efficient also for small numbers of degrees of freedom N as can be seen from Table 6. The larger N becomes, the more efficient is the new method. This cannot directly be seen from the compression rates, which compare the respective approximation with the dense matrix. However, inspecting the actual storage requirements, one can see that the storage benefit actually improves. For the finest discretization almost \(25\%\) of storage (i.e. more than 2.0 GB) are saved.
4.3 Fractional Poisson problem
Let \(\varOmega \subset \mathbb {R}^d\) be a Lipschitz domain, \(s\in (0,1)\), and \(g \in H^r(\varOmega )\), \(r \ge -s\). We consider the fractional Poisson problem
where the fractional Laplacian (see [1]) is defined as
Here, s is called the order of the fractional Laplacian, \(\varGamma \) is the Gamma function, and p.v. denotes the Cauchy principal value of the integral. The solution of this problem is searched for in the Sobolev space
where
denotes the Slobodeckij semi-norm. The space \(H^s(\varOmega )\) is a Hilbert space, equipped with the norm
Zero trace spaces \(H_0^s(\varOmega )\) can be defined as the closure of \(C_0^\infty (\varOmega )\) with respect to the \(H^s\)-norm.
Due to the non-local nature of the operator, we need to define the space of the test functions
where \({\tilde{u}} \) denotes the extension of u by zero:
\({\tilde{H}}^s(\varOmega )\) is also the closure of \(C_0^\infty (\varOmega )\) in \(H^s(\mathbb {R}^d)\); see [29, Chap. 3]. It is known (see [2]) that \({\tilde{H}}^s(\varOmega ) = H_0^s(\varOmega )\) for \(s \ne 1/2\), and for \(s=1/2\) it holds that \({\tilde{H}}^{1/2}(\varOmega ) \subset H_0^{1/2}(\varOmega )\).
The weak formulation of (25) is to find \(u\in {\tilde{H}}^s(\varOmega )\) satisfying
where
Then \({\tilde{H}}^s(\varOmega )\) can be equipped with the energy norm
Let the set \(\{\varphi _{1},\dots , \varphi _{N}\}\) denote the basis of the space of piecewise linear functions \(V(\mathcal {T})\), where \(\mathcal {T}\) is a regular partition of \(\varOmega \) into M tetrahedra and N inner points. The Galerkin method yields the discrete fractional Poisson problem \(Ax=f\) with \(A \in \mathbb {R}^{N \times N}\), \(f \in \mathbb {R}^N\) having the entries
If the supports of the basis functions \(\varphi _i\) and \(\varphi _j\) are disjoint, the computation of the entry \(a_{ij}\) simplifies to
Thus, admissible blocks \(t\times s\) (which satisfy \(\text {dist}(X_t,X_s)>0\)) are of type (1) and can be approximated by the method presented in this article. We remark that the singular part \(f(x,y)=|x-y|^{-d-2s}\) due to its fractional exponent is not covered by the theory presented in Sect. 2. Nevertheless the following numerical results show that the method works and a theory for fractional exponents will be presented in a forthcoming article.
The general setup and our approach is the same as in the second example in Sect. 4.2. We compare two types of \(\mathcal {H}\)-matrix approximations of A using the same block cluster tree generated with \(\eta = 0.8\). The first one is generated via standard ACA and the second one is an \(\mathcal {H}^2\)-matrix approximation obtained from the method introduced in this article. Due to the Galerkin approach, we choose various volume discretizations of the ellipse \(\varOmega := \{ x \in \mathbb {R}^3: x_1^2 + x_2^2 + x_3^2/9 = 1 \}\) as the computational domain, the Dirichlet data \( g \equiv 1 \), the order of the fractional Laplacian is \(s=0.2\) and the accuracy \(\varepsilon _{\text {ACA}}^\mathcal {H}\) of ACA for \(\mathcal {H}\)-blocks is fixed at \(10^{-4}\).
Since no analytical solution is known for this geometry, we cannot directly verify the accuracy of the numerical solution \(u_h\). Instead, we test the quality of \(A_{\mathcal {H}}\) and \(A_{\mathcal {H}^2}\) when applying them to a special vector. For this purpose, we take advantage of the fact that the constant functions are in the kernel of the fractional Laplacian. This also applies to the discrete version, the stiffness matrix A. Hence, in the following we use \(e_h := \Vert A\, \varvec{1}\Vert _2 / \sqrt{N},\, \varvec{1}=[1,\dots ,1]^T\in \mathbb {R}^N\), as a measure of the quality of the approximations \(A_{\mathcal {H}}\) and \(A_{\mathcal {H}^2}\).
Table 7 shows the minimum sizes of the respective clusters \(n_{\min }^\mathcal {H}\) and \(n_{\min }^{\mathcal {H}^2}\) and the corresponding numerical results, the time needed for the respective approximation of A, the compression rate and the error \(e_h\). As in the second example, the accuracy \(\varepsilon _{\text {ACA}}^{\mathcal {H}^2}\) for the \(\mathcal {H}^2\)-blocks was adjusted so that both methods produce almost the same error \(e_h\). The time for the construction of the matrix approximation decreases the more blocks are approximated with the \(\mathcal {H}^2\)-matrix method and for the finest discretization the CPU time for approximating A is reduced by almost \(30\%\). Here however, even for a small number of degrees of freedom N the \(\mathcal {H}^2\)-method is faster. There are two reasons for this. The first is shown in Table 8. The cost of the precalculations is only a small fraction of the cost of the approximation of A. This is because A is a dense matrix whose entries are significantly more expensive to calculate than in the second example. The second reason can be seen from Figs. 7 and 8. These figures show the matrix A for the coarsest discretization, which was approximated as an \(\mathcal {H}\)-matrix and \(\mathcal {H}^2\)-matrix, respectively. As in the Figs. 5 and 6 , the red blocks were calculated entry by entry, the green and blue blocks are low-rank approximations calculated via ACA and the new method, respectively, and the numbers in the low-rank blocks are the ranks \(k_\mathcal {H}\) and \(k_{\mathcal {H}^2}\), respectively. Compared with the second example, the ranks \(k_\mathcal {H}\) and \(k_{\mathcal {H}^2}\) of corresponding blocks hardly differ. Therefore, \(n_{\min }^{\mathcal {H}^2}\) can be chosen relatively small even for a large number of degrees of freedom N in order to ensure memory efficiency and to approximate as many blocks as possible with the \(\mathcal {H}^2\)-method. The reason for the small value of \(k_{\mathcal {H}^2}\) is that for \(|x| > 1\) the kernel function \(K(x)=|x|^{-d-2s}\) is quite easy to approximate due to its decaying behavior. For a small number of degrees of freedom N the condition \(|x|>1\) is almost automatically guaranteed by the admissibility condition of the \(\mathcal {H}^2\)-blocks. On the other hand, we pay for this in the time it takes to calculate A, because the cost of the singular and near-singular integrals scale with \(|\log h|\) per dimension; see [2, Chap. 4.2].

\(A_\mathcal {H}\) for N = 7100

\(A_{\mathcal {H}^2}\) for \(N=7100\)
Of course not only the CPU time benefits from the small difference between \(k_\mathcal {H}\) and \(k_{\mathcal {H}^2}\), but also the storage requirements as can be seen from Table 9. For each selected discretization, less storage is required when using the \(\mathcal {H}^2\)-method. For example, the finest discretization requires \(25\%\) less storage (i.e. more than 6.3 GB). In addition, the \(\mathcal {H}^2\)-approximation becomes more efficient the larger the number of degrees of freedom N becomes, since the precalculations can be exploited for an increasingly larger part of the matrix.
5 Conclusion
A new method for the adaptive and kernel-independent construction of \(\mathcal {H}^2\)-matrices has been presented. It is based on the cross approximation method, which is known from the construction of \(\mathcal {H}\)-matrices, and relies on the harmonicity of the kernel function. The error analysis for the function \(f(x,y)=|x-y|^{-\alpha }\) makes use of an approximation result for radial basis functions. As a result, exponential convergence can be guaranteed with respect to the fill distance. Since this result can also be applied in the convergence analysis of ACA, we obtain a new pivoting strategy, which is based on the fill distance and seems to solve a known difficulty when ACA is applied to non-smooth geometries. While the convergence for the latter strategy in the case of smooth domains can be proved, a rigorous convergence analysis in the case of non-smooth domains needs further investigation.
References
Acosta, G., Borthagaray, J.P.: A fractional Laplace equation: regularity of solutions and finite element approximations. SIAM J. Numer. Anal. 55(2), 472–495 (2017)
Ainsworth, M., Clusa, C.: Towards an efficient finite element method for the integral fractional laplacian on polygonal domains. In: Contemporary Computational Mathematics—A Celebration of the 80th Birthday of Ian Sloan, pp. 17–58. Springer, Cham (2018)
Arya, S., Mount, D.M.: Approximate nearest neighbor searching. In: Proceedings of 4th Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 271–280. ACM Press, New York (1993)
Arya, S., Mount, D.M.: Approximate range searching. In: Proceedings of 11th Annual ACM Symposium on Computational Geometry, pp. 172–181. ACM Press, New York (1995)
Arya, S., Mount, D.M., Netanyahu, N.S., Silverman, R., Wu, A.Y.: An optimal algorithm for approximate nearest neighbor searching. J. ACM 45, 891–923 (1998)
Bateman, H., Erdélyi, A.: Tables of Integral Transforms, Volume 2. Bateman Manuscript Project. McGraw-Hill, New York (1954)
Bäck, J., Nobile, F., Tamellini, L., Tempone, R.: Stochastic spectral Galerkin and collocation methods for PDEs with random coefficients: a numerical comparison. In: Spectral and High Order Methods for Partial Differential Equations, LNCSE 76, pp. 43–62. Springer (2011)
Bebendorf, M.: Approximation of boundary element matrices. Numer. Math. 86(4), 565–589 (2000)
Bebendorf, M.: Hierarchical Matrices: A Means to Efficiently Solve Elliptic Boundary Value Problems, Volume 63 of Lecture Notes in Computational Science and Engineering. Springer, Berlin (2008)
Bebendorf, M., Kuske, C., Venn, R.: Wideband nested cross approximation for Helmholtz problems. Numer. Math. 130, 1–34 (2015)
Börm, S.: Efficient Numerical Methods for Non-local Operators. Tracts in Mathematics 14. EMS (2010)
Börm, S., Grasedyck, L.: Hybrid cross approximation of integral operators. Numer. Math. 205, 221–249 (2005)
Börm, S., Löhndorf, M., Melenk, J.M.: Approximation of integral operators by variable-order interpolation. Numer. Math. 99(4), 605–643 (2005)
Braess, D., Hackbusch, W.: On the efficient computation of high-dimensional integrals and the approximation by exponential sums. In: DeVore, R.A., Kunoth, A. (eds.) Multiscale, Nonlinear and Adaptive Approximation, pp. 39–74. Springer, Berlin (2009)
Buhmann, M.: Radial Basis Functions: Theory and Implementations. Cambridge Monographs on Applied and Computational Mathematics, Cambridge University Press, Cambridge (2003)
Cheng, H., Greengard, L., Rokhlin, V.: A fast adaptive multipole algorithm in three dimensions. J. Comput. Phys. 155(2), 468–498 (1999)
Cipra, B.A.: The best of the 20th century: editors name top 10 algorithms. SIAM News 33(4), 1–2 (2000)
Greengard, L.F., Rokhlin, V.: A fast algorithm for particle simulations. J. Comput. Phys. 73(2), 325–348 (1987)
Greengard, L.F., Rokhlin, V.: A new version of the fast multipole method for the Laplace equation in three dimensions. In: Acta Numerica, 1997, Volume 6 of Acta Numerica, pp. 229–269. Cambridge University Press, Cambridge (1997)
Hackbusch, W.: A sparse matrix arithmetic based on \(\cal{H}\)-matrices. Part I: introduction to \(\cal{H}\)-matrices. Computing 62(2), 89–108 (1999)
Hackbusch, W., Khoromskij, B.N.: A sparse \(\cal{H}\)-matrix arithmetic. Part II: application to multi-dimensional problems. Computing 64(1), 21–47 (2000)
Hackbusch, W.: Hierarchical Matrices: Algorithms and Analysis. Springer Series in Computational Mathematics Springer Series in Computational Mathematics, Springer, Berlin (2015)
Hackbusch, W., Khoromskij, B.N., Sauter, S.A.: On \(\cal{H}^2\)-matrices. In: Bungartz, H.-J., Hoppe, R.H.W., Zenger, Ch. (eds.) Lectures on Applied Mathematics, pp. 9–29. Springer, Berlin (2000)
Harbrecht, H., Peters, M.: Comparison of fast boundary element methods on parametric surfaces. Comput. Methods Appl. Mech. Eng. 261, 39–55 (2013)
Leja, F.: Sur certaines suites liées aux ensembles plans et leur application à la représentation conforme. Ann. Polon. Math. 4, 8–13 (1957)
Madych, W.R., Nelson, S.A.: Multivariate interpolation and conditionally positive definite functions. Approx. Theory Appl. 4(4), 77–89 (1988)
Madych, W.R., Nelson, S.A.: Multivariate interpolation and conditionally positive definite functions II. Math. Comput. 54, 211–230 (1990)
Madych, W.R., Nelson, S.A.: Bounds on multivariate polynomials and exponential error estimates for multiquadric interpolation. J. Approx. Theory 70, 94–114 (1992)
McLean, W.: Strongly Elliptic Systems and Boundary Integral Equations. Cambridge University Press, Cambridge (2000)
Rokhlin, V.: Rapid solution of integral equations of classical potential theory. J. Comput. Phys. 60(2), 187–207 (1985)
Wendland, H.: Scattered Dara Approximation. Cambridge Monographs on Applied and Computational Mathematics, Cambridge University Press, Cambridge (2005)
Ying, L., Biros, G., Zorin, D.: A kernel-independent adaptive fast multipole algorithm in two and three dimensions. J. Comput. Phys. 196(2), 591–626 (2004)
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bauer, M., Bebendorf, M. & Feist, B. Kernel-independent adaptive construction of \(\mathcal {H}^2\)-matrix approximations. Numer. Math. 150, 1–32 (2022). https://doi.org/10.1007/s00211-021-01255-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-021-01255-y