
Abstract
We consider the stochastic Cahn–Hilliard equation with additive noise term \(\varepsilon ^\gamma g\, {\dot{W}}\) (\(\gamma >0\)) that scales with the interfacial width parameter \(\varepsilon \). We verify strong error estimates for a gradient flow structure-inheriting time-implicit discretization, where \(\varepsilon ^{-1}\) only enters polynomially; the proof is based on higher-moment estimates for iterates, and a (discrete) spectral estimate for its deterministic counterpart. For \(\gamma \) sufficiently large, convergence in probability of iterates towards the deterministic Hele–Shaw/Mullins–Sekerka problem in the sharp-interface limit \(\varepsilon \rightarrow 0\) is shown. These convergence results are partly generalized to a fully discrete finite element based discretization. We complement the theoretical results by computational studies to provide practical evidence concerning the effect of noise (depending on its ’strength’ \(\gamma \)) on the geometric evolution in the sharp-interface limit. For this purpose we compare the simulations with those from a fully discrete finite element numerical scheme for the (stochastic) Mullins–Sekerka problem. The computational results indicate that the limit for \(\gamma \ge 1\) is the deterministic problem, and for \(\gamma =0\) we obtain agreement with a (new) stochastic version of the Mullins–Sekerka problem.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
We consider the stochastic Cahn–Hilliard equation with additive noise
We fix \(T>0\), \(\gamma >0\), and \(\varepsilon >0\) is a (small) interfacial width parameter. For simplicity, we assume \({\mathcal {D}}\subset {\mathbb {R}}^{2}\) to be a convex, bounded polygonal domain, with \({n}\in {{\mathbb {S}}}^2\) the outer unit normal along \(\partial {\mathcal {D}}\), and \(W \equiv \{ W_t;\, 0 \le t \le T\}\) to be an \({{\mathbb {R}}}\)-valued Wiener process on a filtered probability space \((\Omega , {{\mathcal {F}}}, \{ {\mathcal F}_t\}_t, {{\mathbb {P}}})\). The function \(g \in C^{\infty }({\mathcal D})\) is such that \(\int _{{{\mathcal {D}}}} g \, {\mathrm{d}}x = 0\) to enable conservation of mass in (1.1), and \(\partial _{n}g =0\) on \(\partial {\mathcal {D}}\). Furthermore, we assume \(u^\varepsilon _0 \in {{\mathbb {H}}}^1\), and impose \(\int _{{\mathcal {D}}} u^{\varepsilon }_0\, {\mathrm{d}}x = 0\), for simplicity; generalization for arbitrary mean values is straightforward.
The nonlinear drift part f in (1.1) is the derivative of the double-well potential \(F(u):=\frac{1}{4}(u^2-1)^2\), i.e., \(f(u)=F'(u)=u^3-u\). Associated to the system (1.1) is the Ginzburg–Landau free energy
The particular case \(g \equiv 0\) in (1.1) leads to the deterministic Cahn–Hilliard equation which can be interpreted as the \({\mathbb {H}}^{-1}\)-gradient flow of the Ginzburg–Landau free energy. It is convenient to reformulate (1.1) as
where w denotes the chemical potential.
The Cahn–Hilliard equation has been derived as a phenomenological model for phase separation of binary alloys. The stochastic version of the Cahn–Hilliard equation, also known as the Cahn–Hilliard–Cook equation, has been proposed in [12, 21, 22]: here, the noise term is used to model effects of external fields, impurities in the alloy, or may describe thermal fluctuations or external mass supply. We also mention [18], where computational studies for (1.1) show a better agreement with experimental data in the presence of noise. For a theoretical analysis of various versions of the stochastic Cahn–Hilliard equation we refer to [8, 9, 13, 14]. Next to its relevancy in materials sciences, (1.1) is used as an approximation to the Mullins–Sekerka/Hele–Shaw problem; by the classical result [1], the solution of the deterministic Cahn–Hilliard equation is known to converge to the solution of the Mullins–Sekerka/Hele–Shaw problem in the sharp interface limit \(\varepsilon \downarrow 0\). A partial convergence result for the stochastic Cahn–Hilliard equation (1.1) has been obtained recently in [3] for a sufficiently large exponent \(\gamma \). We extend this work to eventually validate uniform convergence of iterates of the time discretization Scheme 3.1 to the sharp-interface limit of (1.1) for vanishing numerical (time-step k), and regularization (width \(\varepsilon \)) parameters: hence, the zero level set of the solution to the geometric interface of the Mullins–Sekerka problem is accurately resolved via Scheme 3.1 in the asymptotic limit.
It is well-known that an energy-preserving discretization, along with a proper balancing of numerical parameters and the interface width parameter \(\varepsilon \), is required for accurate simulation of the deterministic Cahn–Hilliard equation; see e.g. [16]: analytically, this balancing of scales allows to circumvent a straight-forward application of Gronwall’s lemma in the error analysis, which would otherwise cause a factor in a corresponding error estimate that grows exponentially in \(\varepsilon ^{-1}\). The present paper pursues a corresponding goal for a structure-preserving discretization of the stochastic Cahn–Hilliard equation (1.1); we identify proper discretization scales which allow a resolution of interface-driven evolutions, and thus avoid a Gronwall-type argument in the corresponding strong error analysis. This allows for practically relevant scaling scenarios of involved numerical parameters to accurately approximate solutions of (1.1) even in the asymptotic regime where \(\varepsilon \ll 1\).
The proof of a strong error estimate for a space–time discretization of (1.1) which causes only polynomial dependence on \(\varepsilon ^{-1}\) in involved stability constants uses the following ideas:
-
(a)
We use the time-implicit Scheme 3.1, whose iterates inherit the basic energy bound [see Lemma 3.1, (i)] from (1.1). We benefit from a weak monotonicity property of the drift operator in the proof of Lemma 3.4 to effectively handle the cubic nonlinearity in the drift part.
-
(b)
For \(\gamma >0\) sufficiently large, we view (1.1) as a stochastic perturbation of the deterministic Cahn–Hilliard equation (i.e., (1.1) with \(g \equiv 0\)), and proceed analogically also in the discrete setting. We then benefit in the proof of Lemma 3.4 from (the discrete version of) the spectral estimate (2.1) from [2, 11] for the deterministic Cahn–Hilliard equation (see Lemma 3.1, v)).
-
(c)
For the deterministic setting [16], an induction argument is used on the discrete level, which addresses the cubic error term (scaled by \(\varepsilon ^{-1}\)) in Lemma 3.4. This argument may not be generalized in a straightforward way to the current stochastic setting where the discrete solution is a sequence of random variables allowing for (relatively) large temporal variations. For this reason we consider the propagation of errors on two complementary subsets of \(\Omega \): on the large subset \(\Omega _2\) we verify the error estimate (Lemma 3.5), while we benefit from the higher-moment estimates for iterates of Scheme 3.1 from (a) to derive a corresponding estimate on the small set \(\Omega \setminus \Omega _2\) (see Corollary 3.7). A combination of both results then establishes our first main result: a strong error estimate for the numerical approximation of the stochastic Cahn–Hilliard equation (see Theorem 3.8), avoiding Gronwall’s lemma.
-
(d)
Building on the results from (c), and using an \({\mathbb {L}}^\infty \)-bound for the solution of Scheme 3.1 (Lemma 5.1), along with error estimates in stronger norms (Lemma 5.2), we show uniform convergence of iterates on large subsets of \(\Omega \) (Theorem 5.5). This intermediate result then implies the second main result of the paper: the convergence in probability of iterates of Scheme 3.1 to the sharp interface limit in Theorem 5.7 for sufficiently large \(\gamma \). In particular, we show that the numerical solution of (1.1) uniformly converges in probability to 1, \(-1\) in the interior and exterior of the geometric interface of the deterministic Mullins–Sekerka problem (5.1), respectively. As a consequence we obtain uniform convergence of the zero level set of the numerical solution to the geometric interface of the Mullins–Sekerka problem in probability; cf. Corollary 5.8.
The error analysis below in particular identifies proper balancing strategies of numerical parameters with the interface width that allow to approximate the limiting sharp interface model for realistic problem setups, and motivates the use of space–time adaptive meshes for numerical simulations; see e.g. [25]. In Sect. 6, we present computational studies which evidence asymptotic properties of the solution for different scalings of the noise term. Our studies suggest the deterministic Mullins–Sekerka problem as sharp-interface limit already for \(\gamma \ge 1\); we observe this in simulations for spatially colored, as well as for the space–time white noise. In contrast, corresponding simulations for \(\gamma = 0\) indicate that the sharp-interface limit is a stochastic version of the Mullins–Sekerka problem; see Sect. 6.4.
To sum up, the convergence analysis presented in this paper is a combination of a perturbation and discretization error analysis. The latter depends on stability properties of the proposed numerical scheme: higher-moment energy estimates for the Scheme 3.1, a discrete spectral estimate for the related deterministic variant, and a local error analysis on the sample set \(\Omega \) are crucial ingredients of our approach. The techniques developed in this paper constitute a general framework which can be used to treat different and/or more general phase-field models including the stochastic Allen-Cahn equation, and apply to settings which involve multiplicative noise, driving trace-class Hilbert-space-valued Wiener processes, and bounded polyhedral domains \({{\mathcal {D}}} \subset {{\mathbb {R}}}^3\), as well.
The paper is organized as follows. Section 2 is dedicated to the analysis of the continuous problem. The time discretization Scheme 3.1 is proposed in Sect. 3 and rates of convergence are shown, while Sect. 4 extends this convergence analysis to its finite-element discretization. The convergence of the numerical discretization to the sharp-interface limit is studied in Sect. 5. Section 6 contains the details of the implementation of the numerical schemes for the stochastic Cahn–Hilliard and the stochastic Mullins–Sekerka problem, respectively, as well as computational experiments which complement the analytical results.
2 The stochastic Cahn–Hilliard equation
2.1 Notation
For \(1\le p \le \infty \), we denote by \(\bigl ( {\mathbb {L}}^p, \Vert \cdot \Vert _{{\mathbb {L}}^p}\bigr )\) the standard spaces of p-th order integrable functions on \({\mathcal {D}}\). By \((\cdot ,\cdot )\) we denote the \({\mathbb {L}}^2\)-inner product, and let \(\Vert \cdot \Vert = \Vert \cdot \Vert _{{\mathbb {L}}^2}\). For \(k\in {\mathbb {N}}\) we write \(\bigl ({\mathbb {H}}^k, \Vert \cdot \Vert _{{\mathbb {H}}^k}\bigr )\) for usual Sobolev spaces on \({\mathcal {D}}\), and \({\mathbb {H}}^{-1} = ({\mathbb {H}}^1)^\prime \). We define \({\mathbb {L}}^2_0 := \{ \phi \in {\mathbb {L}}^2; \,\, \int _{\mathcal {D}} \phi \,\mathrm {d}x= 0\}\), and for \(v \in {\mathbb {L}}^2\) we denote its zero mean counterpart as \({\overline{v}} \in {\mathbb {L}}^2_0\), i.e., \({\overline{v}} := v - \frac{1}{|{\mathcal {D}}|}\int _{{\mathcal {D}}}v\,\mathrm {d}x\). We frequently use the isomorphism \((-\Delta )^{-1}: {\mathbb {L}}^2_0 \rightarrow {{\mathbb {H}}^2} \cap {\mathbb {L}}^2_0\), where \({w} = (-\Delta )^{-1}{\overline{v}}\) is the unique solution of
In particular, \((\nabla (-\Delta )^{-1}{\overline{v}}, \nabla \varphi ) = ({\overline{v}}, \varphi )\) for all \(\varphi \in {\mathbb {H}}^1\), \({\overline{v}}\in {\mathbb {L}}^2_0\). Below, we denote \(\Delta ^{-1/2} {\overline{v}}:= \nabla (-\Delta )^{-1}{\overline{v}}\) and note that norms \(\Vert {\overline{v}} \Vert _{{\mathbb {H}}^{-1}}\) and \( \Vert \Delta ^{-1/2}{\overline{v}} \Vert \) are equivalent for all \({\overline{v}}\in {\mathbb {L}}^2_0\). Throughout the paper, C denotes a generic positive constant that may depend on \({\mathcal {D}}\), T, but is independent of \(\varepsilon \).
2.2 The problem
We recall the definition of a strong variational solution of the stochastic Cahn–Hilliard equation (1.1); its existence, uniqueness, and regularity properties have been obtained in [14, Thm. 8.2], [13, Prop. 2.2].
Definition 2.1
Let \(u_0^\varepsilon \in L^2(\Omega , {\mathcal {F}}_0, {\mathbb {P}}; {\mathbb {H}}^1) \cap L^4(\Omega , {\mathcal {F}}_0, {\mathbb {P}}; {\mathbb {L}}^4)\) and denote \(\underline{{\mathbb {H}}}^2 = \{\varphi \in {\mathbb {H}}^2,\,\, \partial _{n}\varphi = 0\,\,\mathrm {on}\,\, \partial {\mathcal {D}} \}\). Then, the process
is called a strong solution of (1.1) if it satisfies \({\mathbb {P}}\)-a.s. and for all \(0 \le t \le T\)
The following lemma establishes existence and bounds for the strong solution u of (1.1) and for the chemical potential w from (1.2b); cf. [13, Section 2.3] for a proof of (i), while (ii) follows similarly as part (i) by the Itô formula and the Burkholder-Davis-Gundy inequality.
Lemma 2.1
Let \(T>0\). There exists a unique strong solution u of (1.1), and there hold
-
(i)
\( \displaystyle {\mathbb {E}}\big [ {\mathcal {E}}\bigl (u(t)\bigr )\big ] + {\mathbb {E}}\Big [ \int _0^t\Vert \nabla w(s)\Vert ^2\, \mathrm {d}s\Big ] \le C \big ( {\mathcal {E}}(u_0^\varepsilon ) + 1\big ) \qquad \forall \, t\in [0,T]\, , \)
-
(ii)
For any \(p\in {\mathbb {N}}\) there exists \(C\equiv C(p)>0\) such that
$$\begin{aligned}\displaystyle {\mathbb {E}}\big [ \sup _{t\in [0,T]} {\mathcal {E}}\bigl (u(t) \bigr )^p\big ] \le C\bigl ( {\mathcal {E}}(u_0^\varepsilon )^p + 1\bigr )\, . \end{aligned}$$
2.3 Spectral estimate
We denote by \(u_{\texttt {CH}}: {\mathcal {D}}_T \rightarrow {{\mathbb {R}}}\) the solution of the deterministic Cahn–Hilliard equation, i.e., (1.1) with \(g \equiv 0\). Let \(\varepsilon _0 \ll 1\); throughout the paper we assume that for every \(\varepsilon \in (0, \varepsilon _0)\), there exists an arbitrarily close approximation \(u_{\texttt {A}}\in C^2(\overline{{\mathcal {D}}}_T)\) of \(u_{\texttt {CH}}\) which satisfies the spectral estimate (cf. [1, relation (2.3)])
where the constant \(C_0 >0\) does not depend on \(\varepsilon >0\); cf. [1, 2, 11].
2.4 Error bound between u of (1.1) and \(u_{\texttt {CH}}\) of (1.1) with \(g \equiv 0\).
In [3] the authors study the convergence of the solution of the stochastic Cahn–Hilliard equation (1.1) to the deterministic sharp-interface limit. In particular, they show the convergence in probability of the solution u of (1.1) to the approximation \(u_{\texttt {A}}\) of \(u_{\texttt {CH}}\) for sufficiently large \(\gamma >0\). Apart from the spectral estimate (2.1), a central ingredient of their analysis is the use of a stopping time argument to control the drift nonlinearity. The stopping time which, in our setting, is defined as
for some constant \(\sigma _0>0\), enables the derivation of the estimates in Lemma 2.2 below up to the stopping time \(T_\varepsilon \) on a large sample subset
that satisfies \({\mathbb {P}}[\Omega _1] \rightarrow 1\) for \(\varepsilon \downarrow 0\), for some constant \(\kappa _0\). On specifying the condition (A) below it can be shown that \(T_\varepsilon \equiv T\), which yields Lemma 2.2. In this section we extend the work [3] by showing a strong error estimate for \(u-u_{\texttt {CH}}\) in Lemma 2.3.
In Sect. 3 we perform an analogous analysis on the discrete level by using a stopping index \(J_\varepsilon \), and a set \(\Omega _2\) which are discrete counterparts of \(T_\varepsilon \) and \(\Omega _1\), respectively. Both approaches require a lower bound for the noise strength \(\gamma \) to ensure, in particular, positive probability of the sets \(\Omega _1\) and \(\Omega _2\), respectively.
For the analysis in this section we require the following assumptions to hold.
- (A):
-
Let \({\mathcal {E}}(u^\varepsilon _0) \le C\). Assume that the triplet \((\sigma _0, \kappa _0, \gamma ) \in \bigl [{\mathbb {R}}^+\bigr ]^3\) satisfies
$$\begin{aligned} {\sigma _0> 12\,, \qquad \sigma _0> \kappa _0> \frac{2}{3}\sigma _0 + 4\,, \qquad \gamma > \max \big \{ \frac{23}{3}, \frac{\kappa _0}{2}\big \}}\, . \end{aligned}$$
Assumption (A) ensures positivity of all exponents in the estimates in the lemmas of this section. The following lemma relies on the spectral estimate (2.1) and is a consequence of [3, Theorem 3.10] for \(p=3\), \(d=2\), where a slightly different notational setup is used.
Lemma 2.2
Suppose \(\mathbf{(A)}\). There exists \(\varepsilon _0 \equiv \varepsilon _0(\sigma _0, \kappa _0) >0\) such that for any \(\varepsilon \le \varepsilon _0\) and sufficiently large \({\mathfrak {l}}>0\)
where \({\mathfrak {l}}\) and \(C \equiv C({\mathfrak {l}})>0\) are independent of \(\gamma \), \(\sigma _0\), \(\kappa _0\) and \(\varepsilon \).
A closer inspection of the proofs in [3] (cf. [3, Lemma 4.3] in particular) reveals that the parameter \({\mathfrak {l}}\) can be chosen arbitrarily large in the above theorem.
We now use Lemma 2.2 to show bounds for the difference \(u-u_{\texttt {CH}}\) in different norms.
Lemma 2.3
Suppose (A), and \(\varepsilon \le \varepsilon _0\), for \(\varepsilon _0 \equiv \varepsilon _0(\sigma _0, \kappa _0)>0\) sufficiently small. There exists \(C>0\) such that
Proof
By [1, Theorem 2.1] (see also [1, Theorem 4.11 and Remark 4.6]) there exists \(u_{\texttt {A}} \in C^2(\overline{{\mathcal {D}}}_T) {\cap {{\mathbb {L}}}^2_0}\) which satisfies (2.1) and
and, cf. [1, Theorem 2.3],
By using the energy bound for \(u_{\texttt {CH}}\) and (2.3) we get \(\Vert {{u}_{\texttt {A}}}\Vert _{L^\infty (0,T;{\mathbb {H}}^{1})} \le C\).
Consider the subset \({\widetilde{\Omega }}_1 \subset \Omega \) (cf. [3, Lemma 4.5, Lemma 4.6]),
By Lemma 2.2, (ii), we have \({\mathbb {P}}[{\widetilde{\Omega }}_1^c] \le C\varepsilon ^{\big (\gamma + \frac{\sigma _0+1}{3} - \kappa _{0}\big ){\mathfrak {l}}} <1\), for sufficiently large \({\mathfrak {l}}>0\). Then using Lemma 2.1, (ii) and (2.3), we estimate the error
as
It is due to (A) that \(\gamma + \frac{\sigma _0+1}{3} - \kappa _{0} > 0\). We now choose \({\mathfrak {l}}\) sufficiently large such that \(\big (\gamma + \frac{\sigma _0+1}{3} - \kappa _{0}\big )\frac{{\mathfrak {l}}}{2} > \frac{2}{3}\sigma _0\) and the statement follows from the estimate for \({\texttt {Err}}_{\texttt {A}}\) and (2.2) by the triangle inequality. \(\square \)
3 A time discretization Scheme for (1.1)
For fixed \(J \in {{\mathbb {N}}}\), let \(0=t_0<t_1<\cdots <t_J=T\) be an equidistant partition of [0, T] with step size \(k = \frac{T}{J}\), and \(\Delta _j W := W(t_j) - W(t_{j-1})\), \(j=1,\dots , J\). We approximate (1.1) by the following scheme:
Scheme 3.1
For every \(1 \le j \le J\), find a \([{{\mathbb {H}}}^1]^2\)-valued r.v. \((X^j, w^j)\) such that \({{\mathbb {P}}}\)-a.s.
The solvability and uniqueness of \(\{(X^j, w^j)\}_{j\ge 1}\), as well as the \({\mathbb {P}}\)-a.s. conservation of mass of \(\{X^j\}_{j\ge 1}\) are immediate.
For the error analysis of Scheme 3.1, we use the iterates \(\bigl \{ (X^{j}_{\texttt {CH}}, w^{j}_{\texttt {CH}})\bigr \}_{j=0}^J \subset \bigl [ {{\mathbb {H}}}^1\bigr ]^2\) which solve Scheme 3.1 for \(g \equiv 0\). The following lemma collects the properties of these iterates from [16, 17]. We remark that, compared to [16, 17], the results are stated in a simplified (but equivalent) form, which is more suitable for the subsequent analysis.
Lemma 3.1
Suppose \({{\mathcal {E}}}(u^{\varepsilon }_0) \le C\). Let \(\bigl \{ (X^{j}_{\texttt {CH}}, w^{j}_{\texttt {CH}})\bigr \}_{j=0}^J \subset \bigl [ {{\mathbb {H}}}^1\bigr ]^2\) be the solution of Scheme 3.1 for \(g \equiv 0\). For every \(0<\beta < \frac{1}{2}\), \(\varepsilon \in (0, \varepsilon _0) \), \(k \le \varepsilon ^3\), and \({{\mathfrak {p}}}_{\texttt {CH}} >0\), there exist \({{\mathfrak {m}}}_{\texttt {CH}}, {{\mathfrak {n}}}_{\texttt {CH}}, C>0\), and \({{\mathfrak {l}}}_{\texttt {CH}} \ge 3\) such that
Assume moreover \(\Vert u_0^{\varepsilon }\Vert _{{\mathbb {H}}^2} \le C\varepsilon ^{-{\mathfrak {p}}_{\texttt {CH}}}\), then
Assume in addition \(\Vert u_0^{\varepsilon }\Vert _{{\mathbb {H}}^3} \le C\varepsilon ^{-{\mathfrak {p}}_{\texttt {CH}}}\). Then for \(k \le C \varepsilon ^{{{\mathfrak {l}}}_{\texttt {CH}}}\), and \(C_0 >0\) from (2.1) it holds
Proof
The proof of (i), (ii), (iv), (v) is a direct consequence of [16, Lemma 3, Corollary 1, Proposition 2].
To show (iii), we use the Gagliardo–Nirenberg inequality and [16, inequality (76)], (ii), (iv) to get the following \({\mathbb {L}}^{\infty }\)-error estimate for \(k \le C\varepsilon ^{{\mathfrak {l}}_{\texttt {CH}}}\), and some \({\mathfrak {l}}_{\texttt {CH}}>0\),
Hence, \(\Vert X_{\texttt {CH}}^j\Vert _{{\mathbb {L}}^\infty }\le C\) since \(\Vert u_{\texttt {CH}}\Vert _{{\mathbb {L}}^\infty }\le C\); cf. [1, proof of Theorem. 2.3] and [17, Lemma 2.2]. \(\square \)
The numerical solution of Scheme 3.1 satisfies the discrete counterpart of the energy estimate in Lemma 2.1, (i). The time-step constraint in the lemma below is a consequence of the implicit treatment of the nonlinearity; see the last term in (3.2), its estimate (3.3), and (3.4); the lower bound for admissible \(\gamma \) has the same origin.
Lemma 3.2
Let \(\gamma > \frac{3}{2}\), \(\varepsilon \in (0,\varepsilon _0)\) and \(k \le \varepsilon ^3\). Then the solution of Scheme 3.1 conserves mass along every path \(\omega \in \Omega \), and there exists \(C > 0\) such that
-
(i)
\(\displaystyle \max _{1\le j\le J} {\mathbb {E}}\bigl [ {{\mathcal {E}}}(X^j)\bigr ] + \frac{k}{2} \sum _{i=1}^J{\mathbb {E}}\bigl [\Vert \nabla w^i\Vert ^2\bigr ] \le C \,\bigl ( {{{\mathcal {E}}}(u^\varepsilon _0)} +1\bigr )\,,\)
-
(ii)
\(\displaystyle {\mathbb {E}}\big [\max _{1\le j\le J}{{\mathcal {E}}}(X^j) \big ] \le C \bigl ( {{\mathcal {E}}}(u^\varepsilon _0) + 1\bigr )\,.\)
For every \(p = 2^r\), \(r \in {{\mathbb {N}}}\), there exists \(C \equiv C(p, T) > 0\) such that
-
(iii)
\( \displaystyle \max _{1\le j\le J} {\mathbb {E}}\bigl [ \vert {\mathcal E}(X^j)\vert ^p\bigr ] \le C \displaystyle \bigl ( \vert {\mathcal E}(u^\varepsilon _0)\vert ^p +1\bigr )\, ,\)
-
(iv)
\( \displaystyle {\mathbb {E}}\big [ \max _{1\le j\le J} \vert {\mathcal E}(X^j)\vert ^p\big ] \le C \bigl ( \vert {\mathcal E}(u^\varepsilon _0)\vert ^p +1\bigr )\, .\)
Proof
i) For \(\omega \in \Omega \) fixed, we choose \(\varphi =w^j(\omega )\) and \(\psi =[X^j-X^{j-1}](\omega )\) in Scheme 3.1. Adding both equations then leads to \({\mathbb {P}}\)-a.s.
Note that the third term on the left-hand side reflects the numerical dissipativity in the scheme. We can estimate the nonlinear term as (cf. [15, Section 3.1]),
where we employ the notation \({{\mathfrak {f}}}(u) := |u|^2 -1\), i.e., \(f(X^j)= {{\mathfrak {f}}}(X^j)X^j\). The third term on the right-hand side again reflects numerical dissipativity.
By \(\omega \in \Omega \) fixed, and \(\varphi = (-\Delta )^{-1}[X^j-X^{j-1}](\omega )\) in Scheme 3.1, we eventually have \({{\mathbb {P}}}\)-a.s.,
which together with \(\Vert \Delta ^{-1/2} g\Vert \le C\) yields the estimate
Hence, using this estimate, and exploiting again the inherent numerical dissipation of the scheme we can estimate
We substitute (3.2) along with the last inequality into (3.1) and get
which motivates time-steps \(k < 2 \varepsilon ^3\). Next, by using the second equation in Scheme 3.1, we can rewrite the first term on the right-hand side as
Note that \({\mathbb {E}}[A_2]= {\mathbb {E}}[A_4] = 0\). Next, we obtain
On recalling \( f(X^j) = {{\mathfrak {f}}} (X^j) X^j \), we rewrite the remaining term as
Thanks to the embeddings \({{\mathbb {L}}}^s \hookrightarrow {\mathbb {L}}^r\) (\(r \le s\)), and the Cauchy-Schwarz and Young’s inequalities,
The leading term may now be controlled by the numerical dissipation term in (3.2). Finally, by the Poincaré’s inequality, we estimate
By combining the above estimates for \(A_{3,1}\), \(A_{3,2}\) we obtain an estimate for (3.7).
Next, we insert the estimates (3.5), (3.6), and (3.7) into (3.4), account for \(2\gamma - 2 < 1\), sum the resulting inequality over j and take expectations,
On noting that \(\Vert F(u)\Vert _{{{\mathbb {L}}}^1} = \frac{1}{4}\Vert {\mathfrak f}(u)\Vert ^2\), assertion (i) now follows with the help of the discrete Gronwall lemma.
(ii) The second estimate can be shown along the lines of the first part of the proof by applying \(\max _{j}\) before taking the expectation in (3.8). The additional term that arises from the terms \(A_2\), \(A_4\) in (3.5) can be rewritten by using the second equation in Scheme 3.1,
where the equality in the second line follows from the zero mean property of the noise.
The last sum in (3.9) is a discrete square-integrable martingale, and by the independence properties of the summands, the Poincaré inequality and the energy estimate (i) we have
Therefore, (3.9) can be estimated using the discrete BDG-inequality (see Lemma 3.3) and part (i) by
(iii) We show assertion (iii) for \(p=2^1\). By collecting the estimates of the terms in (3.5) in part (i) (cf. (3.6), 3.7)) we deduce from (3.4) that
Multiply this inequality with \({\mathcal {E}}(X^j)\) and use the identity \((a-b)a = \frac{1}{2} [ a^2 - b^2 + (a-b)^2]\), the estimate \(\varepsilon ^{2\gamma +1} \le \varepsilon _0^{4}\varepsilon ^{2\gamma -3}\), Young’s inequality, and the generalized Hölder’s inequality to conclude
We note that to get the above estimate we employed the reformulation \({{\mathcal {E}}}(X^{j}) = {{\mathcal {E}}}(X^{j-1}) + ({\mathcal E}(X^{j})-{{\mathcal {E}}}(X^{j-1}))\) on the right-hand side.
By Poincaré’s inequality, the last term in (3.11) may be bounded as
After summing-up in (3.11) and taking expectations we get for any \(j\le J\) that
where the third term is bounded via (3.8) in part (ii), and the statement then follows from the discrete Gronwall inequality.
For \(p = 2^r\), \(r=2\), we may now argue correspondingly: we start with (3.11), which we now multiply with \(\vert {\mathcal E}(X^j)\vert ^2\). Assertion (iii) now follows via induction with respect to r.
(iv) The last estimate follows analogously to (ii) from the BDG-inequality and (iii). \(\square \)
The error analysis of the implicit Scheme 3.1 in the subsequent Sect. 3.1 involves the use of a stopping index \(J_\varepsilon \), and an associated random variable \(\mathbb {1}_{\{j \le J_\varepsilon \}}\) that is measurable w.r.t. the \(\sigma \)-algebra \({\mathcal {F}}_{t_j}\), but not w.r.t. \({\mathcal {F}}_{t_{j-1}}\). This issue prohibits the use of the standard BDG-inequality since \(\mathbb {1}_{\{j \le J_\varepsilon \}}\) is not independent of the Wiener increment \(\Delta _j W\). The following lemma contains a discrete BDG-inequality which will be used in Sect. 3.1. We take \(\{ {{\mathcal {F}}}_{t_j}\}_{j=0}^J\) to be a discrete filtration associated with the time mesh \(\{ t_j\}_{j=0}^J \subset [0,T]\) on \((\Omega , {{\mathcal {F}}}, {{\mathbb {P}}})\).
Lemma 3.3
For every \(j=1,\dots , J\), let \(F_{j}\) be an \({\mathcal {F}}_{t_j}\)-measurable random variable, and \(\Delta _jW\) be independent of \(F_{j-1}\). Assume that the \(\{{\mathcal F}_{t_j}\}_j\)-martingale \(G_{\ell } := \sum _{j=1}^{{\ell }}F_{j-1}\Delta _j W\) (\(1 \le {\ell } \le J\)), with \(G_0=0\) be square-integrable. Then for any stopping index \(\tau : \Omega \rightarrow {{\mathbb {N}}}_0\) such that \(\mathbb {1}_{\{j\le \tau \}}\) is \({\mathcal {F}}_{t_j}\)-measurable, it holds that
where \(\tau \wedge J = \min \{\tau ,J\}\).
Proof
We start by noting that
With this identity, we obtain
The random variable \(\mathbb {1}_{\{j-1\le \tau \}}\) is \({\mathcal {F}}_{t_{j-1}}\)-measurable, therefore, \({G}_\ell := \sum _{j=1}^{\ell } \mathbb {1}_{\{j-1\le \tau \}} F_{j-1} \Delta _jW\) is also a discrete square-integrable martingale. Hence, by the \(L^2\)-maximum martingale inequality, using the independence of \(\mathbb {1}_{\{j\le \tau \}} F_{j}\) and \(\Delta _\ell W\) for \(j < \ell \) it follows that
The assertion of the lemma then follows from (3.13) and (3.14). \(\square \)
3.1 Error analysis
Denote \(Z^j:=X^j-X_{\texttt {CH}}^j\), use Scheme 3.1 for a fixed \(\omega \in \Omega \), and choose \(\varphi = (-\Delta )^{-1}Z^{j}(\omega )\), \(\psi = Z^j(\omega )\). We obtain \({\mathbb {P}}\)-a.s.
We use Lemma 3.1, v) to obtain a first error bound.
Lemma 3.4
Assume \(\gamma > \frac{3}{2}\), \(\Vert u^\varepsilon _0\Vert _{{{\mathbb {H}}}^3} \le C \varepsilon ^{-{\mathfrak p}_{\texttt {CH}}}\) for \(\varepsilon \in (0,\varepsilon _0)\), and let \(k \le C \varepsilon ^{{{\mathfrak {l}}}_{\texttt {CH}}}\) with \({\mathfrak l}_{\texttt {CH}} \ge 3\) from Lemma 3.1 be sufficiently small. There exists \(C>0\), such that \({\mathbb {P}}\)-a.s. and for all \(1\le {\ell } \le J\),
Proof
1. Consider the last term on the left-hand side of (3.15). On recalling \(Z^j=X^j-X_{\texttt {CH}}^j\), by a property of f, see [17, eq. (2.6)], and Lemma 3.1, (iii), we get for some \(C>0\)
2. In order to later keep a portion of \(\Vert \nabla Z^j\Vert ^2\) on the left-hand side of (3.15) we use the identity
We apply Lemma 3.1, v) to get a lower bound for the first term on the right-hand side,
On noting \(\varepsilon <1\), we estimate the remaining nonlinearities in (3.18) using Lemma 3.1, (iii),
3. We insert the estimates from the steps 1. and 2. into (3.15), and use the bound
to validate
4. We sum the last inequality from \(j=1\) up to \(j={\ell }\), and consider \(\max _{j\le {\ell }}\). On noting \(Z^0=0\), we obtain \({{\mathbb {P}}}\)-a.s.
where
Hence, the implicit version of the discrete Gronwall lemma implies for sufficiently small \(k \le k_0({{\mathcal {D}}})\) that \({{\mathbb {P}}}\)-a.s.
which concludes the proof. \(\square \)
In the deterministic setting (\(g\equiv 0\)), an induction argument, along with an interpolation estimate for the \({\mathbb {L}}^3\)-norm is used to estimate the cubic error term on the right-hand side of (3.16); cf. [16]. In the stochastic setting, this induction argument is not applicable any more, which is why we separately bound errors in (3.16) on two subsets \(\Omega _2\) and \(\Omega \setminus \Omega _2\). In the first step, we study accumulated errors on \(\Omega _2\) locally in time, and therefore mimic a related (time-continuous) argument in [3]. We introduce the stopping index \(1 \le J_\varepsilon \le J\)
where the constant \(\sigma _0>0\) will be specified later. The purpose of the stopping index is to identify those \(\omega \in \Omega \) where the cubic error term is small enough. In the sequel, we estimate the terms on the right-hand side of (3.16), putting \({\ell } = J_{\varepsilon }\). Clearly, the part \(\frac{k}{\varepsilon } \sum _{i=1}^{J_{\varepsilon }-1} \Vert Z^i \Vert _{{{\mathbb {L}}}^3}^3\) of \({{\mathcal {R}}}_{J_{\varepsilon }}\) in (3.20) is bounded by \(\varepsilon ^{\sigma _0}\); the remaining part will be denoted by \(\widetilde{\mathcal R}_{J_{\varepsilon }} := {{\mathcal {R}}}_{J_{\varepsilon }} - \frac{k}{\varepsilon } \sum _{i=1}^{J_{\varepsilon }-1} \Vert Z^i \Vert _{{{\mathbb {L}}}^3}^3\), i.e.,
For \(0< \kappa _0 < \sigma _0\), we gather those \(\omega \in \Omega \) in the subset
where the error terms in Lemma 3.4 which cannot be controlled by the stopping index \(J_\varepsilon \) do not exceed the larger error threshold \(\varepsilon ^{\kappa _0}\). The following lemma quantifies the possible error accumulation in time on \(\Omega _2\) up to the stopping index \(J_\varepsilon \) in terms of \(\sigma _0, \kappa _0 >0\), and illustrates the role of k in this matter; it further provides a lower bound for the measure of \(\Omega _2\) correspondingly.
Lemma 3.5
Assume \(\gamma > \frac{3}{2}\), \(0< \kappa _0 < \sigma _0\), \(\Vert u^\varepsilon _0\Vert _{{{\mathbb {H}}}^3} \le C \varepsilon ^{-{{\mathfrak {p}}}_{\texttt {CH}}}\) for \(\varepsilon \in (0,\varepsilon _0)\), and let \(k \le C \varepsilon ^{{\mathfrak l}_{\texttt {CH}}}\) with \({{\mathfrak {l}}}_{\texttt {CH}} \ge 3\) from Lemma 3.1 be sufficiently small. Then, there exists \(C >0\) such that
Moreover, \({\mathbb {P}}[\Omega _2] \ge 1- \frac{C}{\varepsilon ^{\kappa _0}} \max \bigl \{ \frac{k^2}{\varepsilon ^4}, \varepsilon ^{\gamma +\frac{\sigma _0+1}{3}}, \varepsilon ^{\sigma _0},\varepsilon ^{2\gamma }\bigr \}\).
The proof uses the discrete BDG-inequality (Lemma 3.3), which is suitable for the implicit Scheme 3.1; we use the higher-moment estimates from Lemma 3.2, (iii) to bound the last term in \(\widetilde{{\mathcal {R}}}_{J_{\varepsilon }}\).
Proof
1. Estimate (i) follows directly from Lemma 3.4, using the definitions of \(J_{\varepsilon }\) and \(\Omega _2\).
2. Let \(\Omega _2^{c} := \Omega \setminus \Omega _2\). We use Markov’s inequality to estimate \({\mathbb {P}}[\Omega _{2}^c]\le {\frac{1}{\varepsilon ^{\kappa _0}}}{\mathbb {E}}[\widetilde{{\mathcal {R}}}_{J_\varepsilon }]\). We first estimate the last term in \(\widetilde{\mathcal R}_{J_{\varepsilon }}\): interpolation of \({{\mathbb {L}}}^3\) between \({{\mathbb {L}}}^2\) and \({{\mathbb {H}}}^1\), then of \({{\mathbb {L}}}^2\) between \({{\mathbb {H}}}^{-1}\) and \({{\mathbb {H}}}^1\) (\({{\mathcal {D}}} \subset {{\mathbb {R}}^2}\)) and the Young’s inequality yield
The leading term on the right-hand side is absorbed on the left-hand side of the inequality in Lemma 3.4, which is considered on the whole of \(\Omega \); the expectation of the last term (on the whole of \(\Omega \)) is bounded via Lemma 3.2, iv) by \(\frac{Ck^2}{\varepsilon ^4} \bigl ( \vert {\mathcal E}(u_0^\varepsilon )\vert ^2 +1\bigr )\).
For the first term in \(\widetilde{{\mathcal {R}}}_{J_{\varepsilon }}\) we use the discrete BDG-inequality (Lemma 3.3) to bound its expectation by
In order to benefit from the definition of \(J_{\varepsilon }\) for its estimate, we split the leading summand,
Putting things together leads to \({\mathbb E}[\frac{1}{2}A_{J_{\varepsilon }}] \le C \left( \varepsilon ^{\sigma _0} + \varepsilon ^{\gamma +\frac{\sigma _0+1}{3}} + \varepsilon ^{2\gamma } + \frac{k^2}{\varepsilon ^4}\right) \). Revisiting (3.22) again then yields from Lemma 3.4
3. Consider the inequality in Lemma 3.4 on \(\Omega _2\). The estimate (ii) then follows after taking expectation, using (3.23) and recalling the definition of \(J_\varepsilon \). \(\square \)
The previous lemma establishes local error bounds for iterates of Scheme 3.1 – by using the stopping index \(J_\varepsilon \), and the subset \(\Omega _2 \subset \Omega \); the following lemma identifies values \((\gamma , \sigma _0, \kappa _0)\) such that Lemma 3.5 remains valid globally in time on \(\Omega _2\).
Lemma 3.6
Let the assumptions in Lemma 3.5 be valid. Assume
There exists \(\varepsilon _0\equiv \varepsilon _0(\sigma _0, \kappa _0)\), such that for every \(\varepsilon \in (0,\varepsilon _0)\)
Moreover, \(\lim _{\varepsilon \downarrow 0}{{\mathbb {P}}}[\Omega _2] =1\) if
where \(\beta > 0\) may be arbitrarily small.
Compared to assumption (A), the less restrictive lower bound for \(\gamma \) is due to the use of the discrete spectral estimate (see Lemma 3.1, v)), which introduces a factor \(\varepsilon ^{-4}\) that is absorbed into \(\varepsilon ^{\frac{3}{2}\kappa _0}\) in the proof below. Consequently we only need to require \(\gamma \ge \frac{19}{3}\) in order to ensure positive probability of \(\Omega _2\).
Proof
1. Assume that \(J_\varepsilon < J\) on \(\Omega _2\); we want to verify that
Use (3.22), and the estimate Lemma 3.5 (i) to conclude
The right-hand side above is below \(\varepsilon ^{\sigma _0}\) for \(\frac{3\kappa _0}{2} > \sigma _0 + 5\) and \(\varepsilon < \varepsilon _0\) with sufficiently small \(\varepsilon _0\equiv \varepsilon _0(\sigma _0, \kappa _0)\). The additional condition \(\kappa _0 < \sigma _0\) (which will be required in step 2. below) imposes that \(\sigma _0 > 10\).
2. Recall that the last part in Lemma 3.5 yields \({\mathbb {P}}[\Omega _2] \ge 1- C\varepsilon ^{-\kappa _0} \max \bigl \{ \frac{k^2}{\varepsilon ^4}, \varepsilon ^{\gamma +\frac{\sigma _0+1}{3}}, \varepsilon ^{\sigma _0},\varepsilon ^{2\gamma }\bigr \}\). Hence, to ensure \({\mathbb {P}}[\Omega _2] > 0\) requires \(\gamma + \frac{\sigma _0+1}{3} -\kappa _0 >0\), \(\sigma _0>\kappa _0\), \(\gamma > \frac{\kappa _0}{2}\) and \(k^2 \le C \varepsilon ^{4+\kappa _0+\beta }\), \(\beta >0\). In addition, by step 1., \(\kappa _0 > \frac{2}{3}(\sigma _0 + {5})\), \(\sigma _0>10\), which along with \(\gamma + \frac{\sigma _0+1}{3} -\kappa _0 >0\), \(\sigma _0>\kappa _0\) implies \(\gamma \ge {\frac{19}{3}}\). \(\square \)
Next, we bound \(\max _{1\le i\le J}\Vert \Delta ^{-1/2}Z^i\Vert ^2+\frac{\varepsilon ^4}{2} k\sum _{i=1}^{J}\Vert \nabla Z^i\Vert ^2\) on the whole sample set. We collect the requirements on the analytical and numerical parameters:
- (B):
-
Let \(u^\varepsilon _0 \in {{\mathbb {H}}}^3\), \({\mathcal {E}}(u_0^\varepsilon )<C\). Assume that \((\sigma _0, \kappa _0, \gamma )\) satisfy
$$\begin{aligned}\sigma _0>10, \qquad { \sigma _0}> \kappa _0 > \frac{2}{3}(\sigma _0 + 5), \qquad \gamma \ge \max \{ {\frac{19}{3}}, \frac{\kappa _0}{2}\}\, .\end{aligned}$$For sufficiently small \(\varepsilon _0 \equiv (\sigma _0,\kappa _0) >0\) and \({{\mathfrak {l}}}_{\texttt {CH}} \ge 3\) from Lemma 3.1, and arbitrary \(0< \beta < \frac{1}{2}\), the time-step satisfies
$$\begin{aligned} k \le C \min \bigl \{\varepsilon ^{{{\mathfrak {l}}}_{\texttt {CH}}}, \varepsilon ^{2+\frac{\kappa _0}{2}+\beta }\bigr \} \qquad \forall \, \varepsilon \in (0,\varepsilon _0).\end{aligned}$$
We note that, except for the higher regularity of the initial condition, the assumption (B) is less restrictive than the assumption (A) from Sect. 2. Furthermore, the condition \({\mathcal {E}}(u_0^\varepsilon ) < C\) can be weakened to \({\mathcal {E}}(u_0^\varepsilon ) < C\varepsilon ^{-\alpha }\), \(\alpha >0\), cf. [17, Assumption (\(\hbox {GA}_2\))].
Lemma 3.7
Suppose (B). Then there exists \(C>0\) such that
Proof
Recall the notation from (3.20), and split \({\mathbb {E}}[A_{J}] = {\mathbb {E}}[\mathbb {1}_{\Omega _2} A_J] + {\mathbb {E}}[\mathbb {1}_{\Omega ^c_2} A_J]\). Due to assumption (B) it follows directly from Lemma 3.5, (ii) and Lemma 3.6 that
In order to bound \({{\mathbb {E}}}[\mathbb {1}_{\Omega ^c_2} A_J]\), we use the embedding \({\mathbb {L}}^4\subset {\mathbb {H}}^{-1}\) which along with the higher-moment estimate from Lemma 3.2 iv) implies that
Next, we note that by Lemma 3.5 it follows that
Hence, using the Cauchy-Schwarz inequality we get
After inspecting (3.24), (3.25) we note that the statement follows by assumption (B), since the latter contribution dominates the error. \(\square \)
The dominating error contribution in Lemma 3.7 comes from the term \({{\mathbb {E}}}[\mathbb {1}_{\Omega ^c_2} A_J]\). This is in contrast to Sect. 2 where the error contribution from the set \(\Omega _1^c\) can be made arbitrarily small, due to the additional parameter \({\mathfrak {l}}>0\) in Lemma 2.2 which can be chosen arbitrarily large independently of the other parameters.
We are now ready to prove the first main result of this paper.
Theorem 3.8
Let \(u_0^\varepsilon \in {\mathbb {H}}^3\), let u be the strong solution of (1.1), and let \(\left\{ X^j,\ j=1,\dots , J\right\} \) solve Scheme 3.1. Suppose (A). Then there exists a constant \(C>0\) such that for all \(0 {< } \beta < \frac{1}{2}\)
Due to condition (A)\(_2\) it holds that \(\sigma _0-\kappa _0 < \frac{1}{3}\sigma _0\). Consequently the contribution \(\varepsilon ^{\frac{2}{3}\sigma _0}\) in the error estimate is dominated by \(\varepsilon ^{\frac{\sigma _0-\kappa _0}{2}}\); it is only stated explicitly to highlight the error contribution from the difference \(u-u_{\texttt {CH}}\) from Sect. 2.
Proof
We estimate the error via splitting it into three contributions,
Lemma 2.3 bounds \({{\mathbb {E}}}[I]\), Lemma 3.1, iv) yields \({{\mathbb {E}}}[II] \le \frac{k^{2-\beta }}{\varepsilon ^{{{\mathfrak {m}}}_{\texttt {CH}}}}\), and \({{\mathbb {E}}}[III]\) is bounded in Lemma 3.7. \(\square \)
Remark 3.9
An alternative approach to Theorem 3.8 would be to follow the arguments in [23] for a related problem, which exploit a weak monotonicity property of the drift operator in (1.1), and stability of the discretization to obtain a strong error estimate for Scheme 3.1 of the form
While the error tends to zero for \(k \downarrow 0\) in (3.26), this estimate is only of limited practical relevancy in the asymptotic regime where \(\varepsilon \) is small, since only prohibitively small step sizes \(k \ll \exp (-\frac{1}{\varepsilon })\) are required in (3.26) to guarantee small approximation errors for iterates from Scheme 3.1. Moreover, the error analysis that leads to (3.26) does not provide any insight on how to numerically resolve diffuse interfaces via proper balancing of discretization parameter k and interface width \(\varepsilon \)—which is relevant in the asymptotic regime where \(\varepsilon \ll 1\).
4 Space–time discretization of (1.1)
We generalize the convergence results in Sect. 3 for Scheme 3.1 to its space–time discretization. For this purpose, we introduce some further notations: let \({{\mathcal {T}}} _h\) be a quasi-uniform triangulation of \({{\mathcal {D}}}\), and \({\mathbb V}_h \subset {{\mathbb {H}}}^1\) be the finite element space of piecewise affine, globally continuous functions,
and \(\mathring{{{\mathbb {V}}}}_h := \bigl \{ v_h \in {{\mathbb {V}}}_h:\, (v_h,1) = 0\bigr \}\). We recall the \({{\mathbb {L}}}^2\)-projection \(P_{{{\mathbb {L}}}^2}: {{\mathbb {L}}}^2 \rightarrow {{\mathbb {V}}}_h\), via
and the Riesz projection \(P_{{{\mathbb {H}}}^1}: {{\mathbb {H}}}^1 \cap {{\mathbb {L}}}^2_0 \rightarrow \mathring{{\mathbb {V}}}_h\), via
In what follows, we allow meshes \({{\mathcal {T}}}_h\) for which \(P_{{{\mathbb {L}}}^2}\) is \({{\mathbb {H}}}^1\)-stable; see [10]. Also, we define the inverse discrete Laplacian \((-\Delta _h)^{-1}: {\mathbb {L}}^2_0 \rightarrow \mathring{{\mathbb {V}}}_h\) via
We are ready to present the space discretization of Scheme 3.1.
Scheme 4.1
For every \(1 \le j \le J\), find a \([{{\mathbb {V}}}_h]^2\)-valued r.v. \((X_h^j, w_h^j)\) such that \({{\mathbb {P}}}\)-a.s.
For all \(1 \le j \le J\), the solution \(\{(X_h^j, w_h^j)\}_{1 \le j \le J}\) satisfies \((X_h^j,1) = 0\) \({{\mathbb {P}}}\)-a.s.
Claim 1 \(\{(X_h^j, w_h^j)\}_{1 \le j \le J}\) inherits all stability bounds in Lemma 3.2.
Proof
i’) In order to verify the corresponding version of (i) for \(\{{{\mathcal {E}}}(X^j_h)\}_{1 \le j\le J}\), we may choose \(\varphi _h = w_h^j(\omega )\) and \(\psi _h = [X^j_h - X^{j-1}_h](\omega )\) in Scheme 4.1, as in part (i) of the proof of Lemma 3.2. We then obtain a corresponding version of (3.1), and (3.2).
The next argument in the proof of Lemma 3.2 that leads to (3.3) may again be reproduced for Scheme 4.1 by choosing \(\varphi _h = (-\Delta _h)^{-1}[X^j_h - X^{j-1}_h](\omega )\), and using the definition of \((-\Delta _h)^{-1}\), as well as \(X^j_h, P_{{{\mathbb {L}}}^2} g \in {{\mathbb {L}}}^2_0\) \({\mathbb {P}}\)-a.s., such that
since \(\Vert \nabla (-\Delta _h)^{-1}P_{{{\mathbb {L}}}^2} g\Vert \le \Vert g \Vert \le C\).
To obtain the first identity in (3.5) for Scheme 4.1, we use \(\varepsilon ^\gamma (g, w^j_h)\Delta _jW = \varepsilon ^\gamma \bigl (P_{{{\mathbb {L}}}^2}g, w^j_h \bigr )\Delta _jW\), such that the second equation in Scheme 4.1 with \(\psi _h =P_{{{\mathbb {L}}}^2}g\) may be applied; as a consequence, g has to be replaced by \(P_{{\mathbb {L}}^2}g\) in the rest of equality (3.5). This modification leads to the term \(\Vert \nabla P_{{{\mathbb {L}}}^2}g\Vert \) in (3.6), which is again bounded by \(\Vert \nabla g\Vert \); the bound \(\Vert P_{{{\mathbb {L}}}^2}g\Vert _{{{\mathbb {L}}}^{\infty }} \le C\), which is required to bound the term \(A_{3,1}\) from (3.7), follows by an approximation result; cf. [7, Chapter 7]. The above steps then yield the estimate (3.8) for \(\{ (X^j_h, w^j_h)\}_{1 \le j \le J}\).
ii’), iii’), iv’) We can follow the argumentation in the proof of Lemma 3.2 without change. \(\square \)
Claim 2. Lemma 3.4 holds for \(\{(X_h^j, w_h^j)\}_{1 \le j \le J}\), i.e.: \(Z^j_h := X^j_h - X^j_{{\texttt {CH}};h}\) satisfies \({\mathbb {P}}\)-a.s.
for all \({\ell } \le J\), provided that additionally
for any \(\beta > 0\), and \({{\mathfrak {p}}}_{\texttt {CH}}, \widetilde{{\mathfrak {q}}}_{\texttt {CH}}, \widetilde{{\mathfrak {p}}}_{\texttt {CH}} >0\). The exponents \({{\mathfrak {p}}}_{\texttt {CH}}, \widetilde{{\mathfrak {q}}}_{\texttt {CH}}, \widetilde{{\mathfrak {p}}}_{\texttt {CH}} >0\) are chosen in order to satisfy the assumptions of [16, Corollary 2] and [17, Theorem 3.2]. In particular (4.1) is required to obtain the fully discrete counterpart of Lemma 3.1, (iii)–(iv).
Remark 4.1
Requirement (4.1)\(_2\) comes from [16, Corollary 2, assumption 4)] (see also [17, Theorem 3.1, assumption 3)]). More precisely [16, Corollary 2] in the current setting is applied for \(\gamma _1=1\), \(\delta =1\), \(p=4\), \(\sigma _1=0\), \(N=2\) (where N is the spatial dimension) which yields the condition for \({\hat{\pi }}\) (defined in [16, Corollary 2]):
Hence, (4.1)\(_2\) is a consequence of the above condition for \(N=2\) where for simplicity we estimate \(|\ln k|^{-1} \ge k^{\beta }\) for sufficiently small k. Since \(\beta >0\) may be chosen arbitrarily small, the resulting condition does not severely restrict admissible \(h>0\).
Proof
Again, we here denote by \(\{(X_{{\texttt {CH}};h}^j, w_{{\texttt {CH}};h}^j)\}_{1 \le j \le J} \subset [{{\mathbb {V}}}_h]^2\) the solution of Scheme 4.1 for \(g \equiv 0\), whose stability and convergence properties are studied in [16, 17]. Under the assumption (4.1), [17, Theorem 3.2, (iii)] provides the bound
We use this bound to adapt estimate (3.17) to the present setting and get
Step 2. of the proof of Lemma 3.4 involves the discrete spectral estimate (see Lemma 3.1, iv)) for \(\{X^j_{\texttt {CH}}\}_{j}\) to handle the leading term on the right-hand side of (3.17)—which we do not have for \(\{X^j_{{\texttt {CH}};h}\}_j\) in the present setting. Therefore, we perturb the leading term on the right-hand side of the last inequality, and use the \({\mathbb {L}}^\infty \)-bounds for \(X^j_{{\texttt {CH}}}\), \(X^j_{{\texttt {CH}};h}\), as well as the mean-value theorem to conclude
The remaining steps in the proof of Lemma 3.4 now follow with only minor adjustments. \(\square \)
Claim 3. Additionally assume (4.1). Then Lemma 3.5 holds for \(\{ Z^j_h\}_j\), i.e.,
Moreover, \({\mathbb {P}}[\Omega _{2;h}] \ge 1- \frac{C}{\varepsilon ^{\kappa _0}} \max \bigl \{ \frac{k^2}{\varepsilon ^4}, \varepsilon ^{\gamma +\frac{\sigma _0+1}{3}}, \varepsilon ^{\sigma _0},\varepsilon ^{2\gamma }\bigr \}\), where \({\Omega }_{2;h} := \bigl \{\omega \in \Omega ;\ \widetilde{\mathcal R}_{J_{\varepsilon ,h};h}(\omega ) \le \varepsilon ^{\kappa _0}\bigr \}\), for \(J_{\varepsilon ,h} :=\inf \bigl \{1 \le j \le J:\, \frac{k}{\varepsilon } \sum _{i=1}^{j} \Vert Z_h^{i}\Vert _{{\mathbb {L}}^3}^3 > \varepsilon ^{\sigma _0} \bigr \}\), and
Proof
The proof for Lemma 3.5 directly transfers to the present setting. \(\square \)
Claim 4. Lemma 3.6 remains valid for \(\{Z^j_h\}_h\) accordingly, provided that \(h \le C \varepsilon ^{\widetilde{{\mathfrak {p}}}_{\texttt {CH}}}\) and \(k \le C h^{\widetilde{{\mathfrak {q}}}_{\texttt {CH}}}\), i.e.: \(J_{\varepsilon ,h} = J\) for all \(\omega \in \Omega _{2;h}\).
Proof
We only need to adapt the interpolation argument for \({{\mathbb {L}}}^3\) to the present setting, starting with the estimate \(\Vert Z^i_h\Vert _{{{\mathbb {L}}}^3}^3 \le C \Vert Z^i_h\Vert _{{\mathbb H}^{-1}} \Vert \nabla Z_h^i\Vert ^2\). By the definition of the \({{\mathbb {H}}}^{-1}\)-norm, the definition and \({\mathbb H}^1\)-stability of the \({{{\mathbb {L}}}^2}\)-projection, and again the fact that \((Z^i_h,1) = 0\), we deduce
\(\square \)
Next, we formulate a counterpart of Lemma 3.7 for the fully discrete numerical solution; as a consequence of the Claims 1 to 4 above the corollary can be proven analogically to Lemma 3.7 with the assumption (B) complemented by the additional restriction on the discretization parameters (4.1).
Corollary 4.2
Suppose (B) and (4.1). Then there exists \(C>0\) such that
We are now ready to extend Theorem 3.8 to Scheme 4.1.
Theorem 4.3
Let u be the strong solution of (1.1), and \(\left\{ X^j_h;\, 1 \le j \le J\right\} \) the solution of Scheme 4.1. Assume (B) and (4.1). Then there exists \(C>0\) such that
where \({{\mathfrak {m}}}_{\texttt {CH}}, \widetilde{{\mathfrak {m}}}_{\texttt {CH}} > 0\).
We note that the exponents \({{\mathfrak {m}}}_{\texttt {CH}}, \widetilde{{\mathfrak {m}}}_{\texttt {CH}} > 0\) in the above estimate can be determined on closer inspection of [16, Corollary 2] on assuming (4.1). Furthermore, assumption (4.1), which is a simplified reformulation of assumption 4) in [16, Corollary 2], guarantees that \(\lim _{\varepsilon \downarrow 0}\left( \frac{k^{2-\beta }}{ \varepsilon ^{{{\mathfrak {m}}}_{\texttt {CH}}}} + \frac{{h^4 (1+k^{-\beta })}}{ \varepsilon ^{\widetilde{\mathfrak m}_{\texttt {CH}}}}\right) = 0\).
Proof
We split the error into three contributions,
The first term is bounded by \(C\varepsilon ^{\frac{2}{3}\sigma _0}\) as in Theorem 3.8. The second term is bounded by \(C \bigl (\frac{k^{2-\beta }}{ \varepsilon ^{{{\mathfrak {m}}}_{\texttt {CH}}}} + \frac{{h^4}(1+k^{-\beta })}{ \varepsilon ^{\widetilde{\mathfrak m}_{\texttt {CH}}}}\bigr )\) thanks to [16, Corollary 2] (stated here in a simplified form, cf. Remark 4.1), provided assumption (4.1) holds. The last term is bounded by
thanks to Corollary 4.2. \(\square \)
5 Sharp-interface limit
In this section, we show the convergence of iterates \(\{X^j\}_{j=1}^J\) of Scheme 3.1 to the solution of a sharp interface problem. Recall that in the absence of noise, the sharp interface limit of (1.1) is given by the following deterministic Hele–Shaw/Mullins–Sekerka problem: Find \(v_{\texttt {MS}} : [0,T] \times {\mathcal {D}} \rightarrow {\mathbb {R}}\) and the interface \(\big \{\Gamma ^{{\texttt {MS}}}_t;\, 0 \le t \le T\big \}\) such that for all \(t\in (0,T]\) the following conditions hold:
where \(\varkappa \) is the curvature of the evolving interface \(\Gamma ^{\texttt {MS}}_t\), and \({\mathcal {V}}\) is the velocity in the direction of its normal \({{n_\Gamma }}\), as well as \([\frac{\partial v_{\texttt {MS}}}{\partial {{n_\Gamma }}}]_{\Gamma ^{\texttt {MS}}_t}({z}) = (\frac{\partial v_{{\texttt {MS}},+}}{\partial { {n_\Gamma }}} - \frac{\partial v_{{\texttt {MS}},-}}{\partial {{n_\Gamma }}})({z})\) for all \({z}\in \Gamma ^{\texttt {MS}}_t\). The constant in (5.1c) is chosen as \(\alpha = \tfrac{1}{2}\,c_F\), where \(c_F= \int _{-1}^1 \sqrt{2\,F(s)}\;{\mathrm{d}}s = \tfrac{1}{3}\,2^\frac{3}{2}\), and F is the double-well potential; cf. [1] for a further discussion of the model.
Below, we show that iterates \(\{X^j\}_{j=1}^J\) of Scheme 3.1 converge to the limiting Mullins–Sekerka problem (5.1); see Theorem 5.7 for a precise specification of the convergence result. For this purpose, we need sharper stability and convergence results than those available from Sect. 3, which also requires to tighten the assumptions (B), and so to further restrict admissible choices of \(\gamma >0\). We note that the stronger stability estimates below are derived using the (analytically) strong formulation of Scheme 3.1, i.e., \({\mathbb {P}}\)-a.s., a.e. in \({\mathcal {D}}\):
and \(\partial _{{n}} X^j = \partial _{{n}} w^j = 0\) a.e. on \(\partial {\mathcal {D}}\). The derivation can be justified rigorously (cf. Lemma 3.1, ii)) by the regularity of the Neumann Laplace operator, cf. [24, p. 217, Thm. 4].
Lemma 5.1
Assume (B). For every \(2<p<3\), there exists \(C \equiv C(p)>0\) such that the solution \(\{X^j\}_{j=1}^J\) of Scheme 3.1 satisfies
Proof
1. The second equation in Scheme 3.1 (i.e., (5.2)\(_2\)) implies \(\sqrt{k}\Vert \Delta X^j(\omega )\Vert \le 2\frac{\sqrt{k}}{\varepsilon }\Vert w^j(\omega )\Vert + 2\frac{\sqrt{k}}{\varepsilon ^2}\Vert f(X^j(\omega ))\Vert \), for \(\omega \in \Omega \). Then Lemma 3.2, (ii), and Gagliardo–Nirenberg and Poincaré inequalities imply
which is bounded by \(C \varepsilon ^{{-1}}\) for \(k \le \varepsilon ^4\) (which is guaranteed by assumption (B)).
2. Since \({{\mathbb {W}}}^{1,p} \hookrightarrow {\mathbb {L}}^{\infty }\) (\(p>2\)), by Gagliardo–Nirenberg inequality \(\Vert \cdot \Vert _{{\mathbb {L}}^p}\le C_p\Vert \cdot \Vert _{{\mathbb {L}}^2}^{\frac{2}{p}} \Vert \cdot \Vert _{{\mathbb {H}}^1}^{\frac{p-2}{p}}\) (\(d=2\), \(p>2\)), Hölder inequality, Lemma 3.2, iv), and step 1., we get for \(2<p<3\)
\(\square \)
The following lemma sharpens the statement of Lemma 3.4 for iterates \(\{Z^j\}_{j=1}^J\), where \(Z^j := X^j - X^j_{\texttt {CH}}\). It involves the parameter \({{\mathfrak {n}}}_{\texttt {CH}}>0\) from Lemma 3.1, (ii).
Lemma 5.2
Suppose (B). There exists \(C >0\) such that
In order to establish convergence to zero (for \(\varepsilon \downarrow 0\)) of the right-hand side in the inequality of the lemma, we need to impose a stronger assumptions than (B); for simplicity, we assume \({{\mathfrak {n}}}_{\texttt {CH}} \ge \frac{3}{2}\) in Lemma 3.1:
- (C\(_1\)):
-
Assume (B), and that \((\sigma _0, \kappa _0, \gamma )\) also satisfies
$$\begin{aligned}\sigma _0>10 + \kappa _0 + 4 {{\mathfrak {n}}}_{\texttt {CH}}\,, \qquad \gamma > \max \bigl \{\frac{2\kappa _0+19+8 {{\mathfrak {n}}}_{\texttt {CH}}}{3} , \frac{\kappa _0 + 10 + 4{{\mathfrak {n}}}_{\texttt {CH}}}{2} \bigr \}\, .\end{aligned}$$For sufficiently small \(\varepsilon _0 \equiv (\sigma _0,\kappa _0) >0\) and \({{\mathfrak {l}}}_{\texttt {CH}} \ge 3\) from Lemma 3.1, and arbitrary \(0< \beta < \frac{1}{2}\) the time-step satisfies
$$\begin{aligned} k \le C \min \bigl \{\varepsilon ^{{{\mathfrak {l}}}_{\texttt {CH}}}, \varepsilon ^{7+\frac{\kappa _0}{2}+2 {{\mathfrak {n}}}_{\texttt {CH}} + \beta }\bigr \} \qquad \forall \, \varepsilon \in (0,\varepsilon _0) \,. \end{aligned}$$
Compared to assumption (B), only larger values of \(\sigma _0\), and consequently larger values of \(\gamma \) are admitted, as well as smaller time-steps k.
Proof
1. We subtract Scheme 3.1 [in strong form (5.2)] for \(g\not \equiv 0\) and \(g\equiv 0\), respectively, fix \(\omega \in \Omega \), and multiply the first error equation with \(Z^j(\omega )\) and the second equation with \(-\Delta Z^j(\omega )\). After subtracting the resulting second equation from the first one and using that \((-\Delta w^j, Z^j) = ( w^j, -\Delta Z^j)\) we obtain
We estimate the right-hand side above as
We restate the nonlinear term in (5.4) as
where in the last step we used integration by parts \(\bigl ( \vert Z^j\vert ^2 Z^j, -\Delta Z^j \bigr ) = 3\Vert Z^j \nabla Z^j\Vert ^2\).
Next, we apply integration by parts to \(\texttt {I}_1\), \(\texttt {I}_2\) to estimate
Hence, using Poincaré, Sobolev and Young’s inequalities, Lemma 3.1, (ii), and assumption (B), we deduce that
2. We insert these bounds into (5.4), sum up over all time-steps, take \(\max _{j\le J}\) and expectations,
We use the discrete BDG-inequality (Lemma 3.3) and the Poincaré inequality to estimate the last term as follows,
We now use Lemma 3.7 to bound the right-hand side of (5.5). \(\square \)
A crucial step in this section is to establish convergence of \(\max _{1 \le j \le J}\Vert Z^j\Vert _{{{\mathbb {L}}}^{\infty }}\) for \(\varepsilon \downarrow 0\); it turns out that this can only be validated on large subsets of \(\Omega \), which motivates the introduction of the following (family of) subsets: For every \(2< p < 3\), we define
and the sequence of sets \(\{ {\Omega }_{\kappa , j}\}_{j=1}^J \subset \Omega \) via
Note that \({\Omega }_{\kappa , j} \subset {\Omega }_{\kappa , j-1}\). Markov’s inequality yields that
Clearly, \(\displaystyle {\lim _{\varepsilon \downarrow 0}}\min _{1\le j\le J}{\mathbb {P}}[\Omega _{\kappa ,j}] = 1\) by Lemma 5.1.
We use Lemma 5.2 to show a local error estimate.
Lemma 5.3
Assume (B) and \(2<p<3\). Then there exists \(C>0\) such that
In order to establish convergence to zero (for \(\varepsilon \downarrow 0\)) of the right-hand side in the inequality of the lemma, we impose again a stronger assumptions than (C\(_1\)):
- (C\(_2\)):
-
Assume (C\(_1\)), and that \((\sigma _0, \kappa _0, \gamma )\), and k satisfy
$$\begin{aligned} \lim _{\varepsilon \downarrow 0} {{\mathcal {F}}}_2({k, \varepsilon }; \sigma _0, \kappa _0, \gamma ) =0\,. \end{aligned}$$(5.9)
Remark 5.4
A strategy to identify admissible quadruples \((\sigma _0, \kappa _0, \gamma , k)\) which meet assumption (C\(_2\)) is as follows:
-
(1)
assumption (C\(_1\)) establishes \(\lim _{\varepsilon \downarrow 0} {{{\mathcal {F}}}_1(k,\varepsilon ; \sigma _0, \kappa _0, \gamma )} = 0\), which appears as a factor in the first term on the right-hand side in Lemma 5.3.
-
(2)
the leading factor in \({\mathcal {F}}_2\) is \(\frac{\kappa ^2}{\varepsilon ^2} \equiv \frac{\kappa _p^2}{\varepsilon ^2} \le \varepsilon ^{\frac{1-3p}{p}} \bigl \vert \ln (\varepsilon ^{1-p} )\bigr \vert ^{\frac{2}{p}} k^{\frac{2-p}{p}}\), for \(2<p<3\) via (5.6). To meet (5.9) therefore additionally requires for some p>2
$$\begin{aligned} {k^{\frac{2-p}{p}}} {{{\mathcal {F}}}_1(k,\varepsilon ; \sigma _0, \kappa _0, \gamma )}\varepsilon ^{{\frac{1-3p}{p}}} \bigl \vert \ln (\varepsilon ^{1-p} )\bigr \vert ^{\frac{2}{p}} \rightarrow 0 \qquad (\varepsilon \downarrow 0)\, , \end{aligned}$$(5.10)and hence
$$\begin{aligned} \Bigl [{{{\mathcal {F}}}_1(k,\varepsilon ; \sigma _0, \kappa _0, \gamma )}\varepsilon ^{ {\frac{1-3p}{p}}} \bigl \vert \ln (\varepsilon ^{1-p} )\bigr \vert ^{\frac{2}{p}}\Bigr ]^{{\frac{p}{p-2}}} = o(k)\, . \end{aligned}$$(5.11)A proper scenario is \(k = \varepsilon ^{\alpha }\) for some \(\alpha >0\) to meet assumption \(({\mathbf{C}}_1\mathbf{)}\). We then sharpen this choice of the time-step to \(k = \varepsilon ^{{\widetilde{\alpha }}}\) for some \({\widetilde{\alpha }} \ge \alpha >0\) to have
$$\begin{aligned}{{{\mathcal {F}}}_1(k,\varepsilon ; \sigma _0, \kappa _0, \gamma )}{\varepsilon ^{\frac{1-3p}{p}}} \ln ^{\frac{2}{p}}\bigl (\varepsilon ^{1-p} \bigr ) \le \varepsilon ^\eta \end{aligned}$$for an arbitrary \(\eta > 0\). We now choose \(2<p\), s.t. \({\frac{p}{p-2}} \gg 0\) is sufficiently large to meet (5.11).
-
(3)
We may proceed analogously for the second term on the right-hand side in Lemma 5.3.
Proof
We subtract Scheme 3.1 for \(g\not \equiv 0\) and \(g\equiv 0\) for a fixed \(\omega \in \Omega \), and multiply the first error equation with \(-\Delta Z^j(\omega )\), and the second with \(\Delta ^2 Z^j(\omega )\). We integrate by parts in the nonlinear term and obtain
We proceed as in the proof of Lemma 5.2 and rewrite the nonlinearity on the right-hand side as
We estimate
We estimate \(\sum _{\ell =1}^3\texttt {I}_{\ell }\) on \(\Omega _{\kappa ,j}\) via Lemma 3.1, (ii)-(iii) and the embedding \({\mathbb H}^1 \hookrightarrow {{\mathbb {L}}}^{4}\) on recalling (5.7)
We multiply (5.12) by \(\mathbb {1}_{\Omega _{\kappa ,j}}\), sum up for \(1 \le i \le j\), take \(\max _{1\le j \le J}\) and expectation, employ the identity (recall, \(\mathbb {1}_{\Omega _{\kappa ,j-1}} - \mathbb {1}_{\Omega _{\kappa ,j}}\ge 0\))
use Lemmata 5.2 and 3.7 to estimate (5.13) and obtain
To estimate the stochastic term we use \(\partial _{n}g = 0\) on \(\partial {{\mathcal {D}}}\) and proceed as follows,
The first term on the right-hand side may be bounded by Lemma 5.2, the third term is absorbed in the left-hand side of (5.14), and for the second term we use the discrete BDG-inequality (Lemma 3.3) and Lemma 3.7 to estimate
Hence, the statement of the lemma follows from (5.14) and the above estimates on noting that \((\mathbb {1}_{\Omega _{\kappa ,j}} - \mathbb {1}_{\Omega _{\kappa ,j-1}})^2 = \mathbb {1}_{\Omega _{\kappa ,j-1}} - \mathbb {1}_{\Omega _{\kappa ,j}} \ge 0\). \(\square \)
The \({\mathbb {L}}^\infty \)-estimate in the next theorem is a crucial ingredient to show convergence to the sharp-interface limit.
Theorem 5.5
Assume (C\(_2\)). For any \(2<p<3\), there exists \(C\equiv C(p) >0\) such that
Proof
We proceed analogically as in step 2. in the proof of Lemma 5.1. We use the Sobolev and Gagliardo–Nirenberg inequalities, apply Hölder inequality twice; then use Lemma 5.3, Lemma 5.2 (i.e., \({\mathbb {E}}\big [\varepsilon k\Vert \Delta Z^j\Vert ^2\big ] \le C\)) along with the triangle inequality in combination with Lemma 3.1 (i), Lemma 3.2 (iv) and get for \(2<p<3\) that
\(\square \)
In order to establish convergence to zero (for \(\varepsilon \downarrow 0\)) of the right-hand side in the inequality of the theorem, we impose again a stronger assumption than (C\(_2\)):
- (C\(_3\)):
-
Assume (C\(_2\)), and that \((\sigma _0, \kappa _0, \gamma )\), and k satisfy
$$\begin{aligned} \lim _{\varepsilon \downarrow 0} {\Bigl [\varepsilon ^{-p} k^{2-p} \big ({\mathcal {F}}_2 (k, \varepsilon ; \sigma _0, \kappa _0, \gamma )\big )^{6-2p} \big ({\mathcal {F}}_1 (k, \varepsilon ; \sigma _0, \kappa _0, \gamma )\big )^{p-2}]^{\frac{1}{2}}} = 0\,. \end{aligned}$$(5.15)
Remark 5.6
We discuss a strategy to identify admissible quadruples \((\sigma _0, \kappa _0, \gamma ,k)\) which meet assumption (C\(_3\)): for this purpose, we limit ourselves to a discussion of the leading term inside the maximum which defines \({{\mathcal {F}}}_2\) (see Lemma 5.3), and recall Remark 5.4.
-
(1)
To meet (5.15) instead of (5.10), we have to ensure that for some \(2<p<3\)
$$\begin{aligned} \varepsilon ^{-\frac{p}{2}} k^{\frac{2-p}{2}} \Big ({k^{\frac{2-p}{p}}} \varepsilon ^{{\frac{1-3p}{p}}} \bigl \vert \ln (\varepsilon ^{1-p} )\bigr \vert ^{\frac{2}{p}}\Big )^{3-p}\Big ({{{\mathcal {F}}}_1(k,\varepsilon ; \sigma _0, \kappa _0, \gamma )}\Big )^{\frac{4-p}{2}} \rightarrow 0 \qquad (\varepsilon \downarrow 0) \end{aligned}$$and hence
$$\begin{aligned} {\Bigl [ \Big ({{{\mathcal {F}}}_1(k,\varepsilon ; \sigma _0, \kappa _0, \gamma )}\Big )^{\frac{4-p}{2}} \varepsilon ^{{-\frac{p}{2}}}\varepsilon ^{ {\frac{(1-3p)(3-p)}{p}}}\bigl \vert \ln (\varepsilon ^{1-p} ) \bigr \vert ^{\frac{2(3-p)}{p}} \Bigr ]^{{\frac{2p}{(2-p)(6-p)}}}} = o(k)\, . \end{aligned}$$ -
(2)
We may now proceed as in (2) in Remark 5.4 to identify proper choices \(k = \varepsilon ^{{\alpha }}\) (\(\alpha >0\)) and \(p = 2+\delta \), for sufficiently small \(\delta >0\), that guarantee (5.15).
We are now ready to formulate the second main result of this paper, which is convergence in probability of the solution \(\{X^j\}_{j=0}^J\) of Scheme 3.1 to the solution of the deterministic Hele–Shaw/Mullins–Sekerka problem (5.1) for \(\varepsilon \downarrow 0\), provided that assumption (C\(_3\)) is valid, and (5.1) has a classical solution; cf. Theorem 5.7 below. The proof rests on
-
a)
the uniform bounds for \(\{\mathbb {1}_{{\Omega }_{\kappa ,j}}\Vert Z^j\Vert ^p_{{\mathbb {L}}^{\infty }}\}_{j=1}^J\) (see Theorem 5.5), and the property that \({\lim _{\varepsilon \downarrow 0}}\max _{1\le j\le J}{\mathbb {P}}[\Omega _{\kappa ,j}] = 1\) (in Lemma 5.1) for the sequence \(\{ \Omega _{\kappa ,j}\}_{j=1}^J \subset \Omega \), and
-
b)
a convergence result for \(\{ X^j_{\texttt {CH}}\}_{j=0}^J\) towards a smooth solution of the Hele–Shaw/Mullins–Sekerka problem in [17, Section 4].
For each \(\varepsilon \in (0,\varepsilon _0)\) we consider below the piecewise affine interpolant in time of the iterates \(\{ X^j\}_{j=0}^J\) of Scheme 3.1 via
Let \(\Gamma _{00} \subset {{\mathcal {D}}}\) in (5.1e) be a smooth closed curve, and \((v_{\texttt {MS}}, \Gamma ^{\texttt {MS}})\) be a smooth solution of (5.1) starting from \(\Gamma _{00}\), where \(\Gamma ^{\texttt {MS}} := \bigcup _{0 \le t \le T} \{t\} \times \Gamma ^{\texttt {MS}}_t\). Let \({\mathrm{d}}(t,{x})\) denote the signed distance function to \(\Gamma ^{\texttt {MS}}_t\) such that \({\mathrm{d}}(t,{x}) < 0\) in \({{\mathcal {I}}}^{\texttt {MS}}_t\), the inside of \(\Gamma ^{\texttt {MS}}_t\), and \({\mathrm{d}}(t, { x})>0\) on \({{\mathcal {O}}}^{\texttt {MS}}_t := {{\mathcal {D}}} \setminus (\Gamma ^{\texttt {MS}}_t \cap {{\mathcal {I}}}^{\texttt {MS}}_t)\), the outside of \(\Gamma ^{\texttt {MS}}_t\). We also define the inside \({\mathcal I}^{\texttt {MS}}\) and the outside \({{\mathcal {O}}}^{\texttt {MS}}\),
For the numerical solution \(X^{\varepsilon ,k} \equiv X^{\varepsilon ,k}(t,x)\), we denote the zero level set at time t by \(\Gamma ^{\varepsilon ,k}_t\), that is,
We summarize the assumptions needed below concerning the Mullins–Sekerka problem (5.1).
- (D):
-
Let \({{\mathcal {D}}} \subset {{\mathbb {R}}}^2\) be a smooth domain. There exists a classical solution \((v_{\texttt {MS}},\Gamma ^{\texttt {MS}})\) of (5.1) evolving from \(\Gamma _{00} \subset {{\mathcal {D}}}\), such that \(\Gamma ^{\texttt {MS}}_t \subset {{\mathcal {D}}}\) for all \(t \in [0,T]\).
By [1, Theorem 5.1], assumption (D) establishes the existence of a family of smooth solutions \(\{ u_0^\varepsilon \}_{0 \le \varepsilon \le 1}\) which are uniformly bounded in \(\varepsilon \) and (t, x), such that if \(u^\varepsilon _{\texttt {CH}}\) is the corresponding solution of (1.1) with \(g \equiv 0\), then
The following theorem establishes uniform convergence of iterates \(\{ X^j\}_{j=0}^J\) from Scheme 3.1 in probability on the sets \({{\mathcal {I}}}^{\texttt {MS}}\), \({{\mathcal {O}}}^{\texttt {MS}}\).
Theorem 5.7
Assume (C\(_3\)) and (D). Let \(\{ X^\varepsilon \}_{0 \le \varepsilon \le \varepsilon _0}\) in (5.16) be obtained via Scheme 3.1. Then
Proof
We decompose \(\overline{{{\mathcal {D}}}_T} \setminus \Gamma = {\mathcal I}^{\texttt {MS}} \cup {{\mathcal {O}}}^{\texttt {MS}}\), and consider related errors \(X^{\varepsilon ,k}_{\texttt {CH}} + 1\), \(X^{\varepsilon ,k}_{\texttt {CH}} - 1\) and \(X^{\varepsilon ,k} - X^{\varepsilon ,k}_{\texttt {CH}}\).
1. By [17, Theorem 4.2]Footnote 1, the piecewise affine interpolant \(X^{\varepsilon ,k}\) of \(\{X^j_{\texttt {CH}}\}_{j=0}^J\) satisfies
2. Since \(\Omega _{\kappa ,J} \subset \Omega _{\kappa ,j}\) for \(1 \le j\le J\), Theorem 5.5 and (C\(_3\)) imply (\(2<p < 3\))
The discussion around (5.8) shows \(\lim _{\varepsilon \downarrow 0} {{\mathbb {P}}}[\Omega \setminus \Omega _{\kappa ,J}] = 0\). Let \(\alpha > 0\). By Markov’s inequality
The statement then follows by the triangle inequality and part 1. \(\square \)
A consequence of Theorem 5.7 is the convergence in probability of the zero level set \(\{\Gamma ^{\varepsilon ,k}_t;\, t \ge 0\}\) to the interface \(\Gamma _t^{\texttt {MS}}\) of the Mullins–Sekerka/Hele–Shaw problem (5.1).
Corollary 5.8
Assume (C\(_3\)) and (D). Let \(\{ X^{\varepsilon ,k}\}_{0 \le \varepsilon \le \varepsilon _0}\) in (5.16) be obtained via Scheme 3.1. Then
Proof
We adapt arguments from the proof of [17, Theorem 4.3].
1. For any \(\eta \in (0,1)\) we construct an open tubular neighborhood
of width \(2\eta \) of the interface \(\Gamma ^{\texttt {MS}}\) and define compact subsets
Thanks to Theorem 5.7 there exists \(\varepsilon _0 \equiv \varepsilon _0(\eta ) >0\) such that for all \(\varepsilon \in (0,\varepsilon _0)\) it holds that
In addition, for any \(t \in [0,T]\), and \(x \in \Gamma ^{\varepsilon ,k}_t\), since \(X^\varepsilon (t,x) = 0\), we have
2. We observe that for any \(\eta \in (0,1)\)
On noting (5.18) we deduce that \({\mathbb {P}}[{\widetilde{\Omega }}_3] \le {\mathbb {P}}[\Omega _3]\) where
By (5.17), it holds for \(\varepsilon \in (0,\varepsilon _0)\) that
Inserting this estimate into (5.19) yields for all \(\varepsilon \in (0,\varepsilon _0)\)
which holds for any \(\alpha \ge \eta \). The desired result then follows on noting that \(\eta \) can be chosen arbitrarily small once we take \(\lim _{\varepsilon \downarrow 0}\) in the above inequality. \(\square \)
Remark 5.9
The numerical experiments in Sect. 6 suggest that the conditions on \(\gamma \) and k which are required for Theorem 5.7 to hold are too pessimistic; in particular, they indicate convergence to the deterministic Mullins–Sekerka/Hele–Shaw problem already for \(\gamma =1\), \(k ={\mathcal {O}}(\varepsilon )\).
6 Computational experiments
The computational experiments are meant to support and complement the theoretical results in the earlier sections:
-
Convergence to the deterministic sharp-interface limit (5.1) for the space–time white noise in Sect. 6.3. We study pathwise convergence of the white noise-driven simulations to the deterministic sharp interface limit, which is a scenario beyond the one for regular trace-class noise where Theorem 5.7 and Corollary 5.8 establish convergence in probability.
-
Pathwise convergence to the stochastic sharp interface limit (6.4) (introduced in Sect. 6.2 below) for spatially smooth noise in Sect. 6.4, where we also examine the sensitivity of numerical simulations with respect to the mesh refinement.
6.1 Implementation and adaptive mesh refinement
For the computations below we employ a mass-lumped variant of Scheme 4.1
where the standard \({\mathbb {L}}^2\)-inner product in Scheme 4.1 is replaced by the discrete (mass-lumped) inner product \((v,w)_h = \int _{{\mathcal {D}}} {\mathcal {I}}^h (v(x)w(x))\mathrm {d}x\) for \(v,w\in {\mathbb {V}}_h\), where \({\mathcal {I}}^h:C(\overline{{\mathcal {D}}})\rightarrow {\mathbb {V}}_h\) is the standard interpolation operator. In all experiments we take \({\mathcal {D}} = (0,1)^2\subset {\mathbb {R}}^2\) and g is taken to be a constant. We note that an implicit Euler finite element scheme similar to Scheme 6.1 has been used previously in [19], which also performs simulations to study long time behavior of the system for different strengths of the (space–time white) noise with fixed \(\varepsilon \).
For a given initial interface \(\Gamma _{00}\) we construct an \(\varepsilon \)-dependent family of initial conditions \(\{u^{\varepsilon }_0\}_{\varepsilon >0}\) as \(u^{\varepsilon }_0(x) =\tanh (\frac{\mathrm {d}_0(x)}{\sqrt{2}\varepsilon })\), where \(\mathrm {d}_0\) is the signed distance function to \(\Gamma _{00}\). Consequently, \(\{u^{\varepsilon }_0\}_{\varepsilon >0}\) have bounded energy and contain a diffuse layer of thickness proportional to \(\varepsilon \) along \(\Gamma _{00}\), and \(u^\varepsilon _0(x) \approx -1\), \(u^\varepsilon _0(x) \approx 1\) in the interior, exterior of \(\Gamma _{00}\), respectively. The construction ensures that \(\int _{\mathcal {D}} u^\varepsilon _0\, \mathrm {d}x \rightarrow m_0\) for \(\varepsilon \rightarrow 0\), where \(m_0\) is the difference between the respective areas of the exterior and interior of \(\Gamma _{00}\) in \({\mathcal {D}}\). For convenience we set \(u_0^{\varepsilon , h} = {\mathcal {I}}^h u_0^{\varepsilon }\).
The discrete increments \(\Delta _j W^h = W^h(t_j) - W^h(t_{j-1})\) in (6.1) are \({\mathbb {V}}_h\)-valued random variables which approximate the increments of a \({\mathcal Q}\)-Wiener process on a probability space \((\Omega , {\mathcal {F}},{\mathbb {P}})\) which is given by
where \(\{e_i\}_{i\in {\mathbb {N}}}\) is an orthonormal basis in \({\mathbb {L}}^2({\mathcal {D}})\), \(\{\beta _i\}_{i\in {\mathbb {N}}}\) are independent real-valued Brownian motion, and \(\{\lambda _i\}_{i\in {\mathbb {N}}}\) are real-valued coefficients such that \({\mathcal {Q}}e_i = \lambda _i^2e_i\), \(i\in {\mathbb {N}}\). In order to preserve mass the noise is required to satisfy \({\mathbb {P}}\)-a.s. \(\int _{\mathcal {D}} W(t,x) \,{\mathrm{d}}x = 0\), \(t\in [0,T]\).
In the experiments below we consider two types of Wiener processes: a smooth (finite dimensional) noise and a \({\mathbb {L}}^2_0\)-cylindrical Wiener process (space–time white noise). The smooth noise is given by
where \(\Delta _j \beta _{k\ell } = \beta _{k\ell }(t_j)-\beta _{k\ell }(t_{j-1})\) are independent scalar-valued Brownian increments. The discrete approximation of the smooth noise is then constructed as
where \(\phi _\ell (x_m) = \delta _{\ell m}\), \(\ell =1,\dots , L\) are the (standard) nodal basis function of \({\mathbb {V}}_h\), i.e., \({\mathbb {V}}_h = \mathrm {span}\{\phi _\ell , \, \ell =1, \dots , L\}\). The space–time white noise (\({\mathcal {Q}} = I\)) is approximated as (cf. [5])
In order to preserve the zero mean value property of the noise we normalize the increments as
The Wiener process is simulated using a standard Monte–Carlo technique, i.e., for \(\omega _m \in \Omega \), \(m=1, \dots , M\), we approximate the Brownian increments in (6.2),(6.3) as \(\Delta _j \beta _\ell (\omega _m) \approx \sqrt{k} {\mathcal {N}}_\ell ^j(0,1)(\omega _m)\), where \({\mathcal {N}}_\ell ^j(0,1)(\omega _m)\) is a realization of the Gaussian random number generator at time level \(t_j\). The discrete nonlinear systems related to (realizations of) the scheme (6.1) are solved using the Newton method with a multigrid linear solver.
To increase the efficiency of the computations we employ a pathwise mesh refinement algorithm. For a realization \(X_{h,m}^{j}:=X_h^{j}(\omega _m)\), \(\omega _m\in \Omega \) of the \({\mathbb {V}}_h\)-valued random variable \(X_h^{j}\) we define \(\eta _{grad}(x) = \max \{|\nabla X_{h,m}^{j}(x)|, |\nabla X_{h,m}^{j-1}(x)|\}\) and refine the finite element mesh in such a way that \(h(x) = h_{\mathrm {min}}\) if \(\varepsilon \eta _{grad}(x) \ge 10^{-2}\) and \(h(x) \approx h_{\mathrm {max}}\) if \(\varepsilon \eta _{grad}(x) \le 10^{-3}\); the mesh produced at time level j is then used for the computation of \(X_{h,m}^{j+1}\). The adaptive algorithm produces meshes with mesh size \(h = h_{\mathrm {min}}\) along the interfacial area and \(h \approx h_{\mathrm {max}}\) in the bulk where \(u \approx \pm 1\), see Fig. 3 for a typical adapted mesh. In our computations we choose \(h_{\mathrm {max}} = 2^{-6}\) and \(h_{\mathrm {min}} = \frac{\pi }{4}\varepsilon \), i.e. \(h_{\mathrm {min}} = h_{\mathrm {max}}\) for \(\varepsilon \ge 1/(16\pi )\) and \(h_{\mathrm {min}}\) scales linearly for smaller values of \(\varepsilon \).
In the presented simulations, mesh refinement did not appear to significantly influence the asymptotic behavior of the numerical solution. This is supported by comparison with additional numerical simulation on uniform meshes. The observed robustness of numerical simulations with respect to the mesh refinement can be explained by the fact that the asymptotics are determined by pathwise properties of the solution on a large probability set. This conjecture is supported by the convergence in probability in Theorem 5.7 and Corollary 5.8. In the present setup the (possible) bias due to the pathwise adaptive-mesh refinement did not have significant impact on the results. In general, the use of adaptive algorithms with rigorous control of weak errors may be a preferable approach, cf. [25].
6.2 Stochastic Mullins–Sekerka problem and its discretization
We consider the following stochastic modification of the Mullins–Sekerka problem (5.1)
We note that the only difference between (5.1) and (6.4) is in the equations (5.1a), (6.4a), respectively. Alternatively equation (6.4a) can be stated in an integral form as
For the approximation of the stochastic Mullins–Sekerka problem (6.4), we adapt the unfitted finite element approximation for the deterministic problem (5.1) from [6]. In particular, let \(\Gamma ^{j-1}\) be a polygonal approximation of the interface \(\Gamma \) at time \(t_{j-1}\), parameterized by \({Y}^{j-1}_h \in [{\mathbb {V}}_h(I)]^2\), where \(I = {{\mathbb {R}}} /{{\mathbb {Z}}}\) is the periodic unit interval, and where \({\mathbb {V}}_h(I)\) is the space of continuous piecewise linear finite elements on I with uniform mesh size h. Let \(\pi ^h:C(I) \rightarrow {\mathbb {V}}_h(I)\) be the standard nodal interpolation operator, and let \(\langle \cdot ,\cdot \rangle \) denote the \(L^2\)–inner product on I, with \(\langle \cdot ,\cdot \rangle _h\) the corresponding mass-lumped inner product. Then we find \(v_h^{j} \in {\mathbb {V}}_h\), \({Y}^{j}_h \in [{\mathbb {V}}_h(I)]^2\) and \(\kappa ^{j}_h \in {\mathbb {V}}_h(I)\) such that
In the above, \(\rho \) denotes the parameterization variable, so that \(|[{Y}^{j-1}]_\rho |\) is the length element on \(\Gamma ^{j-1}\) and \({\nu }^{j-1}_h \in [{\mathbb {V}}_h(I)]^2\) is a nodal discrete normal vector, see [6] for the precise definitions.
6.3 Convergence to the deterministic sharp-interface limit
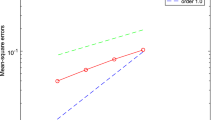
6.3.1 One circle
We set \(\gamma =1\), \(g = 8\pi \) and consider the discrete space–time white noise (6.3). We note that the considered space–time white noise does not satisfy the smoothness assumptions required for the theoretical part of the paper (i.e., \(\gamma > 1\) and \(\mathrm {tr}(\Delta {\mathcal {Q}}) < \infty \)), however the numerical results indicate that for \(\varepsilon \downarrow 0\) the computed evolutions still converge to the deterministic Mullins–Sekerka problem (5.1).
The numerical studies below are performed using the scheme (6.1) with adaptive mesh refinement. The time-step size for \(\varepsilon = 2^{-i}/(64\pi )\), \(i=0, \dots ,4\) was \(k_i=2^{-i}10^{-5}\). The motivation of the different choice of the time-step is to eliminate possible effects of numerical damping and to ensure the convergence of the Newton solver for smaller values of \(\varepsilon \).
For each \(\varepsilon \) we use the initial condition \(u^{\varepsilon ,h}_0\) that approximates a circle with radius \(R=0.2\). Since circles are stationary solutions of the deterministic Mullins–Sekerka problem, the convergence of the numerical solution for the stochastic Cahn–Hilliard equation to the solution of the Mullins–Sekerka problem for \(\varepsilon \downarrow 0\) can be determined by measuring the deviations of the zero level-set of the solution \(X_h^j\), \(j=1,\dots , J\) from the circle with radius \(R=0.2\) for a sufficiently large computational time. We note that the zero level-set of the initial condition \(u^{\varepsilon ,h}_0\) above, exactly approximates the corresponding stationary solution of the Mullins–Sekerka problem, but it is not a stationary solution of the corresponding (discrete) deterministic Cahn–Hilliard equation, i.e., of (6.1) with \(g\equiv 0\). In order to obtain the optimal phasefield profile across the interfacial region, we let \(u^{\varepsilon ,h}_0\) relax towards the discrete stationary state by computing with (6.1) for \(g\equiv 0\) for a short time and then use that discrete solution as the actual initial condition for the subsequent simulations.
The results in Fig. 1 indicate that for decreasing \(\varepsilon \) the evolution of the zero level set of the numerical solution approaches the solution of the deterministic Mullins–Sekerka model, which is represented by the stationary circle with radius 0.2. We observe that the deviations of the interface from the circle are decreasing for smaller \(\varepsilon \).

Deviation of the interface along the x-axes from the circle for \(\varepsilon = 2^{-i}/(64\pi )\), \(i=0, \dots ,4\)

Numerical solution for \(\varepsilon =1/(512\pi )\) at time \(t=0,0.007,0.008\)
6.3.2 Two circles
In this experiment we consider the same setup as in the previous one with an initial condition which consists of two circles with radii \(R_1=0.15\) and \(R_2=0.1\), respectively. The evolution of the solution is more complex than in the previous experiment as the interface undergoes a topological change. To minimize the Ginzburg–Landau energy, the left (larger) circle grows, the right (smaller) circle shrinks and the resulting steady state is a single circle with mass equal to the mass of the two initial circles; see Fig. 2 for an example of a deterministic evolution with \(\varepsilon =1/(512\pi )\). In Fig. 3 we display the graph of the evolution of the position of the x-coordinate of rightmost point of the interface along the x-axis (i.e., we consider the rightmost point on the right (smaller) circle and after the right circle disappears we track the rightmost point of the left circle) for the deterministic Cahn–Hilliard equation as well as for typical realizations of the stochastic Cahn–Hilliard equation for decreasing values of \(\varepsilon \), and of the deterministic Mullins–Sekerka problem. Here the evolutions for the Mullins–Sekerka problem were computed with the scheme (6.5) in the absence of noise. We observe that the solution of the stochastic Cahn–Hilliard equation with the scaled space–time white noise (6.3) converges to the solution of the deterministic Mullins–Sekerka problem for decreasing values of the interfacial width parameter. In addition, the differences between the the stochastic and the deterministic evolutions of the Cahn–Hilliard equation diminish for decreasing values of \(\varepsilon \).

(left) Position of the rightmost point of the interface for the stochastic and the deterministic Cahn–Hilliard equations with \(\varepsilon = 2^{-i}/(64\pi )\), \(i=0, \dots ,4\), \(\gamma =1\) and the deterministic Mullins–Sekerka problem; the values are shifted by \(-0.5\). (right) Zoom on the adapted mesh around the smaller circle for \(\varepsilon =1/(512\pi )\) at \(t=0.007\)
6.4 Comparison with the stochastic Mullins–Sekerka model
We use the numerical scheme (6.1) to study the case of non-vanishing noise, i.e., \(\gamma =0\), with the discrete approximation of the smooth noise (6.2). The noise is symmetric across the center of the domain in order to facilitate an easier comparison with the Mullins–Sekerka problem. The computations below are pathwise, i.e., in the graphs below we display results computed for a single realization of the Wiener process. If not mentioned otherwise we use the time-step size \(k=10^{-5}\).
The initial condition is taken to be the \(\varepsilon \)-dependent approximation of a circle with radius \(R=0.2\) as in Sect. 6.3.1. In the computations, as before, we first let the initial condition relax to a stationary state and then use the stabilized profile \(X^{0}_{h} := X^{j_{s}}_{h}\) as an initial condition for the computation. The zero level-set of the stationary solution \(X^{j_s}_{h}\) is a circle with perturbed radius \(R=0.2+{\mathcal {O}}(\varepsilon )\), where in general the perturbation \({\mathcal {O}}(\varepsilon )\) also depends on the finite element mesh. To compensate for the effect of the perturbation in the initial condition for larger values of \(\varepsilon \) we represent the interface by a level set \(\Gamma _{u_{\Gamma }}^j := \{x\in {\mathcal {D}};\, X^j_h(x) = u_{\Gamma }\}\) (i.e., \(\Gamma _{0}^j\) is the zero level set of the discrete solution at time level \(t_j\)) where the values \(u_{\Gamma } = X^{j_{s}}(0.2,0)\), i.e., it is the ”compensated” level-set for which the stationary profile \(\Gamma _{u_{\Gamma }}^{j_{s}}\) coincides with the circle with radius \(R=0.2\). The usual value for the ”compensated” level-set was \(u_{\Gamma } \approx 0.27\) in the computations below.
We observe that in order to properly resolve the spatial variations of the noise it is necessary to use a mesh size smaller or equal to \(h_{\mathrm {max}} = 2^{-7}\) for the discretization of the Cahn–Hilliard equation. The computations for the Mullins–Sekerka problem, using the scheme (6.5), were more sensitive to the mesh size, and an accurate resolution for the considered noise required a mesh size \(h_{\mathrm {max}} = 2^{-8}\), cf. Fig. 4 which includes the results for \(h_{\mathrm {max}} = 2^{-8}\) as well as \(h_{\mathrm {max}} = 2^{-7}\).
In Fig. 4 we compare the evolution for the stochastic Cahn–Hilliard equation for \(\varepsilon = 1/(32\pi )\), \(\varepsilon = 1/(64\pi )\) on a uniform mesh with \(h = 2^{-7}\), \(h = 2^{-8}\), respectively, with the evolution of the stochastic Mullins–Sekerka problem (6.4) on uniform meshes with \(h = 2^{-7}\), \(h = 2^{-8}\), respectively, for a single realization of the noise. We also include results for \(\varepsilon = 1/(128\pi )\), \(\varepsilon = 1/(512\pi )\), where to make the computations feasible we employ the adaptive algorithm with \(h_{\mathrm {max}}=2^{-8}\) and \(h_{\mathrm {max}}=2^{-9}\), \(h_{\mathrm {max}}=2^{-11}\), respectively. Furthermore, in order to ensure convergence of the Newton solver for \(\varepsilon = 1/(512\pi )\) we decrease the time-step size \(k=10^{-6}\). To be able to directly compare with the results for \(\varepsilon = 1/(512\pi )\), we take the values of the realization of the noise generated with step size \(k=10^{-5}\), which was used in the other simulations, and to obtain values at the intermediate time levels we employ linear interpolation in time. We observe that the results in Fig. 4 for the stochastic Mullins–Sekerka model are more sensitive to the mesh size, i.e., the graph for the mesh with \(h = 2^{-7}\) differs significantly from the remaining results. For the mesh with \(h_{\mathrm {min}} = 2^{-8}\) the results for the stochastic Mullins–Sekerka model are in good agreement with the results for the stochastic Cahn–Hilliard model. We note that for values smaller than \(\varepsilon = 1/(128\pi )\) we do not observe significant improvements of the approximation of the stochastic Mullins–Sekerka problem. This is likely caused by the discretization errors in the numerical approximation of the stochastic Mullins–Sekerka model which, for small values of \(\varepsilon \), are greater than the approximation error w.r.t. \(\varepsilon \) in the stochastic Cahn–Hilliard equation.

Oscillations of the interface along the x-axis (x, 0) on uniform meshes for the stochastic Cahn–Hilliard equation with \(\varepsilon = 1/(32\pi )\), \(h = 2^{-7}\), \(\varepsilon = 1/(64\pi )\), \(h = 2^{-8}\), \(\varepsilon = 1/(128\pi )\), \(h_{\mathrm {min}} = 2^{-9}\), \(\varepsilon = 1/(512\pi )\), \(h_{\mathrm {min}} = 2^{-11}\) and for the stochastic Mullins–Sekerka problem with \(h = 2^{-7}\) and \(h = 2^{-8}\) with the noise (6.2) (top left); detail of the evolution (top right); evolution of the zero level-set of the solution (bottom middle)

Oscillations of the ”compensated” level-set along the x-axis (x, 0) with adaptive mesh refinement with \(h_{\mathrm {max}}=2^{-6}\) for stochastic Cahn–Hilliard equation with \(\varepsilon = 1/(32\pi )\), \(h_{\mathrm {min}} = 2^{-7}\), \(\varepsilon = 1/(64\pi )\), \(h_{\mathrm {min}} = 2^{-8}\), \(\varepsilon = 1/(128\pi )\), \(h_{\mathrm {min}} = 2^{-9}\), and the stochastic Mullins–Sekerka problem with \(h_{\mathrm {min}} = 2^{-8}\), \(h_{\mathrm {max}}=2^{-6}\) with the noise (6.2) (left picture); evolution of the corresponding zero level-set (right picture)
From the above numerical results we conjecture that for \(\varepsilon \downarrow 0\) the solution of the stochastic Cahn–Hilliard equation with a non-vanishing noise term (\(\gamma =0\)) converges to the solution of a stochastic Mullins–Sekerka problem (6.4). Formally, the stochastic Mullins–Sekerka problem (6.4) can be obtained as a sharp-interface limit of a generalized Cahn–Hilliard equation where the noise is treated as a deterministic function \(G_1(t) = g\, {\dot{W}}(t)\), cf. (2.3) in [3] and (1.12) in [4].
To examine the robustness of previous results with respect to adaptive mesh refinement we recompute the previous problems with the noise (6.2) using the adaptive mesh refinement algorithm with \(h_{\mathrm {max}}=2^{-6}\) and \(h_{\mathrm {min}}=\frac{\pi }{4}\varepsilon \). The stochastic Mullins–Sekerka model is computed with \(h_{\mathrm {max}}=2^{-6}\) and the mesh is refined along the interface \(\Gamma \) with mesh size \(h_{\mathrm {min}}=2^{-8}\).
We note that with adaptive mesh refinement the results differ from those computed using uniform meshes, since the noise (6.2) is mesh dependent. For instance, in the regions with coarse mesh the noise (6.2) is not properly resolved. The computed results with the adaptive mesh refinement can be interpreted as replacing the additive noise (6.2) with a multiplicative type noise that has lower intensity when \(u\approx \pm 1\). The presented computations contain an additional ”geometric” factor in the numerical error that is due to the fact that the mesh is adapted according to the position of the interface, as well as due to the fact that the adaptive mesh refinement algorithm for the Mullins–Sekerka problem is different. Nevertheless, the results are still in good agreement with the stochastic Mullins–Sekerka problem, see Fig. 5. In particular we observe that the convergence for smaller values of \(\varepsilon \) is more obvious for the zero level-set of the solution than in the case of uniform meshes. In Fig. 5 we also include a graph (’ftilde’ in pink) which was computed using a modification of scheme (6.1) with \(\bigl (f(X^j_h),\psi _h \bigr )\) replaced by \(\bigl ({\tilde{f}}(X^j_h, X^{j-1}_h),\psi _h \bigr )\) where \({\tilde{f}}(X^j_h, X^{j-1}_h) = \frac{1}{2}(|X^j_h|^2-1)(X^j_h + X^{j-1}_h)\); for equal time-step size the modified scheme provides worse approximation of the Mullins–Sekerka problem due to numerical damping.
Notes
Note that the mesh requirement \(k = {{\mathcal {O}}}(h^q)\) stated in [17, Theorem 4.2] does not apply for the semi-discretization in time of (1.1) with \(g \equiv 0\). In fact, in [17]—where the involved parameters \(k,h,\varepsilon \) tend to zero simultaneously—the given constraint goes back to requirement [17, Theorem 3.1, 3)] which uses [17, (3.28)], where we formally send \(h \downarrow 0\) first (with \(\mu = \nu =\delta =1\), \(N=2\)) to address our case.
References
Alikakos, N.D., Bates, P.W., Chen, X.: Convergence of the Cahn–Hilliard equation to the Hele-Shaw model. Arch. Rat. Mech. Anal. 128, 165–205 (1994)
Alikakos, N.D., Fusco, G.: The spectrum of the Cahn–Hilliard operator for generic interface in higher space dimensions. Indiana Univ. Math. J. 41, 637–674 (1993)
Antonopoulou, D.C., Blömker, D., Karali, G.D.: The Sharp interface limit for the Stochastic Cahn–Hilliard equation. Annales de l’Institut Henri Poincaré Prob.-Stat. 504(1), 280–298 (2018)
Antonopoulou, D.C., Karali, G.D., Kossioris, G.T.: Asymptotics for a generalized Cahn–Hilliard equation with forcing terms. Discrete Contin. Dyn. Syst. A 30(4), 1037–1054 (2011)
Baňas, Ľ., Brzeźniak, Z., Neklyudov, M., Prohl, A.: Stochastic Ferromagnetism. De Gruyter Studies in Mathematics, vol. 58. De Gruyter, Berlin (2014)
Barrett, J.W., Garcke, H., Nürnberg, R.: On stable parametric finite element methods for the Stefan problem and the Mullins–Sekerka problem with applications to dendritic growth. J. Comput. Phys. 229(18), 6270–6299 (2010)
Brenner, S.C., Scott, L.R.: The Mathematical Theory of Finite Element Methods. Springer, New York (1994)
Cardon-Weber, C.: Cahn–Hilliard stochastic equation: existence of the solution and of its density. Bernoulli 7(5), 777–816 (2001)
Cardon-Weber, C.: Cahn–Hilliard stochastic equation: strict positivity of the density. Stoch. Stoch. Rep. 72(3–4), 191–227 (2002)
Carstensen, C.: Merging the Bramble–Pasciak–Steinbach and the Crouzeix–Thomée criterion for \(H^1\)-stability of the \(L^2\)-projection onto finite element spaces. Math. Comp. 7, 157–163 (2002)
Chen, X.: Spectrums for the Allen–Cahn, Cahn–Hilliard, and phase-field equations for generic interface. Comm. Partial Differ. Eqn. 19, 1371–1395 (1994)
Cook, H.: Brownian motion in spinodal decomposition. Acta Metallurgica 18, 297–306 (1970)
Da Prato, G., Debussche, A.: Stochastic Cahn–Hilliard equation. Nonlinear Anal. Theory Methods Appl. 26(2), 241–263 (1996)
Elezovic, N., Mikelic, A.: On the stochastic Cahn–Hilliard equation. Nonlinear Anal. 16(12), 1169–1200 (1991)
Feng, X., Prohl, A.: Numerical analysis of the Allen–Cahn equation and approximation for mean curvature flows. Numer. Math. 3, 35–65 (2003)
Feng, X., Prohl, A.: Error analysis of a mixed finite element method for the Cahn–Hilliard equation. Numer. Math. 99, 47–84 (2004)
Feng, X., Prohl, A.: Numerical analysis of the Cahn–Hilliard equation and approximation of the Hele–Shaw problem. Interfaces Free Bound. 7, 1–28 (2005)
Gameiro, M., Mischaikow, K., Wanner, T.: Evolution of pattern complexity in the Cahn–Hilliard theory of phase separation. Acta Materialia 53, 693–704 (2005)
L. Goudenège Quelques résultats sur l’équation de Cahn–Hilliard stochastique et déterministe”. Ph.D. thesis, École Normale Supérieure de Cachan, (2009)
Gurtin, M.E.: Generalized Ginzburg–Landau and Cahn–Hilliard equations based on a microforce balance. Physica D 92, 178–192 (1996)
Hohenberg, P.C., Halperin, B.I.: Theory of dynamic critical phenomena. Rev. Mod. Phys. 49, 435–479 (1977)
Langer, J.S.: Theory of spinodal decomposition in alloys. Ann. Phys. 65, 53–86 (1971)
Majee, A.K., Prohl, A.: Optimal strong rates of convergence for a space–time discretization of the stochastic Allen–Cahn equation with multiplicative noise. Comput. Methods Appl. Math. 18, 297–311 (2018)
Mikhaĭlov, V.P.: Partial differential equations, “Mir”, Moscow; distributed by Imported Publications Inc., Ill, Chicago (1978)
Prohl, A., Schellnegger, C.: Adaptive concepts for stochastic partial differential equations. J. Sci. Comput. 80, 444–474 (2019)
Acknowledgements
Financial support by the DFG through the CRC ”Taming uncertainty and profiting from randomness and low regularity in analysis, stochastics and their applications” is acknowledged. The authors would like to thank the referees for helpful remarks and suggestions.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Antonopoulou, D., Baňas, Ĺ., Nürnberg, R. et al. Numerical approximation of the stochastic Cahn–Hilliard equation near the sharp interface limit. Numer. Math. 147, 505–551 (2021). https://doi.org/10.1007/s00211-021-01179-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-021-01179-7