
Abstract
The Bayesian approach to inverse problems provides a rigorous framework for the incorporation and quantification of uncertainties in measurements, parameters and models. We are interested in designing numerical methods which are robust w.r.t. the size of the observational noise, i.e., methods which behave well in case of concentrated posterior measures. The concentration of the posterior is a highly desirable situation in practice, since it relates to informative or large data. However, it can pose a computational challenge for numerical methods based on the prior measure. We propose to employ the Laplace approximation of the posterior as the base measure for numerical integration in this context. The Laplace approximation is a Gaussian measure centered at the maximum a-posteriori estimate and with covariance matrix depending on the logposterior density. We discuss convergence results of the Laplace approximation in terms of the Hellinger distance and analyze the efficiency of Monte Carlo methods based on it. In particular, we show that Laplace-based importance sampling and Laplace-based quasi-Monte-Carlo methods are robust w.r.t. the concentration of the posterior for large classes of posterior distributions and integrands whereas prior-based importance sampling and plain quasi-Monte Carlo are not. Numerical experiments are presented to illustrate the theoretical findings.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The identification of unknown parameters from noisy observations arises in various areas of application, e.g., engineering systems, biological models, environmental systems. In recent years, Bayesian inference has become a popular approach to model inverse problems [39], i.e., noisy observations are used to update the knowledge of unknown parameters from a prior distribution to the posterior distribution. The latter is then the solution of the Bayesian inverse problem and obtained by conditioning the prior distribution on the data. This approach is very appealing in various fields of applications, since uncertainty quantification can be performed, once the prior distribution is updated—barring the fact that Bayesian credible sets are not in a one-to-one correspondence to classical confidence sets, see [7, 40].
To ensure the applicability of the Bayesian approach to computationally demanding models, there has been a lot of research effort towards improved algorithms allowing for effective sampling or integration w.r.t. the resulting posterior measure. For example, the computational burden of expensive forward or likelihood models can be reduced by surrogates or multilevel strategies [14, 20, 27, 34] and for many classical sampling or integration methods such as Quasi-Monte Carlo [12], Markov chain Monte Carlo [6, 32, 42], and numerical quadrature [5, 35] we now know modifications and conditions which ensure a dimension-independent efficiency.
However, a completely different, but very common challenge for many numerical methods has drawn surprisingly less attention so far: the challenge of concentrated posterior measures such as
Here, \(n\gg 1\) and \(\mu _0\) denotes a reference or prior probability measure on \(\mathbb {R}^d\) and \(\varPhi _n:\mathbb {R}^d\rightarrow [0,\infty )\) are negative log-likelihood functions resulting, e.g., from n observations.
From a modeling point of view the concentration effect of the posterior is a highly desirable situation due to large data sets and less remaining uncertainty about the parameter to be inferred. From a numerical point of view, on the other hand, this can pose a delicate situation, since standard integration methods may perform worse and worse if the concentration increases due to \(n\rightarrow \infty \). Hence, understanding how sampling or quadrature methods for \(\mu _n\) behave as \(n\rightarrow \infty \) is a crucial task with immediate benefits for purposes of uncertainty quantification. Since small noise yields “small” uncertainty, one might be tempted to consider only optimization-based approaches in order to compute a point estimator (i.e., the maximum a-posteriori estimator) for the unknown parameter which is usually computationally much cheaper than a complete Bayesian inference. However, for quantifying the remaining risk, e.g., computing the posterior failure probability for some quantity of interest, we still require efficient integration methods for concentrated posteriors as \(\mu _n\). Nonetheless, we will use well-known preconditioning techniques from numerical optimization in order to derive such robust integration methods for the small noise setting.
Numerical methods are often based on the prior \(\mu _0\), since \(\mu _0\) is usually a simple measure allowing for direct sampling or explicit quadrature formulas. However, for large n most of the corresponding sample points or quadrature nodes will be placed in regions of low posterior importance missing the needle in the haystack—the minimizers of \(\varPhi _n\). An obvious way to circumvent this is to use a numerical integration w.r.t. another reference measure which can be straightforwardly computed or sampled from and concentrates around those minimizers and shrinks like the posterior measures \(\mu _n\) as \(n\rightarrow \infty \). In this paper we consider numerical methods based on a Gaussian approximation of \(\mu _n\)—the Laplace approximation.
When it comes to integration w.r.t. an increasingly concentrated function, the well-known and widely used Laplace’s method provides explicit asymptotics for such integrals, i.e., under certain regularity conditions [44] we have for \(n\rightarrow \infty \) that
where \(x_\star \in \mathbb {R}\) denotes the assumed unique minimizer of \(\varPhi :\mathbb {R}^d\rightarrow \mathbb {R}\). This formula is derived by approximating \(\varPhi \) by its second-order Taylor polynomial at \(x_\star \). We could now use (2) and its application to \(Z_n\) in order to derive that \(\int _{\mathbb {R}^d} f(x) \ \mu _n(\mathrm {d}x) \rightarrow f(x_\star ) \) as \(n\rightarrow \infty \). However, for finite n this is only of limited use, e.g., consider the computation of posterior probabilities where f is an indicator function. Thus, in practice we still rely on numerical integration methods in order to obtain a reasonable approximation of the posterior integrals \(\int _{\mathbb {R}^d} f(x) \ \mu _n(\mathrm {d}x)\). Nonetheless, the second-order Taylor approximation employed in Laplace’s method provides us with (a guideline to derive) a Gaussian measure approximating \(\mu _n\).
This measure itself is often called the Laplace approximation of \(\mu _n\) and will be denoted by \(\mathcal L_{\mu _n}\). Its mean is given by the maximum a-posteriori estimate (MAP) of the posterior \(\mu _n\) and its covariance is the inverse Hessian of the negative log posterior density. Both quantities can be computed efficiently by numerical optimization and since it is a Gaussian measure it allows for direct samplings and easy quadrature formulas. The Laplace approximation is widely used in optimal (Bayesian) experimental design to approximate the posterior distribution (see, for example, [1]) and has been demonstrated to be particularly useful in the large data setting, see [25, 33] and the references therein for more details. Moreover, in several recent publications the Laplace approximation was already proposed as a suitable reference measure for numerical quadrature [5, 38] or importance sampling [2]. Note that preconditioning strategies based on Laplace approximation are also referred to as Hessian-based strategies due to the equivalence of the inverse covariance and the Hessian of the corresponding optimization problem, cp. [5]. In [38], the authors showed that a Laplace approximation-based adaptive Smolyak quadrature for Bayesian inference with affine parametric operator equations exhibits a convergence rate independent of the size of the noise, i.e., independent of n.
This paper extends the analysis in [38] for quadrature to the widely applied Laplace-based importance sampling and Laplace-based quasi-Monte Carlo (QMC) integration.
Before we investigate the scale invariance or robustness of these methods we examine the behaviour of the Laplace approximation and in particular, the density \(\frac{\mathrm {d}\mu _n}{\mathrm {d}\mathcal L_{\mu _n}}\). The reason behind is that, for importance sampling as well as QMC integration, this density naturally appears in the methods, hence, if it deteriorates as \(n\rightarrow \infty \), this will be reflected in a deteriorating efficiency of the method. For example, for \(\varPhi _n \equiv \varPhi \) the density w.r.t. the prior measure \(\frac{\mathrm {d}\mu _n}{\mathrm {d}\mu _0} = \exp (-n\varPhi )/Z_n\) deteriorates to a Dirac function at the minimizer \(x_\star \) of \(\varPhi \) as \(n\rightarrow \infty \) which causes the shortcomings of Monte Carlo or QMC integration w.r.t. \(\mu _0\) as \(n\rightarrow \infty \). However, for the Laplace approximation we show that the density \(\frac{\mathrm {d}\mu _n}{\mathrm {d}\mathcal L_{\mu _n}}\) converges \(\mathcal L_{\mu _n}\)-almost everywhere to 1 which in turn results in a robust—and actually improving—performance w.r.t. n of related numerical methods. In summary, the main results of this paper are the following:
-
1.
Laplace Approximation: Given mild conditions the Laplace approximation \(\mathcal L_{\mu _n}\) converges in Hellinger distance to \(\mu _n\):
$$\begin{aligned} d_\mathrm {H}(\mu _n, \mathcal L_{\mu _n}) \in \mathcal O(n^{-1/2}). \end{aligned}$$This result is closely related to the well-known Bernstein–von Mises theorem for the posterior consistency in Bayesian inference [41]. The significant difference here is that the covariance in the Laplace approximation depends on the data and the convergence holds for the particularly observed data whereas in the classical Bernstein–von Mises theorem the covariance is the inverse of the expected Fisher information matrix and the convergence is usually stated in probability.
-
2.
Importance Sampling: We consider integration w.r.t. measures \(\mu _n\) as in (1) where \(\varPhi _n(x) = \varPhi (x) - \iota _n\) for a \(\varPhi :\mathbb {R}^d \rightarrow [0,\infty )\) and \(\iota _n \in \mathbb {R}\).
-
Prior-based Importance Sampling: We consider the case of prior-based importance sampling, i.e., the prior \(\mu _0\) is used as the importance distribution for computing the expectation of smooth integrands \(f\in L^2_{\mu _0}(\mathbb {R})\). Here, the asymptotic variance w.r.t. such measures \(\mu _n\) deteriorates like \(n^{d/2-1}\).
-
Laplace-based Importance Sampling. The (random) error \(e_{n,N}(f)\) of Laplace-based importance sampling for computing expectations of smooth integrands \(f\in L^2_{\mu _0}(\mathbb {R})\) w.r.t. such measures \(\mu _n\) using a fixed number of samples \(N\in \mathbb {N}\) decays in probability almost like \(n^{-1/2}\), i.e.,
$$\begin{aligned} n^\delta e_{n,N}(f) \xrightarrow [n\rightarrow \infty ]{\mathbb {P}} 0, \qquad \delta < 1/2. \end{aligned}$$
-
-
3.
Quasi-Monte Carlo: We focus for the analysis of the quasi-Monte Carlo methods on the bounded case of \(\mu _0 = \mathcal U([\frac{1}{2},\frac{1}{2}]^d)\).
-
Prior-based Quasi-Monte Carlo: The root mean squared error estimate for computing integrals of the form (2) by QMC using randomly shifted Lattice rules deteriorates like \(n^{d/4}\) as \(n\rightarrow \infty \).
-
Laplace-based Quasi-Monte Carlo: If the lattice rule is transformed by an affine mapping based on the mean and the covariance of the Laplace approximation, then the resulting root mean squared error decays like \(n^{-d/2}\) for integrals of the form (2).
-
The outline of the paper is as follows: in Sect. 2 we introduce the Laplace approximation for measures of the form (1) and the notation of the paper. In Sect. 2.2 we study the convergence of the Laplace approximation. We also consider the case of singular Hessians or perturbed Hessians and provide some illustrative numerical examples. At the end of the section, we shortly discuss the relation to the classical Bernstein–von Mises theorem. The main results about importance sampling and QMC using the prior measure and the Laplace approximation, respectively, are then discussed in Sect. 3. We also briefly comment on existing results for numerical quadrature and provide several numerical examples illustrating our theoretical findings. The appendix collects the rather lengthy and technical proofs of the main results.
2 Convergence of the Laplace approximation
We start with recalling the classical Laplace method for the asymptotics of integrals.
Theorem 1
(variant of [44, Section IX.5]) Set
where \(D\subseteq \mathbb {R}^d\) is a possibly unbounded domain and let the following assumptions hold:
-
1.
The integral J(n) converges absolutely for each \(n\in \mathbb {N}\).
-
2.
There exists an \(x_\star \) in the interior of D such that for every \(r > 0\) there holds
$$\begin{aligned} \delta _r :=\inf _{x \in B^c_r(x_\star )} \varPhi (x) - \varPhi (x_\star ) > 0, \end{aligned}$$where \(B_r(x_\star ) :=\{x \in \mathbb {R}^d:\Vert x-x_\star \Vert \le r \}\) and \(B^c_r(x_\star ) :=\mathbb {R}^d {\setminus } B_r(x_\star )\).
-
3.
In a neighborhood of \(x_\star \) the function \(f:D\rightarrow \mathbb R\) is \((2p+2)\) times continuously differentiable and \(\varPhi :\mathbb {R}^d \rightarrow \mathbb {R}\) is \((2p+3)\) times continuously differentiable for a \(p\ge 0\), i.e., and the Hessian \(H_\star :=\nabla ^2 \varPhi (x_\star )\) is positive definite.
Then, as \(n\rightarrow \infty \), we have
where \(c_k(f) \in \mathbb {R}\) and, particularly, \(c_0(f) = \sqrt{\det (2\pi H^{-1}_\star )}\, f(x_\star )\).
Remark 1
As stated in [44, Section IX.5] the asymptotic
with \(c_0(f)\) is as above, already holds for \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) being continuous and \(\varPhi :\mathbb {R}^d\rightarrow \mathbb {R}\) being twice continuously differentiable in a neighborhood of \(x_\star \) with positive definite \(\nabla ^2 \varPhi (x_\star )\)—given that the first two assumptions of Theorem 1 are also satisfied.
Assume that \(\varPhi (x_\star ) = 0\), then the above theorem and remark imply
for continuous and integrable \(f:\mathbb {R}^d\rightarrow \mathbb {R}\), where \(\Vert \cdot \Vert _A=\Vert A^{1/2}\cdot \Vert \) for a symmetric positive definite matrix \(A\in \mathbb {R}^{d\times d}\). This is similar to the notion weak convergence (albeit with two different non-static measures). If we additionally claim that \(f(x_\star ) > 0,\) then also
which is sort of a relative weak convergence. In other words, the asymptotic behaviour of \(\int f\ \mathrm e^{-n\varPhi }\ \mathrm {d}x\), in particular, its convergence to zero, is the same as of the integral of f w.r.t. an unnormalized Gaussian density with mean in \(x_\star \) and covariance \( (nH_\star )^{-1}\).
If we consider now probability measures \(\mu _n\) as in (1) but with \(\varPhi _n \equiv \varPhi \) where \(\varPhi \) satisfies the assumptions of Theorem 1, and if we suppose that \(\mu _0\) possesses a continuous Lebesgue density \(\pi _0:\mathbb {R}\rightarrow [0,\infty )\) with \(\pi _0(x_\star ) > 0\), then Theorem 1 and Remark 1 will imply for continuous and integrable \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) that
The same reasoning applies to the expectation of f w.r.t. a Gaussian measure \(\mathcal N(x_\star , (nH_\star )^{-1})\) with unnormalized density \(\exp (- \frac{n}{2} \Vert x-x_\star \Vert ^2_{H_\star })\). Thus, we obtain the weak convergence of \(\mu _n\) to \(\mathcal N(x_\star , (nH_\star )^{-1})\), i.e., for any continuous and bounded \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) we have
where \(\mathcal N_{x,C}\) is short for \(\mathcal N(x,C)\). In fact, for twice continuously differentiable \(f:\mathbb {R}^d \rightarrow \mathbb {R}\) we get by means of Theorem 1 the rate
Note that due to normalization we do not need to assume \(\varPhi (x_\star ) = 0\) here. Hence, this weak convergence suggests to use \(\mathcal N_{x_\star , (nH_\star )^{-1}}\) as a Gaussian approximation to \(\mu _n\). In the next subsection we derive similar Gaussian approximation for the general case \(\varPhi _n \not \equiv \varPhi \), whereas Sect. 2.2 includes convergence results of the Laplace approximation in terms of the Hellinger distance.
Bayesian inference We present some context for the form of equation (1) in the following. Integrals of the form (1) arise naturally in the Bayesian setting for inverse problems with large amount of observational data or informative data. Note that the mathematical results for the Laplace approximation given in Sect. 2 are derived in a much more general setting and are not restricted to integrals w.r.t. the posterior in the Bayesian inverse framework. We refer to [8, 21] and the references therein for a detailed introduction to Bayesian inverse problems.
Consider a continuous forward response operator \({\mathcal {G}}:\mathbb {R}^d \rightarrow \mathbb R^K\) mapping the unknown parameters \(x\in \mathbb {R}^d\) to the data space \(\mathbb R^K\), where \(K\in \mathbb N\) denotes the number of observations. We investigate the inverse problem of recovering unknown parameters \(x\in \mathbb {R}^d\) from noisy observations \(y\in \mathbb {R}^K\) given by
where \(\eta \sim {\mathcal {N}}(0,\varGamma )\) is a Gaussian random variable with mean zero and covariance matrix \(\varGamma \), which models the noise in the observations and in the model.
The Bayesian approach for this inverse problem of inferring x from y (which is ill-posed without further assumptions) works as follows: For fixed \(y\in \mathbb {R}^K\) we introduce the least-squares functional (or negative loglikelihood in the language of statistics) \(\varPhi (\cdot ;y):\mathbb R^d\rightarrow \mathbb R\) by
with \(\Vert \cdot \Vert _{\varGamma ^{-1}}:=\Vert \varGamma ^{-\frac{1}{2}}\cdot \Vert \) denoting the weighted Euclidean norm in \(\mathbb R^K\). The unknown parameter x is modeled as a \(\mathbb {R}^d\)-valued random variable with prior distribution \(\mu _0\) (independent of the observational noise \(\eta \)), which regularizes the problem and makes it well-posed by application of Bayes’ theorem: The pair (x, y) is a jointly varying random variable on \(\mathbb R^d \times \mathbb R^K\) and hence the solution to the Bayesian inverse problem is the conditional or posterior distribution \(\mu \) of x given the data y where the law \(\mu \) is given by
with the normalization constant \(Z :=\int _{\mathbb R^d}\exp (-\varPhi (x;y))\mu _0(\mathrm {d}x)\). If we assume a decaying noise-level by introducing a scaled noise covariance \(\varGamma _n = \frac{1}{n} \varGamma \), the resulting noise model \(\eta _n \sim N(0,\varGamma _n)\) yields an n-dependent log-likelihood term which results in posterior measures \(\mu _n\) of the form (1) with \(\varPhi _n(x) = \varPhi (x ; y)\). Similarly, an increasing number \(n\in \mathbb {N}\) of data \(y_1, \ldots , y_n \in \mathbb {R}^k\) resulting from n observations of \({\mathcal {G}}(x)\) with independent noises \(\eta _1,\ldots ,\eta _n\sim N(0,\varGamma )\) yields posterior measures \(\mu _n\) as in (1) with \(\varPhi _n(x) = \frac{1}{n} \sum _{j=1}^n \varPhi (x ; y_j)\).
2.1 The Laplace approximation
Throughout the paper, we assume that the prior measure \(\mu _0\) is absolutely continuous w.r.t. Lebesgue measure with density \(\pi _0:\mathbb {R}^d\rightarrow [0,\infty )\), i.e.,
Hence, also the measures \(\mu _n\) in (1) are absolutely continuous w.r.t. Lebesgue measure, i.e.,
where \(I_n:\mathrm {S}_0 \rightarrow \mathbb {R}\) is given by
In order to define the Laplace approximation of \(\mu _n\) we need the following basic assumption.
Assumption 1
There holds \(\varPhi _n, \pi _0 \in C^2(\mathrm {S}_0,\mathbb {R})\), i.e., the mappings \(\pi _0,\varPhi _n:\mathrm {S}_0\rightarrow \mathbb {R}\) are twice continuously differentiable. Furthermore, \(I_n\) has a unique minimizer \(x_n \in \mathrm {S}_0\) satisfying
where the latter denotes positive definiteness.
Remark 2
Assuming that \(\min _{x\in \mathrm {S}_0} I_n(x) = 0\) is just a particular (but helpful) normalization and in general not restrictive: If \(\min _{x\in \mathrm {S}_0} I_n(x) = c >-\infty \), then we can simply set
for which we obtain
and \(\min _{x\in \mathrm {S}_0} {\hat{I}}_n(x) = \min _x {\hat{\varPhi }}_n(x) - \frac{1}{n} \log \pi _0(x) = 0\).
Given Assumption 1 we define the Laplace approximation of \(\mu _n\) as the following Gaussian measure
Thus, we have
where we can view
as the second-order Taylor approximation \({\widetilde{I}}_n = T_2 I_n(x_n)\) of \(I_n\) at \(x_n\). This point of view is crucial for analyzing the approximation
Notation and recurring equations Before we continue, we collect recurring important definitions and where they can be found in Table 1 and provide the following important equations cheat sheet
2.2 Convergence in Hellinger distance
By a modification of Theorem 1 for integrals w.r.t. a weight \(\mathrm e^{-n\varPhi _n(x)}\) we may show a corresponding version of (4), i.e., for sufficiently smooth \(f\in L^1_{\mu _0}(\mathbb {R})\)
However, in this section we study a stronger notion of convergence of \(\mathcal L_{\mu _n}\) to \(\mu _n\), namely, w.r.t. the total variation distance\(d_\text {TV}\) and the Hellinger distance\(d_\mathrm {H}\). Given two probability measures \(\mu \), \(\nu \) on \(\mathbb {R}^d\) and another probability measure \(\rho \) dominating \(\mu \) and \(\nu \) the total variation distance of \(\mu \) and \(\nu \) is given by
and their Hellinger distance by
It holds true that
see [17, Equation (8)]. Note that, \(d_\text {TV}(\mu _n,\mathcal L_{\mu _n})\rightarrow 0\) implies that \(|\int f \mathrm {d}\mu _n - \int f \mathrm {d}\mathcal L_{\mu _n}| \rightarrow 0\) for any bounded and continuous \(f:\mathbb {R}^d\rightarrow \mathbb {R}\). In order to establish our convergence result, we require almost the same assumptions as in Theorem 1, but now uniformly w.r.t. n:
Assumption 2
There holds \(\varPhi _n, \pi _0 \in C^3(\mathrm {S}_0,\mathbb {R})\) for all \(n\in \mathbb {N}\) and
-
1.
there exist the limits
$$\begin{aligned} x_\star :=\lim _{n\rightarrow \infty } x_n \qquad H_\star :=\lim _{n\rightarrow \infty } H_n, \qquad H_n :=\nabla ^2\varPhi _n(x_n) \end{aligned}$$(12)in \(\mathbb {R}^d\) and \(\mathbb {R}^{d \times d}\), respectively, with \(H_\star \) being positive definite and \(x_\star \) belonging to the interior of \(\mathrm {S}_0\).
-
2.
For each \(r > 0\) there exists an \(n_r\in \mathbb {N}\), \(\delta _r>0\) and \(K_r < \infty \) such that
$$\begin{aligned} \delta _r \le \inf _{x \notin B_r(x_n)\cap \mathrm {S}_0} I_n(x) \qquad \forall n\ge n_r \end{aligned}$$as well as
$$\begin{aligned} \max _{x\in B_r(0) \cap \mathrm {S}_0} \Vert \nabla ^3 \log \pi _0(x)\Vert \le K_r, \max _{x\in B_r(0)\cap \mathrm {S}_0} \Vert \nabla ^3 \varPhi _n(x)\Vert \le K_r \quad \forall n\ge n_r. \end{aligned}$$ -
3.
There exists a uniformly bounding function \(q:\mathrm {S}_0\rightarrow [0,\infty )\) with
$$\begin{aligned} \exp (-n I_n(x)) \le q(x), \qquad \forall x \in \mathrm {S}_0\ \forall n\ge n_0 \end{aligned}$$for an \(n_0\in \mathbb {N}\) such that \(q^{1-\epsilon }\) is integrable, i.e., \(\int _{\mathrm {S}_0} q^{1-\epsilon }(x)\ \mathrm {d}x < \infty \), for an \(\epsilon \in (0,1)\).
The only additional assumptions in comparison to the classical convergence theorem of the Laplace method are about the third derivatives of \(\pi _0\) and \(\varPhi _n\) and the convergence of \(x_n \rightarrow x_\star \). We remark that (12) implies
and, thus, also \(\lim _{n\rightarrow \infty } C_n = H^{-1}_\star \). The uniform lower bound on \(I_n\) outside a ball around \(x_n\) as well as the integrable majorant of the unnormalized densities \(\mathrm e^{-nI_n}\le 1\) of \(\mu _n\) can be understood as uniform versions of the first and second assumption of Theorem 1. The third item of Assumption 2 implies the uniform integrabtility of the \(\mathrm e^{-nI_n}\le 1\) and is obviously satisfied for bounded supports \(\mathrm {S}_0\). However, in the unbounded case it seems to be crucialFootnote 1 for an increasing concentration of the \(\mu _n\).
We start our analysis with the following helpful lemma.
Lemma 1
Let Assumptions 1 and 2 be satisfied and let \(\pi _n, \widetilde{\pi }_n :\mathbb {R}^d\rightarrow [0,\infty )\) denote the unnormalized Lebesgue densities of \(\mu _n\) and \(\mathcal L_{\mu _n}\), respectively, given by
and
Then, for any \(p\in \mathbb {N}\)
Proof
We define the remainder term
i.e., for \(x\in \mathrm {S}_0\) we have \(\frac{\pi _n(x)}{\widetilde{\pi }_n(x)} = \exp (-nR_n(x))\). Moreover, note that for \(x\in \mathrm {S}_0^c\) there holds \(\pi _n(x) = 0\). Thus, we obtain
where we define for a given radius \(r>0\)
In “Appendix B.1” we prove that
for \(c_r, c_{r,\epsilon } >0\), which then yields the statement. \(\square \)
Lemma 1 provides the basis for our main convergence theorem.
Theorem 2
Let the assumptions of Lemma 1 be satisfied. Then, there holds
Proof
We start with
For the first term there holds due to Lemma 1
For the second term on the right-hand side we obtain
Furthermore, due to Lemma 1 there exists a \(c<\infty \) such that
This yields
which concludes the proof. \(\square \)
Convergence of other Gaussian approximations Let us consider now a sequence of arbitrary Gaussian approximations \(\widetilde{\mu }_n = \mathcal N(a_n, \frac{1}{n} B_n)\) to the measures \(\mu _n\) in (1). Under which conditions on \(a_n \in \mathbb {R}^d\) and \(B_n \in \mathbb {R}^{d\times d}\) do we still obtain the convergence \(d_\text {H}(\mu _n, \widetilde{\mu }_n) \rightarrow 0\)? Of course, \(a_n\rightarrow x_\star \) seems to be necessary but how about the covariances \(B_n\)? Due to the particular scaling of 1/n appearing in the covariance of \(\mathcal L_{\mu _n}\), one might suppose that for example \(\widetilde{\mu }_n = \mathcal N(x_n, \frac{1}{n} I_d)\) or \(\widetilde{\mu }_n = \mathcal N(x_n, \frac{1}{n} B)\) with an arbitrary symmetric and positive definite (spd) \(B \in \mathbb {R}^{d\times d}\) should converge to \(\mu _n\) as \(n\rightarrow \infty \). However, since
and \(d_\text {H}(\mu _n, \mathcal L_{\mu _n}) \rightarrow 0\), we have
The following result shows that, in general, \(\widetilde{\mu }_n = \mathcal N(x_n, \frac{1}{n} I_d)\) or \(\widetilde{\mu }_n = \mathcal N(x_n, \frac{1}{n} B)\) do not converge to \(\mu _n\).
Theorem 3
Let the assumptions of Lemma 1 be satisfied.
-
1.
For \(\widetilde{\mu }_n :=\mathcal N(x_n, \frac{1}{n} B_n)\), \(n\in \mathbb {N}\), with spd \(B_n\), we have that
$$\begin{aligned} \lim _{n\rightarrow \infty } d_\mathrm {H}(\mu _n, \widetilde{\mu }_n) = 0 \quad \text { iff } \quad \lim _{n\rightarrow \infty } \det \left( \frac{1}{2} (H^{1/2}_\star B_n^{1/2} + H_\star ^{-1/2} B_n^{-1/2})\right) = 1.\nonumber \\ \end{aligned}$$(14)If so and if \(\Vert C_n - B_n\Vert \in \mathcal O(n^{-1})\), then we even have \(d_\mathrm {H}(\mu _n, \widetilde{\mu }_n) \in \mathcal O(n^{-1/2})\).
-
2.
For \(\widetilde{\mu }_n :=\mathcal N(a_n, \frac{1}{n} B_n)\), \(n\in \mathbb {N}\), with \(B_n\) satisfying (14) and \(\Vert x_n - a_n\Vert \in \mathcal O(n^{-1})\), we have that \(d_\mathrm {H}(\mu _n, {\widetilde{\mu }_n}) \in \mathcal O(n^{-1/2})\).
The proof is straightforward given the exact formula for the Hellinger distance of Gaussian measures and can be found in “Appendix B.2”. Thus, Theorem 3 tells us that, in general, the Gaussian measures \(\widetilde{\mu }_n = \mathcal N(x_n, \frac{1}{n} I_d)\) do not converge to \(\mu _n\) as \(n\rightarrow \infty \) whereas it is easily seen that \(\widetilde{\mu }_n = \mathcal N(x_n, \frac{1}{n} H_\star )\), indeed, do converge.
Relation to the Bernstein–von Mises theorem in Bayesian inference The Bernstein–von Mises (BvM) theorem is a classical result in Bayesian inference and asymptotic statistics in \(\mathbb {R}^d\) stating the posterior consistency under mild assumptions [41]. Its extension to infinite-dimensional situations does not hold in general [9, 15], but can be shown under additional assumptions [3, 4, 16, 28]. In order to state the theorem we introduce the following setting: let \(Y_i \sim \nu _{x_0}\), \(i\in \mathbb {N}\), be i.i.d. random variables on \(\mathbb {R}^D\), \(d\le D\), following a distribution \(\nu _{x_0}(\mathrm {d}y) = \exp (-\ell (y, x_0)) {\textit{\textbf{1}}}_{\mathrm {S}_y}(y) \mathrm {d}y\) where \(\mathrm {S}_y \subset \mathbb {R}^D\) and where \(\ell :{\mathrm {S}_y}\times \mathbb {R}^d \rightarrow [- \ell _{\min }, \infty )\) represents the negative log-likelihood function for observing \(y \in \mathrm {S}_y\) given a parameter value \(x \in \mathbb {R}^d\). Assuming a prior measure \(\mu _0(\mathrm {d}x) = \pi _0(x) {\textit{\textbf{1}}}_{\mathrm {S}_0}(x) \ \mathrm {d}x\) for the unknown parameter, the resulting posterior after n observations \(y_i\) of the independent \(Y_i\), \(i=1,\ldots ,n\), is of the form (1) with
We will denote the corresponding posterior measure by \(\mu _n^{y_1,\ldots ,y_n}\) in order to highlight the dependence of the particular data \(y_1,\ldots ,y_n\). The BvM theorem states now the convergence of this posterior to a sequence of Gaussian measures. This looks very similar to the statement of Theorem 2. However, the difference lies in the Gaussian measures as well as the kind of convergence. In its usual form the BvM theorem states under similar assumptions as for Theorem 2 that there holds in the large data limit
where \(\mu ^{Y_1,\ldots , Y_n}_n\) is now a random measure depending on the n independent random variables \(Y_1,\ldots , Y_n\) and where the convergence in probability is taken w.r.t. randomness of the \(Y_i\). Moreover, \({\hat{x}}_n = {\hat{x}}_n(Y_1,\ldots , Y_n)\) denotes an efficient estimator of the true parameter \(x_0 \in \mathrm {S}_0\)—e.g., the maximum-likelihood or MAP estimator—and \(\mathcal I_{x_0}\) denotes the Fisher information at the true parameter \(x_0\), i.e.,
Now both, the BvM theorem and Theorem 2, state the convergence of the posterior to a concentrating Gaussian measure where the rate of concentration of the latter (or better: of its covariance) is of order \(n^{-1}\). Furthermore, also the rate of convergence in the BvM theorem can be shown to be of order \(n^{-1/2}\) [19]. However, the main differences are:
-
The BvM states convergence in probability (w.r.t. the randomness of the \(Y_i\)) and takes as basic covariance the inverse expected Hessian of the negative log likelihood at the data generating parameter value \(x_0\). Working with this quantity requires the knowledge of the true value \(x_0\) and the covariance operator is obtained by marginalizing over all possible data outcomes Y. This Gaussian measure is not a practical tool to be used but rather a limiting distribution of a powerful theoretical result reconciling Bayesian and classical statistical theory. For this reason, the Gaussian approximation in the statement of the BvM theorem can be thought of as being a “prior” approximation (in the loosest meaning of the word). Usually, a crucial requirement is that the problem is well-specified meaning that \(x_0\) is an interior point of the prior support \(\mathrm {S}_0\)—although there exist results for misspecified models, see [22]. Here, a BvM theorem is proven without the assumption that \(x_0\) belongs to the interior of \(\mathrm {S}_0\). However, in this case the basic covariance is not the Fisher information but the Hessian of the mapping \(x \mapsto d_\text {KL}(\nu _0 || \nu _x)\) evaluated at its unique minimizer where \(d_\text {KL}(\nu _0 || \nu _x)\) denotes the Kullback–Leibler divergence of the data distribution \(\nu _x\) given parameter \(x \in \mathrm {S}_0\) w.r.t. the true data distribution \(\nu _0\).
-
Theorem 2 states the convergence for given realizations \(y_i\) and takes the Hessian of the negative log posterior density evaluated at the current MAP estimate \(x_n\) and the current data \(y_1,\ldots ,y_n\). This means that we do not need to know the true parameter value \(x_0\) and we employ the actual data realization at hand rather than averaging over all outcomes. Hence, we argue that the Laplace approximation (as stated in this context) provides a “posterior” approximation converging to the Bayesian posterior as \(n\rightarrow \infty \). Also, we require that the limit \(x_\star = \lim _{n\rightarrow \infty } x_n\) is an interior point of the prior support \(\mathrm {S}_0\).
-
From a numerical point of view, the Laplace approximation requires the computation of the MAP estimate and the corresponding Hessian at the MAP, whereas the BvM theorem employs the Fisher information, i.e. requires an expectation w.r.t. the observable data. Thus, the Laplace approximation is based on fixed and finite data in contrast to the BvM.
The following example illustrates the difference between the two Gaussian measures: Let \(x_0\in \mathbb R\) be an unknown parameter. Consider n measurements \(y_k \in \mathbb {R}\), \(k=1,\ldots ,n\), where \(y_k\) is a realization of
with \(\eta _k\sim N(0, \sigma ^2)\) i.i.d.. For the Bayesian inference we assume a prior \(N(0,\tau ^2)\) on x. Then the Bayesian posterior is of the form \(\mu _n(\mathrm {d}x) \propto \exp (-nI_n(x))\) where
The MAP estimator \(x_n\) is the Laplace approximation’s mean and can be computed numerically as a minimizer of \(I_n(x)\). It can be shown that \(x_n\) converges to \(x_\star = x_0\) for almost surely all realizations \(y_k \) of \(Y_k\) due to the strong law of large numbers. Now we take the Hessian (w.r.t. x) of \(I_n\),
and evaluate it in \(x_n\) to obtain the covariance of the Laplace approximation, and, thus,
On the other hand we compute the Gaussian BvM approximation: The Fisher information is given as (recall that \(\varPhi \) is the loglikelihood term as defined above)
and hence we get the Gaussian approximation
Now we clearly see the difference between the two measures and how they will be asymptotically identical, since \(x_n\rightarrow x_\star = x_0\) due to consistency, \(\frac{1}{n}\sum _{k=1}^n y_k\) converging a.s. to \(x_0^3\) due to the strong law of large numbers, and with the prior-dependent part vanishing for \(n\rightarrow 0\).
Remark 3
Having raised the issue whether the BvM approximation \(\mathcal N({\hat{x}}_n, n^{-1} \mathcal I^{-1}_{x_0})\) or the Laplace one \(\mathcal L_{\mu _n}\) is closer to a given posterior \(\mu _n\), one can of course ask for the best Gaussian approximation of \(\mu _n\) w.r.t. a certain distance or divergence. Thus, we mention [26, 30] where such a best approximation w.r.t. the Kullback–Leibler divergence is considered. The authors also treat the case of best Gaussian mixture approximations for multimodal distributions and state a BvM like convergence result for the large data (and small noise) limit. However, the computation of such a best approximation can become costly whereas the Laplace approximation can be obtained rather cheaply.
2.3 The case of singular Hessians
The assumption, that the Hessians \(H_n = \nabla ^2 \varPhi _n(x_n)\) as well as their limit \(H_\star \) are positive definite, is quite restrictive. For example, for Bayesian inference with more unknown parameters than observational information, this assumption is not satisfied. Hence, we discuss in this subsection the convergence of the Laplace approximation in case of singular Hessians \(H_n\) and \(H_\star \). Nonetheless, we assume throughout the section that Assumption 1 is satisfied. This yields that the Laplace approximation \(\mathcal L_{\mu _n}\) is well-defined. This means in particular that we suppose a regularizing effect of the log prior density \(\log \pi _0\) on the minimization of \(I_n(x) = \varPhi _n(x) - \frac{1}{n} \log \pi _0(x)\).
We first discuss necessary conditions for the convergence of the Laplace approximation and subsequently state a positive result for Gaussian prior measures \(\mu _0\).
Necessary conditions Let us consider the simple case of \(\varPhi _n\equiv \varPhi \), i.e., the probability measures \(\mu _n\) are given by
where we assume now that \(\varPhi :\mathrm {S}_0 \rightarrow [c, \infty )\) with \(c>-\infty \). Intuitively, \(\mu _n\) should converge weakly to the Dirac measure \(\delta _{\mathcal M_\varPhi }\) on the set
On the other hand, the associated Laplace approximations \(\mathcal L_{\mu _n}\) will converge weakly to the Dirac measure \(\delta _{\mathcal M_{\mathcal L}}\) in the affine subspace
Hence, it is necessary for the convergence \(\mathcal L_{\mu _n}\rightarrow \mu _n\) in total variation or Hellinger distance that \(\mathcal M_\varPhi = \mathcal M_{\mathcal L}\), i.e., that the set of minimizers of \(\varPhi \) is linear. In order to ensure the latter, we state the following.
Assumption 3
Let \(\mathcal X\subseteq \mathbb {R}^d\) be a linear subspace such that for a projection \(\mathrm {P}_{\mathcal X}\) onto \(\mathcal X\) there holds
and let the restriction \(\varPhi _n :\mathcal X \rightarrow \mathbb {R}\) possess a unique and nondegenerate global minimum for each \(n\in \mathbb {N}\).
For the case \(\varPhi _n = \varPhi \) this assumption implies, that
where \(\mathcal X^c\) denotes a complementary subspace to \(\mathcal X\), i.e., \(\mathcal X \oplus \mathcal X^c = \mathbb {R}^d\) and \(x_\star \in \mathcal X\) the unique minimizer of \(\varPhi \) over \(\mathcal X\). Besides that, Assumption 3 also yields that \(x^\top H_n x = 0\) iff \(x \in \mathcal X^c\). Hence, this also holds for the limit \(H_\star = \lim _{n\rightarrow \infty } H_n\) and we obtain
Moreover, since Assumption 3 yields
where \(x_{\mathcal X} :=\mathrm {P}_{\mathcal X}x\) and \(x_{c} :=\mathrm {P}_{\mathcal X^c}x = x - x_{\mathcal X}\), the marginal of \(\mu _n\) coincides with the marginal of \(\mu _0\) on \(\mathcal X^c\). Hence, the Laplace approximation can only converge to \(\mu _n\) in total variation or Hellinger distance if this marginal is Gaussian. We, therefore, consider the special case of Gaussian prior measures \(\mu _0\).
Remark 4
Please note that, despite this to some extent negative result for the Laplace approximation for singular Hessians, the preconditioning of sampling and quadrature methods via the Laplace approximation may still lead to efficient algorithms in the small noise setting. The analysis of Laplace approximation-based sampling methods, as introduced in the next section, in the underdetermined case will be subject to future work.
Convergence for Gaussian prior \(\mu _0\). A useful feature of Gaussian prior measures \(\mu _0\) is that the Laplace approximation possesses a convenient representation via its density w.r.t. \(\mu _0\).
Proposition 1
(cf. [43, Proposition 1]) Let Assumption 1 be satisfied and \(\mu _0\) be Gaussian. Then there holds
where \(T_2\varPhi _n(\cdot ; x_n)\) denotes the Taylor polynomial of order 2 of \(\varPhi _n\) at the point \(x_n\in \mathbb {R}^d\).
In fact, the representation (17) does only hold for prior measures \(\mu _0\) with Lebesgue density \(\pi _0:\mathbb {R}^d \rightarrow [0,\infty )\) satisfying \(\nabla ^3 \log \pi _0 \equiv 0\).
Corollary 1
Let Assumption 1 be satisfied and \(\mu _0\) be Gaussian. Further, let Assumption 3 hold true and assume that the restriction \(\varPhi _n :\mathcal X \rightarrow \mathbb {R}\) and the marginal density \(\pi _0\) on \(\mathcal X\) satisfy Assumption 2 on \(\mathcal X\). Then the approximation result of Theorem 2 holds.
Proof
By using Proposition 1, we can express the Hellinger distance \(d_\text {H}(\mu _n,\mathcal L_{\mu _n})\) as follows
We use now the decomposition \(\mathbb {R}^d = \mathcal X \oplus \mathcal X^c\) with \(x :=x_{\mathcal X} + x_{c}\) for \(x\in \mathbb {R}^d\) with \(x_{\mathcal X} \in \mathcal X\) and \(x_c \in \mathcal X^c\). We note, that due to Assumption 3, we have that
We then obtain by disintegration and denoting \(\widetilde{\varPhi }_n(x) :=T_2\varPhi _n(x;x_n) = \widetilde{\varPhi }_n(x_{\mathcal X})\)
where \(\mu _0(\mathrm {d}x_{\mathcal X})\) denotes the marginal of \(\mu _0\) on \(\mathcal X\). Since \(\varPhi _n\) and \(I_n(x_{\mathcal X}) = \varPhi _n(x_{\mathcal X}) - \frac{1}{n} \log \pi _0(x_{\mathcal X})\), where \(\pi _0(x_{\mathcal X})\) denotes the Lebesgue density of the marginal \(\mu _0(\mathrm {d}x_{\mathcal X})\), satisfy the assumptions of Theorem 2 on \(\mathrm {S}_0 \cap \mathcal X = \mathcal X\), the statement follows. \(\square \)
We provide some illustrative examples for the theoretical results stated in this subsection.
Example 1
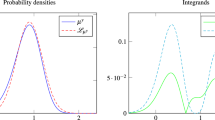
(Divergence of the Laplace approximation in the singular case) We assume a Gaussian prior \(\mu _0 = N(0, I_2)\) on \(\mathbb {R}^2\) and \(\varPhi (x) = \Vert y - \mathcal G(x)\Vert ^2\) where
We plot the Lebesgue densities of the resulting \(\mu _n\) and \(\mathcal L_{\mu _n}\) for \(n=128\) in the left and middle panel of Fig. 1. The red line in both plots indicate the different sets
around which \(\mu _n\) and \(\mathcal L_{\mu _n}\), respectively, concentrate as \(n\rightarrow \infty \). As \(\mathcal M_\varPhi \ne \mathcal M_{\mathcal L}\), we observe no convergence of the Laplace approximation as \(n\rightarrow \infty \), see the right panel of Fig. 1. Here, the Hellinger distance is computed numerically by applying a tensorized trapezoidal rule on a sufficiently large subdomain of \(\mathbb {R}^2\).

Plots of the Lebesgue densities of \(\mu _n\) (left) and \(\mathcal L_{\mu _n}\) (middle) for \(n=128\) as well as the Hellinger distance between \(\mu _n\) and \(\mathcal L_{\mu _n}\) for Example 1. The red line in the left and middle panel represents the set \(\mathcal M_\varPhi \) and \(\mathcal M_{\mathcal L}\) around which \(\mu _n\) and \(\mathcal L_{\mu _n}\), respectively, concentrate as \(n\rightarrow \infty \)
Example 2
(Convergence of the Laplace approximation in the singular case in the setting of Corollary1) Again, we suppose a Gaussain prior \(\mu _0 = N(0, I_2)\) and \(\varPhi \) in the form of \(\varPhi (x) = \Vert y - \mathcal G(x)\Vert ^2\) with
Thus, the invariant subspace is \(\mathcal X^c = \{x \in \mathbb {R}^2 :x_1 = x_2\}\). In the left and middle panel of Fig. 2 we present the Lebesgue densities of \(\mu _n\) and its Laplace approximation \(\mathcal L_{\mu _n}\) for \(n=25\) and by the red line the sets \(\mathcal M_\varPhi = \mathcal M_{\mathcal L} = x_\star + \mathcal X^c\). We observe the convergence guaranteed by Corollary 1 in the right panel of Fig. 2 where we can also notice a preasymptotic phase with a shortly increasing Hellinger distance. Such a preasmyptotic phase is to be expected due to \(d_\text {H}(\mu _n, \mathcal L_{\mu _n}) \in \mathcal O(n^{-1/2}) + \mathcal O(\mathrm e^{- n \delta _r} n^{d/2})\) as shown in the proof of Theorem 2.

3 Robustness of Laplace-based Monte Carlo methods
In practice, we are often interested in expectations or integrals of quantities of interest \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) w.r.t. \(\mu _n\) such as
For example, in Bayesian statistics the posterior mean (\(f(x) = x\)) or posterior probabilities (\(f(x) = {\mathbf {1}}_A(x)\), \(A \in \mathcal B(\mathbb {R}^d)\)) are desirable quantities. Since \(\mu _n\) is seldom given in explicit form, numerical integration must be applied for approximating such integrals. To this end, since the prior measure \(\mu _0\) is typically a well-known measure for which efficient numerical quadrature methods are available, the integral w.r.t. \(\mu _n\) is rewritten as two integrals w.r.t. \(\mu _0\)
If then a quadrature rule such as \(\int _{\mathbb {R}^d} g(x) \ \mu _0(\mathrm {d}x) \approx \frac{1}{N} \sum _{i=1}^N w_i\ g(x_i)\) is used, we end up with an approximation
This might be a good approximation for small \(n \in \mathbb {N}\). However, as soon as \(n\rightarrow \infty \) the likelihood term \(\exp (-n\varPhi _n(x_i))\) will deteriorate and this will be reflected by a deteriorating efficiency of the quadrature scheme—not in terms of the convergence rate w.r.t. N, but w.r.t. the constant in the error estimate, as we will display later in examples.
If the Gaussian Laplace approximation \(\mathcal L_{\mu _n}\) of \(\mu _n\) is used as the prior measure for numerical integration instead of \(\mu _0\), we get the following approximation
where \(\pi _n\) and \(\widetilde{\pi }_n\) denote the unnormalized Lebesgue density of \(\mu _n\) and \(\mathcal L_{\mu _n}\), respectively. This time, we can not only apply well-known quadrature and sampling rules for Gaussian measures, but moreover, we also know due to Lemma 1, that the ratio \(\frac{\pi _n(x)}{\widetilde{\pi }_n(x)}\) converges in mean w.r.t. \(\mathcal L_{\mu _n}\) to 1. Hence, we do not expect a deteriorating efficiency of the numerical integration as \(n\rightarrow \infty \). On the contrary, as we subsequently discuss for several numerical integration methods, their efficiency for a finite number of samples \(N\in \mathbb {N}\) will even improve as \(n\rightarrow \infty \) if they are based on the Laplace approximation \(\mathcal L_{\mu _n}\).
For the sake of simplicity, we consider the simple case of \(\varPhi _n \equiv \varPhi + \text {const}\) in the following presentation—nonetheless, the presented results can be extended to the general case given appropriate modifications of the assumptions. Thus, we consider probability measures \(\mu _n\) of the form
where we assume that \(\varPhi \) satisfies the assumptions of Theorem 1. However, when dealing with the Laplace approximation of \(\mu _n\) and, particularly, with the ratios of the corresponding normalizing constants, it is helpful to use the following representation
where \(\iota _n :=\min _{x \in \mathrm {S}_0} \varPhi (x) - \frac{1}{n} \log \pi _0(x)\) and \( Z_n = \mathrm e^{n \iota _n} \int _{\mathbb {R}^d} \mathrm e^{-n\varPhi (x)} \pi _0(x)\ \mathrm {d}x\). By this construction the resulting \(I_n(x) :=\varPhi _n(x) - \frac{1}{n} \log \pi _0(x)\) satisfies \(I_n(x_n) = 0\) as required in Assumption 1 for the construction of the Laplace approximation \(\mathcal L_{\mu _n}\). Note, that for \(\varPhi _n = \varPhi - \iota _n\) the Assumptions 1 and 2 imply the assumptions of Theorem 1 for \(f = \pi _0\) and \(p=0\).
Preliminaries Before we start analyzing numerical methods based on the Laplace approximation as their reference measure, we take a closer look at the details of the asymptotic expansion for integrals provided in Theorem 1 and their implications for expectations w.r.t. \(\mu _n\) given in (22).
-
1.
The coefficients: The proof of Theorem 1 in [44, Section IX.5] provides explicit expressionsFootnote 2 for the coefficients \(c_k \in \mathbb {R}\) in the asymptotic expansion
$$\begin{aligned} \int _D f(x) \exp (-n \varPhi (x)) \mathrm {d}x = \mathrm e^{-n \varPhi (x_\star )} n^{-d/2} \left( \sum _{k=0}^p c_k(f) n^{- k} + \mathcal O\left( n^{-p-1}\right) \right) , \end{aligned}$$namely—given that \(f \in C^{2p+2}(D, \mathbb R)\) and \(\varPhi \in C^{2p+3}(D, \mathbb R)\)—that
$$\begin{aligned} c_k(f) = \sum _{\varvec{\alpha }\in \mathbb {N}_ 0^d :|\varvec{\alpha }| = 2k} \frac{\kappa _{\varvec{\alpha }}}{\varvec{\alpha }!} D^{\varvec{\alpha }} F(0) \end{aligned}$$(23)where for \(\varvec{\alpha }= (\alpha _1,\ldots ,\alpha _d)\) we have \(|\varvec{\alpha }| = \alpha _1+\cdots +\alpha _d\), \(\varvec{\alpha }! = \alpha _1 ! \cdots \alpha _d!\), \(D^{\varvec{\alpha }} = D^{\alpha _1}_{x_1} \cdots D^{\alpha _d}_{x_d}\) and
$$\begin{aligned} F(x) :=f(h(x))\ \det (\nabla h(x)) \end{aligned}$$with \(h:\varOmega \rightarrow U(x_\star )\) being a diffeomorphism between \(0 \in \varOmega \subset \mathbb {R}^d\) and a particular neighborhood \(U(x_\star )\) of \(x_\star \) mapping \(h(0) = x_\star \) and such that \(\det (\nabla h(0)) = 1\). The diffeomorphism h is specified by the well-known Morse’s Lemma and depends only on \(\varPhi \). In particular, if \(\varPhi \in C^{2p+3}(D, \mathbb R)\), then \(h\in C^{2p+1}(\varOmega , U(x_\star ))\). For the constants \(\kappa _{\varvec{\alpha }} = \kappa _{\alpha _1}\cdots \kappa _{\alpha _d} \in \mathbb {R}\) we have \(\kappa _{\alpha _i} = 0\) if \(\alpha _i\) is odd and \(\kappa _{\alpha _i} = (2/\lambda _i)^{(\alpha _i +1)/2} \varGamma ((\alpha _i+1)/2)\) otherwise with \(\lambda _i>0\) denoting the ith eigenvalue of \(H_\star = \nabla ^2 \varPhi (x_\star )\). Hence, we get
$$\begin{aligned} c_k(f) = \sum _{\varvec{\alpha }\in \mathbb {N}_ 0^d :|\varvec{\alpha }| = k} \frac{\kappa _{2\varvec{\alpha }}}{(2\varvec{\alpha })!} D^{2\varvec{\alpha }} F(0). \end{aligned}$$(24) -
2.
The normalization constant of\(\mu _n\): Theorem 1 implies that if \(\pi _0\in C^2(\mathbb {R}^d; \mathbb {R})\) and \(\varPhi \in C^3(\mathbb {R}^d, \mathbb {R})\), then
$$\begin{aligned} \int _{\mathbb {R}^d} \pi _0(x) \ \exp (-n\varPhi (x)) \ \mathrm {d}x = \mathrm e^{-n\varPhi (x_\star )} n^{-d/2} \left( \frac{(2\pi )^{d/2}\, \pi _0(x_\star )}{\sqrt{\det (H_\star )}} + \mathcal O(n^{-1})\right) . \end{aligned}$$Hence, we obtain for the normalizing constant \(Z_n\) in (22) that
$$\begin{aligned} Z_n = \mathrm e^{n (\iota _n -\varPhi (x_\star ))} n^{-d/2} \left( \frac{(2\pi )^{d/2}\, \pi _0(x_\star )}{\sqrt{\det (H_\star )}} + \mathcal O(n^{-1})\right) . \end{aligned}$$(25)If we compare this to the normalizing constant \({\widetilde{Z}}_n = n^{-d/2} \sqrt{\det (2\pi C_n)}\) of its Laplace approximation we get
$$\begin{aligned} \frac{Z_n}{{\widetilde{Z}}_n} = \mathrm e^{n(\iota _n-\varPhi (x_\star ))} \frac{\frac{\pi _0(x_\star )}{\sqrt{\det (H_\star )}} + \mathcal O(n^{-1})}{\sqrt{\det (C_n)}}. \end{aligned}$$We now show that
$$\begin{aligned} \frac{Z_n}{{\widetilde{Z}}_n} = 1 + \mathcal O(n^{-1}). \end{aligned}$$(26)First, we get due to \(C_n \rightarrow H_\star ^{-1}\) that \(\sqrt{\det (C_n)}\rightarrow \frac{1}{\sqrt{\det (H_\star )}}\) as \(n\rightarrow \infty \). Moreover,
$$\begin{aligned} \mathrm e^{n(\iota _n-\varPhi (x_\star ))} = \frac{\exp (n (\varPhi (x_n) - \varPhi (x_\star )))}{\pi _0(x_n)}. \end{aligned}$$Since \(x_n \rightarrow x_\star \) continuity implies \(\pi _0(x_n) \rightarrow \pi _0(x_\star )\) as \(n\rightarrow \infty \). Besides that, the strong convexity of \(\varPhi \) in a neighborhood of \(x_\star \)—due to \(\nabla ^2 \varPhi (X_\star ) >0\) and \(\varPhi \in C^3(\mathbb {R}^d,\mathbb {R})\)—implies that for a \(c>0\)
$$\begin{aligned} \varPhi (x_n) - \varPhi (x_\star ) \le \frac{1}{2c} \Vert \nabla \varPhi (x_n)\Vert ^2, \end{aligned}$$also known as Polyak–Łojasiewicz condition. Because of
$$\begin{aligned} \nabla \varPhi (x_n) = \frac{1}{n} \nabla \log \pi _0(x_n), \end{aligned}$$since \(\nabla I_n(x_n) = 0\), we have that \(|\varPhi (x_n) - \varPhi (x_\star )| \in \mathcal O(n^{-2})\), and hence,
$$\begin{aligned} \lim _{n\rightarrow \infty } \mathrm e^{n(\iota _n-\varPhi (x_\star ))} = 1/\pi _0(x_\star ). \end{aligned}$$This yields (26).
-
3.
The expectation w.r.t. \(\mu _n\): The expectation of a \(f \in L^1_{\mu _0}(\mathbb {R})\) w.r.t. \(\mu _n\) is given by
$$\begin{aligned} {\varvec{\mathbb E}}_{\mu _n} \left[ f \right] = \frac{ \int _{\mathrm {S}_0} f(x) \pi _0(x) \exp (-n\varPhi (x))\ \mathrm {d}x}{ \int _{\mathrm {S}_0} \pi _0(x) \exp (-n\varPhi (x))\ \mathrm {d}x}. \end{aligned}$$If \(f, \pi _0 \in C^2(\mathbb {R}^d, \mathbb {R})\) and and \(\varPhi \in C^3(\mathbb {R}^d, \mathbb {R})\), then we can apply the asymptotic expansion above to both integrals and obtain
$$\begin{aligned} {\varvec{\mathbb E}}_{\mu _n} \left[ f \right]&= \frac{\mathrm e^{-n \varPhi (x_\star )} n^{-d/2}\ ( c_0(f\pi _0) + \mathcal O(n^{-1}))}{\mathrm e^{-n \varPhi (x_\star )} n^{-d/2}\ ( c_0(\pi _0) + \mathcal O(n^{-1}))} = f(x_\star ) + \mathcal O(n^{-1}). \end{aligned}$$(27)If \(f, \pi _0 \in C^4(\mathbb {R}^d; \mathbb {R})\) and \(\varPhi \in C^5(\mathbb {R}^d, \mathbb {R})\), then we can make this more precise by using the next explicit terms in the asymptotic expansions of both integrals, apply the rule for the division of asymptotic expansions and obtain \( {\varvec{\mathbb E}}_{\mu _n} \left[ f \right] = f(x_\star ) + {\widetilde{c}}_1(f,\pi _0) n^{-1} + \mathcal O(n^{-2})\) where \({\widetilde{c}}_1(f,\pi _0) = \frac{1}{c_0(\pi _0)} c_1(f\pi _0) - \frac{c_1(\pi _0)}{c^2_0(\pi _0)}c_0(f\pi _0)\).
-
4.
The variance w.r.t. \(\mu _n\): The variance of a \(f \in L^2_{\mu _0}(\mathbb {R})\) w.r.t. \(\mu _n\) is given by
$$\begin{aligned} \mathrm {Var}_{\mu _n}(f)&= {\varvec{\mathbb E}}_{\mu _n} \left[ f^2 \right] - {\varvec{\mathbb E}}_{\mu _n} \left[ f \right] ^2. \end{aligned}$$If \(f, \pi _0 \in C^2(\mathbb {R}^d;\mathbb {R})\) and \(\varPhi \in C^3(\mathbb {R}^d, \mathbb {R})\), then we can exploit the result for the expectation w.r.t. \(\mu _n\) from above and obtain
$$\begin{aligned} \mathrm {Var}_{\mu _n}(f)&= f^2(x_\star ) + \mathcal O(n^{-1}) - \left( f(x_\star ) + \mathcal O(n^{-1})\right) ^2 \in \mathcal O(n^{-1}). \end{aligned}$$(28)If \(f,\pi _0\in C^4(\mathbb {R}^d, \mathbb {R})\) and \(\varPhi \in C^5(\mathbb {R}^d, \mathbb {R})\), then a straightforward calculation using the explicit formulas for \(c_1(f^2\pi _0)\) and \(c_1(f\pi _0)\) as well as \(\nabla h(0) = I\) yields
$$\begin{aligned} \mathrm {Var}_{\mu _n}(f) = n^{-1} \Vert \nabla f(x_\star )\Vert ^2_{H_\star ^{-1}} + \mathcal O(n^{-2}). \end{aligned}$$(29)Hence, the variance \(\mathrm {Var}_{\mu _n}(f)\) decays like \(n^{-1}\) provided that \(\nabla f(x_\star ) \ne 0\)—otherwise it decays (at least) like \(n^{-2}\).
Remark 5
As already exploited above, the assumptions of Theorem 1 imply that \(\varPhi \) is strongly convex in a neighborhood of \(x_\star = \lim _{n\rightarrow \infty } x_n\), where \(x_n = \mathop {\mathrm{argmin}}\nolimits _{x\in \mathrm {S}_0} \varPhi (x) - \frac{1}{n} \log \pi _0(x)\). This yields \(|\varPhi (x_n) - \varPhi (x_\star )| \in \mathcal O(n^{-2})\), and thus
3.1 Importance sampling
Importance sampling is a variant of Monte Carlo integration where an integral w.r.t. \(\mu \) is rewritten as an integral w.r.t. a dominating importance distribution\(\mu \ll \nu \), i.e.,
The integral appearing on the righthand side is then approximated by Monte Carlo integration w.r.t. \(\nu \): given N independent draws \(x_i\), \(i=1,\ldots ,N\), according to \(\nu \) we estimate
Often the density or importance weight function\(w = \frac{\mathrm {d}\mu }{\mathrm {d}\nu }:\mathbb {R}^d \rightarrow [0,\infty )\) is only known up to a normalizing constant \({\widetilde{w}} \propto \frac{\mathrm {d}\mu }{\mathrm {d}\nu }\). In this case, we can use self-normalized importance sampling
As for Monte Carlo, there holds a strong law of large numbers (SLLN) for self-normalized importance sampling, i.e.,
where \(X_i\sim \nu \) are i.i.d., which follows from the ususal SLLN and the continuous mapping theorem. Moreover, by the classical central limit theorem (CLT) and Slutsky’s theorem also a similar statement holds for self-normalized importance sampling: given that
we have
Thus, the asymptotic variance \(\sigma ^2_{\mu ,\nu }(f)\) serves as a measure of efficiency for self-normalized importance sampling. To ensure a finite \(\sigma ^2_{\mu ,\nu }(f)\) for many functions of interest f, e.g., bounded f, the importance distribution \(\nu \) has to have heavier tails than \(\mu \) such that the ratio \(\frac{\mathrm {d}\mu }{\mathrm {d}\nu }\) belongs to \(L^2_\nu (\mathbb {R})\), see also [31, Section 3.3]. Moreover, if we even have \(\frac{\mathrm {d}\mu }{\mathrm {d}\nu } \in L^\infty _\nu (\mathbb {R})\) we can bound
i.e., the ratio between the asymptotic variance of importance sampling w.r.t. \(\nu \) and plain Monte Carlo w.r.t. \(\mu \) can be bounded by the \(L^\infty _\nu \)- or supremum norm of the importance weight \(\frac{\mathrm {d}\mu }{\mathrm {d}\nu }\).
For the measures \(\mu _n\) a natural importance distribution (called \(\nu \) above) which allows for direct sampling are the prior measure \(\mu _0\) and the Gaussian Laplace approximation \(\mathcal L_{\mu _n}\). We study the behaviour of the resulting asymptotic variances \(\sigma ^2_{\mu _n,\mu _0}(f)\) and \(\sigma ^2_{\mu _n,\mathcal L_{\mu _n}}(f)\) in the following.
Prior importance sampling First, we consider \(\mu _0\) as importance distribution. For this choice the importance weight function \(w_n :=\frac{\mathrm {d}\mu _n}{\mathrm {d}\mu _0}\) is given by
with \(\varPhi _n(x) = \varPhi (x)-\iota _n\), see (22). Concerning the bound in (31) we immediately obtain for sufficiently smooth \(\pi _0\) and \(\varPhi \) by (25), assuming w.l.o.g. \(\min _x \varPhi (x) = \varPhi (x_\star )=0\), that
explodes as \(n\rightarrow \infty \). Of course, this is just the deterioration of an upper bound, but in fact we can prove the following rather negative result where we use the notation \(g(n) \sim h(n)\) for the asymptotic equivalence of functions of n, i.e., \(g(n) \sim h(n)\) iff \(\lim _{n\rightarrow \infty } \frac{g(n)}{h(n)} =1\).
Lemma 2
Given \(\mu _n\) as in (22) with \(\varPhi \) satisfying the assumptions of Theorem 1 for \(p=1\) and \(\pi _0 \in C^4(\mathbb {R}^d,\mathbb {R})\) with \(\pi _0(x_\star ) \ne 0\), we have for any \(f\in C^4(\mathbb {R}^d, \mathbb {R})\cap L^1_{\mu _0}(\mathbb {R})\) with \(\nabla f(x_\star ) \ne 0\) that
which yields \(\frac{\sigma ^2_{\mu _n,\mu _0}(f)}{\mathrm {Var}_{\mu _n}(f)} \sim {\widetilde{c}}_f n^{d/2}\) for another \({\widetilde{c}}_f > 0\).
Proof
W.l.o.g. we may assume that \(f(x_\star ) = 0\), since \(\sigma ^2_{\mu _n,\mu _0}(f) = \sigma ^2_{\mu _n,\mu _0}(f-c)\) for any \(c\in \mathbb {R}\). Moreover, for simplicity we assume w.l.o.g. that \(\varPhi (x_\star ) = 0\). We study
by analyzing the growth of the numerator and denominator w.r.t. n. Due to the preliminaries presented above we know that \(\mathrm e^{-2n\iota _n}Z^2_n = c_0^2 n^{-d} + \mathcal O(n^{-d-1})\) with \(c_0 = (2\pi )^{d/2}\, \pi _0(x_\star )/\sqrt{\det (H_\star )} >0\). Concerning the numerator we start with decomposing
where this time
We derive now asymptotic expansions of these terms based on Theorem 1. It is easy to see that the assumptions of Theorem 1 are also fulfilled when considering integrals w.r.t. \(\mathrm e^{- 2n\varPhi }\). We start with \(J_1\) and obtain due to \(f(x_\star ) = 0\) that
where \(c'_{1}(f^2\pi _0) \in \mathbb {R}\) is the same as \(c_1(f^2\pi _0)\) in (23) but for \(2\varPhi \) instead of \(\varPhi \).
Next, we consider \(J_2\) and recall that due to \(f(x_\star ) = 0\) we have \( {\varvec{\mathbb E}}_{\mu _n} \left[ f \right] \in \mathcal O(n^{-1})\), see (27). Furthermore, \(f(x_\star ) = 0\) also implies \(\int _{\mathrm {S}_0} f(x) \pi _0(x)\, \mathrm e^{- 2n\varPhi (x)}\ \mathrm {d}x \in \mathcal O(n^{-1-d/2})\), see Theorem 1. Thus, we have
Finally, we take a look at \(J_3\). By Theorem 1 we have \(\int _{\mathrm {S}_0} \exp (- 2n\varPhi (x)) \ \mu _0(\mathrm {d}x) \in \mathcal O(n^{-d/2})\) and, hence, obtain
Hence, \(J_1\) has the dominating power w.r.t. n and we have that
At this point, we remark that due to the assumption \(\nabla f(x_\star ) \ne 0\) we have \(c'_{1}(f^2\pi _0) \ne 0\): we know by (24) that \(c'_{1}(f^2\pi _0) =\frac{1}{2} \sum _{j=1}^d \kappa _{2\textit{\textbf{e}}_j} D^{2\textit{\textbf{e}}_j} F(0)\) where \(F(x) = \pi _0(h'(x)) f^2(h'(x)) \det (\nabla h'(x))\) and \(h'\) denotes the diffeomorphism for \(2\varPhi \) appearing in Morse’s lemma and mapping 0 to \(x_\star \); applying the product formula and using \(f(x_\star )=0\) as well as \(\det (\nabla h'(0)) = 1\) we get that \(D^{2\textit{\textbf{e}}_j} F(x_\star ) = \pi _0(x_\star ) D^{2\textit{\textbf{e}}_j} ( f^2(h'(x_\star )) )\); similarly, we get using \(f(x_\star )=0\) that \(D^{2\textit{\textbf{e}}_j} ( f^2(h'(x_\star ))) = 2 | \textit{\textbf{e}}_j^\top \nabla h'(0) \nabla f(x_\star )|^2\); since \(h'\) is a diffeomorphishm \(\nabla h'(0)\) is regular and, thus, \(c'_{1}(f^2\pi _0) \ne 0\). The statement follows now by
and by recalling that \(\mathrm {Var}_{\mu _n}(f) \sim c n^{-1}\) because of \(\nabla f(x_\star ) \ne 0\), see (29). \(\square \)
Thus, Lemma 2 tells us that the asymptotic variance of importance sampling for \(\mu _n\) with the prior \(\mu _0\) as importance distribution grows like \(n^{d/2-1}\) as \(n\rightarrow \infty \) for a large class of integrands. Hence, its efficiency deteriorates like \(n^{d/2-1}\) for \(d\ge 3\) as the target measures \(\mu _n\) become more concentrated.
Laplace-based importance sampling We now consider the Laplace approximation \(\mathcal L_{\mu _n}\) as importance distribution which yields the following importance weight function
with \(R_n(x) = I_n(x) - {\widetilde{I}}_n(x) = I_n(x_n) - \frac{1}{2} \Vert x-x_n\Vert ^2_{C_n^{-1}}\) for \(x\in \mathrm {S}_0\). In order to ensure \(w_n \in L^2_{\mathcal L_{\mu _n}}(\mathbb {R})\) we need that
Despite pathological counterexamples a sound requirement for \(w_n \in L^2_{\mathcal L_{\mu _n}}(\mathbb {R})\) is that
for example by assuming that there exist \(\delta , c_1 > 0\), \(c_0 > 0\), and \(n_0 \in \mathbb {N}\) such that
If the Lebesgue density \(\pi _0\) of \(\mu _0\) is bounded, then (33) is equivalent to the existence of \(n_0\) and a \({\widetilde{c}}_0\) such that
Unfortunately, condition (33) is not enough to ensure a well-behaved asymptotic variance \(\sigma ^2_{\mu _n,\mathcal L_{\mu _n}}(f)\) as \(n\rightarrow \infty \), since
Although, we know due to (26) that \(\frac{{\widetilde{Z}}_n}{Z_n} \rightarrow 1\) as \(n\rightarrow \infty \), the supremum norm of the importance weight \(w_n\) of Laplace-based importance sampling will explode exponentially with n if \(\min _x R_n(x) < 0\). This can be sharpened to proving that even the asymptotic variance of Laplace-based importance sampling w.r.t. \(\mu _n\) as in (22) deteriorates exponentially as \(n\rightarrow \infty \) for many functions \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) if
by means of Theorem 1 applied to
This means, except when \(\varPhi \) is basically strongly convex, the asymptotic variance of Laplace-based important sampling can explode exponentially or not even exist as n increases. However, in the good case, so to speak, we obtain the following.
Proposition 2
Consider the measures \(\mu _n\) as in (22) with \(\varPhi _n = \varPhi - \iota _n\) and \(\pi _0\) satisfying Assumptions 1 and 2. If there exist an \(n_0\in \mathbb {N}\) such that for all \(n\ge n_0\) we have
then for any \(f \in L^2_{\mu _0}(f)\)
Proof
The assumption (34) ensures that \(R_n(x) = I_n(x) - {\widetilde{I}}_n(x) \ge 0\) for each \(x\in \mathrm {S}_0\). Thus,
and the assertion follows by (31) and the fact that \(\lim _{n\rightarrow \infty } \frac{{\widetilde{Z}}_n}{Z_n} = 1\) due to (26). \(\square \)
Condition (34) is for instance satisfied, if \(I_n\) is strongly convex with a constant \(\gamma \ge \lambda _{\min }(\nabla ^2 I_n(x_n))\) where the latter denotes the smallest eigenvalue of the positive definite Hessian \(\nabla ^2 I_n(x_n)\). However, this assumption or even (34) is quite restrictive and, probably, hardly fulfilled for many interesting applications. Moreover, the success in practice of Laplace-based importance sampling is well-documented. How come that despite a possible infinite asymptotic variance Laplace-based importance sampling performs that well? In the following we refine our analysis and exploit the fact that the Laplace approximation concentrates around the minimizer of \(I_n\). Hence, with an increasing probability samples drawn from the Laplace approximation are in a small neighborhood of the minimizer. Thus, if \(I_n\) is, e.g., only locally strongly convex—which the assumptions of Theorem 2 actually imply—then with a high probability the mean squared error might be small.
We clarify these arguments in the following and present a positive result for Laplace-based importance sampling under mild assumptions but for a weaker error criterion than the decay of the mean squared error.
First we state a concentration result for N samples drawn from \(\mathcal L_{\mu _n}\) which is an immediate consequence of Proposition 4.
Proposition 3
Let \(N\in \mathbb {N}\) be arbitrary and let \(X^{(n)}_i \sim \mathcal L_{\mu _n}\) be i.i.d. where \(i = 1,\ldots ,N\). Then, for a sequence of radii \(r_n \ge r_0 n^{-q}>0\), \(n\in \mathbb {N}\), with \(q \in (0, 1/2)\) we have
Remark 6
In the following we require expectations w.r.t. restrictions of the measures \(\mu _n\) in (22) to shrinking balls \(B_{r_n}(x_n)\). To this end, we note that the statements of Theorem 1 also hold true for shrinking domains \(D_n = B_{r_n}(x_\star )\) with \(r_n = r_0n^{-q}\) as long as \(q <1/2\). This can be seen from the proof of Theorem 1 in [44, Section IX.5]. In particular, all coefficients in the asymptotic expansion for \(\int _{D_n} f(x) \exp (-n \varPhi (x)) \mathrm {d}x\) with sufficiently smooth f are the same as for \(\int _{D} f(x) \exp (-n \varPhi (x)) \mathrm {d}x\) and the difference between both integrals decays for increasing n like \(\exp (-c n^\epsilon )\) for an \(\epsilon >0\) and \(c>0\). Concerning the balls \(B_{r_n}(x_n)\) with decaying radii \(r_n = r_0 n^{-q}\), \(q\in [0,1/2)\), we have due to \(\Vert x_n - x_\star \Vert \in \mathcal O(n^{-1})\)—see Remark 5—that \(B_{r_n/2}(x_\star ) \subset B_{r_n}(x_n) \subset B_{2r_n}(x_\star )\) for sufficiently large n. Thus, the facts for \(\mu _n\) as in (22) stated in the preliminaries before Sect. 3.1 do also apply to the restrictions of \(\mu _n\) to \(B_{r_n}(x_n)\) with \(r_n = r_0 n^{-q}\), \(q\in [0,1/2)\). In particular, the difference between \( {\varvec{\mathbb E}}_{\mu _n} \left[ f \right] \) and \( {\varvec{\mathbb E}}_{\mu _n} \left[ f\ | \ B_{r_n}(x_n) \right] \) decays faster than any negative power of n as \(n\rightarrow \infty \).
The next result shows that the mean absolute error of the Laplace-based importance sampling behaves like \(n^{-(3q-1)}\) conditional on all N samples belonging to shrinking balls \(B_{r_n}(x_n)\) with \(r_n = r_0 n^{-q}\), \(q \in (1/3, 1/2)\).
Lemma 3
Consider the measures \(\mu _n\) in (22) and suppose they satisfy the assumptions of Theorem 2. Then, for any \(f \in C^2(\mathbb {R}^d, \mathbb {R}) \cap L^2_{\mu _0}(\mathbb {R})\) there holds for the error
of the Laplace-based importance sampling with \(N\in \mathbb {N}\) samples that
where \(r_n = r_0 n^{-q}\) with \(q \in (1/3,1/2)\).
Proof
We start with
The second term decays subexponentially w.r.t. n, see Remark 6. Hence, it remains to prove that
To this end, we write the self-normalizing Laplace-based importance sampling estimator as
where we define
and recall that \(w_n\) is as in (32) and \({\widetilde{w}}_n(x) = \exp (-n R_n(x))\). Notice that
Let us denote the event that \(X^{(n)}_1, \ldots , X^{(n)}_N \in B_{r_n}(x_n)\) by \(A_{n,N}\) for brevity. Then,
The first term in the last line can be bounded by the conditional variance of \(S_{n,N}\) given \(X^{(n)}_1, \ldots , X^{(n)}_N \in B_{r_n}(x_n)\), i.e., by Jensen’s inequality we obtain
see Remark 6 and the preliminaries before Sect. 3.1. Thus,
and it remains to study if \( {\varvec{\mathbb E}} \left[ \left. \left| \left( H_{n,N} -1\right) S_{n,N} \right| \ \right| \ A_{n,N} \right] \in \mathcal O(n^{- (3q-1)})\). Given that \(X^{(n)}_1, \ldots , X^{(n)}_N \in B_{r_n}(x_n)\) we can bound the values of the random variable \(H_{n,N}\) for sufficiently large n: first, we have \(Z_n / {\widetilde{Z}}_n = 1 + \mathcal O(n^{-1})\), see (26), and second
Since \(|R_n(x)| \le c_3 \Vert x-x_n\Vert ^3\) for \(|x-x_n| \le r_n\) due to the local boundedness of the third derivative of \(I_n\) and \(r_n = r_0n^{-q}\), we have that
where \(c>0\). Thus, there exist \(\alpha _n \le 1 \le \beta _n\) with \(\alpha _n = \mathrm e^{- c n^{1-3q} } (1 + \mathcal O(n^{-1}))\) and \(\beta _n \sim \mathrm e^{cn^{1-3q}} (1 + \mathcal O(n^{-1}))\) such that
Since \(\mathrm e^{\pm c n^{1-3q} } (1 + \mathcal O(n^{-1})) = 1 \pm cn^{1-3q} + \mathcal O(n^{-1})\) we get that for sufficiently large n there exists a \({\widetilde{c}} >0\) such that
Hence,
since \( {\varvec{\mathbb E}} \left[ |S_{n,N}| \ | \ A_{n,N} \right] \le {\varvec{\mathbb E}}_{\mu _n} \left[ |f| \ | \ B_{r_n(x_n)} \right] \) is uniformly bounded w.r.t. n. This concludes the proof. \(\square \)
We now present our main result for the Laplace-based importance sampling which states that the corresponding error decays in probability to zero as \(n\rightarrow \infty \) and the order of decay is arbitrary close to \(n^{-1/2}\).
Theorem 4
Let the assumptions of Lemma 3 be satisfied. Then, for any \(f \in C^2(\mathbb {R}^d, \mathbb {R}) \cap L^2_{\mu _0}(\mathbb {R})\) and each sample size \(N\in \mathbb {N}\) the error \(e_{n,N}(f)\) of Laplace-based importance sampling satisfies
Proof
Let \(0\le \delta < 1/2\) and \(\epsilon > 0\) be arbitrary. We need to show that
Again, let us denote the event that \(X^{(n)}_1, \ldots , X^{(n)}_N \in B_{r_n}(x_n)\) by \(A_{n,N}\) for brevity. By Proposition 3 we obtain for radii \(r_n = r_0 n^{-q}\) with \(q \in (1/3, 1/2)\) that
The second term on the righthand side in the last line obviously tends to 1 exponentially as \(n\rightarrow \infty \). Thus, it remains to prove that
To this end, we apply a conditional Markov inequality for the positive random variable \(e_{n,N}(f)\), i.e.,
where we used Lemma 3. Choosing \(q \in (1/3, 1/2)\) such that \(q > \frac{1+\delta }{3} \in [1/3, 1/2) \) yields the statement. \(\square \)
3.2 Quasi-Monte Carlo integration
We now want to approximate integrals as in (20) w.r.t. measures \(\mu _n(\mathrm {d}x) \propto \exp (-n\varPhi (x)) \mu _0(\mathrm {d}x)\) as in (22) by Quasi-Monte Carlo methods.
These will be used to estimate the ratio \(Z'_n/Z_n\) by separately approximating the two integrals \(Z'_n\) and \(Z_n\) in (20). The preconditioning strategy using the Laplace approximation will be explained exemplarily for Gaussian and uniform priors, two popular choices for Bayesian inverse problems.
We start the discussion by first focusing on a uniform prior distribution \(\mu _0={\mathcal {U}}([-\frac{1}{2}, \frac{1}{2}]^d)\). The integrals \(Z'_n\) and \(Z_n\) are then
where we set \(\varTheta _n(x) :=\exp (-n\varPhi (x))\) for brevity.
We consider Quasi-Monte Carlo integration based on shifted Lattice rules: an N-point Lattice rule in the cube \([-\frac{1}{2}, \frac{1}{2}]^d\) is based on points
where \(z \in \{1,\ldots , N-1\}^d\) denotes the so-called generating vector, \(\varDelta \) is a uniformly distributed random shift on \([-\frac{1}{2}, \frac{1}{2}]^d\) and \(\mathrm {frac}\) denotes the fractional part (component-wise). These randomly shifted points provide unbiased estimators
of the two integrals \(Z'_n\) and \(Z_n\) in (35). Under the assumption that the quantity of interest \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) is linear and bounded, we can focus in the following on the estimation of the normalization constant \(Z_n\), the results can be then straightforwardly generalized to the estimation of \(Z'_n\). For the estimator \(Z_{n,QMC}\) we have the following well-known error bound.
Theorem 5
[12, Thm. 5.10] Let \(\gamma = \{\gamma _{\varvec{\nu }}\}_{{\varvec{\nu }}\subset \{1,\ldots ,d\}}\) denote POD (product and order dependent) weights of the form \(\gamma _{\varvec{\nu }}=\alpha _{|{\varvec{\nu }}|}\prod _{j\in {\varvec{\nu }}}\beta _j\) specified by two sequences \(\alpha _0=\alpha _1=1, \alpha _2,\ldots \ge 0\) and \(\beta _1\ge \beta _2\ge \ldots >0\) for \({\varvec{\nu }}\subset \{1,\ldots ,d\}\) and \(|{\varvec{\nu }}|=\# {\varvec{\nu }}\). Then, a randomly shifted Lattice rule with \(N=2^m, m\in \mathbb N\), can be constructed via a component-by-component algorithm with POD weights at costs of \({\mathcal {O}}(dN\log N+d^2 N)\) operations, such that for sufficiently smooth \(\varTheta :[-\frac{1}{2}, \frac{1}{2}]^d \rightarrow [0,\infty )\)
for \(\kappa \in (1/2,1]\) with
and \(\zeta (a):=\sum _{k=1}^\infty k^{-a}\).
The norm \(\Vert \varTheta _n\Vert _\gamma \) in the convergence analysis depends on n, in particular, it can grow polynomially w.r.t. the concentration level n of the measures \(\mu _n\) as we state in the next result.
Lemma 4
Let \(\varPhi :\mathbb {R}^d\rightarrow [0,\infty )\) satisfy the assumptions of Theorem 1 for \(p=2d\). Then, for the norm \(\Vert \varTheta _n\Vert _\gamma \) in the error bound in Theorem 5 there holds
The proof of Lemma 4 is rather technical and can be found in “Appendix B.3”. We remark that Lemma 4 just tells us that the root mean squared error estimate for QMC integration based on the prior measure explodes like \(n^{d/4}\). This does in general not indicate that the error itself explodes; in fact the QMC integration error for the normalization constant is bounded by 1 in our setting. Nonetheless, Lemma 4 indicates that a naive Quasi-Monte Carlo integration based on the uniform prior \(\mu _0\) is not suitable for highly concentrated target or posterior measures \(\mu _n\). We subsequently propose and study a Quasi-Monte Carlo integration based on the Laplace approximation \(\mathcal L_{\mu _n}\).
Laplace-based Quasi-Monte Carlo To stabilize the numerical integration for concentrated \(\mu _n\), we propose a preconditioning based on the Laplace approximation, i.e., an affine rescaling according to the mean and covariance of \(\mathcal L_{\mu _n}\). In the uniform case, the functionals \(I_n\) are independent of n. The computation of the Laplace approximation requires therefore only one optimization to solve for \(x_n = x_\star = \mathop {\mathrm{argmin}}\nolimits _{x\in [-\frac{1}{2}, \frac{1}{2}]^d} \varPhi (x)\). In particular, the Laplace approximation of \(\mu _n\) is given by \(\mathcal L_{\mu _n}= {\mathcal {N}}(x_\star , \frac{1}{n} H_{\star }^{-1})\) where \(H_{\star }\) denotes the positive definite Hessian \(\nabla ^2 \varPhi (x_\star )\). Hence, \(H_\star \) allows for an orthogonal diagonalization \(H_\star = QDQ^\top \) with orthogonal matrix \(Q\in \mathbb R^{d\times d}\) and diagonal matrix \(D={{\,\mathrm{diag}\,}}(\lambda _1,\ldots \lambda _d)\in \mathbb R^{d\times d}\), \(\lambda _1\ge \cdots \ge \lambda _d>0\).
We now use this decomposition in order to construct an affine transformation which reverses the increasing concentration of \(\mu _n\) and yields a QMC approach robust w.r.t. n. This transformation is given by
where \(\tau \in (0,1)\) is a truncation parameter. The idea of the transformation \(g_n\) is to zoom into the parameter domain and thus, to counter the concentration effect. The domain will then be truncated to \(G_n :=g_n([-\frac{1}{2}, \frac{1}{2}]^d) \subset [-\frac{1}{2}, \frac{1}{2}]^d\) and we consider
The determinant of the Jacobian of the transformation \(g_n\) is given by \( \det (\nabla g_n(x)) \equiv C_{\text {trans}, n} = \left( \frac{2|\ln \tau |}{n}\right) ^{\frac{d}{2}} \sqrt{\det (H_\star )} \sim c_\tau n^{-d/2}\). We will now explain how the parameter \(\tau \) effects the truncation error. For given \(\tau \in (0,1)\), the Laplace approximation is used to determine the truncation effect:
Thus, since due to the concentration effect of the Laplace approximation we have \(\int _{\mathrm {S}_0} \ \mathcal L_{\mu _n}(\mathrm {d}x) \rightarrow 1\) exponentially with n, we get
thus, the truncation error \(\int _{\mathrm {S}_0{\setminus } G_n} \ \mathcal L_{\mu _n}(\mathrm {d}x)\) becomes arbitrarily small for sufficiently small \(\tau \ll 1\), since \(\mathrm {erf}(t) \rightarrow 1\) as \(t\rightarrow 1\). If we apply now QMC integration using shifted Lattice rule in order to compute the integral over \([-\frac{1}{2}, \frac{1}{2}]^d\) on the righthand side of (38), we obtain the following estimator for \({\hat{Z}}_n\) in (38):
with \(x_i\) as in (36). Concerning the norm \(\Vert \varTheta _n\circ g_n \Vert _\gamma \) appearing in the error bound for \(|{\hat{Z}}_n - {\hat{Z}}_{n,QMC}|\) we have now the following result.
Lemma 5
Let \(\varPhi :\mathbb {R}^d\rightarrow [0,\infty )\) satisfy the assumptions of Theorem 1 for \(p=2d\). Then, for the norm \(\Vert \varTheta _n\circ g_n\Vert _\gamma \) with \(g_n\) as above there holds
Again, the proof is rather technical and can be found in “Appendix B.4”. This proposition yields now our main result.
Corollary 2
Given the assumptions of Lemma 5, a randomly shifted lattice rule with \(N=2^m, m\in \mathbb N\), can be constructed via a component-by-component algorithm with product and order dependent weights at costs of \({\mathcal {O}}(dN\log N+d^2 N)\) operations, such that for \(\kappa \in (1/2,1]\)
with constants \(c_1,c_2, c_3>0\) independent of n and \(h(\tau ) = 1 - \mathrm {erf}(0.5 \sqrt{|\ln \tau }|)^d\).
Proof
The triangle inequality leads to a separate estimation of the domain truncation error of the integral w.r.t. the posterior and the QMC approximation error, i.e.
The second term on the right hand side corresponds to the QMC approximation error. Thus, Theorem 5 and Lemma 5 imply
where the term \(n^{-\frac{d}{2}}\) is due to \(C_{\text {trans}, n} \sim c_\lambda n^{-\frac{d}{2}}\). The domain truncation error can be estimated similar to the proof of Lemma 1:
where \(\widetilde{Z}_n=n^{-\frac{d}{2}}\sqrt{\det (2\pi H_\star ^{-1})}\). The result follows by the proof of Lemma 1. \(\square \)
Remark 7
In the case of Gaussian priors, the transformation simplifies to \(w=g_n(x)=x_\star + n^{\frac{1}{2}}QD^{-\frac{1}{2}}x\) due to the unboundedness of the prior support. However, to show an analogous result to Corollary 2, uniform bounds w.r. to n on the norm of the mixed first order derivatives of the preconditioned posterior density \(\varTheta _n(g_n(T^{-1}x))\) in a weighted Sobolev space, where \(T^{-1}\) denotes the inverse cumulative distribution function of the normal distribution, need to be proven. See [23] for more details on the weighted space setting in the Gaussian case. Then, a similar result to Corollary 2 follows straightforwardly from [23, Thm 5.2]. The numerical experiments shown in Sect. 3.3 suggest that we can expect a noise robust behavior of Laplace-based QMC methods also in the Gaussian case. This will be subject to future work.
Remark 8
Note that the QMC analysis in Theorem 5 can be extended to an infinite dimensional setting, cp. [23] and the references therein for more details. This opens up the interesting possibility to generalize the above results to the infinite dimensional setting and to develop methods with convergence independent of the number of parameters and independent of the measurement noise. Furthermore, higher order QMC methods can be used for cases with smooth integrands, cp. [10, 11, 13], leading to higher convergence rates than the first order methods discussed here. In the uniform setting, it has been shown in [38] that the assumptions on the first order derivatives (and also higher order derivatives) of the transformed integrand are satisfied for Bayesian inverse problems related to a class of parametric operator equations, i.e., the proposed approach leads to a robust performance w.r.t. the size of the measurement noise for integrating w.r.t. posterior measure resulting from this class of forward problems. The theoretical analysis of this setting will be subject to future work.
Remark 9
(Numerical quadrature) Higher regularity of the integrand allows to use higher order methods such as sparse quadrature and higher order QMC methods, leading to faster convergence rates. In the infinite dimensional Bayesian setting with uniform priors, we refer to [35, 36] for more details on sparse quadrature for smooth integrands. In the case of uniform priors, the methodology introduced above can be used to bound the quadrature error for the preconditioned integrand by the truncation error and the sparse grid error.
3.3 Examples
In this subsection we present two examples illustrating our previous theoretical results for importance sampling and quasi-Monte Carlo integration based on the prior measure \(\mu _0\) and the Laplace approximation \(\mathcal L_{\mu _n}\) of the target measure \(\mu _n\). Both examples are Bayesian inference or inverse problems where the first one uses a toy forward map and the second one is related to inference for a PDE model.
3.3.1 Algebraic Bayesian inverse problem
We consider inferring \(x \in [-\frac{1}{2}, \frac{1}{2}]^d\) for \(d=1,2,3,4\) based on a uniform prior \(\mu _0 = {\mathcal {U}}([-\frac{1}{2}, \frac{1}{2}]^d)\) and a realisation of the noisy observable of \(Y = \mathcal G(X) + \eta _n\) where \(X\sim \mu _0\) and the noise \(\eta _n \sim N(0, n^{-1} \varGamma _d)\), \(\varGamma _d = 0.1I_d\), are independent, and \(\mathcal G(x) = (\mathcal G_1(x),\ldots ,\mathcal G_d(x))\) with
for \(x = (x_1,\ldots ,x_d)\). The resulting posterior measure \(\mu _n\) on \([-\frac{1}{2}, \frac{1}{2}]^d\) are of the form (22) with
We used \(y = \mathcal {G}(0.25\cdot {\textit{\textbf{1}}}_d)\) throughout where \({{\textit{\textbf{1}}}}_d = (1,\ldots ,1) \in \mathbb {R}^d\). We then compute the posterior expectation of the quantity of interest \(f(x) = x_1+\cdots +x_d\). To this end, we employ importance sampling and quasi-Monte Carlo integration based on \(\mu _0\) and the Laplace approximation \(\mathcal L_{\mu _n}\) as outlined in the precious subsections. We compare the output of these methods to a reference solution obtained by a brute-force tensor grid trapezoidal rule for integration. In particular, we estimate the root mean squared error (RMSE) of the methods and how it evolves as n increases.
Results for importance sampling In order to be sufficiently close to the asymptotic limit, we use \(N = 10^5\) samples for self-noramlized importance sampling. We run 1000 independent simulations of the importance sampling integration and compute the resulting empirical RMSE. In Fig. 3 we present the results for increasing n and various d for prior-based and Laplace-based importance sampling. We obtain a good match to the theoretical results, i.e., the RMSE for choosing the prior measure as importance distribution behaves like \(n^{d/4 - 1/2}\) in accordance to Lemma 2. Besides that the RMSE for choosing the Laplace approximation as importance distribution decays like \(n^{1/2}\) after a preasymptotic phase. This is relates to the statement of Theorem 4 where we have shown that the absolute errorFootnote 3 decays in probability like \(n^{1/2}\). Note that the assumptions of Proposition 2 are not satisfied for this example for all \(d=1,2,3,4\).

Growth and decay of the empirical RMSE of prior-based (left) and Laplace-based (right) importance sampling for the example in Sect. 3.3.1 for decaying noise level \(n^{-1}\) and various dimensions d
Results for quasi-Monte Carlo We use \(N = 2^{10}\) quasi-Monte Carlo points for prior- and Laplace-based QMC. For the Laplace-case we employ a truncation parameter of \(\tau = 10^{-6}\) and discard all transformed points outside of the domain \([-\frac{1}{2}, \frac{1}{2}]^d\). Again, we run 1000 random shift simulations for both QMC methods and estimate the empirical RMSE. However, for QMC we report the relative RMSE, since, for example, the decay of the normalization constant \(Z_n\in \mathcal O(n^{-d/2})\) dominates the growth of the absolute error of prior QMC integration for the normalization constant. In Fig. 4 and 5 we display the resulting relative RMSE for the quantity related integral \(Z_n'\), the normalization constant \(Z_n\), i.e.,
and the resulting ratio \(\frac{Z'_n}{Z_n}\) for increasing n and various d for prior-based and Laplace-based QMC. For prior-based QMC we observe for dimensions \(d \ge 2\) a algebraic growth of the relative error. In the previous subsection we have proven that the corresponding classical error bound will explode which does not necessary imply that the error itself explodes—as we can see for \(d=1\). However, this simple example shows that also the error will often grow algebraically with increasing n. For the Laplace-based QMC we observe on the other hand in Fig. 5 a decay of the relative empirical RMSE. By Corollary 2 we can expect that the relative errors stay bounded as \(n\rightarrow \infty \). This provides motivation for a further investigation. In particular, we will analysize the QMC ratio estimator for \(\frac{Z'_n}{Z_n}\) in a future work.

Empirical relative RMSE of prior-based quasi-Monte Carlo for the example in Sect. 3.3.1 for decaying noise level \(n^{-1}\) and various dimensions d

Empirical relative RMSE of Laplace-based quasi-Monte Carlo for the example in Sect. 3.3.1 for decaying noise level \(n^{-1}\) and various dimensions d
3.3.2 Bayesian inference for an elliptic PDE
In the following we illustrate the preconditioning ideas from the previous section by Bayesian inference with differential equations. To this end we consider the following model parametric elliptic problem
with \(f(t)=100\cdot t\), \(t\in [0,1]\), and diffusion coefficient
where \(\psi _k(t)= \frac{0.1}{k} \sin (k\pi t)\) and the \(x_k \in \mathbb {R}\), \(k=1,\ldots ,d\), are to be inferred by noisy observations of the solution q at certain points \(t_j \in [0,1]\). For \(d=1,2\) these observations are taken at \(t_1 = 0.25\) and \(t_2 = 0.75\) and for \(d=3\) they are taken at \(t_j \in \{0.125,0.25,0.375,0.6125,0.75,0.875\}\). We suppose an additive Gaussian observational noise \(\eta \sim \mathcal N(0, \varGamma _n)\) with noise covariance \(\varGamma _n = n^{-1}\varGamma _{obs}\) and \(\varGamma _{obs}\in \mathbb {R}^{2\times 2}\) or \(\varGamma _{obs}\in \mathbb {R}^{7\times 7}\), respectively, specified later on. In the following we place a uniform and a Gaussian prior \(\mu _0\) on \(\mathbb {R}^d\) and would like to integrate w.r.t. the resulting posterior \(\mu _n\) on \(\mathbb {R}^d\) which is of the form (22) with
where \(\mathcal {G}:\mathbb {R}^d \rightarrow \mathbb {R}^2\) for \(d=1,2\), and \(\mathcal {G}:\mathbb {R}^d \rightarrow \mathbb {R}^7\) for \(d=3\), respectively, denotes the mapping from the coefficients \(x:=(x_k)_{k=1}^d\) to the observations of the solution q of the elliptic problem above and the vector \(y \in \mathbb {R}^2\) or \(y\in \mathbb {R}^7\), respectively, denotes the observational data resulting from \(Y = \mathcal G(X) + \eta \) with \(\eta \) as above. Our goal is then to compute the posterior expectation (i.e., w.r.t. \(\mu _n\)) of the following quantity of interest \(f:\mathbb {R}^d\rightarrow \mathbb {R}\): f(u) is the value of the solution q of the elliptic problem at \(t=0.5\).
Uniform prior We place a uniform prior \(\mu _0 = {\mathcal {U}}([-\frac{1}{2}, \frac{1}{2}]^d)\) for \(d=1,2\) or 3 and choose \(\varGamma _{obs} = 0.01 I_2\) for \(d=1,2\) and \(\varGamma _{obs} = 0.01 I_7\) for \(d=3\). We display the resulting posteriors \(\mu _n\) for \(d=2\) in Fig. 6 illustrating the concentration effect of the posterior for various values of the noise scaling n and the resulting transformed posterior with \(\varPhi \circ g_n\) based on Laplace approximation. The truncation parameter is set to \(\tau =10^{-6}\). We observe the almost quadratic behavior of the preconditioned posterior, as expected from the theoretical results.

The first row shows the posterior distribution for various values of the noise scaling, the second row shows the corresponding preconditioned posteriors based on Laplace approximation, 2d test case, uniform prior distribution, \(\tau =10^{-6}\)
We are now interested in the numerical performance of the Importance Sampling and QMC method based on the prior distribution compared to the performance of the preconditioned versions based on Laplace approximation. The QMC estimators are constructed by an off-the-shelf generating vector (order-2 randomly shifted weighted Sobolev space), which can be downloaded from https://people.cs.kuleuven.be/~dirk.nuyens/qmc-generators/ (exod2_base2_m20_CKN.txt). The reference solution used to estimate the error is based on a (tensor grid) trapezoidal rule with \(10^6\) points in 1D, \(4\times 10^6\) points in 2D in the original domain, i.e., the truncation error is quantified and in the transformed domain in 3D with \(10^6\) points. Figure 7 illustrates the robust behavior of the preconditioning strategy w.r.t. the scaling 1/n of the observational noise. Though we know from the theory that in the low dimensional case (1D, 2D), the importance sampling method based on the prior is expected to perform robust, we encounter numerical instabilities due to the finite number of samples used for the experiments. The importance sampling results are based on \(10^6\) sampling points, the QMC results on 8192 shifted lattice points with \(2^6\) random shifts.

The (estimated) root mean square error (RMSE) of the approximation of the quantity of interest for different noise levels (\(n=10^{2},\ldots ,10^{10}\)) using the Importance Sampling strategy and QMC method for \(d= 1,2,3\)
Figure 8 shows the RMSE of the normalization constant \(Z_n\) using the preconditioned QMC approach with respect to the noise scaling 1/n. We observe a numerical confirmation of the predicted dependence of the error w.r.t. the dimension (cp. Corollary 2).

The (estimated) root mean square error (RMSE) of the approximation of the normalization constant Z for different noise levels (\(n=10^{2},\ldots ,10^{10}\)) using the preconditioned QMC method for \(d=1,2,3\)
We remark that the numerical experiments for the ratio suggest a behavior \(n^{-1/2}\), i.e., a rate independent of the dimension d, of the RMSE for the preconditioned QMC approach, cp. Figure 7. This will be subject to future work.
Gaussian prior We choose as prior \(\mu _0 = {\mathcal {N}}(0,I_2)\) for the coefficients \(x=(x_1,x_2) \in \mathbb {R}^2\) for \({\hat{u}}_2\) in the elliptic problem above. For the noise covariance we set this time \(\varGamma _{obs}=I_2\). The performance of the prior based and preconditioned version of Importance Sampling is depicted in Fig. 9. Clearly, the Laplace approximation as a preconditioner improves the convergence behavior; we observe a robust behavior w.r.t. the noise level.
The convergence of the QMC approach is depicted in Fig. 10, showing a consistent behavior with the considerations in the previous section.

The (estimated) root mean square error (RMSE) of the approximation of the quantity of interest for different noise levels (\(n=10^{0},\ldots ,10^{8}\)) using the Importance Sampling strategy. The first row shows the result based on prior information (Gaussian prior), the second row the results using the Laplace approximation for preconditioning. The reference solution is based on a tensor grid Gauss–Hermite rule with \(10^4\) points for the preconditioned integrand using the Laplace approximation

The (estimated) root mean square error (RMSE) of the approximation of the quantity of interest for different noise levels (\(n=10^{0},\ldots ,10^{8}\)) using the QMC method (below). The first row shows the result based on prior information (Gaussian prior), the second row the results using the Laplace approximation for preconditioning. The reference solution is based on a tensor grid Gauss–Hermite rule with \(10^4\) points for the preconditioned integrand using the Laplace approximation
4 Conclusions and outlook to future work
This paper makes a number of contributions in the development of numerical methods for Bayesian inverse problems, which are robust w.r.t. the size of the measurement noise or the concentration of the posterior measure, respectively. We analyzed the convergence of the Laplace approximation to the posterior distribution in Hellinger distance. This forms the basis for the design of variance robust methods. In particular, we proved that Laplace-based importance sampling behaves well in the small noise or large data size limit, respectively. For uniform priors, Laplace-based QMC methods have been developed with theoretically and numerically proven errors decaying with the noise level or concentration of the measure, respectively. Some future directions of this work include the development of noise robust Markov chain Monte Carlo methods and the combination of dimension independent and noise robust strategies. This will require the study of the Laplace approximation in infinite dimensions in a suitable setting. Finally, we could study in more details the error in the ratio estimator using Laplace-based QMC methods. The use of higher order QMC methods has been proven to be a promising direction for a broad class of Bayesian inverse problems and the design of noise robust versions is an interesting and potentially fruitful research direction.
Notes
We have also computed the empirical \(L^1\)-error which showed a similar behaviour as the RMSE.
References
Alexanderian, A., Petra, N., Stadler, G., Ghattas, O.: A fast and scalable method for a-optimal design of experiments for infinite-dimensional Bayesian nonlinear inverse problems. SIAM J. Sci. Comput. 38(1), A243–A272 (2016)
Beck, J., Dia, B.M., Espath, L.F., Long, Q., Tempone, R.: Fast Bayesian experimental design: Laplace-based importance sampling for the expected information gain. Comput. Methods Appl. Mech. Eng. 334, 523–553 (2018). https://doi.org/10.1016/j.cma.2018.01.053
Castillo, I., Nickl, R.: Nonparametric Bernstein–von Mises theorems in Gaussian white noise. Ann. Stat. 41(4), 1999–2028 (2013)
Castillo, I., Nickl, R.: On the Bernstein–von Mises phenomenon for nonparametric Bayes procedures. Ann. Stat. 42(5), 1941–1969 (2014)
Chen, P., Villa, U., Ghattas, O.: Hessian-based adaptive sparse quadrature for infinite-dimensional Bayesian inverse problems. Comput. Methods Appl. Mech. Eng. 327, 147–172 (2017). https://doi.org/10.1016/j.cma.2017.08.016. (Advances in Computational Mechanics and Scientific Computation—the Cutting Edge)
Cotter, S.L., Roberts, G.O., Stuart, A.M., White, D.: MCMC methods for functions: modifying old algorithms to make them faster. Stat. Sci. 28(3), 283–464 (2013)
Cox, D.D.: An analysis of Bayesian inference for nonparametric regression. Ann. Stat. 21, 903–923 (1993)
Dashti, M., Stuart, A.M.: The Bayesian approach to inverse problems. In: Ghanem, R., Higdon, D., Owhadi, H. (eds.) Handbook of Uncertainty Quantification, pp. 311–428. Springer, Berlin (2017)
Diaconis, P., Freedman, D.: On the consistency of Bayes estimates. Ann. Stat. 14(1), 1–26 (1986)
Dick, J., Gantner, R.N., Gia, Q.T.L., Schwab, C.: Multilevel higher-order quasi-Monte Carlo Bayesian estimation. Math. Models Methods Appl. Sci. 27(5), 953–995 (2017). https://doi.org/10.1142/S021820251750021X
Dick, J., Gantner, R.N., Le Gia, Q.T., Schwab, C.: Higher order Quasi-Monte Carlo integration for Bayesian Estimation. ArXiv e-prints (2016)
Dick, J., Kuo, F.Y., Sloan, I.H.: High-dimensional integration: the quasi-Monte Carlo way. Acta Numer. 22, 133–288 (2013). https://doi.org/10.1017/S0962492913000044
Dick, J., Le Gia, Q., Schwab, C.: Higher order quasi-Monte Carlo integration for holomorphic, parametric operator equations. SIAM/ASA J. Uncertain. Quantif. 4(1), 48–79 (2016). https://doi.org/10.1137/140985913
Dodwell, T.J., Ketelsen, C., Scheichl, R., Teckentrup, A.L.: A hierarchical multilevel Markov chain Monte Carlo algorithm with applications to uncertainty quantification in subsurface flow. SIAM/ASA J. Uncertain. Quantif. 3(1), 1075–1108 (2015)
Freedman, D.: On the Bernstein–von Mises theorem with infinite-dimensional parameters. Ann. Stat. 27(4), 1119–1140 (1999)
Ghosal, S., Ghosh, J.K., van der Vaart, A.W.: Convergence rates of posterior distributions. Ann. Stat. 28(2), 500–531 (2000)
Gibbs, A.L., Su, F.E.: On choosing and bounding probability metrics. Int. Stat. Rev. 70(3), 419–435 (2001)
Hardy, M.: Combinatorics of partial derivatives. Electron. J. Comb. 13, R1 (2006)
Hipp, C., Michel, R.: On the Bernstein-v. Mises approximation of posterior distributions. Ann. Stat. 4(5), 972–980 (1976)
Hoang, V.H., Stuart, A.M., Schwab, C.: Complexity analysis of accelerated MCMC methods for Bayesian inversion. Inverse Prob. 29(8), 085010 (2013)
Kaipio, J., Somersalo, E.: Statistical and Computational Inverse Problems. Springer, New York (2005)
Kleijn, B.J.K., van der Vaart, A.W.: The Bernstein–von-Mises theorem under misspecification. Electron. J. Stat. 6, 354–381 (2012)
Kuo, F.Y., Nuyens, D.: Application of quasi-Monte Carlo methods to elliptic PDEs with random diffusion coefficients: a survey of analysis and implementation. Found. Comput. Math. 16(6), 1631–1696 (2016). https://doi.org/10.1007/s10208-016-9329-5
Ledoux, M., Talagrand, M.: Probability in Banach Spaces. Springer, Berlin (2002)
Long, Q., Scavino, M., Tempone, R., Wang, S.: Fast estimation of expected information gains for Bayesian experimental designs based on Laplace approximations. Comput. Methods Appl. Mech. Eng. 259, 24–39 (2013)
Lu, Y., Stuart, A., Weber, H.: Gaussian approximations for probability measures on \(\mathbb{R}^{d}\). SIAM/ASA J. Uncertain. Quantif. 5, 1136–1165 (2017)
Marzouk, Y., Dongbin, X.: A stochastic collocation approach to Bayesian inference in inverse problems. Commun. Comput. Phys. 6(4), 826–847 (2009)
Nickl, R.: Bernstein–von Mises theorems for statistical inverse problems I: Schrödinger equation (2017). arXiv:1707.01764
Pardo, L.: Statistical Inference Based on Divergence Measures. No. 185 in Statistics: Textbooks and Monographs. Chapman & Hall/CRC, Boca Raton (2006)
Pinski, F., Simpson, G., Stuart, A., Weber, H.: Kullback–Leibler approximation for probability measures on infinite dimensional spaces. SIAM J. Math. Anal. 47(6), 4091–4122 (2015)
Robert, C.P., Casella, G.: Monte Carlo Statistical Methods (Springer Texts in Statistics). Springer, Berlin (2005)
Rudolf, D., Sprungk, B.: On a generalization of the preconditioned Crank–Nicolson Metropolis algorithm. Found. Comput. Math. 18(2), 309–343 (2018)
Ryan, E.G., Drovandi, C.C., McGree, J.M., Pettitt, A.N.: A review of modern computational algorithms for Bayesian optimal design. Int. Stat. Rev. 84(1), 128–154 (2016). https://doi.org/10.1111/insr.12107
Scheichl, R., Stuart, A.M., Teckentrup, A.L.: Quasi-Monte Carlo and multilevel Monte Carlo methods for computing posterior expectations in elliptic inverse problems. SIAM/ASA J. Uncertain. Quantif. 5, 493–518 (2017)
Schillings, C., Schwab, C.: Sparse, adaptive Smolyak quadratures for Bayesian inverse problems. Inverse Prob. 29(6), 065011:1-28 (2013)
Schillings, C., Schwab, C.: Sparsity in Bayesian inversion of parametric operator equations. Inverse Prob. 30(6), 065007 (2014)
Schillings, C., Sprungk, B., Wacker, P.: On the convergence of the Laplace approximation and noise-level-robustness of Laplace-based Monte Carlo methods for Bayesian inverse problems (2020). arXiv:1901.03958v4
Schillings, C., Schwab, C.: Scaling limits in computational Bayesian inversion. ESAIM: M2AN 50(6), 1825–1856 (2016). https://doi.org/10.1051/m2an/2016005
Stuart, A.M.: Inverse problems: a Bayesian perspective. Acta Numer. 19, 451–559 (2010)
Szabó, B., van der Vaart, A.W., van Zanten, J.: Frequentist coverage of adaptive nonparametric bayesian credible sets. Ann. Stat. 43(4), 1391–1428 (2015)
van der Vaart, A.W.: Asymptotic Statistics. Cambridge University Press, Cambridge (1998)
Vollmer, S.J.: Dimension-independent MCMC sampling for inverse problems with non-Gaussian priors. SIAM/ASA J. Uncertain. Quantif. 3(1), 535–561 (2015)
Wacker, P.: Laplace’s method in Bayesian inverse problems with Gaussian priors (2017). arXiv:1701.07989
Wong, R.: Asymptotic Approximations of Integrals. Classics in Applied Mathematics. SIAM, Philadelphia (2001)
Acknowledgements
Open Access funding provided by Projekt DEAL. The authors are grateful to the Isaac Newton Institute for Mathematical Sciences for support and hospitality during the programme Uncertainty quantification for complex systems: theory and methodologies when work on this paper was undertaken. This work was supported by: EPSRC Grant Numbers EP/K032208/1 and EP/R014604/1. Moreover, the authors would like to thank the anonymous referees and Remo Kretschmann for helpful comments which improved the paper significantly. Furthermore, BS was supported by the DFG Project 389483880 and by the DFG RTG1953 “Statistical Modeling of Complex Systems and Processes”.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Concentration of the Laplace approximation
Due to the well-known Borell-TIS inequality for Gaussian measures on Banach spaces [24, Chapter 3] we obtain the following useful concentration result for the Laplace approximation.
Proposition 4
Let Assumptions 1 and 2 be satisfied. Then, for any \(r>0\) there exists an \(c_r >0\) such that
where \(B^c_r(x_n) = \{x\in \mathbb {R}^d:\Vert x-x_n\Vert >r\}\).
Proof
Let \(X_n \sim \mathcal N\left( 0, n^{-1} C_n\right) \). Then
We now use the well-known concentration of Gaussian measures, namely,
where \(\sigma _n^2 :=\sup _{\Vert x\Vert \le 1} {\varvec{\mathbb E}} \left[ |x^\top X_n|^2 \right] \), see [24, Chapter 3]. There holds \(\sigma _n^2 = \lambda _\text {max}(n^{-1}C_n) = \Vert n^{-1}C_n\Vert \) and we get
Due to Assumption 2, i.e., \(C_n\rightarrow H^{-1}_\star > 0\), there exists a finite constant \(0<c\) such that \(\Vert C_n\Vert \ge c\) for all \(n\in \mathbb {N}\). Analogously, there exist a constant \(K<\infty \) such that \(\mathrm {tr}\,(C_n) \le K\) for all n. The latter implies
Hence, for an arbitrary r let \(n_0\) be such that \( {\varvec{\mathbb E}} \left[ \Vert X_n\Vert \right] \le r/2\) for all \(n\ge n_0\), which yields
\(\square \)
Appendix B: Proofs
We collect the rather technical proofs in this appendix.
1.1 B.1 Proof of Lemma 1
Recall that we want to bound
where \(R_n(x) :=I_n(x) - {\widetilde{I}}_n(x) = I_n(x) - I_n(x_n) - \frac{1}{2} \Vert x-x_n\Vert ^2_{C^{-1}_n}\) and \(r>0\) is an at the moment arbitrary radius which will be specified in the following first paragraph.
Bounding \(J_1\). Due to \(\varPhi _n, \log \pi _0 \in C^3(\mathrm {S}_0; \mathbb {R})\), we have that for any \(x\in B_r(x_n)\) there exists a \(\xi _{x,n} \in B_r(x_n)\) such that
Moreover, since \(x_n \rightarrow x_\star \) there exists an \(0<r_0<\infty \) such that
Hence, the local uniform boundedness of \(\Vert \nabla ^3 I_n(\cdot )\Vert \), see Assumption 2, implies the existence of a finite \(c_3 > 0\) such that for sufficiently large n, i.e., \(n\ge n_r\), we have
Thus, we obtain, due to \(|\mathrm e^{-t} -1| = 1 - \mathrm e^{-t} \le \mathrm e^{t} -1\) for \(t\ge 0\),
which yields
Now, since \(C^{-1}_n \rightarrow H_\star > 0\), there exists for sufficiently large n a \(\gamma >0\) such that
Hence, for \(x\in B_r(x_n)\), i.e., \(\Vert x-x_n\Vert \le r\), we get
By choosing \(r :=\frac{\gamma }{2c_3}\) we obtain further
Let us now introduce the auxiliary Gaussian measure \(\nu _{n} :=\mathcal N \left( 0, \frac{1}{n\gamma } I\right) \) with which we get
There holds now
due to the continuity of the determinant and \(H_\star >0\). Moreover, since \(1-\mathrm e^{-t}\le t\) for \(t\ge 0\) we obtain with \(\xi \sim \mathcal N(0, I)\) that
This yields \(J_1(n)\in \mathcal O(n^{-p/2})\) for the particular choice \(r = \frac{\gamma }{2c_3}\). In the following two paragraphs we will use exactly this particular radius.
Bounding\(J_0\). Due to Assumption 2, we have \(x_n \rightarrow x_\star \) as \(n\rightarrow \infty \). Hence, there exists an \(n_0 < \infty \) such that \(\Vert x_n - x_\star \Vert \le r/2\) for all \(n\ge n_0\). This implies by Assumption 2
and, hence, \(\mathrm {S}_0^c \subseteq B^c_{r/2}(x_n)\). By Proposition 4, we obtain
with a \(0<c_{r/2}<\infty \).
Bounding \(J_2\). We divide the set \(B_r^c(x_n)\cap \mathrm {S}_0\) into several subsets in order to bound \(J_2(n)\). First, we define
i.e., \(B^c_r(x_n) \cap \mathrm {S}_0= \mathrm {P}_n \dot{\cup } \mathrm {P}^c_n\), and notice that
Hence, due to Proposition 4 there exists a \(c_{r} \in (0, \infty )\) such that
Since for \(x \in \mathrm {P}_n^c\) we have \(R_n(x) \le 0\), we get
We now prove that
with \(\epsilon \in (0,1)\) as in Assumption 2. To this end, we observe that due to \(I_n(x) \ge \delta _r\) for all \(x\in \mathrm {P}^c_n \subset B^c_r(x_n)\) the functions
converge pointwise to zero as \(n\rightarrow \infty \). Moreover, \(I_n(x) \ge \delta _r\) yields
with the bounding function q introduced in Assumption 2. Thus, since \(q^{1-\epsilon }\) is integrable we obtain by Lebesgue’s dominated convergence theorem
as \(n\rightarrow \infty \). Hence, (41) holds. Since \({\widetilde{Z}}_n \in \mathcal O(n^{-d/2})\) we get in summary,
with \(c_{r,\epsilon } := \min \{c_r, \epsilon \delta _r\}>0\).
1.2 B.2 Proof of Theorem 3
A straightforward calculation, see also [29, Exercise 1.14], yields that for Gaussian measures \(\mathcal N_{a,Q} :=\mathcal N(a,Q)\), \(\mathcal N_{b,Q} :=\mathcal N(b, Q)\) and \(\mathcal N_{a,R} :=\mathcal N(a, R)\) we have
By (13) we obtain for \(\widetilde{\mu }_n :=\mathcal N(x_n, \frac{1}{n} B_n)\) that
Due to the local Lipschitz continuity of the determinant and \(\Vert C_n^{-1} - H_\star \Vert \rightarrow 0\) we obtain the first statement for \(\widetilde{\mu }_n :=\mathcal N(x_n, \frac{1}{n} B_n)\). Furthermore, by the triangle inequality
and exploiting the local Lipschitz continuity of \(f(x) = \frac{1}{x}\) and of the determinant, we obtain
with a generic constant \(c>0\). Moreover, due to the local Lipschitz continuity of the square root of a matrix, we get
where we used that \(\Vert C_n^{-1/2}\Vert \rightarrow \Vert H_\star ^{1/2}\Vert \).
Furthermore, we get analogously that \(\Vert I - C_n^{1/2}B_n^{-1/2}\Vert \le c \Vert B_n - C_n\Vert \) using that \(\Vert B_n^{-1/2}\Vert \rightarrow \Vert H_\star ^{1/2}\Vert \). Thus, the second statement of the first item follows by
The second item follows by applying the triangle inequality, expressing the Hellinger distance between \(\mathcal N(x_n, \frac{1}{n} B_n)\) and \(\mathcal N(a_n, \frac{1}{n} B_n)\) by
and estimating
where we used the fact that the spd matrices \(B_n\) converge to the spd matrix \(H_\star \), hence, the sequence of the smallest eigenvalue of \(B_n\) is bounded away from zero.
1.3 B.3 Proof of Lemma 4
For the following proof we use the famous Faa di Bruno-formula for higher order derivatives of compositions given in [18]. To this end, let \(v:\mathbb {R}^d \rightarrow \mathbb {R}\) and \(u :\mathbb {R}\rightarrow \mathbb {R}\) be sufficiently smooth functions and define \(w:=u\circ v\), i.e., \(w:\mathbb {R}^d\rightarrow \mathbb {R}\). For a subset \({\varvec{\nu }}\subset \{1,\ldots ,d\}\) we consider the partial derivative \(\frac{\partial ^{|{\varvec{\nu }}|}w}{\partial x_{{\varvec{\nu }}}}\) where we set
We then obtain (see [18])
where \(\varPi ({\varvec{\nu }})\) denotes the set of all partitions P of the set \({\varvec{\nu }}\subset \{1,\ldots ,d\}\), \(B\in P\) refers to running through the elements or blocks of the partition P with |B| denoting the cardinality of \(B\subset {\varvec{\nu }}\) and |P| the number of blocks in P, and the same notational convention for \(\partial x_B\) as above, i.e.,
By the application of the multivariate Faa di Bruno-formula to
we obtain for \({\varvec{\nu }}\subset \{1,\ldots ,d\}\) that
By setting \(x_{-{\varvec{\nu }}} :=x_{\{1,\ldots ,d\}{\setminus }{\varvec{\nu }}}\) we get
where we shortened \(\varPi _d :=\varPi (\{1,\ldots ,d\})\). We will now investigate, how—i.e., to which power w.r.t. n—
decays as \(n\rightarrow \infty \). To this end, we write
and apply in the following Laplace’s method in order to derive the asymptotics of
Since in the considered setting of a uniform prior on \([-\frac{1}{2},\frac{1}{2}]^d\) we have \(I_n (x) = \varPhi (x)\) for \(x \in [-\frac{1}{2},\frac{1}{2}]^d\), there holds that \(x_n = x_\star \), \(\varPhi (x_n) = 0\), and, by construction, also \(\nabla \varPhi (x_n) = 0\). The latter may cause a faster decay of \(\int _{[-\frac{1}{2},\frac{1}{2}]^{d}} h_{P,{\widetilde{P}}} \mathrm e^{-2n \varPhi } \mathrm {d}x\) than the usual \(n^{-d/2}\) depending on the partitions \(P, {\widetilde{P}}\). For example, let \(P = {\widetilde{P}} = \{ \{1\},\ldots , \{d\} \}\), i.e., P and \({\widetilde{P}}\) consist only of single blocks \(B = \{i\}\), \(i = 1,\ldots ,d\), then
Exploiting (24) for the coefficients in the asymptotic expansion of \(\int _{[-\frac{1}{2},\frac{1}{2}]^{d}} h_{P,{\widetilde{P}}} \mathrm e^{-2n \varPhi } \mathrm {d}x\) one can calculate that for these particular partitions \(P = {\widetilde{P}}=\{ \{1\},\ldots , \{d\} \}\) we have
but
since \(\frac{\partial ^2}{\partial x^2_j}\varPhi (x_\star ) \ne 0\) due to \(\nabla ^2 \varPhi (x_\star )\) being positive definite. Hence, for these partitions \(|P|=|{\widetilde{P}}| = d\) we get
We can extend this reasoning to arbitrary partitions \(P,{\widetilde{P}} \in \varPi _d\). To this end, let \(|P|_1 :=|\{B \in P:|B|=1 \} |\) denote the number of single blocks \(|B|=1\) in \(P \in \varPi _d\). Then, we know by the definition of \(h_{P,{\widetilde{P}}}\) that \(h_{P,{\widetilde{P}}}\) posseses a zero of order \(|P|_1+|{\widetilde{P}}|_1\) in \(x_\star \). This in turn, implies that the first \(\left\lfloor \frac{|P|_1+|{\widetilde{P}}|_1}{2}\right\rfloor \) coefficients in the asymptotic expansion of \(\int _{[-\frac{1}{2},\frac{1}{2}]^{d}} h_{P,{\widetilde{P}}} \mathrm e^{-2n \varPhi } \mathrm {d}x\) are zero, hence,
Thus, for arbitrary \(P,{\widetilde{P}} \in \varPi _d\) we have
If we maximize the exponent on the righthand side we get that
where the maximum is obtained, e.g., for the above choice of \(P = {\widetilde{P}}=\{ \{1\},\ldots , \{d\} \}\). This means that certain summands in \(F_d(n)\) grow like \(n^{d/2}\) whereas the other ones grow slower w.r.t. n. Thus, we get that \(F_d(n) \sim c n^{d/2}\) which yields the statement.
1.4 B.4 Proof of Lemma 5
Since the transformation
is linear, we have for \(j \in \{1,\ldots ,d\}\)
where \(A_{\cdot j}\) denotes the jth column of A. Thus, for a \({\varvec{\nu }}\subset \{1,\ldots ,d\}\) we get
where the last term on the righthand side denotes the application of the multilinear form \((\nabla ^{|{\varvec{\nu }}|} \varPhi )(g_n(x)):\mathbb {R}^{d\times |{\varvec{\nu }}|} \rightarrow \mathbb {R}\) to the \(|{\varvec{\nu }}|\) arguments \(A_{\cdot \nu _j} \in \mathbb {R}^d\). To keep the notation short, we denote by \(\nabla ^{|{\varvec{\nu }}|}\varPhi (g_n(x))[A_{\varvec{\nu }}]\) the term \((\nabla ^{|{\varvec{\nu }}|} \varPhi )(g_n(x))[A_{\cdot \nu _1}, \ldots , A_{\cdot \nu _{|{\varvec{\nu }}|}} ]\). By Faa di Bruno we obtain now for any \({\varvec{\nu }}\subset \{1,\ldots ,d\}\) that
which yields
where
Note, that we can bound
where we set the “norm” of the multilinear form \(\nabla ^{|B|}\varPhi (g_n(x)) :\mathbb {R}^{d \times |B|} \rightarrow \mathbb {R}\) as
Setting \(c_A :=\prod _{j=1}^d \Vert A_j\Vert \) we get \( \left| \prod _{B \in P} \nabla ^{|B|}\varPhi (g_n(x))[A_B] \right| \le c_A \prod _{B \in P} \left\| \nabla ^{|B|}\varPhi (g_n(x))\right\| \) and obtain by multiplication—omitting the integral domains for a moment—that
where we used the Cauchy–Schwarz and Jensen’s inequality in the second line. We apply Laplace’s method in order to examine the \(L^2\)-norm above:
where \(h_P = \prod _{B \in P} \left\| \left( \nabla ^{|B|}\varPhi \right) \circ g_n \right\| \). By the substitution \(y :=g_n(x) = x_\star + n^{-1/2} Ax\) we get
where \(C_{J_{Trans}}(n) = \det (n^{-1/2}A) = n^{-d/2}\det (A)\). Since also \(2\varPhi \) satisfies the assumptions of Theorem 1 and \(\varPhi (x_\star )=0\) we obtain
However, since \(\nabla \varPhi (x_\star ) = 0\) there holds \(h_P^2(x_\star )=0\) if there exists a single block \(|B|=1\) in P which then yields to a decay of the \(L^2\)-norm as least as fast as \(n^{-1}\). In particular, denoting by \(|P|_1\) the number of single blocks in P we obtain by the same reasoning as in Sect. 1 that
where \(c_P = c_{|P|_1}(h^2_P)\) as in (23). Hence,
Similarly to Sect. 1 we can derive \(\max _{P \in \varPi ({\varvec{\nu }})} |P|- |P|_1/2 = |{\varvec{\nu }}|/2\) which yields that \( F_{\varvec{\nu }}(n) \in \mathcal O(1)\) as \(n\rightarrow \infty \) and concludes the proof.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schillings, C., Sprungk, B. & Wacker, P. On the convergence of the Laplace approximation and noise-level-robustness of Laplace-based Monte Carlo methods for Bayesian inverse problems. Numer. Math. 145, 915–971 (2020). https://doi.org/10.1007/s00211-020-01131-1
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-020-01131-1