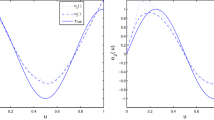
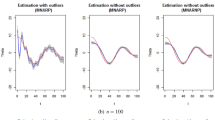
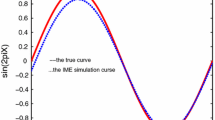
Appendix
1.1 Proofs of Theorem 2.1
For the proofs of the theorem 2.1, we use the fact that \(\rho \) is a strictly convex function and continuously differentiable w.r.t. the second component, then \(\psi \) is strictly monotone and continuous w.r.t. the second component. We give the proofs for the case of an increasing \(\psi (Y-.)\), decreasing case being obtained by considering \(-\psi (Y-.)\). Therefore, we can write, under this consideration, for all \(\kappa > 0\)
$$\begin{aligned} \Psi \left( x,\theta _{x}-\kappa \right) \le \Psi \left( x,\theta _{x}\right) =0\le \Psi \left( x,\theta _{x}+\kappa \right) , \end{aligned}$$
and
$$\begin{aligned} \widehat{\Psi }\left( x,\widehat{\theta }_{x}-\kappa \right) \le \widehat{\Psi }\left( x,\widehat{\theta }_{x}\right) =0\le \widehat{\Psi }\left( x,\widehat{\theta }_{x}+\kappa \right) . \end{aligned}$$
Hence, for all \(\kappa > 0\), we have
$$\begin{aligned} \mathbb {P}\left( \left| \widehat{\theta }_{x}-\theta _{x}\right| \ge \kappa \right)\le & {} \mathbb {P}\left( \left| \widehat{\Psi }\left( x,\theta _{x}+\kappa \right) -\Psi \left( x,\theta _{x}+\kappa \right) \right| \ge \Psi \left( x,\theta _{x}+\kappa \right) \right) \\{} & {} +\mathbb {P}\left( \left| \widehat{\Psi }\left( x,\theta _{x}-\kappa \right) -\Psi \left( x,\theta _{x}-\kappa \right) \right| \ge -\Psi \left( x,\theta _{x}-\kappa \right) \right) . \end{aligned}$$
So, it suffices to show that
$$\begin{aligned} \widehat{\Psi }(x,t)-\Psi (x,t)\rightarrow 0\quad \text {a.co. for}\quad t:=\theta _{x}\pm \kappa . \end{aligned}$$
(19)
Moreover, under ((H4) (i)), we get that
$$\begin{aligned} \widehat{\theta }_{x}-\theta _{x}=\frac{\Psi \left( x,\widehat{\theta _{x}}\right) -\widehat{\Psi }\left( x,\widehat{\theta }_{x}\right) }{\Psi ^{\prime }\left( x,\xi _{n}\right) }, \end{aligned}$$
where \(\xi _n\) is between \(\widehat{\theta }_{x}\) and \(\theta _{x}\). As long as we could be able to check that
$$\begin{aligned} \exists \tau >0,\quad \sum _{n=1}^{\infty }\mathbb {P}\left( \Psi ^{\prime }\left( x,\xi _{n}\right)<\tau \right) <\infty , \end{aligned}$$
(20)
we would have
$$\begin{aligned} \left| \widehat{\theta _{x}}-\theta _{x}\right| = O_{a.co.}\left( \sup _{t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] }\left| \Psi (x,t)-\widehat{\Psi }(x,t)\right| \right) . \end{aligned}$$
Therefore, all that is left to do is to study the convergence rate of
$$\begin{aligned} \sup _{t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] }\left| \Psi (x,t)-\widehat{\Psi }(x,t)\right| . \end{aligned}$$
To do that, we consider the following decomposition
$$\begin{aligned} \widehat{\Psi }(x,t)-\Psi (x,t)= & {} \frac{1}{\widehat{\Psi }_{D}(x)}\left\{ \left( \widehat{\Psi }_{N}(x,t)-\mathbb {E}\left[ \widehat{\Psi }_{N}(x,t)\right] \right) \right. \nonumber \\{} & {} -\left. \left( \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \Psi (x,t)-\mathbb {E}\left[ \widehat{\Psi }_{N}(x,t)\right] \right) \right\} \nonumber \\{} & {} +\frac{\Psi (x,t)}{\widehat{\Psi }_{D}(x)}\left( \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] -\widehat{\Psi }_{D}(x)\right) . \end{aligned}$$
(21)
Therefore, Theorem 2.1’s result is a consequence of the following intermediate results, where their proofs are postponed to the appendix.
Lemma 4.1
Under hypotheses (H1)–(H4 iv), we obtain
$$\begin{aligned} |\widehat{\Psi }_{D}(x)-\mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] |=O_{a.co.}\left( \sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) , \end{aligned}$$
(22)
and
$$\begin{aligned} \lim _{n\rightarrow \infty }\widehat{\Psi }_{D}(x)=\lim _{n\rightarrow \infty }\mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] =p(x),\quad a.co. \end{aligned}$$
(23)
Corollary 4.1
Under hypotheses of Lemma 4.1, we obtain:
$$\begin{aligned} \text {there exists}\,\eta > 0,\quad \text {such that}\,\sum _{n=1}^{\infty }\mathbb {P}\left( \left| \widehat{\Psi }_{D}(x)\right|<\eta \right) <\infty . \end{aligned}$$
(24)
Lemma 4.2
Under hypotheses (H3) and (H4), we have
$$\begin{aligned} \sup _{t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] }\left| \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \Psi (x,t)-\mathbb {E}\left[ \widehat{\Psi }_N(x,t)\right] \right| =O\left( h^{b}\right) . \end{aligned}$$
(25)
Lemma 4.3
Under hypotheses (H1)–(H5), we have
$$\begin{aligned} \sup _{t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] }\left| \widehat{\Psi }_N(x,t)-\mathbb {E}\left[ \widehat{\Psi }_N(x,t)\right] \right| =O_{a.co.}\left( \sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) . \end{aligned}$$
(26)
Lemma 4.4
Under the hypotheses of Theorem 2.1, \(\widehat{\theta }_x\) exists and is unique a.co. for all sufficiently large n and there exists \(\tau >0\) such that
$$\begin{aligned} \sum _{n\ge 1}\mathbb {P}\left\{ \Psi ^{\prime }\left( x,\xi _{n}\right)<\tau \right\} <\infty . \end{aligned}$$
1.2 Proofs of Proposition 2.1
Similarly to (21), we have
$$\begin{aligned} \widehat{F}(y|X=x)-F(y|X=x)= & {} \frac{1}{\widehat{\Psi }_{D}(x)}\left\{ \left( \widehat{R}_{N}(x,y)-\mathbb {E}\left[ \widehat{R}_{N}(x,y)\right] \right) \right. \\{} & {} -\left. \left( \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] F(y|X=x)-\mathbb {E}\left[ \widehat{R}_{N}(x,y)\right] \right) \right\} \\{} & {} +\frac{F(y|X=x)}{\widehat{\Psi }_{D}(x)}\left( \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] -\widehat{\Psi }_{D}(x)\right) . \end{aligned}$$
Then, Proposition 2.1 can be deduced from the following intermediate results, together with Lemma 4.1 and Corollary 4.1.
Lemma 4.5
Under hypotheses (E3) and (E4), we have
$$\begin{aligned} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\left| \mathbb {E} \left[ \widehat{\Psi }_{D}(x)\right] F(y|X=x)-\mathbb {E}\left[ \widehat{R}_N(x,y)\right] \right| =O\left( h^{b_1}\right) . \end{aligned}$$
(27)
Lemma 4.6
Under hypotheses (E1)–(E4), we have
$$\begin{aligned} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\left| \widehat{R}_N(x,y)-\mathbb {E} \left[ \widehat{R}_N(x,y)\right] \right| =O_{a.co.}\left( \sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) . \end{aligned}$$
(28)
1.3 Proofs of Theorem 2.2
Assumption (E5 (i)) leads to
$$\begin{aligned} \widehat{\vartheta }_{x}-\vartheta _{x}=\frac{\Gamma \left( x,\widehat{\vartheta _{x}},\widehat{s}(x)\right) -\widehat{\Gamma }\left( x,\widehat{\vartheta }_{x},\widehat{s}(x)\right) }{\Gamma ^{\prime }\left( x,\xi _{n},\widehat{s}(x)\right) }, \end{aligned}$$
where \(\xi _n\) is between \(\widehat{\vartheta }_{x}\) and \(\vartheta _{x}\). Assumption (E5 (i)) and Lemma 2.1 imply that
$$\begin{aligned} \exists \tau >0,\quad \sum _{n=1}^{\infty }\mathbb {P}\left( \Gamma ^{\prime }\left( x,\xi _{n},\widehat{s}(x)\right)<\tau \right) <\infty , \end{aligned}$$
(29)
we would have
$$\begin{aligned} \left| \widehat{\vartheta _{x}}-\vartheta _{x}\right| = O_{a.co.}\left( \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] } \sup _{A\le \sigma \le B} \left| \Gamma (x,y,\sigma )-\widehat{\Gamma }(x,y,\sigma )\right| \right) . \end{aligned}$$
This result is based on the same kind of decomposition as (21). Indeed, we can write:
$$\begin{aligned} \widehat{\Gamma }(x,y,\sigma )-\Gamma (x,y,\sigma )= & {} \frac{1}{\widehat{\Psi }_{D}(x)}\left\{ \left( \widehat{\Gamma }_{N}(x,y,\sigma ) -\mathbb {E}\left[ \widehat{\Gamma }_{N}(x,y,\sigma )\right] \right) \right. \nonumber \\{} & {} -\left. \left( \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \Gamma (x,y,\sigma )-\mathbb {E}\left[ \widehat{\Gamma }_{N}(x,y,\sigma )\right] \right) \right\} \nonumber \\{} & {} +\frac{\Gamma (x,y,\sigma )}{\widehat{\Psi }_{D}(x)}\left( \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] -\widehat{\Psi }_{D}(x)\right) . \end{aligned}$$
(30)
Finally, the proof of Theorem 2.2 is achieved via the following lemmas, together with Lemma 4.1 and Corollary 4.1.
Lemma 4.7
Under hypotheses (E3) and (E5), we have
$$\begin{aligned} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{A\le \sigma \le B} \left| \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \Gamma (x,y,\sigma )-\mathbb {E}\left[ \widehat{\Gamma }_N(x,y,\sigma )\right] \right| =O\left( h^{b_1}\right) .\nonumber \\ \end{aligned}$$
(31)
Lemma 4.8
Under hypotheses (E1)–(E3) and (E5)–(E6), we have
$$\begin{aligned} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{A\le \sigma \le B} \left| \widehat{\Gamma }_N(x,y,\sigma )-\mathbb {E}\left[ \widehat{\Gamma }_N(x,y,\sigma )\right] \right| =O_{a.co.}\left( \sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) .\nonumber \\ \end{aligned}$$
(32)
Lemma 4.9
Under the hypotheses of Theorem 2.2, \(\widehat{\vartheta }_x\) exists and is unique a.co. for all sufficiently large n.
1.4 Proofs of Lemmas
Proof of Lemma 4.1
First, we have:
$$\begin{aligned} \widehat{\Psi }_{D}(x)-\mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] =\frac{1}{n}\sum _{i=1}^{n} \left( \frac{\delta _iK_{i}(x)}{\mathbb {E}(K_{1}(x))}- \frac{\mathbb {E}(\delta _iK_{i}(x))}{\mathbb {E}(K_{1}(x))}\right) =\frac{1}{n}\sum _{i=1}^{n}\left( \tilde{\Delta }_{i}-\mathbb {E}(\tilde{\Delta }_{i})\right) , \end{aligned}$$
where \(\tilde{\Delta }_{i}=\displaystyle \frac{\delta _iK_{i}(x)}{\mathbb {E}(K_{1}(x))}\). Because of (H1) and (H3), we can write
$$\begin{aligned} C\varphi _{x}\left( h\right)<\mathbb {E}(K_{1}(x))<C^{\prime }\varphi _{x}\left( h\right) . \end{aligned}$$
So, we can get directly that
$$\begin{aligned} \left| \tilde{\Delta }_{i}\right|<C/\varphi _{x}\left( h\right) \quad \text { and }\quad \mathbb {E}\left| \tilde{\Delta }_{i}\right| ^{2}<C^{\prime }/\varphi _{x}\left( h\right) . \end{aligned}$$
Thus, the use of the classical Bernstein’s inequality allows us to write for all \(\eta >0\):
$$\begin{aligned} \mathbb {P}\left( \left| \widehat{\Psi }_{D}(x)-\mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \right| >\eta \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \le C^{\prime }n^{-C\eta ^{2}}. \end{aligned}$$
For the proof of (23), we only need to establish
$$\begin{aligned} \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \rightarrow p(x),\quad a.co. \text { as } n\rightarrow \infty . \end{aligned}$$
(33)
By the properties of conditional expectation and the mechanism of MAR and (H4 iv), it follows that
$$\begin{aligned} \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right]= & {} \frac{1}{nE\left( K_{1}(x)\right) }\sum _{i=1}^{n}\mathbb {E}\left( \delta _{i}K_{i}(x)\right) =\frac{1}{nE\left( K_{1}(x)\right) }\sum _{i=1}^{n}\mathbb {E}\left( \mathbb {E}\left[ \delta _{i}|X_i\right] K_{i}(x)\right) \\= & {} \frac{1}{nE\left( K_{1}(x)\right) }[p(x)+o(1)]\sum _{i=1}^{n}\mathbb {E}\left( K_{i}(x)\right) \rightarrow p(x), ~~a.co. \text { as } n\rightarrow \infty . \end{aligned}$$
Therefore, (23) follows from (22) and (33). \(\square \)
Proof of Corollary 4.1
It is easy to remark that: \(\displaystyle \left| \widehat{\Psi }_{D}(x)\right| \le \frac{p(x)}{2}\) implies that \(\displaystyle p(x)-\widehat{\Psi }_{D}(x) \ge \frac{p(x)}{2}\), which implies that
$$\begin{aligned} \displaystyle \left| \widehat{\Psi }_{D}(x)-p(x)\right| \ge \frac{p(x)}{2}. \end{aligned}$$
We deduce, from Lemma 4.1, that
$$\begin{aligned} \mathbb {P}\left( \left| \widehat{\Psi }_{D}(x)\right| \le \frac{p(x)}{2}\right) \le \mathbb {P}\left( \left| \widehat{\Psi }_{D}(x)-p(x)\right| >\frac{p(x)}{2}\right) . \end{aligned}$$
Consequently
$$\begin{aligned} \sum _{n=1}^{\infty }\mathbb {P}\left( \left| \widehat{\Psi }_{D}(x)\right|<\frac{p(x)}{2}\right) <\infty . \end{aligned}$$
\(\square \)
Proof of Lemma 4.2
Since \((X_1,Y_1,\delta _1),\ldots ,(X_n,Y_n,\delta _n)\) are independents identically distributed, we have:
$$\begin{aligned}{} & {} \forall t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] \left| \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \Psi (x,t)-\mathbb {E}\left[ \widehat{\Psi }_N(x,t)\right] \right| \\{} & {} \quad = \frac{\left| \mathbb {E}\left[ \delta _1K_1(x)\psi (Y_1-t)-\delta _1K_1(x)\Psi (x,t)\right] \right| }{\mathbb {E}(K_1(x))} \\{} & {} \quad = \frac{\left| \mathbb {E}\left( \mathbbm {1}_{B(x,h)}(X_1)K_1(x)p(X_1)\left[ \mathbb {E}(\psi (Y_1-t)|X=X_1)-\Psi (x,t)\right] \right) \right| }{\mathbb {E}(K_1(x))}\\{} & {} \quad = \frac{\left| \mathbb {E}\left( \mathbbm {1}_{B(x,h)}(X_1)K_1(x)p(X_1)\left[ \Psi (X_1,t)-\Psi (x,t)\right] \right) \right| }{\mathbb {E}(K_1(x))}. \end{aligned}$$
Then, by the Hölder hypothesis (H4 (ii)), (H3) and the continuity of p(x), we get that:
$$\begin{aligned}{} & {} \forall t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] \left| \mathbb {E}\left[ \widehat{\Psi }_{D}(x)\right] \Psi (x,t)-\mathbb {E}\left[ \widehat{\Psi }_N(x,t)\right] \right| \\{} & {} \quad \le Ch^b[p(x)+o(1)]\frac{\left| \mathbb {E}\left( K_1(x)\right) \right| }{\mathbb {E}(K_1(x))}=O(h^b). \end{aligned}$$
\(\square \)
Proof of Lemma 4.3
Using the compactness of \(\left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] \), we can write that \(\left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] \subset \bigcup _{k=1}^{s_{n}}S_{k}\) where \(S_{k}=\left( y_{k}-l_{n},y_{k}+l_{n}\right) \).
We consider the intervals extremities gride
$$\begin{aligned} \mathcal {H}_n=\left\{ y_{j}-l_{n},y_{j}+l_{n},1\le j \le s_n\right\} . \end{aligned}$$
Then the monotony of \(\mathbb {E}\left[ \widehat{\Psi }_N(x,t)\right] \) and \(\widehat{\Psi }_N(x,t)\) gives, for \(1 \le j \le s_n\)
$$\begin{aligned} \mathbb {E}\left[ \widehat{\Psi }_{N}\left( x,y_{j}-l_{n}\right) \right]\le & {} \sup _{t\in \left( y_{j}-l_{n},y_{j}+l_{n}\right) }\mathbb {E}\left[ \widehat{\Psi }_{N}(x,t)\right] \le \mathbb {E}\left[ \widehat{\Psi }_{N}\left( x,y_{j}+l_{n}\right) \right] \nonumber \\ \widehat{\Psi }_{N}\left( x,y_{j}-l_{n}\right)\le & {} \sup _{t\in \left( y_{j}-l_{n},y_{j}+l_{n}\right) }\widehat{\Psi }_{N}(x,t)\le \widehat{\Psi }_{N}\left( x,y_{j}+l_{n}\right) . \end{aligned}$$
(34)
Now, from (H4 (ii)) we have, for any \(t_1,t_2\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] \)
$$\begin{aligned} \left| \mathbb {E}\left[ \widehat{\Psi }_{N}\left( x,t_1\right) \right] -\mathbb {E}\left[ \widehat{\Psi }_{N}\left( x,t_2\right) \right] \right| \le C\left| t_1-t_2\right| ^{b'}. \end{aligned}$$
(35)
So, we deduce from (34) and (35) that
$$\begin{aligned}{} & {} \sup _{t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] }\left| \mathbb {E}\left[ \widehat{\Psi }_{N}\left( x,t\right) \right] -\widehat{\Psi }_{N}\left( x,t\right) \right| \nonumber \\{} & {} \qquad \le \max _{1\le j\le s_{n}}\max _{z\in \left\{ y_{j}-l_{n},y_{j}+l_{n}\right\} }\left| \widehat{\Psi }_{N}(x,z)-\mathbb {E}\left[ \widehat{\Psi }_{N}(x,z)\right] \right| +2Cl_{n}^{b'}. \end{aligned}$$
(36)
Take now \(l_n=n^{-\alpha /b'}\) for some \(\alpha >b'/2\), and note that because of \(\lim _{n\rightarrow \infty }l_n=0\) and (H2), we have
$$\begin{aligned} \sup _{t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] }\left| \mathbb {E}\left[ \widehat{\Psi }_{N}\left( x,t\right) \right] -\widehat{\Psi }_{N}\left( x,t\right) \right|\le & {} \max _{z\in \mathcal {H}_n}\left| \widehat{\Psi }_{N}(x,z)-\mathbb {E}\left[ \widehat{\Psi }_{N}(x,z)\right] \right| \nonumber \\{} & {} +O\left( \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) . \end{aligned}$$
(37)
The proof of this part is based on the exponential inequality given in Corollary A.8.ii in Ferraty and Vieu (2006), with
$$\begin{aligned} \displaystyle Z_{i}=\frac{1}{\mathbb {E}(K_1(x))}\left[ \delta _iK_i(x)\psi \left( Y_i-z\right) - \mathbb {E}\left( \delta _iK_i(x)\psi \left( Y_i-z\right) \right) \right] . \end{aligned}$$
To do that, we have to show that:
$$\begin{aligned} \exists C>0, \forall m\ge 2,\quad \mathbb {E}(|Z^m_{1}|)=C\varphi ^{-m+1}_x(h). \end{aligned}$$
(38)
First, we prove for \(m\ge 2\) that:
$$\begin{aligned} \frac{1}{\mathbb {E}^m(K_1(x))}\mathbb {E}\left[ \left| \delta _1K_1(x)\psi \left( Y_1-z\right) \right| ^m\right] = O(\varphi ^{-m+1}_x(h)). \end{aligned}$$
(39)
Then, using (H3) and (H5) we write:
$$\begin{aligned} \mathbb {E}\left[ \left| \delta _1K^m_1(x)\psi \left( Y_1-z\right) ^m\right| \right]\le & {} \mathbb {E}\left[ \mathbb {E}\left( \left| \psi \left( Y_1-z\right) \right| ^m|X_1\right) K^m_1(x)\right] \\\le & {} C\mathbb {E}(K^m_1(x))\\\le & {} C\varphi _x(h). \end{aligned}$$
Which implies that
$$\begin{aligned} \frac{1}{\mathbb {E}^m(K_1(x))}\mathbb {E}\left[ \left| \delta _1\psi \left( Y_1-z\right) ^mK^m_1(x)\right| \right] = O(\varphi ^{-m+1}_x(h)), \end{aligned}$$
and
$$\begin{aligned} \frac{1}{\mathbb {E}(K_1(x))}\mathbb {E}\left[ \left| \delta _1\psi \left( Y_1-z\right) K_1(x)\right| \right] \le C. \end{aligned}$$
Next, by the Newton’s binomial expansion we obtain:
$$\begin{aligned} \mathbb {E}(|Z^m_{1}|)\le & {} C\sum ^m_{k=0} \frac{\mathbb {E}\left[ \left| \delta _1\psi \left( Y_1-z\right) ^kK^k_1(x)\right| \right] }{\mathbb {E}^k(K_1(x))} \left[ \frac{\mathbb {E}\left[ \left| \delta _1\psi \left( Y_1-z\right) K_1(x)\right| \right] }{\mathbb {E}(K_1(x))}\right] ^{m-k} \\\le & {} C\max _{k=0,\ldots ,m} \varphi ^{-k+1}_x(h)\\\le & {} C\varphi ^{-m+1}_x(h). \end{aligned}$$
It follows that:
$$\begin{aligned} \mathbb {E}(|Z^m_{1}|)=O(\varphi ^{-m+1}_x(h)). \end{aligned}$$
(40)
Now apply the exponential inequality given by Corollary A.8.ii in Ferraty and Vieu (2006) for \(Z_i\). Since \(\mathbb {E}[|Z_{i}|^m] = O(\varphi _x(h)^{-m+1})\), then, we can take \(a^2=\frac{1}{\varphi _x(h)}\). Hence, for all \(\eta _0> 0\):
$$\begin{aligned} \mathbb {P}\left( \left| \widehat{\Psi }_N(x,z)-\mathbb {E}\left( \widehat{\Psi }_N(x,z)\right) \right|>\eta \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right)= & {} \mathbb {P}\left( \frac{1}{n}\left| \sum ^n_{i=1}Z_{i}\right| >\eta \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \\\le & {} 2\exp \left( -C\eta ^2\log n\right) . \end{aligned}$$
Then, we have for any \(\eta > 0\)
$$\begin{aligned}{} & {} \mathbb {P}\left( \max _{z\in \mathcal {H}_n}\left| \widehat{\Psi }_N(x,z)-\mathbb {E}\left( \widehat{\Psi }_N(x,z)\right) \right|>\eta \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \\{} & {} \qquad \le s_n\max _{z\in \mathcal {H}_n}\mathbb {P}\left( \left| \widehat{\Psi }_N(x,z)-\mathbb {E}\left( \widehat{\Psi }_N(x,z)\right) \right| >\eta \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \\{} & {} \qquad \le Cs_n n^{-C\eta ^2}\\{} & {} \qquad \le \frac{C}{l_n}n^{-C\eta ^2}. \end{aligned}$$
Thus, by choosing \(\eta \) such that \(C\eta ^2=1/2+2\alpha /b'\), we obtain
$$\begin{aligned} s_n\max _{z\in \mathcal {H}_n} \mathbb {P}\left( \left| \widehat{\Psi }_N(x,z)-\mathbb {E}\left( \widehat{\Psi }_N(x,z)\right) \right| > \eta \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \le n^{-1/2-2\alpha /b'}. \end{aligned}$$
Now, we can conclude
$$\begin{aligned} \sup _{t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] }\left| \widehat{\Psi }_N(x,t)-\mathbb {E}\left( \widehat{\Psi }_N(x,t)\right) \right| =O_{a.co.}\left( \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) . \end{aligned}$$
(41)
\(\square \)
Proof of Lemma 4.4
We give the proof for the case of an increasing \(\psi (Y-.)\), decreasing case being obtained by considering \(-\psi (Y-.)\). Therefore we can Therefore write, under this consideration, for all \(\kappa > 0\)
$$\begin{aligned} \Psi \left( x,\theta _{x}-\kappa \right) \le \Psi \left( x,\theta _{x}\right) =0\le \Psi \left( x,\theta _{x}+\kappa \right) \end{aligned}$$
The results of Lemmas 4.1, 4.2, 4.3 and 4.1 show that
$$\begin{aligned} \widehat{\Psi }(x,t)\rightarrow \Psi (x,t),\quad \text {a.co. as } \; n\rightarrow \infty . \end{aligned}$$
For all real fixed \(t\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] \). So, for sufficiently large n.
$$\begin{aligned} \widehat{\Psi }\left( x,\widehat{\theta }_{x}-\kappa \right) \le 0\le \widehat{\Psi }\left( x,\widehat{\theta }_{x}+\kappa \right) \quad \text { a.co. }. \end{aligned}$$
Since \(\psi \) is a continuous function, then as \(\widehat{\Psi }(x,t)\) is a continuous function of t, there exists a \(\widehat{\theta }_{x}\in \left[ \theta _{x}-\kappa ,\theta _{x}+\kappa \right] \) such that \(\widehat{\Psi }(x,\widehat{\theta }_{x})=0\).
Finally, the uniqueness (in a.co.) of \(\widehat{\theta }_{x}\) is a direct consequence of the strict monotonicity of \(\psi \), while the second part is a direct consequence of the regularity assumption (H4 (i)). \(\square \)
Proof of Lemma 4.5
The same idea in the proof of Lemma 4.2\(\square \)
Proof of Lemma 4.6
As in Lemma 3 of Attouch et al. (2013) using the compactness of \(\left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] \), we can write
$$\begin{aligned} \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] \subset \bigcup _{j=1}^{d_{n}}\left( y_{j}-l_{n},y_{j}+l_{n}\right) . \end{aligned}$$
We consider the intervals extremities gride
$$\begin{aligned} \mathcal {G}_n=\left\{ y_{j}-l_{n},y_{j}+l_{n},1\le j \le d_n\right\} . \end{aligned}$$
Then the monotony of \(\mathbb {E}\left[ \widehat{R}_N(x,y)\right] \) and \(\widehat{R}_N(x,y)\) gives, for \(1 \le j \le d_n\)
$$\begin{aligned} \mathbb {E}\left[ \widehat{R}_{N}\left( x,y_{j}-l_{n}\right) \right]\le & {} \sup _{y\in \left( y_{j}-l_{n},y_{j}+l_{n}\right) }\mathbb {E}\left[ \widehat{R}_{N}(x,y)\right] \le \mathbb {E}\left[ \widehat{R}_{N}\left( x,y_{j}+l_{n}\right) \right] \nonumber \\ \widehat{R}_{N}\left( x,y_{j}-l_{n}\right)\le & {} \sup _{y\in \left( y_{j}-l_{n},y_{j}+l_{n}\right) }\widehat{R}_{N}(x,y)\le \widehat{R}_{N}\left( x,y_{j}+l_{n}\right) . \end{aligned}$$
(42)
Now, from (E4 (iv)) we have, for any \(y_1,y_2\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] \)
$$\begin{aligned} \left| \mathbb {E}\left[ \widehat{R}_{N}\left( x,y_1\right) \right] -\mathbb {E}\left[ \widehat{R}_{N}\left( x,y_2\right) \right] \right| \le C\left| y_1-y_2\right| ^{b_2}. \end{aligned}$$
(43)
So, we deduce from (42) and (43) that
$$\begin{aligned}{} & {} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\left| \mathbb {E}\left[ \widehat{R}_{N}\left( x,y\right) \right] -\widehat{R}_{N}\left( x,y\right) \right| \nonumber \\{} & {} \qquad \le \max _{1\le j\le d_{n}}\max _{z\in \left\{ y_{j}-l_{n},y_{j}+l_{n}\right\} }\left| \widehat{R}_{N}(x,z)-\mathbb {E}\left[ \widehat{R}_{N}(x,z)\right] \right| +2Cl_{n}^{b_2}\end{aligned}$$
(44)
$$\begin{aligned}{} & {} \qquad \le \max _{z\in \mathcal {G}_n}\left| \widehat{R}_{N}(x,z)-\mathbb {E}\left[ \widehat{R}_{N}(x,z)\right] \right| +O\left( \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) . \end{aligned}$$
(45)
Let \(\Lambda _i=(\delta _{i}K_i(x)\mathbbm {1}_{(-\infty ;z]}(Y_{i})-\mathbb {E}[\delta _{i}K_i(x)\mathbbm {1}_{(-\infty ;z]}(Y_{i})])/\mathbb {E}(K_1(x))\). By using similar arguments for the proof of Lemma 4.1, we deduce that \(\mathbb {E}|\Lambda _i|\le C/\varphi _x(h)\) and \(\mathbb {E}(\Lambda _i^2)\le C^{\prime }/\varphi _x(h)\). By applying again the Bernstein’s exponential inequality, we get
$$\begin{aligned} \max _{z\in \mathcal {G}_n}\left| \mathbb {E}\left[ \widehat{R}_{N}\left( x,z\right) \right] -\widehat{R}_{N}\left( x,z\right) \right| =O_{a.co.}\left( \sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) . \end{aligned}$$
(46)
which concluded the proof. \(\square \)
Proof of Lemma 2.1
The proof of this lemma is analogous to Lemma A.4 of Boente and Vahnovan (2015).
By Proposition 2.1 and Assumption (E2) we can check that:
$$\begin{aligned} \sup _{y\in [\vartheta _x-\kappa , \vartheta _x+\kappa ]}\left| \widehat{F}(y|X=x)-F(y|X=x)\right| \rightarrow 0. \end{aligned}$$
(47)
Otherwise by (E4) for a fixed \(x\in \mathcal {F}\) there exist a, b such that \(F(b|X=x)>\frac{7}{8}\) and \(F(a|X=x)<\frac{1}{8}\). Let \(m_n(x)\) be the median of \(\widehat{F}(y|X=x)\). Then, (47) implies that there exists \(n_0\in \mathbb {N}\) such that \(\widehat{F}(a|X=x)<\frac{1}{4}\) and \(\widehat{F}(b|X=x)>\frac{3}{4}\) for all \(n \ge n_0\). Hence, we have that \(a< m_n(x) < b\). It is easy to see that for a good choice of a, b and n also, implies that \(\widehat{s}(x)<b-a\) for all \(n \ge n_0\).
For the lower bound, using that \(F(y|X = x)\) is a continuous distribution function in \(x\in \mathcal {F}\), there exist a(x) and b(x) such that
$$\begin{aligned} F\left( a(x)|X=x\right) =\frac{1}{3},\quad F\left( b(x)|X=x\right) =\frac{7}{10}. \end{aligned}$$
Let \(a(x)=a\) and \(b(x)=b\). Assumption (E4 (i)) entails that for any \(\varepsilon < \frac{1}{30}\) there exists \(\eta >0\), such that
$$\begin{aligned} \frac{1}{3}-\varepsilon<F\left( a-\eta |X=x\right)<\frac{1}{3}+\varepsilon ,\quad \frac{7}{10}-\varepsilon<F\left( b+\eta |X=x\right) <\frac{7}{10}+\varepsilon . \end{aligned}$$
Finally, (47) implies that for all \(n \ge n_0\) we have that \(\widehat{F}(a|X=x)<\frac{1}{2}\), \(\widehat{F}(b|X=x)>\frac{1}{2}\), \(\widehat{F}(a-\eta |X=x)>\frac{1}{4}\) and \(\widehat{F}(b+\eta |X=x)<\frac{3}{4}\). Hence, \(a<m_n(x)<b\), and \(\widehat{s}(x)>\eta \) for all \(n \ge n_0\). \(\square \)
Proof
The proof is analogous to the proof of Lemma 4.2. \(\square \)
Proof of Lemma 4.8
\(\forall y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] , \forall A\le \sigma \le B\) consider a finite covering of \(\left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] \), we have \(\displaystyle \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] \subset \bigcup \nolimits _{k=1}^{d_{n}}\left( y_{k}-l_{n},y_{k}+l_{n}\right) \). Taking \(k_y=\arg \min _{t\in \{y_{1},\ldots ,y_{d_{n}}\}}|y-t|\). On the other hand, by the same way covering \(\displaystyle [A,B]\subset \bigcup \nolimits _{k=1}^{s_{n}}\left( \sigma _{k}-\nu _{n},\sigma _{k}+\nu _{n}\right) \) and taking \(k_{\sigma }=\arg \min _{s\in \{\sigma _{1},\ldots ,\sigma _{s_{n}}\}}|\sigma -s|\).
With same manner in proof of Lemma 4.3, by taking \(\displaystyle l_n=\nu _n=n^{-\alpha }\) for some \(\alpha >1/2\), we have
$$\begin{aligned} l_n=\nu _{n}=o\left( \sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) . \end{aligned}$$
(48)
Note that,
$$\begin{aligned}{} & {} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]}\left| \widehat{\Gamma }_N(x,y,\sigma )-\mathbb {E}\left( \widehat{\Gamma }_N(x,y,\sigma )\right) \right| \\{} & {} \quad \le \underbrace{\sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \widehat{\Gamma }_N(x,y,\sigma )-\widehat{\Gamma }_N(x,k_y,\sigma )\right| }_{F_{1}} \\{} & {} \qquad + \underbrace{\sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \widehat{\Gamma }_N(x,k_y,\sigma )-\widehat{\Gamma }_N(x,k_y,k_{\sigma })\right| }_{F_{2}} \\{} & {} \qquad + \underbrace{\sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \widehat{\Gamma }_N(x,k_y,k_{\sigma })-\mathbb {E}\left( \widehat{\Gamma }_N(x,k_y,k_{\sigma })\right) \right| }_{F_{3}} \\{} & {} \qquad + \underbrace{\sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \mathbb {E}\left( \widehat{\Gamma }_N(x,k_y,k_{\sigma })\right) -\mathbb {E}\left( \widehat{\Gamma }_N(x,k_y,\sigma )\right) \right| }_{F_{4}} \\{} & {} \qquad + \underbrace{\sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \mathbb {E}\left( \widehat{\Gamma }_N(x,k_y,\sigma )\right) -\mathbb {E}\left( \widehat{\Gamma }_N(x,y,\sigma )\right) \right| }_{F_{5}}. \end{aligned}$$
\(\bullet \) Concerning \(F_1\) and \(F_5\), follow the same steps of \(T_1\) and \(T_3\) in Lemma 4.3 by conditions (E3) and (E6), we obtain
$$\begin{aligned}{} & {} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \widehat{\Gamma }_N(x,y,\sigma )-\widehat{\Gamma }_N(x,k_y,\sigma )\right| \\{} & {} \quad \le \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]}\frac{1}{n\mathbb {E}(K_{1}(x))}\sum _{i=1}^{n}\left| \psi \left( \frac{Y_{i}-y}{\sigma }\right) -\psi \left( \frac{Y_{i}-k_y}{\sigma }\right) \right| \delta _{i}K_{i}(x) \\{} & {} \quad \le \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\frac{\Vert \psi ^{\prime }\Vert _{\infty }}{A}\left| y-k_y\right| \left( \frac{1}{n\mathbb {E}(K_{1}(x))}\sum _{i=1}^{n}\delta _{i}K_{i}(x)\right) \\{} & {} \quad \le Cl_{n}. \end{aligned}$$
Now, for n large enough, we can write
$$\begin{aligned}{} & {} \mathbb {P}\left( \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \widehat{\Gamma }_N(x,y,\sigma )-\widehat{\Gamma }_N(x,k_y,\sigma )\right| >\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \nonumber \\{} & {} \quad =0, \end{aligned}$$
(49)
and
$$\begin{aligned}{} & {} \mathbb {P}\left( \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \mathbb {E}\left( \widehat{\Gamma }_N(x,k_y,\sigma )\right) -\mathbb {E}\left( \widehat{\Gamma }_N(x,y,\sigma )\right) \right| >\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \nonumber \\{} & {} \quad =0. \end{aligned}$$
(50)
\(\bullet \) Concerning \(F_2\) and \(F_4\), by assumptions (E3) and (E6)(using that \(\zeta (u)=u\psi ^{\prime }(u)\) is bounded), it follows
$$\begin{aligned}{} & {} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \widehat{\Gamma }_N(x,k_y,\sigma )-\widehat{\Gamma }_N(x,k_y,k_{\sigma })\right| \\{} & {} \quad \le \sup _{\sigma \in [A,B]}\frac{1}{n\mathbb {E}(K_{1}(x))}\sum _{i=1}^{n}\left| \psi \left( \frac{Y_{i}-k_y}{\sigma }\right) -\psi \left( \frac{Y_{i}-k_y}{k_{\sigma }}\right) \right| \delta _{i}K_{i}(x) \\{} & {} \quad \le \frac{\Vert \zeta \Vert _{\infty }}{A}\nu _n\left( \frac{1}{n\mathbb {E}(K_{1}(x))}\sum _{i=1}^{n}\delta _{i}K_{i}(x)\right) \\{} & {} \quad \le C\nu _{n}. \end{aligned}$$
Thus, for n large enough, we can write
$$\begin{aligned}{} & {} \mathbb {P}\left( \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \widehat{\Gamma }_N(x,k_y,\sigma )-\widehat{\Gamma }_N(x,k_y,k_{\sigma })\right| >\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \nonumber \\{} & {} \quad =0, \end{aligned}$$
(51)
and
$$\begin{aligned}{} & {} \mathbb {P}\left( \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{\sigma \in [A,B]} \left| \mathbb {E}\left( \widehat{\Gamma }_N(x,k_y,\sigma )\right) -\mathbb {E}\left( \widehat{\Gamma }_N(x,k_y,k_{\sigma })\right) \right| >\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}\left( h\right) }}\right) \nonumber \\{} & {} \quad =0. \end{aligned}$$
(52)
\(\bullet \) Concerning \(F_3\): Let
$$\begin{aligned} \displaystyle \Omega _i=\frac{1}{\mathbb {E}\left( K_{1}(x)\right) }\left[ \delta _{i}K_{i}(x)\psi \left( \frac{Y_{i}-k_{y}}{k_{\sigma }}\right) -\mathbb {E}\left( \delta _{i}K_{i}(x) \psi \left( \frac{Y_{i}-k_{y}}{k_{\sigma }} \right) \right) \right] . \end{aligned}$$
Note that K and \(\psi \) are bounded and we have \(\displaystyle \widehat{\Gamma }_{N}\left( x,k_y,k_{\sigma }\right) -\mathbb {E}\left( \widehat{\Gamma }_{N}\left( x,k_y,k_{\sigma }\right) \right) =\frac{1}{n}\sum \nolimits _{i=1}^{n}\Omega _{i}\), we deduce that \(\mathbb {E}|\Omega _i|\le C/\varphi _x(h)\) and \(\mathbb {E}(\Omega _i^2)\le C^{\prime }/\varphi _x(h)\).
We apply now again the Bernstein’s exponential inequality to get
$$\begin{aligned}{} & {} \mathbb {P}\left( F_3>\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) \\{} & {} \quad = \mathbb {P}\left( \max _{k_{y}\in \left\{ y_{1},\ldots ,y_{d_n}\right\} }\max _{k_{\sigma }\in \left\{ \sigma _{1},\ldots ,\sigma _{s_n}\right\} }\left| \widehat{\Gamma }_{N}\left( x,k_y,k_{\sigma }\right) -\mathbb {E}\left( \widehat{\Gamma }_{N}\left( x,k_y,k_{\sigma }\right) \right) \right|>\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) \\{} & {} \quad \le d_ns_n\max _{k_{y}\in \left\{ y_{1},\ldots ,y_{d_n}\right\} }\max _{k_{\sigma }\in \left\{ \sigma _{1},\ldots ,\sigma _{s_n}\right\} } \mathbb {P}\left( \frac{1}{n}\left| \sum _{i=1}^{n}\Omega _{i}\right| >\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) \\{} & {} \quad \le d_ns_n2\exp \left( -C\eta ^{2}\log n\right) . \end{aligned}$$
Because \(l_{n}=\nu _{n}=n^{-\alpha }\) for \(\alpha >1/2\), and by choosing \(\eta \) such that \(C\eta ^2=1/2+3\alpha \), we have
$$\begin{aligned}{} & {} \mathbb {P}\left( \max _{k_{y}\in \left\{ y_{1},\ldots ,y_{d_n}\right\} }\max _{k_{\sigma }\in \left\{ \sigma _{1},\ldots ,\sigma _{s_n}\right\} }\left| \widehat{\Gamma }_{N}\left( x,k_y,k_{\sigma }\right) -\mathbb {E}\left( \widehat{\Gamma }_{N}\left( x,k_y,k_{\sigma }\right) \right) \right| >\frac{\eta }{5}\sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) \nonumber \\{} & {} \quad \le Cn^{-\alpha -1/2}. \end{aligned}$$
(53)
Now, from (49)–(53), we conclude that
$$\begin{aligned}{} & {} \sup _{y\in \left[ \vartheta _{x}-\kappa ,\vartheta _{x}+\kappa \right] }\sup _{A\le \sigma \le B} \left| \widehat{\Gamma }_N(x,y,\sigma )-\mathbb {E}\left[ \widehat{\Gamma }_N(x,y,\sigma )\right] \right| \nonumber \\{} & {} \qquad =O_{a.co.}\left( \sqrt{\frac{\log n}{n\varphi _{x}(h)}}\right) . \end{aligned}$$
(54)
\(\square \)