
Abstract
This paper investigates whether and how the systematic forecast errors of the quarterly GDP announcements in China depend on the state of the economy. Our contribution is both theoretical and empirical. On the theoretical side, we extend the predictive threshold regression of Gonzalo and Pitarakis (J Bus Econ Stat 35:202–217, 2017) by incorporating a time-varying and state-dependent threshold, which is a function of macroeconomic variables that affect the separation of regimes. On the empirical side, we apply our model to assess the quality of China’s preliminary GDP data. Our empirical results show that there exist forecast biases in the preliminary GDP data conditional on the state of the economy. Our results also lean toward supporting that there exist behavioral biases of underestimation and over-reaction to new information during periods of relatively good state. These results suggest some scope to improve the accuracy of the preliminary GDP data based purely on econometric models.



Similar content being viewed by others


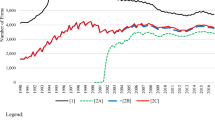
Notes
In terms of a time-varying threshold, to the best of our knowledge, only special cases have appeared in the literature so far. Dueker et al. (2013) propose a smooth transition autoregressive (STAR) model with a time-varying/state-dependent threshold and apply the model to the dynamics of US short-term interest rates. Yang and Su (2018) propose a regression kink with a time-varying threshold and apply the model to the growth-debt nexus.
In Appendix, our Monte Carlo simulations show that ignoring the time-varying nature of a threshold can lead to seriously biased estimates. Also, the power of the test for threshold effect would decrease with the inclusion of a time-varying threshold.
We thank an anonymous referee to raise this point to us.
In Appendix, a number of simulation experiments are conducted to examine the performance of the proposed bootstrap method. The simulation results show that this bootstrap procedure works well.
The sector classification is in accordance with the “Sector Classification of the National Economy”, which is available online at the NBS website (http://www.stats.gov.cn/tjsj/tjbz/hyflbz/). According to the sectoral classification system, the primary sector (i.e., agriculture) comprises farming, forestry, animal husbandry and fisheries; the secondary sector comprises industry and construction; and other subsectors compose the tertiary sector.
As noted by Cashin et al. (2017), China’s real GDP growth slowed from an average of about 10% over the period 1980–2013 to 7% between 2014 and 2016.
The optimal threshold setting is not pursued in this paper, as the relevant literature is scant and indirect. A further investigation of this issue is worthwhile.
To save space, we only report the results with the block size \(b=4\). In an unreported appendix, we show that the empirical results are robust to the choice of block size.
In an unreported appendix, we show that the empirical results are robust to the choice of block size.
We thank the anonymous referee to raise this point to us.
Due to data availability, we cannot compute the past four-quarter growth average for the period 2000Q1–2001Q4, as the preliminary GDP data over the period 1998Q1–1999Q4 are not available. Hence, the model (14) is estimated based on the sample over the period 2002Q1–2016Q4.
We thank an anonymous referee to raise this point to us.
This linear model is estimated based on the sample over the period 2002Q1–2016Q4.
References
Andrews DW, Ploberger W (1994) Optimal tests when a nuisance parameter is present only under the alternative. Econometrica 62(6):1383–1414
Cashin P, Mohaddes K, Raissi M (2017) China’s slowdown and global financial market volatility: Is world growth losing out? Emerg Mark Rev 31(63):164–175
Davies RB (1977) Hypothesis testing when a nuisance parameter is present only under the alternative. Biometrika 64(2):247–254
Davies RB (1987) Hypothesis testing when a nuisance parameter is present only under the alternative. Biometrika 74(1):33–43
Djogbenou A, Goncalves Sílvia, Perron B (2015) Bootstrap inference in regressions with estimated factors and serial correlation. J Time Ser Anal 36(3):481–502
Dueker MJ, Psaradakis Z, Sola M, Spagnolo F (2013) State-dependent threshold smooth transition autoregressive models. Oxf Bull Econ Stat 75(6):835–854
Gali J (2002) New perspectives on monetary policy, inflation, and the business cycle. NBER working paper series, No. 8767, National Bureau of Economic Research. https://www.nber.org/papers/w8767
Gonzalo J, Pitarakis JY (2017) Inferring the predictability induced by a persistent regressor in a predictive threshold model. J Bus Econ Stat 35(2):202–217
Hansen BE (1996) Inference when a nuisance parameter is not identified under the null hypothesis. Econometrica 64(2):413–430
Hansen BE (1999) Threshold effects in non-dynamic panels: estimation, testing, and inference. J Econom 93(2):345–368
Hansen BE (2000) Sample splitting and threshold estimation. Econometrica 68(3):575–603
Hansen BE (2017) Regression kink with an unknown threshold. J Bus Econ Stat 35(2):228–240
Hanson MS, Whitehorn J (2006) Reconsidering the optimality of Federal Reserve forecasts. Wesleyan University, Middletown
Holden K, Peel DA (1990) On testing for unbiasedness and efficiency of forecasts*. Manch School 58(2):120–127
Joutz F, Stekler HO (2000) An evaluation of the predictions of the Federal Reserve. Int J Forecast 16(1):17–38
Lyu C, Wang K, Zhang F, Zhang X (2018) GDP management to meet or beat growth targets. J Account Econ 66(1):318–338
Messina JD, Sinclair TM, Stekler H (2015) What can we learn from revisions to the Greenbook forecasts? J Macroecon 45:54–62
Mincer JA, Zarnowitz V (1969) The evaluation of economic forecasts. In: Economic forecasts and expectations: analysis of forecasting behavior and performance. NBER, pp 3–46
Newey WK, West KD (1994) Automatic lag selection in covariance matrix estimation. Rev Econ Stud 61(4):631–653
Nordhaus WD (1987) Forecasting efficiency: concepts and applications. Rev Econ Stat 69(3):667–674
Seo HM (2008) Unit root test in a threshold autoregression: asymptotic theory and residual-based block bootstrap. Econom Theory 24(06):1699
Shao X (2011) A bootstrap-assisted spectral test of white noise under unknown dependence. J Econom 162(2):213–224
Sinclair TM, Stekler HO (2013) Examining the quality of early GDP component estimates. Int J Forecast 29(4):736–750
Sinclair TM, Stekler HO, Carnow W (2015) Evaluating a vector of the Fed’s forecasts. Int J Forecast 31(1):157–164
Swanson NR, Van Dijk D (2006) Are statistical reporting agencies getting it right? Data rationality and business cycle asymmetry. J Bus Econ Stat 24(1):24–42
Xie Z, Hsu SH (2016) Time varying biases and the state of the economy. Int J Forecast 32(3):716–725
Yang L (2017) An assessment on the quality of China’s preliminary data of quarterly GDP announcements. Appl Econ 49(54):5558–5569
Yang L, Su JJ (2018) Debt and growth: Is there a constant tipping point? J Int Money Finance 87:133–143
Acknowledgements
The author would like to thank the editor and two anonymous referees for very valuable comments and suggestions that result in a substantial improvement in this paper. Remaining errors and omissions are my own. The author acknowledges the financial support from the National Natural Science Foundation of China (Grant No. 71803072).
Funding
This study is supported by the National Natural Science Foundation of China (Grant No. 71803072).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that he has no potential conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by the author.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Monte Carlo Simulations
Appendix: Monte Carlo Simulations
In this Appendix, we conduct Monte Carlo simulations to investigate the finite sample performances of the proposed estimation and testing procedures. We provide simulation evidence to support that overlooking time-varying features in the predictive threshold model can result in biased estimates and a significant power loss of the test for threshold effect. We also present a number of simulation experiments calibrated on the empirical example to demonstrate the accuracy of the parameter estimates and the size and power properties of the tests in the empirical example. First, we consider the data generating process (DGP) specified as
where \(\gamma _t = {\gamma _0} + {\gamma _{1}}z_{t} \). We assume a normally distributed error \(u_t\sim i.i.d. N(0, 1)\), \(q_{t}\) and \(z_t\sim i.i.d. N(0,1)\), \(x_t\sim i.i.d.N(0,4)\). The sample size T is set as 50, 100, 200 or 500.
In the simulations for the estimation procedure, we set \(\alpha _1=\beta _1=1\), \(\alpha _2=\beta _2=2\), \(\gamma _0=0\) and \(\gamma _1=1\). The number of replications is 2000. The simulation results are reported in Table 5, in which we compare the proposed estimation procedure with the estimation procedure assuming a constant threshold. Panel A of Table 5 presents the summary statistics (i.e., mean and standard deviation) for the estimates based on the estimation procedure proposed in Sect. 2. The mean of each parameter comes close to its true value, and the standard deviation becomes small as the sample size increases, indicating that the accuracy of the estimates improves. Overall, for finite sample sizes, in terms of bias and standard deviation the performance of the proposed estimation procedure is generally satisfactory. Panel B of Table 5 reports the summary statistics (i.e., mean and standard deviation) for the estimates based on the estimation procedure assuming a constant threshold. These simulation results show that, if we ignore time-varying features in the threshold, the estimates of the parameters are seriously biased and with large standard errors. Furthermore, these biases could not disappear as the sample size increases, implying that ignoring time-varying features in the threshold would lead to misleading empirical results.
In assessing the finite sample performance of the proposed test statistics, the rejection frequencies under the DGP with \(\{\alpha _1=\alpha _2=\beta _1=\beta _2=1\}\) and \(\{\alpha _1=\beta _1=1, \alpha _2=\beta _2=2\}\) are the sizes and powers of the test statistic \(F_{1C}\) and \(F_{1T}\) defined in Sect. 2, respectively. The rejection frequencies under the DGP with \(\gamma _1= 0\) and \(\gamma _1=1\) are the size and power of the test statistic \(F_{2T}\) defined in Sect. 2, respectively. Table 6 reports the simulation results. In examining the size and power of \(F_{1C}\), we consider two cases: Case 1 with a constant threshold \((\gamma _0, \gamma _1)=(0,0)\) and Case 2 with a time-varying threshold\((\gamma _0, \gamma _1)=(0,1)\), which are reported as \(F_{1C}\) and \(F^*_{1C}\), respectively. The simulation results show that the power of the test statistic \(F_{1C}\) for threshold effect would decrease with the inclusion of a time-varying threshold. Turning now to the test statistics \(F_{1T}\) and \(F_{2T}\), the simulation results support that the size and power properties of the test statistics are generally satisfactory even when the sample size is small (e.g., \(T=50\)). To summarize, we conclude that, if we consider the time-varying threshold correctly, the test statistics work well in finite samples; however, ignoring time-varying features in the threshold would lead to a significant power loss of the test \(F_{1C}\).
Given the small sample size in the empirical part, it is useful to investigate the accuracy of the parameter estimates and the size and power properties of the tests in the empirical example. Moreover, the proposed bootstrap approach does not account for the time series nature of the observations in empirical applications, and highly persistent regressors will distort the test statistics, as discussed in Hansen (2017). Unfortunately, there is little guiding theory for the underlying econometrics in these instances. We therefore present a number of simulation experiments calibrated on the empirical investigation.Footnote 13 Our data generating processes are
in which \(\gamma _t=\gamma _0+\gamma _1{ inflation}_t+ \gamma _2 \overline{{ growth}}_{t-4}\), and we set the parameters as reported in Tables 3 and 4 to match the estimates in the empirical investigation. For example, in the case of model (A2) we set \(\alpha _1=7.683, \beta _1=0.822, \alpha _2=2.800, \beta _2=0.999\), \(u_t\sim N(0,18.783)\) and \(\gamma _t=0.162-0.3{ inflation}_t+ 1.9 \overline{{ growth}}_{t-4}\) to match the estimates for the headline GDP in Table 3. We fix \(F_t, { inflation}_t\) and \(\overline{{ growth}}_{t-4}\) to equal the empirical values used in Sect. 3, and set \(T=60\) as in the empirical example. Setting \(F_t\) to equal the sample values can force the simulations to assess the performance in a setting with the serial correlation properties of the observed GDP data. We generate 2000 samples from this process to evaluate the properties of the proposed estimation procedure. The assessment of the accuracy of the parameter estimates is reported in Table 7, in which we compute the summary statistics (i.e., mean and standard deviation) for the estimates. The mean of each parameter comes close to the estimates reported in Tables 3 and 4, and the magnitude of standard deviation is relatively small, implying that the estimation procedure works well.
To evaluate the size and power properties of the proposed test statistics \(F_{1C}, F_{1T}\) and \(F_{2T}\), we use the same parameterization as above. Take \(F_{1T}\), for example, to evaluate size, we set the parameters of model (A2) as \(\alpha _1=\alpha _2=3.076, \beta _1=\beta _2=0.980\) (null hypothesis), and \(u_t\sim N(0, 44.972)\) for the headline GDP case to match the estimates based on the linear model \({A_{t }} =\alpha + \beta F_t + {u_{t}}\).Footnote 14 Meanwhile, to evaluate the power of the test, we set \(\alpha _1=7.683, \beta _1=0.822, \alpha _2=2.800, \beta _2=0.999\) (alternative hypothesis), \(u_t\sim N(0,18.783)\) and \(\gamma _t=0.162-0.3{ inflation}_t+ 1.9 \overline{{ growth}}_{t-4}\) to match the estimates for the headline GDP in Table 3. We can evaluate the size and power properties of the test statistics \(F_{1C}\) and \(F_{2T}\) using similar techniques. The simulation results with the block length \(b=4\) are reported in Table 8. At the 5% nominal significance level, the simulation results show that the tests have reasonable size for all cases, implying that spurious rejections could not occur in the empirical example. Turning now to the power properties, the rejection frequencies are low in the cases where we could not reject the null hypothesis of no threshold effect in Table 2, as the magnitude of threshold effect (the difference between good and bad states) is relatively small in these cases; however, the rejection frequencies are reasonably high in the cases where we can reject the null hypothesis in Table 2. That is, the power of the test statistics would increase as the magnitude of threshold effect becomes large, which is consistent with the result in Table 6. These simulations indicate that the testing results have reasonable accuracy in the empirical investigation.
Rights and permissions
About this article

Cite this article
Yang, L. State-dependent biases and the quality of China’s preliminary GDP announcements. Empir Econ 59, 2663–2687 (2020). https://doi.org/10.1007/s00181-019-01751-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-019-01751-z