
Abstract
The cross-country declined labor share has been partially attributed to rising trade openness. However, the role of exports and imports in the literature was not studied separately and assumed to be homogeneous across countries. We propose two hypotheses for how exports and imports can affect labor share differently and nonlinearly. We empirically test the hypotheses by re-examining the trade–labor share nexus across 96 countries during 1970–2009, and we employ a partially linear model with fixed effect that allows a general functional form of trade variables to be estimated. Results are fairly consistent with our hypotheses, showing that while export (import) share significantly declines (raises) labor share, both effects diminish as the level of export or import share increases. The indicated nonlinear effects are significant and robust by controlling for related economic, social, and political factors. Also, we find a significant heterogeneous impact of export and import across OECD and non-OECD countries, with its implication also discussed.

Date Source: Penn World Table 8.1. Method: author’s calculation based on kernel smoothing conditional joint density estimates

Source: Penn World Table 8.1.

Source: Penn World Table 8.1.


Similar content being viewed by others
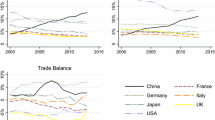


Notes
See the data description in Sect. 3.
See the detailed discussion of the empirical methodology in Sect. 3.
However, their model omitted several important explanatory variables, such as capital schedule, population, and labor regulation. The effect of trade openness also varies both in magnitude and in sign when different labor share proxies are used.
Given that the theorem’s strict assumptions with its weak support by empirical evidence and that the labor share is decreasing for both developed and developing countries, we expect that the effect of export and import is mainly from the latter three mechanisms.
We refer readers to Guerriero and Sen (2012) for a detailed summary of each mechanism.
We also checked the results for OECD and non-OECD countries. Results remain quantitatively similar to what we reported in this paper and are available upon request from the corresponding author.
Bandwidth selection based on cross-validation least square tends to minimize the mean-squared error of conditional mean function. For instance, to estimate \( G(\cdot ) \) local linearly we choose \( h_\mathrm{cvls} \) from
$$\begin{aligned} h_\mathrm{cvls}=\underset{\{h>0\}}{\arg \min }\sum _{i=1}^{N}\sum _{t=1}^{T}\left[ \tilde{Y}_{it}-\hat{G}_{-i}(Z_{it})\right] ^{2} \end{aligned}$$(3)where \( \hat{G}_{-i}(Z_{it}) \) is the local linear estimator, with its ith cross-section unit removed when we evaluate at \( Z_{it} \). Note that the CVLS bandwidth selection in cross-section data is to leave-one-observation-out. Here, we choose to leave one cross-section-unit-out to follow the argument by Henderson and Parmeter (2015). The essential reason is to ensure that a country with its all observations as outliers can be entirely removed, which prevents bandwidth from not being too small. This approach also speeds up the optimization speed dramatically in panel data.
Standard errors are clustered by countries. Constant terms are omitted for brevity.
We also checked the sensitiveness of the p values to bandwidths by adopting different bandwidth selections, such as least-square cross-validation and AIC-based cross-validation. The results remain fairly the same and are available upon request from the corresponding author.
References
Acemoglu D (2003) Labor- and capital-augmenting technical change. J Eur Econ Assoc 1(1):1–37
Azmat G, Manning A, Reenen JV (2012) Privatization and the decline of labour’s share: international evidence from network industries. Economica 79(315):470–492
Bentolila S, Saint-Paul G (2003) Explaining movements in the labor share. Contrib Macroecon 3(1). https://doi.org/10.2202/1534-6005.1103
Bernard AB, Eaton J, Jensen JB, Kortum S (2003) Plants and productivity in international trade. Am Econ Rev 93(4):1268–1290
Besley T, Burgess R (2004) Can labor regulation hinder economic performance? Evidence from India. Q J Econ 119(1):91–134
Blanchard OJ, Nordhaus WD, Phelps ES (1997) The medium run. Brook Pap Econ Act 1997(2):89–158
Boggio L, Dall’Aglio V, Magnani M (2010) On labour shares in recent decades: a survey. Riv Int Sci Sociali 118:283–333
Botero JC, Djankov S, Porta RL, Lopez-de Silanes F, Shleifer A (2004) The regulation of labor. Q J Econ 119(4):1339–1382
Brada JC (2013) The distribution of income between labor and capital is not stable: but why is that so and why does it matter? Econ Syst 37(3):333–344
Buch CM, Monti P, Toubal F (2008) Trade’s impact on the labor share: evidence from German and Italian regions. Working Paper. Retrieved from https://www.econstor.eu/handle/10419/39213. Accessed 15 Nov 2017
Buckley PJ (1994) World investment report 1994: transnational corporations, employment and the workplace. Transnatl Corp 3(3):91–100
Daudey E, García-Peñalosa C (2007) The personal and the factor distributions of income in a cross-section of countries. J Dev Stud 43(5):812–829
Decreuse B, Maarek P (2017) Can the HOS model explain changes in labor shares? A tale of trade and wage rigidities. Econ Syst 41(4):472–491
Diwan I (2001) Debt as sweat: labor, financial crises, and the globalization of capital. Mimeo, The World Bank, Washington
Giles JA, Williams CL (2000a) Export-led growth: a survey of the empirical literature and some non-causality results. Part 1. J Int Trade Econ Dev 9(3):261–337
Giles JA, Williams CL (2000b) Export-led growth: a survey of the empirical literature and some non-causality results. Part 2. J Int Trade Econ Dev 9(4):445–470
Goldberg P, Khandelwal A, Pavcnik N, Topalova P (2009) Trade liberalization and new imported inputs. Am Econ Rev 99(2):494–500
Gollin D (2002) Getting income shares right. J Polit Econ 110(2):458–474
Guerriero M, Sen K (2012) What determines the share of labour in national income? A cross-country analysis. Working paper. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=20896729. Accessed 2 Aug 2018
Guscina A (2006) Effects of globalization on labor’s share in national income. International Monetary Fund, Washington
Gwartney JD, Lawson RJH (2015) Economic freedom of the world 2005 annual report. The Fraser Institute, Vancouver
Harrison A (2005) Has globalization eroded labor share? Some cross-country evidence. Working paper. Retrieved from https://mpra.ub.uni-muenchen.de/39649/. Accessed 2 Aug 2018
Henderson DJ, Parmeter CF (2015) Applied nonparametric econometrics. Cambridge University Press, Cambridge
Hung JH, Hammett P (2016) Globalization and the labor share in the United States. East Econ J 42(2):193–214
Inklaar R, Timmer M (2013) Capital, labor and TFP in PWT8.0. University of Groningen, Groningen
Jaumotte F, Tytell I (2008) How has the globalization of labor affected the labor income share in advanced countries? IMF Working Paper (298), 1–54. Retrieved from http://www.imf.org/external/pubs/ft/wp/2007/wp07298.pdf. Accessed 2 Aug 2018
Jayadev A (2007) Capital account openness and the labour share of income. Camb J Econ 31(3):423–443
Kalecki M (1938) The determinants of distribution of the national income. Econom J Econ Soc 6:97–112
Karabarbounis L, Neiman B (2013) The global decline of the labor share. Q J Econ 129(1):61–103
Keynes JM (1939) Relative movements of real wages and output. Econ J 49(193):34–51
Lawrence RZ (2008) Blue-collar blues: is trade to blame for rising US income inequality?, vol 85. Peterson Institute, Washington
Li Q (1996) Nonparametric testing of closeness between two unknown distribution functions. Econom Rev 15(3):261–274
Li Q, Racine JS (2007) Nonparametric econometrics: theory and practice. Princeton University Press, Princeton
Linton O, Nielsen JP (1995) A kernel method of estimating structured nonparametric regression based on marginal integration. Biometrika 82:93–100
Magee L (1998) Nonlocal behavior in polynomial regressions. Am Stat 52(1):20–22
Marx K (1976) Capital: a critique of political economy, vol 3. Penguin, London
Melitz MJ (2003) The impact of trade on intra-industry reallocations and aggregate industry productivity. Econometrica 71(6):1695–1725
Ortega D, Rodriguez F (2001) Openness and factor shares (August). Retrieved from http://www.cepal.cl/prensa/noticias/comunicados/8/7598/Frodriguez29-08.pdf. Accessed 4 Aug 2018
Parmeter C, Racine J (2018) Nonparametric estimation and inference for panel data models. Working paper. Retrived from https://socialsciences.mcmaster.ca/econ/rsrch/papers/archive/2018-02.pdf. Accessed 10 Aug 2018
Qian J, Wang L (2012) Estimating semiparametric panel data models by marginal integration. J Econom 167(2):483–493
Racine J (1997) Consistent significance testing for nonparametric regression. J Bus Econ Stat 15(3):369–378
Ricardo D (2009) On the principles of political economy and taxation (1821). Kessinger Publishing, Whitefish
Robinson PM (1988) Root-n-consistent semiparametric regression. Econom J Econom Soc 56:931–954
Rodriguez-Poo JM, Soberon A (2017) Nonparametric and semiparametric panel data models: recent developments. J Econ Surv 31(4):923–960
Rodriguez F, Jayadev A (2010) The declining labor share of income. J Glob Dev 3(2):1–18
Rodrik D (2006) What’s so special about China’s exports? China World Econ 14(5):1–19
Severance-Lossin E, Sperlich S (1999) Estimation of derivatives for additive separable models. Stat J Theor Appl Stat 33(3):241–265
Silverman BW (1986) Density estimation for statistics and data analysis. Chapman & Hall, London
Smith A, Skinner AS (1974) The wealth of nation: books I–III. With an introduction by Andrew Skinner. Penguin Books, London
Su L, Ullah A (2006) Profile likelihood estimation of partially linear panel data models with fixed effects. Econ Lett 92(1):75–81
Taylor T (2013) Labor falling share, everywhere. Retrived from https://conversableeconomist.blogspot.com/2013/06/labors-falling-share-everywhere.html. Accessed 4 Jan 2018
Wang Z, Wei S (2010) What accounts for the rising sophistication of China’s exports? In: Wei SJ (ed) China’s growing role in world trade. University of Chicago Press, Chicago, pp 63–104
Young AT, Lawson RA (2014) Capitalism and labor shares: a cross-country panel study. Eur J Polit Econ 33:20–36
Young AT, Tackett MY (2018) Globalization and the decline in labor shares: exploring the relationship beyond trade and financial flows. Eur J Polit Econ 52:18–35
Zhang X, Lu Y (2014) Effects of commodity trade structure variations on labor’s share of income in China—an empirical study based on data of production industry sectors. China Econ 4:71–85
Zheng JX (1996) A consistent test of functional form via nonparametric estimation techniques. J Econom 75(2):263–289
Acknowledgements
We thank the associate editor and the two referees for their constructive comments, which significantly improve our paper. We are also indebted with Feng Yao, who constantly provides valuable comments on the use of semiparametric estimation technique. We are also grateful for Le Wang, who provides generous explanation of programming. All mistakes are our own.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendices
Appendix 1
Following Racine (1997), we evaluate the relevance of Z (i.e., Openness, Exs, or Ims) in the conditional mean function \( G(\cdot ) \) by testing the following null and alternative hypothesis:
where the vector \( \tilde{Y}=Y-X\hat{\varvec{\beta }}_\mathrm{PLM} \) or \( \tilde{Y}=Y-X\hat{\varvec{\beta }}_\mathrm{FEPLM} \) is discussed in Sect. 4.2. To estimate \( \lambda \), we replace the unknown gradients \( G^{'}(Z)\equiv \frac{\partial G(Z)}{\partial Z} \) with its nonparametric estimator \(\hat{G}^{'}(Z)\) as discussed in Sect. 4.2.2. to construct our feasible pivoted test statistic:
where
and \( \hbox {sd}(\cdot ) \) is the sample standard deviation. The following outlines its bootstrap procedure:
- 1.
Given the original sample \(\{\tilde{Y}_{it},Z_{it}\}_{i=1,t=1}^{N,T}\), calculate \( \hat{\lambda }\). Re-sample with replacement the original sample to obtain a new dataset \(\{\tilde{Y}_{it}^*,Z_{it}^*\}_{i=1,t=1}^{N,T}\) to compute \(\hat{\lambda }\). Repeat this step \(B_2\) times to obtain re-sampled test statistics \(\hat{\lambda ^*_1},\hat{\lambda ^*_2},\ldots ,\hat{\lambda ^*_{B2}}\), which is used to compute the standard error \(\hbox {sd}(\hat{\lambda })\) and test statistic \( \hat{t} \).
- 2.
Re-sampling with replacement the sample residual \( \{\hat{u}_{it}\}_{i=1,t=1}^{N,T}\) to get re-sampled residual \( \{\hat{u}_{it}^{*}\}_{i=1,t=1}^{N,T}\) and center it, where \(\hat{u}_{it}=\tilde{Y}_{it}-\bar{Y}\) with \( \bar{Y}\) the sample mean of \( \tilde{Y} \) to impose the null where Z does not show up in \( G(\cdot ) \) so that \(\beta (Z_{it})=0\)\( \forall i=1,\ldots ,N, t=1,\ldots ,T\).
- 3.
Obtain bootstrap sample \(\{\tilde{Y}_{{it}}^*, Z_{it}\}_{i=1,t=1}^{N,T}\), where \( \tilde{Y}_{{it}}^{*}=\bar{Y}+u_{it}^{*} \). Compute \(\hat{\lambda }^{*}\), \(\hbox {sd}(\lambda ^{*})\), and \(\hat{t}^{*}\) as in step 1, except with the bootstrap sample used.
- 4.
Repeat the steps 2–3 \(B_1\) times to obtain \(\hat{t}^*_1\),\(\hat{t}^*_2\),...,\(\hat{t}^*_{B_1}\). We reject \( H_0 \) if \( \hat{t} > \hat{t}^*_{1-\alpha }\), where \( \hat{t}^*_{1-\alpha } \) is the upper \( (1-\alpha ) \) percentile value of its empirical distribution, and \( \alpha \) is the significance level.
We set \( \alpha =0.05 \) and set \(B_1=1000\), and \(B_2=100\) to be in line with Racine (1997). We choose the 2nd-order Gaussian kernel function (i.e., the standard normal p.d.f.) and follow Silverman (1986) to select adaptive rule-of-thumb bandwidth \(h_\mathrm{AROT}=1.059\;A(NT)^{-1/5}\), where \( A = \min \{\hat{\sigma }, \hbox {IQR}_z/1.34\} \) and \( \hbox {IQR}_z \) is the inter-quantile range of the variable Z.
Appendix 2
We employ a model specification test by Zheng (1996) to test the significant nonlinearity of Z in \( G(\cdot ) \), whose null hypothesis states whether the functional form of \( G(\cdot ) \) can be parametrically specified, such as linear or quadratic function. Equivalently, we test whether \( E(U|Z)=0 \) under the null. By the law of iteration, we have the following infeasible test statistic under the null and the alternative:
where \( f(\cdot ) \) is the density of its argument, which can be consistently estimated by its kernel estimator \( \hat{f}(Z)=(1/NT)\sum _{i=1}^{N}\sum _{t=1}^{T} K_h(Z_{it}, Z) \). We estimate I by replacing U with \( \hat{U} \) the residual from the null regression (i.e., the OLS residuals), and replacing the conditional mean with the local constant estimator of U on Z:
By leaving out the diagonal terms to lower its finite-sample bias, we construct the feasible test statistic
with its variance:
so we obtain the standardized version of test statistic:
which converges to the standard normal distribution under the null. The following illustrates its bootstrap procedure.
- 1.
Given the original sample \(\{\tilde{Y}_{it},Z_{it}\}_{i=1,t=1}^{N,T}\), calculate \( \hat{J} \).
- 2.
Generate centered bootstrapped residual \( \{\hat{u}_{it}^*\}_{i,t=1}^{N,T} \), where for each observation \( i =1,\ldots ,N\) and \( t=1,\ldots ,T \), \( \hat{u}_{it}^*=\frac{1-\sqrt{5}}{2}(\hat{u}_{it}-\bar{\hat{u}}) \) with probability \( \frac{1+\sqrt{5}}{2\sqrt{5}} \) and \( \hat{u}_{it}^*=\frac{1+\sqrt{5}}{2}(\hat{u}_{it}-\bar{\hat{u}}) \) with probability \(\frac{1-\sqrt{5}}{2\sqrt{5}} \), where \(\bar{\hat{u}}\) refers to the mean of \(\hat{u}\).
- 3.
Compute \( \hat{J}^{*} \) using the bootstrap sample \(\{\tilde{Y}_{{it}}^*, Z_{it}\}_{i=1,t=1}^{N,T}\), where \( \tilde{Y}_{{it}}^{*}=m(Z_{it};\varvec{\beta })+u_{it}^{*} \), with \( m(Z_{it};\varvec{\beta }) \) the parametric functional form of our choice, including linear, quadratic, or cubic function, that imposes the null.
- 4.
Repeat the steps 2–3 B times to obtain \(\hat{J}^*_1\),\(\hat{J}^*_2\),...,\(\hat{J}^*_{B}\). Reject \( H_0 \) if \( \hat{J} > \hat{J}^*_{1-\alpha }\), where \( \hat{J}^*_{1-\alpha } \) is the upper \( (1-\alpha ) \) percentile value of its empirical distribution, and \( \alpha \) is the significance level.
We choose the second-order Gaussian kernel function, set \( (\alpha , B)=(0.05, 399) \), and implement the adaptive rule-of-thumb bandwidth as in “Appendix 1.”
Appendix 3
We employ a nonparametric test by Li (1996) for the distribution equality of estimated gradients of exports and imports between OECD and non-OECD countries. Let \(\mathbf g ^{1}\) and \(\mathbf g ^{2}\) be vectors that contain the first-order gradient of export (or import) \(\{g^{1}_{it}\}_{i,t=1}^{N_1,T}\) in one group of countries with observations \( N_1 \) and \(\{g^{2}_{it}\}_{i,t=1}^{N_2,T}\) in another one with observations \( N_2 \). We also assume that \( g^{m} \) is i.i.d. distributed for fixed t and strictly stationary for fixed i for \( m=1,2 \). Define their associated density function \(q_1(\cdot )\) and \(q_2(\cdot )\), we test the null hypothesis \(H_{04}: q_1(\mathbf g ^{1})=q_2(\mathbf g ^{1})\) for almost all continuous variables \(\mathbf g ^{1}\). A test statistic with nonzero center term is constructed on the basis of integrated squared error between two different densities evaluating at the same random variable:
which can be extended to:
where \(Q_1(\cdot )\) and \(Q_2(\cdot )\) are the c.d.f. of \(\mathbf g ^{1}\) and \(\mathbf g ^{2}\), respectively, and T converges to zero if and only if the null is true. We replace the density \(q_1(\cdot )\) and \(q_2(\cdot )\) with their univariate kernel density estimator:
and select the bandwidth \( h_1 \) and \( h_2 \) based on adaptive rule-of-thumb\( h_\mathrm{AROT} \). Replacing (8) and (9) into (7), we have the following feasible center-free test statistic:
where \( |H|=h_1h_2 \). The standardized version of T is given by:
where
The following provides procedure for a density equality test by Li (1996):
- 1.
Given the original sample of gradients estimated in two different samples \(\{\hat{g}^{1}_{it},\hat{g}^{2}_{jt}\}_{i,j,t=1}^{N_1,N_2,T}\) obtained by the local linear estimator of \( G(\cdot ) \), compute \( \hat{J} \).
- 2.
To impose the null where two densities are identical in an \( L_2 \) norm sense, pool the original sample into \( \varvec{\Theta }=\{\hat{g}^{1}_{11},\ldots ,\hat{g}^{1}_{N_1T}, \hat{g}^{2}_{11},\ldots ,\hat{g}^{2}_{N_2T}\}\), call it pool sample. Randomly select with replacement \( N_1 \) observations from the pool sample \( \varvec{\Theta } \) for the estimation of \( q_1(\cdot ) \), and also randomly select with replacement \( N_2 \) observations from the pool sample \( \varvec{\Theta } \) for the estimation of \( q_2(\cdot ) \). Call these samples \( \{\hat{g}^{1*}_{it}\}_{i,t=1}^{N_1,T} \) and \( \{\hat{g}^{2*}_{it}\}_{i,t=1}^{N_1,T} \), respectively.
- 3.
Compute \( \hat{J}^{*} \) in the same way as in step 1, except that the original sample \(\{\hat{g}^{1}_{it},\hat{g}^{2}_{jt}\}_{i,j,t=1}^{N_1,N_2,T}\) is replaced with the sample \( \{\hat{g}^{1*}_{it}\}_{i,t=1}^{N_1,T} \) and \( \{\hat{g}^{2*}_{it}\}_{i,t=1}^{N_2,T} \) in step 2.
- 4.
Repeat the steps 2–3 B times to obtain \(\hat{J}^*_1\),\(\hat{J}^*_2\),...,\(\hat{J}^*_{B}\). Reject \( H_0 \) if \( \hat{J} > \hat{J}^*_{1-\alpha }\), where \( \hat{J}^*_{1-\alpha } \) is the upper \( (1-\alpha ) \) percentile value of its empirical distribution, and \( \alpha \) is the significance level.
We choose the second-order Gaussian kernel function, set \( (\alpha , B)=(0.05, 399) \), and implement the adaptive rule-of-thumb bandwidth as in “Appendix 1.”
Appendix 4
See Table 9.
Appendix 5
See Table 10.
Rights and permissions
About this article

Cite this article
Wang, T., Tian, J. Recasting the trade impact on labor share: a fixed-effect semiparametric estimation study. Empir Econ 58, 2465–2511 (2020). https://doi.org/10.1007/s00181-018-1585-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-018-1585-6