
Abstract
Large differences in mortality rates across those with different levels of education are a well-established fact. Cognitive ability may be affected by education so that it becomes a mediating factor in the causal chain. In this paper, we estimate the impact of education on mortality using inverse-probability-weighted (IPW) estimators. We develop an IPW estimator to analyse the mediating effect in the context of survival models. Our estimates are based on administrative data, on men born between 1944 and 1947 who were examined for military service in the Netherlands between 1961 and 1965, linked to national death records. For these men, we distinguish four education levels and we make pairwise comparisons. The results show that levels of education have hardly any impact on the mortality rate. Using the mediation method, we only find a significant effect of education on mortality running through cognitive ability, for the lowest education group that amounts to a 15% reduction in the mortality rate. For the highest education group, we find a significant effect of education on mortality through other pathways of 12%.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Traditionally, causal mediation analysis has been formulated within the framework of linear structural models (Baron and Kenny 1986). These models are difficult to extend to inherently nonlinear duration outcomes such as the mixed proportional hazard model. Recent papers have placed causal mediation analysis within the counterfactual/potential outcomes framework (Imai et al. 2010a, b; Huber 2014; Vander Weele 2015) all assuming sequential unconfoundedness. Tchetgen Tchetgen (2013) also introduced a weighting method by for mediation analysis in a Cox proportional hazard model. His method implies estimating a regression model for the mediator conditional on the treatment and pre-treatment covariates, while our method is based on estimating the propensity score (with and without the mediator). In general, it is more difficult to formulate a suitable model for the mediator than for the propensity score.
Our outcome, the age at death is a duration variable and the mortality hazard rate, the instantaneous probability that an individual dies at a certain age conditional on surviving up to that age, is modelled. Accounting for right censoring, when the individual is only known to have survived up to the end of the observation window, and left-truncation, when only those individuals are observed who were alive at a certain time, are easy to handle in hazard models (Van den Berg 2001). A common way to accommodate the presence of observed characteristics is to specify a proportional hazard model, in which the hazard is the product of the baseline hazard, the age dependence, and a log-linear function of covariates. Neglecting confounding in inherently nonlinear models, such as proportional hazard models, leads to biased inference.
Propensity score methods are increasingly used to take account of confounding in observational studies, e.g. see Caliendo and Kopeinig (2008) for a survey. The advantage of the propensity score is that it enables us to summarize the many possible confounding covariates as a single score (Rosenbaum and Rubin 1983). With a duration outcome, right censoring makes inference of differences in means, as is standard in treatment analysis, unreliable. Propensity score methods for hazard models have been introduced for duration data that account for censoring, truncation and dynamic selection issues (Cole and Hernán 2004; Austin 2014). We apply inverse probability weighting (IPW) methods using the propensity score (Hirano et al. 2003), which belongs to the larger class of marginal structural models that account for time-varying confounders when estimating the effect of time-varying covariates (Robins et al. 2000).
Cognitive ability can be considered a principal source of education selection and an endowment that determines success at school. Then, intelligence precedes education in the causal path to health and mortality. However, cognitive ability, at least as measured by standard IQ-tests, is likely to change with the education attained. Recent research (Falch and Massih 2011; Banks and Mazzonna 2012; Schneeweis et al. 2014; Carlsson et al. 2015; Dahmann 2017) has shown that additional education improves cognitive ability. In that case, cognitive ability is a mediator in the causal path from education to health. Ideally, we would have continuous measurement of the (development) of cognitive ability over the life cycle, to account for both the selection and mediation of cognitive ability in the causal path from education to mortality. However, in our data, we only observe cognitive ability at late adolescence when measured intelligence can be either the result of the attained education or a proxy of early childhood intelligence which influences education choice. When cognitive ability is a mediator we can decompose the effect of education on mortality into an effect running through improvement of cognitive ability and an effect through other pathways. An effect of education through improvement of cognitive ability is likely if education raises cognitive ability that aids disease management and in seeking appropriate treatment where necessary. Other possible pathways from education to mortality emerge if higher education leads to improvement in socioeconomic status later in life, such as labour market signals, non-cognitive skills and peer effects, which influence health and mortality.
In our empirical analyses, we use administrative data on Dutch men who were examined for military service in the Netherlands between 1961 and 1965 after completing their secondary schooling. We followed 39,803 men selected from the national birth cohorts 1944–1947. These examinations are based on yearly listings of all Dutch male citizens aged 18 years in the national population registers. The sampled examination records were linked by Statistics Netherlands to recent national death records (up till the end of 2015). The records include a standardized recording of demographic and socioeconomic characteristics such as education, father’s occupation, religion, family size, and birth order, along with a standardized psychometric test battery. The educational level was classified in four categories: primary school, lower vocational education, lower secondary education, and intermediate vocational education, general secondary education, higher non-university and university education.
Under the assumption that cognitive ability is a mediator of the education effect on mortality we also extend the IPW methods to mediation analysis for a (mixed) proportional hazard (MPH) model, the common model for econometric duration analysis. The main methodological contribution of this paper is that we disentangle the total effect of a treatment on a duration into an effect that runs through the mediator and an effect through other pathways. We derive and implement an IPW estimator for such a decomposition of the total effects in MPH models. The estimator identifies causal mechanisms given that a sequential unconfoundedness condition holds. This is a strong assumption and nonrefutable. We therefore carry out a set of sensitivity analyses to quantify the robustness of our empirical findings to violation of the sequential ignorability assumption. We focus, in particular, on how the possibility of selection into education based on cognitive ability may influence our results.
The empirical results show that improving education has hardly any impact on the mortality rate when accounting for cognitive ability. Using the mediation method, we only find a significant effect of education on mortality running through cognitive ability, for the lowest education group that amounts to a 15% reduction in the mortality rate. For the highest education group, we find a significant effect of education on mortality through other pathways of 12%.
2 Methods
2.1 The mortality hazard rate
We seek to find the impact of education level on the mortality risk for the men in our sample of conscripts. However, mortality may be influenced by factors that also determine the education choice. This may render education a selective choice and makes it endogenous to mortality later in life. We follow a propensity score method to account for selection on observed characteristics and estimate the effect of education on the mortality rate. Figure 1 provides a graphical illustration of the relationship between cognitive ability, education and mortality later in life using a directed acyclic graph, where each arrow represents a causal path (Pearl 2000, 2012). It states that early childhood characteristics X, such as parental background and family size, influence the education choice D, the unmeasured childhood (pre-age 18) factors, \(U_0\), and the cognitive ability at age 18, \(Q_{18}\). The latter is also influenced by other childhood factors, which may include early life cognitive ability, and the education followed up to age 18. In our data, we do not observe these childhood factors (\(U_0\)).
We define the treatment effect, of moving up one education level, in terms of a proportional change in the (mortality) hazard rate. First, we discuss the assumptions, common in the potential outcomes literature that uses propensity score methods, to identify the impact of education on the mortality risk. In Sect. 2.2, we extend this to decompose the effect of education on the mortality rate into an effect running through improvement in cognitive ability and an effect running through other pathways. The main difference with standard propensity score methods is that we use potential hazard rates, the hazard rate that would be observed if the individual was untreated, \(\lambda (t|0)\), or treated \(\lambda (t|1)\). Let \(D_i =1\) be the treatment, moving up one education level. We observe pre-treatment (educational level) covariates X that influence the education choice.
Assumption 1
(Unconfoundedness) \(\lambda (t|d) \bot \; D|X\) for \(d=0,1\)
where \(\bot \) denotes independence. The unconfoundedness assumption (Rubin 1974; Rosenbaum and Rubin 1983) asserts that, conditional on covariates X, treatment assignment (education level) is independent of the potential outcomes. This assumption requires that all variables that affect both the mortality and the education choice are observed. Note that this does not imply that we assume all relevant covariates are observed. Any missing factor is allowed to influence either the outcome or the education choice, not both. We check the robustness of our estimates to this, rather strong, unconfoundedness assumption by assessing to what extent the estimates are robust to violations of this assumption induced by including an additional simulated binary variable to capture unobservables (Nannicini 2007; Ichino et al. 2008).
The overlap, or common support assumption requires that the propensity score, the conditional probability to choose a higher education given covariates X, is bounded away from zero and one. In our data, we distinguish four (ordered) education levels in line with the contemporary Dutch education system (see Sect. 3). By comparing only adjacent education levels, we remove the overlap problems.
Rosenbaum and Rubin (1983) show that if the potential outcomes are independent of treatment conditional on covariates X, they are also independent of treatment conditional on the propensity score, \(p(x)=\Pr (D=1|X=x)\). Hence if unconfoundedness holds, all biases due to observable covariates can be removed by conditioning on the propensity score (Imbens 2004). The average effects can be estimated by matching or weighting on the propensity score. Here, we use weighting on the propensity score. Inverse probability weighting based on the propensity score creates a pseudo-population in which the education choice is independent of the measured confounders. The pseudo-population is the result of assigning to each individual a weight that is proportional to the inverse of their propensity score. Inverse probability weighting (IPW) estimation is usually based on normalized weights that add to unity.
In survival analysis, it is standard to compare the (nonparametric) Kaplan–Meier curves for the treated and the controls. The unadjusted survival curves may be misleading due to confounding. Cole and Hernán (2004) describe a method to estimate the IPW adjusted survival curves. Biostatisticians usually focus on Cox regression models and Cole and Hernán (2004) describe how Cox proportional hazard models can be weighted by the inverse propensity score to estimate causal effects of treatments. This method is related to the g-computation algorithm of Robins and Rotnitzky (1992) and Robins et al. (2000).
In economics the interest is often also in the duration dependence of the hazard. The Gompertz hazard, which assumes that the hazard increases exponentially with age, \(\lambda _0(t) = e^{\alpha _0 + \alpha _1 t}\), is known to provide accurate mortality hazards (Gavrilov and Gavrilova 1991). However, it is hardly ever possible to include all relevant factors, either because the researcher does not know all the relevant factors or because it is not possible to measure then. Ignoring such unobserved heterogeneity or frailty may have a huge impact on inference in proportional hazard models, see e.g. Van den Berg (2001). A common solution is to use a Mixed Proportional Hazard (MPH) model, in which it is assumed that all unmeasured factors and measurement error can be captured in a multiplicative random term V. The hazard rate becomes
The (random) frailty \(V>0\) is time-invariant and independent of the observed characteristics X and treatment D. Note that independence of V and D is crucial; otherwise, Assumption 1 would be violated. So, we assume that some factors influencing the mortality rate are not observed and that these factors do not influence the education choice. In the empirical application, it is assumed that V has a gamma distribution, a common assumption used in the empirical literature.
To adjust for confounding, we estimate a standard MPH model, that does not include the measured confounders as covariates, using the re-weighted pseudo-population. Fitting a (mixed) proportional hazard model in the pseudo-population is equivalent to fitting a weighted MPH model in the original sample. The parameters of such weighted MPH models can be used to estimate the causal effects of education on mortality in the original sample. The IPW estimator in the (M)PH model is equivalent to solving the weighted derivatives of the log-likelihood:
where \(\theta \) is the vector of parameters of the hazard in (2), \(\varLambda (t|\cdot )= \int _0^t \lambda (s|\cdot )\, \mathrm{d}s\), the integrated hazard and \(\delta \) indicates whether the duration for individual i is censored \(\delta _i=0\) or not.Footnote 1
2.2 Mediation analysis for the mortality hazard rate
In this section, we discuss a model in which cognitive ability measured at age 18 mediates the impact of education on mortality. Mediation analysis aims to unravel the underlying causal mechanism into an effect running through changes of an intermediate variable, the mediator, and through other pathways. The counterfactual notation for average treatment effects can be extended to define causal mediation (see Huber 2014). We are particularly interested in the mediating effect of cognitive ability on mortality. It has been proven that high levels of cognitive ability is positively associated with high education (Ceci 1991; Hansen et al. 2004). Recent research (Falch and Massih 2011; Banks and Mazzonna 2012; Schneeweis et al. 2014; Carlsson et al. 2015; Dahmann 2017) has shown that one additional year of education improves intelligence up to 0.3 standard deviations, both for the US and for some European countries. We use \(Q_i\) to denote the observed cognitive ability (IQ-score), which is measured around age 18 when the men had their military examination and after they had completed secondary schooling. The mediation model we assume is illustrated by the DAG in Fig. 1.

Directed acyclic graph of mediation through \(\mathrm {Q}_{18}\) conditional on X
Traditionally, causal mediation analysis has been formulated with the framework of linear structural models (Baron and Kenny 1986). Recent papers have placed causal mediation analysis within the counterfactual/potential outcomes framework (Imai et al. 2010a, b; Huber 2014). In the previous section, the potential outcome was solely a function of the treatment, e.g. education choice, but in mediation analysis the potential outcomes also depend on the mediator. Because cognitive ability can be affected by the education attained,Footnote 2 there exist two potential values, \(Q_i(1)\) and \(Q_i(0)\), only one of which will be observed, i.e. \(Q_i=D_i\cdot Q_i(1) + (1-D_i)\cdot Q_i(0)\). For example, if individual i actually attained education level 1, we would observe \(Q_i(1)\) but not \(Q_i(0)\). Next, we use \(\lambda _i\bigl (t|d, q(d)\bigr )\) to denote the potential mortality hazard that would result from education equals d and cognitive ability equals q. For example, in the conscription data, \(\lambda _i\bigl (t|1, 110\bigr )\) represents the mortality hazard that would have been observed if individual i had education level 1 and a measured IQ-score of 110. As before, we only observe one of the multiple hazards \(\lambda _i=\lambda _i\bigl (t|D_i, Q_i(D_i)\bigr )\).
Because we base our treatment effect on (mixed) proportional hazard models, it is again natural to define the mediator effects proportionally. Abbring and Berg (2003) also define, in a different setting with a dynamic treatment, a proportional treatment effect for a duration outcome. In other nonlinear settings, such as count data regression, a proportional treatment effect has been defined (Lee and Kobayashi 2001). We define the average effect of other pathways, depending on treatment status d:
Assumption 2
Proportional decomposition
This framework enables us to disentangle the underlying causal pathway from education to mortality into an effect of education through improvement of cognitive ability and an effect through other pathways. We assume conditional independence (given X) of the treatment and the mediator:
Assumption 3
Sequential ignorablility:\(\{\lambda (t|d',q), Q(d)\} \bot D|X\) and \(\lambda (t|d',q) \bot Q|D=d,X\), \(\forall d, d' =0,1\) and q in the support of Q.
The first condition of Assumption 3 implies that, conditional on observed covariates X, no unobserved confounder exists that jointly affects the education choice, the cognitive ability and the mortality. The second condition implies that, conditional on observed covariates X and the education attained, no unobserved confounder exists that jointly affects cognitive ability and mortality. This would imply that X explains all the variation in \(U_0\) or that \(U_0\) does not (directly) affect education, the dashed line in Fig. 1. (Huber 2014; Imai et al. 2010a) make the same assumptions for identification of the direct and indirect effects in a linear model. Assumption 3 is a strong assumption and nonrefutable. We therefore carry out a set of sensitivity analyses to quantify the robustness of our empirical findings to violation of the sequential ignorability assumption based on an extension of the sensitivity analyses of Nannicini (2007) and Ichino et al. (2008). We focus, in particular, on how the possibility of selection into education based on cognitive ability may influence our results. We also have a common support restriction for the propensity score including the mediator.
In addition, we assume independent censoringFootnote 3 and a proportional mediator effect \(\theta (d)\):
Assumption 4
(Independent censoring) Censoring is, conditional on the treatment D, independent of the covariates X, the outcome T and the mediator Q.
Assumption 5
(Proportional mediator effect) \(\lambda \bigl (t|1,Q(d)\bigr ) = e^{\theta (d)}\lambda \bigl (t|0,Q(d)\bigr )\).
This is equivalent to assuming that the effect of the treatment, D, is not moderated by the value of the mediator. Thus, we assume no interaction effect, \(D\cdot Q\), in the hazard. Note that Assumption 5 does not rule out an MPH model. It only assumes that the unobserved heterogeneity is independent of the treatment D (as before) and the mediator Q. This leads to the following identification theorem for the effect of a treatment on the hazard running through other pathways (holding the mediator constant):
Theorem 1
(Identification of other pathways effect \(\theta (d)\)) Under Assumptions 1–5, the other pathways effect is identified through a weighted MPH regression with weights:
with weight W(d) for \(\theta (d)\), for \(d=0,1\).
(See Appendix A for the proof.)
The ‘total effect’ of education on the mortality rate, from an IPW estimation in which the mediator is excluded from the propensity score, can be decomposed into an effect of education running through the mediator \(\eta (\cdot )\) and an effect of education running through other pathways \(\theta (\cdot )\) using assumption 2:
The effect running through other pathways (holding the mediator constant) can be estimated solving (3), using W(d) from (5) as weights. The effect running through the mediator can be obtained from the log-difference of the estimated total and the estimated effect running through other pathways, using (6) or (7). The first effect represents the effect of education on the mortality hazard while holding cognitive ability constant at the level that would have been realized for chosen education level d. The second effect represents the effect of education on mortality if one changes cognitive ability from the value that would have been realized for education level 0 to the value that would have been observed for education level 1, while holding the education level at level d.
For estimation, we use normalized versions of the sample implied by the weights in (5), such that the weights in either treatment or control groups add up to unity, as advocated earlier. We estimate the additional propensity scores conditional on the pre-treatment covariates and the mediator, \(\Pr (D=1|X_i,Q_i)\), by probit specifications.
A nice feature of Theorem 1 is that it is straightforward to implement and only involves estimation of two propensity scores and plugging them into standard mixed proportional hazard estimation. No parametric restriction is imposed on the model of the mediator. Tchetgen Tchetgen (2013) also defines mediation analysis in (Cox) proportional hazard models. His method, which is also based on proportional decomposition, sequential ignorability, independent censoring and a proportional mediator effect, implies estimating a regression model for the mediator conditional on the treatment and pre-treatment covariates f(Q|D, X), while our method is based on estimating the propensity score (with and without the mediator). In general, it is more difficult to formulate a suitable model for the mediator than for the propensity score. Vander Weele (2011) also derived a mediation estimator for the Cox proportional hazards model. Although his method does not need assumption 5, a proportional mediator effect, it requires an additional assumption that the outcome is rare over the entire follow-up period.
3 Data
Data from a large sample from the nationwide Dutch Military Service Conscription Register for the years 1961–1965 and male birth cohorts 1944–1947 are analysed. All men, except those living in psychiatric institutions or in nursing institutes for the blind or for the deaf-mute, were called to a military service induction exam. The majority attended the conscription examination around age 18.Footnote 4 We have information from the military examinations for 45,037 men. The data were described elsewhere, Ekamper et al. (2014), here we provide the main characteristics. These data were linked to the Dutch death register through to the end of 2015 using unique personal identification numbers. Follow-up status was incomplete (due to emigration and other right-censoring events) for 1316 (2.9%) and entirely unknown for 2626 (8.3%) men.Footnote 5 The latter were removed from the data. These data allow us to follow a large group of men from age 18 until age 68–72 or until death. At the military examination, a standardized recording of demographic and socioeconomic characteristics such as education, father’s occupation, religion, family size, region of birth, and birth order is recorded. We exploit the information on education attained at age 18 and the age at death to investigate the mortality difference while accounting for other factors that influence both educational level and mortality.
The educational level is classified in four categories,Footnote 6 (Doornbos and Kromhout 1990): primary school (age 6–12 years); lower vocational education (2 years post-primary school); lower secondary education (4 years post-primary school); and higher education (intermediate vocational education, general secondary education, higher non-university and university education, i.e. at least 6 years post-primary school). For this study, we excluded partly institutionalized conscripts who had attended special schools for those with disabilities or learning difficulties and conscripts who had not completed 6 years of schooling. After exclusion of these 2608 conscripts, 39,803 men remain for analysis.
A standardized psychometric test battery is included: comprising Raven Progressive Matrices, a nonverbal untimed test that requires inductive reasoning about perceptual patterns, the Bennett Mechanical Comprehension test, and tests for Clerical Aptitude, Language Comprehension, Arithmetic and a Global comprehensive score, that combines all five tests. All tests were administered to over 95% of the population who were examined at induction. Scores for all tests were grouped in six levels from 1 (highest) to 6 (lowest). The test scores are highly correlated with Pearson’s r values in the range of .63 to .76. Here, we only focus on the scores of the comprehensive test.
Selected demographic and socioeconomic characteristics at the time of military examinations by education level are given in Table 1. First born conscripts tend to have higher education. Father’s occupation was classified into five categories: professional and managerial workers; clerical, self-employed and skilled workers; farmers; semi-skilled workers including operators, process workers and shop assistants; and labourers and miners. Fathers with unknown occupations were classified separately. Education level is also strongly related to father’s occupation; men with the highest education tend to have fathers in professional or managerial occupations. Religion was classified into five categories. The place of birth was categorized in six regions. The combined cognition measure is the Global comprehensive score. Not surprisingly, men with the highest education tend to do best on the comprehensive IQ-test. Our principal measure of health is mortality with ages of death ranging from 18 up to 68–72. The lowest education group has a 70% higher mortality.
The Kaplan–Meier survival curves for the four education categories are shown in Fig. 2 and reflect these mortality differences. Survival increases with the education level and the differences between the education levels increase with age. The curves differ significantly (\(\chi ^2=180.76\) for a log-rank test with 3 degrees of freedom). In subgroup analyses, survival differences comparing adjacent education levels are also statistically significant (\(\chi ^2=54.79, 9.97, 29.80\)). This mortality difference by education is not necessarily due to education per se. It could be that the higher cognitive ability of higher educated people causes the difference. For example, understanding a doctor’s advice and adhering to complex treatments may be driven by cognitive ability rather than education. From Table 1, we have seen already that education and IQ are highly correlated. Figure 3 shows that survival also increases with IQ and the differences are statistically significant (\(\chi ^2=277.72\) for a log-rank test with 5 degrees of freedom). For all, except the two lowest, adjacent IQ-levels the differences in the Kaplan-Meier survival curves are significant. Within each education level the Kaplan–Meier curves also differ significantly by IQ-level (not shown here).

Kaplan–Meier survival curves, by education level

Kaplan–Meier survival curves, by IQ-level (overall level)
Next, we investigate the relationship between IQ and educational attainment. The IQ-scores are measured on a six-point ordinal scale. Comparing individuals on the extremes of the education level is not helpful as these individuals differ too much in many respects. We focus on adjacent education levels only and estimate separate ordered probit models for the IQ-score in relation to the highest education level in each pair and other observed individual characteristics. The results of ordered probit analyses reveal a strong association between education and IQ.Footnote 7
3.1 Results
3.2 Hazard models and mediation analysis
Table 2 presents the estimated effect on the mortality hazard of moving up one educational level and its decomposition. We conclude from these analyses that for the lower educated, with only primary education, and for the lower secondary educated obtaining more education reduces their mortality rate (around 25%). Moving from lower vocational education to lower secondary education only reduces the mortality rate by 9%.Footnote 8
The last four columns in Table 2 present the decomposition of the effects of education on the mortality rate. The effect of education through other pathways is only significant for the highest education group while holding cognitive ability at the level of those with high education and for the lowest education group while holding cognitive ability at the level of those with primary education. About two-thirds of the mortality reduction for men moving from lower secondary to higher education runs through other pathways, such as, for example, an increase in income. For the lowest education groups, the impact of education on mortality mainly runs through the increase in cognitive ability induced by the additional education. For these men, 90% of the reduction in mortality is explained by the effect running through cognitive ability.
3.3 Robustness checks
Throughout, we have assumed that the propensity scores are estimated consistently. Misspecification of the propensity score will generally produce bias. An approach to improve the robustness of the proposed methodology can be obtained using a doubly robust estimator which also includes a regression adjustment. Rotnitzky and Robins (1995) point out that if either the regression adjustment or the propensity score is correctly specified, the resulting estimator will be consistent. Thus, we also estimate doubly robust estimators of the models, including the observed characteristics and the IQ-test both in the propensity score and in the hazard regression, see Table 3. Including regression covariates hardly changes the IPW estimates (compare column 2 of Table 3 and of Table 2). Not surprisingly, including the covariates does change the ‘unadjusted’ results a little (compare column 1 of Table 3 and of Table 2).
The individuals who were removed from the analysis, because their survival status is unknown, may be a selective sample, see Table 8 in “Appendix B”. To account for possible sample selection bias, we estimated the propensity score of an individual being removed, using a probit model for each level of education separately.Footnote 9 Based on this probability of removal, we impose additional weighting of all observations in our estimation sample using the inverse of the probability of inclusion in the sample and we re-estimate the total effect and its decomposition. The results after imposing this additional weighting show very little difference from the original results, see Table 11 in “Appendix B”.
Another issue is that childhood health problems may influence both education choice and mortality later in life. We perform a robustness analysis by adding health indicators to the educational propensity score. Our data are limited and only include health measurements at the military examination, so these can only be used to proxy childhood health. We used indicators for height \(< 170\)cm; height \(> 185\)cm; overweight(bmi \(>25\)), poor general health; poor hearing; poor sight and poor psychological assessment, and re-estimated the propensity scores, both without IQ, to estimate the total effect of education and, with IQ-measurements to decompose the total effect into an effect running through changes in cognitive ability and an effect running through other pathways. The estimated impact of education on mortality changes slightly when accounting for health problems, see Table 4, but only for the lowest education group.
3.4 Sensitivity analyses
The critical assumption in propensity score weighting is that of no selection on unobservables. To test the sensitivity of the estimates to the unconfoundedness assumption, we build on the sensitivity analyses of Nannicini (2007) and Ichino et al. (2008). We extend these analyses to the mixed proportional hazard model. The Ichino et al. (2008) sensitivity analysis assumes that the possible unobserved confounding factors can be summarized in a binary variable, U, and that the unconfoundedness assumption holds conditional on X and U, i.e. \(\lambda (t|0)\; \bot \; D|X, U\). Given the values of the probabilities that characterize the distribution of U, we can simulate a value of the unobserved confounding factor for each individual and re-estimate the IPW-MPH. The probabilities of the distribution of U depend on the value of the treatment and the outcome. The Ichino et al. (2008) sensitivity analysis assumes that the potential outcomes are binary, but Nannicini (2007) shows how to extend this to continuous outcomes by imposing a binary transformation. In survival analysis, we have a natural binary transformation, the censoring indicator \(\delta _i=1\) if individual i is still alive at the end of the observation period. Then, the distribution of the unobserved binary confounding factor U can be characterized by specifying the probabilities in each of the four groups.
for \(i,j = 0,1\).
A measure of how the different configurations of \(p_{ij}\), chosen to simulate U, translate into associations of U with the outcome is \(\omega \), the coefficient of U in a MPH model for the control group (\(D=0\)) using U and X as covariates. Ichino et al. (2008) call this (exponentiated) coefficient the ‘outcome effect’. A measure of the effect of U on the relative probability to be assigned to the treatment is \(\xi \), with \(\xi \) the coefficient of U in a logit model on the treatment assignment (\(D=1\)) using U and X as covariates. Ichino et al. (2008) call this (exponentiated) coefficient the ‘selection effect’.
For identification of the mediation effects, we also impose sequential ignorability (Assumption 2). We therefore also assume that conditional on the binary (unobserved) factor the following two conditions hold (i) \(\{\lambda (t|d',m), Q(d) \} \bot D|X, U\) and (ii) \(\lambda (t|d',q) \bot Q|D=d, X, U\) for \(\forall d, d'=0,1\) and q in the support of Q. A new measure, the mediator effect, is \(\psi \), the coefficient of U in an ordered logit model on the IQ-test values for the control group using U and X as covariates.
The probability values of the distribution for U are chosen so that they mimic the distribution for each included binary variable. For example, consider the probability that an individual in the lowest education group (primary and lower vocational education) is catholic. Then, \(p_{00}\) is this probability for catholics with primary education who died before the end of the observation period, \(p_{01}\) is the probability for catholics with primary education who survived till the end, \(p_{10}\) is the probability for catholics with lower vocational education who died before the end, and \(p_{11}\) is the probability for catholics with lower vocational education who survived till the end. For each probability configuration of U, we repeat the simulation of U, the estimation of the outcome effect, the selection effect and the IPW-MPH treatment effects \(M=100\) times and obtain the average of these 100 simulations. The total variance of these averages can be estimated from (see Ichino et al. 2008):
where \(f \in \{\omega , \xi \}\) of each pairwise education comparison, \({\hat{f}}_m\) is the estimated f in each simulation sample m and \(s^2_m\) is its estimated variance.
Next, we re-estimate the total effect of education on mortality using an IPW Gompertz-gamma MPH model including U in the propensity score and the decomposition of the effect using an IPW Gompertz-gamma MPH including U and the IQ-measurements in the propensity score.
An issue with our empirical application is that early childhood IQ (one of the possible factors of \(U_0\) in Fig. 1) might be a selection variable, explaining selection into education (rather than a mediation variable).Footnote 10 We, therefore, focus on the results of the sensitivity analysis when assuming U mimics the observed distribution of the IQ-measurements, i.e. the observed education choice and censoring probability are equal to the observed education choice and censoring prevalence for individuals with a given IQ level. We find the largest outcome, selection and mediation effects when the distribution of U mimics the impact of IQ on education and censoring.Footnote 11 Table 5 reports the simulated total effect and its decomposition into an effect running through cognitive ability and an effect running through other pathways including U in the IPW that mimics the distribution of the education choice and mortality for each IQ-level.Footnote 12 We find the largest changes in our IPW estimates when U mimics the education–mortality distribution of those with the highest IQ-level. These differences are, however, not statistically significant.
Next, we search for the existence of ‘killer’-confounders, i.e. the existence of a set of probabilities \(p_{ij}\) such that if U were observed, the estimated effects would be driven to zero. The reason for doing this is to assess the plausibility of the resulting configuration of U and how comparable this is to the distribution of observed confounders. In order to reduce the dimensionality of the characterization of the ‘killer’-confounders we follow the suggestion of Nannicini (2007) and fix the probability of \(\Pr (U=1)\) to 0.4 and the difference \(p_{11}-p_{10}\) to zero. Now, the simulated confounders U can be fully described by two differences \(d= p_{01}-p_{00}\) and \(s= p_{1.} - p_{0.}\), with \(p_{i.}= \Pr (U=1|D=i) = p_{i1}\cdot \Pr (\delta _1=1|D=i) + p_{i0}\cdot \Pr (\delta _1=0|D=i)\) for \(i=0,1\), the fraction of individuals with \(U=1\) by education level. Nannicini (2007) argues that d is an (inconsistent) measure of the effect of U on the outcome (mortality, censoring probability) for the untreated (lower education level), while s is an (inconsistent) measure of the selection into treatment (higher education level). Both d and s are inconsistent measures because they do not account for the association between U and W, while our outcome effect, \(\varOmega \), selection effects, \(\xi \) and mediation effects \(\psi \), account for this.
Table 6 reports the simulated total effect and its decomposition when the distribution of U is defined by d, s with \(d,s=0.1, \ldots , 0.5\).Footnote 13 Indeed, by using these ‘killer’-confounders we do find some large deviations from the original results for the impact of moving from primary to lower vocational education, while the estimates for higher levels of education remain remarkably stable. However, these differences apply for combinations of d and s that lie well away from the values implied by our observed confounders. Note that the largest values for d and s we found when the distribution of U mimics the education-censoring distribution of the observed variables was \(d=0.03\) and \(s=0.06\) when using the education-censoring distribution of the highest IQ-level.
3.5 Implied gain in life expectancy
From the Gompertz-hazards, we can estimate the median survival age of the recruits and their post-18 life expectancy. The median survival age is the age at which half of the people have died (conditional on survival up to age 18). Assuming that the estimated Gompertz hazard holds, the life expectancy at age \(t_0=18\) can be very well approximated by (see Lenart 2014):
where 0.5772 is the Euler constant. For the unadjusted Gompertz model, the estimated remaining life expectancies are 59.8 (primary); 62.6 (lower vocational); 63.7 (lower secondary) (64.2 based on last two education groups); and 66.7 (higher), leading to educational gains of 2.8, 1.0 and 2.5 in life expectancy. The median survival ages are 80.1 (primary); 82.9 (lower vocational); 84.1 (lower secondary) (84.6) and 87.1 (higher), thus leading to the same educational gains.
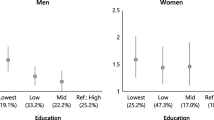
In Table 7, we report the gains in life expectancy. The lower panel of Table 7 reports the gains in life expectancy based on the mediation analysis and decomposes the effects of education into an effect running through cognitive ability and an effect running through other pathways. Based on the IPW estimates, we can conclude that if an individual had improved his education from primary to lower vocational he would have gained 2.5 additional years (and his median age also would have improved by 2.5 years), of which 1.8 years are attributable to cognitive ability and 0.7 years to other changes induced by other pathways. If an individual had improved from lower vocational to lower secondary, the gain in life expectancy is 1.0 year (1.1 attributable to cognitive ability and an negative impact of other pathways). The gain in life expectancy if an individual had improved his education from lower secondary to higher education is 2.2 years. For those who attained higher education, this gain in life expectancy is mainly attributable to the other pathways (1.2 years), while for those with lower secondary education the effect running through cognitive ability is larger (1.3 years) than effect running through other pathways.
4 Discussion
A large literature documents that higher levels of education are positively associated with a longer life. Possible mechanisms include occupational risks, health behaviour, the ability to process information and cognitive ability (Cutler and Lleras-Muney 2008). It is commonly acknowledged that education and cognitive ability are correlated. Cognitive ability may cause differences in educational outcomes, or education may cause differences in cognitive ability. Most of the economics literature on the causal effect of education on health focuses on accounting for endogenous selection into education due to confounding factors, such as cognitive ability, either by exploiting natural experiments in education due to changes in compulsory schooling laws (Mazumder 2012) or by defining a structural model (Conti et al. 2010; Bijwaard et al. 2015). The estimates based on natural experiments find little to no effect of education on health, while the studies based on structural models find that around half of the difference in health by education is due to selection. An alternative perspective is that cognitive ability is part of the causal pathway from education to mortality. For instance, it has been proven that high scores on intelligence tests are positively associated with schooling level (Ceci 1991; Hansen et al. 2004; Carlsson et al. 2015).
We assume that IQ measured at age 18 is affected by educational attainment and has a mediating effect on the mortality difference across education groups. We developed an inverse probability weighting (IPW) method for hazard models to estimate the impact of education on the mortality rate. We use conscription data of Dutch men born between 1944 and 1947 who were examined for military service between 1961 and 1965, and linked to national death records, in which we identified four education groups. Using the IPW methods, we estimate, for each adjacent education group, the impact of improving education on the mortality risk. We decompose the impact of education into an effect running through cognitive ability and an effect running through other pathways.
The results show that controlling for cognitive ability, as a mediating factor, leaves only limited evidence of an educational gain in mortality. When accounting for cognitive ability as a mediator in the causal pathway from education to mortality, we find that cognitive ability plays an important role in explaining the educational gradient. For men with primary school, we find that the effect of education running through an increase in cognitive ability significantly reduces the mortality risk (about 15% reduction in the mortality rate), which is equivalent to 1.6 years longer life expectancy. For the middle group, with lower vocational education, cognitive ability explains most of the educational gradient of a 10% reduction in the mortality rate. For the highest education group, only the effect of education running through other pathways, such as income effects of education, is significant (about 13% reduction in the mortality rate), leading to 1.3 additional years of life.
A limitation of our data, based on military entrance examination, is that we only observe men and no information on women is available. Bijwaard et al. (2015) found that educational gains for women appear to be higher than for men, in spite of the higher survival difference of women with lower versus higher education. These findings are based on much smaller numbers than the current study, however, and therefore need to be interpreted with caution. Another issue is that in the 1960s a major change occurred in the education system in the Netherlands and some of the specific education strata in this study no longer exist. In addition, the percentage of people with more than 6 years of post-primary school education is currently much higher compared to the past. These changes are not likely to affect our general conclusion that increased education only has a small effect on survival, but further long term studies will be needed to quantify these effects for contemporary school types. The issue of reverse causality that early childhood health affects educational attainment might distort our analyses (Case et al. 2005; Currie 2009). We have limited information about childhood health status. However, adding health measurements from the military examination to the propensity score did not change our conclusion that education has only limited impact on mortality.
Notes
In “Appendix A”, we provide a counting process interpretation and prove consistency.
For example, Jones et al. (2011) discuss how performance in IQ-tests could be influenced by coaching received by primary school pupils to prepare them for entrance tests for secondary school.
In principle, it is possible to extend the method to the assumption that censoring is independent of the outcome conditional on the treatment, the covariates and the mediator using a similar weighting for the censoring.
Many men who continued to higher education were examined in their 20s.
Education in the Netherlands is characterized by years of education and by school level. There are two parallel streams in the educational system: general academic and vocational. Streaming choices are made at the end of primary school. Students in the vocational stream cannot directly enter university. Students with more than 12 years of education will nearly always be in the academic stream (Schröder and Ganzeboom 2014; Vrooman and Dronkers 1986).
The results are available upon request.
The estimation results are available upon request.
We estimated a selection version of the model (despite the date of measurement on IQ) and that we got similar results for total effect of IQ and education suggesting that selection (only) is another plausible hypothesis, see Bijwaard and Jones (2016).
The results can be found in Table 12 in “Appendix B”.
The simulated outcome, selection and mediation effects can be found in Table 15 in “Appendix B”.
Doob (1953) published the Doob decomposition theorem which gives a unique decomposition for certain discrete time martingales. Meyer (1963) proved a continuous time version of the theorem, which became known as the Doob–Meyer decomposition. Both Andersen et al. (1993) and Aalen et al. (2009) provide a thorough discussion of this theorem.
The proof for any other MPH model with known functional form of the baseline hazard and given distribution of the unobserved heterogeneity is essentially the same.
References
Aalen OO, Borgan O, Gjessing HK (2009) Survival and event history analysis. Springer, New York
Abbring JH, van den Berg GJ (2003) The non-parametric identification of treatment effects in duration models. Econometrica 71:1491–1517
Andersen PK, Borgan O (1985) Counting process models for life history data: a review. Scand J Stat 12:97–158
Andersen PK, Borgan O, Gill RD, Keiding N (1993) Statistical models based on counting processes. Springer, New York
Austin PC (2014) A tutorial on the use of propensity score methods with survival or time-to-event outcomes: reporting measures of effect similar to those used in randomized experiments. Stat Med 33:1242–1258
Banks J, Mazzonna F (2012) The effect of education on old age cognitive abilities: evidence from a regression discontinuity design. Econ J 122(560):418–448
Baron RM, Kenny DA (1986) The moderator-mediator variable distinction in social psychological research: conceptual, strategic, and statistical considerations. J Pers Soc Psychol 51:1173–1182
Bijwaard GE, Jones AM, (2016) Cognitive ability and the mortality gradient by education: Selection or mediation? Discussion Paper 9798, IZA
Bijwaard GE, van Kippersluis H, Veenman J (2015) Education and health: the role of cognitive ability. J Health Econ 42:29–43
Caliendo M, Kopeinig S (2008) Some practical guidance for the implementation of propensity score matching. J Econ Surv 22:31–72
Carlsson M, Dahl GB, Öckert B, Rooth D-O (2015) The effect of schooling on cognitive skills. Rev Econ Stat 97:533–547
Case A, Fertig A, Paxson C (2005) The lasting impact of childhood health and circumstance. J Health Econ 24:365–389
Ceci SJ (1991) How much does schooling influence general intelligence and its cognitive components? A reassessment of the evidence. Dev Psychol 27:703–722
Cole SR, Hernán MA (2004) Adjusted survival curves with inverse probability weights. Comput Methods Programs Biomed 75:45–49
Conti G, Heckman JJ, Urzua S (2010) The education-health gradient. Am Econ Rev 100:234–238
Currie J (2009) Healthy, wealthy, and wise: socioeconomic status, poor health in childhood and human capital development. J Econ Lit 47:87–122
Cutler D, Lleras-Muney A (2008) Education and health: evaluating theories and evidence. In: House JS, Schoeni RF, Kaplan GA, Pollack H (eds) Making Americans healthier: social and economic policy as health policy. Russell Sage Foundation, New York
Dahmann SC (2017) How does education improve cognitive skills? Instructional time versus timing of instruction. Labour Econ 47:35–47
Doob LJ (1953) Stochastic processes. Wiley, New York
Doornbos G, Kromhout D (1990) Educational level and mortality in a 32-year follow-up study of 18-year-old men in the Netherlands. Int J Epidemiol 19:374–379
Ekamper P, van Poppel F, Stein AD, Lumey LH (2014) Independent and additive association of prenatal famine exposure and intermediary life conditions with adult mortality between age 18–63 years. Soc Sci Med 119:232–239
Falch T, Massih SS (2011) The effect of education on cognitive ability. Econ Inq 49:838–856
Gavrilov LA, Gavrilova NS (1991) The biology of life span: a quantitative approach. Harwood Academic Publisher, New York
Hansen KT, Heckman JJ, Mullen KJ (2004) The effect of schooling and ability on achievement test scores. J Econom 121:39–98
Hirano K, Imbens GW, Ridder G (2003) Efficient estimation of average treatment effects using the estimated propensity score. Econometrica 71:1161–1189
Huber M (2014) Identifying causal mechanisms (primarily) based on inverse probability weighting. J Appl Econom 29:920–943
Ichino A, Mealli F, Nannicini T (2008) From temporary help jobs to permanent employment: What can we learn from matching estimators and their sensitivity? J Appl Econom 23:305–327
Imai K, Keele L, Tingley D (2010a) A general approach to causal mediation analysis. Psychol Methods 15:309–334
Imai K, Keele L, Yamamoto T (2010b) Identification, inference and sensitivity analysis for causal mediation effects. Stat Sci 25:51–71
Imbens GW (2004) Nonparametric estimation of average treatment effects under exogeneity. Rev Econ Stat 86:4–29
Jones AM, Rice N, Rosa Dias P (2011) Long-term effects of school quality on health and lifestyle: evidence from comprehensive schooling reforms in England. J Hum Cap 5:342–376
Klein JP, Moeschberger ML (1997) Survival analysis: techniques for censored and truncated data. Springer, New York
Lee M-J, Kobayashi S (2001) Proportional treatment effects for count response panel data: effects of binary exercise on health care demand. Health Econ 10:411–428
Lenart A (2014) The moments of the Gompertz distribution and the maximum likelihood of its parameters. Scand Actuar J Inst Actuar 3:255–277
Mazumder B (2012) The effects of education on health and mortality. Nordic Econ Policy Rev 1:261–301
Meyer PA (1963) Decomposition of supermartingales: the uniqueness theorem. Ill J Math 7:1–17
Nannicini T (2007) A simulation-based sensitivity analysis for matching estimators. STATA J 7:334–350
Pearl J (2000) Causality: models, reasoning and inference. Cambridge University Press, New York
Pearl J (2012) The mediation formula: a guide to the assessment of causal pathways in nonlinear models. In: Berzuini C, Dawid P, Bernardinelli L (eds) Causality: statistical perspectives and applications. John Wiley, Chichester, pp 151–179
Robins JM, Rotnitzky A (1992) Recovery of information and adjustment for dependent censoring using surrogate markers. In: Jewell N, Dietz K, Farewell V (eds) AIDS epidemiology–methodological issues. Birkhäuser, Boston, pp 297–331
Robins JM, Hernán MA, Brumback B (2000) Marginal structural models and causal inference in epidemiology. Epidemiology 11:550–560
Rosenbaum P, Rubin DB (1983) The central role of the propensity score in observational studies for causal effects. Biometrika 70:41–55
Rotnitzky A, Robins JM (1995) Semiparametric regression estimation in the presence of dependent censoring. Biometrika 82:805–820
Rubin DB (1974) Estimating causal effects of treatments in randomized and non-randomized studies. J Educ Psychol 66:688–701
Schneeweis N, Skirbekk V, Winter-Ebmer R (2014) Does education improve cognitive performance four decades after school completion? Demography 51(2):619–643
Schröder H, Ganzeboom HBG (2014) Measuring and modelling level of education in European societies. Eur Sociol Rev 47(9):119–136
Tchetgen Tchetgen EJ (2013) Inverse odds ratio-weighted estimation for causal mediation analysis. Stat Med 32:4567–4580
Therneau T, Grambsch P (2000) Modeling survival data: extending the Cox model. Springer, New York
Van den Berg GJ (2001) Duration models: specification, identification, and multiple duration. In: Heckman J, Leamer E (eds) Handbook of econometrics, chapter 55, vol V. North-Holland, Amsterdam, pp 3381–3460
Vander Weele TJ (2011) Causal mediation analysis with survival data. Epidemiology 22:575581
Vander Weele TJ (2015) Explanation in causal inference: methods for mediation and interaction. Oxford University Press, New York
Vrooman JC, Dronkers J (1986) Changing educational attainment processes: some evidence from the Netherlands. Sociol Educ 59(2):69–78
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors acknowledge access to linked data resources (DO 1995–2011) by Statistics Netherlands (CBS). We are grateful to seminar participants at Erasmus University Rotterdam, University of York and the Paris School of Economics and participants of the IUSSP workshop on Causal Mediation Analysis on Health and Work in Rostock for helpful comments. This study was part of a research supported by U.S. National Institutes of Health, Grant RO1-AG028593 (Principal Investigator: L. H. Lumey). Andrew Jones acknowledges funding from the Leverhulme Trust Major Research Fellowship (MR-2016-004).
Appendices
Appendices
1.1 Appendix A: Counting processes and proofs
To prove the consistency and the properties of our estimation strategy, we rely on counting process theory for duration models. In a Mixed Proportional Hazard (MPH) model, the waiting time to some event T has a conditional distribution given observed X, treatment D, mediator Q and unobserved heterogeneity V with hazard rate
The cdf and pdf of the distribution of the duration T can be expressed as functions of the hazard rate. The counting process approach has increasingly become the standard framework for analysing duration data, and Andersen et al. (1993) have provided an excellent survey of this literature. Less technical surveys have been given by Klein and Moeschberger (1997), Therneau and Grambsch (2000) and Aalen et al. (2009). The main advantage of this framework is that it allows us to express the duration distribution as a regression model with an error term that is a martingale difference. Regression models with martingale difference errors are the basis for inference in time-series models with dependent observations. Hence, it is not surprising that inference is much simplified by using a similar representation in duration models.
To start the discussion, we first introduce some notation. A counting process \(\{ N(t);t \ge 0 \}\) is a stochastic process describing the number of events in the interval [0, t] as time proceeds. The process contains only jumps of size \(+1\). For single duration data, the event can only occur once, because the units are observed until the event occurs. Therefore, we introduce the observation indicator \(Y(t) = I(T \ge t)\) that equal to 1 if the unit is under observation at time t and zero after the event has occurred. The counting process is governed by its random intensity process \(Y(t)\lambda (t)\), with \(\lambda (t)\) is the hazard in (A.1). If we consider a small interval \((t-\mathrm{d}t,t]\) of length \(\mathrm{d}t\), then \(Y(t)\lambda (t)\) is the conditional probability that the increment \(\mathrm{d}N(t)=N(t)-N(t-\mathrm{d}t)\) jumps in that interval given all that has happened until just before t. By specifying the intensity as the product of this observation indicator and the hazard rate, we effectively limit the number of occurrences of the event to one. It is essential that the observation indicator only depends on events up to time t.
Usually, some of the observations are right-censored \(\tilde{T} = \min (T,C_r)\). By defining the observation indicator as the product of the indicator \(I(t \le T)\) and, if necessary, an indicator of the observation plan, we capture when a unit is at risk for the event. A related concept is left-truncation. Left truncation occurs when individuals are only observed conditional on survival up till some duration \(C_l\), the age of military examination in our application. In the case of right censoring and left-truncation, the at-risk indicator: \(Y(t) = I(t \le T)I(t \le C_r)I(t \ge C_l)\). We assume that \(C_r, C_l\) and T are conditionally independent given X. The history up to t, \(\overline{Y}(t)\) is assumed to be a left continuous function of t. The history of the whole process also includes the (history of the) the covariates, treatment and mediator. Thus, we have
A fundamental result in the theory of counting processes, the Doob–Meyer decompositionFootnote 14, allows us to write
with \(M(t), t \ge 0\) a martingale with conditional mean and variance
The (conditional) mean and variance of the counting process are equal, so that the disturbances in (A.3) are heteroscedastic. The probability in (A.2) is 0, if the unit is no longer under observation. A counting process can be considered as a sequence of Bernoulli experiments because, if \(\text{ d }t\) is small, (A.4) and (A.5) give the mean and variance of a Bernoulli random variable. The relation between the counting process and the sequence of Bernoulli experiments is given in (A.3), which can be considered as a regression model with an additive error that is a martingale difference. This equation resembles a time-series regression model. The Doob–Meier decomposition is the key to the derivation of the distribution of the estimators, because the asymptotic behaviour of partial sums of martingales is well known.
We begin with a proof of the unbiased of the inverse-probability-weighted Gompertz PH-model estimator given in Eq. (3). This applies for the model in which the hazard function does not include a mediator Q.
1.1.1 Proof of Eq. (3): IPW Gompertz is unbiased
In a parametric PH model, the log-likelihood in counting process notation is (Andersen and Borgan 1985):
where \(\lambda _0(t;\alpha )\) is the baseline hazard with parameters \(\alpha \), e.g. for a Gompertz baseline hazard \(\lambda _0(t;\alpha )= e^{\alpha _0 + \alpha _1 t}\). Standard maximum likelihood estimation solves the roots of the derivatives of the log-likelihood:
with \(\theta = (\alpha , \gamma )'\) and \(L_{\alpha }(\theta )\) and \(L_{\gamma }(\theta )\) are the gradients of the log-likelihood w.r.t. \(\alpha \) and \(\gamma \). The IPW version includes the weights W in equation (A.7) and (A.8). Because our main parameter of interest is \(\gamma \), we only focus on \(L_{\gamma }(\theta )\).
First, we derive E\(\bigl [W D \text {d}N(t)\bigr ]\). Redefine the propensity score \(p(d)=\Pr (D_i=d|X_i)\), with \(d=0,1\). Note that the integral of the sum is equal to the sum of the integrals. First, we derive E\([WD \text {d}N(t)]\) and E\([\sum Y(t) \lambda _0(t;\alpha )e^{\gamma D} W D]\).
From (A.9), we have E\([W D \text {d}N(t)]=f(t|D=1)\text {d}t\). Thus, if we assume the right parametric model this implies that \(L_{\gamma }(\theta )\) has zero mean.
1.1.2 Proof of Eq. (3): IPW Gamma-Gompertz is unbiased
In a MPH model with a parametric baseline hazard and a unit-mean Gamma-distributed unobserved heterogeneity with variance \(\sigma ^2\), the (unconditional) hazard is:
and the likelihood (in counting process notation) is:
IPW solves the roots of the weighted derivatives of the log-likelihood. The weighted derivative w.r.t. \(\gamma \) is:
To prove (3), we use similar reasoning as above. First, we derive
and
Thus, if we assume the right parametric model for the baseline hazard and a Gamma distribution for the unobserved heterogeneity, (A.13) has mean zero.Footnote 15
We now turn our attention to specifications that include a mediator Q and provide a proof for Theorem 1 on the identification of the decomposition.
1.1.3 Proof of Theorem 1 and Eq. 5
The direct effect \(\theta (d)\) solves E\(\bigl [L(\theta (d))\bigr ]=0\) with \(L(\theta (d))\) as in (A.12) with \(W_i=W_i(d)\).
and
1.2 Appendix B: Additional tables and figures
See Tables 8, 9, 10, 11, 12, 13, 14 and 15.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Bijwaard, G.E., Jones, A.M. An IPW estimator for mediation effects in hazard models: with an application to schooling, cognitive ability and mortality. Empir Econ 57, 129–175 (2019). https://doi.org/10.1007/s00181-018-1432-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-018-1432-9