
Abstract
Finite mixture of Gaussians are often used to classify two- (units and variables) or three- (units, variables and occasions) way data. However, two issues arise: model complexity and capturing the true cluster structure. Indeed, a large number of variables and/or occasions implies a large number of model parameters; while the existence of noise variables (and/or occasions) could mask the true cluster structure. The approach adopted in the present paper is to reduce the number of model parameters by identifying a sub-space containing the information needed to classify the observations. This should also help in identifying noise variables and/or occasions. The maximum likelihood model estimation is carried out through an EM-like algorithm. The effectiveness of the proposal is assessed through a simulation study and an application to real data.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In a cluster analysis context, a finite mixture of Gaussians is frequently used to classify a sample of observations (see McLachlan and Peel 2000). However, the application of this model in practice presents two major problems. First, a large number of parameters needs to be estimated when many variables are involved. Second, it is difficult to identify the roles that the different variables play in the classification, i.e. to understand if and how the variables discriminate among groups. A simple solution to those problems could be the use of the so called “tandem analysis”, where a preliminary principal component analysis (PCA) to reduce the dimension of the data (in terms of the number of variables) is followed by a cluster analysis performed on the main component scores. Although this procedure is very common in practice, it has been criticized by several authors (e.g., Chang 1983; De Soete and Carroll 1994). The reason is that principal components account for the maximal amount of the total variance of the data but do not necessarily contain information about the classification, even when many components are retained. To avoid this, PCA could be used after the estimation of the cluster structure, to analyse the between covariance matrix. In this case, the principal components are identified to explain the maximum between variability instead of the total one. Nevertheless, even in this case some problems arise. First, it is not known how the number of components to be retained has to be chosen. Second, the discriminating power of any component depends on its both between and within variability. The first should be as high as possible while the latter should be low. The components identified by a PCA of the between covariance matrix do not necessarily satisfy such property because they guarantee only a high level of between variability. Third, the reduction step should help the estimation of the clustering structure by removing noise dimensions from the data and reducing the number of parameters. This is not possible if PCA is done as final step.
In the literature, there is a large consensus in identifying as a solution to the aforementioned problems to perform clustering and dimensionality reduction simultaneously. Indeed, several authors have already proposed such methods (see for example: De Soete and Carroll 1994; Vichi and Kiers 2001) but only in an optimization approach. Others formulated some models following a model based approach (see for example: Kumar and Andreou 1998; Bouveyron and Brunet 2012b; Ranalli and Rocci 2017). Quite frequently information has a complex structure like three-way data, where the same variables are observed on the same units over different occasions. Some typical examples are represented by longitudinal data on multiple response variables or spatial multivariate data. Other examples arise when some objects are rated on multiple attributes by multiple experts or from experiments in which individuals provide multiple ratings for multiple objects (Vermunt 2007). Furthermore, we find some other examples among symbolic data provided that the complex information can be structured as multiple values for each variable (Billard and Diday 2003). In this context, clustering is performed in several ways. We find proposals where three-way data is transformed into two-way data by using some dimension reduction techniques to one of the ways, such as PCA. This allows us to apply conventional clustering techniques. Other proposals take into account the "real" three-way data structure in a least-square approach (see for example: Gordon and Vichi 1998; Vichi 1999; Rocci and Vichi 2005). On the other hand, we find model-based clustering for three-way data. Basford and McLachlan (1985) adapted the Gaussian mixture model to the three-way data, followed by the extensions proposed by Hunt and Basford (1999) for dealing with mixed observed variables. Vermunt (2007) used a hierarchical approach, similar to the one proposed for the multilevel latent class model (Vermunt 2003), to allow units to belong to different classes in different occasions. However, all of them are based on the conditional independence assumption. In other words, the aforementioned proposals do not explicitly estimate the correlations between occasions (they are implicitly taken to be zero). Moreover, correlations between variables are assumed to be constant across the third mode. It is interesting to interpret three-way data as matrix variate rather than multivariate. From this point of view, the Gaussian mixture model has been generalized to the mixtures of matrix Normal distributions within a frequentist (Viroli 2011a) and a Bayesian (Viroli 2011b) framework. Both contributions take into account the full information on the two ways, not separately but simultaneously. At this aim, the model is based on the matrix-variate normal distribution (Nel 1977; Dutilleul 1999). Based on this framework, more recently, further extensions have been proposed by: Melnykov and Zhu (2018) to model skewed three-way data for unsupervised and semi-supervised classification; Sarkar et al. (2020) to reduce the number the number of parameters introducing more parsimonious matrix-variate normal distributions based on the spectral decomposition of covariance matrices; Tomarchio et al. (2020) to handle data with atypical observations introducing two matrix-variate distributions, both elliptical heavy-tailed generalization of the matrix-variate normal distribution; Tomarchio et al. (2021) to extend to the three-way data the cluster-weighted models, i.e. finite mixtures of regressions with random covariates; Ferraccioli and Menardi (2023) where the nonparametric formulation of density-based clustering, also known as modal clustering, is extended to the framework of matrix-variate data.
However, even in the three-way case the problems (large number of parameters when many variables are involved and understanding if and how the variables discriminate among groups) arise and, tentatively, solved by a tandem analysis where dimensionality reduction and clustering are sequentially combined. The components can be extracted by using a three-mode principal component analysis (Kroonenberg and De Leeuw 1980) while the clustering can be done adopting a suitable mixture model (Basford and McLachlan 1985). However, all the issues described above for the two-way data remain unsolved even for the three-way case unless the two steps are performed simultaneously. Several authors have already proposed such methods in the three-way case (see for example: Rocci and Vichi 2005; Vichi et al. 2007; Tortora et al. 2016) but only in an optimization approach.
In this paper a model is proposed in the context of three-way data by using a finite mixture as a form to describe data suspected to consist of relatively distinct groups. In particular, it is assumed that the observed data are sampled from a finite mixture of Gaussians, where each component corresponds to an underlying group. The group-conditional mean vectors and the common covariance matrix are reparametrized according to parsimonious models able to highlight the discriminating power of both variables and occasions while taking into account the three-way structure of the data.
The plan of the paper is the following: in the second section, we present the Simultaneous Clustering and Reduction (SCR) model for two-way data; in Sect. 3, it is extended to the three-way case. The EM algorithm used to estimate the model parameters is presented in Sect. 4. Sections 5 and 6 deal with model interpretation and comparison with related models, respectively. In Sect. 7, the results of a simulation study conducted to investigate the behaviour of the proposed methodology are reported. In Sect. 8, an application to real data is illustrated. Some remarks are pointed out in the last section.
2 The SCR model for two-way data
Let x = [x1, x2, …, xJ]′ be a random vector of J variables. We assume that x is sampled from a population which consists of G groups, in proportions p1, p2, …, pG. The density of x in the gth group is multivariate normal with mean μg and covariance \({\varvec{\varSigma}}_V\). As a result, the unconditional, or marginal, density of x is the homoscedastic finite mixture
The Simultaneous Clustering and Reduction (SCR) model leaves unstructured the covariance matrix as \({\varvec{\varSigma}} = {\varvec{\varSigma}}_V\) and performs a dimensionality reduction on the mean vectors of the groups by a Principal Component Analysis (PCA). In particular, the mean μgj of the jth variable in the gth group is related to a reduced set of Q (< J) latent variables following the linear model below
where ηgq represents the score of the qth latent variable in the gth group, bjq is the loading of variable j on the qth latent variable. In, obvious, compact matrix notation, Eq. (2) is
where for identification purposes, \(\sum^p_g {\varvec{\eta}}_g = 0.\) Therefore, the mean vector of each group, which lies into a J dimensional space, is reproduced into a subspace of (reduced) dimension Q according to the linear model (3). It has to be noted that, as in factor analysis, parameters involved in (3) are not uniquely determined. The loading matrix can be rotated without affecting the model fit, provided that the latent vectors ηg are counter-rotated by the inverse transformation. This can be easily shown by noting that, for any non-singular matrix D, we can write
In words, only the subspace spanned by the columns of B is identified. To make easier the computation and improve the interpretation, we exploit such rotational freedom by requiring that
It is important to note that (5) does not identify a unique solution. This implies that, as in the ordinary factor analysis model, the loading matrix B can be furtherly rotated to enhance model interpretation.
3 The extension of the SCR model to three-way data
In this section, we extend the previous framework to the case of three-way data. Let x = [x11, x21, …, xJ1, …, x1K, x2K, …, xJK]′ be a random vector of J variables observed at K different occasions. We assume that x follows the Gaussian homoscedastic finite mixture model, specified in (1).
To reduce the number of parameters, the within covariance matrix is modelled as a direct product model (Browne 1984)
Where \(\otimes\) is the Kronecker product of matrices and \({\varvec{\varSigma}}_O\) and \({\varvec{\varSigma}}_V\) represent the covariance matrices of occasions and variables, respectively. The dimensionality reduction is performed on the mean vectors of the groups following a Tucker2 (Tucker 1966) model. In particular, the mean μgjk of the jth variable observed at the kth occasion in the gth group is related to a reduced set of Q (< J) latent variables measured in R (< K) latent occasions according to the following bilinear model
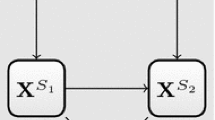
where ηqrg represents the score of the qth latent variable at the rth latent occasion in the gth group, bjq is the loading of variable j on the qth latent variable while ckr is the loading of occasion k at the rth latent occasion. The model can be graphically represented as in Fig. 1.

Graphical representation of Tucker 2 model
In matrix notation, Eq. (7) is
where, for identification purposes, \(\sum^{\text{p}}_g {\varvec{\eta}}_g = 0\). The bilinear model (7, 8) allows us to project the within-group means, lying into a JK dimensional space, onto a subspace of (reduced) dimension QR. The Tucker2 model can be seen as a PCA where the matrix of loadings is constrained to be the Kronecker product of two loading matrices, one for the variables and the other for the occasions, to take into account the three-way structure of the data.
For the same reasons explained at the end of Sect. 2, only the subspaces spanned by the columns of B and C are identified. To make easier the computation and improve the interpretation, we require that
Even in this case, constraints (9) do not identify a unique solution and matrices B and C can be rotated to enhance model interpretation.
4 The EM algorithm
In this section, we describe the EM algorithm needed to carry out the maximum likelihood parameter estimates. We refer to the general three-way data case, but it can be easily adjusted to K = 1, i.e. the two-way data case. Algorithms presented here have been implemented in MatLab. Codes can be found online at https://github.com/moniar412/SCR3waydata.
On the basis of a sample of N independent and identically distributed observations, the log-likelihood of the mixture model in (1), reparameterized according to (6) and (8), is
where \( \varphi_{ng} = \varphi ({x}_n ;{\varvec{\mu}}_g ,{\varvec{\varSigma}})\) and ϑ is the set containing all model parameters. It can be shown (Hathaway 1986) that to maximize (10) is equivalent to maximize
subject to the constraints ung ≥ 0 and \(\sum\nolimits_g {u_{ng} = 1}\) (n = 1, 2,…, N; g = 1, 2, …, G). An algorithm to maximize (11) can be formulated as a grouped version of the coordinate ascent method where the function is iteratively maximized with respect to a group of parameters conditionally upon the others. The basic steps of the algorithm can be described as follows.
First of all, it has to be noted that the ML estimate of μ in (8) is the sample mean \({\overline{\user2{x}}}.\). For sake of brevity, in the following we assume the data as centred and set μ = 0.
a) Update ung. Function (11) attains a maximum when \({\text{u}}_{ng} = {\text{p}}_g {{\varphi }}_{ng} \left( {\sum\nolimits_h {p_h {{\varphi }}_{nh} } } \right)^{ - 1}\), which is the posterior probability that observation n belongs to group g given the data xn.
b) Update pg. As in the ordinary EM algorithm, the update is \({\text{p}}_g = N^{ - 1} \sum\nolimits_n {u_{ng} }\).
c) Update \({\varvec{\varSigma}}_O\). Let Xn and Mg be J × K matrices such that vec(Xn) = xn and vec(Mg) = μg, function (11) can be rewritten as
where c is a constant term and \(\left| {{\varvec{\varSigma}}_O \otimes {\varvec{\varSigma}}_V } \right| = \left| {{\varvec{\varSigma}}_O } \right|^J \left| {{\varvec{\varSigma}}_V } \right|^K\). As a result, the maximizer of (12) is the minimizer of
where \({\bf{S}}_O = \left( {NJ} \right)^{ - 1} \sum\nolimits_{ng} {u_{ng} ({\bf{X}}_n - {\bf{M}}_g )^{\prime}{\varvec{\varSigma}}_V^{ - 1} ({\bf{X}}_n - {\bf{M}}_g )}\). This minimizer is \({\varvec{\varSigma}}_O\) = SO.
d) Update \({\varvec{\varSigma}}_V\). As in previous step, it can be shown that the update is \({\varvec{\varSigma}}_V = {\bf{S}}_V\), where \({\bf{S}}_V = \left( {NK} \right)^{ - 1} \sum\nolimits_{ng} {{\text{u}}_{ng} ({\bf{X}}_n - {\bf{M}}_g ){\varvec{\varSigma}}_O^{ - 1} ({\bf{X}}_n - {\bf{M}}_g )^{\prime}.}\)
e) Update ηg and B. By exploiting the equality \({\varvec{\mu}}_g = ({\bf{C}} \otimes {\bf{B}}){\varvec{\eta}}_g ,\) function (11) can be rewritten as
where \(c^{\prime}\) and \(c^{\prime \prime}\) are constant terms, \({\text{u}}_{ + g} = \sum_n {u_{ng} }\) and \({\overline{\user2{\bf{x}}}}_g = {\text{u}}_{ + g}^{ - 1} \sum\nolimits_n {u_{ng} {\bf{x}}_n }\). It follows that the updating of ηg is simply a weighted regression problem
where \({\overline{2{\bf{z}}}}_g = ({\varvec{\varSigma}}_O^{ - \frac{1}{2}} \otimes {\varvec{\varSigma}}_V^{ - \frac{1}{2}} ){\overline{\user2{\bf{x}}}}_g\) is the so-called within-standardized centroid and \({{{\mathop{ \bf C}\limits^{\frown}} }} = {\varvec{\varSigma}}_O^{ - \frac{1}{2}} {\bf{C}}\) and \({{{\mathop{ \bf B}\limits^{\frown}} }} = {\varvec{\varSigma}}_V^{ - \frac{1}{2}} {\bf{B}}\) are the so-called within-standardized loadings matrices. The update of B can be obtained by noting that (11) can be equivalently maximized with respect to \({{{\mathop{ \bf B}\limits^{\frown}} }}\) under the constraint \({{{\mathop{ \bf B}\limits^{\frown}}^{\prime}{\mathop{B}\limits^{\frown}} }} = {{ {\bf B}^{\prime}\Sigma }}_V^{ - 1} {\bf{B}} = {\bf{I}}.\) Substituting (15) into (14) and indicating with \({\overline{\user2{\bf{Z}}}}_g\) the J × K matrix such that \(vec({\overline{\user2{\bf{Z}}}}_g ) = {\overline{\user2{\bf{z}}}}_g\), we obtain
From (16) it is clear that the update of \({\bf{B}} = {\varvec{\varSigma}}_V^\frac{1}{2} {{{\mathop{ \bf B}\limits^{\frown}} }}\) is obtained by setting \({{{\mathop{ \bf B}\limits^{\frown}} }}\) equal to the first Q eigenvectors of \(\sum\nolimits^u_{ + g} {{\overline{\bf{Z}}}}_g {{{\mathop{ \bf C}\limits^{\frown}} {\mathop{C}\limits^{\frown}}^{\prime}}}{{\overline{\bf{Z}}^{\prime}}}_g .\)
f) Update ηg and C. Formula (16) can also be written as
The update of C is then obtained by setting \({{{\mathop{ \bf C}\limits^{\frown}} }}\) equal to the first R eigenvectors of \(\sum\nolimits^u_{ + g} {{\overline{\bf Z}^{\prime}}}_g {{{\mathop{ \bf B}\limits^{\frown}} {\mathop{B}\limits^{\frown}}^{\prime}}}{\overline{\bf{Z}}}_g .\)
5 Interpretation of components and connection with the Linear Discriminant Analysis (LDA)
On the basis of the results shown in the previous section, we will illustrate some interesting properties of the components generated by the model. For simplicity of exposition, we first discuss the two-way case, i.e. K = 1. Linear discriminant analysis (LDA) is a well-known supervised classification procedure that can also be seen as a data reduction tool. According to this, it can be used to represent multiclass data in a low dimensional subspace highlighting class differences.
First of all, we show how the within-standardized loadings matrix \({{{\mathop{ \bf B}\limits^{\frown}} }} = {\varvec{\varSigma}}_V^{ - \frac{1}{2}} {\bf{B}}\) derives from a PCA of the matrix of within-standardized centroids. This follows if we note that to maximize (11) with respect to B and ηg (g = 1,2, …,G) is equivalent to
where \(c^{\prime}\) and \(c^{\prime \prime}\) are constant terms, \(u_{ + g} = \sum_n {{\text{u}}_{ng} }\) and \({\overline{\bf{x}}}_g = {\text{u}}_{ + g}^{ - 1} \sum_n {{\text{u}}_{ng} {\bf{x}}_n }\). If we multiply (18) by − 2, add the constant term \(\sum\nolimits_g {{\text{u}}_{ + g} {{\overline{}^{\prime}}}_g {\varvec{\varSigma}}_V^{ - 1} {{\overline{\bf{x}}}}_g }\) and ignore c′ and c′′, we can transform the maximization of (18) into the minimization of
where \({\overline{\bf{X}}}\) is the matrix having the centroids \({\overline{\bf{x}}}_g\) as rows, \({\overline{\bf{Z}}} = {{\overline{\bf x}\Sigma }}_V^{ - \frac{1}{2}}\) being its within-standardized version, N is the matrix having the reduced centroids ηg as rows and D is the diagonal matrix with weights u+g on the main diagonal. The within-standardized data projected on the subspace identified by PCA, are the component scores
that are linear combinations of the original variables having the elements of the weight matrix \({{{\mathop{ \bf B}\limits^{\smile}} }}\) as coefficients. It is possible to show that they maximize the between variance subject to the constraint of unit within variance. In fact, the between and within variances for a linear combination v = Xb are \({{{\bf v}^{\prime}}}\left( {\sum\nolimits_g {{\text{u}}_{ + g} {\overline{\bf{x}}}_g {{\overline{\bf{x}}^{\prime}}}_g } } \right){\bf{v}}\) and \({{{\bf v}^{\prime}\Sigma }}_V {\bf{v}}\). Now, setting K = 1, (116 can be rewritten as
we note that the component weights maximize the sum of the between variances of the component scores subject to the constraints \({{{\mathop{ \bf B}\limits^{\smile}} }}^T {\varvec{\varSigma}}_V^{ - 1} {{{\mathop{ \bf B}\limits^{\smile}} }}\) = \({\bf{B}}^T {\varvec{\varSigma}}_V^{ - 1} {\varvec{\varSigma}}_{{V}} {\varvec{\varSigma}}_V^{ - 1} {\bf{B}} = {\bf{B}}^T {\varvec{\varSigma}}_V^{ - 1} {\bf{B}} = {\bf{I}}_Q .\) In other words, the components are chosen in order to maximize the between to within variances ratio as in multiple linear discriminant analysis. The results above can be extended to the general three-way case as follows. First, we note that (19) extend to
thus, the within-standardized component weights matrices can be seen as obtained from a Tucker2 analysis of the matrix of within-standardized centroids. Second, the component scores
are bilinear combinations of the original variables and occasions, and of maximum between variance among those of within variance equal to 1. In fact, the component weights maximize
subject to the constraints \({{{\mathop{C}\limits^{\smile^{\prime}}}\Sigma }}_O {{{\mathop{C}\limits^{\smile}} }} = {\bf{I}}_R\) and \({{{\mathop{B}\limits^{\smile}}^{\prime}\Sigma }}_V {{{\mathop{B}\limits^{\smile}} }} = {\bf{I}}_Q\). In other words, given the classification, the proposal can be seen as a bilinear discriminant analysis, that is the components are chosen in order to maximize the between to within variances ratio for variables and occasions.
6 Related models
In this paper, we propose a way to simultaneously cluster and reduce three-way data by identifying the informative clustering subspace. Such construction mainly allows us to identify the factors that explain the between variability in terms of different class-conditional means. Beside the linear discriminant analysis, seen in the previous section, the model can also be used for variable selection and/or parsimonious modelling purposes. It follows that our model can also be compared to models/methods following one of the two aforementioned purposes. In particular, within the first purpose, Raftery et al. (2006) formulate the problem of variable selection, for two-way data, as a model comparison problem using the BIC. Here the variables are projected into an informative subspace. This allows to identify the relevant variables. Different extensions have been proposed, such as in Maugis et al. (2009) and Witten and Tibshirani (2010). Within the second purpose, parsimonious modelling, the idea is to define model-based clustering by using a reduced set of parameters. One of the earliest parsimonious proposal is given in Celeux and Govaert (1995), where a mixture of Gaussians for two-way data is made parsimonious by imposing some equality constraints on some elements of the spectral decompositions of the class-conditional covariance matrices. Another parsimonious proposal is given by the mixture of factor analyzers (MFA) (see Ghahramani and Hinton 1997; Hinton et al. 1997; Ranalli and Rocci 2023, and references therein). Later, a general framework for the MFA model was proposed by McNicholas and Murphy (2008). Furthermore, we point the reader to see also Tipping and Bishop (1999) and Bishop (1998) who considered the related model of mixtures of principal component analyzers for the same purpose. Further references may be found in chapter 8 of Mclachlan and Peel (2000) and in a review on model-based clustering of high dimensional data (Bouveyron and Brunet 2012a, 2012b).
7 Model assessment
The effectiveness of our proposal has been tested trough a large simulation study where the SCR model (S3) with Q and R components has been compared with: the “ordinary” homoscedastic finite mixture of Gaussians (H); the SCR model applied ignoring the three-way data structure (S2) with Q × R components. Data is sampled from a homoscedastic finite mixture of multivariate J × K Gaussians with parameters randomly generated in a such a way that only Q variables in R occasions are informative for the clustering structure, i.e. have different class-conditional means. Two main scenarios are defined: few (J = 5, Q = 2, K = 5, R = 2—scenario (i) and many variables (J = 20, Q = 5, K = 5, R = 2—scenario (ii). Under each scenario we consider four different data generation processes (dgp) obtained by combining the situations where the S3 model is true or not for the means, with the situations where the S3 model is true or not for the covariance matrix. The levels of the experimental factor dgp are then 4: (1) true model; (2) false means—true covariance; (3) true means—false covariance; (4) false model. In particular, the true means are generated according to (8) with B and C being the first Q and R columns of an identity matrix; while the true covariance is generated according to (6). Additionally, other three different experimental factors are considered: sample size (small: N = 300 for scenario i and N = 500 for scenario ii; large: N = 500 for scenario i and N = 1000 for scenario ii), number of mixture components (G = 3, 5, 7), number of starting points (rep = 1, 3). It is important to note that our proposal is definitely less favored. Indeed, S3 is true only when dgp = 1 while H is always true and S2 is false only when the group means lie on a space of dimension greater than Q × R, i.e. (dgp = 2, G = 7, scenario = i) or (dgp = 4, G = 7, scenario = i). Within each scenario, 250 samples were generated for every combination of factor levels. The performances were evaluated in terms of recovering the true cluster structure calculating the Adjusted Rand Index (ARI) (Hubert and Arabie 1985) between the true hard partition matrix and that estimated. Simple descriptive statistics about the distributions of the ARIs in each setting are reported in the appendix as well as their boxplots. In the following two subsections we report some comprehensive boxplots along with some comments to see the performances in terms of ARI of the models in combination with different number of groups and the level of an experimental factor among sample size, number of repetitions or data generation process.
7.1 Scenario i
Under the first scenario, we explore the clustering performances through some boxplots depending on the sample size, the number of groups and the generation data process (boxplots of ARI distributions aggregated over the remaining experimental factors in Figs. 2, 3, 4).

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture aggregated by number of repetitions (1, 3) and data generation process (1, 2, 3, 4). G = 3, 5, 7, N = 300, 500, J = 5, Q = 2, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture aggregated by sample sizes (300, 500) and data generation process (1, 2, 3, 4). G = 3, 5, 7, nrep = 1, 3, J = 5, Q = 2, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture aggregated by sample sizes (300, 500) and number of repetitions (1, 3). G = 3, 5, 7, dgp = 1, 2, 3, 4, J = 5, Q = 2, K = 5 and R = 2
As the sample size increases (Fig. 2), the performances improve for all models. When.
N = 300 and G = 3, the means of ARI are equal to 0.85, 0.81 and 0.82 for S3, S2 and H, respectively; when N = 300 and G = 5, the means of ARI are equal to 0.84 for S3 and 0.90 for S2 and H; when N = 300 and G = 7, the means of ARI are equal to 0.85 for S3 and 0.83 for S2 and H, respectively. By increasing the sample sizes to N = 500, the means ARI increase mainly for S2 and H, giving better performances: S3 equals to around 0.85 for all G; S2 and H equal to 0.87, 0.92 and 0.88 when G = 3, 5, 7, respectively.
Considering the number of starting points (Fig. 3), when they increases the performances improve for all models. This confirms the fact that the EM algorithm could reach local maxima. With only one starting point and when G = 3, the means of ARI are equal to 0.80 for S3 and 0.78 for S2 and H; when G = 5, the means of ARI are equal to 0.77 for S3 and 0.86 for S2 and H; when G = 7, the means of ARI are equal to 0.69, 0.90 and 0.87 for S3, S2 and H, respectively. We note that the clustering performances of S3 worsen with higher G, i.e. when the model involves a larger number of parameters. The situation improves by increasing the number of starting points to 3: when G = 3, the means ARI increase to 0.90 for all models; when G = 5, the means ARI increase to 0.91 for S3 and 0.95 for S2 and H; while when G = 7, they increases to 0.86, showing a very large improvement, for S3, 0.94 and 0.92 for S2 and H. S3 seems to be the most affected by the number of repetitions among the models analysed. This is due to the fact that it involves more parameter constraints; this means that it is less flexible from a computational point of view; indeed S3 is more parsimonious, but also more computationally complex.
Overall, as regards the data generation process (Fig. 4), it is important to remember that S3 is true only when dgp = 1 while H is always true and S2 is false only when the group means lie on a space of dimension greater than Q × R, i.e. dgp = 2, 4 and G = 7. For G = 3, S3 performs equal or better than S2 and H for all dgp. Indeed, when dgp = 1 the ARI means are equal to 0.84 for S3 and 0.82 for S2 and H; when dgp = 2, the mean are equal to 0.85, 0.81 and 0.82 for S3, S2 and H, respectively; when dgp = 3, they are equal to 0.87 for all models, while when dgp = 4 they are equal to 0.86 for all models.
For G = 5, S3 performs slightly worse than S2 and H for all dgp. Indeed, when dgp = 1 or dgp = 2, the ARI means are equal to 0.85 for S3 and 0.90 for S2 and H; when dgp = 3, the mean are equal to 0.83 for S3 and 0.91 for S2 and H; when dgp = 4, the mean are equal to 0.84 for S3 and 0.91 for S2 and H.
For G = 7 S3 seems to show lower performances than S2 and H. Indeed, when dgp = 1, the ARI means are equal to 0.78, 0.92 and 0.89 for S3, S2 and H, respectively; when dgp = 2, the ARI means are equal to 0.80, 0.91 and 0.89 for S3, S2 and H, respectively; when dgp = 3, the mean are equal to 0.75, 0.92 and 0.90 for S3, S2 and H, respectively; when dgp = 4, the mean are equal to 0.75, 0.93 and 0..90 for S3, S2 and H, respectively.
Finally, as it is possible to see from the appendix, under this scenario, i.e. few variables (J = 5) and low proportion of noise variables/occasions, the computational complexity plays a main role. When G = 3, regardless the specific experimental factor, S3 often results to be the best model in terms of median (varying from 0.96 to 1.00 over different combinations of experimental factors) from a fitting clustering point of view. However, in terms of means, when the model is false (dgp = 4) for S3, then S2 is the best model compared to S3 when the number of repetitions is only one (0.79 compared to 0.77, and 0.85 compared to 0.80 for N = 300 and N = 500, respectively). However, when the number of repetitions is equal to 3, S3 improves and results to be even the best one when N = 300 (0.87 compared to 0.85). As G increases (G = 5, 7), S3 is not anymore the best model, even when the model is well specified and the number of repetitions is equal to 3. Finally, comparing S2 with H, they show similar behavior, since the data structure is not complex at all and the cluster structure can be easily recovered.
7.2 Scenario ii
Differently from the first scenario, under the second one, N is relatively large, many variables (J = 20) and high proportion of noise variables/occasions, the model parsimony plays a main role (rather than computational complexity). Also under this scenario, we consider the clustering performances depending on the sample size, the number of repetitions and the generation data process (see the boxplots of ARI distributions aggregated by the remaining experimental factors in Figs. 5, 6, 7), but in this case the main considerations point against the model competitors, S2 and H (although they are never false under this scenario).

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture aggregated by number of repetitions (1, 3) and data generation process (1, 2, 3, 4). G = 3, 5, 7, N = 500, 1000, J = 20, Q = 5, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture aggregated by sample sizes (500, 1000) and data generation process (1, 2, 3, 4). G = 3, 5, 7, nrep = 1, 3, J = 20, Q = 5, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture aggregated by sample sizes (500, 1000) and number of repetitions (1, 3). G = 3, 5, 7, dgp = 1, 2, 3, 4, J = 20, Q = 5, K = 5 and R = 2
The performances improve for all models when the sample size increases (Fig. 5). When N = 500 and G = 3, the means of ARI are equal to 0.89 for S3 and 0.59 for S2 and H; when N = 500 and G = 5, the means of ARI are equal to 0.90, 0.51 and 0.50 for S3, S2 and H, respectively; when N = 500 and G = 7, the means of ARI are equal to 0.90 for S3 and 0.60 for S2 and H, respectively. By increasing the sample sizes to N = 1000, the means ARI of S2 and H are more affected, even if they are still performing worse than S3. Indeed, for G = 3 the means are equal to 0.89 for S3 and 0.68 for S2 and H; when G = 5, they are equal to 0.92 for S3 and 0.74 for S2 and H; while when G = 7, they are equal to 0.90 for S3 and 0.70 for S2 and H.
As the number of starting points increases, the performances of S3 always improves substantially (Fig. 6). With only one staring point and when G = 3, the means of ARI are equal to 0.86 for S3 and 0.64 for S2 and H; when G = 5, the means of ARI are equal to 0.88 for S3 and 0.61 for S2 and H; when G = 7, the means of ARI are equal to 0.91 for S3 and 0.59 for S2 and H. The situation improves by increasing the number of starting points to 3: when G = 3 or G = 5, the means ARI increase to 0.93 for S3 and 0.30 for S2 and H; while when G = 7, they increases to 0.96, showing a very large improvement, for S3 and 0.40 for S2 and H. We note that, differently from the previous scenario, the clustering performances of S3 improve with higher G, i.e. when the model involves a larger number of parameters. We recall that here we are considering a higher proportion of noise, so S3 works better in capturing the clustering structure in a parsimonious way.
Regarding the data generation process (Fig. 7), it is important to remember that S3 is true only when dgp = 1 while H and S2 are always true. For all G, S3 performs always better than S2 and H. Indeed, when dgp = 1 the ARI means are equal to 0.91, 0.44 and 0.45 for S3, S2 and H, respectively; when dgp = 2, the mean are equal to 0.91 for S3 and 0.48 for S2 and H; when dgp = 3, they are equal to 0.88 for S3 and 0.81 for S2 and H, while when dgp = 4 they are equal to 0.87 for S3 and 0.80 for S2 and H. For G = 5, when dgp = 1 or dgp = 2, the ARI means are equal to 0.91 for S3 and 0.43 for S2 and H; when dgp = 3, the means are equal to 0.91 for S3 and 0.83 for S2 and H; when dgp = 4, the means are equal to 0.91 for S3 and 0.81 for S2 and H. For G = 7 when dgp = 1, the ARI means are equal to 0.92, 0.43 and 0.42 for S3, S2 and H, respectively; when dgp = 2, the ARI means are equal to 0.92 for S3 and 0.42 for S2 and H; when dgp = 3, the means are equal to 0.95, 0.81 and 0.80 for S3, S2 and H, respectively; when dgp = 4, the means are equal to 0.95 for S3 and 0.80 for S2 and H.
Some further details can be drawn from the results in the appendix. Differently from scenario i, under this scenario, S3 wins over the two competitors in all experimental factors, thanks to its ability to take into account the presence of noise variables/occasions. It parsimoniously discards all the uninformative variables/occasions. S3 is not only the best model from a fitting clustering point of view, it also shows robustness. Indeed, although the data generation is different from the structure of data assumed by the model (dgp = 2, 3 and 4), S3 is able to capture the true cluster structure, discarding all the irrelevant information. It shows similar behaviors as the case dgp = 1.
8 An application on real data
The new mixture model for three-way data is illustrated by reanalyzing the classical soybean data set used by Basford and McLachlan (1985). The data originated from an experiment in which 58 soybean genotypes were evaluated at four locations (Lawes, Brookstead, Nambour, Redland Bay) in Queensland, Australia, at two time points (1970, 1971). The eight location × time combinations are referred as environments. Various chemical and agronomic attributes were measured on the genotypes. Following Basford and McLachlan (BandM, Basford and McLachlan 1985) only seed yield (kg/ha) and seed protein percentage are considered. On this data set BandM have found 7 groups forming two clearly distinct subsets (the first three vs. the last four). Reduced mixture models have been estimated for G, Q, and R values ranging in 2:7, 1:2 and 1:8. For the covariance matrix \({\varvec{\varSigma}}_O\) two different forms have been assumed: either diagonal or with non null covariances only between the same locations. The best model selected by the BIC criterion has been: G = 7, Q = 2, R = 2 and \({\varvec{\varSigma}}_O\) diagonal. Table 1 displays the percentage of variation accounted for by the components (two latent variables at two latent occasions), calculated on the within-standardized data.
In Table 2, the classification into 7 groups has been compared with that obtained by BandM. They are quite different but display the same two distinct subsets even if in our analysis group 3 from BandM is split into two groups.
The aforementioned distinction is clear when we look at Fig. 8, where the scores of the genotypes on the first latent variable are displayed at the two latent occasions (the coordinates are the first and third columns of Y, see (23)). The biplot represents both cluster centroids [the coordinates are given by the first and third columns of N, see (15) and (22)] and occasions [the coordinates are given by the columns of \({{{\mathop{ \bf C}\limits^{\frown}} }}\), see (22)]. The scalar products between occasions and centroids represent the deviations from the grand mean of the group-conditional means of the first latent variable at the different occasions (the odd columns of \({\overline{\bf{Z}}}({\bf{I}}_8 \otimes {{{\mathop{ \bf B}\limits^{\frown}} }})\)). This graphical representation helps in identifying the discriminating power of the occasions. For example, we can see that the Redland Bay in 1970 (R0) is the environment better clarifying the separation between the two subsets.

Biplot on the first latent variable at the two latent occasions
9 Concluding remarks
In this paper, we proposed a model that reduces the data dimensionality by identifying latent components that are (informative) able to explain the clustering structure underlying the three or two-way data structure. This allows to overcome the issues arising in applying reduction techniques and clustering methods separately (i.e. sequentially). The proposal involves a finite mixture of Gaussians whose mean vectors present a Tucker2 structure, while the covariance matrix can be decomposed as \({\varvec{\varSigma}} = {\varvec{\varSigma}}_O \otimes {\varvec{\varSigma}}_V\) (commonly used in the multitrait-multimethod literature).
As noted by a referee, on the mean vectors we could impose a Tucker3 model rather than a Tucker2. The difference between the two is that the former would provide also a reduction for the centroids. In formulas we would have
where A = [agp] is a G × P matrix of component loadings for the centroids. The model can be graphically represented as in Fig. 9.

Graphical representation of Tucker 3 model
In this paper, we preferred the Tucker2 model because the centroids can be already considered as a reduced mode derived from the units mode. However, we do not exclude that the Tucker3 model could be useful when the number of centroids is very large.

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture models over 16 settings by varying the number of starting points (1, 3), the data generation process (1, 2, 3, 4) and the sample size (300, 500). G = 3, J = 5, Q = 2, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way, SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture models over 16 scenarios by varying the number of starting points (1, 3), the data generation process (1, 2, 3, 4) and the sample size (300, 500). G = 5, J = 5, Q = 2, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture models over 16 scenarios by varying the number of starting points (1, 3), the data generation process (1, 2, 3, 4) and the sample size (300, 500). G = 7, J = 5, Q = 2, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture models over 16 scenarios by varying the number of starting points (1, 3), the data generation process (1, 2, 3, 4) and the sample size (500, 1000). G = 3, J = 20, Q = 5, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture models over 16 scenarios by varying the number of starting points (1, 3), the data generation process (1, 2, 3, 4) and the sample size (500, 1000). G = 5, J = 20, Q = 5, K = 5 and R = 2

Box-plots of ARI distributions for SCR three-way (S3), SCR two-way (S2), and homoscedastic (H) mixture models over 16 scenarios by varying the number of starting points (1, 3), the data generation process (1, 2, 3, 4) and the sample size (500, 1000). G = 7, J = 20, Q = 5, K = 5 and R = 2
Although the effectiveness of the model has been assessed empirically through a large simulation study and a real data application, we did not discuss a desirable property of the model, i.e. the scale invariance. Given the structure of the covariance and component loading matrices, the model is scale invariant under bilinear transformations. In other terms, if a variable is scaled, it should be scaled in the same way over all occasions. Formally, if data are scaled by a matrix D, scale invariance holds only if D can be decomposed into \({\bf{D}} = {\bf{D}}_O \otimes {\bf{D}}_V\).
The model here presented can be extended in several ways in different directions. For example, it would be interesting to explore the extensions to the case of particular data types such as compositional, functional or mixed.
References
Basford KE, McLachlan GJ (1985) The mixture method of clustering applied to three-way data. J Classif 2:109–125
Billard L, Diday E (2003) From the statistics of data to the statistics of knoweledge: symbolic data analysis. J Am Stat Assoc 98:470–487
Bishop CM (1998) Latent variable models. Learning in graphical models. Springer, Netherlands, pp 371–403
Bouveyron C, Brunet C (2012a) Model-based clustering of high-dimensional data: a review. Comput Stat Data Anal 71:52–78
Bouveyron C, Brunet C (2012b) Simultaneous model-based clustering and visualization in the Fisher discriminative subspace. Stat Comput 22(1):301–324
Browne MW (1984) The decomposition of multitrait-multimethod matrices. Br J Math Stat Psychol 37:1–21
Celeux G, Govaert G (1995) Gaussian parsimonious clustering models. Pattern Recogn 28(5):781–793
Chang W (1983) On using principal components before separating a mixture of two multivariate normal distributions. Appl Stat 32:267–275
De Soete G, Carroll JD (1994) K-means clustering in a low-dimensional Euclidean space. In: Diday E et al (eds) New approaches in classification and data analysis. Springer, Heidelberg, pp 212–219
Dutilleul P (1999) The MLE algorithm for the matrix normal distribution. J Stat Comput Simul 64:105–123
Ferraccioli F, Menardi G (2023) Modal clustering of matrix-variate data. Adv Data Anal Classif 17:323–345. https://doi.org/10.1007/s11634-022-00501-x
Ghahramani Z, Hinton GE (1997) The EM algorithm for mixtures of factor analyzers. Technical Report, University of Toronto
Gordon AD, Vichi M (1998) Partitions of partitions. J Classif 15:265–285
Hathaway RJ (1986) Another interpretation of the EM algorithm for mixture distributions. Statist Probab Lett 4:53–56
Hinton GE, Dayan P, Revow M (1997) Modeling the manifolds of images of handwritten digits Neural Networks. IEEE Trans 8(1):65–74
Hubert L, Arabie P (1985) Comparing partitions. J Classif 2(1):193–218
Hunt LA, Basford KE (1999) Fitting a Mixture Model to three-mode three-way data with categorical and continuous variables. J Classif 16:283–296
Kroonenberg PM, De Leeuw J (1980) Principal components analysis of three-mode data by means of alternating least squares algorithms. Psychometrika 45:69–97
Kumar N, Andreou AG (1998) Heteroscedastic discriminant analysis and reduced rank HMMs for improved speech recognition. Speech Commun 26(4):283–297
Maugis C, Celeux G, Martin-Magniette ML (2009) Variable selection for clustering with gaussian mixture models. Biometrics 65(3):701–709
McLachlan GJ, Peel D (2000) Finite mixture models. Wiley, New York
McNicholas P, Murphy T (2008) Parsimonious gaussian mixture models. Stat Comput 18(3):285–296
Melnykov V, Zhu X (2018) On model-based clustering of skewed matrixdata. J Multivar Anal 167:181–194
Nel HM (1977) On distributions and moments associated with matrix normal distributions. Mathematical Statistics Department, University of the Orange Free State, Bloemfontein, South Africa, (Technical report 24).
Raftery AE, Dean N, Graduate NDI (2006) Variable selection for model-based clustering. J Am Stat Assoc 101:168–178
Ranalli M, Rocci R (2023) Composite likelihood methods for parsimonious model-based clustering of mixed-type data. Adv Data Anal Classif 9:1–27
Ranalli M, Rocci R (2017) A model-based approach to simultaneous clustering and dimensional reduction of ordinal data. Psychometrika 82(4):1007–1034
Rocci R, Vichi M (2005) Three-mode component analysis with crisp or fuzzy partition of units. Psychometrika 70(4):715–736
Sarkar S, Zhu X, Melnykov V et al (2020) On parsimonious models for modeling matrix data. Comput Stat Data Anal 142:106822
Tipping M, Bishop C (1999) Mixtures of probabilistic principal component analyzers. Neural Comput 11(2):443–482
Tomarchio SD, Punzo A, Bagnato L (2020) Two new matrix-variate distributions with application in model-based clustering. Comput Stat Data Anal 152:107050
Tomarchio SD, McNicholas PD, Punzo A (2021) Matrix normal cluster-weighted models. J Classif 38(3):556–575
Tortora C, Gettler SM, Marino M, Palumbo F (2016) Factor probabilistic distance clustering (FPDC): a new clustering method. Adv Data Anal Classif 10(4):441–464
Tucker LR (1966) Some mathematical notes on three-mode factor analysis. Psychometrika 31:279–311
Vermunt JK (2003) Multilevel latent class models. Soc Method 33:213–239
Vermunt JK (2007) A hierarchical mixture model for clustering three-way data sets. Comput Stat Data Anal 51:5368–5376
Vichi M (1999) One mode classification of a three-way data set. J Classif 16:27–44
Vichi M, Kiers HAL (2001) Factorial K-means analysis for two-way data. Comput Stat Data Anal 37:49–64
Vichi M, Rocci R, Kiers AL (2007) Simultaneous component and clustering models for three-way data: within and between approaches. J Classif 24:71–98
Viroli C (2011a) Finite mixtures of matrix normal distributions for classifying three-way data. Stat Comput 21:511–522
Viroli C (2011b) Model based clustering for three-way data structures. Bayesian Anal 6(4):573–602. https://doi.org/10.1214/11-BA622
Witten DM, Tibshirani R (2010) A framework for feature selection in clustering. J Am Stat Assoc 105:490
Funding
Open access funding provided by Università degli Studi di Roma La Sapienza within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Scenario i
See Tables 3, 4, 5, 6, 7 and 8 and Figs. 10, 11, 12.
1.2 Scenario ii
See Tables 9, 10, 11, 12, 13 and 14, Figs. 13, 14, 15.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rocci, R., Vichi, M. & Ranalli, M. Mixture models for simultaneous classification and reduction of three-way data. Comput Stat (2024). https://doi.org/10.1007/s00180-024-01478-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00180-024-01478-1