
Abstract
Countries’ performance can be compared by means of indicators, which in turn give rise to rankings at a given time. However, the ranking does not show whether a country is improving, worsening or is stable in its performance. Meanwhile, the evolutionary behaviour of a country’s performance is of fundamental importance to assess the effect of the adopted policies in both absolute and comparative terms. Nevertheless, establishing a general ranking among countries over time is an open problem in the literature. Consequently, this paper aims to analyze ranks’ dynamic by means of the functional data analysis approach. Specifically, countries’ performances are evaluated by taking into account both their ranking position and their evolutionary behaviour, and by considering two functional measures: the modified hypograph index and the weighted integrated first derivative. The latter are scalar measures that are able to reflect trajectories behaviours over time. Furthermore, a novel visualisation technique based on the suggested measures is proposed to identify groups of countries according to their performance. The effectiveness of the proposed method is shown through a simulation study. The procedure is also applied on a real dataset that is drawn from the Government Effectiveness index of 27 European countries.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Countries’ performances are often measured by elementary or composite indicators, whose values are used for ranking purposes. Indicators and rankings are simplified and widely used representations of complex phenomena, and are increasingly employed by international agencies and governments to assess a country’s achievements (Bellantuono et al. 2020; Kelley and Simmons 2019). In particular, the analysis of ranks provides useful information in a comparative perspective, returning the relative position of each country with respect to the others. Ranking problems can arise in many fields, such as wealth (Malul et al. 2009), human development (Zheng and Zheng 2015; Wu et al. 2014; Cherchye et al. 2008), well-being (Peiro-Palomino and Picazo-Tadeo 2018; Phillis et al. 2011), energy (Lee and Chang 2018), biology (Shah and Wainwright 2017; Di Battista et al. 2016, 2017), growth studies (Ramsay and Silverman 2002), analysis of choices behaviour (Yu et al. 2013), and performance evaluation (Zhang et al. 2021). Although there is a growing agreement on the use of ranks to compare performance, they are generally evaluated from a static point of view. However, the analysis of rank evolution over time is crucial to evaluate whether, comparatively, a country is experiencing an improvement, worsening or stability in its performance and, consequently, to evaluate the effect of adopted policies. The analysis of ranks over time has been restricted to specific applications, such as sports tournaments (Cattelan et al. 2013; Jabin and Junca 2015; Motegi and Masuda 2012). Moreover, dynamic approaches for the analysis of rankings have been largely limited to some syntectic measures, such as average annual ranks, absolute differences among ranking positions at consecutive times, and percentage changes (Tsui 1996; Chakraborty 2011).
Given that the observations of performance over time are constantly evolving and could also be high-dimensional, the functional data analysis (FDA) approach is the most natural tool to analyse these data (Ramsay and Silverman 2005; Ferraty and Vieu 2006). The usefulness of this approach lies in two reasons: the first is the reduction of dimensionality and the second is the possibility to take advantage of additional tools to capture the characteristics of the trends. In the FDA framework, ranks obtained for each country at different times can be considered as discrete observations of smooth rank trajectories. Once the ranking series of each country is approximated by a function, the focus is on modeling the ranks of individuals and their patterns over time. The FDA approach is very useful in this context because it allows us to visualise the rank’s behaviour over time, to introduce functional tools and to tackle cases where data have missing values or are measured at unmatched time points. The FDA approach is widely used in many areas, such as ecology (Lin and Zhou 2017; Febrero et al. 2007; Fortuna et al. 2020), electricity demand (Jan et al. 2022; Shah et al. 2020, 2022; Bibi et al. 2021), economics (Gattone et al. 2021; Bongiorno and Goia 2019), medical research (Cao and Ramsay 2007; Maturo and Verde 2022), behavioural sciences (Aguilera et al. 2021), spectrometric (Reiss and Ogden 2007), and education (Maturo et al. 2019; Ramsay 1991), among the others. However, the analysis of rank dynamics by means of the FDA approach is a rather recent topic. The pioneering work in this field was published by Chen et al. (2020), who suggested a decomposition of rank derivatives into a population and an individual contribution to the rank evolution. The need for this decomposition is due to the dependence of rank dynamics on the interplay between individual and population changes.
Starting from the work of Chen et al. (2020), this paper aims to evaluate countries’ performances by taking into account both their ranking position and their evolutionary behaviour; that is, by jointly considering the magnitude and the evolution of performances in the entire temporal domain. Indeed, it is convenient to complement information concerning the level attained by a country with the dynamic behaviour of its trajectory. Consequently, two functional measures are introduced. The first returns an overall ranking, which reflects the magnitude of ranks and is based on the modified hypograph index (MHI) that was initially suggested by Lopez-Pintado and Romo (2011). MHI represents the proportion of the time span that the graphs of the functions in the sample are in the hypograph of a specific curve; that is, the proportion of time that the curves of the sample are below a specific trajectory. Of course, a high value of MHI corresponds to a high rank position over the whole domain, and vice versa. However, in many cases MHI is not sufficient to distinguish the behaviours of different curves—equal values of MHI could correspond to different shapes. Therefore, a limitation of this measure is that it neglects the way in which a country reaches a specific position. This drawback may be overcome by considering the derivatives of the curves, which emphasise the first signs of growth or decrease of the original function (Ramsay and Silverman 2005). To this end, Chen et al. (2020) proposed the integrated first derivative to quantify how variable the rank of a unit is over time. The disadvantage of this measure is that it reflects the total behaviour of the first derivative without distinguishing how long the original function shows a certain trend. Moreover, the first derivative of the rank trajectory does not represent the single country’s evolution. In fact, a county’s rank is affected by the entire population’s dynamic: a country could change rank while maintaining its trend.
To overcome these limitations, this research suggests the use of the first derivatives computed on the original trajectories as an additional tool to assess a country’s performance over time. Specifically, the weighted integrated first derivative (DW) is proposed as a second functional measure. In addition, a visualisation tool, named \(MHI-DW\) plot, is suggested to jointly interpret magnitude and dynamic variations of a rank’s trajectory. Countries are represented in the Cartesian plane defined by MHI and DW. Consequently, the proposed graph helps to interpret the behaviour of trends and identify countries with similar or dissimilar behaviours based on their positioning in the generated space. To assess the reliability of the two functional measures, a simulation study is carried out, by evaluating MHI in combination with different evolutionary measures. The results indicate that the combined use of MHI and DW is an efficient tool for distinguishing functions with similar magnitude and evolution. Moreover, the suggested methodology is applied to study the rankings’ evolution of an institutional quality services indicator, namely the Government Effectiveness (GE) index (Kaufmann et al. 2010; Gisselquist 2014), using the ranking series of 27 European countries over the period 1996 to 2020.
This paper is organised as follows. In Sect. 2, the ranks functional approximation is presented. In Sect. 3, the two functional measures and the \(MHI-DW\) plot are defined. A simulation study is conducted in Sect. 4. In Sect. 5, the \(MHI-DW\) plot is applied to a real dataset concerning the GE index of 27 European countries. Finally, Sect. 6 concludes the paper.
2 Ranking functions through functional data analysis
Let \(y_i(t)\), \(i=1,2,\ldots ,n\), be a sample of n curves, with \(t \in T\), representing n i.i.d. realisations of a functional stochastic process, Y(t), taking its values in the Hilbert space of square integrable functions, \(L^2(T)\), with inner product \(<\cdot , \cdot>\) and inner norm \(||\cdot ||\). The functional rank process associated with Y(t) is defined through a probability transform for each \(t \in T\) as follows (Chen et al. 2020):
where \(F_t\Bigl (Y(t)\Bigr )=P\Bigl (Y(t)\le y\Bigr )\) is the cross-sectional distribution of Y at time t. In practice, any realisation of the functional process is observed with noise on a discrete set of points, \(t_l\), \(l=1,2,\ldots ,L\), with \(t_l \in T\). Thus, starting from the n pairs \(\{t_{il}, y_{il}\}_{i=1}^n\), functional rank trajectories, \(R_i(t)=F_t\Bigl (Y_i(t)\Bigr )\), are obtained by applying the probability transform at each time point, that is:
where \(F_{n,t}\Bigl (y_i(t)\Bigr )\) is the ranking of the i-th curve relative to the other curves in the dataset, which (in practice) is based on the empirical cumulative distribution function (ECDF) of \(y_i(t)\) at a given time point \(t \in T\); and \(I(\cdot )\) denotes the indicator function. Clearly, the range of \(R_i(t)\) is always the interval [0, 1] and Eq. (2) represents the non-smoothed version of the cross-sectional empirical distribution of the i-th function.
The rank trajectory can easily be obtained by sorting, at each time point, the observed data in ascending order, \(y_{(1)},\ldots ,y_{(n)}\), and (from a practical point of view) it is obtained by computing the ECDF. Given that the ECDF is discontinuous, one might prefer to consider a smoothed version, which leads to approximate ranks. This second choice requires a two-step procedure where in the first step the unsmoothed raw estimates of the ECDF are obtained at a set of distinct time points and in the second step, smoothing methods are applied to the raw estimates. Several smoothed versions can be considered. For ECDFs, the use of Bernstein Polynomials is well-documented in the literature (Vitale 1975; Leblanc 2010) and is particularly suited for ECDFs with compact support (Babu et al. 2002; Menafoglio et al. 2014). A further choice is to consider the kernel estimator of ECDFs (Roussas 1969; Samanta 1989; Ferraty and Vieu 2006; Veraverbeke et al. 2014). In this paper, smooth estimates of the rank trajectories are obtained by considering a kernel estimate of ECDF, as in Chen et al. (2020):
where:
with K and H being a kernel function and an integrated kernel, respectively; and \(h_Y\) and \(h_T\) being the bandwidths controlling the kernel widths, chosen by cross-validation.
3 Functional measures of magnitude and evolution
In the assessment of social phenomena, such as in the case of countries’ performances, it is difficult to provide an overall ranking of units across time. Indeed, in the evaluation process, both the magnitude and evolutionary behaviour of each unit should be taken into account. To this end, two functional measures are considered: the first is the modified hypograph index (MHI), which is computed with respect to the rank trajectories; and the second is the weighted integrated first derivative (DW), which is computed on the original functions. The two distinct orderings induced by these measures reflect the magnitude and the evolutionary behaviour of each country, respectively.
The MHI of a given rank trajectory, R(t), with respect to a sample of functions, \(R_i(t)\), \(i=1,2,\ldots ,n\), is defined as follows (Lopez-Pintado and Romo 2011):
where \(G(R)=\{(t, R(t)), t \in T\}\) is the graph of the rank function R(t); \(hyp(R)=\{(t,y) \in T \times \mathbb {R}: y \le R(t)\}\) is the hypograph of R(t), and \(\lambda (\cdot )\) stands for the Lebesgue measure on \(\mathbb {R}\). Clearly, the graph of any curve R(t) is contained in its hypograph. MHI represents the proportion of T that the graphs of the functions in the sample are in the hypograph of R(t); that is, the proportion of T in which the curves of the sample are below R(t). Roughly speaking, the hypograph of a function is the area under its graph and MHI also considers how long the curves are in the hypograph of a given function. Thus, a high value of MHI indicates that many functions are contained in the hypograph of a given curve. An overall magnitude-based ranking of the curves can be obtained by sorting in descending order the MHI values. Because the functions represent rankings over time, a MHI value equal to 0.5 indicates that the curve is located at the center of the sample. In other words, the curve assumes a central rank position. Meanwhile, MHI values close to 0 and 1 reflect the worst and best rank positions in the whole time span, respectively.
The main disadvantage of MHI is that it does not account for the path taken by each country to reach a given position so that different shapes of the curves can yield equal values of MHI. The analysis of the first derivatives provides a suitable solution to this aspect because it offers a valuable insight into the time dynamics of functional data. For instance, a first derivative that is different from zero indicates that the curve changes over time. Thus, the integrated first derivative can be computed to quantify how variable a rank trajectory is in the time span (Chen et al. 2020). However, the integrated first derivative of the rank trajectories presents two limitations. The first limitation is that it does not represent a single country’s evolution. Indeed, each rank trajectory strongly depends on the entire population’s dynamic—a country could change rank while maintaining its performance. The second limitation is that the integrated first derivative of the rank trajectory reflects the total behaviour of the first derivative without distinguishing how long the function shows a certain trend. To solve the first issue, and hence to better evaluate the dynamics of each country, we suggest to compute the integrated first derivative on the original functions rather than on ranks as Chen et al. (2020) suggests, that is:
To address the second limitation, and hence to take into account how long a curve maintains a specific behaviour, a weighted local integrated first derivative, DW, is proposed. Considering sub-intervals of the domain, determined by the changes of the first derivative sign, DW is obtained as a linear combination of the integrated first derivatives in each sub-interval, with coefficients equal to the proportion of the width of each sub-interval. Specifically, each function is divided into \(M + 1\) segments according to a set of points, \(m=1,2,\ldots ,M\), which are defined by the changes in the first derivative sign. At each sub-interval, \(k_1, k_2,\ldots , k_{M+1}\), the integrated first derivative is computed on the original functions, leading to a series of local values, which are denoted as \(D_{ij}\), \(i = 1, 2,\ldots , n\), \(j = 1, 2,\ldots , M+ 1\). Then, \(D_{ij}\) is locally weighted with the proportion of the width of the segment over the total width. Finally, an overall measure is obtained for each function, as follows:
where:
where \(t_0\) and \(t_L\) are the start and end points of the domain of the curves.
MHI and DW reflect two distinct aspects that should be jointly considered to evaluate countries’ performances. To this end, a visualisation tool is suggested. Countries are represented in the Cartesian plane defined by MHI and DW, which allows us to distinguish countries according to their magnitude and more or less deserving behaviour. The values of MHI are included in the interval [0, 1], while DW assumes values in (\(-\infty ,+ \infty \)). The \(MHI-DW\) plot can be divided into four quadrants by drawing a horizontal and a vertical line at \(DW=0\) and \(MHI=0.5\), respectively. The value \(MHI = 0.5\) discriminates among countries that belong to the top half of the hypograph ranking and those in the lower half; whereas the value \(DW=0\) distinguishes between countries that experience an improvement (\(DW>0\)) or a worsening (\(DW<0\)) of their performance. The first quadrant (top right-hand panel of the plot) includes the most virtuous countries because they present higher magnitude values (\(MHI > 0.5\)) that are obtained by improving their performance over time (\(DW > 0\)). It is worth noting that when DW is close to zero and MHI is close to one, countries start from very high ranking levels and maintain them throughout the period considered. In this case, the stability of the function is to be rewarded. The second quadrant (bottom right-hand panel of the plot) is defined by countries that have a magnitude above the median value (\(MHI> 0.5\)) but whose performance has worsened in the time interval considered (\(DW < 0\)). The third quadrant (bottom left-hand panel of the plot) is defined by countries with \(MHI <0.5\) and \(DW < 0\). Clearly, the countries in this quadrant are in the worst position and policy interventions will have to be stronger than in other cases. Finally, the fourth quadrant (top left-hand panel of the plot) includes countries with a magnitude below the median (\(MHI <0.5\)) but with a predominant improvement of their performance (\(DW> 0\)). Obviously this graphical tool allows us to distinguish countries with different magnitude and evolution trends at a glance. Table 1 provides a summary description of the four quadrants resulting from the \(MHI-DW\) plot.
4 Simulation study
A simulation study is performed to investigate the ability of the proposed functional measures to distinguish countries according to both their magnitude and evolution in the entire domain. To reflect specific magnitude and evolutionary behaviour of the trajectories, a population of n functions is divided into \(G=4\) groups, each with sample size \(n_g=30\) with \(g=1,2,\ldots ,G\) and \(n=\sum _{g=1}^Gn_g=120\). The curves are observed in the interval [0, 1] with a grid of \(L=30\) equally spaced points. For each g-th group, functional data, \(y_1(t), \ldots , y_{n_g}(t)\), are obtained as realisations of a Gaussian process, \(Y_g(t)\in L^2(T)\), of the following form:
where \(\mu _g(t)\) accounts for the specific performance of the g-th group, and e(t) is a Gaussian process, which is common for all the G groups, with mean 0 and covariance function \(\gamma (s,t)=\exp (-|t-s|)\). The functional means of the G groups are defined as follows:

Simulated functions of each g-th group in the s-th simulation, with \(s=1\)
This procedure is replicated \(S=3000\) times. Figure 1 shows the simulated functions for each g-th group in a single simulation, \(s=1\), \(s=1,2,\ldots ,S\). The first group of functions (solid lines in Figs. 1 and 2) is characterised by a rather high magnitude and a predominantly increasing trend. The second group of functions (dotted lines in Figs. 1 and 2) is characterised by a rather high magnitude and a predominantly decreasing trend. The third group of functions (dashed lines in Figs. 1 and 2) is characterised by medium magnitude and a predominantly decreasing trend. Finally, the fourth group of functions (dot-dash lines in Figs. 1 and 2) is characterised by rather low magnitude and a predominantly increasing trend. In Fig. 2 the functional means of the G groups for \(s=1\) are plotted in the same graph. The average function of \(g_1\) shows an increasing trend with high levels of magnitude throughout the domain. The mean function of \(g_2\) shows high levels of magnitude, especially in the middle part of the domain with an initially increasing and then decreasing trend that persists for more than half of the domain. The average function of \(g_3\) has an almost always decreasing trend (even if slightly) and shows an intermediate level of magnitude compared to the other groups, but with some exceptions. Indeed, the magnitude of \(g_3\) is almost always below that of \(g_1\) and \(g_2\), whereas it is above the magnitude of \(g_4\), except for the first and last part of the domain. Throughout most of the domain, the mean function of \(g_4\) shows the lowest magnitude with an initially decreasing and then increasing trend for most of the domain.

Functional means of the G groups in the s-th simulation, with \(s=1\)
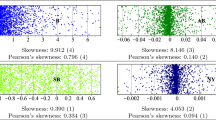
Starting from the n functions, \(y_i(t)\), and for each s-th replication, functional rank trajectories, \(R_i(t)\), are obtained by applying the probability transform at each time point as in Eq. (2). Their smooth versions are then obtained using the Kernel estimator in Eq. (3). Each function is placed in a specific group according to its MHI and DW values, which are computed as in Eqs. (6) and (8), respectively. Each group corresponds to one of the four quadrants defined by the \(MHI-DW\) plot. The representation of each curve in the \(MHI-DW\) plot allows us to understand the behaviour of each country with respect to the considered characteristics and to check the consistency with the simulated data. Figure 3 shows the functional observations for \(s=1\) in the \(MHI-DW\) plot. The curves of the first group (black dots in Fig. 3) are prevalently located in the first quadrant, which indicates high MHI values and positive DW values. The curves of the second group (black triangles in Fig. 3) are mainly placed in the second quadrant, which is the one with \(MHI > 0.5\) and \(DW < 0\). The curves of the third (white dots in Fig. 3) and of the fourth (black squares in Fig. 3) group are, respectively, concentrated in the third and fourth quadrants of the plot because both groups present low MHI values with negative and positive DW values, respectively.
To examine the performance of the proposed method, the proportion of correct assignment is recorded for each i-th observation among the S replications, as follows:
with \(p_s\) representing the proportion of correct assignments of the functions in the quadrant divided by the total number of curves, for the s-th replication. \(P_c\) is computed with respect to four evolutionary measures combined with MHI: the weighted local integrated first derivative computed on both the original functions (DW) and the rank trajectories (\(DW_{R}\)); and the integrated first derivative computed on both the original functions (D) and the rank trajectories (\(D_R\)). Table 2 shows the \(P_c\) values and the respective standard deviations for the four different cases. The results show that the weighted local integrated first derivative of the original functions (DW) is the best evolutionary measure to complement the information provided by MHI because it leads to the highest level of correct assignment of the functional observations in the four groups. Meanwhile, the combination of MHI with the integrated (non-weighted) first derivative of the original functions (D) leads to lower performance than using DW. Moreover, when the evolutionary behaviour is evaluated on the rank trajectories, the weighted local integrated first derivative yields the best results compared to its unweighted counterpart.
To quantify the between simulation variability, the following squared error measure is provided:
where \(f_{is}\) is a generic measure, which can be one of the following: \(MHI_{is}\), \(DW_{is}\), \(DW_{R_{is}}\), \(D_{is}\) or \(D_{R_{is}}\), respectively; and \(\overline{f}\) is the mean of each functional measure across the S replications. Table 3 reports the squared error values for the MHI and the four evolutionary measures. In all cases, the variability is extremely low.

Functional observations in the \(MHI-DW\) plot for the s-th simulation, with \(s=1\)
5 Application
The proposed method is applied to the Government Effectiveness (GE) index of 27 European countries in the period from 1996 to 2020. The GE index captures perceptions of the quality of public services, the quality of public administration and the degree of its independence from political pressures, the quality of policy formulation and implementation, and the credibility of the government’s commitment to these policies (Kaufmann et al. 2010). The GE index is part of the Worldwide Governance Indicators (WGI) project, which reports aggregate and individual governance indicators for over 200 countries and territories based on six dimensions of governance, including political stability, government effectiveness, and control of corruption. Data are available at https://databank.worldbank.org/reports.aspx?source=1181 &series=GE.EST and in the supplementary material. The analysis is performed in the R environment (R Core Team 2020) and the R script is available in the supplementary material.
The GE index is obtained by aggregating 45 basic variables by means of the Unobserved Component Model (UCM) (Goldberger 1972). The main variables that are considered refer to quality of bureaucracy, quality of road infrastructure, quality of primary education, satisfaction of the public transportation system, quality of the health care system, allocation and management of public resources for rural development, infrastructure disruption, state failure, and policy instability. The resulting composite measures are in units of a standard normal distribution, with mean zero, standard deviation one, and range approximately between – 2.5 and 2.5, with higher values corresponding to best governance effectiveness.

Functional GE index and smooth rank trajectories of the European countries
The GE time series of each country are considered as continuous functions observed at \(L = 22\) discrete points. Therefore, raw temporal sequences of GE index are converted into a sample of functions, \(y_i(t)\), by adopting a kernel smoothing method. The upper panel of Fig. 4 shows the reconstructed functional GE index for each country; that is, the smooth version of the original functions, \(y_i(t)\). A list of countries in the sample is provided in Table 4. Starting from the GE functions, smooth rank trajectories, \(R_i(t)\), are obtained as in Eq. (3). The functional rank trajectories are plotted in the bottom panel of Fig. 4. Figure 5 shows the first derivatives of both the functional GE index (upper panel of Fig. 5) and the functional rank trajectories (bottom panel of Fig. 5). The range of the first derivatives is rather limited because their values vary between − 0.126 and 0.105 for the original functions, and between − 0.205 and 0.163 for the rank trajectories. To provide information regarding the temporal evolution of the indicator itself, we compute DW on the functional GE index for each country as in Eq. (8). Figure 6 displays the 27 European counties on the \(MHI-DW\) plot. In total, 41% of the counties are located in the second quadrant. This result raises some concern because a high number of countries, although highly ranked on GE index, are experiencing a decrease over time. Furthermore, within this quadrant, Belgium occupies the worst position, presenting the lowest value of DW. Meanwhile, 33% of countries are located in the fourth quadrant: these are countries with a low rank position but which are experiencing a growth in their GE over time. In particular, the performances of Latvia and Lithuania are highlighted due to their best position within this quadrant with reference to the evolutionary behaviour. The third quadrant contains 19% of countries. These countries are struggling to increase their GE level, which makes policy intervention necessary. The first quadrant is occupied only by Finland and Portugal. Specifically, Finland is in a better position than Portugal because it has a significantly higher level of GE. It is certainly important to note that countries with low GE index values tend to experience the highest increase. In contrast, when GE index becomes high, it is difficult to increase it further (Sen 1981; Chakraborty 2011). On the basis of these considerations, the countries in the second and third quadrants are those with the greatest degree of criticality. For each country, Table 4 reports the orderings induced by the MHI and DW values, which are considered both individually and jointly. The joint ordering is obtained from the \(MHI-DW\) plot and consists of identifying the quadrant of the plot occupied by each country.

Functional GE first derivatives (\(y_i^{\prime }(t)\)) and rank trajectories first derivatives (\(R_i^{\prime }(t)\)) of the European countries

\(MHI-DW\) plot for the European countries
6 Conclusions
Countries’ performances are usually evaluated through rankings that arise from single or, more often, composite indicators. Rankings are often analysed from a static point of view, which makes it impossible to determine whether a country is undergoing an increase, a decline or a stability in its performance. In this context, the functional data analysis (FDA) approach represents a useful method for the analysis of rank dynamics. Specifically, by approximating the time series of both the original data and the resulting ranks with smooth functions, functional tools can be exploited to provide additional information. This paper proposes to use two overall functional measures to evaluate countries’ performances, while taking into account both their ranking position and their evolutionary behaviour: the modified hypograph index (MHI) and the weighted integrated first derivative (DW). The first measure refers to the magnitude of the rank position over the entire domain, whereas the second measure relates to the increasing or decreasing behaviour of the smoothed time series. One of the main advantages provided by DW is that it reflects how long the original function shows a certain trend. Moreover, we suggest to evaluate the evolutionary aspect on the original trajectories rather than on the rank functions to focus on the country’s evolution. Simulation results reveal that DW is more successful in identifying the predominant trend of countries than other evolutionary measures. Finally, a visualisation tool that combines information resulting from MHI and DW is suggested. A scatterplot of these measures allows an immediate understanding and perception of countries according to their magnitude and evolution trends.
A further research project could be to extend DW to the second functional derivatives, highlighting the acceleration with which countries show a certain trend. However, indicators are used for assessing complex phenomena that change slowly over time, thus, DW computed on the second derivative should be used in conjunction with the two introduced measures, to cluster countries according to their functional characteristics. Moreover, since many indicators are the result of the aggregation of multiple elementary indicators, a possible development of this work could be to generalize DW to the more complex multivariate functional case, to take into account the behaviour of each component of the indicator. In conclusion, FDA appears to be a useful approach to analyze rank dynamics. However, a possible limitation of this approach is that it is necessary to have a sufficient number of temporal observations of the phenomenon under study and, in the case of complex social phenomena, this condition is not always met.
Change history
13 December 2022
The original online version of this article was revised as the corresponding author Francesca Fortuna was incorrectly published.
28 December 2022
A Correction to this paper has been published: https://doi.org/10.1007/s00180-022-01313-5
References
Aguilera A, Fortuna F, Escabias M, Di Battista T (2021) Assessing social interest in burnout using google trends data. Soc Indic Res 156:587–599
Babu G, Canty A, Chaubey Y (2002) Application of Bernstein polynomials for smooth estimation of a distribution and density function. J Stat Plan Inference 105:377–392
Bellantuono L, Monaco A, Tangaro S, Amoroso S, Aquaro V, Bellotti R (2020) An equity-oriented rethink of global rankings with complex networks mapping development. Nat Sci Rep 10:18046
Bibi N, Shah I, Alsubie A, Ali S, Lone S (2021) Electricity spot prices forecasting based on ensemble learning. IEEE Access 9:150984–150992
Bongiorno E, Goia A (2019) Describing the concentration of income populations by functional principal component analysis on lorenz curves. J Multivar Anal 170:10–24
Cao J, Ramsay J (2007) Parameter cascades and profiling in functional data analysis. Comput Stat 22:335–351
Cattelan M, Varin C, Firth D (2013) Dynamic bradley-terry modelling of sports tournaments. J R Stat Soc Ser C (Appl Stat) 62:135–150
Chakraborty A (2011) Human development: how not to interpret change. Econ Pol Wkly 46:16–19
Chen Y, Dawson M, Muller H (2020) Rank dynamics for functional data. Comput Stat Data Anal 149:106963. https://doi.org/10.1016/j.csda.2020.106963
Cherchye L, Ooghe E, Van Puyenbroeck T (2008) Robust human development rankings. J Econ Inequal 6:287–321
Di Battista T, Fortuna F, Maturo F (2016) Environmental monitoring through functional biodiversity tools. Ecol Ind 60:237–247
Di Battista T, Fortuna F, Maturo F (2017) BioFTF: an R package for biodiversity assessment with the functional data analysis approach. Ecol Ind 73:726–732
Febrero M, Galeano P, Gonzalez-Manteiga W (2007) A functional analysis of NOx levels: location and scale estimation and outlier detection. Comput Stat 22:411–427
Ferraty F, Vieu P (2006) Nonparametric functional data analysis. Springer-Verlag, New York
Fortuna F, Gattone S, Di Battista T (2020) Functional estimation of diversity profiles. Environmetrics 31(8):e2645. https://doi.org/10.1002/env.2645
Gattone S, Fortuna F, Evangelista A, Di Battista T (2021) Simultaneous confidence bands for the functional mean of convex curves. Econom Stat. https://doi.org/10.1016/j.ecosta.2021.10.019
Gisselquist R (2014) Developing and evaluating governance indexes: 10 questions. Policy Stud 35:513–531
Goldberger A (1972) Maximum likelihood estimation of regressions containing unobservable independent variables. Int Econ Rev 13:13–15
Jabin P, Junca S (2015) A continuous model for ratings. SIAM J Appl Math 75:420–442
Jan F, Shah I, Ali S (2022) Short-term electricity prices forecasting using functional time series analysis. Energies. https://doi.org/10.3390/en15093423
Kaufmann D, Kraay A, Mastruzzi M (2010) The worldwide governance indicators: methodology and analytical issues. World Bank Policy Research Working Paper No 5430
Kelley J, Simmons B (2019) Introduction: the power of global performance indicators. Int Organ 73:491–510
Leblanc A (2010) A bias-reduced approach to density estimation using bernstein polynomials. J Nonparametr Stat 22:459–475
Lee H, Chang C (2018) Comparative analysis of MCDM methods for ranking renewable energy sources in Taiwan. Renew Sustain Energy Rev 92:883–896
Lin Z, Zhou Y (2017) Ranking of functional data in application to worldwide \(PM_{10}\) data analysis. Environ Ecol Stat 24:469–484
Lopez-Pintado S, Romo J (2011) A half-region depth for functional data. Comput Stat Data Anal 55:1679–1695
Malul M, Hadad Y, Secchi P (2009) Measuring and ranking of economic, environmental and social efficiency of countries. Int J Soc Econ 36:832–843
Maturo F, Verde R (2022) Pooling random forest and functional data analysis for biomedical signals supervised classification: theory and application to electrocardiogram data. Stat Med 41:2247–2275
Maturo F, Fortuna F, Di Battista T (2019) Testing Equality of functions across multiple experimental conditions for different ability levels in the IRT context: the case of the IPRASE TLT 2016 survey. Soc Indic Res 146:19–39
Menafoglio A, Guadagnini A, Ben-Yair A (2014) A kriging approach based on aitchison geometry for the characterization of particle-size curves in heterogeneous aquifers. Stoch Environ Res Risk Assess 28:1835–1851
Motegi S, Masuda N (2012) A network-based dynamical ranking system for competitive sports. Sci Rep 2:1–7
Peiro-Palomino J, Picazo-Tadeo A (2018) OECD: One or many? Ranking countries with a composite well-being indicator. Soc Indic Res 139:847–869
Phillis Y, Grigoroudis E, Kouikoglou V (2011) Sustainability ranking and improvement of countries. Ecol Econ 70:542–553
R Core Team (2020) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria, URL https://www.R-project.org/
Ramsay J (1991) Kernel smoothing approaches to nonparametric item characteristic curve estimation. Psychometrika 56:611–630
Ramsay J, Silverman B (2002) Applied functional data analysis: methods and case studies. Springer, New York
Ramsay J, Silverman B (2005) Functional data analysis, 2nd edn. Springer, New York
Reiss P, Ogden R (2007) Functional principal component regression and functional partial least squares. J Am Stat Assoc 102:984–996
Roussas G (1969) Nonparametric estimation of the transition distribution function of a markov process. Ann Math Stat 40:1386–1400
Samanta M (1989) Non-parametric estimation of conditional quantiles. Stat Probab Lett 7:407–412
Sen A (1981) Public action and the quality of life in developing countries. Bull Econom Stat 43:287–319
Shah I, Bibi H, Ali S, Wang L, Yue Z (2020) Forecasting one-day-ahead electricity prices for Italian electricity market using parametric and nonparametric approaches. IEEE Access 8:123104–123113. https://doi.org/10.1109/ACCESS.2020.3007189
Shah I, Jan F, Ali S (2022) Functional data approach for short-term electricity demand forecasting. Math Probl Eng. https://doi.org/10.1155/2022/6709779
Shah N, Wainwright M (2017) Simple, robust and optimal ranking from pairwise comparisons. J Mach Learn Res 18:7246–7283
Tsui K (1996) Improvement indices of well-being. Soc Choice Welf 13:291–303
Veraverbeke N, Gijbels I, Omelka M (2014) Preadjusted non-parametric estimation of a conditional distribution function. J R Stat Soc Ser B (Stat Methodol) 76:399–438
Vitale R (1975) A bernstein polynomial approach to density function estimation. Stat Inference 2:87–99
Wu P, Fan C, Pan S (2014) Does human development index provide rational development rankings? Evidence from efficiency rankings in super efficiency model. Soc Indic Res 116:647–658
Yu P, Lee P, Wan W (2013) Factor analysis for paired ranked data with application on parent-child value orientation preferences data. Comput Stat 28:1915–1945
Zhang Y, Xiao Y, Wu J, Lu X (2021) Comprehensive world university ranking based on ranking aggregation. Comput Stat 36:1139–1152
Zheng B, Zheng C (2015) Fuzzy ranking of human development: a proposal. Math Soc Sci 78:39–47
Funding
Open access funding provided by Università degli Studi Roma Tre within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fortuna, F., Naccarato, A. & Terzi, S. Evaluating countries’ performances by means of rank trajectories: functional measures of magnitude and evolution. Comput Stat 39, 141–157 (2024). https://doi.org/10.1007/s00180-022-01278-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-022-01278-5