
Abstract
In an individualized shee metal assembly line, form and dimensional variation of the in-going parts and different disturbances from the assembly process result in the final geometrical deviations. Securing the final geometrical requirements in the sheet metal assemblies is of importance for achieving aesthetic and functional quality. Spot welding sequence is one of the influential contributors to the final geometrical deviation. Evaluating spot welding sequences to retrieve lower geometrical deviations is computationally expensive. In a geometry assurance digital twin, where assembly parameters are set to reach an optimal geometrical outcome, a limited time is available for performing this computation. Building a surrogate model based on the physical experiment data for each assembly is time-consuming. Performing heuristic search algorithms, together with the FEM simulation, requires extensive evaluations times. In this paper, a neural network approach is introduced for building surrogate models of the individual assemblies. The surrogate model builds the relationship between the spot welding sequence and geometrical deviation. The approach results in a drastic reduction in evaluation time, up to 90%, compared to the genetic algorithm, while reaching a geometrical deviation with marginal error from the global optimum after welding in a sequence.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Mass production of the complex-assembled products has increased the need for controlling the geometrical variation. Form and dimensional variation of the included parts in the assembly, referred to as part variation, and the assembly process disturbances are the main sources of the final geometrical variation in the assemblies. These disturbances have been identified in several studies [1]. In order to secure the geometrical outcome of the welded assemblies, Söderberg et al. have introduced a virtual tool-box to support the decision-making during all the product development phases [2]. In the early design phases, variation simulations are used. Spot welding simulation is alsot introduced for predicting the geometrical outcome of the spot-welded assemblies in the early verification phases. The sequence, with which the spot welding is performed, has a considerable effect on the final geometrical outcome.
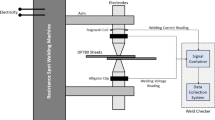
In the automotive industry, the spot welding process for the Body-In-White (BIW) assemblies is often divided into two stations. Initially, the parts are spot welded by a limited number of spot welds, referred to as geometry points. The purpose of these spot welds is to lock the geometry when the parts are being released from the fixture. The sequence in which these points are being set has a significant effect on the final geometrical outcome [3]. In Fig. 1, the layout in a geometry assembly cell is shown. In this setup, the geometry points are being welded by one or multiple robot arms, holding a welding gun. The assemblies, after these processes, are transported to other cells, where the rest of the welding points, referred to as re-spot points, are being welded. Minimum effect from these weld points is expected on the final geometrical deviation [4]. Predicting the outcome of all the possible sequences, with simulations, is computationally expensive. This is due to the large number of permutations available and the iterative finite element analysis (FEA) calculations, which are required for this purpose [5]. In this paper, an efficient surrogate approach has been developed for estimation and optimization of the geometrical deviations after spot welding with a specific sequence.

Layout in a geometry assembly cell
1.1 Spot welding sequence optimization
Welding sequence optimization for minimum geometrical deviation has been studied in the literature. Fukuda et al. have considered applying a neural network (NN) to solve the continuous welding problem with a traveling salesman formulation [6]. They have shown the fundamental effectiveness of NN for this purpose. Huang et al. have applied a genetic algorithm (GA) to minimize the displacements after spot welding, with a specific sequence [7]. Other studies have also shown the applicability and effectivity of the GA on the welding and clamping sequence problem [8,9,10]. Different evolutionary algorithms, namely, ant colony and particle swarm optimization, have been evaluated using the FEA approach. It has been shown that the performance of these algorithms might be faster, for spot weld sequencing, depending on the complexity of the assembly [5]. Heuristic approaches have also been considered for obtaining near-optimal sequences with regard to geometrical variation. Wärmefjord et al. have introduced strategies for spot welding sequence selection. They have shown that sorting the spot welds based on the relative sensitivity can represent a desirable sequence with a lower geometrical variation [11].
Several studies have considered identifying the optimal weld sequence for continuous welding [12]. For finding the optimal continuous weld path, Voutchkov et al. [13] have applied a surrogate model, built using the FEA simulation and identification of the hot zones from the physical experiments. To obtain the minimum displacements by an optimized weld path, they have considered the total displacements as the summation of the displacements of the smaller weld paths on the nominal geometries. A Design of Experiment (DoE) approach is followed to build the surrogate model. The displacements after welding in a sequence are then estimated, finding the common elements of the sequence in the DoE and the evaluated sequence. The displacements of each element of the sequence are then added up linearly to generate the estimation of the final geometrical displacement. They have shown that application of a surrogate model with this approach can reduce the computation time drastically. However, the effect of the sequence in spot welding is not accumulative. This means that the deformation after welding one point cannot be stacked up until all the welds are set.
To explain this further, consider an assembly of two parts with five weld points {w1,w2,w3,w4,w5}. The deformation after welding w1 and w2 are calculated in a sequence \(w_{1}\rightarrow w_{2}\) and denoted as d1. In a new calculation, the deformation after welding w3, w4, and w5 are calculated in a sequence \(w_{3}\rightarrow w_{4} \rightarrow w_{5}\), d2. The total deformation dt = d1 + d2 may not be the same as the total deformation dt, when all the weld points are welded in the same sequence, \(w_{1}\rightarrow w_{2}\rightarrow w_{3}\rightarrow w_{4} \rightarrow w_{5}\). This can be a result of the part deviation that should be included in the simulation while calculating the springback [14].
Previous studies have focused on the estimation of the welding sequence outcome, summing up the displacements of the sequence elements linearly, without taking the part deviations into consideration [13]. However, the existing part deviation between the assembly components results in significant forces exposed to the assembly, and thereby internal stresses built up and spring back effect is more challenging to model. Therefore, in this paper, a new surrogate approach is proposed representing all the possible permutations of spot welding sequence with an input-output function for reducing computation time. The surrogate model is built using non-rigid variation simulation, taking the part deviations into consideration. The surrogate approach is based on a NN method.
1.2 Non-rigid variation simulation
To predict the geometrical outcome of the assemblies, variation simulation is often performed within the Computer-Aided Tolerancing (CAT) tools. Variation simulation of rigid bodies is performed by calculating the transformation and rotation matrices of the positioning points of the assemblies [14]. This simulation, in combination with the Monte Carlo simulations (MCS), for building part variation models, will result in a statistical analysis of the assembly’s geometrical variation. However, for non-rigid parts, like sheet metals, parts are bent and deformed during the assembly. Therefore, over constrained positioning system, with more than six positioning points, are often applied to the part’s and assembly’s locating schemes [14]. To foresee the non-rigid behavior of the sheet metal assemblies, the FEA in combination with MCS is shown to be an efficient approach [15]. Method of influence coefficients (MIC) is an approach that is implemented on the sheet metal assemblies, and have proved to be accurate and time-efficient [15].
During the assembly in the FEA, the parts may penetrate each other in the adjacent areas. To solve this issue, a contact algorithm has been included in the variation simulation tools [16]. In contact modeling, a search algorithm identifies all the nodes that are in contact between the parts prior to the assembly steps. During the assembly, if penetration occurs on the position of the contacts, negative forces are applied by the contact points to bring the nodes back to their mating condition. The contact algorithm has been developed for faster a response using a quadratic programming (QP) formulation [17].
Spot welding is realized in this method by introducing a stiff beam, locking all the degrees of freedom, in the weld pairs. The effect of the sequences on the welded assemblies has been introduced to the method by calculating the updated stiffness matrix after welding each pair, where the contact algorithm avoids the penetration during all the steps [4].
The calculation time for updating the stiffness matrices has been reduced by a Sherman-Morrison-Woodbury formula to avoid the intermediate springback calculations [18, 19]. In this work, the CAT tool RD&T is used to retrieve the geometrical outcome of the assembly. State of the art in non-rigid variation simulation, introduced above, is realized within this tool [20].
1.3 Self-compensating assembly line
Söderberg et al. [21] have introduced a sheet metal assembly line, in which the assembly parameters are being optimized for each individual assembly for maximum geometrical quality. Figure 2 shows the scheme of this assembly line. The parts are being scanned to retrieve the part deviations on single part level [22]. Later, the parts are being selectively matched for optimal mating conditions [23]. Within the assembly cell, the optimal parameters for locating adjustments are retrieved. Finally, spot welding is performed in a sequence. The optimization of the spot welding sequences takes place at this stage. For this, within the analysis module, the CAT tool RD&T is in interaction with an optimizer to retrieve the optimal spot welding sequence. In this environment, where the locators are adjusted in the assembly cell, a limited amount of time is available for spot welding sequence optimization. Therefore, faster approaches to propose a sequence for the optimal geometrical outcome are required.

Self-compensating assembly line
1.4 Scope of the paper
Spot welding sequence optimization belongs to the class of combinatorial problems, where for each permutation, non-rigid variation simulation is needed. This makes the optimization, using the standard genetic algorithms, time consuming for proposing a sequence. In spot welding, the effect of the welding sequence is not cumulative, and can not be broken into steps. Therefore, an approach to build accurate surrogate models considering the time aspect for building the models for each individual spot-welded assembly has not been introduced. In this paper, an approach to build efficient surrogate models for spot welding sequence optimization is introduced. The surrogate model intends to represent the behavior of each spot-welded assembly, while the final deformations are retrieved after the assembly is released from the fixture and springback occurs. The proposed surrogate models have been evaluated on three reference automotive BIW assemblies. For comparison, the results achieved by the proposed method have been compared to an exhaustive search, where all the permutations are evaluated. A time comparison with a standard GA has been performed. The proposed method has shown to be accurate and time-efficient. The rest of the paper is structured as follows. Section 2 introduces the formulation on which the surrogate model is built and the application of the neural networks and the sampling strategy is introduced. Section 3 introduces the reference assemblies in detail. Section 4 presents the results of the application of the proposed surrogate model on the selected assemblies. The comparison with the exhaustive search is presented to evaluate the accuracy. Time comparison with a standard GA is also presented. In Section 5, the conclusions are drawn based on the presented results and the future research is presented.
2 Surrogate modeling
Spot welding sequence optimization for minimum geometrical deviations, in individual assemblies, is of NP-hard combinatorial problems. There are no analytical functions that can model the effect of the sequence of the spot welding, which is the input, to the geometrical deviation, the output. However, with the state-of-the-art, non-rigid variation simulation, the geometrical deviation of each node, included in the FEA, can be retrieved. As mentioned in Section 1.2, several steps, together with a contact algorithm, are considered for this calculation. In this paper, black-box surrogate models are built for individual assemblies, mapping the direct behavior of the welding sequences to the final geometrical deviation after welding. The formulation for retrieving the geometrical deviations and input-output processing functions using NN are described in the following.
2.1 Model formulation
To retrieve the geometrical deviation of the assembly after the spot welding, the state-of-the-art non-rigid variation simulation, Section 1.2, is used. In the simulation, firstly, parts are being positioned and clamped in the fixture. Spot welding is performed, and contact iterations are considered to avoid penetration of the adjacent surfaces. Finally, the assembly is released from the fixture, and springback occurs. The steps above are formulated in the following, building the linear relationships between the forces and displacements. In an assembly of parts a and b, the following applies:
- i
Positioning the parts and clamping
$$ \boldsymbol{F}^{a}=\boldsymbol{K}_{a}\boldsymbol{u}^{a} ,\quad \boldsymbol{F}^{b}=\boldsymbol{K}_{b}\boldsymbol{u}^{b} $$(1)where:Fa,b= force needed to close the gap between the partsua,b= gap between the parts, resulting from part deviationsKa,b= stiffness matrix of parts a and b.
- ii
Welding and contact iteration
$$ \boldsymbol{F}_{w}^{i}=\boldsymbol{K}_{w}^{i-1}\boldsymbol{u}_{w}^{i-1} $$(2)\(\boldsymbol {{F_{w}^{i}}}\)= welding gun force of the i th weld,\({\boldsymbol {u}}_{w}^{i-1}\)= gap between the weld nodes before the i th weld,\(\boldsymbol {K_{w}^{i-1}}\)= stiffness before weld i,these forces are applied using a balanced welding gun where equal forces are applied to the welding nodes on parts a and b.At each step after clamping or welding, the contact forces avoid penetration of the adjacent parts into each other,
$$ \boldsymbol{F}_{c}^{i}=\boldsymbol{K}_{w}^{i}\boldsymbol{u}_{c}^{i} $$(3)\(\boldsymbol {F}_{c}^{i}\)= contact force needed to compensate for the penetration,\(\boldsymbol {K}_{w}^{i}\)= stiffness after weld i,\(\boldsymbol {u}_{c}^{i}\)= penetrated distance between the contact nodes after the i th weld, sensitivity matrix S, can be constructed, reformulating the response from the contact forces.
- iii
Release and springback
$$ \boldsymbol{u}_{s}=\boldsymbol{S}\boldsymbol{u}_{w} $$(4)us= deformation after springback,S= sensitivity matrix,uw= displacements of the weld points,The final deformation can then be calculated as:
$$ \boldsymbol{u}=\boldsymbol{u}_{c}+\boldsymbol{u}_{s} $$(5)u= final deformation,uc= calculated clamping displacements by the sensitivity matrix,the details of the matrix multiplications and inversions to retrieve the updated stiffness matrices are presented in [18, 19].
2.2 Function approximation
To build the relations, a NN is used to fit the input to output. In this study, the spot welding sequence has been used as the input to the NN. The total root mean square (RMS) of the deviation of each node included in the assembly after welding is considered as the measure (Q) of the output.
where:qi= deviation of node i from its nominal position,qu= position of the node after welding and springback,qnom= nominal position of the node,Q= root mean square of the deviation of each node,N=\(\{1,2,{\dots } n\}\) number of the nodes in the assembly.
This measure is chosen due to its generic form representing all the nodes included in the assembly. Any available critical points, representing the characteristics of the assembly, can also be defined as a measurement point.
To build the input-output relation, a radial basis function (RBF) NN [24] is used. This type of network has shown to be a universal approximator and has been used for function approximation extensively [25, 26].
The input-output function can be formulated as:
where, ξ is the vector of the weld sequence, and Q is the total RMS of the deviations of all the nodes in millimeter.
2.3 Sampling strategy
The number of the possible permutations to spot weld, in an assembly with Nw number of weld points, is Nw!. To choose a limited number of the permutations of the weld sequences, denoted as the number of the samples Ns, in a setup to represent all the possible permutations, is the challenge. Different sorting strategies for the weld point sequences have been tested. During these tests, it was identified that the sequence of the initial weld points in the sequence plays a crucial role to determine the complete sequence. Therefore, the samples have been chosen in a set up where the sequence of the first “s” weld points are taken into consideration. To clarify this point further, consider the sequence of five weld points {1,2,3,4,5}. If the first two weld points are considered to generate the sample, the sequences {1,2,3,4,5}, {2,1,3,4,5}, {3,1,2,4,5} to {5,1,2,3,4} for the first element, and {2,1,4,5,3}, {1,2,4,5,3}, {1,3,2,4,5} to {1,5,2,4,3} for the second element are chosen for evaluation.
The number of the ways that the s can be selected from Nw follows the binomial coefficient:
where Nw is the number of the weld point to be welded and s is the number of the first weld points in the sequence to be used for sampling. Thereby, the number of evaluations needed to be performed to retrieve the sample is:
with this strategy, the number of samples required to be performed is a small portion of all the possible sequences. This ratio can be presented as:
in the case of a seven-weld point assembly, Nw = 7, s can be selected from one to five. Choosing s = 6 corresponds to all the permutations of Nw. Increasing the s number increases the number of the sequences that need to be evaluated. In this case, the sequence of seven-weld points was taken into consideration; therefore, in total, 7! = 5040 sequences are available.
The sample size, including all the permutations of the first five welds, is Ns = 2520, Eq. 10. This for s = 4 decreases to Ns = 840, s = 3 to Ns = 210, s = 2 to Ns = 42, and finally s = 1 to Ns = 7 sequences.
Figure 3 shows the differences in the different RMS of the deviation of all the nodes (Q) for each sequence in an assembly. Sampled sequences and the corresponding RMS of the deviation are also visualized, where s = {1,2,3,4,5}. By reducing the s value, the accuracy of the representation of all the permutation will decrease. However, at s = 3, the sample shows to provide a lucid representation of all the possible sequences. This means that only four percent of the total permutations need to be evaluated, Eq. 11, to represent the behavior of all the permutations.
To further evaluate this aspect, an exhaustive search has been performed on all the reference assemblies. This strategy has been examined for all the assemblies, and the applicability of the sampling strategy is analyzed. This is described further in Section 4.2.

Sampling strategy for a seven-weld point assembly
2.4 Radial basis function network
The function approximation of Eq. 8 is achievable by an RBF NN. Figure 4 shows the structure of a three-layer RBF network. In the radial basis (RB) layer, a Gaussian transfer function is used to calculate the weights of the input layer [25, 26]. This is realized by computing the Euclidean distance between the input vector ξ, and the network parameter input vector. The output of RB layer is calculated as:
where \(i=\{1,{\dots } M\}\) with M number of the output neurons, \(j=\{1,\dots ,P\}\) with P number of the neurons in the RB layer. yi is the output of the i th neuron of the RB layer. x is the input vector, which is ξ with \(R_{N_{s}\times N_{w}}\) number of elements. wij is the weight of the j th hidden neuron to the i th output in the RB layer. cj is the center of the RBF of the j th neuron in the RB layer, and σj is the standard deviation of the j th RBF. The bias of the j th RBF is denoted as \(b_{j}=1/(\sigma _{j}\sqrt {2})\).

Radial basis function NN structure
In the second layer, a linear transfer function is used to map the network input to the outputs. The output is calculated as:
where \(i=\{1,{\dots } M\}\) with M number of output neurons. \(\hat {y}_{i}\) is the output of the i th neuron, which can be translated as the approximation of Q, \(\hat {Q}\). Wi is the weight vector of the neuron i and yi is the output vector from the i th RB layer. This process continues until the mean square of the errors becomes lower than the assigned goal. In this study, zero error is considered where biases have been represented in both layers.
The RBF network is set up with MATLAB RBF network function, and used to approximate the sample, chosen with the strategy presented above. The network is then used to evaluate all the possible permutations. The minimum Q value among all the permutation is looked for. The sequence corresponding to the minimum Q is then evaluated using the CAT tool RD&T, to retrieve the simulated displacements after welding. The values retrieved from the network and the CAT tool are then compared to verify the accuracy of the surrogate models.
To further increase the accuracy of the surrogate models, a larger data set is required. Increasing the number of data points for training the network increases the accuracy of the network. For this purpose, before training the network, the generated sample can be interpolated using the nearest neighbor interpolation method [27] over all the possible sequences. New data points can be generated using the interpolated function for a larger data set without any additional evaluations by the CAT tool.
3 Reference assemblies
To evaluate the proposed sampling strategy and the surrogate model, three automotive BIW reference assemblies have been chosen. The assembly models have been built for evaluation of the spot welding sequences, with the formulation presented in Section 2.1. In the following, the details of these models are presented.
3.1 Assembly I
This assembly consists of two sheet metal parts. Seven spot welds are to be welded, joining the two sheets together. Figure 5 shows the CAT model of the assembly. The positions of the spot welds are shown with gray spheres. The numbering of these weld points is shown by the text boxes, in the figure. The positioning points of the parts are shown with the red arrows. Both parts have six locating points locking the degrees of freedom. The mid-surface meshes of both parts represent the nominal parts. Deformed meshes have been used to introduce the part deviations to the nodes. These meshes are generated by running a preliminary non-rigid CAT simulation on the nominal geometries with a deviation within the specified design tolerances on the positioning points. Contact modeling is performed, to avoid the penetration in the adjacent surfaces, using 159 contact nodes.

Assembly I
3.2 Assembly II
In this assembly, three sheet metal parts are to be welded together using seven weld points. The position and the numbering of the weld points are shown in Fig. 6. In this figure, the assembly model is shown. The yellow and the purple parts have six positioning points, shown with red arrows and one extra clamp, shown with an orange arrow. The green part is located using six positioning points. Deformed meshes have been used to introduce part deviations to the model by running the preliminary non-rigid variation simulation. Contact modeling is performed with 59 contact nodes, defining the mating surfaces.

Assembly II
3.3 Assembly III
This assembly is composed of three sheet metals with nine weld points. The position of the weld points and their numbering are shown in Fig. 7 The first seven-weld points of this assembly is considered as geometry spot welds, and thereby considered in sequence evaluation. The last two weld points, w8 and w9, are set simultaneously, according to the assembly procedure. Therefore, in the sequence evaluations, the first seven-weld points are set in a sequence, and the last two weld points are welded simultaneously.

Assembly III
The purple part has nine positioning points, shown with the arrows. The small, blue part has six positioning points. The yellow part has eight positioning points. To avoid the penetration states, 194 contact points define the contact areas. In this assembly, the non-ideal shape is coming from the 3D-scanned data of the single parts.
4 Method evaluation
In this section, the proposed method is applied to the three reference assemblies. The proposed method is composed of the following steps:
- 1.
Create the sample based on the sampling strategy proposed in Section 2.3.
- 2.
Evaluate the sample with the provided model formulation, Section 2.1, to retrieve the geometrical deviation corresponding to the sampled sequences.
- 3.
Approximate the sample input-output, weld sequence, and geometrical deviation, function using the RBF network.
- 4.
Evaluate all the feasible sequences using the approximated RBF network.
- 5.
Retrieve the sequence corresponding to the minimum geometrical deviation.
- 6.
Evaluate the proposed sequence with the formulation provided, Section 2.1, to retrieve the numerical simulation of the geometrical deviation when welding is performed with the proposed sequence.
4.1 Exhaustive search
To verify the accuracy of the method, an exhaustive search has been performed, evaluating all the possible sequences of the three reference assemblies. The sample input-output relation and the surrogate performance have been compared against the exhaustive search results. The outcome of the exhaustive search on each assembly is presented in Fig. 8, where the RMS of geometrical deviation of the assembly for all the permutations is presented. In assemblies I and II, one sequence results in the minimum RMS of geometrical deviation. These sequences are presented in Table 1. In assembly III, sixty sequences result in a RMS of geometrical deviation equal to the minimum of this value. The sequence presented in Table 1 for the assembly III is one of the sequences among the sixty.

Comparison between the sampled sequences and all the feasible sequences
4.2 Surrogate model
To build the surrogate models, initially the sample required to train the RBF network is generated. Based on the comparison that is made between different sample sizes, Fig. 3, for all the three assemblies, all the permutations of the initial three weld points, s = 3, are considered to generate the sample to be evaluated. Having the Nw = 7 and s = 3, then the Ns can be calculated to 210 samples. These sample sequences are generated for all the three assemblies. The geometrical deviation, Q in Eq. 7, representing each sequence is evaluated using the CAT tool RD&T, with the formulation provided in Section 2.1. Figure 8 shows the Q value, corresponding to all the possible sequences and for the sampled sequences. The sampled sequences provide a clear representation of all the permutations, for all the three assemblies. This shows that analyzing the first three elements of a sequence vector, s = 3, results in a satisfying sample size with an accurate representation of all the possible permutations. The sampling strategy can be used to build an accurate surrogate model to reduce the geometrical deviation caused by applying a different sequence of spot welding.
Using the presented RBF network, Section 2.4, the samples are approximated. The goal is set to approximate the function with zero error. The spread, σj (see Eq. 12), is set to 1 for assembly I and III, while in assembly II where the sample data is much noisier, this spread is reduced to 0.001, to achieve a zero error approximate function.
Figure 9 presents the trained network approximating the sample data. The red dashed line represents the network output, while the black line represents the sampled data input. The correlation between the trained data and the output is visualized in this figure. Perfect fit on the R = 1, representing the highest correlation value, is achieved. The error has been less than e− 15 in all the three trained networks. These three trained networks are used to evaluate all the feasible sequences.

Trained networks for each assembly
4.3 Spot welding sequence evaluation
The three networks have been applied to all the feasible sequences for the three assemblies. The outcome of the network has been compared with the exhaustive search performed on all the sequences, in Fig. 10. The surrogate, for all the three cases, has identified the minimum regions. The minimum sequences corresponding to the minimum Q has been retrieved for all the three assemblies. These sequences have been evaluated to retrieve the geometrical deviation, by the formulation presented in Section 2.1. The results of this evaluation are presented in Table 1.

Surrogate model output compared with exhaustive search
The optimum results show that the surrogate model is capable of proposing sequences with neglectable error ranges. Provided that the surrogates are built based on a sample size, which consists of four percent of the total feasible permutations, the accuracy of the proposed sequences is considerably high.
To build a surrogate model that can be representative of all the sequences, the interpolated function of the assembly model using the sampled data is built. These models are referred to as enhanced surrogates. After generating the sample with the approach proposed in Section 2.3, the interpolated function is generated using the nearest neighbor method over all the sequences, using the previously generated 210 samples. The interpolated assembly functions are built by a one-dimensional interpolation function with the nearest neighbor method in MATLAB. This function is built for each assembly, and 840 data points generated by the interpolated function are used to train the RBF network. These 840 data points are created with the presented sampling strategy when s = 4. The RBF network parameters are adjusted to the new data set with 840 data points.
Figure 11 shows the comparison between the enhanced surrogates and the exhaustive search. These models have increased accuracy for all the sequences. In Table 1, the results retrieved by the enhanced models are presented. The error in the retrieved optimum is reduced to zero in assemblies I and III, and in assembly II, this error is reduced by 38%.

Enhanced surrogate model trained with interpolated data set compared with exhaustive search
4.4 Evaluation time
To compare the evaluation time required to build the surrogate models and the previously applied GA optimization algorithms, the numbers of the function evaluations (NFE) are compared with each other. NFE corresponds to the number of the times that the CAT tool is called to evaluate the geometrical deviation, Q value, of a proposed sequence. The evaluation time of a standard GA applied previously on the reference assemblies is compared with the surrogate modeling approach in Table 2.
In this comparison, a standard discrete GA with a single-point crossover using a roulette wheel selection approach has been applied to the three reference assemblies. The mutation operator has been based on inversion, insertion, and swapping. The crossover parameter has been 0.5, and the mutation parameter 0.9. A range of population sizes from 2 to 100 have been considered. For each population size, the optimization algorithm has been run 1000 times. The mean NFE, \(\bar {NFE}\), has been calculated for each population. The minimum \(\bar {NFE}\) achieved in this range of population for each assembly has been reported in Table 2.
For assemblies I and II, the minimum \(\bar {NFE}\) has been achieved in the population of size two. In assembly III, the population size 28 resulted in the minimum \(\bar {NFE}\), for achieving the sequence with optimum RMS of the geometrical deviation among all the possible permutations.
Table 2 shows that the proposed surrogate modeling approach can save up to 91% of the time that is required to reach a sequence with the minimum Q value. This depends on the number of evaluators that are applied to evaluate the generated sample. The surrogate modeling approach can also help to save up to 11% of the time with a single evaluator, compared with the applied GA with optimal parameters.
One of the advantages of the proposed surrogate modeling approach is that the sampling strategy is fully parallelizable. This means that the time required to use the proposed approach for real-time optimization of the individual assemblies can be decreased drastically by increasing the number of evaluators. Unlike any heuristic optimization algorithm, namely, GA, where the evaluations are dependent on each other to evolve, the sampling strategy can be performed using as many evaluators as available. As an example, having two evaluators, in this case, the CAT tools, will reduce the computation time to half, ten evaluators to one-tenth of the time, and so on (Table 2). This is a great advantage to reduce the calculation time required to optimize the sequence of the spot welding for minimized geometrical deviation.
The other advantage of the proposed surrogate approach compared to the GA is that the RBF parameter tuning does not require extra evaluation time. However, in the GAs, to find the optimal algorithm parameters, like population size, mutation, and crossover rate, extra evaluation time is required.
Parallel GAs have also shown to reduce the computational time compared with the standard GA. In these algorithms, a master algorithm initiates the population randomly, in the first step. Depending on the fitness of this step, crossed over and mutated populations are generated by several parallel sub-algorithms [28]. Therefore, several dependent evaluation steps need to be performed in such algorithms. The advantage of the proposed surrogate modeling approach over these algorithms is that the sample is generated in one step, where the sequences can be evaluated in parallel, and the model is built based on this evaluation. The sample is built by the proposed strategy in Section 2.3, for reduced evaluation time.
5 Conclusion
A new surrogate model approach for individualized spot welding sequence optimization with respect to geometrical quality is proposed. The method takes advantage of a time-efficient sampling strategy to build an input-output function. The function is approximated using the RBF network. The network is used to retrieve the optimal sequence corresponding to the minimum RMS of geometrical deviation in all the nodes of the assembly after welding. The proposed approach is successfully applied to three reference BIW assemblies for evaluation. The results achieved from the surrogate model are compared with the exhaustive search performed on the three reference assemblies.
The approach has shown to provide the sequence within the minimum area with a marginal error from the global optimum. The advantage of the approach is the ability to propose a sequence with the partial evaluation of the complete sequence problem, where only \(\frac {1}{(N_{w}-s)!}\) percent of all the permutations needs to be evaluated. This makes the approach to use a fixed number of parallelizable evaluations. This is on the contrary to other heuristic optimization and search algorithms where the number of evaluations is fluctuating relative to the algorithm parameters.
Previous studies have considered applying the evolutionary algorithms for this purpose, while in these algorithms the number of evaluations is changing based on the population sizes and other parameters that are set in the algorithm. Moreover, in heuristic search algorithms, the evaluations are dependent on each other, meaning that a new solution can only be produced based on the evaluated value of the previous solution. This makes them more complex to parallelize. However, in the proposed surrogate approach, the sample evaluations can be fully parallelized, and there is no dependency between the evaluations. This is a great advantage, for real-time optimization of the individualized assemblies, Section 1.3, compared with the other heuristic optimization algorithms. In the time comparison that is performed in Section 4.4, the surrogate modeling approach has shown to reduce up to 90 percent of the evaluation time required by a standard GA, depending on the number of the evaluators that are deployed.
Further studies are required to evaluate the application of the approach on the assemblies with a large number of weld points. The authors intend to propose a clustering approach to identify the critical weld points for geometrical quality to be considered for sequence analysis, using the proposed surrogate modeling approach.
References
Wärmefjord K, Söderberg R, Ericsson M, Appelgren A, Lundbäck A, Lööf J, Lindkvist L, Svensson HO (2016) Welding of non-nominal geometries – physical tests. Procedia CIRP 43:136–141. https://doi.org/10.1016/j.procir.2016.02.046, 14th CIRP CAT 2016 - CIRP Conference on Computer Aided Tolerancing
Söderberg R, Lindkvist L, Wärmefjord K, Carlson JS (2016) Virtual geometry assurance process and toolbox. Procedia CIRP 43:3–12. https://doi.org/10.1016/j.procir.2016.02.043, 14th CIRP CAT 2016 - CIRP Conference on Computer Aided Tolerancing
Moos S, Vezzetti E (2012) Compliant assembly tolerance analysis: guidelines to formalize the resistance spot welding plasticity effects. Int J Adv Manuf Tech 61(5):503–518. https://doi.org/10.1007/s00170-011-3729-0
Wärmefjord K, Söderberg R, Lindkvist L (2010) Variation simulation of spot welding sequence for sheet metal assemblies. In: Proceedings of NordDesign2010 international conference on methods and tools for product and production development, vol 2, pp 519–528
Tabar RS, Wärmefjord K, Söderberg R (2018) Evaluating evolutionary algorithms on spot welding sequence optimization with respect to geometrical variation. Procedia CIRP 75:421–426. https://doi.org/10.1016/j.procir.2018.04.061
Fukuda S, Yoshikawa K (1990) Determination of welding sequence: a neural net approach. Engineering Analysis with Boundary Elements 7(2):78–82. https://doi.org/10.1016/0955-7997(90)90024-4
Huang MW, Hsieh CC, Arora JS (1997) A genetic algorithm for sequencing type problems in engineering design. Int J Numer Methods Eng 40(17):3105–3115
Liao YG (2005) Optimal design of weld pattern in sheet metal assembly based on a genetic algorithm. Int J Adv Manuf Tech 26(5):512–516. https://doi.org/10.1007/s00170-003-2003-5
Xie LS, Hsieh C (2002) Clamping and welding sequence optimisation for minimising cycle time and assembly deformation. Int J Materials Product Technol 17(5-6):389–399. https://doi.org/10.1504/IJMPT.2002.005465
Tabar RS, Wärmefjord K, Söderberg R, Lindkvist L (2019) A novel rule-based method for individualized spot welding sequence optimization with respect to geometrical quality. J Manuf Sci Eng 141(11). https://doi.org/10.1115/1.4044254 , 111013
Wärmefjord K, Söderberg R, Lindkvist L (2010) Strategies for optimization of spot welding sequence with respect to geometrical variation in sheet metal assemblies. In: ASME international mechanical engineering congress and exposition, vol 3, pp 569–577, DOI https://doi.org/10.1115/IMECE2010-38471
Chen BQ, Guedes SC (2016) Effect of welding sequence on temperature distribution, distortions, and residual stress on stiffened plates. Int J Adv Manuf Tech 86(9):3145–3156. https://doi.org/10.1007/s00170-016-8448-0
Voutchkov I, Keane AJ, Bhaskar A, Olsen TM (2005) Weld sequence optimization: the use of surrogate models for solving sequential combinatorial problems. Comput Methods Appl Mech Eng 194(30):3535–3551. https://doi.org/10.1016/j.cma.2005.02.003
Söderberg R, Lindkvist L, Dahlström S (2006) Computer-aided robustness analysis for compliant assemblies. J Eng Des 17(5):411–428
Liu SC, Hu SJ (1997) Variation simulation for deformable sheet metal assemblies using finite element methods. J Manuf Sci Eng 119:368–374
Dahlström S, Lindkvist L (2007) Variation simulation of sheet metal assemblies using the method of influence coefficients with contact modeling. J Manuf Sci Eng 129(3):615–622
Lindau B, Lorin S, Lindkvist L, Söderberg R (2016) Efficient contact modeling in nonrigid variation simulation. J Comput Inf Sci Eng 16(1):11002–11007. https://doi.org/10.1115/1.4032077
Lorin S, Lindau B, Lindkvist L, Söderberg R (2018) Efficient compliant variation simulation of spot-welded assemblies. ASME J Comput Inf Sci Eng 19(1):011007–011007–7
Lorin S, Lindau B, Sadeghi Tabar R, Lindkvist L, Wärmefjord K, Söderberg R (2018) Efficient variation simulation of spot-welded assemblies. In: ASME 2018 international mechanical engineering congress and exposition, vol 1, p V002T02A110
RD&T Technology AB (2017) RD&T Software Manual
Söderberg R, Wärmefjord K, Carlson JS, Lindkvist L (2017) Toward a digital twin for real-time geometry assurance in individualized production. CIRP Annals 66(1):137–140. https://doi.org/10.1016/j.cirp.2017.04.038
Wärmefjord K, Söderberg R, Lindkvist L, Lindau B, Carlson JS (2017) Inspection data to support a digital twin for geometry assurance. In: ASME international mechanical engineering congress and exposition. Advanced Manufacturing, pp V002T02A101, https://doi.org/10.1115/IMECE2017-70398, vol 2
Aderiani AR, Wärmefjord K, Söderberg R, Lindkvist L (2019) Developing a selective assembly technique for sheet metal assemblies. Int J Production Res 57(22):7174–7188. https://doi.org/10.1080/00207543.2019.1581387
Lippmann RP (1989) Pattern classification using neural networks. IEEE Commun Magazine 27(11):47–50. https://doi.org/10.1109/35.41401
Park J, Sandberg IW (1991) Universal approximation using radial-basis-function networks. Neural Comput 3(2):246–257. https://doi.org/10.1162/neco.1991.3.2.246
Hagan MT, Demuth HB, Beale MH, De Jesús O (1996) Neural network design, vol 20. Pws Pub., Boston
Lehmann TM, Gonner C, Spitzer K (1999) Survey: interpolation methods in medical image processing. IEEE Trans Med Imag 18(11):1049–1075. https://doi.org/10.1109/42.816070
Mühlenbein H, Schomisch M, Born J (1991) The parallel genetic algorithm as function optimizer. Parallel Comput 17(6):619–632. https://doi.org/10.1016/S0167-8191(05)80052-3
Acknowledgments
Open access funding provided by Chalmers University of Technology.
Funding
The work was carried out in collaboration with Wingquist Laboratory and the Area of Advance Production at Chalmers within the project Smart Assembly 4.0, financed by The Swedish Foundation for Strategic Research. The support is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tabar, R.S., Wärmefjord, K. & Söderberg, R. A new surrogate model–based method for individualized spot welding sequence optimization with respect to geometrical quality. Int J Adv Manuf Technol 106, 2333–2346 (2020). https://doi.org/10.1007/s00170-019-04706-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-019-04706-x