
Abstract
Theories of inter-jurisdictional tax and yardstick competition assume that the tax decisions of one jurisdiction will influence the tax decisions of other jurisdictions. This paper empirically addresses the issue of horizontal dependence in local personal income tax rates across jurisdictions. Based on a large data set covering Swedish municipalities over a period of 14 years, we test for interactions across municipalities that share a common border, across municipalities within a distance of 100 km of each other, and across municipalities with similar political representation in the local council. We also test the hypothesis that the tax rate of relatively larger municipalities has a greater influence on their neighbors' tax rate compared to the influence of their smaller neighbors. Our results suggest that when lagged tax rates are controlled for, the horizontal correlation across municipalities that share a common border or are within a distance of 100 km from each other becomes insignificant. This result is of importance as it suggests that lagged tax rates should be included or at least tested for when testing for horizontal interactions or mimicking in local tax rates. However, our results support the hypothesis of horizontal interactions across municipalities that share a common border when the influence of neighboring municipalities is also weighted by their relative population size, i.e. relatively larger neighbors tend to have a greater impact on their neighbor's tax rates than their relatively smaller neighbors. This is of importance as it suggests that distance or proximity matters, although only in combination with the relative population size. We also find some evidence of horizontal dependence across municipalities with similar political preferences.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The aim of this paper is to empirically test the hypothesis of horizontal interactions or mimicking in local personal income taxes. There are at least two theoretical reasons why such interactions may exist: inter-jurisdictional tax competition and yardstick competition. In theories of tax competition, which builds on Tiebout (1956) and Mirrlees (1971), local jurisdictions compete for a mobile tax base, in this case, individuals and their incomes, using a (low) tax rate as their primary tool. The theory of tax competition predicts a local tax rate that is below the socially optimal level possibly leading to a race-to-the-bottom in the provision of local public services, i.e. local governments tend to lower their tax rates resulting in under-provision of local public services. However, the conclusion that tax competition reduces taxes below a socially optimal level could be challenged if taxes are too high from the outset or if they finance an inefficient provision of (public) services or projects that could be provided more efficiently by other sectors. In yardstick competition, it is information rather than individuals that crosses borders as voters use information about taxes and spending levels in other jurisdictions as a yardstick for measuring the competence of their own incumbent politicians. By observing and comparing policies in neighboring jurisdictions, voters can update their understanding of their incumbent politicians as being either good or bad where bad politicians extract rents while in office. Regarding local income taxes, the likelihood of re-election depends on the relative tax rate in neighboring jurisdictions. In short, bad politicians set tax levels low enough so that voters cannot distinguish them from good ones. Thus, the likelihood of re-election depends on the income tax rates in neighboring jurisdictions. The theory of yardstick competition was first expressed by Salmon (1987) and predicts increased efficiency in the political system through better informed voters.Footnote 1
Even though there are theoretical arguments for the presence of horizontal interactions, testing for the existence of such interactions remains an empirical issue. Evidence in favor of horizontal interactions has been found in many different settings: US states (Case 1993; Besley and Case 1995); the metropolitan areas surrounding Boston (Brueckner and Saavedra 2001) and Barcelona (Sollé Ollé 2003); non-metropolitan districts in England (Revelli 2001, 2002); Swiss cantons (Feld and Reulier 2009; Schaltegger and Kuttel 2002; Parchet 2019); and Dutch (Allers and Elhorst, 2005), French (Leprince et al. 2007; Agrawal et al. 2020a), Italian (Bordignon et al. 2003), Belgian (Heyndels and Vuchelen 1998), Swedish (Edmark and Ågren 2008) and German municipalities (Büttner 2001; and Hauptmeier et al. 2012). A few studies, such as Lyytikäinen (2012), Isen (2014) and Baskaran (2014), found no evidence of strategic interactions in local tax policies across Finnish municipalities, local governments in Ohio or the German state of North Rhine-Westphalia, respectively.
As the causes of interaction give rise to diametrically different policy implications, many authors have tried to discriminate between tax and yardstick competition. However, this is far from easy. As shown by Brueckner (2003), Agrawal et al. (2020b) and others, the causes of interaction give rise to similar reduced forms and spatial reaction functions. Nevertheless, many studies point in the direction of yardstick competition. For example, Case (1993) showed that tax rates are only influenced by the tax rates in neighboring states when the governor is eligible to be re-elected. Besley and Case (1995) found that the likelihood of a US state governor being re-elected decreased as state taxes rise, and increased in the event of tax increases in neighboring states. Revelli (2002) concluded that tax increases diminished the popularity of incumbent politicians, while tax increases in neighboring districts raised their popularity. Schaltegger and Kuttel (2002) found that tax mimicking depended on the political setting, and Bordignon et al. (2003) found that business property tax mimicking only existed in cities in which mayors were seeking re-election and were not backed by strong majorities. Sollé Ollé (2003) showed that tax mimicking was stronger in municipalities in which most of the ruling parties were smaller and in which right-wing parties ruled, as well as during election years. Edmark and Ågren (2008) found strong evidence of a spatial correlation in tax rates but weak evidence of tax competition effects in the setting of tax rates.
In the empirical literature, the spatial lag model (see the seminal work by Anselin 1988) is frequently used to identify and test for interactions in local taxes. As the tax rate of neighboring jurisdictions are by construction endogenous in the reaction function, inference is often based on either maximum likelihood (ML), instrumental variable (IV) or general methods of moments (GMM) estimators. In the IV and GMM setup, other characteristics such as income, demographic structure or political preferences of neighboring jurisdictions are often used as instruments for the neighboring jurisdiction's tax rate. However, this hinges on the crucial assumption that these variables only explain the local tax rate in neighboring jurisdictions and can be excluded from the second stage of the regression in which the tax rate of "our" jurisdiction is explained. Gibbons and Overman (2012) argued that this assumption most likely does not hold. First, the characteristics of neighboring jurisdictions might have a direct effect on the tax rate of a given jurisdiction. Second, the tax policies of neighboring jurisdictions are likely to have a direct effect on their own demographic structure, income levels and other characteristics. Finally, a spatially correlated omitted variable might influence both the characteristics of neighboring jurisdictions and the tax rate of a given jurisdiction. Using Monte Carlo simulations, Driscoll and Kraay (1998) have shown that the presence of even modest spatial dependence can impart large bias to OLS standard errors when Ν is large.
In this paper, we use both the time and space dimension in our data to construct instruments for neighboring jurisdictions tax rates to avoid the critique put forward by Gibbons and Overman (2012). Based on a data set covering 289 out of 290 Swedish municipalities between 2003 and 2016 and in contrast to many previous studies (Chirinko and Wilson (2017) being one exception), we argue that the influence of the tax rates of other municipalities is delayed one period. We also elaborate with different definitions of neighbors. In contrast to Edmark and Ågren (2008), who have also analyzed Swedish municipalities, we control for potential persistence in tax setting behavior. In other words, the own tax rate lagged one period is included in the model. Vertical interactions due to tax base sharing (Andersson et al. 2004; Devereux et al. 2007) or provision of complementary public services (Aronsson et al. 2000) are controlled for by including the county tax rate. The explicit modelling of both horizontal and vertical interaction processes can help avoid mistaking the omitted variable correlation for an actual expenditure spill-over.
Our main results suggest that when introducing persistence into the empirical model, much of the horizontal correlation disappears. Also, even when not controlling for previous tax rates, we only found limited evidence of horizontal interactions. However, we found that a relatively large neighbor compared to other neighbors (in terms of population) has a stronger impact on its neighbor's income taxes than a relatively small municipality. To some extent, this is in line with the results presented by Lundberg (2014). We also found weak evidence of a positive correlation in local personal income taxes across jurisdictions with similar political preferences.
The remaining part of this paper is organized as follows: The next section provides some background to the Swedish situation and tax setting procedure at the local level. Section 3 presents an empirical specification, definition of neighbors and econometric issues, followed by a description of the data set in Sect. 4. The empirical results are presented and discussed in Sect. 5. The paper ends in Sect. 6 with concluding comments.
2 Background
In Sweden, local governments are the main providers of services such as childcare, elementary schools, secondary schools and care for the elderly, while the county level is the main provider of health care. Even though there are private alternatives, the local government has primary responsibility for these services. These services are mainly financed through a proportional income tax (66.1% of total revenues including grants in 2016), a tax which local and regional governments are at liberty to set as they choose, intergovernmental grants (21.3%), and fees (5.2%).Footnote 2 For a long time, both local and regional governments have enjoyed considerable autonomy from the national government insofar as they set their own budgets, make their own priorities and exercise powers of income taxation.
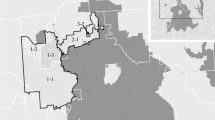
Over the last four decades, the main part of the expansion of the public sector in Sweden has been at the local level of government, partially because the national government has delegated and imposed new obligations on local governments and partially because local governments have gradually increased their engagement in other non-mandatory activities such as business development, culture, sports arenas and recreation facilities. Over the last decade, many local governments have suffered considerable financial stress. Consequently, 170 out of 289 jurisdictions have increased their local personal income tax rates. However, in 2016, 23% of municipalities reported deficits while only 18% raised their taxes. Moreover, looking at Fig. 1, it is evident that the lowest tax rates in 2016 were near the major urban areas of Stockholm, Gothenburg and Malmö, while the highest income tax rates were in the central and northern Sweden.

Local personal income taxrates 2016
2.1 Tax setting procedure
Horizontal interactions are of course not the only mechanism that affect the local income tax. The local personal income tax rates for the next year are decided by the local councils in November each year. By this time, decision makers have a good estimate of the financial situation of their respective municipality, such as intergovernmental grantsFootnote 3 for the next year and their own financial report for the current year. They also have good knowledge about the local tax base and conditions on the local labor market such as the local unemployment rate. As local governments are the main providers of childcare, elementary and secondary schools, and elderly care, demographic factors are also of importance. As the local tax rate is decided on in November the year before the tax rate is implemented, it is reasonable to assume the tax decision (or tax rate) for year t taken at time \(t-1\) is based on the financial situation and demographic factors at time \(t-1\).
The local income tax rate is decided by the local council. A common perception is that social democrats and left-wing representatives have a positive attitude towards public spending and high tax rates, making the political representation in the local council a potentially important factor in these decisions. As elections to the local council take place in September every fourth year, the tax rate for year t is decided by the political representation in the local council at time \(t-1\).
In evaluating the performance of local politicians, there is an obvious information asymmetry between politicians and the public. Local politicians are naturally better informed about local public expenditure in different areas, intergovernmental grants, etc. As the local tax rate is displayed on pay slips and on income tax returns, the public in general and wage earners in particular are quite well informed about local income taxes. Changes to and lists of next year's local income taxes are often headline news in November each year and are frequently discussed in both the local and national media, making wage earners generally well informed about local income tax rates and how they differ across jurisdictions. Thus, it is possible that the local tax rate is used to win votes. One potential strategy is to lower taxes in election years and raise taxes the year after an election.
It is reasonable to assume some persistence in the tax policy, for example, the tax rate at time t depends on the tax rate at time \(t-1\), that is, the current tax rate serves as a point of departure when setting the tax rate for the next year. In their ambition to attract new inhabitants, both local and regional governments may be concerned about the total local income tax rate, which is the sum of the local and regional tax rate. Thus, local governments may also take the regional tax rate into consideration when deciding upon the local tax rate. Aronsson et al. (2000) found that the expenditure decisions made by county councils preceded those decisions made by municipalities, suggesting that the local income tax rate is adjusted to the county tax level. One possible explanation put forward by Aronsson et al. is that the county councils are acting Stackelberg leaders. If so, the expenditure decision (and also the tax decision) by the county council (leaders) precedes those decisions of the municipalities (followers). The statistical implication is that the county income tax decision is exogenous in the local tax equation. However, it is not obvious whether local governments respond immediately to the county tax level or whether the response is delayed one period. Here, it is assumed that there is an immediate response by the local government to the county tax level.Footnote 4
3 Empirical specification, definition of neighbors and econometric issues
3.1 Empirical specification
Spatial econometrics and the spatial lag model are frequently used when testing for strategic interactions. Denote by \({\rm tax}_{i,t}\) the local income tax rate in jurisdiction i at time t and let \(\mathbf {x}_{i.t-1}\) contain all other observed characteristics of jurisdiction i which have a potential impact on \({\rm tax}_{i,t}\) such as the local tax base, intergovernmental grants, the financial situation, political preferences, and socioeconomic factors. Let \({\rm tax}_{i,t-1}\) capture the influence of past tax rates and \(\alpha _{i}\) time invariant omitted variables and/or unobservables. Define a matrix \(\mathbf {W}\) of dimension \(\left( nT\times nT\right)\) where n is the number of jurisdictions in the data set and T is the number of time periods. The elements of \(\mathbf {W}\), \(w_{ij}\), reflect the influence that jurisdiction j is expected to have on jurisdiction i’s tax decision, that is, \(w_{ij}>0\) if, based on some exogenous pre-knowledge or theoretical model, the tax rate of jurisdiction j is assumed to affect the tax rate of jurisdiction i, otherwise \(w_{ij}=0\). This influence can either be based on the fact that i and j share a common border or are located within a pre-determined geographical distance from each other. However, it may also be based on some other measure of similarity such as political preferences, socioeconomic variables or demographic structure. To avoid the influence of jurisdiction i’s tax rate on its own tax rate \(w_{ii}=0\).
Leaving the nature of the influence between jurisdictions for the moment and just assuming it is reflected by the elements in \(\mathbf {W}\), the tax rate of jurisdiction i at time t is assumed to be determined by the equation
where \(\mathbf {x}\) contains k potentially important regressors, \(\mathbf { \beta }\) is a vector of k parameters to be estimated, \(\delta\) is a parameter to capture potential persistence in tax policies, and \(\tau\) is time fixed effects. The error term \(\varepsilon _{i,t}\) is assumed to be normally distributed, uncorrelated with the k regressors and every other \(\varepsilon\), and to have constant variance \(\sigma ^{2}\). A test of strategic interaction in tax levels boils down to a test of the parameter \(\rho\) where \(\rho \ne 0\) implies some type of strategic interactions.
As noted by Wildasin (2006), Agrawal et al. (2020b) and others, \(\rho =0\) does not automatically rule out tax competition. For example, \(\rho =0\) may mean that strategic interactions do not exist among the (small) set of jurisdictions defined as neighbors by \(\mathbf {W}\) but do exist among another set of neighbors. Another possibility is that different jurisdictions have reaction functions with opposite signs. Cassette et al. (2012) elaborate and include several weight matrices. Even though we also elaborate with different specifications and definitions of neighbors, our focus is on a general pattern.
Also note that we allow for sequential decision making in that the tax decision made by jurisdiction i at time t depends on the tax rate in an neighboring jurisdiction j at time \(t-1\).
3.2 Different definitions of the elements in \(\mathbf {W}\)
From Eq. (1) it is evident that \(\rho\) depends on the specification of \(\mathbf {W}\). Since \(\mathbf {W}\) is of dimension \(\left( nT\times nT\right)\), it is not possible to estimate its elements together with the other parameters in the model. Hence, \(\mathbf {W}\) has to be determined prior to estimation and five different definitions are used here to capture different causes of horizontal dependence or influence across jurisdictions defined through a two step procedure. First, the elements are defined based on some criteria, for example \(w_{ij}=1\) if i and j share a common border. Then, \(\mathbf {W}\) is row-normalized, meaning that the elements are transformed so that the sum of all elements of each row is equal to 1, that is, \(tax_{i,t}\) is regressed on a weighted average of the tax rates of those jurisdictions that are defined as its neighbors.
One key issue in testing for tax and yardstick competition is the definition of neighbors. In a tax competition model, who does jurisdiction i compete with? In a yardstick model, who do politicians in jurisdiction i mimic? Tax competition is probably most severe across jurisdictions who share a common border in which individuals may move across jurisdictional borders at a low social cost, i.e. without changing workplace, colleagues and/or social networks. Regarding yardstick competition, it is likely that, when comparing the performance of the politicians running their own jurisdiction through local media and their social network, individuals will have more information about the conditions in nearby jurisdictions. If this is the case, both tax and yardstick competition give rise to similar spatial reaction functions, making it difficult to discriminate between these two causes of horizontal interactions. However, regarding yardstick competition, it is also reasonable to assume that individuals will compare the performance of their own politicians with the performance of politicians from comparable jurisdictions in terms of population size and political preferences, i.e. individuals living in a major urban area may relate to and compare their situation and local income taxes with the conditions and taxes in other major urban areas. Janeba and Osterloh (2013) have presented empirical evidence that large jurisdictions are competitors with towns in different states or even different countries. Moreover, a questionnaire in which respondents were asked to rank their interest in the local politics of municipalities other than the municipality in which they lived revealed a higher interest in the local politics of larger municipalities (see Lundberg 2014). This suggests that politicians in relatively large municipalities compared to their geographically close neighbors are to a larger extend influenced by the tax setting behavior of more distance jurisdictions with similar or larger population than by geographically closer located but relatively smaller jurisdictions.
Based on the discussion above, the following five different definitions of connectivity, or horizontal interactions, is used:
-
\(\mathbf {W}_{n}:\) \(w_{ij}>0\) if the two jurisdictions i and j share a common border.
-
\(\mathbf {W}_{1/d}:w_{ij}=1/d_{ij}\) where \(d_{ij}\) is the distance in 10 kilometers between the geographical centers of jurisdictions i and j. A cut-off value of \(w_{ij}=0.1\) is used (within 100 kilometers).
-
\(\mathbf {W}_{p/d}:\) \(w_{ij}=\left( pop_{j}/pop_{i}\right) /d_{ij}\). A cut-off value of \(w_{ij}=0.1\) is used.
-
\(\mathbf {W}_{pop}:w_{ij}=pop_{j}/pop_{i}\) where \(pop_{i}\) is the population of jurisdiction i. Jurisdictions who share a common border only.
-
\(\mathbf {W}_{pol}:w_{ij}=1-\left| soc_{i}-soc_{j}\right|\) where \(soc_{i}\) is the proportion of seats in the local council held by the social democrats, the left wing party or the green party. A cut-off value of \(w_{ij}=0.7\) is used.
\(\mathbf {W}_{n}\), \(\mathbf {W}_{1/d}\) and \(\mathbf {W}_{p/d}\) are in line with both tax competition and yardstick competition while \(\mathbf {W}_{pop}\) and \(\mathbf {W}_{pol}\) are more in line with yardstick competition. As the weight matrices are row-standardized, the influence of one neighbor depends on the relative influence of other neighbors, i.e. if one municipality only has one neighbor, the influence of that neighbor is 1, but if the same municipality has two neighbors, their total influence is still 1. Thus, the influence of one neighbor depends on the relative influence of each neighbor relative to the influence of other neighbors.Footnote 5
3.3 Econometric issues
As is well known in the spatial econometric literature, ordinary least squares (OLS) will provide biased as well as inconsistent parameter estimates. Instead of OLS, inference is often based either on maximum likelihood (ML), instrumental variable (IV) or general methods of moments (GMM) estimators (see, for example, Anselin 1988). Here, Eq. (1) is estimated by 2SLS.
Some authors have recently discussed problems with the identification of causal effects in spatial econometric models. The most severe critique has perhaps been made by Gibbons and Overman (2012), whose main concern is the validity of \(\mathbf {W}x\) as instruments for the endogenous \(\mathbf {W }y\). This objection stems from the fact that the reduced form of the regression equation \(y=\alpha +\rho \mathbf {W}y+\beta x+\varepsilon\) includes \(\mathbf {W}x\) which implies that both the average value of x in neighboring municipalities and that for the “neighbors’ neighbors” enter the reduced form equation.
In our specification, we make the crucial assumption that the spatial neighbor effects specified by \(\mathbf {W}\) are correct and known. That is, our estimates of \(\rho\) are only valid if we accept the definition of the elements in \(\mathbf {W}\). Even though its not obvious that \(\mathbf {W} y_{i,t-1}\) is endogenous in equation (1), we take a conservative stance and use the time and spatial dimension in our data to construct valuable instruments for both \(\mathbf {W}y_{i,t-1}\) and \(y_{i,t-1}\).
To describe how the instruments are constructed, consider the weights matrix \(\mathbf {W}\) where \(w_{ij}=1\) if i and j share a common border, otherwise \(w_{ij}=0\). Instead of using \(\mathbf {W}x_{i,t-1}\) as instruments for \(\mathbf {W}y_{i,t-1}\) we use different combinations of \(\mathbf {W} ^{inst}x_{i,t-2}\), \(\mathbf {W}^{inst}y_{i,t-2}\), \(\mathbf {W}y_{i,t-3}\) and \(\mathbf {W}x_{i,t-3}\) where \(\mathbf {W}^{inst}\ne \mathbf {W}\). To be more precise, \(w_{ij}^{inst}\ne w_{ij}\), and \(w_{ij}^{inst}>0\) if \(w_{ij}=0\) and \(w_{ij}^{inst}=0\) if \(w_{ij}>0\) for all i, j. However, we need to accept the exclusion restriction that combinations of \(\mathbf {W}^{inst}x_{i,t-2}\), \(\mathbf {W}^{inst}y_{i,t-2}\), \(\mathbf {W}y_{i,t-3}\) and \(\mathbf {W}x_{i,t-3}\) do not enter Eq. (1). Moreover, based on the standard dynamic panel data literature, \(y_{i,t-3}\) qualify as an instrument for \(y_{i,t-1}\). Tests for overidentifying restrictions are provided for each specification.
As noted by Baltagi (2005) and Elhorst and Fréret (2009), spatial fixed effects control for all space-specific, time-invariant variables whose omission could bias the estimates in a typical cross-sectional study. The justification for adding time-period fixed effects notes that they control for all time-specific, spatial-invariant variables whose omission could bias the estimates in a typical time-series study. Time-period fixed effects also correct for spatial interaction effects among the error terms, such as unobserved shocks following a spatial pattern or variables that increase or decrease together in different jurisdictions along the same (business) cycle over time. Time-period fixed effects are mathematically equivalent with a spatially autocorrelated error term and a spatial weights matrix whose elements are equal to 1/N, including the diagonal elements (see Elhorst 2014). The large set of covariates presented in the next section are included in order to avoid omitted variable bias and potential correlation between the fixed effect and the error term.
4 Data
The data set originates from Statistics Sweden (SCB) and covers 289 out of 290 Swedish municipalities over the period 2003 to 2016. One municipality, Gotland, has been excluded due to it being an island with no fixed road/railroad connections with the mainland. This leaves us with a balanced panel comprising a total of 4,046 observations spanning a period of 14 years.
One advantage of using data on Swedish local governments is that they have enjoyed considerable autonomy from the national government insofar as they set their own budgets, make their own priorities and exercise powers of income taxation. Local income tax also constitutes the main source of revenue for local governments. Another advantage is that since local governments work in the same legal and institutional system, many of the problems associated with cross-country studies are avoided.
The local and county income tax rates (\(tax_{i,t}\) and \(ctax_{i,t}\)) are measured in percentage points. Financial characteristics are captured by the local tax base (\(taxbase_{i,t-1}\)), intergovernmental grants (\(tsub_{i,t-1}\)), and the financial outcome (\(result_{i,t-1}\)) measured in SEK 10,000 per capita. Local labor market conditions are reflected by the share of the population aged 25–65 years registered at the Swedish Public Employment Service (\(unempl_{i,t-1}\)) and the share of foreign born (\(for_{i,t-1}\)).
Political preferences and the fragmentation of the local council are often assumed to be important determinants of the local income tax rate and changes therein in which it is presumed that members of the social democratic and left-wing parties have a more positive attitude towards higher tax rates. It is often assumed that a more fragmented council might find it hard to hold back on public spending, which would have a positive effect on the local income tax rate. Here, political preferences (\(lw_{i,t-1}\)) is measured as the share of the seats in the local council held by social democrats, members of the left-wing party and the green party. It is assumed that the fragmentation of the local council is reflected in a Herfindahl-index (\(h_{i,t-1}\)). A dummy variable taking the value 1 for election year (\(elect_{t}\)) is included in order to capture a different tax setting behavior during election years.
Demographic structure is another potentially important determinate of the local tax rate as municipalities are the main providers of childcare, elementary and secondary schools, and elderly care. To control for these factors, net migration (\(mig_{i,t-1}\)), the share of the population aged 0-6 years (\(a06_{i,t-1}\)), the share of the population aged 7–15 years (\(a715_{i,t-1}\)) and the share of the population aged 70 or above (\(a70_{i,t-1}\)) are included in Eq. (1). Net migration, or migration, is an important component in models of tax competition. Here, net migration is defined as \(mig_{i,t-1}=\left( pop_{i,t-1}+migration_{i,t-1}\right) /pop_{i,t-1}\) where pop is the population on January 1 and migration is the net of in-and-out migration during that year. Potential agglomeration effects in the provision of local public services are captured by the population density measured as inhabitants per square kilometer (\(dens_{i,t-1}\)). A dummy variable (kd) is used to control for the tax-shift between the county and municipal level in Kalmar introduced in 2008, when Kalmar municipality took over some of the health care responsibilities from the county level.Footnote 6
For the reasons discussed earlier, ctax is treated as an exogenous variable. Even though tbase is typically endogenous in models of tax competition and tsub is based, among other things, on taxbase, both tsub and taxbase are treated as exogenous. The reason is that in Sweden, the effective taxable income for jurisdiction i at time t is based on the tax assessment in \(t-1\), and the tax assessment in period \(t-1\) refers to the taxable income in period \(t-2\). Hence, the effective taxable income is not affected by the tax rate at time t. Thus, both tbase and tsub are treated as exogenous (see Edmark and Ågren 2008).
Summary statistics are shown in Table 1.
5 Results
5.1 No spatial effects
Parameter estimates and the corresponding standard deviation (in parenthesis below the parameter estimate) of two specifications of Eq. (1) with the restriction \(\rho =0\) are shown in Table 2. In the first column (A) \(mtax_{i,t-1}\) is excluded. These two specifications are used as a point of reference for the following specifications when spatial effects are introduced.
In brief, the results presented in Table 2 suggest a negative correlation between the county income tax rate (\(ctax_{i,t}\)) and the local tax rate suggesting that high county tax rates render in low(er) local income tax rates. One potential interpretation is that in order to keep total local and regional income tax rates at a "reasonable" level, regions with a relatively high county tax rate tend to set lower local income tax rates. Thus, the local income tax rate is adjusted to the county tax level, which is also in line with Aronsson et al. (2000) who found that the the expenditure decisions made by counties to precede expenditure decisions made by the municipalities. This also suggests that the services provided by the two bodies are substitutes, such as care for the elderly (provided by the local level) and health care (provided by the regional level).
The previous tax rate \(mtax_{i,t-1}\) is estimated to have a positive and significant impact on the current tax rate which suggests that the previous tax rate serves as a point of departure for the next year’s tax rate. As information on previous conditions are captured by \(mtax_{i,t-1}\) this is also one reason why some of the other covariates become insignificant when the previous tax rate is included in the model. This accounts for the local tax base (taxbase), unemployment rate (unempl), net migration (mig), share of population aged 7–15 years (a715), and population density (dens). Only the county tax rate, ctax, and intergovernmental grants, tsub, are estimated to have a significant negative effect on mtax in both specifications. The negative correlation between tsub and mtax indicates that the combined subsidies and redistribution scheme serves one of its purposes and has a dampening effect on the local income tax rate.
It is interesting to note is that the effect from election year (elect) change from positive to negative as \(mtax_{i,t-1}\) is included in the model. If the income tax rate is used to win votes it is unlikely that local politicians raise taxes prior to an election. This suggests that \(mtax_{i,t-1}\) should be included in the model. Also note the positive effect of population density even though it is not significant at the conventional 95% level in specification 2. This positive correlation between dens and mtax indicates that agglomeration tends to increase the cost of providing local public services.Even though this is not significant, all other parameter estimates except age distribution have expected signs.
5.2 Spatial effects
Models in which different specifications of interactions across municipalities are introduced are presented in Table 3 below. Based on these results, the hypothesis of horizontal interactions or mimicking in local tax rates across municipalities that share a common border or within a distance of 100 km is rejected (see columns 1 and 3). The hypothesis of horizontal interactions is also rejected when the weights matrix is adjusted to capture both the inverse distance and the relative population (column 2). The main conclusion is that geographical proximity only is not enough to cause interactions or mimicking. As discussed above, based on these estimates, it is not possible to rule out the existence of a mix of positive and negative interactions across municipalities and in different regions. However, we have also re-estimated the model using two weight matrices: one to capture interactions across municipalities in major urban areas and one for the rest of the country, in order to generate different parameter estimates for the different regions. The results reject the hypothesis of horizontal interactions. In order to save space, these results are not presented in Table 3.
Turning to column 5 in which the influence on i is based on the relative size of the neighboring municipalities and that they share a common border with i.The results now indicate a positive correlation, suggesting that the relative size of each neighbor matters where larger neighbors have a larger influence on its neighbors. The results also suggest that municipalities with similar political representation in the local council tend to mimic each other, which is reasonable (see column 4). Even though the correlation in local income taxes across municipalities with similar political preferences could also result in a race-to-the-bottom in the provision of local public services, such behavior is more likely to be present across municipalities that share a common border or are located close to each other. Also, it is natural to expect municipalities (or local politicians) with similar political preferences to compare, discuss and influence each other.
Looking at the other parameter estimates, only two variables are estimated to have a significant effect on the local income tax in all five specifications. One is the previous local income tax rate \(mtax_{i,t-1}\). The other is the county tax rate, ctax, which again is estimated to have a negative impact on the local income tax rate; the local income tax rate adjust to the tax rate decided on by the county level. Both these results are in line with those presented in Table 2. Even if not significant in all specifications, the covariates have in general expected signs except for the share of elderly (a70).
The results presented in Table 3 are in contrast to the results by Edmark and Ågren (2008) also based on Swedish municipalities. Why is that? The time period differs, but also the included covariates. Another difference is the time lag. To compare the results presented by Edmark and Ågren with the results presented in Table 3, the model is reestimated using the same specification as Edmark and Ågren for the period 2003–2016. Parameter estimates based on the weights matrix \(\mathbf {W}_{n}\) (neighbors are defined as municipalities that share a common border, which is the same definition used in Edmark and Ågren) are shown in Table 4, where the results presented in Table 2 on page 853 in Edmark and Ågren are shown in column 3.
Leaving past taxes out (column 1) the results based on the period 2003–2016 suggests in line with Edmark and Ågren a positive and significant correlation in local taxes across municipalities. The estimated effect is about the same magnitude. However, when including \(mtax_{i,t-1}\), shown in column 2, the horizontal effect is only significant at the 90% level. Also note that everything but the share of population aged 65 or above (a65) becomes insignificant when \(mtax_{i,t-1}\) is included.
The results shown in Table 3 and Table 4 suggest that the only clear indication of tax mimicking is when the number of covariates are reduced or neighbors are defined based on the relative population or political preferences. To further elaborate with different specifications, Eq. (1) has been re-estimated imposing the restriction \(\delta =0\). To save space, only estimates of \(\rho\) are presented in Table 5.
The results presented in Table 5 suggest a significant positive effect in tax rates across municipalities in all but one of the specifications. How can this be explained? First, note that \(\rho\) is estimated to be out of its parameter space \(\left( \rho >1\right)\) when neighbors are defined based on \(\mathbf {W}_{p/d}\) (column 2) and \(\mathbf {W}_{pop}\) (column 5). This indicates that the model is misspecified which suggests that \(mtax_{i,t-1}\) should be included in the specification. Therefore we rule out these two results. Next, the correlation between the two variables \(mtax_{i,t-1}\) and \(\mathbf {W}_{n}mtax_{i,t-1}\) is 0.87 making it difficult to separate the effects. However, when both \(mtax_{i,t-1}\) and \(\mathbf { W}_{n}mtax_{i,t-1}\) are included, \(mtax_{i,t-1}\) is significant while \(\mathbf {W}_{n}mtax_{i,t-1}\) is not. Moreover, the correlation between \(mtax_{i,t-1}\) and \(\mathbf {W}_{1/d}mtax_{i,t-1}\) is (only) 0.33 but, again, when both \(mtax_{i,t-1}\) and \(\mathbf {W}_{1/d}mtax_{i,t-1}\) are included, \(mtax_{i,t-1}\) is significant while \(\mathbf {W}_{1/d}mtax_{i,t-1}\) is not.
The results presented so far are based on the presumption of both a lagged dependent variable and time-invariant fixed effects to capture omitted variables and/or unobservables. Even though it is reasonable to assume municipalities to differ in some way not captured by the included covariates or the lagged dependent variable, the model has been re-estimated with spatial effects and lagged dependent variable while leaving the fixed effects out. If a specification without fixed effects is correct the spatial effects presented in Table 3 tend to be overestimated or too big. On the other hand, if including fixed effects is the correct specification, the spatial effect will be underestimated in a model without fixed effects. Hence, the true estimate is bounded between these two. See for instance Angrist and Pischke (2009) on this matter.Footnote 7
The estimates presented in Table 3 should be bounded by those presented in Table 5 (upper) and 6 (lower) which is the case except for \(\mathbf {W }_{pol}\). In both Table 5 and 6, using \(\mathbf {W}_{pol}\), the estimate of \(\rho\) is quite imprecise with a confidence interval ranging between \(-\,1.929\) to 1.554 and \(-\,0.044\) to 0.118 respectively. This cast some doubt on the robustness regarding mimicking across municipalities with similar political preferences.
6 Conclusions
The focus of this paper has been to test the hypothesis of horizontal interaction (or mimicking) in local personal income taxes. We test for interactions across municipalities who share a common border, across municipalities within a distance of 100 km, and across municipalities with similar political representation in the local council. We also test the hypothesis that the tax rate of relatively larger neighboring municipalities have a larger influence on their neighbors tax rate compared to the influence from relatively smaller neighbors. As it is reasonable to assume that when deciding on the next years tax rate local governments use the past tax rate as a point of departure, the tax rate lagged one year is controlled for. Our results suggest that when lagged tax rates are controlled for, the horizontal correlation across municipalities who share a common border or are within a distance of 100 km become insignificant. This result is of importance as it suggests that lagged tax rates should be included or at least tested for when testing for horizontal interactions or mimicking in local tax rates. However, the results presented support the hypothesis of horizontal interactions across municipalities who share a common border when the influence from neighboring municipalities are also weighted with their relative population size. That is, relatively larger neighbors tend to have a larger impact on neighbors tax rates than relatively smaller neighbors. This is of importance as it suggests that distance or vincinity matters but only in combination with relative population. We also find some evidence of horizontal dependence across municipalities with similar political preferences.
From a methodological perspective, the findings are of interest as they suggests the influence to be non symmetric. The findings also highlight the need in empirical work to test for different types of interactions. From a policy perspective, the results indicate a potential problem if the horizontal dependence in local income taxes lead to a race-to-the-bottom or at least not sufficiently high taxes to finance public services. As 23% of the municipalities reported deficits in 2016 while only 18% decided on a tax increase, this could cause even higher financial stress. It is however not possible to based on the estimates presented here to discriminate between tax competition (which may lead to underprovision of local public services) and yardstick competition (which predicts increased efficiency in the political system through better informed voters).
Notes
See Agrawal et al. (2020b) for a critical survey of the theoretical and empirical literature on local interactions.
The local income tax is the only local tax. Other taxes such as business and value added taxes are national taxes.
This is basically an equalization system. In 2020, the national government paid SEK 129 billion to the system while SEK 8 billion was redistributed across municipalities and regions. In 2016, only 11 municipalities paid into the system while 279 municipalities received subsidies from the system. This system will reduce the incentives to compete for a mobile tax base.
See also Agrawal (2016) for a model of both horisontal and vertical externalities in sales tax.
This clarification was highlighted by one referee.
To save space, \(\beta _{kd}\) is not presented in the tables.
We thank one of the referees for suggesting this robustness check.
References
Agrawal DR (2016) Local fiscal competition: an application to sales taxation with multiple federations. J Urban Econ 91:122–138
Agrawal DR, Breuillé M-L, Le Gallo J (2020a) Tax competition with intermunicipal cooperation. SSRN: https://ssrn.com/abstract=3560611 or 10.2139/ssrn.3560611
Agrawal DR, Hoyt WH, Wilson JD (2020b) Local policy choice: theory and empirics. SSRN: https://ssrn.com/abstract=3545542. or https://doi.org/10.2139/ssrn.3545542
Allers MA, Elhorst JP (2005) Tax mimicking and yardstick competition among local governments in the Netherlands. Int Tax Public Finance 12:493–513
Andersson L, Aronsson T, Wikström M (2004) Testing for vertical fiscal externalities. Intern Tax Public Finance 11:243–263
Angrist JD, Pischke J-S (2009) Mostly harmless econometrics: an empiricists’s companion. Princeton University Press, New Jersey
Anselin L (1988) Spatial econometrics: methods and models. Kluwer Academic Publishers, Dordrecht
Aronsson T, Lundberg J, Wikström M (2000) The impact of regional public expenditures on the local decision to spend. Reg Sci Urban Econ 33:185–202
Baltagi BH (2005) Econometric analysis of panel data, 4th edn. Wiley, West Sussex
Baskaran T (2014) Identifying local tax mimicking with administrative borders and a policy reform. J Public Econ 118:41–51
Besley T, Case A (1995) Incumbent behavior: vote-seeking, tax-setting, and yardstick competition. Am Econ Rev 85(1):25–45
Bordignon M, Cerniglia F, Revelli F (2003) In search of yardstick competition: a spatial analysis of Italian municipality property tax setting. J Urban Econ 54:199–217
Brueckner JK (2003) Strategic interaction among governments: an overview of empirical studies. Int Reg Sci Rev 26(2):175–188
Brueckner JK, Saavedra L (2001) Do local governments engage in strategic property tax competition? Natl Tax J 54:203–229
Büttner T (2001) Local business taxation and competition for capital: the choice of the tax rate. Reg Sci Urban Econ 31:215–245
Case A (1993) Interstate tax competition after TRA86. J Policy Anal Manag 12(1):136–148
Cassette A, DiPorto E, Foremny D (2012) Strategic fiscal interaction across borders: evidence from French and German local governments along the Rhine valley. J Urban Econ 72(1):17–30
Chirinko RS, Wilson DJ (2017) Tax competition among U.S. states: Racing to the bottom or riding on a seesaw? J Public Econ 155:147–163
Devereux MP, Lockwood B, Redoano M (2007) Horizontal and vertical indirect tax competition: theory and some evidence from the USA. J Public Econ 91:451–479
Driscoll JC, Kraay AC (1998) Consistent covariance matrix estimation with spatially dependent panel data. Rev Econ Stat 80:549–560
Edmark K, Ågren H (2008) Identifying strategic interactions in Swedish local income tax policies. J Urban Econ 63:849–857
Elhorst JP (2005) Unconditional maximum likelihood estimation of linear and log-linear dynamic models for spatial panels. Geogr Anal 37:85–106
Elhorst JP (2014) Spatial econometrics from cross-sectional data to spatial panels. Springer Heidelberg, New York, Dordrecht, London
Elhorst JP, Fréret S (2009) Evidence of political yardstick competition in France using a two-regime spatial Durbin model with fixed effects. J Reg Sci 49(5):931–951
Feld LP, Reulier E (2009) Strategic tax competition in Switzerland: evidence from a panel of the Swiss cantons. German Econ Rev 10(1):91–114
Gibbons S, Overman HG (2012) Mostly pointless spatial econometrics. J Reg Sci 52:172–191
Heyndels B, Vuchelen J (1998) Tax mimicking among Belgian municipalities. Natl Tax J 51:89–101
Hauptmeier S, Mittermeier F, Rincke J (2012) Fiscal competition over taxes and public inputs: theory and evidence. Reg Sci Urban Econ 42:407–419
Isen A (2014) Do local government fiscal spillovers exist? Evidence from counties, municipalities, and school districts. J Public Econ 110:57–73
Janeba E, Osterloh S (2013) Tax and the city: a theory of local tax competition. J Public Econ 106:89–100
Lyytikäinen T (2012) Tax competition among local governments: evidence from a property tax reform in Finland. J Public Econ 96:584–595
Leprince M, Madiès T, Paty S (2007) Business tax interactions among local governments: an empirical analysis of the French case. J Reg Sci 47:603–621
Lundberg J (2014) On the definition of W in empirical models of yardstick competition. Ann Reg Sci 52(2):597–610
Mirrlees JA (1971) An exploration in the theory of optimum income taxation. Rev Econ Stud 38(2):175–208
Parchet R (2019) Are local tax rates strategic complements or strategic substitutes? Am Econ J Econ Policy 11(2):189–224
Revelli F (2001) Spatial patterns in local taxation: Tax mimicking or error mimicking? Appl Econ 33:1101–1107
Revelli F (2002) Local taxes, national politics and spatial interactions in English district election results. Eur J Polit Econ 18:281–299
Revelli F (2006) Performance rating and yardstick competition in social service provision. J Public Econ 90:459–475
Salmon P (1987) Decentralization as an incentive scheme. Oxf Rev Econ Policy 3(2):24–43
Schaltegger CA, Küttel D (2002) Exit, voice, and mimicking behavior: evidence from Swiss Cantons. Public Choice 113:1–23
Sollé Ollé A (2003) Electoral accountability and tax mimicking: the effects of electoral margins, coalition government, and ideology. Eur J Polit Econ 19:685–713
Tiebout C (1956) A pure theory of local expenditures. J Polit Econ 64(5):416–424
Wildasin DE (2006) Fiscal competition. In: Weingast BR, Wittman DA (eds) Handbook of political economy, Oxford. Oxford University Press, UK
Acknowledgements
The author would like to thank the editor and referee for their constructive comments. The author would also like to thank participants at the NARSC meeting in Pittsburgh 2019, especially Jan Bruckner, Steven Craig, Bo Feng and Jeff Chan for their comments and suggestions.
Funding
Open Access funding provided by Umea University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
