
Abstract
This research formulates, and numerically quantifies the optimal response that can be discovered in a design space characterized by main effects, and two-way and three-way interactions. In an experimental design setup, this can be conceptualized as the response of the best treatment combination of a \(2^k\) full factorial design. Using Gaussian and Uniform priors for the strength of main effects and interaction effects, this study enables a practitioner to make estimates of the maximum possible improvement that is possible through design space exploration. For basic designs up to two factors, we construct the full distribution of the optimal treatment. Whereas, for values of \(k\ge 3\), we analytically formulate two indicators of a greedy heuristic of the expected value of the optimal treatment. We present results for these formulations up to \(k=7\) factors and validate these through simulations. Finally, we also present an illustrative case study of the power loss in disengaged wet clutches, which confirms our findings and serves as an implementation guide for practitioners.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Methods that involve systematic design space exploration are an essential pillar of design engineering. There are design benefits to planning and integrating techniques like designed experiments, optimization through computational modelling, and robust design into the overall development process (Goetz et al. 2020). These methods require a commitment of resources if they are to yield subsequent benefits. These commitments must be based on some expectations of the costs entailed and the benefits that are likely to materialize. In many settings, the cost is not always linearly related to the number of resources expended but carries a fixed cost of committing to the process of exploration. This is particularly true when computer models of the system, like digital twins, need to be built. In such environments, we also find that there is less of a role for noise (or irreducible error) and experimentation in a particular space primarily reveals a more-or-less non-stochastic view of the expected response. Therefore, in such settings, the decision to study the design space is based primarily on the expected benefit.
In this study, we characterize the expected benefit of exploring a design space where the design variables have a linear effect on the response, along with interaction effects. The benefit in such a space can be simply conceptualized as the normalized response of optimal treatment combination of \(2^{k}\) full factorial design which is governed by the general linear model. Our study provides a translation from the distributional priors of the strength of the effects to distributions (or their parameters) of the optimal treatment. We believe this has immense practical applicability in many settings. There are many situations where it would be reasonable for the practitioner to estimate prior distributions and their parameters, but would have minimal ability to estimate the optimal outcome. As an example, take the case of determining the best settings for a foundry process where our goal is to minimize casting defects. One of the difficulties of this process is that the exact settings are dependent on the shape of the cast and therefore change from part-to-part. We are trying to decide if it makes sense to build a simulator, rather than the traditional experiments which we have run in the past. If we knew the best possible improvement achievable, we could decide if it is worth building the simulator. While we don’t know the best settings (hence the need for design space exploration), our past experiments on other parts provide us with a distribution of potential benefit that is achievable by experimenting.
The rest of the paper is structured as follows. In Sect. 2, we present the pertinent literature. In Sect. 3, we present two formulations and results for the distribution of the optimal treatment for the \(2^2\) design. In Sect. 4, we discuss two theoretical indicators of the expected value of the optimal treatment for designs with more than two factors. Finally, in Sect. 5, we conclude our work and suggest some directions for future work.
2 Related work
We discuss the related literature along four levels of granularity, starting from the broader, high-level connections and leading to more methodological and contextual similarity. First, we discuss the related work in design space exploration and modeling uncertainties that affect a design process. The second part explores previous efforts towards quantifying the worth of information against the costs involved. We then discuss the related work specifically in the experimental design setup, and the use of distributional priors in model building. Finally, we discuss previous studies that quantify the expected improvement in factorial designs.
One important model of design as exploration is C-K theory which models design as the interplay between two spaces, the space of concepts (C-space), and the space of knowledge (K-space). Within this theory, an experimental exploration of a set of design options such as a \(2^k\) experiment is defined in the C-space and its execution adds to the K-space (Kroll et al. 2014). Various metamodeling techniques have been developed to support design optimization, including model approximation and design space exploration (Wang and Shan 2006). A larger design space can be systematically reduced to a relatively small region, and the design optimum can be identified within the reduced design space (Wang and Simpson 2004). Qian et al. (2006) propose an approach to explore a design space with enhanced surrogate models, built by integrating data from approximate and detailed simulations. Simpson et al. (2001) demonstrate the use of kriging models for accurate global approximations to facilitate multidisciplinary design optimization. It addresses the modeling of uncertainties that affect the design process. The sources of uncertainty in a design include the parameters that control the design and the models used to relate inputs to system performance measurements. Martin and Simpson (2006) propose a methodology for managing uncertainty during the system-level conceptual design of complex multidisciplinary systems. Apley and Kim (2011) use a Bayesian formulation to discuss the impact of parameter uncertainty on robust design objectives.
A view of quantifying the expected benefit can be taken from decision theory. The expected increase in utility with access to additional information is termed the value of information. The expected value of sample information (EVSI) quantifies the expected increase in utility gained from conducting experiments before making a decision, against the costs involved. A similar term from an ideal experiment is the expected value of perfect information (EVPI) (Raiffa and Schlaifer 1961). The value of information based on a Bayesian approach allows for prior assumptions of parameters. One use case is to determine the sample size based on the cost of gathering the sample and its expected benefits (Willan 2008; Pham-Gia and Turkkan 1992). Various metrics for computing the expected value of information build on these ideas (Brennan and Kharroubi 2007; Strong et al. 2015). EVSI and EVPI have also been used in sensitivity analysis, and for the quantification of various measures of uncertainty (Felli and Hazen 1998).
In an experimental design setup, the response may be modeled as a general linear model, where the factors have a linear relationship with the response in terms of the main effects and interaction effects (Frey and Wang 2006). The coefficients of the linear model may be quantified as independent random variables, with suitable prior distributions. Prior distributions for the parameters in a linear model can be induced from functional priors using Gaussian processes, which require specifying only a few hyperparameters (Joseph 2006). Joseph and Delaney (2007) propose an extension with Gaussian process priors for experiments with qualitative and quantitative factors with three or more levels. These studies consider ways of incorporating effect hierarchy in model building and estimation. Deng et al. (2017) further use an additive Gaussian process for computer experiments.
In a general linear model with the factors having a linear relationship with the response, the expected improvement is considered as the average performance of the system at selected factor levels. Frey and Wang (2006) derive the expected value of improvement and the probability of exploiting factor effects in an adaptive experimentation setting. Sudarsanam et al. (2019) derive the expected cumulative improvement when experiments are conducted in an online setting. Using a Bayesian framework, Sudarsanam et al. (2019) further derive the optimal number of replicates for a given design.
3 Distribution for the optimal treatment for \(2^{2}\) Design
In a \(2^1\) design, the density distribution of the optimal treatment is straightforward, given a distributional assumption on the effect size. If we assume a Gaussian distribution centered at 0 for the effect and that the treatment takes on values \(\{-1,+1\}\), then the distribution of the optimal treatment will be a Half-Normal distribution. Similarly, a Uniform distribution centered at 0 for the effect will translate to another Uniform distribution with support from 0 to the upper limit.
In this section, we explore the \(2^2\) case. We assume a general linear model (GLM) which includes the two main effects and a single 2-way interaction term which is characterized in Eq. 1. We further assume a Bayesian framework, where different distributional priors are assumed for the strength of the main effects (\(\beta _1, \beta _2\)) and the two-way interaction effects (\(\beta _{12}\)). The distribution of the optimal response translates to the distribution of the response of the best treatment combination from the GLM. We propose two formulations for determining the distribution of the response associated with the optimal treatment. While both formulations of the density function lead to the same results when solved numerically, we hope to motivate further research which could explore the full distribution for three or more factors.
3.1 Formulation 1: an order statistics approach
To formulate the optimal treatment distribution, we model the joint distribution of the three order statistics which characterize the absolute values of the two main effects and one two-way interaction.
We first introduce a well-established principle in order statistics. Let us suppose \(Z_1, Z_2, ..., Z_n\) are independently distributed, with \(Z_i\) having probability density function (PDF) \(f_i(z)\) and cumulative distribution function (CDF) \(F_i(z)\). If one sample is taken from each of the n distributions, the jth order statistic after the sampling process is denoted as \(Z_{(j)}\). From Vaughan and Venables (1972), it can be seen that the density of the full joint distribution of all the n order statistics, \(Z_{(1)}, Z_{(2)}, ..., Z_{(n)}\), at \(z_1, z_2, ..., z_n\) is given as:
where the summation is over all possible distinct terms, or selection of subscripts of the density functions. Vaughan and Venables (1972) further show that this summation can be written in terms of the Permanent of a square matrix (Aitken 1939).
For a \(2^2\) full factorial design, with 2 main effects having density function \(f_{\rm{main}}(z)\) and 1 two-way interaction effect having density function \(f_{\rm{int}}(z)\), the joint distribution of the three order statistics (say a, b, c) can be represented in terms of the Permanent of a square matrix (per[A]), as follows:
The formulation of the CDF of the optimal treatment combination can be derived with the help of Eq. 3. From the GLM described in Eq. 1, we consider two components in this derivation - the synergistic component and the anti-synergistic component. A synergistic two-factor interaction will satisfy the condition \(\beta _i\beta _j\beta _{ij} > 0\). An anti-synergistic two-factor interaction will satisfy the condition \(\beta _i\beta _j\beta _{ij} < 0\).
Suppose the optimal treatment combination is represented by W, the CDF of W is given by the probability \(P(W \le w)\). Given the three order statistics \(a \le b \le c\) of a \(2^2\) design, \(c+b+a\) should be less than w for the synergistic case. For the anti-synergistic case, in order for \(W \le w\), \(c+b-a\) should be less than w. Applying these constraints in the integral limits, Eq. 4 gives the formulation of the CDF of the optimal treatment.
Given that a is the first order statistic, b is the second order statistic, and c is the third order statistic, the rationale behind the integral limits in Eq. 4 is as follows:
-
(I)
Integral limits for the synergistic component:
-
1.
a goes from 0 to w/3. If \(a > w/3\), then b and c which have to be \(\ge a\), will result in \(a+b+c > w\).
-
2.
b goes from a to \((w-a)/2\), given that a is between 0 and w/3. If \(b > (w-a)/2\), then \(c \ge b\), will result in \(b+c > (w-a)\), and therefore \(a+b+c > w\).
-
3.
c goes from b to \(w-b-a\). If \(c > w-b-a\), then \(a+b+c > w\).
-
1.
-
(II)
Integral limits for the anti-synergistic component:
-
1.
a can be as low as 0 and as high as w. If \(a>w\), say \(a = w+\epsilon \), then \(b+c \ge 2w +2\epsilon \). This will result in \(b+c-a \ge w+\epsilon \), which is greater than w.
-
2.
\(b>a\), so b goes from a to \((w+a)/2\). If \(b > (w+a)/2\), then \(c+b > w+a\) and \(c+b-a > w\).
-
3.
\(c>b\), so c goes from b to \((w-b+a)\). If \(c > (w-b+a)\), then \(c+b-a > w\).
-
1.
3.2 Formulation 2: a geometric approach
The approach used in the second formulation essentially compartmentalizes the space of possible values of the main effects a,b into 8 symmetric spaces resulting from the combinations 3 binary variables : \(a<0 | a>0, b<0 | b>0\), and \(|a |< |b |\text { } | \text { } |a |> |b |\). We compute Pr(\(Z\le z\)) for one of them, where the optimal response is denoted by Z. The space of interest is \(a>0, b>0, a>b\). The final formulation is given in Eq. 5, where f(a) and f(b) are density functions of the main effects and f(ab) is the density function of the interaction effect. The first integral corresponds to the synergistic case where \(ab>0\), and the second integral corresponds to the anti-synergistic case where \(ab<0\).
The rationale behind the integral limits in Eq. 5 is as follows:
-
(I)
Integral limits in the synergistic case:
-
1.
\(b>0\), so it starts at 0. b is the smaller main effect. It cannot be \(> z/2\). If it is, then \(a+b>z\) and \(ab \ge 0\), so \(a+b+ab > z\).
-
2.
\(a>b>0\), so a starts at b. a cannot be greater than \(z-b\), because \(a>z-b\) means \(a+b>z\) and \(ab\ge 0\) would result in \(a+b+ab > z\).
-
3.
This integral considers the case where \(ab>0\), hence starts at 0. ab cannot be greater than \(z-a-b\). If \(ab > z-a-b\), then \(a+b+ab > z\).
-
1.
-
(II)
Integral limits in the anti-synergistic case:
-
1.
\(b>0\), so it starts at 0. No term (a, b, or ab) can be above z. If the term ‘X’ is greater than z, then a strategy to exploit it will guarantee that the best treatment combination is \(> z\). This is because we can always also exploit the better of the other two terms, leading to a contribution \(\ge 0\) from the other two. Therefore, b cannot be \(> z\).
-
2.
\(a>b\), so it starts at b. Due to the same reason cited in 3.2, a cannot be \(>z\).
-
3.
This integral should really be written with lower limit as \(-min[z,z-a+b]\) and upper limit as \(-max[0,a+b-z]\). However, these two formulations are equivalent. Also, it is easier to focus on the “magnitude” and assume that sign of ab is negative, rather than think of negative numbers. With this construct, there are two lower bounds on the magnitude: (a) 0 , (b) ab cannot be too low in the anti-synergistic case, since \(a+b > z\). Here, if \(z<a+b-ab\), \(a+b-z < ab\). Similarly, there are two upper bounds on the magnitude: (a) z as discussed in 3.2, (b) Since \(a>b\), there is the scenario where \(ab>b\) could mean we seek to exploit a and ab, and b is large enough (anti-synergistically) to allow for \(a+ab-b < z\), then \(ab < z-a+b\).
-
1.
3.3 Results for the density distribution of the optimal treatment
In this section, we discuss the distribution of the optimal treatment for Uniform and Gaussian assumptions for the main and interaction effects. We use both the formulations discussed above, and discuss a few specific examples based on the parameter values of the assumed distributions.
3.3.1 Assuming Uniform priors for Main effects and Interaction effects
We discuss the distribution of the optimal treatment when the strength of main and interaction effects have Uniform priors. For a \(2^2\) design, suppose we fix the support of the two main effects as [\(-d_1, +d_1\)], and the support of the one interaction effect as [\(-d_2, +d_2\)].
In formulation 1 (as in Sect. 3.1), we are interested in the absolute value of the effects. The absolute values of the main and interaction effects will also follow Uniform distributions, with support [\(0,+d_1\)] and [\(0,+d_2\)], respectively. The joint distribution of the order statistics, using Eq. 3, is then derived as:
The CDF of the optimal treatment then follows from Eq. 4, and differentiating the CDF with respect to w, would give the PDF of the optimal treatment combination.
Using formulation 2 (as in Sect. 3.2), the density functions of the main effects (f(a),f(b)) substituted in Eq. 5 is equal to \(1/(2d_1)\), which is the PDF of the Uniform distribution with support of [\(-d_1, +d_1\)]. The density function of the interaction effect (f(ab)) is \(1/(2d_2)\), which is the PDF of the Uniform distribution with support of [\(-d_2, +d_2\)].
Both formulations of the distribution of the optimal response lead to the same results numerically. We illustrate three specific cases of having Uniform priors for the main and interaction effects in a \(2^2\) full factorial design. In all three cases, the main effect support is fixed as [− 15, + 15]. The interaction effect support is varied between [− 15, + 15], [− 10, + 10], and [− 5, + 5].

PDF of the optimal response when the support of main effects is Unif[\(-15, +15\)], and support of the interaction effect is Unif[\(-15, +15\)]

PDF of the optimal response when the support of main effects is Unif[\(-15, +15\)], and support of the interaction effect is Unif[\(-10, +10\)]

PDF of the optimal response when the support of main effects is Unif[\(-15, +15\)], and support of the interaction effect is Unif[\(-5, +5\)]
The PDF plots for the three cases are shown in Fig. 1, 2, 3. In each of the plots, the assumed Uniform distributions are also shown for main and interaction effects. The vertical lines indicate the mean of the various distributions. We further discuss the parameters of the obtained distributions in Sect. 3.3.3.
3.3.2 Assuming Gaussian priors for Main effects and Interaction effects
When Gaussian priors are assumed for the main and interaction effects, the absolute values may be obtained by folding the Normal distribution to get a Half-Normal distribution (Leone et al. 1961; Johnson et al. 1995). For a Normal distribution \(N(0,\sigma ^2)\), the Half-Normal distribution is defined with a parameter \(\theta = \sqrt{\pi }/\sigma \sqrt{2}\).
Consider a \(2^2\) design, with main effects following a \(N(0,\sigma _m^2)\) distribution and interaction effect following a \(N(0,\sigma _{int}^2)\) distribution.
Let us assume that this translates to the absolute value distributions for the main and interaction effects having parameter values \(\theta _1\) and \(\theta _2\), respectively. Then, using formulation 1, the joint distribution of the order statistics using Eq. 3, is derived as:
This joint PDF can be used to derive the CDF of the optimal treatment, as shown in Eq. 4, and subsequently differentiating the CDF with respect to w, would give the PDF of the optimal treatment combination.
Using formulation 2, the density functions of the main effects (f(a),f(b)) substituted in Eq. 5 is the PDF of the Normal distribution with mean 0 and standard deviation \(\sigma _m\). The density function of the interaction effect (f(ab)) is the PDF of the Normal distribution with mean 0 and standard deviation \(\sigma _{int}\).
We consider three specific cases when the main effect is fixed as \(N(0,10^2)\). The interaction effects are varied between \(N(0,10^2)\), \(N(0,5^2)\) and \(N(0,3^2)\).
The PDF plots for all three cases are shown in Fig. 4, 5, 6. In each of the plots, the assumed Gaussian distributions are also shown for main and interaction effects, with vertical lines indicating the respective distribution means. We discuss the parameters of the distribution of optimal response in Sect. 3.3.3.

PDF of the optimal response when the main effects are assumed as \(N(0,10^2)\), and the interaction effect is \(N(0,10^2)\)

PDF of the optimal response when the main effects are assumed as \(N(0,10^2)\), and the interaction effect is \(N(0,5^2)\)

PDF of the optimal response when the main effects are assumed as \(N(0,10^2)\), and the interaction effect is \(N(0,3^2)\)
3.3.3 Discussion
The parameters of the distribution of optimal response with both Gaussian and Uniform assumptions are given in Tables 1 and 2.
The PDF of the optimal response may be compared with that of the assumed distributions for the effects. While we can visualize this through Figs. 1, 2, 3 for the Uniform case and Figs. 4, 5, 6 for the Gaussian case, the numerical values are given in Tables 1 and 2. It can be noticed that as the ratio of the standard deviations of main and interaction effects increases, both the mean and the standard deviation of the optimal response decrease. The mean of the optimal response, in general, is lesser than the corresponding sum of the means of the Half-Normal distributions/Uniform distributions (absolute values), considered for both main and interaction effects. A simple heuristic for practitioners maybe to expect the mean improvement to be between 0 and 20% of the higher end of the support in the Uniform case. In the Gaussian example, one could expect the mean of the optimal treatment to be approximately 1.5 to 2 \(\sigma \) beyond the mean of the main effects.
4 Two theoretical indicators of the expected value of optimal treatment for \(2^{3}\) or higher designs
Derivations of the distribution of the optimal treatment, which are shown in Section 3, are only applicable for cases where there are 2 factors. In this section, we use an order statistics-based approach to study two specific formulations of a greedy heuristic which can be used to establish a useful range to indicate the expected value of the optimal treatment, which can be extended to more than 2 factors. The greedy heuristic that we analyze seeks to exploit all the exploitable terms in descending order of the absolute value of the terms. The best possible order serves as an upper bound on the heuristic, which from a practical standpoint can be seen as a good estimate of the expected value. Whereas the worst possible order will serve as a lower bound on the expected value.
4.1 Formulation
Given the Bayesian priors used to describe the model, the uncertainty in main and interaction effects can be broken down across two broad dimensions. One is the uncertainty in the sign and the other is the uncertainty in magnitude. Using an order statistics framework, the uncertainty in magnitude (characterized by the sign-free joint distribution of all the effects) can be further split into the uncertainty in the values and the order in which they occur. In essence, we break down the uncertainty across three dimensions of sign, magnitude, and order, the latter two being interrelated. This breakdown is important, as the position of an effect with relation to other effects (its order) primarily dictates whether a term could or should be exploited. The magnitude and sign, despite affecting the expected value, play a minimal role in telling us whether an effect should be exploited. This allows for a heuristic that uses order as the only criterion to make decisions on the exploitation of effects. Take the case where there are three main effects a, b, c and therefore three two-way interactions ab, ac, bc and one three-way interaction abc, and the effect values are \(a=+10.2\), \(b = +3.6\), \(c=-3.0\), \(ab=-6.1\), \(ac = +0.2\), \(bc = +0.1\) and \(abc = -0.08\). Here, the descending order of absolute magnitudes would be \(|a|>|ab|>|b|>|c|>|ac|>|bc|>|abc|\). In such a setting, it is clear that one would choose to exploit the effects a, ab, and c, resulting in setting \(a= +1, b = -1, c = -1\). Note that we do not choose to exploit b which is the third-largest term, because it is not exploitable as a and ab have been already exploited. Similarly, we cannot choose to exploit ac, bc, and abc, and these terms could go for-or-against the experimenter depending on the sign.
In this study, we use the uncertainty framework of sign, magnitude, and order discussed above, to provide two specific quantitative indicators of the expected value of the optimal treatment. We explore the worst and best case ordering of terms (by their absolute value) which can be guaranteed to be exploited. We take expectation across the other two dimensions of sign and the magnitude. For instance, an order of \(|a|>|ab|>|b|>|c|>|ac|>|bc|>|abc|\) would be an example of the worst-case, since it precludes the guaranteed exploitation of the 3rd largest, 5th largest, 6th largest and 7th largest terms. Whereas, \(|a|>|ac|>|b|>|c|>|ab|>|bc|>|abc|\) would be the best order since it precludes the guaranteed exploitation of the 4th largest, 5th largest, 6th largest and 7th largest terms, only.
However, we need to note that an algorithm that seeks to exploit the top exploitable terms in descending order of magnitude is itself a greedy heuristic which could lead to a suboptimal solution. For instance, take the case where \(a=+10.2\), \(b = +3.6\), \(c=-3.0\), \(ab=-0.1\), \(ac = +2.9\), \(bc = +2.9\) and \(abc = -0.08\). Here if we exploit the largest exploitable terms in descending order of magnitude, it would result in exploiting a, b, c by setting them to \(+1,+1,-1\), respectively. However, we can see that setting c to be \(+1\) is a better decision as it allows for gaining the benefits of ac and bc which are individually lower than c but are collectively more than c. Therefore, our studies on the best case scenario need not be better than the expected value. In other words, the best case optimism in the order of terms is being opposed by the lower performance resulting from the analysis being conducted on the greedy heuristic and not the actual optimal treatment. Therefore the results from the best case ordering can only be described as a useful indicator or approximation of the expected value of the optimal treatment. However, the worst-case ordering will serve as an inviolable, but weak bound on the expected value since it showcases the worst possible ordering of a greedy heuristic. The advantage of using this heuristic (for the expected value for the worst-case and best-case ordering) is that it enables us to create an analytical formulation. Whereas, the authors are not aware of any formulation that directly captures the expected value of the optimal treatment.
To establish the worst case, we deploy the greedy heuristic that seeks to exploit all the exploitable terms in descending order of absolute value. Further, we assume that the order of the magnitude of terms is as pathological to improvement as possible. In Table 3, we enumerate this scenario of the worst order of guaranteed exploitability of terms. Earlier in this section, we provided an example of the \(k=3\) case. To illustrate this more clearly, here we present one possible ordering for \(k=4\) and show that this ordering represents the sequence of exploiting the 14, 13, 11, and 7th order statistic as shown in Table 3. Take the case where the four main effects are a, b, c, d. We have six two-way interactions and four three-way interactions. Here an ordering of \(|a|>|c|>|ac|>|b|>|abc|>|ab|>|bc|>|bcd|>|d|>|abd|>|acd|>|ad|>|cd|>|bd|\), would be an example of worst-case ordering. The exploitation of the 14th and 13th order stats of a and c precludes the guaranteed exploitation of ac which is the 3rd largest term. Similarly, exploiting the 11th order stat of b disallows the exploitation of abc, ab, and bc (since a and c were already fixed). In a similar fashion, the remaining steps can be explored by the reader for confirmation.
Table 3 shows a clear pattern. If there are x effects resulting from k factors, \(^kC_2\) two-way interactions, and \(^kC_3\) three-way interactions, then under a worst-case scenario we are guaranteed to exploit \(x,x-1,x-3,x-7,x-14...\) until we reach 0. The pattern here is that the terms we are guaranteed to exploit in the worst case are \(x,x-1,x-(2+^2C_2),x-(3+^3C_2+^3C_3)...\) and so on until 0. Essentially, exploitation of the 2nd term leads to 1 unexploitable term, the exploitation of the 3rd term leads to 3 more unexploitable terms, and so on. Another way to characterize this is to show that the sequential pattern in the difference in difference of exploitable orders simply increases as 1, 2, 3, 4, 5..., where the highest value of this sequence for any given k can be derived as \((^{k-1}C_2+1)-(^{k-2}C_2+1) = k-2\).
The reason behind this pattern can be explained as follows. Take the case where there are k factors and therefore \(^kC_2\) two-way interactions and \(^kC_3\) three-way interactions. Following the introduction of a new factor, we have a total of \(k+1\) main effects, \(^{k+1}C_2\) two-way interactions, and \(^{k+1}C_3\) three-way interactions. The increase in the number of terms is always therefore (\(k+1\)) + \(^{k+1}C_2\) + \(^{k+1}C_3\) - k - \(^kC_2\) - \(^kC_3\), which when simplified is \(1+k(k+1)/2\). Of these terms, only one of them can be exploited. If you fix the main effect, then all the two-way and three-way interactions get fixed (since all other main and interaction effects were fixed). If you fix a two-way interaction, then since one parent was already fixed, this therefore also fixes the new main effect (the other parent), which in turn fixes all other new interactions. Similarly, if you fix a three-way interaction, since two parents were already fixed, this fixes the new main effect and all other new interactions. Therefore, the entry of the \(k+1^{th}\) factor will always lead to the guaranteed exploitation of 1 term (the highest among the \(1+k(k+1)/2\) new terms) and lead to \(k(k+1)/2\) unexploitable terms. This is the most pathological case since it assumes that all the other terms prior to the entry of this factor were of higher magnitude.
Since our study performs an analysis on a greedy heuristic, which is guaranteed to be lower than the optimal strategy, when we look at the worst-case ordering, this results in the analytical formulation of an unambiguous lower bound.
In contrast to the worst-case orders for the heuristic, the best-case is fairly straightforward. If there are x effects resulting from k factors, \(^kC_2\) two-way interactions, and \(^kC_3\) three-way interactions, then under a best-case scenario we are guaranteed to exploit \(x,x-1,x-2...x-k\) order stats. The simplest example of this is to assume that the top k largest terms are the k main effects, all of which can be exploited, and will lead to the remaining \(^kC_2 + ^kC_3\) interaction terms that cannot have any guarantee of exploitation. However, these are not the only cases. Whenever, interactions, whose parents have not been exploited exhibit high magnitude, this results in a conducive setting. For example, when there are 4 main effects a, b, c, d, their 6 two-way interactions and 4 three-way interactions, the order of \(|c|>|b|>|bd|>|ad|>|d|>|a|>|cd|>|abc|>|bcd|>|ab|>|ac|>|bc|>|abd|>|acd|\) allows for contiguous exploitation of the top \(k=4\) terms and all others cannot be guaranteed. Note that in both the worst-case and the best-case we are only guaranteed to exploit k terms out of x effects (which result from k factors, \(^kC_2\) two-way interactions and \(^kC_3\) three-way interactions). This is also the case for other orderings between the best and worst cases. We leave it to the reader to confirm this property.
Following the establishment of the worst-case and best-case order of terms in the greedy heuristic, we present a general formulation to ascertain the expected value of any order statistic when the parent distributions for main-effects and interaction effects are different. This will allow us to sum over the exploitable orders of the specific sequences to determine the expected improvement, assuming that the unexploitable terms could go for-or-against the experimenter. Note that while the order distributions are themselves not independent of each other, the sum of their expected values is.
Similar to the nomenclature used in Sect. 3, we assume that the response is a general linear model with main effects, two-way and three-way interaction terms. The main effects can be characterized by a random variable with a probability density function (PDF) f(x) and a cumulative distribution function (CDF) F(x). Whereas, the two-way interaction terms are distributed with PDF g(x) and CDF G(x), and three-way interaction terms are distributed with PDF h(x) and CDF H(x). It is well established that the CDF of the rth order statistic (\(C_{r}(x)\)), when variates come from a single distribution, say F(x) can be written as: \(C_{r}(x) = \sum _{i=r}^{k} (^kC_{i}).F^{i}(x).[1-F(x)]^{k-i}\). An explanation for the same can be obtained from David and Nagaraja (2003). However, in our setting the variates come from independent, but non-identical distributions, with a specific link between the number of samples (if there are k factors then there are exactly \(^kC_2\) two-way interactions and \(^kC_3\) three-way interactions). Hence, we formulate that the CDF of the rth order stat when there are k factors as:
This provides us with the CDF of the rth order statistic. An explanation for its form is as follows. The probability that the rth order statistic is less than or equal to a value x depends on the probability that across the main effects and interaction terms there are at least r terms or more that are below the value of x. This is essentially the cumulative Binomial form with the limits expressing the inverse of the probability space (at least as opposed to at most). For any given number of main effects that are less than x, we require that at least \(r-i\) interaction terms are less than x. The set S provides the combinations of the number of main and interaction terms that satisfy this condition. In order to obtain the expected value, we use the well-known relationship that if the support is non-negative:
In Sect. 4.2 we present the results from this indicator along with simulation results of the expected value of optimal treatment and the expected value of the heuristic for comparison.

Worst-case and best-case of the greedy heuristic on the expected value of the optimal treatment when main effects are \(N(0,10^2)\), two-way interactions are \(N(0,2.78^2)\) and three-way interactions are \(N(0,1.37^2)\)

Worst-case and best-case of the greedy heuristic on the expected value of the optimal treatment when main effects are \(N(0,10^2)\), two-way interactions are \(N(0,1.39^2)\) and three-way interactions are \(N(0,0.69^2)\)

Worst-case and best-case of the greedy heuristic on the expected value of the optimal treatment when main effects are \(N(0,10^2)\), two-way interactions are \(N(0,5.56^2)\) and three-way interactions are \(N(0,2.74^2)\)
4.2 Results
We can use Equations 8 and 9, to numerically evaluate the expected value of the order statistic for any value of k and r and for any set of distributions F(x), G(x) and H(x). We can then take the worst and best case sequences of guaranteed exploitation discussed in Sect. 4.1, to determine the worst-case and best-case of a greedy heuristic on the expected value of the optimal treatment. We present our results across Figs. 7, 8, 9, 10, 11, 12. We present the results for evaluations of \(k = 2\) to 7, and cases where F(x), G(x) and H(x) represent the CDFs of main effects, two-way and three-way interaction effects. These distributions take the Gaussian form and Uniform form. We present three results for the Gaussian form and three for the Uniform. In the Gaussian case \(F(x)\sim N(0,\sigma _m^2)\), \(G(x)\sim N(0,\sigma _{2i}^2)\) and \(H(x)\sim N(0,\sigma _{3i}^2)\). In all three experiments we fix \(\sigma _m = 10\), but vary \(\sigma _{2i}\) to be equal to 2.78, 1.39, 5.56 and \(\sigma _{3i}\) to be equal to 1.37, 0.69, 2.74 respectively, to convey different strengths of interaction terms. We pick a lower range of values for \(\sigma _{2i}\) and \(\sigma _{3i}\) w.r.t \(\sigma _m\), to be in conformance to the general idea of Hierarchy (Frey and Li 2008). Similarly, we study three settings for the Uniform case. We consider the scenario where the support for the main effect is fixed between \(-15\) to \(+15\), the support for two-way interaction terms varies from \(-4\) to \(+4\), \(-2\) to \(+2\), \(-8\) to \(+8\) and the support for three-way interaction terms varies from \(-2\) to \(+2\), \(-1\) to \(+1\), \(-4\) to \(+4\) respectively.

Worst-case and best-case of the greedy heuristic on the expected value of the optimal treatment when main effects are Unif[\(-15, +15\)], two-way interactions are Unif[\(-4, +4\)] and three-way interactions are Unif[\(-2, +2\)]

Worst-case and best-case of the greedy heuristic on the expected value of the optimal treatment when main effects are Unif[\(-15, +15\)], two-way interactions are Unif[\(-2, +2\)] and three-way interactions are Unif[\(-1, +1\)]

Worst-case and best-case of the greedy heuristic on the expected value of the optimal treatment when main effects are Unif[\(-15, +15\)], two-way interactions are Unif[\(-8, +8\)] and three-way interactions are Unif[\(-4, +4\)]
4.3 Case study: power loss in disengaged wet clutches
In this section, we present an example of using our proposed method to quantify the expected value of the optimal treatment. We use a \(2^7\) full factorial experiment from Lloyd (1974). This experiment determines how seven factors affect the power loss in disengaged wet clutches, with each factor at two levels. The response variable is considered to be the drag torque, a property that one would normally wish to minimize. The response values in Lloyd (1974) were in foot*pounds, but that is not essential in understanding the comparisons made in this case study. Since drag will not possibly be less than zero, an additive model of effects will work better on a transformed response. Therefore, we use the log-transformed response values in our discussion. Though the units of the variable change after the log transformation, the units of factor effects and improvement are meaningful in an engineering sense. A mean improvement of x in this case study means that the drag would be reduced by a factor of \(exp(-x)\).
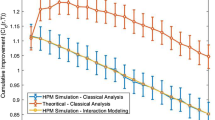
The standard deviation (\(\sigma _m\)) of the main effects was computed to be 0.17. Let us assume that experts decide an estimate of \(\sigma _m\) to be 0.1. From Fig. 7, adjusting by a factor of 100, we can see that the range of expected values of the optimal treatment is in the range of 0.52 to 0.92 for 7 factors (shaded region). The maximum possible improvement from the experiment is 0.67. This means that the drag would be reduced by a factor of \(exp(-0.67)=0.51\), that is, drag could be cut in half using a \(2^7\) experiment. It is to be noted that in order to make comparisons, we take the negated values from the experiment (since the experiment has a minimization objective). As shown in Table 4, the corresponding analytical lower bound from the worst-case ordering of the greedy heuristic is 0.47, while the approximate indicator of the expected value from the best-case ordering of the greedy heuristic is 0.63. Hence, these two analytical values can be considered as reasonable indicators of the maximum possible improvement.
We illustrate the estimates across different number of factors in Table 4 with medium interaction effects. If we want to estimate the maximum possible improvement for six factors with the same experiment, we can leave out a factor one at a time and compute the improvement. The average of all such improvements is 0.55. Our results in Fig. 7, give a range of 0.40 to 0.78 for the expected improvement. The corresponding indicators from the worst-case and best-case ordering are 0.42 and 0.54 respectively, as shown in Table 4. Similarly, if we want to estimate the maximum possible improvement for 5 factors, it seems reasonable to leave out two factors at a time, and compute the improvement for each case. The average from this computation is 0.45. The corresponding range from Fig. 7 is 0.30 to 0.64, whereas the indicators from the worst-case and best-case ordering are 0.36 and 0.44 respectively. It can be observed that the improvement drops as the number of factors reduces. The spread in the improvements for 5 and 6 factors are slightly wider from the experiment than in the figure, which could be attributed to the way the factors were dropped. When the factors dropping out are among the largest ones, the expert’s assessment of the variance of effect sizes should also drop. By maintaining the same estimate of effect size variance, we underestimate the range over which the results will vary. Similarly, to estimate the maximum possible improvement for K=4,3,2 factors, we can leave out 3,4,5 factors at a time respectively, and compute the improvement for each case. The results from the experiment and the corresponding analytical indicators from the greedy heuristic are given in Table 4.
We compare and discuss three possible estimates of \(\sigma _m/\sigma _{2i}\) that an expert could decide on for the \( 2^7 \) experiment. The standard deviation of the two-way interactions (\( \sigma _{2i} \)) from the experiment was found to be 0.04 and the maximum possible improvement was 0.67. Keeping the estimate of \(\sigma _m\) as 0.1, we compare three cases, where the estimates of \( \sigma _{2i} \) are made as 0.0278, 0.0139 and 0.0556 (following the principle of Hierarchy (Frey and Li 2008) with medium, low and high interaction effects). The analytical results assuming these effect estimates are presented in Table 4 and in Figs. 7, 8, 9. It can be observed that the respective worst-case orderings provide a good estimate of a lower bound in all three cases. The approximate indicators of the expected value from the best-case ordering are 0.63, 0.58 and 0.79 for medium, low and high interaction effects respectively. While these indicators are not too far off among the three estimates of \(\sigma _{2i}\), it can be noticed that the medium interaction effect seems to be a better estimate of the maximum possible improvement from the experiment (0.67). This can be verified by comparing the values of \(\sigma _m/\sigma _{2i}\) from the actual experiment (0.17/0.04) and the assumed estimates by an expert (0.1/0.0278).
We illustrate different estimates of \(\sigma _m\) that could have been assumed for the experiment. While the discussion till now has been with an assumed estimate of \(\sigma _m\)=0.1, we present the analytical results with an under-estimate (\(\sigma _m\) = 0.05) and an over-estimate (\(\sigma _m\) = 0.2) of \(\sigma _m\), both with medium two-way interaction effects. These results are shown in Table 4. For the experiment with 7 factors, the indicators from the worst-case and best-case ordering are 0.23 and 0.32 when \(\sigma _m\) = 0.05, and 0.94 and 1.27 when \(\sigma _m\) = 0.2 respectively. While the worst-case ordering gives a good lower bound for 5 or more factors when \(\sigma _m\)=0.05, the corresponding approximate indicators from the best-case ordering under estimates the maximum possible improvement from the experiment. With \(\sigma _m\)=0.2, both the lower bound and approximate indicator from the greedy heuristic seem to be over-estimates of the maximum possible improvement from the experiment across different number of factors.
The percentage error of the indicators with respect to the maximum possible improvement from the experiment can provide a notion of the closeness of the indicators to the actual experimental values. This may be calculated as a percentage form of the relative change (in absolute value terms). In the \( 2^7 \) experiment, we observe that the best-case ordering is 5.97% away from the corresponding value from the case study when \(\sigma _m\)=0.1 with medium interaction effect. The corresponding percent errors are 1.81% and 2.22% for the experiments with six and five factors, respectively. In the worst-case, our indicator is 29.85% away from the actual \( 2^7 \) experiment value. With different strengths of the interaction effects, we observe that the percent error from the best-case ordering is at most 17.91% for the \( 2^7 \) experiment, and at most 20% for the \( 2^6 \) and \( 2^5 \) experiments. Across different number of factors, an under-estimate of \(\sigma _m\) gives an error of at most 55.55%, and an over-estimate of \(\sigma _m\) can give an error up to 100%.
5 Conclusion and future work
The study formulates and quantifies the maximum possible improvement that is possible through design space exploration. We consider \(2^k\) full factorial designs assuming a GLM. The optimal response or the expected benefit may be formulated in terms of the distributional priors of the strength of the main effects and interaction effects. For designs up to two factors, we propose two formulations for the full distribution of the optimal response. For designs with more than two factors, we formulate two analytical indicators of the expected value of the optimal response through a greedy heuristic.
The first formulation of the distribution of the optimal response for a \(2^2\) full factorial design is based on order statistics (Sect. 3.1). The second formulation of the distribution of the optimal response is based on a geometric approach (Sect. 3.2). Both formulations lead to the same results when solved numerically. We consider Uniform and Gaussian priors for the main and interaction effects to illustrate the distribution of the optimal treatment (Sect. 3.3). When Gaussian priors are assumed for the effects, the absolute value may be obtained by folding the Normal distribution to get a Half-Normal distribution. When a Uniform distribution (centered at 0) is assumed for the effect, the absolute value will be another Uniform distribution with support from 0 to the upper limit. As the ratio of the standard deviations of main and interaction effects increases, both the mean and the standard deviation of the optimal response decrease. When applied to a Uniform assumption of effects, the optimal treatment was found to have a mean improvement between 0 to 20% of the higher end of the support. When applied to a Gaussian assumption, the mean of optimal treatment could be 1.5 to 2 standard deviations beyond the mean of the main effects.
The study presents two analytical indicators of the range of the expected value of the optimal response, which can be extended to designs with more than two factors (Sect. 4). A quantitative indicator of the expected value of the optimal treatment may be obtained by a greedy heuristic which uses the uncertainty in the order of effects. This heuristic seeks to exploit all the exploitable terms in descending order of the absolute value. If there are k factors and their main effects, two-way and three-way interactions, a pattern for the worst-case ordering of terms is that the number of unexploitable terms between the exploitable terms increases as \(^mC_2, m = 1,2,..k\). If there are k factors and their main effects, two-way and three-way interactions, a pattern for the best case ordering of terms is the exploitation of k largest terms. To obtain the expected improvement from the worst-case and best-case scenarios of guaranteed exploitation, we formulate the expected value of any order statistic. This formulation is based on the CDF of the order statistic in a cumulative Binomial form when the parent distributions for main effects and interaction effects are different. The worst possible ordering of terms (which are guaranteed to be exploited) of the greedy heuristic serves as an analytical lower bound on the expected value of the optimal treatment. The best possible ordering of terms of the greedy heuristic does not serve as an upper bound for the expected value (it is only an upper bound for the heuristic). While the best-case scenario need not be better than the expected value, our wide range of experiments suggests that it can be a useful indicator of the expected value of the optimal treatment. We also present a case study of the power loss in disengaged wet clutches, which can serve as a guide for implementation (Section 4.3). We show that the worst-case and best-case orderings from the greedy heuristic can serve as good estimates for a lower bound and an approximate indicator of the expected improvement, respectively. These formulations can be useful analytical indicators of the maximum possible benefit that can be obtained from design space exploration.
One concrete step for future work is to derive the full distribution of the optimal treatment when there are three or more factors. In this paper, in section 4, we only present a lower bound (worst case of a greedy heuristic) and an approximate indicator (best case of a greedy heuristic) on the expected value. However, in section 3 we present the full distribution when there are two factors. We achieve this through two different approaches. Our motivation is that either of these approaches may lend themselves to further analysis that can be extended to three or more treatments.
References
Aitken AC (1939) Determinants and matrices. Oliver and Boyd, Ltd, Edinburgh
Apley DW, Kim J (2011) A cautious approach to robust design with model parameter uncertainty. IIE Trans 43(7):471–482
Brennan A, Kharroubi SA (2007) Efficient computation of partial expected value of sample information using Bayesian approximation. J Health Econ 26(1):122–148
David HA, Nagaraja HN (2003) Order statistics, 3rd edn. Wiley Series in Probability and Statistics, New Jersey
Deng X, Lin CD, Liu KW, Rowe RK (2017) Additive Gaussian process for computer models with qualitative and quantitative factors. Technometrics 59(3):283–292
Felli JC, Hazen GB (1998) Sensitivity analysis and the expected value of perfect information. Med Decis Mak 18(1):95–109
Frey DD, Li X (2008) Using hierarchical probability models to evaluate robust parameter design methods. J Qual Technol 40(1):59–77
Frey DD, Wang H (2006) Adaptive one-factor-at-a-time experimentation and expected value of improvement. Technometrics 48(3):418–431
Goetz S, Schleich B, Wartzack S (2020) Integration of robust and tolerance design in early stages of the product development process. Res Eng Des 31:157–173. https://doi.org/10.1007/s00163-019-00328-2
Johnson NL, Kotz S, Balakrishnan N (1995) Continuous univariate distributions, vol 1, 2nd edn. John Wiley and Sons, New Jersey
Joseph VR (2006) A Bayesian approach to the design and analysis of fractionated experiments. Technometrics 48(2):219–229
Joseph VR, Delaney JD (2007) Functionally induced priors for the analysis of experiments. Technometrics 49(1):1–11
Kroll E, Le Masson P, Weil B (2014) Steepest-first exploration with learning-based path evaluation: uncovering the design strategy of parameter analysis with C-K theory. Res Eng Des 25:351–373. https://doi.org/10.1007/s00163-014-0182-8
Leone FC, Nelson LS, Nottingham RB (1961) The folded normal distribution. Technometrics 3(4):543–550
Lloyd FA (1974) Parameters contributing to power loss in disengaged wet clutches. Soc Automot Eng Trans 83:2498–2507
Martin JD, Simpson TW (2006) A methodology to manage system-level uncertainty during conceptual design. ASME J Mech Des 128(4):959–968
Pham-Gia T, Turkkan N (1992) Sample size determination in Bayesian analysis. J R Stat Soc 41(4):389–397
Qian Z, Seepersad CC, Joseph VR, Allen JK, Jeff Wu CF (2006) Building surrogate models based on detailed and approximate simulations. ASME J Mech Des 128(4):668–677
Raiffa H, Schlaifer R (1961) Applied statistical decision theory, Harvard University Press, Boston
Simpson TW, Mauery TM, Korte JJ, Mistree F (2001) Kriging models for global approximation in simulation-based multidisciplinary design optimization. AIAA J 39(12):2233–2241
Strong M, Oakley JE, Brennan A, Breeze P (2015) Estimating the expected value of sample information using the probabilistic sensitivity analysis sample: a fast, nonparametric regression-based method. Med Decis Mak 35(5):570–583
Sudarsanam N, Pitchai Kannu B, Frey DD (2019) Optimal replicates for designed experiments under the online framework. Res Eng Des 30(3):363–379
Vaughan R, Venables W (1972) Permanent expressions for order statistic densities. J R Stat Soc 34(2):308–310
Wang GG, Shan S (2006) Review of metamodeling techniques in support of engineering design optimization. ASME J Mech Des 129(4):370–380
Wang GG, Simpson T (2004) Fuzzy clustering based hierarchical metamodeling for design space reduction and optimization. Eng Optim 36(3):313–335
Willan AR (2008) Optimal sample size determinations from an industry perspective based on the expected value of information. Clin Trials 5(6):587–594
Acknowledgements
The authors acknowledge the partial support provided by the Robert Bosch Centre for Data Science and Artificial Intelligence (RBCDSAI), Indian Institute of Technology Madras, India.
Funding
Open Access funding provided by the MIT Libraries.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sudarsanam, N., Kumar, A. & Frey, D.D. Quantifying the maximum possible improvement in \(2^{k}\) experiments. Res Eng Design 33, 367–384 (2022). https://doi.org/10.1007/s00163-022-00390-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00163-022-00390-3