
Abstract
The present work investigates the feasibility of finite element methods and topology optimization for unstructured meshes in massively parallel computer architectures, more specifically on Graphics Processing Units or GPUs. Challenges in the parallel implementation, like the parallel assembly race condition, are discussed and solved with simple algorithms, in this case greedy graph coloring. The parallel implementation for every step involved in the topology optimization process is benchmarked and compared against an equivalent sequential implementation. The ultimate goal of this work is to speed up the topology optimization process by means of parallel computing using off-the-shelf hardware. Examples are compared with both a standard sequential version of the implementation and a massively parallel version to better illustrate the advantages and disadvantages of this approach.



















Similar content being viewed by others

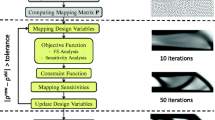

Notes
A thread is an independent unit of processing that can handle and process a task.
A race condition or race hazard is a flaw where the output and/or result of a process is wrong because two events that cannot take place at the same time race against each other to influence the result. In FEM this typically occurs when two local stiffness matrices \([\mathbf {k^e}]\) are being added at the same time to the same positions in the global \([\mathbf {K}]\).
The hardware used for all benchmarks consists of a dual-socket dual-core AMD Opteron 2216, 8 GB of RAM and a NVIDIA Tesla T10 GPU with 4 GB of RAM.
References
AMD (2009) ACML - AMD Core Math Library v4.3.0. http://developer.amd.com/cpu/Libraries/acml/Pages/default.aspx. Accessed Jan 2010
Anderson E, Bai Z, Bischof C, Blackford S, Demmel J, Dongarra J, Du Croz J, Greenbaum A, Hammarling S, McKenney A, Sorensen D (1999) LAPACK users’ guide
Bendsøe MP (1989) Optimal shape design as a material distribution problem. Struct Optim 1:193–202
Bendsøe MP, Kikuchi N (1988) Generating optimal topologies in structural design using a homogenization method. Comput Methods Appl Mech Eng 71(2):197–224
Bendsøe MP, Sigmund O (1999) Material interpolation schemes in topology optimization. Arch Appl Mech 69:635–654
Bendsøe MP, Sigmund O (2003) Topology optimization: theory, methods and applications. Engineering Online Library, 2nd edn. Springer, Berlin, Germany
Blackford LS, Demmel J, Dongarra J, Duff I, Hammarling S, Henry G, Heroux M, Kaufman L, Lumsdaine A, Petitet A, Pozo R, Remington K, Whaley RC (2002) An updated set of basic linear algebra subprograms BLAS. ACM Trans Math Softw 28(2):135–151
Bruns TE (2005) A reevaluation of the SIMP method with filtering and an alternative formulation for solid-void topology optimization. Struct Multidiscip Optim 30(6):428–436
Cannondale (2010) Cannondale Bicycle Corporation. http://www.cannondale.com/. Accessed May 2011
Carvalho RF, Martins CAPS, Batalha RMS, Camargos AFP (2010) 3D parallel conjugate gradient solver optimized for GPUs. In: Digests of the 2010 14th biennial IEEE conference on electromagnetic field computation (CEFC). IEEE
Cecka C, Lew AJ, Darve E (2011) Assembly of finite element methods on graphics processors. Int J Numer Methods Eng 85(5):640–669
Cuthill E, Mckee J (1969) Reducing the bandwidth of sparse symmetric matrices. In: 24th national conference of the ACM, pp 157–172
Dailey DP (1980) Uniqueness of colorability and colorability of planar 4-regular graphs are NP-complete. Discrete Math 30(3):289–293
Dziekonski A, Lamecki A, Mrozowski M (2010) Jacobi and Gauss-Seidel preconditioned complex conjugate gradient method with GPU acceleration for finite element method. In: 40th European microwave conference, pp 1305–1308
EM Photonics (2004) CULA Tools - GPU Accelerated LAPACK. http://www.culatools.com/. Accessed Oct 2012
Gebremedhin AH, Manne F, Pothen A (2005) What color is your Jacobian? Graph coloring for computing derivatives. SIAM Rev 47(4):629–705
Gibbs NE, Poole Jr WG, Stockmeyer PK (1976a) A comparison of several bandwidth and profile reduction algorithms. ACM Trans Math Softw 2(4):322–330
Gibbs NE, Poole Jr WG, Stockmeyer PK (1976b) An algorithm for reducing the bandwidth and profile of a sparse matrix. SIAM J Numer Anal 13(2):236–250
Gödel N, Schomann S, Warburton T, Clemens M (2010) GPU accelerated Adams-Bashforth multirate discontinuous Galerkin FEM simulation of high-frequency electromagnetic fields. IEEE Trans Magn 46(8):2735–2738
Guney ME (2010) High-performance direct solution of finite element problems on multi-core processors. PhD thesis, Georgia Insitute of Technology, Atlanta, GA
Haftka RT, Gürdal Z (1992) Elements of structural optimization Solid mechanics and its applications series, 3rd edn. Kluwer, Norwell, MA
Hemp WS (1973) Optimum structures Oxford engineering science series. Clarendon Press, Oxford, UK
Kakay A, Westphal E, Hertel R (2010) Speedup of FEM micromagnetic simulations with graphical processing units. IEEE Trans Magn 46(6):2303–2306
Kucěra L (1991) The greedy coloring is a bad probabilistic algorithm. J Algor 12(4):674–684
Liu W-H, Sherman AH (1976) Comparative analysis of the Cuthill-McKee and the reverse Cuthill-McKee ordering algorithms for sparse matrices. SIAM J Numer Anal 13(2):198–213
Liu Y, Jiao S, Wu W, De S (2008) GPU accelerated fast FEM deformation simulation. IEEE Asia Pac Conf Circ Syst 606–609
Mahdavi A, Balaji R, Frecker M, Mockensturm EM (2006) Topology optimization of 2D continua for minimum compliance using parallel computing. Struct Multidiscip Optim 32(2):121–132
Matsui K, Terada K (2004) Continuous approximation of material distribution for topology optimization. Int J Numer Methods Eng 59(14):1925–1944
Michell AGM (1904) The limits of economy of material in frame-structures. Philos Mag Ser 8(47):589–597
NVIDIA (2007) CUDA programming guide. http://www.nvidia.com/. Accessed June 2009
NVIDIA (2009) CUDA C programming - best practices guide. http://www.nvidia.com/cuda/. Accessed June 2009
NVIDIA (2012) cuBLAS - CUDA Basic Linear Algebra Subroutines http://developer.nvidia.com/cublas. Accessed Oct 2012
Oliker L, Biswas R (2000) Parallelization of a dynamic unstructured algorithm using three leading programming paradigms. IEEE Trans Parallel Distrib Syst 11(9):931–940
Paulino GH, Menezes IFM, Gattass M, Mukherjee S (1994a) Node and element resequencing using the Laplacian of a finite element graph: part I - general concepts and algorithm. Int J Numer Methods Eng 37(9):1511–1530
Paulino GH, Menezes IFM, Gattass M, Mukherjee S (1994b) Node and element resequencing using the Laplacian of a finite element graph: part II - implementation and numerical results. Int J Numer Methods Eng 37(9):1531–1555
Peressini AL, Sullivan FE, Uhl Jr JJ (1988) The mathematics of nonlinear programming Undergraduate texts in mathematics series. Springer-Verlag, New York
Remón A, Quintana-Ortí E, Quintana-Ortí G (2006) Cholesky factorization of band matrices using multithreaded BLAS. In: PARA 2006, pp 608–616
Remón A, Quintana-Ortí E, Quintana-Ortí G (2007) The implementation of BLAS for band matrices. In: PPAM 07, pp 668–677
Rozvany GIN (1997) Topology optimization in structural mechanics. CISM International Centre for Mechanical Sciences. Springer, New York, NY
Schmidt S, Schulz V (2011) A 2589 line topology optimization code written for the graphics card. Comput Vis Sci 14(6):249–256
Sigmund O (2001) A 99 line topology optimization code written in Matlab. Struct Multidiscip Optim 21(2):120–127
SIMULIA (Dassault Systèmes) (1978) Abaqus FEA. http://www.3ds.com/products/simulia/overview/. Accessed Dec 2012
Tomov S, Nath R, Du P, Dongarra J (2009) MAGMA users’ guide v0.2. http://icl.cs.utk.edu/magma/. Accessed Dec 2012
Tomov S, Nath R, Ltaief H, Dongarra J (2010) Dense linear algebra solvers for multicore with GPU accelerators. In: 2010 IEEE international symposium on parallel & distributed processing workshops and PhD forum (IPDPSW)
Vemaganti K, Lawrence WE, Parallel methods for topology optimization (2004). Comput Methods Appl Mech Eng 194(34–35):3637–3667
Volkov V, Demmel JW (2008) Benchmarking GPUs to tune dense linear algebra. In: 2008 ACM/IEEE conference on supercomputing
Zegard T (2010) Topology optimization with unstructured meshes on graphics processing units GPUs. Ms thesis, University of Illinois at Urbana-Champaign
Zegard T, Paulino GH (2011) GPU-based topology optimization on unstructured meshes. In: 11th US National Congress on computational mechanics
Acknowledgments
We also thank Dr. Cameron Talischi for his help in the preparation of this manuscript. We acknowledge support from the National Science Foundation (NSF) under grant 1321661, and from the Donald B. and Elizabeth M. Willett endowment at the University of Illinois at Urbana-Champaign (UIUC).
Author information
Authors and Affiliations
Corresponding author
Appendix A: Nomenclature
Appendix A: Nomenclature
1.1 A.1 Symbols
- \({[\mathbf {B}]}\) :
-
Strain-displacement matrix
- \(b_w\) :
-
Bandwidth of a matrix
- c:
-
Compliance
- \({[\mathbf {D}]}\) :
-
Constitutive matrix
- E:
-
Young’s modulus
- f:
-
Volume fraction
- \({\{\mathbf {f}\}}\) :
-
Global force vector
- \(\hat {H}_j\) :
-
Convolution function
- \({[\mathbf {J}]}\) :
-
Transformation Jacobian
- \({[\mathbf {K}]}\) :
-
Global stiffness matrix
- \({[\mathbf {k}]}\) :
-
Local stiffness matrix
- \({[\mathbf {L}]}\) :
-
Lower triangular matrix
- \({\mathbf {L} ( G^C )}\) :
-
Communication matrix for graph G
- m:
-
Density move limit
- n:
-
Number of elements, matrix size or other depending on the context
- p:
-
Penalization factor for SIMP
- R:
-
Filter radius
- u:
-
Displacement
- V:
-
Volume
- \({[\mathbf {XY}]}\) :
-
Nodal coordinates of an element
- \({[\boldsymbol {\Gamma }]}\) :
-
Inverse of the transformation Jacobian\([\mathbf {J}]\)
- \(\eta \) :
-
Numerical damping parameter
- \(\mathcal {L}\) :
-
Lagrangian function
- \(\lambda \) :
-
Lagrange multiplier
- \(\nu \) :
-
Poisson’s ratio
- \(\rho \) :
-
Density
- \({\chi ( G )}\) :
-
Chromatic number for graph G
1.2 A.2 Abbreviations
- ALU:
-
Arithmetic Logic Unit
- CAMD:
-
Continuous Approximation of Material Distribution
- CPU:
-
Central Processing Unit
- CUDA:
-
NVIDIA’s Compute Unified Device Architecture
- DOF:
-
Degree Of Freedom
- DRAM:
-
Dynamic Random-Access Memory
- FEM:
-
Finite Element Method
- GPU:
-
Graphics Processing Unit
- MBB:
-
Messerschmitt–Bölkow–Blohm
- OC:
-
Optimality Criteria
- PCGS:
-
Pre-conditioned Conjugate Gradient Solver
- SIMP:
-
Solid Isotropic Material with Penalization
- TOP:
-
Topology Optimization
Rights and permissions
About this article
Cite this article
Zegard, T., Paulino, G.H. Toward GPU accelerated topology optimization on unstructured meshes. Struct Multidisc Optim 48, 473–485 (2013). https://doi.org/10.1007/s00158-013-0920-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-013-0920-y