
Abstract
This study addresses the problem of hand–eye calibration in robotic systems by developing Continual Learning (CL)-based approaches. Traditionally, robots require explicit models to transfer knowledge from camera observations to their hands or base. However, this poses limitations, as the hand–eye calibration parameters are typically valid only for the current camera configuration. We, therefore, propose a flexible and autonomous hand–eye calibration system that can adapt to changes in camera pose over time. Three CL-based approaches are introduced: the naive CL approach, the reservoir rehearsal approach, and the hybrid approach combining reservoir sampling with new data evaluation. The naive CL approach suffers from catastrophic forgetting, while the reservoir rehearsal approach mitigates this issue by sampling uniformly from past data. The hybrid approach further enhances performance by incorporating reservoir sampling and assessing new data for novelty. Experiments conducted in simulated and real-world environments demonstrate that the CL-based approaches, except for the naive approach, achieve competitive performance compared to traditional batch learning-based methods. This suggests that treating hand–eye calibration as a time sequence problem enables the extension of the learned space without complete retraining. The adaptability of the CL-based approaches facilitates accommodating changes in camera pose, leading to an improved hand–eye calibration system.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
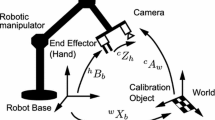
Humans have the ability to manipulate objects in their daily lives with ease. However, robots need an explicit model to transfer knowledge from camera observation to its hands or base. This issue is commonly known as hand–eye calibration. In the literature, the hand–eye calibration problem has been extensively investigated from the mathematical optimisation perspective for one-camera configuration [1,2,3,4]. This means the estimated hand–eye calibration parameters are valid only for the current camera and robot. However, the camera pose may change with respect to the robot base because of contact with the environment or layout changes in the workspace. Hence, a flexible and autonomous hand–eye calibration system is crucial to design a more adaptable industrial manufacturing system.
Recent advancements in deep learning architectures, such as convolutional neural networks, have led to the development of hand–eye calibration systems [5,6,7] capable of estimating different camera poses with respect to a single robot base, thus providing greater flexibility and adaptability to industrial manufacturing systems. However, these deep learning-based approaches have limitations. Deep learning-based approaches are typically trained offline on fixed datasets, resulting in static models that cannot adapt to new data or environmental changes. These models require retraining when the environment or the relative positions of the camera and robot fall outside the learned space. This retraining process necessitates extensive data storage and management, which can become cumbersome. Additionally, it necessitates stopping robotic manipulation tasks during the training process, leading to costly downtime. These approaches are also highly dependent on the sensor used during training. If the sensor is changed post-training, the calibration error tends to increase due to the models’ static nature. Similarly, Recurrent Neural Networks (RNNs) [8] share this static characteristic, lacking the capability for incremental learning. Upon the arrival of new data, the entire network must be retrained from scratch. Additionally, RNNs suffer from catastrophic forgetting, where the network loses previously acquired knowledge when extensively processing new data. As the sequence length increases, the computational cost escalates, and the vanishing gradient problem [8] becomes more pronounced.
In contrast, humans can continuously update and refine their internal hand-to-eye model based on new experiences. In robotic manipulation, continuous learning can be achieved through Continual Learning (CL) [9], an active and ongoing learning paradigm in deep learning where a model is trained on a continuous data stream over time. By utilising CL, robots can learn and adapt similarly to human learning, enabling them to perform more complex tasks and operate in a broader range of environments.
One of the main challenges in CL is the catastrophic forgetting problem [9], which means that when new data is processed, the previously learned information is degraded over time. To overcome this problem, three main strategies have been proposed: regularisation [10,11,12], modular architectural design [13, 14] and rehearsal model (buffer) [15,16,17]. The regularisation methods aim to prevent catastrophic forgetting by adding terms in the objective function to control changes in model weights. Modular architecture design methods mitigate the catastrophic forgetting problem by dedicating sub-modules for different tasks or expanding the network architecture when a new task is defined. Rehearsal approaches replay stored old data (some parts) to the model again periodically to prevent the catastrophic forgetting problem.

This figure depicts this paper’s real-world robotic experimental setup. The robotic manipulator (labelled in red) is positioned on a stable platform (table) and outfitted with a three-fingered gripper (labelled in blue). The experiment systematically alters the robot’s configuration by manipulating the gripper’s final joint (link), thereby exploring the robot’s workspace. Additionally, a camera (labelled in green) is strategically positioned in various configurations throughout the experiment to span the hand–eye calibration space comprehensively (colour figure online)
While humans can manipulate objects effortlessly, robots require an explicit model to transfer knowledge from the camera to their hands or base. hand–eye calibration, a well-known concept in the literature, has been extensively studied via mathematical optimization for one camera configuration. However, the estimated hand–eye calibration parameters are only applicable to the current pair of the camera and robot. This limitation has significant implications for the accuracy and efficiency of robotic systems, making our research particularly relevant and impactful in fields such as manufacturing and healthcare.
In this paper, we introduce a novel Continual Learning hand–eye calibration approach, which extends the learned camera extrinsic parameters over the robot’s working volume. This approach tackles the issue of the camera pose changing over time, a factor that can impact the accuracy of robotic manipulation tasks. To overcome this, we propose three innovative approaches: naive CL, reservoir rehearsal, and reservoir rehearsal with camera pose selection. The naive CL approach, which updates the model with new data, can result in catastrophic forgetting of previously learned information. To counter this, we employ the reservoir buffer approach, which samples uniformly from old data at the previous time step and combines it with new data. Finally, we develop a hybrid approach that combines old data sampling (reservoir) and evaluates new data for the presence of new information.
Our experiments include simulated and real-world environments. We placed a stereo vision camera at 108 different locations in the simulation environment, and we ran 50 different end-effector configurations for each camera pose to collect samples. As for the real world (presented in Fig. 1), we placed a stereo vision camera at 24 different locations and ran 100 end-effector configurations for each camera pose. We divided our datasets into subsets to train our models in a Continual Learning manner and evaluated the success of our approach based on the accuracy of the hand–eye calibration in both environments. Finally, we compared the performance of our three Continual Learning approaches with batch training for both environments.
To address the question of how we demonstrate the proposed methods’ capability to accurately estimate the calibration matrix of hand–eye beyond the learned space, we leverage CL to extend the learned hand–eye calibration space effectively. The network is updated using current (new) data while incorporating sampled past observations. This dynamic updating process enables the network to adapt to new data and maintain performance accuracy even when confronted with significant deviations from the initially learned calibration parameters. The results of our study demonstrate that, except for the naive CL approach, our newly developed CL-based methodologies yield competitive outcomes with the batch training approach. These results show that our CL-based approaches’ flexibility and robustness, particularly in scenarios involving significant variations in camera poses that extend beyond the initially learned calibration space. Furthermore, our approach enables efficient adaptation to novel camera poses outside the learned calibration space without the need for extensive data storage or the retraining of the network on the complete dataset. This feature underscores our proposed method’s practicality and resource efficiency in scenarios where camera pose changes are common.
2 Related work
The literature review is divided into three sections, each providing an in-depth analysis of existing research. Section 2.1 focuses on hand–eye calibration, while the second part examines Deep Learning-based hand–eye calibration (baseline). Finally, Sect. 2.3 addresses Continual Learning.
2.1 Hand–eye calibration
The hand–eye calibration problem has been intensively investigated through mathematical optimisation approaches. There are three mainstream approaches to formulate this problem: \(AX=XB\), \(AX=YB\), and reprojection error.
In the \(AX=XB\) approach, A and B represent the relationship of the coordinate poses in n different frames for the robot’s end-effector and the camera, respectively. Meanwhile, X represents the unknown static transformation between the camera and the robot’s end-effector. In this formulation, A and B are the observable variables via the robot kinematic chain and camera calibration, respectively. Besides, A, B and X are the rotation and translation components to represent the transformation in 3D cartesian space. The solution of this formulation can be divided into two categories: separation and simultaneous approaches. Separation-based approaches [1, 4] solve the rotational component of the unknown transformation (X) and find the translational component using the estimated rotational component. These approaches transfer errors from the rotation to translation components. To eliminate this error transfer, simultaneous approaches [18,19,20] handle these two components simultaneously with nonlinear objective functions. However, these approaches require good initialisation parameters for the nonlinear optimisation solver. Additionally, the solution quality for \(AX=XB\) highly depends on the sampling of A and B.
\(AX=YB\) eliminates the necessity of good sampling of A and B by defining one extra unknown variable, Y, which represents the static transformation between the end-effector of the robot and the calibration target. Observable variables, A and B, represent the pose of the end-effector and the camera. In this formulation, separation [3, 21, 22] and simultaneous [2, 21, 23, 24] approaches have been proposed, similar to the \(AX=XB\) formulation.
The formulations, \(AX=XB\) and \(AX=YB\), fundamentally rely on the geometric relationships within the three-dimensional Cartesian space. The solutions derived from these formulations are particularly susceptible to errors stemming from camera calibration, denoted by the variable B in both formulations. To mitigate this issue, reprojection error-based approaches [25, 26] have emerged. These approaches utilise the disparity between the estimated and actual feature key points in the two-dimensional image plane. These feature key points are either predefined or extracted from the images. By quantifying this disparity, reprojection error serves as the guiding metric in determining optimal hand–eye calibration parameters, striving to enhance the robustness and accuracy of the calibration process.

The figure illustrates the hand–eye calibration architecture, which consists of two encoders that extract features from RGB and depth images individually. The extracted features are combined with the pose of the reference point, represented by a blue circle, and fed into three fully connected layers. The network outputs either the translation component in 3D or the orientation component in 4D [5]
The above approaches are known as classic hand–eye calibration in the literature, and they are not flexible against the camera pose change with respect to the robot base. That is, they are only valid for the current camera and robot configurations, and when this configuration changes, the hand–eye calibration process has to be performed from scratch to obtain valid hand–eye calibration parameters. To address this limitation, researchers have proposed deep learning-based hand–eye calibration methods. For example, Lambrecht [27] and Lee et al. [7] used deep learning as a keypoint detection method, followed by the Perspective-N-Point (PnP) algorithm [28] to obtain the hand–eye calibration parameters. Valassakis et al. [6] employed an end-to-end deep learning architecture that directly estimates the hand–eye calibration parameters, where the camera is attached to the end-effector of the robot. In our previous work [5], we proposed a deep-learning architecture that estimates the hand–eye calibration parameters directly from a single pair of RGB and depth images. Although [6] and [5] achieved flexibility for a wide range of hand–eye calibration spaces, they are trained offline and cannot adapt to changes in data distribution and the robotic environment on-the-fly.
2.2 Deep learning-based hand–eye calibration
Our previous work [5] proposed a supervised learning appraoch to estimate the camera’s pose from RGB and depth images and the pose of a single reference point on the robot manipulator. For this, we [5] employed two separate encoders (depicted in Fig. 2) to extract features from the RGB and depth images, which are then concatenated with the reference point’s pose. We must note that we do not explicitly segment this reference point on the end-effector. Due to the robot’s kinematic chain, which is used as input for the designed network, its pose relative to the robot base is known. Hence, the occlusion of this reference point does not impact our results. The resulting feature vectors are fed into a neural network that estimates either the translation or orientation component of the camera pose. By adopting this approach, we [5] avoided the need for a calibration target, as in traditional approaches such as Tsai’s hand–eye calibration [1], and implicitly handled the camera extrinsic parameters for each end-effector’s pose.
To train the network for the translation component (measured in millimetres) of the hand–eye calibration parameters, we used the Mean Squared Error (MSE) loss function. The Root Mean Squared Error (RMSE) between the ground truth and the predicted values was employed for performance evaluation. We adopted a 10-dimensional quaternion representation approach described in [29] for the orientation component. This method transforms the network’s output of 10 values into a 4D unit quaternion, ensuring compatibility with any network architecture and integration with the main network. Additionally, this approach addresses the double cover problem inherent in 4D unit quaternions by using one half-space of the unit quaternion. The network training for the orientation component was conducted using Eq. 1, which calculates the distance between two given unit quaternions. To interpret the orientation parameters, they were converted to degrees using Eq. 2.
where R and \(R_{gt}\) represent estimated and ground-truth unit quaternions, respectively, and F is the Frobenius norm.
To achieve hand–eye calibration in both simulated and real-world environments, a stereo-vision camera was placed in various configurations. The camera’s pose relative to the robot base was determined using Tsai’s hand–eye calibration approach [1], which was repeated at least five times to ensure accurate calibration. The selection of end-effector movements during data collection was found to be critical for a successful calibration. Once the camera was calibrated, the robot’s end-effector was run through multiple configurations to map out the robot’s workspace. During these tests, both RGB and depth images were recorded, along with the poses of the reference point for each end-effector and camera configuration.
Our previous results [5] indicate that our approach outperforms classical hand–eye calibration approaches by a factor of 96 times in terms of repeatability (mm), demonstrating its ability to produce the same results consistently under identical conditions. Furthermore, the hand–eye calibration error achieved by [5] is comparable to traditional methods while eliminating the need for data recollection. Overall, [5] enables the acquisition of hand–eye calibration parameters without data recollection after the initial training within the learned space. This renders it applicable to various robotic contexts, particularly in dynamic environments necessitating periodic recalibration within the learned space (constrained area).
2.3 Continual learning
Continual Learning (CL) enables deep learning models to continuously learn, update and adapt these models with new data streams or batches. Specifically, Continual Learning refers to the ability of a model to learn continuously from new data without forgetting previously learned concepts. This enables models to evolve and improve over time as new data becomes available. These approaches are characterised by two main features: stability and plasticity. Stability refers to the ability of the model to preserve previously learned concepts, and poor stability can result in catastrophic forgetting [9]. Plasticity represents the model’s ability to adapt to new data.
CL approaches can be categorised as task-incremental, domain-incremental, and class-incremental learning [30]. In the task-incremental scenario, independent tasks are learned with new data over time. An example of this scenario in a robotics context consists of learning to recognise sub-skills, such as reaching, grasping, and placing, to accomplish a pick-and-place task [31]. In the second scenario, domain-incremental approach maintains consistency in the learning task while accommodating evolving data distributions. An illustrative scenario is encountered in autonomous driving, where a pre-trained object detection model must adapt to diverse environmental conditions like varying weather patterns, seasonal changes, or different geographical locations [32]. In the class-incremental scenario, the model learns an increasing number of new classes using new data over time. An example of this scenario is learning new household objects for service robotics [33].
The inherent stability-plasticity predicament within Continual Learning (CL) paradigms, arising from the challenge of retaining past knowledge while accommodating new information, necessitates thoughtful solutions. In the context of CL, a common issue is the potential for catastrophic forgetting when a neural network processes only the data from the current time step. To mitigate this issue, CL can be categorised into three key solution categories: parameter isolation (architectural design),regularisation-based approaches, and replay-based (memory). Parameter isolation methods, often achieved through architectural design, manage the stability-plasticity problem by assigning dedicated parameters to each task. In dynamic models, the network evolves as new tasks are integrated into the training dataset. Weights of previous tasks are treated differently, with options including freezing [13] or copying to preserve past knowledge [14]. On the other hand, static models employ unchanging architectures with task-specific weight sets [34, 35]. These solution strategies strike a crucial balance between maintaining the stability of previously acquired knowledge and fostering the plasticity required for new information, offering a comprehensive response to the stability-plasticity challenge in CL. The choice among these strategies hinges on the specific demands and constraints of the given learning problem.
Regularisation-based approaches offer valuable mechanisms for preserving essential knowledge while accommodating new information. These strategies typically involve adapting loss functions to penalise substantial changes in critical weights. This is achieved through two primary strategies: parameter importance estimation and knowledge distillation. The parameter importance estimation approach focuses on identifying and safeguarding essential weights within the neural network by using Elastic Weight Consolidations [10, 11], Memory Aware Synapses [36], or Deep Model Consolidation [12]. On the other hand, the knowledge distillation strategy is concerned with preserving previously consolidated knowledge while learning new tasks. This is accomplished by employing knowledge distillation functions [37, 38].
Replay methods sample previously used raw data while updating the model with new stream data to overcome the stability problem. Several methods have been employed to select samples from previous data. A straightforward approach is random selection [15], which involves randomly choosing observations at regular intervals. While this method is easy to implement and provides a diverse representation of past data, it may overlook important features and focus on unnecessary data. Additionally, it does not ensure an even distribution of classes, leading to uneven data representation. Reservoir sampling [17], on the other hand, uses a normal distribution to stochastically sample data instances from a historical sample reservoir, thereby preserving a diverse and representative subset of the training set. However, it also does not guarantee an even distribution of classes. To address this issue, class balance approaches have been introduced [16], which ensure equal representation of each class by selecting samples within classes. Reply methods directly address the catastrophic forgetting problem by sampling previous data; however, parameter isolation approaches try to handle this problem by segregating parameters associated with different datasets. This segregation cannot be easily defined in complex neural networks because parameters in these networks are highly interconnected. As for regulation, parameters are highly task-dependent and require hyperparameter fine-tuning for each task. Hence, they have limited generalisability.
To the best of the author’s knowledge, no study has investigated hand–eye calibration with a Continual Learning approach. The closest related work can be found in the study conducted by Wang et al. [39]. Wang et al. [39] developed a CL-based visual localisation approach, which sequentially trained a network with a novel buffer system. They combined reservoir and class-balance buffer methods to overcome the catastrophic forgetting problem. The reservoir method enabled them to sample previous data with uniform distribution, while the class-balance method ensured that selected samples represented all scenes.
It is worth noting that their investigation is centred around the domain of visual localisation, particularly in the context of neural network training with a novel buffer system. The distinctiveness of our research lies in its application of CL to the intricate domain of hand–eye calibration, specifically to extend the learned calibration space. This critical divergence underscores the innovative and unexplored nature of our investigation, positioning it as a pioneering study within the field.
3 Methodology
In our prior research [5], we developed a deep learning-based method for hand–eye calibration that enables continuous estimation of calibration parameters within a specified region. This was achieved by placing the camera at multiple locations and performing various configurations of the robot end-effector for each camera pose. It is important to note that all camera and end-effector poses were assumed to be known at the outset of the training phase. Figure 3 illustrates the continuous representation of the 360-degree environment surrounding the robot base, centred within a semi-spherical 3D space. The blue-colored region denotes the learned 3D space, acquired through discrete camera poses (represented as black dots) within this area. Conversely, the red region falls outside the learned space, and the success of the hand–eye calibration model in [5] degrades in this region.

The figure illustrates the observed and non-observed 3D Cartesian Space 360 degrees around the robot base, which is located in the centre. The observed space is learned continuously by sampling discrete camera poses (black dots) inside this region. The hand–eye calibration model has great success in the learned space; however, its success reduces when the camera is placed outside of this space
In the hand–eye calibration approach based on Continual Learning (CL), the acquisition of camera poses occurs progressively over time, facilitating the expansion of the learned space. In the hand–eye calibration approach based on Continual Learning (CL), the acquisition of camera poses occurs progressively over time, facilitating the expansion of the learned space. We initially collected the data and subsequently divided it into subsets to train the network, thereby mitigating long-tail effects. To address data distribution concerns, we strategically positioned m camera configurations and moved the robot arm through n uniformly selected configurations. We utilised sine and cosine functions in the simulation phase to generate camera poses relative to the robot base frame. This approach ensured an even data distribution throughout the training process.
The collected camera poses can be effectively managed by defining time steps. We propose two methodologies for transforming the hand–eye calibration problem into a continual learning (CL) framework, conceptualised as a time sequence problem. For the Naive and the reservoir buffer with class balance approaches, we define a region containing several camera poses as a single time step. While, for the reservoir buffer with class balance and camera pose selection, each camera pose is treated as a separate time step to facilitate the elimination operation. It is important to note that time steps correspond to the instances at which we update our network.
The first approach involves treating a collection of camera poses representing a specific area within the 3D Cartesian space as a single-time step. This approach enables the training and updating of the hand–eye calibration model based on the camera poses encompassed within that particular region. By systematically defining time steps in this manner, the entire space can be learned over time using Continual Learning. Figure 4 provides a visual representation of this concept, illustrating the semi-spherical 3D space around the robot base, as depicted in Fig. 3. In Fig. 4, the space is divided into six distinct regions, each denoted by a different colour. These regions enable the gradual acquisition of knowledge across the entire space by sampling camera poses within each region.
The second approach involves treating each individual camera pose as a separate time step. In this case, each camera pose represents a unique instance in time, and the hand–eye calibration model is updated based on the information provided by each pose individually.
The remainder of this section presents the adopted Continual Learning (CL) approaches to address the hand–eye calibration problem. First, we describe the straightforward CL approach, Naive CL. Following this, we introduce replay-based methods designed to mitigate the issue of catastrophic forgetting. As noted by [39], these techniques have demonstrated robust performance in regression tasks for domain-incremental scenarios.
3.1 Naive approach
The traditional approach of updating a trained model without any buffering is known as the naive approach. This approach uses a small batch size to update the network weights with new observations each time step. The naive approach trains the network with the dataset in the current time step and passes the learned weights to the new time step. Moreover, the naive CL approach evaluates the performance of the trained model for each time step by using all testing subsets. This evaluation shows the performance of the Naive CL approach in both the observed and non-observed spaces.

This figure depicts a 3D half-sphere surrounding the robot base, divided into six distinct regions. The regions provide a framework for gradually acquiring hand–eye calibration parameters over time, employing Continual Learning. The black dots represent discrete camera poses sampled within all regions, enabling the continuous estimation of parameters throughout the entire space
3.2 Replay-based CL approaches
3.2.1 The reservoir buffer with class balance
The reservoir buffer with class balance approach (Fig. 5) employs two distinct techniques to tackle the catastrophic forgetting problem. Specifically, this approach combines the use of reservoir and class balance techniques. The reservoir component employs a normal distribution to randomly sample from a buffer of previous data points, which helps maintain a diverse and representative sample of the training data. Meanwhile, class balance ensures that the training data is balanced across all classes, in this case, the camera poses. It prevents the model from focusing excessively on one class at the expense of others.

The reservoir buffer with class balance algorithm
Algorithm 1 details the training of the network procedure with the reservoir buffer with the class balance approach. This algorithm requires training and testing datasets in the time domain. It also requires three parameters that are \(c_1\), \(c_2\) and \(c_3\). \(c_1\) is the number of sample sizes for previous camera poses, while \(c_2\) is the number of camera poses used for sample collection. Finally, \(c_3\) is the number of training samples for the current time. The dataset partition is detailed in sections 4.1 and 5.1, and m camera poses and n end-effector poses are used for training in each time step, which means m \(\times \) n data (RGB and depth images and the pose of the reference point).

This figure illustrates the reservoir buffer using the class balance (CL) approach. It comprises N time steps, where each time step represents a region within the 3D Cartesian subspace (presented in Fig. 4) defined by m distinct camera poses and n distinct end-effector poses. In each time step, the acquired weights are propagated to the subsequent step and updated based on the current data and samples in the buffer. Furthermore, the buffer undergoes updates every time step by sampling the current data through the class balance selection approach

This figure visualises the reservoir buffer with the class balance and camera pose selection approach. Unlike previous approaches, the buffer is structured around individual camera poses, treating each pose as a distinct time step. This design allows for gradually expanding the learned space while identifying and eliminating redundant poses lacking novelty. Within each time step, a selection process occurs, wherein 10 % of the data associated with the current camera pose is chosen for testing against the previously learned weights. If the average error falls above a predefined threshold, the weights are updated based on the entirety of the data in the current time step, and the buffer undergoes an update. In cases where no novelty is observed, the weights remain unchanged, and the process advances to the subsequent time step
This approach considers a set of camera poses as a time step presented in Fig. 4, which represents a 3D region of the calibration space. In the first time step, the deep learning-based regression architecture was trained on the current dataset, and the learned weights were passed to the next time step. The learned weights were updated for the following time steps by processing the current training data and buffer data from previous observations. The performance of the approach was evaluated on the current and all test sets for each time step.
3.2.2 The reservoir buffer with class balance and camera pose selection
The reservoir buffer with class balance and camera pose selection is a hybrid method to streamline the processing of camera poses while maintaining the integrity of previously acquired data through the use of a reservoir buffer and the class balance technique. The reservoir buffer plays a crucial role in this process, enabling the retention of relevant data while eliminating redundant information. To determine whether a new camera pose contains novel information, a random sample is drawn and compared to a threshold value, which is determined experimentally and described in the experimental design Sects. 4.2 and 5.2. The network is updated only if the current hand–eye calibration parameters are not already within the learned space. The camera pose selection component reduces data storage and training time, making it more suitable for real-time robotics applications.
To determine whether a new camera pose contains novel information, a random sample is drawn and compared to a threshold value, which is determined experimentally and described in the experimental design Sects. 4.2 and 5.2. The reservoir buffer plays a crucial role in this process, enabling the retention of relevant data while eliminating redundant information. Additionally, the camera pose selection component reduces data storage and training time, making it more suitable for real-time robotics applications.
Algorithm 2 details the reservoir buffer with class balance and camera pose selection approach. This algorithm requires a threshold for judging whether the current camera pose contains novelty or not. When a new subset is introduced, a sample consisting of 10% of each camera pose is randomly selected using a normal distribution. Next, the mean errors for each camera pose are computed based on the last trained model. If the mean error for any camera pose exceeds a predefined threshold, that camera pose is considered to be novel and marked as such for further processing.

The reservoir buffer with class balance and camera pose selection algorithm
The training stage starts by processing the dataset consisting of a set of camera poses via DL-based regression architecture [5] in the first time step. Then this approach considers each camera pose as a new time step (as presented in Fig. 6). Hence, when the new camera pose arrives, algorithm 2 is used to determine whether the current camera pose contained novelty. If it contains novelty, the learned weights are updated by processing this camera pose and buffer from past observations. The success of the trained model in each time step is evaluated on all test sets to show the progress of the trained model.
4 Simulation experiments
4.1 Data generation and split

This figure visualises the Universal Robot 5 (UR5) equipped with a parallel gripper in the PyBullet simulation environment
A Universal Robot 5 (presented in Fig. 7) with a parallel gripper was placed in the PyBullet simulation environmentFootnote 1 The data split is depicted in Fig. 8, which shows a three-dimensional Cartesian space with each subset represented by a different colour. It should be noted that each subset is considered a time step for the naive CL and reservoir buffer with a class balance approach. On the other hand, for the reservoir buffer with a class balance and camera pose selection approach, the first subset (blue) is considered the first time step, and subsequently, each camera pose is treated as a separate time step. The overview of the adopted time step strategies is presented in Table 1.
The training and testing camera configurations for each subset are indicated by dots and stars in Fig. 8. This visualisation allows for a better understanding of the distribution of the camera configurations and the data split across the different subsets.
For each camera pose, the end-effector was moved to 50 different configurations to capture the robot’s movement in various configurations. For each end-effector and camera pose, RGB and depth images and the pose of the reference point on the robot’s end-effector were collected. This process was repeated for all 50 end-effector configurations for each camera pose. The reference point on the robot’s end-effector served as a marker for tracking the robot’s movement and was located at a specific point on the end-effector for consistency.

This figure visualises the camera configurations used in the PyBullet simulation environment. The 108 camera configurations are divided into six subsets, each represented by a different colour. The dots and stars indicate the camera configurations used for training and testing within each subset, respectively. The black star in the figure represents the robot’s base, serving as a reference point for the camera configurations (colour figure online)
4.2 Experimental design
4.2.1 Naive CL
The naive Continual Learning approach starts with training the DL-based regression architecture [5] with the first subset (coloured blue), which consists of 14 training camera poses, in the first time step. The learned weights are then updated using the new subsets (\(S_2\) to \(S_5\)) in the subsequent time steps. This approach encompasses six-time steps, each containing 14 and 4 camera poses for training and testing, respectively (detailed in Table 1). The performance of the naive CL approach is assessed on each test set across all time steps, thereby providing insights into the model’s progress over time in both the observed and non-observed calibration spaces.
4.2.2 The reservoir buffer with class balance
The reservoir buffer with the class balance approach follows the same training procedure as the naive approach for the first subset. However, for the second and subsequent subsets, the training set of the current subset is augmented with a small sample of the previous subsets using parameters \(c_1\) and \(c_2\). The \(c_3\) parameter uniformly selects samples from the current training set. Then the learned weights in the first time step are updated by using the sampled training set and the buffer set. This process is repeated until all time steps are visited. The model’s success is evaluated on all test sets for each time step.
Table 2 presents the selected parameters and corresponding buffer and training data size according to these parameters. The first row in this table shows if the DL-based regression architecture [5] is trained without Continual Learning each time step. This means each time step considers the current dataset and all observed camera pose from past time steps. The following row shows the buffer size according to the \(c_1\) and \(c_2\) parameters and the sampling of the current training dataset using the \(c_3\) parameter. It should be noted that each camera pose consists of 50 RGB and depth images, and each time step has 14 camera poses (detailed in Table 1).
4.2.3 The reservoir buffer with class balance and camera pose selection
The reservoir buffer with class balance and camera pose selection approach is a new method that incorporates the buffer system and camera pose elimination steps. Similar to the previous approach, the DL-based regression architecture [5] is initially trained with the first subset (marked blue in Fig. 9). However, each camera pose is considered a time step in this approach (detailed in Table 1 ). When a new camera pose arrives, the elimination step is triggered using Algorithm 2 to identify the camera poses marked as a novel. The novel camera poses are combined with the buffer dataset obtained using Algorithm 1 and used to update the model, while unmarked camera poses are excluded from the buffer system in the next time steps. This process is repeated until all time steps (camera poses) are covered.
As noted in our previous work [5], the deep learning-based regression architecture comprises two networks: one for estimating the translation and the other for the orientation components of the calibration parameters. For each network, the novelty thresholds for translation and orientation are determined separately, given their distinct solution spaces (millimetres for translation and degrees for orientation). Based on the experimental results in [5], which indicate the error range necessary for effective robotic manipulation, the novelty thresholds were set at 3 mm and 6 mm for translation and 4 degrees and 8 degrees for orientation. The small thresholds (3 mm and 4 degrees) are double the best result acquired by training networks without CL, so they eliminate only unnecessary camera poses. The other threshold values (6 mm and 8 degrees) allow networks to eliminate more camera poses, reducing computational complexity and forcing them to learn more distinctive features. Figure 9 shows the eliminated camera configurations for the translation network with a threshold of 6 mm.

This figure illustrates the training stage of the reservoir buffer with class balance and camera pose selection approach in a simulation environment. The testing camera configurations for each subset are represented by colourful stars. The eliminated camera configurations, which are marked as not novel through algorithm 2, are indicated by black crosses (Colour figure online)
4.3 Experimental results
This section presents the individual results for Naive, the reservoir buffer with class balance, and the reservoir buffer with class balance and camera pose selection approaches. Additionally, the comparison of the success of these approaches is presented in this section.
4.3.1 Naive CL experimental results
Tables 3 and 4 show the results of the experiments conducted to evaluate the performance of naive CL for each time step for translation and orientation components. To this end, the trained model in each time step was tested on all test set across all calibration space (S1 to S6). Each row in the tables represents a specific time step, while each column displays the error (testing) for the sub-testing sets.
The results indicate that the naive CL approach suffers from catastrophic forgetting in translation and orientation components. Notably, the errors on the diagonal of both tables, where the training and test sets belong to the same subset, are relatively low (only 1.5 times worse than the baseline results), indicating that naive CL can only handle camera configurations within the current spanned space. Therefore, this approach is limited in adapting to new camera configurations outside this space.
4.3.2 Experimental results of the reservoir buffer with class balance

This figure shows the performance of the parameter for \(c_1\), \(c_2\), and \(c_3\) for the translation with the reservoir buffer with the class balance approach
The experiment evaluated the performance of the reservoir buffer with the class balance approach by computing the error for each subtest set (S1 to S6) at every time step (\(\mathbf {T_1}\) to \(\mathbf {T_6}\)). An ablation study was conducted to find the best values for the \(c_1\), \(c_2\), and \(c_3\) parameters, as mentioned in Sect. 4.2.2. Figures 10 and 11 show the results of the ablation study, which examined the influence of different parameterisations of \(c_1\), \(c_2\), and \(c_3\) on translation and orientation estimation, respectively. The figures display the average error for each time step in the estimation process.

This figure shows the performance of the parameter for \(c_1\), \(c_2\), and \(c_3\) for the orientation with the reservoir buffer with the class balance approach
The study found that there was no significant difference in performance for translation estimation between the various parameterisations of \(c_1\), \(c_2\), and \(c_3\). This suggests that the network can converge to good results regardless of the values used. Furthermore, the study suggests that estimating the translation component with a reduced amount of data may be possible.
In contrast, for orientation estimation, the parameterisation of \(c_1\)=4, \(c_2\)=14, and \(c_3\)=100% yielded the most accurate results. Decreasing the value of \(c_3\) resulted in slower convergence and an increase in average error in the final step. Additionally, reducing the buffer sample size led to a corresponding increase in error. However, the error for a parameterisation of \(c_1\)=4, \(c_2\)=14, and \(c_3\)=50% was still relatively low, suggesting that some data can be omitted during the training stage.
Tables 5 and 6 show the experimental translation and orientation parameter estimation results for each time step and sub-testing set using the reservoir buffer with the class balance approach. The values of \(c_1\), \(c_2\), and \(c_3\) are set to four, 14, and 100% of the training set in the current time step, respectively, and these parameter settings yielded the best performance based on the ablation study.
The model’s error was computed for the unseen sub-test sets across the entire calibration space (S1 to S6) at each time step. The error for a given time step indicated how well the model had performed on the sub-test sets that spanned the space covered by observed training sets. The final row (\(\mathbf {T_6}\)) showed the best performance for each sub-test set because the model had spanned all the calibration space in the class balance CL manner. This suggests that the model had learned to generalise well to new data by incorporating class balance during training.
4.3.3 Experimental results of the reservoir buffer with class balance and camera pose selection
Tables 7 and 8 show the experimental results of the final time step for each testing set (S1 to S6) by employing the reservoir buffer with class balance and came pose estimation approach with two different thresholds. The results in Table 7 indicate that the translation error was lower for the 3 mm threshold for each sub-testing set when compared to the 6 mm threshold, implying that a smaller threshold led to increased accuracy. However, the difference in error between the two thresholds was found to be minimal, with a difference of less than 1 mm. Additionally, it was observed that the 6 mm threshold was able to eliminate 29 camera poses, whereas the 3 mm threshold could only eliminate 17 camera poses. These findings suggest that the 6 mm threshold processed fewer data points while performing with similar levels of error.
As indicated in Table 8, the final time step orientation error for each testing set was evaluated using both 8 degrees and 4 degrees thresholds. The results showed that a higher error threshold (8 degrees) led to better performance. However, the lower threshold results were still relatively strong, with an average of only 18% or 0.6 degrees worse than the higher threshold. It should be noted that the 8 degrees threshold eliminated 42 camera poses (60%). In comparison, the 4 degrees threshold eliminated 32 camera poses (45%).
4.3.4 Comparison of the CL approaches
Figures 12 and 13 illustrate the performance of the CL approaches for each testing set in terms of the translation and orientation components with the baseline (batch-learning) approach, which is DL-based regression architecture trained with all training sets building from the ground up without CL. Comprehensive results are additionally provided in Tables 9 and 10.

This figure compares each testing set’s translation errors for adopted CL approaches with the baseline approach in the final time step. The baseline approach is DL-based regression architecture trained by all training sets building from the ground up without CL

This figure compares each testing set’s orientation errors for adopted CL approaches with the baseline approach in the final time step. The baseline approach is DL-based regression architecture trained by all training sets building from the ground up without CL
The results demonstrate that the naive CL approach has the poorest performance for translation and orientation error, primarily due to forgetting previously learned knowledge over time. The naive CL approach has competitive results with the final testing subset (S6) because this sub-test set is in the final training subset, where the naive CL last updates the model.
In contrast, the buffer-based approaches, including the class balance approach, did not suffer from the catastrophic forgetting problem. Figures 12 and 13 show no significant performance differences among these approaches for both components. However, the buffer-based approach with camera pose selection allowed for the elimination of unnecessary camera poses, resulting in reduced computational time, as demonstrated in Table 11. This makes them more adaptable for processing stream (online) data. It should be noted that the best parameters for the reservoir buffer with the class balance approach were only included in the plots for simplicity. Except for the naive approach, CL-based approaches have competitive results with the baseline for both translation and orientation, as shown in Tables 9 and 10.
Based on the comparison of CL approaches with the baseline approach, it can be concluded that CL approaches improve the model’s translation and orientation estimation performance, as shown in Tables 10 and 9. The buffer-based approaches, including the class balance approach, performed better than the naive approach, which suffered from the catastrophic forgetting problem. Moreover, as presented in Table 11, the buffer-based approaches with camera pose selection allowed for eliminating unnecessary camera poses, reducing computational time and making them more suitable for processing stream (online) data. The reservoir with the class balance approach has 1.5 mm and 0.5 degrees higher errors for the translation and orientation compared to the baseline [5] while reducing data requirements by 65% (presented in Table 11). The reservoir with the class balance and camera pose selection approach has 0.3 mm and 1.1 degrees higher errors than the baseline , but it used 75% less data (depicted in Table 11). Overall, these results suggest that CL approaches, particularly buffer-based approaches, can improve the accuracy and efficiency of camera pose estimation models.
5 Real-world experiments
5.1 Data collection and split
A Universal Robot 3 with a three-finger grasper (depicted in Fig. 14) was placed on the table. To span camera space from different viewpoints, a stereo pair of cameras was positioned in 24 locations, illustrated in Fig. 15. These camera configurations cover three sides of the table where the robot is mounted, which enables us to consider 90 and 180 degrees rotations which contain the challenging perpendicular and reflection configurations. These rotations cause a significant change in the appearance of the robot and the environment. To span the robot workspace space, the end-effector of the robot was moved to 100 configurations for each camera pose.

This figure visualizes a Universal Robot 3 with a three-finger grasper in the real-world environment
Figure 15 shows the camera configurations, where red and blue dots represent the train (19 camera poses) and test (5 camera poses) sets. For data partition, three subsets (S1-S3) were used, where each side was composed of the one-time step. Table 12 shows the time step selection strategy used in real-world experiments.

This figure shows the camera configurations used in the real-world environment. The 24 camera configurations are divided into three subsets. The red and blue colours represent the training and testing sets, respectively (Colour figure online)
5.2 Experimental design
5.2.1 Naive CL
The naive CL approach processes the data separately for translation and orientation components by employing the DL-based regression architecture [5]. It starts to train the network using the first subset and then updates the trained model until all subsets are covered.
5.2.2 The reservoir buffer with class balance
This approach, similar to the naive CL approach, processes the data separately for the translation and orientation components using the DL-based regression architecture [5]. The training process starts with the first subset, and the model is updated until all subsets are covered. However, unlike the naive approach, this approach utilises algorithm 1 to augment the training set with past observations. The parameters \(c_1\), \(c_2\), and \(c_3\) are chosen for the real-world experiments as four, all observed camera poses in the previous time step, and 100% based on the simulation results discussed in Sect. 4.3.
5.2.3 The reservoir buffer with class balance and camera pose selection
The reservoir buffer with class balance and camera pose selection approach (Fig. 6) follows a training procedure different from the buffer and naive CL approaches. Initially, the translation and orientation networks are trained using the first subset, which includes six camera poses. In contrast to the previous approaches, the other 13 camera poses are considered independent time steps, a more realistic representation of camera pose changes in real-world applications, which resembles a stream (online) hand–eye calibration.
At the end of the first time step, Algorithm 2 is used to test whether the new camera pose includes novelty. If so, the camera poses with novelty at any time step are used to update the last model using the reservoir buffer with the class balance approach. Specifically, four samples are taken from past novel camera observations to augment the current training set.
To determine the presence of novelty, a threshold is used for the translation and orientation components. Based on experimental results obtained from simulations, the thresholds for the translation and orientation components are set to 3 mm and 4 degrees, respectively.
5.3 Experimental results
This section presents individual and comparison results of each CL approach for the translation and orientation components in the real-world environment.
5.3.1 Naive CL experimental results in the real-world environment
Tables 13 and 14 present the experimental results of the Naive CL approach for the translation and orientation error at each time step and the unseen test set in the real-world environment. The results indicate that there is a good performance for the test set at the current time step, but catastrophic forgetting occurs for the previous time steps. Specifically, the average translation errors (as shown in Table 13) for the S2 and S3 test sets in the final step are 4.14 and 3.49 mm, respectively, while the error for the S1 test set is 31.51 mm.
5.3.2 Experimental results of the reservoir buffer with class balance in the real-world environment
Tables 15 and 16 present the translation and orientation error results for each time step and sub-testing set when using the reservoir buffer with the class balance approach, with parameters four, all observed camera poses in the previous time step, and 100% chosen based on the ablation study results in the simulation environment.
Table 15 indicates a decrease in translation error as camera poses are processed over time for both the current and previous test sets. Moreover, the average error for each test set in the final step is competitive with the DL-based HEC [5], and the catastrophic forgetting problem observed in the Naive CL approach is resolved.
Regarding the orientation component (detailed in Table 16), a similar trend is seen in the translation regarding model success over time, and the impact of the catastrophic forgetting problem is reduced. However, the average results in the final time step are above the baseline [5], which are 1.4 mm and 2.8 degrees for translation and orientation, respectively.
5.3.3 Experimental results of the reservoir buffer with class balance and camera pose selection in the real-world environment
Tables 17 and 18 display experimental results for the translation and orientation components, respectively, in a real-world environment using the reservoir buffer with the class balance and camera pose selection approach. This approach considers each camera pose in the subsets as a time step, except for the first subset, resulting in 14 time steps. Parameters used include four, all observed novel camera poses in the previous time step, and 100% for the buffer approach, while 3 mm and 4 degrees thresholds for the camera pose selection for translation and orientation, respectively. It should be noted that each experiment was repeated three times to mitigate the effects of stochasticity.
Table 17 demonstrates that the translation error for the first subset marginally increases after the first time step (\(\mathbf {T_1}\)) when new camera poses are considered. However, this increase is only 1 mm and can be tolerated. For S2 and S3, the errors decrease over time. Additionally, the threshold eliminates six camera poses, excluding novelty, which reduces computational complexity.
Table 18 shows that the orientation trend is similar to the translation for S1, S2, and S3. Although the error in the S3 test set decreases over time, it is still high compared to S1 and S2. Increasing camera pose in that region may address this performance gap.
5.3.4 Comparison of the CL approaches in the real-world environment
Figures 16 and 17 present a comparison of different CL approaches with the baseline [5] for the translation and orientation components, respectively. Comprehensive results are additionally provided in Tables 20 and 19. The naive CL approach exhibits the worst performance for both translation and orientation components. Compared to the baseline, it is 14 and 31 times worse for translation and orientation components in the S1 test set in the final time step. Figure 16 demonstrates that the buffer-based CL approaches have results that are competitive with the baseline for the translation error. On the other hand, Fig. 17 shows that the buffer-based approaches perform comparably to the baseline for the first two test sets, but there is a performance gap in the final test set. This difference may be due to the camera pose in this set representing the reflection (180-degree rotation), which is a challenging scenario because it causes a significant change in the appearance of the robot and the environment. The experimental result in the simulation (detailed in the Sect. 4.3.4) shows that CL-based approaches have the potential to produce the same success. The gap in the final test set can be eliminated by increasing the number of camera poses in that region.

This figure compares each testing set’s translation errors for adopted CL approaches with the baseline in the final time step

This figure compares each testing set’s orientation errors for adopted CL approaches with the baseline in the final time step
Table 21 also compared the CL approaches with the baseline in terms of computational requirements and errors. This table revealed that the reservoir buffer with class balance CL approach had 1.4 mm and 4.5 degrees higher error for translation and orientation, respectively, compared to the baseline, while reducing data requirements by 48%. As for the reservoir buffer with class balance and camera pose selection, it had 1.0 mm and 2.5 degrees higher error compared to the baseline, but it reduced computational requirements by 66%. It should also be noted that CL-based approaches update the hand–eye calibration model progressively, unlike the baseline approach.
6 Conclusion
This paper presented a Continual Learning (CL)-based approach for hand–eye calibration, demonstrating its potential for extending the calibration space with new observations over time. Three CL-based methods were proposed: a naive approach, a reservoir buffer with class balance, and a camera pose selection approach with the buffer. Experimental results on both simulated and real-world environments have shown that the CL-based approaches, except for the naive one, achieved competitive performance compared to the batch learning-based approach. These findings suggest that the hand–eye calibration problem can effectively be addressed as a time sequence problem, enabling the extension of the learned space without requiring complete network retraining with all camera poses. This adaptability in extending the learned space also enhances the hand–eye calibration system’s ability to accommodate changes in camera pose over time.
Real-time updates of robotic system calibration using CL-based hand–eye calibration approaches are crucial for maintaining accuracy over time. This is especially significant in production environments where the robotic system may encounter variations in the environment or the manipulated products, necessitating adjustments to the calibration parameters. The system can preserve accuracy and precision throughout its operation by updating the calibration parameters in real-time, resulting in higher-quality output and improved efficiency. This approach is particularly beneficial in manufacturing, logistics, warehousing, and agriculture, where robots require periodic recalibration and operate over extensive areas.
Integrating a hand motion model into the calibration process could potentially reduce the amount of data required and enhance the efficiency of data collection. Moreover, incorporating different sensors to augment visual information could lead to the development of more effective hand–eye calibration approaches, thereby reducing the data needed to train the network. However, this would increase the model’s complexity and inference time, which is critical for CL-based approaches. To address this, we can leverage subnetwork-based encoding structures [40, 41] for dimensionality reduction, enabling real-time CL-based hand–eye calibration.
Acquiring accurate camera poses with respect to the robot base poses challenges in real-world scenarios. The proposed approach relies on labelled data during the training phase, which can be a challenging and time-consuming task in certain application areas. Furthermore, the success of the approach is highly reliant on the accuracy and reliability of the data labelling process. In future work, we plan to further enhance the CL-based hand–eye Calibration (HEC) approach by exploring other learning paradigms, such as reinforcement learning and self-supervised learning. Reinforcement Learning can be applied to approach the hand–eye calibration problem, treating the robot as an agent and the camera and object spaces as the environment. The agent’s objective is to maximise a reward function by manipulating an object detected in the camera space using the current hand–eye calibration parameters. By formulating hand–eye calibration as a Reinforcement Learning problem, we can develop more flexible and adaptive calibration methods applicable to diverse robotic systems and environments.
In addition, using a variational autoencoder [42] can be explored to learn the robot and camera parameter space distribution in the encoder part. The decoder part can then generate images using encoded features, and the discrepancy between the constructed and real images can serve as a learning signal. This approach can yield more efficient and flexible calibration methods that adapt to changing environments and hardware configurations.
Overall, the presented CL-based approach for hand–eye calibration demonstrates its effectiveness in extending the learned space over time, allowing for real-time updates and preserving accuracy in robotic systems. Exploring alternative learning paradigms and utilising variational autoencoders offer promising directions for further advancement in hand–eye calibration.
Notes
https://github.com/ozanbahadir/Hand-eye-Calibration. To span the camera space from multiple viewpoints, a stereo pair of cameras was positioned in 108 different configurations using sine and cosine functions with a distance relative to the robot base. These camera poses were divided into six subsets of 18 configurations each. Each subset represents 1/6 of the entire spanned space, enabling the extension of the calibration space over time. For each subset of these six regions, 14 camera configurations were used for training and four for testing.
References
Tsai, R.Y., Lenz, R.K., et al.: A new technique for fully autonomous and efficient 3d robotics hand/eye calibration. IEEE Trans. Robot. Autom. 5(3), 345–358 (1989)
Li, A., Wang, L., Wu, D.: Simultaneous robot-world and hand–eye calibration using dual-quaternions and Kronecker product. Int. J. Phys. Sci. 5(10), 1530–1536 (2010)
Zhuang, H., Roth, Z.S., Sudhakar, R.: Simultaneous robot/world and tool/flange calibration by solving homogeneous transformation equations of the form ax= yb. IEEE Trans. Robot. Autom. 10(4), 549–554 (1994)
Chou, J.C., Kamel, M.: Finding the position and orientation of a sensor on a robot manipulator using quaternions. Int. J. Robot. Res. 10(3), 240–254 (1991)
Bahadir, O., Siebert, J.P., Aragon-Camarasa, G.: A deep learning-based hand-eye calibration approach using a single reference point on a robot manipulator. In: 2022 IEEE International Conference on Robotics and Biomimetics (ROBIO), pp. 1109–1114 (2022). IEEE
Valassakis, E., Dreczkowski, K., Johns, E.: Learning eye-in-hand camera calibration from a single image. In: Conference on Robot Learning, pp. 1336–1346 (2022)
Lee, T.E., Tremblay, J., To, T., Cheng, J., Mosier, T., Kroemer, O., Fox, D., Birchfield, S.: Camera-to-robot pose estimation from a single image. In: 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 9426–9432 (2020). IEEE
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Parisi, G.I., Kemker, R., Part, J.L., Kanan, C., Wermter, S.: Continual lifelong learning with neural networks: a review. Neural Netw. 113, 54–71 (2019)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. 114(13), 3521–3526 (2017)
Liu, X., Masana, M., Herranz, L., Weijer, J., Lopez, A.M., Bagdanov, A.D.: Rotate your networks: better weight consolidation and less catastrophic forgetting. In: 2018 24th International Conference on Pattern Recognition (ICPR), pp. 2262–2268 (2018). IEEE
Zhang, J., Zhang, J., Ghosh, S., Li, D., Tasci, S., Heck, L., Zhang, H., Kuo, C.-C.J.: Class-incremental learning via deep model consolidation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 1131–1140 (2020)
Rusu, A.A., Rabinowitz, N.C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., Hadsell, R.: Progressive neural networks. arXiv preprint arXiv:1606.04671 (2016)
Aljundi, R., Chakravarty, P., Tuytelaars, T.: Expert gate: Lifelong learning with a network of experts. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3366–3375 (2017)
Hayes, T.L., Cahill, N.D., Kanan, C.: Memory efficient experience replay for streaming learning. In: 2019 International Conference on Robotics and Automation (ICRA), pp. 9769–9776 (2019). IEEE
Rebuffi, S.-A., Kolesnikov, A., Sperl, G., Lampert, C.H.: icarl: Incremental classifier and representation learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2001–2010 (2017)
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., Wayne, G.: Experience replay for continual learning. In: Advances in Neural Information Processing Systems, 32 (2019)
Horaud, R., Dornaika, F.: Hand–eye calibration. Int. J. Robot. Res. 14(3), 195–210 (1995)
Daniilidis, K.: Hand–eye calibration using dual quaternions. Int. J. Robot. Res. 18(3), 286–298 (1999)
Zhao, Z.: Hand–eye calibration using convex optimization. In: 2011 IEEE International Conference on Robotics and Automation, pp. 2947–2952 (2011). IEEE
Dornaika, F., Horaud, R.: Simultaneous robot-world and hand–eye calibration. IEEE Trans. Robot. Autom. 14(4), 617–622 (1998)
Shah, M.: Solving the robot-world/hand–eye calibration problem using the Kronecker product. J. Mech. Robot. 5(3), 031007 (2013)
Zhao, Z.: Simultaneous robot-world and hand–eye calibration by the alternative linear programming. Pattern Recognit. Lett. 127, 174–180 (2019)
Tabb, A., Yousef, K.M.A.: Parameterizations for reducing camera reprojection error for robot-world hand–eye calibration. In: 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3030–3037 (2015). IEEE
Zhi, X., Schwertfeger, S.: Simultaneous hand-eye calibration and reconstruction. In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1470–1477 (2017). IEEE
Ali, I., Suominen, O., Gotchev, A., Morales, E.R.: Methods for simultaneous robot-world-hand–eye calibration: a comparative study. Sensors 19(12), 2837 (2019)
Lambrecht, J.: Robust few-shot pose estimation of articulated robots using monocular cameras and deep-learning-based keypoint detection. In: 2019 7th International Conference on Robot Intelligence Technology and Applications (RiTA), pp. 136–141 (2019). IEEE
Lepetit, V., Moreno-Noguer, F., Fua, P.: Epnp: an accurate o(n) solution to the pnp problem. Int. J. Comput. Vis. 81(2), 155 (2009)
Peretroukhin, V., Giamou, M., Rosen, D.M., Greene, W.N., Roy, N., Kelly, J.: A smooth representation of belief over so (3) for deep rotation learning with uncertainty
Ven, G.M., Tuytelaars, T., Tolias, A.S.: Three types of incremental learning. Nat. Mach. Intell., pp. 1–13 (2022)
Pore, A., Aragon-Camarasa, G.: On simple reactive neural networks for behaviour-based reinforcement learning. In: 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 7477–7483 (2020). IEEE
Mirza, M.J., Masana, M., Possegger, H., Bischof, H.: An efficient domain-incremental learning approach to drive in all weather conditions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3001–3011 (2022)
Li, D., Tasci, S., Ghosh, S., Zhu, J., Zhang, J., Heck, L.: Rilod: near real-time incremental learning for object detection at the edge. In: Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, pp. 113–126 (2019)
Fernando, C., Banarse, D., Blundell, C., Zwols, Y., Ha, D., Rusu, A.A., Pritzel, A., Wierstra, D.: Pathnet: Evolution channels gradient descent in super neural networks. arXiv preprint arXiv:1701.08734 (2017)
Mallya, A., Lazebnik, S.: Packnet: adding multiple tasks to a single network by iterative pruning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7765–7773 (2018)
Aljundi, R., Babiloni, F., Elhoseiny, M., Rohrbach, M., Tuytelaars, T.: Memory aware synapses: learning what (not) to forget. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 139–154 (2018)
Li, Z., Hoiem, D.: Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 40(12), 2935–2947 (2017)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
Wang, S., Laskar, Z., Melekhov, I., Li, X., Kannala, J.: Continual learning for image-based camera localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3252–3262 (2021)
Zhang, W., Wu, Q.J., Yang, Y., Akilan, T.: Multimodel feature reinforcement framework using Moore–Penrose inverse for big data analysis. IEEE Trans. Neural Netw. Learn. Syst. 32(11), 5008–5021 (2020)
Zhang, W., Wu, J., Yang, Y.: Wi-hsnn: a subnetwork-based encoding structure for dimension reduction and food classification via harnessing multi-cnn model high-level features. Neurocomputing 414, 57–66 (2020)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
Acknowledgements
We want to thank all Computer Vision and Autonomous Systems (CVAS) research group members for the insightful discussions at the early stages of this work during the group seminars. Ozan Bahadir thanks for the funding received by the Turkish Ministry of National Education for this research. The source code and data supporting this paper are provided at 10.5281/zenodo.12667044.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bahadir, O., Siebert, J.P. & Aragon-Camarasa, G. Continual learning approaches to hand–eye calibration in robots. Machine Vision and Applications 35, 97 (2024). https://doi.org/10.1007/s00138-024-01572-w
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00138-024-01572-w