
Abstract
The automatic assessment of perceived image quality is crucial in the field of image processing. To achieve this idea, we propose an image quality assessment (IQA) method for blurriness. The features of gradient and singular value were extracted in this method instead of the single feature in the traditional IQA algorithms. According to the insufficient size of existing public image quality assessment datasets to support deep learning, machine learning was introduced to fuse the features of multiple domains, and a new no-reference (NR) IQA method for blurriness denoted Feature fusion IQA(Ffu-IQA) was proposed. The Ffu-IQA uses a probabilistic model to estimate the probability of each edge detection blur in the image, and then uses machine learning to aggregate the probability information to obtain the edge quality score. After that uses the singular value obtained by singular value decomposition of the image matrix to calculate the singular value score. Finally, machine learning pooling is used to obtain the true quality score. Ffu-IQA achieves PLCC scores of 0.9570 and 0.9616 on CSIQ and TID2013, respectively, and SROCC scores of 0.9380 and 0.9531, which are better than most traditional image quality assessment methods for blurriness.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Digital images inevitably subject to various kinds of distortions during their acquisition, compression, storage, and transmission. Among these distortions, blur is a common one. For example, camera shake when taking a photo, or uploading and downloading images [1, 2]. Therefore, there is an urgent need for a reliable algorithm to simulate human vision to evaluate the quality of various images and select high-quality images for users.
There are two main methods for image quality assessment (IQA): subjective image quality assessment (SIQA), which is mainly performed by human observers, and objective image quality assessment (OIQA), which involves simulating human perception to design metrics for judging image quality. Since the human eye is the final recipient of visual information, subjective evaluation can directly reflect human visual perception and is an accurate and effective method for evaluating visual quality. However, subjective evaluation involves many participants in the experimental process, is complex, time-consuming, expensive, and the data is not real-time. Therefore, the implementation of SIQA has limitations. OIQA does not require direct human participation in evaluation, and quality evaluation results are obtained by algorithms, which are more efficient. Typically, image quality assessment (IQA) is divided into three major categories based on the availability of the original image: full reference (FR), reduced reference (RR) and no reference (NR). Full reference uses the reference information of the original image to reduce the features extracted from the image. However, in most scenarios, we face an environment without original images. In contrast, no-reference indicators do not require any reference information and can adapt well to environments without original images. But at the same time, the scarcity of reference information also brings huge challenges to NR methods [3,4,5].
2 Related work
In the field of image blur assessment, Marziliano [6] was one of the first researchers to propose the use of edge extraction methods for assessing blur. His method involved calculating the average width of all edges in an image to determine the image's blur score,created a new path for the objective quality assessment (IQA) of image blur. However, subsequent studies demonstrated that while Marziliano's method was pioneering, the accuracy of her method had limitations. Based on this discovery, Ferzli et al. [7] proposed the Just Noticeable Blur (JNB) algorithm, aimed at enhancing the accuracy of image blur assessment. However, the JNB method is highly sensitive to image content and structure, and it may mistakenly judge images with rich textures or complex backgrounds as blurred, reducing the accuracy of the assessment. This sensitivity also somewhat limits the applicability of the JNB method in broader application scenarios. To address this issue, Niranjan et al. [8] proposed an assessment method based on the cumulative concept of blur, which evaluates image quality by segmenting the image and calculating the number of blocks containing edges. This method achieved excellent results on the LIVE dataset. However, it is still limited by the reliance on a single feature, where oversensitivity to a single feature may affect the applicability and accuracy in more complex or diverse image quality assessment scenarios.
To further explore IQA methods based on different image features, researchers have developed a variety of methods based on different characteristics. The MLV algorithm proposed by Bahrami et al. [9] assesses the degree of blur in an image by calculating the maximum change in brightness of a pixel and eight pixels around it. This method focuses on local brightness changes in the image, effectively identifying and assessing blurry areas in the image. The method by Tsomko, et al. [10] uses the variance of prediction residuals as an indicator of differences between adjacent pixels, thus finely assessing the degree of blur. This method captures the loss of image details by analyzing the relationships between pixels. Saad et al. [11] explored a method of estimating sharpness based on the discrete cosine transform (DCT) feature. This method offers a new perspective on image sharpness assessment through frequency composition analysis. The method proposed by Zhan et al. [12] considered luminance variations both at block boundaries and within blocks, resulting in more accurate image quality assessments. This approach is innovative in that it accounts for local features of the image, not just global characteristics, enhancing the precision of the assessment. On the other hand, Maleki et al. [13] adopted a different methodology. They extracted Gray Level Co-occurrence Matrix (GLCM) from distorted and reference images, and then evaluated image quality by comparing and analyzing the similarity of matrix features. This method leverages subtle differences in image texture information to assess image quality. With the development of deep learning, attempts have been made to solve IQA problems using deep neural networks. Gao et al. [14] proposed a Deep Similarity Index (DeepSim) based on Deep Neural Networks (DNN). Researchers estimate the local similarity of DNN features between images to obtain the final quality score, an innovative method in the field of deep learning. Jin et al. [15] proposed a multi-task hierarchical blind image quality assessment model capable of assessing images with multiple types of distortion. This method improves the generalization performance of the model by creating an ensemble algorithm of deep neural networks that combines a penalty term and shared layers. Although contrast is a major issue in overall image quality assessment, there are still few reasonably performing contrast evaluators currently available. Khosravi et al. [16] proposed a learning-based blind/no-reference (NR) image quality assessment model called Histogram Feature-based Contrast Scoring (HEFCS) for assessing image contrast. Pan et al. [17] proposed an NR-IQA method based on a multi-branch convolutional neural network (MB-CNN), including spatial domain feature extractors, gradient domain feature extractors, and a weighting mechanism, aiming to use deep learning to replace traditional feature extraction. Li et al. [18] innovatively introduced a new feature distillation method, proposing a new IQA framework for learning comparative knowledge from non-aligned reference images. Shi et al. [19] proposed a Transformer-based NR-IQA model, using predicted objective error maps and perceptual quality labels. Although these methods make full use of image information, they combine with machine learning and deep learning, requiring extensive training, and the assessment results are highly dependent on the dataset. In contrast, traditional IQA algorithms have the advantages of being interpretable, low in time complexity, and high in efficiency.Cuong Vu et al. [20] proposed an S3 quality assessment model, which discussed a solution for image quality assessment in hybrid domain. This scheme uses frequency domain and spatial domain combined as quality score, uses amplitude frequency slope to describe high-frequency energy drop caused by blur in frequency domain, spatial domain uses total variation to describe local contrast change of image, and finally takes blur before 1% of blur image Calculate blur score. It achieved the best evaluation results at that time on LIVE, CSIQ, TID. In our scheme, we learned this idea and proposed Ffu-IQA that combines edge extraction and singular value features.
In summary, this paper makes the following contributions:
-
(1)
A hybrid gradient and singular value training network strategy is proposed, which combines two features through machine learning to adapt to scenarios with limited training data.
-
(2)
An gradient feature extraction method is proposed. We divide the image into blocks and calculate the edge length of each block. Then we calculate five edge feature values and fit them into a SVR model.
-
(3)
An singular value feature extraction method is proposed. We fit the SVD singular value curve with another SVR model to obtain the scores representing the singular value features.
-
1.
The rest of this paper is organized as follows. Section 3 describes the extraction methods of the two features (gradient feature and singular value feature), and the overall structure of Ffu-IQA also introduced in this section. The experimental results on five databases are presented and analyzed in Sect. 4. Section 5 concluded the paper.
3 3 The proposed method
3.1 I Feature extraction
3.1.1 A Overall flow chart gradient feature
The Ffu-IQA introduced an improved CPBD [7] model to extract gradient features. Similar to the original CPBD, the image is divided into 64 × 64 blocks, and the edges of the image are detected using a sobel filter. The blocks are divided into edge blocks and non-edge blocks according to whether the number of edges detected in each block is greater than a threshold. For non-edge blocks, no further processing is taken, and more operations focus on the edge blocks. In CPBD, for edge blocks, the JNB method [6] is used to calculate the edge length and obtain the edge length matrix in each block.
Marziliano method: This method is used in JNB to calculate edge length. Marziliano extracts image edges using a sobel filter. For the edge which was greater than a threshold, find the starting position and end position (maximum and minimum values), and take the distance between the two points as the edge width. The mean of all edge widths is used as the final quality score in Ffu-IQA.
CPBD uses JNB width to calculate the blur probability of each edge block and sums it up to get the final CPBD quality score. Our Ffu-IQA method takes a different approach from CPBD. It uses machine learning instead of the final blur probability calculation. To use machine learning, representative features need to be selected. We use edge length to extract 6 features for machine learning.
(1) Median of all edge lengths.
When n is odd, calculate the median by formula (1). Where \({\text{x}}_{{\left( {\text{i}} \right)}}\) denotes the \({\text{i}}\)-th smallest number.
When n is even then calculate the median by formula (2).
(2) Mean of all edge lengths
where \({\text{n}}\) denotes the number of edges, \({\text{e}}_{{\text{i}}}\) denotes the \( {\text{i}}\)-th edge.
(3) Max and Min of all edge lengths.
The extreme value of edge lengths in each edge block excluding 0
(4) Use \({\text{W}}_{{{\text{max}}}}\) and \({\text{W}}_{{{\text{min}}}}\) to calculate the range \({\text{E}}_{{{\text{i}},{\text{j}}}}\)
(5) Calculate the contrast derived from Michelson contrast \({\text{C}}_{{{\text{i}},{\text{j}}}}\)
Formula (1) and (2) calculate the median of all edge lengths in the image, which can represent the median level of all edge lengths in the image. Formula (3) calculates the mean of all edge lengths, formula (4) and (5) calculate the extreme values and range of all edges, they can represent the distribution of edge lengths. Formula (6) calculates the contrast value based on Michelson contrast, which is often used to calculate the luminance contrast of the image to indicate the clarity of the image. We modify it to represent the contrast between all edges in the entire image. By combining these six values, we can know the distribution of the lengths of all edges in the entire image. Therefore, we need a method to merge these six values that represent the distribution of edge lengths into one value that represents the gradient feature.
For merge method, we pooled the six values by SVR to obtain the feature value representing the gradient as the first feature of the model.For further introduction to the SVR model we used in Ffu-IQA, please check section IIA.
3.1.2 B Singular value features
Because a single feature can easily leads overfitting, another feature added into the model. The singular value curve (SVC) is composed of the singular values obtained by singular value decomposition. Since most of the data in the matrix is used in the process of the singular values’ calculation, so each singular value can represent some information of the matrix. And the singular value curve composed of all singular values, so it can represent the information of the entire matrix [21]. We first convert the image to grayscale, and then perform singular value decomposition on the image matrix.
where U and V are orthogonal matrices, \({\Sigma }\) is a diagonal matrix. After calculating the singular value matrix by orthogonal matrix and diagonal matrix, all singular values in the singular value matrix are extracted.
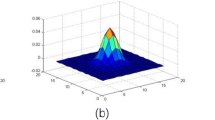
Qingbing Sang et al. [22] proposed an algorithm to calculate the blurriness by using SVC to generate regular curves for different blurred images. It also utilizes the characteristic of singular value curve. We introduce machine learning to learn from the singular value curve, replacing their original formula calculation method and directly generating SVC scores. As shown in Figs. 1 and 2, the images a, b, c, d, e and their corresponding SVC curves. Obviously, the SVC curve in Fig. 2 can accurately reflect the image blurriness in Fig. 1.

The DMOS values of five images a, b, c, d, and e with increasing blurriness from left to right are 0.043, 0.142, 0.341, 0.471, and 0.750 respectively (the larger the DMOS value, the worse the subjective quality of the corresponding image)

The singular value curves of image a, b, c, d, e shown in Fig. 1
3.2 II Pooling
In order to prevent the pooling model from overfitting to a single feature, we use the singular value score and the gradient quality score to pool and generate the final quality score. Due to the excellent tolerance of support vector regression (Support Vector Regression, SVR), it serves as the final pooling model.
3.2.1 A Support vector regression
In recent years, as the booming development of deep neural network enable its application in almost all fields of computer science. However, deep neural networks often require a large amount of training data to train, and using deep neural networks to train on datasets with small data volume such as CSIQ can easily lead to problems such as model overfitting and poor generalization. Therefore, we choose to use the features.
obtained by edge detection and singular value decomposition as the training set of the SVR model. To cope with the small data sets. SVR is also a tolerant regression model, which is different from strict linear regression and has a certain robustness. That’s why it acted as the training model in Ffu-IQA.
As shown in Fig. 3 we used SVR model twice in this algorithm. For the gradient feature extraction part, we extracted five features by formula (1–6). After fitting the five features with the SVR model, a score is obtained to represent the gradient features. For the singular value feature extraction part, after singular value decomposition, a SVR model used to fit the singular value curve. Then obtained the score to represent the singular value features. The second time another SVR model was used to pool edge blur score and signal blur score, therefore, the final score is obtained.

The overall structure of Ffu-IQA
4 Experiment
4.1 A Experimental setups
In this paper, all experiments are performed on Windows 10 64-bit CPU Intel i5 2.9GHz with 8.00GB memory. The training of Ffu-IQA model consists of two main parts: (1) training two feature extractors separately and (2) training the final IQA score model.
4.2 B Image quality assessment datasets
This paper selects the commonly used image quality assessment datasets: TID2008 [23], TID2O13 [24], CSIQ [25] to compare the performance of the Ffu-IQA method proposed in this paper with other image quality assessment methods. The details of each datasets are shown in Table 1. The evaluation index MOS in the table means mean opinion score, the larger the MOS value, the higher the image quality, while DMOS is differential mean opinion score, which means the difference between the scores of reference image and distorted image evaluated by people. The smaller the DMOS value, the higher the image quality.
4.3 C Image quality assessment index
Human recognition of images depends on the information captured by human eyes and the analysis and integration of image information by the brain. In order to verify whether this algorithm conforms to the human judgment standard for images, we adopted two assessment indicators. PLCC and SROCC are commonly used judgment indicators in the field of image quality assessment. PLCC describes the linear correlation between two sets of data, and the value range of PLCC is [− 1, 1]. SROCC is considered to be the best nonlinear correlation indicator, and any monotonic nonlinear transformation applied to the model will not have any impact on SROCC, and the value range of SROCC is [0, 1]. Therefore, PLCC is used to judge the accuracy of model assessment results, and SROCC is used to judge the monotonicity of model assessment results.
(1) Pearson linear correlation coefficient (PLCC)
(2) Spearman rank-order correlation coefficient (SROCC)
where \({\text{x}}_{i}\) and \({\text{y}}_{i}\) respectively represent the DMOS value and the objective assessment value, n represents the number of images, \({\overline{\text{x}}}\) and \({\overline{\text{y}}}\) respectively represent the mean of DMOS and the mean of objective assessment scores.
4.4 D Kernel function
SVR provides a variety of kernel functions. In order to obtain the best fitting effect, we tried to fit the features with these kernel functions respectively. As shown in Tables 1 and 2, by applying different kernel functions to Ffu-IQA and training on the CSIQ dataset, we obtained several PLCC and SROCC values for different kernel functions respectively. It is easy to see from the results that rbf has better result than other kernel functions. Therefore, we finally adopted rbf as the kernel function to train the model.
Formula 8 is the expression of rbf kernel function. where γ represents the influence degree of a single training instance. The larger γ, the closer the distance affected by other instances.
For better performance, we customized multiple parameters of SVR. For example, we adjusted the gamma parameter to 0.2 and set parameter C to 1. Parameter C represents the penalty coefficient of the error classification. The larger C is, the greater the penalty for misclassified samples. The higher the accuracy in the training samples, but the lower the generalization ability. In order to improve the accuracy of Ffu-IQA model, we obtained the optimal values of these coefficients after multiple training.
4.5 E Experimental results and analysis
In order to verify the effectiveness of the Ffu-IQA method, it used to evaluate the quality of the image set with blur distortion type on CSIQ, TID2008, TID2013. And get the results with DMOS/MOS values in each dataset respectively, demonstrated in Figs. 4, 5, 6

The scatter plot of the proposed method relative to DMOS on CSIQ

The scatter plot of the proposed method relative to DMOS on TID2008

The scatter plot of the proposed method relative to DMOS on TID2013
As can be seen from Figs. 4, 5, and 6, the Ffu-IQA method can effectively fit the blurred distortion image dataset. The assessment results of Ffu-IQA on the three datasets have good consistency with DMOS/MOS, and can accurately reflect the true quality of the image.
To test the generalization and accuracy of the model, we selected a set of images from CSIQ for blur prediction. In Fig. 7, we can see that our model’s score is highly correlated with the blurriness of the image. In Fig. 8, we also selected an original image to generate five images with increasing blur, and our model’s quality scores for this set of images also show an increasing trend.

A set of images with increasing blur from left to right in CSIQ, our model’s quality scores from left to right are 0.720, 0.63, 0.457, 0.137, and 0.009

A set of images with increasing blur generated from an original image from left to right, our model’s quality scores from left to right are 0.710, 0.70, 0.157, 0.051, and 0.0
To further verify the performance of Ffu-IQA, this paper selects three groups of images with different texture complexities from the CSIQ dataset (Figs. 9, 10, and 11). Ffu-IQA model used to evaluate the quality of the blurred images from a to e.

Simple texture image and its gradient image, a–e are five images with increasing blurriness of the ground truth

Moderate texture image and its gradient image, a–e are five images with increasing blurriness of the ground truth

Complex texture image and its gradient image, a–e are five images with increasing blurriness of the ground truth
The DMOS and SSIM [26] were used to compare with the quality scores obtained by Ffu-IQA model, as shown in Figs. 12, 13, and 14. It can be found that our model can fit well with the DMOS values obtained by human observation, and the results obtained by the SSIM method in FR-IQA are consistent. Among the three groups of images, Ffu-IQA method has poor consistency in quality scores for images with simple textures, and has consistently higher quality scores for images with complex textures and moderate textures.

Quality assessment comparison of simple texture images

Quality assessment comparison of moderate texture images

Quality assessment comparison of complex texture images
Similar to refs [26,27,28] multiple ways were chosen to verify the effectiveness of our model. This paper selected several commonly used quality assessment algorithms for blur distortion on CSIQ,TID2008, TID2013: S3[20], MLV, DIQA[29], DB-CNN [30], LPC [31] HyperIQA [32], P2P-BM [33], LiNuIQA [34], MANIQA [35] for comparison. And using PLCC and SROCC as measurement indicators, as shown in Tables 3 and 4 below. S3, MLV, and LPC are NR-IQA algorithms targeting blur that also employ traditional machine learning algorithms, similar to our approach. On the other hand, DIQA, DB-CNN, HyperIQA, LiNuIQA and MANIQA are NR-IQA algorithms based on deep learning proposed in recent years.
From Table 3, it can be seen that Ffu-IQA has achieved relatively good performance in terms of accuracy and monotonicity on the three IQA databases. According to the PLCC and SROCC values obtained from experiments, Ffu-IQA method gained better performance compared to methods that also use machine learning which also focus on blur distortion. Ffu-IQA method also surpasses most of the recent deep learning algorithms except for MANIQA, which has an extremely large network. In addition, our method is based on machine learning do not require massive training dataset. The results indicating that our Ffu-IQA algorithm structure is stable and has high consistency with human eye recognition of image quality.
In order to further study the effectiveness of Ffu-IQA method, we conducted ablation experiments on the CSIQ dataset. The baseline method was to train our model on CSIQ using only a single feature and then test the model. For the dataset, 80% of the images are used for training and the remaining 20% are used for testing.
As shown in Table 4, Ffu-IQA method has better performance than the single-feature model, indicating that combining gradient features and singular value features can indeed improve the performance of NR-IQA models. This verifies that multi-feature models have better generalization ability than single-feature models.
4.6 F Discussion
The overall performance of our algorithm exceeds that of traditional NR-IQA algorithms targeting blurriness in recent years. Similar to these traditional algorithms, Ffu-IQA does not require large datasets as training support since it does not use deep learning. At the same time, our algorithm also outperforms most NR-IQA deep learning algorithms in recent years. Although our algorithm does not perform as well as MANIQA, it does not require a large training set and trains faster. Ffu-IQA uses PLCC and SROCC index and has achieved performance second only to MANIQA on three public IQA datasets, proving that the proposed solution is effective for NR-IQA focus on blur distortion.
5 Conclusion and future recommendations
An image quality assessment method denoted Ffu-IQA was proposed that integrates gradient information and singular value decomposition, which extracts the gradient features and singular value features of the image respectively. The method combines the SVR model to fit MOS and DMOS, to overcome the problem of model overfitting caused by small data sets. We conducted extensive experiments on several mainstream public data sets in the IQA field, and the experimental results show that our algorithm can achieve better PLCC and SROCC scores than most traditional NR-IQA algorithms and some of the recent deep learning-related NR-IQA algorithms which focus on blur. It verifying the effectiveness of Ffu-IQA method. In the follow-up work, we plan to further optimize the algorithm's execution speed to highlight the advantage of rapid machine learning execution. And to leveraging it's benefits of swift execution, we plan to apply this method to the factory's production line by detecting whether the image quality captured by the cameras meets the standards.
Data availability
The research does not use any public or private dataset as it is an algorithmic proposition.
References
Basar, S., Ali, M., Waheed, A., Ahmad, M., Miraz, M.H.: A novel defocus-blur region detection approach based on DCT feature and PCNN structure. IEEE Access. 11, 94945–94961 (2023). https://doi.org/10.1109/ACCESS.2023.3309820
Basar, S., Waheed, A., Ali, M., Zahid, S., Zareei, M., Biswal, R.R.: An efficient defocus blur segmentation scheme based on hybrid LTP and PCNN. Sensors. (2022). https://doi.org/10.3390/s22072724
Zhai, G., Min, X.: Perceptual image quality assessment: a survey. Sci. China Inform. Sci. (2020). https://doi.org/10.1007/s11432-019-2757-1
Lu, P., Liu, K.Y., Zou, G.L.: No reference image quality assessment based on fusion of multiple features and convolutional neural network. Chinese J. Liquid Cryst. Disp. 37, 66–76 (2022)
Xu, P., Guo, M., Chen, L., Hu, W., Chen, Q., Li, Y.: No-reference stereoscopic image quality assessment based on binocular statistical features and machine. Learning (2021). https://doi.org/10.1155/2021/8834652
Marziliano, P., Dufaux, F., Winkler, S., Ebrahimi, T.: Perceptual blur and ringing metrics: application to JPEG2000. Signal Process. Image Commun. 19, 163–172 (2004)
Ferzli, R., Karam, L.J.: A no-reference objective image sharpness metric based on the notion of just noticeable blur (JNB). IEEE Trans. Image Process. 18, 717–728 (2009). https://doi.org/10.1109/tip.2008.2011760
Narvekar, N.D., Karam, L.J.: A no-reference image blur metric based on the cumulative probability of blur detection (CPBD). IEEE Trans. Image Process. 20, 2678–2683 (2011). https://doi.org/10.1109/tip.2011.2131660
Bahrami, K., Kot, A.C.: A fast approach for no-reference image sharpness assessment based on maximum local variation. IEEE Signal Process. Lett. 21, 751–755 (2014). https://doi.org/10.1109/lsp.2014.2314487
Tsomko, E., and Kim, H.J.: Efficient method of detecting globally blurry or sharp images. In 2008 Ninth International Workshop on Image Analysis for Multimedia Interactive Services, pp. 171–174 (2008)
Saad, M.A., Bovik, A.C., Charrier, C.: Blind image quality assessment: a natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 21, 3339–3352 (2012). https://doi.org/10.1109/tip.2012.2191563
Zhan, Y., Zhang, R.: No-reference JPEG image quality assessment based on blockiness and luminance change. IEEE Signal Process. Lett. 24, 760–764 (2017). https://doi.org/10.1109/lsp.2017.2688371
Maleki, S.A., and Ghassemian, H.: Spatial quality assessment of pansharpened images based on gray level co-occurrence matrix. In 2022 International Conference on Machine Vision and Image Processing (MVIP), pp. 1–6 (2022)
Gao, F., Wang, Y., Li, P., Tan, M., Yu, J., Zhu, Y.: DeepSim: deep similarity for image quality assessment. Neurocomputing 257, 104–114 (2017). https://doi.org/10.1016/j.neucom.2017.01.054
Jin, C., Zhao, X., Xiong, Q., Guo, Y.: Blind image quality assessment for multiple distortion image. Circuits Syst. Signal Process. 41, 5807–5826 (2022). https://doi.org/10.1007/s00034-022-02055-x
Khosravi, M.H., Hassanpour, H.: Blind quality metric for contrast-distorted images based on eigendecomposition of color histograms. IEEE Trans. Circuits Syst. Video Technol. 30, 48–58 (2020). https://doi.org/10.1109/tcsvt.2018.2890457
Pan, Z., Yuan, F., Wang, X., Xu, L., Shao, X., Kwong, S.: No-reference image quality assessment via multibranch convolutional neural networks. IEEE Trans. Artif. Intell. 4(1), 148–160 (2022)
Li, X., Zheng, G., Zheng. A., Hu, R., Zhang, E., Gao, Y., Shen Y. et al. Less is More: Learning Reference Knowledge Using No-Reference Image Quality Assessment.2312.00591 (2023)
Shi, J., Gao, P., Smolic, A.: Blind Image Quality Assessment Via Transformer Predicted Error Map and Perceptual Quality Token, ARXIV-CS.CV, (2023)
Vu, C.T., Phan, T.D.: Chandler DM.S3: A spectral and spatial measure of local perceived sharpness in natural images. IEEE Trans. Image Process. 21, 934–945 (2012). https://doi.org/10.1109/tip.2011.2169974
Chen, Z., Assoc Comp, M.: Singular Value Decomposition and its Applications in Image Processing, In: International Conference on Mathematics and Statistics (ICoMS), pp. 16–22 (2018)
Sang, Q., Qi, H., Wu, X., Li, C., Bovik, A.C.: No-reference image blur index based on singular value curve. J. Vis. Commun. Image Represent. 25, 1625–1630 (2014). https://doi.org/10.1016/j.jvcir.2014.08.002
Ponomarenko, N., Lukin, V., Zelensky, A., Egiazarian, K., Carli, M., Battisti, F.: TID2008-a database for evaluation of full-reference visual quality assessment metrics. Adv. Mod. Radioelectron. 10, 30–45 (2009)
Ponomarenko, N., Jin, L., Ieremeiev, O., Lukin, V., Egiazarian, K., Astola, J., et al.: Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 30, 57–77 (2015). https://doi.org/10.1016/j.image.2014.10.009
Larson, E.C., Chandler, D.M.: Most apparent distortion: full-reference image quality assessment and the role of strategy. J. Electron. Imaging (2010). https://doi.org/10.1117/1.3267105
Montaha, S., Azam, S., Rafid, A.R., Hasan, M.Z., Karim, A., Islam, A.: TimeDistributed-CNN-LSTM: a hybrid approach combining CNN and LSTM to classify brain tumor on 3D MRI scans performing ablation study. IEEE Access. 1(10), 60039–60059 (2022). https://doi.org/10.1109/access.2022.3179577
Chowdhury, A.I., Shahriar, M.M., Islam, A., Ahmed, E., Karim, A., Islam, M.R. et al., An Automated System in ATM Booth Using Face Encoding and Emotion Recognition Process, In: 2nd International Conference on Image Processing and Machine Vision / International Conference on Pattern Recognition and Machine Learning (IPMV), pp. 57–62 (2020)
Montaha, S., Azam, S., Rafid, A.K.M.R.H., Hasan, M.Z., Karim, A., Hasib, K.M., et al.: MNet-10 A robust shallow convolutional neural network model performing ablation study on medical images assessing the effectiveness of applying optimal data augmentation technique. Front. Med. (2022). https://doi.org/10.3389/fmed.2022.9249794
Li, H., Zhu, F., Qiu, J., IEEE, CG-DIQA: No-reference Document Image Quality Assessment Based on Character Gradient, In: 24th International Conference on Pattern Recognition (ICPR), pp. 3622–6 (2018)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. Publ. IEEE Signal Process. Soc. 13, 600–612 (2004). https://doi.org/10.1109/tip.2003.819861
Hassen, R., Wang, Z., Salama, M.: IEEE No-Reference Image Sharpness Assessment Based On Local Phase Coherence Measurement, In: 2010 IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 2434–7 (2010)
Su, S., Yan, Q., Zhu, Y., Zhang, C., Ge, X., Sun, J., et al. Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network, In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3664–73 (2020)
Ying, Z., Niu, H., Gupta, P., Mahajan, D., Ghadiyaram, D., Bovik, A., et al. From Patches to Pictures (PaQ-2-PiQ): Mapping the Perceptual Space of Picture Quality, In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3572–82 (2020)
Kim, W.H., Hahm, C.H., Baijal, A., Kim, N., Cho, I. and Koo, J.: LiNuIQA: Lightweight No-Reference Image Quality Assessment Based on Non-Uniform Weighting, ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023), Rhodes Island, Greece (2023)
Yang, S., Wu, T., Shi, S., Lao, S., Gong, Y., Cao, M., et al. MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment, In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1190–9 (2022)
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions.
Author information
Authors and Affiliations
Contributions
LZ and CL wrote the draft main manuscript text and figures. AY Finalized the writeup. SA and AK Supervised the project. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhou, L., Liu, C., Yadav, A. et al. An image quality assessment method based on edge extraction and singular value for blurriness. Machine Vision and Applications 35, 37 (2024). https://doi.org/10.1007/s00138-024-01522-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00138-024-01522-6