
Abstract
This paper proposes a novel method for enhancing the dynamic range of structured-light cameras to solve the problem of highlight that occurs when 3D modeling highly reflective objects using the structured-light method. Our method uses the differences in quantum efficiency between R, G, and B pixels in the color image sensor of a monochromatic laser to obtain structured-light images of an object under test with different luminance values. Our approach sacrifices the resolution of the image sensor to increase the dynamic range of the vision system. Additionally, to enhance our system, we leverage the backgrounds of structured-light stripe pattern images to restore the color information of measured objects, whereas the background is often removed as noise in other 3D reconstruction systems. This reduces the number of cameras required for 3D reconstruction and the matching error between point clouds and color data. We modeled both highly reflective and non-highly reflective objects and achieved satisfactory results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
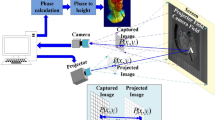
Three-dimensional measurement methods based on structured light are widely used in reverse engineering, heritage reconstruction, industrial inspection, and other fields based on their advantages in terms of high accuracy, non-contact measurement, and high efficiency [1,2,3]. A typical structured-light measurement system consists of a structured-light projector and one or more cameras. The projector is used to project a group of encoded structured-light stripes onto a measured object, and the cameras are used to capture the stripes projected onto the object [4,5,6]. By using structured-light algorithms, stripe images collected by cameras can be decoded into 3D point cloud information [7, 8].
It is known that structured-light depth cameras need to project a group of coded patterns of a certain intensity of light onto measured objects during the measurement process [9,10,11,12]. When an object’s surface is rough and its reflectivity is low, structured light diffuses on the surface, and the accuracy of 3D reconstruction is relatively high. However, when an object’s surface is smooth and its reflectivity is high, specular reflection will occur in some regions. Such reflections are highly likely to generate local brightness saturation, which leads to difficulties in structured-light deconstruction, resulting in the reduction of 3D reconstruction accuracy or even the inability to generate 3D point clouds [13, 14]. This is the highlight problem in structured-light modeling.
Whit’s more, color information plays an essential role in characterizing objects, particularly in computer vision processes (e.g., artificial intelligence, segmentation, classification, and object recognition) [15,16,17]. Therefore, if we can obtain point cloud data with color information for 3D reconstruction, an object can be restored with more detail so that subsequent processes (e.g., modeling, computer vision, and artificial intelligence) can be conducted more effectively [18, 19].
To solve the two problems described above, this paper proposes an RGB fusion method to perform 3D reconstruction of highly reflective objects and obtain complete 3D color point cloud for highly reflective objects using a color camera. The proposed method provides good results for both highly reflective and non-highly reflective objects.
The paper is organized as follows: Sect. 2 reviews the related work of the highlight problem and the registration problem of color information and point cloud data. Section 3 introduces the principle of the proposed method, following the experiment details and analysis in Sect. 4. Section 5 shows the strengths and limitations of our method. The conclusion is given in the last section.
2 Related work
2.1 Highlight problem
At present, the highlight problem is typically solved in two main ways: inpainting and highlight suppression [20, 21].
To solve the highlight problem using inpainting methods, interpolation methods and other methods are used to repair overexposed regions to obtain complete point clouds. Sun used a region-filling method based on priority theory to fix highlight regions in structured-light stripe images and then calculated complete point clouds [22]. Li proposed a two-way slicing method based on a smoothing spline model to fit the discrete points of an overexposed region [23]. Both methods achieved good results in their corresponding experiments, but the disadvantage of these methods is that their error increases as the highlight area increases, and when highlight area is large, the error can be very large.
To solve the highlight problem using highlight-suppression methods, researchers use polarization methods, multi-camera methods, high-dynamic-range (HDR) imaging methods, and spraying methods to ensure that the highlight phenomenon does not occur in the same region of multiple images captured by structured-light cameras [24,25,26,27]. However, multi-camera and multi-angle methods require more cameras, which not only increase costs but also generate more registration errors between point clouds from different cameras. Polarization methods and HDR methods consume more time because they require capturing more images. And spraying methods change the appearance of measured objects.
In recent years, scholars have attempted to solve the problem of high reflectivity in structured-light 3D reconstruction from the perspectives of different structured-light encoding methods and the phase-measuring deflectometry (PMD) method. Zaixing He decomposed Gray coded structured-light stripes into chessboard-like high-frequency stripes to reduce the dynamic range of the projected structured light and probability of highlight [28].The PMD method projects the stripe pattern of a highly reflective area onto a screen and a camera captures the stripe pattern on the screen to extract the 3D information of the object [29,30,31]. However, both of these methods have limitations. The high-frequency structured-light encoding method can only be used for objects with low specular reflectivity, and the PMD method is only applicable to objects with high specular reflectivity that are relatively flat.
2.2 Obtain color point clouds
Currently, the acquisition of color point cloud data is mainly achieved through data fusion from more than two sensors [32,33,34]. Gu proposed a road-detection method using range and color information based on a LIDAR camera fusion strategy [35]. The Kinect device is frequently used in the field of color 3D reconstruction. It obtains RGB-D data by fusing RGB data from a central color camera with point cloud data generated by 3D structured-light depth sensors consisting of infrared emitters and cameras on the left and right sides [36]. However, when we use multiple sensors to measure objects and fuse their 3D point clouds with color data, there are always fusion errors, which will have a negative effect on subsequent processes.
Generally, the errors in color data registration with point cloud data stem from two factors: calculation errors in point clouds and registration errors between color images and structured-light images. To improve the registration accuracy of point clouds and color information, many algorithms have been developed, such as genetic algorithm-based algorithms [37], four initial point pairs (FIPP) algorithms [38], and depth filtering algorithms [39]. However, regardless of how good a registration algorithm is, there will always be errors when performing registration between color images and structured-light images. Therefore, if both color images and structured-light images can be obtained by a single sensor, it should be possible to obtain more accurate color point cloud data because no errors will be generated by the registration process of color images and structured-light images.
3 RGB fusion method
3.1 Rationale for the RGB fusion method

Pixel distribution in color image sensors
As shown in Fig. 1, a color image sensor contains R, G, and B pixels that are evenly distributed in the light-sensitive area of the image sensor. For a particular laser wavelength, these three types of pixels have different quantum efficiencies (Fig. 2). Quantum efficiency refers to the ability of pixels to convert light signals into electrical signals. For a given amount of light energy, the higher the quantum efficiency, the stronger the ability to convert light into electrical signals and the greater the brightness value of a pixel. The lower the quantum efficiency, the weaker the ability to convert light into electrical signals and the smaller the brightness value of the pixel. In other words, these three types of pixels exhibit different brightness values when capturing the same image of the same laser stripe. Therefore, pixels with low quantum efficiency can be used to capture bright regions, and those with high quantum efficiency can be used to capture dark regions, which equates to an increase in the dynamic range of the image sensor.

Quantum efficiency of R pixels, G pixels and B pixels

Principle of structured light method

a Gray code and b phase shift code stripes used in this study
3.2 Selection of light source
To maximize the dynamic range of a depth camera, the light source should be selected with the wavelength that produces the greatest difference in the quantum efficiencies of the R, G, and B pixels in the color image sensor. Here, we define the difference in quantum efficiency as the ratio of the quantum efficiency corresponding to the pixel with the greatest quantum efficiency to that corresponding to the pixel with the smallest quantum efficiency.
here \(\textrm{Diff}_\lambda \) is the difference in the quantum efficiencies of the R, G, and B pixels at a wavelength \({\lambda }\). \(Q_{\lambda R}\), \(Q_{\lambda G}\), and \(Q_{\lambda B}\) are the quantum efficiencies of the R, G, and B pixels at the wavelength \(\lambda \), respectively.
3.3 Adopted structured light method
The structured-light method is a commonly used 3D reconstruction method. First, we project Gray code stripes and phase-shifted code stripes onto an object under test, while cameras capture images of the stripes projected onto the object (Fig. 3). A 3D point cloud can then be calculated based on the stripe images. The calculation process is divided into the following steps:
-
1.
Calculate the correspondence between each pixel in the images and the structured light stripes. As shown in Fig. 4, the Gray code and phase shift code patterns we use divide the measured area into 1280 regions. By binarizing the captured Gray code and phase shift code images and performing Gray code decoding, it is possible to calculate the number of structured light stripes corresponding to each pixel.
-
2.
Calculate the sub-pixel coordinates of the structured-light boundary. Although there are 1279 structured-light boundaries for the 1280 structured-light regions mentioned above, not all of them will be imaged by the camera. By using the M.Trobina method, the sub-pixel coordinates of the structured-light boundaries can be calculated relatively accurately.
-
3.
By calculating the relative displacement of each boundary in the captured images and calibration images, the Z-directional coordinate values of each point on the object can be calculated.
-
4.
Based on the Z-directional coordinate values of each point on the measured object and calibration data of the camera, the X-directional coordinate values and Y-directional coordinate values of each point can be calculated.
-
5.
Post-processing such as filtering is performed.
3.4 Theory of the RGB fusion method for computing point clouds of highly reflective objects
R, G, and B pixel images can be obtained from the R, G, and B pixels, respectively, in a color image sensor. These three types of images are processed separately. First, we consider R-pixel images as an example.
A set of structured-light images is required when 3D modeling is performed using the structured-light method. Each image is composed of bright and dark stripes. The bright stripes correspond to where the structured light is illuminated, whereas the dark stripes correspond to where the structured light is not illuminated. We can reconstruct an object according to the positions of the bright and dark stripes on the object.

Six types of images defined: a original code images, b original code stripe patterns, c binarization patterns, d inverse code images, e inverse code stripe patterns, and f background images

Theory of the RGB fusion method for computing point clouds. (1) Relationship between an original code image, original code stripe pattern, and background image. (2) Relationship between an original code image, original code stripe pattern, and background image. (3) Equation 1 minus Eq. 2. (4) Binarization pattern obtained from an original code stripe pattern and inverse code stripe pattern. (5) Binarization pattern obtained from an original code image and inverse code image. (6) OR operations in the binarization patterns of R, G, and B pixels
To illustrate our method clearly, six types of images are defined in this paper: original code images, inverse code images, original code stripe patterns, inverse code stripe patterns, binarization patterns, and background images (Fig. 5).
The original and inverse code images are pairs of R-pixel images with opposite phases of structured light stripes. That is, the areas with dark stripes in the original code image contain bright stripes in the corresponding inverse code image, and those with bright stripes in the original code image contain dark stripes in the corresponding inverse code image. The original and inverse code stripe patterns are R-pixel images obtained when there is no ambient light. Background images are R-pixel images of the measured object in ambient light without being illuminated by structured light. Therefore, an original code image can be considered a superposition of an original code stripe pattern and background image. Meanwhile, an inverse code image can be considered a superposition of an inverse code stripe pattern and background image. Binarization patterns are binarized images of the original and inverse code images.
Equations 1 and 2 in Fig. 6 are defined separately. We then subtract Eq. 2 from Eq. 1 to obtain Eq. 3.
When computing the correspondence between pixels and structured-light stripes, each inverse code stripe pattern must be subtracted from the corresponding original code stripe pattern and then binarized to obtain its corresponding binarized pattern. According to Eq. 3 in Fig. 6, the original code image minus the inverse code image is equivalent to the original code stripe pattern minus the inverse code stripe pattern. In other words, a binarized image can be obtained by subtracting the inverse image from the original image and then by binarizing.
In this manner, we process all original code images and inverse code images to obtain the binarized patterns of R pixels. Similarly, we can obtain the binarized patterns of G and B pixels. We then combine the binarization patterns of R, G, and B pixels through OR operations by pixel, allowing us to obtain binarization patterns with a larger dynamic range.
Based on the Gray code decoding method, we can calculate the correspondence between pixels and Gray code stripes. To elucidate our process, we discuss why binarized pictures have larger dynamic ranges following the OR operation in the pixel process.
As shown in Fig. 7, we can consider four adjacent pixels as a unit, which we refer to as a large pixel. In such a large pixel, one R pixel, one B pixel, and two G pixels are present. When processing G-pixel images, we average the brightness values of the two G pixels in each large pixel to obtain a G-pixel image with the same resolution as the R- and B-pixel images. Each brightness value in an R-pixel, B-pixel, and G-pixel image represents the brightness value of an R or B pixel, or average brightness value of a G pixel in a large pixel, respectively.
The structured-light method of 3D reconstruction projects coded bright and dark stripes onto an object and calculates phase information based on whether each pixel represents a bright or dark stripe at the moment of capture to obtain 3D information regarding the object corresponding to each pixel. The binarization of images is performed to determine whether a pixel is in a bright or dark stripe at a particular time. For each pixel, the binarization result is used to subtract the corresponding brightness value in the inverted image from that in the original image. If the difference between these values is greater than a threshold, then the pixel is considered to be in a bright stripe. If the difference is less than a threshold, then the pixel is considered to be in a dark stripe.
Therefore, the setting of a threshold value is key to the binarization process. If a pixel is in a bright stripe, it is illuminated by the structured-light projector. If it is in a dark stripe, it is not illuminated by the structured-light projector. Because the brightness value of a pixel illuminated by a structured-light projector must be greater than that of a pixel that is not illuminated by the structured light projector, we subtract the brightness value of a pixel in an inverse code image from the brightness value of the corresponding pixel in an original code image. If the result is greater than zero, it means that the pixel is illuminated in the original code image and not in the inverse code image. If it is less than zero, it means that the pixel is not illuminated in the original code image and is illuminated in the inverse code image. Therefore, zero is the threshold value.
However, to reduce the influence of noise and pixel points at the edges of bright and dark stripes, improve the accuracy of recognizing bright stripes in original code images, and prevent the pixels of dark stripes in an original code image from being recognized as bright stripes, the threshold should be set greater than zero. The exact value should be determined experimentally and should be as small as possible to ensure that the pixels of bright stripes in an original code image are not recognized as dark stripes.
When exposed normally, the brightness of a pixel can correctly reflect its phase after being binarized. When underexposure occurs, the brightness of a pixel is too low. Thus, the brightness value of the pixel in a original image minus the brightness value in an inverse image is less than the threshold value, and the pixel is marked as a dark stripe, regardless of whether it is actually a bright stripe or dark stripe. When overexposure occurs, the brightness value of a pixel is always the maximum brightness (e.g., 255 in 8 bit pixel format), regardless of whether it is actually a bright stripe or dark stripe. Therefore, the brightness value of such a pixel in a original image minus the brightness value in an inverse image is less than the threshold, and the pixel is marked as a dark stripe after binarization. In summary, both underexposure and overexposure can cause pixels in bright stripes to be marked as dark stripes after binarization and do not cause pixels with dark stripes to be marked as bright stripes. For a large pixel, provided that one of the brightness values corresponding to that pixel in the R-pixel, G-pixel, or B-pixel image is not overexposed or underexposed, then the large pixel will reflect the proper phase information after its binarized value is calculated.
As shown in Fig. 2, the R, G, and B pixels have different quantum efficiencies for red light, which will eventually result in original code images and inverse code images with different brightness values. Therefore, we only need to ensure that no overexposure occurs for quantum-inefficient pixels and no underexposure occurs for quantum-efficient pixels. The correct binarization pattern can be obtained after binarizing the patterns of R, G, and B pixels. Finally, the number of structured-light stripes corresponding to each large pixel can be obtained. This process yields binarized patterns with a greater dynamic range based on pixel-by-pixel OR operations.

Large pixels in color image sensors
After calculating the correspondence between pixels and structured-light stripes, it is necessary to calculate the sub-pixel values of structured-light stripe boundaries. To improve the accuracy of the sub-pixel values of structured-light stripe boundaries, the method proposed by M.Trobina was adopted and improved in this study. In the M.Trobina method, the original code image of a phase-shift code is subtracted from its inverse code image to obtain a difference image. In this difference image, if two adjacent pixel values have opposite signs, then the boundary of a stripe is judged to lie between those two pixels. In Fig. 8, the brightness values of four adjacent pixels A, B, C, and D in an original code image are presented in part (a). The brightness values in the inverse code image are presented in part (b) and the pixel values in the difference image are presented in part (c). One can observe that the stripe boundary lies between pixels B and C. The specific calculation formula used in this process is defined as follows:
Here, \(u'\) is the horizontal coordinate value of the structured-light stripe boundary, u is the horizontal coordinate value of pixel B, and \(b_B\) and \(b_C\) are the pixel values of pixel B and C in the difference image, respectively.
However, in a color image sensor, two R pixels are separated by a G pixel, two B pixels are separated by a G pixel, and two G pixels are separated by an R pixel or B pixel. The positions of structured-light boundaries calculated using the M.Trobina method for R-pixel, G-pixel, and B-pixel images are presented in parts (Rc), (Gc), and (Bc) in Fig. 8, respectively.
The structured-light boundary of the R-pixel image is calculated as follows:
The structured-light boundary of the G-pixel image is calculated as follows:
The structured-light boundary of the B-pixel image is calculated as follows:
Consequently, the final structured light boundary is calculated as follows:
Here \(\textrm{factor}_R\), \(\textrm{factor}_G\), and \(\textrm{factor}_B\) indicate whether the sub-pixel values of the R, G, and B pixels are valid at the corresponding large pixel location, respectively. If a pixel is neither overexposed nor underexposed, then the sub-pixel value of the pixel is valid. Otherwise, it is invalid. Additionally, \(\textrm{factor}_R\), \(\textrm{factor}_G\), and \(\textrm{factor}_B\) cannot all be zero simultaneously.

Sub-pixel calculation method. a, b, and c represent the M. Trobina sub-pixel calculation method. (Ra), (Rb), and (Rc) represent the sub-pixel calculations of R-pixel images in our method. (Ba), (Bb), and (Bc) represent the sub-pixel calculations of B-pixel images in our method. (Ga), (Gb), and (Gc) represent the sub-pixel calculations of G-pixel images in our method
3.5 Theory of the RGB fusion method for registration of color information and point cloud data
Based on the analysis above, we know that the background images of R, G, and B pixels are images of a measured object in ambient light without being illuminated by structured light. These images represent the red, green, and blue information of an object, respectively. Therefore, obtaining a color image of an object actually involves obtaining background images of the R, G, and B pixels.
Taking the R pixel image as an example, for a large pixel, if it is bright in the original image, it must be dark in the inverse image, and the value in the dark stripe is the red information of the measured object, so our purpose becomes to calculate the dark stripe value for all pixels. Therefore, for all pixels, we just need to minimize their corresponding brightness values in a original code image and its inverse code image to get the background image.

Theory of RGB fusion method for registration of color information and point cloud data. (1) The original code image and the inverse code image are operated by taking the minimum value by pixel. a original code image, d inverse code image, f background image. (2) The three images selected to calculate the background image. a1 original code image1, d1 inverse code image1, a2 original code image2, f background image
When a pixel is in the area of a bright or dark stripe, the correct color information can be acquired using the method described above. However, when a pixel is at the junction of a bright and dark stripe, correct color information cannot be obtained. Therefore, we select three images and extract the minimum value by pixel to ensure that a pixel does not lie on a junction in at least one of the three images (Fig. 9)
Similarly, we can obtain the background images of G and B pixels, meaning we can obtain the color information of a measured object. For any large pixel, its point cloud data and color information are calculated from its brightness values. Therefore, it is only necessary to assign its color information to a point cloud to obtain a point cloud with color information without any registration error between the color images and structured-light images.

Flowchart of the RGB Fusion Method
3.6 Implementation process of the RGB fusion method
The proposed RGB fusion method consists of two processes: calculating high dynamic range point cloud and adding color information to the point cloud. A flowchart of these processes is presented in Fig. 10, and the specific steps are detailed below.
-
Step 1 A sequence of structured-light raw images captured by a color image sensor in a structured-light camera is obtained.
-
Step 2 The structured-light image sequence is separated into an R-pixel structured-light image sequence, G-pixel structured-light image sequence, and B-pixel structured-light image sequence.
-
Step 3 The R-pixel structured-light image sequence, G-pixel structured-light image sequence, and B-pixel structured-light image sequence are binarized to obtain R-pixel, G-pixel, and B-pixel binarized image sequences, respectively.
-
Step 4 The R-pixel, G-pixel, and B-pixel binarized image sequences are subjected to OR operations to obtain an OR-operated binarized image sequence.
-
Step 5 The correspondence between pixels and structured-light stripes is calculated according to the OR-operated binarized image sequence.
-
Step 6 The sub-pixel coordinates of stripe boundaries are calculated, using the improved M.Trobina method.
-
Step 7 The point cloud of the measured object is calculated based on the sub-pixel coordinates of the stripe boundaries.
-
Step 8 From the R-pixel image sequence, G-pixel image sequence, and B-pixel image sequence, a raw image of the measured object is extracted.
-
Step 9 Image signal processing (ISP) on the raw image is performed to obtain a color image of the measured object.
-
Step 10 A color image to the point cloud is assigned to obtain a point cloud with color information.
4 Experiment
4.1 System introduction
Figure 11 presents our 3D reconstruction system, which consists of a computer, a structured-light camera, and connection cables. The structured-light camera mainly consists of a red structured-light projector, a color image sensor, and an RK3399 processor for data processing.

Our 3D reconstruction system
4.2 Selection of a light source in our system
The quantum efficiencies of the three types of pixels in the color image sensors in our system are presented in Fig. 2. We calculated the differences between their quantum efficiencies, as shown in Fig. 12. We selected the light source with the wavelength producing the largest difference value, the wavelength range of which is presented in the red rectangle in Fig. 12.

Differences in the quantum efficiency of R, G, and B pixels
4.3 Three-dimensional reconstruction of highly reflective objects
Highly reflective objects such as metals are widely used in industrial production and daily life. However, as a result of their smooth surfaces, structured light is easily reflected by the surfaces of metal objects, resulting in very high brightness values in specular areas, whereas the brightness values of non-specular areas are very low, making it difficult for typical structured-light cameras to reconstruct these objects in 3D. In the experiment presented below, we used the RGB fusion method presented in this paper to reconstruct a metal wheel.
First, we obtained a set of images of the R, G, and B pixels of the metal wheel.

Images of R, G, and B pixels of a metal wheel. a Images of R pixels, b images of G pixels, and c images of B pixels
We zoomed in on regions 1 and 2 in Fig. 13. The zoomed images are presented in Figs. 14 and 15.

Region 1 of R, G, and B pixels in Fig. 13 after zooming: a region 1 of R pixels, b region 1 of G pixels, and c region 1 of B pixels

Region 2 of R, G, and B pixels in Fig. 13 after zooming: a region 2 of R pixels, b region 2 of G pixels, and c region 2 of B pixels
As shown in Fig. 14, the image of R pixels is overexposed in region 1, whereas the image of B pixels is normally exposed in this region. As shown in Fig. 15, the image of B pixels is underexposed in region 2, and the image of R pixels is exposed normally in region 1.
We binarized the images of R, G, and B pixels separately. The results are presented in Fig. 16.

Results of R pixel images, G pixel images and B pixel images after being binarized. a results of R pixels, b results of G pixels, c results of B pixels
As shown in Fig. 16, the binarized images of the R and G pixels appear empty outside region 1, whereas they are detailed outside of region 2. Additionally, the binarized images of the B pixels perform well in region 2, whereas they appear empty outside region 1. Therefore, we applied the OR operation on these three types of images by pixel and the results are presented in Fig. 17.

Results of binarized images of R, G, and B pixels after applying the OR operation by pixel
As shown in Fig. 17, the binarized images of the R, G, and B pixels no longer appear empty after the OR operation. We used these results to calculate the correspondence of each pixel with the structured-light stripes and calculated the point cloud based on this correspondence and the improved M.Trobina method, the point cloud is shown in Fig. 18.

Obtained point cloud
After obtaining a point cloud of the wheel, we colored the point cloud using the method described in Sect. 3.5. First, we calculated the background images of the R, G, and B pixels (Fig. 19).

Background images of a R, b G, and c B pixels of the metal wheel
By performing ISP the background images of the R, G, and B pixels, we can obtain a color image of the wheel (Fig. 20).

Color image of the wheel
We assign color data to the point cloud by pixel to obtain a point cloud with color information (Fig. 21).

Point cloud of the wheel with color
4.4 Three-dimensional reconstruction of non-highly reflective objects
To test the effectiveness of our method for the 3D modeling of non-highly reflective objects, we selected several real-world objects for testing. First, we consider a face model as an example.
We began by obtaining a set of images of the R, G, and B pixels of the face model.

Images of the a R, b G, and c B pixels of a face model

Results of a R-pixel, b G-pixel and c B-pixel images after binarization
As shown in Fig. 22, no underexposure or overexposure appears in the R-pixel images. The G- and B-pixel images contain underexposed areas. We binarized the images of R, G, and B pixels separately. The results are presented in Fig. 23.

Results of the binarized images of R, G, and B pixels being subjected to an OR operation

Obtained point cloud of a face model
In Fig. 23, one can see that the R-pixel images are complete after binarization, whereas the binarized images of the G pixels contain voids in some regions. The values are all zero in the binarized images of the B pixels because the stripes are quite dark in the B-pixel images. We applied the OR operation to these three types of images by pixel. The results are presented in Fig. 24. These results were used to calculate a point cloud, which is presented in Fig. 25.
We used the method described in Sect. 3.5 to obtain the background images of R, G, and B pixels (Fig. 26) and calculated a color image (Fig. 27).

Background images of a R, b G, and c B pixels of a face model

Color image of a face model
We then assigned the color image to the point cloud to obtain a point cloud of the face model with color information.

Point cloud of a face model with color
As shown in Fig. 28, the color image and 3D point cloud are perfectly matched. We also modeled apples and bananas and achieved good results (Fig. 29).

Point clouds of a an apple and b a banana with color
4.5 Comparisons with other methods
Because the most common method currently used for the 3D modeling of highly reflective objects is the HDR method, we compared our method to the HDR method. Specifically, we used the R pixels of the above image sensor to capture three sets of images with brightness levels corresponding the R-pixel, G-pixel, and B-pixel images in our method. Then, we used the M.Trobina method to calculate point clouds from each of the three sets of images and combined the three sets of point clouds into a point cloud of the target object. The point clouds calculated from these three sets of structured-light images are presented in Fig. 30.

Point clouds generated from structured-light images acquired with different exposure time. a Point clouds with 16 ms exposure time. b Point clouds with 4.8 ms exposure time. c Point clouds with 0.36 ms exposure time
The resulting point cloud after combining the three sets of point clouds is presented in Fig. 31.
To verify the measurement accuracy of our method, we compared the point clouds obtained by our method and the HDR method to a high-precision 3D model of the wheel discussed above. The comparison results are presented in Fig. 32.
Three-dimensional reconstruction using a structured-light camera consists of two steps: capturing structured-light stripe images and computing 3D point clouds. Figure 32a, b presents the time spent on these two steps in our method and the HDR method, respectively. The shooting time of our method is 16 \(\times \) 26 = 416 ms (we use temporal structured-light coding, where each set of coding requires 26 images), the calculation time is 4.024 s, and the total time is 4.024 + 0.416 = 4.44 s. The shooting time of the HDR method is (16 + 4.8 + 0.36) \(\times \) 26 = 550.16 ms, the calculation time is 3.453 + 3.419 + 1.162 = 8.034 s, and the total time is 8.034 + 0.550 = 8.584 s. Therefore, our method saves 8.584 − 4.44 = 4.144 s compared to the HDR method.
Additionally, Fig. 32c, d presents the 3D modeling errors of our method compared to those of the HDR method. One can observe that both the mean error and standard deviation of our method are smaller than those of the HDR method.
4.6 Discussions of the experimental results
The experiments presented above prove that our method is capable of the color 3D modeling of highly reflective objects and provides good measurement accuracy with short exposure and computation time while improving the dynamic range of a 3D structured-light measurement system.
The reason for the short exposure time of our method is that our method uses a single exposure to achieve the effect of three exposures of the HDR method. The reason for the short computation time of our method is that our method first fuses the images and performs only one computation from sub-pixel to point cloud.

Resulting point cloud after combining the three sets of point clouds
The reason for the high accuracy of our method is that we revised the M.Trobina method of calculating sub-pixels according to the pixel distribution of color image sensors. Meanwhile, we calculate the mean value for the sub-pixel coordinates of the R, G, and B pixels in each large pixel, which is equivalent to mean filtering in the calculation process, improving the measurement accuracy.
Two or more cameras are typically required for 3D color reconstruction using structured-light cameras. The first one is used to capture structured-light stripes to calculate point clouds, and the other one is used to capture the color information of an object. Because each point in a point cloud corresponds to a pixel in the structured-light images, the color image is typically aligned with the point cloud by aligning it with the structured-light images. Therefore, there are two sources of registration errors between color images and point clouds, namely, the calculation error of point clouds and registration error between color images and structured-light images. Because color images are calculated from structured-light images in our system, there is no registration error between the color images and structured-light images. Thus, registration error between color images and point clouds only stems from the calculation errors of point clouds. Overall, our system reduces the number of cameras required and the cost of reconstruction.

Comparison of our method to the HDR method. a Exposure time of our method and the first exposure time (red bar), second exposure time (green bar), and third exposure time (blue bar) of the HDR method. b Computation time of our method and the HDR method for the first exposure images (red bar), second exposure images (green bar), and third exposure images (blue bar). c Average accuracy of our method and the HDR method. d Standard deviation of our method and the HDR method
5 Strengths and limitations
5.1 Strengths
Compared to existing structured-light 3D reconstruction systems, the proposed system has the following advantages:
-
1.
It consumes less time while maintaining a higher dynamic range. Our method achieves the effect of the HDR (multiple-exposure) method, but with a shorter exposure time and calculation time.
-
2.
It simplifies the process of fusing multiple images. When performing image fusion, our method significantly simplifies the image fusion process by performing an OR operation after binarizing images.
-
3.
It improves 3D measurement accuracy. According to the pixel distribution of color image sensors, we revised the M.Trobina method of calculating sub-pixels, thereby improving the accuracy of measurement.
-
4.
It performs the 3D color reconstruction of objects using a color camera. Our method uses a single color camera to achieve the 3D reconstruction and extraction of color information of a measured object, which not only reduces the number of cameras required but also reduces the registration error of color information and point clouds.
-
5.
The introduction of the quantum efficiency difference parameter facilitates the selection of the laser wavelength that is most suitable for a particular color image sensor and also facilitates the selection of the color image sensor that is most suitable for our method (i.e., the greater the quantum efficiency difference, the more suitable a sensor is for our method).
5.2 Limitations
Our system has the following limitations:
-
1.
Our method can only improve the dynamic range of structured-light systems and cannot completely solve the problem of the 3D reconstruction of specular reflective objects. Our system may fail to reconstruct certain areas when the brightness ratio of overexposed and underexposed areas exceeds its dynamic range. To improve the dynamic range of our system further, we can take the following measures:
-
(1)
We can use our method in conjunction with other techniques such as multiple exposures or multi-angle shots.
-
(2)
Chip manufacturers can add more types of pixels with different quantum efficiencies to image sensor chips.
-
(1)
-
2.
When the environment is too dark, color images cannot be calculated from structured-light images. In such a scenario, we can turn off the structured-light projector and capture another image without structured light as a color image or add a fill light to increase the brightness of the environment.
6 Conclusions
When using structured-light methods for the 3D modeling of highly reflective objects such as metals, the specular reflection of structured light on the object surface will cause specular regions to be quite bright and non-specular regions to be quite dark. This causes overexposure and underexposure to occur in these regions and results in point cloud voids or modeling failure when 3D reconstruction of the object is performed.
Point clouds with color are widely used in computer vision and artificial intelligence. However, errors in point clouds and color data registration have created significant obstacles.
To solve these two problems, this paper proposed an RGB fusion method. This approach not only improves the dynamic range of a 3D structured-light system but also captures the color information of measured objects without increasing the number of cameras required, thereby enabling the color 3D reconstruction of highly reflective objects.
To test the effectiveness of the proposed method for modeling highly reflective objects, a metal wheel was considered as a test object. Experiments proved that our method can not only model specular reflective regions and non-specular reflective regions simultaneously to generate 3D point clouds but can also capture the color information of an object under test. Additionally, to test the effectiveness of the proposed method for modeling non-highly reflective objects, a face model, an apple, and a banana were also 3D modeled in this study and good results were obtained.
References
Song, L., Li, X., Yang, Y.-G., Zhu, X., Guo, Q., Liu, H.: Structured-light based 3d reconstruction system for cultural relic packaging. Sensors 18(9), 2981 (2018)
Adamczyk, M., Liberadzki, P., Sitnik, R.: Temperature compensation method for mechanical base of 3d-structured light scanners. Sensors 20(2), 362 (2020)
Sun, J., Ding, D., Cheng, X., Zhou, F., Zhang, J.: Calibration of line-structured light vision sensor based on free-placed single cylindrical target. Opt. Lasers Eng. 152, 106951 (2022)
Van der Jeught, S., Dirckx, J.J.: Real-time structured light profilometry: a review. Opt. Lasers Eng. 87, 18–31 (2016)
Zhang, S.: High-speed 3d shape measurement with structured light methods: a review. Opt. Lasers Eng. 106, 119–131 (2018)
Barone, S., Neri, P., Paoli, A., Razionale, A.: 3d acquisition and stereo-camera calibration by active devices: a unique structured light encoding framework. Opt. Lasers Eng. 127, 105989 (2020)
Hu, Y., Chen, Q., Feng, S., Zuo, C.: Microscopic fringe projection profilometry: a review. Opt. Lasers Eng. 135, 106192 (2020)
Xu, J., Zhang, S.: Status, challenges, and future perspectives of fringe projection profilometry. Opt. Lasers Eng. 135, 106193 (2020)
Blake, A., McCowen, D., Lo, H., Lindsey, P.: Trinocular active range-sensing. IEEE Trans. Pattern Anal. Mach. Intell. 15(5), 477–483 (1993)
Chen, C.-S., Hung, Y.-P., Chiang, C.-C., Wu, J.-L.: Range data acquisition using color structured lighting and stereo vision. Image Vis. Comput. 15(6), 445–456 (1997)
Geng, J.: Structured-light 3d surface imaging: a tutorial. Adv. Opt. Photon. 3(2), 128–160 (2011)
Wang, Y., Chen, J., Peng, Y., Du, Y.: Design of thin-structured-light projection system for small-height measurement. Microsc. Res. Tech. 85(3), 1180–1193 (2022)
Nayar, S.K., Gupta, M.: Diffuse structured light. In: 2012 IEEE international conference on computational photography (ICCP), pp. 1–11 (2012). IEEE
Liu, X., Zhang, Z., Gao, N., Meng, Z.: 3d shape measurement of diffused/specular surface by combining fringe projection and direct phase measuring deflectometry. Opt. Express 28(19), 27561–27574 (2020)
Güven, İ, Şimşir, F.: Demand forecasting with color parameter in retail apparel industry using artificial neural networks (ann) and support vector machines (svm) methods. Comput. Ind. Eng. 147, 106678 (2020)
Salmi, A., Hammouche, K., Macaire, L.: Constrained feature selection for semisupervised color-texture image segmentation using spectral clustering. J. Electron. Imaging 30(1), 013014 (2021)
Diaz-Ramirez, V.H., Juarez-Salazar, R.: Multiple object tracking in color scenes using composite-matched filtering with complex constrains. Opt. Photon. Inf. Process. 11841, 85–91 (2021)
Tan, Y., Rahman, M.M., Yan, Y., Xue, J., Shao, L., Lu, K.: Fine-grained categorization from rgb-d images. IEEE Trans. Multimedia 24, 917–928 (2021)
Xu, X., Chen, Z., Yin, F.: Cutresize: Improved data augmentation method for rgb-d object recognition. IEEE Robot. Autom. Lett. 7(1), 183–190 (2021)
Zhang, Z., Gao, N., Liu, X.: Three-dimensional shape measurement of specular object with discontinuous surfaces by direct phase measuring deflectometry. Dimens. Opt. Metrol. Insp. Pract. Appl. 10991, 52–65 (2019)
Xu, X.-B., Zhang, X.-M., Zhang, D.-Y.: 3d measurement of specular reflection surface by learning sfs algorithm-based rbf model. In: 2007 International conference on machine learning and cybernetics 5, pp. 2911–2914 (2007). IEEE
Sun, X., Liu, Y., Yu, X., Wu, H., Zhang, N.: Three-dimensional measurement for specular reflection surface based on reflection component separation and priority region filling theory. Sensors 17(1), 215 (2017)
Li, B., Xu, Z., Gao, F., Cao, Y., Dong, Q.: 3d reconstruction of high reflective welding surface based on binocular structured light stereo vision. Machines 10(2), 159 (2022)
Zhou, P., Kong, L., Sun, X., Xu, M.: Three-dimensional measurement of specular surfaces based on the light field. IEEE Photon. J. 12(5), 1–13 (2020)
Wang, M., Yin, Y., Deng, D., Meng, X., Liu, X., Peng, X.: Improved performance of multi-view fringe projection 3d microscopy. Opt. Express 25(16), 19408–19421 (2017)
Song, Z., Jiang, H., Lin, H., Tang, S.: A high dynamic range structured light means for the 3d measurement of specular surface. Opt. Lasers Eng. 95, 8–16 (2017)
Yang, Y., Chen, S., Wang, L., He, J., Wang, S.-M., Sun, L., Shao, C.: Influence of coating spray on surface measurement using 3d optical scanning systems. In: International manufacturing science and engineering conference 58745, pp. 001–02009 (2019). American Society of Mechanical Engineers
He, Z., Li, P., Zhao, X., Kang, L., Zhang, S., Tan, J.: Chessboard-like high-frequency patterns for 3d measurement of reflective surface. IEEE Trans. Instrum. Meas. 70, 1–12 (2021)
Zhang, Z., Chang, C., Liu, X., Li, Z., Shi, Y., Gao, N., Meng, Z.: Phase measuring deflectometry for obtaining 3d shape of specular surface: a review of the state-of-the-art. Opt. Eng. 60(2), 020903 (2021)
Han, H., Wu, S., Song, Z., Gu, F., Zhao, J.: 3d reconstruction of the specular surface using an iterative stereoscopic deflectometry method. Opt. Express 29(9), 12867–12879 (2021)
Leung, Y.-C., Cai, L.: Untangling parasitic reflection in phase measuring deflectometry by multi-frequency phase-shifting. Appl. Opt. 61(1), 208–222 (2022)
Shimizu, S., Fujita, Y., Kameyama, N., Hasebe, N.: Space-variant color point cloud measurement system-enomous data reduction using saliency map. In: 2020 IEEE 16th International workshop on advanced motion control (AMC), pp. 367–372 (2020). IEEE
Shinohara, T., Xiu, H., Matsuoka, M.: Point2color: 3d point cloud colorization using a conditional generative network and differentiable rendering for airborne lidar. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp. 1062–1071 (2021)
Henry, P., Krainin, M., Herbst, E., Ren, X., Fox, D.: Rgb-d mapping: using kinect-style depth cameras for dense 3d modeling of indoor environments. Int. J. Robot. Res. 31(5), 647–663 (2012)
Gu, S., Zhang, Y., Tang, J., Yang, J., Alvarez, J.M., Kong, H.: Integrating dense lidar-camera road detection maps by a multi-modal crf model. IEEE Trans. Veh. Technol. 68(12), 11635–11645 (2019)
Li, C., Li, B., Zhao, S.: A 3d compensation method for the systematic errors of kinect v2. Remote Sens. 13(22), 4583 (2021)
Liu, D., Hong, D., Wang, S.: Genetic algorithm-based optimization for color point cloud registration. Front. Bioeng. Biotechnol. (2022). https://doi.org/10.3389/fbioe.2022.923736/full
Li, P., Wang, R., Wang, Y., Gao, G.: Fast method of registration for 3d rgb point cloud with improved four initial point pairs algorithm. Sensors 20(1), 138 (2019)
Choi, O., Hwang, W.: Colored point cloud registration by depth filtering. Sensors 21(21), 7023 (2021)
Funding
This research received support from the National Natural Science Foundation of China (Grant Nos. U21B2035, 62074128) and the Key-Area Research and Development Program of Guangdong Province (Grant No. 2021B0101410001).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Y., Qiao, D., Xia, C. et al. A method for high dynamic range 3D color modeling of objects through a color camera. Machine Vision and Applications 34, 6 (2023). https://doi.org/10.1007/s00138-022-01355-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00138-022-01355-1