
Abstract
The aim of this study is to assess and identify the most suitable geospatial interpolation algorithm for environmental sciences. The research focuses on evaluating six different interpolation methods using annual average PM10 concentrations as a reference dataset. The dataset includes measurements obtained from a target air quality network (scenery 1) and a sub-dataset derived from a partitive clustering technique (scenery 2). By comparing the performance of each interpolation algorithm using various indicators, the study aims to determine the most reliable method. The findings reveal that the kriging method demonstrates the highest performance within environmental sciences, with a spatial similarity of approximately 70% between the two scenery datasets. The performance indicators for the kriging method, including RMSE (root mean square error), MAE (mean absolute error), and MAPE (mean absolute percentage error), are measured at 3.2 µg/m3, 10.2 µg/m3, and 7.3%, respectively.
This study addresses the existing gap in scientific knowledge regarding the comparison of geospatial interpolation techniques. The findings provide valuable insights for environmental managers and decision-makers, enabling them to implement effective control and mitigation strategies based on reliable geospatial information and data. In summary, this research evaluates and identifies the most suitable geospatial interpolation algorithm for environmental sciences, with the kriging method emerging as the most reliable option. The study’s findings contribute to the advancement of knowledge in the field and offer practical implications for environmental management and planning.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Environmental sciences encompass a broad range of disciplines that investigate the interrelationship between humans and the environment. These disciplines include ecology (Zhao 2023), climatology (Tu’uholoaki et al. 2022), environmental geochemistry (Deng et al. 2022), geology (Tadesse et al. 2023), and others, addressing various topics such as climate change (Deivanayagam et al. 2023), green building (Zhao et al. 2022), groundwater remediation (Beker et al. 2022), and air quality (Galán-Madruga 2021). Of particular significance within the field of environmental sciences is air quality, as atmospheric pollution poses a significant global environmental risk to human health (Madruga et al. 2019). Assessing human exposure levels to air pollutants is crucial in the context of public health. European legislation, such as Directive 2008/50/EC, emphasizes the importance of monitoring and controlling air quality through air quality networks comprising fixed monitoring stations to safeguard human health.
In this context, interpolation methods are widely employed to estimate human exposure levels in areas that have not been previously assessed. These methods facilitate spatial estimation and analysis, which play a crucial role in decision-making processes aimed at mitigating poor air quality conditions. Several research groups have utilized geospatial analysis to assess air quality in specific regions. For instance, Cardito et al. (2023) employed the inverse distance weighting tool to analyze the spatial distribution of six air pollutants and evaluate the impact of COVID-19 lockdown regulations on air pollution in Campania, Italy. Similarly, Broomandi et al. (2023) utilized the same interpolation algorithm to assess the health risks associated with metal-containing particulate matter in 158 European cities between 2013 and 2019, mapping the spatial correlation between potentially toxic elements and time. In another study, Kumar et al. (2020) investigated the influence of traffic-related air pollutants and associated risks along major transport corridors in Delhi. They utilized the kriging interpolation method to analyze air pollution levels and their spatial patterns. Galán-Madruga and García-Cambero (2022) focused on modeling benzene levels in an air quality network by considering other air pollutants and meteorological variables as predictor inputs. They applied the kriging interpolation technique to identify representative fixed stations within the target network.
While the previously mentioned research studies contribute valuable insights to scientific progress, they primarily focused on specific interpolation algorithms without evaluating a comprehensive range of methods for spatial interpolation. To address this gap, the current study aims to assess multiple conventional interpolation techniques commonly employed in geospatial estimation within environmental sciences. The goal is to provide robust evidence that identifies the most suitable interpolation method to be utilized in this field. By conducting a thorough analysis of various algorithms, this study aims to contribute to the advancement of geospatial estimation practices in environmental sciences.
Materials and Methods
Study Area and Reference Pollution Dataset
To achieve the proposed objective, this study was conducted in the Community of Madrid, located in the central region of the Iberian Peninsula. The Community of Madrid is home to an estimated population of over 6.7 million people and encompasses a land area of approximately 8,000 km2. It is comprised of 179 municipalities (INE 2022), making it a suitable area for investigation.
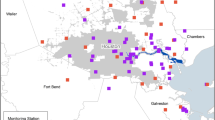
For this specific case study, the annual average PM10 concentrations in 2022 were examined rather than PM2.5 particles. Despite both atmospheric pollutants being included in the current European legislation, the limit values set for PM10 are stricter than for PM2.5 in terms of temporal scale. The legislation establishes a daily and annual average limit value for PM10 and only annual for PM2.5 (Directive 2008/50/EC). For this reason, PM10 particles were regarded for developing the present study. The PM10 concentrations were obtained from the fixed measurement stations included in the target air quality measurement network (AQMN) of the Community of Madrid. The measurement method for monitoring PM10 was beta absorption, and the equipment was an automatic analyzer. PM10 particles were chosen as they are known to be harmful to health and are subject to mandatory control by the European Union. During the investigation period, the AQMN in the Community of Madrid consisted of 24 fixed monitoring stations, with 79% of these stations measuring the target pollutant (as shown in Fig. 1). This constituted the reference dataset for the study, with a total of 19 stations included. The regional government was responsible for managing and ensuring the validity of the data obtained from the AQMN. In this regard, Directive 2008/50/EC (Annex I) sets data quality objectives for ambient air quality assessment to guarantee the validity of monitored data. For particulate matter, criteria such as 25% uncertainty and 90% minimum data capture should be complied.

Location and type of fixed measurement stations belonging to the Community of Madrid’s AQMN
Proposed Approach: Background
In geospatial estimation methods, interpolation algorithms play a crucial role in providing unbiased information about values at non-sampled sites (Baume et al. 2011). To determine the most suitable method for environmental sciences, specifically in the context of air quality, the following sequence of steps was undertaken: (1) a sub-dataset was derived from a reference dataset by selecting fixed stations as sampling sites, (2) different interpolation algorithms were applied to the data from both the reference dataset (scenery 1) and the sub-dataset (scenery 2), and (3) the outcomes obtained from both scenery 1 and scenery 2 were evaluated to identify the best geospatial estimation method.
Laying Down a Working Sub-Dataset
The initial step towards achieving the proposed objective involves creating a sub-dataset from the reference dataset using a scientifically established approach. In this study, a partitive clustering technique known as k-means clustering with a maximum of 10 iterations was utilized. This technique is commonly employed in data mining and aims to partition a set of n-observations (in this case, annual average PM10 levels) into k clusters, with each observation assigned to the group whose average value is most similar to it (Galán Madruga et al. 2018). The average value of each cluster is calculated by considering all observations within that cluster (Galán-Madruga et al. 2023).
Consistent with previous studies (Galán-Madruga et al. 2022), the Euclidean distance was used as an objective criterion to generate the clusters, serving as a spatial indicator. The study conducted nine clusters, varying the value of k from 2 to 10. The selection of the appropriate cluster required a coefficient of determination higher than 0.99 between the current annual average PM10 levels obtained from the reference dataset and those estimated by the clustering technique. The fixed stations within the selected cluster with less favorable Euclidean distance values were excluded, resulting in the remaining stations forming the working sub-dataset.
Applying Various Interpolation Algorithms
This study evaluated six different interpolation algorithms, namely Inverse distance to the power, kriging, minimum curvature, nearest neighbor, radial basic function, and Shepard’s method. Each algorithm operates based on distinct principles to estimate values for non-measured data points. In the Inverse distance to the power method, the influence of one point relative to another decreases as the distance between them increases (Yang et al. 2023). Kriging calculates weighted averages of neighboring data points to determine non-measured values (Wang et al. 2023). The minimum curvature method assigns weights iteratively until changes in values are below a specified threshold (Ford and Moghrabi 1996). Nearest neighbor assigns the value of the nearest point to non-monitored data (Zaidi 2021). Radial basic function employs a weighted sum of radial basis functions to estimate non-measured values, encompassing various data interpolation techniques (Liu and Zhao 2022). Shepard’s method, on the other hand, represents the simplest form of inverse distance weighted interpolation (Dell’Accio et al. 2023).
To develop PM10 particle iso-concentration maps, Surfer for Windows (Win32) was utilized as a geographical information system (Surface Mapping System, v.6.04, Golden Software, Inc., Golden, CO, USA). Statistical analysis of the data was performed using IBM SPSS Statistics v29 (IBM Corp., Armonk, NY, USA).
Appointing the Best Geospatial Estimation Method for Environmental Sciences
The selected interpolation algorithms were utilized to estimate PM10 concentrations in both scenery 1 (it corresponds to the original PM10 dataset) and scenery 2 (it corresponds to sub-dataset derived from original PM10 dataset). The comparison between the actual annual average PM10 concentrations of the removed stations and the estimated concentrations using the interpolation algorithms was conducted through simple linear regression analysis. Furthermore, the performance of the interpolation algorithms was assessed using indicators commonly employed in atmospheric sciences (Karunasingha 2022). These indicators include root mean square error (RMSE), mean prediction error (MPE), and mean absolute percentage errors (MAPE), which are calculated according to the equations provided by Dai et al. (2022).
Results and Discussion
Laying Down a Working Sub-Dataset
Figure 2 illustrates the results obtained from the application of k-means clustering analysis to the reference dataset. The coefficient of determination, determined through a simple linear regression analysis between the current PM10 concentrations and those estimated by the clustering technique, ranged from 0.795 (CI: 0.737–0.958) to 0.998 (CI: 0.997-1.000) for clusters 2 and 10, respectively. It is important to note that as the number of clusters decreases, the coefficient of determination also diminishes. A coefficient of determination higher than 0.99 was considered as the selection criterion to identify the working cluster for further evaluation of the interpolation algorithms. Cluster 6 emerged as the first group with a coefficient of determination exceeding the established cutoff value (r2 = 0.992). Cluster 6 encompassed almost the entire information from the reference dataset, exhibiting a high level of similarity (> 99%). However, the Euclidean distance increased as the number of clusters decreased, resulting in a value of 0.733 µg PM10/m3 for cluster 6, equivalent to 6.75% expressed as relative data.

Outcomes resulting from k-means clustering analysis
Once the working cluster (cluster 6) was determined, the subsequent step involved identifying the fixed stations that formed the working sub-dataset. To achieve this, the fixed stations within cluster 6 with the highest Euclidean distance for each sub-cluster (ranging from 1 to 6) were excluded. The remaining stations were selected to form the sub-working dataset, with the following stations being removed: FUE, COS, PDC, MAJ, SMV, and MOS, and the following stations being selected: ALH, CLV, ARJ, LEG, RVM, AGR, EAT, GDS, ODT, ALB, VDP, GET, and TDA (refer to Table 1 for details).
Applying Interpolation Algorithms and Appointing the Most Suitable One
Various interpolation algorithms were evaluated for geospatial estimation. Figure 3 illustrates the spatial distribution of PM10 gradients based on annual average concentrations from the reference dataset and the working sub-dataset, using each applied interpolation algorithm. Generally, there is a noticeable similarity in spatial representation between scenery 1 and 2 for most interpolation techniques. However, the minimum curvature algorithm stands out as it exhibits significantly different gradients, making it unsuitable for further evaluation within the scope of the study. Similarly, Shepard’s method is excluded from the assessment because it is unable to interpolate concentration levels for the six previously removed fixed stations, specifically SMV.

Annual average PM10 particles iso-concentration maps in 2022. (A) Map represented with the reference dataset (scenery 1, n = 19), and (B) Map represented with the working sub-dataset (scenery 2, n = 12)
To determine the most suitable geospatial estimation technique in the field of environmental sciences, the Pearson’s coefficient of correlation was calculated between the current annual average PM10 levels at the removed fixed stations and the estimated values obtained from different interpolation algorithms. The calculated correlation coefficients were as follows (in ascending order): 0.204 for the nearest neighbor method, 0.602 for inverse distance to the power, 0.624 for radial basis function, and 0.697 for kriging. To interpret these results, the categorization proposed by Dancey and Reidy (2007) was applied, which classifies the degree of association between variables into five categories based on the correlation coefficient value: zero (0), weak (± 0.1–0.3), moderate (± 0.4–0.6), strong (± 0.7–0.9), and perfect (± 1).
Among the evaluated interpolation algorithms, inverse distance to the power and radial basis function demonstrates a moderate level of association, while kriging exhibits a strong level of association. On the other hand, the nearest neighbor technique shows a weak connection and is not suitable for the proposed objective of this study. To further confirm this finding, the bias between the current and estimated annual average PM10 levels at the removed stations was calculated. The average bias values were 15.3%, 14.9%, and 14.3% for inverse distance, radial basis function, and kriging, respectively. Performance indicators such as root mean square error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE) were also evaluated. The outcomes for inverse distance were 3.6 µg/m3, 13.3 µg/m3, and 8.2% for RMSE, MAE, and MAPE, respectively. For radial basis function, the values were 3.5 µg/m3, 12.3 µg/m3, and 8.1%. Lastly, kriging resulted in 3.2 µg/m3, 10.2 µg/m3, and 7.3% for RMSE, MAE, and MAPE, respectively. Based on the evidence gathered, the kriging method is considered the most suitable geospatial estimation technique for applications in environmental sciences.
Shukla et al. (2020) utilized kriging and inverse distance weighting as interpolation methods to generate particulate matter distribution maps in the megacity of Delhi. They reported an average error of 22% for kriging and 24% for inverse distance weighting. While the performance of these algorithms was slightly lower compared to the findings of this study, qualitatively, they also identified kriging as the superior spatial interpolation algorithm.
The relevance of geospatial analysis is sustained in providing (i) solutions to complex issues (Ahasan et al. 2022; Tadese et al. 2022), knowledge of scientific information in terms of geographics (Saldias et al. 2022), studying patterns (Kang et al. 2021), and conducting trend analysis and predictions (Liu et al. 2020). Given its wide application in environmental research, it is crucial to determine the most suitable interpolation method that can generate reliable outcomes for specific geospatial estimation processes. The procedure developed in this study fills the gap in scientific knowledge by comparing different geospatial interpolation techniques used in various environmental sciences, thus providing a robust body of evidence to identify the best interpolation method.
In conclusion, the findings presented in this study have important implications for environmental management, as geospatial information serves as a fundamental basis for decision-making (Hoang Tu et al. 2023). The results of this work can benefit research groups worldwide that require the application of spatial interpolation algorithms in their studies, facilitating the development of control plans, implementation of mitigation strategies, and informed decision-making by environmental managers.
References
Ahasan R, Alam MS, Chakraborty T, Ali SMA, Alam TB, Islan T, Hossain MM (2022) Applications of geospatial analyses in health research among homeless people: a systematic scoping review of available evidence. Health Policy Technol 11:100647. https://doi.org/10.1016/j.hlpt.2022.100647
Baume OP, Gebhardt A, Gebhardt C, Heuvelink GBM, Pilz J (2011) Network optimization algorithms and scenarios in the context of automatic mapping. Comput Geosci 37:289–294. https://doi.org/10.1016/j.cageo.2010.04.014
Beker SA, Khudur LS, Krohn C, Cole I, Ball AS (2022) Remediation of groundwater contaminated with dye using carbon dots technology: Ecotoxicological and microbial community responses. J Environ Manage 319:115634. https://doi.org/10.1016/j.jenvman.2022.115634
Broomandi P, Rodríguez-Seijo A, Janatian N, Fathian A, Tleuken A, Mohammadpour K, Galán-Madruga D, Jahanbakhshi A, Kim JR, Satyanaga A, Bagheri M, Morawska L (2023) Health risk assessment of the European inhabitants exposed to contaminated ambient particulate matter by potentially toxic elements. Environ Pollut 323:121232. https://doi.org/10.1016/j.envpol.2023.121232
Cardito A, Carotenuto M, Amoruso A, Libralato G, Lofrano G (2023) Air quality trends and implications pre and post Covid-19 restrictions. Sci Total Environ 879:162833. https://doi.org/10.1016/j.scitotenv.2023.162833
Dai H, Huang G, Wang J, Zeng H, Zhou F (2022) Spatio-temporal characteristics of PM2.5 concentrations in China based on multiple sources of data and LUR-GBM during 2016–2021. IJERPH 19:6292. https://doi.org/10.3390/ijerph19106292
Dancey CP, Reidy J (2007) Statistics without Maths for Psychology. Pearson Education
Deivanayagam TA, English S, Hickel J, Bonifacio J, Guinto RR, Hill KX, Huq M et al (2023) Envisioning environmental equity: climate change, health, and racial justice. The Lancet S0140673623009194. https://doi.org/10.1016/S0140-6736(23)00919-4
Dell’Accio F, Di Tommaso F, Guessab A, Nudo F (2023) On the improvement of the triangular Shepard method by non conformal polynomial elements. Appl Numer Math 184:446–460. https://doi.org/10.1016/j.apnum.2022.10.017
Deng H, Li L, Kim JJ, Ling FT, Beckingham LE, Wammer KH (2022) Bridging environmental geochemistry and hydrology. J Hydrol 613:128448. https://doi.org/10.1016/j.jhydrol.2022.128448
Directive (2008) /50/EC of the European Parliament and of the Council on 21 May 2008 on ambient air quality and cleaner air for Europe
Ford JA, Moghrabi IA (1996) Minimum curvature Multistep Quasi-newton methods. Computers Math Applic 31:179–186
Galán Madruga D, Fernández Patier R, Sintes Puertas MA, Romero García MD, Cristóbal López A (2018) Characterization and Local Emission Sources for Ammonia in an urban environment. Bull Environ Contam Toxicol 100:593–599. https://doi.org/10.1007/s00128-018-2296-6
Galán-Madruga D (2021) A methodological framework for improving air quality monitoring network layout. Applications to environment management. J Environ Sci 102:138–147. https://doi.org/10.1016/j.jes.2020.09.009
Galán-Madruga D, García-Cambero JP (2022) An optimized approach for estimating benzene in ambient air within an air quality monitoring network. J Environ Sci 111:164–174. https://doi.org/10.1016/j.jes.2021.03.005
Galán-Madruga D, Ubeda RM, Terroba JM, dos Santos SG, García-Cambero JP (2022) Influence of the products of biomass combustion processes on air quality and cancer risk assessment in rural environmental (Spain). Environ Geochem Health 44:2595–2613. https://doi.org/10.1007/s10653-021-01052-4
Galán-Madruga D, Cárdenas-Escudero J, Broomandi P, Oleniacz R, Cáceres JO (2023) Performance assessment of air quality monitoring networks. A specific case study and methodological approach. Air Qual Atmos Health 16:113–126. https://doi.org/10.1007/s11869-022-01254-4
Hoang Tu L, Thi Ha P, Ngoc Quynh Tram V, Ngoc Thuy N, Nguyen Dong Phuong D, Thong Nhat T, Kim Loi N (2023) GIS application in Environmental Management: a review. https://doi.org/10.25073/2588-1094/vnuees.4957. EES 39
INE (2022) National Statistical Institute (https://www.ine.es/ accessed June 26, 2023)
Kang W, Jang EK, Yang CY, Julien PY (2021) Geospatial analysis and model development for specific degradation in South Korea using model tree data mining. CATENA 200:105142. https://doi.org/10.1016/j.catena.2021.105142
Karunasingha DSK (2022) Root mean square error or mean absolute error? Use their ratio as well. Inf Sci 585:609–629. https://doi.org/10.1016/j.ins.2021.11.036
Kumar A, Mishra RK, Sarma K (2020) Mapping spatial distribution of traffic induced criteria pollutants and associated health risks using kriging interpolation tool in Delhi. J Transp Health 18:100879. https://doi.org/10.1016/j.jth.2020.100879
Liu Y, Zhao M (2022) An obsolescence forecasting method based on improved radial basis function neural network. Ain Shams Eng J 13:101775. https://doi.org/10.1016/j.asej.2022.101775
Liu C, Cao Y, Yang C, Zhou Y, Ai M (2020) Pattern identification and analysis for the traditional village using low altitude UAV-borne remote sensing: multifeatured geospatial data to support rural landscape investigation, documentation and management. J Cult Herit 44:185–195. https://doi.org/10.1016/j.culher.2019.12.013
Madruga DG, Ubeda RM, Terroba JM, dos Santos SG, García-Cambero JP (2019) Particle‐associated polycyclic aromatic hydrocarbons in a representative urban location (indoor‐outdoor) from South Europe: Assessment of potential sources and cancer risk to humans. Indoor Air 29:817–827. https://doi.org/10.1111/ina.12581
Saldias DSM, Aguayo LG, Wallace L, Reinke K, Mclennan B (2022) Perceptions of land use and land cover analysed using geospatial data. Appl Geogr 146:102757. https://doi.org/10.1016/j.apgeog.2022.102757
Shukla K, Kumar P, Mann GS, Khare M (2020) Mapping spatial distribution of particulate matter using Kriging and Inverse Distance weighting at supersites of megacity Delhi. Sustain Cities Soc 54:101997. https://doi.org/10.1016/j.scs.2019.101997
Tadese B, Wagari M, Tamiru H (2022) MCA and geospatial analysis-based suitable dumpling site selection for urban environmental protection: a case study of Shambu. Oromia Reg State Ethiopia Heliyon 8:e09858. https://doi.org/10.1016/j.heliyon.2022.e09858
Tadesse E, Azagegn T, Alemayehu T (2023) Characterizing groundwater and surface water interaction using geological, environmental tracers (222Rn, EC, δ18O, and δ2H) and baseflow index methods for part of the Upper Awash and the adjacent Blue Nile Basin, Ethiopia. J Afr Earth Sci 104992. https://doi.org/10.1016/j.jafrearsci.2023.104992
Tu’uholoaki M, Singh A, Espejo A, Chand S, Damlamian H (2022) Tropical cyclone climatology, variability, and trends in the Tonga region, Southwest Pacific. Weather Clim Extrem 37:100483. https://doi.org/10.1016/j.wace.2022.100483
Wang Y, Pan H, Shi Y, Wang R, Wang P (2023) A new active-learning estimation method for the failure probability of structural reliability based on kriging model and simple penalty function. Comput Methods Appl Mech Eng 410:116035. https://doi.org/10.1016/j.cma.2023.116035
Yang Q, Deng Y, Yang Y, He Q, Zhang S (2023) Neural networks based on power method and inverse power method for solving linear eigenvalue problems. Comput Math Appl 147:14–24. https://doi.org/10.1016/j.camwa.2023.07.013
Zaidi SAR (2021) Nearest neighbour methods and their applications in design of 5G & beyond wireless networks. ICT Express 7:414–420. https://doi.org/10.1016/j.icte.2021.01.003
Zhao H (2023) Research on the environmental science and sustainable sport development the perspective of geological ecology. J King Saud Univ Sci 35:102564. https://doi.org/10.1016/j.jksus.2023.102564
Zhao C, Liu M, Wang K (2022) Monetary valuation of the environmental benefits of green building: a case study of China. J Clean Prod 365:132704. https://doi.org/10.1016/j.jclepro.2022.132704
Acknowledgements
The authors thank the Community of Madrid government for the data use and spread transparency policy.
Funding
This research does not have commercial purposes, only scientific ones. This research received no specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that there are no conflicts of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
de Lourdes Berrios Cintrón, M., Broomandi, P., Cárdenas-Escudero, J. et al. Elucidating Best Geospatial Estimation Method Applied to Environmental Sciences. Bull Environ Contam Toxicol 112, 6 (2024). https://doi.org/10.1007/s00128-023-03835-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00128-023-03835-0