
Abstract
Speech enhancement, or SE, is a method of converting an input speech signal into a target signal with improved quality of voice and readability. To hear the voice, the skeleton bone vibrates ultra smooth thanks to bone conduction. The benefits of Bone-Conducted Microphone (BCM) speech include noise reduction and enhanced communication quality in high-noise environments. To acquire signals and precisely model word phonemes, BCM relies on the placement of bones. Certain computer techniques are expensive and ineffective in simulating signal phonemes. Three wavelet transform techniques are presented in this work: complex continuous wavelet transforms (CCWT), steady wavelet transforms (SWT), and discrete wavelet transforms (DWT). The right ramp, the voice box, and the mastoid were the three distinct bony locations for which the speech intelligibility of the BCM signal was evaluated. The listener evaluated the comprehension of the speech after obtaining the BCM signal for Tamil words. Speech quality is enhanced by the location of the larynx bone in comparison to alternative calculation methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Bone conduction refers sound conducted from the bone. Bone conduction conduct ultra-fine vibrations from skeleton bone to hear the voice. Air conduction refers air waves transferred to electrical waves to hear the voice. Air conduction is slightly noisy but bone conduction gives subtle voice to hear. Bone is a good conductor compared to air.Bone conduction is main tool to increase activation of ear. Bone conduction use similar technique of sea mammals in underwater. If the sea mammals lost their hearing it follows their vibrations. Bone conducted microphone (BCM) utilizes the vibrations from skull, throat, and back skin of ear to conduct electrical signal. BCM is extensively utilized in military communications systems (helicopters) and civil activities (mine, forestry, and emergency rescue). BCM plays additional role to improving the quality of air conduction microphone (ACM) in noisy environments. ACM is unintelligent in extreme noisy situations. But BCM can handle extreme noise environment and it gives precise sound.
Bone conduction speech enhanced through different methods such as Long Short-Term Memory (LSTM), deep learning, Finite Element Analysis (FEA), machine learning andCycle-Consistent Adversarial Networks (CycleGAN). However, these methods have some disadvantages to conduct vibrations from bone such as long-time, high-level noise, sensitive and technically challenging. BCM is kindly helping for deaf people to hear sounds and understand speech of normal people.Bone conduction mainlyused on mastoid prominence or forehead bones to conduct vibrations. Bone conduction implantation device can restore the ability of hearing. Bone conduction headphones transmit the sound from bone vibration of head or jaw.The frequency range of bone conduction should be between 500 and 4000 Hz or threshold should be between 1 and 25 dB ranges. High frequency of bone conduction can cause hearing loss. BCM gives high quality speech signals. This research suggests a BCM conversion of speech technique with reference to the Advanced Intermittent Wavelet Transformed efficiently enhances the quality of BCM conversation and fully utilizes semantics. (CCWT).
1.1 Problem Statement
Voice recognition software occasionally produces errors that are frequently the result of interpretation since words are not always displayed on the screen precisely. Workflow may be slowed down until the program catches up if it takes some time to adjust to the user's voice and speaking habits. Accent recognition software is not immune to issues. Programs may also have problems recognizing speech as normal when a person has a phonetic shift, for example when individuals have a cold, cough, sinus sickness, or throat problem. Excessive noise from the background degrades system performance..voice recognition technology gives physical discomfort and vocal problems.There are lot of methods available to increase speech quality and intelligibility of voice signal from bone.Discrete wavelet transform (DWT) gives low speech qualityand noisy output.Stationary wavelet transform (SWT) overcome the drawbacks of DWT but it gives less accuracy speech quality. The above problems are solved through the Complex continuous wavelet transform (CCWT).
1.2 Contributions
To increase speech quality and intelligibility ofvoice signal from bone plays a vital role. To solve the above problemComplex continuous wavelet transform (CCWT) method is proposed.
-
(i)
To determine the voice signal through proposed methodComplex continuous wavelet transform (CCWT) from bone.
-
(ii)
Toincrease speech quality and intelligibilityof voice signal through proposed methodComplex continuous wavelet transform
-
(iii)
To denoise the signal from bone conduction microphone through proposed methodComplex continuous wavelet transforms.
2 Literature Survey
Reference no/year | Problem | Methodology | Results | Advantages (ad)/disadvantages (disad) |
|---|---|---|---|---|
[1]/2021 | Retrosigmoidalimplantation of the Bonebridge system | Surgical technique | Improvement of quality | Ad: minimally invasive& better cosmetic outcome Disad:technically challenging |
[2]/2022 | Weak BC Enhancement | Artificial neural networks for speaker-independent BC speech augmentation | Superiority Demonstrated | Ad: Improved Speech Quality Disad: Variable Effectiveness, Optimization Needed |
[3]/2023 | Robust Voice Applications | Bone Vibration Enhancement | Improved Performance Metrics | Ad: Lightweight, Multi-Modal Disad: Limited Paired Data |
[4]/2017 | To lessen ambient noise interference for wearing bone-conducted speech | Deep neural network | Excellent reusable bone-conducted speech quality | Ad: automatically deduced features & flexible Disad: requires huge amount of data |
[5]/2021 | Damaged by equipment recording limitations or additional or convoluted sounds | The HELM model stands for Hierarchy Intense Intelligence Machine Learning, or HELM for short | Robust against noise and record missed frequency | Ad: efficient handling of data Disad: possibility of high error |
[6]/2020 | Implantable bone conduction hearing aids | Finiteelement Analysis | Good performance of transducer | Ad: handle complex restraints Disad: approximate solution & errors |
[7]/2021 | Degradation of speech audibility | Deep learning | Higher speech quality | Ad: robustness & flexible Disad: requires huge amount of data & high cost |
[8]/2018 | To enhance the comprehensibility and quality of speech | Deep-denoising autoencoder (DDAE) | Improves automatic speech recognition (ASR) performance | Ad: learn compressed raw data Disad: time acquisition |
[9]/2021 | Bone-conducted speech enhancement to increase voice fidelity and comprehensibility | Dual adversary loss in CycleGAN (CycleGAN-DAL) | Outperforms baseline methods such as CycleGAN, GMM, and BLSTM | Ad: highly suitable for colour pictures Disad: does not perform well |
Reference no/year | Problem | Methodology | Results | Advantages (ad)/disadvantages (disad) |
|---|---|---|---|---|
[10]/2020 | bone-conducted transformation into words | Cycle: The adversarial Network with Consistency (CycleGAN) | Better reconstruct the high-frequency | Ad: highly suitable for colour pictures Disad: does not perform well |
[12]/2016 | Low Bit-Rate Video Compression | Empirical Wavelet + H.264 | Improved Rate Distortion | Ad: Efficient, Reliable Process Disad: Threshold Selection Critical |
[13]/2018 | To enhance the bone-conducted voice quality | Deep brain networks and long memory that is short-term | Better and achieves satisfactory performance | Ad: provide large range of parameters Disad: long time to train |
[14]/2020 | To measure the transmission characteristics of bone conduction | Sweep-sine Method | Better frequency | Ad: simple and easy to use Disad: sensitive |
[15]/2022 | Enhancing speech quality | end-to-end multi-modal model | Reduces error rate | Ad: Intelligibility Disad: computational complexity |
[16]/2022 | Enhancement of Noisy Speech | Attention-based Sensor Fusion | Superior Enhancement Performance | Ad: Full Bandwidth Utilization Disad: Limited BC Data |
[17]/2017 | Vocal tractcomponents appear only on the low-order cepstrum | Deep Neural Network (DNN) | Good performance | Ad: automatically deduced features & flexible Disad: requires huge amount of data |
[18]/2020 | Enhanced speech performance (SE) | Fully convolutional network powered by deep learning | Achieves better results | Ad: robustness & flexible Disad: requires huge amount of data & high cost |
[19]/2020 | Explores the noise robustnessof bone-conductedspeech in different noise environments | Signal-to-noise ratio(SNR) analysis | SNR gain of about 10 dB | Ad: better specification Disad: noise |
[20]/2022 | Challenges of Robust pitch extraction | air-conducted (AC) and bone-conducted (BC)signals | Accurate pitch extraction | Ad: robust pitch extraction Disad: computational complexity |
[21]/2019 | suffers from low speech quality due to thesevere loss of high-frequency components | Deep neural networks | Better objective results | Ad: automatically deduced features & flexible Disad: requires huge amount of data |
[22]/2020 | hampered when making broadband audio calls due to noise from neighboring intrusion | Deep learning | notable advancements in voice comprehension and quality of sound | Ad: robustness & flexible Disad: requires huge amount of data & high cost |
2.1 Inference from Literature Survey
Bone conduction has different methods such DNN and LSTM Hierarchical extreme learning machine learning (HELM),Cycle-ConsistentAdversarial Networks (CycleGAN),Deep-denoising autoencoder (DDAE),FiniteelementAnalysis (FEM) and Signal-to-noise ratio(SNR) analysis. HierarchicalExtreme Learning Machines gives inaccuracy and unstable to analyse voice signal.Finiteelement analysis givesapproximate solution and errors. Long short-term memory works with multiple variables but it gives less accuracy. To solve the above DWT, SWT and CCWT methods are proposed. In proposed methodsComplex continuous wavelet transform (CCWT) gives high accuracy, high speech quality and intelligibility.
3 Methodology
The MEMS acoustic sensor is used to acquire BCM speech. The transducer creates a spectral-rich electrical signal from the noise produced by the bones in the head. The piezoelectric component produces electrical charges when the sensor receives mechanical vibrations from bone structures in the skull's interior. These charges are proportional to the applied mechanical force, signifying the vibration intensity. The electrical signal is then amplified and processed to obtain the voice signal's spectral content. This method accurately converts bone-conducted vibrations into electrical signals that may then be analyzed and recorded. The vocal tract vibrates through bone structures during speech. The speech track vibrates bones such as the right and mastectomy, as seen in Fig. 1. Right ramus aids transfer of vibrations from the jawbone, capturing articulary movements. The larynx, being the source of vocal cord vibrations, adds basic frequencies to the signals. The right mastoid picks up vibrations from the temporal bone of the skull, which provide resonance and timbral properties to the collected speech signal. These areas work together to create a full representation of speech via bone conduction. During the recording, the male speaker said Tamil words in the background at a steady volume of 60 decibels. The microphone, which was three feet from the speaker's mouth, recorded the voice signal precisely. The signals were sampled at 22 kHz to retain good recording quality. A microphone model ADMP401 positioned at the right larynx, mastoid tissue, and ramsey captured the words. For speaking purposes, the ADMP401 was worn over the bone and fastened with a band to keep it from sliding. A class B power amplifier was used to amplify the ADMP401 signal, and a laptop made by HP running the Sigview program was used to record it.

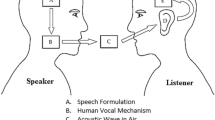
shows the block diagram of speech signal processing
The block diagram for processing voice signals obtained by bone conduction is shown in Fig. 1. At first, bone-conducted speech impulses from certain anatomical areas, such as the correct ramus, larynx, and mastoid tissue, are detected by the ADMP401 MEMS auditory vibrational transducer. Following that, these signals are subjected to some processing techniques, such as Fast Fourier Transform (FFT) analysis, which shifts the signals' time domain to the frequency domain and reveals their spectrum information. To extract specific data from the signals, several wavelet transforms are also utilized: the Complex Continuous Wavelet Transformed (CCWT), Stationary Wavelet Transform (SWT), and the Discrete Wavelets Transform (DWT). The processed signals are then classified into words using Support Vector Machine (SVM), Least Squares Support Vector Machine (LS-SVM), and Support Vector Regression (SVR) algorithms, which aids in the categorization and analysis of speech content. Throughout the process, the 3D DAQ system collects data from the sensors to ensure comprehensive signal gathering and accurate analysis. Further explanation is required regarding the actual operation of the 3D DAQ system and the specific bone locations depicted in Fig. 2 for a thorough comprehension of the methodology. It shows the precise places on the skull and throat where the MEMS acoustic sensor is positioned for speech recording. It allows to Understanding these exact anatomical areas improves the reliability and effectiveness of the recording setup for speech analysis via bone conduction.

Shows the bone location in skull and throat
However, using the skull's bones as conduits for voice vibrations has various benefits. First of all, while the microphone is in direct contact with the bone, it decreases ambient noise interference. Second, it enables for more steady and constant recording because bone-conducted signals are less impacted by distance or movement than air-conducted signals. Finally, it allows for clearer speech capture, especially in noisy surroundings, improving the overall quality of recordings.
3.1 Discrete Wavelet Tranform (DWT)
Using a wavelet transform with a discrete wavelet (DWT), the supplied sound is divided into several sets. DWT is a important transform to denoise the real signal. DWT can decompose the original signal and remove the noise of signal then recompose the signal. DWT has ability to identify the fine structure of signal. DWT can used for signature analysis in vibrational monitoring, acoustics and speech processing. DWT provides a method for analysis of vibrational signal. Although DWT is not invariant, it is highly sensitive to the signal's time congruence. DWT is utilized in a variety of disciplines, including mathematics, the sciences, engineering, and computer science. The primary application of DWT is signal coding, which represents separate signals. And also used for gaut analysis, image processing, digital communications and so on. It is implement to biomedical signal processing and wireless communications. Discrete wavelet transform formulated as,
Where, N is an even integer, a and k defines scalling functions. Ѱ is a wavefunction.
3.2 Stationary Wavelet Transform (SWT)
To overcome the drawbacks of the Intermittent Wavelet Conversion (DWT), the Sustained Wavelet Transform (SWT) was developed. SWT is decomposition method to split the signals into many frequency band. SWT has no lack of translation invariance by removing of downsamplers. Translation invariance is main drawback of DWT. SWT is a redundancy method with the same level of output samples as the input. Different applications of SWT include pattern recognition, diseased cerebral detection, brain picture classification, and noise denoising. The main purpose of SWT is denoising. Stationnary wavelet transform is implement in up sampled version as,
where j is wavelet decomposition stage, a low-frequency rate (h) filter and a filter with a high pass rate (g) filter. and n is a sample number for up sampled version.
3.3 Complex Continuous Wavelet Transform (CCWT)
A helpful method for identifying the evolving characteristics of irregular signals and determining if a signal is stationary in the aggregate is the Chronic Wavelets Transform (CWT). CWT can be used to discover and characterise singularities in a non-stationary signal by identifying stationary parts of the data stream. The complex CWT (CCWT) uses complex wavelets to perform continuous wavelet analysis on real data. It is mathematially model as follows,
where, x(t) is the input signal, \(\varphi \) (t) is the mother wavelet and a denotes scale parameter. x is the translation parameter. \(\varphi \) ∗(t) represents the complex conjugate of the mother wavelet.
Signal analysis benefits greatly from the use of the complex-valued wavelet transform. When it comes to signal detection, wavelets' complex nature allows for even better results than real-valued wavelet analysis. By looking for noteworthy aspects in its modulation coefficient and frequency, the produced complex-valued time–frequency information can be further examined.
3.4 Support Vector Machine (SVM)
Algorithms for ranking are advanced by support vector machines. Text categorising, digital picture analysis, character identification, and genomics are just a few of the many productive uses for SVM. Comparing SVMs to other supervised classification methods, they are a relatively new technology. SVM algorithms are basic. SVM requires less processing power and yields remarkably accurate results. This is the main reason why SVM is favored. Regression and classification techniques can also be applied with support vector machines. However, SVM is a popular method for categorization. The data points are classified using the support vector machine technique, which locates a hyper plane in N-dimensional space. SVM is superior to other classifiers in a few ways. Several of these benefits are strong, precise, and highly efficient. There are not many training samples in it. The best classifiers are produced using SVM approaches because of their increased capacity for generalization. In essence, SVMs are binary classification methods. The most common perspectives used are one-against-one nand one-against-all techniques. In terms of mathematics, SVM maps input data into higher-dimensional feature spaces where linear separation is feasible by using kernel functions. A frequently utilized kernel function is the dot product, denoted by,
To make the process of classifying data points easier, this kernel function computes the dot product of the input vectors a and a'. The Radial Basis Function (RBF), which is expressed by the following equation, is another frequently used kernel function:
In this case, the kernel's parameter is represented by a real value, σ. SVM can capture intricate relationships between data points by taking into account the distances between them in the input space thanks to the RBF kernel. SVMs also employ polynomial kernels, which are represented by the equation:
In this equation, γ represents the kernel coefficient, ris the independent term, and d is the degree of the polynomial.
Semantic Vector Machines (SVMs) are approaches for binary classification that use different kernel functions to translate input into spaces of higher dimensions where linear separation is possible. This method, along with SVM's efficiency, accuracy, and capacity for generalization, make it the recommended option for a variety of classification jobs.
3.5 Least-Squares Support-Vector Machines (LS-SVM)
Support-vector machines (SVM) are a set of related supervised learning techniques for the recognition of patterns and data analytics that are used in regression and classification. Least-squares support-vector machines (LS-SVM) are the least-squares versions of SVM. This version solves a system of linear algebraic problems as opposed to tackling a convex algebraic programming (QP) problem.
3.6 Support Vector Regression (SVR)
Discrete values are predicted using supervised learning methods such as Support Vector Reconstruction. The foundation of both supports vector regression and SVMs is the same. Finding the line that fits the best is the fundamental idea of SVR. In SVR, a hyperplane with the highest amount of points is the best-fit line. Within a given threshold value, the SVR tries to match the optimal line.
4 Results and Discussion
The Bone Conducted Speech signal takes from different locations. The Indian Languages Audio Dataset comprises 5-s audio samples representing 10 diverse Indian languages, provided in MP3 format. Derived from regional videos on YouTube, it's a subset of the broader "Audio Dataset with 10 Indian Languages," with each sample being publicly available and not owned by the dataset creator, It can accessible at https://www.kaggle.com/datasets/hmsolanki/indian-languages-audio-dataset/data.The speech signal recorded for five common tamil words such as athichudi, awvaiyar, gavani, ingae vaa and nill. The pair of vertical portions (rami) on either side of the scalp which articulate with the glenoid cavity of the temporal bone of the skull to form movable hinge joints are referred to as the "ramus". Furthermore, the rami serves as the swallowed muscles' connection point. Thickened and supported is the central front of the arch. The larynx is made up of a cartilaginous skeleton, ligaments, muscles, and mucous membranes that move and stabilize it. The thyroid gland, the cricoid, glottis, arytenoid, corniculate, and tablet cartilages are among those that make up the larynx. The hyoid bone encases the larynx or throat, bone, creating a little U-shaped structure. Where the mastoid bone is located. The hyoid bone envelops the larynx bone, forming a little U-shaped structure. The mastoid bone is placed right behind the inner ear and is part of the temporal bone of the skull. Mastoiditis is a mastoid bone infection. A honeycomb-like structure made up of mastoid air cells makes up the mastoid bone.
The final result of the DWT (discrete wavelet transforms) is displayed in Fig. 3. Figure 4 shows the output of Stationary Wavelet Transform (SWT). Figure 5 shows the output of Complex ContinuousWavelet Transform (CCWT).

Shows the output of DWT for tamil words

shows the output of SWT

shows the output of CCWT
Table 1 shows the statistical parameters of DWT for five common Tamil words. The words are commonly used in speech and illustrate phonetic qualities of the Tamil language. The link between the BCM information and voice utilizing LSSVM, SVM, and SVR in Table 2
For the Tamil words "ingae vaa" and "nill," Fig. 3's histograms in images (a) and (b) provide information on the distribution of wavelet coefficients. These histograms show the frequency and amplitude of the coefficients, which provide information on the properties and possible patterns of the signal. The denoised signals obtained using DWT are presented in Images (c) and (d), which demonstrate how noise reduction techniques can improve the quality and clarity of signals. Images (e) and (f), on the other hand, show compressed signals produced using DWT, emphasizing the signal size reduction attained while maintaining crucial information. All things considered, Fig. 3 offers a thorough visual depiction of all the modifications and improvements made to the DWT outputs for the Tamil words under analysis.
The average value in Table 1 is called the median, which is determined by dividing the total number of values in the information set by the sum of the digits. Median refers a midpoint of the values. Range shows the difference between lowest values and highest values. Athichudi, awvaiyar, gavani, ingae vaa and nill has value of range is 2.Standard deviation is a measument of variabilities of dataset. Less variability identifies by small standard deviation. ‘Ingae vaa’ tamil word has high standard deviation (0.06614).
Figure 4a displays the SWT signal analysis for the Tamil word "ingae vaa," showing the waveform obtained by applying the Stationary Wavelet Transform. This illustrates the signal's frequency components and temporal fluctuations, shedding light on its phonetic properties. The waveform generated from the SWT technique applied to the corresponding Tamil word is displayed in image (b), which exhibits the studied signal of SWT for 'awvaiyar'. This facilitates the analysis and interpretation of the word "awvaiyar" by enabling the observation of its unique spectrum characteristics and temporal dynamics. The waveform produced by applying SWT to the Tamil word "nill" is depicted in image (c), which displays the signal analysis for the word "nill." This allowed for the evaluation of the word's phonetic and linguistic features by providing representation of the word's temporal structure and frequency distribution. All things considered, these subgraphs provide comprehensive insights into the altered signals that arise from applying SWT to various Tamil words, allowing researchers to thoroughly examine the temporal and spectral properties of each word's waveform.
Figure 5 shows an image (a) that illustrates the wavelet coefficient magnitudes derived from the Complex Continuous Wavelet Transform (CCWT) for the Tamil word "ingae vaa." This shows the distribution of energy in the signal and sheds light on amplitude fluctuations across various time–frequency ranges. The frequency distribution of the wavelet coefficients that are produced when CCWT is applied to the Tamil word is shown in Image (b), the frequency of CCWT for "ingae vaa". This subgraph helps with the investigation of the signal's spectral and linguistic qualities by showing how the frequency content varies over time. Image (c): The wavelet coefficients obtained from CCWT for the equivalent Tamil word are shown in terms of magnitude by the modulus of CCWT for 'awvaiyar'. This provides information about the temporal dynamics and phonetic characteristics of the signal by illuminating its amplitude changes and energy distribution. Picture (d), which displays the frequency of CCWT for the Tamil word "awvaiyar," shows the frequency distribution of the wavelet coefficients produced by CCWT. This subgraph makes it possible to track the evolution of the signal's frequency content over time, which makes it easier to analyze the spectral and linguistic characteristics of the signal. All things considered, these subgraphs in Fig. 5 provide comprehensive visual representations of the altered signals that arise from applying CCWT to various Tamil words, allowing researchers to thoroughly examine the spectrum content and time–frequency properties of each word's waveform.
In Table 2, ‘athichudi’, ‘ingae vaa’ and ‘gavani’ has 3 syllabi. ‘awvaiyar’ has 2 syllabi and ‘nill’ has 1 syllabus. For instance, "Athichudi" demonstrates correlations of 81.23, 84.3, and 88.91% with DWT, SWT, and CCWT respectively, utilizing SVR. "Awvaiyar" exhibits correlations of 84.34, 86.27, and 89.32% with LSSVM, while "Ingae vaa" shows correlations of 83.84, 85.49, and 89.1% with SVR. "Gavani" demonstrates high correlations across all algorithms, reaching 89.31, 90.23, and 93.43% with DWT, SWT, and CCWT respectively, using SVR. Finally, "Nill" yields correlations of 87.79, 89.76, and 92.91% with DWT, SWT, and CCWT respectively, employing SVM. Three syllabi word correlated with SVR algorithm. Two syllabi word correlated with LSSVM algorithm and one syllabi word correlated with SVM algorithm.
Table 2 displays correlations between voice and bone-conducted speech (BCM) signals using classical methods (SVR, SVM, LSSVM) and machine learning approaches (U-Net, S-Net, and Capsule Net). U-Net achieves 86.89% correlation with SVR for the Tamil words studied, like 'Engae va'. This correlation is similar to DWT (83.84%) and CCWT (89.1%) in Table 2. Likewise, SVM achieves 89.25% for 'Va' using U-Net, which is in good agreement with SVM's performance (87.79%) in Table 2. Significantly, Table 3 shows that 'Enna' performs differently across several machine learning models, with greater correlations with LSSVM using conventional methods (88.15%) than with Capsule Net (91.25%) [11]. Overall, Table 3 provides insights into the efficacy of novel machine learning approaches compared to conventional methods, with varying degrees of correlation achieved for different Tamil words and syllabi, contributing to a comprehensive analysis of voice-BCM signal associations.
5 Conclusion
The optimal bone for speech intelligibility when utilizing BCM is discussed in the paper. To gather BCM speech signals, the voice box, middle mastoid, as well as the right ramus was used. The BCM was carried out spectral analysis of the speech signals from different bones to determine listeners' comprehension and suggested techniques like DWT, SWT, and CCWT. The average spoken comprehension of the voice signal produced by the larynx bone is 94%. The DWT, SWT, and CCWT successfully identified Tamil phrases in comparison to other ramus and mastoid bones for BCM impulses derived from the larynx.However, we must accept our study's limitations, which include a small sample size and a concentration primarily on Tamil phrases. Future research efforts could overcome these limitations by expanding the study to include a bigger and more diverse dataset, including more languages and a greater range of speech circumstances. Furthermore, future research should focus on enhancing the proposed signal processing approaches and studying the possible impact of ambient conditions on speech intelligibility via BCM technology. Overall, our research helps to advance the knowledge and application of BCM technology in improving speech communication in a variety of circumstances.
References
P. Canzi, I. Avato, M. Beltrame, G. Bianchin, M. Perotti, L. Tribi, B. Gioia, F. Aprile, S. Malpede, A. Scribante, M. Manfrin, Retrosigmoidal placement of an active transcutaneous bone conduction implant: surgical and audiological perspectives in a multicentre study. Acta Otorhinolaryngol. Ital. Otorhinolaryngol. Ital. 41(1), 91 (2021)
L. Cheng, Y. Dou, J. Zhou, H. Wang, L. Tao, Speaker-independent spectral enhancement for bone-conducted speech. Algorithms 16(3), 153 (2023)
L.He, H. Hou, S. Shi, X. Shuai, Z. Yan, Towards Bone-Conducted Vibration Speech Enhancement on Head-Mounted Wearables. In Proceedings of the 21st Annual International Conference on Mobile Systems, Applications and Services (pp. 14–27) (2023, June).
B. Huang, Y. Gong, J. Sun, Y. Shen, Y, A wearable bone-conducted speech enhancement system for strong background noises. In 2017 18th International Conference on Electronic Packaging Technology (ICEPT) (pp. 1682–1684). IEEE . (2017, August)
T. Hussain, Y. Tsao, S.M. Siniscalchi, J.C. Wang, H.M. Wang, W.H. Liao, Bone-conducted speech enhancement using hierarchical extreme learning machine. In Increasing Naturalness and Flexibility in Spoken Dialogue Interaction (pp. 153–162). Springer, Singapore (2021)
S.H. Lee, K.W. Seong, K.Y. Lee, D.H. Shin, Optimization and performance evaluation of a transducer for bone conduction implants. IEEE Access 8, 100448–100457 (2020)
Y. Li, Y. Wang, X. Liu, Y. Shi, S.F. Shih, Enabling Real-time On-chip Audio Super Resolution for Bone Conduction Microphones (2021). arXiv preprint arXiv:2112.13156
H.P. Liu, Y. Tsao, C.S. Fuh, Bone-conducted speech enhancement using deep denoising autoencoder. Speech Commun.Commun. 104, 106–112 (2018)
Q.Pan, T. Gao, J. Zhou, H. Wang, L. Tao, H.K. Kwan, CycleGAN with Dual Adversarial Loss for Bone-Conducted Speech Enhancement (2021). arXiv preprint arXiv:2111.01430.
Q. Pan, J. Zhou, T. Gao, L. Tao, Bone-Conducted Speech to Air-Conducted Speech Conversion Based on CycleConsistent Adversarial Networks. In 2020 IEEE 3rd International Conference on Information Communication and Signal Processing (ICICSP) (pp. 168–172). IEEE (2020, September)
V.S. Putta, A.S.M. Priyadharson, V.P. Sundramurthy, Regional Language Speech Recognition from Bone-Conducted Speech Signals through Different Deep Learning Architectures. Computational Intelligence and Neuroscience (2022)
A.R.D.A. Rajaram, M.S.D.M. Sabrigiriraj, K.S.D.K. Sivasankari, Very low bit-rate video coding by combining H. 264/AVC standard and empirical wavelet transform. J. Electr. Eng.Electr. Eng. 16(1), 9–9 (2016)
D. Shan, X. Zhang, C. Zhang, L. Li, A novel encoder-decoder model via NS-LSTM used for bone-conducted speech enhancement. IEEE Access 6, 62638–62644 (2018)
T. Toya, P. Birkholz, M. Unoki, Measurements of transmission characteristics related to bone-conducted speech using excitation signals in the oral cavity. J. Speech Lang. Hear. Res. 63(12), 4252–4264 (2020)
M. Wang, J. Chen, X. Zhang, Z. Huang, S. Rahardja, Multi-modal speech enhancement with bone-conducted speech in time domain. Appl. Acoust.Acoust. 200, 109058 (2022)
H. Wang, X. Zhang, D. Wang, Fusing bone-conduction and air-conduction sensors for complex-domain speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 30, 3134–3143 (2022)
D. Watanabe, Y. Sugiura, T. Shimamura, H. Makinae,Speech enhancement for bone-conducted speech based on low-order cepstrum restoration. In 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS) (pp. 212–216). IEEE (2017, November)
C. Yu, K.H. Hung, S.S. Wang, Y. Tsao, J.W. Hung, Time-domain multi-modal bone/air conducted speech enhancement. IEEE Signal Process. Lett. 27, 1035–1039 (2020)
S. Zhang, Y. Sugiura, N. Yasui, T. Shimamura, Quantifying noise robustness of bone-conducted speech. In 2020 IEEE 63rd International Midwest Symposium on Circuits and Systems (MWSCAS) (pp. 582–585). IEEE (2020, August)
S. Zhang, Y. Sugiura, N. Yasui, T. Shimamura, Air-conducted and bone-conducted speeches combination for noise-robust pitch extraction. IEEJ Trans. Electr. Electron. Eng.Electr. Electron. Eng. 17(7), 1061–1071 (2022)
C. Zheng, J. Yang, X. Zhang, M. Sun, K. Yao, Improving the spectra recovering of bone-conducted speech via structural similarity loss function. In 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) (pp. 1485–1490). IEEE (2019, November)
Y. Zhou, Y. Chen, Y. Ma, H. Liu, A real-time dual-microphone speech enhancement algorithm assisted by bone conduction sensor. Sensors 20(18), 5050 (2020)
Acknowledgements
There is no acknowledgement involved in this work.
Funding
No funding is involved in this work.
Author information
Authors and Affiliations
Contributions
There is no authorship contribution.
Corresponding author
Ethics declarations
Conflict of interest
Conflict of Interest is not applicable in this work.
Ethical Approval
No participation of humans takes place in this implementation process.
Human and Animal Rights
No violation of Human and Animal Rights is involved.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Putta, V.S., Priyadharson, A.S.M. Regional Language Speech Recognition from Bone Conducted Speech Signals Through CCWT Algorithm. Circuits Syst Signal Process (2024). https://doi.org/10.1007/s00034-024-02733-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00034-024-02733-y