
Abstract
We test a deep learning based denoising autoencoder algorithm on regional and teleseismic seismological and hydroacoustic datasets, which we compile from the International Monitoring System of the Comprehensive Nuclear-Test-Ban Treaty Organisation. We focus on stations which can be relevant to investigate North Korean nuclear tests. Denoising of waveform records using autoencoder techniques potentially enables improved signal detection and processing due to lowered signal-to-noise ratios. We train and compare the performance of several different denoising autoencoder models, for short- and long waveform periods, trained on the complete station network as well as on individual stations. We investigate if the denoised waveform signals are useful for seismic source analysis and if they can still be reliably used in downstream analysis for further inferences on the seismic source type, i.e. seismic moment tensor analysis. The declared North Korean nuclear tests are a suitable benchmark test set, as they have extensively been researched and their source type and location might be assumed known. Verification of the source type is of particular interest for potential nuclear tests under international law. We find that care needs to be taken using the denoised waveform data, as a slight bias is introduced in the seismic moment tensor analysis. However we also find promising results hinting at possible future use of the technique for standard analyses, as it improves the investigation of smaller events. Autoencoder based denoising techniques could be employed in future routine frameworks to increase earthquake catalog completeness and possibly aid in detecting smaller potential treaty relevant events.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The detection and characterization of potential nuclear explosions is a keystone in the Comprehensive Nuclear-Test-Ban Treaty (CTBT) verification regime. The CTBTO (CTBT organization) established a network of measurement stations, the International Monitoring System (IMS), which, among other technologies, employs seismic and hydroacoustic stations to enable the identification and localization of potential treaty-relevant events. In this study we test the potential of machine learning based denoising to improve available IMS waveform data and products. The potential advantages of denoised waveforms are for example lowered detection thresholds due to an increased signal-to-noise ratio (SNR). This could for example result in more available phase picks of potentially higher accuracy as derived using frequency filtering (Tibi et al., 2021) and also better constrained source mechanisms for smaller events.
Several methods to reduce the impact of noise in seismological data exist, such as frequency filtering, continuous wavelet transform (Mousavi et al., 2016) or array methods (Rost and Thomas, 2002). Deep learning based denoising autoencoder-decoders (DAE) are a technology from the field of information retrieval (Chandna et al., 2017) and are novel in the seismological field (Zhu et al., 2019). They could be used for noise reduction in the pre-processing stage of an seismic analysis, if the output proves reliable and robust after the denoising. DAE are based on convolutional neural networks (CNN), which learn to retrieve relevant information from a sparse representation of input data. This is achieved by learning to map a mask function, which allows to apply the predicted mask on the input data to separate mask functions for predicted signal and noise. Previous autoencoder based denoising studies in seismology mostly used regional and local distance seismicity based datasets, such as the STEAD dataset Mousavi et al. (2019). This studies showed that DAE are able to suppress white noise, a variety of coloured noise, and non-earthquake signals resulting in a lowered detection threshold and increase in detections (Zhu et al., 2019; Tibi et al., 2021; Heuel and Friederich, 2022). Seismic DAE have both been trained for seismic records of single stations (Tibi et al., 2021) as well as for local or regional networks (Zhu et al., 2019; Heuel and Friederich, 2022). We train several DAE with both regional and teleseismic IMS datasets as well as station specific data sets with the goal of denoising specifically the P-wave train and compare the performance.
DAE use the same basic ideas as previously developed and established methods of time-frequency based filtering of seismic waveforms (e.g. Zhu et al., 2015; Huang et al., 2017; Donoho and Johnstone, 1995; Gaci, 2013; Naghizadeh and Sacchi, 2012). Most denoising methods have in common that they calculate the time-frequency coefficients after transforming the waveform data into a sparse representation and threshold to attenuate noise coefficients and promote the signal coefficients (Zhu et al., 2019). The advantage of using machine learning to handle this task is that a powerful mapping function of the coefficients is trained automatically based on the training data, without any need of user input for determining thresholds. Another method to determine the thresholding function is to construct a noise model, based either on the immediate pre-event noise or on similar signals (Heuel and Friederich, 2022). It has been shown that DAE based methods outperform such noise model based methods in both the improvement of SNR and the generalized ability to adapt to filter colored noise, which has not been represented sufficiently in the noise model (Heuel and Friederich, 2022). This is however only possible if a sufficiently large and diverse set of noise samples is used in the training of the DAE. In some cases, such as new stations or changing anthropogenic noise conditions, it might be advantageous to be able to use a transferable denoising method. Generalizable denoising methods and models might therefore be preferable, if they perform well, based on larger regional datasets, such as the IMS network and the Reviewed Event Bulletin provided by the International Data center (IDC) of the CTBTO.
The six declared North Korean nuclear tests act as an ideal benchmark to test the benefit and reliability of current machine learning based denoising methods. This is because the seismic signals of the nuclear tests have the same source mechanism and location, and have overall already very good SNR. One goal of this study is to determine if denoised waveform records can reliably be used for further analysis of North Korean nuclear tests. We test the reliability of using denoised waveform data for further analysis, such as phase picking, array methods, moment tensors (MT) and moment magnitude estimates. For seismic moment tensors and moment magnitude estimation we use the denoising technique as a pre-processing step. If so, using ML based denoising techniques and the IMS dataset to train them might prove beneficial to CTBT related tasks such as the investigation of small but potentially treaty relevant events.
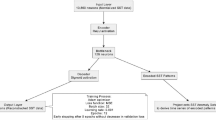
2 Dataset
2.1 Seismological Dataset
We first train three different DAE on all regional data of the IMS network surrounding the North Korean nuclear test site Punggye-ri at Mount Mantap, to test a broadly generalized and possibly transferable model. For the regional dataset based DAE we train both a model with the specific task to denoise P-phases, which we call the P-model, and another with the specific task to denoise S-phases and surface waves, which we call in the following the LP-model (long period). We further train a set of DAE for several selected individual IMS network stations. These selected stations are the seismic array broadband stations KS31 of the IMS array KSRS, station MJB9B of the MJAR array and USA0B of the IMS array USRK and BJT. For each of these stations we train a station and P-phase specific denoising model, to which we refer to as the PS-models, which are a set of DAE. In total we train three separate DAE, the P-model for P-waves, the LP-model for low-periods and the set of stations specific PS-models.
We train our models on data from regional IMS primary stations, the main seismic stations of the CTBT treaty which mainly seismic array stations and transmit data to the IDC in near real time, and auxiliary stations, which are supporting seismic stations (mostly thee component stations) and transmit data on request to the IDC. We use waveform data relevant to the analysis of North Korean nuclear tests, based on 16 years (2006–2022) of events retrieved from the Reviewed Event Bulletin (REB). We use REB events of all magnitudes with 10 or more associated phase picks on IMS stations up to 50\(^\circ\) distances from the North Korean nuclear test site. In total >110,000 events fulfill these criteria (Fig. S1). All waveforms are resampled to a common 20 Hz sampling frequency. We use the raw waveforms in counts for training, validation and testing, after removing the instrument response.
We only use waveforms at stations where the Z-component has an SNR > 20dB, measured at 1–8 Hz from 10 s before the P-phase onset and 15 s afterwards. This reduces the number of suitable events in the dataset to a total 26,000 events (Figs. 1a, S3), with around 23,000 events between magnitudes 3–5 and 3000 events with magnitudes > 5. A negligible number of events in the remaining training dataset are smaller than magnitude 3. This dataset with an emphasis on magnitudes 3–5 is suitable for training of DAE with the task to denoise signals from the six nuclear tests, which had reported magnitudes between 3.8 and 5.2. It is important to note that the reduction in the number of suitable events for training is not representative of the quality of the phase picks in the REB catalog, but rather a result of the chosen strict criteria for training data selection to ensure a high SNR of the signal samples. For the single station DAEs an average of 6000 events per station remains in the training dataset. We also tested a threshold of SNR > 10dB, which doubles the available number of events in the dataset (Fig. S2) but leads to a degradation in denoising quality and reduces the validation accuracy during training by around 20%. The test set consists of the six declared nuclear tests (2006-10-09 01:35:28.053, 2009-05-25 00:54:43.074, 2013-02-12 02:57:51.2725, 2016-01-06 01:30:00.927, 2016-09-09 00:30:00.955, 2017-09-03 03:30:01.934) and the collapse after the test in 2017 (2017-09-03 03:38:31.809) as well as two earthquakes in South Korea (the 2016-09-12 11:32:54.953 Mw 5.5 earthquake and the 2017-11-15 05:29:32.040 Mw 5.5 earthquake). The events in the test set are explicitly excluded from the training and validation datasets.

Map illustrating the seismic and hydroacoustic data set used in the DAE. a Seismic stations and events used in the DAE. Seismic primary and auxiliary stations are given as colored squares, FDSN stations used for downstream analysis are given as yellow triangles. Colored circles represent seismic events. b Hydroacoustic station HA11 is given as blue rectangle, events used for training are given as colored circles
We consider as signal samples for training the waveforms of stations with P-phase picks in the REB for the P-model and for the LP-model waveforms of stations where S-phases where picked as well. For the P-model we use a fixed length of 60 s and for training the LP-model we use 360 s of waveforms. Therefore in the P-model denoiser dataset some S-phases are contained for events close to a station and in the LP-model always P-phases as well. Using varying start times deals with potential wrongful sample dependent pattern recognition, i.e. the model learning where after a certain number of samples a phase onset should occur and artificially increase the estimated signal amplitudes. We adapt this by using varying start times of each waveform in the training and in each epoch by applying uniform random choices of relative start times of each time window. The relative difference between beginning of the waveform snippet and the first phase onset can vary between 0 s and 14 s before the onset. The end of the signal window is shifted accordingly to adhere to the fixed waveform length of 60 and 360 s for the P- and LP-DAE, respectively. Five noise samples are taken for each station with phase picks from random times in the hours before the events in the training dataset and checked with a STA/LTA filter to not include any transient signals. Noise samples from three different time windows per event and per station for all components are considered. The length of the noise sample is the same as the length of the respective signal samples, 60 s for the P-model DAE and 360 s for the LP-model DAE.
2.2 Hydroacoustic Dataset
A separate dataset for hydroacoustic training and validation is used to test the potential application of the DAE to hydroacoustic waveform data. The DAE is tested on the two hydrophone triplets of the IMS station HA11 in the northern Pacific Ocean, north (HA11N) and south (HA11S) of Wake island. We use the same conditions for the hydroacoustic dataset assembly as for the seismic data, including a fixed length of 60 s time windows. We calculate the SNR as the mean of each of the triplets for each event, resulting in 4000 suitable events (Fig. 1b) for training. The low frequency band <1 Hz is extremely noisy at hydroacoustic stations, due to dominant microseisms, therefore denoising is of high interest to hydroacoustic data. We train and test the denoising explicitly only on crustal seismic phase arrivals of earthquakes P-waves and not T-waves propagating from the source region to the hydrophones in an Ocean duct, as it requires only little adaption from the seismic data based DAE’s and is sufficient to validate the possible applicability of the method to hydroacoustic data.
3 Methods
3.1 Description of Autoencoder Method
DAE have been introduced to seismology (Zhu et al., 2019) and have been used in several seismological studies (Tibi et al., 2021; Heuel and Friederich, 2022). DAE are a self-supervised CNN, which learns sparse representations of spectrograms of any time domain waveform. A mask function between 0 (noise) and 1 (signal) is learned without explicitly labeling them, based on the known training dataset signal and noise waveforms. Outputs are the signal and noise masks in the spectral domain, which are element-wise multiplied with the noisy time-frequency coefficients to get two time-frequency representations for signal and noise (Heuel and Friederich, 2022), which can be transformed back into time domain waveforms representing the signal and noise separately. This separation allows for the check of the quality of the predicted noise and signal mapping.
To calculate the time-frequency coefficients input of the DAE two options exist, the continuous wavelet transform method (Mousavi et al., 2016) and the short-time Fourier transform (STFT) (Zhu et al., 2019). The STFT method is discussed to perform better (Tibi (xxx) or comparable (Heuel and Friederich, 2022) to the continuous wavelet transform, but has less computational needs. To calculate the STFT transforms we use windows with 0.3s length for the P-model and 1 s windows for the LP model, whereas for hydroacoustic data we only use the P-model with 0.5s windows. We use respective 50 percent overlap between windows. Our autoencoder network architectures design (Fig. 2) is modified based on previous works (Zhu et al., 2019; Tibi et al., 2021; Heuel and Friederich, 2022). In contrast to Heuel and Friederich (2022) we do not use dropout layers and batch normalization but use only the latter. Inputs are the real and imaginary parts of waveform records, which are min-max-normalised independently of each other. We give here a short overview of the method following Heuel and Friederich (2022), as the method in general has been described elsewhere in depth (Tibi et al., 2021; Zhu et al., 2019). The recorded time-frequency record of the data D(t, f) is the sum of signal S and noise N:
The application of the desired mask functions for the signal \(M_S(t,f)\) and noise \(M_N(t,f)\) produce a separated signal:
and separated noise:
where \(TFT^{-1}\) denotes the inverse time-frequency transform.
The DAE therefore learns the two mask functions, ranging from 0 to 1, for the signal:
and for the noise:
During training in each epoch the signal is randomly shifted (data augmentation), then a noise waveform is randomly selected from the noise waveform dataset. Both signal and selected noise are scaled independently by a positive random number before addition (Tibi et al., 2021; Heuel and Friederich, 2022). This mixture of signals and noise realisations greatly increases the number of trainable waveforms to several millions (Heuel and Friederich, 2022), while still using only real recorded waveforms as input. The addition of noise is also the difference between simple encoders and denoising encoders. For the regional DAE noise waveforms are added at random from all available sample waveforms to the signals. This means that for the regional dataset DAEs also noise from a different station can be used. This is of interest to make the DAE resistant to at a singular site up to the time of dataset collection unseen noise conditions, for example construction work. Also our tests showed that high SNR signal waveforms are needed for successful training (>20dB). This however restricts the available events for training DAE for new stations or stations which have a general low SNR. Transferability is of key interest for application of the DAE method. The mask functions \((M_S(t,f), M_N(t,f))\) of the training and validation dataset interact as labels of the CNN (Heuel and Friederich, 2022), and the DAE has the objective to minimize the expected error E between the true mask functions and the predicted mask functions \((\hat{M}_S(t,f), \hat{M}_N(t,f))\):
where i is either S or N and \(\vert \vert \cdot \vert \vert _2\) denotes the Euclidean norm, which has proven as computationally efficient measure for the given problem (Heuel and Friederich, 2022). We use a binary-crossentropy function as the loss-function for optimization. To achieve the encoder in the first part of the network the data are passed through several layers. Each layer has a 2D convolution with a filter size of 3x3 which is followed by a leaky rectified linear unit (ReLU) as activation function. We use also batch normalisation to improve the optimisation of the network (Ioffe and Szegedy, 2015; Goodfellow et al., 2016) in each layer. Each layer reduces the spectral information therefore to more and more sparse representation. This inherently acts as filter function for relevant information. The second part of the network is the decoder part, which reverses the compression in the encoder part by up-sampling the sparse representations again, using 2D deconvolutions. The last layer produces the desired masks by applying a 1x1 convolution (Heuel and Friederich, 2022) with a softmax activation function (Goodfellow et al., 2016). We use skip connections, a cropping layer, which also improve convergence (Liu and Yang, 2018), to match the size of output layers in the decoder part of the network to the corresponding hidden layer in the encoder network as they do not always match. An overview of the neural network architecture used for the DAE is shown in Fig. 2.

Architecture of the neural network used for the DAE, blue connecting lines indicate skip connections.
We use a stride size of 2 \(\times\) 2 and employ an Adam optimizer with 0.001 learning rate. A batch size of 32 for 50 epochs is used, with an early stopping criteria if the validation accuracy does not improve for 5 iterations. This hyperparameters were chosen based on a previous publication (Heuel and Friederich, 2022). We adapted them manually through trial and error until a set of values was found minimizing the validation loss. We split the data into 80% training and 20% validation and achieve an validation prediction accuracy based on Eq. 6 of 84% for the regional P-model and 82% for the LP-model, for the PS-models prediction validation accuracy varies between 84-88%. The validation prediction accuracy here measures how many percent of predictions equal labels of the validation set in the last epoch. We train the DAE on an Nvidia A100 GPU with keras (Chollet, 2017) and tensorflow (Tensorflow Developers, 2022), which took about 10 h per model. We use the described fixed window length for the waveforms of 60 s and 360 s for training of the P- and LP- models, respectively. The denoising framework is able to handle longer and continuous waveform data by splitting them in overlapping windows to match the window length trained for with adaptive overlap but an default overlap of 20% between windows. Shorter waveform data windows as trained for can also be used, as internally zero padding to the full time window is done, but can produce artefacts at the edges.
3.2 Seismic Moment Tensor Analysis
Further analysis of the North Korean nuclear tests involves the determination of the source mechanism. The initial characterization of the source mechanism of a potential treaty-relevant event to either be of explosive or non-explosive nature can be based on seismic analysis. A positive isotropic component of an MT is related to an explosion, while a negative isotropic component is related to an implosion or collapse. Natural earthquakes typically do not have large isotropic components but are rather double-couple type sources. The source mechanism is normally determined at long-periods, therefore we also train a specific DAE with longer time windows to denoise the waveforms of the S- and surface wave trains. Seismic MT analysis for the six declared nuclear tests of North Korea have already been carried out extensively (Alvizuri and Tape, 2018; Cesca et al., 2017; Ford et al., 2010; Gaebler et al., 2019; Chiang et al., 2018). This provides a well defined set of events for comparison, where most model assumptions can be fixed, such as the location, frequencies and the velocity model. The most significant potential bias on the source mechanism inference stems from model assumptions and theory error (Duputel et al., 2012), i.e. the velocity model and other modelling assumptions, especially for larger events with high SNR. We emphasize that generally the model error is the main source of bias in moment tensor analysis and not data error, which is the only error type that can be potentially decreased using denoised data. It has been shown that an error in Earth’s structure is often compensated by increased compensated linear vector dipole and isotropic MT components (Valentine and Trampert, 2012; Hejrani and Tkalčić, 2020; Vasyura-Bathke et al., 2021). The model assumption induced bias is also the main reason for the variation in reported source mechanism estimates of the North Korean nuclear tests (Alvizuri and Tape, 2018; Barth, 2014; Gaebler et al., 2019). For the analysis of the North Korean nuclear tests the choice of the velocity model and the frequency filters will introduce a systematic bias, as the inversion problem is otherwise well constrained. This makes them a good choice to consistently check the influence of the effect of using denoised waveforms in comparison to not-denoised data.
We employ a Bayesian bootstrap-based probabilistic inversion scheme to invert for the seismic moment tensor using the open-source software Grond (Heimann et al., 2018). Green’s functions are provided by a pre-computed database to facilitate the fast calculation of synthetic waveforms Heimann et al. (2019). The Green’s function database is calculated based on the AK-135 1-D velocity model (Kennett et al., 1995; Montagner and Kennett, 1996) using the QSSP code (Wang et al., 2017). Input waveform records are processed using the Pyrocko package (Heimann et al., 2017) by instrument restitution, demeaning, detrending, filtering and are downsampled to a 2 s sampling rate to match the Green’s function store. The waveforms are converted to displacement. The horizontal components are rotated from the geographical coordinate system (ZNE) into the event-centric coordinate system (ZRT). We use empirically determined amplitude correction weight factors (Steinberg et al., 2023), with respect to the expected earthquake signal amplitude, correcting for the decay of amplitude with distance (Steinberg et al., 2023; Kühn et al., 2020).
To demonstrate the generalisation and transferability of the trained DAE models we apply them before the inversion on waveform data on relevant regional FDSN stations (see Fig. 1), which were not included in either training or validation datasets. We always use all available stations (Fig. 1) as much as the data availability allows and ensure that the same station selection is used for each test between the not-denoised and denoised waveform based MT inversions. Onward from the 2013 test all MT inversions use the same exact station selection. We invert simultaneously for the six moment tensor components, origin time and source time duration of a triangular source time function. The epicentral location of the events was fixed to 41.3007° N and 129.0728° W Gaebler et al. (2019) and the depth to 4.5 km in order to reduce the number of inversion parameters. Geometric spreading is compensated by applying a distance related weighting scheme to all stations. For all nuclear tests and earthquakes we use the same inversion setup. We invert surface waves using a butterworth bandpass of fourth order between 0.02\(-\)0.05 Hz to be consistent with previous studies (Gaebler et al., 2019; Alvizuri and Tape, 2018). We apply the bandpass filter for the MT inversions on the denoised data. This is done because the point source assumption and corner frequencies of the event necessitate the misfit calculation between observed and synthetic data in a small frequency band. The use of bandpassed denoised waveforms allows to check for the consistency of the changed waveform. We note that after denoising it would be possible also for the smaller events for some of the waveforms to increase the frequency range in the inversion and fit body waves. Station individual time shifts of \(\pm 2\,\)s are in each inversion step to compensate the velocity model. The inversion is done jointly in the time domain and frequency domain with an L2 norm and is performed in 100 parallel so called "bootstrap chains" with pseudo-random station weights combinations. Therefore each bootstrap chain is an independent optimisation process with a different misfit function. This allows to estimate the importance of waveform records. We use 1000 uniform distribution sampler iterations, followed by 20,000 iterations using the directed sampler of Grond, where the sampled distribution shrinks in relation to the variance of the best performing models in the bootstrap chains (Kühn et al., 2020).
4 Results
4.1 Denoising of Seismic Data
We apply the trained DAE on the original waveforms of several events for demonstration. We first present the effect of the denoising for the strongest nuclear test on station BJT (2017, Fig. 3) and for station MJB9B for the weakest nuclear test (2006, Fig. 4). Denoising of the waveforms of the 2017 nuclear test, with already very high SNR, shows that the phase information is conserved, especially for the LP denoiser results at low periods (Fig. 3e). For the 2006 North Korean test (Fig. 4) the results of denoising on MJB9B are demonstrated for the Pg and Pn-phases (Fig. 4). A possible local impulsive signal from a source close to MJB9B is also promoted after denoising. The low-frequency content is well recovered (Fig. 4e), potentially allowing for the use of the P-wave in downstream source analysis, i.e. moment tensor estimation. We note that the denoising of the 2006 test signals on station BJT (Fig. S4) produces good results at first glance but the P-phase denoiser promotes an apparent P-phase arrival 20 s after the theoretical arrival.

Plot of waveforms at station BJT at a distance of 1100 km from the 2017 test which are a original and filtered between 1 and 40 Hz, b original and filtered between 20-50 s, c denoised with the BJT specific DAE filtered between 1 and 40 Hz, d denoised with the general P-phase model filtered between 1 and 40 Hz, e denoised with the LP model and filtered between 0.02 and 0.05 Hz. The waveform amplitudes are maximum normalized for each trace individually

Plot of P-waves at station MJB9B at distance of 970 km from the 2006 nuclear test, else the same as caption of Fig. 3
We further show examples of applying the denoising on two tectonic events in North Korea in Fig. 5, with the larger one being located in the REB at 41.6367 latitude and 127.1054 longitude - roughly 160 km north-west of the North Korean test site with ML 1.9. We note that the ML 1.9 was also included in the test dataset.

Plot of raw waveforms, general IMS P-model and respective station specific (PS) model denoised recordings at IMS array stations KS31 (blue) and USAB0 (red) of earthquakes inside North Korea. a Waveforms from an earthquake located in the REB catalog at latitude 41.6367, longitude 127.1054. Distance to KS31 is 472 km and the distance to USAB0 is 487 km. b shows the respective waveforms of a previously not reported fore-shock of the event shown in (a)
We also show the influence of denoising on long-term spectrograms for the hours after the 2016-09-12 11:32 Mw 5.4 earthquake in Southern Korea (Fig. 6 and Fig. S5), for which in the catalog of the Korean Meteorological Administration Korean Meteorological Administration (xxx) over 900 aftershocks are recorded in the first 24 h.

Plot of spectra of vertical components at station KS31 on 2016-09-12 between 10:30 and 13:30, at distance of 180 km from the 2016-09-12 11:32 Mw 5.4 earthquake and its aftershocks from a original and b P-model denoised waveforms
4.2 Effect on Phase Picking
We test for all six nuclear tests how the phase picks and SNR are affected after denoising for the stations USA0B, KS31, MJB9B, and BJT. The denoised waveforms are not frequency-filtered. We find that in all test cases the phase picks are consistent within a few samples between using frequency-filtered waveforms or denoised waveforms. This is in line with findings from previous studies that the DAE technique is accurately conserving the phase information, compared to frequency filtering methods (Tibi et al., 2021; Heuel and Friederich, 2022). In general, onset time, frequency and amplitude ratios of the wave trains are well preserved for the P-phase signals of the later five nuclear tests (2009–2017) after denoising. This is not surprising, since the signals are impulsive and exhibit a clear shape. However, the fit of the denoised data for the weakest nuclear test (2006) decreases with the lower SNR. In detail, we compare the denoised data and the simple 1 Hz high pass filtered data with the original recorded data. It becomes apparent that the signal amplitude and the slope of the first positive half-wave in the denoised data is often less decreased than in the high pass filtered data. This may contribute to a more reliable phase picking in several cases. For quantitative evaluation, the SNR was continuously estimated for the denoised data and the high pass filtered data. At each time, the maximum amplitude difference of a 0.5 second window is set in relation to the RMS value of the 2 s before. Exemplarily, Fig. 7 shows the comparison for KS31. The corresponding figures for USA0B, MJB9B, and BJT are provided in the supplements (Figs. S6–8). The SNR values for the four analyzed stations and the six North Korean nuclear explosions is shown in Fig. 8. The general improvement of the SNR of the first onset is obvious for most of the events at KS31, MJB9B, and BJT. In contrast, USA0B shows no improvement. The SNR for the denoised and the high pass filtered waveforms are about the same size. Besides the general evaluation of the good fit of denoised data with the original data, each station exhibits some individual effects. E.g. the denoised waveform for the 2006 nuclear explosion shows at KS31 a minor time shift, whereas the denoised data for the other events is quite good in phase. Furthermore, the denoised data for the last two events reveal a negative half-wave prior to the P-phase, which will associate a negative polarity, if it is adjusted to the first onset of P-phase. In Table S.1 we compile the results of comparing ML based phase picking Mousavi et al. (2020) and localization of three aftershocks of the 2016-09-12 earthquake in South Korea. This limited tests show a slight improvement in the number of phase picks using denoised waveforms and also show that at an SNR of around 1 no further improvement is achieved using denoised waveforms.

Plot of waveforms for all six North Korean nuclear explosions at the vertical component of station KS31 zoomed in for the P wave. The traces for original data (red), high pass filtered data (purple) and denoised data (black) are overlayed. The continuously estimated SNR is included for the high pass filtered data (light green) and the denoised data (dark green). The waveform traces as well as the SNR traces are normalized for each event individually. Each event is marked by its origin time, as given in the Reviewed Event Bulletin (REB) of CTBTO

SNR estimates between pre-event noise and first P-wave onset for the six nuclear test (in chronological order numbered 1–6) for the stations USA0B, KS31, MJB9B, and BJT for 1 Hz high pass filtered waveforms (light green) and denoised waveforms (dark green)
4.3 Effect on Array Processing
We further evaluate the effect of denoising procedures on array processing methods. As a test we use the collapse signal after the 2017 nuclear test as recorded on the KSRS array in Southern Korea to validate that FK-analysis results are consistent between frequency filtered and denoised data (Figs. 9,a and b and S9). We bandpass filter the restituted data between 1 and 8 Hz, we do not filter the denoised data. We find the same backazimuth and slowness using both datasets. The denoised data based FK-analysis has a relatively higher beampower value compared to the frequency filtered data ones. Furthermore we stack the waveforms using the recovered backazimuth and assuming a P-wave slowness. The resulting beam of the frequency filtered and denoised waveforms (Fig. 9c and d) are similar, however the SNR of the denoised beam is significantly increased. In Table S.2 we compile the results of comparing the cross-bearing localization from KSRS and URSK arrays for the 2017 nuclear test and two earthquakes in the vicinity of the test site.

Array analysis of the records at vertical elements of the KSRS array in South Korea from the collapse event roughly 8 min after the 2017 test. Polar plots of the FK analysis results of a 1–8 Hz bandpass filtered original data, b denoised data. The color indicates the relative beampower. The beam of all KSRS vertical elements for the determined backazimuth and P-wave slowness from c 1–8 Hz bandpass filtered original data and d denoised data
4.4 Effect on Seismic Moment Tensor Analysis
To visualize the resolution of the MT components we convert them into the spherical coordinates of the fundamental lune description of the moment tensor (Tape and Tape, 2012). We also test the recovery of a predefined MT after denoising of synthetic signals with added real pre-event noise, from before the 2017 test (Fig. S10). The synthetic input MT is recovered, but is on the edge of the area of maximum likelihood. Lune parameters of the six tests before and after denoising are shown in Fig. 10. We also check the consistency of the MT estimates for non-explosive events in Fig. 11. The blue dot in both plots indicates the reference solution of Alvizuri and Tape (2018), which we use as measure of the accuracy of our source parameter inference. We note that all our non-denoised data based MT inferences deviate from the reference solution, except for the 2009 test. This deviation from the reference can however be expected due to the choice of different modeling assumptions and is still in the range of other available MT solutions (Barth, 2014; Gaebler et al., 2019). Furthermore the important information to assess a potential bias incurred from using denoised data can already be estimated from the relative position of both non-denoised and denoised inferences to the references. A denoised data based MT should not deviate further from the reference as non-denoised data ones, else we can assume in that case a negative impact on precision when using denoised data.

Lune plots of the ensemble of the best 500 estimated moment tensors for each declared nuclear test from 2017 to 2006 in chronologically descending order from original (a, c, e, g, i, k) and denoised waveforms (b, d, f, h, j, l). The color indicates the density of estimates, with warmer colors indicating higher densities. The blue dot indicates the reference solution by Alvizuri and Tape (2018).

Lune plots of the ensemble of the best 500 estimated moment tensors from each original and denoised waveforms for the collapse event 8 min after the 2017 test in subfigures a and b respectively, and the two tectonic events in the southern Korean peninsula on 2016-09-12, in subfigures c and d respectively, and for the one on 2017-11-15 in subfigures, e and f respectively. The color indicates the density of estimates, with warmer colors indicating higher densities. The blue dot indicates the reference solution by Alvizuri and Tape (2018).
We further compare the precision (or spread) of the likelihood distributions between not-denoised and denoised data based MT inferences. Precision increases in all cases after denoising, except for the 2017 test. After denoising the source mechanism inference is shifted in comparison between not-denoised and denoised waveform based MT estimates, however the accuracy in comparison with the reference increases. We find similar misfits in all cases between not-denoised and denoised inversions. For the entire set of predicted parameters, misfits and further result details see the inversion reports (Steinberg et al., 2023). In all real data test cases, except the 2017 test, the ensemble of the estimated MTs after denoising have higher or at least similar precision (Fig. 10). This does not necessarily mean that they have higher accuracy. Taking the reference solutions (Alvizuri and Tape, 2018) as the goal for achieving accuracy, both the not-denoised and denoised waveform based MT inversion perform equally well. In case of the 2006 test the denoised waveform based estimated MT ensemble has higher accuracy in comparison to the not-denoised inversion estimates as well as higher precision, meaning it is relatively closer to the reference solution.
Tab. 1 shows the determined Mw before and after denoising, together with the Mw values from Alvizuri and Tape (2018). As the amplitudes of the waveforms are changed during denoising based on pre-event noise, the determined Mw is slightly less well constrained. The estimated moment magnitudes in Table 1 are in general consistent with the reference values (Alvizuri and Tape, 2018) despite the difference in the used velocity model. The estimated moment magnitudes tend to be slightly higher and less constrained after denoising, except for the test in 2006 and 2009.
4.5 Denoising of Seismic Signals at Hydroacoustic Stations
As a proof of concept for the successful application of the denoising procedure on hydroacoustic data, station recordings of HA11 are also taken into account here. P-wave signals from various earthquakes recorded at the northern and southern hydrophone triplet of the station can be identified before and after denoising, which were taken from the IDC-REB catalogue to train the DAE denoiser. Special emphasis is given here to the P-waves of the last North Korean nuclear test (Fig. 12).

Long period (20-50 s) waveform signals for the 2017 North Korean nuclear test recorded at hydroacoustic stations H11N and H11S. Top six channels (dark purple) show filtered data from the sensor triplets of stations H11S and H11N, bottom six waveform traces (light purple) show data after applying denoising procedures. Middle trace (orange) shows the synthetic waveform from forward modelling. Note the appearance of coherent waveform signals in agreement with the synthetics at at least 4 out of the 6 channels after the application of the denoising method
The denoising of hydroacoustic data clearly improves the SNR of the nuclear test signal in a way similar the seismological data. After bandpass filtering the denoised data at low frequencies (below 1Hz, even in the range between 20 s and 50 s) P-wave signals can be retrieved, which are mostly consistent with a synthetic waveform resulting from forward modelling. No signals of the nuclear test can be retrieved at such low frequencies before denoising for this event. We also apply the trained DAE model to hydroacoustic data of IMS station HA08 at the Chagos archipelago in the northern Indian Ocean to demonstrate the transferability and generalization capabilities of the model. For this we denoise a complete year of raw data from southern hydrophone triplet of HA08 using the same training (and events) as for HA11. One episode of ten hours of data is explicitly shown in Fig. 13, demonstrating the capability of the DAE model to remove the dominant noise and improve the signal detection. This is clearly visible at frequencies below 1 Hz where the noise is mainly related to microseismic activity, but also at higher frequencies, where natural (e.g. surf) and anthropogenic (e.g. shipping) activities might be responsible for nearly continuous noise. Accordingly the SNR can be increased within the complete frequency bandwidth of hydroacoustic datasets using the denoising method for an improved detection and characterisation of transient signals as e.g. earthquake events.

Spectra of raw (a) and denoised (b) waveforms for one hydrophone of IMS hydroacoustic station HA08 in the Northern Indian Ocean. Shown are ten hours of data for 7 May 2021 with a window length of 60 s. Solid lines mark three nearby (< 20\(^\circ\) distance, mid Indian ridge) earthquake events of magnitudes 3.6 to 4.5 from REB and ISC catalogues, which explain the dominant spectral content in the denoised data. Dashed lines show further, more remote earthquakes from the Macquarie Island region up to magnitude 6 from the REB catalogue with HA08 station detections, which can also be identified as transient, vertical features in the denoised spectra
5 Discussion and Conclusions
We concur with previous findings (Tibi et al., 2021; Heuel and Friederich, 2022) that DAEs denoising does not incur phase shifts for the studied six North Korean nuclear tests, in contrast to certain frequency filtering methods. Previous studies also found that the amplitude information is better persevered for the denoised waveforms in comparison to frequency filtered ones (Tibi et al., 2021, 2023). We also agree with findings from previous study (Tibi et al., 2023) which stated that if the input waveforms have already high SNR (low noise), only very little improvement can be achieved by denoising (Fig. 8). We note that when applying frequency filtering on the DAE denoised waveforms the phase is changed similar to when using only frequency filtering. The SNR and phase comparison results (Figs. 7 and 8) confirm, that standard filtering is still sufficient for clear signals, however, denoising can improve the reliability of phase picking if the signal onsets are more emergent and disturbed. We do therefore see a great potential improvement in the phase pick accuracy for smaller events, due to increased SNR. Those effects need further investigation in order to estimate the limitations and to find improvements of the DAE technique. The timing of phase picking is not significantly affected in the studied six nuclear test cases, proving the suitability of DAE denoised data for localization.
We also see improvement for array processing methods using denoised waveforms, which is of particular interest to the primary seismic stations of the IMS network consisting of many arrays. We find consistent FK-results using the frequency filtered and denoised data of the collapse after the 2017 nuclear test on the KSRS array (Fig 9a and b) but with higher relative and absolute beam values using the denoised data. This means that array methods are not biased by using denoised waveforms. The SNR of the respective stacked waveforms is greatly improved across the spectrum using denoised data (Fig 9c and d), demonstrating the potential benefits using DAE. Another good example is the application of the trained models to North Korean earthquakes (Fig. 5), hinting at the possible increase in magnitude of completeness using denoising techniques.
DAE denoising however incurs some minor amplitude changes. As the denoised signal is resulting from a subtraction of recorded data with assumed noise (Fig. 5) the denoised signal is always smaller than the frequency filtered recorded data amplitudes. This amplitude reduction of the denoised signal is in proportion to the immediate pre-event noise and therefore might not be consistent between different stations or even different noise conditions at the same station. In case of moment tensor analysis this individual station dependent amplitude changes can introduce biases, as it heavily relies on relative amplitudes between stations. Our results show however that the moment tensors are mostly consistent before and after denoising (Figs. 10 and 11) and allow for the same interpretation of the source mechanism, either being an explosion or an tectonic earthquake. The lune parameter estimates from (Alvizuri and Tape, 2018) are used by us as the goal for achieving accuracy. The denoised waveform based MT estimations perform similar or even better in terms of accuracy, compared to the inferences based on the non-denoised data. Furthermore the precision is always improved, with the exception being the 2017 test, for which the SNR is already good. The MT inversion results of the 2006 test are the most significantly improved after denoising, which is the smallest test and has the lowest number of available IMS waveform records, therefore an increase in SNR at some stations can make a difference. In contrast the estimated moment magnitudes tend to be slightly less well constrained after denoising, except for the 2006 and 2009 North Korean nuclear tests (Fig. 10). This is the result of the denoising working on individual stations and slightly changing the amplitudes based on observed pre-event noise at the station level, due to imperfect mapping of signal and noise coefficients. The estimated moment magnitudes from both not-denoised and denoised data (Tab. 1) are consistent with the reference values (Alvizuri and Tape, 2018) despite the difference in the used velocity model. The largest impact on the MT estimation still remains to be model error in form of the choice of the velocity model and other source of theory error, as evident by the difference in MT estimates from different publications and also from the difference between our estimates and our reference Alvizuri and Tape (2018). The application of the IMS data trained DAE to FDSN stations for the MT inversions proves the transferability and generalization of the DAE.
We expect a higher false positive rate when running standard detectors on denoised data in comparison with running them on the frequency filtered data. This is the case because the objective in every time window is to find a mask function. The mask function will almost never be perfectly 1 or 0, so there is always a mapping of denoised waveform data into a "pseudo" earthquake signal, as the DAE is trained to recover earthquake signals. We find however that the relative amplitudes of the noise and signal masks are a good first indication if the denoised waveforms contain an actual signal. For false positives the signal mask may contain a waveform signal which appears in phase content like a transient earthquake signal but has extremely small amplitudes in comparison with the noise. We highlight the heightened need for robust phase association from several stations after denoising to avoid false positives. A method to test the robustness of single station defections after denoising is to add different random realizations of real noise to the waveform of interest and check the consistency of the recovered signal part. Detections using arrays data should therefore inherently be more robust, even without the need of adapted detection algorithms. Impulsive electronic or impulsive noise, not explicitly included in the training dataset can be wrongly transformed into apparent signals, as seen for the waveforms of the 2006 test at station BJT (Fig. S4). Future work should include respective dedicated noise samples.
The application of denoising on hydroacoustic data shows certain benefits, since SNR is increased and transient signal features can be extracted and highlighted from raw hydrophone data within a broad frequency range. Signals visible after denoising of e.g. the 2017 nuclear test at 20-50 s are ascribed by the predicted signal mask based on the information contained in the raw data at higher frequencies. They do match however well with the forward modeled synthetic waveform and therefore indicate the potential of DAE based denoising to construct meaningful signals at masked frequency bands based on information of other parts of the spectrum. We observe inconsistencies between observed and modeled waveform shape at one, probably two of the six hydrophone traces. The reason for this could either be a polarity switch or local interaction with seafloor topography at the site, rather than an issue with the DAE. Furthermore, the denoising is generally capable of suppressing continuous noise features not related to the trained signal classes, as prominently demonstrated for HA08. The denoising applied to this station was learned with a set of earthquake detections from another station, HA11, therefore showing a good training transferability and generalization of the method.
Generally the IMS data and the REB catalog proved a good basis for dataset construction with many events in the magnitude range of interest (Fig. 1 and S.2/3) to train a DAE for regional waveform denoising. We find that the dataset curation is the most crucial part in training suitable and performing DAE. This is evident by the difference in performance using different thresholds for SNR as well as the different performance of the regional and station specific DAE (Figs. 3, 4 and 5). Signals with very high SNR need to be used for training, thus limiting the number of available data for individual stations and simultaneously increasing the magnitude threshold of the events used. This is however not unproblematic as the signal characteristics of larger earthquakes do not well represent the signal of smaller earthquakes. Imbalance in the training dataset of signal types is not desirable, as this will skew the signal predictions towards the signal type which was over-represented in the training dataset. Our transfer application of both generalized and station specific DAE to stations which were not included in the training dataset were successful for both seismological and hydroacoustic data. As a possible approach for future work we therefore propose using DAE to use signal waveforms of interest from all available stations and use the specific noise from a station of interest to train a station specific but signal generalized model.
Future work related to testing the denoising of IMS stations needs to involve the systematic testing of the impact of denoising on earthquake catalogs, such as the REB, to check for the statistical significance of improvements under different SNR conditions. The denoised waveforms of both the P- and LP-models could be potentially combined afterwards to generate a broadly denoised waveform valid for all phases. The transferability of the method to seismic signals in hydroacoustic data is also a promising indicator that this method is potentially applicable in the future to purely hydroacoustic signals as well and probably even to any kind of IMS station waveform data for the detection of transient, hazardous or explosive events. We conclude that DAE, as trained here on IMS data and the REB catalog, could potentially provide a useful, mostly unsupervised and generalizable, alternative to other established noise removal methods, i.e. frequency filtering methods.
Data Availability
Data from regional seismometers are available via FDSN services from GEOFON and IRIS. Data from global IMS seismic arrays are available to National Data Centers of the CTBT and to others upon request through the virtual Data Exploitation Center (vDEC) of the IDC at https://www.ctbto.org/specials/vdec. The trained models and the DAE code variant used here are made available on https://github.com/braunfuss/denoising-ims (Doi: 10.5281/zenodo.10047693). When using the code or models please cite the publication by Heuel and Friederich (2022), with the respective raw version of the code used here under https://github.com/JanisHe/seisDAE. The specific datasets used for training are available upon request.
References
Tibi, R., Hammond, P., Brogan, R., Young, C. J., & Koper, K. (2021). Deep learning denoising applied to regional distance seismic data in Utah. Bulletin of the Seismological Society of America, 111(2), 775–790.
Mousavi, S. M., Langston, C. A., & Horton, S. P. (2016). Automatic microseismic denoising and onset detection using the synchrosqueezed continuous wavelet transform. Geophysics, 81(4), 341–355.
Rost, S., & Thomas, C. (2002). Array seismology: Methods and applications. Reviews of Geophysics, 40(3), 2–1227. https://doi.org/10.1029/2000RG000100
Chandna, P., Miron, M., Janer, J., Gómez, E.: Monoaural audio source separation using deep convolutional neural networks. In: Latent Variable Analysis and Signal Separation: 13th International Conference, LVA/ICA 2017, Grenoble, France, February 21-23, 2017, Proceedings 13, pp. 258–266 (2017). Springer
Zhu, W., Mousavi, S. M., & Beroza, G. C. (2019). Seismic signal denoising and decomposition using deep neural networks. IEEE Transactions on Geoscience and Remote Sensing, 57(11), 9476–9488.
Mousavi, S. M., Sheng, Y., Zhu, W., & Beroza, G. C. (2019). Stanford earthquake dataset. A global data set of seismic signals for ai. IEEE Access: STEAD).
Heuel, J., & Friederich, W. (2022). Suppression of wind turbine noise from seismological data using nonlinear thresholding and denoising autoencoder. Journal of Seismology, 26(5), 913–934.
Zhu, L., Liu, E., & McClellan, J. H. (2015). Seismic data denoising through multiscale and sparsity-promoting dictionary learning. Geophysics, 80(6), 45–57.
Huang, W., Wang, R., Zu, S., & Chen, Y. (2017). Low-frequency noise attenuation in seismic and microseismic data using mathematical morphological filtering. Oxford University Press.
Donoho, D. L., & Johnstone, I. M. (1995). Adapting to unknown smoothness via wavelet shrinkage. Journal of the American Statistical Association, 90(432), 1200–1224.
Gaci, S. (2013). The use of wavelet-based denoising techniques to enhance the first-arrival picking on seismic traces. IEEE Transactions on Geoscience and Remote Sensing, 52(8), 4558–4563.
Naghizadeh, M., & Sacchi, M. (2012). Multicomponent f-x seismic random noise attenuation via vector autoregressive operators. Geophysics, 77(2), 91–99.
Tibi, R. (2024). Personal communications.
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: International Conference on Machine Learning (pp. 448–456). pmlr.
Goodfellow, I.J., Bengio, Y., Courville, A.: Deep Learning. MIT Press (2016). http://www.deeplearningbook.org
Liu, J.-Y., Yang, Y.-H.: Denoising auto-encoder with recurrent skip connections and residual regression for music source separation. In: 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pp. 773–778 (2018). IEEE
Chollet, F.: Deep learning with python. Manning (2017)
Developers, T.: Tensorflow. Zenodo (2022)
Alvizuri, C., & Tape, C. (2018). Full moment tensor analysis of nuclear explosions in north korea. Seismological Research Letters, 89(6), 2139–2151.
Cesca, S., Heimann, S., Kriegerowski, M., Saul, J., & Dahm, T. (2017). Moment tensor inversion for nuclear explosions: What can we learn from the 6 january and 9 september 2016 nuclear tests, north korea? Seismological Research Letters, 88(2A), 300–310.
Ford, S. R., Dreger, D. S., & Walter, W. R. (2010). Network sensitivity solutions for regional moment-tensor inversions. Bulletin of the Seismological Society of America, 100(5A), 1962–1970.
Gaebler, P., Ceranna, L., Nooshiri, N., Barth, A., Cesca, S., Frei, M., Grünberg, I., Hartmann, G., Koch, K., Pilger, C., et al. (2019). A multi-technology analysis of the 2017 north korean nuclear test. Solid Earth, 10(1), 59–78.
Chiang, A., Ichinose, G. A., Dreger, D. S., Ford, S. R., Matzel, E. M., Myers, S. C., & Walter, W. (2018). Moment tensor source-type analysis for the democratic people’s republic of korea-declared nuclear explosions (2006–2017) and 3 september 2017 collapse event. Seismological Research Letters, 89(6), 2152–2165.
Duputel, Z., Rivera, L., Fukahata, Y., & Kanamori, H. (2012). Uncertainty estimations for seismic source inversions. Geophysical Journal International, 190(2), 1243–1256.
Valentine, A. P., & Trampert, J. (2012). Assessing the uncertainties on seismic source parameters: Towards realistic error estimates for centroid-moment-tensor determinations. Physics of the Earth and Planetary Interiors, 210, 36–49.
Hejrani, B., & Tkalčić, H. (2020). Resolvability of the centroid-moment-tensors for shallow seismic sources and improvements from modeling high-frequency waveforms. Journal of Geophysical Research: Solid Earth, 125(7), 2020–019643.
Vasyura-Bathke, H., Dettmer, J., Dutta, R., Mai, P. M., & Jonsson, S. (2021). Accounting for theory errors with empirical bayesian noise models in nonlinear centroid moment tensor estimation. Geophysical Journal International, 225(2), 1412–1431.
Barth, A. (2014). Significant release of shear energy of the north korean nuclear test on february 12, 2013. Journal of Seismology, 18, 605–615.
Heimann, S., Isken, M., Kühn, D., Sudhaus, H., Steinberg, A., Daout, S., Cesca, S., Bathke, H., Dahm, T.: Grond: A probabilistic earthquake source inversion framework. GFZ Data Services (2018)
Heimann, S., Vasyura-Bathke, H., Sudhaus, H., Isken, M. P., Kriegerowski, M., Steinberg, A., & Dahm, T. (2019). A Python framework for efficient use of pre-computed Green’s functions in seismological and other physical forward and inverse source problems. Solid Earth, 10(6), 1921–1935.
Kennett, B. L. N., Engdahl, E. R., & Buland, R. (1995). Constraints on seismic velocities in the Earth from traveltimes. Geophysical Journal International, 122, 108–124.
Montagner, J.-P., & Kennett, B. L. N. (1996). How to reconcile body-wave and normalmode reference Earth models? Geophysical Journal International, 125, 229–248.
Wang, R., Heimann, S., Zhang, Y., Wang, H., & Dahm, T. (2017). Complete synthetic seismograms based on a spherical self-gravitating earth model with an atmosphere-ocean-mantle-core structure. Geophysical Journal International, 210(3), 1739–1764.
Heimann, S., Kriegerowski, M., Isken, M., Cesca, S., Daout, S., Grigoli, F., Juretzek, C., Megies, T., Nooshiri, N., Steinberg, A., et al.: Pyrocko - An open-source seismology toolbox and library. GFZ Data Services (2017)
Steinberg, A., Gaebler, P., Hartmann, G., Johanna, L., Christoph, P.: Grond reports for "Deep neural network based denoising of regional seismic waveforms and impact on analysis of North Korean nuclear tests". Zenodo (2023)
Kühn, D., Heimann, S., Isken, M. P., Ruigrok, E., & Dost, B. (2020). Probabilistic moment tensor inversion for hydrocarbon-induced seismicity in the groningen gas field, the netherlands, part 1: Testing. Bulletin of the Seismological Society of America, 110(5), 2095–2111.
Korean Meteorological Administration, K.: Korean Meteorological Administration Earthquake Catalog. https://www.weather.go.kr/w/eqk-vol/search/
Mousavi, S. M., Ellsworth, W. L., Zhu, W., Chuang, L. Y., & Beroza, G. C. (2020). Earthquake transformer-an attentive deep-learning model for simultaneous earthquake detection and phase picking. Nature communications, 11(1), 3952.
Tape, W., & Tape, C. (2012). A geometric setting for moment tensors. Geophysical Journal International, 190(1), 476–498.
Tibi, R., Young, C. J., & Porritt, R. W. (2023). Comparative study of the performance of seismic waveform denoising methods using local and near-regional data. Bulletin of the Seismological Society of America, 113(2), 548–561.
Acknowledgements
We thank Janis Heuel for discussion. We thank Rigobert Tibi and two anonymous reviewers for helpful and very appreciated feedback. All authors thank the CTBTO and the IMS station operators for guaranteeing the high quality of the data. Visualkeras was used for visualization of the network architecture.
Funding
Open Access funding enabled and organized by Projekt DEAL. Johanna Lehr was funded by the DFG Projekt DO 1833/3-1 “NonDC-BoVo - Non-double-couple moment tensor components and their relation to fluid flow in the West-Bohemia/Vogtland region”.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Steinberg, A., Gaebler, P., Hartmann, G. et al. Deep Neural Networks Based Denoising of Regional Seismic Waveforms and Impact on Analysis of North Korean Nuclear Tests. Pure Appl. Geophys. (2024). https://doi.org/10.1007/s00024-024-03491-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00024-024-03491-3