
Abstract
Our study examines the role of auxiliary variables in the process of spatial modelling and mapping of climatological elements, with air temperature in Poland used as an example. The multivariable algorithms are the most frequently applied for spatialization of air temperature, and their results in many studies are proved to be better in comparison to those obtained by various one-dimensional techniques. In most of the previous studies, two main strategies were used to perform multidimensional spatial interpolation of air temperature. First, it was accepted that all variables significantly correlated with air temperature should be incorporated into the model. Second, it was assumed that the more spatial variation of air temperature was deterministically explained, the better was the quality of spatial interpolation. The main goal of the paper was to examine both above-mentioned assumptions. The analysis was performed using data from 250 meteorological stations and for 69 air temperature cases aggregated on different levels: from daily means to 10-year annual mean. Two cases were considered for detailed analysis. The set of potential auxiliary variables covered 11 environmental predictors of air temperature. Another purpose of the study was to compare the results of interpolation given by various multivariable methods using the same set of explanatory variables. Two regression models: multiple linear (MLR) and geographically weighted (GWR) method, as well as their extensions to the regression-kriging form, MLRK and GWRK, respectively, were examined. Stepwise regression was used to select variables for the individual models and the cross-validation method was used to validate the results with a special attention paid to statistically significant improvement of the model using the mean absolute error (MAE) criterion. The main results of this study led to rejection of both assumptions considered. Usually, including more than two or three of the most significantly correlated auxiliary variables does not improve the quality of the spatial model. The effects of introduction of certain variables into the model were not climatologically justified and were seen on maps as unexpected and undesired artefacts. The results confirm, in accordance with previous studies, that in the case of air temperature distribution, the spatial process is non-stationary; thus, the local GWR model performs better than the global MLR if they are specified using the same set of auxiliary variables. If only GWR residuals are autocorrelated, the geographically weighted regression-kriging (GWRK) model seems to be optimal for air temperature spatial interpolation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Providing accurate, high-resolution spatial information is one of the most challenging tasks of contemporary environmental sciences. However, this particularly concerns climatological and meteorological data as they are used not only for climatological analysis itself, but they are frequently applied as the significant input for modelling and studies in many other scientific disciplines or applications, for example, in bioclimatology, dispersion of atmospheric pollutants, or for planning and supporting location decisions. There are two general approaches to the development of continuous spatial climatological information: physically based and data based. The first is performed by means of the climatological models in either global [General Climate Models (GCMs)] or regional/mesoscale models [Regional Climate Models (RCMs)]. To the RCMs class belong such models as, e.g. Weather Research and Forecasting (WRF; Skamarock et al. 2008) or Regional Atmospheric Modeling System (RAMS; Pielke et al. 1992). The GCMs are typically run at coarse spatial resolution (max. ~50 km) and do not account for local scale features and phenomena caused, e.g. by topography, local land use/land cover or clouds. To overcome these problems, various dynamical or statistical downscaling techniques can be applied to process GCMs’ outputs (Wilby and Wigley 1997). For example, the WRF model can be used to dynamically downscale GCM simulations even up to a few kilometres spatial grid (Kryza et al. 2012; Bowden et al. 2012). But still, even if RCMs are continuously developing and their accuracy and spatial resolution are increasing, spatial interpolation allowing for transformation from discretely distributed point data into continuous high-resolution spatial information is the most frequently used for mapping climatological/meteorological elements. However, the final choice between physically based or data-based spatialization procedures is strongly dependent on many factors, including, e.g. the specific user’s needs and skills, and the access to required datasets, specialized software or computational resources.
There are dozens of methods available to perform the spatial interpolation of various elements of the natural environment. For example, Li and Heap (2008) reviewed 62 methods and their variations applied and described in 51 publication. These methods can be considered as universal which means that they can be used for various environmental features. The choice of the optimal algorithm in a given case is a difficult task as it depends on characteristics of the spatial process, properties of the modelled variable, the expectations of the modeller, e.g. assumed accuracy and resolution, the number and spatial distribution of input data and many others. In the selection of interpolation procedure, the classifications of the algorithms, presented, e.g. by Hengl (2007), Li and Heap (2008) or in COST Action 719 Final Report (2008), or the decision trees (Hengl 2007; Szymanowski et al. 2013) allowing for selection and grouping methods accordingly to their theoretical basis and properties, might become useful. Most of the “universal” spatialization methods have been used for the interpolation of climatological elements, like air temperature and atmospheric precipitation. There are also some methods that have been intentionally developed or modified for the use in climatology, e.g. lapse rate method (LR; Lennon and Turner 1995; Willmott and Matsuura 1995), thin-plate splines (TPS; Hutchinson 1995), AURELHY (Benichou and Le Breton 1987), PRISM (Daly et al. 1994, 2008) and MISH (Szentimrey and Bihari 2004). There are also significant advances in hierarchical Bayesian and non-stationary process modelling techniques (Huerta et al. 2004; Al-Awadhi and Al-Awadhi 2006; Cressie and Johannesson 2008; Yue and Speckman 2010; Wilson and Silander 2014).
In the case of the air temperature spatialization, where the physical processes and environmental co-variables determining spatial distribution are quite well known, the multivariable techniques based on deterministic or geostatistical (or both) assumptions are the most frequently used. The reviews of papers and applications show that the most proper and frequently applied for air temperature spatial interpolation are residual kriging (regression-kriging, RK), regression methods—mostly multiple linear (MLR), and TPS (COST Action 719 Final Report 2008; Szymanowski et al. 2012). Less frequently, other techniques, such as LR, PRISM, co-kriging (CK), kriging with external drift (KED) or combination MLR + IDW [inverse distance weighting (IDW)], are also applied. All of them are multivariable approaches, performed with the use of one or more environmental auxiliary variables.
In multivariate climatological interpolation, the role of an explanatory variable is to replicate the impact of environmental factor on the magnitude and the distribution of the interpolated climate element. A review of previous works, taking into account the multidimensional techniques in air temperature spatialization, indicates that there are variables that can be considered as universal and almost always included in the analysis (e.g. elevation for air temperature), and those that are used depending on the climate (geographical) characteristic of a study area and the scale of impacts (usually macro- to local scale) taken into account. Altitude is the major factor determining the spatial pattern of air temperature at global/regional scales and when the longer averaging periods are considered. Its level of influence on temperature is usually many times greater than that of other environmental factors (Szymanowski et al. 2012). In practice, one can be assured that if the multivariate technique is used for air temperature interpolation, the altitude is included in the set of explanatory variables. However, there can be some exceptions, as, for example, in the case of the urban heat island interpolation for a city located in a flat terrain (Szymanowski and Kryza 2012).
The same, general group of auxiliary variables is represented by coordinates, even if they are used less frequently than altitude. Latitude and longitude (or their counterparts in local coordinate systems) are used to reflect an overall spatial trend. This trend can be, for instance, a consequence of systematic changes in insolation, the impact of the oceans, lands, or mountain ranges and, in some cases, circulation-driven regularities with the advection of air masses (e.g. Nalder and Wein 1998; Ninyerola et al. 2000; Ustrnul and Czekierda 2005; Perry and Hollis 2005a, b; Szymanowski et al. 2012, 2013). As the coordinates are used to characterize general tendencies over a study area, they are usually less applicable for small areas with strong locally determined air temperature fields (Szymanowski and Kryza 2009, 2012). In some papers, in addition to coordinates, the index of continentality has also been used (Attorre et al. 2007; Hogewind and Bissolli 2011; Krahenmann et al. 2011).
Another, very frequently used variable is a distance from the sea (White 1979; Bjornsson et al. 2007; Boi et al. 2011; Joly et al. 2011) or distance from other major bodies of water (Holdaway 1996; Hiebl et al. 2009; Tietavainen et al. 2010). Distance from water bodies, like most of the variables capturing the impact of land use/land cover, is typical of regional or local scale. Their impact, decreasing with distance, is clearly marked up to 10 km and negligible in practice for distances exceeding 100 km from the sea (Daly 2006). The influence of other land cover classes can also be observed locally (Jarvis and Stuart 2001a, b; Percec Tadic 2010). Here, the specific role is played by the impact of urban areas, especially due to well-known phenomena of air temperature rise in cities—the urban heat island (Choi et al. 2003; Hiebl et al. 2009; Szymanowski et al. 2013).
Terrain relief usually also has a local influence on the air temperature field. Various terrain derivatives can be used to reflect the relief-controlled effects. One of the most frequently applied is slope inclination (Lennon and Turner 1995; Szymanowski et al. 2013); however, its role in physical processes determining air temperature is ambiguous. This variable probably should not stand alone but rather in conjunction with terrain aspect (Agnew and Palutikof 2000; Attorre et al. 2007; Hiebl et al. 2009; Apaydin et al. 2011). The role of the relief, particularly associated with the disposal of cooler air from the slopes and a tendency to the accumulation of cold air in concave terrain forms, is expressed in such variables as concavity/convexity, relative height and terrain curvature (Ninyerola et al. 2007; Esteban et al. 2009; Hiebl et al. 2009; Szymanowski et al. 2013).
Relatively rarely used explanatory variable of air temperature is solar irradiation (Vicente-Serrano et al. 2003; Attorre et al. 2007; Benavides et al. 2007; Esteban et al. 2009; Joly et al. 2011), even if this variable is complex, representing general geographic, atmospheric and astronomic energetic conditions, as well as local influence of terrain height and relief (slope, aspect, and hillshades).
The above-mentioned variables can be used in various shapes, for example, taking into account the feature in certain directions only (Vicente-Serrano et al. 2003; Perry and Hollis 2005a, b). Explanatory variables can also be further modified by application of various moving window filters (focal functions) to simulate the effect of the so-called source area (defined by the window size) on the air temperature distribution (Agnew and Palutikof 2000; Jarvis and Stuart 2001a, b; Szymanowski et al. 2013). Auxiliary variables can also be created as combinations of environmental factors using map algebra or grouping in principal components to reduce the dimension of the model (White 1979; Lennon and Turner 1995; Bjornsson et al. 2007; Percec Tadic 2010).
In previous studies focused on multivariate interpolation of air temperature, two main strategies of appointing the set of explanatory variables were used to specify the regression model. These were the stepwise regression selection (Kurtzman and Kadmon 1999; Brown and Comrie 2002; Apaydin et al. 2011; Boi et al. 2011) or mandatory appointment of auxiliary variables accordingly only to known physical processes but without in-depth analysis of statistical interrelations (Chuanyan et al. 2005; Hogewind and Bissolli 2011). However, in all these attempts, it was assumed that the more spatial variation of air temperature is deterministically explained, the better is the quality of spatial interpolation. The correctness of this assumption, although intuitively justified, has not been thoroughly verified. Thus, one of the purposes of this paper is to review the above thesis—does the incorporation of additional explanatory variables lead to the statistically significant improvement of the model performance, compared with simpler models?
In the above-mentioned research, significantly correlated variables were usually also introduced to the model by the fact that their spatial patterns were “reproduced” on the maps of air temperature. However, there are some reports claiming that the introduction of certain auxiliary variables to the spatial models, even if they are significantly correlated with air temperature, may lead to the unexpected artefacts seen on the maps, if the expert judgment is applied (Szymanowski et al. 2012).
This work addresses the role of the explanatory variable selection for spatial interpolation of climatological elements with air temperature used as an example. We evaluate the role of auxiliary variables in the spatial air temperature models, and present how the environmental co-variables affect the quality of spatial interpolation and how they affect the final maps. This is the novelty of this paper both for climatologists and for the researchers that perform spatial interpolation of climate data with multivariate geostatistical methods and use these data for their own studies at various fields. We demonstrate the importance of proper, conscious application of spatial statistical approaches, and we quantitatively show that over-reliance on physical deterministic relationships may lead to less reliable results than finding a balance between deterministic and stochastic model components. Spatialization in this study is performed with two spatial models frequently used for air temperature interpolation: deterministically applied regression and deterministic-stochastic combined model—the residual kriging. Regression techniques are represented here by two models: global—MLR, and local—geographically weighted regression (GWR), which are also extended to a deterministic-stochastic form. These are relatively frequently used multiple linear regression-kriging (MLRK) and recently developed geographically weighted regression-kriging (GWRK), respectively. All four methods are included in the decision scheme for selection an optimal interpolation method and have been used for spatial modelling of air temperature in Poland (Szymanowski et al. 2012, 2013). Two main aspects of the models’ quality are considered. First, how introducing the additional co-variables affects the goodness-of-fit and the model errors in the points of measurements. Second, how the auxiliary variables visually modify the air temperature maps.
2 Study Area
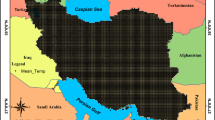
The study area is the territory of Poland, located in Central Europe, between 49°00′N and 54°50′N, and 14°07′E and 24°09′E. The overall area of Poland is 312 679 km2 (with 791 km2 of marine internal waters included). The altitude in the country varies from 1.8 m below (N Poland) to 2499 m above sea level (S Poland). The average height of Poland (173 m a.s.l) is about 100 m less than that for Europe. The areas located in zones: 100–200 m a.s.l. (49.7 %) and 0–100 m a.s.l. (25.2 %) cover the majority of the country area, and the areas located over 1000 m a.s.l. cover only about 0.2 % (Fig. 1). Poland is characterized by transitional climate with strong, varying maritime and continental influences and prevailing western flow.

Study area and location of meteorological stations
The annual mean temperature in Poland changes from below 0 °C in the upmost parts of the highest mountains (Tatra Mts.) to >8.5 °C in W and SW Poland (Słubice, Legnica, Wrocław; Fig. 1). However, in the lowland areas, mean values <7 °C are observed only in the NE part of the country. Differences of mean air temperature in the coldest and warmest years in relation to the long-term annual average do not exceed 3 °C (Woś 2010), except for the mountains. The spatial distribution of long-term annual mean temperature, with general increasing tendency to the south-west, indicates a general impact of latitude and oceanic influences, strongly affected by altitude. The highest values are observed in lowlands and in the valleys of large rivers, and the lowest annual means are noticed on the mountain tops (Kożuchowski 2011).
There are large annual changes in the spatial distribution of air temperature due to large scale climatological factors. The W–E-oriented isotherms are shaped by the insolation energy and compounded by the impact of the Baltic Sea in the north and latitudinally stacked mountain ranges in the south. The effect of altitude, regardless of the season, is constant (decrease in temperature with height), while the role of the Baltic Sea changes seasonally from warming in autumn and winter, to cooling in spring and summer. Zonal arrangement of isotherms is most clearly visible in summer. Azonal factors, such as circulation-driven impact of the Atlantic Ocean, are apparently showed up in winter, forming a N–S course of isotherms.
Regardless of the season, the coldest areas are the uppermost parts of the mountains and the lowland parts in NE Poland. In winter, except for the coldest mountain areas, the temperature decreases from west to east, where it reaches an average below −3 °C. In the west of the country, especially in the coastal zone, where warming effects of the Baltic Sea are clearly marked, the average winter air temperature is above 0 °C. The temperature field in spring is transitional between winter and summer conditions—isotherms are NW–SE oriented, with the highest temperatures (>8 °C) in the SW part of the country. In summer, most of the area of Poland is characterized by seasonal average temperatures exceeding 18 °C, with the exception of lakeland areas in the north of the country and uplands and mountains in the south. In autumn, the warming influence of the Baltic Sea is already seen; however, a general decrease in temperature into the north-east is also clearly visible. The average seasonal air temperature in NE Poland is below 7 °C.
On average, the coldest and warmest months in Poland are January and July, respectively, and the characteristics of the spatial distribution of temperature in these months are analogous to those seen in winter and summer. Changing effects of various climate factors result in significantly different spatial distribution and values of the air temperature from the long-term averages (Ustrnul 2006).
The highest temperature, 39.5 °C, was observed in Słubice (W Poland) on 30 Jul 1956, and the lowest one, −36.9 °C, in Jelenia Góra (SW Poland) on 10 Feb 1956 (Ustrnul and Czekierda 2009). The highest maximum temperatures can be observed in Poland in various circulation types, but mainly in anticyclonic situations. In the case of the lowest minimum temperatures, the coldest, below −35 °C, are observed in areas in the east of the country (Białystok, Rzeszów). The only exception is station Jelenia Góra, located in a valley where a tendency to accumulate cold air masses is typical. As in the case of the maximum temperature, minimum temperatures are also observed mainly in anticyclonic circulation types, especially in winter, during the continental cold air advections from Eastern Europe and Asia, and also under a cloudless weather conditions in nighttime (strong radiation loss).
Maps of the mean daily temperature usually show a significant variability of the air temperature field and rather slight similarity of thermal field pattern, in comparison with climatologic, highly aggregated maps for the corresponding months or seasons. This reflects the greater role of dynamic, circulation factors influencing the daily temperature field in comparison to the impact factors of more static geo-environmental features such as altitude or distance from the sea (Ustrnul and Czekierda 2009).
3 Data
3.1 Air Temperature Data
Air temperature measurements for this study were gathered mostly in the meteorological network operated by the Institute of Meteorology and Water Management (IMGW) in Poland. Data were available from 197 stations and were next complemented by data from 53 meteorological stations located in the closest neighbourhood of Poland (up to about 100 km from the country boundaries; Fig. 1). The inclusion of these additional stations was done to avoid extrapolation for grids located outside the convex hull of Polish stations. Second, this additional set has increased the number of stations located in the higher elevated area, which allows for a more precise modelling of relation between temperature and altitude—one of the most significant environmental correlations of air temperature. And third, the enlarged set of stations, allowed improving the relevance of statistical inference accordingly to the increased number of observations in statistical models and, as a result, enhanced the quality of air temperature estimation.
Meteorological stations used in the study are rather evenly distributed over the study area. The spatial distribution is dispersed, according to the nearest neighbour analysis (Mitchell 2005), although there are clear regional differences in network density. 83 % of the study area is located no further than 30 km from the nearest station, and less than 0.3 % of the area is located further than 50 km, mainly in the central and north-eastern parts of the country. On average, for the whole country, station density is about 6.3 stations/10,000 km2, with the highest density, reaching 16 stations/10,000 km2 in the western part of the Polish Carpathians (Fig. 1). The representativeness of the stations in relation to one of the most dominant climate factors, which is the altitude, is of particular importance for the quality of modelling the air temperature using multivariate spatialization techniques. In the case of the Polish meteorological network, low-elevated areas are characterized by relatively large number of stations, mainly due to numerous stations located close to the seashore. Areas located up to 50 m a.s.l., covering 6.4 % of the country are represented by ca 9 % of the stations. Only 33 % of the stations are located in the zone of 100–200 m a.s.l., which covers 49.7 % of the area of Poland, so this zone is slightly underrepresented. Above 200 m a.s.l., there is some over-representation of the number of stations in relation to altitude. The areas elevated above 500 m a.s.l. (~3.5 % of the country area) are covered by 13.2 % of stations. However, a problem is that stations are not evenly distributed over the highest altitude zones. For example, there are no Polish stations between 900 m (Bukowina Tatrzańska) and 1520 m a.s.l. (Hala Gąsienicowa). The extension of a dataset by foreign stations allowed for getting additional 4 stations located in the zone above 900 m a.s.l.: Lysa Hora, Štrbské Pleso, Chopok and Lomnický Štít (Fig. 1). The last two are situated higher than the highest Polish station at Kasprowy Wierch (1991 m a.s.l.).
Data from the Polish stations were provided by the Institute of Meteorology and Water Management. Daily temperatures for Polish and foreign stations were calculated using the same formula: (T06 + T18 + TMAX + TMIN)/4. The measurements for the foreign stations were taken from the Global Summary of the Day, and the Deutscher Wetterdienst (http://www.dwd.de) databases. Sixty-nine cases on five levels of data aggregation from the decade 1996–2005 were prepared for spatial interpolation:
-
Level 1: 1996–2005 annual mean air temperature (one case),
-
Level 2: annual means of the warmest (2000) and coldest (1996) years of the decade 1996–2005 (two cases),
-
Level 3: 1996–2005 monthly mean air temperatures (12 cases),
-
Level 4: monthly means of the warmest and coldest months of the 1996–2005 decade (24 cases),
-
Level 5: daily means, selected to represent varying synoptic conditions, seasons and ranges of variability (30 cases).
The study encompasses all cases of annual and monthly air temperature means from the period 1996–2005 (levels 1 and 3). The selection of cases of individual years and months (levels 2 and 4) was performed based on the highest and lowest areal air temperature mean, calculated with the measurements from the Polish meteorological stations. This made it possible to select the coolest and the warmest year (month) in the analysed decade. Daily cases (level 5) were selected considering thermal and circulation criteria. Cases of high and low spatial variability of air temperature, occurring at different temperature ranges and in different seasons, were included. In addition, selected cases covered a variety of situations in terms of synoptic circulation types, air masses advections and the occurrence of atmospheric fronts. This allowed for spatial modelling of cases characterized by diversified overall level of environmental correlations, as well as by different proportions of deterministic impacts of particular environmental features.
All the cases are summarized in this work. Two cases of air temperature were selected for a detailed analysis. These were the level 1—1996–2005 annual mean (TY) air temperature and one case from the level 5—daily mean of 8 Jan 2003 (TD). The first was characterized by a very high degree of the variance explained by regression model, and the latter was characterized by the lowest determination coefficient of all cases.
3.2 Environmental Variables
Taking into account the causes of climate determining air temperature distribution in Poland (Sect. 2) and former attempts to multidimensional spatial interpolation of air temperature (Sect. 1), a set of potential environmental predictors for the study was prepared, including (Fig. 2):

Sample layers of potential predictors of air temperature in Poland used in this study: a X, b Y, c SDI, d DEM, e IT, f FI, g CCI, h SLP, i AS (explanation of acronyms in the text)
-
Variables describing general spatial tendency (e.g. continentality of climate): coordinates (X, Y) and the sea distance index (SDI),
-
Digital elevation model (DEM) and its derivatives: slope inclination (SLP), concavity/convexity index (CCI), foehn index (FI) and potential total insolation (IT),
-
Land use/land cover derivatives: percentage share of natural (NS) and artificial (AS) surfaces in the vicinity of a given location and the normalized difference vegetation index (NDVI).
All variables were prepared as raster layers of 250 m resolution, projected to the Polish local coordinate system PUWG1992. X and Y coordinates of each cell’s centre were assigned to the corresponding raster cells. Coordinate X was assumed to represent changes in longitude, reflecting the macroscale impact of lands and oceans in central Europe, while coordinate Y—corresponding to the latitude and general solar energy distribution. Both variables, together or separately, may also express the impact of air masses advections and atmospheric circulation (Fig. 2a, b).
The influence of the Baltic Sea on air temperature is described by SDI. Former studies (Szymanowski et al. 2012, 2013) showed that this impact decreases non-linearly with distance; therefore, the index was constructed as the square root of the shortest Euclidean distance (expressed in number of 250 m raster cells) from the coastline (Fig. 2c).
Altitude (DEM) was taken from the SRTM-3 digital elevation model (http://www2.jpl.nasa.gov/srtm), which was projected to PUWG1992 and resampled to 250 m resolution (Fig. 2d). DEM was then used to calculate derivatives: IT, FI, CCI and SLP.
Potential insolation for a given period/day, IT, expressed spatial distribution of potential incoming solar energy (Fig. 2e). Insolation was calculated on the real, inclined surface by the r.sun model, implemented in GIS-GRASS software (GRASS Development Team 2011).
The thermal effect of the foehn wind is well- known in the forelands of various mountain ranges, which can also be found in Poland. So far, however, attempts to simulate the effect of foehn wind were limited to the variables based only on distance from the mountain barrier (Carrega 1995). Because it is not only the distance alone, but, first of all, the combination of distance and height difference that determines the temperature rise on the leeward side of the mountain, a new foehn index (FI) was introduced and tested in the interpolation of selected thermal parameters for the south-western Poland (Szymanowski et al. 2007). The index combines the distance to the mountain barrier with the maximum difference in elevation between the given raster cell and the highest raster in the foehn-favourable direction of advection (Fig. 2f).
The CCI, describing the cold air accumulation in concave landforms, was defined as the difference between the altitude in a given location and DEM averaged in a moving window (circular shape; radii: 1250, 2500 or 5000 m). CCI values close to zero mean that the area is flat, positive values indicate a convex landform, and negative—concave landform.
Local, land use/land cover impact on temperature was described by AS, NS and NDVI variables. The first two were calculated for the surrounding of each grid cell using the same radii of moving window filter as in the case of CCI. The percentage share was calculated using the CORINE Land Cover 2000 (2004) and, for the areas of Ukraine, Belarus and Russia, USGS Land Cover (2011) databases (Fig. 2i). Additionally, the vegetation index NDVI (Tucker 1979) was used to characterize local land cover features. The relationship between NDVI and air temperature is known and proven, both at the country (Kożuchowski and Żmudzka 2001) and local scales (Szymanowski and Kryza 2012). NDVI values were prepared based on MODIS and AVHRR data processed by Clark Labs, Clark University, USA (http://www.clarklabs.org/products/global-gis-image-processing-data.cfm). NDVI was used as a potential predictor of air temperature only for the cases of levels 4 and 5 of data aggregation (Fig. 2j).
4 Methods
Extensive set of statistical methods were used in this study, with the most important
-
regression methods: MLR and GWR, as well as their extensions to the regression-kriging form: MLRK and GWRK were used to spatialize the air temperature,
-
stepwise regression (SWR) was applied to select sets of significant auxiliary variables, to specify and calibrate regression models and to evaluate a goodness-of-fit of these models in each step of SWR forward selection,
-
cross-validation (CV) results were applied to evaluate the quality of interpolation and to compare spatial models, based mostly on CV mean absolute error (MAE) as a main diagnostic measure used together with MAE error bars as the method to assess the statistical significance of differences between models.
4.1 Spatial Interpolation Methods
The basic assumption of this study is that the air temperature can be treated as a regionalized variable (Matheron 1963), which suggests that spatial variation can be modelled as the sum of deterministic and stochastic components. Such a model was termed the ‘universal model of spatial variation’ (Matheron 1969) and its mathematical representation is the regression-kriging (residual kriging; RK) model, which is the implementation of the best linear unbiased predictor (BLUP) for spatial data (Hengl 2007). Until recently, residual kriging for spatial interpolation of the air temperature was used in the conventional way: the deterministic part was modelled using MLR, and then regression residuals were spatialized using the kriging technique (e.g. Holdaway 1996; Courault and Monestiez 1999; Brown and Comrie 2002; Szymanowski and Kryza 2009). However, recent studies on spatial variation of the air temperature (Szymanowski and Kryza 2012; Szymanowski et al. 2012, 2013) draw attention to two issues:
-
1.
The spatial process determining the air temperature can be expected to be non-stationary. This was shown both for the local and regional scales, with the examples of the urban heat island in Wrocław (Szymanowski and Kryza 2011) and air temperature in Poland (Szymanowski et al. 2012, 2013). The non-stationary spatial process has different spatial correlation in different regions. In such a case, the local, dedicated for non-stationary conditions GWR model, is better fitted to the observations than global MLR (Fotheringham et al. 2002). Consequently, it is a prerequisite to use GWR instead of MLR to perform modelling of the deterministic part of air temperature spatial variation. Such solution was suggested and applied in the selection scheme of the optimal interpolation method by Szymanowski et al. (2012, 2013). The goodness-of-fit of the regression models and, indirectly, non-stationarity of the spatial process, can be assessed by various measures as, e.g. determination coefficient (R 2) or standard error of estimation (STE), which were used in the study.
-
2.
The full applicability of the RK scheme may be limited in some cases. The reason is the lack of spatial autocorrelation of regression residuals. In the absence of autocorrelation, the variogram takes the form of a pure nugget effect, and hence, prediction at each point in the study area is equal to the average of the regression residuals, which, by the assumption, is in the MLR model equal to zero. In the GWR model, an unbiased estimate of the local coefficients is not possible because the bias results from inferring the outcome of a non-stationary process at given location from data collected at other locations. This means that the average regression residual is likely to be different but sufficiently close to zero (Fotheringham et al. 2002). Thus, when GWR residuals are not autocorrelated (pure nugget variogram), we are allowed to assume that the modification of the GWR prediction contributed by kriging of the GWR residuals is negligible in the RK model. Therefore, when a stochastic component can be omitted, the entire variation in the spatial model is explained deterministically only by either MLR or GWR. The decision on the existence of positive spatial autocorrelation was taken in the study based on the Moran’s I statistics (Moran 1950), assuming its statistical significance at p < 0.05. In GWRK, similarly to the general RK scheme, the deterministic component is modelled using GWR and after that regression residuals are modelled with the kriging technique.
The spatialization models for predicting variable \(\hat{z}\) in location \(s_{0}\) can be mathematically expressed as MLR:
GWR:
MLRK:
GWRK:
where \(\hat{\beta }_{k}\) are estimated deterministic model coefficients (\(\hat{\beta }_{0}\)—estimated intercept), \(q_{k}\) are explanatory variables, \(\lambda_{i}\) are kriging weights determined by the spatial dependence structure of the residual and \(e(s_{i} )\) is the residual at location \(s_{i}\).
All four types of models (or only two types if the regression residuals’ autocorrelation was not statistically significant) were used to evaluate the impact of auxiliary variables on the quality of air temperature spatial interpolation.
4.2 Stepwise Selection of Auxiliary Variables
The basic question in the initial phase of the analysis was which variables from the entire set of potential predictors should be included in the model for a given case. Generally, it is probably the most subjective part of modelling and it is likely that each modeller may consider various determinant factors of the spatial process, prepare different sets of potential predictors, establish different criteria to include variables to the model, etc. Nevertheless, if the set of potential predictors is prepared, the selection of statistically significant auxiliary variables could be done in an objective way using, for example, a stepwise regression approach (Draper and Smith 1998). SWR is an automatic procedure for statistical model selection in cases where there are a large number of potential explanatory variables. The goal is to choose a small subset from the larger set so that the resulting regression model is simple, in the sense that it only includes the significant predictors. Here, the SWR forward selection based on partial F tests (with F to include >1.0, slightly less than F critical for 250 observations at p = 0.05) was applied in the initial phase of variable selection and model calibration. The partial F test performs fitting of two models: full and reduced, and assesses whether the improvement in model fit is too large to be ascribed to chance alone (Jamshidian et al. 2007). The model is accepted for final analysis based on two conditions: F test result (model is significant at p < 0.05) and statistical significance of all the predictors included, which is described by the t test (all the model parameters are significant at p < 0.05). The SWR technique starts with no variables in the model, tests the addition of each variable based on assumed criterion, adds the variable that improves the model the most, and then repeats this process until adding any of the omitted variables does not improve the model.
Stepwise regression forward selection is subject to various imperfections (e.g. Wilkinson and Dallal 1981; Hurvich and Tsai 1990); however, for this study it was found a good mechanism for tracking the quality of the interpolation model when entering step by step the significant explanatory variables. Despite the fact that properties of the selection scheme are known, the form of the regression model is still dependent on the set of potential predictors that can be prepared in different ways by different researchers. In such situations, the initial selection of explanatory variables can have a decisive influence on the final result of interpolation. Checking whether this claim is true is one of the primary objectives of this study. The best way to assess this would be a comparison of the results of interpolation performed, based on the models selected by the stepwise procedure from all possible subsets of the initial (full) set of predictors. However, taking into account 11 variables in the initial set of predictors (Sect. 3.2) would require analysing thousands of possible combinations for each of the 69 cases of air temperature, which was beyond the computational capabilities of this project. Instead, the evaluation of models in each step of the SWR (with additional criteria described below), based on the full initial set of predictors, was performed. For each air temperature case, the aim was to specify and calibrate the regression model including all the statistically significant variables indicated by stepwise selection. These kinds of models are referred to as the MP models in this paper, as they include the maximum (for each case) possible number of significant predictors (n). This purpose has been achieved by specification of the series of models that include a limited number of not more than n − 1, significant predictors (LP models). The comparison between MP and LP models in each step allows assessing the effect of introducing additional explanatory variables on the air temperature spatialization process.
Some additional criteria were also incorporated to complete each model specification. Multicollinearity was checked using the value inflation factor (VIF < 10), statistical significance was assumed when p < 0.05 and the maximum number of variables in the model should not exceed seven with the number of observations n = 250 (Szymanowski et al. 2012, 2013). The same variables at each step were then used in MLR and GWR models. Given the irregular spatial distribution of meteorological stations, the GWR model was calibrated using adaptive kernels with bi-square weighting scheme. The size of the adaptive kernel, called a bandwidth, was defined as the number of data points used to calibrate the local linear regression function. Due to a known property of GWR, termed a ‘bias-variance trade-off’ (Fotheringham et al. 2002), the bandwidth size was chosen to be the smallest possible, but with respect to two limitations. First, the bandwidth size should be large enough to include at least 25 measuring sites to assure sufficient number of data for proper specification of the local regression model (using up to seven explanatory variables). Second, the sign of the regression coefficient should be in agreement with the assumed physical process to allow for the possibility of deterministic explanation of spatial process in each part of the study area (Szymanowski and Kryza 2012; Szymanowski et al. 2012). Once the Moran’s I statistic confirmed significant spatial autocorrelation, the variogram of regression residuals was modelled automatically with the use of a spherical function (best fit) with a nugget effect included.
4.3 Validation of Model Errors
The model errors were evaluated using the leave-one-out cross-validation approach (CV). The mean absolute error (MAE) was applied as the basic diagnostic statistics of the model quality. MAE is considered as one of the most natural summary measures for the model performance (Willmott and Matsuura 1995) and it can also be used to determine statistical difference between models’ performance (Szymanowski et al. this issue). This can be done by compering severability of MAE error bars. The model with the smallest MAE can be considered as performing best only if its MAE error bar does not overly the MAE error bar of any other model for the same case. The error bar was determined as MAE ± \(\hat{\sigma }_{\text{MAE}}\), where \(\hat{\sigma }_{\text{MAE}}\) was the error of MAE calculation. For the n-element set with standard deviation \(\sigma_{\text{CV}}\), it can be calculated as (Kalarus et al. 2010):
Cross-validation approach results allow for the assessment of the model quality with respect to the data measured in meteorological stations. The model performance in other locations was based on visual inspection of the maps, paying special attention to the artefacts and the incredible values of the modelled air temperature (Szymanowski et al. 2012). The maps of air temperature for the case analysis were prepared in two ways. The overall changes in air temperature for a given case, depending on the set of variables in the model and the type of interpolation model, were presented as classified (every 0.5°) colour ramp. These maps were complemented by spatial distribution of CV errors in data points shown using point symbols. To introduce the local effect and very detailed changes in the air temperature field caused by some explanatory variables, maps were drawn with the use of stretched colour scale.
5 Results and Discussion
5.1 Deterministic Component of Spatial Model
The frequency of occurrence of individual auxiliary variables in MP models for all 69 air temperature cases in Poland shows that each of the considered potential predictors (Sect. 3.2) is included in at least a few models (Fig. 3). Some of variables are introduced to almost all models, e.g. DEM (in 66 of 69 models) and X coordinate (65). Some are included very frequently: SDI (52), coordinate Y (40), SLP (34) and land use/land cover surfaces AS and NS (43 times in total). Variables AS and NS should be treated as complementary because they are strongly collinear and, accordingly to the assumptions (Sect. 4), only one of them is included in a model specified for a given case. Less often such variables as NDVI (24 out of 54 models—analysed only at levels 4 and 5), IT (21) and FI (17) are included in MP models. CCI is the least frequent (only six times) variable introduced into the regression models. This may be the consequence of the features of input air temperature dataset because meteorological stations are located in open, flat terrain, usually free from the local impact of relief.

Number of MP models including individual explanatory variables for each level of data aggregation
Digital elevation model is most frequently introduced as the first variable to the regression model which means that, due to assumptions of SWR forward selection, it is most significantly correlated with air temperature, taking into account the F statistics. DEM is selected as the first in all the models at levels 1–3, and in 21 out of 24 models at level 4. However, it is included only in 12 out of 30 cases at level 5. This shows that the lower the levels of data aggregation, the less significant is the impact of terrain height and more significant are, e.g. synoptic factors. However, it is strongly case dependent and this statement cannot be generalized with the set of 30 cases presented here. In some level 5 cases, the air temperature can be strongly correlated with elevation, whereas in other cases the correlation may be relatively weak or even statistically insignificant. In situations where the DEM is not the first variable introduced to the MP model, it is usually substituted by coordinate X, which is selected as first in 3 of 24 models at level 4 and in 11 of 30 models at level 5. Only in 6 models, different variables are introduced as the most significant (all only at level 5): SDI—4 times, NDVI—2 times and IT—once. Both coordinates (X—18 times, Y—17 times) and DEM (12 times) are introduced most frequently as a second significant explanatory variable. The role (expressed in terms of statistical significance) of locally determined factors expressed by such variables as AS/NS, SLP or CCI is relatively low. Even if some of them are frequently introduced into the regression models, they are never added as the first and very rarely as the second most important variable (AS/NS—1 time, SLP—2 times, CCI—none).
Each MP model includes from 3 to 7 statistically significant explanatory variables. Most frequently, the models are specified based on six auxiliary variables (21 cases), and less frequently based on 4, 5 or 7 variables (15, 15 and 13 cases, respectively). The least frequent are models including only three additional variables (five cases). There is also no clear dependence of the number of predictors included in the model on the aggregation level, but 3- or 4-variable models are more typical of lower level of data aggregation (levels 4 and 5).
According to the assumptions, all MP models are statistically significant (in terms of the F test, detailed description in Sect. 4.2), even if they differ significantly in terms of goodness-of-fit. In individual cases, these models explain over 90 % (max. 96 %) of the air temperature variance at aggregation levels 1–3 but, in some cases, it falls to 70 % on level 4, and can be as low as 31 % for daily means cases (level 5). Generally, it can be stated that the higher the level of data aggregation, the higher the determination coefficients. The level of air temperature variance explained by the MP model is shown in Fig. 3—the value corresponding to the last step of the SWR procedure. The lower the level of data aggregation, the larger the observed variability of R 2. This suggests that for short-time averaged air temperature (e.g. daily means), some models can fit the data as well as for the long-term means, but there are also cases for which the overall fitting of the regression model is relatively poor (R 2 < 0.6; Fig. 4).

Determination coefficients depending on the level of the air temperature aggregation and the number of explanatory variables in the SWR model
The next questions are, however, what the level of determination is when only the most significant variable is introduced to the model and how does the goodness-of-fit of the model change when adding subsequent variables. One-variable LP models are characterized by very different values of determination coefficients depending also on the level of data aggregation (Fig. 4). The R 2 of such models at level 1 is 0.82; at levels 2–4, they change in the range of 0.78–0.81 (level 2), 0.61–0.86 (level 3) and 0.31–0.92 (level 4). At level 5, there is one case for which the one-variable model explains only about 3 % of the air temperature variance. This is the case of 8 Jan 2003 that will be analysed in detail below. However, it is very surprising that the model with such a low determination coefficient meets the criterion of statistical significance (in terms of the F test, detailed description in Sect. 4.2). Nevertheless, the lower the level of data aggregation, the more one-variable models explain smaller amount of variance, even if well-explaining one-variable models can be found at each level of aggregation as well. At levels 1–3, all one-variable models explain >60 % of air temperature variance, while at levels 4 and 5, it is only 16 out of 24 and 10 out of 30, respectively (Fig. 4). At level 4, lower values of the determination coefficients are observed for the winter months, which may indicate a declining role of environmental factors with respect to synoptic conditions that are not directly included in the regression model. This is also the case at level 5, where atmospheric circulation with passing fronts and air masses advections deteriorate the statistical relation of air temperature with static environmental factors represented by the set of potential predictors prepared for this study.
The most significant changes in the determination coefficient are observed mostly when adding second and third variables to the model. The second variable in the model increases the explained variance by more than 10 %, mostly at lower aggregated levels (3–5). This happens in 8 out of 12 models at level 3, 17 out of 24 models at level 4 and 16 out of 30 models at level 5. The third variable added to the model rarely increases the variance explained by more than 10 %. This is the case in 4 out of 24 models at level 4 and 6 out of 30 at level 5 (Fig. 4).
In some cases, the introduction of subsequent variables to the model does not make significant changes in the coefficient of determination in comparison to the one-variable model. In such cases, the curves of the determination coefficient are flattened and the LP and MP models do not differ significantly. This can be observed not only in cases when the first auxiliary variable explains 80 % or more of air temperature variance, but also in cases in which the determination coefficient of one-variable model is quite low (Fig. 4).
As it was indicated in earlier studies (Szymanowski et al. 2012, 2013), in each of the analysed cases for Poland, the local GWR model, with the same explanatory variables, provides a better fit to the data compared to the MLR. While comparing the MP models, GWR is characterized by the same or greater determination coefficients (up to 15 % of variance explained) and lower standard errors of estimation, residual sums of squares and Akaike Information Criterion in comparison to MLR (Szymanowski et al. 2013). This means that the process can be considered as non-stationary, and the change of the global to local model with the same explanatory variable leads to an increase in the explained variance.
5.2 Deterministic-Stochastic Interpolation—a Case Study
Due to significant computational load, GWR models as well as all RK models are not analysed in this study for all 69 cases in each step of SWR, as it would again require calibrating and validating more than a thousand additional models. Here, two cases representing different levels of air temperature aggregation: level 1—decadal annual mean (TY) and level 5—daily mean on 8 Jan 2003 (TD) are analysed in details, comparing all four types of spatialization algorithms for all LP and MP models. These two cases are characterized also by one of the highest (TY) and lowest (TD) determination coefficients independently on the subset of explanatory variables included in the regression model.
The air temperature in the TY case is strongly determined by static environmental explanatory variables (Table 1). The most significant variable is elevation and it explains 83 % of the variance while using the MLR model and even 96 % using the GWR approach. Other statistically significant variables are coordinates, artificial surfaces and slope, and they increase the determination coefficient to 0.95 for MLR and 0.97 for GWR. A significant change of R 2 and decrease of standard error (STE) are especially pronounced for the first three LP-MLR models. In the LP-GWR approach, introducing additional variables does not produce any significant change in neither R 2 nor STE (Table 1).
Additional analysis of regression residuals’ spatial autocorrelation shows that residuals are not autocorrelated for all 3-, 4- and 5-variable MLR and GWR models. This means that regression and regression-kriging models are considered as identical in these cases (Table 1). Changes in CV MAE are analogous to changes in the goodness-of-fit for both regression models. The MAE decreases significantly for the first three LP models, and the decrease is larger for the MLR and smaller for the GWR (Fig. 5). The extension of the spatial model to the RK form produces a significant decrease in MAE for both MLRK and GWRK models, starting already from the one-variable model. It can be summarized that for 1- and 2-variable models, GWR performs significantly better than the MLR, both RK models perform significantly better than the corresponding regression models, and that MLRK and GWRK perform similarly. Adding the third (X) and next (AS, SLP) variables does not improve the MAE significantly, as the error bars overlap for MLR and GWR models and their extensions by residual kriging (Fig. 5).

Cross-validation mean absolute errors (MAE) together with error bars depending on model type and number of explanatory variables included in the model for the 1996–2005 annual mean air temperature in Poland (TY)
Tendencies discussed above are also seen in the maps of air temperature and CV errors distribution (Figs. 6, 7, 8, 9, 10). The most significant changes are observed for maps prepared using 1-, 2- and 3-variable MLR models. The least accurate, in terms of CV errors, is the map prepared using only elevation as predictor in a global regression approach (Fig. 6a). Distinct spatial pattern in CV error is observed showing the tendencies to overestimate the air temperature over NE Poland and to underestimate the air temperature over SW Poland. Similar features are noticed on the corresponding GWR map (Fig. 6b), but the CV errors are smaller. Visually, both MLR and GWR regression-kriging maps are very similar, starting already from the one-variable models. Introduction of additional explanatory variables does not change the modelled air temperature field, but involve local adjustments (Figs. 6, 7, 8, 9, 10). This issue will be discussed in details later in this section.

1996–2005 annual mean air temperature in Poland (TY) mapped using a MLR, b GWR, c MLRK and d GWRK algorithms with the use of DEM as the only explanatory variable in the regression model

1996–2005 annual mean air temperature in Poland (TY) mapped using a MLR, b GWR, c MLRK and d GWRK algorithms with the use of DEM and Y as the explanatory variables in the regression model

1996–2005 annual mean air temperature in Poland (TY) mapped using a MLR and b GWR algorithms with the use of DEM, Y and X as the explanatory variables in the regression model

1996–2005 annual mean air temperature in Poland (TY) mapped using a MLR and b GWR algorithms with the use of DEM, Y, X and AS as the explanatory variables in the regression model

1996–2005 annual mean air temperature in Poland (TY) mapped using a MLR and b GWR algorithms with the use of DEM, Y, X, AS and SLP as the explanatory variables in the regression model
The TD case differs significantly from TY. First of all, globally the air temperature is only determined to a small extent by static environmental factors, described by explanatory variables. The MP-MLR model, with six predictors included, explains only 38 % of the observed variance (Table 2). The spatial process is significantly non-stationary; therefore, the MP-GWR model is much better fitted to observation than MLR, with 67 % of the variance explained. The LP-GWR with four predictors included explains 71 % of the variance and its STE is significantly lower than STE of the corresponding MP model (Table 2).
Regression residuals are autocorrelated for all the global and local models for the TD case, and all the models can be extended to the deterministic-stochastic form. Low determination causes the stochastic component to play a dominating role in the regression-kriging algorithm, and significantly affects the modelled air temperature field (Fig. 11).

Cross-validation mean absolute errors (MAE) together with error bars depending on the model type and number of explanatory variables included in the model for air temperature on 8 Jan 2003 in Poland (TD)
It is surprising that the first variable introduced to the model by stepwise procedure is NDVI, of which the correlation with air temperature in this winter case is rather ambiguous. This time most of the territory of Poland was covered by snow that resulted in very small differences in NDVI values between vegetated and non-vegetated areas. There is probably no clear physical explanation of air temperature—NDVI dependence in this case. The relation was detected “by chance”, and even though it is statistically significant, NDVI explains only 2 % of air temperature variance in the MLR model (Table 2). The air temperature field determined by NDVI is very “rough” (Fig. 12). The changes in the CV MAE show that the introduction of second (X) and third (DEM) variables does not improve the quality of spatial interpolation (Fig. 11). What is more, in this case the temperature is also very slightly determined by elevation. The last three variables (IT, SDI, Y) improve the interpolation done by the MLR model and, to a smaller extent, by GWR (Fig. 11). More interesting are the changes in quality of both RK models while introducing subsequent auxiliary variables. For the predictors’ subsets, GWRK performs better than MLRK, but not significantly better. Both MP-RK models perform best; however, they do not differ significantly (according to MAE error bars) from the results achieved by the corresponding one-variable LP models (Fig. 11). As the geostatistical component brings large information on modelled air temperature in the TD case, the maps prepared by both regression models differ significantly from those done using RK algorithms (Figs. 12, 13). Some interesting features of air temperature distribution are different to the to “expected” characteristics of averaged field (as for examples in the TY case). Due to the cold eastern air mass advection, a belt of low temperatures in central Poland is noticeable. Apart from that, a zone of relatively high temperature, caused by the impact of the Baltic Sea, is observed along the coast. Quite interesting and unexpected is also the area of high temperature in the part of mountains in SE Poland (the Bieszczady Mts.), which might be explained by the air mass subsidence in anticyclonic pressure system (Fig. 13). Except for the warming influence of the sea, the remaining features of dynamic/synoptic origin are not explained deterministically and are modelled by the geostatistical component of the RK model.

Air temperature on 8 Jan 2003 in Poland (TD) mapped using a MLR, b GWR, c MLRK and d GWRK algorithms with the use of NDVI as the only explanatory variable in the regression model

Air temperature on 8 Jan 2003 in Poland (TD) mapped using a MLR, b GWR, c MLRK and d GWRK algorithms with the use of NDVI, X, DEM, IT, SDI and Y as the explanatory variables in the regression model
5.3 The Signal of Explanatory Variables in Air Temperature Maps—a Case Study
Concerning the large added value introduced by interpolation of regression residuals in RK algorithms, one could conclude that the large variance explained by the deterministic component is not crucial for the quality of interpolation. If the 3 or 4 most significant explanatory variables are included in the regression model, the remaining variance is well explained by the stochastic component of the RK model. It was shown that introducing additional auxiliary variables does not necessarily lead to the improvement of the CV MAE. However, in some cases, additional explanatory variables may significantly change the spatial distribution of the CV errors because of the reduction of regional/local tendencies leading to over or under-estimation. This is of large importance for the final distribution of air temperature, but it is missed if only the CV MAE is analysed. More importantly, the additional variables may lead to formation of effects in the modelled field that are “imprinted” by these variables, like the effects of urban heat island or warm slopes. Such effects, even if statistically justified, may also lead to undesired artefacts in the maps. This problem will be discussed based on TY case again, but this time the attention is put on not only to the statistical evaluation of the model, which significance has been confirmed above, but also on the global (Poland) and local (surrounding of the city of Cracow) changes in the modelled air temperature field induced by introduction of additional, to DEM, Y and X, explanatory variables.
According to the changes in MAE, the 3-variable TY regression model (including DEM, Y and X) that explains 95 % (MLR) or 96 % (GWR) of variance is not significantly different from the 4- and 5-variable models (Fig. 5). In both cases, the regression residuals are not autocorrelated and the stochastic components of the RK models can be omitted (Sect. 4.1). Therefore, the question is whether it makes sense to introduce additional variables and if so, what changes in modelled air temperature field will be observed? This will be considered starting from the 3-variable model, where temperature is determined by elevation and both coordinates (Fig. 14a). In the next two steps, AS and SLP will be added. It will show how these variables influence the spatial pattern of the modelled air temperature, with no statistically significant effects on statistical model performance.

1996–2005 annual mean air temperature in Poland (TY) mapped using GWRK algorithm with the use of a DEM, Y and X, b DEM, Y, X and AS and c DEM, Y, X, AS and SLP as the explanatory variables in the regression model
The incorporation of AS, as the fourth explanatory variable, increases the modelled air temperature over the urban areas (Fig. 14b). This warming effect might be considered as realistic, both when it comes to the location and magnitude of change, which was confirmed with measurements of the urban heat island for Wrocław (Szymanowski and Kryza 2012). The incorporation of the SLP variable leads to lower MAE but the change is not statistically significant (Fig. 5). However, SLP results in noticeable local changes in the modelled air temperature field. Steep slopes are now relatively warmer, regardless to the slope aspect, comparing to surrounding flat areas (Fig. 14c). This does not look realistic, even if there are no measurements to verify this effect quantitatively. It is very likely that the temperature over most of steep slopes, especially in the highest parts of the highest mountain ranges (the Tatra Mts.), will be significantly overestimated. This effect is caused in fact by the extrapolation process that “exports” the relation between temperature and inclination to the slopes inclined more than the range of SLP observed for available meteorological stations. Meteorological stations are located mostly on flat terrains—248 of 250 stations in this study are characterized by slope inclination less than 10°, and the most inclined station has inclination of about 15°. The regression model is linear, so the relation estimated for the 0–15° range is then extrapolated for the slopes inclined by >15° with the same assumption of linearity, which is barely realistic. The only solution would be to fit non-linear function; however, the lack of stations located on steep slopes prevents to confirm any considered theoretical model. The conclusion is that in this case (given set of meteorological stations for Poland), the SLP should be probably removed from the set of potential predictors, because its introduction to linear regression models may lead to unrealistic results, seen as artefacts in the air temperature maps. The SLP should be excluded even if it is so frequently introduced to the regression models by stepwise selection (Fig. 3).
6 Summary and Conclusions
Taking into account the results of analysis carried out on 69 cases of air temperature in Poland, aggregated on five different levels (from long-term annual mean to daily means), the following main conclusions can be formulated:
-
1.
The environmental factors, most significantly determining spatial distribution of air temperature in Poland, are elevation, geographical location and the distance from the sea, expressed in this study by variables: DEM, X, Y and SDI, respectively. The leading role is played by DEM and X (corresponding to longitude), which were introduced to almost all MP regression models. Using the stepwise method, these factors were usually introduced as the first (mainly DEM) or second most significant explanatory variable. DEM and X were most frequently followed in the model structure by SDI and Y (corresponding to latitude). The role of regional [e.g. foehn impact (FI)] and local—land use and relief factors (e.g. AS/NS, NDVI, SLP, CCI) should be considered as complementary, and, as was shown for SLP, these variables should be very carefully introduced to the regression models. Even if some of them were very often introduced into the regression models (e.g. AS/NS), they have never been added as the first and very rarely as the second variable.
-
2.
The fully specified MP models included from 3 to 7 explanatory variables. In individual cases, these models explained over 90 % (maximum 96 %) of the air temperature variance, but only at data aggregation levels 1–3. In some cases, the explained variance was as low as 70 % at level 4, and dropped to 31 % at aggregation level 5. Generally, it can be stated that the higher the level of data aggregation, the higher determination coefficients are observed.
-
3.
The first variable introduced to the model, accordingly to stepwise selection’s assumptions, usually explained the majority of the air temperature variance, but it is not a general rule. For the lower levels of data aggregation, there are more one-variable models that explain only a small part of variance, even if well-explaining one-variable models can be found at each level of aggregation as well. The reason might be a declining significance of static environmental factors and increasing role of atmospheric dynamics and weather conditions on spatial pattern of air temperature, which are not directly represented in the regression models.
-
4.
The most significant changes in determination coefficients are observed mostly when adding the second and third variables to the regression model. However, there are also cases in which the first, most significant variable explains the majority of air temperature variance and the incorporation of additional variables does not lead to further improvement of the deterministic model.
-
5.
For all the MP models and for all analysed cases, local GWR models are better fitted to the observations than global MLR models. This means that the spatial process determining the air temperature distribution over Poland can be considered as non-stationary.
A detailed study of two selected cases from levels 1 and 5 additionally revealed that
-
6.
Introducing significantly correlated explanatory variables improves the goodness-of-fit of the regression model (MLR or GWR), but it does not necessarily mean a significant improvement of the quality of spatial interpolation expressed by CV errors. Thus, the thesis from many previous interpolation attempts, claiming that the more spatial variation is explained by the deterministic part of the model, the better is the quality of spatial interpolation, cannot be indisputably accepted.
-
7.
Regression-kriging models (MLRK, GWRK) as spatial interpolators usually perform better than their corresponding regression models (MLR, GWR), but the improvement strongly depends on the particular case.
-
8.
If the GWR or MLR residuals are autocorrelated, the model should be expanded to residual kriging. GWRK usually gives better results of spatial interpolation than MLRK; however, the difference in performance quality is very rarely statistically significant.
-
9.
The signal of each explanatory variable, even if it explains relatively small part of the air temperature variance, might introduce large and noticeable effects in the final map prepared by using either regression alone or regression-kriging interpolation algorithm. However, despite a statistically significant correlation, the effect of the introduction of certain variables into the model may not be climatologically justified. This is due to the extrapolation of air temperature—variable relation in the case of not representative distribution of measuring points with respect to the environmental feature (variable) determining the air temperature distribution. In the analysed TY case, it was seen, while introducing SLP as a 5th variable in the model, that it led to significant changes in air temperature over steep slopes.
Although the analysis was performed on only a limited number of cases for Poland, some general conclusions can also be drawn. The Matheron’s universal model of spatial variation and its mathematical representation—the regression-kriging, are very effective models for spatial interpolation and mapping the air temperature. The air temperature spatial variation can be assumed non-stationary, so it is justified to model deterministic part using local GWR model instead of global MLR. If regression residuals are spatially autocorrelated, it is recommended to extend the spatialization model to the regression-kriging form: GWRK. It should be emphasized that some of the processes that are deterministic in nature, for example, caused by atmospheric circulation, cannot be modelled in the deterministic part of the model. This is because it is hardly possible to prepare proper layers of variables expressing such dynamic features. Thus, this part of spatial variation is explained by the stochastic part of the model.
Although the leading explaining role is played by such environmental variables as elevation, location and the distance from the sea, and usually most of air temperature variance is explained by the first 1–3 auxiliary variables, the set of potential predictors for deterministic part specification should be as wide as possible. This is because each statistically significant predictor is reflected in the final map regardless whether regression or regression-kriging method is used for spatialization. It is up to the modeller to decide which statistically justified effects are desired and climatologically realistic, and should be expressed on the air temperature map, depending for example on the map purpose. The expert judgment is, therefore, necessary to compliment the cross-validation statistics of the models performance.
References
Agnew, M.D., and Palutikof, J.P. (2000), GIS-based construction of baseline climatologies for the Mediterranean using terrain variables, Clim. Res. 14, 115–127.
Al-Awadhi F.A., and Al-Awadhi S.A. (2006), Spatial-temporal model for ambient air pollutants in the state of Kuwait, Environmetrics 17, 739–752.
Apaydin, H., Anli, A.S., and Ozturk, F. (2011), Evaluation of topographical and geographical effects on some climatic parameters in the Central Anatolia Region of Turkey, Int. J. Climatol. 31, 1264–1279.
Attorre, F., Alfo, M., De Sanctis, M., Francesconia, F., and Brunoa, F. (2007) Comparison of interpolation methods for mapping climatic and bioclimatic variables at regional scale, Int. J. Climatol. 27, 1825–1843.
Benavides, R., Montes, F., Rubio, A, and Osoro K. (2007), Geostatistical modelling of air temperature in a mountainous region of Northern Spain, Agr. Forest Meteorol. 146, 173–188.
Benichou, P., and Le Breton, O. (1987), Prise en compte de la topographie pour la cartographie des champs pluviométriques statistiques, La Météorologie 7, 23–34.
Bjornsson, H., Jonsson, T., Gylfadottir, S.S., and Olason, E.O. (2007), Mapping the annual cycle of temperature in Iceland, Meteorol. Z. 16(1), 45–56.
Boi, P., Fiori, M., and Canu, S. (2011), High spatial resolution interpolation of monthly temperatures of Sardinia, Meteorol. Appl. 18, 475–482.
Bowden, J.H., Otte, T.L., Nolte, C.G., and Otte, M.J. (2012), Examining interior grid nudging techniques using two-way nesting in the WRF model for regional climate modeling, J. Climate. 25, 2805–2823.
Brown, D.P., and Comrie , A.C. (2002), Spatial modeling of winter temperature and precipitation in Arizona and New Mexico, USA, Clim. Res. 22, 115–128.
Carrega, P. (1995), A method for the reconstruction of mountain air temperatures with automatic cartographic applications, Theor. Appl. Climatol. 52(1), 69–84.
Choi, J., Chung, U., and Yun, J.I. (2003), Urban-effect correction to improve accuracy of spatially interpolated temperature estimates in Korea, J. Appl. Meteorol. 42, 1711–1719.
Chuanyan, Z., Zhongren, N., and Guodong, C. (2005), Methods for modelling of temporal and spatial distribution of air temperature at landscape scale in the southern Qilian mountains, China, Ecol. Model. 189, 209–220.
COST Action 719 Final Report: The use of Geographic Information Systems in climatology and meteorology (ed. Tveito O.E., Wegehenkel M., van der Wel F., and Dobesch H.) (Office for Official Publications of the European Communities, Luxembourg 2008).
Courault, D., and Monestiez, P. (1999), Spatial interpolation of air temperature according to atmospheric circulation patterns in southeast France, Int. J. Climatol. 19, 365–378.
Cressie N., and Johannesson G. (2008), Fixed rank kriging for very large spatial data sets, J. Roy Stat. Soc. B. 70, 209–226.
Daly, C. (2006), Guidelines for assessing the suitability of spatial climate data sets, Int. J. Climatol. 26, 707–721.
Daly, C., Halbleib, M., Smith, J.I., Gibson, W.P., Doggett, M.K., Taylor, G.H., Curtis, J., and Pasteris, P.P. (2008), Physiographically sensitive mapping of climatological temperature and precipitation across the conterminous United States. Int. J. Climatol. 28, 2031–2064.
Daly, C., Neilson, R.P., and Phillips, D.L. (1994), A statistical-topographic model for mapping climatological precipitation over mountainous terrain. J. Appl. Meteorol. 33, 140–158.
Draper, N., and Smith, H., Applied Regression Analysis, 3rd Edition (John Wiley & Sons Inc., New York 1998).
Esteban, P., Ninyerola, M., and Prohom, M. (2009), Spatial modelling of air temperature and precipitation for Andorra (Pyrenees) from daily circulation patterns, Theor. App. Climatol. 96, 43–56.
Fotheringham, A.S., Brunsdon, C., and Charlton, M., Geographically weighted regression: the analysis of spatially varying relationships (Wiley, Chichester 2002).
GRASS Development Team (2011), Geographic Resources Analysis Support System (GRASS) Software, Version 6.4.0. Open Source Geospatial Foundation. http://grass.osgeo.org.
Hengl, T., A practical guide to geostatistical mapping of environmental variables (Office for Official Publications of the European Communities, Luxembourg 2007).
Hiebl, J., Auer, I., Böhml, R., Schöner, W., Maugeri, M., Lentini, G., Spinoni, J., Brunetti, M., Nanni, T., Percec Tadic, M., Bihari, Z., Dolinar, M., and Müller-Westermeier, G. (2009), A high-resolution 1961–1990 monthly temperature climatology for the greater Alpine region, Meteorol. Z. 18(5), 507–530.
Holdaway, M.R. (1996), Spatial modeling and interpolation of monthly temperature using kriging, Clim. Res. 6, 215–225.
Hogewind, F., and Bissolli, P. (2011), Operational maps of monthly mean temperature for WMO Region VI (Europe and Middle East), Idojaras 115(1–2), 31–49.
Huerta G., Sanso B., and Stroud J.R. (2004), A spatiotemporal model for Mexico City ozone levels, J. Roy Stat. Soc. C-App. 53, 231–248.
Hurvich, C.M., and Tsai, C.L. (1990), The impact of model selection on inference in linear regression, Am. Stat. 44, 214–217.
Hutchinson, M.F. (1995), Interpolating mean rainfall using thin plate smoothing splines, Int. J. Geogr. Inf. Syst. 9(4), 385–403.
Jamshidian, M., Jennrich, R.I., and Liu, W. (2007), A study of partial F tests for multiple linear regression models, Comput. Stat. Data Anal. 51, 6269–6284.
Jarvis, C.H., and Stuart, N. (2001a), A comparison among strategies for interpolating maximum and minimum daily air temperature. Part I: the selection of “guiding” topographic and land cover variables, J. Appl. Meteorol. 40, 1060–1074.
Jarvis C.H., and Stuart, N. (2001b) A comparison among strategies for interpolating maximum and minimum daily air temperature. Part II: the interaction between number of guiding variables and the type of interpolation method, J. Appl. Meteorol. 40, 1075–1084.
Joly, D., Brossard, T., Cardot, H., Cavailhes, J., Hilal, M., and Wavresky, P. (2011), Temperature interpolation based on local information: the example of France, Int. J. Climatol. 31, 2141–2153.
Kalarus, M., Schuh, H., Kosek, W., Akyilmaz, O., Bizouard, C., Gambis, D., Gross, R., Jovanović, B., Kumakshev, S., Kutterer, H., Mendes Cerveira, P.J., Pasynok, S., and Zotov, L. (2010), Achievements of the Earth orientation parameters prediction comparison campaign, J. Geodesy 84, 587–596.
Kożuchowski, K., Klimat Polski. Nowe spojrzenie (Wydawnictwo Naukowe PWN, Warszawa 2011).
Kożuchowski, K., and Żmudzka, E. (2001), Assessment of relations between the normalised difference vegetation index (NDVI), frequency of forest fires, air temperature, sunshine, precipitation in Poland, Geographia Polonica 74(2), 29–40.
Krahenmann, S., Bissolli, P., Rapp, J., and Ahrens, B. (2011) Spatial gridding of daily maximum and minimum temperatures in Europe, Meteorol. Atmos. Phys. 114, 151–161.
Kryza, M., Werner, M., Dore, A.J., Vieno, M., Błaś, M., Drzeniecka-Osiadacz, A., and Netzel, P. (2012), Modelling meteorological conditions for the episode (December 2009) of measured high PM10 air concentrations in SW Poland—application of the WRF model, Int. J. Environ. Pollut. 50, 41–52.
Kurtzman, D., and Kadmon, R. (1999), Mapping of temperature variables in Israel: a comparison of different interpolation methods, Clim. Res. 13, 33–43.
Lennon, J.J., and Turner J.R.G. (1995), Predicting the spatial distribution of climate: temperature in Great Britain, J. Anim. Ecol. 64, 370–392.
Li, J., and Heap, A.D., A review of spatial interpolation methods for environmental scientists (Geoscience Australia, Canberra 2008).
Matheron, G. (1963), Principles of geostatistics, Econ. Geol. 58, 1246–1266.
Matheron, G., Le Krigeage universel (Cahiers du Centre de Morphologie Mathematique, Ecole des Mines de Paris, Fontainebleau 1969).
Mitchell, A., The ESRI guide to GIS analysis. Spatial measurements and statistics, vol 2 (ESRI Press, Redlands, California 2005).
Moran, P.A.P. (1950), Notes on Continuous Stochastic Phenomena, Biometrika 37(1), 17–23.
Nalder, I.A., and Wein, R.W. (1998), Spatial interpolation of climatic normals: test of a new method in the Canadian boreal forest, Agr. Forest Meteorol. 92, 211–225.
Ninyerola, M., Pons, X., and Roure, J.M. (2000), A methodological approach of climatological modelling of air temperature and precipitation through GIS techniques, Int. J. Climatol. 20, 1823–1841.
Ninyerola, M., Pons, X., and Roure, J.M. (2007), Objective air temperature mapping for the Iberian Peninsula using spatial interpolation and GIS, Int. J. Climatol. 27, 1231–1242.
Perčec Tadić M. (2010), Gridded Croatian climatology for 1961–1990, Theor. Appl. Climatol. 102, 87–103.
Perry, M., and Hollis, D. (2005a), The development of a new set of long-term climate averages for the UK, Int. J. Climatol. 25, 1023–1039.
Perry, M., and Hollis D. (2005b), The generation of monthly gridded datasets for a range of climatic variables over the UK, Int. J. Climatol. 25, 1041–1054.
Pielke, R.A., Cotton, W.R., Walko, R.L., Tremback, C.J., Lyons, W.A., Grasso, L.D., Nicholls, M.E., Moran, M.D., Wesley, D.A., Lee, T.J., and Copeland, J.H. (1992), A comprehensive meteorological modeling system—RAMS, Meteorol. Atmos. Phys. 49, 69–91.
Skamarock, W.C., Klemp, J.B., Dudhia, J., Gill, D.O., Baker, D.M., Duda, M.G., Huang, X., Wei, W., and Powers, J.G. (2008), A Description of the Advanced Research WRF Version 3, NCAR Technical Note NCAR/TN-475 + STR, National Center for Atmospheric Research, Boulder, Colorado, USA. doi:10.5065/D68S4MVH.
Szentimrey, T., and Bihari, Z., Mathematical background of spatial interpolation, meteorological interpolation based on surface homogenized data bases (MISH), In COST Action 719: The use of Geographic Information Systems in climatology and meteorology (ed. Szalai, S., Bihari, Z., Szentimrey, T., and Lakatos M.) (Proceedings from the Conference on Spatial Interpolation in Climatology and Meteorology, Budapest, 25–29 October 2004) pp. 17–27.
Szymanowski, M., and Kryza, M. (2009), GIS-based techniques for urban heat island spatialization, Clim. Res. 38, 171–187.
Szymanowski, M., Kryza, M. (2011), Application of geographically weighted regression for modelling the spatial structure of urban heat island in the city of Wroclaw (SW Poland), Procedia Environmental Sciences 3, 87–92, doi:10.1016/j.proenv.2011.02.016.
Szymanowski, M., and Kryza M. (2012), Local regression models for spatial interpolation of urban heat island—an example from Wrocław, SW Poland. Theor. App. Climatol. 108, 53–71.
Szymanowski, M., Kryza, M., and Smaza, M. (2007), A GIS approach to spatialize selected climatological parameters for wine-growing in Lower Silesia, Poland, In Střelcová, K., Škvarenina, J. & Blaženec, M. (ed.) Bioclimatology and natural hazards, International Conference, Poľana nad Detvou, Slovakia, 17–20 September 2007, CD-ROM, ISBN 978-80-228-17-60-8.
Szymanowski, M., Kryza, M., and Spallek, W., Air temperature atlas for Poland: the methodical approach (Uniwersytet Wrocławski, Wrocław 2012) (in Polish, English summary).
Szymanowski, M., Kryza, M., and Spallek, W. (2013), Regression-based air temperature spatial prediction models: an example from Poland, Meteorol. Z. 22, 577–585.
Tietavainen, H., Tuomenvirta, H., and Venalainen, A. (2010), Annual and seasonal mean temperatures in Finland during the last 160 years based on gridded temperature data, Int. J. Climatol. 30, 2247–2256.
Tucker, C.J. (1979), Red and Photographic Infrared Linear Combinations for Monitoring Vegetation, Remote Sens. Environ. 8(2), 127–150.
Ustrnul, Z. (2006), Spatial differentiation of air temperature in Poland using circulation types and GIS, Int. J. Climatol. 26(11), 1529–1546.
Ustrnul, Z., and Czekierda, D. (2005), Application of GIS for the development of climatological air temperature maps: an example from Poland, Meteorol. Appl. 12, 43–50.
Ustrnul, Z., and Czekierda, D., Atlas of extreme meteorological phenomena and synoptic situations in Poland (IMGW Warszawa 2009).
Vicente-Serrano , S.M., Saz-Sánchez, M.A. and Cuadrat, J.M. (2003), Comparative analysis of interpolation methods in the middle Ebro Valley (Spain): application to annual precipitation and temperature, Clim. Res. 24, 161–180.
White, E.J. (1979), The prediction and selection climatological data for ecological purposes in Great Britain, J. Appl. Ecol. 16, 141–160.
Wilby, R.L., and Wigley, T.M.L. (1997), Downscaling general circulation model output: a review of methods and limitations, Prog. Phys. Geog. 21, 530–548.
Wilkinson, L., and Dallal, G.E. (1981), Tests of significance in forward selection regression with an F-to-enter stopping rule, Technometrics 23, 377–380.
Willmott, C.J., and Matsuura, K. (1995), Smart interpolation of annually averaged air temperature in the United States, J. Appl. Meteorol. 34, 2577–2586.
Wilson, A.M., and Silander J.A. (2014), Estimating uncertainty in daily weather interpolations: a Bayesian framework for developing climate surfaces, Int. J. Climatol. 34, 2573–2584.
Woś, A., Klimat Polski w drugiej połowie XX wieku (Wydawnictwo Naukowe UAM, Poznań 2010).
Yue U., and Speckman P.L. (2010), Nonstationary Spatial Gaussian Markov Random Fields, J. Comput. Graph. Stat. 19, 96–116.
Acknowledgments
The authors thank Ryszard Kryza for his help in improving the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Szymanowski, M., Kryza, M. The Role of Auxiliary Variables in Deterministic and Deterministic-Stochastic Spatial Models of Air Temperature in Poland. Pure Appl. Geophys. 174, 595–621 (2017). https://doi.org/10.1007/s00024-015-1199-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-015-1199-2