
Abstract
This work proposes a capacitive load cell for conical picks to enable underground continuous mining machine operators to perform their roles away from known hazardous regions near the machine. The load cell is embedded in commercially available flexible printed circuit board, integrates with the target tooling, and demonstrates in situ force sensing of vibration signatures for continuous mining cutting tools. Changes in material constitution, tool mass, and tool geometry cause modal variations in vibrational response measurable with force sensors at the cutting interface. Time-series measurements are captured during rock cutting tests using a linear cutting machine. These measurements are segmented into small windows, less than 0.25 s, and are preprocessed using the fast Fourier transform, which highlights the modal variations. The transformed measurements are then classified into different material and wear categories using support-vector machines with the radial basis function kernel. Different normalization schemes and Fourier transform methods are tested for signal preprocessing. Results show that the power spectral density measurements with normally distributed coefficients give good results for material classification, while the normalized time-domain measurements give better results for wear classification. Under laboratory conditions, this technique is shown to classify material and wear categories with F1 score above 0.85 out of 1.0 for our experiment. This technology could be used to assist operators in assessing material and wear conditions from a safer distance. It has applications in the coal mining industry as well as other applications which use conical picks such as road milling.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Operators monitoring important process feedback in hazardous regions is dangerous [1]. Operators are expected to monitor machine alignment, tool wear, machine condition, and the material being cut [2]. The hazards that the operators are exposed to in underground mining can be difficult to model [3]. To allow operators to perform their role from a greater distance, we propose a sensor suitable for assisting operators in assessing material type and tool wear that integrates with conical picks on continuous miners used in underground coal mining.
Underground mining is dangerous and safety has not been improved over the last decade, with fatalities per 100,000 full time equivalent employees averaging 21.4 from 2011 to 2020 [4]. In particular, coal workers are roughly 50% more likely to be injured than workers in other mining sectors and account for roughly 50% of fatalities from 1983 to 2020 [4]. Existing technologies for mitigating these hazards monitor the environment with micro-seismic sensors, distributed pressure sensors, or electromagnetic analysis [3]. These technologies only identify hazards after they occur. Elimination of hazardous conditions is the most effective method for reducing risk to workers in any application [5]. The only way to eliminate these hazardous conditions is to allow the operators to perform their role from a greater distance.
Previous efforts to allow operators to perform their role from a greater distance, namely development of remote controls, have allowed operators to collect better visual feedback; however, operators often put themselves in hazardous positions to do so [6]. Technologies also assist operators by automating some tasks. For example, automated hydraulic diagnostic systems can help operators monitor the machine’s hydraulic conditions [7]. One of the most effective technologies for reducing worker injury is the personnel proximity detector, which disables certain machine operations if designated zones near the machine are entered by persons tracked with the device [8]. This device was implemented about a decade ago; however, there have not been any major improvements since.
Direct measurements of rock and pick interaction have previously noted significant differences in forces between tool wear levels [9, 10]. Material has been differentiated by vibration signatures using various classification techniques as early as 1993 [11]. Previous efforts for smart bit or intelligent pick tooling to perform these tasks in real-time during operation have taken place over the last few decades, and examples include as follows: using neural networks to classify tool wear in potash [12], using acoustic data to classify both material and tool wear in coal cutting [13], using piezo sensors to deduce rock chipping [14], and, most recently, using an instrumented block with integrated strain gauges to measure cutting forces [15]. So far, results using capacitive load cells have not been found for material and tool wear classification in underground mining. Advances in both capacitive sensing and vibration classification have unearthed a variety of applications in other domains. Our sensor, shown in Fig. 1, can assist operators in assessing material type and tool wear by measuring differences in vibrational responses between the different conditions.

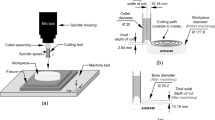
A prototype of the sensor integrated with the U92 4.0 22NB Conical Pick and K35 Block system, from Kennametal. The device is shown without the measurement collection system and is situated between the sleeve and the block. The FlexPCB interface is exposed, which provides access to the capacitive sensors’ electrodes. A steel case protects the FlexPCB sensor and provides the necessary stiffness to transfer the input forces to the sensor. An embedded electronics platform, not shown in this figure, takes measurements suitable for dynamic classification of tool-wear and material. A cutaway of the sensor shows the thin film design for the force sensor
To test our sensor for material and wear classification, full-scale rock cutting experiments are performed using the linear cutting machine at Colorado School of Mines, a popular type of tool for rock cutting mechanics testing [16]. A limestone sample cast in concrete is used to test material classification. Conical picks of three different wear levels at an attack angle of 45∘ are used for tool wear classification. The wear levels are new, moderate, and worn, where moderate represents a pick halfway through its useful life, and worn is a tool at the end of its useful life. The tool tips are artificially worn to a spherical diameter using a lathe to approximate an even wear pattern and for reproducibility. A closeup view of the tool tips and the values for their spherical diameters is shown in Fig. 2. The low profile sensor sits between the sleeve and block. The sleeve has been machined down to a slip fit in the block to allow force transfer to the sensor. The sleeve and block are both retained by a large pin. Measurements are collected from the sensor using an embedded capacitance to digital converter and sent to a computer over USB.

The different pick wear levels. The new, moderate, and worn pick tips have spherical diameters of 3.71 mm, 17.9 mm, and 27.5 mm respectively. This approximates and even wear pattern. The moderate and worn tips were artificially worn using a lathe
To highlight the changes in vibrational modes, the data is transformed using short window fast Fourier transform preprocessing before classification. The resulting vectors are classified into material and wear categories using the support-vector machine technique. Data from strain gauges embedded in the linear cutting machine and our custom sensor are both used on their own for classification. Each classification system in our experiment is scored using the F1 score [17, 18]. The best performance for material and wear classification yielded F1 scores around 0.85 out of 1.0 for our experiment. Performance in tool wear classification is shown to be comparable between the custom sensor and the strain gauges embedded on the linear cutting machine. For material classification, the additional sensitivity due to the proximity of the custom sensor to the cutting interface allows it to perform better using the same algorithm.
The rest of this article is organized into six sections. First, background information regarding material and wear classification algorithms is given along with a description of the algorithm we use. Then, the sensor design and characterization are described. After, the procedure for the rock cutting experiment is given, followed by the performance results of the classification algorithm. Finally, some discussion points and conclusions regarding the experiment and results are shared.
2 Material and Wear Classification
Material identification techniques for rock cutting can use metrics based in force and energy measurements, as different rock materials are known to require varying energy to break down [19, 20]. For tool wear classification, force or vibration feedback is commonly used in other domains such as metal milling or oil drilling because changes in tool mass and geometry cause the vibrational modes to shift [21,22,23,24]. Both material and tool wear classification can be framed as a vibration classification problems. Vibration classification lends itself towards certain standard signal processing and classification techniques, primarily with frequency domain preprocessing [25].
Preprocessing the input sensor data using different spectral or statistics based methods to improve classification results is popular [23, 24, 26, 27]. For this research, the fast Fourier transform is chosen as the preprocessing technique as it has been shown to give good results in many domains [28]. Depending on the chosen kernel for the support-vector machine, data standardization can range from beneficial to necessary, as the kernel may be built with assumptions on data mean values and range. The effects of the chosen normalization and preprocessing methods, or their absence, on the classification results are explored in this work.
The classification technique used after preprocessing is the support-vector machine (SVM) using the default “C-Support Vector Classification” implementation in the Python library Scikit Learn [29], [30]. SVM has long been known to be able to classify model behaviors [31]. It has also shown useful specifically in tool monitoring [32]. In general, the SVM works by finding a hyperplane in the data set which separates the data into the prescribed categories then, this hyperplane can be used as a quick decision rule for classification of future inputs [29]. The advantage of the SVM is it first transforms the input data to a higher dimension using a kernel function which helps to separate the data. This method has few hyperparameters and is considered generalizable, only needing relatively little training data to achieve good performance.
The SVM technique has few hyperparameters when compared to other machine learning techniques like feed-forward or convolutional neural networks, which allows it to be implemented quickly and be generalizable. The SVM is also typically better performing than simple techniques like k-nearest neighbors. The k-nearest neighbors method is another popular and low hyperparameter technique for vibration classification, and it works by selecting the majority class of the “k” samples closest to the input in its memorized training data [33]. The SVM solves the classification problem in a similar way, but reduces the training data for computational efficiency and better sensitivity to general trends. More advanced techniques, such as feed-forward or convolutional neural networks, are flexible techniques for vibration classification that work by numerically optimizing a series of weighted vector functions to approximate the statistical likelihood of a given input being from each output class based on the training data [34]. SVM strikes a balance between these techniques as it generally has better performance than k-nearest neighbors but is not as prone to over-fitting as the feed-forward or convolutional neural network.
2.1 Classification Methods
Time-series measurements are recorded from the four channels of our custom sensor and the four channels of the strain gauges on the linear cutting machine. For either sensor, we denote these measurements as CHx[n], where x is the channel index ranging from 1 to 4 and n is the sample index ranging from 1 to T, the total number of measurements. These time-series measurements from each sensor are then chopped into small segments representing short duration (≤ 0.25 s) windows of signal. These discrete vectors are preprocessed to form the feature vectors to be classified by the support-vector machine. For an individual classification sample, the data from a particular channel can be denoted as \(\overrightarrow {C_{kx}} = [CH_{x}[k], CH_{x}[k+1], \ldots , CH_{x}[k+M-1]]^{\top }\), where k is the index corresponding to the start time of the sample window, x is again the channel index, M is the number of samples in the window, and [ ⋅ ]⊤ represents the matrix transpose operation.
Both window overlap and window size are varied during our tests to observe their effects on performance. Increasing window overlap generates more data vectors for training and testing, but the resulting samples are more redundant than those generated with less overlap. Increasing window size gives data with more features which can improve classification accuracy. The classification rate is limited to one classification per window, and windows may overlap to increase the rate. A short window which gives acceptable performance is desired for rapid classification suitable for real-time use.
Each point in time can be assigned a class label for both material and wear. Only windows with contiguous labels are used in the experiment. Samples which are near the beginning or end of a material are discarded, as they do not have a clear ground truth label and are not representative of the steady state cutting dynamics. Separate classification systems are trained to identify material and wear. For an individual classification experiment, the set of paired measurement and class data is split randomly into testing and training sets. The set with the training indices is denoted in this work as R, while the set of testing indices is Q. After being windowed and split, the feature vectors for classification via support-vector machine are represented as follows:
where \(\mathcal {P}\) is the preprocessing pipeline for the data and 𝜃 are the parameters fit from the samples in the training set. The subscript, i, is the sample index and ranges from 1 to N, the total number of vectors in the data set. The specific mapping between i and k depends on the window parameters. The Scikit “sklearn” library [29, 30] provides a convenient data structure, the Pipeline object, which encapsulates these steps for consistent application and ensures that data from the testing set is not used during parameter fitting.
For our experiment, the pipeline consists of the composition of three optional operations, detailed in Table 1, and discussed here:
where ∘ represents the function composition operator. The steps denoted with \(\mathcal {N}\) are normalization steps which transform the input data to be zero mean and unit variance along each feature using the sample mean and variance from the training set. The \(\mathcal {F}\) operation is the frequency based transform, and different variations of the fast Fourier transform are used. Every combination of processing steps is used, and the results are compared to determine the best methods for this application. Each step is also substituted with the identity function during this process as a control.
In addition to the preprocessing step, the support-vector machine also can apply a transform to the input data during its use. A description of the support-vector machine algorithm, adapted from [35], is given here. Intuitively, the support-vector machine finds a hyperplane between two sets of data. This is done efficiently by representing the hyperplane as a linear combination of a subset of the training data. These vectors from the training data are known as the support vectors. The binary classification support-vector machine works by solving the primal problem:
where w and b are the vector and offset representing the decision boundary hyperplane, and ξi are slack variables which allow for error in classification in case of an infeasible problem. The yi are binary class labels with value − 1 or 1, C is a regularization parameter, and ϕ(⋅) is an implicit function which transforms the feature vectors into a higher dimension before separation with the hyperplane. The function ϕ(⋅) is implicit because in practice the dual of the primal problem is solved and only the inner product of the transformed input vectors is computed. This is done with the “kernel trick,” whereby a kernel function, K(x,y) =< ϕ(x),ϕ(y) > is used, which is less costly to compute than the full inner product in the higher dimension. After solving the dual problem, the decision function for an unseen sample, x is given by:
where the αi are the new coefficients given from the dual formulation and S is the set of support-vector indices. It is noteworthy that the final decision function does not explicitly use the hyperplane as represented by w, but instead relies the offset variable b and dot products (through the kernel) with the training data. To use the support-vector machine for multi-class problems, the chosen implementation uses a “one-vs-one” voting scheme where a binary classifier is trained for each pair of class combinations. The class with the lowest index and most votes is chosen as the output.
The radial basis function is a popular kernel choice, as it was one of the first to be developed. It is similar in function and performance to using auto-correlation as the implicit function [36]. Since the radial basis function gave acceptable performance and to limit the number of hyperparameters, only it is used for this study.
To test our classification system, the feature vectors are sorted into testing and training sets using ratios of 25:75, 50:50, and 75:25. Each split is done randomly, 100 times, for each combination of preprocessing parameters. Hyperparameters for our method are window duration, window overlap ratio, and window shape. Window duration is set to 0.05, 0.10, 0.15, 0.20, and 0.25 s, while overlap ratio is set to 0.25, 0.50, and 0.75. The window shape is left as rectangular for the entire study. Ringing effects from frequency convolution with the sinc(⋅) shape of the window in the frequency domain will be applied consistency across samples. Discovery of the optimal window shape would require its own extensive hyperparameter study across the many popular window functions. To limit the scope of the study, and since adequate performance was given with the rectangular window, focus is given to the other hyperparameters.
The effect of the preprocessing steps or their absence is investigated for this classification system across the hyperparameters of window size and overlap. Each classification setup is scored using the F1 score [17, 18] which is the harmonic mean of the classifiers precision and recall:
Precision is the ratio of positive classifications that are correct while recall is the ratio of positive samples which are correctly identified [18]. The F1 score provides a numeric value between zero and one, with one being a perfect score. For our multi-class problem, we train the SVM using the “balanced” strategy where classes are given equal weight, regardless of class samples size, by setting regularization term, C, inversely proportional to the class frequency in the input data. We score the classifier using “macro” averaging for the F1 score where the final score is the unweighted average of the F1 scores for each class. Using this setup, the classifier is trained to give equal weight to each class type, regardless of population size, and classification performance and is scored with a metric which also gives equal weight classifier performance for each class. Additionally, confusion matrices and accuracy measurements are used to get a more complete sense of classifier performance.
From this study, the optimal subset of steps may be found in a verifiable way. The training and testing computations are performed on the Isengard supercomputer at Colorado School of Mines. Individual classifiers can be trained on a consumer laptop in less than a minute, but to run the thousands of tests for this study in a batch manner, the supercomputer is more appropriate. For each set of parameters, the mean and standard deviation of the F1 scores are recorded for a population of 100 experiments with different random splits of data. Setups giving scores with large deviations or high dependence on the test and train ratio are suspect for overfitting to non-relevant features in the data set, while a low deviation with a high mean F1 score that is similar across test and train ratios can be considered generalizable and useful for the target application. To meaningfully compare distributions of scores generated for each method, the Welch-Satterthwaite method (Welch’s t-test) is used to determine if differences are significant [37].
2.2 Sensor Design Literature Review
When it comes to designing a sensor for underground mining applications, there are several key constraints: the device must be low power, low cost, and highly durable. Capacitive sensors generally meet these requirements. Sensors that are not considered directly for this study are inertial measurement units (IMUs) or custom microelectromechanical systems (MEMS) devices due to their power consumption, cost, and fragility. The most promising fabrication technology found during our literature review was capacitive load cells embedded in flexible printed circuit boards. The sensor dynamics can be non-linear, so the collected measurements are compared to those of a linear force sensor.
Capacitive pressure sensor designs have used steel enclosures [38], film dielectric [39], and sensors made directly from flexible circuits [40]. Larger film dielectrics can be modeled with a general system of springs and dampers; however, with thin films only a few dozen μ m thick, the molecular dynamics contribute greatly to the response [41] and make it non-linear. Encasing the flexible circuit element in an enclosure provides a rigid structure with more linear deformation, but the dielectric still affects the relationship between the input force and the measured capacitance. These flexible sensors are low in cost, while sensors which provide more linear measurements normally employ careful manufacturing processes, air gap designs, and different signal processing techniques such as those seen in [42,43,44,45,46]. Sensors which use thin films with non-linear deformation must use appropriate models and algorithms to achieve the desired classification results.
Popular flexible dielectric materials like carbon-doped thermoplastic poly-urethane and silicone can exhibit non-linearity through hysteresis, viscoelastic effects, or measurement creep [47,48,49,50]. The choice of dielectric material for a capacitive sensor will influence much of its performance, so it is important that the material has robust properties for the expected range of conditions. Polyimide is a notable flexible dielectric material and sensor substrate for capacitive sensors due to its high temperature range, solvent resistance, and low surface roughness [51]. It is also easily integrated with electronic circuits boards, known as flexible printed circuit boards, where it serves as the substrate for conductive traces. However, when used in a thin film, polyimide has nonlinear deformation dynamics due to the complex molecular interactions of the constituent polymer chains [52]. This viscoelastic-plastic behavior can be difficult to model for a large range of input, with models either incorporating complicated numerical integration techniques [53, 54], only capturing the linear viscoelastic portion for small ranges [55], or ignoring the unloading phase [56]. Thicker films generally have a greater linear range [57] and most models incorporate some mix of viscoelastic and viscoplastic elements like the model seen in [58].
Other works which have used polyimide as the force or pressure sensor dielectric show mixed results for sensor performance. In one study, electrospun polyimide nanofibers were used as the dielectric to achieve measurement repeatability and sensitivity [59]. When the device was cycled from 0 to 10 % change in nominal capacitance for 10,000 cycles, no noticeable measurement creep was observed. In another study, spin-coated polyimide was used, and the sensor response was much noisier and subject to some initial transient effects [60]. Another group used a FlexPCB force sensor encased in polymeric materials and it showed good linearity and low hysteresis for 1% changes in capacitance [61]. These studies indicate that polyimide is a good low-cost material choice that can still give good performance.
2.3 Sensor Design
To design a capacitive force sensor for material and wear classification, suitable choices must be made for materials, geometry, and the balance between sensor accuracy and bandwidth. Based on the sensor design literature review, a steel case with a load cell embedded in a flexible polyimide circuit board is chosen for the design. The steel is 303 series stainless, chosen to reduce potential for corrosion and for its resistance to fatigue. The steel case is made by chemical etching of 0.036-inch steel plates. A channel of 0.018-inch depth is formed on one plate and the two are laser welded together after a steel shim and the sensing membrane have been put in place. As noted in the prior section, polyimide is chosen for the sensing membrane for its wide range of operating conditions and robust properties. The sensor case geometry is largely determined by the target tooling, but must still be tuned to the operational requirements of the sensor. Likewise, the balance between sensor accuracy and bandwidth must be tuned to achieve the desired results.
To tune the case geometry for the desired stiffness, appropriate values must be chosen for the thickness and height of the side walls. These values are shown as h,w1, and w2 in Fig. 3. The donut-shaped sensor has a center filled with viscous polyimide. The thickness and height of the side walls chiefly determine the spring constant of the sensor. The polyimide is much more compliant than the surrounding steel, so the overall case deformation is not influenced by its deformation in a significant way. However, the capacitive cells are directly embedded in the polyimide, so the measurement is greatly influenced by its deformation.

A cutaway of the sensor with the geometric parameters shown. The dimensions of the walls may be tuned to give the sensor the appropriate stiffness. The thickness of the top and bottom plates does not significantly influence the overall stiffness of the device
The sensor is designed for a maximum expected force of 200 kN. This provides some margin above the expected forces, which can be in excess of 100 kN for hard rocks. The sensor case is tuned to have around 10% strain at maximum load, and in this way, material fatigue can be mitigated and the measured capacitance should be close to linear with dielectric deformation. The thickness and height of the side walls, h,w1, and w2, are set to about two and a half millimeters. The deformation of the steel case is expected to be mostly linear within this range of deformation.
The balance between sensor accuracy and bandwidth is determined by the range of deformation of the sensor as well as the capacitance and resonant frequency of the sensing circuit. In general, larger capacitance values will provide greater accuracy at the cost of sensor bandwidth. For the chosen hardware, the effective number of bits for the measurement is proportional to the square of the measurement time. Larger capacitances take longer to settle but can make more accurate measurements.
Given the tool geometry, four cells are placed in the donut: two large and two small. For our parallel plate design, it is important that the electrodes receive even loading; otherwise, the parallel plate approximation is no longer valid. The large cells are designed for a nominal capacitance of 541 pF and the small cells are designed for a nominal capacitance of 412 pF. All four pads occupy about 50∘ and are spaced evenly around the donut. The larger cells have about 30% greater area.
Since we are focused on high-frequency vibration classification, sensor bandwidth is maximized while still providing sufficient resolution and accuracy for classification. At a rate of 400 samples per channel per second, and using a gain of 4, the embedded system is able to provide 128 levels for up to a 25% change in capacitance. At 10% max expected deformation, the max expected change in capacitance is also about 10%. The true deformation of the polyimide around the electrodes is nonlinear and must be characterized to make informed decisions with the resulting measurements.
2.4 Sensor Characterization
The sensor was characterized using load frame testing. Five different load rates were applied to three separate sensors to achieve a max force of 200 kN momentarily before ramping back down at an equal rate. Linear sensors show symmetric behavior for such a test, but the sensor measurements for this test, shown in Fig. 4, reveal that our sensor exhibits hysteresis and rate dependence for these loads. These effects can be expected from the previous literature regarding polyimide deformation [51,52,53,54,55,56,57,58,59,60,61], and they obscure the effect of the average force on the measurement. It can be seen that, as the loading rate increases, the traces converge. This implies that the sensor can still be used to detect the changes in the high frequency components of the response that are useful for vibration classification. The overall deformation of the sensor case during these same loads is shown in Fig. 5, and the deformation is linear. This confirms that the nonlinear deformation is happening in the polyimide and suggests that this case could be used to house other sensing technologies that can transduce displacement to electrical signals.

The triangular load profiles and the resulting measurements from the sensor. The sensor response is not symmetric and therefore non-linear. Lower load rates cause greater changes in displacement, which is consistent with previous studies for thin film polyimide

The case deformation during the load frame tests. The case deformation is symmetric for the loading and unloading phases, it also has a consistent slope for force over displacement. This means the case has approximately linear deformation for these load profiles
3 Rock Cutting Experiment
To test the sensor for in situ force signature capture, rock cutting experiments were performed using the Linear Cutting Machine in the Earth Mechanics Institute at the Colorado School of Mines. A limestone sample cast in concrete was cut using a conical pick on the instrumented block. Time series measurements were made with the custom sensor as well as strain gauges integrated with the test equipment. The measurements were cut into small intervals and used with the classification algorithms to build separate material and wear classifiers.
To capture the capacitive measurements, a capacitance to digital converter made by Texas Instruments is used: the FDC2114. This device interfaces with a generic microcontroller over I2C, a popular circuit to circuit interface. The software used on the microcontroller is available on Github as well as the data-acquisition software which is ran on the host computer to collect the measurements. The software that performs the classification experiment described in the previous section is also available. The microcontroller code is available here: https://github.com/Fworg64/DAQuery. The data-acquisition code is available here: https://github.com/Fworg64/reDAQ. The machine learning and classification code is available here: https://github.com/Fworg64/limestone_experiment.
The Linear Cutting Machine, shown in Fig. 6, uses hydraulic actuators to drag the sample against the cutting tool. A cutting speed of 10 inches per second was used, which is relatively slow compared to the cutting speeds used in the field. The integrated strain gauges measure forces at a rate of 537.6 samples per second. The custom load cell makes measurements at a rate of 400 samples per second. Typical measurements from each sensor during a cutting experiment are shown in Fig. 7. For applications with greater cutting speed and more materials, consider that rock fracture is largely static and machine vibration is dynamic. The frequency domain features associated with tool wear should scale with cutting speed and depend largely on the machine’s natural modes, while those associated with material breakdown occur at much higher frequencies.

The Linear Cutting Machine in action. Hydraulic actuators push the sample into the cutting tool while the custom sensor and the embedded strain gauges record measurements. The tool is normally surrounded by the plastic curtain to aid in capturing dust for a simultaneous study of the effect of tool wear on dust generation

Measurements for typical rock cuts with different tool wear levels. The measurements from the linear sensors are shown in the top graph while the measurements from the custom sensor are shown below
4 Classification Results
Using the method outlined in Section 2, the collected data is used to train and test the classification algorithm. The capacitive sensor data gave results similar to the linear sensor in tool wear classification. For material classification, the capacitive sensor generally performed better. The distribution of feature vectors, before being processed with the support-vector machine kernel, are shown for both sensors by material in Fig. 8 and by tool wear in Fig. 9. From these distributions, it can be seen that the capacitive sensor is much more sensitive to the higher frequency components of the interaction forces. This is likely a result of its closer proximity to the cutting interface.

The frequency signature distributions collected from the custom sensor organized by material. The concrete material shows exponential decay after each primary mode, while the limestone has a more varied response. These differences can be used for classification of the signals by material

The frequency signature distributions collected from the custom sensor organized by tool wear. The New tool has a distinct response compared to the Moderate and Worn tools, and the energy in the higher modes generally increases with wear. These differences can be used for classification of the signals by tool wear
For each sensor and application, five window sizes were tested. This gives ten pairs for comparison among each group of five, so we choose p < 0.01 as statistically significant for differences in performance. The distributions of F1 scores for the classifiers with different window sizes are shown in Fig. 10. For tool wear classification, performance was similar for all window sizes for both sensors. For material classification, the capacitive sensor gave measurements which could be more reliably classified. The differences in performance across window sizes are significant for material classification with either sensor.

Bar chart with error bars for F1 score distributions by window size. For tool wear, both sensors were able to provide sufficient data for very accurate classification. For material classification, the capacitive sensor generally performed better than the strain gauge sensor. Some of the differences in performance are significant within the application and sensor combinations, but in general performance was similar across window sizes
Classification scores broken down by technique for the 0.2-s window size are shown in Fig. 11. Trends in relative method performance were the same across window sizes. It was found that normalization after transformation, and not before, gave the best performance for the Fourier-based methods. Also, the normalized time-series data with the SVM gave the best performance for tool wear classification in both the strain gauge and capacitive sensor cases. For material classification with the strain gauges, most methods gave similar performance. Normalization improved classification performance in nearly all categories.

Performance of different preprocessing methods for each application. In general, normalization after transformation proved most effective for the frequency-based techniques. Using the normalized time domain data was most effective for tool wear classification
Overall, tool wear in our data was classified with greater accuracy than material type. For tool wear, the normalized time domain data gave better classification results than the frequency data. For material type, only the capacitive sensor gave results that would be useful. The strain gauge data was classified with about 50% accuracy by the classifier. With the capacitive sensor classification of material type, performance using the frequency-based data gave slightly better accuracy than the time domain data.
When using only 25% of the data for training, the classifier was still able to perform reliably using the capacitive sensor data. This shows that performance was not very dependent on the test and train ratio. F1 scores with standard deviations are given for the best setup for each application at different test and train ratios in Table 2. The scores do not change by a large magnitude, which indicates that the classifier is general and should perform well for larger data sets.
Individual confusion matrices are given for the 25:75 test and train ratio for material classification in Table 3 and for tool wear classification in Table 4. For these confusion matrices, rows represent the true class for the samples and columns represent the predicted class. Diagonal entries represent correct classifications, and each column is normalized to the number of predictions made of that class. The strain gauge material classifier has poor precision for concrete samples, as many of its concrete predictions are actually limestone samples. The F1 score is sensitive to this, and it is reflected in the much lower score. The accuracy of the strain gauge material classifier is around 80%, which is still useful. The accuracy of the capacitive sensor material classifier is higher, above 95%. This highlights the importance of using multiple metrics to accurately assess classifier performance.
5 Discussion
Our sensor, as used in our experiment, shows promise as a method to objectively assess material type and tool wear. Under laboratory conditions, the sensor and classification scheme was able to detect differences in mode excitation caused by different materials and tool wears. For our experiment, the materials chosen were limestone and concrete. These materials are both much stronger than coal, but our experiment shows that they excite distinct modes in our cutting equipment. For tool wear, it is known that more worn tools can require several times the force to cut when compared to a new tool. The modes that are excited in the machine also change based on the changing tool geometry. For the target application of coal mining, coal is known to be much weaker than the material in which it is embedded, e.g., limestone. So, if our sensor is able to differentiate between concrete and limestone, it is postulated that it could differentiate between limestone and coal, which is much softer.
Using the support-vector machine, the hyperplane between the measured datasets is found. This means that for a given input of discrete frequency or time samples, each value is multiplied by a coefficient and then combined to a single value, similar to a digital filter. The support-vector nachine has few hyperparameters, and the chosen measurements are shown to contain modal shifts that correspond with the categories of interest. The fundamental change in signal occurs as a mode distribution shift. This is readily detected by the support-vector machine.
To adapt our sensor to the target application, the target machine would need to be characterized in terms of dynamic modes. The sampling rate of the sensor system will need to be sufficiently higher than the primary modes of the target tooling; otherwise, the measurements could be subject to aliasing. So long as the sampling rate at least satisfies the Nyquist criterion for the tool primary modes, aliasing should be minimized due to the high frequency attenuation caused by massive mechanical systems. Furthermore, the viscous nature of the polyimide sensor provides even more damping, reducing the possibility for aliasing at the physical level.
Additional sensor designs such as an air-gap capacitive displacement sensor should also be investigated, as they could likely achieve more linear measurements at the cost of sensitivity. Development of a suitable power source and communication system must still be considered for this application. Other technologies such as acoustic sensors also show promise for material and wear classification, as they have been used with success in other domains and acoustic information is one of the primary feedback mechanisms currently employed by operators. A load cell-based technology would likely be less susceptible to outside interference by unrelated signal when compared to an acoustic sensor, as it is closer to the mining interface and collects signal from a more narrow bandwidth.
6 Conclusion
A sensor suitable for in situ sensing of vibration signatures for material and wear classification was developed and tested for underground mining using conical picks. The classification accuracy achieved in the laboratory tests indicates that this is a promising technology for this application. The capacitive sensing design is low cost and low power due to its flexible circuit design. This technology could assist operators in material and wear classification by providing an objective measurement without requiring the operators to enter known hazardous regions near the machine and mining interface.
The capacitive load cell, to the authors knowledge, has not been used publicly for conical picks in rock cutting applications. This is a relatively new sensor technology that has been enabled by the steady advancement of capacitive sensor research over the last few decades. Existing solutions for hazard monitoring in underground coal mining primarily identify problems after they begin. Existing research in improving operator performance and safety has included acoustic classification systems and algorithms, strain-gauge based solutions, and piezo-electric sensors. By shifting the paradigm to predictive maintenance and more responsive control, operators are enabled to be safer and more efficient.
References
Jobes C, Carr J, Ducarme J (2012) Evaluation of an advanced proximity detection system for continuous mining machines. Int J Appl Eng Res 7(6):649–671
Bartels J, Jobes C, Lutz T, Ducarme J (2009) Evaluation of work positions used by continuous miner operators in underground coal mines, vol 53. https://doi.org/10.1518/107118109X12524444080792https://doi.org/10.1518/107118109X12524444080792
Jiang Y, Zhao Y, Wang H, Zhu J (2017) A review of mechanism and prevention technologies of coal bumps in China. J Rock Mech Geotechnical Eng (Online) 9(1):180–194
(2021). Mine safety and health administration (MSHA): NIOSH mine and mine worker charts. Online. Available: https://wwwn.cdc.gov/NIOSH-Mining/MMWC
(2015). NIOSH: hierarchy of controls. Centers for disease control and prevention. https://www.cdc.gov/niosh/topics/hierarchy/default.html
Bartels J, Jobes C, DuCarme J, Lutz T (2009) Evaluation of work positions used by continuous miner operations in underground coal mines. In: Proceedings of the human factors and ergonomics society. Human factors and ergonomics society, pp 1622– 1626
Mitchell J (1991) Research into a sensor-based diagnostic maintenance expert system for the hydraulics of a continuous mining machine. In: Conference record of the 1991 IEEE industry applications society annual meeting, pp 1192–11992. https://doi.org/10.1109/IAS.1991.178014
Bissert PT, Carr J, Ducarme J (2016) Proximity detection zones: designs to prevent fatalities around continuous mining machines. Prof Safety 61(6):72–77
Sundae LS (1985) Measurement of coal-cutting forces underground with the in-seam tester vol 9033. US department of the interior, Bureau of Mines, Wachington, DC
Anderson DL (1990) Laser tracking and tram control of a continuous mining machine. Report of investigations (United States Bureau of Mines), vol 9319
Pazuchanics MJ, Mowrey GL (1993) Recent progress in discriminating between coal cutting and rock cutting with adaptive signal processing techniques. Report of investigations (United States Bureau of Mines), vol 9475
Myers D (1999) Predicting mining machine cutting tool wear using neural networks. University of Saskatchewan, University Library. http://hdl.handle.net/10388/11756
Shen H-LW (1996) Acoustic emission potential for monitoring cutting and breakage characteristics of coal the pennsylvania state university
Miller BH (2003) Smartbit: in-situ bit/rock interface monitoring device. Colorado School of Mines. Arthur lakes library. http://hdl.handle.net/11124/170545
Biały W, Fries J, Galecki G (2021) Determination of coal cutting forces using the cutting head of pou-bw/01-wap device. Multidiscip Aspects Product Eng 4(1):281–289. https://doi.org/10.2478/mape-2021-0025https://doi.org/10.2478/mape-2021-0025
Yagiz S, Yermukhanbetov K, Yazitova A, Rostami J (2021) Utilizing linear cutting machine test for estimating cutting force via intact rock properties. U.S. Rock mechanics/geomechanics symposium, vol. all days. ARMA-2021-1108
Sasaki Y et al (2007) The truth of the f-measure. Teach Tutor Mater 1(5):1–5
Powers DM (2020) Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv:2010.16061
Teale R (1965) The concept of specific energy in rock drilling. In: International journal of rock mechanics and mining sciences & geomechanics abstracts. Elsevier, vol 2, pp 57–73
Klyuchnikov N, Zaytsev A, Gruzdev A, Ovchinnikov G, Antipova K, Ismailova L, Muravleva E, Burnaev E, Semenikhin A, Cherepanov A et al (2019) Data-driven model for the identification of the rock type at a drilling bit. J Petroleum Sci Eng 178:506– 516
Klaic M, Murat Z, Staroveski T, Brezak D (2018) Tool wear monitoring in rock drilling applications using vibration signals. Wear 408:222–227
Abu-Mahfouz I (2003) Drilling wear detection and classification using vibration signals and artificial neural network. Int J Mach Tools Manuf 43(7):707–720
Tao X, Zhigang F (2009) Tool wear identifying based on EMD and SVM with AE sensor. In: 2009 9th International conference on electronic measurement & instruments. IEEE, pp 2–948
Tao X, Tao W (2010) Cutting tool wear identification based on wavelet package and SVM. In: 2010 8th World congress on intelligent control and automation. IEEE, pp 5953–5957
Liu L, Wu F, Qi C, Liu T, Tian J (2018) High frequency vibration analysis in drilling of GFRP laminates using candlestick drills. Compos Struct 184:742–758
Nie P, Li Z, Liu Y, Liu X, Xu H (2011) Study on identification method of tool wear based on singular spectrum analysis and support vector machine. In: 2011 Second international conference on digital manufacturing & automation. IEEE, pp 1164–1167
Qian Y, Tian J, Liu L, Zhang Y, Chen Y (2010) A tool wear predictive model based on SVM. In: 2010 Chinese control and decision conference. IEEE, pp 1213–1217
Ramón MM, Atwood T, Barbin S, Christodoulou CG (2009) Signal classification with an SVM-FFT approach for feature extraction in cognitive radio. In: 2009 SBMO/IEEE MTT-S international microwave and optoelectronics conference (IMOC). IEEE, pp 286–289
Chang C-C, Lin C-J (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol (TIST) 2(3):1–27
Platt JC (1999) Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In: Advances in large margin classifiers. MIT Press, pp 61–74
Mukherjee S, Osuna E, Girosi F (1997) Nonlinear prediction of chaotic time series using support vector machines. In: Neural networks for signal processing VII. Proceedings of the 1997 IEEE signal processing society workshop. IEEE, pp 511–520
Sun J, Hong GS, Rahman M, Wong Y (2004) The application of nonstandard support vector machine in tool condition monitoring system. In: Proceedings. DELTA 2004. Second IEEE international workshop on electronic design, test and applications. IEEE, pp 295–300
Hu H, Qin C, Guan F, Su H (2021) A tool wear monitoring method based on WOA and KNN for small-deep hole drilling. In: 2021 International symposium on computer technology and information science (ISCTIS), pp 284–287. https://doi.org/10.1109/ISCTIS51085.2021.00065https://doi.org/10.1109/ISCTIS51085.2021.00065
Chen J-F, Lo S-K, Do QH (2016) An approach to the classification of cutting vibration on machine tools. Information, vol 7(1). https://doi.org/10.3390/info7010007
Smola AJ, Schölkopf B (2004) A tutorial on support vector regression. Stat Comput 14 (3):199–222
Kong R, Zhang B (2007) Autocorrelation kernel functions for support vector machines. In: Third international conference on natural computation (ICNC 2007). IEEE, vol 1, pp 512– 516
Tamhane A, Dunlop D (2000) Statistics and data analysis: from elementary to intermediate, vol 280
Lee D-H, Kim U, Jung H, Choi HR (2016) A capacitive-type novel six-axis force/torque sensor for robotic applications. IEEE Sensors J 16(8):2290–2299. https://doi.org/10.1109/JSEN.2015.2504267
Bodini A, Pandini S, Sardini E, Serpelloni M (2018) Design and fabrication of a flexible capacitive coplanar force sensor for biomedical applications. In: 2018 IEEE sensors applications symposium (SAS), pp 1–5. https://doi.org/10.1109/SAS.2018.8336775https://doi.org/10.1109/SAS.2018.8336775
Lee H-K, Chung J, Chang S-I, Yoon E (2008) Normal and shear force measurement using a flexible polymer tactile sensor with embedded multiple capacitors. J Microelectromech Syst 17(4):934–942. https://doi.org/10.1109/JMEMS.2008.921727
Willam K (2002) Constitutive models for engineering materials. Encyclopedia Phys Sci Technol 3:603–633
Barile G, Leoni A, Fern G (2019) A differential capacitive multi-material 3d printed sensor for portable anemometric applications. In: 2019 IEEE 8th international workshop on advances in sensors and interfaces (IWASI), pp 234–238. https://doi.org/10.1109/IWASI.2019.8791283
Lu Y, Bai Y, Zeng T, Li Z, Zhang Z, Tan J (2016) Coplanar capacitive sensor for measuring horizontal displacement in joule balance. In: 2016 Conference on precision electromagnetic measurements (CPEM 2016), pp 1–2. https://doi.org/10.1109/CPEM.2016.7540791
Zaitsev IO, Levytskyi AS (2017) Determination of response characteristic of capacitive coplanar air gap sensor. In: 2017 IEEE microwaves, radar and remote sensing symposium (MRRS), pp 85–88. https://doi.org/10.1109/MRRS.2017.8075034
Prit G, Goyal P, Islam T (2019) A novel design of the parallel plate capacitive sensor for displacement measurement. In: 2019 IEEE 16th India council international conference (INDICON), pp 1–4. https://doi.org/10.1109/INDICON47234.2019.9029007
Liu X, Peng K, Chen Z, Pu H, Yu Z (2016) A new capacitive displacement sensor with nanometer accuracy and long range. IEEE Sensors J 16(8):2306–2316. https://doi.org/10.1109/JSEN.2016.2521681https://doi.org/10.1109/JSEN.2016.2521681
Schouten M, Sanders R, Krijnen G (2017) 3d Printed flexible capacitive force sensor with a simple micro-controller based readout. In: 2017 IEEE sensors, pp 1–3. https://doi.org/10.1109/ICSENS.2017.8233949https://doi.org/10.1109/ICSENS.2017.8233949
Wolterink G, Sanders R, Krijnen G (2018) Thin, flexible, capacitive force sensors based on anisotropy in 3d-printed structures. In: 2018 IEEE sensors, pp 1–4. https://doi.org/10.1109/ICSENS.2018.8589584https://doi.org/10.1109/ICSENS.2018.8589584
Van Dommelen R, Berger J, Haque RI, Binelli MR, De Freitas Siqueira G, Studart AR, Briand D (2020) Fully 3d printed mechanical pressure sensors: a comparison of sensing mechanisms. In: 2020 IEEE sensors, pp 1–4. https://doi.org/10.1109/SENSORS47125.2020.9278862https://doi.org/10.1109/SENSORS47125.2020.9278862
Kisić M, Blaž N, živanov L, Damnjanović M (2019) Capacitive force sensor fabricated in additive technology. In: 2019 42nd International spring seminar on electronics technology (ISSE), pp 1–5. https://doi.org/10.1109/ISSE.2019.8810154
Khan S, Lorenzelli L, Dahiya RS (2015) Technologies for printing sensors and electronics over large flexible substrates: a review. IEEE Sensors J 15(6):3164–3185. https://doi.org/10.1109/JSEN.2014.2375203https://doi.org/10.1109/JSEN.2014.2375203
Valavala PK, Clancy TC, Odegard GM, Gates TS (2007) Nonlinear multiscale modeling of polymer materials. Int J Solids Structures 44(3):1161–1179. https://doi.org/10.1016/j.ijsolstr.2006.06.011https://doi.org/10.1016/j.ijsolstr.2006.06.011
Dharmadasa BY, McCallum M, Jimenez FL (2020) Characterizing and modeling the viscoplastic behavior of creases in Kapton polyimide films. https://doi.org/10.2514/6.2020-2165
Li H, Chen J, Chen Q, Liu M (2021) Determining the constitutive behavior of nonlinear visco-elastic-plastic PMMA thin films using nanoindentation and finite element simulation. Materials Design 197:109239
He W, Goudeau P, Le Bourhis E, Renault P-O, Dupré JC, Doumalin P, Wang S (2016) Study on Young’s modulus of thin films on Kapton by microtensile testing combined with dual DIC system. Surface Coatings Technol 308:273–279
Wang Y, Shang L, Zhang P, Yan X, Zhang K, Dou S, Zhao J, Li Y (2020) Measurement of viscoelastic properties for polymers by nanoindentation. Polym Test 83:106353
Chang W-Y, Fang T-H, Lin Y-C (2008) Physical characteristics of polyimide films for flexible sensors. Appl Phys A 92(3):693– 701
Wei PJ, Shen WX, Lin JF (2008) Analysis and modeling for time-dependent behavior of polymers exhibited in nanoindentation tests. J Non-Crystalline Solids 354(33):3911–3918
Zhu Y, Wu Y, Wang G, Wang Z, Tan Q, Zhao L, Wu D (2020) A flexible capacitive pressure sensor based on an electrospun polyimide nanofiber membrane. Org Electron 84:105759. https://doi.org/10.1016/j.orgel.2020.105759
Dobrzynska JA, Gijs MA (2012) Flexible polyimide-based force sensor. Sensors Actuators A Phys 173(1):127–135
Bodini A, Pandini S, Sardini E, Serpelloni M (2018) Design and fabrication of a flexible capacitive coplanar force sensor for biomedical applications. In: 2018 IEEE sensors applications symposium (SAS), pp 1–5. https://doi.org/10.1109/SAS.2018.8336775https://doi.org/10.1109/SAS.2018.8336775
Funding
This work was funded by NIOSH Contract 75D30119C05413, “IMPROVING HEALTH AND SAFETY OF MINING OPERATIONS THROUGH DEVELOPMENT OF THE SMART BIT CONCEPT FOR AUTOMATION OF MECHANICAL ROCK EXCAVATION UNITS AND DUST MITIGATION.”
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Oltmanns, A.F., Petruska, A.J. Low-Profile Capacitive Load Cells for Underground Mining Material and Wear Classification to Promote Worker Safety. Mining, Metallurgy & Exploration 40, 757–771 (2023). https://doi.org/10.1007/s42461-023-00732-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42461-023-00732-2