
Abstract
This article reviews and analyzes the approaches utilized for monitoring cutting tool conditions. The Research focuses on publications from 2012 to 2022 (10 years), in which Machine Learning and other statistical processes are used to determine the quality, condition, wear, and remaining useful life (RUL) of shearing tools. The paper quantifies the typical signals utilized by researchers and scientists (vibration of the cutting tool and workpiece, the tool cutting force, and the tool’s temperature, for example). These signals are sensitive to changes in the workpiece quality condition; therefore, they are used as a proxy of the tool degradation and the quality of the product. The selection of signals to analyze the workpiece quality and the tool wear level is still in development; however, the article shows the main signals used over the years and their correlation with the cutting tool condition. These signals can be taken directly from the cutting tool or the workpiece, the choice varies, and both have shown promising results. In parallel, the Research presents, analyzes, and quantifies some of the most utilized statistical techniques that serve as filters to cleanse the collected data before the prediction and classification phase. These methods and techniques also extract relevant and wear-sensitive information from the collected signals, easing the classifiers’ work by numerically changing alongside the tool wear and the product quality.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The analysis of cutting tools has been a relevant topic for many years. Proper maintenance results in the tool’s productive life prolongation and high-quality performance. The main goal of condition monitoring systems is to allow maintenance or other actions to be predicted; therefore, extra costs due to out-of-specification (OOS) products or damage in the machinery can be avoided. Even though the producers extensively explain the appropriate maintenance which should be implemented to obtain efficient performance, the occurrence and the frequency of failures increase the production costs, especially in those cases where the material must be reformed and reprocessed, resulting in a financial loss for the company. In those scenarios, incorporating methods to predict an imminent failure or a reduction in the quality of the cut can save and reduce production costs. In 2012, Cai et al. [22] stated that approximately 20% of a machine downtime which results in reduced productivity and economic losses was attributed to cutting tool failure; in the very same year, Gahni et al. [39] concluded that around 3–12% of the total production cost are accounted to tool’s replacements. It has also been calculated that the tool-related issues downtime is approximately 7–20% of the machine’s productive time, as Drouillet et al. [35] stated. In more recent studies; researchers concluded that the 15-40% of costs of produced goods is influenced by tool machine failures [26, 27, 99]. As clearly stated, the financial impact of tool maintenance is relevant and substantial; therefore, a monitoring system has become a proper course of action to mitigate these losses.
An ideal monitoring system can supervise the wear in the tools over time to avoid unexpected downtime or non-precise cuts [5]. Most of the recent approaches comprise two main parts: The data-measuring process and the classification systems. As described further, the data measuring process is in charge of the data collection, which uses sensors to measure a physical or electrical signal taken during the production process. The classification system uses this information to determine the condition of the tool or the Remaining Useful Life (RUL). It can improve tools sustainability [108] and enables the reliability prediction [101].
The data measuring process is a sensor or a set of sensors to capture specific information from the tool and the machine. Data acquisition through the Monitoring Systems (MS) is crucial since it must be capable of accurately and continuously measuring some defined variables, which are then analyzed to predict future failures. Several signals are being used for those purposes; however, as will be discussed in further chapters, some physical signals have shown a high correlation to the tool’s wear, such as cutting force [96, 117, 129], acoustic signals [15, 103, 138], the cutting tools and work-piece vibration signal [116, 121, 141], among others.
On the other hand, the classification system is the final part of the monitoring system. In 2013 [15] implemented Super Vector regression to predict and monitor the wear of a shearing tool. From 2019 most of the approaches are Neural Network-based, in any of its variations (auto-encoder, Recurrent Neural Network, Convolutional Neural Networks.) Preez et al., [88]; Sun et al., [107]; Traini et al., [114]; Kong et al., [57]; Patange et al., [87]; Lee et al., [66]. It can also work with limited data collection [70].
Several methods have been developed over the year for classification and prediction purposes. Artificial Neural Networks [10, 29, 114, 121], specifically Long Short Time Memory, Convolutional Neural Network; also Support Vector Machine, Wang et al., [118]; Lee et al., [66] and others.
The tool’s life prediction and remaining life are typically modelled using data-driven approaches. Some researchers have also shown promising results by modelling the tools’ wear and creating mathematical models. A review paper from Kuntoǧlu et al., [62] also mentioned other possible ways to design the indirect tool condition monitoring system; their Work also presents various decision-making methods used for condition monitoring of steel machining. In 2011, the work [18] was published, where hidden discrete Markov models were used for tool wear/fracture and bearing failures. The technique was tested and validated successfully. In this case, the model correctly detected the state of the tool (i.e., sharp, worn, or broken), resulting in a 95% success rate obtained for fault severity classification.
There are also hybrid systems where both approaches are implemented. Hanachi, in their work [42], managed the uncertainties and noise of both methods, implementing a hybrid framework where they fused the results of the prediction model and the measurement-based inference data step-wise. They concluded that the results of their hybrid system showed significant improvements in tool wear state estimation, reducing the prediction errors by almost half, compared to the prediction model and sensor-based monitoring method independently used.
The correct operation of many systems is often guaranteed by post-manufacturing testing; therefore, it will be considered that they work correctly right after installation. Although it is possible to analyze situations with manufacturing defects, this paper does not aim to. The focus is the cases where systems gradually degrade to reach a failure state eventually. Such problems are the focus of the Survival Analysis.
Because of the stochastic nature of a tool degradation, its time to failure is usually modeled as a random variable, say T. By the reliability (of a non-repairable system) at a given time t, meaning the probability that the actual failure time has not occurred yet, \(R(t):=P(T>t)\). Various models (exponential, gamma, Weibull, log-normal, etc.) and their applications are given in the basic textbooks on Reliability theory [12, 105, 113].
The basic models can be constructed via standard statistical inference methods from historical data like the Maximal-Likelihood method, Bayesian inference, or, in the case of latent variables in the model, the Expectation-Maximization algorithm. The reason for constructing the models is to use them in the subsequent analyses in which the maintenance is optimized [48] and [83] to ensure that the system will deliver the required functionality.
The remaining life can be regressed directly as in Wu et al., [130], who used Artificial Neural Networks (ANN) and, subsequently, polynomial curve fitting for condition-based predictions regresses the remaining life by correlating the force with the wear rates [125]. The inferred statistical models described in the following section can also be assessed.
2 Tool Condition Monitoring Chain
Tool Condition Monitoring (TCM) systems monitor production, optimize it and prevent breakdowns. Figure 1 shows a standard schematic of the composition of the monitoring system, which includes signal converters/amplifiers, processing systems, and HMI (monitor) [82]. These measurement systems key elements are the sensors, which must be optimally positioned close to the target location. The raw sensor signals are usually unusable and must be amplified or adjusted. The signal is then processed to obtain helpful information about the process being monitored [132]. This task is performed by processing units such as personal computers and embedded systems. The last part of the measuring system is the visualization via an HMI panel or monitor. Information about the machine status can be sent to the maintenance planning system or the plant Information System (IS) [5, 84]. Today, edge or fog computing nodes are also being commissioned as part of the Smart Factoring trend. This enables large amounts of data to be monitored and processed efficiently [128].
The connection of sensors to the machine depends on the type of sensors used to collect the data. In the case of signals generated by the physical action of the equipment, these signals are measured by direct coupling to the tool, e.g., tool cutting forces, tool vibration, and work-piece vibration, among others. For accurate measurements, the instrument must be adjusted appropriately to avoid resonance. Similar rules apply when installing contact sensors, where the correct procedure and method must be followed. In the case of non-contact measurements using a microphone, the effect of surrounding machines must be considered. Suitable filters [72] or an adaptive system must be installed. If necessary, a second acoustic signal source must be installed to sense ambient noise.

Block diagram of standard TCM system

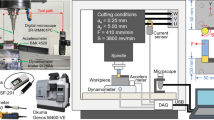
Milling machine, an example of using different types of sensors to capture multi-domain features

Signal sources - usage frequency 2012–2022
Frameworks for condition monitoring could be based on various hardware and software solutions. For example, TCM system presented in Assad et al., [9] consists of a manufacturing station with PLC system, and an Open Platform Communications-Unified Architecture (OPC–UA) is used for data exchange. Data is saved to the database and processed with maintenance software. Specific frequency alarm values in the frequency domain are checked.
The signal extraction can be done using specialized software and hardware and customized hardware and software such as measuring cards and personal computers. Nowadays, in the age of Industry 4.0, technological initiatives, such as cyber-physical systems, the internet of things, and predictive maintenance play essential roles in equipping existing manufacturing systems with intelligent capabilities such as self-awareness, self-adaptation, and condition monitoring in delivering agile and uninterrupted productions [74].
Currently, more technologies are being developed to manage signal processing. High-performance, cloud, and edge computing are being investigated as potential solutions to enable intelligent manufacturing in the machining industry. Current research aims to realize a tool condition monitoring system using the edge computing-based architecture [74].

Features usage Frequency 2012-2022
2.1 Signals and Features
A typical representation of metalworking machines is a milling machine. As shown in Table 2, it was the most used in selected TCM articles between 2012 and 2022. An illustrative picture of the milling machine is shown in Fig. 2 and includes all the sensor systems typically used as signal sources in this application area. The Fig. 3 graph shows the frequency of occurrence of the same types of signal sources during the selected time frame.
The measured signals can be cutting force, vibrations, temperature, acoustic emission, motor current, etc. It is generally acknowledged that a reliable process based on a single signal feature is not feasible [110] and it is necessary to use the most meaningful signal features to build a robust and reliable TCM system [34, 110]. Figure 4 shows the top 4 signals scientists and researchers used in the last ten years. Leading the top is the cutting force of the cutting tool and its vibration. During those ten years, 35% of the signals varied from electrical signals to even the volume of material removed from the cut products.
2.1.1 Cutting Force
Measuring cutting force is one of the most effective ways to determine tool wear [117]; it can optimize the milling process and measure strain on the tool. The force applied to the tool is directly proportional to its wear, feed rate, and thickness or hardness of the material. A three-axis dynamometer is used to measure these forces.
2.1.2 Vibration Signals
In 1987, Lee Minyouing et al. [64] introduced vibration analysis of cutting tools used in metal forming processes. Their main conclusions were that the vibration signals from metal-cutting processes contain beneficial information and offer excellent possibilities for diagnosing many metal-cutting problems, including tool wear.
Milling, turning, or drilling machines generate vibrations based on the rotational movement of the tool or workpiece in the case of turning. In contrast to cutting, vibration in these machines is caused by the rotational motion of unbalanced rotating parts or a defective bearing; shear and frictional forces result from the vibration generated during cutting. Therefore, an approach that could monitor industrial motors or machine bearings cannot usually be used in other metal-forming applications. It is possible to process raw vibration signals [136]. Still, for a nonlinear system with high variability in the time domain, detection and analysis of features in the frequency domain [67] is also required.
2.1.3 Acoustic Signal
Another indirect method of condition monitoring is acoustic emissions from the production process. They are usually caused by contact between the tool and the workpiece at higher speeds (milling machine, drilling machine, lathe). This method does not interfere with the monitored process, is easy to set up, has a fast dynamic response, and has a reasonable price/performance ratio [148]. The problem of acoustic emission lies in ambient noise and other acoustic signal sources from moving parts of machines or other nearby machines. A direction sensor or adaptive filtering can be used to reduce the impact of overlapping signals [91].
2.1.4 Electrical Signal
Various ways of analyzing the influence of energy consumption on the condition of a machine appear in the articles. The electrical signals mainly used are the current and power consumption.
The article [149] evaluates the past and future of the production process in terms of energy consumption. Under constant pressure from environmental and economic trends, manufacturing companies must develop and seek new ways to plan and optimize production; this requires a proper evaluation of the energy efficiency of machine tools. The system can show inefficient parts of the production process that can be optimized or redesigned with a deeper understanding. The author suggests that an indicator for the overall evaluation of the energy efficiency of machine tools should be investigated and developed. This would help to create a comparable industry benchmark for energy efficiency evaluation. The possible form of energy consumption models of milling machines was divided into three categories, such as:
-
Linear type of energy consumption model based on material removal rate,
-
Detailed parameter type of cutting energy consumption correlation models,
-
Processed oriented machining energy consumption model.
The distribution can be used for most machines and as an additional input to TCM system for estimating tool wear. The signal has many advantages since it does not need to be located near the tool and does not disturb the monitored process. The source of the signal cannot be affected by oil, metal debris, or other things that can affect the measurement in an industrial environment.
2.1.5 Other Signal Sources
Other signal sources for the TCM system are information provided directly by the machine, such as depth of cut [109], the speed at which the tool head is moving [114] or the time the tool is active. In this way, we can calculate the volume of material removed [99] or, with the addition of a temperature sensor, monitor the additional thermal load that correlates with the tool wear rate [60].
A final source of information about the machining process can be a visual inspection of the tool [31] or the work-piece [36] itself using image processing techniques.
2.2 Signal Features
Various methods have been developed to monitor tool wear. An essential problem in a TCM system is processing the signal with sufficient features that match the target problem. The signal from the sensor needs to be transformed into features that could describe the signal sufficiently while preserving relevant information about the tool condition in the extracted features [43, 71]. The time domain, frequency domain, mean, RMS, skewness, kurtosis, and other signal features listed in Table 1 can extract the signal features.
RMS An RMS value is also known as the effective value and is defined in terms of the equivalent heating effect of direct current. The RMS value of a sinusoidal voltage (or any time-varying voltage) is equivalent to the value of a dc voltage that causes an equal amount of heat (power dissipation) due to the circuit current flowing through a resistance [41].
Arithmetical Mean represents a point about which the numbers balance. For example, if unit masses are placed on a line at points with coordinates x1, x2,..., xn, then the arithmetic mean is the coordinate of the system’s center of gravity. In statistics, the arithmetic mean is commonly used as the single value typical of a data set. For a system of particles having unequal masses, the center of gravity is determined by a more general average, the weighted arithmetic mean.
Skewness is a measurement of the symmetry of the surface deviations about the mean reference line and is the ratio of the mean cube value of the height values and the cube of Rq within a sampling area [63].
Kurtosis The kurtosis factor is a common dimensionless time series statistic that can reflect the random distribution of time series data. The larger the value is, the more frequency of random fluctuation of the large value of the sequence [41].
Crest Factor The crest factor [94], which is defined as the ratio of the peak value and the RMS value of a data series
The information obtained from the sensors is then combined into a single TCM system, which can be based on various statistical methods, autoregressive modeling, pattern recognition, fuzzy logic systems, neural networks, and combinations of these methods [49].
3 Methods to Predict Cutting Tool Failures
As previously mentioned, researchers have been using and developing various methods to determine the condition of the cutting tools. In Sect. 2.1, the signals and features normally collected by developers as a proxy of the tool and work-piece condition were mentioned. Kong et al., [57]; Marwala et al., [79] Since these signals are complex sequences of values continuously collected by the sensor, the classifiers and methods to determine the condition of the tools must efficiently correlate the tool’s state with the corresponding numerical input [9, 61, 126]. Different methods can be used based on the data being monitored during the machine operation.

Classifier - usage frequency 2012–2022
Machine Learning is a frequently used approach to predict the failure of these tools. Thanks to its accuracy and effectiveness, researchers, scientists, and engineers have increased its utilization in industry and academia.
From Table 2, Figs. 10 and 5 were elaborated. Figure 5 summarizes the most used Machine Learning and Statistical algorithms. The result is as follows:
-
Artificial Neural Networks [32%].
-
Support Vector Machine [14.4%].
-
Customized Algorithms [7.2%].
-
Random Forest [7.2%].
-
Others [39.2%].
In general, there are three types of Learning:
Supervised Learning includes a variety of function algorithms that can map inputs to desired outputs. Usually, supervised Learning is used in classification and regression problems: classifiers map inputs into pre-defined classes, while regression algorithms map inputs into a real-value domain. In other words, classification allows predicting the input category, while regression allows predicting a numerical value based on collected data [61].
Unsupervised machine learning aims to discover features from labelled examples, so it is possible to analyze unlabeled examples with possibly high accuracy. The program creates a rule according to the data to be processed and classified. Among supervised algorithms, the most widely used are the following algorithms: linear and logistic regression, Naive Bayes, nearest neighbour, and random forest. In condition monitoring and diagnostics of electrical machines, the most suitable supervised algorithms are decision trees and support vector machines [61].
Semi-supervised Learning is halfway between supervised and unsupervised Learning. In addition to unlabeled data, the algorithm is provided with some supervision information - but not necessarily for all examples. Often, this information standard setting will be the target associated with some of the examples.
Reinforcement learning is one of the ML methods where the system (agent) learns by interacting with some environment. Different from supervised algorithms, there is no need for labelled data pairs. Reinforcement learning balances an unknown environment and existing knowledge [61].
Researchers and engineers usually use Supervised, Semi-Supervised, and Unsupervised Learning since the labelled or unlabeled data is typically available.
3.1 Artificial Neural Network
Artificial neural network is leading the survey with 30.9% of the articles utilizing some neural network to evaluate the prediction of the tool. as Doriana M. D’Addona et al. stated in D’Addona et al., [31] “ANN learns from examples and classifies/recognizes the hidden structures underlying the examples. This way, it helps establish functional relationships among some input and output parameters. As described in the “Introduction” section, ANN has extensively been used in developing computing systems for predicting the degree of wear and recognizing the patterns underlying tool-wear.”

Most frequently used-neural networks model
Artificial neural networks fall into three categories:
3.1.1 Methods without any Spatial-time Processing
This is the fully connected dense layer, where the process focuses on the numerical interaction of the data.

Neural network basic structure
The research shows that within the 30.9% of papers that used Artificial Neural Networks as the classifier, 40.7% chose Dense-Connected Layers in all its current variations, as can be seen in Fig. 6.
Dense-Connected Layers are the most basic Neural Network structure; see Fig. 7. A Dense-Connected layer is composed of a network of single neurons mathematically defined as Eq. 4. To complete the whole learning process, the network of neurons is activated or deactivated based on the type of Activation function used in the model, see Eq. 56. The model learns during the pass-forward and back-propagation process, where all the trainable parameters are multiplied by their corresponding weights and bias. The back-propagation process calculates all the gradients and then uses an optimization function to minimize the loss value.
The research shows that most papers extract numerical values from the measurements and feed the neurons with the information. As can be seen in the Wang et al., [117]; Chen et al., [25]; D’Addona et al., [31]; Yuqing et al., [140]; Rao et al.,[92]. One example of this procedure is what Baig Ulla et al. did in their article [11]; they used the following:
-
Material of the workpiece.
-
Spindle Speed.
-
Feed Rate.
-
Depth of cut.
-
Tool Vibration.
The structure is divided into three main parts Input Layer, Hidden Layers, and Output Layer. The input layer length depends on the feature size.
The mathematical model of a single neuron:
where,
W represents a set of weights initially randomized; they are updated after the optimization during the training process. B represents a set of biases, one per neuron randomly initialized; they are updated after the optimization function during the back-propagation \(X = Input Value\).

Convolutional neural Network Architecture
After each neuron, the activation function takes place. Several activation functions are used depending on the case and the complexity of the implementation. Some of the most used activation functions are RELU and SIGMOID; however, researchers and scientists also use other Activation Functions or customized ones depending on their needs.
In the case of RELU, its range is [0,1]. Mathematically:
In the case of SIGMOID, its range is [– 1,1]. Mathematically:
The optimal weights and biases within the network are continuously “learned” or “updated” by a back-propagation algorithm, which usually implements stochastic gradient descent, where a single data point is used to update the weights in one iteration [35]. Then, the output layer errors are calculated using the target training output for the data point and the defined error function. In regression problems [31], mean squared error is most frequently used as an error function; in the case of classification problems, typically binary-cross-entropy is used. The advantage of using Neural Networks is their adaptation to non-linear problems and their effectiveness in solving complex classification tasks.
3.1.2 Methods that Focus on the Spatial Information of the Data
These methods use Sliding Windows, kernels, and other spatial image processing methods to extract visual and 2D features of the data. This type of Network is called a “Convolutional neural network”. As Ambadekar et al. [4] concluded in their article: The CNN can extract features, select required features from the extracted ones and classify the data into the required number of classes. The training process of the CNN differs from the Dense layers in the trainable parameters. The optimization function in CNN updates the “kernels” (filters), which are then convoluted into the images and feature maps, see Fig. 8.
The research shows that most CNN architectures were mainly used when collecting the workpiece and cutting tool images. Cases were also found where the researchers used the spectrogram of the data as an image or simply the data in the time domain. Guofa Li et al. [69] collected the Vibration and the cutting force of the cutting tool in all its axes. They rearranged the data as multi-layer images where each layer was one component of the vibration or the force, obtaining satisfactory results. As Meng Lip [80] stated, the most significant advantage of the Convolutional Neural Network and all its derivations is extracting visual features from the data eventually results in classification based on shapes, appearance, colors, and visual structures. Sayyad et al., [102].
Ambadekar et all [4] experimented with Convolutional Neural networks using the tool and work-piece images as the input data. The results reached an accuracy of 87%, which for their purposes was satisfactory.
Figure 6 it is presented as a standard CNN architecture. CNN commonly comprises four parts: Input data, Convolutional Layers, Dense Layers (the dense layers which are simple number neurons that are then used for classification or clustering purposes), and Output. Nowadays, many CNNs can be easily found; researchers also use them to customize their trainable parameters for their use case; this method is called “Transfer Learning” [76].
3.1.3 Methods that Focus on the Sequence of the Data
Instead of treating each input individually, these methods consider the sequential variation of the data. Recurrent Neural Networks solve one of the most significant issues of the Dense Layers and Convolutional layers, the “Vanishing gradient problem” [27], which is the reduction of the impact of the first layers into the final output. This problem causes the last weights and biases to be more dominant in the loss function.
This problem has been overcome, by reusing the trainable parameters from the first layers to more deep layers, see Fig. 9. It also uses neurons, Eq. 5 as part of the structure of the model, but their importance stems from the fact that they can create a model which perceives and considers the sequential and continuous change in data in a time frame. Publication [1] summarized some of the most used types of RCNN:
-
Binary.
-
Linear.
-
Continuous-Nonlinear.
-
Additive STM equation.
-
Shunting STM equation.
-
Generalized STM equation.
-
MTM: Habituative transmitter gates and depressing synapses.
-
LTM: Gated steepest descent learning: not hebbian learning.
Wennian Yu et al., in the article [138], utilized and compared the different types of RNN networks (Long-Term Short Memory and Elman) to determine the tool condition in a Milling process. Cutting forces and other signals were used, and it was then concluded that LSTM results in a more accurate method but requires a longer time to train.
The research shows that even though the RNNs model’s results are time-dependent, robust, and sensitive to the sequential change of the data, they are more laborious algorithms, especially when combined with CNN (Spatial Feature Extractors). Since you do not only work with the standard weights, biases, and kernel parameters, you also should manage the parameters which model the impact of the time in the data; that is one of the assumptions why the research shows that only the 11.1% of the analyzed papers used this method for cutting tools monitoring.

Basic structure of recurrent neural network

Classifier-usage frequency 2012–2022
3.2 Support Vector Machine (SVM)
SVM is a machine learning algorithm used for classification and, in some cases, for Clustering tasks. It employs the structural risk minimization principle while introducing a kernel trick. Support Vector Machine problems originated from a supervised binary classification, in which most of the solutions are evaluated by obtaining a separating hyper-plane among classes.
The Data set in SVM can be illustrated as follows:
where, \(x_{i\ }\)=Vector of M dimension of features.
In the case of the Vibration-Data, this is the raw data (Each sample) obtained by the sensor(s). If any Feature extraction is applied, all the features should be converted to a 1D vector indexed by each feature. It indicated to which class their corresponding Xi belongs. SVM aims to find the separating boundary between defined classes. This is done by maximizing the margin between the decision hyperplane and the data set while minimizing the misclassification. The decision/separating hyper-plane is defined as:
where w is the weight vector defining the direction of the separating boundary. b is the bias. The decision function is defined as:
where \(sgn\left( \alpha \right) =-1,\alpha < 01, = \& \alpha \ge 0\)
The SVM algorithm aims to maximize the margin by minimizing ||w||, which results in the following constrained optimization problem.
3.3 Customized Algorithms
As shown in Fig. 5, a relevant number of articles developed what the researchers decided to call “Customized Algorithms”. These algorithms are methods, approaches, and solutions designed to monitor individual case. Bouzakis K.D et al. [19], Cerke Luka et al. [24] and Tangjitsitcharoen et al. [109] designed a method to predict the tool-life by modelling the geometry of their tool and then experimentally tested the tool-life, by loading the tool and measuring the continuous measurement of the tool-wear.
3.4 Random Forest
Leo Breiman [20] developed the random forest algorithm. Random Forest model grows and combines multiple decision trees to create a “forest” [126]. A decision tree is another algorithm for classifying data [114]. In straightforward terms, you can think of it like a flowchart that draws a clear pathway to a decision or outcome; it starts at a single point and then branches off into two or more directions, with each branch of the decision tree offering different possible outcomes [38].
Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest [85]. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large. The error of a forest of tree classifiers depends on the strength of the individual trees in the forest and the correlation between them [38]. Using a random selection of features to split each node yields error rates that compare favourably to Adaboost, but are more robust concerning noise. Internal estimates monitor error, strength, and correlation, which show the response to increasing the number of features used in the splitting (Fig. 11).

Random forest
3.5 Others
The issue of tool conditional monitoring and fault prediction is complex, and to successfully describe the behaviour of the observed system; it is necessary to study all its aspects, not just a narrow look at one approach. Most of the machining processes are non-linear, and the computation of the wear of the monitoring tool is complex.
In practice, the application of algorithms that reduce the dimension of the input vector and highlight essential properties of the measured signals was encountered [17, 26, 67, 67, 104, 148]. It is used to reduce computing power and eliminate redundant information. The principles of adaptive techniques can be found in several advanced algorithms, namely well-known adaptive linear element (ADALIN) neural networks, adaptive neuro-fuzzy interface systems (ANFIS), and linear programming.
In the article [104], authors presented a wear predictive model based on a combination of PCA and least squares support vector machines (LS-SVM). LS-SVM uses functions from multiple sensor signals and is resistant to typical problems with using a small learning set thanks to statistical learning theory. The authors present a good correlation between LS-SVM results and subsequence optical analysis.
In 2007 another article [67], the authors divided signals into three streams for feature detection. The features were extracted from raw, filtered data and data processed by Empirical Mode Decomposition (EMD). All features have been processed by an improved distance evaluation (IDE) technique, which reduces redundant information and selects the most important ones. Finally, the data were processed by ANFIS.
In 2016 article [99] analyzed the performance of these most widely used methods of tool condition monitoring (TCM), namely artificial neural network (ANN), fuzzy logic (FL), and least squares (LS) model. The experiments were performed on CNC turning machine, and milling parameters (cutting depth, feed, speed, and force) were used as model input of the model. The models were computed on three datasets (108, 12, and 12 samples). The ANN model \((R_ANN^2=0.952)\) scored nearly the same as the FL model \((R_FL^2=0.94)\), and the LS scored the least \((R_LS^2=0.81)\). As the ANN method scored the most, the FL model would be much more feasible for small-scale applications.
3.5.1 Tool Wear Modelling
As mentioned earlier, the tool to work correctly at its installation is considered and aimed to model its gradual degradation. The specific work influences this degradation the tool is performing - the parameters of the cut steel sheet in our case. Therefore, an inference from bulk historical data gathered from heterogeneous jobs would lead to sub-optimal performance of our predictive models because of a significant variation in the predicted failure times.
Another peculiarity for shear cutter operation lies in yet another variation in cutting conditions during a single tool’s useful life. The metal coils are changed according to the manufacturing plan and may differ in dimensions and material properties. Therefore, the conditions are not homogeneous during the cutting tool service.
This restricts us from using the well-established Proportional Hazards Model [30] described in section 3.5.2, successfully used for tool wear modeling in different industries and medical sciences. That’s because it requires stable conditions for each investigated unit, e.g. a tool blade. An alternative might lie in using stress-varying techniques known from accelerated life tests, e.g. by Liu et al., [73] for analysis of cutting tools or virtual age models [21].
A similar applies to Bayesian parameter inference for some basic physics-based wear models. The models specified in the differential form can nevertheless be used when the tool condition is monitored in case of direct observation (see Sect. 3.5.3) or estimation of the model parameters online (Sect. 3.5.5).
Therefore, the information about the processed material should be included in our degradation models, available from the operator. This can be done by using some of the theoretical models, which identify the mechanical stresses on the tool as the most influential covariate (see [52, 53]) and using empirical models for modelling the tool wear rate [8, 78, 86].
3.5.2 Proportional Hazards Models
The proportional hazards model is a reliability theory technique for regressing the dependency of the failure time on known covariates of statistical units. Hazard rate (or hazard function) is a non-negative function that can fully represent a positive random variable. It is defined as the immediate rate of failure,
knowing the hazard rate, the reliability can be calculated as
The quantity
is also known as the cumulative hazard and represents the accumulated virtual wear of the investigated system.
In the proportional hazards model, it is assumed that the hazard rate is proportional to known covariates. A baseline hazard, \(h_0\), is modelled (and inferred) for the investigated bulk observations, and the hazard rate for each individual is then computed as a combination of both:
where \(Z_{i,j}\) represents known covariates corresponding to the individual i and \(\beta _j\) are coefficients to be inferred via statistical methods. Cox [30] developed an efficient method for estimating the model parameters. Once the individual failure rate is specified, the remaining useful life can be calculated for each item as the expected value
Nevertheless, the original method doesn’t allow us to include information about the monitored condition. But it can still be used either for offline maintenance scheduling or as a partial model for a more complex one, like in Aramesh et al., [6, 7] where they were used to model transitions between discrete tool wear states.
Proportional hazard models were successfully used for tool life estimations when the working conditions stayed constant during the whole tool life. Aramesh et al., [7]; Diamoutene et al., [33]; Salonitis et al., [100]; Wang et al., [124].
Shaban Y. and Yacout S. used the proportional hazards model to estimate remaining useful life and later also for optimal maintenance decisions [134, 135].
3.5.3 Parameter Pegression for Physics-based Models
Some empirical models which link tool working conditions and their useful life were developed in the past and originated by Taylor [78]. Statistical methods can estimate the parameters of these models and their uncertainty. Several authors have attempted this [53, 54]. Yet these approaches might suffer from similar issues as the proportional hazards models if they relate only to the tool’s useful life as they can be used only for prior offline predictions. If the empirical model is stated in a differential form, it can be used to model state transition in Hidden Markov Models [123]. Rodriguez et. al. [97] fitted the Taylor model by the Maximum likelihood method and used the obtained tool reliability for Palmai, [86] introduces a new differential model for flank wear.
3.5.4 Wear Regression
The wear mechanism for a cutting tool consists of gradual abrasion of its blades. Empirical measurements show that this wear rate is not constant but changes during the tool’s life [111]. A typical curve representing the gradual wear is depicted in Fig. 12, which shows three distinguished phases of the wear out - a design phase (D), an initial phase of the new asset (I), a steady life phase (P), and the accelerated wear region of rapid degradation (F). Each phase is suitable for a certain type of maintenance. Thus, it is not always predictive maintenance [2, 150].
-
D-I phase
The most important thing here is to set up the machine correctly and prepare it for long-term operation. This requires an initial set-up, optimization of the operation and a proper maintenance schedule.
-
I-P phase
The initial start-up of the machine is followed by a phase of long-term operation and, if all machine components are correctly adjusted, maintenance interventions are generally not necessary.
At the beginning of this phase, the machine normally exhibits increased vibration, followed by an interval of standard machine operation. The maintenance focuses only on the execution of the standard maintenance schedule.
-
P-F phase
If predictive maintenance methods are applied to the machine, they are mainly applied in the P-F phase. Here, wear of individual machine parts, or even the whole mechanism, occurs. The machine is ageing. This results in higher vibrations, power supply imbalances, increased noise, or operating temperature. Properly applied, predictive maintenance can detect an impending failure and alert maintenance to this fact, which can eliminate the cause before the failure occurs [2, 51].
-
F+ phase
The final stage in the life of a given machine is when the impending failure is not corrected in time. Partial or complete destruction of the machine occurs. Predictive diagnostics methods are designed to prevent this phase.
This knowledge can be used for modelling purposes. Tool reliability is often defined heuristically by the extent of this wear, and a crisp limit is used to denote the failure state. Zhang et al. proposed a generic parametric model, which they fitted by a genetic algorithm [141]. These publications [6, 7] infer the tool life as a semi-Markov process of transition between these three phases. Baruah et al. [13] use discrete phases; their number is chosen by a clustering algorithm based on the available monitored signal for constructing a Hidden Markov Model for tool diagnosis.
Another possibility is to use regression techniques to predict the wear state. The actual wear usually needs to be determined by visual inspections, which is impractical during regular operations. An estimation based on available information from a monitoring system can be used to estimate the actual wear state instead [16, 32, 40, 47, 55].
Salonitis et al. in their work [100] uses the surface response method for wear regression based on operational parameters and, subsequently, the First order reliability method and Monte Carlo simulations to estimate tool reliability. Also [16, 98].

Wear curve
3.5.5 Hidden Markov Models
The Hidden Markov Models model estimates unobserved processes out of indirect observation. A Markov process is used to model the hidden process (Fig 13b), e.g. the tool wear. Its evolution can be general, drifting Gaussian processes or a homogeneous Markov Chain in the discrete case (state transition diagram in Fig. 13a), or inspired by physics-based models (Sect. 3.5.3). The observation model can be obtained from inference/regression from the monitored signal. Labelling of the data is desired (e.g. by a less-frequent visual inspection of the accumulated wear as was done in many papers mentioned in this section), but the pooled inference is also possible as in Wang et al., [119, 123] who used hmm for joint state and parameter estimation using physics-based tool wear model and subsequent remaining useful life estimation.

Hidden Markov Model from Baruah et al., [13]
Mnighg et al. [81] compare support vector machines and hidden Markov models for tool diagnosis and claims that SVM outperforms HMM. But they use a homogeneous Markov chain to model the evolution of the hidden states, which can be improved by using differential wear models. Generally, Hidden Markov Models can be used for both fault diagnostics [13] or prognostics [119].
3.5.6 Kalman Filter (KF)
One of the older recursive algorithms, the Kalman filter, is widely used to remove uncertainty and noise from the measured signal. It is ale used as a basic tool for solving the problem of estimating the state and the parameters of linear systems. It has been used in artificial neural networks for mass transfer [89], which is more efficient than the backpropagation algorithm. This helped reduce the size of the input layer, arithmetic operations, and the required number of iterations.
3.5.7 Particle Filter (PF)
With a nonlinear system, a particle filter can provide better results at the cost of additional computing power. It works with a set of particles representing an uneven distribution of stochastic processes. As in the paper [146], the authors combined the long short-term memory (LSTM) network with a particle filter (PF) algorithm to improve the performance of the tool wear prediction algorithm. The average prediction error was reduced from 15.07% to 11.67%.
3.5.8 Least Mean Squares (LMS)
The LMS filter is mainly used for adaptive signal noise suppression. The algorithm aims to minimize the mean square error between the desired signal and the filter output.
3.5.9 Recursive Least Squares (RLS)
The RLS filter works similarly to the LMS but minimizes the total square error and requires more computing power. The Zhou et al. [147] applied RLS algorithm to the collected data using singular value decomposition (SVD), which was applied to the raw data. SVD helped to reduce the size of data to extract dominant features. The predicted values differed by approximately 8.86% to 11.61% from the actual tool wear measurement.
4 Conclusion
The paper analyzed different methods to estimate the condition of cutting tools. The research covered articles from 2012 to 2022. It is concluded that most of the consulted algorithms followed a similar pattern:
-
The data is acquired using specialized sensors. The sensors are strategically placed in the machine to collect the information effectively; then it is used different methods to transform, filter, and extract relevant information from the collected data. The research showed that the 27.4% of the analyzed articles use Cutting Force as the proxy to evaluate the condition of the tool, followed by the Vibration of the cutting tool with a 21.7%, Acoustic Signal, and the speed of the tool with 10.2% and 5.7% respectably.
-
The classification process. The classification algorithms are methods to determine the condition of the tool based on the provided data. As it was explained, the most used methods are Neural Networks (30.9%), Support Vector Machine (14.4%), Random Forest (7.2%), and others (40.2%). Neural Networks have shown promising results even in noisy environments where the data usually comes with many outliers, which are hard to eliminate in prepossessing methods. Based on the research, the use of neural networks has increased since 2016, and according to those papers’ conclusions, the results are promising, even in real-time projects. When analyzing the Artificial Intelligence approaches, the researchers based their model on three categories, Recurrent Neural Network at 11.1%, Dense Layers at 40.7%, and Convolutional Layers at 48.1%. There were also combinations of these models. Support Vector machine is the second most used method for classification. The research showed that it is mostly used when unsupervised or semi-supervised learning is needed.
This review article is part of a sequence of articles dealing with TCM problems in shearing and other types of machines. The team will utilize the most used methods for feature extraction and, subsequently, classification methods of custom data. Data comprises information from cutting blades, such as cut length, material, vibrations, and energy consumption during production. In addition, RGB images and thermal images of the metallic sheet (within the cut zone) and the cutting tool edge are collected. Promising results for TCM and potential fault predictions from these multiple signals are aimed to be generated.
5 Discussion
Notwithstanding the advancements in accuracy and reaction time developed over the years, some drawbacks still exist. These challenges range from the data collection and labeling to the algorithm’s dynamic adaptation to changes in the system.
In a production line, all the equipment produces data that can be analyzed. The issue arises in the labeling process, in other words, assigning a label to data indicating its status or condition. This drawback worsens when there is no intelligent system classifying the condition of the tool or machine. The failure appears during the quality inspection process, which occurs almost at the end of the production cycle. At this moment, it is difficult to determine when the tool started to fail. For cases like the one above explained, researchers are improving their unsupervised learning methods to detect and predict relevant changes in the data over time. Clustering algorithms are already known (K-Mean, Self-Organizing Map, Auto-Encoders...), and their role in the final solution became a mandatory pre-processing process before classification or regression tasks.
Another challenging problem is the changes in the system conditions over time. Production lines are dynamic systems based on the market; industries modify their products according to new clients to target and reduce production costs. Those changes might affect the products’ material and shape, dramatically affecting the data collected for the classification. For those cases, the system will attempt to classify data for which it was not developed. Self-Adaptive systems are used for those scenarios where the system can adapt its parameters over time; nevertheless, these algorithms are still in development due to the number of variations, the complexity of the tasks, and the targets to aim for.
References
(2011) Chapter 2 Dynamic models of networks. In: Chapter 2 Dynamic models of networks. De Gruyter, p 9–23, https://doi.org/10.1515/9783110879971.9, https://www.degruyter.com/document/doi/10.1515/9783110879971.9/html
Achouch M, Dimitrova M, Ziane K et al (2022) On predictive maintenance in industry 4.0: overview models and challenges. Appl Sci 12(16):8081. https://doi.org/10.3390/app12168081
Akhavan Niaki F, Ulutan D, Mears L (2015) Stochastic tool wear assessment in milling difficult to machine alloys. Int J Mech Manuf Sys 8:134–159. https://doi.org/10.1504/IJMMS.2015.073090
Ambadekar P, Choudhari C (2020) CNN based tool monitoring system to predict life of cutting tool. SN Appl Sci. https://doi.org/10.1007/s42452-020-2598-2
Ambhore N, Kamble D, Chinchanikar S et al (2015) Tool condition monitoring system: a review. Mater Today 2(4):3419–3428
Aramesh M, Shaban Y, Balazinski M et al (2014) Survival life analysis of the cutting tools during turning titanium metal matrix composites (Ti-MMCs). Procedia CIRP 14:605–609. https://doi.org/10.1016/J.PROCIR.2014.03.047
Aramesh M, Attia MH, Kishawy HA et al (2016) Estimating the remaining useful tool life of worn tools under different cutting parameters: a survival life analysis during turning of titanium metal matrix composites (Ti-MMCs). CIRP J Manuf Sci Technol 12:35–43. https://doi.org/10.1016/j.cirpj.2015.10.001
Archard JF (1953) Contact and rubbing of flat surfaces. J Appl Phys 24(8):981–988. https://doi.org/10.1063/1.1721448
Assad F, Konstantinov S, Nureldin H et al (2021) Maintenance and digital health control in smart manufacturing based on condition monitoring. Procedia CIRP 97:142–147. https://doi.org/10.1016/j.procir.2020.05.216
Attanasio A, Ceretti E, Giardini C et al (2013) Tool wear in cutting operations: experimental analysis and analytical models. J Manuf Sci Eng 135(051):012. https://doi.org/10.1115/1.4025010
Baig R, Syed J, Khaisar M et al (2021) Development of an ANN model for prediction of tool wear in turning EN9 and EN24 steel alloy. Adv Mech Eng 13(168781402110):267. https://doi.org/10.1177/16878140211026720
Barlow R (1996) Mathematical theory of reliability. SIAM, Philadelphia
Baruah P, Chinnam RB (2005) HMMs for diagnostics and prognostics in machining processes. Int J Prod Res 43(6):1275
Barzani M, Zeinali M, Kouam J et al (2020) Prediction of cutting tool wear during a turning process using artificial intelligence techniques. Int J Adv Manuf Technol 111:1–11. https://doi.org/10.1007/s00170-020-06144-6
Benkedjouh T, Medjaher K, Zerhouni N et al (2013) Health assessment and life prediction of cutting tools based on support vector regression. J Intel Manuf. https://doi.org/10.1007/s10845-013-0774-6
Bhattacharyya P, Sengupta D, Mukhopadhyay S (2007) Cutting force-based real-time estimation of tool wear in face milling using a combination of signal processing techniques. Mech Sys Signal Process 21(6):2665–2683. https://doi.org/10.1016/j.ymssp.2007.01.004
Binsaeid S, Asfour S, Cho S et al (2009) Machine ensemble approach for simultaneous detection of transient and gradual abnormalities in end milling using multisensor fusion. J Mater Process Technol 209(10):4728–4738
Boutros T, Liang M (2011) Detection and diagnosis of bearing and cutting tool faults using hidden Markov models [J]. Mech Sys Signal Process. https://doi.org/10.1016/j.ymssp.2011.01.013
Bouzakis KD, Paraskevopoulou R, Katirtzoglou G et al (2013) Predictive model of tool wear in milling with coated tools integrated into a CAM system. CIRP Ann Manuf Technol 62:71–74. https://doi.org/10.1016/j.cirp.2013.03.008
Breiman L (2001) Random Forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Breniere L, Doyen L, Berenguer C (2020) Virtual age models with time-dependent covariates: a framework for simulation, parametric inference and quality of estimation. Reliab Eng Sys Saf 203(107):054. https://doi.org/10.1016/j.ress.2020.107054
Cai G, Chen X, Li B et al (2012) Operation reliability assessment for cutting tools by applying a proportional covariate model to condition monitoring information. Sensors 12(12):964–87. https://doi.org/10.3390/s121012964
Cai W, Zhang W, Hu X et al (2020) A hybrid information model based on long short-term memory network for tool condition monitoring. J Intel Manuf. https://doi.org/10.1007/s10845-019-01526-4
Cerce L, Pusavec F, Kopac J (2015) A new approach to spatial tool wear analysis and monitoring. Strojniski Vestnik/J Mech Eng 61:489–497. https://doi.org/10.5545/sv-jme.2015.2512
Chen Y, Jin Y, Jiri G (2018) Predicting tool wear with multi-sensor data using deep belief networks. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-018-2571-z
Chen Y, Li H, Hou L et al (2018) An intelligent chatter detection method based on EEMD and feature selection with multi-channel vibration signals. Measurement 127:356–365
Chiu SM, Chen YC, Kuo CJ et al (2022) Development of lightweight RBF-DRNN and automated framework for CNC tool-wear prediction. IEEE Trans Instrum Meas 71:1–1. https://doi.org/10.1109/TIM.2022.3164063
Corne R, Nath C, Mansori EL (2016) Enhancing spindle power data application with neural network for real-time tool wear/breakage prediction during inconel drilling. Procedia Manuf 5:1–14. https://doi.org/10.1016/j.promfg.2016.08.004
Corne R, Nath C, Mansori ME et al (2017) Study of spindle power data with neural network for predicting real-time tool wear/breakage during inconel drilling. J Manuf Sys 43:287–295. https://doi.org/10.1016/j.jmsy.2017.01.004
Cox DR (1972) Regression models and life-tables. J Roy Stat Soc: Ser B 34(2):187–202. https://doi.org/10.1111/j.2517-6161.1972.tb00899.x
D’Addona D, Ura S, Matarazzo D (2017) Tool-wear prediction and pattern-recognition using artificial neural network and DNA-based computing. J Intel Manuf. https://doi.org/10.1007/s10845-015-1155-0
De Agustina B, Rubio EM, Sebastián M (2014) Surface roughness model based on force sensors for the prediction of the tool wear. Sensors 14(4):6393–6408. https://doi.org/10.3390/s140406393
Diamoutene A, Noureddine F, Noureddine R et al (2019) Proportional hazard model for cutting tool recovery in machining. Proceed Inst Mech Eng J Risk Reliab. https://doi.org/10.1177/1748006X19884211
Dimla DE (2000) Sensor signals for tool-wear monitoring in metal cutting operations-a review of methods. Int J Mach Tools Manuf 40(8):1073–1098. https://doi.org/10.1016/S0890-6955(99)00122-4
Drouillet C, Karandikar J, Nath C et al (2016) Tool life predictions in milling using spindle power with the neural network technique. J Manuf Process 22:161–168. https://doi.org/10.1016/j.jmapro.2016.03.010
Dutta S, Pal S, Sen R (2015) Tool Condition Monitoring in Turning by Applying Machine Vision. J Manuf Sci Eng 10(1115/1):4031770
Gadelmawla E, Al-Mufadi F, Alaboodi A (2014) Calculation of the machining time of cutting tools from captured images of machined parts using image texture features. Proceed Inst Mech Eng Part B J Eng Manuf 228:203–214. https://doi.org/10.1177/0954405413481291
Gao Z, Hu Q, Xu X (2022) Condition monitoring and life prediction of the turning tool based on extreme learning machine and transfer learning. Neural Comput Appl. https://doi.org/10.1007/s00521-021-05716-1
Ghani J, Rizal M, Nuawi M et al (2012) Development of an adequate online tool wear monitoring system in turning process using low cost sensor. Adv Sci Lett 13:702–706. https://doi.org/10.1166/asl.2012.3939
Ghani JA, Rizal M, Nuawi MZ et al (2010) Online cutting tool wear monitoring using I-Kaz method and new regression model. Adv Mater Res 126–128:738–743. https://doi.org/10.4028/WWW.SCIENTIFIC.NET/AMR.126-128.738
Guo B, Song S, Ghalambor A et al (2014) Offshore pipelines: design, installation, and maintenance, second, edition. Elsevier, Amsterdam
Hanachi H, Yu W, Kim IY et al (2019) Hybrid data-driven physics-based model fusion framework for tool wear prediction. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-018-3157-5
He Z, Shi T, Xuan J (2022) Milling tool wear prediction using multi-sensor feature fusion based on stacked sparse autoencoders. Measurement 190(110):719. https://doi.org/10.1016/j.measurement.2022.110719
Huang Y, Lu Z, Dai W et al (2021) Remaining useful life prediction of cutting tools using an inverse gaussian process model. Appl Sci 11:5011. https://doi.org/10.3390/app11115011
Huang Z, Zhu J, Lei J et al (2019) Tool wear predicting based on multisensory raw signals fusion by reshaped time series convolutional neural network in manufacturing. IEEE Access 7:178640–178651. https://doi.org/10.1109/ACCESS.2019.2958330
Huang Z, Zhu J, Lei J et al (2020) Tool wear predicting based on multi-domain feature fusion by deep convolutional neural network in milling operations. J Intell Manuf 31:1–14. https://doi.org/10.1007/s10845-019-01488-7
J.A G, M R, M N, et al (2010) Statistical analysis for detection cutting tool wear based on regression model. Proceedings of the International MultiConference of Engineers and Computer Scientists https://www.academia.edu/3023006/Statistical_analysis_for_detection_cutting_tool_wear_based_on_regression_model
Jardine AKS, Lin D, Banjevic D (2006) A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech Sys Signal Process 20(7):1483–1510. https://doi.org/10.1016/j.ymssp.2005.09.012
Jemielniak K, Urbański T, Kossakowska J et al (2012) Tool condition monitoring based on numerous signal features. Int J Adv Manuf Technol 59:73–81. https://doi.org/10.1007/s00170-011-3504-2
Jia W, Wang W, Li Z et al (2022) Prediction of tool wear in sculpture surface by a new fusion method of temporal convolutional network and self-attention. Int J Adv Manuf Technol 121:1–19. https://doi.org/10.1007/s00170-022-09396-6
Kamat P, Sugandhi R (2020) Anomaly Detection for Predictive Maintenance in Industry 4.0- A survey. E3S Web of Conferences 170: 02,007. https://doi.org/10.1051/e3sconf/202017002007, https://www.e3s-conferences.org/articles/e3sconf/abs/2020/30/e3sconf_evf2020_02007/e3sconf_evf2020_02007.html, publisher: EDP Sciences
Karandikar J, Abbas A, Schmitz T (2014) Tool life prediction using bayesian updating. Part 2: turning tool life using a markov chain monte carlo approach. Precis Eng 38:18–27. https://doi.org/10.1016/j.precisioneng.2013.06.007
Karandikar JM, Abbas AE, Schmitz TL (2013) Remaining useful tool life predictions in turning using Bayesian inference. Int J Progn Health Manag. https://doi.org/10.36001/ijphm.2013.v4i2.2122
Karandikar JM, Abbas AE, Schmitz TL (2014) Tool life prediction using Bayesian updating Part 1: milling tool life model using a discrete grid method. Precis Eng 38(1):9–17. https://doi.org/10.1016/j.precisioneng.2013.06.006
Kolios A, Salonitis K (2013) Surrogate modelling for reliability assessment of cutting tools. Proceedings of the 11th International Conference on Manufacturing Research (ICMR2013) pp 405–410
Kong D, Chen Y, Li N et al (2019) Relevance vector machine for tool wear prediction. Mech Syst Signal Process 127:573–594. https://doi.org/10.1016/j.ymssp.2019.03.023
Kong D, Yongjie C, Li N (2019) Monitoring tool wear using wavelet package decomposition and a novel gravitational search algorithm-least square support vector machine model. Proc Inst Mech Eng C J Mech Eng Sci 234(095440621988):731. https://doi.org/10.1177/0954406219887318
Kong D, Yongjie C, Li N et al (2019) Tool wear estimation in end-milling of titanium alloy using NPE and a novel WOA-SVM model. IEEE Trans Instrum Meas. https://doi.org/10.1109/TIM.2019.2952476
Kothuru A, Nooka S, Liu R (2018) Application of audible sound signals for tool wear monitoring using machine learning techniques in end milling. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-017-1460-1
Kovac P, Gostimirović M, Rodic D et al (2019) Using the temperature method for the prediction of tool life in sustainable production. Measurement 133:320–327. https://doi.org/10.1016/j.measurement.2018.09.074
Kudelina K, Vaimann T, Asad B et al (2021) Trends and challenges in intelligent condition monitoring of electrical machines using machine learning. Appl Sci 11(6):2761. https://doi.org/10.3390/app11062761
Kuntoǧlu M, Aslan A, Pimenov DY et al (2021) A review of indirect tool condition monitoring systems and decision-making methods in turning: critical analysis and trends. Sensors 21(1):108. https://doi.org/10.3390/s21010108
Leach RK, Leach RK (2010) Fundamental principles of engineering nanometrology, 1st edn. Micro and nano technologies, Elsevier, Amsterdam
Lee M, Thomas CE, Wildes DG (1987) Prospects for in-process diagnosis of metal cutting by monitoring vibration signals. J Mater Sci 22(11):3821–3830. https://doi.org/10.1007/BF01133328
Lee S, Yu H, Yang H et al (2021) A study on deep learning application of vibration data and visualization of defects for predictive maintenance of gravity acceleration equipment. Appl Sci. https://doi.org/10.3390/app11041564
Lee WJ, Wu H, Yun H et al (2019) Predictive maintenance of machine tool systems using artificial intelligence techniques applied to machine condition data. Procedia CIRP 80:506–511. https://doi.org/10.1016/j.procir.2018.12.019
Lei Y, He Z, Zi Y et al (2007) Fault diagnosis of rotating machinery based on multiple ANFIS combination with GAs. Mech Syst Signal Process 21(5):2280–2294
Letot C, Serra R, Dossevi M et al (2016) Cutting tools reliability and residual life prediction from degradation indicators in turning process. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-015-8158-z
Li G, Wang Y, He J et al (2021) Tool wear prediction based on multidomain feature fusion by attention-based depth-wise separable convolutional neural network in manufacturing. Int J Adv Manuf Technol. https://doi.org/10.21203/rs.3.rs-681400/v1
Li H, Wang W, Li Z et al (2020) A novel approach for predicting tool remaining useful life using limited data. Mech Sys Signal Process 143(106):832. https://doi.org/10.1016/j.ymssp.2020.106832
Li J, Lu J, Chen C et al (2021) Tool wear state prediction based on feature-based transfer learning. Int J Adv Manuf Technol 113:1–19. https://doi.org/10.1007/s00170-021-06780-6
Li W, Liu T (2019) Time varying and condition adaptive hidden Markov model for tool wear state estimation and remaining useful life prediction in micro-milling. Mech Syst Signal Process 131:689–702. https://doi.org/10.1016/j.ymssp.2019.06.021
Liu H, Makis V (1996) Cutting-tool reliability assessment in variable machining conditions. IEEE Trans Reliab 45(4):573–581. https://doi.org/10.1109/24.556580
Liu R (2021) A novel edge computing based architecture for intelligent tool condition monitoring. Am Soci Mech Eng Digit Collect. https://doi.org/10.1115/MSEC2020-8499
Malakizadi A, Gruber H, Sadik I et al (2016) An FEM-based approach for tool wear estimation in machining. Wear. https://doi.org/10.1016/j.wear.2016.08.007
Marei M, Li W (2022) Cutting tool prognostics enabled by hybrid CNN-LSTM with transfer learning. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-021-07784-y
Marei M, El Zaatari S, Li W (2021) Transfer learning enabled convolutional neural networks for estimating health state of cutting tools. Robotics Comput-Integr Manuf 71(102):145. https://doi.org/10.1016/j.rcim.2021.102145
Marksberry PW, Jawahir IS (2008) A comprehensive tool-wear/tool-life performance model in the evaluation of NDM (near dry machining) for sustainable manufacturing. Int J Mach Tools Manuf 48(7):878–886. https://doi.org/10.1016/j.ijmachtools.2007.11.006
Marwala T, Vilakazi C (2007) Computational intelligence for condition monitoring. Handb Comput Intel Manuf Prod Manag. https://doi.org/10.4018/978-1-59904-582-5.ch006
Meng Lip L, Derani N, Ratnam M et al (2022) Tool wear prediction in turning using workpiece surface profile images and deep learning neural networks. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-022-09257-2
Miao Q, Huang H, Fan X (2007) A comparison study of support vector machines and hidden Markov models in machinery condition monitoring. J Mech Sci Technol 21:607–615. https://doi.org/10.1007/BF03026965
Mohanraj T, Shankar S, Rajasekar R et al (2020) Tool condition monitoring techniques in milling process - a review. J Mater Res Technol 9(1):1032–1042. https://doi.org/10.1016/j.jmrt.2019.10.031
Moubray J (1997) Reliability-centered maintenance. Butterworth Heinemann, Oxford
O’Donnell G, Young P, Kelly K et al (2001) Towards the improvement of tool condition monitoring systems in the manufacturing environment. J Mater Process Technol 119:133–139. https://doi.org/10.1016/S0924-0136(01)00928-1
Ouda E, Maalouf M, Sleptchenko A (2021) Machine Learning and Optimization for Predictive Maintenance based on Predicting Failure in the Next Five Days. In: Proceedings of the 10th International Conference on Operations Research and Enterprise Systems - ICORES,. SciTePress, pp 192–199, https://doi.org/10.5220/0010247401920199, backup Publisher: INSTICC ISSN: 2184-4372
Palmai Z (2013) Proposal for a new theoretical model of the cutting tool’s flank wear. Wear 303(1):437–445. https://doi.org/10.1016/j.wear.2013.03.025
Patange A, Jagadeeshwaran R, Dhobale N (2019) Milling cutter condition monitoring using machine learning approach. IOP Conf Series Mater Sci Eng 624(012):030. https://doi.org/10.1088/1757-899X/624/1/012030
Preez A, Oosthuizen G (2019) Machine learning in cutting processes as enabler for smart sustainable manufacturing. Procedia Manuf 33:810–817. https://doi.org/10.1016/j.promfg.2019.04.102
Purushothaman S (2010) Tool wear monitoring using artificial neural network based on extended Kalman filter weight updation with transformed input patterns. J Intell Manuf 21(6):717–730
Radetzky M, Stürwold T, Bracke S (2021) Image based wear behaviour analyis of cutting tools. J Intel Manufa. https://doi.org/10.3850/978-981-18-2016-8_609-cd
Raja E, Sayeed S, Samraj A et al (2011) Tool flank wear condition monitoring during turning process by SVD analysis on emitted sound signal. Eur J Sci Res 49(4):503–509
Rao K, Murthy B, Mohan Rao N (2014) Prediction of cutting tool wear, surface roughness and vibration of work piece in boring of AISI 316 steel with artificial neural network. Measurement 51:63–70. https://doi.org/10.1016/j.measurement.2014.01.024
Rao K, Yekula PK, Sing V et al (2021) Vibration based tool condition monitoring in milling of Ti-6Al-4V using an optimization model of GM(1N) and SVM. Int J Adv Manuf Technol. https://doi.org/10.21203/rs.3.rs-285124/v1
Rawlins JC, Fulton SR (2000) Basic AC circuits, 2nd edn. Newnes, Boston
Ren Q, Balazinski M, Baron L et al (2014) Type-2 fuzzy tool condition monitoring system based on acoustic emission in micromilling. Inf Sci 255:121–134. https://doi.org/10.1016/j.ins.2013.06.010
Rizal M, Ghani J, Nuawi M et al (2013) Online tool wear prediction system in the turning process using an adaptive neuro-fuzzy inference system. Appl Soft Comput 13:1960–1968. https://doi.org/10.1016/j.asoc.2012.11.043
Rodriguez CEP, Souza GFMd (2010) Reliability concepts applied to cutting tool change time. Reliab Eng Sys Safety 95(8):866–873. https://doi.org/10.1016/j.ress.2010.03.005
Rosenfield AR (1987) A shear instability model of sliding wear. Wear 116(3):319–328. https://doi.org/10.1016/0043-1648(87)90180-3
Salimiasl A, Özdemir A (2016) Analyzing the performance of artificial neural network (ANN)-, fuzzy logic (FL)-, and least square (LS)-based models for online tool condition monitoring. Int J Adv Manuf Technol 87(1):1145–1158
Salonitis K, Kolios A (2013) Reliability assessment of cutting tools life based on advanced approximation methods. Procedia CIRP 8:397–402. https://doi.org/10.1016/j.procir.2013.06.123
Salonitis K, Kolios A (2020) Force-based reliability estimation of remaining cutting tool life in titanium milling. Int J Adv Manuf Technol 106(7):3321–3333. https://doi.org/10.1007/s00170-019-04883-9
Sayyad S, Kumar VCS, Bongale A et al (2022) Tool wear prediction using long short-term memory variants and hybrid feature selection techniques. Int J Adv Manuf Technol 121:1–23. https://doi.org/10.1007/s00170-022-09784-y
Shah M, Vakharia V, Chaudhari R et al (2022) Tool wear prediction in face milling of stainless steel using singular generative adversarial network and LSTM deep learning models. Int J Adv Manuf Technol Article press. https://doi.org/10.1007/s00170-022-09356-0
Shi D, Gindy NN (2007) Tool wear predictive model based on least squares support vector machines. Mech Syst Signal Process 21(4):1799–1814
Singpurwalla ND (2006) Reliability and Risk: A Bayesian Perspective. PAPERBACKSHOP UK IMPORT, https://www.ebook.de/de/product/6392791/nozer_d_singpurwalla_reliability_and_risk_a_bayesian_perspective.html
Stavropoulos P, Papacharalampopoulos A, Vasiliadis E et al (2015) Tool wear predictability estimation in milling based on multi-sensorial data. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-015-7317-6
Sun C, Ma M, Zhao Z et al (2018) Deep transfer learning based on sparse auto-encoder for remaining useful life prediction of tool in manufacturing. IEEE Trans Ind Inform. https://doi.org/10.1109/TII.2018.2881543
Sun H, Liu Y, Pan J et al (2020) Enhancing cutting tool sustainability based on remaining useful life prediction. J Clean Prod 244(118):794. https://doi.org/10.1016/j.jclepro.2019.118794
Tangjitsitcharoen S, Lohasiriwat H (2018) Intelligent monitoring and prediction of tool wear in CNC turning by utilizing wavelet transform. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-017-1424-5
Teti R, Jemielniak K, O’Donnell G et al (2010) Advanced monitoring of machining operations. CIRP Annals 59(2):717–739. https://doi.org/10.1016/j.cirp.2010.05.010
Tiddens W, Braaksma J, Tinga T (2020) Exploring predictive maintenance applications in industry. J Qual Maintenance Eng 28(1):68–85. https://doi.org/10.1108/JQME-05-2020-0029
Tiwari K, Nara A (2018) Tool wear prediction in end milling of Ti-6Al-4V through Kalman filter based fusion of texture features and cutting forces. Procedia Manuf 26:1459–1470. https://doi.org/10.1016/j.promfg.2018.07.095
Todinov M (2015) Reliability and Risk Models: Setting Reliability Requirements. PAPERBACKSHOP UK IMPORT, https://www.ebook.de/de/product/24211710/michael_todinov_reliability_and_risk_models_setting_reliability_requirements.html
Traini E, Bruno G, D’Antonio G et al (2019) Machine learning framework for predictive maintenance in milling. IFAC-PapersOnLine 52:177–182. https://doi.org/10.1016/j.ifacol.2019.11.172
Venkata Rao K, Murthy BSN, Mohan Rao N (2013) Cutting tool condition monitoring by analyzing surface roughness, work piece vibration and volume of metal removed for AISI 1040 steel in boring. Measurement 46(10):4075–4084. https://doi.org/10.1016/j.measurement.2013.07.021
Wang B, Lei Y, Li N et al (2020) Multi-scale convolutional attention network for predicting remaining useful life of machinery. IEEE Trans Ind Electron. https://doi.org/10.1109/TIE.2020.3003649
Wang G, Qian L, Guo Z (2012) Continuous tool wear prediction based on Gaussian mixture regression model. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-012-4470-z
Wang J, Wang P, Gao R (2015) Particle filter for tool wear prediction. J Manuf Sys. https://doi.org/10.1016/j.jmsy.2015.03.005
Wang J, Wang P, Gao RX (2015) Enhanced particle filter for tool wear prediction. J Manuf Sys 36:35–45. https://doi.org/10.1016/j.jmsy.2015.03.005
Wang J, Li Y, Zhao R et al (2020) Physics guided neural network for machining tool wear prediction. J Manuf Syst 57:298–310. https://doi.org/10.1016/j.jmsy.2020.09.005
Wang J, Li Y, Hua J et al (2021) An accurate tool wear prediction method under different cutting conditions based on network architecture search. Procedia Manuf 54:274–278. https://doi.org/10.1016/j.promfg.2021.07.043
Wang M, Zhou J, Gao J et al (2020) Milling tool wear prediction method based on deep learning under variable working conditions. IEEE Access. https://doi.org/10.1109/ACCESS.2020.3010378
Wang P, Gao RX (2016) Stochastic tool wear prediction for sustainable manufacturing. Procedia CIRP 48:236–241. https://doi.org/10.1016/j.procir.2016.03.101
Wang W, Scarf PA, Smith MAJ (2000) On the application of a model of condition-based maintenance. J Operat Res Soci 51(11):1218–1227
Wiklund H (1998) Bayesian and regression approaches to on-line prediction of residual tool life. Qual Reliab Eng Int 14(5):303–309
Wu D, Jennings C, Terpenny J et al (2016) Cloud-based machine learning for predictive analytics: tool wear prediction in milling. IEEE Int Conf Big Data. https://doi.org/10.1109/BigData.2016.7840831
Wu D, Jennings C, Terpenny J et al (2017) A comparative study on machine learning algorithms for smart manufacturing: tool wear prediction using random forests. J Manuf Sci Eng Doi 10(1115/1):4036350
Wu D, Liu S, Zhang L et al (2017) A fog computing-based framework for process monitoring and prognosis in cyber-manufacturing. J Manuf Sys 43:25–34. https://doi.org/10.1016/j.jmsy.2017.02.011
Wu D, Jennings C, Terpenny J et al (2018) Cloud-based parallel machine learning for tool wear prediction. J Manuf Sci Eng 140(4):041005
Wu J, Su Y, Cheng Y et al (2018) Multi-sensor information fusion for remaining useful life prediction of machining tools by adaptive network based fuzzy inference system. Appl Soft Comput 68:13–23. https://doi.org/10.1016/j.asoc.2018.03.043
Wu X, Li J, Jin Y et al (2020) Modeling and analysis of tool wear prediction based on SVD and BiLSTM. Int J Adv Manuf Technol 106(9):4391–4399
Wu Y, Hong GS, Wong W (2014) Prognosis of the probability of failure in tool condition monitoring application-a time series based approach. Int J Adv Manuf Technol. https://doi.org/10.1007/s00170-014-6299-0
Xia P, Huang Y, Xiao D et al (2021) Tool wear prediction under varying milling conditions via temporal convolutional network and auxiliary learning. IEEE Int Conf Progn Health Manag. https://doi.org/10.1109/ICPHM51084.2021.9486566
Y S, S Y (2016a) Identifying Optimal Intervene Hazard for Cutting Tools Considering Cost-availability Optimization. Proceedings of the 2016 International Conference on Industrial Engineering and Operations Management
Shaban Y, Yacout S (2016) Predicting the remaining useful life of a cutting tool during turning titanium metal matrix composites. Proceed Inst Mech Eng Part B J Eng Manuf. https://doi.org/10.1177/0954405416654184
Hb Yang, Ja Zhang, Ll Chen et al (2019) Fault diagnosis of reciprocating compressor based on convolutional neural networks with multisource raw vibration signals. Math Prob Eng. https://doi.org/10.1155/2019/6921975
Yao J, Lu B, Zhang J (2021) Tool remaining useful life prediction using deep transfer reinforcement learning based on long short term memory networks. Int J Adv Manuf Technol. https://doi.org/10.21203/rs.3.rs-352693/v1
Yu W, Mechefske C, Kim IY (2020) Identifying optimal features for cutting tool condition monitoring using recurrent neural networks. Adv Mech Eng 12(168781402098):438. https://doi.org/10.1177/1687814020984388
Yuan J, Liu L, Yang Z et al (2020) Tool wear condition monitoring by combining variational mode decomposition and ensemble learning. Sensors 20:6113. https://doi.org/10.3390/s20216113
Yuqing Z, Sun B, Suen V et al (2022) Tool wear condition monitoring based on a two-layer angle kernel extreme learning machine using sound sensor for milling process. J Intel Manuf. https://doi.org/10.1007/s10845-020-01663-1
Zhang C, Wang W, Li H (2021) Tool wear prediction method based on symmetrized dot pattern and multi-covariance Gaussian process regression. Measurement 189(110):466. https://doi.org/10.1016/j.measurement.2021.110466
Zhang G, To S, Xiao G (2014) Novel tool wear monitoring method in ultra-precision raster milling using cutting chips. Precis Eng 38:555–560. https://doi.org/10.1016/j.precisioneng.2014.02.004
Zhang H, Zhang C, Zhang J et al (2014) Tool wear model based on least squares support vector machines and Kalman filter. Prod Eng. https://doi.org/10.1007/s11740-014-0527-1
Zhang J, Zeng Y, Starly B (2021) Recurrent neural networks with long term temporal dependencies in machine tool wear diagnosis and prognosis. SN Appl Sci 3(4):442. https://doi.org/10.1007/s42452-021-04427-5
Kf Zhang, Hq Yuan, Nie P (2015) A method for tool condition monitoring based on sensor fusion. J Intell Manuf 26:1011–1026. https://doi.org/10.1007/s10845-015-1112-y
Zhang X, Yu T, Xu P et al (2022) In-process stochastic tool wear identification and its application to the improved cutting force modeling of micro milling. Mech Syst Signal Process 164(108):233
Zhou JH, Pang CK, Lewis FL et al (2009) Intelligent diagnosis and prognosis of tool wear using dominant feature identification. IEEE Trans Industr Inf 5(4):454–464
Zhou JH, Pang CK, Zhong ZW et al (2010) Tool wear monitoring using acoustic emissions by dominant-feature identification. IEEE Trans Instrum Meas 60(2):547–559
Zhou L, Li J, Li F et al (2016) Energy consumption model and energy efficiency of machine tools: a comprehensive literature review. J Clean Prod 112:3721–3734
Zonta T, da Costa CA, da Rosa Righi R et al (2020) Predictive maintenance in the industry 4.0: a systematic literature review. Comput Ind Eng 150:106889. https://doi.org/10.1016/j.cie.2020.106889
Acknowledgements
This work was supported by the European Regional Development Fund in Research Platform focused on Industry 4.0 and Robotics in the Ostrava project, CZ.02.1.01/0.0/0.0/17_049/0008425 within Operational Programme Research, Development and Education. This article was also supported by the Student Grant System of VSB Technical University of Ostrava (Project No. SP2023/042 and SP2023/009).
Funding
Open access publishing supported by the National Technical Library in Prague.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lara de Leon, M.A., Kolarik, J., Byrtus, R. et al. Tool Condition Monitoring Methods Applicable in the Metalworking Process. Arch Computat Methods Eng 31, 221–242 (2024). https://doi.org/10.1007/s11831-023-09979-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11831-023-09979-w