
Abstract
Groundwater and its upcoming crisis are the present-day concern of the scientist. This research mainly focuses on responses of groundwater dynamicity to some important drivers, viz. agricultural yield, groundwater irrigated area, groundwater draft, landuse/landcover, and stage of development. The result of this study has been done under three sections. In the first section, the spatiality of groundwater has been discussed where it has been noticed that the western side of the district groundwater level is near the surface due to low drafting and low agricultural yield. Moreover, hard rock geology in the western part disappoints the drilling process. On the eastern part, rich alluvial soil influences high agricultural yield hence groundwater level lowering down rapidly. In the second section, the nature of groundwater levels has been analyzed through the boxplot, and cluster diagram, where boxplots have been drawn over different geological facies, which depicts groundwater is highly fluctuating in hard clay geology. For example, high agricultural intensity and high groundwater draft is the characteristic feature of hard clay geology. The dendrogram in cluster analysis represents a homogeneous groundwater level fluctuating station in three different time series. Last section deals with the future of groundwater level where an artificial neural network (ANN) model has been applied to extract the predicted groundwater level for 2030. This type of environmental analysis, such as groundwater fluctuations in relation to different sensitive parameters and the use of a machine learning model, would aid potential researchers and communities in making wise groundwater use decisions.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Groundwater is one of the earth’s precious natural sub-surface assets, and is used in various economic sectors such as irrigation, manufacturing and households. Groundwater is the only source of drinking water and represents 50 per cent of the population of the planet (Tharme 2003; Kløve et al. 2011; Razandi et al. 2015; Das and Mukhopadhyay 2020). Several experiments explain that the freshness of soil water is contaminated by climate change and increased human demand (Wada et al. 2016; Boretti and Rosa 2019; van Rooyen et al. 2020). The overflow of groundwater through irrigation for cultivation often simulates a daily increase in its depth (Tizro et al. 2018). However, groundwater is expected to be refilled by runoff and water supply (Adhikari et al. 2020). Not only irrigation, but also land use/land cover (LULC), agricultural yield, and soil drainage for different uses spatially and temporarily impact the amount of soil water. Differences in groundwater level impact its consistency directly (Das et al. 2019). LULC variation determines groundwater fluctuations, e.g. land use as well as urban and urbanization processes, affects the drafting and consistency of groundwater, on the one side, and, on the other, forest surface storage and supports groundwater for a long period of time (Wakode et al. 2018). The massive population increase, agricultural growth, urban expansion and changes in the structure of the LULC pattern directly lead to the use of groundwater resources and the degradation of their levels ((Lu et al. 2014; Ahirwar et al. 2020; Ansari et al. 2016). Consequently, LULC distressed groundwater through the changes in recharge patterns or by changing its demand (Tetzlaf et al. 2007; Lerner and Harris 2009; Fan 2015).
The area is very productive since the area of research is under the Indo Gangetic basin. Recent studies have shown that the ongoing scarcity of groundwater throughout the Indo Gangetic basin concerns. The increased usage of irrigation groundwater raises legitimate concerns regarding potential sustainability.
After the green revolution, large amounts of irrigated water are required to introduce the high yield (HYV) crop. This is why demand for sub-surface water in all parts of the world is rising faster (Morris et al. 1994; Schirmer et al. 2013). Groundwater fluctuation depends on certain fundamental parameters such as agricultural yields, groundwater irrigated areas, extent of groundwater usage for agricultural, industrial and domestic purposes and stages of groundwater production (Prabhakar and Tiwari 2015). The groundwater table in several areas of this country has been studied to decrease by 1–2 m/year (Singh and Singh 2002). In the meanwhile, the groundwater volume in the canal command area increases (Chowdhury et al. 2010).
Remote sensing and geographic information system (GIS) are some of the latest geospatial techniques used in the extraction of land use/land cover and geographical variations of the groundwater table across a variety of periods (Choudhury et al. 2019; Das et al. 2020). Using these technologies, LULC shifts can be identified over a separate time period (Hathout 2002) and their evolving connection to the groundwater level. Geospatial technology is ideally adapted for the application of different thematic groundwater mapping (Ahmad et al. 2020). Moreover, computer-based GIS technology also helps to define best-adapted groundwater recharge areas of the world on the one hand, while also helping to connect groundwater table to other physical and socio-economic parameters and developing forecast maps of potential groundwater levels on the other (Ashtekar and Mohammed-Aslam 2019; Das and Mukhopadhyay 2020).
This article seeks to identify the following objectives: (1) spatio-temporal heterogeneity in groundwater in the concerned research region; (2) to identify the association between groundwater and other metrics, such as agricultural yield, groundwater drafts, irrigated soilwater field and construction stage of groundwater. (3) Find out groundwater sustainability for potential generation.
In the present age of exponential population development, new agricultural regionalization, urbanization, and industrialization results into rapid groundwater depletion, so we have to worry about groundwater sustenance. In this regard, this type of environmental study is important for the safe usage and proper storage of groundwater.
Materials and methods
Description of the study area
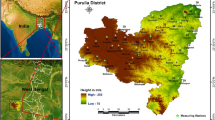
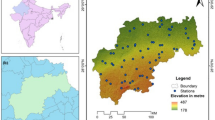
Birbhum District is located between the latitude of 23° 32′ 30″ N–24° 35′ 00″ N and longitude of 87° 05′ 04″ E–88° 01′ 04″ E, covering an area of 4545 sq. km, and it contains 19 Community Development (CD) blocks (Fig. 1) Administratively, the study area is confined by the Jharkhand state in the west and the north and Murshidabad in the east and Burdwan district in the south. All the maps, viz. India, West Bengal, and Birbhum District, have been downloaded from http://www.diva-gis.org/ website and the digital elevation data of Birbhum District has been downloaded from USGS earth explorer. The location of the test area has been mapped using the downloaded shapefiles (Fig. 1).

Location map of a India b West Bengal and c Birbhum Ddistrict
From a geomorphological point of view, this region is under the “Rarhbanga” area where lateritic soil is predominant. Geologically, this district is characterized by many rock formations like dissected plateau composed of granitic gneiss of Archean age present in the western portion of the district. Contrary to this, the Eastern part of the district has been formed by sediments of the Gondwana period and also formed by laterite and the alluvium deposit (Fig. 2). The given geological map has been collected from the office of Geological Survey of India, Kolkata branch. A large number of rivers are running from the western part where Chota Nagpur plateau is present to the east (Fig. 3) with a little bit southeasterly inclination in the Suri subdivision (Das and Mukhopadhyay 2020). The river widths vary according to the configuration of the country, from 200 yards to half a mile (Majumdar 1975). The major rivers of this district are Mayurakshi, Ajoy, Kopai, Brakreswar, Brahmhani, Dwarka, Bansloi, etc.

Geological facies of Birbhum District

Major river networks
This district typically experiences the tropical monsoon climate where 80% of rainfall received between June and September with an annual rainfall of 14,305 mm and the summer temperature rises to 40 °C and the winter temperature falls around 10 °C.
Database and methods
For the classification of land use/land cover, 3 years has been taken for the study, viz. 1996, 2006, and 2019. For 1996 and 2006 LANDSAT TM data having path/row: 139/43 and 139/44 with 30-m spatial resolution and for 2019 LANDSAT OLI data having the same path/row and spatial resolution have been used in this study, and the data have been collected from USGS earth explorer official website. The downloaded data were pre-georeferenced to UTM zone 42 North projection with WGS 84 global datum. There is a slight difference in terms of the number of bands and band information for both LANDSAT 5 and LANDSAT 8. These differences are shown in Table 1. The database and its sources are depicted in Fig. 4.

Flow chart of database and their sources
Method to prepare land use/land cover classification from satellite image
LULC maps for 1996, 2006, and 2019 have been prepared from LANDSAT satellite imagery with the help of the supervised classification technique using the maximum likelihood method classification tool in ArcGIS software (Evaluation copy).
For LANDSAT TM (1996 & 2006), supervised classification bands 1–5 and band 7 have been taken for band composition, but band 6 has to be excluded as this band indicates thermal band (Das et al. 2020). On the other hand, bands 1–7 have been used in LANDSAT OLI supervised classification. For the classification of LULC in the supervised classification method, the following steps are used in ArcGIS software (Evaluation copy).
The entire process is depicted in Fig. 5.

Source: rafatieppo.github.io
Process to make landuse and landcover map with accuracy assessment.
Method to measure the accuracy of land use/land cover map
Accuracy assessment is necessary for the prepared land use/land cover maps with the help of Kappa coefficient or Kappa hat \((\hat{K})\). This coefficient mainly main works with the method of confusion or error matrix (Yuan 1979; Prisley and Smith 1987; Hay 1988; Jupp 1989; Czaplewski 1992; Van Deusen 1996). Before calculation of the Kappa coefficient, three types of accuracy have to be calculated
-
(i)
Overall accuracy or total accuracy has been calculated as
$$T = \frac{{\sum D_{ii} }}{N}$$(1)where T—overall accuracy, ∑Dii- total number of pixel that has been correctly classified, N—total number of pixel in the matrix.
-
(ii)
The producer’s accuracy or PA is a kind of reference-based accuracy assessment that can be understand using the prediction method and the unit of total accuracy has been expressed in percentage (Bogoliubova and Tymków 2014). PA can be calculated as
$${\text{PA}} = \frac{{\sum D_{ij} }}{{R_{i} }}$$(2)where PA—Producer’s accuracy, Dij—Correctly classified pixel in diagonal cell or ith row, Ri—total number of pixels in ith row
-
(iii)
User accuracy is the revision of map-based referenced data accuracy assessment which also has been expressed in percentage (Story and Congalton 1986). User accuracy has been mathematically expressed as
$${\text{UA}} = \frac{{\sum D_{ij} }}{{C_{j} }}$$(3)where UA—User’s accuracy, Dij—correctly classified pixel in the horizontal cell or jth column, Cj—total number of pixels in jth column
Besides the above-mentioned methodology, Kappa coefficient or kappa hat (\(\hat{K}\)) is one of the best methods to extract the accuracy of the land use/land cover maps (FOODY 1992; Ma and Redmond 1995). The value of the Kappa coefficient ranges between 0 and 1, where 1 indicates perfect agreement and 0 indicates no agreement. Landis and Koch (1977) describe the other values and interpretations of Kappa hat (Table 2). The mathematical expression of the Kappa coefficient as follows [4]:
where \(\hat{K}\)—Kappa coefficient, N—total number of pixels, m—number of classes, \(\sum D_{ij}\)—total diagonal elements in the matrix, Rj—total number of pixels in ith row, Cj—total number of pixels in jth column.
To run Kappa statistic 560 training sample sites have been selected all through the district. Based on the ground truth verification using these 560 sample training sites, the accuracy assessment of 3 years of land use/land cover maps has been done. The result of the Kappa coefficient has been described in the Results and discussion section.
Method to prepare all thematic maps
To under the variability of groundwater level, some predicted factors have been taken as influencing driver in this study, viz. agricultural yield, groundwater irrigated area, groundwater draft, and stage of development of groundwater. All of these predicted factors working as directly influencing drivers to groundwater table variability. To make thematic layers of concerning factor Inverse Distance Weighting or IDW method has been implied using spatial analyst tool in ArcGIS 10.5 software (Bronowicka-Mielniczuk et al. 2019). IDW is a kind of interpolation method where missing values have been estimated by averaging other neighborhood sample values, and it assumes that closer values are more similar than the farthest value and it is used here to estimate the unknown stations’ value (Manson et al. 1999). Figure 6 depicts the principle of IDW, where an unknown value can be calculated from the nearest value. This concept was developed by the US National Weather Service in the year 1972 (Chen and Liu 2012).

IDW Principle
Mathematically, IDW can be expressed with the help of the following formulas
where \(\hat{R}_{p}\) = unknown data in thematic layers, \(R_{i}\) = known data value of the thematic layer, \(N =\) data value of each thematic layer, Wi = weighting of each thematic layer, di = distance from the unknown station to a known station for each thematic layer
Method of preparation of predicted groundwater level map
For the study of sustainability of groundwater level, future prediction of groundwater level is taken as consideration in this part. In this section, future groundwater level has been predicted for the next 23 years through the method of simulation (Li et al. 2017; Yang et al. 2017). Various machine learning models have been applied to predict the future value like Markov chain, artificial neural network (ANN), hybrid neural model, regression model, etc. (Husaini et al. 2011; San and Khin 2016; Saba et al. 2017; Tettey et al. 2017; Das et al. 2020). Based on past data of groundwater monitoring stations, attempt has been made to forecast groundwater level using Artificial Neural Network. The entire process has been carried out in RStudio with the “nnfor” package. Initially, the “Ljung–Box” test has been done to verify the nature of the data, whether there is autocorrelation or not (Fig. 7). After the last 23 years (1996–2019), data have been used as a test dataset to fit the ANN-based time series model. Multilayer perceptions (mlp) and extreme learning machines (elm) are two different types of neural networks. This will automatically specify autoregressive inputs and any necessary pre-processing of the time series. Significant test programs or Ljung- Box and ANN forecasting programs have been run in R statistical software with the help of the necessary script (Fig. 7).

R script for Ljung–Box and ANN model
Based on this operation, future groundwater level has been forecasted and spatial maps have been made based on the forecasted data using the inverse distance weighted (IDW) tool of ArcGIS 10.5 software (evaluation copy). The entire procedure of this study is presented in Fig. 8

Schematic presentation of the entire study
Quantitative methods to explain the dataset
Some simple statistical techniques have been used in this study for the analysis of data. First, to understand the nature of the data boxplot has been used. Boxplot represents the upper and lower limit of the data, median, and inter-quartile range of data, which are the most useful statistical measure to identify the characteristics of the data (Fernando and Tian 2010). Box plot also represents the outlier of the data, which represents the extremities of the data value or the different data values of the data set (Hubert and Vandervieren 2008). In this study, box plots represent fluctuation of groundwater level in response to different geological facies.
Before going to the correlation matrix, we have to know the influence of independent variables (viz. agricultural yield, groundwater draft, groundwater irrigated area, and groundwater stage of development) over the dependent variable (groundwater level). For this, linear regression is the best statistical tool to identify the linear regression between variables. But when independent variables are more than two and the dependent variable is only one, multilinear regression or MLR is best suited for the extraction of linearity. So, multiple linear regression or MLR has been used in this study to identify the direct influence of multiple independent variables over a single dependent variable (Jobson 1991). In this statistical method, a linear relationship has been drawn between several explanatory (independent) and one response (dependent) variables (Jobson 1991; Hanley 2016). Here multiple linear regression has been used to show the influence of agricultural yield, groundwater irrigated area, groundwater draft, and stage of groundwater development on groundwater level. Agricultural yield, groundwater irrigated area, groundwater draft, and stage of groundwater development parameters are considered as explanatory or independent variables, and groundwater level has been taken as a response or dependent variable. Mathematically multiple linear regression expressed as
yi = response or dependent variable, xi1, xi2, xi3…xp = Explanatory or independent variables, β0 = Intercept or constant, βp = slope coefficients for each explanatory variable, ε = standard estimation error.
Before calculation of MLR, we have to test the linearity of independent variables over the dependent variable. For this, correlation matrix has been calculated. This is the pre-processing event. Then using various statistical tools like the model fit, confidence level, and error estimation, we can get the result of model output as a model summary, coefficient, ANOVA, etc. The diagrammatic presentation of the MLR model is shown in Fig. 9

Schematic presentation of multi linear regression
Another statistical technique is Pearson’s Product Moment Correlation has been used here to represent relational analysis between groundwater level and other concerning drivers, viz. agricultural yield, groundwater irrigated area, groundwater draft and groundwater stage of development using SPSS software (Evaluation copy). The following formula has been used to calculate the correlation.
Cluster analysis is another multivariate statistical approach to this study. Various methods of cluster analysis like Hierarchical cluster analysis (HCA), Q-mode hierarchical cluster, etc. have been used in different studies (Kebede et al. 2005; Kowalkowski et al. 2006; Park et al. 2015; Das et al. 2019). Hierarchical Cluster Analysis or HCA has been applied in this study using Euclidean distance, and it helps to measure similarity in terms of groundwater level fluctuation between ith and jth stations. The mathematical expression of HCA is
where dij represents Euclidean distance between ith and jth points, Zik and Zjk are the variables k for object ith and jth points, respectively, m is the number of variables.
The dendrogram is the graphical presentation of cluster and dendrogram that has been derived using Euclidean distance and Ward’s method in SPSS V. 25 software.
Results and discussion
Spatial pattern of groundwater level
In terms of spatiality, the groundwater level fluctuates and varies in different parts of the district. Figure 5a and b and Fig. 6a and b represent the situation of groundwater level of pre-monsoon and post-monsoon of 1996 and 2019, respectively. In all the figures, the groundwater level is the near to the surface along the western part of the district, but in the eastern part, the groundwater level is quite below the surface. That means the eastern part of the district is in more critical condition in terms of groundwater level depletion. The reason for such phenomena is that the western side of the district is part of the Jharkhand plateau fringe and built up with granitic gneiss, sandstone, and a raajmahal trap (Majumdar 1975). So, the porosity is very low on the one hand, but the secondary fracture-like lineament may allow percolating water to a small depth. Hardrock aquiclude is present near the surface. Except for this, the drafting of water is very low due to the difficulties of drilling in this part. On the other hand, in the eastern part of the district where alluvial soil is predominant, agriculture activity is intensive, and the draft of groundwater is quite high, the level has been automatically decreased. Pre-monsoon maps reveal that during 1996 the highest height of groundwater level was 14 m from the surface, and the lowest height was 2.5 m from the surface (Fig. 10a); again in 2019, the height level was 22 m, and the lowest level was 6 m from the surface (Fig. 10b).

Pre-monsoon groundwater level in 1996 and 2019
Due to rainfall recharge, during the post-monsoon season, the groundwater level is slightly increased. For example, in 1996, the post-monsoon highest and lowest levels were 11 and 0.7 (Fig. 11a) meters, respectively, and in 2019 highest and lowest levels were 20 and 2.5 m, respectively (Fig. 11b).

Post-monsoon groundwater level in 1996 and 2019
Nature of groundwater level data
To identify the nature of groundwater level data, some statistical measures have been applied here. Box plot is one of the best measures to extract the characteristics of the data. Here box plots have been drawn to detect the changing groundwater level over different geological facies. Three different seasons, viz. pre-monsoon, monsoon, and post-monsoon, have been taken to test it. Figure 9a–c depicts that the groundwater level highly fluctuates in hard clay geological facies in three seasons. But the fluctuation rate is very low in granitic gneiss because of the low percolation rate.
Moreover, outliers are present over-sand, silt and clay geological facies (Fig. 12a, c). Outlier represents extremities of data, therefore, due to the high percolation rate, exceptional water table fluctuation can be observed.

Boxplots of groundwater level fluctuation in different geological facies during pre-monsoon, monsoon and post-monsoon
Another multivariate statistical technique cluster analysis has been implied here. For the development of dendrogram, Euclidean distance has been applied to get the similarity among the data set (Vide methodology) Here three clusters have been prepared, viz. 1996, 2006, and 2019 for three seasons. Figure 13 (a,b,c) tells us that four clusters have been formed for each year, and among the four clusters one cluster consists of Khagra, Kirnahar, Kurukdigi, Tumboni, Sahapur, Second cluster represents Brajabelpahari, Satpalsa, Tejhati, Batikar, Joypur, etc., Third cluster forms Narayanpur, Mitrapur, Ahmadpur, etc., and the last cluster indicates Donaipur and Gangarampur.

a Cluster 1996 b Cluster 2006 c Cluster 2019
LOWESS (Locally Weighted Scatterplot smoothing) or simply LOESS or locally weighted smoothing has been applied here to identify the pattern and change of groundwater level in the concerned region (Wanishsakpong and Notodiputro 2017). Figure 14a, b represents the deviation of the groundwater level from the mean weighted regression line. In 2006 Bahiri, Labpur, Ganpur, Nasipur, Brajabelpahari, Bartala, and Chakmandala are highly fluctuating stations because most of the stations are in hard basaltic and lateritic geology. So, infiltration rates have highly been varied as well as groundwater levels also fluctuating (Fig. 13a). On the other hand, in 2019, the groundwater level highly fluctuated in Bahiri, Amlai, Siuri, Bolpur, Labpur, and Nanoor. All these areas have high drafting due to intensive agriculture, which results in the large-scale deviation of groundwater level (Fig. 14b).

a Locally weighted regression and scatterplot for groundwater level 1996. b Locally weighted regression and scatterplot for groundwater level 2019
Relational analysis between groundwater level with concerned drivers
This section focuses on groundwater level relation with other concerning parameters like agricultural yield, groundwater irrigated area, groundwater draft, landuse/landcover, and stages of groundwater development.
In this study, multiple linear regression (MLR) model has been used to identify the influence of explanatory variables, viz. agricultural yield, groundwater draft, groundwater irrigated area, groundwater stage of development, to predict response variable, viz. groundwater level. So, MLR represents here the linear relationship between multiple independent variables with one dependent variable. The entire model has been run in SPSS statistical software (evaluation version), and the result has come out in three tables. Table 3 represents model summery where the r value is 0.994 (Fig. 15) which means a strong positive correlation between variables r2 = 0.988 (Fig. 15; Table 3) means 98% variables are explained variables. Here the value of the standard error of the estimate is 0.4656 (Fig. 15; 3) which indicates a very low error in the MLR model or the precision level is very high. The significant value of this model is 0.000, so here the null hypothesis (H0) is rejected. Hence, the model is significant (Fig. 15; Table 3).

Schematic presentation of multiple linear regression with input, processing and output of this study
Table 4 is an important table that tells us much more about the justification of the model. All parameters, viz. agricultural yield, groundwater draft, groundwater irrigated area and groundwater stage of development, are significantly influence dependent variable as the significant values of first three variables are 0.000 and the last one is 0.051 (Fig. 15; Table 4). Here the value of intercept (β0) is 1.818 (Fig. 15; Table 4). The values of agricultural yield (Xi1), groundwater draft (Xi2), groundwater irrigated area (Xi3), and groundwater stage of development (Xi4) are − 0.014, 0.002, 0.001, and 0.047, respectively (Table 4). After getting all the values, the linear relationship between explanatory and response variables is mathematically expressed as
So, if we get all the values of explanatory variables, we can easily calculate the predicted groundwater level of any future year.
If we look at agricultural yield for the years 1996 and 2019, we can be observed that in 1996 only the southeastern part experienced high agricultural yield in the C.D. blocks like Labpur and Nanoor (Fig. 16a). But the western part remains less cultivated due to hard rock geology. But during 2019, except Rajnagar and Khoyrasole C.D blocks most of the study area has been experiencing high to very high agricultural yield (Fig. 16b) due to the introduction of the green revolution and large-scale use of groundwater as irrigation. The correlational value between agricultural yield and groundwater draft is 0.9 and with level is 0.89; both indicate a very high positive relation (Fig. 17) which means with the increase in agricultural yield, the groundwater draft becomes increased as well as groundwater level also increased.

a Agricultural yield 1996 b Agricultural yield 2019

Relational matrix between concerning drivers
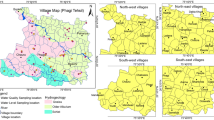
Groundwater irrigated areas are also positively associated with groundwater draft (0.98) and groundwater level (0.98) (Fig. 17). It has been expected that extensive irrigated area results in large scale draft of groundwater and lowering down the groundwater level. The irrigated area data have been collected from the district statistical handbook for the years 1996 and 2018. In terms of temporal analysis in 1996, the total groundwater irrigated area was 32,323 ha, and in 2018 the groundwater irrigated area was 72,195.5 hectares, indicating in the last 22 years groundwater irrigated areas have been increased by 55.22% in the study area. If we look into block-level spatiality, then we can observe that in 1996, Mayureswar-II, Sainthia, and Labpur blocks have the highest groundwater irrigation (Table 5, Fig. 18a). But in 2018, the scenario has been changed. Most of the district has experienced moderate groundwater irrigation (Fig. 18b). Only Mayureswar-I, II, and Sainthia blocks have the highest groundwater irrigation (Fig. 18b). It is important to notice that the Mayuresawar-II and Sainthia blocks in 1996 and 2018 have the highest irrigation rates since their yield capability (Fig. 16a, b) is still good due to the rich new alluvial soil deposited by the Mayurakshi River. Figure 14 reveals that Mayureswar-I and II, Nanoor and Murarai-I have experienced the highest increases in groundwater irrigated area. The entire district has been characterized by a 55.22% increase in groundwater irrigated area (Table 5; Fig. 19).

Irrigated area of 1996 and 2018

Increase in irrigated area between 1996 and 2018
The groundwater draft (Fig. 21) interacts favorably with agricultural yield, irrigated areas, and groundwater growth stage for farm and household purposes. All relationships indicate a very good partnership between groundwater draft and other drivers (Fig. 17). Figure 18 shows that the eastern section of the research region has a high level of soil water drain because the agricultural yield in this portion is very strong (Fig. 16). However, the drilling method is very difficult in the western part of hard rock geology, so the ground water drain is very poor in this area.
Acute changes in groundwater levels have been related to landuse/landcover. Four maps for 2 years, viz. 1996 and 2016, have been generated for the relational analysis with the groundwater level. Figure 20a, b represents groundwater level scenarios during pre-monsoon concerning landuse/landcover in 1996 and 2019. It has been depicted from the figure that groundwater contour is very steep in 2019 than in 1996 mainly in the agricultural field consisting Murarai-I and II, Mayureswar-I and II, Sainthia, Bolpur-Sriniketan blocks. This is due to high agricultural productivity in these blocks. In 1996, steep isoline only was observed in Nanoor and Bolpur-Sriniketan blocks. Fallow and wasteland in the western part always represent gentle groundwater isolines because in that part due to low agricultural activity groundwater drafting is very low.

a Relationship between LULC and pre-monsoon groundwater level, 1996. b Relationship between LULC and pre-monsoon groundwater level, 2019

Spatial pattern of groundwater draft
On the other hand, the post-monsoon groundwater level of 1996 and 2019 concerning LULC (Fig. 22a, b) also expressed that in 1996 groundwater isolines were moderate to gentle all through the study area (Fig. 22a). But in 2019 due to intensive rabi cultivation (Winter Cultivation), the isolines were closely spaced which means highly exploitation of groundwater resources (Fig. 22b). This huge drafting of groundwater for agriculture during the winter season makes the isolines steeper (Fig. 22b). Steep isolines during post-monsoon of 2019 can be observed in Murarai-I, Rampurhat-I, Mayureswar-I, II, Sainthia, Labpur, Nanoor, and Bolpur-Sriniketan C.D. blocks. All of the above-mentioned blocks are experiencing high agricultural yield (Fig. 16b).

a Relationship between LULC and post-monsoon groundwater level, 1996. b Relationship between LULC and post-monsoon groundwater level, 2019
Groundwater development are another parameter that is positively connected to other parameters. The stage of the formation of groundwater shows the strength of the groundwater draft. The higher the draft, the higher the growth level. Figure 23 reveals that groundwater in the Mayureswar-II, Murarai-II, Labpur, Nanoor C.D. block is highly developed. Due to the low drafting potential, groundwater has been poorly built in the western part of the study region. The stage therefore has a clear positive relationship (r = 0.99) to the draft (Fig. 17) and to agricultural yield (r = 0,95) in terms of relational study.

Stage of groundwater development
Future of groundwater level through a predictive model
It is one of the important parts of the study, where the groundwater level has been predicted for the year 2030. The artificial neural network model has been used as a predictive model for the future detection of groundwater (Vide methodology Sect. 2.2.4). Figure 24a and b represents the predicted level of groundwater for pre and post-monsoon for the year 2030. Both figures reveal the fact that groundwater levels will rapidly decline in the eastern and southeastern parts of the study area, where large-scale agriculture has been done. During pre-monsoon, the maximum level will be 38.24 m, and during post-monsoon maximum groundwater level will be 32.45 m, which is a matter of concern. High agricultural yield and high drafting of groundwater for irrigation purposes are the major causes for the future lowering down of groundwater level. The western part of the study is more sustainable because of low agriculture and low drafting. So, in the future, this part will always hold sustainability for the preservation of groundwater (Fig. 24a, b).

a Pre-monsoon groundwater level of 2030. b Post-monsoon groundwater level of 2030
Figure 25 indicates the predicted groundwater level for the entire district for 2030, where the ANN model predicts that in 2030 the groundwater level will be at the depth of 38.61 m. The probability value of this model is p value = 0.000001 at a 5% significant level. Based on this p value, we can say that the model is justified and truly predicted.

Predicted groundwater level for 2030 for entire district
Conclusion
In 2020, Mother Earth had multiple global threats such as deforestation, forest fire, and the loss of the ozone hole. One of them is the groundwater crisis. Rising demand for food accelerates the agriculture economy, leading to the over-use of groundwater supplies. In this analysis, the reactions of groundwater dynamics to key parameters, such as agricultural production, soil water irrigated region, soil water drainage, landuse/land coverage and groundwater growth, are identified. Both parameters are relevant to the dynamics of the groundwater. Contrasting characteristics can be found on both sides of the study region; for example, the west half of the study area is mostly made up by hard basalt and granite hard rocks. In addition, drilling in hard rocks is challenging. In the opposite, cultivation is very intensive here in the East, where fertile alluvial deposits are accumulated on the water. Strong farm output therefore influences a major drain of groundwater that reduces water levels. An artificial neural network model has been used to identify the future of groundwater level. This model shows that the groundwater level would reach a depth of 38 m by 2030 which is a serious issue. But this kind of model does not always give an accurate result due to high variability of groundwater level as lack of continuous data of the same station. Moreover, this type of environmental study is very productive and essential for hydrologists, geologists and environmentalists. Predictive groundwater research will help to raise the consciousness of current and future generations, so they are conscious of groundwater sustainability and can gain a sense of its usage.
References
Adhikari RK, Mohanasundaram S, Shrestha S (2020) Impacts of land-use changes on the groundwater recharge in the Ho Chi Minh city, Vietnam. Environ Res 185:109440. https://doi.org/10.1016/j.envres.2020.109440
Ahirwar R, Malik MS, Shukla JP (2020) Groundwater vulnerability assessment of Hoshangabad and Budni industrial area, Madhya Pradesh, India, using geospatial techniques. Appl Water Sci 10:1–14. https://doi.org/10.1007/s13201-020-1172-9
Ahmad I, Dar MA, Andualem TG, et al (2020) GIS-Based Multi-criteria Evaluation for 10.1016/j.envres.2020.109440. Deciphering of Groundwater Potential. J Indian Soc Remote Sens 48:305–313. https://doi.org/10.1007/s12524-019-01078-3
Ansari TA, Katpatal YB, Vasudeo AD (2016) Spatial evaluation of impacts of increase in impervious surface area on SCS-CN and runoff in Nagpur urban watersheds, India. Arab J Geosci. https://doi.org/10.1007/s12517-016-2702-5
Ashtekar AS, Mohammed-Aslam MA (2019) Geospatial Technology Application for Groundwater Prospects Mapping of Sub-Upper Krishna Basin, Maharashtra. J Geol Soc India 94:419–427. https://doi.org/10.1007/s12594-019-1331-5
Bogoliubova A, Tymków P (2014) Accuracy assessment of automatic image processing for land cover classification of St. Petersburg protected area. Acta Sci Pol Geod Descr Terrarum 13:5–22
Boretti A, Rosa L (2019) Reassessing the projections of the World Water Development Report. npj Clean Water 2. https://doi.org/10.1038/s41545-019-0039-9
Bronowicka-Mielniczuk U, Mielniczuk J, Obroślak R, Przystupa W (2019) A comparison of some interpolation techniques for determining spatial distribution of nitrogen compounds in groundwater. Int J Environ Res 13:679–687. https://doi.org/10.1007/s41742-019-00208-6
Choudhury D, Das K, Das A (2019) Assessment of land use land cover changes and its impact on variations of land surface temperature in Asansol-Durgapur Development Region. Egypt J Remote Sens Sp Sci 22:203–218. https://doi.org/10.1016/j.ejrs.2018.05.004
Chowdhury A, Jha MK, Chowdary VM (2010) Delineation of groundwater recharge zones and identification of artificial recharge sites in West Medinipur district, West Bengal, using RS, GIS and MCDM techniques. Environ Earth Sci 59:1209–1222. https://doi.org/10.1007/s12665-009-0110-9
Chen FW, Liu CW (2012) Estimation of the spatial rainfall distribution using inverse distance weighting (IDW) in the middle of Taiwan. Paddy Water Environ 10:209–222. https://doi.org/10.1007/s10333-012-0319-1
Czaplewski RL (1992) Misclassification bias in areal estimates. Photogramm Eng Remote Sens 58:189–192
Das N, Mukhopadhyay S (2020) Application of multi-criteria decision making technique for the assessment of groundwater potential zones: a study on Birbhum district, West Bengal, India. Environ Dev Sustain 22:931–955. https://doi.org/10.1007/s10668-018-0227-7
Das N, Mondal P, Ghosh R, Sutradhar S (2019) Groundwater quality assessment using multivariate statistical technique and hydro-chemical facies in Birbhum District, West Bengal, India. SN Appl Sci 1:1–21. https://doi.org/10.1007/s42452-019-0841-5
Das N, Mondal P, Sutradhar S, Ghosh R (2020) Assessment of variation of land use/land cover and its impact on land surface temperature of Asansol subdivision. Egypt J Remote Sens Sp Sci. https://doi.org/10.1016/j.ejrs.2020.05.001
Fan Y (2015) Groundwater in the Earth’s critical zone: Relevance to large-scale patterns and processes. Water Resour Res 51:3052–3069. https://doi.org/10.1002/2015WR017037
Fernando M-R, Tian TS (2010) The shifting boxplot. A boxplot based on essential summary statistics around the mean. El diagrama de caja cambiante. Un diagrama de caja basado en sumarios estadíst. Int J Psychol Res 3:37–45. https://doi.org/10.21500/20112084.823
Foody G (1992) On the compensation for chance agreement in image classification accuracy assessment. Photogramm Eng Remote Sensing 58:1459–1460
Hanley JA (2016) Simple and multiple linear regression: sample size considerations. J Clin Epidemiol 79:112–119. https://doi.org/10.1016/j.jclinepi.2016.05.014
Hathout S (2002) The use of GIS for monitoring and predicting urban growth in East and West St Paul, Winnipeg, Manitoba, Canada. J Environ Manage 66:229–238. https://doi.org/10.1006/jema.2002.0596
Hay AM (1988) Remote sensing letters the derivation of global estimates from a confusion matrix. Int J Remote Sens 9:1395–1398. https://doi.org/10.1080/01431168808954945
Hubert M, Vandervieren E (2008) An adjusted boxplot for skewed distributions. Comput Stat Data Anal 52:5186–5201. https://doi.org/10.1016/j.csda.2007.11.008
Husaini NA, Ghazali R, Mohd Nawi N, Ismail LH (2011) Jordan pi-sigma neural network for temperature prediction. Commun Comput Inf Sci 151:547–558. https://doi.org/10.1007/978-3-642-20998-7_61
Jobson JD (1991) Multiple linear regression. Appl Multivar Data Anal. https://doi.org/10.1136/bmj.b167
Jupp DLB (1989) The stability of global estimates from confusion matrices. Int J Remote Sens 10:1563–1569. https://doi.org/10.1080/01431168908903990
Kebede S, Travi Y, Alemayehu T, Ayenew T (2005) Groundwater recharge, circulation and geochemical evolution in the source region of the Blue Nile River, Ethiopia. Appl Geochem 20:1658–1676. https://doi.org/10.1016/j.apgeochem.2005.04.016
Kowalkowski T, Zbytniewski R, Szpejna J, Buszewski B (2006) Application of chemometrics in river water classification. Water Res 40:744–752. https://doi.org/10.1016/j.watres.2005.11.042
Landis JR, Koch GG (1977) Landis amd Koch1977_agreement of categorical data. Biometrics 33:159–174. https://doi.org/10.2307/2529310
Lerner DN, Harris B (2009) The relationship between land use and groundwater resources and quality. Land use policy 26:265–273. https://doi.org/10.1016/j.landusepol.2009.09.005
Li Z, Yang Q, Wang L, Martín JD (2017) Application of RBFN network and GM (1, 1) for groundwater level simulation. Appl Water Sci 7:3345–3353. https://doi.org/10.1007/s13201-016-0481-5
Lu WX, Zhao Y, Chu HB, Yang LL (2014) The analysis of groundwater levels influenced by dual factors in western Jilin Province by using time series analysis method. Appl Water Sci 4:251–260. https://doi.org/10.1007/s13201-013-0111-4
Ma Z, Redmond RL (1995) Tau coefficients for accuracy assessment classification remote sensing data. Photogramm Eng Remote Sens 61:435–439
Majumdar D (1975) Bengal District Gazetteer, Birbhum. State editor, Government of West Bengal
Manson SM, Burrough PA, McDonnell RA (1999) principles of geographical information systems: spatial information systems and geostatistics. Econ Geogr 75:422. https://doi.org/10.2307/144481
Morris B, Lawrence A, Stuart M (1994) The impact of urbanisation on groundwater quality (project summary report). Nottingham, UK, WC/94/056
Park Y, Kim N, Lee JY (2015) Geochemical properties of groundwater affected by open loop geothermal heat pump systems in Korea. Geosci J 19:515–526. https://doi.org/10.1007/s12303-014-0059-x
Prabhakar A, Tiwari H (2015) Land use and land cover effect on groundwater storage. Model Earth Syst Environ 1:1–10. https://doi.org/10.1007/s40808-015-0053-y
Prisley SP, Smith JL (1987) Using classification error matrices to improve the accuracy of weighted land-cover models. Photogramm Eng Remote Sensing 53:1259–1263
Razandi Y, Pourghasemi HR, Neisani NS, Rahmati O (2015) Application of analytical hierarchy process, frequency ratio, and certainty factor models for groundwater potential mapping using GIS. Earth Sci Inform 8:867–883. https://doi.org/10.1007/s12145-015-0220-8
Saba T, Rehman A, AlGhamdi JS (2017) Weather forecasting based on hybrid neural model. Appl Water Sci 7:3869–3874. https://doi.org/10.1007/s13201-017-0538-0
San THH, Khin MM (2016) River flood prediction using Markov model. Adv Intell Syst Comput 387:435–443. https://doi.org/10.1007/978-3-319-23204-1_44
Schirmer M, Leschik S, Musolff A (2013) Current research in urban hydrogeology - A review. Adv Water Resour 51:280–291. https://doi.org/10.1016/j.advwatres.2012.06.015
Singh DK, Singh AK (2002) Groundwater situation in India: Problems and perspective. Int J Water Resour Dev 18:563–580. https://doi.org/10.1080/0790062022000017400
Story M, Congalton RG (1986) Remote sensing brief accuracy assessment: a user’s perspective. Photogramm Eng Remote Sensing 52:397–399
Tetzlaf D, Bacon PJ, Youngson AF, et al (2007) Connectivity between landscapes and riverscapes—a unifying theme in integrating hydrology and ecology in catchment science? Hydrol Process 21:1385–1389. https://doi.org/10.1002/hyp.6701
Tizro AT, Voudouris K, Mattas C, et al (2018) Evaluation of Irrigation Efficiency Effect on Groundwater Level Variation by Modflow and Weap Models: A Case Study from Tuyserkan Plain, Hamedan, Iran. Springer International Publishing
Tharme RE (2003) A global perspective on environmental flow assessment: emerging trends in the development and application of environmental flow methodologies for rivers. Riv Res Appl 19 (5–6):397–441
Tettey M, Oduro FT, Adedia D, Abaye DA (2017) Markov chain analysis of the rainfall patterns of five geographical locations in the south eastern coast of Ghana. Earth Perspect. https://doi.org/10.1186/s40322-017-0042-6
Van Deusen PC (1996) Unbiased estimates of class proportions from thematic maps. Photogramm Eng Remote Sensing 62:409–412
van Rooyen JD, Watson AP, Miller JA (2020) Combining quantity and quality controls to determine groundwater vulnerability to depletion and deterioration throughout South Africa. Environ Earth Sci. https://doi.org/10.1007/s12665-020-08998-1
Wada Y, Flörke M, Hanasaki N, et al (2016) Modeling global water use for the 21st century: The Water Futures and Solutions (WFaS) initiative and its approaches. Geosci Model Dev 9:175–222. https://doi.org/10.5194/gmd-9-175-2016
Wakode HB, Baier K, Jha R, Azzam R (2018) Impact of urbanization on groundwater recharge and urban water balance for the city of Hyderabad, India. Int Soil Water Conserv Res 6:51–62. https://doi.org/10.1016/j.iswcr.2017.10.003
Wanishsakpong W, Notodiputro KA (2017) Locally weighted scatter-plot smoothing for analysing temperature changes and patterns in Australia. Meteorol Appl 25:357–364
Yang Q, Wang Y, Zhang J, Delgado J (2017) A comparative study of shallow groundwater level simulation with three time series models in a coastal aquifer of South China. Appl Water Sci 7:689–698. https://doi.org/10.1007/s13201-015-0282-2
Yuan D (1979) A simulation comparison of three marginal area estimators for image classification. Photogramm Eng Rermote Sens 63:385–392
Funding
The authors received no specific funding for this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical standard
The manuscript includes no issue related to ethical compliance.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Das, N., Sutradhar, S., Ghosh, R. et al. The response of groundwater to multiple concerning drivers and its future: a study on Birbhum District, West Bengal, India. Appl Water Sci 11, 79 (2021). https://doi.org/10.1007/s13201-021-01410-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-021-01410-8