
Abstract
Multilevel structural equation modeling (MSEM) is a statistical framework of major relevance for research concerned with people’s intrapersonal dynamics. An application domain that is rapidly gaining relevance is the study of individual differences in the within-person association (WPA) of variables that fluctuate over time. For instance, an individual’s social reactivity – their emotional response to social situations – can be represented as the association between repeated measurements of the individual’s social interaction quantity and momentary well-being. MSEM allows researchers to investigate the associations between WPAs and person-level outcome variables (e.g., life satisfaction) by specifying the WPAs as random slopes in the structural equation on level 1 and using the latent representations of the slopes to predict outcomes on level 2. Here, we are concerned with the case in which a researcher is interested in nonlinear effects of WPAs on person-level outcomes – a U-shaped effect of a WPA, a moderation effect of two WPAs, or an effect of congruence between two WPAs – such that the corresponding MSEM includes latent interactions between random slopes. We evaluate the nonlinear MSEM approach for the three classes of nonlinear effects (U-shaped, moderation, congruence) and compare it with three simpler approaches: a simple two-step approach, a single-indicator approach, and a plausible values approach. We use a simulation study to compare the approaches on accuracy of parameter estimates and inference. We derive recommendations for practice and provide code templates and an illustrative example to help researchers implement the approaches.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Many constructs examined in psychological research are latent, meaning that they are not directly observable and can be measured only indirectly. Random slopes as defined in multilevel models are one kind of latent variable that is rapidly gaining relevance in psychological research. Random slopes can be used to represent within-person associations (WPAs) between variables that fluctuate over time (e.g., Back , 2021; Borsboom & Cramer, 2013; Denissen & Penke, 2008; Fleeson , 2007; Kuper et al. , 2022; Mischel & Shoda, 1995; Neubauer & Schmiedek, 2020; Wrzus, Luong, Wagner & Riediger, 2021) and hence allow researchers to investigate effects of WPAs on person-level psychological outcomes. For example, people’s social reactivity can be operationalized as the WPA between repeated measurements of momentary social interaction frequency and well-being (Kroencke, Harari, Back, & Wagner, 2023; Sun, Harris & Vazire, 2020), stress reactivity as the WPA between momentary stress level and negative affect (Bolger & Schilling, 1991; Hisler, Krizan, DeHart, & Wright, 2020; Wrzus et al., 2021), and both might be predictive of people’s interpersonal adjustment or psychological health.
One possible analytical approach for testing effects of WPAs is multilevel structural equation modeling (MSEM; Asparouhov, Hamaker, & Muthén, 2018; Hamaker, Asparouhov, Brose, Schmiedek, & Muthén, 2018; Liang & Bentler, 2004; McNeish & Hamaker, 2019; Muthén , 1989; Muthén & Asparouhov, 2008; Preacher, Zyphur, & Zhang, 2010). MSEM is an extension of regular, single-level SEM to multiple levels of analysis. It can be used to examine the effects of WPAs on person-level outcomes by specifying the WPAs as random slopes \(\beta \) in the structural equation at level 1 and using their latent representation as predictors of a person-level outcome on level 2 (e.g., Brose, Neubauer, & Schmiedek, 2022; Liu & Rhemtulla, 2022; Lüdtke et al. , 2008). Treating the random slopes as latent variables when using them in the model of interest takes their imperfect reliability into account (Asparouhov & Muthén, 2019; Lüdtke et al., 2008). Consequently, previous research has found that, for the case of linear effects of random slopes on an outcome, MSEM can yield accurate parameter estimates and inferences even in situations in which the slopes can only be estimated with low reliability (e.g., Liu & Rhemtulla, 2022; Neubauer, Brose, & Schmiedek, 2022).
However, psychological theories often imply nonlinear associations between WPAs and other psychological constructs, and it is currently unknown how well MSEM can be applied to test them. Therefore, one aim of the present article is to evaluate an MSEM approach that models nonlinear effects of random slopes. Specifically, we considered three classes of nonlinear hypotheses that are often investigated in psychological studies. First, an (inverse) U-shape hypothesis captures the idea that a certain level of a predictor variable minimizes (or maximizes) an outcome (e.g., Cohen, Gunthert, Butler, O’Neill, & Tolpin, 2005; Sternberg , 2003). A U-shaped effect of a WPA \(\beta \) (e.g., social reactivity) on a person-level outcome z (e.g., life satisfaction) can be investigated with an MSEM that estimates the quadratic effect of \(\beta \) on z in the model on level 2. Second, a moderation hypothesis reflects the idea that the strength of the linear relationship between two variables depends on the value of a third variable (e.g., Cummins , 1989; Sung, Chang, & Liu, 2016). In the context of WPAs, a moderation effect of two WPAs \(\beta _1\) and \(\beta _2\) (e.g., social reactivity and stress reactivity) can be tested with an MSEM that estimates the effect of the interaction between \(\beta _1\) and \(\beta _2\) on z. Finally, a congruence hypothesis posits that the similarity between two psychological variables has a positive (or negative) effect on an outcome (e.g., Higgins , 1996; Kim et al. , 2021; Kristof-Brown, Zimmerman, & Johnson, 2005). Drawing from the literature on testing congruence effects with response surface analysis (RSA; Box & Draper, 1987; Box & Wilson, 1951; Edwards & Parry, 1993), the effect of congruence between two WPAs \(\beta _1\) and \(\beta _2\) can be investigated with an MSEM that estimates the second-order polynomial effects of the two WPAs (i.e., \(z = b_0 + b_1\beta _1 + b_2\beta _2 + b_3\beta _1^2 + b_4\beta _1\beta _2 + b_5 \beta _2^2\)).
A second aim of this article is to compare the performance of the MSEM approach with alternative modeling approaches that are easier to implement and estimate. One alternative is a simple two-step approach, where the WPAs are first estimated as random slopes in a conventional multilevel analysis and the resulting random effect estimates are used to predict the person-level outcome variable in a nonlinear regression analysis. Two-step approaches are often employed as alternatives to fully latent models (SEMs) for their simplicity, especially when the need to implement latent interaction terms can thereby be avoided (Cortina, Markell-Goldstein, Green, & Chang, 2021). However, they are usually inferior to the latent approach because two-step approaches do not account for the unreliability of the estimated scores (Bollen, 1989; Brose et al., 2022; Cole & Preacher, 2014; Neubauer, Voelkle, Voss, & Mertens, 2020; Westfall & Yarkoni, 2016). A second alternative to MESM is a single-indicator (SI) approach (Bollen, 1989; Hayduk, 1987) in which latent variables are defined via single-indicator measurement models for the estimated random slopes \(\beta \) and then used as predictors in a single-level SEM. This approach is simpler than a fully latent MSEM approach because it proceeds in two separate steps, while it simultaneously takes the slopes’ unreliability into account. A third alternative to MSEM comprises plausible values (PV) approaches, which are commonly used to obtain latent variable scores for secondary analysis in large-scale assessment studies (Mislevy , 1991; see also Asparouhov & Muthén, 2010b; Lüdtke, Robitzsch, & Trautwein, 2018; von Davier, Gonzalez, & Mislevy, 2009; Yang & Seltzer, 2016). In this approach, the individual slopes \(\beta \) are regarded as missing data and “filled in” with multiple PVs that are generated on the basis of the observed data and a statistical model. The nonlinear level 2 model is then estimated separately for each set of values, and the results are pooled using Rubin’s rules (Rubin, 1987). To our knowledge, the SI and PV approaches have not been evaluated in the context of testing (linear or nonlinear) effects of random slopes. By comparing the four approaches, we aim to contribute to methodological research on estimating nonlinear functions of random slopes, and we aim to support applied research by guiding the choice of method to test hypotheses about nonlinear effects of WPAs.
In the following, we first explain the MSEM approach and the three alternative approaches (simple two-step, SI, PV) for investigating U-shaped, moderation, and congruence effects of WPAs. We then report the results of a simulation study in which we compared the four approaches on accuracy of estimates and inferences. Finally, we derive recommendations for best practice in testing nonlinear effects of WPAs, illustrate their application with example data from a daily diary study, and discuss possible extensions and future developments. To help researchers implement the approaches in their research, we also provide computer code templates for each method (https://osf.io/xucwf).
MSEM approach for investigating U-shaped, moderation, and congruence effects of WPAs
MSEM is a statistical framework for modeling relationships between variables on different levels of analysis (e.g., Asparouhov et al. , 2018; Hamaker et al. , 2018; Liang & Bentler, 2004; McNeish & Hamaker, 2019; Muthén , 1989; Muthén & Asparouhov, 2008; Preacher et al. , 2010). In the present context, the levels of analysis are repeated measures on level 1 (L1) that are nested within individuals at level 2 (L2). Conceptually, when the aim is to investigate nonlinear effects of WPAs, the general idea of the MSEM approach is to operationalize an individual’s WPA between two repeatedly measured L1 variables x and y as their individual slope in predicting y from x. The slopes are then used to predict the L2 outcome z of interest in a respective analysis model (e.g., a quadratic model) on level 2. A key feature of the MSEM framework is that all these components are specified in the same model, so that the parameters are estimated in a single step. Below, we describe the MSEM specifications for the three classes of hypotheses (U-shape, moderation, congruence) in more detail.
MSEM for a WPA-U-shape hypothesis
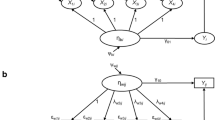
As an illustrative example, assume that we are interested in individual differences in people’s social reactivity – the extent to which social interactions positively affect an individual’s well-being (e.g., Kroencke et al. , 2023; Sun et al. , 2020) – and that we expect a U-shaped (or inverse U-shaped) effect of people’s social reactivity on their life satisfaction. To test this WPA-U-shape hypothesis, we could have collected repeated measures of the quantity of people’s social interactions (x) and their momentary well-being (y). Assume that we have collected these L1 variables \(x_{it}\) and \(y_{it}\) at each of \(T_i\) time points (\(t \in \{1, ..., T_i\}\)) for a total of P individuals (L2 units) \(i \in \{1, ..., P\}\). In addition, assume that we have assessed the life satisfaction \(z_i\) for each individual i as the L2 outcome of interest.
In the measurement model of the MSEM that can be used to test the example hypothesis, the L1 predictor x (sociality) is decomposed into a person’s latent mean, which varies only between persons (\(x_B\)) and reflects individual differences in people’s sociality, and a second part that captures the person’s within-person fluctuations across time (\(x_W\)):
In the structural model, a person i’s social reactivity is then modeled as the L1 association \(\beta _{yi}\) between the person’s fluctuations in sociality \(x_W\) and their momentary well-being y (e.g., Brose et al. , 2022; Neubauer et al. , 2020):
Due to the latent decomposition of the predictor variable x into between- and within-person parts, the individual slopes \(\beta _{yi}\) represent individual i’s WPA between sociality x and well-being y (Asparouhov & Muthén, 2019; Enders & Tofighi, 2007; Raudenbush & Bryk, 2002). The individual slopes vary around an average slope \(\alpha _{\beta y}\) with a person-specific deviation \(\zeta _{\beta yi}\), whose variability reflects interindividual differences in social reactivity. Similarly, the latent variable \(x_{Bi}\) (person i’s average sociality) and the random intercept \(y_{Bi}\) (person i’s average well-being) vary around the overall averages of sociality and well-being (\(\alpha _x\) and \(\alpha _y\)), respectively, with person-specific deviations (\(\zeta _{Bxi}\) and \(\zeta _{Byi}\)).
The expected (inverse) U-shaped association between social reactivity \(\beta _{y}\) and life satisfaction z is modeled as a quadratic effect in a second part of the structural model on level 2:
Here, the regression weights (\(b_1\), \(b_3\)) are numbered nonconsecutively for consistency with a more general second-order polynomial model that we introduce for the WPA-congruence hypothesis below. The coefficient \(b_3\) in Eq. 6 reflects the (inverse) U-shaped effect of interest.
The definition of the MSEM is completed by distributional assumptions for the latent variables on level 1 and level 2:
All of the nonzero terms in \(\Phi _W\) and \(\Phi _B\) can be estimated freely, whereas the others must be restricted to zero. The diagonal entries of \(\Phi _W\) refer to the within-person variance of sociality (\(\sigma ^2_x\)) and the L1 residual variance of well-being (\(\sigma ^2_y\)). The diagonal of \(\Phi _B\) contains the between-person variances of sociality (\(\tau ^2_x\)), well-being (\(\tau ^2_y\)), and social reactivity (\(\tau ^2_{\beta _y}\)) and the L2 residual variance of life satisfaction (\(\tau ^2_z\)). The covariance terms in \(\Phi _B\) reflect between-person associations between these components, that is, between the measured variables, the random effects, and the L2 residuals. In practice, it is often reasonable to restrict some of these covariance terms in \(\Phi _B\) (e.g., the conceptually least plausible ones) to zero, to simplify the estimation of the model (Bates, Kliegl, Vasishth, & Baayen, 2018).
MSEM for a WPA-moderation hypothesis
A WPA-moderation hypothesis refers to the effect of an interaction between two WPAs on an outcome. For example, social reactivity may moderate the linear association between people’s stress reactivity – the WPA between situational stressfulness and negative affect – and life satisfaction. The data include \(T_i\) assessments of sociality (\(x_{it}\)), well-being (\(y_{it}\)), stressfulness (\(u_{it}\)), and negative affect (\(v_{it}\)) for each individual i, and an L2 measure \(z_i\) of life satisfaction.
The corresponding MSEM specifies an individual i’s social reactivity \(\beta _{yi}\) and their stress reactivity \(\beta _{vi}\) as individual slopes, extending the model above to a bivariate model:
Here, the interpretation of the model components is analogous to that of Eqs. 1 to 5. The main difference between the WPA-moderation and the WPA-U-shape model is that an interaction effect instead of a quadratic effect is now specified in the second part of the L2 structural model:
The coefficient \(b_4\) of the interaction term reflects the potential moderation effect of interest. The model is again completed by distributional assumptions on both levels:
On level 1, the elements of \(\Phi _W\) are the within-person variances of sociality (\(\sigma ^2_x\)) and situational stressfulness (\(\sigma ^2_u\)), the L1 residual variances (\(\sigma ^2_y\), \(\sigma ^2_v\)), the L1 covariance between momentary sociality and stressfulness (\(\sigma _{xu}\)), and the covariance of the L1 residuals (\(\sigma _{yv}\)). On level 2, \(\Phi _B\) contains the between-person variances of sociality (\(\tau ^2_x\)), stressfulness (\(\tau ^2_u\)), well-being (\(\tau ^2_y\)), negative affect (\(\tau ^2_v\)), social reactivity (\(\tau ^2_{\beta _y}\)), and stress reactivity (\(\tau ^2_{\beta _v}\)) and the L2 residual variance of life satisfaction (\(\tau ^2_z\)). The covariances involving a combination of x, y, \(\beta _y\), and z are interpreted in the same way as described above for Eq. 8, and those involving a combination of u, v, \(\beta _v\), and z have analogous interpretations referring to stressfulness, negative affect, and stress reactivity. In addition, \(\Phi _B\) contains all pairwise covariances between the L2 parts of the social reactivity set of variables (people’s average sociality, well-being, social reactivity) and the stress reactivity variables (average stressfulness, negative affect, stress reactivity). Again, it will often be reasonable to set several of the covariances to zero to simplify the estimation of the model.
MSEM for a WPA-congruence hypothesis
A WPA-congruence hypothesis also involves two WPAs. It posits that individuals (L2 units) with more congruent values of the two WPAs have higher (or lower) values on an outcome variable. As an example, assume that we expect positive effects of intrapersonal consistency in reactivities, in the sense that individuals whose level of social reactivity is similar to their level of stress reactivity have higher life satisfaction than people with more incongruent reactivities. An investigation of this hypothesis requires the same data as the WPA-moderation hypothesis, the same models for the two WPAs \(\beta _{yi}\) and \(\beta _{vi}\) (Eqs. 9 to 13), and identical distributional assumptions.
The L2 structural model that represents the WPA-congruence hypothesis is based on Response Surface Analysis (RSA; Box & Draper, 1987; Box & Wilson, 1951; Edwards & Parry, 1993). It is a second-order polynomial model in which life satisfaction z is predicted from the two slopes \(\beta _{y}\) and \(\beta _{v}\), their squared terms, and their interaction (see also Humberg et al. , in press):
The usual procedure of RSA involves using the regression weights \(b_1, \dots , b_5\) to calculate six auxiliary parameters (\(a_1, a_2, a_3, a_4, p_{10}, p_{11}\)) that help interpret the model’s predictions. The model represents the congruence hypothesis if the parameters satisfy six respective conditions (\(a_1=a_2=a_3=p_{10}=p_{11}-1=0, a_4<0\)), which are typically checked with null hypothesis significance tests. For readers unfamiliar with RSA, we provide additional information about the auxiliary parameters in the supplement (https://osf.io/xucwf; for more detailed explanations, see, e.g., J. R. Edwards , 1993, 2002; Humberg, Nestler, & Back, 2019; Schönbrodt , 2016).
Implementation and estimation
A major complexity of all three MSEM models (U-shape, moderation, congruence) is that their L2 structural models involve nonlinear functions of random slopes (\(\beta _{yi}^2\), \(\beta _{yi}\beta _{vi}\), \(\beta _{vi}^2\)). To date, it is possible to estimate such models only by using Bayesian analysis software, such as Mplus (versions 8 or newer; Asparouhov & Muthén, 2010a; Muthén & Muthén, 2017 see the code template at https://osf.io/xucwf), JAGS (Plummer, 2016), or Stan (Stan Development Team, 2022). These software programs employ MCMC algorithms with Gibbs and Metropolis-Hastings sampling techniques to sample the latent variables and their (potentially) nonlinear effects (Asparouhov & Muthén, 2010a, 2021; Gelman et al., 2013). For the case of linear WPA hypotheses, recent simulation research has shown that the MSEM approach performs well with regard to estimation accuracy, whereas it also tends toward high estimation uncertainty, especially when the numbers of time points and individuals are small (e.g., Liu & Rhemtulla, 2022; Neubauer et al. , 2022).
However, it is currently unclear whether these results generalize to the nonlinear case that we consider here. In addition, the application of MSEM in this manner currently requires either commercial software (Mplus) or significant familiarity with Bayesian software (e.g., JAGS, Stan), thus limiting the accessibility of the approach for applied researchers. Therefore, the first aim of this paper is to assess how well the MSEM approach performs in testing the three hypotheses (U-shape, moderation, congruence). The second aim is to compare it with alternative methods that avoid the complexity of the MSEM approach and its Bayesian estimation procedures. The alternative approaches can be implemented with only basic statistical methods and are described in more detail below.
Alternatives to the MSEM approach
We considered three alternatives to MSEM, all of which consist of two separate computational steps. All three approaches require the same data as described above for the MSEM approach, that is, repeated measures of two L1 variables x and y (or four, with u and v as well, if two WPAs are of interest) and an L2 variable z.
Simple two-step approach
The simple two-step approach separates the estimation of the individual slopes (Step 1) from the estimation of their nonlinear effects (Step 2). More specifically, in Step 1, estimates of individuals’ WPAs between x and y are obtained by estimating a multilevel random coefficients model, where individual i’s WPA is represented by the L1 slope \(c_{yi}\) (e.g., Brose et al. , 2022; Neubauer et al. , 2020):
Conceptually, this model’s specification of the individual slopes is similar to MSEM’s (Eqs. 1 to 5). One technical difference is that the L1 predictor x is centered at the (manifest) person means, thus implying that its between- and within-person components (\(\bar{x}_{i\bullet }\) and \(x^C_{it}\), respectively) represent manifest rather than latent variables. Moreover, the between-person association between x and y is not included as a covariance (as in \(\Phi _B\) in MSEM) but as an L2 regression coefficient (\(\gamma _{y01}\) in Eq. 20). The individual slope \(c_{yi}\) defined in Eq. 19 represents the WPA between x and y for individual i. In the simple two-step approach, estimates \(\hat{c}_{yi}\) of these slopes are obtained for each individual.
When the aim is to test a WPA-moderation or a WPA-congruence hypothesis, which involve two WPAs, estimates \(\hat{c}_{vi}\) of \(c_{vi}\), representing the WPA between u and v, are obtained with an analogous multilevel model:
In Step 2 of the simple two-step approach, the individual slope estimates \(\hat{c}_{yi}\) and, if appropriate, \(\hat{c}_{vi}\), are used as predictors in a regular regression model that tests the suggested nonlinear effect on z. For example, the most complex analysis model, the second-order polynomial for investigating a WPA-congruence hypothesis, uses the WPA estimates \(\hat{c}_{y}\) and \(\hat{c}_{v}\) and their squared and interaction terms to predict the outcome z:
The models for the WPA-U-shape hypothesis (quadratic model: \(b_2 = b_4 = b_5 = 0\)) and the WPA-moderation hypothesis (interaction model: \(b_3 = b_5 = 0\)) are special cases of the second-order polynomial in Eq. 28. The interpretation of the model coefficients in terms of the hypotheses of interest is analogous to the interpretation of MSEM.
The simple two-step approach can be implemented, for example, in R with the lme4 package (Bates, Mächler, Bolker, & Walker, 2015) in Step 1 and the lm() function in Step 2 (R Core Team , 2023, see the code template at https://osf.io/xucwf). To obtain estimates of the individual slopes (\(\hat{c}_{yi}\) and, potentially, \(\hat{c}_{vi}\)) in Step 1, we use the expected a posteriori (EAP) estimates. In comparison with the alternative OLS estimate, one advantage of EAP estimates is that they include a reliability correction via shrinkage and therefore yield fewer parameter biases when they are used in a subsequent L2 model (Croon & van Veldhoven, 2007).Footnote 1
Whereas the simple two-step approach is thereby straightforward to implement and also intuitive to understand (see also Cortina et al. , 2021), it has several limitations that originate from the fact that \(\hat{c}_{yi}\) and \(\hat{c}_{vi}\) are unreliable estimates of the (latent) individual slopes (Lüdtke et al., 2008; Neubauer et al., 2020; Raudenbush & Bryk, 2002); in fact, the first empirical investigations of psychologically relevant WPA constructs reported slope reliabilities around .5 even for studies with many measurement occasions (Kuper et al., 2022). The unreliability of the slopes is automatically taken into account by the MSEM approach because it uses their latent representations in the L2 analysis model of interest. By contrast, the simple two-step approach uses the estimated slopes as manifest variables in the L2 model and thereby falsely assumes that they are perfectly reliable. The use of EAP estimates of the slopes already represents a partial correction for unreliability, but prior work has shown that this partial correction is not always sufficient to ensure accurate estimates and inferences of their effects on L2 outcomes (Humberg et al., in press; Liu & Rhemtulla, 2022; Lüdtke et al., 2018). The SI and PV approaches that we describe below extend the simple two-step approach by implementing two different ways to take the unreliability of the slope estimates into account.
Single-indicator (SI) approach
The general idea behind SI approaches is to avoid using the potentially unreliable estimates of interest (here: the estimated individual slopes) in the analysis model but instead use a latent representation thereof (Bollen, 1989; Hayduk, 1987). In the following, we adopt the SI approach described by Lai and Hsiao (2022), which is very general in that it contains several other SI approaches as special cases (e.g., fixed-reliability SI described by Savalei , 2019, see also the Discussion).
The first step of the SI approach is again to obtain EAP estimates of the individual slopes \(\hat{c}_{yi}\) (and possibly \(\hat{c}_{vi}\)) for each individual i as in the simple two-step approach, while also estimating their standard errors \(\hat{s}_{c_yi}\) (of \(\hat{c}_{yi}\); and possibly \(\hat{s}_{c_vi}\) of \(\hat{c}_{vi}\)), which correspond to the standard deviation of the slope’s conditional posterior distribution (e.g., Snijders & Berkhof, 2008). The estimated standard errors \(\hat{s}_{c_yi}\) (and \(\hat{s}_{c_vi}\)) can vary across individuals, reflecting the fact that the reliabilities of individuals’ slope estimates can differ.
In the second step of the SI approach, a single-level SEM is used to estimate the nonlinear effect of interest. Its measurement model represents the individual slopes \(\hat{c}_{y}\) as a latent variable \(\eta _{y}\) with \(\hat{c}_{y}\) as its only indicator (and analogous for \(\hat{c}_{v}\)). The factor variances, factor loadings, and error variances are defined as follows (Lai & Hsiao, 2022):
The latent variable \(\eta _{y}\) (and, if applicable, \(\eta _{v}\)) is then used in the structural model. For example, the second-order polynomial model used to test a WPA-congruence hypothesis is specified as follows:
The WPA-U-shape hypothesis (quadratic model: \(b_2 = b_4 = b_5 = 0\)) and the WPA-moderation hypothesis (interaction model: \(b_3 = b_5 = 0\)) are represented by respective special cases of Eq. 30.
Whereas the first step of the SI approach can be implemented in R using the code for the simple two-step approach, estimating the SEM in the second step is challenging for two reasons: (a) the measurement models in Eq. 29 are person-specific and therefore need to be implemented with definition variables (Mehta & Neale, 2005) and (b) the structural model includes nonlinear effects of latent variables (e.g., \(\eta _{yi}^2\)). To our knowledge, estimating models with these two attributes is not (yet) possible with R. It can be achieved, for example, with Mplus, which uses maximum likelihood estimation with an EM algorithm for this purpose (see also Lai & Hsiao, 2022; see OpenMx as a potential alternative, Boker et al. , 2023; Neale et al. , 2016). Furthermore, due to the computational demand of estimating the person-specific model parameters, the estimation process can be computationally intensive. It can therefore be reasonable to simplify the model by setting the factor loadings and error variances to constant values: \(\lambda _y = 1 - \overline{\hat{s}^2_{c_y\bullet }}\) and \({{\,\textrm{Var}\,}}(\xi _{yi}) = \overline{\hat{s}^2_{c_y\bullet }} \cdot (1 - \overline{\hat{s}^2_{c_y\bullet }})\), where \(\overline{\hat{s}^2_{c_y\bullet }} = \frac{1}{P} \sum _{i} \hat{s}^2_{c_yi}\) is the average estimated variance of the slopes across individuals (see the code template at https://osf.io/xucwf). As Lai and Hsiao (2022) pointed out, the simplified SI approach is equivalent to approaches that have been investigated by, for example, Hsiao et al. (2018) and Savalei (2019). The only remaining challenge in the simplified SI approach then is the estimation of a single-level SEM with latent interaction terms, which can be achieved with a wider selection of software, including software for Bayesian analysis (e.g., Arminger & Muthén, 1998; Asparouhov & Muthén 2021) or latent moderated SEM (Klein & Moosbrugger, 2000; see also Sardeshmukh & Vandenberg, 2017).
Plausible values (PV) approach
Plausible values (PV) approaches are usually discussed in the context of latent ability measurement as an alternative to using estimated person parameters in secondary analyses (Mislevy , 1991; see also Asparouhov & Muthén, 2010b; Lüdtke et al. , 2018). To account for unreliability, this method regards the individuals’ values on the latent variable of interest as missing data and generates multiple (e.g., \(M=20\)) so-called plausible values (PVs) for the latent variables for each individual by drawing them from their posterior predictive distribution given the observed data and a statistical model. The analysis model is then applied separately to each set of draws, and the results are pooled with Rubin’s rules (Rubin, 1987).
Here, we adapted the PV approach to the case in which the estimated person parameters are the individual slopes (e.g., \(c_{yi}\)). When these slopes are defined as random effects in a multilevel model (e.g., as in Eqs. 18 to 22), the person-specific posterior predictive distribution of each individual i’s slope \(c_{yi}\) that is implied by the multilevel model is normal around \(\hat{c}_{yi}\) with variance \(\hat{s}^2_{c_yi}\) , provided that the estimates \(\hat{c}_{yi}\) and \(\hat{s}^2_{c_yi}\) have been obtained with an adequate (e.g., Bayesian) estimation procedure (Hoff, 2009). In addition, when drawing PVs, it is important to specify the multilevel model in such a way that it correctly reflects all associations that are present in the data, which – in our case – includes the nonlinear associations between the individual slopes and the L2 outcome variable (Asparouhov & Muthén, 2021; Goldstein, Carpenter, & Browne, 2014; Lüdtke et al., 2018; Mislevy, 1991; Monseur & Adams, 2009).
For the present purpose, however, we consider an implementation of the PV method that only approximates such an optimal PV approach without fully satisfying all of its requirements. The reason is that, for the complex task of modeling nonlinear effects of random slopes, the optimal PV approach would be more complex in terms of implementation and computation than the MSEM approach. By contrast, we focus on a simplified PV approach that attempts to strike a compromise between the benefits of PV and the simplicity of alternative approaches to MSEM and that can be implemented with only basic statistical methods.
Specifically, the first step of the PV approach considered here is to estimate a multilevel model that extends the one used in the simple two-step approach by including the L2 variable z as an L2 predictor of the random intercept and slope:
The corresponding distributional assumptions are analogous to those stated in Eq. 22. We denote the parameters of this model with a prime (\('\)) to distinguish them from those in Eqs 18 to 21. By using z as a predictor of the individual slopes \(c'_{yi}\) in Eq. 33, the EAP estimate of an individual i’s slope (\(\hat{c}'_{yi}\)) and its standard error (\(\hat{s}'_{c_yi}\)) take into account a potential linear (but not a nonlinear) association between z and the slopes (Zyphur, Zhang, Preacher, & Bird, 2019). As a result of this first step, estimates of \(\hat{c}'_{yi}\) and \(\hat{s}'_{c_yi}\) are obtained for each individual i.
In a next step, for each individual i, a set of M plausible values \(c_{yi(m)}\) for the individual’s slope are generated from the normal distribution
and similarly for \(c_{vi}\). The analysis model (e.g., the second-order polynomial model in Eq. 28) is then estimated separately for each set of PVs, and the resulting estimates of the regression coefficients and standard errors are pooled using Rubin’s rules (Rubin, 1987).
This simplified PV approach can be implemented, for example, in R by estimating the multilevel model (Eqs. 31 to 33) with the lme4 package (Bates et al., 2015) and the analysis model for each draw (e.g., Eq. 28) as a standard regression model. The simplified PV approach is thus easier to implement and estimate than the MSEM approach, and it addresses a central criticism of the simple two-step approach by taking the unreliability of the slope estimates into account via the variation in individuals’ slope draws. However, it has two limitations in comparison with an optimal implementation of the PV method. First, it ignores the uncertainty with which the parameters in the multilevel model are estimated. Second, the multilevel model that is used to obtain the PVs (Eqs. 31 to 33) includes only the linear relationship between the slopes and the L2 variable z while ignoring any nonlinear effects. One aim of our simulation study is to examine whether these limitations severely affect the performance of the approach or whether, by contrast, this version of the PV approach provides a reasonable, simpler alternative to the MSEM approach.
Comparison of the approaches
We introduced four possible approaches for testing nonlinear WPA hypotheses (MSEM, simple two-step, SI, PV). In comparing these approaches from a practical perspective, the simple two-step approach is clearly the easiest to implement, as both steps can be conducted in R using basic multilevel and regression modeling. By contrast, it is more complex to implement SI and PV: The SI approach requires software that can estimate latent interaction terms in a single-level SEM, and the PV approach requires the generation and analysis of several draws of the individual slopes and thereby has more analytical steps than the simple two-step approach. The MSEM approach is the most computationally complex because it involves nonlinear functions of random slopes. Its estimation is thereby more time-consuming when compared with the other approaches, and it is currently possible only with a Bayesian approach as implemented in commercial software (Mplus) or in Bayesian statistical software (e.g., JAGS, Stan).
Comparing the approaches in terms of their model definitions, the simple two-step approach is based on the most restricted model. In comparison with the most complex MSEM approach, the simple two-step approach involves several (implicit) assumptions that prior research has shown to be problematic: First, the simple two-step approach does not take the unreliability of the individual slopes (\(\hat{c}_{yi}\), \(\hat{c}_{vi}\)) into account when estimating the analysis model in Step 2, thereby implicitly assuming perfectly reliable slopes. This assumption is usually not met, which can lead to biased estimates and inferences (e.g., Bollen , 1989; Brose et al. , 2022; Cole & Preacher, 2014; Neubauer et al. , 2020; Westfall & Yarkoni, 2016); even more so given that the nonlinear combinations of the slopes used in the regression model are less reliable than the original slopes (Busemeyer & Jones, 1983). Second, a consequence of assuming perfectly reliable slopes is that the simple two-step approach implicitly assumes that there are no between-person differences in the slopes’ reliabilities, leading to heteroscedastic errors in the regression model when this assumption is not met (Lewis & Linzer, 2005). Third, the simple two-step approach uses a manifest decomposition of the L1 predictor variable(s); it therefore does not account for unreliability in the person means (\(\bar{x}_{i\bullet }\) and \(\bar{u}_{i\bullet }\); Grilli & Rampichini, 2011; Lüdtke et al. , 2008; Raudenbush & Bryk, 2002). Finally, because the slopes \(\hat{c}_{y}\) and \(\hat{c}_{v}\) are estimated in separate models, several of the covariances that can be freely estimated in MSEM (see Eqs. 15 and 16) are ignored in the simple two-step approach (e.g., the L1 residual covariance \(\sigma _{yv}\); the L2 covariance \(\tau _{yv}\)). Ignoring these covariances may induce bias when they are in fact nonzero in the population.
Both the SI and PV approaches differ from the simple two-step approach in that they take into account the slopes’ imperfect reliabilities and between-person differences in these reliabilities. However, like the simple two-step approach, they also use a manifest decomposition of the predictors and restrict the same covariances to zero. The MSEM approach makes none of the mentioned assumptions and thus avoids introducing any potentially unjustified model constraints and the biases that may arise from them. At the same time, the fully latent nature of the MSEM approach can render its parameter estimates unstable under certain conditions, implying that the simpler approaches may even have advantages over MSEM in this regard (Humberg et al., in press; Lai & Hsiao, 2022; Ledgerwood & Shrout, 2011; Lüdtke et al., 2008; Savalei, 2019).
Simulation study
We conducted a simulation study to evaluate the performance of the MSEM approach for modeling nonlinear effects of WPAs and compared it with the performances of the three simpler methods (two-step, SI, PV). To the best of our knowledge, these questions have only scarcely been examined before (see also Rohloff, Kohli, & Chung, 2022). Specifically, one study (Humberg et al., in press) compared the MSEM and the simple two-step approaches only for the WPA-congruence hypothesis. In this case, the simple two-step approach tended to underestimate the parameters and their standard errors, whereas MSEM yielded more accurate estimates and inferences but was also more prone to convergence problems and more variable estimates when the sample sizes on both levels were small. In the present simulation, we considerably extend this research by examining two further two-step approaches (SI and PV) and two additional classes of nonlinear effects of WPAs (U-shaped, moderation).
Specifically, in the simulation study, we varied the hypothesis of interest (U-shape, moderation, congruence). In each of the three corresponding conditions, we specified the relevant effect (e.g., U-shape) in the population model and estimated only the corresponding model (e.g., quadratic model) using the four approaches (MSEM, two-step, SI, PV). We also varied the strength of the respective nonlinear effect and the sample sizes on both levels of analysis (L1 \(=\) time points, L2 \(=\) individuals). We evaluated and compared the approaches on parameter estimation accuracy, inference accuracy, power, and false positive rates. At https://osf.io/xucwf, we provide code templates that implement the four approaches in the same way as in the simulation study (folder code_templates), and we provide the code for the study itself (folder simulation_code).
Population model
We generated data for three variables \(x_{it}, y_{it}, z_i\) (U-shape condition) or for five variables \(x_{it}, y_{it}, u_{it}, v_{it}, z_{i}\) (moderation condition, congruence condition). Here, \(i \in \{1, \dots , P\}\) denotes the L2 units (e.g., individuals) and \(t \in \{1, \dots , T\}\) denotes the L1 units (time points). We considered \(P = 200\) and 500 L2 units, representing typical and large sample sizes, respectively. Likewise, we considered \(T = 15\) and 40 L1 measurements per individual (see Table 1). The four sample size conditions that resulted (each combination of \(P = 200, 500\) and \(T = 15, 40\)) had balanced data, meaning that all individuals had L1 data for the same number of time points. In an additional sample size condition, we simulated unbalanced data, where the number of L1 measurements differed between L2 units. To this aim, we first generated data for \(P = 200\) L2 units and \(T = 40\) L1 measurements. Adopting the strategy and code from Neubauer et al. (2020), we then deleted varying numbers of L1 measurements for the different participants. The number of deleted values ranged from 0 to 60% (i.e., \(T_i\) was between 16 and 40) and was drawn from a positively skewed distribution that yielded a typical pattern of unbalance (for more details, see https://osf.io/xucwf; Neubauer et al. , 2020). The results for the conditions with unbalanced data are reported after the results for the balanced data.
Population model: Level 1 structural model
We used the L1 and L2 models defined in Eqs. 9 to 16 as the data-generating model with the parameter values given in Table 1. We set all L1 variances to 1, and we set the L1 covariances to 0, except for the covariance of the L1 residuals (\(\sigma _{yv}\)), which was set to 0.2. All L2 intercepts were 0. The variances of the individual slopes were \(\tau ^2_{\beta _y} = \tau ^2_{\beta _v} = 0.1\). The reliability of the slopes was thus .80 when \(T = 40\), and it was .58 when \(T=15\). The L2 variances \(\tau ^2_x, \tau ^2_u, \tau ^2_y\), and \(\tau ^2_v\) were set to values that implied ICCs of .5 for all variables. Most of the L2 covariance terms were set to 0. The exceptions were the L2 covariances \(\tau _{xy}\), \(\tau _{uv}\), and \(\tau _{yv}\), the intercept-slope covariances \(\tau _{y\beta _y}\) and \(\tau _{v\beta _v}\), and the covariance of the individual slopes \(\tau _{\beta _y \beta _v}\). These covariances were set to values that implied correlations of .20.
Population model: Level 2 structural model
We generated the L2 outcome variable z from special cases of the second-order polynomial model:
For the U-shape condition, we set \(b_2\), \(b_4\), and \(b_5\) to zero to obtain the quadratic model (U-shape model), and we also set \(b_0\) and \(b_1\) to zero for simplicity. We varied the size \(b_3\) of the quadratic effect as shown in Table 1. Specifically, we varied \(b_3\) in three steps that corresponded to a certain amount of variance explained in the outcome z, namely, \(R^2=.25\) (large effect), \(R^2=.09\) (moderate effect), and \(R^2=0\) (no effect). For the moderation condition, the corresponding moderation model is a special case of Eq. 35 with \(b_3=b_5=0\). We set \(b_0, b_1\), and \(b_2\) to zero for simplicity, and we varied the size of the interaction effect \(b_4\) to yield \(R^2=.25, .09\), and 0 (see Table 1). Finally, for the congruence condition, we set the values of the coefficients to correspond with a congruence model (Schönbrodt, 2016), as shown in Table 1. In such a model, \(b_1\) and \(b_2\) are zero, \(b_3\) and \(b_5\) have the same (negative) value, and \(b_4 = -2 b_3\), so that we only had to specify the value for \(b_3\). We varied \(b_3\) such that the variance explained by the congruence effect was \(R^2=.25, .09\), and 0 (see Table 1).
In total, we considered \(2 (P) \times 2 (T) \times 3 (hypothesis) \times 3 (R^2) = 36\) conditions with balanced data and \(3 (hypothesis) \times 3 (R^2) = 9\) conditions in the unbalanced case. In each condition, we generated and analyzed 1,000 replications.
Model estimation
In each of the three hypothesis conditions (U-shape, moderation, congruence), we estimated the correct model (quadratic, interaction, RSA) with each of the four approaches (MSEM, simple two-step, SI, PV).
MSEM approach
The parameters of the MSEM approach were estimated with Mplus (version 8, Muthén & Muthén, 2017; see the code templates at https://osf.io/xucwf). We specified the models as defined in Eqs. 1 to 17. To simplify the model, we set several of the covariances (Eqs. 15 and 16) to zero, all of which were also zero in the population (see Table 1). Specifically, we estimated the model with the following covariance structure (or a special case of it in the U-shape conditions involving only one WPA), where the bold zeroes refer to covariances that could be theoretically estimated but were set to zero:
To estimate the models, we used the Bayes estimator with the default (flat) priors implemented in Mplus (Asparouhov & Muthén, 2010a). We used 120,000 MCMC iterations (half of which are discarded as burn-in) because a small presimulation showed that this was necessary to achieve convergence as indicated by effective sample sizes, trace plots, and potential scale reduction factors (Depaoli & van de Schoot, 2017; Gelman & Rubin, 1992; Zitzmann & Hecht, 2019). In the congruence condition, we also obtained estimates of the auxiliary RSA parameters (\(a_1, ..., p_{11}\)) with the model constraint option.
Simple two-step approach
We implemented the two-step approach in R (R Core Team , 2023; see the code template at https://osf.io/xucwf). We manually centered the L1 predictors \(x_{it}\) and \(u_{it}\) using their L2 means \(\bar{x}_{i\bullet }\) and \(\bar{u}_{i\bullet }\), estimated the multilevel models with the R package lme4 (Bates et al., 2015), and extracted the EAP estimates of the individual slopes \(\hat{c}_{yi}\) and \(\hat{c}_{vi}\). The respective L2 analysis model (quadratic, interaction, or RSA model; e.g., Eq. 28) was estimated with the lm function. In the congruence condition, we computed estimates and standard errors for the auxiliary RSA parameters with the multivariate delta method implemented in the car package (Fox & Weisberg, 2019).
SI approach
For the SI approach, we used the multilevel model results from Step 1 of the simple two-step approach. Besides the EAP estimates of the individual slopes (\(\hat{c}_{yi}\), \(\hat{c}_{vi}\)), we also extracted their conditional variances (\(\hat{s}^2_{c_yi}\), \(\hat{s}^2_{c_vi}\)). We implemented the simplified version of the SI approach by aggregating the conditional variances across individuals. In the simulation conditions with balanced data, this simplification was in line with the simulated population (Lai & Hsiao, 2022) because all individuals in the simulation condition had the same number of time points and the same L1 residual variance, which implies that the population value of the slope reliability was the same for all individuals (Neubauer et al., 2020; Raudenbush & Bryk, 2002). We also used the simplified version of the SI approach in the conditions with unbalanced data, although the approach did not take the implied heterogeneity of the slope reliabilities into account (Lai & Hsiao, 2022; see also the Discussion section). To be consistent with the MSEM approach, we implemented Step 2 of the SI approach with the Bayesian estimator in Mplus (see the code template at https://osf.io/xucwf). We used the default priors and set the number of iterations to 12,000 (a tenth of the number in MSEM) because a presimulation showed that this number was sufficient for obtaining good convergence. Estimates of the auxiliary RSA parameters were obtained in the same way as in the MSEM approach.
PV approach
We implemented the PV approach in R (see the code template at https://osf.io/xucwf). In the first step, we computed the means, \(\bar{x}_{i\bullet }\) and \(\bar{u}_{i\bullet }\), estimated the multilevel model in Eqs. 31 to 33 (and, if appropriate, a respective model for the second slope \(c'_{v}\)) with the lme4 package (Bates et al., 2015), extracted EAP estimates of the slopes (\(\hat{c}'_{yi}\), \(\hat{c}'_{vi}\)) and also their conditional variances (\(\hat{s}'^{2}_{c_yi}\), \(\hat{s}'^{2}_{c_vi}\)). For each individual and each of the two slopes, we drew \(M=20\) plausible values as outlined above (see also Lüdtke et al. , 2018). Then, we estimated the analysis model separately for each set of PVs with the lm function and used Rubin’s rules to pool the results (Rubin , 1987; see also Enders , 2010). Standard errors of the auxiliary RSA parameters were obtained with the multivariate delta method (car package, Fox & Weisberg, 2019) and pooled in the same way.
Evaluation criteria
We evaluated and compared the four approaches on parameter estimation accuracy, inference accuracy, power, and false positive rates. More specifically, first, we computed the bias for all regression coefficients (\(b_1, ..., b_5\)) in the respective analysis model as the difference between the average estimate and the true parameter value. For the parameters that were nonzero in the respective population model, we also computed the relative bias as the ratio of the bias and the true parameter value.
Second, we examined the estimation variability by inspecting the widths of the parameters’ empirical 95% confidence (two-step, PV) and credibility (MSEM, SI) intervals. To simplify the notation, we will use the abbreviation CI to refer to both types of intervals. For the two-step and PV approaches, the empirical CI width is given by \({{\,\mathrm{CI-width}\,}}_{emp}=2 \cdot z_{.975} \cdot s_{emp}\), where \(s_{emp}\) is the empirical standard error. In MSEM and SI, the empirical CI width is computed as the range between the 2.5% and 97.5% quantiles of the sampling distribution.Footnote 2 In addition, we computed the root-mean-squared error (RMSE) as the square root of the average squared difference between the estimate and the true parameter value, providing a measure that combines parameter bias and estimation variability.
Third, turning to the approaches’ quality of inference, we first calculated each parameter’s estimated CI width as the average width of its estimated CI across replications. We then calculated the relative CI width differences, \(({{\,\mathrm{CI-width}\,}}_{est}-{{\,\mathrm{CI-width}\,}}_{emp})/{{\,\mathrm{CI-width}\,}}_{emp}\), to assess the accuracy of the approaches in estimating the estimation uncertainty. We also computed the coverage rate of a parameter as the percentage of CIs across simulation conditions that include the true parameter value.
Finally, in each of the three hypothesis conditions (U-shape, moderation, congruence), we inspected the acceptance rates of the respective hypothesis of interest. That is, we determined the proportion of cases per simulation condition in which the estimated coefficient of the respective nonlinear term (\(b_3\) for U-shape, \(b_4\) for moderation) was significant (95% CI excluded zero), or, in the congruence condition, in which the auxiliary parameters satisfied the six conditions that the RSA literature suggests for testing a congruence effect (\(\hat{a}_1, \hat{a}_2, \hat{a}_3, \hat{p}_{10}\), and \(\hat{p}_{11}-1\) not significantly different from zero, \(\hat{a}_4\) significantly negative; e.g., see Edwards , 2002; Humberg et al. , 2019). The acceptance rate reflects the power to detect the respective nonlinear effect in conditions with \(R^2=.25\) or \(R^2=.09\), and the false positive rate when \(R^2=0\).
Convergence issues and run times
In the conditions with small sample sizes on both levels (\(P=200, T=15\)) and a model including one or more quadratic terms (U-shape model, congruence model), the MSEM model often failed to converge, meaning that even after 120,000 iterations, the potential scale reduction exceeded the cut-off that Mplus used for the respective model. In these cases, we redrew the respective data set. Overall, this happened 412 times out of the 6000 replications in the conditions in question (\(P=200, T=15\), U-shape/congruence condition). The SI approach, which also uses a Bayesian estimator like MSEM, converged in 100% of the cases (after 12,000 iterations), including the cases in which MSEM did not converge.Footnote 3 In a small follow-up simulation, we additionally explored the performance of the SI approach for cases in which MSEM did not converge. The results concerning the accuracy of the estimated parameters were comparable to the results reported below, whereas the SI approach tended to overestimate the widths of the CIs in samples that were problematic for MSEM. Therefore, we consider the SI approach a reasonable alternative when MSEM does not converge, whereas users should be aware that the significance tests tend to be conservative in such cases.
Moreover, we removed the CI width estimates for eight replications in the final MSEM results in conditions with the congruence model and the smallest sample sizes (\(P=200, T=15\)) because they were extreme outliers. For example, in one of these three replications, the CI width of \(\hat{b}_5\) was 68,650 for this single case, whereas it ranged from 2 to 25 with a mean of 5.7 in the other cases from the same simulation condition.
The four approaches largely differed in the time they required for estimation. The simple two-step approach (0.06–0.07 s on average, depending on the sample size condition) and the PV approach (1.3–1.5 s) were the fastest approaches. The Bayesian estimation of the SI approach required between 40 s (when \(P = 200\)) and 100 s (\(P = 500\)). The MSEM approach had an average run time between 1 h (\(P = 200\), \(T = 15\)) and 3 h (\(P = 500\), \(T = 40\)) and was thereby clearly the approach that required the most time.
Results for balanced data
Parameter estimates
Table 2 presents the biases of the regression weights \(b_1\) to \(b_5\) for all conditions with balanced data (all L2 units have the same number of L1 measurements). Biases printed in bold deviated from the true parameter value by more than 5%, and biases printed in italics and violet exceeded 10% (see https://osf.io/xucwf for a table with the relative biases).
For all approaches, the biases were almost always larger for parameters that were nonzero in the population, whereas parameters with a true value of zero were more accurately estimated. Considering the MSEM approach in the smallest sample size condition (\(P=200, T=15\); first column of Table 2), MSEM estimates of the second-order term coefficients (\(b_3, b_4, b_5\)) were biased in some cases for all four hypothesis conditions, with relative biases up to 8% (\(b_3\) in the congruence condition with \(R^2=.25\)). The direction of the biases was always away from zero, such that MSEM overestimated the strengths of some nonlinear effects. For the larger L1 sample size (\(T=40\)) and in all conditions with \(P=500\), MSEM yielded approximately unbiased parameter estimates. Turning to the simpler approaches, the biases of the two-step and SI approaches seemed to depend on which hypothesis was considered. Both two-step and SI yielded approximately unbiased parameter estimates for the U-shape model for all sample sizes. Their estimates were thereby slightly more accurate than those of MSEM in the smallest sample size condition (\(P=200, T=15\)) in which the MSEM estimates were sometimes biased. For the moderation model, the two-step and SI approach provided approximately unbiased parameter estimates in all but the smallest sample size condition (\(P=200, T=15\)). In the smallest sample size condition (\(P=200, T=15\)), SI yielded a bias of slightly above 5% in one case, just like the MSEM approach, whereas the two-step approach was biased up to 7%. By contrast, for the congruence model, both the two-step and SI approaches underestimated the sizes of all nonlinear coefficients for all sample sizes, with about 10-20% bias in conditions with \(T=15\) and around 10% bias when \(T=40\). The two-step and SI approaches thereby estimated the congruence model with more bias than was the case for the MSEM approach. Finally, the PV approach tended to provide the most biased parameter estimates of all four approaches, throughout all simulation conditions. Specifically, this approach consistently underestimated the true parameter values (biased toward zero), with estimates that deviated from the true parameter values by 66–77% in the conditions with \(T=15\) and by 35-49% in the conditions with \(T=40\). The biases of two-step, SI, and PV varied only with the L1 sample size T, and thus with the reliability of the individual slopes, whereas they did not notably depend on the number of L2 units. The biases of the MSEM approach, by contrast, tended to decrease with increasing sample sizes on either level.
To summarize, the parameters of the U-shape model could be accurately estimated only with the simple two-step or SI approaches in the smallest sample size condition (\(P=200, T=15\)), and with MSEM, two-step, or SI for larger L1 or L2 sample sizes. The moderation model was almost accurately estimated by the MSEM and SI approach when both sample sizes were small, and again with MSEM, two-step, or SI for larger samples. By contrast, the most complex congruence model could be accurately estimated only by MSEM and only if the L1 or L2 sample size was not too small, whereas all other approaches yielded biased estimates. The PV approach consistently yielded large biases in all conditions.
Estimation variability
We inspected the empirical CI widths as a measure of estimation variability. The left half of Table 3 illustratively shows this criterion for the smallest and largest sample size conditions (\(P=200, T=15\) and \(P=500, T=40\); see https://osf.io/xucwf for all conditions). First comparing only MSEM, two-step, and SI (leaving the PV approach aside), the estimation variability for the parameters of the U-shape and moderation models tended to be smallest for MSEM and SI and larger for the two-step approach. For the congruence model, the variability tended to be smallest for the SI approach and largest for MSEM, with two-step in-between. With larger sample sizes, the empirical CI widths became very similar for MSEM, two-step, and SI. The RMSEs (reported in the supplement, see https://osf.io/xucwf) that balance this estimation variability with the accuracy of estimates exactly mimicked the pattern just described. In particular, the SI approach was among the approaches with the lowest RMSE in all conditions, whereby all differences in the RMSEs between the three approaches (MSEM, two-step, SI) were rather small and completely vanished in the largest sample size condition (\(P=500, T=40\)). The PV approach yielded the narrowest empirical CIs across all simulation conditions but the highest RMSEs (for the parameters \(b_3, b_4\), and \(b_5\) for the nonlinear terms), a result that likely came from the substantive parameter biases.
Parameter inference
The average widths of the estimated CIs for the parameters are reported in the supplement (https://osf.io/xucwf). A general pattern that occurred in almost all simulation conditions was that the estimated CI widths were largest for MSEM, followed by SI, then two-step, and finally the PV approach. Comparing the estimated and empirical CI widths (right half of Table 3), the CIs estimated with the MSEM approach tended to be wider than the respective empirical CIs, exceeding them by up to 18% for the congruence model in the smallest sample size condition (\(P=200, T=15\)). As the L2 sample size increased, and to a lesser extent as the L1 sample size increased, the CI estimates of MSEM became more accurate; but some CIs in the congruence model were still too wide (by up to 12%) even when both sample sizes were large (\(P=500, T=40\)). By contrast, the two-step approach consistently underestimated the CI widths, providing parameter estimates with overly narrow CIs (except for one case for which the CIs were too large in the congruence condition). These underestimations decreased as the L1 sample size increased but were not influenced by the L2 sample size. Even in the largest sample size condition (\(P=500, T=40\)), the two-step approach often underestimated the CI widths by more than 10%, with the bias tending to be strongest for the most complex congruence model (up to 17%). The SI approach yielded unsystematic discrepancies of up to 14% in estimating CI widths for some parameters for all sample sizes. The PV approach systematically and substantially overestimated the widths of the CIs for the parameters \(b_3, b_4\), and \(b_5\).
To summarize, the two-step (which underestimated the CI widths) and PV (which overestimated them) approaches clearly had the least accurate CI estimates. Comparing MSEM and SI, MSEM tended to provide more accurate estimates of the CI widths than SI for the U-shape and moderation models, particularly in conditions with \(T=40\) or \(P=500\). For the congruence model, SI yielded more accurate CI estimates than MSEM for samples with the smaller L2 sample size (\(P=200\)), whereas the two approaches’ CI estimates were on average similarly accurate for the larger L2 sample size (\(P=500\)).
The coverage rates (reported in the supplement, see https://osf.io/xucwf) are consistent with the results reported so far. They were most favorable for the MSEM approach, which yielded coverage rates in an acceptable range between 92.5% and 97.5% for all parameters and conditions. The two-step approach had consistent undercoverage (with a minimum of 80%) in all conditions, as a result of the CIs that were too narrow. The SI approach yielded undercoverage (minimum of 84%) in some of the cases in which either the parameter or its CI width was estimated with bias. The performance of the PV approach regarding coverage was again unacceptable.
Acceptance rates
Focusing on the MSEM, two-step, and SI approaches, first in terms of their power to detect the nonlinear effect in the population, MSEM was consistently the approach or was among the approaches with the highest power for all three hypotheses (see Table 4). The power of the simple two-step approach was similar to that of MSEM for the U-shape and moderation hypotheses. However, this high power was afforded by CIs that were too narrow for parameters that were nonzero in the population (see Table 3). For the congruence hypothesis, the power of the two-step approach was lower than that of the MSEM approach. The power of the SI approach was slightly lower than that of MSEM in the smallest sample size condition (\(P=200, T=15\)) for all hypotheses and was similar to that of MSEM when either of the sample sizes increased.
Considering the cases with \(R^2=0\), for the U-shape and moderation hypotheses, the false positive rates for MSEM, two-step, and SI all varied unsystematically around the nominal level of 5%. For the congruence hypothesis, the false positive rates of the three approaches were much lower than 5% and increased as the sample sizes increased. This pattern could be expected due to the special nature of the hypothesis test, which involved significance tests of six parameters simultaneously. A comparison of the three approaches (MSEM, two-step, SI) showed no systematic differences in terms of falsely accepting the respective hypothesis.
The PV approach had the least favorable acceptance rates, as its power was usually much lower than the power of the other approaches, and it had false positive rates well below the nominal level of 5%. In the conditions with a congruence effect, the sometimes high power of almost 90% may seem like an advantage of the PV approach at first glance, but in fact, it reflects the approach’s violation of the chosen \(\alpha \) level for the five auxiliary parameters (\(\hat{a}_1, ..., \hat{p}_{11}-1\)) that need to be nonsignificant in order to accept the congruence hypothesis.
Results for unbalanced data
Table 5 presents the bias in the parameter estimates, the empirical CI widths, and the relative CI width differences for the conditions with unbalanced data in which the number of L2 units was \(P=200\) and the number of L1 measurements \(T_i\) ranged from 16 to 40 (for the remaining results, see https://osf.io/xucwf). Altogether the results indicated that all the approaches tended to perform better when the data were unbalanced than when the data were balanced with \(P=200\) and \(T=15\) but worse than when the data were balanced with \(P=200\) and \(T=40\). At the same time, the differences between the approaches were similar to the balanced case but favored the MSEM approach more when the data were unbalanced.
More specifically, the PV approach again yielded the least accurate parameter estimates and inferences as it did in the conditions with balanced data. For this reason, we now focus on comparing MSEM, two-step, and SI. An inspection of the biases (first three columns of Table 5) showed that the regression weight estimates provided by MSEM were approximately unbiased, whereas two-step and SI yielded accurate estimates for the U-shape and moderation models but 10–15% bias in estimating the parameters of the congruence model. This pattern was the same as in the balanced condition with \(P=200\) and \(T=40\).
Regarding estimation variability, the empirical CI widths (middle columns of Table 5) tended to be smallest for MSEM, followed by SI, and then the two-step approach. This result favored the MSEM approach more than when the data were balanced, where the variability in MSEM was similar to SI (U-shape and moderation models) or larger (congruence model).
Turning to parameter inferences, the average widths of the estimated CIs (reported at https://osf.io/xucwf) tended to be largest for the SI approach, followed by MSEM, and then the two-step approach. This pattern differed from the balanced case, where the CIs estimated with MSEM tended to be wider than those from the SI approach. Comparing the estimated and empirical CI widths (last three columns of Table 5), the nuanced differences that we reported for the balanced case (MSEM had more accurate CIs than SI for the U-shape and moderation models; vice versa for the congruence model) vanished when the data were unbalanced. Here, MSEM and SI had similar amounts of bias in estimating the widths of the CIs. The two-step approach tended to yield CIs that were too narrow by up to 18%, in line with its performance in the balanced case. The coverage rates (reported at https://osf.io/xucwf) of MSEM and SI were between 92.5% and 97.5% in all cases, whereas undercoverage occurred for the two-step approach as in the balanced case.
Finally, the power to detect an effect that was present in the population (see the last columns in Table 4) was highest for MSEM, as in the balanced case. However, in contrast to the balanced case, the power of two-step and SI to detect a nonlinear effect was about 8% lower than that of MSEM in the conditions with \(R^2 = .09\).
Discussion of the simulation results and recommendations
In the simulation study, we evaluated MSEM for testing nonlinear effects of WPAs and compared it with a simple two-step approach, an SI approach, and a PV approach. Overall, the MSEM approach performed well in testing the nonlinear WPA hypotheses that we considered. With the exception of conditions with sample sizes that were too small, MSEM yielded good performance in terms of its accuracy in estimating the parameters, coverage rates, and its likelihood of correctly detecting or rejecting the suggested nonlinear effects (consistent with, e.g., Humberg et al. , in press; Liu & Rhemtulla, 2022; Lüdtke et al. , 2008).
Concerning the alternative methods, our results imply that the SI approach qualifies as a viable alternative to MSEM, especially when only a small number of individuals (L2 units) participated in the study and when they provide (approximately) the same number of L1 assessments. In these conditions, SI and MSEM each had advantages when compared with each other. For example, for the U-shape model, SI yielded more accurate parameter estimates, but MSEM yielded more accurate CIs; this pattern was reversed for the congruence model. The differences between the approaches leveled out when it came to the final conclusion of the analysis, as the SI approach’s power to detect the nonlinear effect fell only slightly below that of MSEM. Moreover, when not only the L2, but also the L1 sample size was small, the SI approach outperformed MSEM in terms of its RMSEs for the U-shape and congruence model. When the L2 sample size was large, the MSEM approach outperformed SI in parameter accuracy for the congruence model and in the accuracy of the CIs of U-shaped and moderation effects. However, these advantages did not have any noticeable effect on the RMSE or acceptance rates. When the data were unbalanced, SI was as accurate as MSEM in estimating the coefficients of the U-shape and moderation models and in estimating the CIs for all three models. The only weakness in its performance relative to MSEM was that SI had about 8% less power to detect a nonlinear effect of medium strength.
The good performance of the SI approach is particularly encouraging from a practical point of view because the approach is less computationally demanding and thus less time-consuming than MSEM. SI may also be beneficial in terms of its accessibility to researchers because the simplified version of the SI approach (without person-specific reliabilities) can be implemented in noncommercial software (e.g., R; see the Discussion).
Taken together, the SI approach appears to be an alternative that is equal to MSEM when the data are balanced and the L2 sample size is small. Moreover, even when the L2 sample size is large, we consider it justifiable to use SI instead of the slightly better performing MSEM approach when MSEM is not feasible due to the complexity of its estimation (e.g., convergence problems) or implementation (e.g., Mplus not affordable).
Moreover, extrapolating our results beyond the simulation conditions considered here, SI may even outperform the MSEM approach when L2 sample sizes are even smaller. Recent research has suggested replacing single-level SEM with SI in analyses of small samples (Lai & Hsiao, 2022; Savalei, 2019). Our study suggests that this principle might generalize to the testing of nonlinear effects of random slopes. The smallest L2 sample size that we considered here was \(P=200\) L2 units, which is the upper boundary of what is categorized as a “small” sample in the literature (e.g., Savalei , 2019). Nonetheless, with this L2 sample size “at the boundary of small” (and for both L1 sample sizes), the SI approach outperformed MSEM in estimation accuracy for the U-shape model and in CI accuracy for the coefficients of the congruence model. Also, its power and false positive rates were similar to those of the MSEM approach (see also Kelcey , 2019; Lai & Hsiao, 2022; Savalei , 2019). It seems plausible to assume that the advantages of SI would be more pronounced for even smaller L2 samples – a conjecture that awaits confirmation in future studies. Also in line with prior studies, we found that in the small sample size conditions, none of the approaches yielded unbiased results overall; which emphasizes that the promising performance of SI should not be misconstrued as a justification to assess small samples, but as a glimpse of hope in situations that inhibit the recruitment of a large number of subjects (see also Zondervan-Zwijnenburg, Peeters, Depaoli, & vandeSchoot, 2017).
For the simple two-step approach, our results indicate that it systematically underestimated the width of all CIs for all population models, thereby suggesting a higher level of certainty in parameter estimation than was warranted. This finding is consistent with prior studies that have evaluated two-step approaches as alternatives to single- or multilevel SEMs (e.g., Ledgerwood & Shrout, 2011; Liu & Rhemtulla, 2022; Lüdtke et al. , 2018; Savalei , 2019; Westfall & Yarkoni, 2016). Overall, these findings underline that the simple two-step approach – despite being attractive from a practical perspective – should be avoided in practice (Brose et al., 2022; Cole & Preacher, 2014; Cortina et al., 2021; Savalei, 2019).
The simplified PV approach that we investigated here underestimated the coefficients of the nonlinear terms and overestimated their sampling variability, resulting in distorted acceptance rates in almost all conditions. One potential reason for the shortcomings of the PV approach was its simplified construction, which ignored estimation uncertainty and included only linear associations between the WPAs and the outcome. To investigate this possibility, we conducted additional simulations in which we (a) evaluated a fully nonlinear PV approach in which the PVs were generated directly on the basis of the MSEM model and (b) included conditions in which the population model included only linear effects (see https://osf.io/xucwf for these supplementary results). In both of these cases, each respective PV approach performed better than in our main simulation, but each tended to underestimate the widths of the parameters’ CIs and still tended to show inflated false positive rates. Future research could pursue these examinations, for example, by investigating tailored implementations of the PV approach and the effects of the parameters’ prior distributions (see Depaoli & Clifton, 2015; Holtmann, Koch, Lochner, & Eid, 2016; Zitzmann, Lüdtke, Robitzsch, & Marsh, 2016).
Recommendations
For applied researchers who aim to investigate nonlinear effects of WPAs, our first recommendation is to make an effort to assess large sample sizes at both levels, which can mean, for example, implementing ESM assessments with only a few items in order to increase participant commitment (Eisele et al. , 2022; but see also Hasselhorn, Ottenstein, & Lischetzke, 2022). If a large number of participants can be recruited (e.g., 500 or more), or if the participants differ essentially in their number of assessments, we recommend using the MSEM approach if Mplus is available or if the researcher is familiar enough with Bayesian statistical software to manually implement the model. If neither Mplus nor Bayesian software can be used (e.g., due to restricted financial resources), or if the MSEM model does not converge even with a large number of iterations, then researchers can instead implement the SI approach. By contrast, when the achievable sample size is small (e.g., 100 or less) and the data are approximately balanced, we recommend using the SI approach. This recommendation is based on our finding that SI’s performance was similar to MSEM’s in the smallest sample we considered (200) and on our conjecture that the small-sample benefits of SI reported in the literature (e.g., Lai & Hsiao 2022) will generalize to the modeling of nonlinear effects of random slopes. For “in between” sample sizes or amounts of balance, where it is unclear whether MSEM or SI performs best or where each approach can be expected to have its respective advantages (as in the balanced \(P=200\) condition in our study), we recommend applying both approaches if possible. When they yield the same conclusion, the evidence found for the hypothesized nonlinear effect could then, also in the spirit of robustness analyses, be considered reliable.
Empirical illustration
We illustrate the investigation of nonlinear effects of WPAs with combined data from two daily diary studies (see https://osf.io/xucwf for the data and code). Detailed descriptions of the study procedures and measures can be found in the study codebooks (https://osf.io/xucwf). The data we use here were provided by a total of \(P=181\) individuals (143 female), who provided daily assessments for an average of \(T=64\) time points (\(min=19, max=82\)). These L1 data were collected in daily assessments (on consecutive days in one study; over the course of four measurement waves in the other study).
We focus on a WPA-U-shape hypothesis positing an inverse U-shaped effect of social reactivity on life satisfaction. Here, social reactivity is operationalized as the WPA between repeated measures of sociality (“I spent a lot of time with other people today”; scale ranging from 1 = not at all to 6 = very; Schönbrodt & Gerstenberg, 2012) and a state measure of self-esteem (“I am satisfied with myself”; same scale from 1 to 6; Rosenberg , 1989). The L2 variable life satisfaction was measured with the satisfaction with life scale (Diener, Emmons, Larsen, & Griffin, 1985) in an online questionnaire at the beginning of the study.
Following the recommendations given above, we implemented both the MSEM and SI approaches for data analysis because the L2 sample size of \(P=181\) was neither clearly large nor clearly small. Both approaches were implemented in the same way as in the simulation study, fitting a quadratic model on level 2.
The parameters of the quadratic L2 model for both approaches are shown in Table 6 and visualized in Fig. 1. The \(b_3\) coefficient from the quadratic term was significantly negative for both approaches, meaning that the association between social reactivity and life satisfaction had an inverted U-shape. For both approaches, the vertex of the inverted U was positioned at a slope value of \(\beta _y=0.26\) (\(=-b_1/2b_3\)). The approaches differed only in the curvature \(b_3\), which was stronger for MSEM than for SI (see Fig. 1 for a visualization). To reveal which parts of the inverted U could be interpreted in the final conclusion, we inspected the distribution of the EAP estimates of the individual slopes used in the SI approach. They were distributed around a mean of 0.24 with a standard deviation of 0.11, meaning that both “sides” of the inverted U may be interpreted. Overall, thus, both MSEM and SI point to an inverted U-shaped effect, such that people whose social reactivity is about average have the highest life satisfaction.

Graphs of the estimated quadratic models for the daily diary study
Discussion
This article was concerned with evaluating statistical approaches that can be used to investigate nonlinear effects of random slopes, which are increasingly used in psychological research as measures of constructs that refer to the WPA between variables that fluctuate over time. Our research aims were to evaluate an MSEM approach and compare MSEM with three simpler approaches (simple two-step, SI, PV) that can also be used to investigate nonlinear effects of WPAs but that can more easily be implemented and estimated. In a nutshell, we found that the MSEM approach is a well-suited analytical strategy, at least for studies in which a large number of individuals participate. However, we also found that the SI approach can reasonably be recommended as an alternative approach, especially for balanced data with a small number of participants or when MSEM is unfeasible due to its complexity (e.g., when it does not converge). By contrast, the simple two-step approach and the PV approach cannot be recommended, as MSEM and SI outperformed them both.
A key finding of our simulation study is that the MSEM approach is well-suited for modeling nonlinear effects of random slopes. However, strictly speaking, we can infer this only for the specific implementation of MSEM considered in our simulation, in which many covariances were fixed to zero for simplification. We do not believe this decision affected the result of the simulation because we fixed the same covariances to zero in the population model. However, some of the covariance terms will not necessarily be zero in real data. Therefore, future research should explore (a) whether the MSEM approach produces biased results when the constrained covariances differ from zero in the population and (b) whether MSEM’s performance and its comparison with the simpler alternatives (especially SI) is affected when additional covariances are allowed in the model. Such work would also increase our understanding of how MSEM behaves in terms of the bias-variance trade-off, given that a model with a larger number of free covariances will fit the data more closely but is also more prone to convergence problems and larger estimation variabilities. In a similar vein, future research could explore whether the population variances of the L1 and L2 variables or the ICCs of the L1 variables have an impact on a method’s relative performance (see https://osf.io/xucwf for an additional simulation with variation in the ICCs).
Given the good performance of the SI approach in our simulation and respective prior findings for single-level SEMs (e.g., Lai & Hsiao, 2022; Savalei , 2019), we propose that it would be particularly interesting to conduct a more thorough comparison of the MSEM and SI approaches. For instance, future research could compare the two approaches for smaller sample sizes or in situations with more complex patterns of dependencies (e.g., correlated random slopes). Furthermore, other nonlinear population models (e.g., a violation of the congruence hypothesis due to shift or rotation of the model, see Humberg & Grund, 2022) should also be considered. Ultimately, the results of such studies may improve our recommendations regarding the choice between the two approaches. For example, we hope such results will help refine the sample size boundaries for choosing between MSEM and SI or develop tools to optimally allocate a given amount of financial resources to the necessary study investments (e.g., L1 sample size, L2 sample size, statistical software) in the interest of achieving the most reliable results (see also Zimmer, Henninger, & Debelak, 2022). Beyond comparing the SI approach to fully latent MSEM, it will also be relevant to compare it with two-step approaches that implement alternative reliability corrections for the random slopes. One promising approach would be Croon’s method (Croon, 2002). For the case of latent variables defined via multiple indicators in a measurement model, Croon’s correction has recently been adapted to multilevel models and shown to be a viable alternative to MSEM (Cox, Kelcey, & Bai, 2023; Devlieger & Rosseel, 2020; Kelcey, Cox, & Dong, 2019). Future research could adapt Croon’s method to models with latent interactions of random slopes and evaluate how well it performs in comparison with MSEM and SI.
Another important question for future studies refers to the performance of the methods when the data are unbalanced. In most longitudinal studies, the number of measurements varies between individuals, causing the reliabilities of the slopes to also differ across individuals. We considered one sample size condition with unbalanced data and found that the general pattern of results was similar to the balanced case but with MSEM outperforming the other approaches, including SI, in terms of the power to detect the nonlinear effects. However, we consider it important to continue to explore the differences between MSEM and SI in other unbalanced conditions and also to compare the different variants of the SI approach in such settings. In our simulation study, we implemented a version of the SI approach in which the person-specific estimation uncertainties of the slopes were averaged across all individuals, and this average was used to specify the factor loading and error variance in the single-indicator model on level 2. One alternative is to incorporate person-specific measurement models (Lai & Hsiao, 2022) that could be particularly beneficial when applied to unbalanced data. In the supplement, we report the results of this person-specific implementation of the SI approach in the simulated conditions with unbalanced data. Under the conditions considered here, the simplified SI approach outperformed the person-specific SI approach, especially in terms of overestimated sampling variability (consistent with results reported by Lai and Hsiao , 2022). However, we think that these observations require replication and deeper exploration in future studies. Moreover, a second alternative to simplified SI would be to simplify the approach even further than in our simulation study, by implementing a fixed-reliability approach in which reliabilities are not estimated from the data but are set to a fixed value (Savalei, 2019). Research has shown that this can stabilize the parameter estimates by removing the estimation step for the reliabilities (Oberski & Satorra, 2013; Savalei, 2019). However, the fixed-reliability SI approach can be used only if a good estimate (at least an upper bound) of the reliability is available (Savalei, 2019; Ulitzsch, Lüdtke, & Robitzsch, 2023), whereas applied research on WPAs is only just beginning to investigate their reliability (Kuper et al., 2022; Neubauer et al., 2020).
Furthermore, for consistency with the MSEM approach, we used a Bayesian approach to estimate the parameters of the SI approach here. However, it is also possible to estimate the SI parameters with other approaches that were suggested to estimate latent nonlinear effects (for guidance, see Cortina et al. , 2021), such as the latent moderated SEM approach (Klein & Moosbrugger, 2000; see also Sardeshmukh & Vandenberg, 2017) and a constrained or an unconstrained product indicator approach (Jaccard & Wan, 1995; Kenny & Judd, 1984; Marsh, Wen, & Hau, 2004). The main challenge in implementing the latter approach is in deriving the constraints of the product terms (i.e., the products of two random slopes). These derivations and a comparison of the different latent interaction approaches when combined with the SI approach seem to be interesting tasks for future research. In a similar vein, it would be worthwhile to evaluate the MSEM approach when using maximum likelihood for its estimation. However, this is currently not possible because it requires integration over a large number of random effects, and existing approaches are still restricted to the case of linear effects of random slopes (Nestler, 2020, 2021; Rockwood, 2020). A related question concerns the prior distributions. It may be possible that both the MSEM and SI approaches (when estimated with Bayes) would profit from using weakly informative prior distributions instead of the uninformative priors used here. When accurate prior information is available, so that the chosen priors are appropriate, their use could, for example, improve and stabilize the estimates in small samples (Depaoli & Clifton, 2015; Holtmann et al., 2016; Lai & Hsiao, 2022; Lüdtke et al., 2018; Ulitzsch et al., 2023; Zitzmann, Lüdtke, & Robitzsch, 2015). Lastly, all approaches examined in our simulation study are based on certain statistical assumptions (e.g., normally distributed data, homoscedastic residual terms) that do not have to be met in real data applications. It would therefore be interesting to examine how the approaches perform, for example, with nonnormal data (see Brandt, Umbach, Kelava, & Bollen, 2020 for corresponding insights in the context of single-level latent interaction models).
In addition to exploring different estimation methods, future research is also needed to better understand the influence of model complexity on the performances of the four approaches (see also Cole & Preacher, 2014). In our simulation study, we considered three L2 models with increasing complexity, namely, the quadratic model (one predictor, one nonlinear term), the interaction model (two predictors, one nonlinear term), and the RSA model (two predictors, three nonlinear terms). The patterns of results that we found for these three models indicate that model complexity affected how the approaches performed in nuanced ways. For example, the parameter bias monotonically increased as model complexity increased for all methods, but this increase in bias was steeper for the SI approach in comparison with MSEM. For example, SI outperformed MSEM in terms of bias for the quadratic model, whereas the opposite was true for the RSA model. Concerning the accuracy of the estimated CIs, model complexity did not appear to have any systematic effects. For example, the SI approach estimated the CIs of the quadratic model with more bias than the CIs of the more complex congruence model, whereas the MSEM estimates were similarly biased for these two models. Overall, these patterns indicate that it may be reasonable for applicants to tailor their choice of method (especially the choice between MSEM and SI) to the model considered, whereas the present findings do not support a conclusive recommendation for this choice. Future simulation studies should aim to unravel the mechanisms that underlie the nuanced differences and determine the extent to which they are driven by differences in the reliabilities of the nonlinear terms (e.g., quadratic terms are less reliable than interaction terms; MacCallum & Mar, 1995) or differences between how the methods represent the slope variability and the accuracy thereof. Beyond the three nonlinear models we considered in our simulation, the four approaches could also be evaluated for the simpler case of a linear model (for a comparison between MSEM and a simple two-step approach for this situation, see Liu & Rhemtulla, 2022). Although not the focus of the present study, we conducted an additional simulation for the linear model and report the results in the supplement (https://osf.io/xucwf). In short, the four approaches generally performed better in a linear than in a nonlinear model, and the differences between them were very similar to those in the U-shape model: MSEM performed well, and the SI approach was similar to MSEM in terms of estimation accuracy, variability, and power, but it provided CIs that were too narrow when the number of time points was small. In contrast to the main simulations, the simple two-step approach and the PV approach showed little bias in these conditions but again provided CIs that were too narrow. Future methodological work is needed to extend these initial results, particularly by conducting a more extensive comparison of MSEM and SI under varying conditions.
Finally, to go even one step further in terms of model complexity, it would also be interesting to apply the four approaches to models that incorporate measurement error into the assessed variables. Specifically, the models that we considered here treated the measured L1 (e.g., momentary well-being) and L2 (e.g., life satisfaction) variables as manifest, measurement-error-free variables. However, these variables will usually be not perfectly reliable, which can affect the results in undesired ways (Cole & Preacher, 2014). For example, if the L1 variables are measured with substantial measurement error, the random slopes will tend to be underestimated for all individuals. This underestimation can influence their variance across individuals and, consequently, the parameter estimates of the L2 model. As Lai and Hsiao (2022) pointed out, it would be interesting to investigate model extensions, particularly for the MSEM and SI approaches, which take this measurement error into account. This could be achieved, for example, by replacing the respective variable with a latent factor defined via multiple indicators (Rockwood, 2020) or by using a single-indicator factor model if the variable is measured with a single item with known reliability.
To sum up, our findings support the applicability of MSEM for testing nonlinear effects of random slopes, and they emphasize that single-indicator approaches are a promising alternative to MSEM, particularly in studies with few participants. Overall, both MSEM and SI seem to be valuable enrichments for the toolboxes of applied researchers, who can use our recommendations and templates to test theories that predict nonlinear effects of WPAs on relevant psychological outcomes.
Availability of data and materials
All data used in this article is available at https://osf.io/xucwf.
Code Availability
All code is available at https://osf.io/xucwf.
Notes
In fact, in our simulation study, we also inspected the performance of a simple two-step approach using OLS instead of EAP estimates (see https://osf.io/xucwf for these additional results). However, it showed a comparatively inferior performance than the EAP version in terms of parameter biases and inferences, indicating that it cannot provide a preferable alternative to the two-step approach involving EAPs or to MSEM.
Although the Bayesian credibility intervals in MSEM and SI are not estimates of the 95% confidence intervals of the sampling distributions, we view the empirical CI width as providing a reasonable approximation of the estimation precision given that we used improper priors so that the Bayesian posterior distribution asymptotically converges toward the sampling distribution.
Because of a limitation in the implementation that we used to generate the first set of 500 replications, the comparison of MSEM and SI with respect to their convergence, as well as the statistics on computation times, was based on only 500 of the 1000 replications.
References
Arminger, G., & Muthén, B. O. (1998). A Bayesian approach to nonlinear latent variable models using the Gibbs sampler and the Metropolis-Hastings algorithm. Psychometrika, 63(3), 271–300. https://doi.org/10.1007/BF02294856
Asparouhov, T., & Muthén, B. O. (2010a). Bayesian analysis using Mplus: Technical implementation. https://www.statmodel.com/download/Bayes3.pdf
Asparouhov, T., & Muthén, B. O. (2010b). Plausible values for latent variable using mplus. https://www.statmodel.com/download/Plausible.pdf
Asparouhov, T., Hamaker, E. L., & Muthén, B. O. (2018). Dynamic structural equation models. Structural Equation Modeling, 25(3), 359–388. https://doi.org/10.1080/10705511.2017.1406803
Asparouhov, T., & Muthén, B. O. (2019). Latent variable centering of predictors and mediators in multilevel and time-series models. Structural Equation Modeling, 26(1), 119–142. https://doi.org/10.1080/10705511.2018.1511375
Asparouhov, T., & Muthén, B. O. (2021). Bayesian estimation of single and multilevel models with latent variable interactions. Structural Equation Modeling, 28(2), 314–328. https://doi.org/10.1080/10705511.2020.1761808
Back, M. D. (2021). Social interaction processes and personality. In J. F. Rauthmann (Ed.), The handbook of personality dynamics and processes. Elsevier Academic Press.
Bates, D., Kliegl, R., Vasishth, S., & Baayen, H. (2018). Parsimonious mixed models. https://arxiv.org/pdf/1506.04967.
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Boker, S., von Oertzen, T., Pritikin, J. N., Hunter, M. D., Brick, T., Brandmaier, A., & Neale, M. (2023). Products of variables in structural equation models. Structural Equation Modeling, 30(5), 708–718. https://doi.org/10.1080/10705511.2022.2141749
Bolger, N., & Schilling, E. A. (1991). Personality and the problems of everyday life: The role of neuroticism in exposure and reactivity to daily stressors. Journal of Personality, 59(3), 355–386. https://doi.org/10.1111/j.1467-6494.1991.tb00253.x
Bollen, K. A. (1989). Structural equations with latent variables. John Wiley & Sons. https://doi.org/10.1002/9781118619179
Borsboom, D., & Cramer, A. O. J. (2013). Network analysis: An integrative approach to the structure of psychopathology. Annual Review of Psychology, 9, 91–121. https://doi.org/10.1146/annurev-clinpsy-050212-185608
Box, G. E. P., & Draper, N. R. (1987). Empirical model-building and response surfaces. John Wiley & Sons.
Box, G. E. P., & Wilson, K. B. (1951). On the experimental attainment of optimum conditions. Journal of the Royal Statistical Society: Series B (Methodological), 13(1), 1–38. https://doi.org/10.1111/j.2517-6161.1951.tb00067.x
Brandt, H., Umbach, N., Kelava, A., & Bollen, K. A. (2020). Comparing estimators for latent interaction models under structural and distributional misspecifications. Psychological Methods, 25(3), 321–345. https://doi.org/10.1037/met0000231
Brose, A., Neubauer, A. B., & Schmiedek, F. (2022). Integrating state dynamics and trait change: A tutorial using the example of stress reactivity and change in well-being. European Journal of Personality, 36(2), 180–199. https://doi.org/10.1177/08902070211014055
Busemeyer, J. R., & Jones, L. E. (1983). Analysis of multiplicative combination rules when the causal variables are measured with error. Psychological Bulletin, 93(3), 549–562. https://doi.org/10.1037/0033-2909.93.3.549
Cohen, L. H., Gunthert, K. C., Butler, A. C., O’Neill, S. C., & Tolpin, L. H. (2005). Daily affective reactivity as a prospective predictor of depressive symptoms. Journal of Personality, 73(6), 1687–1713. https://doi.org/10.1111/j.0022-3506.2005.00363.x
Cole, D. A., & Preacher, K. J. (2014). Manifest variable path analysis: Potentially serious and misleading consequences due to uncorrected measurement error. Psychological Methods, 19(2), 300–315. https://doi.org/10.1037/a0033805
Cortina, J. M., Markell-Goldstein, H. M., Green, J. P., & Chang, Y. (2021). How are we testing interactions in latent variable models? surging forward or fighting shy? Organizational Research Methods, 24(1), 26–54. https://doi.org/10.1177/1094428119872531
Cox, K., Kelcey, B., & Bai, F. (2023). Croon’s bias-corrected estimation for multilevel structural equation models with latent interactions. Structural Equation Modeling, 30(3), 467–480. https://doi.org/10.1080/10705511.2022.2140290
Croon, M. A. (2002). Using predicted latent scores in general latent structure models. In G. A. Marcoulides & I. Moustaki (Eds.), Latent variable and latent structure modeling (pp. 195–223). Erlbaum.
Croon, M. A., & van Veldhoven, M. J. P. M. (2007). Predicting group-level outcome variables from variables measured at the individual level: A latent variable multilevel model. Psychological Methods, 12(1), 45–57. https://doi.org/10.1037/1082-989X.12.1.45
Cummins, R. (1989). Locus of control and social support: Clarifiers of the relationship between job stress and job satisfaction. Journal of Applied Social Psychology, 19(9,Pt 2), 772–787. https://doi.org/10.1111/j.1559-1816.1989.tb01258.x
Denissen, J. J. A., & Penke, L. (2008). Motivational individual reaction norms underlying the five-factor model of personality: First steps towards a theory-based conceptual framework. Journal of Research in Personality, 42(5), 1285–1302. https://doi.org/10.1016/j.jrp.2008.04.002
Depaoli, S., & Clifton, J. P. (2015). A bayesian approach to multilevel structural equation modeling with continuous and dichotomous outcomes. Structural Equation Modeling, 22(3), 327–351. https://doi.org/10.1080/10705511.2014.937849
Depaoli, S., & van de Schoot, R. (2017). Improving transparency and replication in bayesian statistics: The wambs-checklist. Psychological Methods, 22(2), 240–261. https://doi.org/10.1037/met0000065
Devlieger, I., & Rosseel, Y. (2020). Multilevel factor score regression. Multivariate Behavioral Research, 55(4), 600–624. https://doi.org/10.1080/00273171.2019.1661817
Diener, E., Emmons, R. A., Larsen, R. J., & Griffin, S. (1985). The satisfaction with life scale. Journal of Personality Assessment, 49(1), 71–75. https://doi.org/10.1207/s15327752jpa4901_13
Edwards, J. R. (1993). Problems with the use of profile similarity indices in the study of congruence in organizational research. Personnel Psychology, 46(3), 641–665. https://doi.org/10.1111/j.1744-6570.1993.tb00889.x
Edwards, J. R. (2002). Alternatives to difference scores: Polynomial regression analysis and response surface methodology. In F. Drasgow & N. W. Schmitt (Eds.), Measuring and analyzing behavior in organizations: Advances in measurement and data analysis (pp. 350–400). Jossey-Bass.
Edwards, J. R., & Parry, M. E. (1993). On the use of polynomial regression equations as an alternative to difference scores in organizational research. Academy of Management Journal, 36(6), 1577–1613.
Eisele, G., Vachon, H., Lafit, G., Kuppens, P., Houben, M., Myin-Germeys, I., & Viechtbauer, W. (2022). The effects of sampling frequency and questionnaire length on perceived burden, compliance, and careless responding in experience sampling data in a student population. Assessment, 29(2), 136–151. https://doi.org/10.1177/1073191120957102
Enders, C. K. (2010). Applied missing data analysis. Guilford Press.
Enders, C. K., & Tofighi, D. (2007). Centering predictor variables in cross-sectional multilevel models: A new look at an old issue. Psychological Methods, 12(2), 121–138. https://doi.org/10.1037/1082-989X.12.2.121
Fleeson, W. (2007). Situation-based contingencies underlying trait-content manifestation in behavior. Journal of Personality, 75(4), 825–861. https://doi.org/10.1111/j.1467-6494.2007.00458.x
Fox, J., & Weisberg, S. (2019). An r companion to applied regression (Third edition). SAGE Publications, Inc.
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian data analysis (Third edition). Francis Group: CRC Press Taylor.
Gelman, A., & Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences. Statistical Science, 7(4), 457–472.
Goldstein, H., Carpenter, J. R., & Browne, W. J. (2014). Fitting multilevel multivariate models with missing data in responses and covariates that may include interactions and non-linear terms. Journal of the Royal Statistical Society. Series A: Statistics in Society, 177(2), 553–564. https://doi.org/10.1111/rssa.12022
Grilli, L., & Rampichini, C. (2011). The role of sample cluster means in multilevel models: A view on endogeneity and measurement error issues. Methodology, 7(4), 121–133. https://doi.org/10.1027/1614-2241/a000030
Hamaker, E. L., Asparouhov, T., Brose, A., Schmiedek, F., & Muthén, B. O. (2018). At the frontiers of modeling intensive longitudinal data: Dynamic structural equation models for the affective measurements from the cogito study. Multivariate Behavioral Research, 53(6), 820–841. https://doi.org/10.1080/00273171.2018.1446819
Hasselhorn, K., Ottenstein, C., & Lischetzke, T. (2022). The effects of assessment intensity on participant burden, compliance, within-person variance, and within-person relationships in ambulatory assessment. Behavior Research Methods, 54(4), 1541–1558. https://doi.org/10.3758/s13428-021-01683-6
Hayduk, L. A. (1987). Structural equation modeling with lisrel: Essentials and advances. Johns Hopkins University Press.
Higgins, E. T. (1996). The "self digest": Self-knowledge serving self-regulatory functions. Journal of Personality and Social Psychology,71(6), 1062–1083. https://doi.org/10.1037/0022-3514.71.6.1062
Hisler, G. C., Krizan, Z., DeHart, T., & Wright, A. G. C. (2020). Neuroticism as the intensity, reactivity, and variability in day-to-day affect. Journal of Research in Personality,87. https://doi.org/10.1016/j.jrp.2020.103964
Hoff, P. D. (2009). A first course in bayesian statistical methods. Springer, New York. https://doi.org/10.1007/978-0-387-92407-6
Holtmann, J., Koch, T., Lochner, K., & Eid, M. (2016). A comparison of ml, wlsmv, and bayesian methods for multilevel structural equation models in small samples: A simulation study. Multivariate Behavioral Research, 51(5), 661–680. https://doi.org/10.1080/00273171.2016.1208074
Hsiao, Y.-Y., Kwok, O.-M., & Lai, M. H. C. (2018). Evaluation of two methods for modeling measurement errors when testing interaction effects with observed composite scores. Educational and Psychological Measurement, 78(2), 181–202. https://doi.org/10.1177/0013164416679877
Humberg, S., Kuper, N., Rentzsch, K., Gerlach, T. M., Back, M. D., & Nestler, S. (in press). Investigating the effects of congruence between within-person associations: A comparison of two extensions of response surface analysis. Psychological Methods.
Humberg, S., & Grund, S. (2022). Response surface analysis with missing data. Multivariate Behavioral Research, 57(4), 581–602. https://doi.org/10.1080/00273171.2021.1884522
Humberg, S., Nestler, S., & Back, M. D. (2019). Response surface analysis in personality and social psychology: Checklist and clarifications for the case of congruence hypotheses. Social Psychological and Personality Science, 10(3), 409–419. https://doi.org/10.1177/1948550618757600
Jaccard, J., & Wan, C. K. (1995). Measurement error in the analysis of interaction effects between continuous predictors using multiple regression: Multiple indicator and structural equation approaches. Psychological Bulletin, 117(2), 348–357. https://doi.org/10.1037/0033-2909.117.2.348
Kelcey, B. (2019). A robust alternative estimator for small to moderate sample sem: Bias-corrected factor score path analysis. Addictive Behaviors, 94, 83–98. https://doi.org/10.1016/j.addbeh.2018.10.032
Kelcey, B., Cox, K., & Dong, N. (2021). Croon’s bias-corrected factor score path analysis for small- to moderate-sample multilevel structural equation models. Organizational Research Methods, 24(1), 55–77. https://doi.org/10.1177/1094428119879758
Kenny, D. A., & Judd, C. M. (1984). Estimating the nonlinear and interactive effects of latent variables. Psychological Bulletin, 96(1), 201–210.
Kim, J. J., Muise, A., Barranti, M., Mark, K. P., Rosen, N. O., Harasymchuk, C., & Impett, E. (2021). Are couples more satisfied when they match in sexual desire? new insights from response surface analyses. Social Psychological and Personality Science, 12(4), 487–496. https://doi.org/10.1177/1948550620926770
Klein, A., & Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with the lms method. Psychometrika, 65(4), 457–474. https://doi.org/10.1007/BF02296338
Kristof-Brown, A. L., Zimmerman, R. D., & Johnson, E. C. (2005). Consequences of individuals’ fit at work: A meta-analysis of person-job, person-organization, person-group, and person-supervisor fit. Personnel Psychology, 58(2), 281–342. https://doi.org/10.1111/j.1744-6570.2005.00672.x
Kroencke, L., Harari, G. M., Back, M. D., & Wagner, J. (2023). Well-being in social interactions: Examining personality-situation dynamics in face-to-face and computer-mediated communication. Journal of Personality and Social Psychology, 124(2), 437–460. https://doi.org/10.1037/pspp0000422
Kuper, N., Breil, S. M., Horstmann, K. T., Roemer, L., Lischetzke, T., Sherman, R. A., ... Rauthmann, J. F. (2022). Individual differences in contingencies between situation characteristics and personality states. Journal of Personality and Social Psychology,123(5), 1166–1198. https://doi.org/10.1037/pspp0000435
Lai, M. H. C., & Hsiao, Y.-Y. (2022). Two-stage path analysis with definition variables: An alternative framework to account for measurement error. Psychological Methods, 27(4), 568–588. https://doi.org/10.1037/met0000410
Ledgerwood, A., & Shrout, P. E. (2011). The trade-off between accuracy and precision in latent variable models of mediation processes. Journal of Personality and Social Psychology, 101(6), 1174–1188. https://doi.org/10.1037/a0012869
Lewis, J. B., & Linzer, D. A. (2005). Estimating regression models in which the dependent variable is based on estimates. Political Analysis, 13(4), 345–364. https://doi.org/10.1080/00273171.2017.1406793
Liang, J., & Bentler, P. M. (2004). An em algorithm for fitting two-level structural equation models. Psychometrika, 69(1), 101–122. https://doi.org/10.1037/met0000155
Liu, S., & Rhemtulla, M. (2022). Treating random effects as observed versus latent predictors: The bias-variance tradeoff in small samples. The British Journal of Mathematical and Statistical Psychology, 75(1), 158–181. https://doi.org/10.1037/a0024776
Lüdtke, O., Marsh, H. W., Robitzsch, A., Trautwein, U., Asparouhov, T., & Muthén, B. O. (2008). The multilevel latent covariate model: A new, more reliable approach to group-level effects in contextual studies. Psychological Methods, 13(3), 203–229. https://doi.org/10.1093/pan/mpi026
Lüdtke, O., Robitzsch, A., & Trautwein, U. (2018). Integrating covariates into social relations models: A plausible values approach for handling measurement error in perceiver and target effects. Multivariate Behavioral Research, 53(1), 102–124. https://doi.org/10.1007/BF02295842
Lüdtke, O., Robitzsch, A., & Wagner, J. (2018). More stable estimation of the starts model: A bayesian approach using markov chain monte carlo techniques. Psychological Methods, 23(3), 570–593. https://doi.org/10.1111/bmsp.12253
MacCallum, R. C., & Mar, C. M. (1995). Distinguishing between moderator and quadratic effects in multiple regression. Psychological Bulletin, 118(3), 405–421. https://doi.org/10.1037/0033-2909.118.3.405
Marsh, H. W., Wen, Z., & Hau, K.-T. (2004). Structural equation models of latent interactions: Evaluation of alternative estimation strategies and indicator construction. Psychological Methods, 9(3), 275–300. https://doi.org/10.1037/1082-989X.9.3.275
McNeish, D., & Hamaker, E. L. (2019). A primer on two-level dynamic structural equation models for intensive longitudinal data in mplus. Psychological Methods, 25(5), 610–635. https://doi.org/10.1037/met0000250
Mehta, P. D., & Neale, M. C. (2005). People are variables too: Multilevel structural equations modeling. Psychological Methods, 10(3), 259–284. https://doi.org/10.1037/1082-989X.10.3.259
Mischel, W., & Shoda, Y. (1995). A cognitive-affective system theory of personality: Reconceptualizing situations, dispositions, dynamics, and invariance in personality structure. Psychological Review, 102(2), 246–268. https://doi.org/10.1037/0033-295x.102.2.246
Mislevy, R. J. (1991). Randomization-based inference about latent variables from complex samples. Psychometrika, 56(2), 177–196. https://doi.org/10.1007/BF02294457
Monseur, C., & Adams, R. (2009). Plausible values: How to deal with their limitations. Journal of Applied Measures, 10(3), 320–334.
Muthén, B. O., & Asparouhov, T. (2008). Growth mixture modeling: Analysis with non-gaussian random effects. In G. M. Fitzmaurice (Ed.), Longitudinal data analysis (pp. 143–165). Chapman & Hall/CRC. https://doi.org/10.1201/9781420011579.ch6
Muthén, L. K., & Muthén, B. O. (2017). Mplus user’s guide: Eighth edition (Eighth edition). Muthén & Muthén.
Muthén, B. O. (1989). Latent variable modeling in heterogeneous populations. Psychometrika, 54(4), 557–585. https://doi.org/10.1007/BF02296397
Neale, M. C., Hunter, M. D., Pritikin, J. N., Zahery, M., Brick, T. R., Kirkpatrick, R. M., ... Boker, S. M. (2016). Openmx 2.0: Extended structural equation and statistical modeling. Psychometrika,81(2), 535–549. https://doi.org/10.1007/s11336-014-9435-8
Nestler, S. (2020). Modelling inter-individual differences in latent within-person variation: The confirmatory factor level variability model. The British Journal of Mathematical and Statistical Psychology, 73(3), 452–473. https://doi.org/10.1111/bmsp.12196
Nestler, S. (2021). Modeling intraindividual variability in growth with measurement burst designs. Structural Equation Modeling, 28(1), 28–39. https://doi.org/10.1080/10705511.2020.1757455
Neubauer, A. B., Brose, A., & Schmiedek, F. (2022). How within-person effects shape between-person differences: A multilevel structural equation modeling perspective. Psychological Methods, (Advance online publication). https://doi.org/10.1037/met0000481
Neubauer, A. B., & Schmiedek, F. (2020). Studying within-person variation and within-person couplings in intensive longitudinal data: Lessons learned and to be learned. Gerontology, 66(4), 332–339. https://doi.org/10.1159/000507993
Neubauer, A. B., Voelkle, M. C., Voss, A., & Mertens, U. K. (2020). Estimating reliability of within-person couplings in a multilevel framework. Journal of Personality Assessment, 102(1), 10–21. https://doi.org/10.1080/00223891.2018.1521418
Oberski, D. L., & Satorra, A. (2013). Measurement error models with uncertainty about the error variance. Structural Equation Modeling, 20(3), 409–428. https://doi.org/10.1080/10705511.2013.797820
Plummer, M. (2016). Jags: A program for analysis of bayesian graphical models using gibbs sampling (version 4.2.0). http://sourceforge.net/projects/mcmc-jags/
Preacher, K. J., Zyphur, M. J., & Zhang, Z. (2010). A general multilevel sem framework for assessing multilevel mediation. Psychological Methods, 15(3), 209–233. https://doi.org/10.1037/a0020141
R Core Team. (2023). R: A language and environment for statistical computing. https://www.R-project.org/
Raudenbush, S. W., & Bryk, A. S. (2002). Hierarchical linear models: Applications and data analysis methods (2. ed.). SAGE Publications, Inc.
Rockwood, N. J. (2020). Maximum likelihood estimation of multilevel structural equation models with random slopes for latent covariates. Psychometrika, 85(2), 275–300. https://doi.org/10.1007/s11336-020-09702-9
Rohloff, C. T., Kohli, N., & Chung, S. (2022). The impact of functional form complexity on model overfitting for nonlinear mixed-effects models. Multivariate Behavioral Research, (Advance online publication), 1–20. https://doi.org/10.1080/00273171.2022.2119360
Rosenberg, M. (1989). Society and the adolescent self-image (Rev. ed.). Wesleyan University Press.
Rubin, D. B. (1987). Multiple imputation for nonresponse in surveys. John Wiley & Sons, Inc. https://doi.org/10.1002/9780470316696
Sardeshmukh, S. R., & Vandenberg, R. J. (2017). Integrating moderation and mediation: A structural equation modeling approach. Organizational Research Methods, 20(4), 721–745. https://doi.org/10.1177/1094428115621609
Savalei, V. (2019). A comparison of several approaches for controlling measurement error in small samples. Psychological Methods, 24(3), 352–370. https://doi.org/10.1037/met0000181
Schönbrodt, F. D. (2016). Testing fit patterns with polynomial regression models. https://doi.org/10.31219/osf.io/ndggf
Schönbrodt, F. D., & Gerstenberg, F. X. R. (2012). An irt analysis of motive questionnaires: The unified motive scales. Journal of Research in Personality, 46(6), 725–742. https://doi.org/10.1016/j.jrp.2012.08.010
Snijders, T. A. B., & Berkhof, J. (2008). Diagnostic checks for multilevel models. In J. de Leeuw & E. Meijer (Eds.), Handbook of multilevel analysis (pp. 141–175). Springer Science \(+\) Business Media. https://doi.org/10.1007/978-0-387-73186-5_3
Stan Development Team. (2022). Stan modeling language user’s guide and reference manual (2.31). http://mc-stan.org
Sternberg, R. J. (2003). Intelligence: Can one have too much of a good thing? In E. C.-H. Chang & L. J. Sanna (Eds.), Virtue, vice, and personality (pp. 39–51). American Psychological Association. https://doi.org/10.1037/10614-003
Sung, Y.-T., Chang, K.-E., & Liu, T.-C. (2016). The effects of integrating mobile devices with teaching and learning on students’ learning performance: A meta-analysis and research synthesis. Computers & Education, 94, 252–275. https://doi.org/10.1016/j.compedu.2015.11.008
Sun, J., Harris, K., & Vazire, S. (2020). Is well-being associated with the quantity and quality of social interactions? Journal of Personality and Social Psychology, 119(6), 1478–1496. https://doi.org/10.1037/pspp0000272
Ulitzsch, E., Lüdtke, O., & Robitzsch, A. (2023). Alleviating estimation problems in small sample structural equation modeling – a comparison of constrained maximum likelihood, bayesian estimation, and fixed reliability approaches. Psychological Methods, 28(3), 527–557. https://doi.org/10.1037/met0000435
von Davier, M., Gonzalez, E., & Mislevy, R. J. (2009). What are plausible values and why are they useful? IERI Monograph Series, 2, 9–36.
Westfall, J., & Yarkoni, T. (2016). Statistically controlling for confounding constructs is harder than you think. PLoS ONE, 11(3), e0152719. https://doi.org/10.1371/journal.pone.0152719
Wrzus, C., Luong, G., Wagner, G. G., & Riediger, M. (2021). Longitudinal coupling of momentary stress reactivity and trait neuroticism: Specificity of states, traits, and age period. Journal of Personality and Social Psychology, 121(3), 691–706. https://doi.org/10.1037/pspp0000308
Yang, J. S., & Seltzer, M. (2016). Handling measurement error in predictors using a multilevel latent variable plausible values approach. In J. R. Harring, L. M. Stapleton, & S. N. Beretvas (Eds.), Advances in multilevel modeling for educational research (pp. 295–333). Information Age Publishing Inc.
Zimmer, F., Henninger, M., & Debelak, R. (2022). Sample size planning for complex study designs: A tutorial for the mlpwr package. https://doi.org/10.31234/osf.io/r9w6t
Zitzmann, S., & Hecht, M. (2019). Going beyond convergence in bayesian estimation: Why precision matters too and how to assess it. Structural Equation Modeling, 26(4), 646–661. https://doi.org/10.1080/10705511.2018.1545232
Zitzmann, S., Lüdtke, O., & Robitzsch, A. (2015). A bayesian approach to more stable estimates of group-level effects in contextual studies. Multivariate Behavioral Research, 50(6), 688–705. https://doi.org/10.1080/00273171.2015.1090899
Zitzmann, S., Lüdtke, O., Robitzsch, A., & Marsh, H. W. (2016). A bayesian approach for estimating multilevel latent contextual models. Structural Equation Modeling: A Multidisciplinary Journal, 23(5), 661–679. https://doi.org/10.1080/10705511.2016.1207179
Zondervan-Zwijnenburg, M., Peeters, M., Depaoli, S., & van de Schoot, R. (2017). Where do priors come from? applying guidelines to construct informative priors in small sample research. Research in Human Development, 14(4), 305–320. https://doi.org/10.1080/15427609.2017.1370966
Zyphur, M. J., Zhang, Z., Preacher, K. J., & Bird, L. J. (2019). Moderated mediation in multilevel structural equation models: Decomposing effects of race on math achievement within versus between high schools in the united states. In S. E. Humphrey & J. M. LeBreton (Eds.), The handbook of multilevel theory, measurement, and analysis (pp. 473–494). American Psychological Association. https://doi.org/10.1037/0000115-021
Acknowledgements
We thank our student assistant Leon Kasseckert for his valuable support in preparing this manuscript.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Author Note
Additional materials for this article can be found at https://osf.io/xucwf.
Conflicts of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Ethics approval
The two empirical studies used in the illustrative example were approved by the Ethics Committee of the University of Leipzig (331/17-ek) and by the review board of the German Society of Psychology (SN072018), respectively.
Consent to participate
For the empirical studies used in the illustrative example, informed consent was obtained from all individual participants included in the study.
Consent for publication
Not applicable
Open Practices Statement
All code and data for the simulation study and the illustrative example analysis are available at https://osf.io/xucwf. This study was not preregistered.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Humberg, S., Grund, S. & Nestler, S. Estimating nonlinear effects of random slopes: A comparison of multilevel structural equation modeling with a two-step, a single-indicator, and a plausible values approach. Behav Res 56, 7912–7938 (2024). https://doi.org/10.3758/s13428-024-02462-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-024-02462-9