
Abstract
The existence of implicit (unconscious) learning has been demonstrated in several laboratory paradigms. Researchers have also suggested that it plays a role in complex real-life human activities. For instance, in social situations, we may follow unconscious behaviour scripts or intuitively anticipate the reaction of familiar persons based on nonconscious cues. Still, it is difficult to make inferences about the involvement of implicit learning in realistic contexts, given that this phenomenon has been demonstrated, almost exclusively, using simple artificial stimuli (e.g., learning structured patterns of letters). In addition, recent analyses show that the amount of unconscious knowledge learned in these tasks has been overestimated by random measurement error. To overcome these limitations, we adapted the artificial grammar learning (AGL) task, and exposed participants (N = 93), in virtual reality, to a realistic agent that executed combinations of boxing punches. Unknown to participants, the combinations were structured by a complex artificial grammar. In a subsequent test phase, participants accurately discriminated novel grammatical from nongrammatical combinations, showing they had acquired the grammar. For measuring awareness, we used trial-by-trial subjective scales, and an analytical method that accounts for the possible overestimation of unconscious knowledge due to regression to the mean. These methods conjointly showed strong evidence for implicit and for explicit learning. The present study is the first to show that humans can implicitly learn, in VR, knowledge regarding realistic body movements, and, further, that implicit knowledge extracted in AGL is robust when accounting for its possible inflation by random measurement error.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
It is unclear to what extent nonconscious knowledge influences human behaviour in realistic, ecological, contexts. Studies conducted in several experimental paradigms have found that humans have the capacity to extract and use knowledge they seem to have no conscious access to. The prototypical example is the artificial grammar learning (AGL) paradigm, in which participants are exposed to meaningless strings of letters that are structured by a complex regularity (an artificial grammar). In subsequent test phases, participants are able to discriminate new strings that follow the artificial grammar from strings that do not, indicating they have learned the grammar. However, they are able to report limited amounts of knowledge of the grammar, which indicates they are not completely aware of the acquired knowledge (e.g., Dienes & Scott, 2005; Norman et al., 2019; Reber, 1967). This process of nonconscious knowledge acquisition, called implicit or unconscious learning (e.g., Dienes & Seth, 2018; Reber, 1967, in press), has been proposed to play a role in human behaviour not only in such laboratory paradigms but also in domains of human activity governed by regularities that are not always taught in an intentional, explicit manner. An often-suggested area regards the social realm: We might be able to anticipate the behaviour of a familiar person based on cues that are difficult to verbalize (e.g., a subtle configuration of their facial muscles), or we seem to follow scripts of appropriate social behaviour without resorting to a conscious representation of those scripts (cf. Costea et al., 2022; Dienes & Seth, 2018; Lewicki, 1986; Lieberman, 2000; consider the rules of politeness in Fox, 2014). Similarly, theories of decision-making in sports propose that decisions about the best course of action during gameplay could be sustained by implicit knowledge (e.g., Raab & Johnson, 2008; Weiss & Masters, 2022).
However, the evidence that implicit learning and knowledge can operate in real life-like contexts is limited, from at least two perspectives. First, the vast majority of the studies showing evidence of implicit learning have been conducted in experimental paradigms that use relatively simple, artificial stimuli. As mentioned, in AGL, participants are typically exposed to meaningless letter strings (e.g., XMVTRM) that follow a structure; or, in visuomotor sequence learning tasks, participants learn a regularity that determines the location of a simple stimulus (e.g., a dot; cf. Nissen & Bullemer, 1987). In other words, the stimuli and learning contexts are different from those that could appear in ecological situations. This is an important limitation, since numerous studies have found that characteristics of the surface stimuli significantly influence the amount of implicit learning: In AGL, the magnitude of learning differs as a function of the nature of the stimuli (Norman & Price, 2012), of the familiarity with the stimuli (Scott & Dienes, 2010a), of the typical mode of interacting with the stimuli (Jiménez et al., 2020), or of their ecological relevance (Eitam et al., 2014; Ziori & Dienes, 2015). Consequently, it is difficult to make sound inferences about the functioning of implicit learning in real-life social contexts based on the extant results; almost all empirical data on implicit learning and knowledge have been obtained with simpler and more artificial stimuli compared with those that may occur in real-life situations (cf. Costea et al., 2022; Jiménez et al., 2020; Norman & Price, 2012).Footnote 1
There have been, however, attempts to use more realistic socially relevant stimuli in implicit learning: Norman and Price (2012) presented participants with sequences of static images depicting a person in different postural positions (yoga poses), and their order was determined by an artificial grammar. Participants acquired implicit knowledge of the grammar since, in the trials attributed to implicit knowledge, they were accurate in classifying novel sequences as grammatical or ungrammatical (see also Orgs et al., 2013). Similarly, Ziori and Dienes (2015) showed the implicit learning of face sequences. To our knowledge, only one previous study has shown implicit learning of human-like movement (Q. Zhang et al., 2020; see also Opacic et al., 2009). Q. Zhang et al. (2020) used sequences of simplified patterns of point-light displays showing biological movements (waving, jumping, etc.) and found people could implicitly learn sequences showing an inversion symmetry, again as shown by participants’ accuracy in classifying novel sequences in the trials attributed to implicit knowledge. Although there is anecdotal evidence that sports performance can be sustained by unconscious knowledge, there have been very few investigations focused on disentangling the conscious or unconscious status of knowledge supporting behaviours relevant for sport contexts. Reed et al. (2010) showed that humans can determine where a flying ball will land by unconsciously tracking the changes in the angle at which their gaze follows the ball. Masters et al. (2009) also showed that feedback below the subjective threshold of where a golf ball landed allowed learning of how to strike a golf ball to a concealed target. However, most investigations on implicit knowledge in sport focus not so much on the conscious availability (or lack thereof) of the knowledge that supports performance, but rather on its mode of acquisition (i.e., implicit operationalized as incidental, as opposed to intentional, acquisition) or on its automaticity and efficiency (i.e., implicit operationalized as automatic and robust to pressure or to interference from a secondary task; e.g., Raab & Johnson, 2008; Weiss & Masters, 2022). For instance, Abernethy et al. (2012) exposed participants to video recordings of handball penalty throws. In the explicit condition, participants were provided with explicit contingencies between the body dynamics prior to the release of the ball and the ball’s subsequent trajectory and were instructed to predict the ball’s trajectory based on these contingencies. In the implicit condition, participants were incidentally exposed to these contingencies, under the disguise of a short-term memory task. Following training, participants in the implicit condition were able to formulate fewer rules compared with those in the explicit condition. However, when asked to predict the ball’s trajectory under stress, only participants in the implicit condition outperformed the control group. This pattern of results suggests that in sports-relevant situations, incidental learning may produce knowledge that is less conscious but more robust to pressure—though counting rules in post-task recall is not the best way of measuring quality of conscious knowledge.
A second impediment in establishing the magnitude of involvement of implicit learning, in realistic and in laboratory contexts, stems from the difficulty in determining whether, when learning occurs, it is indeed unconscious. The issue of properly measuring the conscious/unconscious status of knowledge has been the subject of many theoretical and methodological debates (e.g., Berry & Dienes, 1993; Shanks & John, 1994; Timmermans & Cleeremans, 2015). The current theories of consciousness agree on the reportable character of conscious knowledge (e.g., Baars, 2007; Dienes, 2012; Rosenthal, 2004), and the majority of consciousness researchers favour the use of subjective (i.e., introspective, self-reported) methods for assessing whether participants possess conscious knowledge (Francken et al., 2021; Rosenthal, 2019; but see Shanks, 2005). To ensure the sensitivity of a subjective report, it is usually collected immediately after the participant uses that knowledge (e.g., for a grammaticality judgment in AGL) in a trial-by-trial manner. A common approach is then to analyze, separately, participants’ accuracy in the trials in which they claim to possess no conscious knowledge, and an above-chance accuracy in these trials is taken to indicate the presence of unconscious knowledge. This approach has important advantages: It ensures a high level of measurement sensitivity (e.g., Jurchiș et al., 2020; Newell & Shanks, 2014) and can detect momentary fluctuations in awareness (Skora et al., 2020). Also, this approach has produced most of the evidence for the existence of implicit learning from the past two decades, in AGL and many other paradigms (e.g., Dienes & Scott, 2005; Fu et al., 2010; Fu et al., 2018; Jurchiș et al., 2020; Waroquier et al., 2020). However, Shanks and colleagues (Shanks, 2017; Shanks et al., 2021) have shown that whenever a task produces both conscious and unconscious trials, some conscious trials will inevitably be misclassified as “unconscious” due to some amount of random measurement error. Accordingly, the observed unconscious accuracy might be, at least partially, explained by knowledge that is, in reality, conscious.
To conclude, it is difficult to determine the involvement of implicit learning even in some established paradigms, given that most of the evidence for this phenomenon could have been inflated by measurement error. It is even more difficult to infer to what extent implicit learning could be involved in real life situations, since the extant research has employed stimuli and contexts that are very different from those found in real life.
The present study
To our knowledge, only one previously published study investigated whether people could implicitly learn regularities from dynamic stimuli showing human movement by using schematic patterns of point-light displays (Q. Zhang et al., 2020). We aim to determine whether implicit learning can be involved in extracting regularities in a realistic yet controlled context, from stimuli that are relatively complex, dynamic, and socially relevant. In this sense, we take the basic structure of an AGL paradigm and, for the first time, implement it in an immersive virtual reality environment, in which participants are exposed not to strings of letters, but rather to sequences of continuous, dynamic body movements executed by a virtual human agent—namely, boxing/martial arts punches. In an acquisition phase, participants are exposed to combinations of punches, while the order of the punches is determined by an artificial grammar. Then, in a test phase, we test whether they can discriminate novel “grammatical” from “nongrammatical” combinations. To determine the conscious/unconscious status of learning, we use a subjective, trial-by-trial awareness scale and test whether participants are accurate in the trials in which they claim to lack conscious knowledge. Importantly, we adapt a method of testing whether the observed unconscious accuracy is superior to the maximum amount of the observed unconscious learning effect that could be attributed to the conscious contamination of “unconscious” trials, due to regression to the mean based on random measurement error (Shanks, 2017; Shanks et al., 2021; Skora et al., 2020). This method was recently developed by one of the authors in the context of a subliminal conditioning study (Dienes, 2022; Skora et al., 2020), and we adapt it here in the context of implicit learning. As an additional method for minimizing possible effects of measurement error, we include a secondary trial-by-trial awareness scale and test whether there is evidence of learning in the trials deemed unconscious by both awareness scales (Shanks, 2017; Shanks et al., 2021).
Method
Participants
Ninety-three (74 women, Mage = 20.60 years, SD = 4.09 years) undergraduate students from two Romanian universities attended the experiment voluntarily or in exchange for course credit. All had normal or corrected-to-normal vision.
Materials
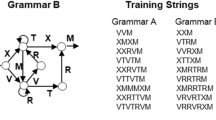
We employed two commonly used artificial grammars that typically generate strings of letters by following the order of the arrows (e.g., Dienes & Scott, 2005; Jurchiș et al., 2020; Reber, 1967; Norman et al., 2019; Fig. 1). We replaced, however, the letters from the structure of these grammars with body movements—specifically, boxing punches—executed by a virtual human (cf. Norman & Price, 2012; Opacic et al., 2009; see Fig. 2). We chose boxing punches because they also appear as structured sequences in real life; also, they are relatively fast movements, which increases the chances of chunking successive stimuli in a unitary structure. We used a list of strings generated from the mentioned grammars that was used in several previous studies, which comprises 32 acquisition strings and 20 test strings for each grammar (Dienes et al., 1995; Jurchiș, 2021; Jurchiș et al., 2020; Norman et al., 2011; Norman et al., 2016; Norman et al., 2019; Wan et al., 2008), but we transformed each letter string into a boxing combination (e.g., the string XMVRXM became straight left—left hook—straight right—right hook—straight left—left hook). For examples, see the following: https://youtube.com/playlist?list=PL9Lh7Wa5XrwiyhF2e19dd5p3aFtvusL9Y or https://osf.io/94xbv/. The combinations were five to nine punches long, and there was no break between two consecutive punches from a combination.


The mappings between punches and the letters from the grammars. The punches consisted in continuous movements in the study, but in the figure they are depicted as static images at their peak departure from the guard position
The virtual human agent consisted in a 3D, high-resolution photorealistic representation of a human male, generated for the Character Creator 3 software (Reallusion, Inc). The virtual human was “rigged,” meaning that it supported motion files that made it move similar to a real human body. From Character Creator, we exported the agent into the Unity game engine (Unity Technologies Inc), where we applied the motion files and programmed the VR task. For the guard position and for the boxing punches, we downloaded from Adobe Mixamo (Adobe Inc) motion files, generated by capturing movements of real humans with motion capture devices. As in real boxing, each punch involves the movement of almost the entire body (e.g., legs, torso, shoulders, arms, head), starting from, and returning to, the guard position. Using the uMotion plugin for Unity, we trimmed the downloaded motion files, resulting movements with durations from 500 ms to 850 ms for the punches, and of 2,700 ms for the guard position. Finally, we arranged the motion files in the order specified by the grammars, using Unity’s Animator component. The agent was placed inside a boxing ring, and the entire scene took place in the default environment provided by Unity, which contains no other stimuli apart from the sky. Unity broadcasted the entire VR experience, through the SteamVR plugin, to an HTC VIVE Cosmos Elite (HTC Inc) VR headset, powered by a VR-ready laptop.
Procedure
Acquisition phase
After signing informed consent, participants were informed that they would see, in an immersive VR environment, a person that executed several continuous boxing combinations. They were instructed to pay close attention and try to memorize as much as possible from these combinations, because they will undergo a subsequent task that relied on what they observe regarding those combinations. Nothing was mentioned about the existence of any structure or regularity. The experimenter ensured the VR headset was properly fitted on the participants’ head, that they could clearly see the VR environment and the virtual agent, then the experimenter initiated the first acquisition block. There were four acquisition blocks, and 32 unique combinations presented in a fixed sequence in each block. In each block, all 32 combinations were exposed once; hence, in the entire acquisition phase, participants saw 32 combinations × 4 blocks = 128 total combinations. Between each two consecutive combinations, the virtual agent displayed the guard position for 2,700 ms. Each block lasted approximately four and a half minutes, and participants could take a one-minute break after each block.
Test phase
Following typical AGL protocol, before beginning the test phase, participants were informed that the previously seen combinations were generated from a complex set of rules. Also, they were informed that they would see novel combinations, some of which followed the previous rules, some of which violated the rules, but no details were given about the structure of these rules. They also received extensive explanations regarding the use of the awareness scales, detailed below. Given that the entire experimental session lasted for about 50 minutes, for reducing fatigue and possible sickness associated with a prolonged use of VR (Chang et al., 2020), the test phase did not take place in VR; participants saw the stimuli, instructions, questions, and response options on a wide screen (108-cm diagonal) and gave the responses using the mouse. The test phase was conducted using the platform gorilla.sc (Anwyl-Irvine et al., 2020). The combinations were thus presented in a video format. In this phase, participants saw 20 new combinations from Grammar A and 20 new from Grammar B in a random sequence generated for each participant. For participants that saw combinations from Grammar A in the previous phase, the novel Grammar A combinations were grammatical, while the Grammar B combinations were nongrammatical; for participants exposed to Grammar B in the acquisition, the grammatical/nongrammatical status of the test combinations was reversed. After seeing each combination, participants performed a grammaticality judgment, then responded to two scales that probed their awareness level.
Grammaticality judgment
Participants judged for each test combination whether it followed the previous grammar or not (“Does this combination follow the previous rules? Yes/No”). An above-chance (50%) accuracy in discriminating whether the combinations followed the grammar or not would indicate that participants learned the grammar.
Structural and judgment knowledge attribution (Dienes & Scott, 2005; Norman et al., 2019; Waroquier et al., 2020)
In the test phase of an AGL (or other implicit learning paradigm) study, participants can use two main types of knowledge. Their structural knowledge refers to the knowledge acquired in the acquisition phase about the structure, the configuration, of the grammar (e.g., “Whenever the combination began with a straight left, the second punch was a left hook”). Then, in the test phase, when they judge whether a stimulus is grammatical or not, they apply judgment knowledge (e.g., “This combination is grammatical”), which is based on the structural knowledge (“. . . because the first punch was a straight left, and the second one was a left hook”). Structural and judgment knowledge can be either conscious or unconscious. Whenever participants possess conscious structural knowledge (e.g., “I remember that whenever the first punch was a straight left, the second one was a left hook”), their judgment knowledge is also conscious (“. . . hence I [consciously] believe this combination is grammatical”), and they have the experience of using a conscious rule or a conscious recollection. However, when their structural knowledge is unconscious (“I have no clue what the rule was”), their judgment knowledge can be either conscious, experienced as a feeling of intuition or (un)familiarity (“. . . but I [consciously] feel this combination is somehow similar to the previous ones”) or the judgment knowledge can be unconscious, experienced as a guess (“. . . so I just guessed/put at random that the combination is grammatical”). In sum, conscious structural knowledge of the rules generally results in conscious judgment knowledge, experienced as using a conscious rule or recollection; unconscious structural knowledge results either in conscious judgment knowledge (a feeling of intuition or familiarity) or in unconscious judgment knowledge (guessing; e.g., Dienes, 2012; Dienes & Scott, 2005). Hence, after each grammaticality judgment, participants report whether they used conscious rules/recollection, a feeling of intuition or familiarity, or whether they just guessed. Using this method, numerous studies have found evidence that participants extract conscious and unconscious structural knowledge, in AGL (Dienes & Scott, 2005; Ivanchei & Moroshkina, 2018; Jurchiş & Opre, 2016; Mealor & Dienes, 2013a, 2013b; Norman et al., 2016; Norman et al., 2019; Norman & Price, 2012; Scott & Dienes, 2008, 2010a, 2010b; Wan et al., 2008), and in a variety of other implicit learning and conditioning tasks (e.g., Fu et al., 2010; Fu et al., 2018; Jurchiș, 2021; Neil & Higham, 2012, 2020; Paciorek & Williams, 2015; Waroquier et al., 2020; J. Zhang & Liu, 2021). In the context of AGL, studies show that the present method distinguishes between conscious and unconscious structural knowledge consistent with theories of conscious and unconscious knowledge: For instance, the instruction to actively search for rules increases the accuracy of explicit, but not that of implicit responses; the accuracy of explicit knowledge decreases when participants’ attention is divided in the acquisition phase, but implicit knowledge remains unaffected. Further, when asked to classify twice the same string, conscious knowledge generates more stable responses compared with implicit knowledge (Dienes & Scott, 2005; see Dienes, 2012, and Mealor & Dienes, 2013a, 2013b, for other empirical dissociations between the conscious and unconscious knowledge revealed by this method). Ivanchei and Moroshkina (2018) show that this method makes participants think more analytically and attend more closely to their conscious knowledge, compared to other awareness measures. A recent fMRI study showed, in a different paradigm, that implicit and explicit attributions are supported mostly by different brain areas (J. Zhang & Liu, 2021).
To test their awareness of structural and judgment knowledge, we asked participants to report the basis of their grammaticality judgment (“What was the basis of your response?”), choosing from the options presented in Table 1. Before the start of the test phase, participants first read the written definitions of these options (Table 1), then the experimenter discussed the definitions with the participant and stressed the fact that they should use the Guess, Intuition, and Familiarity options only when they have absolutely no conscious information about the rules, and that they should use Rules or Remembering whenever they possess some conscious information, even if it is fragmentary and they are unsure of its accuracy. The written definitions also appeared on the screen on each trial, when participants had to report their structural/judgment knowledge attribution. Note that the wording of the definitions and the mode of administering the scale were thought as to maximize its adherence to the recommended criteria of immediacy, sensitivity, reliability, information (relevance; Berry & Dienes, 1993; Newell & Shanks, 2014; Shanks & John, 1994; Sweldens et al., 2017): participants reported their awareness immediately after the grammaticality judgment (immediacy); participants were explicitly and repeatedly encouraged to report as conscious even knowledge that is fragmentary and they are usure of (sensitivity); they were instructed that conscious knowledge could refer to any information they are aware of (rules, fragments, etc.; information criterion); regarding the reliability criterion: reporting conscious knowledge was less influenced by irrelevant factors, such as participants’ expressive language abilities (as it required one mouse click), and the scale had excellent split-half reliability when distinguishing between conscious and unconscious structural knowledge (r = .94, Spearman–Brown corrected, calculated as the proportion of unconscious trials in the odd and even trials).
The Rule Awareness Scale (RAS; Wierzchoń et al., 2012)
Immediately after participants reported their structural/judgment knowledge attribution, they were directly enquired about their level of awareness of the rule, using an adaptation of the RAS. RAS provides a continuous assessment of awareness of the structural knowledge, using four levels: “1–I did not have the vaguest idea or experience of any rule/rule fragment”; “2–I had a vague idea or experience of a rule, but I am not sure of it”; “3–I think I knew the rule”; “4–I knew the rule.” Participants could choose one of these four options as a response to the question “To what extent have you noticed the rule/rule fragment that the combination follows or violates?” Following Wierzchoń et al. (2012), we only interpret Level 1 of the scale as excluding, unequivocally, any conscious knowledge of the rule; Level 2 could mean that the participant had an impression that there is a rule or structure in the combination without having access to the content of the rule, but could also mean they held a low confidence idea about the content of the rule; Levels 3 and 4 indicate that participants think they had conscious access to the rule. For increasing the sensitivity of the RAS, we slightly rephrased the response options and included the reference to “rule fragments”; also, we made explicit the fact that vague knowledge held with low confidence should be attributed to level 2 (“. . . not sure of it”), so to decrease the chances that participants would use Level 1 for conscious knowledge held with low confidence. The RAS had excellent split-half reliability (r = .97, Spearman–Brown corrected) and very good convergent validity (i.e., it correlated r = .77, with the structural/judgment attribution scale).
While both structural/judgment knowledge attribution and the RAS evaluate the conscious/unconscious status of the structural knowledge, they do so from different angles: While the former requires participants to report what they think it was that supported their grammaticality judgment, the latter asks them to only and directly consider their level of awareness of the grammar. However, as explained, there is ambiguity whether level 2 of the RAS captures conscious or unconscious knowledge, while structural/judgment knowledge attribution clearly differentiates between the two. Moreover, there is more empirical evidence for the validity of the structural/knowledge attribution scale. Consequently, we use structural/judgment attribution as our main method of discriminating conscious from unconscious knowledge and use Level 1 of the RAS as a supplementary check of the unconscious status of knowledge.
Results
The data set is available online (https://osf.io/28vbj/). We use both significance testing and Bayesian analyses and interpret Bayes factors (noted as “B”) as follows: 3 ≤ B < 10 represents moderate, and B ≥ 10 represents strong evidence for the alternative hypothesis; 0.10 < B ≤ 0.33 represents moderate, and B ≤ 0.10 represents strong evidence for the null; 0.33 < B < 3 is interpreted as insensitive (e.g., Lee & Wagenmakers, 2014). Bayesian analyses are conducted with a normal prior distribution with the mean equal to an expected learning effect of 5% above the 50% chance level, and the SD = mean/2 = 2.5% (noted BN[5%; 2.5%]; e.g., Dienes, 2016, 2021). This expected learning effect was estimated from the implicit learning effect (55% accuracy) obtained by Norman and Price (2012). We also report Robustness Regions (noted as RR), which indicate, in our case, the range of means of the models of H1 that would yield the same qualitative conclusions (i.e., support for H1, for H0, or insensitive data; e.g., Dienes, 2021). For example, a RRB > 3 = [0.2%; 50%] signifies that a Bayes factor above 3 (i.e., supporting the alternative hypothesis) would be obtained with priors with means ranging from 0.2% to 50% (50% being the maximum possible performance above chance, which corresponds to a raw performance of 100%; the SDs of the priors are always mean/2).
The null hypothesis was modelled as a point null, except for the analyses on unconscious structural knowledge, where we use an interval (uniform) null, ranging from 0 to the maximum effect that could be attributed to measurement error—namely, 0.9% (Dienes, 2022; Skora et al., 2020). The logic was as follows. Assume that whatever the true proportion of unconscious and conscious trials is, each is misclassified by the same percentage. Given that the percentage of conscious structural knowledge attributions was 33%, the maximum proportion error in measurement is 33% (i.e., if all trials were in fact unconscious). One can then consider all possible error proportions between 0 and 33% and find the error proportion that maximizes the proportion of measured unconscious trials which are misclassified (see Skora et al., 2020, and the supplementary material for equations and full description). Applying the formulae derived in Skora et al. (2020), this maximum contaminated effect would be achieved at a classification error of the conscious vs unconscious structural knowledge of 21%, which would translate to 6.7% of the trials measured as unconscious being, in reality, misclassified conscious trials. The accuracy of the conscious trials was 14% above the chance level of 50%, see below, thus the maximum percentage above chance in the measured unconscious trials that could have been explained by conscious contamination is 6.7% × 14% = 0.9%. For the analyses that account for this maximum contamination effect, we note the corresponding Bayes factor as BM0:U[0; 0.9%]; M1:N[5%; 2.5%] (cf. Palfi & Dienes, 2019). The analyses were conducted with the General Bayesian Tests module from the JASP (JASP Team, 2022).
Table 2 shows the frequency of different response types and their associated accuracy. A one-sample t test showed strong evidence that participants’ overall accuracy was above chance, indicating they had learned the grammar and were accurate in judging whether the combinations from the test phase followed the grammar or not, BN[5%; 2.5%] = 2.09 × 1019, RRB > 3 = [0.2%; 50%], t(92) = 9.68, p < .001, Cohen’s dz = 1.00, Maccuracy = 59.46%, 95% CI [57.55%, 61.38%]. When analyzing the responses to the structural/judgment attribution scale, we found that two thirds of responses (M = 66.67%, SD = 15) were attributed to unconscious structural knowledge (Guess, Intuition, Familiarity), while one third (M = 33.33%, SD = 15) were attributed to conscious structural knowledge (Rules, Remembering). The trials attributed to conscious structural knowledge had above chance accuracy, indicating that participants extracted accurate conscious knowledge of the grammar, BN[5%; 2.5%] = 1.01 × 1011, RRB > 3 = [0.2%; 50%], t(87) = 7.58, p < .001, dz = 0.81, Maccuracy = 63.97%, 95% CI [60.36%, 67.59%].
For testing our key hypothesis, that participants will extract implicit knowledge of the structure, firstly, we compared the accuracy of trials attributed to unconscious structural knowledge (Guess, Intuition, Familiarity, pooled together), while accounting for the possible inflation of unconscious accuracy due to measurement error. We found strong evidence that participants’ accuracy was above chance, BM0:U[0; 0.9%]; M1:N[5%; 2.5%] = 2.14 × 106, RRB > 3 = [1%; 50%], t(92) = 5.97, p < .001, dz = 0.62, Maccuracy = 58.45%, 95% CI [55.67%, 61.22%]. Secondly, we tested whether the accuracy was above chance only on the trials shown by both awareness scales as unconscious. From the trials attributed to Guess, Intuition, and Familiarity, 71.00% (SD = 34.40) were also rated with Level 1 at the RAS and their accuracy was above chance, BN[5%; 2.5%] = 1.52 × 106, RRB > 3 = [0.5%, 50%], t(86) = 5.11, p < .001, dz = 0.55, Maccuracy = 58.20%, 95% CI [55.06%; 61.35%].Footnote 2 Finally, we compared participants’ conscious and unconscious structural knowledge accuracies (as classified by the judgment/structural attribution scale) and found moderate evidence that conscious structural knowledge was more accurate than unconscious structural knowledge, BN[5%; 2.5%] = 6.56, RRB > 3 = [2%; 10%], t(87) = 2.19, p = .03, dz = 0.23, Mdifference = 5.16%, 95%CI [0.48%, 9.84%].
Discussion
The present study adapted the AGL task and structured, based on artificial grammars, successions of dynamic body movements executed by a realistic virtual human. We found strong evidence that participants learned the grammars, since they were able, in the test phase, to discriminate grammatical from nongrammatical combinations. Importantly, we found strong evidence that participants were able to do so even when they reported having no conscious knowledge of the grammar; that is, participants implicitly learned the structures followed by these realistic body movements.
Studies conducted mostly in the AGL task have shown that implicit learning is influenced by the characteristics of the surface stimuli (e.g., Jiménez et al., 2020; Norman & Price, 2012), but there have been very few attempts to test whether this process can operate on stimuli that are as complex and dynamic as a moving human body. While previous studies have already shown that structures of images depicting static body postures and movements revealed by point-light displays can be learned implicitly, we find that is also true for dynamic body movements. Similar to Norman and Price (2012), and to typical AGL studies, we found that two thirds of participants’ responses were attributed to unconscious structural knowledge. However, Norman and Price found that implicit knowledge was more accurate than explicit knowledge, but in the present study the accuracies were reversed (i.e., explicit knowledge outperformed implicit knowledge), likely because our participants saw 128 combinations in acquisition, as opposed to 45 sequences in Norman and Price. Q. Zhang et al. (2020) found virtually all the attributions indicated unconscious structural knowledge; but their grammar was supra-finite state (inversion symmetry).
A methodological contribution of the present study is that it showed, for the first time, that implicit knowledge in the AGL paradigm is robust even when accounting for the possible contamination of the detected unconscious trials with misclassified conscious trials (cf. Skora et al., 2020). This is a significant aspect, given that several recent analyses cast doubt on the extant evidence for learning in the absence of awareness due to the problem of conscious contamination, and even advocate for ceasing the classification of conscious and unconscious trials using subjective measures (Shanks, 2017; Shanks et al., 2021). Another methodological contribution of the present research is that it shows VR as a viable tool for producing implicit learning effects in more realistic settings, which could stimulate future explorations of the ecological relevance of this phenomenon (see also Sense & van Rijn, 2018). While in our study only the acquisition phase was conducted in VR, the fact that we observed robust evidence of both implicit and explicit learning even with the non-VR-testing phase suggests that a VR-testing phase that better matches the encoding environment should also show learning.
The present results are consistent with dual-process models of social cognition. These models essentially maintain that that the judgments and predictions we make regarding the characteristics and behavior of social stimuli can be guided not only by explicit reasoning, but can also be intuitive and based, sometimes, on nonconscious knowledge (e.g., Amodio, 2019; Lieberman, 2000; Smith & DeCoster, 2000). However, recent analyses have found little evidence that implicit (defined as nondeliberative) social cognition is supported by unconscious social knowledge (e.g., Greenwald & Lai, 2020; Hahn et al., 2014). We propose that the absence of this evidence has been caused, partly, by a lack of robust experimental methods to investigate the possibility of unconscious acquisition of socially relevant information (cf. Norman & Price, 2012). While the present study shows that judgments regarding a virtual human's behavior can be based on unconscious knowledge, our learning paradigm tackles only an isolated form of behavior of a social agent (structured body movements), and lacks the motivational, emotional and interactive aspects that usually characterize social situations (see Costea et al., 2022). Nevertheless, future studies could develop the present paradigm and experiment with more complex, emotionally relevant behaviors, structured by regularities. Relatedly, an important task for future research would be to determine the constraints on the behaviors that can be chunked in implicit structures, including constraints on the temporal span, complexity, and the nature of such behaviors.
Theories of sport-specific skill learning suggest that much of the knowledge involved in sports judgment and decision-making (e.g., anticipating the opponent's action, quickly identifying the best course of action) is acquired through implicit learning (e.g., Raab & Johnson, 2008; Weiss & Masters, 2022). We find that one can acquire unconscious knowledge about sports-specific body movements and can use it to judge sequences of such movements. Clearly, the extent to which such acquisitions can facilitate actual training or athletic performance is a matter that future research could address.
In conclusion, the present study is the first to show that humans can implicitly learn, in VR, knowledge regarding realistic body movements. Hence, it extends our knowledge concerning the realism and complexity boundaries of implicit learning and brings support for the tenet that implicit learning could sustain social and sports-related cognition. It is also the first to show that implicit knowledge extracted in the AGL is robust when accounting for its possible inflation by random measurement error.
Notes
Most exceptions seem to be restricted to the linguistic domain, where researchers have been able to embed regularities in simple linguistic phrases that resemble those used in real life (e.g., Chen et al., 2011; Paciorek & Williams, 2015). Results from social paradigms, which claimed to induce learning of covariations between physical and psychological traits of persons (e.g., Lewicki, 1986) have been difficult to replicate (e.g., Hendrickx et al., 1997).
The remaining trials attributed to Guess, Intuition, Familiarity, were rated at the RAS as follows: 25.5% (SD = 31.2) with Level 2; 3.4% (SD = 12.1) with Level 3; 0.02% (SD = 2.65) with Level 4.
References
Abernethy, B., Schorer, J., Jackson, R. C., & Hagemann, N. (2012). Perceptual training methods compared: The relative efficacy of different approaches to enhancing sport-specific anticipation. Journal of Experimental Psychology: Applied, 18(2), 143–153.
Amodio, D. M. (2019). Social Cognition 2.0: An interactive memory systems account. Trends in Cognitive Sciences, 23(1), 21–33.
Anwyl-Irvine, A. L., Massonnié, J., Flitton, A., Kirkham, N., & Evershed, J. K. (2020). Gorilla in our midst: An online behavioral experiment builder. Behavior Research Methods, 52(1), 388–407.
Baars, B. (2007). Conscious contents provide coherent, global information. In H. Liljenström, H. Århem, & P. Århem (Eds.), Consciousness transitions phylogenetic, ontogenetic, and physiological aspects (pp. 249–280). Elsevier.
Berry, D., & Dienes, Z. (1993). Implicit learning: Theoretical and empirical issues. Psychology Press.
Chang, E., Kim, H. T., & Yoo, B. (2020). Virtual reality sickness: a review of causes and measurements. International Journal of Human–Computer Interaction, 36(17), 1658–1682.
Chen, W., Guo, X., Tang, J., Zhu, L., Yang, Z., & Dienes, Z. (2011). Unconscious structural knowledge of form–meaning connections. Consciousness and Cognition, 20(4), 1751–1760.
Costea, A., Jurchiș, R., Cleeremans, A., Visu-Petra, L., Opre, A., & Norman, E. (2022). Implicit and explicit learning of socio-emotional information in a dynamic system control task. Psychological Research.
Dienes, Z. (2012). Conscious versus unconscious learning of structure. In P. Rebuschat & J. Williams (Eds.), Statistical learning and language acquisition (pp. 337–364). Mouton de Gruyter.
Dienes, Z. (2016). How Bayesian statistics are needed to determine whether mental states are unconscious. In M. Overgaard (Ed.), Behavioural methods in consciousness research (pp. 199–220). Oxford University Press.
Dienes, Z. (2021). How to use and report Bayesian hypothesis tests. Psychology of Consciousness: Theory, Research, and Practice, 8(1), 9–26.
Dienes, Z. (2022, May 19). When does selecting out conscious trials create regression to the mean or instead improve rigour? [Conference presentation]. Implicit Learning Seminar, Graz, Austria. Available at https://www.youtube.com/watch?v=N1G9_5MNTUA
Dienes, Z., & Scott, R. (2005). Measuring unconscious knowledge: Distinguishing structural knowledge and judgment knowledge. Psychological Research, 69(5-6), 338–351.
Dienes, Z., & Seth, A. K. (2018). Conscious versus unconscious processes. In G. C. L. Davey (Ed.), Psychology (pp. 262–323). Chichester.
Dienes, Z., Altmann, G., Kwan, L., & Goode, A. (1995). Unconscious knowledge of artificial grammars is applied strategically. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(5), 1322–1338.
Eitam, B., Glass-Hackel, R., Aviezer, H., Dienes, Z., Shoval, R., & Higgins, E. T. (2014). Are task irrelevant faces unintentionally processed? Implicit learning as a test case. Journal of Experimental Psychology: Human Perception and Performance, 40(5), 1741–1747.
Fox, K. (2014). Watching the English: The hidden rules of English behaviour. Hodder & Stroughton.
Francken, J., Beerendonk, L., Molenaar, D., Fahrenfort, J., Kiverstein, J., Seth, A., & van Gaal, S. (2021). An academic survey on theoretical foundations, common assumptions and the current state of the field of consciousness science. PsyArXiv. https://doi.org/10.31234/osf.io/8mbsk
Fu, Q., Dienes, Z., & Fu, X. (2010). Can unconscious knowledge allow control in sequence learning? Consciousness and Cognition, 19(1), 462–474.
Fu, Q., Sun, H., Dienes, Z., & Fu, X. (2018). Implicit sequence learning of chunking and abstract structures. Consciousness and Cognition, 62, 42–56.
Greenwald, A. G., & Lai, C. K. (2020). Implicit social cognition. Annual Review of Psychology, 71, 419–445.
Hahn, A., Judd, C. M., Hirsh, H. K., & Blair, I. V. (2014). Awareness of implicit attitudes. Journal of Experimental Psychology: General, 143(3), 1369–1392.
Hendrickx, H., De Houwer, J., Baeyens, F., Eelen, P., & Van Avermaet, E. (1997). Hidden covariation detection might be very hidden indeed. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23(1), 201–220.
Ivanchei, I. I., & Moroshkina, N. V. (2018). The effect of subjective awareness measures on performance in artificial grammar learning task. Consciousness and Cognition, 57, 116–133.
JASP Team. (2022). JASP (Version 0.16.1) [Computer software]. https://jasp-stats.org
Jiménez, L., Oliveira, H. M., & Soares, A. P. (2020). Surface features can deeply affect artificial grammar learning. Consciousness and Cognition, 80, Article 102919.
Jurchiș, R. (2021). Unconscious knowledge produces adaptive decisions via conscious judgments in a novel instrumental conditioning paradigm. PsyArXiv Preprints. https://doi.org/10.31234/osf.io/b6d3h
Jurchiş, R., & Opre, A. (2016). Unconscious learning of cognitive structures with emotional components: Implications for cognitive behavior psychotherapies. Cognitive Therapy and Research, 40(2), 230–244.
Jurchiș, R., Costea, A., Dienes, Z., Miclea, M., & Opre, A. (2020). Evaluative conditioning of artificial grammars: Evidence that subjectively-unconscious structures bias affective evaluations of novel stimuli. Journal of Experimental Psychology: General, 149(9), 1800–1809.
Lee, M. D., & Wagenmakers, E. J. (2014). Bayesian cognitive modeling: A practical course. Cambridge University Press.
Lewicki, P. (1986). Nonconscious social information processing. Academic Press.
Lieberman, M. D. (2000). Intuition: a social cognitive neuroscience approach. Psychological Bulletin, 126(1), 109–137.
Masters, R. S. W., Maxwell, J. P., & Eves, F. F. (2009). Marginally perceptible outcome feedback, motor learning and implicit processes. Consciousness and Cognition, 18(3), 639–645.
Mealor, A. D., & Dienes, Z. (2013a). The speed of metacognition: Taking time to get to know one’s structural knowledge. Consciousness and Cognition, 22(1), 123–136.
Mealor, A. D., & Dienes, Z. (2013b). Explicit feedback maintains implicit knowledge. Consciousness and Cognition, 22(3), 822–832.
Neil, G. J., & Higham, P. A. (2012). Implicit learning of conjunctive rule sets: An alternative to artificial grammars. Consciousness and Cognition, 21(3), 1393–1400.
Neil, G. J., & Higham, P. A. (2020). Repeated exposure to exemplars does not enhance implicit learning: A puzzle for models of learning and memory. Quarterly Journal of Experimental Psychology, 73(3), 309–329.
Newell, B. R., & Shanks, D. R. (2014). Unconscious influences on decision making: A critical review. Behavioral and Brain Sciences, 37(1), 1–19.
Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of learning: Evidence from performance measures. Cognitive Psychology, 19(1), 1–32.
Norman, E., & Price, M. C. (2012). Social intuition as a form of implicit learning: Sequences of body movements are learned less explicitly than letter sequences. Advances in Cognitive Psychology, 8(2), 121–131.
Norman, E., Price, M. C., & Jones, E. (2011). Measuring strategic control in artificial grammar learning. Consciousness and Cognition, 20, 1920–1929.
Norman, E., Scott, R. B., Price, M. C., & Dienes, Z. (2016). The relationship between strategic control and conscious structural knowledge in artificial grammar learning. Consciousness and Cognition, 42, 229–236.
Norman, E., Scott, R. B., Price, M. C., Jones, E., & Dienes, Z. (2019). Can unconscious structural knowledge be strategically controlled? In A. Cleeremans, V. Allakhverdov, & M. Kuvaldina (Eds.), Implicit learning: 50 years on (pp. 159–173). Routledge.
Opacic, T., Stevens, C., & Tillmann, B. (2009). Unspoken knowledge: Implicit learning of structured human dance movement. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35(6), 1570–1577.
Orgs, G., Hagura, N., & Haggard, P. (2013). Learning to like it: Aesthetic perception of bodies, movements and choreographic structure. Consciousness and Cognition, 22(2), 603–612.
Paciorek, A., & Williams, J. N. (2015). Semantic generalization in implicit language learning. Journal of experimental Psychology: Learning, Memory, and Cognition, 41(4), 989–1002.
Palfi, B., & Dienes, Z. (2019, December 10). When and how to calculate the Bayes factor with an interval null hypothesis. PsyArXiv Preprints. https://doi.org/10.31234/osf.io/9chmw
Raab, M., & Johnson, J. G. (2008). Implicit learning as a means to intuitive decision making in sports. In H. Plessner, C. Betsch, & T. Betsch (Eds.), Intuition in judgment and decision making (pp. 119–133). Erlbaum.
Reber, A. S. (1967). Implicit learning of artificial grammars. Journal of Verbal Learning and Verbal Behavior, 6(6), 855–863.
Reber, A. S. (in press). Implicit Learning: Background, History, Theory. In A. S. Reber & R. Allen (Eds.), Implicit Learning: The First Half Century. Oxford University Press.
Reed, N., McLeod, P., & Dienes, Z. (2010). Implicit knowledge and motor skill: What people who know how to catch don’t know. Consciousness and Cognition, 19(1), 63–76.
Rosenthal, D. M. (2004). Varieties of higher-order theory. Advances in Consciousness Research, 56, 17–44.
Rosenthal, D. (2019). Consciousness and confidence. Neuropsychologia, 128, 255–265.
Scott, R. B., & Dienes, Z. (2008). The conscious, the unconscious, and familiarity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34(5), 1264–1288.
Scott, R. B., & Dienes, Z. (2010a). Prior familiarity with components enhances unconscious learning of relations. Consciousness and cognition, 19(1), 413–418.
Scott, R. B., & Dienes, Z. (2010b). Knowledge applied to new domains: The unconscious succeeds where the conscious fails. Consciousness & Cognition, 19, 391–398.
Sense, F., & van Rijn, H. (2018). Probabilistic motor sequence learning in a virtual reality serial reaction time task. PLOS ONE, 13(6), Article e0198759.
Shanks, D. R. (2005). Implicit learning. In K. Lamberts & R. Goldstone (Eds.), Handbook of Cognition (pp. 202–220). SAGE Publications.
Shanks, D. R. (2017). Regressive research: The pitfalls of post hoc data selection in the study of unconscious mental processes. Psychonomic Bulletin & Review, 24(3), 752–775.
Shanks, D. R., & John, M. F. S. (1994). Characteristics of dissociable human learning systems. Behavioral and Brain Sciences, 17(3), 367–395.
Shanks, D. R., Malejka, S., & Vadillo, M. A. (2021). The challenge of inferring unconscious mental processes. Experimental Psychology. https://doi.org/10.1027/1618-3169/a000517
Skora, L., Livermore, J. J. A., Dienes, Z., Seth, A., & Scott, R. B. (2020). Feasibility of unconscious instrumental conditioning: A registered replication. PsyArXiv Preprints. https://doi.org/10.31234/osf.io/p9dgn
Smith, E. R., & DeCoster, J. (2000). Dual-process models in social and cognitive psychology: Conceptual integration and links to underlying memory systems. Personality and Social Psychology Review, 4(2), 108–131.
Sweldens, S., Tuk, M. A., & Hütter, M. (2017). How to study consciousness in consumer research. A commentary on Williams and Poehlman. Journal of Consumer Research, 44(2), 266–275.
Timmermans, B., & Cleeremans, A. (2015). How can we measure awareness? An overview of current methods. In M. Overgaard (Ed.), Behavioural methods in consciousness research (pp. 21–46). Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199688890.003.0003
Wan, L., Dienes, Z., & Fu, X. (2008). Intentional control based on familiarity in artificial grammar learning. Consciousness and Cognition, 17(4), 1209–1218.
Waroquier, L., Abadie, M., & Dienes, Z. (2020). Distinguishing the role of conscious and unconscious knowledge in evaluative conditioning. Cognition, 205, Article 104460.
Weiss, S. M., & Masters, R. S. W. (2022). The locus of focus and curing the yips. In A. S. Reber & R. Allen (Eds.), Implicit learning: The first half century. Oxford University Press.
Wierzchoń, M., Asanowicz, D., Paulewicz, B., & Cleeremans, A. (2012). Subjective measures of consciousness in artificial grammar learning task. Consciousness and Cognition, 21(3), 1141–1153.
Zhang, J., & Liu, D. (2021). The gradual subjective consciousness fluctuation in implicit sequence learning and its relevant brain activity. Neuropsychologia, 160, Article 107948.
Zhang, Q., Li, L., Guo, X., Zheng, L., Wu, Y., & Zhou, C. (2020). Implicit learning of symmetry of human movement and gray matter density: Evidence against pure domain general and pure domain specific theories of implicit learning. International Journal of Psychophysiology, 147, 60–71.
Ziori, E., & Dienes, Z. (2015). Facial beauty affects implicit and explicit learning of men and women differently. Frontiers in Psychology, 6, Article 1124.
Acknowledgements
Răzvan Jurchiș was supported by a postdoctoral grant awarded by the Executive Unit for Financing Higher Education, Research, Development and Innovation (UEFISCDI), PN-III-P1-1.1-PD-2019-0975.
Author information
Authors and Affiliations
Corresponding author
Additional information
Open science practices
The data set is available online (https://osf.io/28vbj/). The experiment reported in the study was not preregistered.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
ESM 1
(DOCX 17 kb)
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jurchiș, R., Dienes, Z. Implicit learning of regularities followed by realistic body movements in virtual reality. Psychon Bull Rev 30, 269–279 (2023). https://doi.org/10.3758/s13423-022-02175-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-022-02175-0