
Abstract
The relationship between visual attentional selection of items in particular spatial locations and selection by nonspatial criteria was investigated in a partial report experiment with report of letters (as many as possible) from brief postmasked exposures of circular arrays of letters and digits. The data were fitted by mathematical models based on Bundesen’s (Psychological Review, 97, 523-547, 1990) theory of visual attention (TVA). Both attentional weights of targets (letters) and attentional weights of distractors (digits) showed strong variations across the eight possible target locations, but for each of the ten participants, the ratio of the weight of a distractor at a given location to the weight of a target at the same location was approximately constant. The results were accommodated by revising the weight equation of TVA such that the attentional weight of an object equals a product of a spatial weight component (weight due to being at a particular location) and a nonspatial weight component (weight due to having particular features other than locations), the two components scaling the effects of each other multiplicatively.
Similar content being viewed by others


The relationship between visual attentional selection based on spatial location and selection by nonspatial criteria such as color and shape has long been debated (see, e.g., Bundesen, 1993; Logan, 1996; Maunsell & Treue, 2006; Scholl, 2001; van der Velde & van der Heijden, 1993). One issue is whether selection by location is special (Bundesen, 1991; Nissen, 1985; Pilz, Roggeveen, Creighton, Bennett, & Sekuler, 2012; van der Heijden, 2004). While some studies suggest that location is special (e.g., Moore & Egeth, 1998; Posner, Snyder, & Davidson, 1980), others have indicated that selection by spatial and nonspatial criteria have similar effects on performance (e.g., Maunsell & Treue, 2006), although the effects occur with different delays after stimulus presentation (Liu, Stevens, & Carrasco, 2007) and are likely mediated by different mechanisms (Ling, Lui, & Carrasco, 2009; White, Rolfs, & Carrasco, 2015). A related issue is the way in which selection based on spatial location interacts with selection based on nonspatial criteria. Here too, there is no clear agreement. Andersen and colleagues (2011), for example, found that selection by spatial and nonspatial criteria influenced the amplitude of visually evoked potentials, as measured by EEG, in an additive manner, with virtually no interaction between the two factors. Other studies, however, have found superadditive relations between spatial and nonspatial selection (e.g., Bengson, Lopez-Calderon, & Mangun, 2012; Kingstone, 1992), and White and colleagues (2015) found different results depending on timescale and stimulus competition. In this article, we treat these issues by experimental investigation and computational modeling based on the theory of visual attention (TVA; Bundesen, 1990; also see Bundesen & Habekost, 2008; Bundesen, Habekost, & Kyllingsbæk, 2005, 2011; Bundesen, Vangkilde, & Habekost, 2015).
In TVA, visual objects compete to become encoded into a visual short-term memory (VSTM) with limited storage capacity (about three to four independent objects) before the sensory representations of the stimulus objects have disappeared or VSTM capacity has been filled (cf. Luck & Vogel, 1997; Shibuya & Bundesen, 1988; Sperling, 1960; see also Bays & Husain 2008). The rate of processing (processing speed), v(x, i), at which the visual categorization that object x has feature i races towards encoding into VSTM, is given by the rate equation:
where \( \eta \left( x, i\right) \) is the strength of the sensory evidence that object x has feature i, \( {\beta}_i \) is the perceptual bias in favor of categorizing objects as having feature i, and
is the relative attentional weight of object x.
Every visual feature is supposed to be associated with a template. The template associated with feature i, template i, is a memory representation of sensory characteristics of feature i, and \( \eta \left( x, i\right) \) is regarded as a measure of a density of neural firing or a level of activation representing the instantaneous degree of match between object x and template i with a time lag due to the limited speed of neural conduction and computation (see, e.g., Li, Bundesen, & Ditlevsen, 2016; Li, Kozyrev, Kyllingsbæk, Treue, Ditlevsen, & Bundesen, 2016). However, TVA is neutral with respect to the exact representational format (as defined by Kosslyn, 1980) of the templates.
Visual search for an object with feature i may proceed by comparing stimulus objects with a template for feature i—a target template—and compute the degree of match. However, as recently argued by Töllner, Conci, and Müller (2015; see also Töllner, Müller, & Zehetleitner, 2011), not only target templates but also templates for different types of distractors may be used in search. In terms of TVA, η values may be computed by comparing stimuli with both target and distractor templates and possibly with templates containing both target and distractor information (Töllner et al., 2015).
The (absolute) attentional weight of object x, w x , is given by the weight equation of TVA. In the original form, the weight equation was that
where \( \eta \left( x, j\right) \) is the strength of the sensory evidence that object x has feature j, and \( {\pi}_j \) is the pertinence of feature j. In this version of the weight equation, the attentional weight of an object is a sum of the \( \eta *\pi \) products for all features—both spatial and nonspatial. However, recent results (Nordfang, Dyrholm, & Bundesen, 2013) suggest that a revision of the weight equation is needed.
In partial report experiments, Nordfang and colleagues (2013) investigated the way the attentional weight of a visual object depends on both the contrast of the features of the object to its local surroundings (feature contrast) and the relevance of the features to our goals (feature relevance). The task was to report the letters from a mixture of letters (targets) and digits (distractors). Partial report by the shape-feature alphanumeric class had previously been thoroughly investigated with results that were qualitatively similar to those obtained with selection based on differences in color (see Bundesen, Pedersen, & Larsen, 1984; Bundesen, Shibuya, & Larsen, 1985; Shibuya & Bundesen, 1988). In the task used by Nordfang and colleagues, the letters were briefly presented but responses were not speeded. Color was irrelevant to the task, but many stimulus displays contained an item (target or distractor) in a deviant color (a color singleton). Location too was irrelevant to the task, nevertheless the participants revealed large variations in attentional weights across location. Furthermore, the results showed concurrent effects of feature contrast (color singleton vs. nonsingleton) and relevance (target vs. distractor). A singleton target had a higher probability of being reported than a nonsingleton target, and a singleton distractor interfered more strongly with report of targets than did a nonsingleton distractor, despite the fact that the singleton color was entirely irrelevant to the task at hand. Measured by use of TVA, the attentional weight of a singleton object was nearly proportional to the weight of an otherwise similar nonsingleton object, with a factor of proportionality that increased with the strength of the feature contrast of the singleton. This result was explained by generalizing the weight equation of TVA such that the attentional weight of an object became a product of a bottom-up (feature contrast) and a top-down (feature relevance) component.
Method
The relationship between visual attentional selection based on spatial location and selection by alphanumeric class was investigated in a partial report experiment with report of letters from briefly exposed, postmasked displays of circular arrays of letters and digits (see Fig. 1). We have previously found large variations in the attentional weight of the same item at different locations (e.g., Nordfang et al., 2013). In the present experiment, we therefore chose to manipulate only nonspatial selection and let this interact with participants’ own, individually set spatial weights. We fitted the data from each participant individually, thereby preserving the individual variation in spatial weights in our analysis.

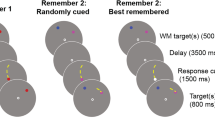
Flow chart of the trial sequence in the experiment
Task
Participants were instructed to report as many letters as possible of those they had seen in the stimulus display but refrain from pure guessing. Each participant served individually in 1,920 trials.
Stimuli
On each trial, the participant was presented with a briefly exposed circular array of eight alphanumeric characters—letters to be reported (targets, T) and digits to be ignored (distractors, D). The array was centered on fixation at a viewing distance of approximately 70 cm. The diameter of the imaginary circle composed of the array subtended approximately 12° of visual angle measured from the center of the array characters. Individual stimulus characters subtended approximately 2.5° (width) by 3° (height) of visual angle. The target-distractor configuration (TD-configuration) varied from trial to trial between 8T0D (i.e., eight targets and zero distractors), 6T2D, 4T4D, and 2T6D. All characters were blue (RGB 43, 53, 255) on a black background. The exposure duration varied at random from trial to trial. It was either 10 ms, 20 ms, 30 ms, 70 ms, 100 ms, or 180 ms. Stimulus displays were postmasked with a pattern mask that had previously been demonstrated to efficiently mask the stimuli (Gillebert, Dyrholm, Vangkilde, Kyllingsbæk, Peeters, & Vandenberghe, 2012; Vangkilde, Bundesen, & Coull, 2011). Combining four TD-configurations with six exposure durations yielded 24 experimental conditions, each of which was represented by 80 trials per participant.
Participants
Ten paid volunteers took part in the study (three men and seven women). Their mean age was 24.6 years. All reported normal or corrected-to-normal vision, and no history of color blindness.
Results and discussion
The proportion of correctly reported targets, averaged across the ten participants, is plotted in Fig. 2 as a function of exposure duration with TD-configuration as the parameter. As expected from previous TVA-based studies of partial and whole report (e.g., Shibuya & Bundesen, 1988), the proportion of correctly reported targets increased with the exposure duration. At an exposure duration of 10 ms, the proportion of correctly reported targets was nearly zero. As the exposure duration increased, the proportion of correctly reported targets first showed a strong increase and then leveled off at a value that decreased as the number of items to be reported (targets) increased (see Fig. 2).

The proportion of the presented targets that was correctly reported, for each combination of exposure duration and TD-configuration, averaged across all participants
Modeling
The individual data from each participant were fitted by a mathematical model based on TVA (Bundesen, 1990). For each participant, we computed maximum likelihood estimates for the minimum effective exposure duration t 0 (see, e.g., Shibuya & Bundesen, 1988), a six-parameter integer-valued distribution of VSTM-capacity K (see Dyrholm et al., 2011), processing speed C (e.g., Shibuya & Bundesen, 1988), the attentional weight of a target at each of the eight stimulus locations (w T[l], l = 1, …, 8), and the attentional weight of a distractor at each of the eight locations (w D[l], l = 1, …, 8; see Nordfang, Dyrholm, & Bundesen, 2013; see Dyrholm et al., 2011, for a comprehensive methodological account of TVA-based fitting of data from partial and whole report). Figure 3 shows a plot of the model fit compared with the data observed for a representative participant. Results from all participants are available in the appendix (Fig. 6). Pearson’s product moment coefficient for the correlation between observed and predicted mean scores was greater than .95 and highly significant, p < .001, for all participants.

Typical individual results obtained with Participant 4. For each combination of exposure duration and TD-configuration, the observed mean score is indicated by a triangle (TD-configuration 8T0D), a diamond (6T2D), a square (4T4D), or a circle (2T6D). Predicted mean scores are indicated by unmarked points connected with straight lines
Estimated weights
Without loss of generality, for each participant the eight attentional weights for targets were constrained to sum-up to a value of 1. Otherwise, instead of trying to account for the data with as few parameters as possible, we let the data speak for themselves through the estimated weight parameters. Separate attentional weights were estimated for items at different locations, thereby revealing the variation in the weights participants allocated to different locations, and separate weights were estimated for targets and distractors, respectively. Figure 4 shows attentional weights recorded from two participants. The individual data for all participants are shown in Fig. 7. As can be seen, the weights varied strongly across the eight stimulus locations. For all participants, attentional weights of targets were higher than weights of distractors, and for typical participants, the distribution of attentional weights of targets across locations looked like a scaled-up version of the distribution of attentional weights of distractors across locations.

Typical distributions of estimated attentional weights for individual participants, obtained with Participants 7 and 8. Separate weights were estimated for each stimulus type (target, distractor) at each of the eight stimulus locations. In terms of compass directions, Locations 1–8 are NE, E, SE, S, SW, W, NW, and N, respectively
For each participant, the relationship between target and distractor weights at the eight stimulus locations was fitted by three competing linear models: a one-parameter additive model,
a one-parameter multiplicative model,
and a two-parameter linear model,
The three fits are shown for Participants 7 and 8 in Fig. 5. The individual data for all participants are shown in Fig. 7, and details of the fits are listed in Table 1. The two nested one-parameter models were compared with the two-parameter model by likelihood ratio tests. The tests supported the one-parameter multiplicative model: First, across all participants, the two-parameter linear model (black lines) did not explain significantly more of the variation as compared with the one-parameter multiplicative model (green lines), χ2(10) = 5.52, p = .854. Second, the two-parameter model fitted the data significantly better than the one-parameter additive model (blue lines), χ2(10) = 97.86, p < .001.

Relationship between attentional weights of targets and distractors. Typical individual results, obtained with Participants 7 and 8. Estimated weights of distractors at the eight stimulus locations are plotted against estimated weights of targets at the same locations, and the relationship is fitted by three competing linear models. Black line: best fit by a standard two-parameter linear model with slope and intercept as free parameters; green line: best fit by a one-parameter multiplicative model; blue line: best fit by a one-parameter additive model. Note that for Participant 8 the black line is virtually masked by the green line
Towards a new weight equation
The results of the experiment go against expectations from the original version of the weight equation (Eq. 2) and also against the notion that spatial location is a feature like any other one (e.g., Maunsell & Treue, 2006). By Eq. 2, effects of location and type of objects (target vs. distractor) on attentional weights should be additive and not multiplicative, the total weight of an item being a sum across all categories, both spatial and nonspatial. Thus, by Eq. 2, the difference in attentional weight between a distractor at location l and an otherwise similar target at location l should be a constant, k, independent of the spatial weight component associated with location l. This means that the one-parameter additive model,
follows from Eq. 2. However, the results supported the multiplicative one-parameter model for the relationship between target and distractor weights at the eight stimulus locations: For each observer, the ratio of the weight of a distractor to the weight of an otherwise similar target at the same location,
appeared to be the same across locations l = 1, …, 8.
The finding that the ratio w D(l)/w T(l) was approximately constant may be explained in terms of TVA by assuming that the attentional weight of an object is a product of a spatial weight component,
and a nonspatial weight component,
such that the effects of the two components scale each other multiplicatively.
The new weight equation may be elaborated as follows:
where η[x, location(x)]
-
= the strength of the sensory evidence that object x is located where it is
-
\( \approx \) the extent to which x stands out from the background
-
\( \approx \) the local feature contrast of object x, \( {\kappa}_x \) (see Nordfang et al., 2013; Wolfe, 1994).
Impact of local contrast
The new weight equation can explain the main findings of Nordfang et al. (2013). Nordfang et al. provided evidence that—provided the pertinence of feature contrast per se, π contrast, is small enough to be neglected—attentional weights of color singletons and otherwise similar nonsingletons vary in direct proportion to each other,
where the constant c > 1 increases with the strength of the feature contrast of the singleton. By the new weight equation, introducing a color singleton x into a display without singletons by changing the color of x should change the spatial component of the attentional weight of x by multiplication with the new value of
divided by the old value. Furthermore, by the new, multiplicative weight equation, any factor that changes the spatial component of the attentional weight of object x by multiplication with a factor c, indirectly changes the total attentional weight of x by multiplication with the same factor c. Hence, consistent with the findings of Nordfang et al., and provided that other things are equal, the change in the color of x should multiply the attentional weight of x by the same factor c, regardless of whether x is a target or a distractor.
The multiplicative weight equation proposed in this article becomes highly similar to the weight equation suggested by Nordfang et al. (2013) if the spatial weight component is set equal to \( {\kappa}_x \)(i.e., the local feature contrast of object x) multiplied by π location(x) (i.e., the pertinence of being at the location of x). Note that, in most applications of TVA, stimuli in the same display have had approximately the same local feature contrast (the same spatial weight component). In all such cases, the actual value of the spatial weight component should be immaterial, because the rate equation implies that the probability that a stimulus becomes encoded into VSTM depends on the relative attentional weight of the stimulus rather than the absolute attentional weight.
Concluding remarks
Location seems to be “special” in many ways (see Nissen, 1985). Most striking, perhaps, is the finding that visual search for conjunctions of features other than location (e.g., conjunctions of color and shape) tends to be difficult (see, e.g., Treisman, 1988), but search for a nonspatial feature conjoined with a spatial location (i.e., search for the feature at a particular location) is easy and barely regarded as “search” (see, e.g., Harms & Bundesen, 1983). The present experimental and theoretical analysis of the role of spatial location extended findings on visual search by showing strong variations in the attentional weights of the items to be reported depending on their spatial locations, although formally location was irrelevant to the task. The results could be explained by revising the weight equation of TVA such that the attentional weight of an object becomes a product of a spatial and a nonspatial weight component, the two components scaling the effects of each other multiplicatively.
Our conjecture that the attentional weight of an object is a product of a spatial and a nonspatial weight component is highly general. It provides a nice explanation for the results we obtained in the current experiment on the role of spatial location in partial report based on alphanumeric class. In future experiments, however, one would like to see the generality of the conjecture tested in other paradigms, including some in which the roles of location and nonspatial features are more nearly symmetrical.
References
Andersen, S. K., Fuchs, S., & Müller, M. M. (2011). Effects of feature-selective and spatial attention at different stages of visual processing. Cognitive Neuroscience, 23(11), 238–246.
Bays, P. M., & Husain, M. (2008). Dynamic shifts of limited working memory resources in human vision. Science, 321(5890), 851–854.
Bengson, J. J., Lopez-Calderon, J., & Mangun, G. R. (2012). The spotlight of attention illuminates failed feature-based expectancies. Psychophysiology, 49(8), 1101–1108.
Bundesen, C. (1990). A theory of visual attention. Psychological Review, 97, 523–547.
Bundesen, C. (1991). Visual selection of features and objects: Is location special? A reinterpretation of Nissen’s (1985) findings. Attention, Perception, & Psychophysics, 50, 87–89.
Bundesen, C. (1993). The notion of elements in the visual field in a theory of visual attention: A reply to van der Velde and van der Heijden (1993). Attention, Perception & Psychophysics, 53, 350–352.
Bundesen, C., & Habekost, T. (2008). Principles of Visual Attention: Linking Mind and Brain. Oxford Psychology Series. Oxford, UK: Oxford University Press.
Bundesen, C., Habekost, T., & Kyllingsbæk, S. (2005). A neural theory of visual attention: Bridging cognition and neurophysiology. Psychological Review, 112, 291–328.
Bundesen, C., Habekost, T., & Kyllingsbæk, S. (2011). A neural theory of visual attention and short-term memory. Neuropsychologia, 49, 1446–1457.
Bundesen, C., Pedersen, L. F., & Larsen, A. (1984). Measuring efficiency of selection from briefly exposed visual displays: A model for partial report. Journal of Experimental Psychology: Human Perception and Performance, 10, 329–339.
Bundesen, C., Shibuya, H., & Larsen, A. (1985). Visual selection from multielement displays: A model for partial report. In M. I. Posner & O. S. M. Marin (Eds.), Attention and Performance 11 (pp. 631–649). Hillsdale, NJ: Erlbaum.
Bundesen, C., Vangkilde, S., & Habekost, T. (2015). Components of visual bias: A multiplicative hypothesis. Annals of the New York Academy of Sciences, 1339, 116–124.
Dyrholm, M., Kyllingsbæk, S., Espeseth, T., & Bundesen, C. (2011). Generalizing parametric models by introducing trial-by-trial parameter variability: The case of TVA. Journal of Mathematical Psychology, 55, 416–429.
Gillebert, C. R., Dyrholm, M., Vangkilde, S., Kyllingsbæk, S., Peeters, R., & Vandenberghe, R. (2012). Attentional priorities and access to short-term memory: Parietal interactions. NeuroImage, 62, 1551–1562.
Harms, L., & Bundesen, C. (1983). Color segregation and selective attention in a nonsearch task. Attention, Perception, & Psychophysics, 33, 11–19.
Kingstone, A. (1992). Combining expectancies. The Quarterly Journal of Experimental Psychology Section A, 44(1), 69–104.
Kosslyn, S. M. (1980). Image and mind. Cambridge, MA: Harvard University Press.
Li, K., Bundesen, C., & Ditlevsen, S. (2016). Responses of leaky integrate-and-fire neurons to a plurality of stimuli in their receptive fields. Journal of Mathematical Neuroscience. doi:10.1186/s13408-016-0040-2
Li, K., Kozyrev, V., Kyllingsbæk, S., Treue, S., Ditlevsen, S., & Bundesen, C. (2016). Neurons in primate visual cortex alternate between responses to multiple stimuli in their receptive field. Frontiers in Computational Neuroscience, 10, Article 141. Doi: 103389/fncom.2016.00141.
Ling, S., Liu, T., & Carrasco, M. (2009). How spatial and feature-based attention affect the gain and tuning of population responses. Vision Research, 49, 1194–1204.
Liu, T., Stevens, S. T., & Carrasco, M. (2007). Comparing the time course and efficacy of spatial and feature-based attention. Vision Research, 47, 108–113.
Logan, G. D. (1996). The CODE theory of visual attention: An integration of space-based and object-based attention. Psychological Review, 103, 603–649.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281.
Maunsell, J. H. R., & Treue, S. (2006). Feature-based attention in visual cortex. Trends in Neuroscience, 29(6), 317–322.
Moore, C. M., & Egeth, H. E. (1998). How does feature-based attention affect visual processing? Journal of Experimental Psychology: Human Perception and Performance, 24, 1296–1310.
Nissen, M. J. (1985). Accessing features and objects: Is location special? In M. I. Posner & O. S. M. Marin (Eds.), Attention and Performance (Vol. 11, pp. 205–219). Hillsdale, NJ: Erlbaum.
Nordfang, M., Dyrholm, M., & Bundesen, C. (2013). Identifying bottom-up and top-down components of attentional weight by experimental analysis and computational modeling. Journal of Experimental Psychology: General, 142, 510–535.
Pilz, K. S., Roggeveen, A. B., Creighton, S. E., Bennett, P. J., & Sekuler, A. B. (2012). How prevalent is object-based attention? PLoS one, 7(2), e30693.
Posner, M. I., Snyder, C. R., & Davidson, B. J. (1980). Attention and the detection of signals. Journal of Experimental Psychology: General, 109(2), 160–174.
Scholl, B. J. (2001). Objects and attention: The state of the art. Cognition, 80, 1–46.
Shibuya, H., & Bundesen, C. (1988). Visual selection from multielement displays: Measuring and modeling effects of exposure duration. Journal of Experimental Psychology: Human Perception and Performance, 14, 591–600.
Sperling, G. (1960). The information available in brief visual presentations. Psychological Monograhs, 74 (Whole No. 498).
Töllner, T., Conci, M., & Müller, H. J. (2015). Predictive distractor context facilitates attentional selection of high, but not intermediate and low, saliency targets. Human Brain Mapping, 36, 935–944.
Töllner, T., Müller, H. J., & Zehetleitner. (2011). Top-down dimensional weight set determines the capture of visual attention: Evidence from the PCN component. Cerebral Cortex, 22, 1554–1560.
Treisman, A. M. (1988). Features and objects: The Fourteenth Bartlett Memorial Lecture. Quarterly Journal of Experimental Psychology, 40A, 201–237.
van der Heijden, A. H. C. (2004). Attention in Vision: Perception, Communication and Action. Hove, UK: Psychology Press.
van der Velde, F., & van der Heijden, A. H. C. (1993). An element in the visual field is just a conjunction of attributes: A critique of Bundesen (1991). Perception & Psychophysics, 53(3), 345–349.
Vangkilde, S., Bundesen, C., & Coull, J. T. (2011). Prompt but inefficient: Nicotine differentially modulates discrete components of attention. Psychopharmacology, 218, 667–680.
White, A. L., Rolfs, M., & Carrasco, M. (2015). Stimulus competition mediates the joint effects of spatial and feature-based attention. Journal of Vision, 15(14), 1–21.
Wolfe, J. M. (1994). Guided search 2.0: A revised model of visual search. Psychonomic Bulletin & Review, 1, 202–238.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Results for each individual participant

Mean number of correctly reported targets as a function of exposure duration with the number of targets (T) in the stimulus display as the parameter. T was 2, 4, 6, or 8, and the number of distractors (D) in the display equaled 8 – T. Observed mean scores are indicated by triangles (T = 8), diamonds (T = 6), squares (T = 4), and circles (T = 2). Predicted mean scores are indicated by unmarked points connected with straight lines

Relationship between attentional weights of targets and distractors for each of the participants. Participant number is noted in the lower right corner of each coordinate system. Estimated weights of distractors at the eight stimulus locations are plotted against estimated weights of targets at the same locations, and the relationship is fitted by three competing linear models. Black line: best fit by a standard two-parameter linear model with slope and intercept as free parameters; green line: best fit by a one-parameter multiplicative model; blue line: best fit by a one-parameter additive model. Note that for Participants 6 and 8 the black line is virtually masked by the green line
Rights and permissions
About this article

Cite this article
Nordfang, M., Staugaard, C. & Bundesen, C. Attentional weights in vision as products of spatial and nonspatial components. Psychon Bull Rev 25, 1043–1051 (2018). https://doi.org/10.3758/s13423-017-1337-1
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-017-1337-1